SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
What is LDA Topic modelling and how does it correlate with SEO Rankings?
LDA (Latent Dirichlet Allocation) Topic Modeling:
LDA is a generative probabilistic model used to discover the underlying topics present in a collection of documents. It is one of the most popular methods (target page relevance) for topic modeling and is often used in natural language processing (NLP) tasks.

Here’s a simplified explanation of how LDA works:
Initialization: Specify the number of topics (K) you believe exist in your corpus.
Random Assignment: Each word in each document is assigned randomly to one of the
(K) topics.
Iterative Refinement: For each document, the LDA algorithm goes through each word and reassigns it to a topic, based on:
- How prevalent that word is across topics.
- How prevalent topics are within the document.
Convergence: After many iterations, the algorithm converges, and you get topics (a distribution of words) and the topic distribution (target page relevance) for each document.
Correlation with SEO Rankings:
LDA topic modeling and SEO (Search Engine Optimization) might seem unrelated at first, but there’s an intersection in content relevance:
- Relevance of Content: Search engines aim to deliver the most relevant content to users. If content on a website is well-organized around clear topics (using LDA or another topic modeling technique), it can signal to search engines that the content is comprehensive and relevant to particular queries.
- Content Gap Analysis: By applying LDA on top-performing articles in a specific niche, one can identify key topics that are being discussed. This information can help content creators understand gaps in their content and areas where they can expand or improve.
- Semantic Search: Modern search engines use semantic search techniques, where the intent and contextual meaning of a query are considered. Understanding the topics within your content can help ensure that it aligns with relevant search queries.
- Enhanced User Experience: By organizing content around clear topics (target page relevance), users can navigate and find the information they need more efficiently. A positive user experience can lead to lower bounce rates and increased time on site, which are factors that search engines might consider for rankings.
- Internal Linking: Topic modeling can help identify related content within a website. This can be used to create internal links between related articles, enhancing the site’s structure and potentially boosting SEO.
Main Objective
The main Objective of this analysis is to enhance the Relevance of a particular page against a Target Query using a Document Corpus of competitor Top Ranking content for the target query.
Methodology
- The Application should be able to input the Main Focus Keyword and the Target URL to be optimized.
- Then it should input a bunch of competitor URLs that it can analyse.
The Tool is to be used for SEO Purposes and should be able to do Two Things:
1. The Assigning a Similarity or Relevance Score on a scale of 0-100 between the Target URL Content and the Focus Keyword and display it visually in the form of a bar diagram.
2. Finding the most relevant topics for a given Keyword by analysing the Given Set of Competitor URLs. Also Mention their relevance to the focus keyword and display it visually in the form of a Bar Chart
Steps:
- Web Scraping: Extract content from the target URL and competitor URLs.
- Text Preprocessing: Clean and preprocess the extracted content.
- LDA Model Training: Train an LDA model on the content of the competitor URLs.
- Relevance Score Calculation: Calculate the relevance score between the target URL content and the focus keyword.
- Topic Identification: Identify relevant topics based on the LDA model.
- Visualization: Display the results using bar charts.
Run the Below Code
# Libraries
import requests
from bs4 import BeautifulSoup
import gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
from nltk.stem import WordNetLemmatizer
from gensim import corpora
from gensim.matutils import cossim
import matplotlib.pyplot as plt
import nltk
nltk.download(‘wordnet’, quiet=True)
from langdetect import detect
# Web Scraping
def scrape_website(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, ‘html.parser’)
paragraphs = soup.find_all(‘p’)
content = ‘ ‘.join([p.text for p in paragraphs])
return content
# Text Preprocessing
def preprocess(text):
try:
lang = detect(text)
if lang != ‘en’:
return []
except:
return []
result = []
for token in gensim.utils.simple_preprocess(text, deacc=True):
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:
result.append(WordNetLemmatizer().lemmatize(token, pos=’v’))
return result
# LDA Model Training
def train_lda_model(texts, num_topics=50, passes=5):
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
lda_model = gensim.models.LdaModel(corpus, num_topics=num_topics, id2word=dictionary, passes=passes)
return lda_model, dictionary
# Relevance Score Calculation
def calculate_relevance_scores(lda_model, dictionary, target_content, competitor_content, focus_keyword):
target_bow = dictionary.doc2bow(preprocess(target_content))
target_lda = lda_model.get_document_topics(target_bow, minimum_probability=0)
competitor_bow = dictionary.doc2bow(preprocess(competitor_content))
competitor_lda = lda_model.get_document_topics(competitor_bow, minimum_probability=0)
keyword_bow = dictionary.doc2bow(preprocess(focus_keyword))
keyword_lda = lda_model.get_document_topics(keyword_bow, minimum_probability=0)
target_similarity = cossim(target_lda, keyword_lda) * 100
competitor_similarity = cossim(competitor_lda, keyword_lda) * 100
return target_similarity, competitor_similarity
# Topic Identification
def identify_topics(lda_model, focus_keyword, dictionary):
keyword_bow = dictionary.doc2bow(preprocess(focus_keyword))
keyword_lda = lda_model.get_document_topics(keyword_bow)
keyword_lda = sorted(keyword_lda, key=lambda x: x[1], reverse=True)
aggregated_topics = {}
for topic_weight in keyword_lda:
topic_id = topic_weight[0]
for word, weight in lda_model.show_topic(topic_id):
if word not in aggregated_topics:
aggregated_topics[word] = 0
aggregated_topics[word] += weight * topic_weight[1]
sorted_aggregated_topics = sorted(aggregated_topics.items(), key=lambda x: x[1], reverse=True)
return sorted_aggregated_topics
# Visualization
def plot_relevance_scores(target_score, competitor_score):
plt.bar([‘Target URL’, ‘First Competitor’], [target_score, competitor_score], color=[‘blue’, ‘red’], alpha=0.7)
plt.ylabel(‘Relevance’)
plt.title(‘Relevance Score Comparison with Focus Keyword’)
plt.ylim(0, 100)
plt.show()
# Print the exact relevance scores
print(f”Relevance score of Target URL content against the focus keyword: {target_score:.2f}”)
print(f”Relevance score of First Competitor URL content against the focus keyword: {competitor_score:.2f}”)
def plot_bar_chart(labels, values, title):
plt.figure(figsize=(10, 8))
plt.barh(labels, values, align=’center’, alpha=0.7)
plt.xlabel(‘Relevance’)
plt.title(title)
plt.gca().invert_yaxis()
plt.show()
# Main Function
def seo_tool(focus_keyword, target_url, competitor_urls):
target_content = scrape_website(target_url)
competitor_contents = [scrape_website(url) for url in competitor_urls]
preprocessed_texts = [preprocess(content) for content in competitor_contents]
preprocessed_texts = [text for text in preprocessed_texts if text]
lda_model, dictionary = train_lda_model(preprocessed_texts)
target_score, competitor_score = calculate_relevance_scores(lda_model, dictionary, target_content, competitor_contents[0], focus_keyword)
plot_relevance_scores(target_score, competitor_score)
topics = identify_topics(lda_model, focus_keyword, dictionary)
topic_labels = [word for word, _ in topics][:50]
topic_values = [weight for _, weight in topics][:50]
plot_bar_chart(topic_labels, topic_values, ‘Topics Relevance with Focus Keyword’)
if __name__ == ‘__main__’:
# Take user input
focus_keyword = input(“Enter the focus keyword: “)
target_url = input(“Enter the target URL: “)
competitor_urls = []
num_competitor_urls = int(input(“Enter the number of competitor URLs you want to analyze: “))
for i in range(num_competitor_urls):
competitor_url = input(f”Enter competitor URL {i+1}: “)
competitor_urls.append(competitor_url)
# Run the Tool
seo_tool(focus_keyword, target_url, competitor_urls)
Run the Following Command in Terminal
pip install requests beautifulsoup4 gensim nltk matplotlib langdetect
python lda_tool.py
Sample Test:
Enter the focus keyword: ai seo services
Enter the target URL: https://thatware.co/ai-based-seo-services/
Enter the number of competitor URLs you want to analyze: 3
Enter competitor URL 1: https://neuraledge.digital/ai-seo-services/
Enter competitor URL 2: https://influencermarketinghub.com/ai-seo-tools/
Enter competitor URL 3: https://wordlift.io/blog/en/artificial-intelligence-seo-software/2/
OUTPUT

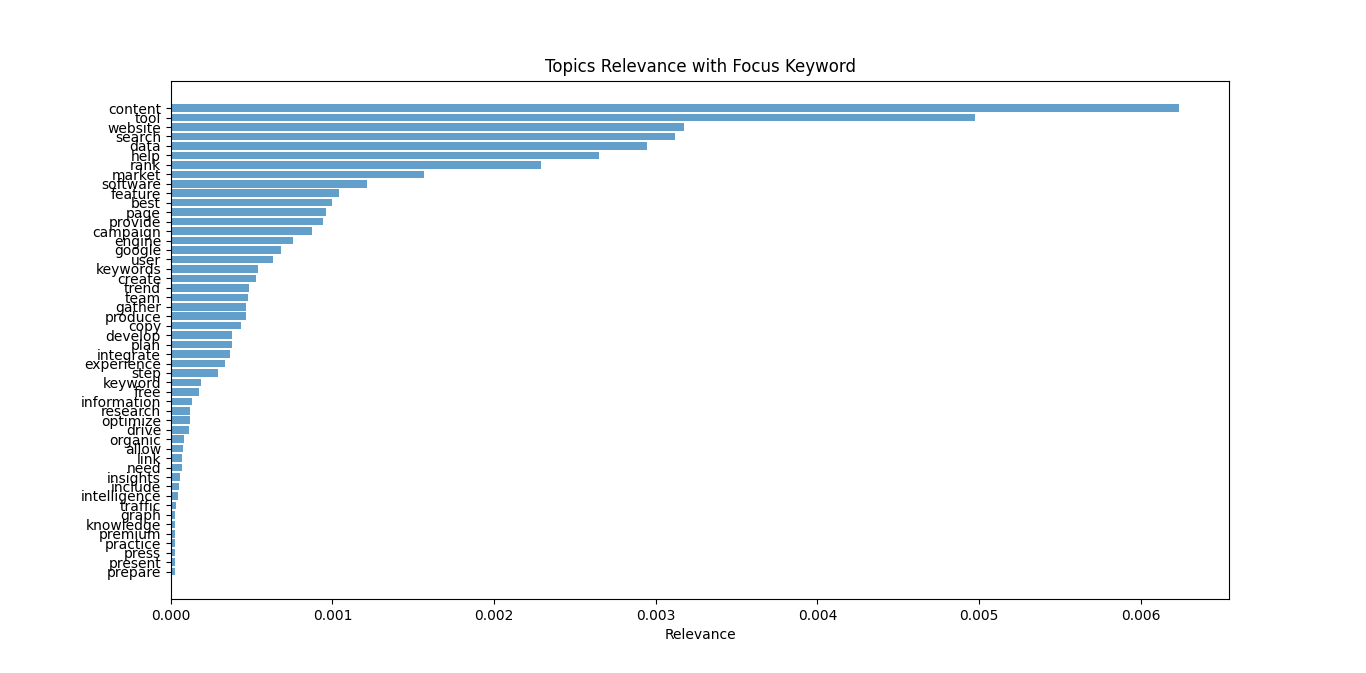
Conclusion
Using the Suggested List of Terms using LDA Analysis we can create our own Topics in the Website or Subtopics in the Document to improve the Document Relevancy for better Ranking.
