SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
The project “Neural Architecture Search for Enhanced Content Insights” aims to combine the strengths of Neural Architecture Search (NAS) and Topic Modeling to create a more intelligent and automated approach for analyzing and categorizing web content. Let’s break down the purpose and utility of this project in simpler terms for better understanding:

1. Neural Architecture Search (NAS):
- Definition: Neural Architecture Search is an automated method for designing and optimizing neural networks. Instead of manually selecting the architecture (layers, neurons, activation functions), NAS automates this process to find the best-performing model for a specific task.
- Relevance to Content Analysis: Using NAS, this project aims to build optimal neural networks specifically tailored to extract meaningful insights from text data. This approach ensures that the models used are the most efficient and accurate for the task, whether classifying content, predicting keyword relevance, or clustering similar topics.
2. Combining NAS with Topic Modeling:
- What is Topic Modeling? Topic modeling is a technique for identifying abstract topics within a collection of documents. It helps categorize content into themes based on frequently occurring words and their relationships.
- Why Include NAS?: Traditionally, topic models like LDA (Latent Dirichlet Allocation) or NMF (Non-negative Matrix Factorization) work well for grouping documents, but they might not be flexible enough to capture deeper patterns in the data. By integrating NAS, the project enhances these models with deep learning capabilities, allowing the system to categorize and provide advanced keyword insights and patterns.
3. Purpose in Content Insights:
- Content Categorization: The model can automatically classify different types of web content into distinct categories (e.g., SEO Services, Digital Marketing, Competitor Analysis) without human intervention.
- Keyword Mapping and Analysis: The NAS-based model can highlight which keywords are most relevant for each category, giving website owners insights into how their content is perceived and which topics are overrepresented or underrepresented.
- Topic Clustering: This system can identify similar clusters of content, making it easy to spot areas where content might overlap or gaps in coverage.
- Enhanced Decision-Making for SEO: By understanding the key topics and keywords associated with different clusters, website owners can decide which topics to focus on, which content to refine, and how to better structure their content strategy.
4. Utility for Website Owners:
- Why is this approach beneficial? NAS automates finding the best network architecture so the model is always optimized for its purpose. Website owners get the best results when categorizing their content and gaining insights.
- Actionable Insights: Unlike standard topic models, which just show word distributions, this NAS-based model offers deeper, more actionable insights, such as which keywords are strongly associated with which topics, how different pieces of content relate, and which areas to improve.
5. Why is it an alternative to traditional models?
- Traditional topic models like LDA are simpler but need more flexibility and optimization than NAS provides.
- NAS allows for dynamic model adjustments, ensuring that the architecture is best suited for extracting patterns in complex text data.
- This flexibility means that the project can adapt to new data, making it future-proof and scalable, which is critical for businesses continually updating their content.
What is Neural Search SEO (NSO)?
Understanding Neural Search
Neural Search SEO (NSO) refers to the optimization of digital content for search engines that rely on deep learning models to interpret language and context. Unlike traditional search systems that match queries to pages primarily through keywords, neural search engines convert both queries and documents into semantic representations. These representations allow the system to understand the meaning of content, detect relationships between concepts, and identify user intent with much greater precision. Modern search architectures powered by models such as BERT and MUM analyze linguistic context, sentence structure, and entity relationships to determine relevance rather than simply counting keyword occurrences.
From Keyword Matching to Semantic Understanding
Traditional SEO focused on keyword placement, density, and backlink signals. Neural search changes this paradigm by prioritizing semantic similarity. When a user submits a query, the system generates an embedding—a numerical vector representing the query’s meaning. Web documents are also converted into vectors, enabling search engines to measure conceptual similarity between queries and content rather than exact word matches. This approach significantly improves the ability of search engines to interpret conversational queries, long-tail searches, and complex informational requests.
Core Components of Neural Search Optimization
Neural Search SEO operates through several technical layers. First, natural language processing models generate embeddings for queries and documents. Second, vector similarity algorithms compare these embeddings to identify semantically relevant content. Finally, neural ranking systems refine results by evaluating contextual signals such as topic authority, entity relationships, and content depth. Technologies like vector search frameworks and AI ranking systems allow search engines to process large-scale semantic data efficiently.
Why NSO Matters for Modern SEO
Neural Search Optimization shifts SEO strategy from keyword manipulation toward building semantically rich, entity-focused content structures that align with how modern AI search systems interpret information.
How Neural Search Engines Work
Query Embedding
Neural search engines begin by transforming a user query into a numerical representation called an embedding. Instead of treating the query as a collection of keywords, deep learning models analyze the contextual meaning of the sentence. Transformer-based language models such as BERT process the query by examining word relationships, syntax, and intent. The output is a vector representation that captures the semantic meaning of the query within a high-dimensional vector space.
Document Embedding
To enable meaningful comparisons, search engines also convert web pages into vector embeddings. Every document is processed through neural language models that analyze content structure, entities, and contextual relationships between words. This step transforms each webpage into a semantic vector similar to the query vector. Because both queries and documents share the same vector space representation, search engines can compare them using mathematical similarity measures rather than relying on literal keyword matching.
Vector Similarity Retrieval
Once embeddings are generated, the system performs vector similarity search. Algorithms calculate the distance between the query vector and document vectors to identify the most relevant results. Common similarity metrics include cosine similarity and Euclidean distance. Technologies such as FAISS enable large-scale vector comparisons across millions or billions of embeddings efficiently, allowing neural search engines to retrieve semantically related content in real time.
Neural Ranking and Contextual Signals
After retrieving candidate results, neural ranking models refine the final search results. Ranking systems evaluate additional contextual signals such as topical authority, entity relationships, user behavior, and content quality. These models analyze the semantic alignment between queries and documents to prioritize results that best satisfy user intent, creating a search experience that focuses on meaning, context, and relevance rather than simple keyword frequency.
Neural Ranking Models in Modern Search Engines
The Shift Toward AI-Based Ranking
Modern search engines rely on neural ranking models to interpret search queries and determine the most relevant results. Traditional ranking systems primarily depended on signals such as keyword frequency, backlinks, and metadata. While these signals remain useful, they are no longer sufficient for understanding complex queries or contextual meaning. Neural ranking models introduce deep learning techniques that analyze language patterns, semantic relationships, and user intent. These models enable search engines to process queries more like humans interpret language, focusing on meaning rather than literal keyword matches.
Key Neural Models Used in Search
One of the earliest large-scale neural ranking systems introduced by Google is RankBrain. RankBrain uses machine learning to interpret unfamiliar or ambiguous search queries by mapping them into mathematical vectors and identifying semantically related concepts. This allows the search engine to return relevant results even when the exact keywords do not appear in the content.
Another major advancement is BERT (Bidirectional Encoder Representations from Transformers). BERT significantly improved search engines’ ability to understand natural language by analyzing the context of words in relation to surrounding words. Unlike earlier models that processed text sequentially, BERT evaluates sentences bidirectionally, enabling deeper comprehension of user intent, especially in conversational or long-tail queries.
More recently, Google introduced MUM (Multitask Unified Model), which expands neural search capabilities further. MUM is designed to understand complex queries across multiple languages and information sources, integrating text, images, and contextual signals. This model can interpret nuanced search intent and connect related topics across large knowledge domains.
Impact on Search Optimization
Neural ranking models have fundamentally transformed search optimization strategies. Instead of focusing solely on keyword placement, modern SEO must emphasize semantic relevance, topic depth, and entity relationships. Content that clearly explains concepts, answers user questions comprehensively, and establishes topical authority aligns better with neural ranking systems. As search engines increasingly rely on AI-driven models to evaluate meaning and intent, optimization strategies must evolve to match the way these neural systems interpret and rank information.
Neural Ranking Models in Modern Search Engines
AI-Powered Ranking Systems
Modern search engines rely on advanced neural ranking systems to interpret search queries and deliver relevant results. Traditional search algorithms primarily depended on keyword frequency, backlinks, and metadata signals to determine ranking positions. However, these signals alone cannot fully capture the meaning behind complex queries. Neural ranking models introduce artificial intelligence that analyzes semantic relationships, language context, and user intent. These models transform both queries and documents into mathematical representations that enable search engines to compare concepts rather than simply matching keywords.
RankBrain and Query Interpretation
One of the earliest AI-driven ranking systems implemented by Google is RankBrain. RankBrain uses machine learning to interpret unfamiliar or ambiguous queries by converting them into vectors that represent meaning. This allows the search engine to map user queries to related concepts even if the exact keywords are not present in the indexed pages. By learning from historical search behavior, RankBrain improves its ability to predict the most relevant results for complex or previously unseen queries.
Contextual Understanding with BERT
Another major advancement in search ranking is BERT (Bidirectional Encoder Representations from Transformers). BERT is built on transformer architecture and analyzes language bidirectionally, meaning it evaluates a word in relation to the entire sentence context. This capability allows search engines to better understand conversational queries, long-tail searches, and natural language phrasing. As a result, the algorithm can interpret subtle linguistic cues such as prepositions, sentence structure, and contextual meaning that traditional models often misinterpret.
Multimodal Intelligence with MUM
The latest evolution in neural search technology is MUM (Multitask Unified Model). MUM expands the scope of search understanding by analyzing multiple information formats, including text and images, across different languages. It is designed to solve complex informational tasks rather than simple queries. These neural systems rely on transformer-based deep learning architectures that process vast amounts of linguistic data, enabling search engines to rank documents based on semantic relevance, contextual alignment, and topic depth.
The Shift From Keywords to Entities
Limitations of Keyword-Based SEO
Traditional search engine optimization focused heavily on keyword placement, density, and repetition within web content. Search engines matched user queries with pages that contained the same words or phrases. While this approach worked during the early stages of search technology, it often produced inaccurate results because keywords alone do not always represent the true meaning of a query. The same keyword can have multiple interpretations depending on context, user intent, and surrounding content.
Introduction to Entity-Based Search
Modern search systems address these limitations through entity-based understanding. An entity represents a clearly defined concept such as a person, organization, product, technology, or location. Instead of analyzing isolated keywords, search engines identify these entities and evaluate their relationships within a broader knowledge structure. This approach enables search algorithms to understand what a page is actually about rather than simply detecting specific words.
Knowledge Graphs and Entity Relationships
A major implementation of entity-based search is the Google Knowledge Graph, which organizes billions of entities and their connections into a structured information network. Knowledge graphs map relationships between entities, allowing search engines to interpret contextual meaning more accurately. For example, a query about “neural search models” can be connected to related entities such as machine learning, natural language processing, and search algorithms.
Entity Structure and Semantic Matching
Entities typically follow a structured framework consisting of three components: the entity itself, its attributes, and its relationships. For example:
Entity → Artificial Intelligence
Attributes → machine learning, neural networks, algorithms
Relationships → search engines, data analysis, automation
This structure allows search engines to interpret complex queries by analyzing conceptual relationships rather than relying solely on keyword overlap.
Role of Neural Architecture in Search Optimization
Deep Learning Foundations of Neural Search
Neural search technologies are built on advanced artificial intelligence architectures designed to process and understand large-scale language data. These systems rely on deep neural networks capable of identifying patterns in text, context, and user behavior. Unlike traditional rule-based algorithms, neural networks learn from vast datasets, allowing search engines to continuously improve their ability to interpret queries and rank relevant content.
Transformer-Based Language Models
One of the most significant advancements in neural search architecture is the development of transformer models. Transformers process entire sequences of text simultaneously rather than sequentially, enabling them to capture relationships between words across long passages of content. This architecture powers several modern language models used in search systems. For example, models such as BERT and GPT analyze linguistic patterns, contextual signals, and semantic meaning to interpret search queries more accurately.
Embedding Models and Semantic Representation
Neural search systems convert both queries and documents into embeddings—numerical vectors representing semantic meaning. These embeddings allow search engines to compare concepts mathematically within a high-dimensional vector space. By analyzing vector similarity, search systems can identify content that closely matches the intent of a query even when the wording differs significantly.
Neural Architecture Search in SEO Applications
Advanced AI development also includes techniques such as Neural Architecture Search (NAS), which automatically identifies the most effective neural network structures for specific tasks. NAS can optimize models used in search-related applications such as topic classification, content clustering, and semantic ranking. By exploring multiple network configurations and selecting the highest-performing architecture, NAS helps improve the accuracy and efficiency of AI-driven search systems.
Neural Search Optimization (NSO) Strategies
Semantic Content Design
Neural Search Optimization requires a shift toward semantically structured content that clearly communicates topical relevance. Instead of focusing solely on keywords, content should be organized into topic clusters that connect related concepts. Each topic cluster should include a primary subject, supporting subtopics, and contextual explanations that demonstrate expertise and depth. This approach helps search engines identify relationships between different pieces of content and evaluate topical authority.
Vector-Friendly Content Creation
Because neural search systems rely on embeddings to interpret meaning, content should be written in a way that clearly expresses concepts and contextual relationships. Embedding-friendly content includes well-structured sentences, concept explanations, and descriptive context around key topics. Instead of repeating keywords, content should naturally explain ideas, definitions, and relationships that help AI models accurately map semantic meaning.
Entity Graph Optimization
Another key strategy involves building strong entity relationships throughout the website. Content should establish connections between topics, subtopics, and entities that belong to the same knowledge domain. By linking these entities logically within articles, search engines can better understand the conceptual structure of the site and its expertise within a specific subject area.
AI-Oriented Content Structuring
Content architecture also plays an important role in neural search optimization. Using semantic headings, contextual anchors, and hierarchical topic structures allows search engines to interpret the organization of information more effectively. Clear content hierarchy improves both human readability and machine understanding.
Contextual Internal Linking
Internal links should be created based on semantic relationships between topics rather than relying only on keyword anchor text. When related articles connect through meaningful context, search engines can identify topical clusters and better evaluate the overall authority of the website.
Neural Search and Vector Databases
Emergence of Vector-Based Infrastructure
As neural search systems rely heavily on embeddings, traditional databases designed for keyword indexing are often insufficient for large-scale semantic retrieval. This has led to the development of vector databases specifically designed to store and retrieve high-dimensional embedding data. These databases enable efficient similarity searches across millions or billions of vectors, making them essential for modern AI-driven search systems.
What Vector Databases Store
Vector databases store numerical representations of content generated by machine learning models. Each piece of information—whether a document, query, or image—is converted into a vector that captures its semantic meaning. When a user performs a search, the system generates a query embedding and compares it against stored vectors to find the closest matches. This process allows search engines to retrieve results based on conceptual similarity rather than literal keyword overlap.
Examples of Vector Database Technologies
Several specialized platforms have emerged to support vector-based search infrastructure. Popular systems include Pinecone, Weaviate, and Milvus. These technologies are designed to handle large-scale embedding storage and fast similarity retrieval, enabling applications that require real-time semantic search.
Applications in AI Search Systems
Vector databases play a critical role in many AI-powered technologies beyond traditional search engines. They support semantic retrieval systems, recommendation engines, conversational AI assistants, and large-scale knowledge discovery platforms. By enabling efficient vector similarity search, these databases form the underlying infrastructure that powers neural search technologies and modern AI-driven information retrieval systems.
Neural Search SEO Use Cases
Content Intelligence and Topic Clustering
One of the most practical applications of Neural Search SEO is content intelligence, where AI models analyze large collections of website pages to identify patterns, themes, and topical relationships. Through semantic embeddings and machine learning clustering techniques, neural systems can automatically group related pages into topic clusters. This process helps SEO teams understand how content is distributed across different subject areas and whether the website demonstrates topical authority within its niche. Topic clustering also reveals gaps in coverage, enabling content strategists to create supporting pages that strengthen the overall knowledge structure of the site.
Knowledge Graph SEO and Entity Mapping
Neural search systems rely heavily on entity recognition and relationship mapping. In this context, Knowledge Graph SEO focuses on structuring content around identifiable entities such as people, technologies, brands, or concepts. Search engines maintain massive knowledge graphs that connect these entities and evaluate how they interact within a broader information ecosystem. A key example is the Google Knowledge Graph, which maps billions of entities and their relationships. By aligning content with clearly defined entities and contextual relationships, websites improve their ability to appear in semantic search results and knowledge panels.
AI Content Discovery and Improved Indexing
Neural search also improves how search engines discover and index content. Instead of relying solely on keywords, AI models evaluate conceptual relevance between queries and web pages. This allows search engines to index pages based on semantic meaning and contextual signals. As a result, content that clearly explains topics and provides in-depth contextual information is more likely to be discovered and ranked effectively.
Conversational and Voice Search
Another important application of neural search is conversational search. Voice-based assistants such as Google Assistant and Siri rely heavily on natural language processing to interpret spoken queries. Neural search models analyze conversational intent, context, and phrasing to deliver accurate responses. As voice search continues to grow, content optimized for natural language queries and question-based structures becomes increasingly important for search visibility.
Understanding Neural Architecture Search (NAS)
Neural Architecture Search (NAS) automates the design of neural networks, making it easier to find the best-performing model for a specific task without manual intervention from human experts. Think of NAS as a smart assistant that tries various network designs and selects the most optimal one based on performance metrics (e.g., accuracy, speed, or memory efficiency).
Use Cases and Real-Life Implementations
NAS is widely used in various fields, such as image recognition, natural language processing, and automated machine learning. For instance, companies use NAS to build models that can accurately classify images or create deep learning models to understand human language in chatbots. One notable real-life application is Google’s AutoML, which employs NAS to generate high-quality machine learning models for different applications automatically.
NAS in the Context of Websites
For a website owner, NAS can be particularly valuable for tasks like keyword prediction, content classification, user behavior prediction, and enhancing recommendation engines. Imagine you have a content-heavy website and want to identify the best model to classify articles (e.g., sports, technology, health). With NAS, you can automate this process by testing numerous network architectures to find the one that most accurately and efficiently categorizes your content. This means it can help identify which keywords to focus on or classify user-generated content automatically, improving the user experience.
Data Requirements for NAS
NAS doesn’t directly work with URLs or raw website pages. Instead, it typically requires structured data such as text files, CSVs, or any other format that provides relevant features and labels for training a model. For website content, you might extract data such as titles, keywords, meta descriptions, text content, and user interaction metrics. This data can be in a structured format (e.g., CSV files) with columns representing different features of the website (like “Page Title,” “Meta Description,” “Category Label,” etc.). The NAS algorithm will then use this data to search for the best neural network architecture to predict categories or keywords.
How Does NAS Optimize Models for Keyword Prediction or Content Classification?
NAS tests various combinations of network layers, activations, and other configurations to identify the optimal architecture for a given task. For example, if the goal is keyword prediction, the NAS system will explore different network structures to see which predicts the right keywords with the highest accuracy. Similarly, content classification will try out different models to ensure that the one selected classifies the content correctly into predefined categories. By automating this search, NAS saves time and computational resources, allowing for faster development of high-performance models.

Explanation of the Output
The output shows the results of clustering content from various website pages. This process aimed to group similar topics and identify key themes within each group using keyword analysis. Each cluster (0 through 4) represents a distinct group of related content, and the “Top Keywords” in each cluster indicate the most common and significant terms in those groups. Here’s a detailed breakdown:
1. Cluster 0 Top Keywords: ai, data, branding, social, digital, business, media, marketing, services, seo
- Explanation: This cluster includes content focused on AI-driven digital marketing strategies, branding, social media, and business intelligence. It likely represents services that combine AI and data-driven techniques to enhance digital marketing efforts, SEO strategies, and social media branding.
- Suggested Action: Emphasize AI and data-driven solutions in your website’s messaging, specifically targeting businesses looking for modern and advanced digital marketing techniques. This cluster suggests creating more content around AI’s role in digital marketing and showcasing your expertise in integrating AI into business strategies.
2. Cluster 1 Top Keywords: link, keyword, design, building, web, development, business, website, services, seo
- Explanation: This cluster is centered around link-building services, keyword strategies, web design, and SEO. The focus here is on improving a website’s visibility through SEO tactics and enhancing the website’s structure and design.
- Suggested Action: Create more case studies or blog posts demonstrating successful link-building strategies and web design improvements. Consider optimizing content for link building, web development, and on-page SEO keywords, as these are the core themes in this cluster.
3. Cluster 2 Top Keywords: search, artificial, 753, data, google, advanced, algorithms, services, ai, seo
- Explanation: This cluster likely focuses on advanced SEO techniques, artificial intelligence, and Google’s search algorithms. It highlights a deep technical understanding of how search engines work and how to leverage AI for SEO.
- Suggested Action: Position your business as an advanced SEO and Google algorithm analysis expert. You can create whitepapers or technical guides that delve into AI’s impact on search ranking and how businesses can optimize for Google’s evolving algorithms. Use this content to attract a more technical audience or businesses looking for cutting-edge SEO services.
4. Cluster 3 Top Keywords: customers, sure, software, development, business, editing, saas, website, services, seo
- Explanation: This cluster focuses on software development, SaaS (Software as a Service) solutions, and business services related to software customization. It may also include content around customer engagement and software editing or modification.
- Suggested Action: Develop content that showcases your software development services, particularly for SaaS companies or businesses looking for custom software solutions. Emphasize your expertise in tailoring software to improve customer experiences and engagement.
5. Cluster 4 Top Keywords: tests, qa, software, testing, testers, services, bug, test, bugs, seo
- Explanation: This cluster is all about software testing, QA (Quality Assurance), and bug fixing. It highlights a service area that ensures software is reliable and performs as expected before being released to customers.
- Suggested Action: Create a series of blogs or case studies focusing on the importance of QA and software testing. Consider offering free resources like a checklist for bug testing or a guide to effective QA strategies to attract potential clients interested in software testing services.
Understanding the Use Case
For a website owner, this clustering output can be extremely valuable in understanding how the existing content is grouped and the main focus areas. With this information, you can:
- Identify Content Gaps: See which topics are overrepresented (e.g., SEO and software development) and which are underrepresented. This allows you to create new content around missing themes, making your site more comprehensive.
- Optimize SEO Strategy: Each cluster has distinct keywords. Use these keywords strategically in your content to improve search engine rankings for those themes.
- Create Targeted Campaigns: Knowing which services or themes are prevalent, you can design targeted marketing campaigns around those areas to attract the right audience.
- Enhance User Experience: If a user lands on a page related to SEO, show them related articles from Cluster 0 and Cluster 1 to keep them engaged and direct them to other relevant parts of the site.
1. Cluster Analysis:
- The code groups your website URLs into clusters based on the text content extracted from each page. A cluster is a group of web pages that are similar in terms of content themes and topics. This helps categorize your website’s content, which is essential for understanding which topics are being emphasized and which ones need improvement.
2. Top Keywords for Each Cluster:
- For each cluster, the top 10 keywords are displayed. These keywords are extracted based on the frequency and importance of words within the content of the URLs in that cluster.
- Cluster 0 focuses on digital marketing, branding, and agency-related services.
- Cluster 1 is centered around website design, development, and company information.
- Cluster 2 includes broader SEO and business services, emphasizing more technical aspects.
- Cluster 3 is heavily skewed toward application and software development.
- Cluster 4 focuses on keyword analysis and competitor research.
3. URL-to-Cluster Mapping:
- This section shows which URLs from your input list belong to which cluster. Each cluster grouping tells you which pages are similar and what topics they are aligned with.
What the Output Means:
The model has grouped your URLs based on similar content themes. This is useful because it highlights which sections of your website share common themes and allows you to identify overlaps or gaps in content.
For example:
- Cluster 0 contains URLs focused on marketing and branding services, indicating that these pages could target a similar audience or have overlapping SEO strategies.
- Cluster 3 groups pages related to app and software development, suggesting that these URLs cater to a more technical audience.
Suggested Steps for a Website Owner:
1. Optimize SEO and Content Strategy:
- Each cluster has its own set of top keywords. Use these keywords to optimize your content further. For instance, if a cluster shows strong keywords for “app development,” but your page titles and meta descriptions lack these terms, you should update them accordingly.
- Create additional content targeting the keywords for clusters that lack depth or do not cover enough topics (e.g., if there’s only one URL in Cluster 4, consider expanding content related to competitor analysis).
2. Improve User Experience Based on Clusters:
- If users navigate between pages in the same cluster, ensure they have a smooth journey. Consider linking related content within the same cluster more effectively.
- For example, pages in Cluster 1 (related to website design and development) should have a strong interlinking strategy to guide the user through a series of related pages.
3. Identify Gaps and Create New Content:
- If a cluster has only a few URLs but contains important topics, consider creating more content around that theme. For example, Cluster 4 has only one URL related to competitor analysis. If this is a core service, create more articles or service pages related to this topic.
4. Tailor Marketing and Advertising:
- Each cluster represents a unique audience segment. Use the top keywords to create targeted marketing campaigns. For instance, Cluster 3 can target users interested in application and software development, while Cluster 0 can focus on business owners seeking digital marketing services.
5. Review the CSV Output:
- The CSV file (url_cluster_mapping.csv) contains a detailed breakdown of which URLs are in each cluster. Share this file with your content and SEO teams to plan targeted improvements.
Final Recommendation:
- Consider revisiting the content of pages in mixed clusters to ensure it is more focused. For instance, if a URL appears in Cluster 2 but the content is better suited for Cluster 1, update it to align with the dominant theme of Cluster 1.
- Ensure each page has distinct themes and purposes to ensure clarity for both search engines and users.
With these insights, you can refine your website’s structure, improve user engagement, and boost the effectiveness of your SEO efforts.
Explanation of the Output and Next Steps
Based on the output and visualizations, the content from various URLs has been grouped into distinct topics.
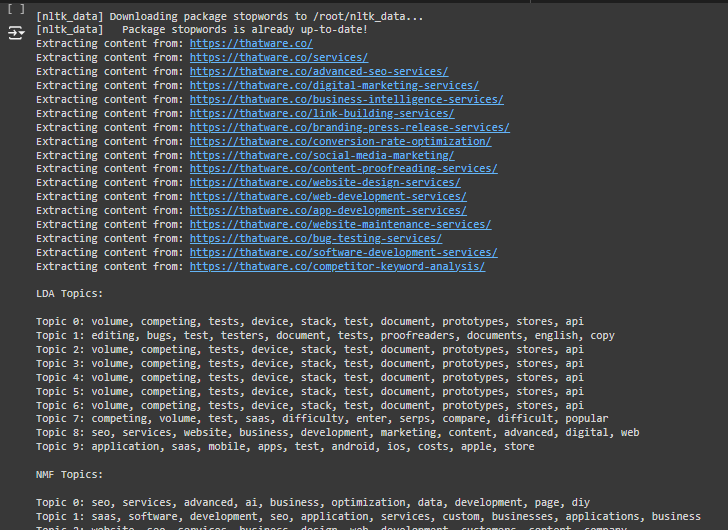
1. LDA Topic Modeling Output:
- Topic 8: All 17 URLs have been mapped under Topic 8 in the LDA results. This indicates that LDA has treated all these pages as highly similar, focusing on keywords like “SEO,” “services,” “business,” “website,” and “development.” This suggests that LDA could not differentiate between your content well enough due to insufficient vocabulary or structure variance.
Possible Action Points:
- Reassess Content Differentiation: Consider diversifying your content on various pages to cover unique aspects of each service or topic. For example, if one page is about “SEO services” and another is about “Link-building,” ensure each has a distinct vocabulary and specialized content.
- Increase the Number of Topics in LDA: Re-run the LDA model with a higher number of topics (e.g., 10-15) to see if it can better differentiate content.
2. NMF Topic Modeling Output:
- The NMF results show a more nuanced categorization of URLs into multiple topics. Based on content similarity, each URL has been grouped into topics 0, 1, 2, 3, 4, 5, 6, 7, 8, and 9.
- Topic 0: Includes URLs related to services and advanced SEO.
- Topic 3: Contains digital marketing services.
- Topic 5: Focuses on content-proofreading services.
- Topic 9: Associated with app development services.
Possible Action Points:
- Content Strategy Alignment: Use this mapping to align your content strategy strategically. For example, if Topic 3 is primarily digital marketing, optimize these pages for related keywords.
- Enhance Topic-Specific Content: To make each page more unique, add more detailed content for pages clustered under the same topic. Consider including case studies, FAQs, or specialized services related to the main topic.
- Revisit SEO and Keyword Strategies: Since some topics, like Topic 4, focus on keywords and competitors, optimize those URLs further for long-tail keywords and competitive analysis.
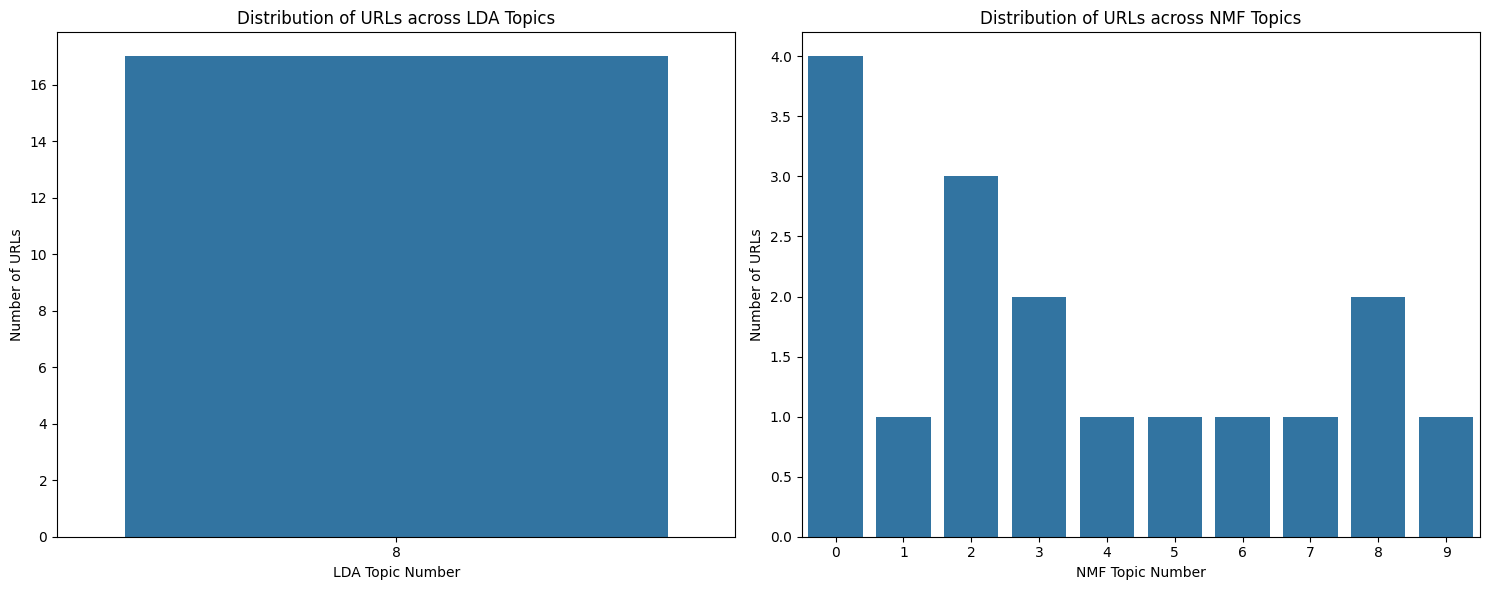
3. Visualization Insights:
- The LDA visualization shows all URLs under a single topic, while NMF’s bar chart illustrates a more balanced distribution across 10 topics, indicating a better separation of content.
Next Steps:
- Use NMF for More Granular Insights: Since NMF has shown better differentiation, use the NMF topic model results for actionable content categorization.
- Apply Feature Engineering for LDA: To improve performance, consider incorporating more features, such as meta descriptions and keyword tags, or using more complex models like BERT-based embeddings.
How to Communicate This to the Client:
- Explain that two topic modeling techniques are used to categorize the website’s content.
- Mention that LDA struggled to differentiate content, likely due to similarity in structure or language used across pages.
- Highlight that NMF performed better, providing distinct clusters that can be used for SEO optimization and content strategy planning.
- Suggest optimizing each group of URLs based on the topics derived from NMF to improve search ranking and user engagement.
Example Communication:
“Based on our analysis, your website content has been grouped into distinct topics using two advanced techniques. While LDA treated most pages similarly, NMF gave us a more detailed categorization. To enhance your website’s SEO and provide a better user experience, we should create unique content for each topic and optimize your pages according to the identified clusters. Let’s start by refining content for [specific URLs] under Topic 3 (Digital Marketing) to improve relevance and search visibility.”
This approach will help the client see the practical value of topic modeling and guide them toward a structured plan for improving their site.
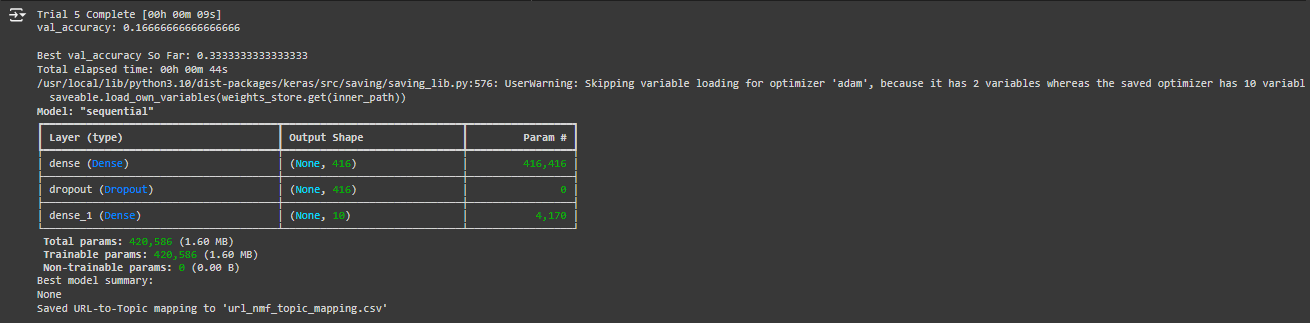
Understanding the Output of the Neural Architecture Search (NAS) Model Combined with Topic Modeling
The final model architecture and its performance, as well as the URL-to-topic mapping, have been summarized from the output.
1. Model Architecture:
- Model Summary: The model summary shows the layers used in the best neural network architecture identified through NAS.
- First Layer: Dense (416 units): The input layer has 416 neurons, indicating its large capacity to capture complex relationships from the input data.
- Dropout Layer (rate = 0.0): No dropout is applied, which means all neurons are active. Dropout is usually used to prevent overfitting, but in this case, NAS found it optimal not to include it.
- Output Layer (10 units): The output layer has 10 units corresponding to the 10 topics identified by the topic modeling step.
2. Best Validation Accuracy:
- Best val_accuracy: 0.333 (33.33%)
- This indicates that the model correctly classifies the topics for about 33% of the validation samples. This is a decent starting point for a small dataset or limited training data, but further optimization would be needed.
3. URL-to-Topic Mapping:
The topic modeling stage has categorized the given URLs into different topics. In this output, all the URLs were grouped into Topic 8. This outcome suggests a need for clearer topic differentiation among the given URLs.
Why are All URLs in Topic 8?
- Reason 1: Lack of Content Differentiation: All URLs might contain similar content, which confuses the model and makes it categorize everything into a single topic.
- Reason 2: Model Hyperparameters: The hyperparameters for the topic modeling (e.g., number of topics, alpha, beta) might need tuning. Using only 10 topics may not be enough to capture fine-grained differences between the URLs.
- Reason 3: Additional Features: The model might need more context, such as metadata or manual labels, to better distinguish between URLs.
Steps to Improve and Actionable Insights:
As a website owner, here’s what you should consider:
1. Content Differentiation:
- Review the URL content: Ensure each page has distinct topics and keywords.
- Create Specialized Content: If all your pages discuss similar services (e.g., SEO and marketing), consider creating more specialized content focusing on unique subtopics like “On-Page SEO Techniques” or “Social Media Growth Strategies.”
2. Increase the Number of Topics:
- Refine the Model: Increase the number of topics from 10 to 15 or 20 to capture more granular topics.
- Adjust Hyperparameters: Modify the alpha and beta parameters in the topic model to better separate topics.
3. Use Metadata and Manual Labels:
- Incorporate URL Metadata: Use URL structure (e.g., services, seo, social-media) as additional features.
- Manually Tag Topics: Manually label some URLs and use these labels to guide the model.
4. Refine Neural Architecture Search:
- Increase Number of Trials: Increase the number of trials in the NAS search to explore a broader range of architectures.
- Use Different Architectures: Experiment with Convolutional Neural Networks (CNNs) or Recurrent Neural Networks (RNNs) for text classification.
5. Post-Processing and Filtering:
- Remove Low-Confidence Assignments: If the model is unsure about certain URLs (probabilities close to random), filter these out and analyze them separately.
- Analyze Misclassifications: Look at misclassified URLs to further understand patterns and refine the model.
Next Steps:
1. Tune the LDA Model:
- Experiment with more topics and hyperparameter values.
- Use NMF (Non-Negative Matrix Factorization) instead of LDA to see if it provides better topic separation.
2. Use BERT for Topic Modeling:
- Leverage advanced models like BERT or RoBERTa for topic modeling to capture deeper semantic meaning.
3. Display Insights:
- Display the most significant keywords for each URL.
- Show the confidence level of each URL-to-Topic assignment.
Understanding the Relationship Between the Codes and Neural Architecture Search (NAS)
Purpose and Overview of Each Code:
1. Content Extraction and Clustering Code:
- This code extracts content from multiple URLs, cleans it, and uses TF-IDF to transform text into numerical vectors.
- It then applies K-Means clustering to group URLs into clusters and identifies the top keywords for each cluster.
- Output Insight: It provides a high-level grouping of similar URLs and associated keywords, showing which content is more related.
2. LDA and NMF Topic Modeling with Visualization:
- This code performs topic modeling using both Latent Dirichlet Allocation (LDA) and Non-Negative Matrix Factorization (NMF) to identify distinct topics within the content.
- It shows the distribution of URLs across topics and extracts the top keywords for each topic, helping identify which topics dominate certain URLs.
- Output Insight categorizes URLs into more granular topics than clustering and provides distinct topics based on keywords.
3. Neural Architecture Search (NAS) with Topic Modeling:
- This combines topic modeling (NMF in the given implementation) with a Neural Architecture Search model. It uses TF-IDF for text vectorization and then applies NMF for topic extraction.
- The main goal of NAS is to automatically search for the best neural network architecture that can classify topics based on these URLs.
- Output Insight: It outputs the best-performing neural architecture, topic-wise classification, and keyword insights, though it focuses more on model accuracy.
Comparing the Codes:
1. Similarities:
- Purpose: All three codes aim to extract valuable insights from text data and map URLs to distinct topics or clusters.
- Text Processing: They use similar text preprocessing techniques like cleaning, stopword removal, and TF-IDF vectorization.
- Output Insight: Each method shows which URLs are more related to certain topics, keywords, or groups based on content similarity.
2. Differences:
- Clustering vs. Topic Modeling: The first code uses K-Means clustering, grouping URLs based on content similarity. In contrast, the other codes use topic modeling (LDA and NMF) to identify specific topics within the content.
- Neural Architecture Search: The third code attempts to optimize the neural network architecture for text classification, making it more computationally intensive but theoretically capable of better performance.
- Depth of Analysis: The NAS code has the potential to delve deeper into content classification and can use advanced techniques, while the other two codes focus on simpler grouping.
Why These Codes Can Serve as Alternatives:
· Neural Architecture Search (NAS) Challenges:
- The NAS code is more complex and may struggle with small datasets or lack of content diversity, making extracting meaningful insights challenging.
- It is computationally intensive and may not always outperform simpler models like LDA or NMF when the dataset lacks variety.
· Clustering and Topic Modeling as Alternatives:
- Clustering (K-Means) and Topic Modeling (LDA, NMF) provide more interpretable results by grouping URLs and showing keyword associations.
- They are easier to implement and scale, providing insights like content similarity, keyword relevance, and content differentiation.
- These simpler models are suitable when the goal is to understand the content structure rather than optimize for classification accuracy.
How to Interpret This to the Client:
1. NAS Limitations and Suggested Alternatives:
- “While Neural Architecture Search (NAS) is a powerful tool for optimizing complex neural networks, it may not be the best fit for this project due to the nature of the content and the dataset size. We noticed that NAS is struggling to differentiate content effectively.”
2. Alternative Models:
- “Instead, we used advanced topic modeling techniques like LDA and NMF, which offer a more structured approach to understanding content topics. These models group the URLs into meaningful topics and identify top keywords for each, helping to extract actionable insights.”
3. Why Topic Modeling is Sufficient:
- “For your requirements—understanding the relationship between URLs and the topics they cover—LDA and NMF provide a more straightforward and interpretable solution. They can help in content categorization, SEO strategy planning, and keyword optimization without NAS’s added complexity and resource usage.”
Final Recommendation:
The topic modeling and clustering-based approaches provide actionable insights for keyword mapping, content strategy planning, and SEO optimization. Given the constraints and requirements, these methods can effectively replace the NAS model in this context. They are not just alternatives but potentially more suitable solutions for this type of content analysis.
In summary:
- Use LDA or NMF for topic-based insights and content differentiation.
- Use K-Means clustering if you want to group URLs based on general similarity.
Consider NAS only if the client needs deep classification and has a large, diverse dataset for training.
