Get a Customized Website SEO Audit and Online Marketing Strategy and Action
Do you have pages that have the potential for ranking and organic search traffic but aren’t part of your site structure? Or pages that aren’t supposed to be in your site structure, but Google finds them anyway?
The answer is most likely yes. At least, it is for the majority of websites!

These pages are known as orphan pages, and re-associating the excellent ones with your website structure helps you to fully utilize their potential (as does banning search engine bots from your low-value ones!).
⭐️So, Just What Are Orphan Pages?
Orphan pages are those that have no links to them anyplace on your website. Because there are no connections to them, neither website users nor site spiders will locate them.
So, how do you go about finding orphan pages?
You’ll need to employ a web crawler as well as a log file analyzer. Go for Screaming Frog!
⭐️How To Identify Orphaned Pages
If you wish to detect orphan pages, it is often best to compare the current URLs on your website to the URLs found in your log files. To do this, you must utilize a program to crawl your site and generate a list of your URLs. Then you must repeat the process with your log files. Once you get the lists, you must determine whether any URL matches the two of them. If you come across any, these are orphan pages.
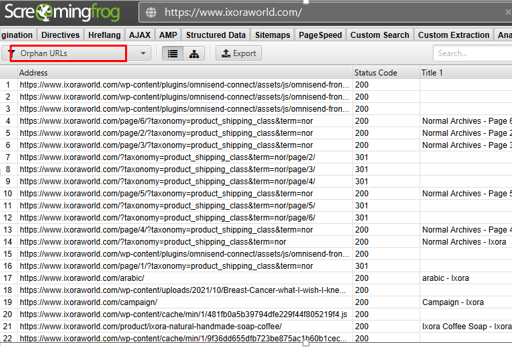
This method can be time-consuming and might result in blunders (missing orphan pages), especially when dealing with big websites. Fortunately, there is a more convenient and faster approach to locating orphaned pages. And all it takes is crawling your page with a program like Screaming Frog and granting it access to your log files. The system displays a list of your Orphan pages with a single click. Furthermore, you’ll obtain pertinent information about each page, such as its status code or the amount of GoogleBot visits.
⭐️Why Are Orphan Pages Detrimental To SEO?
Orphan pages generate two major SEO issues:
- Low traffic and rankings: Even if they have exceptional content, orphan sites seldom rank well in SERPs or receive a lot of organic search traffic.
- Crawl Waste: Low-value orphan pages (such as duplicate pages) can divert crawl money away from vital pages.
When orphan pages account for a sizable portion of the pages Google investigates on your website, such as more than 70% in the example below, you get a decent picture of how serious the situation is.
⭐️How Do I Resolve Orphan Pages?
Orphan pages are classified into two types:
- The predicted orphan pages that you shouldn’t be concerned about
- The unexpected orphan pages that you should be concerned about
Their type will determine the path you follow to fix your orphan pages. So, when we notice a significant amount of orphan pages, the first thing we do is look at what they look like and whether to expect them or not.
⭐️Expected Orphan Pages: Usually Not A Reason For Worry
After doing a site crawl and comparing it to your server log files to identify pages Google is finding but aren’t in your site structure, you can click on “found by Google” to receive a list of all your orphan pages.
Many of these orphan pages will be generated by:
- Pages that do not already exist on your site but have links to another site. It is usual to receive an external link to a page, which you subsequently erase or redirect. Google will still detect the old link because it still exists on the other website.
How to solve: Because you have no control over the links on other websites, the only method to remedy this sort of orphan page is to contact the site owner and request that they update the page to the right new location.
- Pages that return status codes other than 200. Google may continue to crawl pages that produce 4xx status codes even though it’s updated on your site.
How to resolve: Google will ultimately cease indexing these pages. Nothing to be concerned about.
- Pages that have expired. This is prevalent on websites with a large number of short-lived pages, such as classified ads that expire fast.
How to fix: We should only be concerned about expired sites discovered by Google if they have been orphaned for an extended period. Otherwise, the number of orphan pages only indicates the website’s page rotation rate.
⭐️Unexpected Orphan Pages: Cause For Concern?
- Expired pages that continue to return content: Some websites stop referring to expired material (such as goods withdrawn from the catalogue) and fail to produce a status code (such as HTTP 404 or 410), indicating that the content is no longer available. As a result, the previous page is still accessible.
How to Repair: In addition to eliminating links to expired information, you should ensure that the expired page is updated with the correct status code. Make sure to 404 or 410 the content if it is no longer available.
- Pages left out of a prior site migration: These were not redirected pages; thus, old material may still be visible.
How to fix:
If your new website has equivalent information, you should redirect these old URLs to it. If there isn’t, these outdated/omitted pages should produce a 404 or 410 status code.
- A syntactic error occurred when creating sitemaps: These generate erroneous URLs, which can deliver content, duplicates, or HTTP errors.
How to fix: If you discover erroneous URLs caused by a syntax problem, work with your development team to find a solution.
- A syntactic error occurred when creating canonical tags: Erroneous URLs. These URLs might be delivering status codes 200 OK or error codes.
How to Repair: If you discover erroneous URLs caused by a syntax problem, work with your development team to find a solution.
- Important, high-quality sites that aren’t connected in your website structure: Some websites employ navigation pages (content lists such as category pages or internal search result pages) that are only linked when one or more criteria are satisfied. Sub-categories, for example, will display in a menu only if the list is not empty or exceeds a certain amount of items. There are several instances in which we may fail to connect to high-value sites, whether due to an error in automation or not.
How to Repair: The correct technique is to decide when a page no longer meets business requirements for organic traffic and then delete it once and for all: remove links and return HTTP 404 or 410. By that time, link it to some other pages on the website.
⭐️Orphan Pages With Expired Content
When pages expire, it might result in the creation of orphan pages. This is sometimes natural and anticipated. In other circumstances, it is abnormal, and it requires corrective action.
The HTTP status code distinguishes between expired content’s anticipated and unexpected orphan pages. There were links to the page when Google crawled, but the pages weren’t linked when Screaming Frog crawled. Then, when the content expires, the regular orphan page reports that it is no longer available (it returns HTTP 404 or 410); however, the abnormal one remains (it returns HTTP 200).
Here’s how to tell them apart in Screaming Frog:
- Normal orphan pages: The number of HTTP 404 pages will rapidly increase, while the number of HTTP 200 pages will remain relatively consistent.
- Abnormal orphan pages: The number of HTTP 200 orphan pages will continue to rise over time.
⭐️Finding and Repairing Orphan Pages
Search engines cannot index orphan sites unless they appear in your sitemap – and even if they do, they might cause additional SEO concerns.
After you’ve completed these procedures and located your orphan pages, ask yourself the following questions:
- How significant is this page? If it is, figure out how to include it. If it isn’t, take it out.
- Despite being an orphan page, does this page rank for any keywords? If it is, figure out how to include it. If it isn’t, take it out.
- Where should the page be located in the taxonomy of your website?
- Is this a duplicate or a near copy of another page? Consider incorporating the material onto a related page that isn’t an orphan.
- Is the page optimized? Can you improve or link it?
- Does the page have links to other websites?
Use the procedures mentioned in this post to locate your orphan pages and remedy this issue.
⭐️Detailed Steps
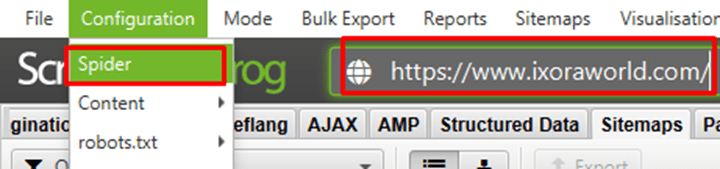
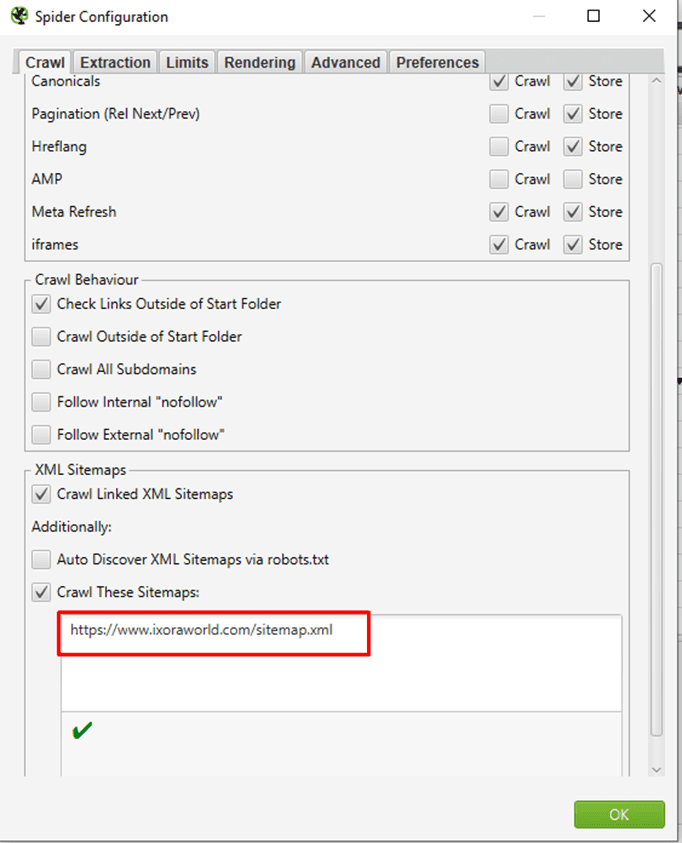
⭐️Step 1: Select ‘Crawl Linked XML Sitemaps’ under ‘Configuration > Spider > Crawl’
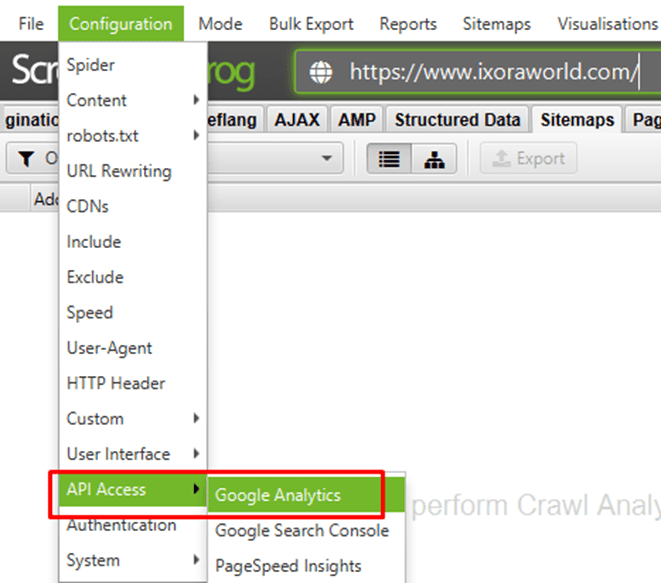
⭐️Step 2: Connect to Google Analytics under ‘Configuration > API Access
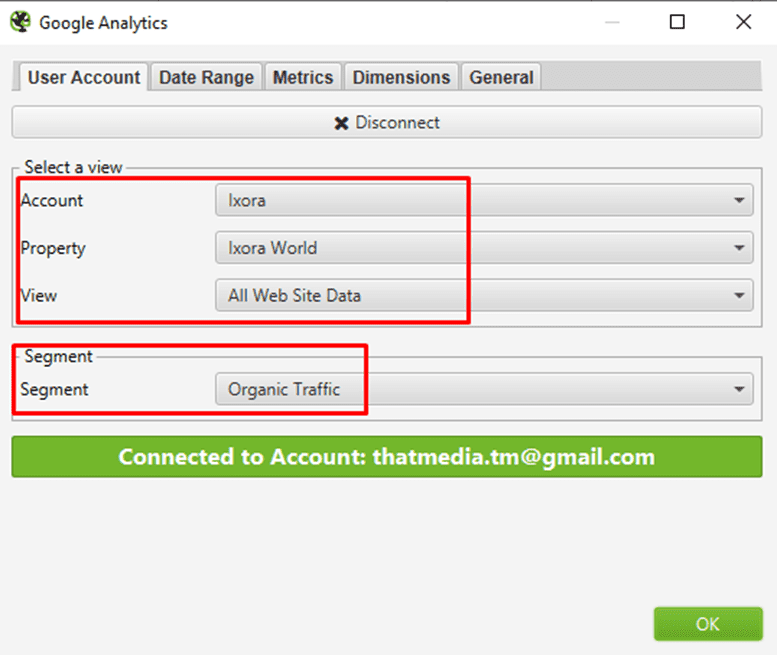
The segment can be tweaked to ‘All Users’ or ‘Paid Traffic’ if you’re interested in finding orphan pages via other sources as well.
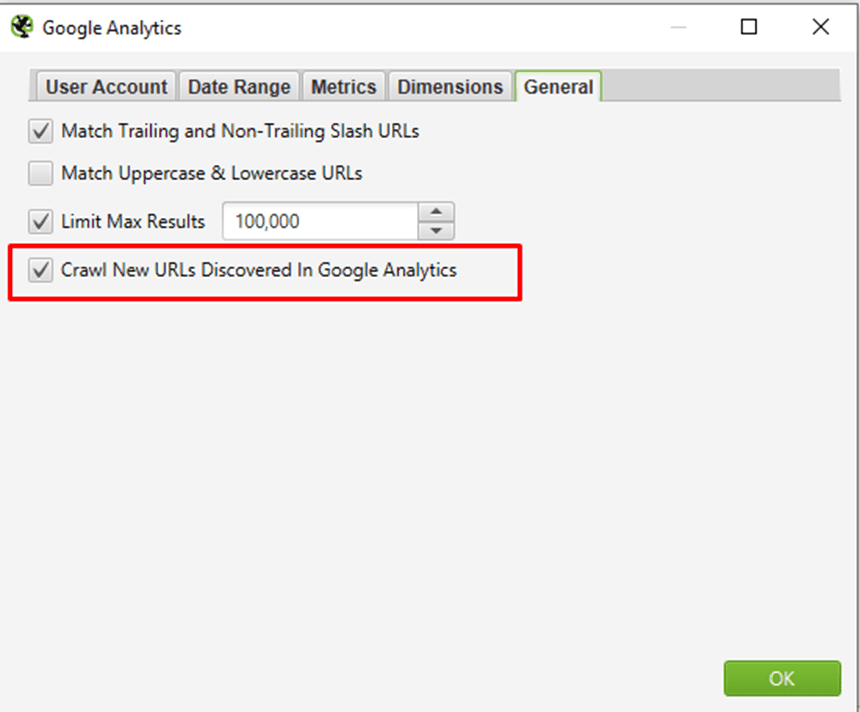
⭐️Step 3: Select ‘Crawl New URLs Discovered In Google Analytics’
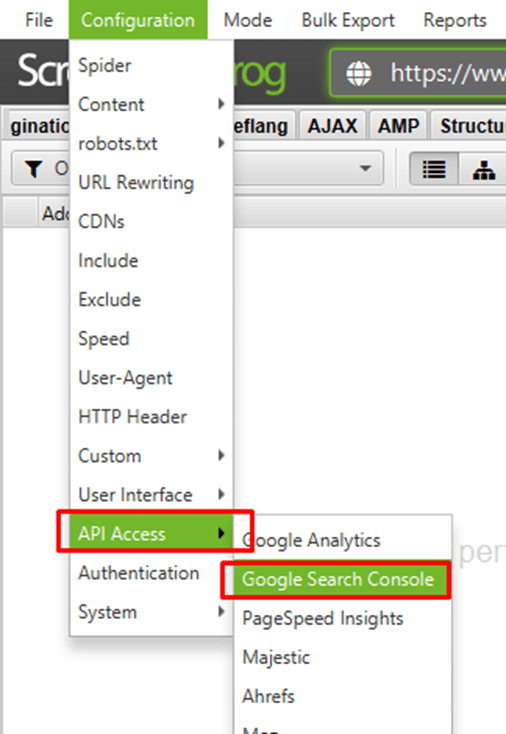
⭐️Step 4: Connect to Google Search Console under ‘Configuration > API Access’
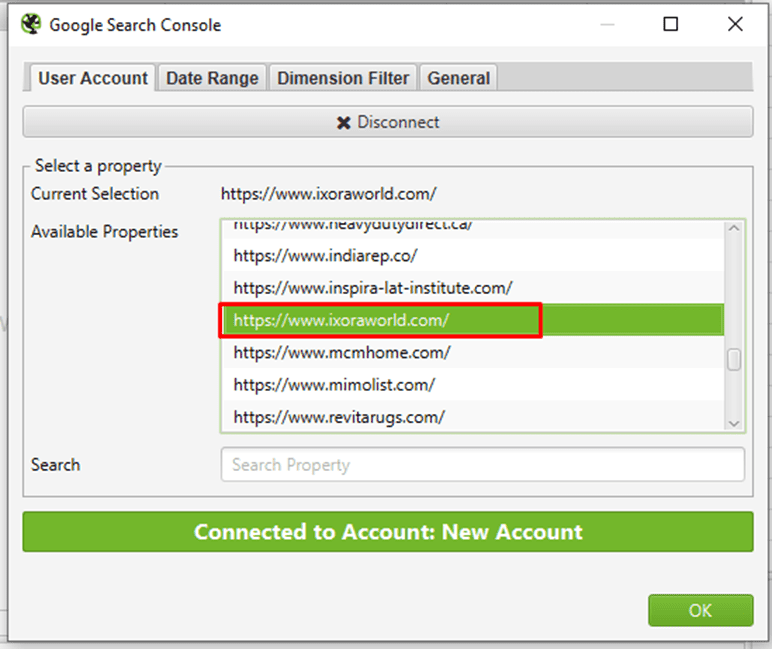
To find orphan pages that are receiving impressions under search but are not linked to internally, simply choose the correct property.
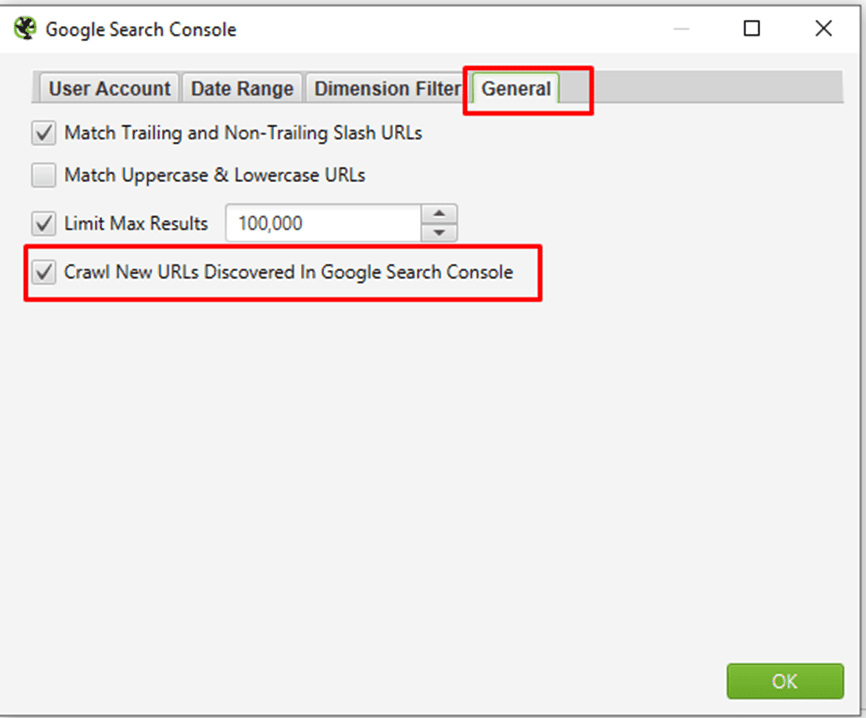
⭐️Step 5: Select ‘Crawl New URLs Discovered In Google Search Console’
⭐️Step 6: Crawl The Website


⭐️Step 7: Click ‘Crawl Analysis > Start’ To Populate Orphan URLs Filters

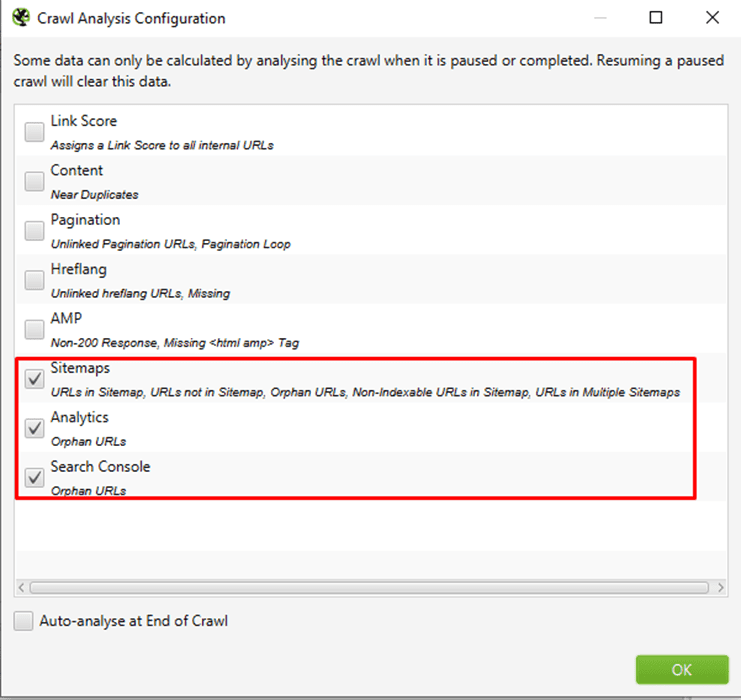
After clicking crawl analysis set the configuration.
Under ‘Crawl Analysis > Configure’ that ‘Sitemaps’, ‘Analytics’ and ‘Search Console’ are ticked.
Then start ‘Crawl Analysis’
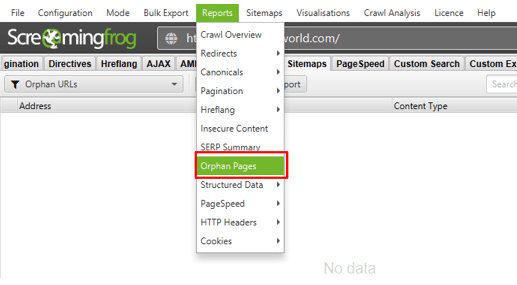
⭐️Step 8: Export Combined Orphan URLs via ‘Reports > Orphan Pages’
We have attached an exported excel file with these orphan pages found in the website.
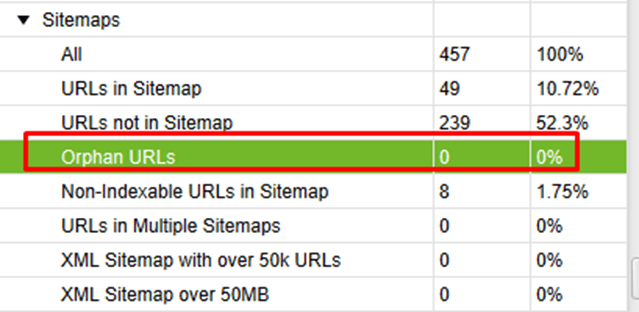
Orphan Pages Found By Sitemap:
Current Observation: No page found in sitemap.
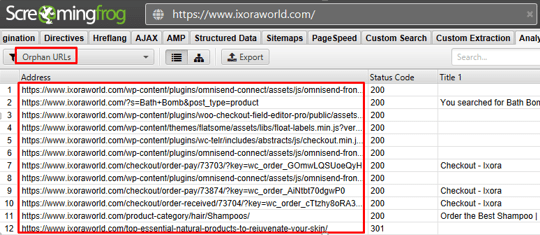
Orphan Pages Found By Google Analytics:
Current Observation: 12 orphan pages found.
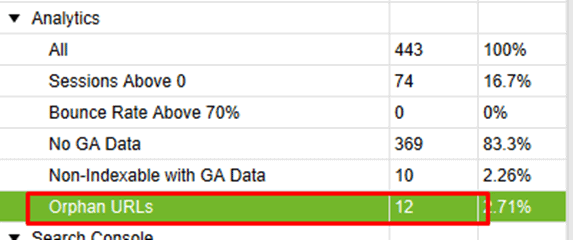
Orphan Pages Found By Google Search Console:
Current Observation: 24 orphan pages found.
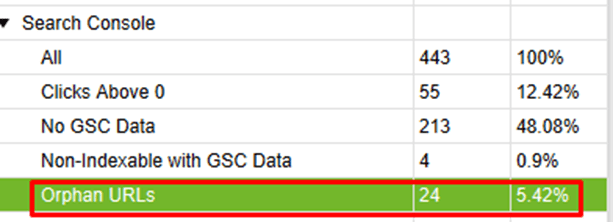
Once you understand what purpose the orphan page serves and how it aids in driving your website and marketing goals, you can determine what step if any to take with the page:
Link to it from other internal pages if it’s imperative for site visitors to find it via browsing.
Archive it if it’s no longer needed.
Leave it as-is if it’s serving a business need that doesn’t require internal linking to the page.
Expanding the Understanding of Orphan Pages and Their Impact on SEO
Orphan pages, as mentioned, are those hidden gems (or sometimes hidden problems) within your website’s structure. These pages, while often overlooked, can have significant implications on your SEO performance. Let’s explore further how orphan pages can impact not just your site’s crawlability but also your user experience, and how they can be turned into valuable assets.
Understanding the Role of Orphan Pages in Site Architecture
Before diving into advanced techniques for identifying orphan pages, it’s important to remember that a well-structured website is the foundation of any strong SEO campaign. This structure doesn’t only impact user experience but also plays a critical role in helping search engine bots understand your content hierarchy. Each page on your website should have at least one internal link leading to it. This makes it accessible to both users and search engines.
Orphan pages defy this basic principle, meaning that while they may exist on your site, they’re not linked from any other pages. This lack of connectivity is a signal to Google that these pages may not be important. If these pages are crucial to your business, their lack of visibility in the website’s internal link structure can hinder your SEO performance.
The Negative Impact on Crawl Budget
One of the most critical SEO challenges posed by orphan pages is related to crawl budget. Crawl budget refers to the number of pages a search engine will crawl on a website within a given timeframe. Googlebot and other search engine bots use this budget to index and evaluate pages.
When orphan pages exist in large numbers, they may consume unnecessary crawl budget, diverting resources away from more important pages. This means that even if you have high-quality content, valuable products, or key services buried in orphan pages, Googlebot might never find them because the crawl budget was spent crawling irrelevant or unnecessary orphan pages.
The result is that Google may never index these pages or, worse, may rank them poorly because they aren’t fully optimized in the context of the overall website structure. This highlights the importance of not only identifying orphan pages but also strategically linking to them.
User Experience and Orphan Pages
From a user experience perspective, orphan pages are a missed opportunity. Imagine landing on a website and finding great content, but it’s not linked to any other page. Users may find themselves unable to navigate to it unless they specifically search for it, or worse, they may never even discover it exists.
Orphan pages can also cause confusion for site visitors if they appear in search results but aren’t easily accessible or linked within the site itself. It leaves the impression that the website is poorly organized, which can deter users from engaging with the content or returning in the future. Properly integrating orphan pages into your website structure can boost navigation and help users discover all that your site offers.
SEO Benefits of Fixing Orphan Pages
While orphan pages are often seen as a hindrance, fixing them offers substantial SEO advantages. When managed properly, orphan pages can:
- Increase Crawl Efficiency: By fixing orphan pages, you help search engines crawl your site more efficiently, ensuring that important pages receive the attention they deserve.
- Improve Page Authority: If orphan pages are high-quality, linking them internally helps transfer link equity (page authority) from other pages to the orphan page, improving its chances of ranking.
- Boost User Engagement: By properly linking orphan pages, you increase the chances that users will engage with more content. This can lower bounce rates, increase time on site, and improve conversion rates.
- Enhance Keyword Relevance: If the orphan page targets a specific keyword or long-tail search term, linking it internally from other relevant pages can help boost its visibility in search results for those keywords.
Now that we’ve discussed the impact of orphan pages on your site’s SEO, let’s dive deeper into the strategies for finding and resolving these pages effectively.
Advanced Techniques for Identifying Orphan Pages
While using tools like Screaming Frog to crawl your website is an excellent first step, there are more sophisticated approaches to ensure you aren’t missing any orphan pages.
Leveraging Google Analytics and Google Search Console
Both Google Analytics and Google Search Console can be incredibly valuable in identifying orphan pages that might be receiving traffic or impressions but aren’t linked from within your website.
- Google Analytics: By examining traffic patterns, you can discover pages that are being visited directly or through external search traffic. These pages are likely orphan pages if no internal links point to them.
- Google Search Console: You can look for pages that are appearing in search results but aren’t linked internally. This can help pinpoint pages that may be ranking well but aren’t part of the website’s navigation, making them prime candidates for internal linking.
Audit Server Logs for Crawling Behavior
Another advanced technique for identifying orphan pages is to audit your server logs. Server logs contain detailed records of which pages search engine bots have crawled. By analyzing these logs, you can identify pages that Googlebot is crawling but aren’t visible through your site’s internal links or your sitemap.
This method is especially useful for larger websites, where crawling behavior might be different for various bots. It also helps detect pages that might be being crawled by Google, even if they don’t show up in your site structure.
Third-Party SEO Tools
While Screaming Frog is an excellent tool for site crawling, other third-party SEO tools can provide a more comprehensive analysis of orphan pages.
- Ahrefs: Known for its backlink analysis, Ahrefs can help identify orphan pages by showing pages that have backlinks from external sites but aren’t linked internally.
- SEMrush: SEMrush’s Site Audit tool can help uncover orphan pages, as well as provide insights into potential issues with your internal linking structure.
Combining Data for a More Complete Picture
One of the most effective strategies is to combine data from several sources—Screaming Frog, Google Analytics, Google Search Console, and server logs. By cross-referencing this information, you can build a complete picture of which pages are orphaned and need attention.
Resolving Orphan Pages: Best Practices
Once you’ve identified orphan pages, the next step is to resolve the issues efficiently. Here’s how to do it:
1. Internal Linking Strategy
After identifying orphan pages that are important for your business, the next step is to link to them internally. This helps Googlebot discover them and gives users an easier path to access these pages.
- Contextual Links: Use keyword-rich anchor text to link orphan pages from within relevant content. This helps Google understand the relevance of the page in relation to your other content.
- Navigation and Footer Links: If the orphan pages are highly important, consider adding them to the main navigation or footer. This increases their visibility and accessibility.
2. 301 Redirects for Legacy Content
If orphan pages contain outdated or no longer relevant content, implementing a 301 redirect is often the best solution. This ensures that any traffic or link equity flowing to these orphaned pages is redirected to an appropriate live page.
- Redirect to a Relevant Page: If the orphan page had valuable content but is no longer needed, redirect it to a related, active page.
- Avoid Redirect Chains: Redirecting to one page, and then from that page to another, creates a redirect chain that can negatively affect SEO. Make sure each page is redirected directly to the most relevant one.
3. 404 or 410 Status Codes for Deleted Pages
If the orphan page no longer serves a purpose or has expired, it’s better to return a 404 (Not Found) or 410 (Gone) status code. This tells search engines that the page no longer exists and prevents it from consuming a crawl budget.
- 404 for Pages Removed Temporarily: Use this status code for pages that might be reintroduced in the future or for soft-deleted pages.
- 410 for Permanently Removed Pages: For content that is no longer needed, a 410 status code is a more definitive signal that the page should be removed from search engine indexes.
4. Content Consolidation
Sometimes, orphan pages might be redundant or have similar content to other pages on your site. In these cases, it’s worth considering consolidating the content into a single, comprehensive page.
- Canonical Tags: If you have two pages with similar content, make sure to set the canonical tag on the less important page to point to the more authoritative one. This will help prevent duplicate content issues.
- Content Merging: Merge the content from multiple orphan pages into one page to ensure that your content is not thin or duplicated, which could lead to a better ranking.
Final Thought
Orphan pages should never be ignored in your SEO strategy. Whether they are high-quality pages that deserve more visibility or outdated content that needs removal, handling orphan pages properly can significantly enhance your site’s SEO performance. By identifying and fixing orphan pages, you improve your website’s crawl efficiency, user experience, and organic search rankings.
Remember, the process of managing orphan pages requires continuous monitoring. As your website evolves, new orphan pages can emerge, and old ones may need to be archived. Regularly auditing your site’s structure and linking practices is crucial to keeping your website SEO-friendly.
By making orphan pages a part of your regular website management strategy, you can ensure that all of your content gets the attention it deserves, ultimately driving more traffic and improving your rankings.

Thatware | Founder & CEO
Tuhin is recognized across the globe for his vision to revolutionize digital transformation industry with the help of cutting-edge technology. He won bronze for India at the Stevie Awards USA as well as winning the India Business Awards, India Technology Award, Top 100 influential tech leaders from Analytics Insights, Clutch Global Front runner in digital marketing, founder of the fastest growing company in Asia by The CEO Magazine and is a TEDx speaker and BrightonSEO speaker.
