SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
In web development and content management, identifying low-content pages on a website is crucial for maintaining quality and user experience. These pages typically offer minimal value to users and can contribute to a cluttered and unengaging online presence. Python, with its versatile libraries and tools, can be employed to automate the process of finding low-content pages on a website.

What Are Low-Content Pages?
Low-content web pages contain minimal textual or substantive information, often characterized by sparse or thin content. These pages typically need more substantial written content and may primarily consist of images, videos, or user-generated content. While low-content pages can serve various purposes and may be suitable for specific contexts, they are generally considered to have limited value in terms of providing meaningful information or satisfying user intent.
Types of Low-Content Pages
Placeholder Pages and Landing Pages
One common example of low-content pages is placeholder pages or landing pages designed to be temporary or serve as placeholders until more substantial content is developed. These pages may contain minimal text, such as a brief description or headline, along with basic navigation elements or calls to action. Placeholder pages are often used during website development or when launching a new product or service, providing a basic online presence until more detailed content is created.
Thin Content Pages
Another type of low-content page is what is often referred to as a “thin content” page. These web pages need more substantive or unique content and may offer little value to users. Thin content pages may be created for the purpose of keyword targeting or search engine optimization (SEO) without providing meaningful information or addressing user needs. Examples of thin content pages include doorway, affiliate, or content scraped from other websites.
User-Generated Content Pages
Additionally, low-content pages can refer to pages primarily consisting of user-generated content, such as forums, social media platforms, or online communities. While user-generated content can be valuable for engaging users and fostering community interaction, it may only sometimes provide substantial information or meet specific user needs. The content may be considered low-quality or low-value, particularly if it lacks relevance, accuracy, or depth.
Implications of Low-Content Pages
The presence of low-content pages can significantly impact a website’s overall quality. Websites that contain numerous low-content pages may appear incomplete or lacking in substance to users. When visitors encounter pages with minimal information or value, it can diminish their perception of the website’s quality and credibility. This can ultimately result in a negative user experience and may deter users from returning to the site in the future.
Effect on User Experience
Low-content pages can have a detrimental effect on the user experience. When users land on a page expecting to find valuable information or solutions to their queries, but instead encounter sparse or irrelevant content, it can lead to frustration and disappointment. Users may quickly navigate away from the page, resulting in increased bounce rates. Additionally, low-content pages may need to be more effective in engaging users effectively, reducing overall user engagement metrics such as time on page and pageviews.
Impact on Search Engine Rankings
Search engines prioritize high-quality, relevant content that satisfies user intent when determining search engine rankings. Low-content pages that provide little value to users may be perceived negatively by search engines and penalized in search engine rankings algorithms. As a result, websites with abundant low-content pages may experience reduced visibility and lower rankings in search engine results pages (SERPs). This can have a significant impact on organic traffic and overall website performance.
Strategies to Avoid Low-Content Pages
One of the key strategies to avoid low-content pages is to conduct thorough keyword research. By understanding the search terms and phrases that users use to find information related to your website’s topic or niche, you can create relevant and valuable content to your audience. Keyword research helps identify the topics and themes that interest your target audience, allowing you to tailor your content to meet their needs effectively.
Create Comprehensive and Informative Content
Another important strategy is to create comprehensive and informative content that provides value to your users. Instead of focusing solely on quantity, prioritize the quality of your content by ensuring that it is well-researched and well-written and addresses the needs and interests of your target audience. Comprehensive content that covers a topic in depth is more likely to be perceived as valuable and authoritative by users and search engines alike.
Regularly Update and Optimize Existing Pages
In addition to creating new content, it’s essential to regularly update and optimize existing pages to ensure they remain relevant and valuable to users. This may involve refreshing outdated information, adding new insights or data, or optimizing content for search engines. By keeping your content up-to-date and relevant, you can maintain its value over time and avoid the risk of it becoming low-content or obsolete.
Monitor User Engagement and Feedback
Monitoring user engagement and feedback is another effective strategy for avoiding low-content pages. Pay attention to metrics such as bounce rate, time on page, and social shares to gauge how users interact with your content. Additionally, solicit user feedback through surveys, comments, or reviews to better understand their needs and preferences. Use this feedback to guide your content creation efforts and ensure you deliver value to your audience.
Incorporate Multimedia Elements
To enhance the value and appeal of your content, consider incorporating multimedia elements such as images, videos, infographics, and interactive features. Multimedia can help convey information more effectively, engage users visually, and make your content more shareable and memorable. By diversifying the format of your content, you can create a more engaging and valuable user experience that encourages users to spend more time on your website and return for future visits.
What is Python?
Python is an open-source, object-oriented interactive programming language known for its simplicity, readability, and versatility. Due to its ease of learning and extensive support for modules and libraries, it is widely used across various industries and applications.
Key Features of Python
- Simple and Easy-to-Learn Syntax: Python’s syntax is designed to be straightforward to understand, making it accessible to beginners and experienced programmers.
- Readability: Python emphasizes code readability with a clean, intuitive syntax promoting clear and concise programming practices.
- Support for Modules and Libraries: Python offers a vast ecosystem of modules and libraries that extend its functionality for diverse purposes, from web development to scientific computing.
Applications of Python
Python is utilized in a wide range of applications, including:
- Web Development: Python is a popular choice for developing web applications, as many web frameworks, such as Django and Flask, are built using it.
- Data Analysis: Python’s extensive data manipulation and analysis libraries, such as Pandas and NumPy, make it a preferred tool for data scientists and analysts.
- Machine Learning and Artificial Intelligence: Python’s simplicity and flexibility make it well-suited for building and deploying machine learning models and AI applications. Libraries like TensorFlow and PyTorch are widely used for this purpose.
- Automation and Scripting: Python’s scripting capabilities make it ideal for automating repetitive tasks and writing scripts for system administration and automation.
- Scientific Computing: Python is widely used in scientific computing and research, with libraries like SciPy and Matplotlib providing numerical computing and data visualization tools.
Adoption by Major Organizations
Python is endorsed and used by some of the world’s largest organizations, including:
- Google: Python is extensively used at Google for various purposes, including web development, infrastructure management, and data analysis. Google’s first web crawler was written in Python.
- YouTube: Python powers many backend services and tools at YouTube, facilitating content management, recommendation systems, and analytics.
- Netflix: Python is utilized at Netflix to build and maintain critical systems, including content delivery, recommendation algorithms, and data analysis.
- NASA: Python is employed by NASA for scientific computing, data analysis, and mission planning, owing to its reliability and versatility.
- Spotify: Python is used at Spotify for backend development, data analysis, and machine learning applications, contributing to the platform’s robustness and scalability.
- IBM: Python is integrated into various IBM products and services, including cloud computing solutions, analytics platforms, and AI-powered applications.
How Do We Find Low Content Pages With Python?
Using this Python tool, we can analyse the low-content pages of a website; after analysis, we can improve the content on those pages so that the authority and keyword rank will improve.
Step 1:
Using this Python tool, we can analyse the low-content pages of a website; after analysis, we can improve the content on those pages so that the authority and keyword rank will improve.
Step 1:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse
def extract_urls(domain):
# Send a GET request to the domain
response = requests.get(domain)
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.text, ‘html.parser’)
# Find all anchor tags (<a>) in the HTML
anchor_tags = soup.find_all(‘a’)
urls = []
# Extract the href attribute from each anchor tag
for tag in anchor_tags:
href = tag.get(‘href’)
if href:
# Check if the URL is relative or absolute
parsed_url = urlparse(href)
if parsed_url.netloc:
# Absolute URL
urls.append(href)
else:
# Relative URL, construct absolute URL using the domain
absolute_url = domain + href
urls.append(absolute_url)
return urls
def analyze_urls(urls):
word_counts = []
for url in urls:
response = requests.get(url)
soup = BeautifulSoup(response.text, ‘html.parser’)
text = soup.get_text()
# Count the number of words
word_count = len(text.split())
word_counts.append((url, word_count))
return word_counts
# Example usage
domain = ‘https://www.minto.co.nz/’
urls = extract_urls(domain)
url_word_counts = analyze_urls(urls)
for url, word_count in url_word_counts:
print(f”URL: {url}”)
print(f”Word Count: {word_count}”)
print()
Edit the code and replace the domain as per the screenshot –
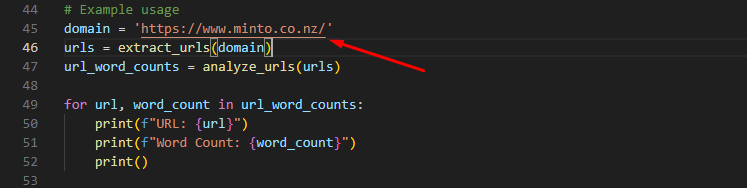
Put your desired domain here.
Now create a folder on desktop –
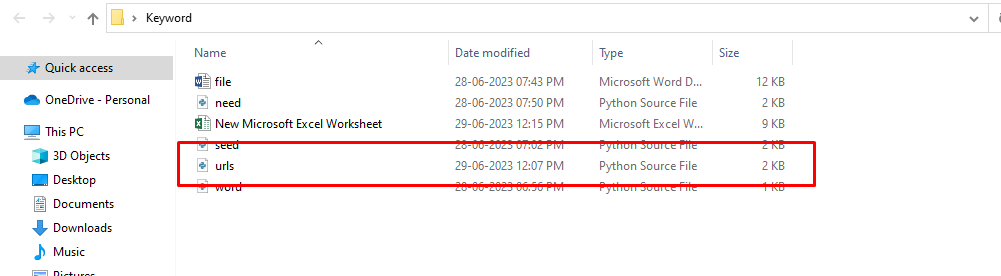
And save the code a as python on this folder –
Step 2:
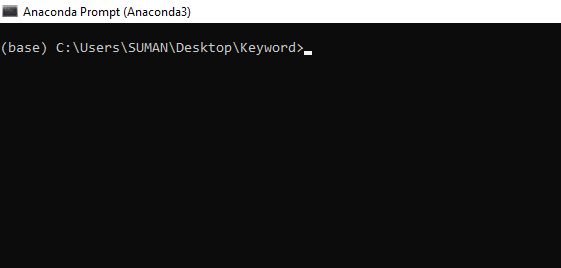
Now open anaconda prompt –
And go to that folder using cd command –
Now install those PIPs –
pip install beautifulsoup4
one by one
pip install requests

Now run the python code –
python urls.py
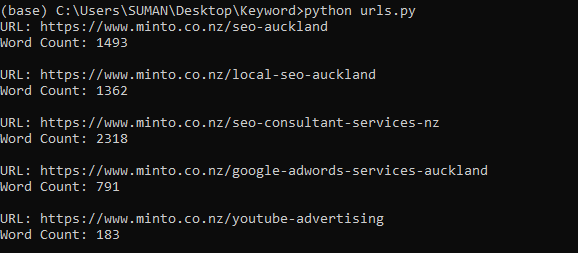
We have extracted the word count of all pages.
Now copy the list on a excel file –

To excel –
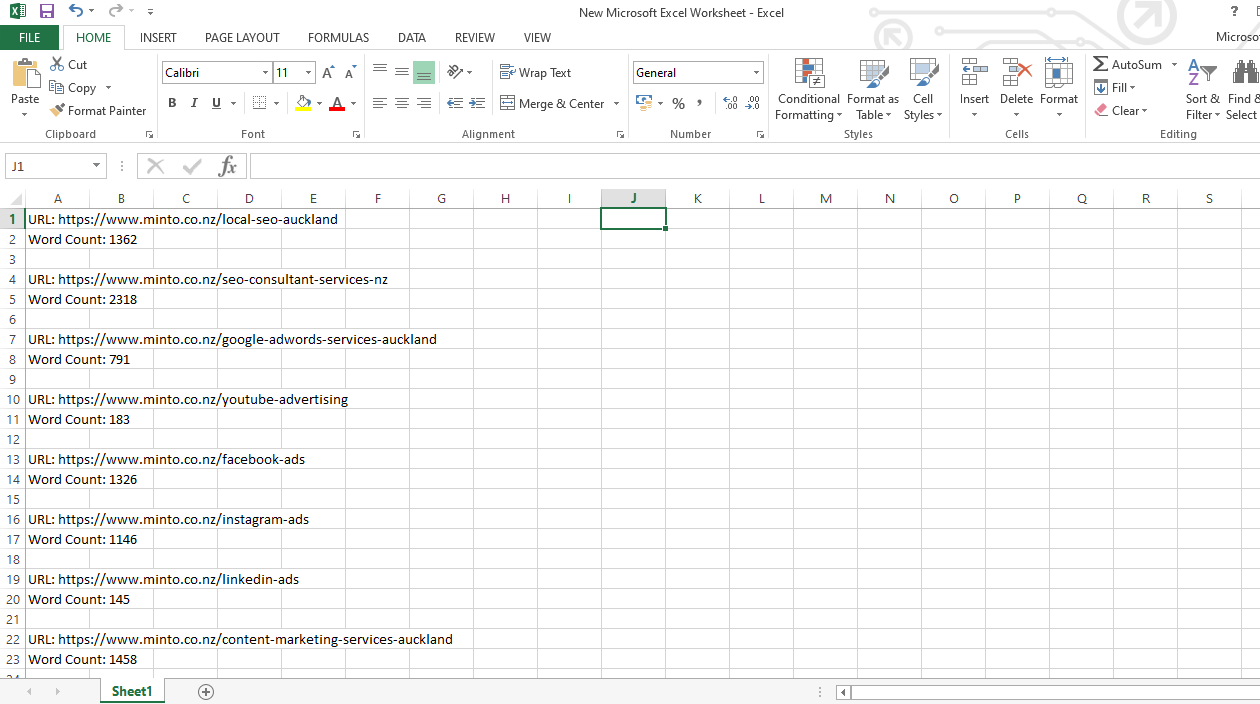
Now manually analyse the list and delete the landing page which has above 1200 words on a page.
Also remove the irrelevant pages like contact us, login page, sign-up page etc.
And make a list of below 1200 word pages for further improvement.
Remember that web scraping should be done responsibly and ethically, adhering to a website’s terms of use and respecting robots.txt guidelines. Also, websites’ structures may change, so periodic updates to your scraping script might be necessary.
