SUPERCHARGE YOUR Online VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
On occasion, you may require that certain areas of your website be invisible to both search engines and visitors. The causes vary, as do the methods of implementation. You can use any of the following tools to assist you in controlling the indexing process: meta robots tag, X-Robots-Tag, robots.txt file, sitemap. In this blog article, we’ll discuss the peculiarities of X-Robots-Tag use, as well as its key risks and benefits.

INTRODUCTION:
Robots.txt instruct search engine how to crawl pages on their website, Robots.txt files inform search engine crawlers how to interact with indexing your content.search engines tend to index as much high-quality information as they can & will assume that they can crawl everything unless you tell them otherwise.
Robots.txt can help prevent the appearance of duplicate content. Sometimes your website might purposefully need more than one copy of a piece of content.
The Role of X-Robots-Tag in SEO Optimization
In SEO, one of the primary concerns for website owners is managing how search engines index and crawl their site content. The X-Robots-Tag is a powerful tool that complements other directives such as the robots.txt file and the meta robots tag. This HTTP header-based directive is vital for ensuring optimal crawling and indexing behavior for search engines, helping SEOs manage their site’s visibility in search engine results pages (SERPs).
As search engines continue to refine their algorithms, understanding and controlling the way in which they interact with your website’s content is critical. The use of directives like X-Robots-Tag can significantly impact your site’s ability to rank effectively, as it allows for finer control over how various parts of your website are treated by search engine crawlers.
Why SEO Needs X-Robots-Tag
SEO professionals often struggle with ensuring that irrelevant or low-value pages aren’t indexed or crawled by search engines. The X-Robots-Tag, because it can be applied to non-HTML files, is particularly valuable in cases where robots.txt or meta robot tags cannot provide the necessary level of control. For example, images, PDFs, and other non-HTML resources are often left out of traditional directives.
Let’s explore some practical use cases where the X-Robots-Tag becomes indispensable:
- Controlling PDF, Image, and Non-HTML File Indexing As mentioned earlier, the X-Robots-Tag is the only way to prevent search engines from indexing non-HTML files like PDFs, images (JPEG, PNG, GIF), and other media types. If these files are publicly available on your site, but you don’t want them to appear in search engine results, the X-Robots-Tag can be implemented to signal to crawlers that the content should not be indexed.
Consider a scenario where your website hosts numerous downloadable PDFs containing detailed product information or confidential data, and you do not want these documents to show up in search engine results. By applying an X-Robots-Tag to the HTTP response header of the PDFs, you can prevent search engines from indexing these files. - Controlling URL Indexing at the Server Level Unlike the meta robots tag, which is embedded in the HTML code of a page, the X-Robots-Tag can be applied at the server level. This is particularly useful when you want to block certain URL patterns or file types across your entire site. For instance, if you run an e-commerce site and want to exclude pages with filters or sorting parameters from being indexed, you can add X-Robots-Tag headers to these dynamic URLs without needing to manually edit every page.
- Mass Noindex for Large Sections of a Site X-Robots-Tag becomes particularly powerful for sites with large subdomains or sections that are irrelevant to search engines. For example, you may have a staging subdomain, admin areas, or support portals that do not need to appear in search results. The X-Robots-Tag can be applied globally across these sections by configuring your server to apply the “noindex” directive for the entire subdomain or directory.
- Preventing Crawling of Duplicate Content Duplicate content remains one of the most common SEO issues that websites face. In many cases, content might be intentionally duplicated for different purposes, such as A/B testing or content variations. The X-Robots-Tag allows you to instruct search engines not to index these duplicate pages, even if they are still accessible to users. This is particularly beneficial in e-commerce, where products may appear in multiple categories, leading to potential content duplication.
- Use in Development and Testing Environments During the development phase, it’s essential to ensure that search engines do not crawl staging environments or incomplete pages. The X-Robots-Tag can be implemented on a staging server to prevent search engines from indexing these pages while they are still being developed.
Implementing X-Robots-Tag
Although implementing the X-Robots-Tag can be straightforward for some users, for others, it can be a bit tricky. Since it’s an HTTP response header, this directive is implemented at the server level. Let’s break down how to implement it correctly for various environments:
For Apache Servers If your website is hosted on an Apache server, the X-Robots-Tag can be configured through the .htaccess file. This file controls how the server handles requests for resources. This configuration tells the server to add the X-Robots-Tag header to any PDF file on the site, ensuring that these files are not indexed by search engines.
- Nginx is known for its performance and scalability, and implementing the X-Robots-Tag at the server level ensures it is applied efficiently.
- For Cloudflare If you’re using Cloudflare as your Content Delivery Network (CDN), you can use its Page Rules feature to implement the X-Robots-Tag header. You can set up page rules to apply the X-Robots-Tag to specific URLs or types of content across your website.
- For WordPress Users Although most SEO plugins like Yoast SEO or RankMath handle robots.txt files and meta robots tags, WordPress doesn’t provide built-in support for adding HTTP headers like X-Robots-Tag. However, you can add custom headers by using a plugin like “Insert Headers and Footers” or by editing the .htaccess or wp-config.php files directly.
ROBOTS.TXT FOLLOW PRE-DEFINED PROTOCOLS:
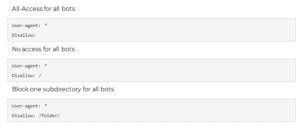
User-agent: A means of identifying a specific crawler or set of crawlers.
Allow: All content may be crawled.
Disallow: No content may be crawled.
CREATE A ROBOTS.TXT FILE IN WORDPRESS:
Using Yoast SEO

A robots.txt file can be a powerful tool in any SEO’s usage as it’s a great way to control how search engine crawlers/bots access certain areas of your site. Keep in mind that you need to be sure you understand how the robots.txt file works or you will find yourself accidentally disallowing Googlebot or any other bot from crawling your entire site and not having it be found in the search results!
X-Robots-Tag and Its Companions
The X-Robots-Tag is an essential component of the REP – Robots Exclusion Protocol. The REP (or robots exclusion standard) is a collection of rules that governs how search robots act on your website, including what material they crawl and index. The so-called ‘directives’ come into play when determining how the material on your web page is displayed. In reality, several directives instruct search engine robots which specific sites and material to crawl and, obviously, index. The most common is robot.txt files, which work with the meta robots tag. Despite being a pair, they are self-sufficient.
The robots.txt file is placed in the website’s root directory. Search robots should crawl portions of the website based on that information. It might be a page, a subdirectory, or other site elements. In general, Google robots should crawl parts of your website that you provide information first and should be pushed less or even ignored. The directives ‘allow’ and ‘disallow’ in robots.txt take effect. However, keep in mind that these bots are not required to follow the regulations you specify. Google formally invalidated robots.txt instructions in July 2019.
If you work with page content and wish to control it, you should use the meta robots tag. The meta robots tag, inserted in the head> portion of a web page, contains a slew of useful advice.
However, you should mention another method of managing noindex and nofollow directives. This is X-Robots-Tag, and it differs from the preceding members in a few ways.
When Should You Use X-Robots-Tag?
Of course, you can manage the bulk of website crawling issues with the aid of robots.txt files and the meta robots tag. However, there are a few instances where X-Robots-Tag appears to be a better fit:
- You don’t want particular video, picture, or PDF file formats indexed. Let’s say you wish to make a certain URL inaccessible for a defined length of time.
- Make good use of your crawl budget. The primary goal is to guide a robot in the appropriate path. Robots do not need to waste time indexing irrelevant areas of the webpage (such as admin and thank-you pages, shopping cart, promotions, etc.). But it doesn’t imply these sections aren’t essential to users, and you don’t have to spend your optimization time improving the quality of these pages.
- You must noindex a whole subdomain, subfolder, pages with specified criteria, or anything else that necessitates mass modification.
How To Implement X-Robots-Tag On A Website
X-Robots-Tag is an HTTP header supplied by the webserver (hence the name response header). Remember that X-Robots-Tag is the only way to noindex non-HTML files such as PDFs or picture files (jpeg, png, gif, etc.). The X-Robots-Tag can be introduced to a site’s HTTP replies using the .htaccess file in an Apache server setup.
One should note that the X-Robot-Tag implementation technique is fairly hard because it occurs at the code level. Web admins typically set up X-Robot-Tags. Any blunder might lead to major problems. For example, a syntax problem might cause the site to fail. It’s also a good idea to check for faults in the X-Robots-Tag frequently because it’s a big location for all types of problems.
If you opt not to index the page, the X-Robots-Tag header will appear like this:
HTTP/1.1 200 OK
Date: Tue, 25 May 2019 20:23:51 GTM
X-Robots-Tag: noindex
Compared to the meta robots tag:
<!DOCTYPE html>
<html><head>
<meta name=”robots” content=”noindex” />
(…)
</head>
<body>(…)</body>
</html>
If several directions are used simultaneously, it will appear the following way:
HTTP/1.1 200 OK
Date: Tue, 25 May 2019 20:23:51 GTM
X-Robots-Tag: noindex, nofollow
X-Robots-Tag: noarchive
3.1 Directives Concerning X-Robots
The instructions are, for the most part, the same as those of the meta robots tag:
- follow – directs search robots to the page and instructs them to crawl all available links on the page
- nofollow – prevents robots from crawling all available links on the page
- index – directs bots to the page and allows them to index the page
- noindex – prevents bots from indexing the page, preventing it from appearing in SERPs
- noarchive — prevents Google from caching the page.
How To Examine X-Robots-Tag For Potential Issues
There are several different approaches for searching the web for an X-Robots-Tag.
One option is to use Screaming Frog.
After running a site via Screaming Frog, go to the “Directives” page and look for the “X-Robots-Tag” column to see which areas of the site use the tag, as well as which individual directives.
A few plugins are available that allow you to identify whether an X-Robots-Tag is being utilized, such as the Web Developer plugin.
You may examine the various HTTP headers used by clicking on the plugin in your browser and then heading to “View Response Headers.”
Common Directives Used in X-Robots-Tag
The syntax of the X-Robots-Tag is very similar to the meta robots tag, with a few key directives to manage crawling and indexing. Here’s a breakdown of the most commonly used directives:
- noindex: Instructs search engines to not index the page or file. This prevents the page from appearing in search engine results.
- nofollow: Instructs search engines to not follow any links on the page, meaning that link equity will not be passed to linked pages.
- index: The default behavior, which instructs search engines to index the page. It is often used explicitly when a page should be indexed after having a “noindex” tag removed.
- noarchive: Prevents search engines from showing a cached version of the page in search results. This can be useful for pages with dynamic content or sensitive information that you do not want to be stored by search engines.
- nosnippet: Tells search engines not to display a snippet (such as a description or image thumbnail) in search results. This can be useful for pages where the snippet might not accurately represent the content or if you don’t want to show preview images.
- unavailable_after: This directive tells search engines to stop indexing a page after a certain date and time. For example, if you have a limited-time offer or promotion, you can set the page to stop being indexed after the promotion ends.
Risks and Considerations
Despite its usefulness, there are some risks and considerations to keep in mind when using the X-Robots-Tag:
- Accidental Exclusion: A common risk when implementing X-Robots-Tag is accidentally blocking important content or pages that should be indexed. Given that it’s applied at the HTTP header level, even a small mistake, such as a typo or incorrect file path, can prevent a page from appearing in search results.
- Impact on User Experience: While X-Robots-Tag helps control crawling, it is essential to ensure that critical pages are not inadvertently excluded. For instance, if product pages or blog posts are accidentally marked as “noindex,” they won’t appear in search engine results, which could negatively impact traffic.
- Server Configuration Issues: Since the X-Robots-Tag is applied at the server level, incorrect configurations or other server files can lead to larger server issues or performance degradation. Always test changes on a staging server before deploying them to production.
- Crawl Budget Mismanagement: While X-Robots-Tag helps control crawling and indexing, mismanagement can lead to under-indexing, where important pages are not crawled enough, or over-indexing, where unnecessary pages are indexed. Both situations can hurt SEO efforts, as the search engine’s crawl budget is limited.
Best Practices for X-Robots-Tag Implementation
To make the most of the X-Robots-Tag, consider the following best practices:
- Use it to control low-priority pages: Use the X-Robots-Tag to prevent the crawling of irrelevant pages, such as login pages, admin areas, and duplicate content pages, but ensure that critical pages are not blocked.
- Test changes carefully: Before making large-scale changes to your site’s robot handling, always test on staging versions of your website. This will help prevent accidental blocking of valuable pages.
- Monitor search engine performance: Keep an eye on how changes to your X-Robots-Tag affect your site’s search engine performance. Use Google Search Console and other analytics tools to monitor changes in indexing and traffic.
- Combine with robots.txt for comprehensive control: For maximum control over crawling and indexing, combine the X-Robots-Tag with a well-structured robots.txt file. While robots.txt controls access to certain pages, the X-Robots-Tag can provide more granular control for specific content types.
Advanced Applications of X-Robots-Tag
As SEO practices evolve, so too does the need for more sophisticated strategies to manage search engine indexing. The X-Robots-Tag provides webmasters and SEO professionals with fine-grained control over how search engines interact with their content. Beyond basic use cases, here are several advanced applications of the X-Robots-Tag that can enhance your website’s SEO performance:
1. Control Over Dynamic Content
Many modern websites use dynamic content that changes based on user behavior, session data, or A/B testing. For instance, e-commerce sites often generate custom URLs for search results, product filters, or user-specific content. In such cases, you may want to prevent search engines from indexing these dynamically generated pages to avoid indexing low-value content or duplicates.
By applying the X-Robots-Tag with the noindex directive to these dynamic URLs, you can control which pages are indexed. This is particularly helpful in e-commerce and large-scale websites where many unique URLs are generated for session-based views or custom filters. The X-Robots-Tag allows you to exclude these pages from search engine results, ensuring only valuable, unique content is indexed.
This will prevent dynamic or user-specific pages from appearing in search results, preserving the crawl budget for higher-value pages.
2. International SEO and Geo-Targeting
When dealing with international websites or multiple language versions of the same content, SEO professionals often encounter challenges in preventing search engines from indexing duplicate content. For example, a website that serves different language versions of the same content might run into duplicate content issues. While hreflang tags are commonly used to address this, the X-Robots-Tag can further control the indexing of regional versions of content.
For instance, if a webpage exists in both English and Spanish, you may want to apply the X-Robots-Tag to one of the versions (like the Spanish version) to prevent it from being indexed, especially if the content is near-identical. This ensures that search engines prioritize the original page, improving SEO and preventing penalties for duplicate content.
This ensures that only one version of the content gets indexed, thus improving your overall international SEO strategy.
3. Advanced Noindex Strategies for Temporary Pages
There are instances where temporary content, such as seasonal promotions, event pages, or countdown timers, should not remain indexed once they are no longer relevant. A good SEO practice is to prevent these pages from being indexed while they are active, and then remove the noindex tag once the content is no longer relevant.
For example, if your website features limited-time offers, you can apply the X-Robots-Tag to “noindex” the page during the promotion period. After the promotion ends, you can either update the page or remove the X-Robots-Tag, allowing it to be indexed again if necessary.
This strategy helps prevent expired content from appearing in search results, reducing the risk of penalties for outdated or irrelevant pages.
4. Control Over User-Generated Content
Many websites, especially forums, blogs, and social media platforms, allow users to generate content. While user-generated content (UGC) is valuable for community engagement, it can also lead to SEO problems, especially if that content is of low quality or duplicates existing pages. In such cases, the X-Robots-Tag can be used to control the indexing of certain types of user-generated content.
For instance, user reviews or comments might not be indexed by default because they don’t contribute significantly to search engine rankings or might contain duplicate content. The X-Robots-Tag allows webmasters to noindex such user-generated content without impacting the overall visibility of the website.
The Future of X-Robots-Tag and SEO
As search engines continue to refine their algorithms, the X-Robots-Tag’s role in SEO will likely become even more critical. With Google’s emphasis on providing users with the most relevant, high-quality content, the need for controlling the flow of indexing and crawling will remain a priority for SEO professionals.
1. Enhanced Personalization
Future trends in SEO suggest that personalized search results will become more prominent. With the X-Robots-Tag, SEO experts will be able to manage which personalized or session-based pages should be indexed and which should be kept private, improving both user experience and SEO performance. For example, websites with login-based content (like e-commerce sites with personalized shopping experiences) will need to prevent search engines from indexing pages tied to individual users or accounts.
2. Integration with Schema Markup
SEO professionals are increasingly using schema markup to provide additional information to search engines. It is likely that the X-Robots-Tag will integrate with advanced schema markup in the future, offering more precise control over which parts of a page’s schema should be considered for indexing. For instance, it could be useful to noindex a specific schema element (like an event or product detail) while still allowing the rest of the page to be indexed, enabling more targeted search results.
3. Automated SEO with AI
The future of SEO is likely to be heavily influenced by artificial intelligence (AI) and automation. As AI tools continue to develop, it’s possible that automated systems could adjust X-Robots-Tag headers dynamically based on SEO audits, user behavior data, and content performance metrics. This could allow for real-time updates to indexing strategies without requiring manual intervention from webmasters.
Final Thoughts
The breadth of X-Robot-Tag benefits for page indexing and crawling is rather extensive. The X-Robots-Tag header intends to help search engine crawlers in utilizing their crawl budget wisely, especially if the website is large and has a variety of materials. So here are the important takeaways:
In conjunction with the robots meta tags, the use of X-Robots-Tag is to optimize the crawl budget by directing a robot to be crucial for indexing sites.
Because the X-Robots-Tag appears in the HTTP response header, SEOs frequently require the aid of web admins to apply it on the website.
Review all directives with Screaming Frog Spider or other SEO crawlers regularly, as their power might affect future indexing of the website and potentially lead to ranking decreases.
