Get a Customized Website SEO Audit and Online Marketing Strategy and Action
What is website architecture?
Website architecture comprises a set of parameters and standard checks which ensures that the website is SEO-friendly from an architectural perspective. The key benefits of a better architecture are ensuring that the link juice flows properly throughout the website. Also, no-hidden crawl errors might disrupt the SERP visibility in the long run!

The Analysis
Chapter 1: URL Structure Analysis
Type a: Navigational Page URL analysis
Navigational pages are basically the important and the important secondary pages of a given website! An example of the navigational page for this particular campaign is as under:
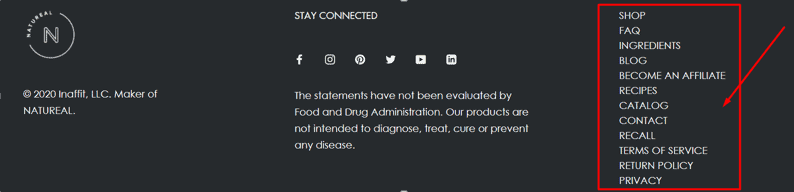
Observation:
SHOP: https://www.natu-real.com/collections/weight-loss-supplements
OUR STORY: https://www.natu-real.com/pages/our-story
RECIPES: https://www.natu-real.com/pages/recipes
Now, as we can see, all the navigational pages contain a slug prior to starting the main permalink such as “/pages”, “collections”.
Recommendation:
- The pages should not contain any extra slugs such as /pages, /collections, etc. This reduces the link equity and link juice flow
- Once the URLs changes are made, then a 301 redirection should be made from the OLD URL to the new URL, say for example: for the RECIPE page, we made the new URL https://www.natu-real.com/recipes
Then we need to re-direct using a 301 redirection from https://www.natu-real.com/pages/recipes —> https://www.natu-real.com/recipes
THIS WILL PREVENT SEO Juice Losses!
Type b: BLOG Page URL analysis
Here are a few tips before indulging in a blog page URL optimization:
- A blog page URL should always be free from any additional slug
- Blog page URLs should be as SHORT as Possible
- Blog page URLs must contain at least one keyword which depicts the topic of the blog, this will create a relevancy signal to the web crawlers
- Blog Page URLs must be free from any stop words
Observation:
On one of the Blog pages we opened, and we spotted an URL: https://www.natu-real.com/blogs/news/5-super-easy-n-effective-weight-loss-exercises-you-should-start-today-for-faster-results
The TOPIC of the Page is: 5 ‘Super-Easy n Effective’ Weight Loss Exercises You Should Start Today For Faster Results
Recommendation:
The new URL should be:
https://www.natu-real.com/blogs/5-effective-weight-loss-exercises
- The above URL is short
- The above URL is to the point on what the topic is all about
- The above URL is free from any stop words
- The above URL contains the main keyword
Chapter 2: FLAT Structure Analysis / Crawl-Depth Analysis
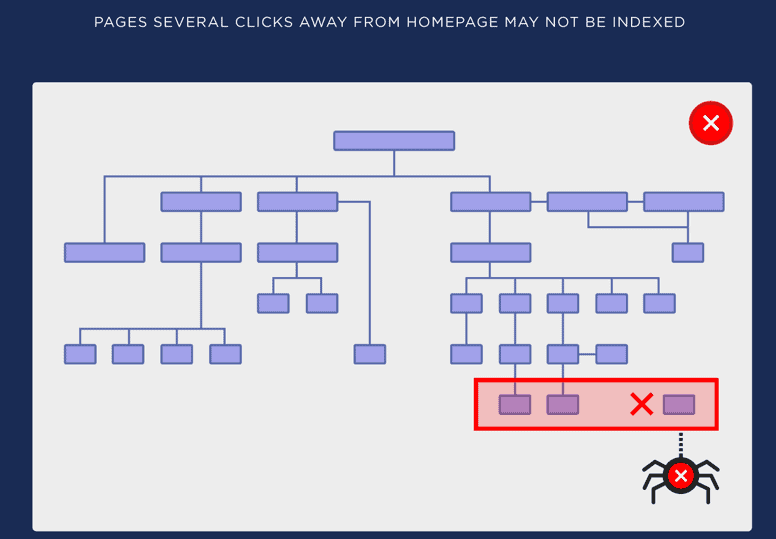
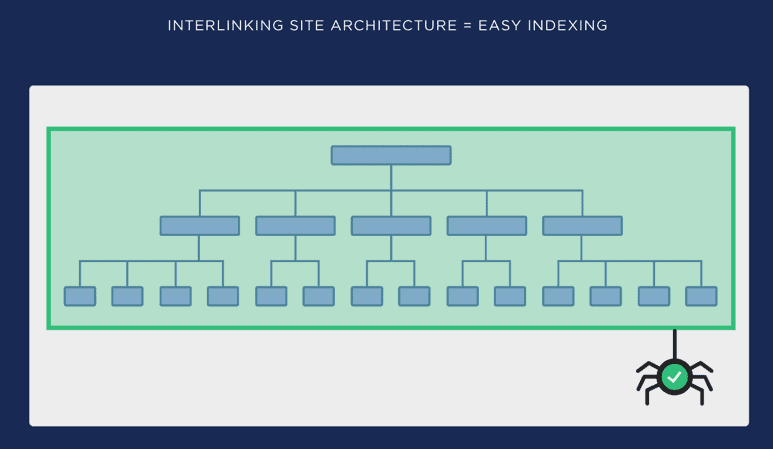
Flat architecture is nothing but just a standard architecture where a user can reach any given page in less than 4 clicks from the home page. This factor is often referred to as Crawl-depth analysis, which measures the number of clicks a user needs to perform to reach a particular page.
Diagrammatically, it’s represented as under:
Observation:
- Open Screaming Frog Spider
- Scan your Website
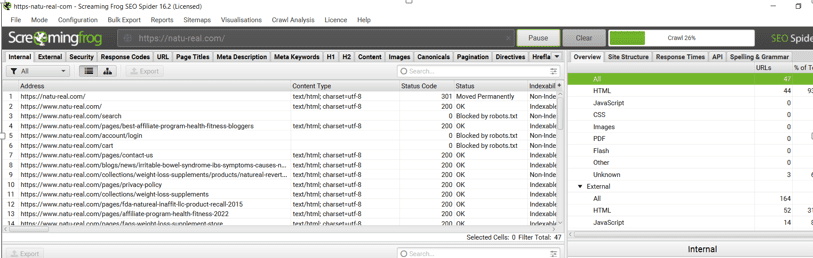
Click on “Visualizations”. Then Click on “Crawl Tree Graph”.
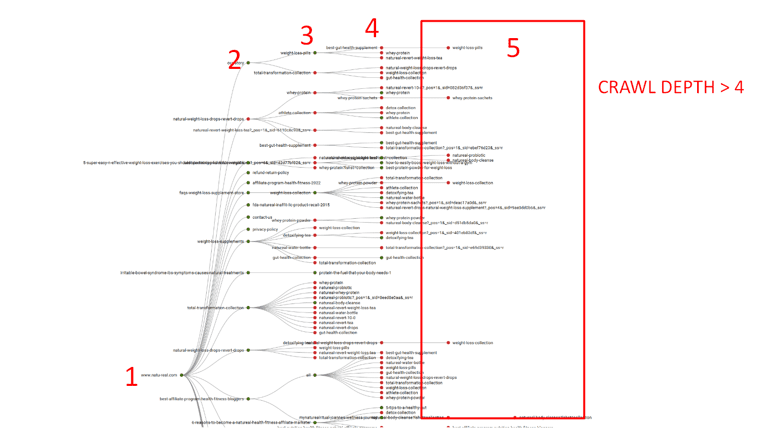
As seen from the above tree graph we can easily check the “CRAWL DEPTH” marked as 1,2,3,4 and 5. Now, all the pages which fall under “5” should be optimized to reduce the depth to 4 or less.
Recommendation:
- Make a list of all the pages that fall under “Crawl Depth > 4”
- Now either include these pages on an HTML sitemap linked with the home page for reducing the depth else, you can even connect them using pillar internal linking strategies to reduce the crawl depth!
Chapter 3: Hierarchical Analysis
Type a: Orphan Page analysis
Orphaned pages normally describe such pages which are orphaned from the rest of the pages of the website. In other words, such pages have high crawl depth and have poor user responses such as high bounces and are buried deep inside a website’s architecture.
Observation:
- Click on “Visualizations” and click “Force-Directed Crawl Diagram”.
You will see something as shown below:
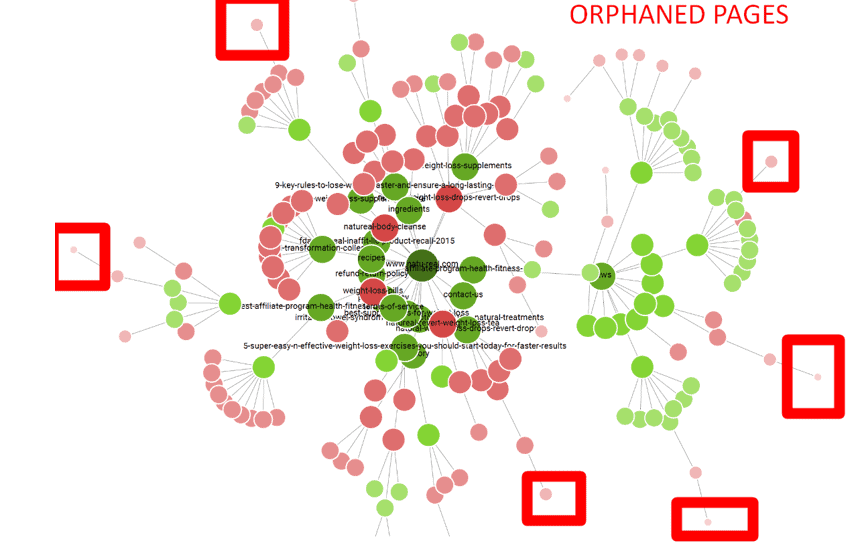
- As seen from the above screenshot, the URLs (NODES) marked as RED Boxes are the URLs that can be treated as Orphaned as they have high Crawl-depth and are buried deep down.
- For example, I have chosen one NODE (URL), as you can see from the screenshot below, the URL can be identified and also the Crawl-depth can be spotted!
P.S: Please note that these pages are different than the page ones, which you can spot from simple Crawl-tree crawl depth as in “Force-Directed Crawl”, extreme nodes can be visualized, which will show the pages that are buried deep down without any trackback on linking to other pages!

Recommendation:
- Make a list of all end NODES
- If you find these pages are not valuable, then you can delete them
- If you find they are valuable, then you can either merge them to a relevant page using the Merger technique as seen here: https://thatware.co/merge-pages-to-gain-rank/
- Lastly, you can also include them in the HTML sitemap and utilize better interlinking strategy for reducing the depth.
Type b: Non-index-able Page analysis
Often crawlers can encounter severe problems with any respective URLs that will prevent them from indexing due to any unprecedented indexing error. With the help of Screaming Frog Spider, such pages can be tracked and thus, one can obtain a clean architecture without any hassle.
Observation:
- Click on “Visualizations” and click “Force-Directed Directory Tree Diagram”.
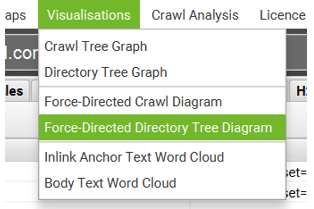
You will see something as shown below. Please note, that the deeper the red color is, the more serious the index issue is with those URLS. Now you can filter and shortlist all the bright spotted Red Marked NODES, as shown below!
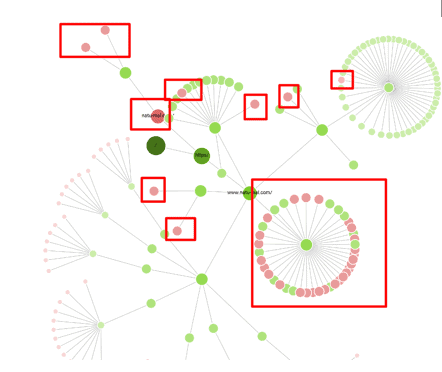
Recommendation:
- Make a list of all the NODES that appear bright RED in color
- Verify if those pages serve meaningful value for your audience. If Yes, then please implement an HTML sitemap or internal linking to reduce the Crawl depth. You can also look for additional page mobility issues to spot the page mobility friendliness of such URLs as well
- If you feel that the identified URLs are not valuable to your audience, then you can delete them and it will help preserve your Crawl budget wastage and index bloat issues.
Chapter 4: Spotting Issues within the XML Sitemap
An XML sitemap is a very important element when it comes to SEO and website Crawling. XML file is the file that web crawlers crawl first-hand to get a complete idea and the list of the URLs present within a given website. Any issues within the same will be a problematic factor for the overall website crawling and the efficiency of SEO will decrease!
Observation:
Click on “Configuration” and select “Spider”
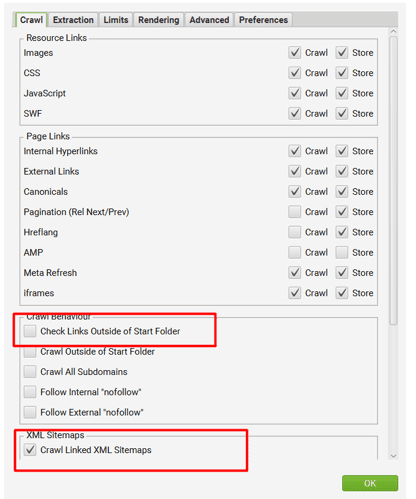
Then Keep the settings as shown below. Basically, you need to untick all options and only allow the XML to be crawled.
- Once done, then you will be able to see all the issues pertaining to the XML sitemap as shown on the below screenshot:

Recommendation:
- URLs not in Sitemap = If any URL is not present within the XML sitemap then please add them, as not having an URL within a XML will not help with any indexing of that particular URL.
- Orphan URLs = Any URLs under this segment should be immediately removed!
- Non-index able URLs in Sitemap = Any URLs under this segment should be immediately removed!
- URLs in Multiple Sitemaps = Any URLs under this segment should be immediately removed!
- XML Sitemap with over 50K URLs = As per general rule, a given .xml file can only contain up to 50K URLs, if you have more than 50K URLs, try creating another XML. For example, suppose you have a website with 100K pages.
Then www.example.com/sitemap1.xml can contain 50K URLs
And www.example.com/sitemap2.xml can contain 50K URLs
- XML Sitemap over 50 MB = As per general rule, a given .xml file size needs to be within 50MB. If the size exceeds, try creating another sitemap to lower the load and size.
Chapter 5: Mobile Usability and Responsive Design Analysis
Website architecture isn’t just about internal link structures and crawl depth; it also includes ensuring that a website is mobile-friendly and adheres to best practices for responsive design. Mobile usability has become a critical ranking factor for search engines like Google, and a non-responsive website can hinder user experience, negatively affecting your site’s performance in search engine results pages (SERPs).
Observation: A common mistake that many websites make is designing only for desktop users and neglecting the mobile experience. With more than half of all web traffic coming from mobile devices, a website that is not mobile-friendly can lose significant traffic. This can affect bounce rates, session duration, and even conversion rates. Mobile usability issues include improper scaling of images, overlapping text, small touch targets, and slow loading speeds.
You can use tools like Google’s Mobile-Friendly Test or check mobile usability directly in Google Search Console to identify any mobile-specific issues.
Recommendation: Ensure your website is fully responsive, meaning it adapts to the size of the screen it’s being viewed on, whether it’s a phone, tablet, or desktop. Use responsive web design principles, such as flexible grids, fluid images, and media queries, to create a seamless user experience across all devices. Key considerations should include:
- Page load times: Mobile users expect fast loading times. If your website takes more than a few seconds to load, you’re likely to lose visitors. Optimize image sizes, compress files, and leverage browser caching to improve mobile page speed.
- Text size and readability: Ensure that text on mobile screens is large enough to read without zooming. Avoid small font sizes and lines of text that are too close together.
- Touchscreen usability: Make sure buttons and links are large enough to be easily tapped on mobile devices. Small buttons or closely spaced links can frustrate users.
- Mobile-specific content: Consider whether you need to create separate content for mobile users, such as lightweight versions of heavy media like videos or interactive features that might not work well on small screens.
By ensuring your website is mobile-friendly, you not only enhance user experience but also align with Google’s mobile-first indexing, which prioritizes mobile-friendly sites in its ranking algorithm.
Chapter 6: Site Speed and Performance Optimization
Website performance is another critical aspect of website architecture. Slow loading times can negatively impact user experience, leading to higher bounce rates and lower conversion rates. Additionally, Google considers site speed a ranking factor, so a slow website can hurt your SEO efforts. Optimizing site speed is an essential part of the architectural analysis.
Observation: You can identify performance issues through tools like Google PageSpeed Insights, GTMetrix, or Pingdom. Common site speed issues include large image files, excessive use of JavaScript, uncompressed CSS or HTML, and slow server response times.
Recommendation: To improve your website’s speed and performance, here are some essential steps to follow:
- Optimize images: Ensure that all images are appropriately compressed without compromising quality. Use modern image formats like WebP, which offer better compression compared to traditional formats like JPEG or PNG.
- Minify and compress files: Minify JavaScript, CSS, and HTML files by removing unnecessary whitespace, comments, and code. Compress these files to reduce their size and improve load times.
- Leverage browser caching: Implement caching to store commonly used resources in users’ browsers so they don’t have to be reloaded every time they visit the site. This can greatly reduce loading times for returning users.
- Use Content Delivery Networks (CDNs): A CDN distributes your website’s content across multiple servers located in various geographical regions. This reduces latency and improves load times by serving content from the server closest to the user.
- Reduce server response time: Use a reliable hosting provider that can handle high traffic without slowing down. If you’re using shared hosting, consider upgrading to VPS or dedicated hosting for better performance.
By addressing site speed and performance, you’ll improve both user experience and SEO rankings.
Chapter 7: Structured Data and Schema Markup Analysis
Structured data and schema markup are integral elements of modern SEO and website architecture. Implementing schema markup allows search engines to better understand your content, which can result in enhanced search engine results with rich snippets, such as star ratings, pricing, and availability for products.
Observation: When performing an architecture analysis, it’s important to check if structured data is being used correctly. A lack of structured data can result in missed opportunities for rich snippets. Common issues include improperly implemented schema types or missing essential information, such as product details or article metadata.
Recommendation: Review your website to ensure that relevant schema markups are applied. Depending on the type of website, this could include:
- Product schema: For e-commerce sites, ensure each product page includes product schema with details such as price, availability, and reviews.
- Article schema: For blogs or news websites, implement article schema to mark up the headline, image, author, and publishing date.
- FAQ schema: If your site features a frequently asked questions section, include FAQ schema markup to potentially display these questions and answers directly in search results.
- Local business schema: For businesses with physical locations, local business schema helps search engines display key details such as your address, phone number, and hours of operation.
Test your structured data using Google’s Structured Data Testing Tool to ensure it’s implemented correctly and free of errors. Proper implementation of structured data can help your site stand out in search results and improve CTR (click-through rate).
Chapter 8: Internal Linking and Navigation Optimization
Internal linking plays a crucial role in website architecture. It helps search engines crawl and index content, distributes link equity across your pages, and ensures that users can easily navigate your site.
Observation: Inadequate internal linking can lead to orphan pages, excessive crawl depth, and a poor user experience. Furthermore, a disorganized or confusing navigation structure can make it difficult for users and search engines to find important content.
Recommendation: To improve internal linking and navigation:
- Use descriptive anchor text: Ensure that your anchor text accurately reflects the content of the linked page. Avoid using generic terms like “click here” or “read more.”
- Create a clear hierarchy: Organize your content into a clear, logical hierarchy with primary, secondary, and tertiary pages. Your main categories should be easily accessible from the homepage, and related content should be linked together within the body text.
- Use breadcrumb navigation: Implement breadcrumb navigation to help users and search engines understand the structure of your site. This feature allows users to easily navigate back to previous pages and helps search engines understand the hierarchy of your site’s content.
- Link to important pages: Ensure that your most important pages, such as high-converting product pages or cornerstone content, are easily accessible from multiple locations on your site through internal links.
- Monitor broken links: Regularly check for broken links using tools like Screaming Frog or Ahrefs, and fix them promptly to prevent users from encountering 404 errors and losing link equity.
A well-organized internal linking structure will improve both SEO performance and user experience, ensuring that all pages are easily accessible and crawlable.
Chapter 9: Security and HTTPS Implementation
Security is an essential component of website architecture, especially in an era of growing cyber threats. Websites that are not secure can experience loss of customer trust, data breaches, and ranking penalties from search engines.
Observation: A website without HTTPS (SSL/TLS encryption) is seen as unsecure by modern browsers, and Google has confirmed that HTTPS is a ranking factor. Websites lacking HTTPS are flagged as “Not Secure” in the browser, which can deter users from interacting with the site.
Recommendation: To secure your website:
- Implement HTTPS: Ensure that your website uses HTTPS by installing an SSL certificate. This will encrypt data between the user and the website, providing a secure browsing experience.
- Regularly update software: Ensure your website’s CMS (Content Management System), plugins, and themes are up to date to protect against known vulnerabilities.
- Use a Web Application Firewall (WAF): A WAF can help protect your site from malicious traffic and attacks, such as SQL injection or cross-site scripting (XSS).
By ensuring that your website is secure, you protect your users and boost your website’s credibility and trustworthiness, both of which are important for SEO.
Website Architecture: A Key Component for Success
Website architecture refers to the structure and organization of a website, influencing everything from design and navigation to SEO and user experience. Proper website architecture ensures smooth navigation, efficient functionality, and enhanced search engine optimization (SEO). Let’s break down key elements of effective website architecture:
1. Clear and Intuitive Navigation
One of the most crucial aspects of website architecture is an intuitive navigation system. Visitors should be able to find what they are looking for with minimal effort. A clean, well-organized menu with clearly labeled categories makes it easy for users to navigate the site. Important pages, such as the homepage, services, and contact page, should be easily accessible from anywhere on the site. A structured navigation system helps reduce bounce rates, as users are more likely to stay on the site when they can navigate it easily.
2. Information Hierarchy and Structure
Website information should be organized in a clear hierarchy. This typically includes a logical progression from broad to specific content. For example, on an e-commerce site, categories of products should be placed on the main menu, with subcategories for detailed listings. This structure helps both users and search engines understand how content is organized. Logical categorization not only makes browsing easier but also improves SEO by ensuring that search engines can crawl and index the site properly.
3. SEO-Friendly URL Structure
SEO-friendly URL structures are crucial for both user experience and search engine rankings. URLs should be short, descriptive, and easy to read. For instance, instead of using random characters or long strings of numbers, URLs should incorporate relevant keywords. For example, a product page URL might look like: “www.example.com/winter-coats,” rather than “www.example.com/productID12345.” This approach helps search engines understand the page content and can improve organic rankings.
4. Mobile Optimization
With a growing number of users accessing websites from mobile devices, it is essential to design websites with mobile users in mind. Mobile optimization involves creating responsive designs that adapt to various screen sizes and ensure a consistent user experience across all devices. A mobile-optimized site improves user engagement and is also favored by Google’s search algorithm, which prioritizes mobile-friendly sites in search rankings.
5. Internal Linking and Content Strategy
A solid internal linking strategy supports both SEO and user experience. Internal links connect relevant pages within the website, guiding users to additional content. For SEO, internal links help distribute page authority throughout the site, boosting the visibility of individual pages. A well-structured content strategy ensures that pages are interlinked logically, increasing the chances of driving traffic to important sections of the site.
6. Page Speed and Technical Performance
Page load speed is crucial for both user satisfaction and SEO. A slow-loading website can lead to high bounce rates and poor rankings in search engines. Optimizing images, utilizing content delivery networks (CDNs), and minimizing scripts can help speed up website performance. Technical performance, such as ensuring no broken links or errors on the website, is also critical for maintaining a smooth user experience.
7. Security and User Trust
Website security, including the use of SSL certificates for encryption, builds trust with users. A secure website protects sensitive data and reassures visitors that their personal information is safe. Google also factors security into rankings, so having HTTPS in your URL can give you a slight edge in search results.
