SUPERCHARGE YOUR Online VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
In the intricate world of SEO, technical precision can mean the difference between success and failure. One crucial but often overlooked aspect of technical SEO is the robots.txt file, a small yet powerful tool that determines how search engine crawlers interact with a website. ThatWare, a leading SEO agency, leverages the robots.txt file to ensure maximum crawl efficiency and improved website performance.

In this robots.txt comprehensive guide, we will explore what a robots.txt file is, its importance, and how ThatWare strategically implements it. Additionally, we will provide a detailed explanation of the specific directives used by ThatWare and their impact on SEO.
What is a Robots.txt File?
A robots.txt file is a text file placed in the root directory of a website. It serves as a guide for search engine bots, specifying which parts of the site they are allowed to crawl and index. This file is a critical component of the Robots Exclusion Protocol, designed to regulate crawler activity and prevent overloading servers or exposing irrelevant content.
Why is Robots.txt Crucial for SEO?
Efficient Use of Crawl Budget
Search engines assign a crawl budget for each website. By preventing bots from crawling low-value or irrelevant pages, a robots.txt file ensures the budget is focused on essential content.
Prevention of Duplicate Content Issues
Pages like archives, tag listings, and dynamic URLs often generate duplicate content, which can harm SEO. Properly configuring the robots.txt file minimises this risk.
Enhanced Website Security
Although it is not a security measure, the robots.txt file can restrict crawlers from accessing administrative areas or confidential sections of the site.
Improved User Experience
By ensuring that only valuable content is indexed, the robots.txt file contributes to a cleaner, more relevant search result experience for users.
How ThatWare Implements Robots.txt
ThatWare takes a meticulous, strategic approach to robots.txt implementation, ensuring that each directive aligns with the site’s overall SEO strategy. Here’s how ThatWare manages the robots.txt file, step by step:
Step 1: Conducting a Comprehensive Website Audit
ThatWare begins by performing a thorough audit of the website to identify:
- High-priority pages for crawling and indexing.
- Low-value pages that add little to SEO.
- Dynamic URLs or pages that may create duplicate content issues.
This analysis forms the foundation for creating a robots.txt file tailored to the website’s specific needs.
Detailed Breakdown of Robots.txt Directives
Below is a detailed explanation of each directive commonly used in ThatWare’s robots.txt files and its impact:
Allow Directives
The Allow command specifies which parts of the site search engine bots are permitted to crawl and index.
Allow: /
This directive grants bots permission to crawl all pages by default unless explicitly restricted elsewhere. It ensures that essential parts of the website are accessible for crawling.

Allow: /wp-admin/admin-ajax.php
While the WordPress admin area is typically blocked from crawlers, the admin-ajax.php file must remain accessible. This file handles important backend operations, such as AJAX requests, which are critical for certain website functionalities like dynamic content loading.
These directives ensure that JavaScript (.js) and CSS (.css) files are accessible to crawlers. Search engines like Google rely on these files to render and index pages correctly, ensuring that the website appears as intended in search results.
These directives permit search engines to crawl image files in common formats like JPEG, PNG, and GIF. This is vital for image-based SEO, as it enables the indexing of images for search queries, enhancing visibility in image search results.
Disallow Directives
The Disallow command blocks specific parts of the website from being crawled or indexed. This ensures that irrelevant or sensitive pages do not consume the crawl budget.

Disallow: /category
This prevents crawlers from indexing category pages, which often generate duplicate content across different posts and can dilute SEO value.
Disallow: /author/
Author archive pages, especially on multi-author blogs, can create duplicate content issues. Blocking these pages ensures that the focus remains on primary content.
Disallow: /work_genre/
This directive restricts crawlers from accessing niche or less relevant sections, ensuring the crawl budget is not wasted.
Disallow: /plus-mega-menu
Mega menus are often used for navigation but do not contribute to the SEO value of a website. Blocking these URLs prevents them from cluttering search engine indexes.
Disallow: /page/
Paginated pages are typically thin content pages that add little value to SEO. By blocking them, ThatWare ensures that only comprehensive and relevant content is indexed.
Disallow: /refund-cancellation-policy
Policy pages like refund and cancellation policies are important for users but not for SEO. Blocking these pages prevents them from competing for crawl budget or ranking.
Disallow: /basecamp
Sections like /basecamp that may serve operational purposes but have no relevance to search visibility are restricted from crawling.
Disallow: /career/
The /career/ section, while useful for prospective employees, often contains dynamic or low-value content for SEO. Restricting it ensures that the focus remains on content that serves broader SEO goals.
Disallow: /deep-crawl/?unapproved=
This directive blocks URLs with unapproved query strings, which could lead to duplicate content or thin pages being indexed.
Disallow: /?utm_source=
Tracking parameters, such as those added by UTM tags, do not add any SEO value and can create duplicate URLs. Blocking them ensures a cleaner and more efficient crawl process.

Step 2: Testing and Validation
After creating the robots.txt file, ThatWare rigorously tests its functionality using tools such as:
- Google Search Console’s Robots Testing Tool to simulate how Googlebot interacts with the website.
- Other third-party crawler simulators to ensure consistency across platforms.
Goals of Testing
- Verifying that essential pages are crawlable.
- Ensuring restricted pages are correctly blocked.
- Avoiding unintended consequences, such as blocking high-value content.
Step 3: Monitoring and Updates
Websites evolve, and so do their SEO strategies. ThatWare continuously monitors the robots.txt file to:
- Adapt to changes in website structure or content strategy.
- Align with updates in search engine algorithms.
- Ensure ongoing optimisation of crawl efficiency.
Advanced Features of Robots.txt
ThatWare also employs advanced techniques for specific scenarios:
Crawl Delay
For websites experiencing heavy bot traffic, a crawl delay can reduce server load.
Sitemap Inclusion
Including a sitemap in the robots.txt file helps search engines locate important pages more effectively.
User-Agent Specific Rules
ThatWare customises crawling behaviour for different bots using user-agent-specific directives.
Benefits of ThatWare’s Robots.txt Strategies
Optimised Crawl Efficiency
By prioritising high-value content, ThatWare maximises the impact of a website’s crawl budget.
Improved Indexation
Strategic allow and disallow rules ensure that only relevant and valuable pages appear in search results.
Enhanced SEO Rankings
A well-structured robots.txt file contributes to improved rankings by focusing search engine attention on optimised content.
Streamlined Search Results
Restricting duplicate or irrelevant pages ensures a cleaner and more effective user experience in search results.
From the next section of the blog, we will talk about various bots, search engines and social media platforms by basing the central aspect on robots.tx.
Googlebot
Googlebot is the name of Google’s web crawling bot, also known as a spider or web robot. It is responsible for crawling and indexing the web’s vast content, ensuring that Google’s search engine has up-to-date and relevant information to display in search results. When you visit a page on Google, it’s the result of Googlebot’s work in crawling, interpreting, and indexing the page.
Googlebot is a critical part of Google’s search infrastructure, and its directives in the robots.txt file can either allow or block different types of crawls, depending on the goals of the website owner.
Here’s a breakdown of various Googlebot user-agents and their specific functions:
1. User-agent: Googlebot
This is the main crawler responsible for discovering and indexing the majority of web pages. Googlebot uses a general-purpose algorithm to crawl websites and determine their relevance for search. It starts by crawling from a seed list of web pages and follows the links on each page to discover other pages on the internet. Every page that Googlebot crawls is evaluated based on its content, metadata, and other signals to assess how relevant it is for search queries.
- Significance: This user-agent is critical for most websites because it enables the crawling of HTML content, which is essential for ranking in Google’s search engine.

2. User-agent: Googlebot-Mobile
Googlebot-Mobile is the crawler designed specifically for mobile-optimized versions of websites. With mobile-first indexing becoming the standard, Googlebot-Mobile plays a crucial role in ensuring that mobile pages are properly indexed and rank in search results, particularly on mobile devices. It can crawl content that has been optimized for mobile, including mobile-specific HTML pages, stylesheets, and JavaScript.
- Significance: This bot ensures that websites with mobile-friendly designs are ranked effectively in mobile search results. In the era of mobile-first indexing, having a mobile-optimized website is key to SEO success.
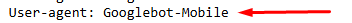
3. User-agent: Googlebot-Image
Googlebot-Image is a specialized crawler designed to index image files on the web. When Googlebot encounters an image on a webpage, Googlebot-Image crawls it, evaluating the image content for indexing in Google Images. This allows Google to provide users with relevant image search results based on what they are looking for.
- Significance: Websites that rely heavily on visual content (e.g., photography sites, e-commerce platforms) benefit from allowing Googlebot-Image to crawl their images. Optimizing your image files and ensuring they are properly indexed can significantly improve visibility in Google Image Search.
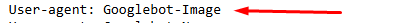
4. User-agent: Googlebot-News
Googlebot-News is a specialized version of Googlebot designed to crawl news websites and gather fresh content for Google News. It focuses on real-time and breaking news content, indexing articles and news sources that meet Google’s criteria for news-based results.
- Significance: Websites with news content can benefit from allowing Googlebot-News to crawl them, as this ensures that timely, relevant news articles are indexed for Google News search results. Getting indexed by Google News can boost a website’s visibility and authority within the news niche.

5. User-agent: Googlebot-Video
Googlebot-Video is the bot responsible for crawling and indexing video content. Websites that host video content, like YouTube or other video platforms, will have their video content indexed by this user-agent. Googlebot-Video helps Google understand the context and metadata of video files, allowing them to appear in video search results.
- Significance: Websites that feature video content must allow Googlebot-Video to crawl and index their videos. Proper video indexing can result in improved visibility in video search results, potentially increasing traffic and engagement.

How Googlebot Works: A Deep Dive into Web Crawling
Googlebot, the web crawler for Google’s search engine, plays a crucial role in how web pages are discovered and indexed. When you perform a Google search, the results you see are based on the content that Googlebot has crawled, analyzed, and added to Google’s index. But how does Googlebot work?
1. Crawling the Web: Googlebot begins its journey by crawling the web starting from a list of known URLs, which might include links from previous crawls or from sitemaps submitted by website owners. Googlebot follows these links to discover new pages. It mimics the behavior of a user by visiting websites, clicking on internal and external links, and traversing the web.
2. Crawling Different Versions (User-Agents): Googlebot operates in several versions, each designed for specific types of content:
- Googlebot (Standard Web Crawler): Primarily used to crawl HTML pages.
- Googlebot-Mobile: Focuses on mobile-friendly websites, ensuring mobile-first indexing.
- Googlebot-Image: Specializes in crawling and indexing image content.
- Googlebot-News: Crawls news sites for up-to-date information for Google News.
- Googlebot-Video: Targets video content for indexing in Google’s video search.
3. Rendering and Indexing: Once Googlebot discovers a webpage, it doesn’t just gather the text. It renders the page, just like a browser would, processing all the content, images, videos, and JavaScript. It then interprets the page to determine what the content is about, using algorithms that assess the relevance and quality. This step is vital for properly understanding and indexing dynamic or interactive websites that rely on JavaScript and other client-side elements.
The final result of this process is the addition of the page to Google’s index, where it will be stored and made available for search queries. Without Googlebot, no pages would be added to Google’s vast index, and websites would not appear in search results.
The Significance of Googlebot in SEO: Boosting Visibility and Rankings
Googlebot’s role extends beyond just crawling and indexing web pages. Its significance in SEO cannot be overstated, as it directly impacts how websites perform in Google’s search results. Let’s explore how Googlebot influences SEO and why it’s crucial for your website’s success.
1. Effective Indexing of Content: Googlebot ensures that relevant content is indexed in Google’s database, making it searchable for users. When Googlebot crawls a page, it evaluates its content, structure, and metadata. This evaluation helps Google determine the page’s relevance for specific search queries. If Googlebot is unable to crawl or index important pages (due to improper configuration or blocked access), those pages won’t appear in search results, significantly harming the website’s visibility.
2. Mobile-First Indexing and Ranking: With Google’s shift to mobile-first indexing, the mobile version of your website becomes the primary source for determining how your site ranks. Googlebot-Mobile plays a key role here by ensuring that mobile-optimized pages are correctly crawled and indexed. A site that is not mobile-friendly may suffer from lower rankings, especially as more users access the internet via mobile devices. Thus, having Googlebot-Mobile properly crawl and index your site is critical for SEO success.
3. Impact on Crawl Budget and Site Performance: Googlebot has a limited crawl budget, meaning it can only crawl a specific number of pages within a given timeframe. Website owners can manage how Googlebot spends this budget by setting directives in the robots.txt file. Efficiently managing this budget allows Googlebot to focus on high-value pages, improving the likelihood of these pages being indexed and ranking higher. For example, by blocking Googlebot from crawling duplicate content, scripts, or non-essential pages, you free up crawl resources for the most important content on your website.
4. The Role of Media and Rich Content: Googlebot doesn’t just index text. Its specialized versions, like Googlebot-Image and Googlebot-Video, index images and videos, making it crucial for websites with visual or multimedia content. Websites that include rich media and allow Googlebot to index these elements can rank higher in search results for image and video-related queries.
Googlebot’s role in SEO is foundational. By ensuring proper crawling, indexing, and content evaluation, Googlebot directly influences a website’s search rankings and visibility. Understanding how to optimize your website for Googlebot is essential for achieving success in search engine optimization.
Understanding OAI-Search in robots.txt
When optimizing a robots.txt file, it’s important to understand the role of various search engine bots. One such bot is OAI-Search, which is related to the Open Archives Initiative (OAI) protocols. This bot is specifically designed to crawl and index repositories of scholarly articles, research papers, and other academic resources. The presence of User-agent: OAI-Search and Crawl-delay: 10 in a robots.txt file instructs the web server on how to manage this particular crawler’s activity.

The Role of OAI-Search
OAI-Search is part of the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH), which is a standard protocol used to share metadata from digital repositories. These repositories typically host academic content such as journals, dissertations, and scientific publications. The OAI-Search bot helps index this academic content, making it discoverable to a broader audience through search engines and academic platforms.
The Crawl-delay directive (Crawl-delay: 10) is significant for regulating how often OAI-Search accesses a website, ensuring that it doesn’t overwhelm the server with too many requests in a short time. Setting a crawl delay of 10 seconds allows for more efficient indexing without causing unnecessary strain on the website’s resources.
Why Optimize for OAI-Search?
For academic repositories and institutions, allowing OAI-Search to crawl their content is beneficial because it increases the visibility of their research and publications. However, it is crucial to balance accessibility with server load management. By configuring the robots.txt file to control crawl behaviour, websites can ensure that OAI-Search indexes their content efficiently while avoiding overloading their infrastructure.
By understanding and managing the OAI-Search bot through the robots.txt file, websites can enhance their SEO efforts while maintaining control over how their content is indexed and accessed by external systems.
The Role of OAI-SearchBot in Robots.txt File Optimization
Introduction to OAI-SearchBot
OAI-SearchBot is a specialized web crawler designed to gather data for the Open Archives Initiative (OAI). It is primarily used for harvesting metadata from repositories that implement the OAI Protocol for Metadata Harvesting (OAI-PMH). This bot plays an essential role in indexing scholarly articles, research papers, and other academic resources, making them accessible to the broader web community.
How OAI-SearchBot Operates
The OAI-SearchBot uses the OAI-PMH to collect metadata and other relevant information from digital repositories. It scans websites that host open-access content and indexes the information for research databases, helping scholars, students, and other users find resources more easily. The bot’s main function is to crawl open archives and retrieve metadata, including abstracts, authorship details, and publication dates.
The Importance of Crawl-Delay in Robots.txt
The Crawl-delay: 10 directive within the robots.txt file is particularly important when managing the OAI-SearchBot’s interaction with a site. By specifying a delay of 10 seconds, webmasters can prevent the bot from overloading their servers. While this is a standard best practice for many search engines, it is crucial for bots like OAI-SearchBot, which may make frequent requests to a server to harvest a large amount of metadata.
This crawl delay helps balance the bot’s need to gather information with the server’s capacity to handle requests, ensuring smooth performance for both the bot and the hosting site.
Managing OAI-SearchBot in Robots.txt
For websites with content relevant to academic research, setting specific guidelines for OAI-SearchBot in the robots.txt file is critical.
allows the webmaster to control how frequently the bot accesses their server, preventing unnecessary strain on their resources while ensuring the bot can still crawl and gather metadata.
In summary, the OAI-SearchBot’s role in metadata harvesting is significant for academic and research-oriented sites, and using the Crawl-delay 10 directive in robots.txt is an effective way to manage this interaction.
Understanding the User-Agent: Gemini in Robots.txt Optimization
The User-Agent directive in the robots.txt file is a critical element for controlling how search engine crawlers and bots interact with your website. Among the many bots accessing websites, “Gemini” has emerged as an important User-Agent to address. Gemini is the updated name for Google’s Bard, an AI-based tool designed to enhance search capabilities, provide insights, and process information efficiently. Optimizing for Gemini in your robots.txt file is essential to ensure compatibility, efficient crawling, and enhanced visibility in AI-enhanced search experiences.
What Is a User-Agent in Robots.txt?
A User-Agent is a specific identifier that a web crawler, bot, or browser uses to identify itself when accessing a website. The robots.txt file utilizes the User-Agent directive to specify permissions and restrictions for each crawler. For example:
In this example, the Googlebot is restricted from accessing the /private/ directory. Similarly, the User-Agent: Gemini directive can be used to configure how Gemini interacts with your site.

The Evolution from Bard to Gemini
Google’s Bard was initially launched as an experimental AI chatbot, designed to process queries, provide answers, and generate human-like conversational responses. In late 2023, Bard evolved into Gemini, reflecting advancements in AI capabilities. Gemini represents a shift towards integrating generative AI more deeply into search and other web-based functions, making it a critical bot for webmasters to understand.
With Gemini’s enhanced AI features, it crawls websites to gather high-quality, structured data that improves search and conversational experiences. Optimizing for Gemini ensures your content aligns with the latest AI-driven search methodologies.
Why Optimize for User-Agent: Gemini?
- Improved Search Visibility:
Gemini, as an AI-powered bot, plays a vital role in processing data for Google’s search engine, especially in conversational and context-based queries. Ensuring Gemini can access your site appropriately helps improve visibility in AI-powered search results. - Better User Experience:
Gemini focuses on delivering accurate and relevant information by understanding context and user intent. Allowing Gemini to crawl and access critical sections of your website ensures users receive relevant and up-to-date information. - Efficient Resource Utilization:
By tailoring your robots.txt file for Gemini, you can control which areas of your site it can crawl, minimizing unnecessary strain on your server and preserving bandwidth for essential pages. - Stay Ahead in AI-Enhanced SEO:
As AI-driven tools like Gemini become integral to search engines, early optimization ensures your website remains competitive and benefits from the latest AI advancements.
Best Practices for Optimizing Gemini in Robots.txt
- Identify Critical Content Areas:
Determine which sections of your site are most important for search visibility and user engagement. Ensure Gemini can crawl these sections without restrictions. - Restrict Non-Essential Directories:
Limit Gemini’s access to areas to protect sensitive data and reduce unnecessary crawling. - Test Your Robots.txt File:
Use tools like Google Search Console’s Robots.txt Tester to validate your configurations and ensure Gemini can access the intended parts of your site. - Monitor Crawl Activity:
Regularly review server logs and analytics to track Gemini’s crawl behavior. This helps identify any issues with your robots.txt settings or uncover opportunities to fine-tune access. - Provide a Sitemap:
Include a link to your XML sitemap in the robots.txt file to guide Gemini and other bots to your site’s most valuable pages - Update Regularly:
As Gemini evolves, update your robots.txt file to reflect new crawling capabilities or SEO strategies.
Common Issues to Avoid When Configuring Gemini
- Overblocking Content:
Restricting too many directories or files may prevent Gemini from accessing important content, negatively affecting your visibility in AI-driven search results. - Forgetting to Test Changes:
Always test your robots.txt updates to avoid accidental errors that block critical User-Agents like Gemini. - Ignoring Mobile Optimization:
Gemini processes data for both desktop and mobile searches. Ensure mobile-friendly content is accessible to enhance your site’s relevance in mobile-first indexing.
Gemini and Future SEO Trends
As Google continues to integrate AI tools like Gemini into its ecosystem, businesses must adapt their SEO strategies to remain competitive. Gemini represents the convergence of traditional crawling and AI-enhanced data processing, making it more important than ever to optimize your site for this bot.
By focusing on accessibility, data accuracy, and user intent, you can position your website to benefit from Gemini’s capabilities. Remember, the bots that power search engines are evolving to prioritize user experience and contextual relevance, and optimizing for Gemini ensures you are aligned with these advancements.
By allowing Gemini to crawl key sections of your website, you improve the likelihood of appearing in conversational and intent-based search results. At the same time, using strategic restrictions ensures your site’s resources are utilized effectively. As AI continues to reshape the search landscape, investing in Gemini optimization is an essential step toward future-proofing your online presence.
The Gemini bot to wait for 10 seconds between each request, reducing server load during crawling.
Generative AI’s Function as a Bot: Unlocking Its Potential in the Age of Robots.txt and Search Engine Crawlers
The rise of generative AI has revolutionized the way we interact with digital systems. As an advanced form of artificial intelligence, generative AI functions as a bot that creates content automates tasks, and improves user experiences across industries. Its interplay with tools like robots.txt files and its impact on managing search engine crawlers make it a valuable topic for exploration. This article dives into the role of generative AI as a bot, examining its functions, applications, and relevance in the context of website accessibility, SEO, and modern automation.
Understanding Generative AI as a Bot
Generative AI refers to artificial intelligence capable of creating content such as text, images, and videos. When functioning as a bot, it performs tasks autonomously based on predefined algorithms and learned behaviour. Unlike traditional bots, generative AI exhibits creativity and adaptability, enabling it to:
- Produce high-quality, human-like text or multimedia.
- Respond contextually to user queries.
- Adapt to evolving data and usage patterns.
These capabilities distinguish generative AI bots from simpler web crawlers or chatbots.
Key Functions of Generative AI Bots
Generative AI bots play various roles, offering unique functionalities that set them apart in a tech-driven world. Below are their key functions:
1. Content Creation and Automation
Generative AI bots can create SEO-optimized articles, blog posts, product descriptions, and marketing material. For example, platforms like OpenAI’s GPT models generate tailored content for diverse use cases. This function is particularly valuable in industries like e-commerce, education, and media.
2. Customer Interaction
Generative AI bots are used in chat applications to provide customer support. They respond to complex inquiries with a natural flow, significantly enhancing user satisfaction.
3. Data Processing
These bots analyze large datasets to generate insights, making them essential in fields like finance, healthcare, and marketing. Their ability to summarize information or predict outcomes is transformative.
4. Personalized Recommendations
Generative AI bots analyze user behavior to generate personalized suggestions, such as recommending products on an e-commerce site or curating playlists on streaming platforms.
5. Integration with Search Engine Crawlers
Generative AI bots can assist search engines in understanding the intent behind user queries and generating rich search results. They also interact with robots.txt files, which control bot access to website pages, to navigate data responsibly.
Generative AI Bots and Robots.txt: A Strategic Interaction
The robots.txt file is a simple text file used by websites to manage bot access. It tells search engine crawlers (and other bots) which parts of a website they can or cannot access. While generative AI bots don’t always follow the rules set in robots.txt files, they often need to adhere to them to ensure ethical data usage.
1. How Robots.txt Affects Generative AI Bots
The robots.txt file provides directives, such as:
- Allowing specific bots: You can permit AI bots by specifying their user-agent (e.g., Googlebot or GPTBot).
- Restricting access: Sensitive or private areas can be blocked to prevent unauthorized scraping.
Generative AI bots, especially those designed for large-scale tasks like data scraping or content generation, respect robots.txt configurations to maintain compliance with website policies.
2. Managing Generative AI Bots Using Robots.txt
To ensure smooth interactions with generative AI bots:
- Whitelist AI Bots: Include user-agents of AI bots you wish to allow, such as those used by OpenAI or Google Bard.
- Set Clear Directives: Use Disallow or Allow directives to control access effectively.
- Combine with Meta Tags: Use meta tags in conjunction with robots.txt for finer control over indexing and content visibility.
Applications of Generative AI Bots in SEO
Generative AI bots play a significant role in search engine optimization (SEO), both as content creators and as tools for optimizing website visibility. Their interactions with search engine crawlers amplify their impact on SEO practices.
1. Content Optimization
Generative AI bots can analyze search trends and keywords to generate optimized, high-ranking content. This includes meta descriptions, headings, and structured data.
2. Rich Snippets
By understanding schema markup, generative AI bots help create rich snippets that improve click-through rates. For instance, they can generate FAQs or product highlights directly from website data.
3. Crawl Budget Management
Generative AI bots can simulate search engine crawlers to identify unnecessary pages consuming the crawl budget. This helps webmasters refine robots.txt files for better efficiency.
Ethical Considerations for Generative AI Bots
While generative AI bots bring numerous advantages, ethical considerations must guide their use. The interaction between bots and websites via robots.txt raises questions about data ownership, privacy, and responsible AI deployment.
1. Data Privacy
AI bots must respect website restrictions and avoid scraping sensitive or private data. Transparent handling of robots.txt directives is critical to ethical practices.
2. Fair Use
Generative AI bots should avoid creating content based on plagiarized or copyrighted material. Adhering to robots.txt and licensing agreements can mitigate legal risks.
3. Transparency
Clearly identifying AI-generated content is essential. For example, marking text as “Generated by AI” builds trust among users and aligns with regulatory guidelines.
Future Trends: Generative AI Bots in Search Ecosystems
As search engines evolve, generative AI bots are becoming an integral part of their infrastructure. Key trends to watch include:
1. AI-Driven Search Engine Crawlers
Search engines like Google increasingly use generative AI to interpret user intent and generate direct answers. Bots powered by AI can understand complex queries and deliver nuanced results.
2. Personalized Search Experiences
Generative AI bots enable highly personalized search experiences by analyzing individual preferences. This trend is redefining how users interact with search engines.
3. AI Bots as Co-Crawlers
In the future, generative AI bots might work alongside traditional crawlers, not only indexing web content but also curating it for enhanced search engine functionality.

The GenerativeAI bot to wait for 10 seconds between every request that mitigate the load from server during the crawl.
Predictive AI: Revolutionizing Online Search and Bot Functionality
Predictive AI has become a cornerstone of modern technological advancement, influencing everything from personalized shopping experiences to healthcare diagnostics. In the context of web crawling and content indexing, Predictive AI plays a vital role as a bot, enhancing the efficiency and accuracy of data collection, interpretation, and delivery. This content delves into the multi-faceted functionalities of Predictive AI bots, their significance in web ecosystems, and how their capabilities can be optimized through a strategic robots.txt setup.
Understanding Predictive AI Bots
A Predictive AI bot is an advanced software application powered by artificial intelligence and machine learning algorithms designed to anticipate and respond to user behaviors or queries. Unlike traditional bots that follow predefined instructions, Predictive AI bots analyze historical data, recognize patterns, and make real-time predictions to deliver tailored outcomes.
These bots operate across diverse industries, often functioning invisibly to enhance user experience, streamline processes, and improve decision-making. For web crawling and indexing, their predictive capabilities transform how search engines and other digital systems interact with web content.
Key Functions of Predictive AI Bots
- Advanced Web Crawling
Predictive AI bots bring intelligence to the table by prioritizing and organizing the content they crawl. By analyzing metadata, user engagement metrics, and contextual relevance, they decide which pages are most critical for indexing.- Example: Instead of crawling every single webpage on a site, a predictive bot identifies which pages have the highest traffic or keyword density and prioritizes them.
- Real-Time Data Interpretation
With predictive algorithms, these bots can provide dynamic updates to their crawling and indexing strategies based on current trends and user behaviors. For instance, during a viral event, the bot may shift its focus to content that aligns with the trending topic. - Personalized Search Enhancements
Search engines rely on Predictive AI bots to refine search results by understanding individual user preferences. These bots use data like browsing history, location, and past interactions to tailor search outcomes, making them more relevant to the user. - Sentiment Analysis and Content Categorization
Predictive AI bots utilize Natural Language Processing (NLP) to assess the tone and context of web content. This allows them to categorize pages more accurately, ensuring that users are presented with the most contextually appropriate information. - Optimizing Content Delivery
Predictive AI bots ensure faster and more accurate content delivery by preemptively identifying what users might look for next. This capability reduces loading times and enhances the overall online experience.
How Predictive AI Bots Interact with Robots.txt Files
The robots.txt file serves as the gatekeeper for website crawling and indexing activities. A well-configured robots.txt file determines which parts of a website can be accessed by bots, ensuring compliance with the site owner’s preferences and reducing server load.
For Predictive AI bots, the robots.txt file becomes more than just a set of instructions—it serves as a roadmap for intelligent crawling.
- Tailored Access Permissions
Predictive AI bots can interpret robots.txt directives in a way that aligns with the site’s goals. By allowing AI bots in specific sections of the site, webmasters can ensure these intelligent crawlers focus on high-value pages. - Efficient Resource Management
Predictive AI bots use the robots.txt file to avoid redundant crawling, conserving both the website’s server resources and the bot’s processing power. For example, they can be programmed to skip multimedia files or low-priority sections. - Integration with Structured Data
By combining robots.txt instructions with structured data like schema markup, Predictive AI bots gain a more nuanced understanding of the content they crawl, leading to more accurate indexing and categorization.
Advantages of Predictive AI Bots in Search Engine Crawling
- Improved Search Engine Rankings
By intelligently crawling and indexing the most relevant pages, Predictive AI bots help websites improve their visibility and rankings in search engine results. - Data-Driven Content Optimization
Predictive bots analyze user engagement and provide insights into which content performs best. These insights can guide website owners in optimizing their content strategies. - Faster Content Updates
Predictive AI bots can detect when content has been updated and prioritize re-crawling these pages, ensuring search engines reflect the most current information. - Enhanced User Experience
With personalized and accurate search results, users enjoy a seamless online experience, increasing trust in the platforms they use.
Ethical Considerations for Predictive AI Bots
As with any powerful technology, Predictive AI bots must be deployed responsibly. Ethical considerations include:
- Privacy Protection
Ensuring compliance with data privacy laws like GDPR and CCPA is critical. Predictive AI bots should only access publicly available data or data explicitly permitted by the robots.txt file. - Avoiding Bias
AI algorithms must be free from biases to ensure fair and accurate predictions and categorizations. - Transparency
Websites using Predictive AI bots should clearly communicate their use of such technology to users and stakeholders.
How to Optimize Robots.txt for Predictive AI Bots
- Utilize Crawl Delay
Set a crawl delay to prevent server overload while ensuring bots have sufficient access to index critical pages. - Leverage Sitemap Directives
Include links to XML sitemaps within the robots.txt file to guide Predictive AI bots toward structured data. - Monitor and Adjust Regularly
Periodically review the robots.txt file to ensure it aligns with your site’s evolving content strategy and bot interactions.
Predictive AI Bots and the Future of Web Interaction
The evolution of Predictive AI as a bot signifies a transformative shift in how data is gathered, interpreted, and utilized. As websites grow increasingly complex, the role of predictive technology becomes indispensable. By integrating Predictive AI bots with an optimized robots.txt setup, businesses and individuals can achieve a harmonious balance between accessibility, privacy, and efficiency.
The future promises even more sophisticated applications of Predictive AI bots, including deeper integrations with the Internet of Things (IoT), voice search optimization, and automated content creation. These advancements will redefine how users interact with digital ecosystems, making predictive technology an essential element of modern web functionality.

The gap between two crawls in PredictiveAI is 10 sec.
Section-7 Decoding “User-Agent: Bingbot” and “Crawl-delay: 15” in robots.txt: A Comprehensive Guide
When optimizing a website’s robots.txt file for search engines, certain directives help guide search engine bots on how to crawl and index the site’s content. One such directive involves specifying a “User-Agent” followed by the Crawl-delay command.
This line plays a crucial role in regulating how Microsoft’s Bingbot, a web crawling bot responsible for gathering information for the Bing search engine to interact with your website.
What is a “User-Agent”?
The term “User-Agent” refers to a specific web crawler or bot’s name that a website’s robots.txt file identifies. The User-Agent identifies the crawler that is requesting access to the website’s pages. In this case, the User-Agent is Bingbot.
Bingbot is the official web crawling bot for Bing, which is Microsoft’s search engine. Its role is to visit web pages, analyze the content, and index it for search results. Just like other search engine crawlers (e.g., Googlebot for Google), Bingbot follows the rules outlined in the robots.txt file when crawling websites.
By setting up the “User-Agent: Bingbot” in your robots.txt file, you are giving specific instructions that apply only to this crawler, meaning the rules following it will only be enforced when Bingbot visits the site. For example, you can limit Bingbot’s access to certain pages or control its crawling speed through directives like Crawl-delay.
What is the “Crawl-delay” Directive?
The Crawl-delay directive is used to regulate how often and how quickly a web crawler should access the pages of a site. This delay instructs the bot to pause between each request to the server, effectively controlling the crawl rate. The crawl delay is measured in seconds, and it allows website administrators to balance between efficient indexing and reducing the load on the web server.
The 15 represents the number of seconds Bingbot should wait between successive requests to the web server. Essentially, this means that after Bingbot crawls a page, it will wait 15 seconds before it attempts to crawl another page on the same site.
Why is “Crawl-delay” Important?
Setting the right Crawl-delay can have significant effects on both the website’s server performance and search engine optimization (SEO). Here’s why it’s important:
- Server Load Management: When search engine bots, like Bingbot, crawl a website, they send multiple requests to the server to retrieve content. For websites with limited server resources, too many simultaneous requests from bots can overwhelm the server, causing slower response times or even downtime. By implementing a Crawl-delay, webmasters can limit the impact bots have on server performance, ensuring a smoother experience for users.
- Optimizing Crawl Budget: For websites with a lot of pages or frequent updates, managing the crawl budget is essential. The crawl budget is the number of pages a search engine is willing to crawl on your site within a given timeframe. By regulating the crawl rate with a Crawl-delay, webmasters can help ensure that search engines focus on the most important or updated content first, rather than being slowed down by irrelevant or redundant pages.
- Preventing Over-Crawling: In some cases, search engines may crawl a website too aggressively, which can result in the server becoming overwhelmed. If this happens, it can slow down the entire site, including the user experience. By introducing a Crawl-delay, a website can prevent over-crawling, ensuring that its server resources are available for visitors, not just bots.
- SEO Considerations: If a bot’s crawl rate is too high and it causes the site to load slowly, it can impact user experience and, consequently, SEO rankings. Google, Bing, and other search engines consider website speed and user experience when ranking pages. By regulating the crawl rate using the Crawl-delay, webmasters can help prevent any negative impact on both the server’s performance and the website’s search engine rankings.
How Does the “Crawl-delay: 15” Affect Bingbot?
Let’s explore what happens when Crawl-delay: 15 is set specifically for Bingbot:
- Slower Crawling for Bingbot: Setting a crawl delay of 15 seconds means that after Bingbot crawls one page, it will pause for 15 seconds before attempting to crawl another page. This slower pace ensures that Bingbot does not send too many requests in a short time, which could strain the server. This is particularly beneficial for websites that may experience high traffic or run on servers with limited resources.
- Less Server Load: For a website that may experience significant traffic spikes or is hosted on shared servers, limiting Bingbot’s crawl rate helps distribute the server’s resources more evenly, ensuring that other visitors are not impacted by the bot’s activity. This can improve the overall site performance, both for users and for bots.
- More Control Over Bingbot’s Crawling Behavior: The Crawl-delay setting gives webmasters granular control over how Bingbot interacts with the website. By specifying a 15-second delay, you are effectively telling Bingbot to be more considerate when accessing your site, ensuring that the site is not overwhelmed by automated traffic. This can help maintain site stability and optimize resource usage.
- Impact on SEO: While a crawl delay is useful for server performance, it can also slow down how quickly Bingbot indexes new content. For example, if a website frequently publishes fresh content and needs to be crawled more often, a 15-second delay might slow down Bingbot’s ability to re-crawl the site in a timely manner. In cases like these, webmasters should assess whether the delay is too long or if their site could benefit from a faster crawl rate.
Best Practices for Using Crawl-delay
While setting a crawl delay can be useful, it’s important not to overdo it. Here are a few best practices when using Crawl-delay in your robots.txt file:
- Test Crawl Delays: Regularly monitor your site’s server load and adjust the crawl delay as needed. If your server is still under heavy load despite a 15-second delay, consider increasing the delay further or exploring other optimization methods.
- Use It Sparingly: Setting a crawl delay should be done only when necessary. In many cases, bots like Bingbot are designed to crawl websites without putting undue strain on servers. Overly strict crawl delay settings can hinder the bot’s efficiency in indexing your site, potentially delaying content updates in search results.
- Set Specific Delays for Different Bots: If you have multiple bots crawling your site, you can tailor the crawl delay specifically for each bot. For instance, you might set a more generous delay for resource-heavy bots like Bingbot, while allowing other, lighter bots to crawl at a faster pace.
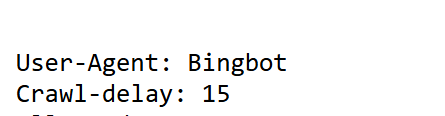
Understanding User-agent: Baiduspider
Search engine optimization (SEO) continues to be a game-changer for digital visibility, especially in diverse global markets. One essential aspect of SEO involves understanding how search engine bots, such as Baiduspider, operate and their interaction with your website.
In this section, we’ll explore the concept of the user-agent Baiduspider and why setting appropriate crawl-delay matters for your online presence.
Crawl-delay in Baiduspider
Crawl-delay is a directive in your robots.txt file that instructs web crawlers to pause between requests to your server. By spacing out these requests, you can reduce server strain, especially when dealing with high-traffic sites.
For Baiduspider, crawl-delay becomes particularly significant due to its rapid crawling behavior. Without a crawl delay, Baiduspider might overwhelm your server, affecting website performance for users and other crawlers.
For example, if Baiduspider visits multiple pages simultaneously, website loading times may spike, leading to a poor user experience. Implementing crawl-delay ensures smoother operation, balancing crawler activity with user accessibility.
Hence, we use Crawl-delay at 30
How to Set Crawl-Delay for Baiduspider Effectively?
Configuring crawl-delay for Baiduspider involves editing your robots.txt file, an essential part of your website’s backend.
First, locate the file within your website’s root directory using FTP or your website’s hosting platform. Then, add the directive.
- sonalized search profiles or ad targeting, unlike many mainstream crawlers. Its privacy-focused approach aligns with DuckDuckGo’s mission to deliver unbiased search results without compromising user trust.
- With DuckDuckGo gaining users globally, ensuring visibility on their platform is a key step for forward-thinking SEO strategies. Hence, webmasters should recognize its importance and tailor their SEO efforts to align with DuckDuckBot’s crawling behavior.
So, we can say that DuckDuckBot is an essential component of DuckDuckGo’s private search ecosystem. Optimizing your site for this user-agent ensures broader reach. As privacy-centric search engines continue rising, leveraging DuckDuckBot effectively could unlock new opportunities for your digital presence.

Slurp and Its Role in SEO
In the world of search engine optimization (SEO), one important factor to consider is how search engines crawl and index websites. A significant part of this process involves robots.txt files, which give instructions to web crawlers about how they should interact with a site. One common user-agent mentioned in robots.txt files is “Slurp.” But what exactly does “User-agent: Slurp” mean, and why is it crucial to your site’s SEO strategy?
What is a User-Agent?
Before diving into Slurp, it’s important to understand what a user-agent is in the context of web crawling and SEO. A user-agent is essentially the name that a web crawler or bot uses to identify itself when it accesses a website. This helps the website server recognize which bot is making the request, allowing the website to treat different crawlers differently.
What is Slurp?
Slurp is the user-agent used by Yahoo! Search, a major search engine. In the past, Yahoo! Search was a dominant player in the search engine industry, although it has since been overshadowed by Google. Nevertheless, Yahoo still holds a significant presence, especially in certain markets.
Slurp is used by Yahoo’s web crawler, known as Yahoo Slurp. When Slurp accesses a website, it reads the site’s content, follows links, and indexes relevant pages to include in Yahoo’s search results. Webmasters can control how Slurp interacts with their site using a robots.txt file, where they can allow or disallow the crawler from accessing specific pages or sections of their site.
The Role of User-agent: Slurp in SEO
In the context of SEO, User-agent: Slurp has several important implications for how your website is indexed by Yahoo. Just like other search engine bots, Slurp crawls websites to gather content for search indexing, which helps improve your site’s visibility on Yahoo’s search results pages.
The robots.txt file serves as a gatekeeper for bots. It tells them what content to crawl, what to ignore, and how frequently they should interact with the site. Here’s a breakdown of how this works:
1. Controlling Crawl Access
With “User-agent: Slurp” in your robots.txt file, you can provide specific instructions for how the Yahoo Slurp bot should crawl your website. For example, you might want Slurp to crawl your homepage but not your admin panel. You can specify that Slurp should not visit certain parts of the site, like duplicate content or areas that don’t add value to search engines.
2. Setting Crawl Delays
Another important aspect of using “User-agent: Slurp” in your robots.txt file is the ability to control the crawl rate. If your site is being crawled too frequently, it might experience performance issues, such as slow loading times or server overloads. By setting a crawl-delay, you can instruct Slurp to wait a specified number of seconds between requests.
3. Optimizing Crawl Efficiency
The goal of any SEO strategy is to make sure that search engines efficiently crawl and index the most important pages on your website. The User-agent: Slurp directive in the robots.txt file allows you to prioritize which pages are most valuable to index. For example, you might want Slurp to focus on your primary product pages, blog posts, or landing pages, while leaving out less important or irrelevant pages like old promotional offers or unoptimized content.
This can significantly enhance your website’s SEO performance by ensuring that only valuable content is indexed, which in turn improves your chances of ranking higher in Yahoo search results.
Best Practices for User-agent: Slurp
While controlling Slurp’s access to your site is essential for SEO, there are some best practices to keep in mind when dealing with the Yahoo Slurp bot:
- Be Transparent: It’s important to remember that the main purpose of user-agent directives is to help search engines index your site better. By blocking certain sections of your site or adjusting the crawl rate, you’re helping the search engine focus on your most valuable content.
- Monitor Crawl Stats: Keep an eye on your website’s crawl stats, especially if you’ve set crawl-delay values or disallowed certain pages. You can do this through Yahoo’s search console or other website analytics tools. If Slurp is not crawling key pages, you may need to adjust your robots.txt file to allow access.
- Don’t Overblock: While it’s tempting to block crawlers from accessing certain parts of your site, excessive blocking can hurt your SEO. If you block Slurp from indexing critical pages or ignore your blog content, for example, Yahoo might miss valuable ranking opportunities. It’s best to block only content that truly doesn’t need to be indexed.
- Test Your Robots.txt File: Before implementing changes to your robots.txt file, use online tools to test it. This ensures that Slurp and other search engines can crawl and index your site as intended.
The User-agent: Slurp directive is a key aspect of managing how Yahoo’s search bot interacts with your website. By carefully controlling access, setting crawl delays, and ensuring the most relevant content is indexed, you can improve the effectiveness of Yahoo’s indexing process. Optimizing your robots.txt file for Slurp not only helps your site perform better but also ensures that your SEO efforts are well-aligned with how Yahoo views and ranks your content. While Yahoo Search may not be the dominant force it once was, it still plays a critical role in driving organic search traffic, especially in certain regions. For businesses looking to improve their SEO strategy, understanding how Slurp operates and how to manage its access via robots.txt is crucial for long-term success.

Yahoo’s Slurp bot to wait 20 seconds between requests, helping to reduce server load and control the crawl rate.
ChatGPT
ChatGPT, developed by OpenAI, is a powerful language model based on the GPT (Generative Pre-trained Transformer) architecture. It uses machine-learning techniques to generate human-like text based on the input it receives. ChatGPT is trained on a vast range of text data from books, websites, and other publicly available sources, allowing it to understand and generate responses on various topics, from technical questions to casual conversations.
At its core, ChatGPT operates by analyzing patterns in language and using statistical probabilities to predict the next word or sentence. This enables it to maintain context and coherence in conversations, making it suitable for a wide range of applications, including customer support, content creation, tutoring, and more.
The model is continuously fine-tuned with user feedback and updates, improving its ability to generate accurate, relevant, and contextually appropriate responses. While ChatGPT is a powerful tool, it has some limitations, such as occasionally generating incorrect or biased information. OpenAI has incorporated safety mechanisms and guidelines to minimize these risks, but it is important to approach its responses with critical thinking.
ChatGPT represents a significant advancement in natural language processing (NLP) and continues to evolve, helping users across different industries to interact with AI in meaningful and productive ways.
Here is the breakdown of ChatGpt’s user intent
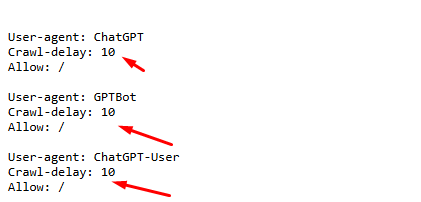
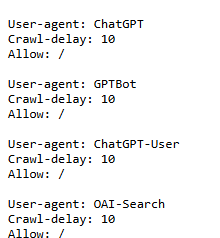
User-agent: ChatGPT:
This specifies the bot or crawler to which the rule applies. In this case, it targets the ChatGPT bot (or similar bots from OpenAI). The User-agent line defines the name of the crawler or bot so that the website can set specific instructions for how this bot should behave.
Crawl-delay 10 tells the bot to wait 10 seconds between each request it makes to the website. This is done to prevent the bot from overwhelming the web server with too many requests in a short period, which could slow down or disrupt the server’s normal functioning.
User-agent: GPTBot:
This targets a specific bot, in this case, GPTBot, which is used by OpenAI’s GPT models. Crawl delay 10 tells the bot to wait for 10 seconds between requests when crawling the website, to reduce server load.
User-agent: ChatGPT-User
This targets a bot or crawler identified as “ChatGPT-User.” It’s meant to apply rules specifically for this user-agent. Crawl-delay: 10 tells the targeted bot to wait for 10 seconds between each request to the website to reduce strain on the server and avoid overwhelming it with too many requests in a short period.
User-agent: OpenAI
This specifies that the rule applies to any bot identified as “OpenAI,” which could refer to OpenAI’s web crawlers or bots. Crawl-delay: 10 sets a delay of 10 seconds between requests made by the OpenAI bot, helping to reduce the load on the server and ensure it doesn’t get overwhelmed by too many requests in a short time.
How does ChatGPT help in the SEO process?
ChatGPT can be a valuable tool in the SEO (Search Engine Optimization) process by assisting with various tasks that can improve a website’s search engine rankings. Here are several ways ChatGPT can help
Keyword Research and Suggestions:
ChatGPT can help generate relevant keywords based on a topic, industry, or product. It can provide long-tail keyword suggestions, variations, and synonyms, which can enhance content optimization for SEO.
Content Creation:
SEO requires high-quality content that is optimized for both users and search engines. ChatGPT can assist in creating engaging, informative blog posts, articles, product descriptions, and more, using targeted keywords that align with SEO best practices.
Content Optimization:
ChatGPT can assist in ensuring that content is keyword-rich while maintaining readability. It can suggest improvements in sentence structure, help in adding appropriate headings (H1, H2, etc.), and even offer meta descriptions and title tags.
Creating SEO-Friendly Titles and Meta Descriptions:
Effective titles and meta descriptions are essential for SEO. ChatGPT can generate compelling and keyword-optimized titles and descriptions that are more likely to attract clicks and improve search rankings.
Improving Readability:
Good SEO content must be user-friendly. ChatGPT can suggest edits to make content more readable, ensuring it’s accessible and engaging for a broader audience. This includes improving sentence structure, grammar, and flow.
Answering FAQs and Structured Data:
ChatGPT can help generate a list of frequently asked questions (FAQs) relevant to your topic, which can be used to create structured data (FAQ schema markup). This can improve visibility in search results by qualifying for rich snippets.
Internal Linking Suggestions:
ChatGPT can suggest relevant internal links to include in content, helping to improve site navigation, and spread link equity across important pages, which can enhance SEO.
Content Ideas & Topic Clusters:
ChatGPT can generate content ideas based on a specific topic, helping to create a series of interconnected articles (topic clusters) that help improve site architecture and SEO performance.
Competitor Analysis:
While ChatGPT cannot directly analyze competitors’ websites, you can ask it for advice on SEO strategies that are commonly used by top-ranking websites in your industry, helping you refine your approach.
Voice Search Optimization:
As voice search grows in importance, ChatGPT can help create content that is more conversational and optimized for voice queries, improving visibility in voice search results.
Localization and Multilingual Content:
For businesses targeting different regions or languages, ChatGPT can assist in creating localized content and translations, helping with international SEO efforts.
Content Updates & Rewriting:
ChatGPT can help rewrite or update old content to make it fresh, relevant, and more SEO-friendly, which is important for maintaining good search rankings over time.
The Role of Apple and Amazon Bots in Robots.txt
The robots.txt file, an essential part of web robots’ interaction with websites, defines the rules that guide web crawlers and bots on how to index or interact with a website’s content. It plays a crucial role in controlling which parts of a website should be crawled and which parts should be avoided, and it helps in maintaining privacy and preventing the overload of a server.
Among the many web crawlers that obey robots.txt directives, bots from major corporations like Apple and Amazon play significant roles. Both Applebot (from Apple) and Amazon’s bots are prominent web crawlers that respect these rules. They contribute to various aspects of Internet services, including search engine optimization (SEO), advertising, and app indexing. This essay explores how these bots interact with robots.txt and their broader role in the ecosystem of the web.

Understanding the robots.txt File
Before diving into the role of Applebot and Amazon bots, it’s important to understand the purpose and structure of the robots.txt file. A robots.txt file is a text file located at the root of a website’s domain that provides directives to web crawlers on which parts of the site they can or cannot access. It uses a simple format consisting of two primary directives:
User-agent: Identifies the bot or web crawler.
Disallow: Instructs the bot to not access a specific part of the website.
Allow: (Optional) Explicitly permits access to specific parts of the site, even if other sections are disallowed.
This indicates that the Applebot is instructed not to crawl any content in the /private/ directory but may access anything in /public/. The structure of robots.txt allows website owners to set policies that dictate how their content is accessed by different crawlers.
Applebot: Apple’s Search Engine Crawler
Applebot is the web crawler used by Apple, primarily to help index content for Apple’s services like Siri, Spotlight, and Apple Search. It operates similarly to other search engine bots but is specifically tailored to help improve user experience across Apple’s ecosystem. This bot respects the robots.txt file just as Googlebot or Bingbot do. By adhering to the directives in a website’s robots.txt, Applebot helps avoid unnecessary or unwanted traffic that could burden servers.
How Applebot Uses robots.txt
When a website owner specifies rules in the robots.txt file, Applebot checks and follows those rules to determine which pages should be crawled. Applebot generally crawls content that is freely available, such as publicly accessible web pages and images. However, website owners may restrict access to certain directories or pages that they do not wish to be indexed, and Applebot will comply with these rules.
Here, Applebot will not crawl anything in the /index/ folder, which could contain private or sensitive information, while it is allowed to crawl the /public/ folder. The key idea is that Applebot follows these instructions to help with the indexing of relevant content across Apple’s search systems.
Amazon Bots: A Range of Web Crawlers
Amazon also uses bots to crawl the web. The most famous bot from Amazon is associated with its product search functionality, where bots crawl various product listings, reviews, and other relevant data across the internet to provide the most accurate results for Amazon’s customers. These bots are used for indexing and categorizing content, advertising, and gathering information for Amazon’s recommendation engines.
Amazon bots are not limited to product information gathering. They also support Amazon Web Services (AWS) products, scraping data for analysis and providing insights. Amazon’s bot system can be complex, as there are different crawlers for different services, including Alexa, Amazon Product Ads, and AWS.
How Amazon Bots Use robots.txt
Amazon bots, like Applebot, obey the rules in the robots.txt file. If a website owner does not wish to have their content indexed or scraped by Amazon’s bots, they can use the robots.txt file to block access. Amazon bots, particularly those crawling for advertising and product-related purposes, respect these directives as a way to avoid unwanted data gathering.
In this scenario, Amazon’s bot is instructed not to crawl anything in the private directory but is allowed to crawl product listings in the products directory. This is important for ensuring that only relevant information is indexed and sensitive data remains private.
Ethical Considerations of Web Crawling
The use of bots, including Applebot and Amazon bots, is an integral part of the modern web. However, there are ethical considerations around web crawling and respecting the robots.txt rules. If bots do not adhere to the robots.txt file, they could overwhelm a website’s server by requesting too many pages, potentially causing disruptions. More importantly, bots that ignore robots.txt may crawl private or restricted content, which could violate user privacy or expose sensitive information.
Both Applebot and Amazon bots are designed to respect the rules set by website owners through the robots.txt file. Applebot, for example, crawls websites to provide data for Siri and Spotlight, but it ensures that it does not access data that the website owner has restricted. Similarly, Amazon’s bots help index product information but avoid scraping unnecessary or private content, ensuring that they are compliant with ethical standards and not overburdening website servers.
Social Media Crawlers
In the era of artificial intelligence and social media, platforms like Facebook, Twitter, LinkedIn, Pinterest, and Instagram use their own bots to index content. Configuring the robots.txt file to manage these AI-driven bots is crucial for balancing accessibility and server performance. This section explores a custom setup to manage crawl rates for popular AI and social media bots while maintaining optimal functionality.
Understanding Crawl-Delay and Its Importance
What Is Crawl-Delay?
The crawl-delay directive in a robots.txt file specifies the time (in seconds) a bot should wait between consecutive requests to the server. By managing the crawl rate, you can prevent overloading your server while still allowing bots to index your content.
Why Is Crawl-Delay Important?
Server Performance
High-traffic websites or those hosted on shared servers can experience slowdowns or crashes if multiple bots crawl simultaneously. Crawl-delay helps distribute bot activity more evenly over time.
Targeted Indexing
By setting crawl delays for specific bots, you can prioritize indexing by search engines and platforms most relevant to your business.
Efficient Resource Usage
A carefully configured crawl-delay minimizes bandwidth consumption and ensures that vital resources are accessible to human users.
Customizing Crawl-Delays for AI Bots and Social Media Crawlers
Below is a tailored approach to configuring crawl delays for major AI and social media bots, ensuring efficient and controlled interactions:
1. Facebook Bots
Configuration in Robots.txt:
User-agent: facebookexternalhit
Crawl-delay: 30
Explanation:
The facebookexternalhit bot is used by Facebook to generate previews for shared links. A crawl delay of 30 seconds ensures that this bot can access your website’s resources without causing server strain.
Benefits:
Enables rich previews for Facebook users, enhancing engagement.
Prevents the bot from overloading your server during high traffic periods.
Best Practices:
Test the impact of this setting using server logs to ensure Facebook previews remain accurate and timely.

2. Facebot
Configuration in Robots.txt:
User-agent: Facebot
Crawl-delay: 10
Explanation:
Facebot is Facebook’s web crawler for general indexing. A shorter delay (10 seconds) is recommended for Facebot to allow timely updates of public content shared on Facebook.
Benefits:
Ensures up-to-date indexing of your public content on Facebook.
Supports Facebook’s ability to surface relevant posts in its search and feed algorithms.
Best Practices:
Review your server’s capacity to handle frequent requests before implementing a shorter crawl delay.

3. Twitterbot
Configuration in Robots.txt:
User-agent: Twitterbot
Crawl-delay: 30
Explanation:
Twitterbot is responsible for fetching metadata to generate Twitter cards. A 30-second delay balances the need for timely updates with server performance.
Benefits:
Facilitates visually appealing Twitter cards that increase click-through rates.
Reduces unnecessary strain on server resources.
Best Practices:
Use tools like Twitter’s Card Validator to verify how your content appears on Twitter after applying these settings.

4. LinkedInBot
Configuration in Robots.txt:
User-agent: LinkedInBot
Crawl-delay: 10
Explanation:
LinkedInBot fetches data for generating rich previews on LinkedIn posts. A 10-second crawl delay ensures LinkedIn’s crawling activity does not interfere with website performance.
Benefits:
Improves the quality of link previews on LinkedIn, enhancing professional engagement.
Ensures consistent updates for publicly shared articles and blogs.
Best Practices:
Monitor LinkedIn’s crawl behavior via server logs to refine the crawl-delay setting as needed.

5. Pinterestbot
Configuration in Robots.txt:
User-agent: Pinterestbot
Crawl-delay: 10
Explanation:
Pinterestbot is designed to fetch images and metadata for pins. A crawl delay of 10 seconds supports efficient resource indexing without overwhelming the server.
Benefits:
Promotes your website’s visual content effectively on Pinterest.
Drives traffic through visually engaging pins linked to your site.
Best Practices:
Use Pinterest’s Rich Pins Validator to ensure your site’s metadata is correctly implemented.

6. Instagram Bot
Configuration in Robots.txt:
User-agent: Instagram
Crawl-delay: 10
Explanation:
Instagram bots primarily interact with website metadata to improve link previews. A 10-second delay is sufficient for their relatively infrequent crawling needs.
Benefits:
Enhances the visibility of your website content shared on Instagram.
Minimizes disruptions to server performance while maintaining timely updates.
Best Practices:
Regularly audit how Instagram bots interact with your website to ensure optimal performance.

MSN Bot
The MSN bot refers to the web crawler used by Microsoft’s search engine to explore the web, index content, and determine how pages rank in search results. Originally a part of the MSN Search, the bot now operates as part of Bing, Microsoft’s search engine platform. MSN bot plays a crucial role in web content discovery, ensuring that search engines are updated with new and relevant information from websites.
Significance of MSN Bot
The significance of the MSN bot lies in its contribution to search engine optimization (SEO). As a search engine crawler, its purpose is to index web pages, making them accessible through Bing’s search engine results. Without crawlers like the MSN bot, Bing wouldn’t be able to provide accurate, up-to-date search results. It helps improve visibility for websites by ensuring their pages are indexed and available for search queries. Additionally, the MSN bot ensures that dynamic content, such as frequently updated blog posts, news articles, and product pages, is regularly checked and indexed, keeping search results relevant and timely.
How MSN Bot Works
The MSN bot operates by systematically crawling websites across the internet. It starts with a list of URLs, often referred to as a seed list, and follows links on those pages to discover additional content. The process involves:
- Crawling: The bot visits websites and retrieves content, including text, images, and metadata.
- Indexing: After crawling, the bot processes and indexes the content, making it searchable through Bing’s search engine.
- Re-crawling: The MSN bot continuously revisits websites at set intervals to keep the index updated. This ensures that any changes in the website content (like a new blog post or product page) are reflected in search results.
To avoid overloading websites with requests, MSN bot respects certain parameters defined in the website’s robots.txt file, such as which pages it can and cannot crawl, and how often it can revisit the site.
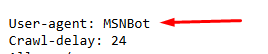
Crawl Delay in MSN Bot
The crawl delay for the MSN bot is set at 24 seconds, meaning that after visiting a page, the bot will wait for 24 seconds before making a request to the next page. This delay helps prevent overwhelming servers with too many requests in a short period, ensuring that the crawling process is more considerate and does not negatively impact website performance. By managing the crawl delay, MSN bot strikes a balance between gathering content efficiently and minimizing the load on web servers.
This crawl delay can be adjusted through the robots.txt file if necessary, allowing website owners to manage how frequently crawlers access their site.
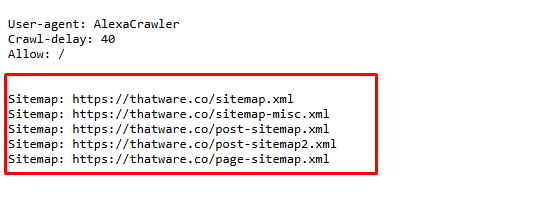
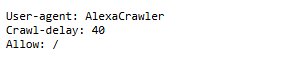
Alexa Crawler
Search engines use crawlers—automated bots that scour the web to index content— to gather and catalog websites. One such crawler is the Alexa Crawler, used by Amazon’s Alexa service. This section delves into the role of the Alexa Crawler, its interaction with the robots.txt file, and how businesses can leverage this knowledge for enhanced SEO performance.
What Is the Alexa Crawler?
The Alexa Crawler is a bot used by Alexa Internet, a subsidiary of Amazon, which specializes in web traffic analysis and ranking services. Alexa provides tools for website owners to track site performance, understand user engagement, and optimize for better ranking in search results. The crawler’s primary role is to access and analyze web pages to gather data regarding traffic, user behaviour, and engagement metrics. This data is subsequently used by Alexa to rank websites in comparison to others within its global index.
Alexa ranks websites based on several factors, including the volume of traffic they receive, the number of backlinks, and user engagement metrics. Alexa’s index is widely regarded in the digital marketing community, and many businesses rely on it to assess their online performance and track competitors. Understanding how the Alexa Crawler works is essential for managing your site’s SEO effectively.
How the Alexa Crawler Works
Like other web crawlers, the Alexa Crawler visits websites by following hyperlinks found on pages it has already visited. This crawler collects various data points to generate Alexa’s traffic estimates, which are used in the Alexa Traffic Rank.
Here’s a simplified breakdown of the process:
- Crawl the Web: The Alexa Crawler visits your website to analyze the content. It looks at HTML, images, scripts, and other elements.
- Data Collection: The crawler then aggregates information, such as page content, site structure, and external links, to create a profile of your website’s traffic and performance.
- Indexing: The gathered data is indexed to be used by Alexa in generating traffic rankings, which are visible in their database and can be accessed by businesses for competitive analysis.
Interaction Between Alexa Crawler and Robots.txt
The robots.txt file plays an essential role in determining which parts of your website are accessible to crawlers, including the Alexa Crawler. This file, placed in the root directory of a website, contains instructions for search engine bots on how to crawl or index your site. It is a vital component for controlling crawler traffic, preventing overloading servers, and protecting sensitive information from being indexed.
Alexa’s crawler respects the directives outlined in your robots.txt file, meaning that if you want to prevent Alexa from crawling specific pages or sections of your website, you can include rules that explicitly disallow the Alexa Crawler. However, there are some nuances to understand when configuring robots.txt for Alexa’s crawler.
How ThatWare Implements it:
Best Practices for Optimizing Alexa Crawler Traffic
To ensure a healthy relationship with the Alexa Crawler, webmasters should follow best practices when configuring the robots.txt file and managing crawler traffic. Here are some tips for optimizing Alexa Crawler interactions:
1. Avoid Blocking Essential Pages
While it’s tempting to block search engines from crawling certain pages, it’s important to ensure you’re not inadvertently blocking valuable content. Make sure the pages you want to be indexed by search engines for ranking purposes are accessible to the Alexa Crawler. Block only non-essential pages like admin panels or duplicate content.
2. Set Crawl-Delay for Server Performance
If you notice that Alexa’s crawler is overloading your server or causing performance issues, set an appropriate crawl delay. This allows you to control the rate at which Alexa accesses your site without blocking it entirely, helping balance server resources while allowing Alexa’s bot to index your site over time.
3. Use Alexa Analytics Data to Inform SEO Strategy
Alexa provides webmasters with valuable insights about how their sites perform relative to competitors. This data can be used to adjust your SEO strategy, improve content engagement, and optimize user experience. The more Alexa can crawl and index your site, the more accurate these analytics will be.
4. Monitor Alexa Rankings and Traffic
Monitoring how your website ranks in Alexa’s index can provide valuable insights into your SEO efforts. The data can also help inform business decisions, marketing strategies, and competitive analysis. Ensure that the Alexa Crawler can access the parts of your site that provide meaningful data, such as landing pages and high-traffic areas.
5. Use Sitemap Files for More Efficient Crawling
In addition to robots.txt, consider submitting an XML sitemap to Alexa and other search engines. A sitemap gives bots a clear overview of your site’s structure and content, ensuring they can easily locate and index the most important pages of your site.

Thatware | Founder & CEO
Tuhin is recognized across the globe for his vision to revolutionize digital transformation industry with the help of cutting-edge technology. He won bronze for India at the Stevie Awards USA as well as winning the India Business Awards, India Technology Award, Top 100 influential tech leaders from Analytics Insights, Clutch Global Front runner in digital marketing, founder of the fastest growing company in Asia by The CEO Magazine and is a TEDx speaker.
