SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This document provides a complete strategic, architectural, semantic, retrieval-oriented, and implementation-level explanation of the context-engine.json file.

This file is designed to orchestrate how AI systems:
· assemble contextual information
· prioritize semantic relevance
· build retrieval-aware context windows
· optimize token allocation
· maintain contextual continuity
· reduce hallucinations
· coordinate semantic retrieval
· manage dynamic context injection
· preserve semantic grounding
· adapt context for user intent
· construct coherent answer environments
· optimize memory-aware reasoning
This file is specifically intended for:
· Generative Engine Optimization (GEO)
· Large Language Model optimization
· Retrieval-Augmented Generation (RAG)
· semantic retrieval systems
· AI context orchestration
· AI grounding systems
· contextual answer generation
· AI memory systems
· semantic chunk fusion
· dynamic retrieval pipelines
· enterprise AI architectures
· AI-native semantic infrastructure
This guide explains:
· what context-engine.json is
· why it matters
· how AI context windows work
· how contextual grounding functions
· how retrieval-aware context systems operate
· how token prioritization works
· how semantic continuity should be preserved
· how hallucinations can be reduced
· how adaptive context assembly works
· how dynamic context injection functions
· how enterprise AI context systems are designed
· reusable production-grade JSON structures
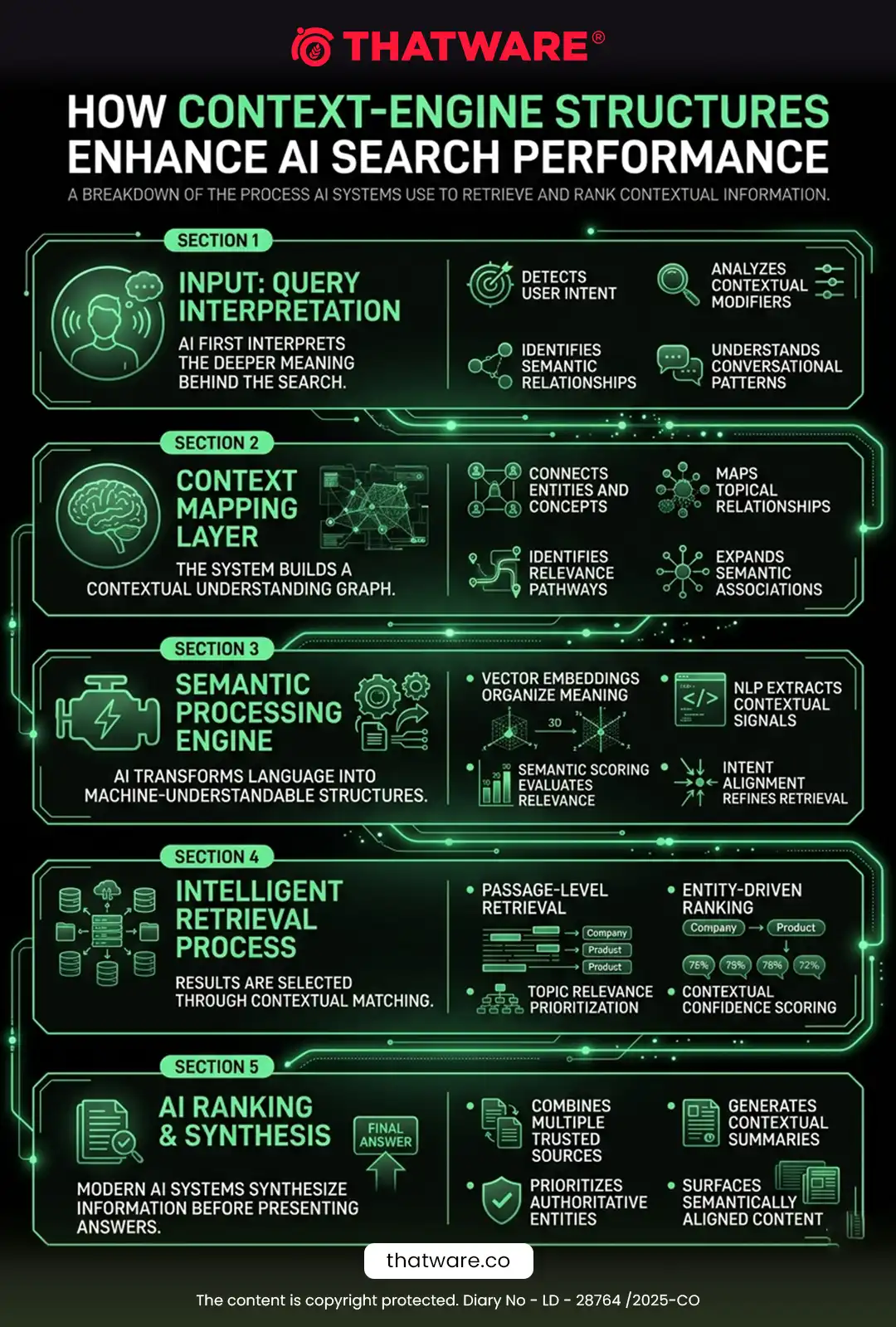
1. What Is context-engine.json?
context-engine.json is a machine-readable context orchestration framework that defines:
· how context should be assembled
· which semantic assets should be prioritized
· how retrieval outputs should be merged
· how token allocation should be optimized
· how contextual continuity should be preserved
· how supporting evidence should be injected
· how AI systems should maintain grounding
· how semantic relevance should be scored
· how contextual conflicts should be resolved
· how answer-ready context should be constructed
In simple terms:
It is the contextual intelligence layer of an AI-native website.
2. Why context-engine.json Exists
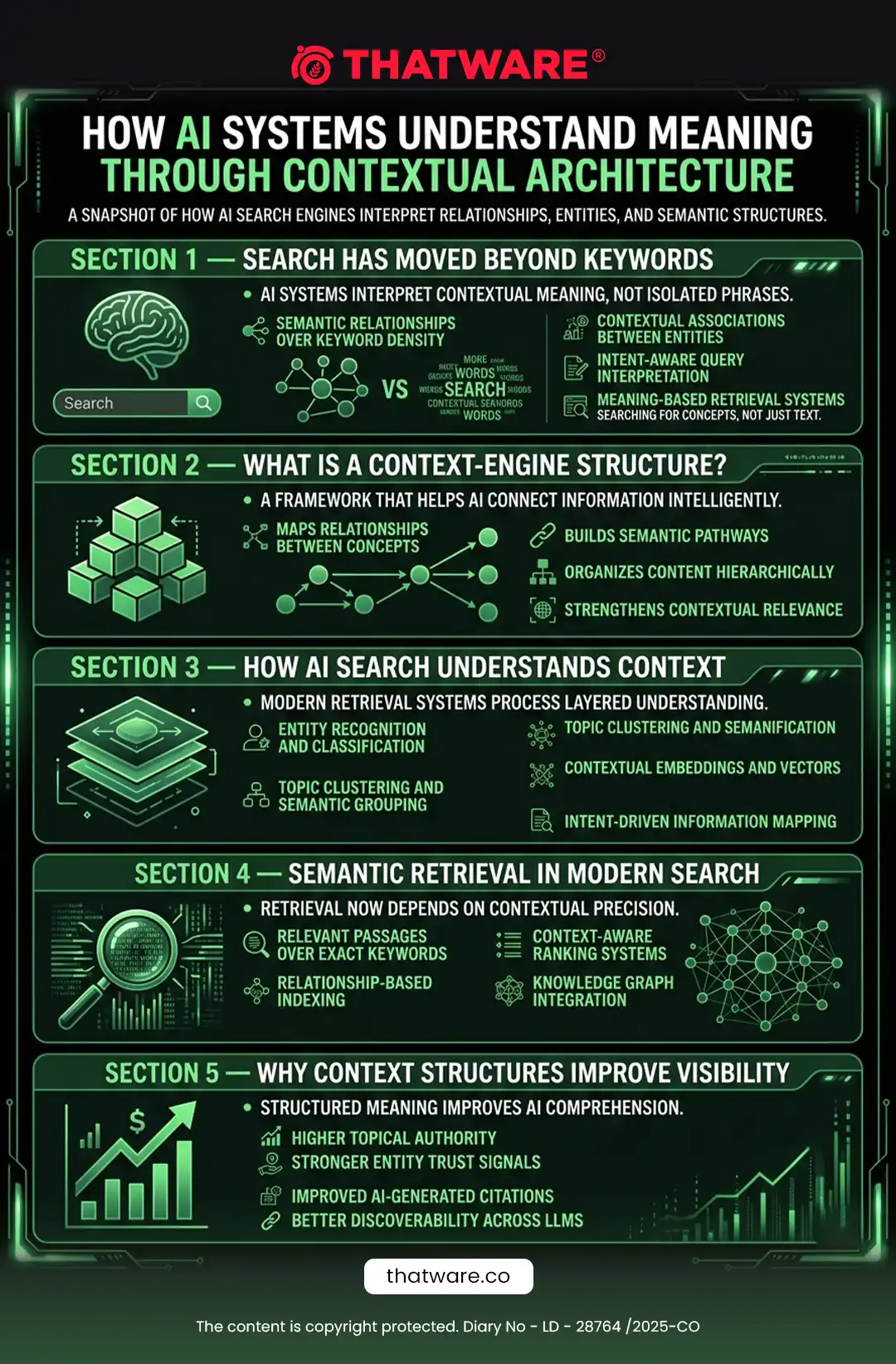
Modern AI systems depend heavily on context.
Even powerful LLMs fail when context is:
· incomplete
· noisy
· fragmented
· irrelevant
· contradictory
· semantically weak
· poorly prioritized
Traditional websites were never designed for:
· context-aware retrieval
· token-aware assembly
· adaptive context construction
· AI memory optimization
context-engine.json solves this problem.
3. Core Objective of context-engine.json
The file helps AI systems answer:
· Which context should be included?
· Which context should be excluded?
· Which semantic entities matter most?
· Which chunks deserve priority?
· How should context windows be structured?
· How should retrieval outputs merge?
· Which supporting evidence should appear?
· How should token budgets be allocated?
· How should semantic continuity be preserved?
· How should hallucination risks be minimized?
4. Why This Matters for GEO
In Generative Engine Optimization, context quality determines:
· answer quality
· retrieval effectiveness
· citation probability
· semantic relevance
· grounding strength
· hallucination prevention
· contextual coherence
Even excellent retrieval can fail if:
· context is poorly assembled
· important chunks are omitted
· token limits remove key information
· semantic continuity breaks
context-engine.json directly improves AI answer generation.
5. Understanding AI Context Windows
LLMs operate within context windows.
A context window contains:
· user queries
· retrieved chunks
· instructions
· supporting evidence
· conversational history
· semantic metadata
Context windows are limited.
Therefore context must be:
· prioritized
· compressed
· optimized
· structured
· semantically coherent
6. The Importance of Context in AI Systems
AI systems generate answers based on:
· current context
· retrieved information
· semantic relationships
· instructions
· memory state
The quality of context heavily influences:
· factual accuracy
· reasoning quality
· answer usefulness
· hallucination rate
· citation quality
· semantic relevance
Bad context causes:
· hallucinations
· contradictions
· incomplete answers
· poor retrieval grounding
· weak reasoning
7. Relationship With RAG Systems
A RAG pipeline typically works like this:
User Query
→ Retrieval
→ Context Assembly
→ LLM Processing
→ Answer Generation
Most systems focus heavily on retrieval.
But context assembly is equally important.
context-engine.json controls this layer.
8. Relationship With Other GEO Files
context-engine.json works together with:
| File | Role |
| rag-index.json | Retrieval orchestration |
| reasoning-map.json | Semantic reasoning flow |
| knowledge-graph.json | Entity relationships |
| entity-authority.json | Authority weighting |
| citation-preferences.json | Citation routing |
| answer-primitives.json | Atomic answer blocks |
| trust-signals.json | Trust grounding |
The context engine coordinates all contextual information.
9. Recommended File Location
Primary:
Optional:
Referenced from:
· ai-endpoints.json
· llmsfull.txt
· reasoning-map.json
· rag-index.json
10. Recommended MIME Type
application/json
11. Core Design Principles
11.1 Context-First Design
AI answers depend on context quality.
11.2 Semantic Coherence
Context should preserve logical continuity.
11.3 Token Efficiency
Token budgets should be optimized.
11.4 Retrieval Coordination
Context should align with retrieval systems.
11.5 Dynamic Adaptation
Context should adapt to intent and query complexity.
11.6 Grounding Preservation
Context should reduce hallucinations.
11.7 Hierarchical Prioritization
Not all context is equally important.
12. Main Components of context-engine.json
A complete context engine should include:
1. metadata
2. context assembly rules
3. token allocation systems
4. semantic prioritization
5. contextual relevance scoring
6. grounding rules
7. retrieval coordination
8. semantic continuity systems
9. hallucination prevention logic
10. adaptive context flows
11. chunk fusion systems
12. contextual compression logic
13. memory-aware systems
14. evidence prioritization
15. fallback context logic
16. conflict resolution systems
17. context validation systems
13. Context Assembly Fundamentals
Context assembly determines:
· which information enters the context window
· how information is ordered
· how semantic flow is preserved
· which supporting evidence is injected
Strong context assembly is critical.
14. Token Budget Optimization
LLMs have token limits.
Example:
4k tokens
32k tokens
128k tokens
1M+ tokens
Context engines should optimize:
· token allocation
· redundancy reduction
· semantic density
· chunk prioritization
15. Semantic Prioritization
The engine should prioritize:
· authoritative content
· canonical definitions
· foundational concepts
· highly relevant chunks
· supporting evidence
· trusted citations
Example:
{
“priority”: “critical”
}
16. Contextual Relevance Scoring
Every chunk should receive relevance scoring.
Example:
{
“contextRelevance”: 0.94
}
Factors may include:
· semantic similarity
· authority
· freshness
· retrieval confidence
· contextual continuity
· evidence quality
17. Semantic Continuity Systems
Good context should:
· preserve logical flow
· maintain semantic continuity
· avoid disconnected chunks
· reduce fragmentation
Example:
Definition
→ Mechanism
→ Example
→ Benefits
→ Implementation
18. Contextual Compression
Sometimes context must be compressed.
Compression should:
· preserve meaning
· preserve entities
· preserve evidence
· reduce redundancy
· maintain semantic density
Avoid:
· losing foundational context
· removing critical dependencies
· fragmenting explanations
19. Dynamic Context Adaptation
Context should adapt based on:
· query intent
· user expertise
· token availability
· retrieval quality
· reasoning depth
Example:
Beginner query
→ broader explanations
Expert query
→ concise technical context
20. Hallucination Prevention Systems
Hallucinations often occur when:
· retrieval is weak
· context is incomplete
· evidence is absent
· semantic continuity breaks
The context engine should:
· prioritize trusted sources
· preserve grounding
· inject supporting evidence
· validate semantic coherence
21. Grounding Architecture
Grounding means anchoring answers to:
· retrieved evidence
· authoritative definitions
· trusted sources
· contextual references
Grounded systems produce:
· safer answers
· more accurate answers
· more citable answers
22. Chunk Fusion Systems
AI systems often retrieve multiple chunks.
The context engine should define:
· how chunks merge
· how conflicts resolve
· how semantic overlap is handled
· how redundancy is reduced
23. Contextual Hierarchies
Context should have layers.
Suggested hierarchy:
Primary Context
→ Core Definitions
→ Supporting Evidence
→ Examples
→ Extended Context
24. Context Window Structuring
Recommended order:
1. Foundational definitions
2. Relevant retrieval chunks
3. Supporting evidence
4. Contextual examples
5. Citations
6. Supplemental information
25. Relationship With AI Memory Systems
Future AI systems may maintain:
· persistent memory
· long-term semantic state
· user preference memory
· retrieval history
The context engine can support:
· memory-aware retrieval
· adaptive context construction
· semantic reinforcement
26. Contextual Conflict Resolution
Retrieved chunks may conflict.
The engine should define:
· conflict resolution priorities
· canonical preference rules
· authority overrides
· freshness overrides
Example:
{
“ifConflict”: “preferHigherAuthority”
}
27. Retrieval Coordination
Context engines should coordinate with retrieval systems.
Example flow:
Query
→ Intent Analysis
→ Retrieval
→ Context Scoring
→ Chunk Fusion
→ Grounding Validation
→ Final Context Assembly
28. Relationship With AI Agents
Future AI agents may:
· dynamically assemble context
· perform multi-stage retrieval
· optimize token usage
· validate grounding
· coordinate reasoning systems
context-engine.json supports these systems.
29. Relationship With AI Search Engines
AI search engines increasingly optimize for:
· contextual coherence
· semantic continuity
· grounded retrieval
· answer usefulness
The context engine improves all of these.
30. Relationship With GEO
This is one of the most advanced GEO files.
Because future AI visibility may depend not only on:
· authority
· retrieval
· citations
but also:
· context quality
· grounding quality
· semantic continuity
· token optimization
· answer assembly
31. Common Mistakes
Mistake 1: Overloading Context Windows
Too much context reduces answer quality.
Mistake 2: Ignoring Semantic Continuity
Disconnected chunks damage reasoning.
Mistake 3: Weak Prioritization
Not all chunks deserve equal weight.
Mistake 4: No Grounding Logic
Ungrounded context increases hallucinations.
Mistake 5: Redundant Context
Repetition wastes token budgets.
Mistake 6: No Adaptive Logic
Different queries require different context structures.
32. Best Practices
32.1 Prioritize Foundational Context
Core concepts should appear first.
32.2 Optimize for Semantic Density
High-information chunks perform best.
32.3 Maintain Contextual Continuity
Preserve logical flow.
32.4 Reduce Redundancy
Avoid repeated concepts.
32.5 Align With Retrieval Systems
Context should reinforce retrieval quality.
32.6 Include Supporting Evidence
Ground answers whenever possible.
32.7 Use Dynamic Adaptation
Adjust context based on query complexity.
33. Enterprise-Level Use Cases
AI Search Engines
Context-aware answer assembly.
Enterprise AI Assistants
Internal contextual reasoning.
Customer Support AI
Grounded support answers.
Educational AI Systems
Progressive contextual learning.
Research Systems
Evidence-driven synthesis.
Autonomous AI Agents
Dynamic contextual planning.
34. Recommended Update Frequency
| Asset | Frequency |
| Context rules | Monthly |
| Token prioritization | Quarterly |
| Semantic continuity review | Quarterly |
| Grounding systems | Monthly |
| Retrieval coordination | Monthly |
| Full context audit | Every 6 months |
35. Full Reusable Prototype JSON Structure
{
“metadata”: {
“fileType”: “context-engine”,
“version”: “1.0.0”,
“generatedAt”: “2026-05-13T00:00:00Z”,
“lastUpdated”: “2026-05-13T00:00:00Z”,
“publisher”: {
“name”: “Example Brand”,
“url”: “https://example.com”
},
“description”: “Machine-readable context orchestration framework for retrieval-aware AI systems and semantic answer generation.”
},
“contextFramework”: {
“primaryModel”: “dynamic-semantic-context”,
“supportsAdaptiveContext”: true,
“supportsGrounding”: true,
“supportsSemanticContinuity”: true,
“supportsTokenOptimization”: true
},
“contextAssemblyRules”: {
“maxContextTokens”: 4000,
“prioritizeCanonicalSources”: true,
“prioritizeHighAuthorityChunks”: true,
“allowSupportingEvidence”: true,
“avoidRedundantConcepts”: true,
“preserveSemanticFlow”: true,
“preferFoundationalDefinitions”: true
},
“semanticPrioritization”: {
“critical”: [
“Generative Engine Optimization”,
“AI SEO”,
“LLM Optimization”
],
“high”: [
“Semantic SEO”,
“Entity SEO”
],
“medium”: [
“Technical SEO”
]
},
“tokenAllocation”: {
“foundationalContext”: 0.30,
“retrievalChunks”: 0.35,
“supportingEvidence”: 0.15,
“examples”: 0.10,
“citations”: 0.10
},
“contextFlows”: [
{
“flowId”: “context:geo-definition”,
“queryExamples”: [
“What is GEO?”,
“Explain Generative Engine Optimization”
],
“contextStructure”: [
{
“order”: 1,
“type”: “foundational-definition”,
“source”: “https://example.com/generative-engine-optimization/”,
“priority”: “critical”
},
{
“order”: 2,
“type”: “comparison-context”,
“source”: “https://example.com/seo-vs-geo/”,
“priority”: “high”
},
{
“order”: 3,
“type”: “supporting-evidence”,
“source”: “https://example.com/case-study/”,
“priority”: “medium”
}
],
“contextRelevance”: 0.96,
“groundingConfidence”: 0.94
}
],
“groundingRules”: {
“requireSupportingEvidence”: true,
“preferAuthoritativeSources”: true,
“allowCitationInjection”: true,
“minimumAuthorityThreshold”: 0.75
},
“semanticContinuity”: {
“preserveConceptOrder”: true,
“avoidAbruptTransitions”: true,
“allowContextExpansion”: true,
“maintainTopicHierarchy”: true
},
“contextCompression”: {
“enabled”: true,
“preserveEntities”: true,
“preserveDefinitions”: true,
“preserveEvidence”: true,
“removeRedundancy”: true
},
“hallucinationPrevention”: {
“preferGroundedSources”: true,
“avoidLowConfidenceChunks”: true,
“requireSemanticValidation”: true,
“allowFallbackRetrieval”: true
},
“conflictResolution”: {
“ifConflict”: “preferHigherAuthority”,
“ifEqualAuthority”: “preferFresherContent”,
“ifSemanticConflict”: “preferCanonicalDefinition”
},
“adaptiveContext”: {
“beginnerQueries”: {
“expandDefinitions”: true,
“includeExamples”: true
},
“expertQueries”: {
“compressFoundationalContext”: true,
“prioritizeTechnicalDepth”: true
}
},
“retrievalCoordination”: {
“useRagIndex”: true,
“preferHighConfidenceChunks”: true,
“semanticThreshold”: 0.78,
“maxRetrievalChunks”: 5
},
“citationPolicy”: {
“preferCanonicalSources”: true,
“allowSupportingCitations”: true,
“citationPlacement”: “end-of-context”
},
“maintenance”: {
“maintainedBy”: “AI Context Team”,
“reviewFrequency”: “monthly”,
“lastReviewed”: “2026-05-13”,
“nextReview”: “2026-06-13”
}
}
36. ThatWare-Specific Strategic Direction
For ThatWare, the context engine should strongly prioritize:
Generative Engine Optimization
AI SEO
LLM Optimization
Semantic SEO
Entity SEO
Knowledge Graph Optimization
AI Search Visibility
Recommended context priorities:
Foundational Definitions
→ Retrieval Mechanisms
→ Semantic Authority
→ GEO Methodologies
→ Implementation Frameworks
→ Supporting Case Studies
ThatWare’s context systems should optimize for:
· semantic density
· retrieval precision
· grounding strength
· contextual continuity
· AI answer usefulness
· citation readiness
The goal is not simply retrieval.
The goal is:
Building the most contextually understandable AI-native SEO infrastructure possible.
37. Final Strategic Summary
context-engine.json should be treated as the contextual orchestration brain of an AI-optimized website.
It defines:
· how context should be assembled
· how retrieval outputs should merge
· how semantic continuity should be preserved
· how grounding should function
· how token budgets should be optimized
· how hallucinations should be reduced
· how semantic relevance should be prioritized
· how answer-ready context should be constructed
For GEO and AI-native search infrastructure, this file can become one of the most technically advanced contextual orchestration systems in the entire architecture.
A properly designed context-engine.json transforms a website from merely retrievable into being contextually grounded, semantically coherent, dynamically adaptable, and AI-answer optimized.
