SUPERCHARGE YOUR SEO Strategy & VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
What is This Project About?
This project is a sophisticated tool designed to analyze, categorize, and extract meaningful insights from textual content. The goal is to help businesses, website owners, and digital marketers make sense of large volumes of text data by organizing it into specific categories and extracting refined keywords.
At its core, this project uses machine learning techniques to classify and cluster text data dynamically. It does not rely on predefined rules or hardcoded logic. Instead, it adapts to the patterns in the input data, making it a highly flexible and powerful solution.

Key Features and Components
- Text Preprocessing and Cleaning:
- The project cleans raw textual data by removing unnecessary elements such as stopwords (common words like “the,” “is”), special characters, and numbers.
- It ensures the text is uniform and meaningful for further processing.
- Dynamic Text Classification:
- Using machine learning algorithms like KMeans clustering, the project groups similar text content into predefined or dynamically identified clusters.
- These clusters represent logical categories like “SEO Services,” “Web Development,” or “Digital Marketing.”
- Keyword Extraction:
- For each text entry, the project identifies the most important keywords or phrases (unigrams, bigrams, trigrams).
- These keywords provide insights into the main topics or focus areas of the content.
- Categorization Mapping:
- The project maps the clusters to predefined categories such as “Content Writing” or “SEO Services.”
- This mapping helps businesses align their content with specific strategic goals.
- SEO Optimization Focus:
- By extracting relevant keywords and categorizing content, the project enables website owners to improve their search engine rankings.
- It helps identify which content works best for SEO and where improvements are needed.
Purpose and Use Cases
1. For Website Owners:
- Organize Content: Automatically categorize website content into meaningful sections like “SEO Services” or “Digital Marketing.”
- Improve Search Rankings: Use the extracted keywords to optimize web pages for search engines.
- Identify Gaps: Understand which content categories are underrepresented on the website.
2. For Digital Marketers:
- Keyword Strategy: Develop a keyword strategy based on refined and relevant terms extracted from the text.
- Campaign Optimization: Create more targeted campaigns by understanding the focus of existing content.
3. For Businesses:
- Customer Insights: Analyze customer-facing content to ensure it aligns with their needs and search behaviors.
- Competitor Analysis: Compare categorized data to competitors’ content strategies to find unique opportunities.
4. For Researchers and Analysts:
- Data Analysis: Use the categorized data to study trends, patterns, and emerging topics.
- Content Strategy: Make data-driven decisions for publishing and marketing.
Why Is This Project Important?
- Efficient Content Management:
- Manually analyzing and categorizing large amounts of text is time-consuming and error-prone. This project automates the process, saving time and ensuring consistency.
- SEO Impact:
- Keywords and well-organized content play a critical role in improving search engine rankings. This project simplifies the process of keyword discovery and content optimization.
- Flexibility and Scalability:
- The model is dynamic, meaning it can adapt to different types of text data and categories, making it useful for a wide range of industries.
- Business Growth:
- By aligning content with customer needs and search behavior, businesses can attract more traffic, increase engagement, and drive conversions.
Benefits to the User
Immediate Insights:
- Users get a clear understanding of their content and how it fits into broader categories.
Actionable Recommendations:
- Based on the output, users can make informed decisions about content creation, editing, and strategy.
Improved Visibility:
- The refined keywords and categorized content improve website visibility on search engines, leading to higher organic traffic.
Steps for Clients to Take After Seeing the Output
- Review the Categorized Data:
- Understand how your content is grouped and ensure the categories align with your goals.
- Utilize Extracted Keywords:
- Incorporate the keywords into your web pages, meta descriptions, and blogs for better SEO performance.
- Fill Content Gaps:
- If certain categories are missing or underrepresented, create new content to balance your portfolio.
- Optimize Underperforming Content:
- Use the keywords and category insights to improve underperforming pages.
- Plan Strategic Campaigns:
- Develop targeted campaigns based on the categorized content and extracted keywords.
Summary
This project helps you understand and organize your content better. It automatically categorizes your text into groups like “SEO Services” or “Web Development” and gives you important keywords to improve your website’s search rankings. Whether you’re a business owner, a marketer, or a researcher, this tool makes your content more effective, saves time, and helps you attract more visitors to your website. It’s like having a smart assistant for managing and improving your online content.
What is Text Classification?
Text Classification is a method used in computers to automatically organize or categorize text into predefined groups. For example:
- Classifying emails as spam or not spam.
- Categorizing customer reviews as positive, negative, or neutral.
- Grouping articles into topics like sports, technology, or health.
The computer uses a model (a set of rules or patterns) to make these decisions, and this model is created by learning from examples of previously categorized text.
Use Cases of Text Classification
- Email Filtering: Automatically detect spam or promotional emails and separate them from important ones.
- Customer Feedback Analysis: Categorize reviews as positive or negative to understand customer satisfaction.
- News Categorization: Group articles based on topics like politics, business, or entertainment.
- Chatbot Support: Recognize customer queries and route them to the right department, such as billing or technical support.
Real-Life Implementations
- Social Media Platforms: Automatically detect and remove harmful or abusive content.
- E-commerce Websites: Classify product reviews, tag products with relevant categories, and filter inappropriate comments.
- Healthcare: Analyze patient feedback or categorize medical records.
- Search Engines: Categorize and rank content to display relevant results for user queries.
Use Case for a Website
For a website owner, Text Classification can be used to:
- Spam Detection: Identify and block spam comments or messages submitted through contact forms.
- Content Organization: Automatically tag articles or blogs into categories like “Technology”, “Lifestyle”, or “Education”.
- Customer Feedback Analysis: If the website collects feedback, classify it to understand customer sentiment.
- Personalization: Recommend articles, products, or services by analyzing user behavior or submitted text.
- Search Optimization: Improve the website’s search functionality by categorizing and tagging text content.
What Kind of Data Does Text Classification Need?
A Text Classification model typically needs the following types of data:
- Text Data: This could be:
- Raw text from the website (like blog posts, comments, or messages).
- A structured dataset in formats like CSV, containing columns such as:
- Text: The actual content to classify.
- Label: The category it belongs to (e.g., “spam”, “not spam”).
- Labels/Groups: These are the predefined categories you want the model to classify the text into (e.g., spam or not spam).
- Website Context:
- If you’re processing website content, you may need to extract the text using URLs or scrape the text directly from the pages.
- Alternatively, the client might already have this data in a file (like CSV or JSON) for you to use.
How Does the Model Work?
- Training the Model:
- The model is taught using examples. For example, if you want to classify text as spam or not spam, you provide the model with examples of both.
- It learns patterns from these examples, like keywords or writing style.
- Prediction:
- Once trained, the model takes new, unseen text and predicts the category it belongs to.
How to Provide Data to the Model?
- Using URLs of Website Pages:
- The content from the website (like text on blogs or pages) can be extracted using tools or scripts that crawl the website and collect data.
What Output Does a Text Classification Model Provide?
- Predicted Category:
- For each text input, the model gives a category it belongs to. Example:
- Input: “This is an amazing product!”
- Output: “Positive Review”
- For each text input, the model gives a category it belongs to. Example:
- Confidence Score:
- The model might also provide a score indicating how confident it is about its prediction. Example:
- “Positive Review (Confidence: 90%)”
- The model might also provide a score indicating how confident it is about its prediction. Example:
- Context for Websites:
- For a website, you can expect outputs like:
- Categorized blog posts: “This article is about Technology.”
- Spam detection: “This comment is spam.”
- Sentiment analysis: “This feedback is negative.”
- For a website, you can expect outputs like:
How is This Useful for a Website Owner?
- Automation: Automatically organize content, saving time and effort.
- Improved User Experience: Make navigation easier with properly categorized and tagged content.
- Better Insights: Understand user behavior and preferences by analyzing submitted text.
Summary
- Text Classification organizes text into predefined categories.
- For websites, it automates content tagging, spam detection, or sentiment analysis.
Step-by-Step Analysis
1. Nature of the Website and Its Content
The URLs provided are from a website offering SEO services and digital marketing solutions. The pages likely contain text that:
- Describes services (e.g., “advanced SEO services”, “branding services”).
- Provides educational or promotional content related to SEO and marketing.
From this, we can conclude that the content on the pages is mostly informative and service-oriented. Hence, tasks like spam detection, which are more suited to emails or user-generated comments, will not be relevant here.
2. Relevant Text Classification Tasks
Based on website’s content, the following Text Classification tasks are most applicable:
- Topic Categorization
- Classify each webpage into predefined categories like:
- “SEO Services”
- “Digital Marketing”
- “Web Development”
- “Content Writing”
- This will help in organizing the content and tagging each page with its appropriate topic.
- Classify each webpage into predefined categories like:
- Sentiment Analysis
- Analyze the tone or sentiment of the text (positive, neutral, or negative).
- This might not be as useful here because the website’s content is likely neutral and informative, not user-generated or emotional.
- Keyword and Service Identification
- Identify and extract keywords that describe the service being offered.
- This can help the client in enhancing their website’s SEO or creating structured metadata.
- Search Query Understanding
- If users search for specific terms on the website, classify their queries to direct them to the most relevant pages.
- Example: A user searching for “SEO for e-commerce” should be directed to the page on “e-commerce SEO services.”
3. Expected Outputs
Here’s what the model is expected to provide when applied to the website:
- Topic Categorization Output:
- Input: Text content of a webpage (e.g., “Our advanced SEO services are designed to improve your website rankings.”)
- Output: Category (e.g., “SEO Services”).
- Sentiment Analysis Output (if implemented):
- Input: Text content of a webpage.
- Output: Sentiment label (e.g., “Neutral” or “Positive”).
- Note: For this website, most sentiment outputs will likely be neutral or positive, as the content is promotional.
- Keyword Extraction Output:
- Input: Text content of a webpage.
- Output: List of keywords (e.g., [“SEO”, “marketing”, “rankings”, “services”]).
4. Process for Implementing the Model
Here’s how we can proceed step by step:
- Data Collection
- Use the list of URLs to scrape the content of the webpages. Extract headings, paragraphs, and any relevant text.
- Preprocessing the Data
- Clean the text (remove HTML tags, stop words, etc.).
- Tokenize the text (break it into words or phrases).
- Convert it into a format suitable for the model (e.g., numerical vectors).
- Defining Categories
- Predefine categories based on the website’s structure (e.g., “SEO Services”, “Digital Marketing”, “Web Development”).
- Training the Model
- Use examples of text from the website to train the model to recognize different categories or extract keywords.
- Classification
- Apply the model to classify the text from each page into the predefined categories or extract keywords.
Different Websites and Outputs
Yes, Text Classification Model outputs can vary based on the website because the content and purpose of websites differ. For example:
- An e-commerce site might focus on product categorization.
- A news website might focus on topic classification like “politics”, “sports”, or “technology”.
- A blog platform might focus on sentiment analysis of user comments or feedback.
For Thatware.co, the primary focus would be topic categorization and keyword extraction because the website is service-oriented.
Expected Output for Thatware.co
If we apply a Text Classification Model to the URLs provided, the expected output will be:
- Categories for Webpages:
- Each page will be classified into a relevant topic like “SEO Services”, “Digital Marketing”, or “Web Development”.
- Keywords for Each Page:
- A list of keywords extracted from the page content. For example:
- For the page on “Advanced SEO Services”, keywords could be: [“SEO”, “advanced techniques”, “rankings”].
- A list of keywords extracted from the page content. For example:

Part 1: Validating URLs
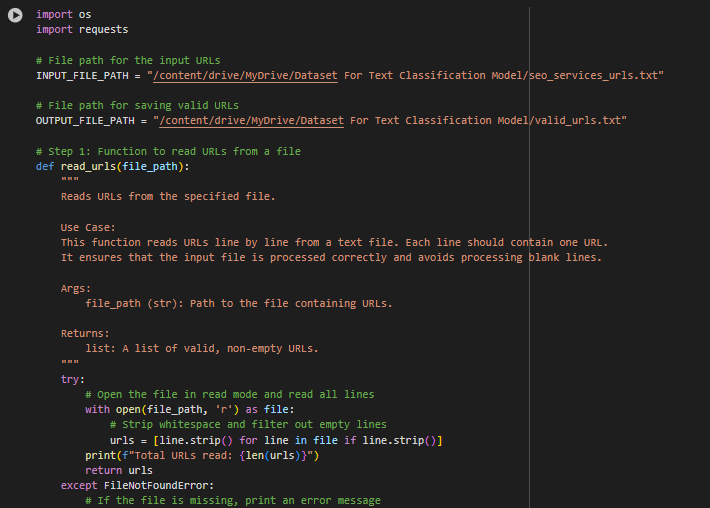
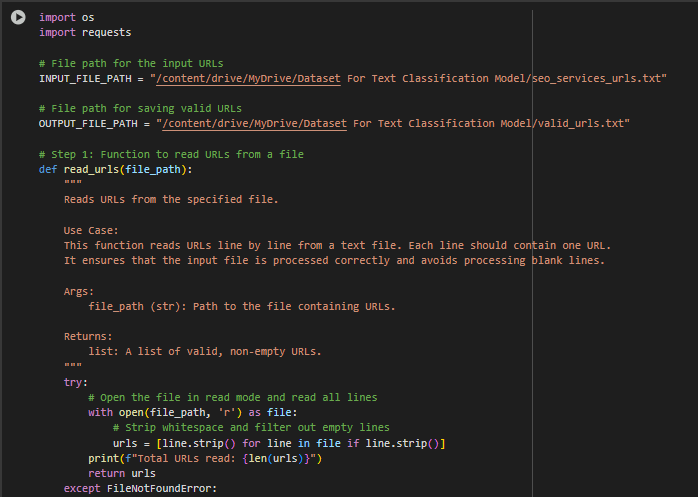
Code Name: validate_urls.py
Purpose: This part ensures that only active and valid web links (URLs) are processed further in the model.
How it works:
- Reads URLs from a file.
- Sends a request to each URL to check if it is active and accessible.
- Saves valid URLs to a separate file for further processing.
- Invalid or inaccessible URLs are ignored.
Part 2: Scraping Web Content
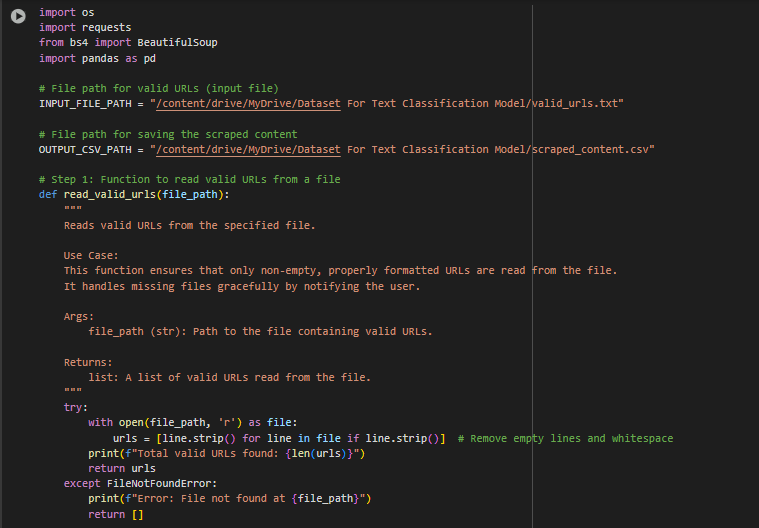
Code Name: scrape_content.py
Purpose: This part retrieves the title and main content of web pages from the validated URLs.
How it works:
- Reads valid URLs from the output of Part 1.
- Extracts the title and text content from each webpage.
- Displays a preview of the first 20 URLs’ content for verification.
- Saves all the scraped data (URL, title, and content) into a structured CSV file.
Step-by-Step Explanation of the Output
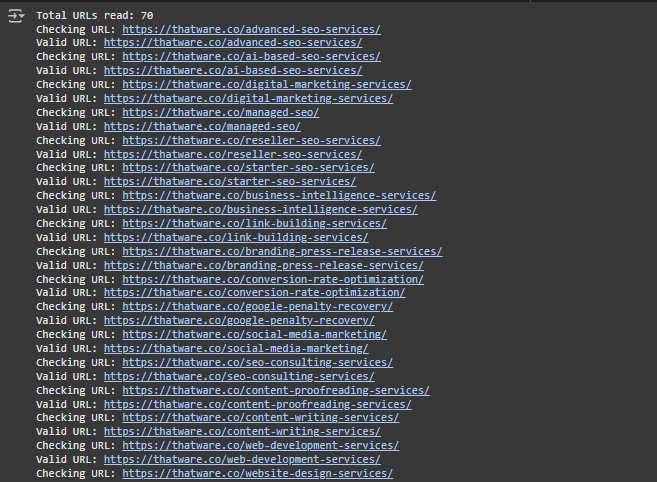
Step 1: Total Valid URLs Found
- Output Line: Total valid URLs found: 70
- What It Means:
This tells us that there are 70 active and valid web links (URLs) that were checked and passed the validation process in the first part of the project (validating URLs). - Why This Step Matters:
It ensures that only functioning links are passed to the next step, preventing errors during the web scraping process.
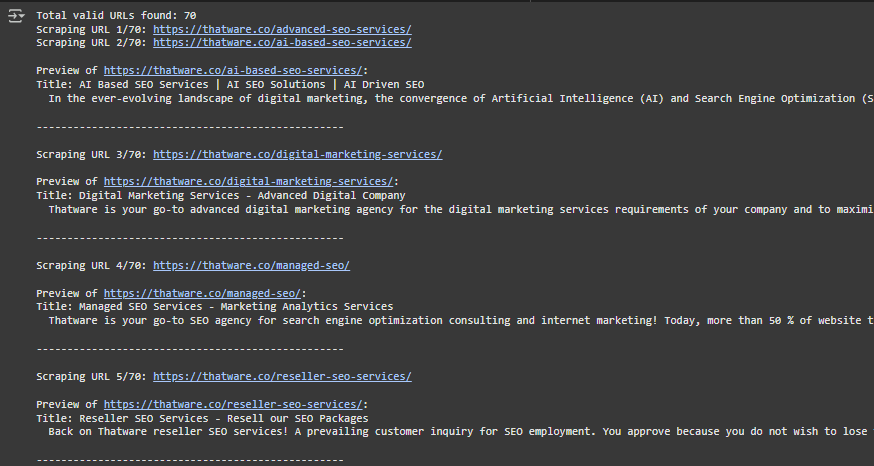
Step 2: Scraping URL (Start of Scraping Process)
- Output Lines:
- Scraping URL 1/70: https://thatware.co/advanced-seo-services/
- Scraping URL 2/70: https://thatware.co/ai-based-seo-services/
- … (and so on for all 70 URLs)
- What It Means:
The script processes each valid URL one by one. For each URL, the web scraper:- Visits the webpage.
- Extracts the title and the main content.
- Why This Step Matters:
This step forms the core of the web scraping process, where actual data is fetched from the web pages.
Step 3: Preview of Scraped Content
- Output Structure:
For each URL, the scraper displays a preview:- Title of the Page:
- Example:
Title: AI Based SEO Services | AI SEO Solutions | AI Driven SEO
This shows the title of the webpage, which summarizes its main purpose or content.
- Example:
- Content Preview (First 500 Characters):
- Example:
- Title of the Page:
In the ever-evolving landscape of digital marketing, the convergence of Artificial Intelligence (AI) and Search Engine Optimization (SEO) has ushered in a new era of innovation and efficiency. AI-Based SEO Services represent a paradigm shift…
This provides a brief look at the text content extracted from the page.
- Separator Line:
A line (————————————————–) separates previews to make the output more readable. - Why This Step Matters:
- The preview is a quality check to ensure the scraper is working correctly.
- It provides a quick look at the data for validation purposes without saving it to a file.
Step 4: Example of a Preview
Here’s what the output of a single preview tells us:
- URL Scraped:
- https://thatware.co/ai-based-seo-services/
This is the web address from which the content is scraped.
- https://thatware.co/ai-based-seo-services/
- Title of the Page:
- AI Based SEO Services | AI SEO Solutions | AI Driven SEO
This indicates the primary focus of the webpage (e.g., AI-based SEO services).
- AI Based SEO Services | AI SEO Solutions | AI Driven SEO
- Content (First 500 Characters):
o In the ever-evolving landscape of digital marketing, the convergence of Artificial Intelligence (AI) and Search Engine Optimization (SEO) has ushered in a new era of innovation and efficiency…
This shows the beginning of the extracted content, helping you understand what the page is about.
- Use Case:
- Validates the scraper’s ability to extract titles and meaningful content.
- Highlights key information about the webpage (title and an initial summary).
Step 5: Process Repeated for All URLs
- Observation:
The scraping process repeats for all 70 valid URLs, displaying a preview for each. - Why This Step Matters:
This ensures that all valid URLs are processed systematically, capturing the required data for later analysis.
Why This Output is Useful
- Data Quality Validation:
The previews ensure the scraper is extracting correct and meaningful information. - Error Checking:
If the scraper fails to fetch data for any URL, it will display an error message, helping to debug issues. - Content Gathering:
This step collects the raw data needed for text classification, categorization, and keyword extraction in subsequent parts of the project.
Part 3: Cleaning and Preprocessing Content
Code Name: clean_content.py
Purpose: This part cleans the scraped web content by removing unnecessary words and symbols to make it suitable for analysis.
How it works:
- Loads the scraped data (from Part 2) into memory.
- Cleans the text by:
- Converting it to lowercase.
- Removing common words (like “is”, “the”) using spaCy’s stopword list.
- Retaining only meaningful words and phrases.
- Saves the cleaned content into a new file for further analysis.
Step-by-Step Explanation of the Output
Step 1: SpaCy English Model Loaded Successfully
- What It Means:
- The script uses SpaCy, a Natural Language Processing (NLP) library, to clean and process text data.
- This line confirms that the SpaCy English language model (en_core_web_sm) has been successfully loaded.
- Why It Matters:
- SpaCy enables the script to perform operations like removing unnecessary words, converting text to lowercase, and simplifying it for analysis.
- Without this model, text cleaning would not be possible.
Step 2: Dataset Loaded
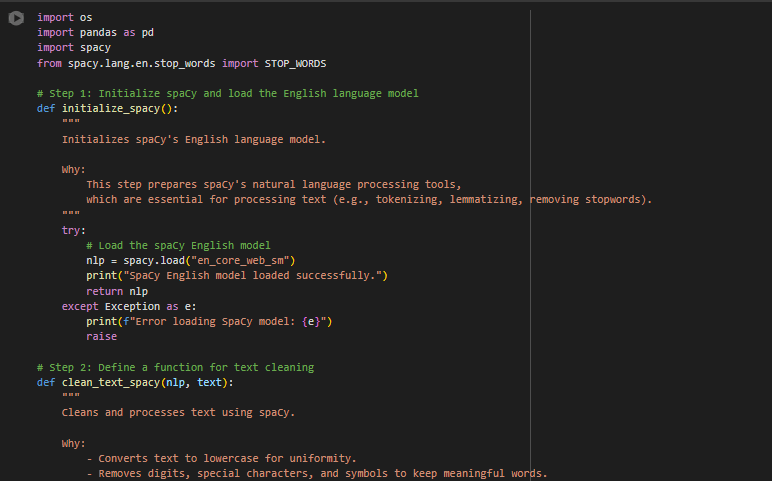
- Output:
- Loaded data from /content/drive/MyDrive/Dataset For Text Classification Model/scraped_content.csv. Total rows: 68
- What It Means:
- The script loaded a file named scraped_content.csv.
- This file contains 68 rows of data, where each row represents the content extracted from a URL (webpage).
- Why It Matters:
- Loading this data is the first step before processing it.
- This ensures the script has data to work with and validates the previous steps (web scraping).
Step 3: Processing Text Data
- Output:
- Processing text data…
- What It Means:
- The script begins cleaning and processing the raw content from the file.
- Text processing involves removing unnecessary details, making the text uniform, and keeping only meaningful words for further analysis.
- Why It Matters:
- Raw content often contains noise (unimportant information).
- Cleaning helps focus on the most relevant parts of the text, improving accuracy in downstream tasks like keyword extraction or categorization.
Step 4: Sample Processed Output
- Output (Preview):
- Column 1: Content: The original raw text extracted from the webpage.
- Example:
- Column 1: Content: The original raw text extracted from the webpage.
In the ever-evolving landscape of digital marketing, the convergence of Artificial Intelligence (AI) and Search Engine Optimization (SEO) has ushered in a new era of innovation and efficiency…
- What It Represents:
- This is the original text scraped from a webpage.
- It may include unnecessary words, punctuation, and stopwords (common words like “the,” “is,” etc.).
- Column 2: Cleaned_Content: The processed version of the Content column.
- Example:
evolving landscape digital marketing convergence artificial intelligence search engine optimization ushered era innovation efficiency
- What It Represents:
- This is the cleaned text, with stopwords removed and unnecessary details eliminated.
- It keeps only meaningful and important words, which are easier to analyze.
Step 5: Processed Content Saved
- Output:
- Processed content saved to: /content/drive/MyDrive/Dataset For Text Classification Model/processed_content.csv
- What It Means:
- The cleaned data (both Content and Cleaned_Content columns) has been saved to a new file for future use.
- Why It Matters:
- Saving ensures the cleaned data is available for the next steps (e.g., categorization or keyword extraction).
- It avoids redoing the cleaning process, saving time and computational resources.
Part 4: Categorizing Content into Clusters
Code Name: categorize_content.py
Purpose: This part groups similar web content into clusters and assigns predefined categories to each cluster.
How it works:
- Converts the cleaned content into numerical data using TF-IDF (a method to weigh the importance of words).
- Groups similar content using KMeans clustering.
- Maps each cluster to a predefined category (like “SEO Services” or “Content Writing”) based on its similarity to category descriptions.
- Saves the categorized content (with cluster and category labels) into a file.
Detailed Explanation of the Output
Step 1: Loading the Dataset
- Output:
- Loading the dataset…
- Dataset loaded successfully. Total rows: 68
- What It Means:
- The program successfully read a file named /content/drive/MyDrive/Dataset For Text Classification Model/processed_content.csv.
- This file contains 68 rows of processed content (text data) from previous steps.
- Why It Matters:
- This step ensures the program has valid data to analyze and work with.
- Without this dataset, the remaining steps (clustering and categorization) wouldn’t be possible.
Step 2: Vectorizing Text Content Using TF-IDF
- Output:
- Vectorizing text content using TF-IDF…
- Text content vectorized successfully.
- What It Means:
- TF-IDF (Term Frequency-Inverse Document Frequency): A mathematical method to represent text data as numerical values.
- Words are given scores based on how important they are in a document compared to others in the dataset.
- The program converted the Cleaned_Content column into a matrix of numbers.
- TF-IDF (Term Frequency-Inverse Document Frequency): A mathematical method to represent text data as numerical values.
- Why It Matters:
- Machines cannot directly process raw text, so TF-IDF converts text into a format that clustering algorithms like KMeans can understand.
- Words that occur frequently but are common across all documents (like “the,” “and”) are assigned lower importance.
Step 3: Clustering Content Using KMeans
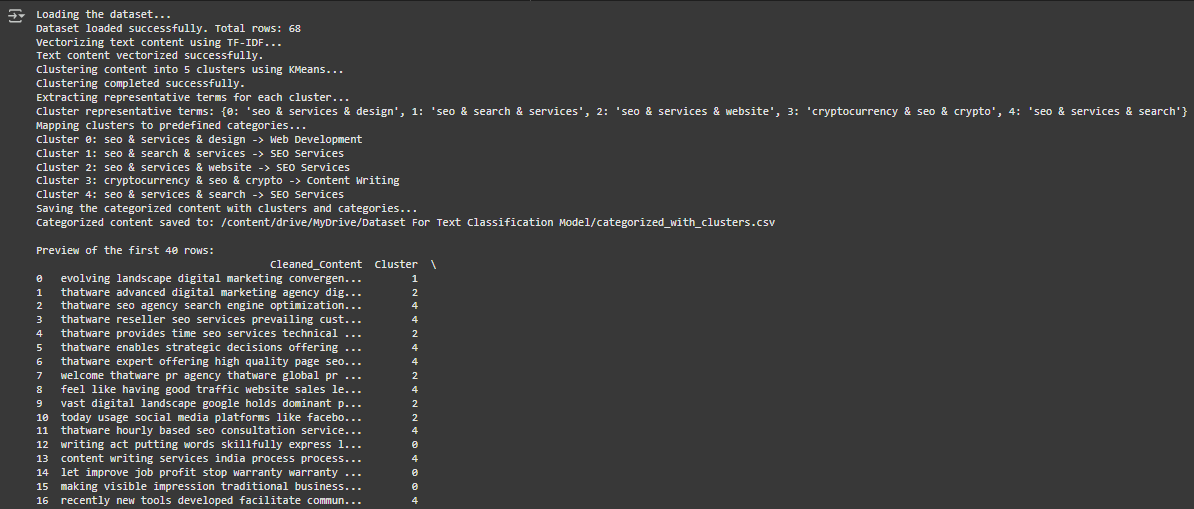
- Output:
- Clustering content into 5 clusters using KMeans…
- Clustering completed successfully.
- What It Means:
- The program grouped the text data into 5 clusters using the KMeans algorithm.
- Each cluster represents a group of similar text based on word patterns and context.
- Every row of data is assigned a cluster label (e.g., Cluster 0, Cluster 1).
- Why It Matters:
- Clustering helps organize large amounts of data into smaller, more manageable groups.
- Similar documents (e.g., those discussing SEO) are grouped together, making analysis easier.
Step 4: Extracting Representative Terms for Each Cluster
- Output:
- Cluster representative terms: {0: ‘seo & services & design’, 1: ‘seo & search & services’, …}
- What It Means:
- The program identified the most significant words (representative terms) for each cluster.
- Example: For Cluster 0, the key terms are “seo,” “services,” and “design.”
- Why It Matters:
- These terms summarize the topics within each cluster.
- For example, a cluster with terms like “seo” and “services” likely represents documents about SEO services.
Step 5: Mapping Clusters to Predefined Categories
- Output:
- Mapping clusters to predefined categories…
- Example: Cluster 0: seo & services & design -> Web Development
- What It Means:
- The program compared the representative terms of each cluster with predefined categories (like “SEO Services” or “Web Development”).
- Each cluster is assigned the category it most closely matches.
- Example: Cluster 0 matched the “Web Development” category.
- Why It Matters:
- This step provides meaningful labels to clusters, making the data easier to interpret.
- Instead of just “Cluster 0,” we now know it represents “Web Development.”
Step 6: Saving the Categorized Content
- Output:
- Categorized content saved to: /content/drive/MyDrive/Dataset For Text Classification Model/categorized_with_clusters.csv
- What It Means:
- The program saved the dataset with two additional columns:
- Cluster: The cluster assigned to each row.
- Category: The human-readable label for each cluster.
- This file is ready for further analysis or reporting.
- The program saved the dataset with two additional columns:
- Why It Matters:
- Saving the output ensures you can review and reuse the categorized data.
- It avoids reprocessing, saving time and computational resources.
Step 7: Preview of the Categorized Content
- Output:
- The preview shows the first 40 rows of the categorized data.
- Each row has three key columns:
- Cleaned_Content: The processed version of the raw content.
- Cluster: The cluster number assigned by KMeans.
- Category: The human-readable label assigned to the cluster.
- Why It Matters:
- This preview allows you to verify if the clustering and categorization look accurate.
- For example:
- Cluster 0: Contains terms about “design” and is labeled as “Web Development.”
- Cluster 3: Contains terms about “cryptocurrency” and is labeled as “Content Writing.”
Key Insights from the Output
- Clustering Patterns:
- Most rows are categorized under “SEO Services” (Clusters 1, 2, 4).
- A few rows relate to “Web Development” (Cluster 0) or “Content Writing” (Cluster 3).
- Use Case of Categorization:
- Helps in organizing content by topic, making it easier to analyze or present to clients.
- For example: You can identify how much of the content focuses on SEO vs. other categories like “Web Development.”
- Next Steps with the Output:
- Use the categorized data to generate insights, reports, or summaries for clients.
- Perform keyword extraction or sentiment analysis within each category for deeper insights.
Part 5: Extracting Refined Keywords
Code Name: extract_keywords.py
Purpose: This part extracts meaningful keywords (single words, phrases) from each content for insights.
How it works:
- Uses the same TF-IDF data from Part 4.
- Extracts important single words (unigrams), two-word phrases (bigrams), and three-word phrases (trigrams).
- Combines these keywords into a list for each content.
- Saves the URLs with their refined keywords into a CSV file.

Detailed Explanation of the Output
Step 1: Loading the Dataset
- Output Message:
- Loading dataset…
- Dataset loaded successfully. Total rows: 68
- What This Means:
- The program successfully loaded a dataset from a file named /content/drive/MyDrive/Dataset For Text Classification Model/processed_content.csv.
- This file contains 68 rows, meaning there are 68 entries (URLs and their content) to process.
- Use Case:
- This step ensures the program has the necessary data to analyze. Without this, the subsequent steps (extracting keywords) cannot happen.
Step 2: Vectorizing Text Content Using TF-IDF
- Output Message:
- Vectorizing text content using TF-IDF…
- TF-IDF vectorization complete.
- What This Means:
- The Cleaned_Content column (preprocessed text data) is converted into a numerical representation using a method called TF-IDF (Term Frequency-Inverse Document Frequency).
- Why TF-IDF?
- Term Frequency (TF): Measures how often a word appears in a document.
- Inverse Document Frequency (IDF): Reduces the importance of common words that appear across all documents (like “the,” “is”).
- Together, TF-IDF identifies important and unique words in each document.
- Use Case:
- Text needs to be converted into numbers so that algorithms (like keyword extraction) can process it. TF-IDF assigns higher scores to important terms.
Step 3: Extracting Keywords for Each Row
- Output Message:
- Extracting keywords for each row…
- What This Means:
- For each row in the dataset, the program identifies unigrams (single words), bigrams (two-word phrases), and trigrams (three-word phrases) that are most important.
- These keywords are selected based on their TF-IDF scores (higher scores indicate more importance).
- Preview Example:
- For the first URL, the extracted keywords are:
[‘search’, ‘search engine’, ‘user intent’, ‘seo services’, …] - This means the URL’s content is likely about search engines, user intent, and SEO services.
- For the first URL, the extracted keywords are:
- Use Case:
- Extracting keywords helps summarize and understand what each piece of content is about.
- It enables search engines, analysts, and businesses to quickly identify key topics in their data.
Step 4: Displaying a Preview of Keywords
- Output Message:
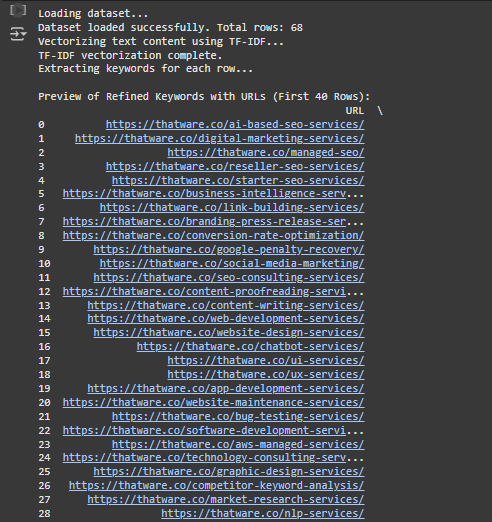
- Preview of Refined Keywords with URLs (First 40 Rows):
- What This Means:
- The program shows the first 40 rows of the dataset, including:
- URL: The link to the webpage.
- Cleaned_Content: The processed version of the webpage content.
- Refined_Keywords: The extracted keywords for each row.
- The program shows the first 40 rows of the dataset, including:
- Example Row:
URL: https://thatware.co/ai-based-seo-services/
Cleaned_Content: evolving landscape digital marketing convergence …
Refined_Keywords: [search, search engine, user intent, seo services, …]
- This means the URL is about AI-based SEO services, and the keywords help summarize the key topics in its content.
- Use Case:
- The preview allows analysts to verify the accuracy of the extracted keywords.
- If the keywords match the expected topics of the URLs, it confirms the process is working correctly.
Step 5: Saving the Results to an Output File
- Output Message:
- Saving the results to the output file…
- Refined keywords saved successfully to: /content/drive/MyDrive/Dataset For Text Classification Model/improved_refined_keywords_with_urls.csv
- What This Means:
- The program saved the dataset (including URLs, cleaned content, and refined keywords) to a file for future use.
- The file path is /content/drive/MyDrive/Dataset For Text Classification Model/improved_refined_keywords_with_urls.csv.
- Use Case:
- This step ensures the results are saved permanently.
- You can share this file with others, use it for analysis, or upload it to another system without rerunning the program.
Summary of Key Concepts
- Dataset Loading: Ensures the program has the raw data to work with.
- TF-IDF Vectorization: Converts text into numerical data, highlighting important words.
- Keyword Extraction: Identifies the most meaningful words and phrases from each document.
- Preview: Allows verification of the results before saving them.
- Saving Results: Stores the output for reuse, avoiding repeated computation.
Text Classification Model

Understanding the Query and Output
What Is This Model Doing?
The Text Classification Model categorizes the content of a dataset into specific categories (e.g., SEO Services, Web Development, Content Writing). It achieves this using clustering algorithms like KMeans and predefined categories.
Key Parts of the Output
1. Mapping Clusters to Predefined Categories
· Output Example:
Cluster 0: seo & services & design -> Web Development
Cluster 1: seo & search & services -> SEO Services
Cluster 2: seo & services & website -> SEO Services
Cluster 3: adult & escort & seo -> Content Writing
Cluster 4: pharmaceutical & seo & search -> SEO Services
· Explanation:
- Clusters: Groups of similar content identified using the KMeans algorithm.
- Representative Terms: Keywords like seo, services, design that describe the main topic of the cluster.
- Mapped Categories: Predefined business categories (e.g., SEO Services, Web Development) assigned to each cluster based on its keywords.
· Use Case:
- Helps identify the primary topics of your website content.
- Enables website owners to focus on the right strategies for their content.
2. Preview of Categorized Content
· Output Example:
Each row contains:
- Cleaned_Content: The processed content without unnecessary words or symbols.
- Cluster: The assigned cluster (0 to 4 in this case).
- Category: The mapped category based on the cluster.
· Explanation of Columns:
- Cleaned_Content: Shows the text after cleaning (removing noise like stopwords).
- Example:
Cleaned_Content: rapidly evolving digital landscape importance …- This indicates the content is about the “digital landscape.”
- Example:
- Cluster: Groups content into clusters based on similarity.
- Example:
Cluster: 2- This content is grouped under Cluster 2.
- Example:
- Category: Assigns a business-relevant category to each cluster.
- Example:
Category: SEO Services- This means the content belongs to the “SEO Services” category.
- Example:
· Use Case:
- Helps businesses identify the type of content they are producing and how it aligns with their goals.
- Provides clarity on the topics dominating their website.
How Is This Output Beneficial for SEO?
1. Understand Website Content Focus
- The output shows what topics (categories) dominate the website.
- Example: Most of your content is categorized under “SEO Services.” This indicates your website is heavily focused on SEO-related services.
2. Improve Keyword Targeting
- The representative terms for each cluster provide insights into what keywords your content is naturally optimized for.
- Example: seo & search & services indicates these are frequent and important keywords for your website.
3. Identify Content Gaps
- If a category like “Web Development” has fewer entries, it might indicate a content gap.
- Businesses can create more content for underrepresented categories to attract a wider audience.
4. Enhance User Engagement
- By understanding which topics are most relevant to your audience, you can focus on creating engaging and valuable content in those areas.
What Steps Should Clients Take?
1. Analyze Content Distribution
- Look at the “Cluster” and “Category” columns to understand where most of your content falls.
- If a category aligns with your business goals, strengthen it with more content.
2. Leverage Keywords
- Use the representative terms and Refined_Keywords to optimize meta tags, headers, and descriptions for better search engine rankings.
3. Fill Content Gaps
- If certain categories are underrepresented, create new content targeting those areas.
4. Target Specific Audiences
- For clusters like “Cryptocurrency SEO,” develop marketing campaigns to attract businesses in that niche.
What Does This Output Convey?
- It categorizes website content into meaningful clusters and maps them to predefined business categories.
- It identifies keywords that can improve SEO and content strategy.
- It helps website owners understand their current focus and plan their next steps.
Why Is This Beneficial for Website Owners?
1. Better Content Strategy:
- Owners can prioritize creating content in the most valuable categories.
2. SEO Optimization:
- Focus on the most relevant keywords to improve rankings and traffic.
3. Actionable Insights:
- Use category distribution to decide on new services, campaigns, or marketing initiatives.
Detailed Explanation of the Output
Purpose of the Model
This model is used for:
- Organizing and Categorizing Content: It processes website data (URLs and their content) and categorizes them into meaningful topics or areas like SEO services, Web Development, etc.
- Keyword Extraction: Identifies important words or phrases (keywords) from the content for SEO optimization.
- Actionable Insights for Website Owners: It provides insights into what kind of content exists on the website and helps to improve SEO strategies by leveraging these keywords.
Explanation of Each Part of the Output
1. Preview of Refined Keywords with URLs
This section lists:
- URL: The web address where the content resides.
- Cleaned_Content: The cleaned version of the text content from the URL.
- Refined_Keywords: The important keywords and phrases extracted from the content.
Example Row:
URL: https://thatware.co/advanced-seo-services/
Cleaned_Content: rapidly evolving digital landscape importance …
Refined_Keywords: [potential customers, search engine optimization, seo services, search, seo]
Explanation:
- URL: Shows where the content exists online (e.g., https://thatware.co/advanced-seo-services/).
- Cleaned_Content: This is the raw content from the page after removing unnecessary words, symbols, and stopwords. It retains only meaningful text.
- Refined_Keywords: The top keywords and phrases extracted from the cleaned content. These keywords represent the most important and relevant topics on the page.
Use Case:
- SEO Benefits: The extracted keywords can be used to optimize meta tags, headers, and other SEO elements to improve search engine rankings.
- Content Strategy: It helps in identifying which words are essential and should be emphasized in future content creation.
2. How This Output Is Beneficial for SEO
This model provides actionable insights that are directly beneficial for SEO:
1. Keyword Targeting:
- The keywords in the Refined_Keywords column represent the most important phrases for each page.
- Website owners can use these keywords in their meta titles, meta descriptions, and content headers to increase visibility in search engine results.
2. Content Gap Analysis:
- By analyzing the Refined_Keywords for each URL, website owners can identify missing topics or under-optimized pages.
- For example, if keywords like “SEO trends” are missing but relevant, the website can create content specifically targeting those keywords.
3. Improved User Intent Matching:
- Keywords like “search engine optimization” or “user intent” indicate what the page is about and align it with what users are searching for.
- This improves the chances of appearing for relevant searches.
4. Boosting Organic Traffic:
- Refining and optimizing content using these keywords can attract more visitors to the website organically (without paid ads).
3. Steps Clients Should Take After This Output
After analyzing this output, website owners or clients should:
1. Review the Refined Keywords:
- Check if the keywords match the intended focus of the website or page.
- Example: For a page about “Advanced SEO Services,” keywords like “search engine optimization” and “SEO services” are relevant.
2. Update On-Page SEO:
- Use these keywords to optimize:
- Meta Titles
- Meta Descriptions
- Headings (H1, H2, etc.)
- Alt Text for Images
- Example: If “SEO services” is a top keyword, ensure it appears naturally in the title and first paragraph.
3. Create New Content:
- If certain important keywords are missing from your website’s content, create blog posts or pages targeting those topics.
- Example: If “cryptocurrency SEO” is identified as a keyword but there’s no page dedicated to it, create a page on that topic.
4. Monitor Performance:
- Use tools like Google Analytics or Search Console to track how the keywords impact rankings and traffic over time.
5. Improve Content for Underserved Areas:
- For clusters like “Content Writing” or “Web Development,” ensure that these categories have sufficient and high-quality content if they align with business goals.
What Does This Output Convey?
This output tells you:
1. What Content Exists on the Website:
- The URLs and their cleaned content give you a summary of what your website is currently offering.
2. What Topics Each Page Covers:
- Refined keywords highlight the most important topics or themes of each page.
3. Opportunities for SEO Optimization:
- By focusing on the keywords and optimizing content, the website can rank higher in search engines.
Why Is This Output Beneficial for Website Owners?
1. Clarity on Current Content:
- Understand what your website is already optimized for and where improvements are needed.
2. Actionable SEO Insights:
- Helps you use the right keywords to attract more organic traffic.
3. Improved ROI (Return on Investment):
- By aligning content with user searches, you can drive more qualified leads without spending on paid ads.
4. Enhanced User Experience:
- Optimized pages with relevant keywords ensure that users find exactly what they are looking for.
1. What is the Purpose of a Text Classification Model?
A Text Classification Model is designed to:
- Organize and categorize large volumes of textual content (e.g., webpages, blogs, articles).
- Identify the main topics or categories of each piece of content.
- Extract meaningful keywords or key phrases that highlight the focus or intent of the content.
For website owners, this helps in improving content management, boosting SEO performance, and enhancing user engagement.
2. What is Content Categorization?
Content Categorization means assigning a specific topic or label to a webpage or piece of text based on its content. For example:
- A blog on “How to Boost Website Traffic with SEO” might be categorized as “SEO Services.”
How It Helps Website Owners:
1. Improved User Navigation:
- Categories help organize a website, making it easier for visitors to find what they’re looking for.
- For example, a visitor searching for “Content Writing Services” will find all related blogs under that category.
2. Better Content Targeting:
- Website owners can identify which category generates the most traffic or engagement.
- Example: If “Digital Marketing Services” receives high traffic, owners can create more content in this category.
3. SEO Optimization:
- Search engines favor websites with well-organized content structures, improving overall ranking.
4. Personalization:
- By categorizing content, businesses can offer personalized recommendations to users, improving customer satisfaction.
Example:
For the URL https://thatware.co/advanced-seo-services/:
- The model identifies that the page discusses “Advanced SEO Services” based on phrases like:
- “Techniques to improve website rankings.”
- “Advanced SEO tools and services.”
Output:
- Category: “Advanced SEO Services.”
3. What is Keyword Extraction?
Keyword Extraction is the process of identifying important words or phrases in a piece of text that summarize its main ideas. These could be:
- Single words: “SEO.”
- Multi-word phrases: “online visibility,” “tailored solutions.”
How It Helps Website Owners:
1. Boost SEO Ranking:
- Keywords help search engines understand the content better, improving visibility for relevant searches.
- Example: Keywords like “advanced SEO” or “website rankings” will help the page rank higher when users search for these terms.
2. Ad Campaigns:
- Keywords can guide paid ad campaigns by identifying the terms users are most likely to search for.
- Example: A business offering “SEO services” can run ads targeting phrases like “affordable SEO solutions.”
3. Content Strategy:
- Knowing which keywords resonate with audiences helps create more focused and relevant content.
- Example: If users often search for “content writing services,” the owner can create related blog posts or guides.
4. Competitor Analysis:
- Keywords help analyze competitors’ strategies by understanding which terms they target.
Example:
For the same URL https://thatware.co/advanced-seo-services/:
- The extracted keywords might include:
- “Advanced SEO.”
- “Website rankings.”
- “Online visibility.”
- “Tailored solutions.”
Output:
- Keywords: [“advanced SEO,” “website rankings,” “online visibility,” “tailored solutions.”]
4. Handling Multiple Pages
The model also processes multiple pages to categorize and extract keywords for each. This ensures the entire website is organized and optimized.
Example:
1. URL: https://thatware.co/content-writing-services/
- Category: “Content Writing Services.”
- Keywords: [“content writing,” “blog posts,” “SEO optimized content.”]
2. URL: https://thatware.co/web-development-services/
- Category: “Web Development Services.”
- Keywords: [“web development,” “responsive design,” “website performance.”]
Benefits for Website Owners:
- Streamlined Content Management: Group similar pages together under one category.
- Enhanced User Experience: Visitors can easily navigate between related pages.
- Improved SEO: Categorized content with focused keywords boosts search rankings for specific topics.
5. Why Are These Outputs Important?
Content Categorization:
- Example Scenario:
- A business has 500+ pages on its website.
- Without categorization, managing and updating content is chaotic.
- By categorizing pages (e.g., “SEO Services,” “Digital Marketing,” “Web Development”), the business gains clarity on what content exists and where.
Keyword Extraction:
- Example Scenario:
- A webpage discusses “SEO tools.”
- Extracting keywords like “SEO tools,” “ranking strategies,” “Google optimization” helps search engines understand the page’s focus, leading to better ranking.
6. The Final Goal of the Text Classification Model
The ultimate purpose of the model is to:
1. Enhance Website Organization:
- By categorizing and tagging pages, the website becomes easier to navigate and manage.
2. Boost Search Engine Rankings:
- With extracted keywords, pages rank higher for relevant search queries.
3. Improve User Engagement:
- Users find relevant content quickly, increasing time spent on the website.
4. Guide Content Strategy:
- By analyzing categories and keywords, owners can identify gaps in their content and create high-demand topics.
Final Thoughts:
The Text Classification Model is a powerful tool for website owners to:
- Organize content.
- Improve SEO.
- Attract the right audience.
- Enhance user experience.
Hiring ThatWare provides businesses with strategic expertise, affordable pricing, extensive experience in digital marketing, and access to a full team capable of implementing successful search marketing campaigns. The company’s adaptability and commitment to experimentation are key advantages for businesses seeking effective SEO solutions.

Thatware | Founder & CEO
Tuhin is recognized across the globe for his vision to revolutionize digital transformation industry with the help of cutting-edge technology. He won bronze for India at the Stevie Awards USA as well as winning the India Business Awards, India Technology Award, Top 100 influential tech leaders from Analytics Insights, Clutch Global Front runner in digital marketing, founder of the fastest growing company in Asia by The CEO Magazine and is a TEDx speaker.
