SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
Regex URL validation involves creating a regular expression pattern that accurately represents the structure of a valid URL. This pattern is then applied to a given string to determine if it conforms to the rules of a well-formed URL.
The regular expression pattern for URL validation typically includes the following components:
Protocol: This part specifies the communication protocol used, such as “http://” or “https://”. It may be optional or required depending on the context.
Domain: The domain name identifies the web server hosting the resource. It consists of one or more labels separated by dots, such as “example.com” or “subdomain.example.co.uk”.
Path: The path specifies the location of the resource on the server. It starts with a slash (“/”) and may contain additional directories or file names, such as “/path/to/resource” or simply “/”.
Query Parameters: These parameters provide additional information to the server, typically in the form of key-value pairs. They are preceded by a question mark (“?”) and separated by ampersands (“&”), such as “?param1=value1¶m2=value2”.
Fragment Identifier: This optional component identifies a specific section within the resource, such as a section heading or anchor tag. It is preceded by a hash (“#”), followed by the fragment identifier, such as “#section” or “#anchor”.
The regular expression pattern is constructed to match each of these components according to the syntax rules defined by the URL specification (RFC 3986). This includes rules for allowed characters, length limits, and the order of components.
By applying regex URL validation, developers can perform client-side or server-side validation to ensure that user-provided URLs are properly formatted before further processing. This helps prevent errors, improve user experience, and mitigate security risks associated with malformed or malicious URLs.
Additionally, regex URL validation can be customized to meet the specific requirements of different applications, such as supporting internationalized domain names (IDNs) or validating URLs with custom protocols.
As SEOs, we are quite familiar with seo friendly urls and how to optimize and maintain them. Typically SEO friendly URLs are of the following formats.

https://www.domain.com
https://domain.com
http://domain.com
http://www.domain.com
https://domain.com/category/subcategory/page
And so on…
You get a general idea.
However actually maintaining SEO-friendly URLs can be a painstaking task, especially for giant commercial websites like ecommerce. Sometimes parameter-based urls are almost unavoidable.
However, as SEOs, we must always have the means to identify these unusual URLs in order to minimize their presence.
In this exercise, we will be learning how to identify these Unusual URLs in your website using Google search console and Regex.
In this Domain Name Validation Regex exercise, we will be learning how to identify these Unusual URLs in your website using Google search console and Regex.
WHAT IS REGEX Validation For URL?
In its most basic definition, a Regex is a string of text that allows you to create patterns that help match, locate, and manage text. This helps allows us to search for various URLs, and queries in the Search Console and other Regex-supported platforms based on various custom-made parameters.
Regex, short for Regular Expression, is a powerful tool used in computer science and programming to manipulate and analyze strings of text. At its core, a regex is a sequence of characters that form a search pattern, allowing users to perform complex searches, substitutions, and validations within text data. With its versatile functionality, regex is widely used across various platforms and programming languages to match, locate, and manage text based on specific patterns and criteria.
Understanding the fundamentals of regex is essential for anyone working with text data, particularly in fields such as web development, data analysis, and search engine optimization (SEO). By mastering regex, users gain the ability to perform advanced text processing tasks efficiently and accurately.
One of the primary functions of Valid Domain Name Regex is pattern matching. Patterns in regex are defined using a combination of literal characters, metacharacters, and quantifiers. Literal characters represent themselves and match the exact characters they denote. Metacharacters, on the other hand, have special meanings within regex and are used to define more complex patterns. Quantifiers specify the number of occurrences of a particular character or group within a pattern.
For example, we will be finding specific URLs which are not SEO friendly. Such kinds of urls usually contain parameters with useful information like pricing, paginations, values, etc.
In this pattern, \d represents any digit, and {3} specifies that the preceding digit should occur exactly three times. The hyphens – serve as literal characters, matching themselves. Therefore, this regex pattern would match strings in the format of a phone number, such as “123-456-7890”.
Regular Expression HTTP URL patterns can be used for a wide range of tasks, including:
Search and Replace: Regex allows users to search for specific patterns within text data and replace them with desired values. This functionality is particularly useful for performing bulk text transformations and data cleaning tasks.
Validation: Regex can be used to validate user input in web forms, ensuring that data entered by users conforms to specified formats and criteria. For example, regex can validate email addresses, phone numbers, and credit card numbers to ensure they meet the required format.
Text Extraction: Regex enables users to extract specific information from text data based on predefined patterns. This capability is commonly used in data extraction tasks, such as extracting URLs, email addresses, and other structured data from unstructured text documents.
Text Parsing: Pattern URL Regex facilitates the parsing of structured text data, allowing users to break down complex strings into individual components. This functionality is essential for tasks such as parsing log files, extracting data from web pages, and processing structured documents.
URL Matching: In the context of SEO and web development, regex is often used to match and identify specific URLs based on custom-made parameters. For example, regex can be used to identify URLs that contain parameters such as pricing, pagination, or query strings, which may impact a website’s search engine optimization efforts.
Using regex, we can construct patterns to identify and extract relevant information from this URL, such as the product ID (B08R2DY7JH), page number (2), and sorting criteria (price). This level of granularity allows SEO professionals and web developers to analyze and optimize website URLs effectively.
Regex is a versatile and powerful tool that plays a crucial role in text processing, data manipulation, and pattern-matching tasks. By mastering regex, users can unlock a wide range of capabilities for working with text data, making it an indispensable skill for professionals across various industries. Whether you’re a programmer, data analyst, or SEO specialist, understanding regex empowers you to tackle complex text processing challenges with confidence and efficiency.
Benefits of Regular Expression For Website URL
Regex offers a multitude of benefits across various fields and industries, making it an invaluable tool for professionals working with text data. From web development and data analysis to search engine optimization and text processing, regex empowers users to perform complex tasks efficiently and accurately. Here are some key benefits of using regex:
- Flexible Pattern Matching: One of the primary benefits of regex is its ability to perform flexible pattern matching. With regex, users can define complex search patterns using a combination of literal characters, metacharacters, and quantifiers. This flexibility allows for precise and customizable matching of text data, making it suitable for a wide range of applications.
- Efficient Text Processing: URL Regex Tester enables users to perform efficient text processing tasks, such as searching, replacing, and extracting specific information from text data. By leveraging regex patterns, users can automate repetitive tasks and manipulate large volumes of text data with ease, saving time and effort in the process.
- Data Validation and Verification: Regex is commonly used for data validation and verification purposes, particularly in web development and form validation. By defining regex patterns for valid input formats, developers can ensure that user-submitted data meets the required criteria, reducing the risk of errors and security vulnerabilities.
- Structured Data Extraction: Regex facilitates the extraction of structured data from unstructured text documents, such as log files, web pages, and emails. By defining regex patterns to match specific data formats, users can extract relevant information efficiently, enabling further analysis and processing.
- Customized Search and Filtering: Regex allows for customized search and filtering of text data based on user-defined criteria. Whether searching for specific patterns, keywords, or entities within text documents, regex provides a powerful mechanism for narrowing down search results and identifying relevant information.
- Enhanced SEO Strategies: In the realm of search engine optimization (SEO), regex is often used to analyze and optimize website URLs, meta tags, and content. By identifying and targeting specific patterns within URLs, regex enables SEO professionals to optimize website structure, improve crawlability, and enhance search engine visibility.
- Pattern-Based Analysis: Regex enables pattern-based analysis of text data, facilitating insights and discoveries that may not be apparent through manual inspection. By identifying recurring patterns and trends within text documents, users can uncover valuable information and make data-driven decisions more effectively.
- Cross-Platform Compatibility: Domain Validation Regex is supported across a wide range of programming languages, platforms, and text editors, making it a versatile tool for developers and analysts. Whether working with Python, JavaScript, Java, or other programming languages, users can leverage regex to perform text-processing tasks consistently across different environments.
- Automation and Scripting: Regex can be integrated into automated scripts and workflows to streamline text processing tasks and enhance productivity. By incorporating regex patterns into scripts, users can automate repetitive tasks, such as data cleaning, parsing, and validation, enabling faster and more efficient data processing.
Scalability and Performance: Regex is well-suited for handling large volumes of text data and performing complex matching operations with minimal performance overhead. Whether processing small text files or analyzing massive datasets, regex offers scalability and performance optimizations to ensure efficient execution.
Here’s an Amazon product page url. You will get the idea.
Example URL:
How to Find Unusual URL patterns?
Step 1: Open Search Console and go to the Performance Tab
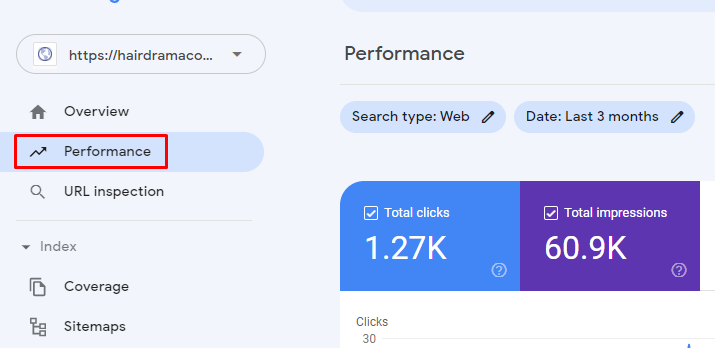
It is often referred to as the search results tab.

Step 2: Click on New > Page. A dialog box will open.
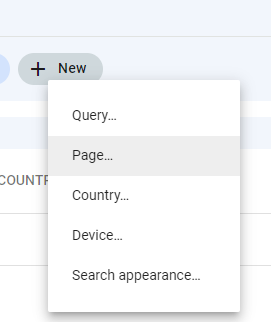
Step 3: Select “Custom (regex)” as the filter. And select “Doesn’t match regex” in the next drop-down list.
Now enter the following Regex code:
^(ht|f)tp(s?)\:\/\/[0-9a-zA-Z]([-.\w]*[0-9a-zA-Z])*(:(0-9)*)*(\/?)([a-zA-Z0-9\-\.\?\,\’\/\\\+&%\$#_]*)?$

Step 4: Hit Apply and you will obtain all unusual URLs currently present on your website.
Here’s a Sample Result:

Explanation
So it’s actually to define a Regex for an unusual url since an unusual url can have various patterns. So the best way is to define a regex for all defined and valid url patterns.
The following regex serves that exact purpose:
^(ht|f)tp(s?)\:\/\/[0-9a-zA-Z]([-.\w]*[0-9a-zA-Z])*(:(0-9)*)*(\/?)([a-zA-Z0-9\-\.\?\,\’\/\\\+&%\$#_]*)?$
We can test this in a regex tester tool. As you can see in the picture below different formats of the valid urls are matched by this regex pattern.

But as you can see in the pics below, all parameterized URLs are not getting matched.
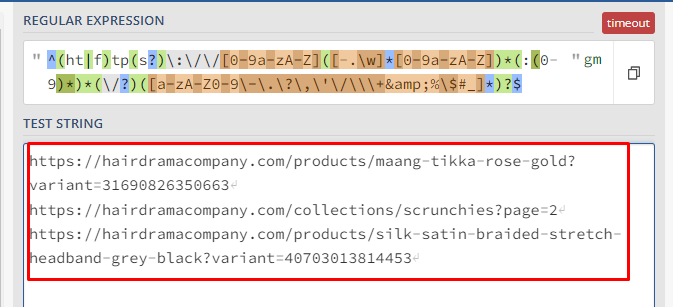
Hence, we simply used the above expression a filtered all URLs that don’t satisfy it. That way all invalid URLs are shown in the results.
Common Mistakes in Regex URL Validation & How to Avoid Them
Regex (regular expressions) is invaluable for URL validation, but small errors can lead to big problems. Let’s explore some typical mistakes and solutions:
- Overcomplicating Patterns: Beginners often create unnecessarily complex regex. Stick to simple patterns for clarity and maintainability.
- Ignoring Edge Cases: Failing to test patterns with diverse URLs can lead to false positives or negatives. Always test comprehensively.
- Misusing Wildcards: Overusing wildcards (.*) can match unintended strings. Define boundaries to ensure specificity.
- Improper Anchoring: Missing anchors (^ and $) can cause matches beyond the desired scope. Use them strategically for precision.
How to Avoid These Mistakes?
- Break patterns into smaller chunks for easier debugging.
- Use regex testers like Regex101 to visualize matches.
- Regularly review patterns against actual website URLs.
The Future of Regex in URL Validation: Trends &Innovations
As digital ecosystems evolve, so does the way we manage URLs. Here are key trends transforming regex usage:
- Automation with AI: Machine learning tools are beginning to automate regex generation, reducing manual effort. These tools analyze URL data and suggest optimized patterns.
- Enhanced Validation Tools: Modern SEO platforms now include regex-assisted URL validation features, offering real-time error detection.
- Integration with Web Frameworks: Frameworks like Angular and React are leveraging regex for dynamic routing, making it a critical skill for developers.
Why Does This Matter?
Keeping up with these trends ensures your website remains competitive, SEO-friendly, and future-proof. Hence, staying informed about regex innovations can also improve your ability to handle complex URL patterns efficiently.
Why Choose ThatWare for Regex URL Validation?
- Expertise in Regular Expressions: ThatWare boasts a team of skilled developers with extensive experience in crafting robust regular expressions for URL validation. With a deep understanding of regex syntax and URL structure, our experts can create highly accurate patterns that effectively validate URLs according to industry standards.
- Customized Solutions: We understand that different applications may have unique requirements for URL validation. That’s why we offer customized solutions tailored to your specific needs. Whether you need to support internationalized domain names (IDNs), validate URLs with custom protocols, or enforce strict validation rules, our team can deliver a solution that meets your requirements.
- Comprehensive Validation: Our regex URL validation solutions go beyond basic checks for syntax and structure. We implement comprehensive validation routines that ensure URLs are not only well-formed but also adhere to best practices for security and usability. This includes checks for allowed characters, length limits, and proper encoding to prevent security vulnerabilities such as injection attacks or phishing attempts.
- Performance Optimization: At ThatWare, we understand the importance of performance in web applications. That’s why we optimize our regex URL validation routines to ensure minimal impact on application performance. By carefully crafting efficient regular expressions and leveraging caching techniques, we ensure that URL validation is fast and scalable, even in high-traffic environments.
- Continuous Support and Maintenance: Our commitment to customer satisfaction doesn’t end with the delivery of a solution. ThatWare provides ongoing support and maintenance services to ensure that your regex URL validation remains effective and up-to-date. Whether you need assistance with troubleshooting, updates to accommodate changes in URL standards, or enhancements to support new features, our team is here to help.
Choose ThatWare for regex URL validation and ensure that your web applications maintain robust security, usability, and performance standards. With our expertise, customized solutions, comprehensive validation, performance optimization, and continuous support, you can trust ThatWare to meet your URL validation needs effectively and efficiently.
