Get a Customized Website Audit and Online Marketing Strategy and Action Plan
1. LDA COSINE
LDA
Latent Dirichlet Allocation (LDA) is a “generative probabilistic model” of a collection of composites made up of parts. In terms of topic modelling, the composites are documents and the parts are words and/or phrases (phrases n-words in length are referred to as n-grams).
Topic models provide a simple way to analyze large volumes of unlabeled text. Topic modelling is a method for the unsupervised classification of documents. Latent Dirichlet allocation (LDA) is a particularly popular method for fitting a topic model. It treats each document as a mixture of topics, and each topic as a mixture of words. This allows documents to “overlap” each other in terms of content, rather than being separated into discrete groups, in a way that mirrors the typical use of natural language.
Although LDA has many applications in many various fields, we used LDA to find out the keyword’s belonging probability in a particular topic from a particular document. Each and every keyword has a belonging probability in the particular topic which also indicates their relevance to a particular document.
Cosine Similarity
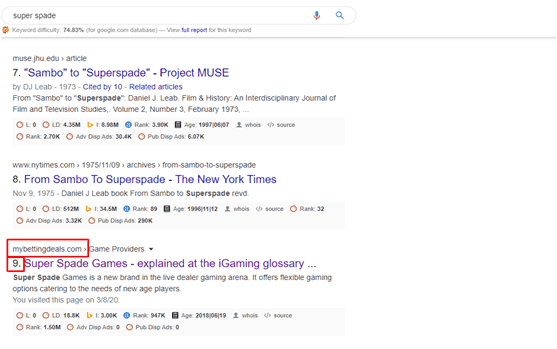
Cosine Similarity is a measure of similarity between two non-zero vectors that estimates the cosine angle between them. If the cosine angle orientations between two vectors are the same then they have a cosine similarity of 1 and also with different orientation the cosine similarity will be 0 or in between 0-1. The cosine similarity is particularly used in positive space, where the outcome is neatly bounded in [0, 1]. Keyword: super spade URL: https://mybettingdeals.com/glossary/s/super-spade-games/
PRINCIPLES OF MECHANISM
URL: https://mybettingdeals.com/glossary/s/super-spade-games/
Keyword: super spade
Cosine value:
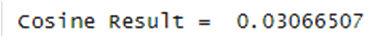
Cosine value will tell us how many keywords are available in the document. If the cosine value is 0 that means the keyword is not present in the document. If the cosine value is 0.5 or greater than 0.5 that means keyword presence in the document is very good & as well as keyword rank is definitely good.
APPLIED SEMANTIC
This is called a package which will help to scrap the website & run the program.

1. Scrap the website
2. Calculate the cosine value
3. Calculate LDA

OUTPUT
Before LDA cosine keyword rank
keyword rank is on the 6th page of the google rank.
After LDA cosine keyword rank
We can see that rank increases and came on the first page of the google rank.
2. COSINE WITH RELATIVE PERCENTAGE USING BERT
BERT stands for Bidirectional Encoder Representations from Transformers
It is Google’s neural network-based technique for natural language processing (NLP) pre-training. BERT helps to better understand what you’re actually looking for when you enter a search query. BERT can help computers understand the language a bit more than humans do. BERT helps better understand the nuances and context of words in searches and better match those queries with more relevant results. It is also used for featured snippets.
Cosine Similarity
Cosine Similarity is a measure of similarity between two non-zero vectors that estimates the cosine angle between them. If the cosine angle orientations between two vectors are the same then they have a cosine similarity of 1 and also with different orientations the cosine similarity will be 0 or between 0-1. The cosine similarity is particularly used in positive space, where the outcome is neatly bounded in [0, 1].
Keyword: best betting deals
URL:https://mybettingdeals.com/best-betting-deals/
PRINCIPLES OF MECHANISM
URL: https://mybettingdeals.com/best-betting-deals/
Keyword: best betting deals
Cosine value:
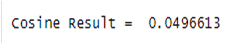
Cosine value will tell us how many keywords available in the document. If the cosine value is 0 that means the keyword is not present in the document. If the cosine value is 0.5 or greater than 0.5 that means keyword presence in the document is very good.
Relative Percentage
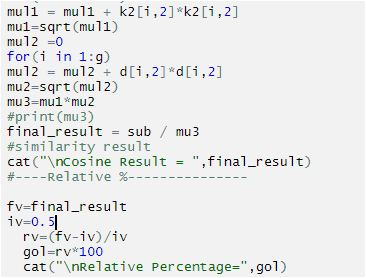
Formula is:
(Final value-initial value)/initial value *100
Always initial value start with= 0.5
Cosine value of landing page taken as final value.

OBSERVATION
I have taken competitors to compare cosine value with Relative Percentage of landing page.
https://www.gamblingsites.com/sports-betting/sites/bonuses-rewards/
https://bookiesbonuses.com/betting-deals

Proposed Semantic
Competitors Compare with landing page
We can see that the Landing page’s cosine value is smaller than the average competitors’ cosine value.
APPLIED SEMANTIC
This is called a package which will help to scrap the website & run the program.
1. Scrap the website
2. Calculate the cosine value
3. Calculate Relative percentage
OUTPUT
Before using BERT- keyword rank
keyword rank is on the 2nd page of the Google rank.
After using BERT- keyword rank
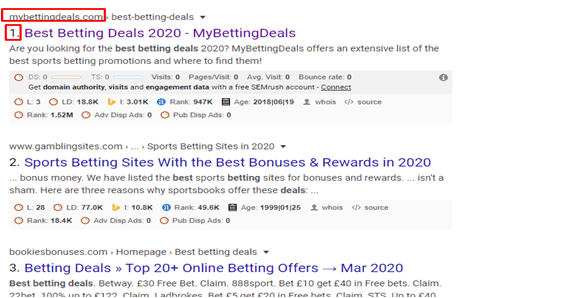
We can see that rank increases and came on the first page of the google rank.
3. BAG OF WORDS
Bag of Words, in short BOW, is used to extract a featured keyword from a text document. These features can be used for training machine learning algorithms. Basically speaking Bag of words is an algorithm that counts how many times a word appears in a document. Word counts allow us to compare documents and their similarities and it is used in many various fields.
Keyword : bovada
URL: https://mybettingdeals.com/sports-betting/bovada-sports-betting/

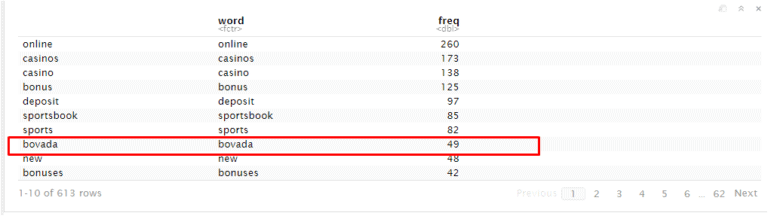
As we can see that landing page use “bovada” keyword 49 times
PRINCIPLES OF MECHANISM
URL: https://mybettingdeals.com/sports-betting/bovada-sports-betting/
Keyword: bovada


Bag of words tell us how many important words available in the document as well as tell how many time they appear. we can see here “bovada” keyword available in the document 49 times. Now we will compare with competitor and check how many time they use “bovada” keyword in the document. Then we will try to add the keyword in the content of landing page and try to increase the rank.
OBSERVATION
I have taken competitors to compare the bag of words value of particular keywords
https://www.bovada.lv/
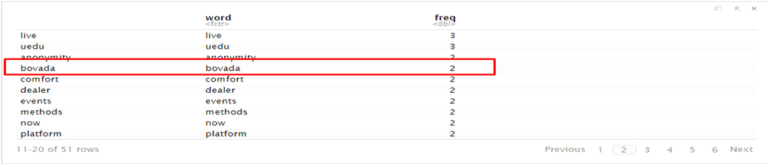
https://www.sportsbookreview.com/best-sportsbooks/bovada/

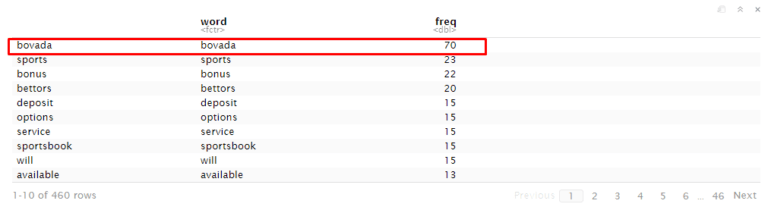
onlineunitedstatescasinos.com/bovada-casino/

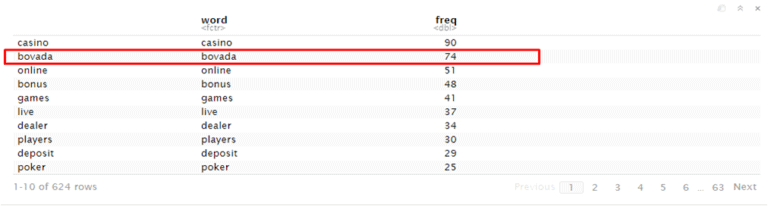
As we can see that competitors use bovada keyword much more rather than a landing page. For this reason, the frequency of the word on the competitor sites is high.
APPLIED SEMANTIC
This is called a package which will help to scrap the website & run the program.
1. Scrap the website

2. Fetching words

OUTPUT
Before Bag of words keyword rank
keyword rank is “NA” of the google rank.
After Bag of words keyword rank
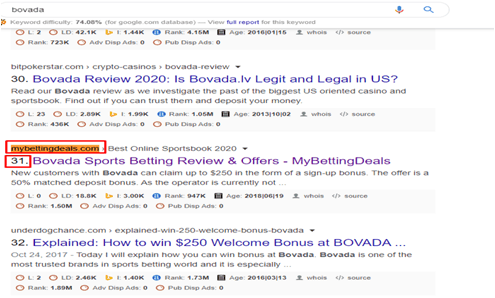
We can see that rank increases and came in 31st position of the google rank.
4. TOPIC MODEL USING BERT
BERT stands for Bidirectional Encoder Representations from Transformers
It is Google’s neural network-based technique for natural language processing (NLP) pre-training. BERT helps to better understand what you’re actually looking for when you enter a search query. BERT can help computers understand the language a bit more than humans do. BERT helps better understand the nuances and context of words in searches and better match those queries with more relevant results. It is also used for featured snippets.
In machine learning and natural language processing, a topic model is a type of statistical model for discovering the abstract “topics” that occur in a collection of documents. Topic modelling is a frequently used text-mining tool for the discovery of hidden semantic structures in a text body. LDA is also a topic model.
URL:https://mybettingdeals.com/online-casinos/
PRINCIPLES OF MECHANISM
URL:https://mybettingdeals.com/online-casinos/
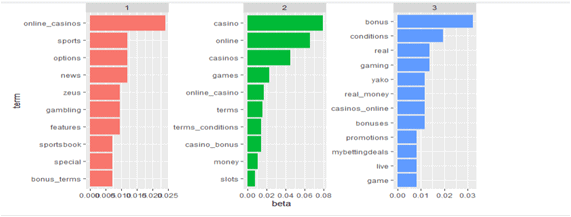
Here we take competitors’ keywords and landing page keywords then find which keywords are common between a landing page and competitors’ keywords.
OBSERVATION
I have taken competitors to collect words
https://www.caesarscasino.com/
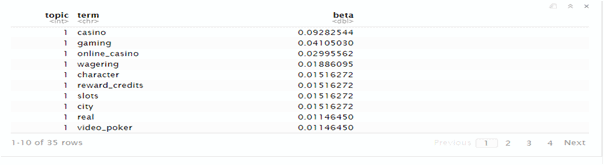
https://www.slotsup.com/online-casinos
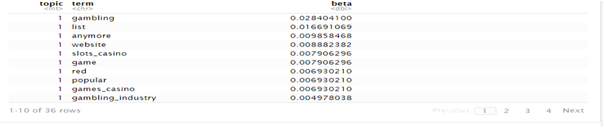
Similar words between competitors and landing page
APPLIED SEMANTIC
This is called package which will help to scrap the website & run the program.
1. Scrap the website




OUTPUT
Before using BERT- keyword rank
keyword rank is in “NA” of the Google rank.
After using BERT- keyword rank
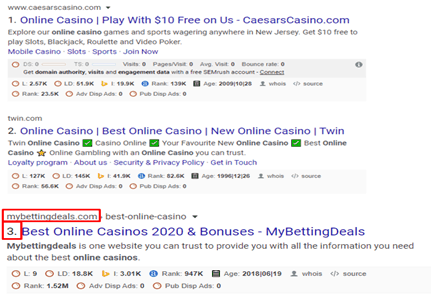
We can see that rank is increases and came in the first page of the google rank.
5. HIERARCHICAL CLUSTERING
BERT stands for Bidirectional Encoder Representations from Transformers
It is Google’s neural network-based technique for natural language processing (NLP) pre-training. BERT helps to better understand what you’re actually looking for when you enter a search query. BERT can help computers understand the language a bit more as humans do. BERT helps better understand the nuances and context of words in searches and better match those queries with more relevant results. It is also used for featured snippets.
In machine learning and natural language processing, a topic model is a type of statistical model for discovering the abstract “topics” that occur in a collection of documents. Topic modelling is a frequently used text-mining tool for the discovery of hidden semantic structures in a text body. LDA is also a topic model.
URL:https://mybettingdeals.com/online-casinos/
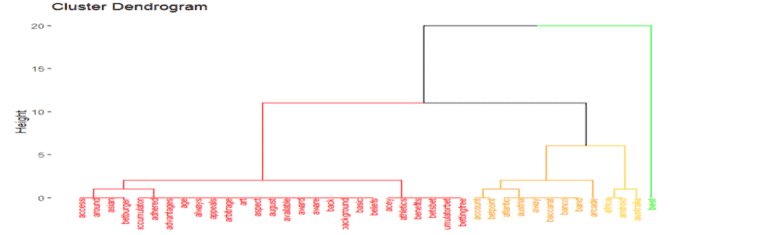
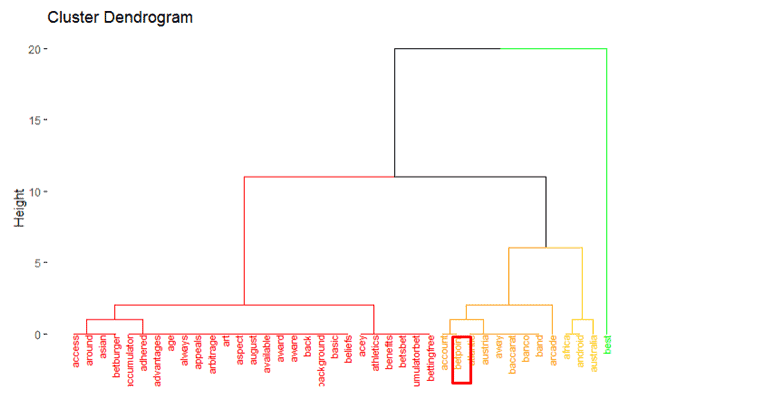
OBSERVATION
I have taken competitors to compare bag of words value of particular keyword
https://www.betpoint.it/
sgdigital.com/game360-extends-reach-with-betpoint-in-italy
rcdmallorca.es/en/content/news/news/el-rcd-mallorca-goes-to-menorca-with-betpoint
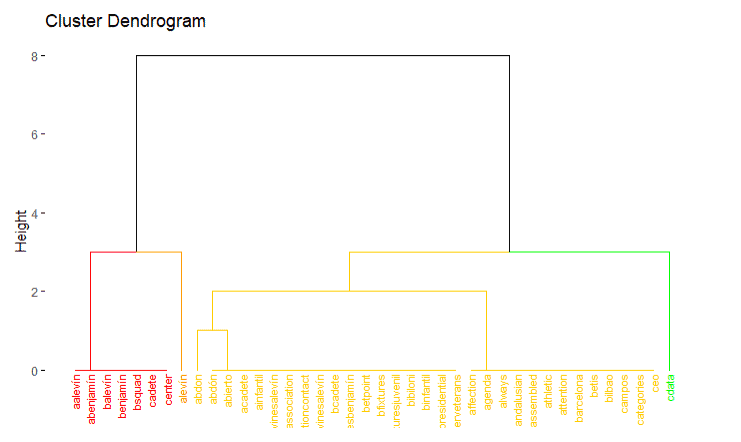
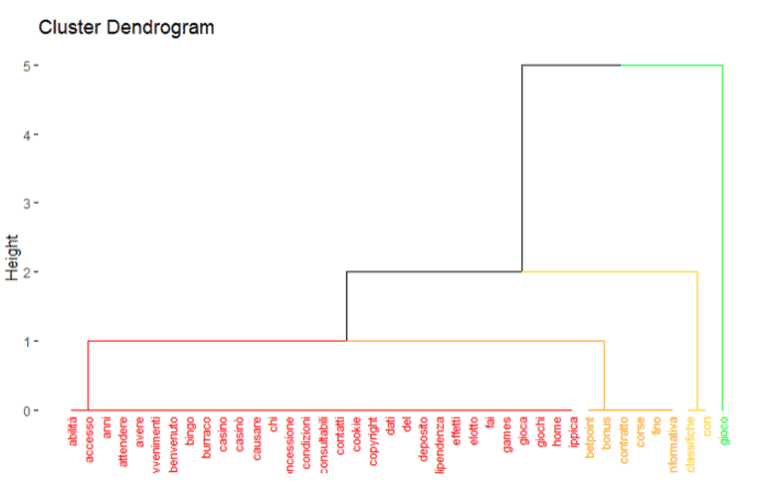
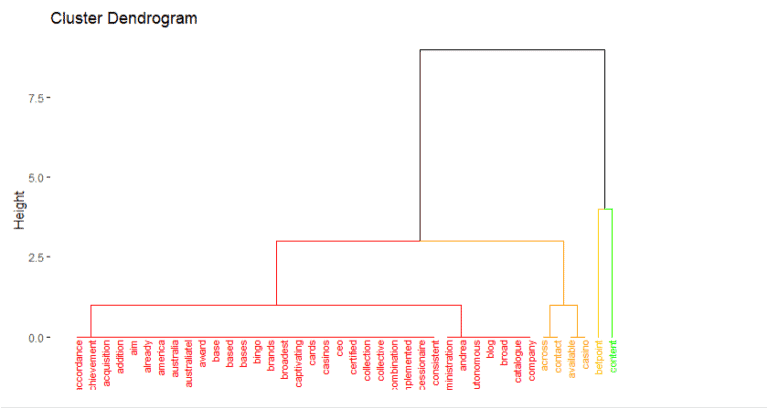
As we can see that competitors grouping is small rather than landing page grouping. So landing page have seven groups of cluster available.
APPLIED SEMANTIC
This is called package which will help to scrap the website & run the program.
1. Scrap the website

OUTPUT
Before Hierarchical clustering keyword rank
keyword rank is in 2nd page of the google rank.
After Hierarchical clustering keyword rank
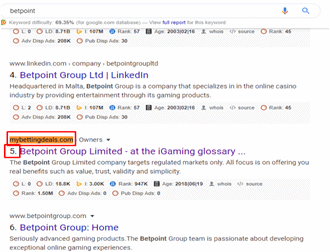
We can see that rank increases and came in 1st page of the google rank.
6. COSINE SIMILARITY
Cosine Similarity
Cosine Similarity is a measure of similarity between two non-zero vectors that estimates the cosine angle between them. If the cosine angle orientations between two vectors are the same then they have a cosine similarity of 1 and also with different orientation the cosine similarity will be 0 or in between 0-1. The cosine similarity is particularly used in positive space, where the outcome is neatly bounded in [0, 1].
Keyword : android casino bonus
URL: https://mybettingdeals.com/android-casinos/

PRINCIPLE OF MECHANISM
URL: https://mybettingdeals.com/android-casinos/
Keyword: android casino bonus
Cosine value:
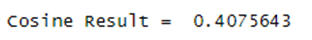
Cosine value will tell us how many keywords available in the document. If the cosine value is 0 that means the keyword is not present in the document. If the cosine value is 0.5 or greater than 0.5 that means keyword presence in the document is very good & as well as keyword rank is definitely good.
Here the result came above 0.5 so the keyword of this landing page cosine value is very good. That means this keyword use on my landing page very frequently.
OBSERVATION
I have taken competitors to compare cosine value
https://www.nodepositkings.com/no-deposit-casino-mobile/
http://www.nodepositrewards.com/mobile/
https://www.casinobonuscheck.com/android-bonus/
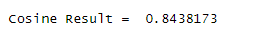
As we can see that competitors grouping is small rather than landing page grouping. So landing page has seven groups of cluster available.
APPLIED SEMANTIC
This is called package which will help to scrap the website & run the program.
1. Scrap the website
2. Calculate cosine value
OUTPUT
Before cosine keyword rank
keyword rank is in 4th page of the google rank.
After cosine keyword rank
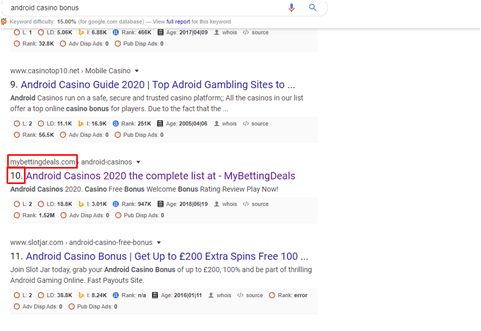
We can see that rank increases and came in the first page of the google rank.
7. STOP WORDS CHECKING USING BERT
BERT stands for Bidirectional Encoder Representations from Transformers.
It is Google’s neural network-based technique for natural language processing (NLP) pre-training. BERT helps to better understand what you’re actually looking for when you enter a search query. BERT can help computers understand the language a bit more as humans do. BERT helps better understand the nuances and context of words in searches and better match those queries with more relevant results. It is also used for featured snippets.
Stop word is a commonly used word that a search engine has been programmed to ignore, both when indexing entries for searching and when retrieving them as the result of a search query.
Keyword : online casino
URL:https://mybettingdeals.com/online-casinos/
MECHANISM
URL: https://mybettingdeals.com/online-casinos/
Keyword : online casino
Cosine value:
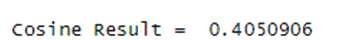
Cosine value will tell us how many keywords available in the document. If the cosine value is 0 that means the keyword is not present in the document. If the cosine value is 0.5 or greater than 0.5 that means keyword presence in the document is very good.
Latent Dirichlet Allocation (LDA) is a “generative probabilistic model” of a collection of composites made up of parts. In terms of topic modelling, the composites are documents and the parts are words and/or phrases (phrases n-words in length are referred to as n-grams).
Topic models provide a simple way to analyze large volumes of unlabeled text. Topic modelling is a method for the unsupervised classification of documents. Latent Dirichlet allocation (LDA) is a particularly popular method for fitting a topic model. It treats each document as a mixture of topics, and each topic as a mixture of words. This allows documents to “overlap” each other in terms of content, rather than being separated into discrete groups, in a way that mirrors the typical use of natural language.
Although LDA has many applications in many various fields, we used LDA to find out the keyword’s belonging probability in particular topic from a particular document. Each and every keyword has a belonging probability in particular topic which also indicates their relevance to a particular document.

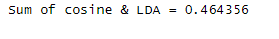
OBSERVATION
I have taken competitors to Differentiate.
First I search with stop words two competitors and make lda cosine of two competitors then search without stop words two competitors and make LDA cosine. Then differentiate those result and compare with landing page lda cosine.
https://www.caesarscasino.com/
https://www.foxwoods.com/
https://www.sanmanuel.com/
After Differentiate
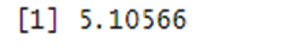
https://www.casinobonuscheck.com/android-bonus/
As we can see that competitors grouping is small rather than landing page grouping. So landing page have seven groups of cluster available.
APPLIED SEMANTIC
This is called package which will help to scrap the website & run the program.
1. Scrap the website

OUTPUT
Before using BERT- keyword rank
keyword rank is in “NA” of the Google rank.
After using BERT- keyword rank
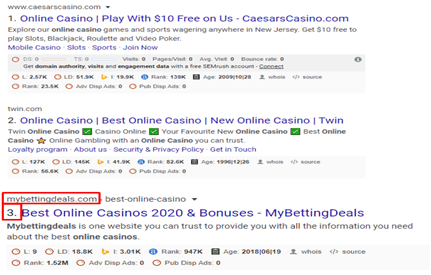
We can see that rank increases and came in the first page of the google rank.
8. LDA COSINE USING BERT
BERT stands for Bidirectional Encoder Representations from Transformers.
It is Google’s neural network-based technique for natural language processing (NLP) pre-training. BERT helps to better understand what you’re actually looking for when you enter a search query. BERT can help computers understand the language a bit more as humans do. BERT helps better understand the nuances and context of words in searches and better match those queries with more relevant results. It is also used for featured snippets
LDA
Latent Dirichlet Allocation (LDA) is a “generative probabilistic model” of a collection of composites made up of parts. In terms of topic modelling, the composites are documents and the parts are words and/or phrases (phrases n-words in length are referred to as n-grams).
Topic models provide a simple way to analyze large volumes of unlabeled text. Topic modelling is a method for the unsupervised classification of documents. Latent Dirichlet allocation (LDA) is a particularly popular method for fitting a topic model. It treats each document as a mixture of topics, and each topic as a mixture of words. This allows documents to “overlap” each other in terms of content, rather than being separated into discrete groups, in a way that mirrors the typical use of natural language.
Although LDA has many applications in many various fields, we used LDA to find out the keyword’s belonging probability in a particular topic from a particular document. Each and every keyword has a belonging probability in the particular topic which also indicates their relevance to a particular document.
Cosine Similarity
Cosine Similarity is a measure of similarity between two non-zero vectors that estimates the cosine angle between them. If the cosine angle orientations between two vectors are the same then they have a cosine similarity of 1 and also with different orientation the cosine similarity will be 0 or in between 0-1. The cosine similarity is particularly used in positive space, where the outcome is neatly bounded in [0, 1].
Keyword : super spade
URL: https://mybettingdeals.com/glossary/s/super-spade-games/
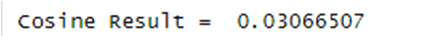
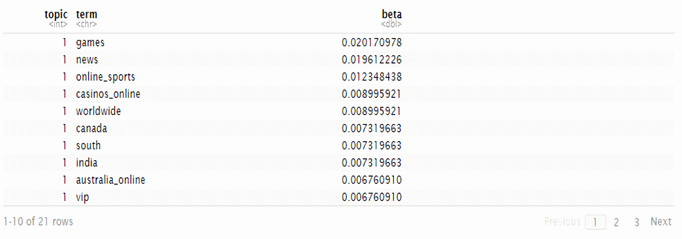

No keywords available for LDA value.

OBSERVATION
I have taken competitors to compare LDA cosine value
https://www.urbandictionary.com/define.php?term=Super%20Spade
https://findwords.info/term/superspade
https://www.superspadegames.com/

Proposed Semantic
Competitors Compare with a landing page, we can see that the Landing page LDA cosine value is smaller than the average of competitors LDA cosine value applied SEMANTIC This is called package which will help to scrap the website & run the program.
1. Scrap the website
OUTPUT
Before using BERT keyword rank
keyword rank is in 6th page of the Google rank.
After using BERT keyword rank
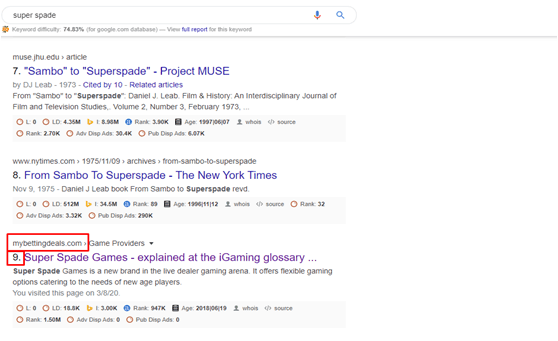
We can see that rank is increases and came in the first page of the Google rank.
9. NLP USING BERT
BERT stands for Bidirectional Encoder Representations from Transformers.
It is Google’s neural network-based technique for natural language processing (NLP) pre-training. BERT helps to better understand what you’re actually looking for when you enter a search query. BERT can help computers understand the language a bit more as humans do. BERT helps better understand the nuances and context of words in searches and better match those queries with more relevant results. It is also used for featured snippets
Natural language processing is also known as NLP. It deals with the interaction between computers and humans. In SEO, NLP is used to classify your content. This will help search engine index.
URL: https://mybettingdeals.com/online-casinos
Keyword : best betting deals


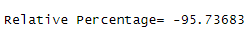
No keywords available for LDA value.
PRINCIPLES OF MECHANISM
URL: https://mybettingdeals.com/online-casinos/
We use NLP using BERT to retrieve all the words from the website and calculate cosine value of all words and make total of all cosine values and then compare them with the relative percentage of a particular keyword.
Relative Percentage
Formula is:
(Final value-initial value)/initial value *100
Always initial value start with= 0.5
Cosine value of landing page taken as final value
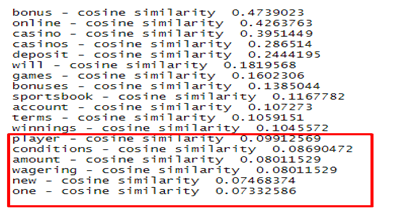
OBSERVATION
URL: https://mybettingdeals.com/online-casinos/
Main focus of this Algorithm is to check all the words frequencies with cosine value in the web page . Then check which words cosine value is low. Identify those words then try to increases the cosine value of those words in the web page.Here can see that marked words cosine values are very low. Those words need to increase cosine value.
APPLIED SEMANTIC
This is called package which will help to scrap the website & run the program.
1. Scrap the website

OUTPUT
Before using BERT keyword rank
keyword rank is in 3rd page of the Google rank.
After using BERT keyword rank
We can see that rank is increases and came in the first page of the Google rank.
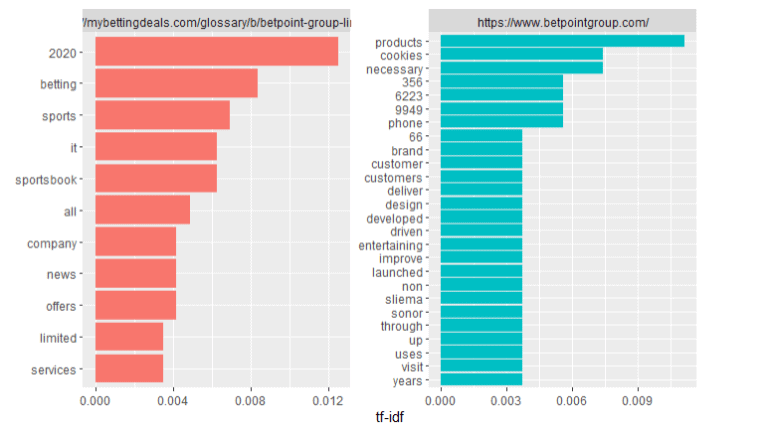
10. TF-IDF REPORT
TF-IDF stands for Term Frequency-Inverse Document frequency. The tf-idf weight in often used to indicate a keyword’s relevance of a particular
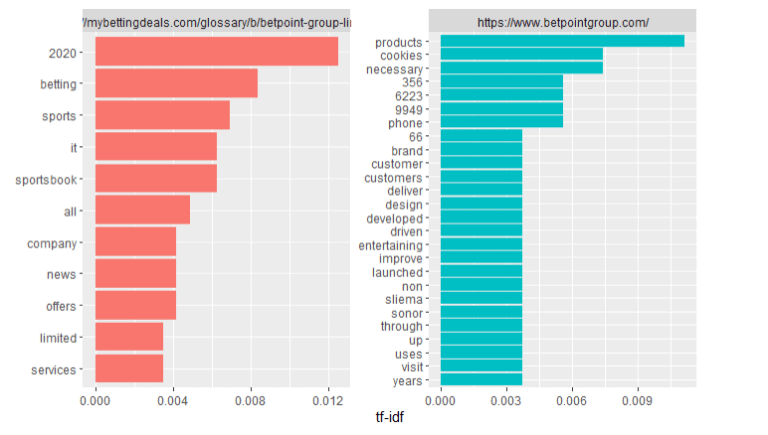
URL: https://mybettingdeals.com/glossary/b/betpoint-group-limited/
OBSERVATIONI have taken competitor to compare TF_idf term frequencies of words
https://www.betpointgroup.com/
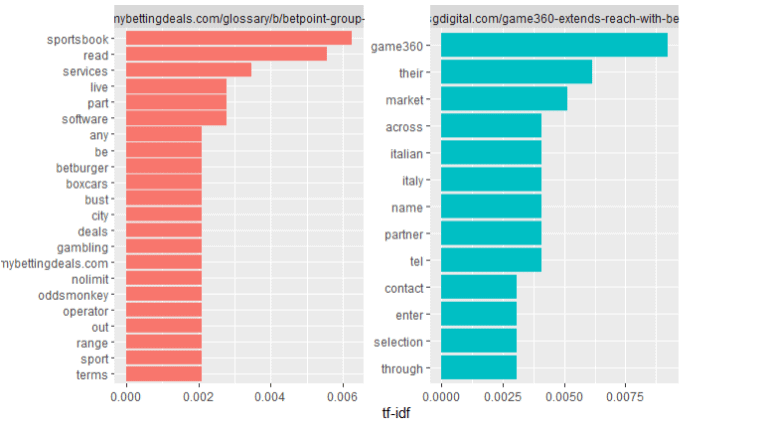
http://sgdigital.com/game360-extends-reach-with-betpoint-in-italy
casino.guru/betpoint-casino-it-review
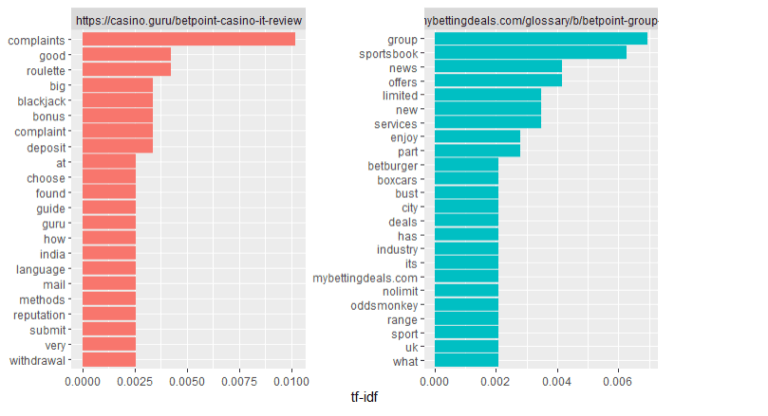
As we can see that landing page keywords compare with competitors keywords for make tf_idf. As we can see that sports book keyword available on first two site compare with competitors. But compare with third competitor we can see that landing page not showing sports book keyword. It happen Because of landing page compare term frequency with competitors.
APPLIED SEMANTIC
This is called package which will help to scrap the website & run the program.
1. Scrap the website
2. Fetching words

OUTPUT