SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
The purpose of this project is to leverage K-Means Clustering to optimize website content and user segmentation for improving SEO strategies. By analyzing user behavior data (e.g.,page views, time spent on page) and content features (e.g., keywords, article types), the project aims to identify distinct clusters of users and content. This segmentation allows for a more targeted approach in content delivery, enhancing user experience and improving search engine rankings. The project demonstrates how data-driven insights can drive intelligent decision-making for digital marketing, enabling businesses to deliver personalized content and better understand their audience.

What is K-Means Clustering?
At its core, K-Means Clustering is a machine learning technique used to group or classify data into different clusters (groups). Imagine you have a set of data points, and you want to divide them into separate groups that are similar to each other. This is what K-Means does: it finds patterns in the data and groups things that are alike into clusters.
For example, if you have data about your website users (age, interests, or behavior), K-Means can help divide them into clusters like “young adults,” “seniors,” or “frequent buyers,” so you can better understand and target them.
How does K-Means Clustering work?
- Input Data: You provide the algorithm with some data, such as user characteristics or webpage performance statistics.
- Choose Number of Clusters (K): You decide how many groups (or clusters) you want to divide your data into. This is where the “K” in K-Means comes from. If you want to split users into 3 groups, K would be 3.
- Assign to Clusters: The algorithm looks at the data and tries to divide it into clusters by finding data points that are close to each other in some way (similar).
- Adjust Clusters: It keeps adjusting these clusters to make sure that each group is as tight and distinct from others as possible.
- Final Clusters: Once it has grouped the data points, it outputs the final clusters.
Use Cases of K-Means Clustering
K-Means Clustering is widely used in various fields, including:
- Customer Segmentation: Grouping users based on their behavior (like purchase history or demographics) so businesses can target them with personalized marketing campaigns.
- Content Personalization: Grouping webpage content or blogs based on the type of users visiting, so you can show the right content to the right group of people.
- Market Segmentation: Dividing a market into distinct customer groups based on needs, preferences, or location.
- Image Compression: Reducing the size of an image by grouping similar colors together.
- SEO and Digital Marketing: Identifying user patterns, grouping users or webpages based on behavior, and optimizing content for better ranking.
Real-Life Implementations of K-Means Clustering
In the context of SEO strategies, K-Means can be used to segment:
- Website Visitors: You can group visitors into categories based on behavior (like bounce rate, time spent on page, or specific interests) to create targeted marketing campaigns.
- Content Segmentation: By clustering similar pages or articles based on content, it helps to identify which type of content appeals most to certain user segments, allowing for optimized SEO strategies.
- E-commerce: Online stores use K-Means to group customers based on shopping behavior to offer personalized product recommendations.
Does K-Means Clustering Need URLs of Web Pages?
No, K-Means Clustering does not directly work with URLs of webpages. Instead, it needs data about users or content. For example, you might feed it:
- User behavior data (e.g., number of page views, time spent on a page).
- Content features (e.g., keywords, type of articles).
What You Need to Get an Output from K-Means
- Data: You’ll need to provide the algorithm with data that can be used for clustering. This can be:
- User Data: Information like age, location, purchase behavior, or how they interact with your site.
- Content Data: Information about the content on your website, like keywords, topic categories, or user engagement metrics.
- Keywords: What keywords are the site using, and which ones bring the most traffic?
- Type of Content: Is the content a blog post, a service description, or a product page?
- User Engagement: How many people read or interact with the content? Are there comments or shares?
- User Behavior Data:
- Page Views: Find out which pages are being visited the most.
- Time Spent on Pages: Identify how much time users spend on each page.
- Bounce Rate: Check how often users leave the site after visiting only one page.
- Number of Clusters (K): You must choose how many groups (clusters) you want the algorithm to split the data into.
Example
Let’s say you run an online store and you want to group your customers to understand them better. You might provide the algorithm with customer data such as:
- Number of purchases
- Average spend per purchase
- Number of website visits You could choose K = 3 to divide them into 3 clusters: “Low spenders,” “Medium spenders,” and “High spenders.” This way, you can tailor your marketing strategy to each group.
How to Choose the Number of Clusters (K)
Now, let’s talk about how to choose the number of groups, or clusters.
- Understanding Your Goal: First, think about what you want to achieve. If you are trying to segment users, maybe you want to create groups like “frequent buyers” and “first-time visitors.” Similarly, if you are segmenting content, you may want groups like “informational pages” and “transactional pages.”
- Start Small: A good starting point is 3 to 5 clusters. For example, if you are dividing users, you might start with 3 clusters:
- Frequent Visitors
- Occasional Visitors
- New Visitors
- Trial and Error: There’s no perfect answer for how many clusters to use. Start with a number (like 3 or 5), run the model, and then look at the results. If the groups seem too broad or too narrow, you can adjust the number of clusters.
- Use the Elbow Method: This is a simple way to choose how many clusters to use. After trying different numbers of clusters (like 3, 4, 5, etc.), you graph the results. When you notice the graph bending like an “elbow,” that’s a good number of clusters to choose. Don’t worry, this can be done automatically with tools like Python, so you don’t need to do this manually!
Code Breakdown:

Explanation of Each Step:
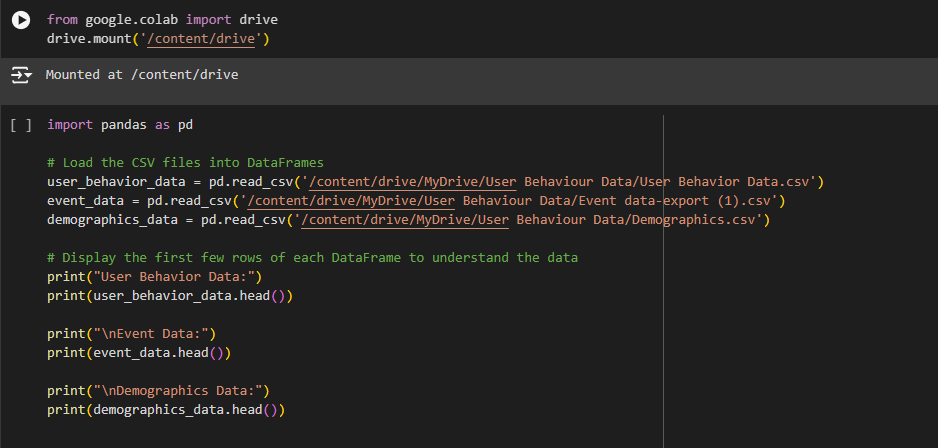
1. Importing the Google Drive Library

· What it does: This line imports a special library called drive from Google Colab. This library allows you to access your Google Drive directly from your Colab notebook.
· Example in real life: Imagine you’re working on a project in a shared office space and you need access to documents from your locker. In this case, your locker is like Google Drive, and the notebook (Colab) needs permission to access it. The drive library is like a key that lets the notebook open your locker.
2. Mounting Google Drive

· What it does: This line mounts your Google Drive, which means it connects your Google Drive to the Colab environment. By doing this, Colab can read and write files stored in your Google Drive.
· What happens when you run this code:
o When you run this code, Colab will ask you to authenticate (give permission) by logging in to your Google account.
o After logging in, you’ll see a pop-up asking for permission to allow Google Colab to access your Google Drive. Once you give permission, Colab will be able to access all the files in your Google Drive.
· Why ‘/content/drive‘?: The directory /content/drive is a folder inside the Colab environment where your Google Drive will be mounted. Once mounted, all your files from Google Drive will appear inside this folder, and you can access them like any other folder.
Example to Understand:
Imagine your Google Drive is a physical storage locker where you keep important documents. You want to use a computer in a public library (Colab) to work on a project that needs access to those documents. However, you don’t want to store the documents directly on the public computer; you just want to access them temporarily.
· Step 1: You use the locker key (the drive library) to unlock your storage locker (Google Drive).
· Step 2: After unlocking, the library allows you to view and edit your documents stored in the locker through the computer.
Now, every time you run this code, the Colab notebook (library computer) can directly access files from your Google Drive (locker).
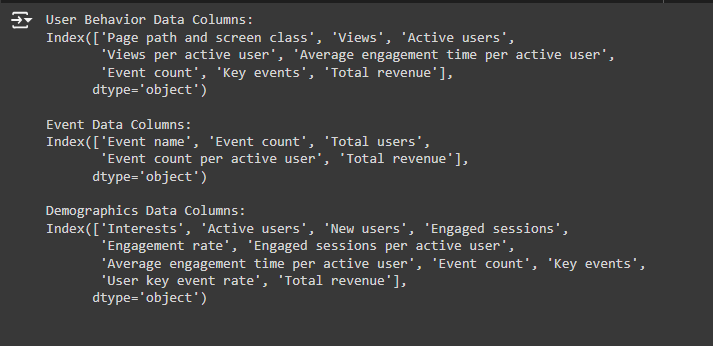
How Do We Decide Which Columns to Select?
When working with multiple datasets (like you have here), it’s important to understand the goal of your analysis or model. In this case, you want to use K-Means Clustering to group similar pages or users based on their behavior. To achieve that, you need to pick the columns (features) that best describe the behavior of the users or performance of the pages.
Here are the key questions that guide this process:
1. What Is the Goal of the Analysis?
The goal is to group website pages based on their user behavior. To do this, you need data that describes how users are interacting with each page.
- Example: To group pages based on user behavior, we need to look at data like how many times each page was viewed and how much time users are spending on each page.
2. Which Columns Directly Relate to the Goal?
Once you know the goal, you need to identify the columns that are most relevant for clustering.
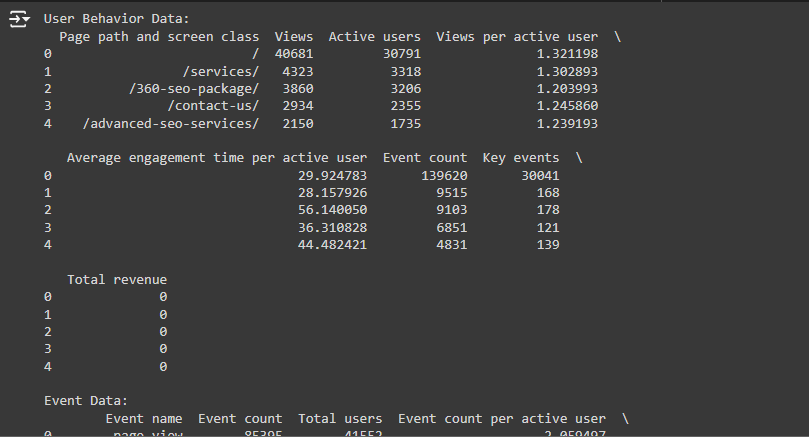
- In this case, the columns ‘Views’ (how many times a page was viewed) and ‘Average engagement time per active user’ (how much time users spend on the page) are directly related to understanding user behavior on a page.
- Why we selected these columns: These columns provide numerical data, which is essential for clustering. K-Means works by grouping similar data points based on numbers, so we need columns that are numeric and describe the pages’ performance.
3. Is the Data Usable in Its Current Form?
Next, we need to ensure the columns are in a format that the model can use. For K-Means, we need numeric data. Columns like page URLs (text) can’t be directly used in clustering, but they are still important for identifying the results (like knowing which page belongs to which cluster).
- ‘Page path and screen class’ (the URL of the page) is important for identification but isn’t used for clustering because it’s text-based. We use this column later to understand which page belongs to which cluster.
- ‘Views’ and ‘Average engagement time per active user’ are numeric, which means they can be used in the clustering process.
Step 4: Check for Relationships Between Datasets
In some cases, you can combine datasets to enrich your analysis. For example, if the Event Data contained a column like ‘Page path and screen class’, you could merge it with the user behavior data to add more insights into the clustering.
- In this case: The Event Data doesn’t have a direct link to the pages (there’s no common column like ‘Page path and screen class’), so we don’t merge it.
Why Did We Choose the User Behavior Data?
Let’s break down why we chose the User Behavior Data for clustering:
1. Direct Relevance to User Behavior:
- The ‘Views’ column tells us how many people visited each page.
- The ‘Average engagement time per active user’ tells us how long people stayed on each page.
- These are the most relevant indicators of user interaction with the web pages, and they are perfect for clustering similar pages together.
2. Numeric Format:
- Both ‘Views’ and ‘Average engagement time per active user’ are numeric, which is required for K-Means clustering to work.
3. Page Identification:
- The ‘Page path and screen class’ column (the URL) is useful to identify the pages after clustering, even though it’s not used in the clustering process itself (because it’s text-based).
How to Decide on the Number of Clusters?
In K-Means Clustering, clusters represent groups of similar data points (in this case, similar web pages based on behavior). Deciding on the number of clusters depends on what insights you want to gain and the structure of the data.
Here’s how to approach it:
- Start Small: It’s common to start with a small number of clusters (like 3 or 5) and see how well the data fits into these groups. You can adjust based on the results.
- Example: If you have 100 pages, starting with 3 clusters might group pages into:
- High traffic, high engagement (popular pages).
- Low traffic, low engagement (underperforming pages).
- Low traffic, high engagement (niche but valuable pages).
- Use the Elbow Method: This is a common technique used to determine the right number of clusters. It involves running K-Means with different numbers of clusters and plotting the sum of squared distances from each point to its assigned cluster center. The “elbow” point on the graph helps you decide the optimal number of clusters.
Step 1: Import the Necessary Libraries

What this does:
· KMeans: This is the algorithm we use to group (cluster) similar data points together. In our case, the data points are web pages, and we want to group them based on how users behave on those pages.
· StandardScaler: This is a tool that helps to “scale” the data. Scaling makes sure that all the numbers are treated fairly by the algorithm, especially when the numbers are very different in size (like views vs. engagement time).
Real-life Example:
· Think of KMeans as a tool that helps you organize socks in your drawer. Imagine you have socks of different colors and lengths, and you want to group them based on their similarity (color, length, etc.). KMeans will help you sort them into groups.
· StandardScaler is like folding all the socks to the same size before sorting them. If some socks are too long and others too short, scaling makes sure they all look similar in size before you organize them.
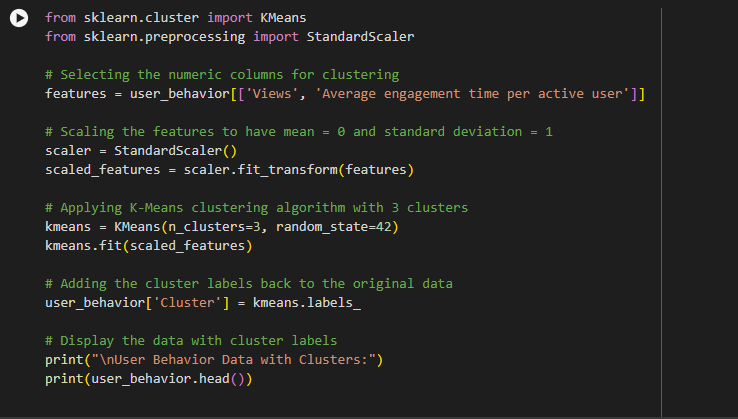
Step 2: Select the Numeric Columns for Clustering

What this does:
· We are selecting the columns ‘Views’ and ‘Average engagement time per active user’ from our data (which is about web pages).
· These two columns represent the numeric information we want to use for grouping web pages. ‘Views’ tells us how many people visit the page, and ‘Average engagement time’ tells us how long they stay on the page.
Example: Imagine you have a list of 10 web pages, and each page has two numbers:
· One number tells you how many people visited the page (Views).
· The other number tells you how long each visitor spent on that page (Engagement Time).
By selecting these two columns, you’re telling the computer, “Use these two numbers to figure out how similar these pages are to each other.”
Step 3: Scale the Features

What this does:
· Scaling means adjusting the numbers so they are easier for the algorithm to work with.
· Why is this important? If one column (like Views) has very large numbers (e.g., 40,000 views) and another column (like Engagement Time) has smaller numbers (e.g., 20 seconds), the algorithm might give too much importance to the larger numbers (Views). Scaling makes sure both columns are treated equally.
Example:
· Imagine you’re comparing apples and oranges. If one box of apples has 100 fruits and the other box of oranges has only 5 fruits, it’s hard to compare them. Scaling makes them more comparable by adjusting the units so that the difference isn’t overwhelming.
· After scaling, both columns will have a mean of 0 and a standard deviation of 1, meaning that both are on the same level for comparison.
Step 4: Apply the K-Means Clustering Algorithm

What this does:
- We are applying the K-Means Clustering algorithm to the scaled data.
- K-Means tries to group the web pages into 3 clusters (because we set n_clusters=3), based on their Views and Engagement Time.
Example:
- Imagine you’re sorting books in a library. You want to create 3 groups based on how often each book is borrowed and how long people spend reading each book. The K-Means algorithm will figure out which books are similar to each other based on those two criteria (borrow frequency and reading time).
- Similarly, here the computer is grouping similar web pages based on how many people visit them and how long people stay on them.
Why random_state=42?
- This just ensures that the algorithm gives the same result every time you run it. If you leave this out, you might get slightly different results each time.
Step 5: Add the Cluster Labels to the Original Data

What this does:
· After K-Means groups the web pages into 3 clusters, it assigns a label to each page, telling us which cluster it belongs to (Cluster 0, Cluster 1, or Cluster 2).
· Here, we are adding a new column called ‘Cluster’ to the original user_behavior data, which shows which cluster each page belongs to.
Step 6: Display the Data with Cluster Labels

What this does:
- This simply shows the first few rows of the data, including the new Cluster labels. Now you can see which pages belong to which cluster.
Example:
- After the computer sorts the pages into 3 clusters, this will show something like:
- Page 1: Cluster 0 (low traffic, low engagement)
- Page 2: Cluster 1 (high traffic, high engagement)
- Page 3: Cluster 2 (low traffic, high engagement)
- Why this is useful: Once you know which pages belong to each cluster, you can take action based on the performance of those pages. For example, if Cluster 0 contains underperforming pages, you can focus on improving those pages.
1. Analyze the Clusters by Calculating the Average for Each Cluster

What it does:
- This line groups the data by the ‘Cluster’ column, which was created earlier when we ran the K-Means clustering algorithm. For each cluster (group of similar web pages), it calculates the average (mean) for the ‘Views’ and ‘Average engagement time per active user’ columns.
Why this is important:
- We want to know how pages in each cluster perform on average. This can help us understand the overall behavior of the pages in each group (cluster). For example, one cluster might have pages with high views but low engagement, while another cluster might have the opposite.
Real-life example:
- Imagine you’ve grouped your socks into three piles based on their color and length. Now, you want to figure out the average length of the socks in each pile. This would give you a summary of each group. Similarly, here, we are calculating the average views and average engagement time for the web pages in each cluster.
Technical Explanation:
- groupby(‘Cluster’): This groups the data by the cluster number (e.g., Cluster 0, Cluster 1, Cluster 2).
- [[‘Views’, ‘Average engagement time per active user’]]: These are the columns we want to calculate the averages for.
- mean(): This function calculates the average value for each column within each cluster.
Step 16: Display the Cluster Summary

What it does:
- This line prints the summary of each cluster, showing the average ‘Views’ and ‘Average engagement time per active user’ for the pages in each group.
- Real-life example:
- After grouping your socks into three piles and calculating the average length of socks in each pile, you now look at the results. You can see that the socks in Pile 1 are on average 10 inches long, Pile 2 socks are 8 inches long, and so on. Here, we’re looking at the average views and engagement time for pages in each group (cluster).
What you learn:
- This summary helps you understand the behavior of the pages in each cluster. For example, Cluster 1 might represent high-traffic pages with lots of views, while Cluster 0 might represent pages that are visited less often but have higher engagement time.
Step 17: Save the Clustered Data to a CSV File

What it does:
- This line saves the updated user_behavior data (which now includes the cluster labels) to a CSV file in your Google Drive. The file is named ‘clustered_user_behavior_data.csv’. This allows you to keep a record of the data with the cluster labels for future analysis or sharing.
Why this is important:
- Saving the data with the cluster labels allows you to share the results with others or analyze them later. You can open this file in Excel, Google Sheets, or any other data analysis tool.
Technical Explanation:
- to_csv(): This function saves the user_behavior data to a CSV file. A CSV file is like a table saved as plain text, where each row represents a web page and each column contains its data (including the cluster it belongs to).
- ‘/content/drive/MyDrive/User Behaviour Data clustered_user_behavior_data.csv’: This is the path where the CSV file will be saved. In this case, it’s being saved to your Google Drive folder.
- index=False: This tells Python not to include row numbers in the saved file.
Final Step: Confirmation Message

What it does:
· This simply prints a message to the screen to let you know that the CSV file was saved successfully. Why this is important:
· It’s always helpful to get a confirmation message so you know the data was saved without any errors.
Why Is This Data Saved?
This data is saved because it helps you:
1. Understand User Behavior: By looking at the clusters, you can see how different pages are performing based on user behavior. It helps you identify which pages are doing well and which ones need improvement.
2. Identify Patterns: Pages in the same cluster likely share similar patterns (e.g., low traffic but high engagement). You can focus on improving underperforming clusters or promoting well-performing ones.
3. Take Action: Based on the analysis of clusters, you can take specific actions like:
- Improving Low-Performing Pages: For pages in low-engagement clusters, you might want to update the content, improve the design, or optimize them for SEO.
- Promoting High-Performing Pages: For pages in high-engagement clusters, you can use them in marketing campaigns or internal linking to drive more traffic.
How Can You Use This Data?
1. Business Insights:
- This data allows website owners to understand which pages are performing well and which ones need improvement. You can use this information to make informed decisions about content strategy, user experience, or marketing efforts.
2. SEO and Content Strategy:
- Pages with high engagement but low views may be hidden gems that could benefit from better SEO or promotion. You can optimize these pages to attract more traffic.
3. User Experience Improvements:
- Pages with high traffic but low engagement might need user experience improvements. Perhaps users are landing on these pages but not finding the information they need, leading them to leave quickly.
What is K-Means Clustering in Simple Terms?
Think of K-Means Clustering like sorting socks into different piles. Imagine you have a bunch of socks of different colors and patterns, and you want to organize them into groups. K-Means does the same thing with data: it groups similar data points (in your case, web pages) together.
In this case, we applied K-Means clustering to group pages from a website based on:
- Views: How many times a page has been viewed.
- Average engagement time per active user: How long users are spending on that page.
Understanding Your Output
You’ve got three main pieces of output here:
- Cluster Assignments for Each Page: This tells you which “group” (cluster) each page on your website belongs to.
- Cluster Summary: This shows the average statistics (like views and engagement time) for each group (cluster).
- Clustered Data Saved to a File: You saved the data with these clusters so that you can analyze or show it later.
Let’s break these down one by one:
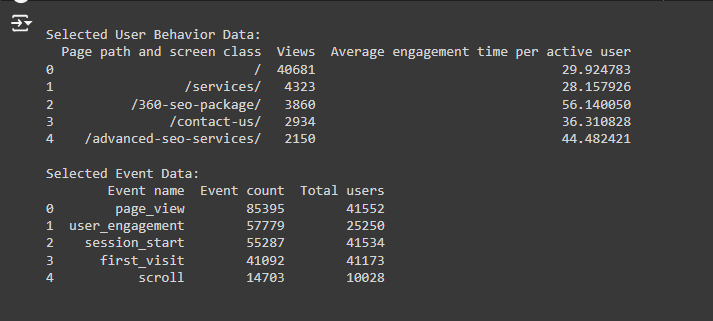
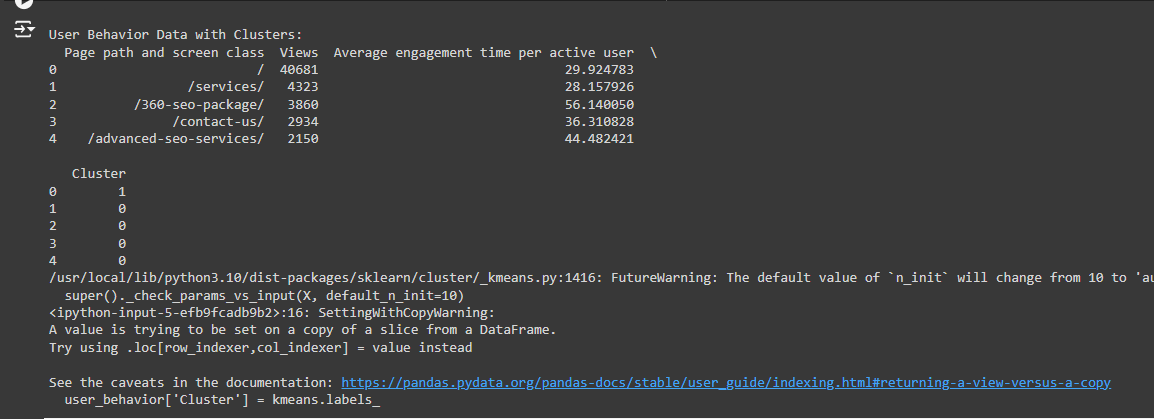
1. Cluster Assignments for Each Page
Here’s part of output:
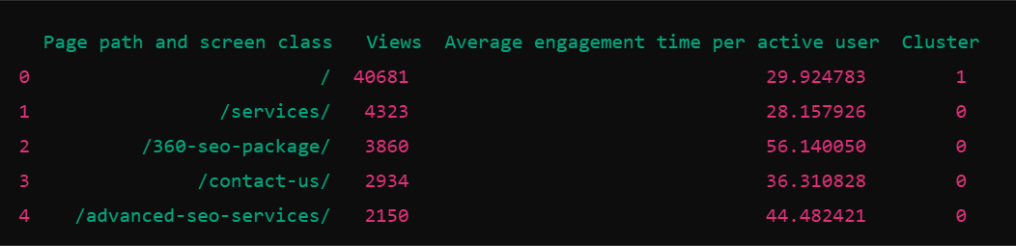
What this means:
· Each row represents a page on your website.
· Views: The number of times this page was viewed.
· Average engagement time per active user: The average time users spend on the page.
· Cluster: This is the group the page has been assigned to. For example:
o The page “/” (home page) is in Cluster 1.
o The page “/services/” is in Cluster 0.
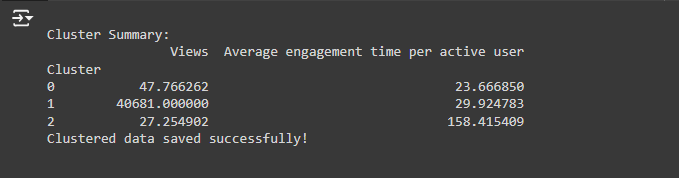
2. Cluster Summary
This section shows the average statistics for each cluster:
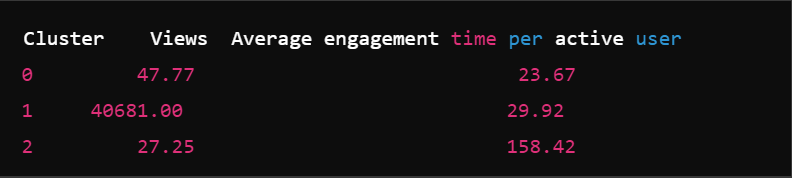
What this means:
· There are 3 clusters (groups) numbered 0, 1, and 2.
· Each cluster has its own average Views and Average engagement time per active user.
Let’s break it down:
· Cluster 0:
o Average Views: 47.77 (low traffic, not many visitors).
o Average Engagement Time: 23.67 seconds (people don’t spend much time here).
Interpretation: The pages in Cluster 0 are likely low-traffic pages. These pages are not very popular, and people don’t stay on them for long. You may want to review these pages to improve their content or make them more attractive.
Cluster 1:
· Average Views: 40,681 (extremely high traffic).
· Average Engagement Time: 29.92 seconds.
Interpretation: Pages in Cluster 1 are likely your high-traffic pages, like your home page. Lots of people are visiting these pages, and they are spending a reasonable amount of time on them. These pages are doing well, and you should keep them optimized.
Cluster 2:
· Average Views: 27.25 (very low traffic).
· Average Engagement Time: 158.42 seconds (people stay a long time).
Interpretation: Cluster 2 pages are visited very rarely, but when people do visit, they spend a lot of time on these pages. This could mean these pages are very detailed or informative, but you may need to promote them more to get more visitors.
What Should a Website Owner Do with This Information?
1. Cluster 0 (Low-traffic, Low-engagement Pages):
· Action: Review these pages. Ask yourself:
o Is the content clear and engaging?
o Are there enough calls to action (buttons, links, etc.)?
o Can you make the design more appealing?
Example: If your /services/ page is here, you might want to redesign the page to highlight your services more clearly or add testimonials to make it more attractive.
2. Cluster 1 (High-traffic Pages):
· Action: These pages are doing well, so keep them optimized. Ensure they are fast-loading, have clear content, and are mobile-friendly.
· Example: If your home page is in this cluster, you should ensure it stays fast and efficient since it’s a major gateway to your website. Add links to other pages to guide users further into your site (internal linking).
3. Cluster 2 (Low-traffic, High-engagement Pages):
· Action: These pages are valuable but aren’t getting much traffic. Consider promoting these pages more by:
· SEO optimization: Add more relevant keywords so they rank better in Google.
· Internal Linking: Link to these pages from your popular pages (e.g., home page) to drive more traffic.
· Example: If a page about a detailed service offering (like “/360-seo-package/”) is in this cluster, you can promote it in blog posts or social media to drive more traffic.
Next Steps for Business Growth
1. Content Improvement:
· Use the cluster data to decide which pages need content updates. For pages in Cluster 0, think about adding more relevant information, images, videos, or links to make the page more engaging.
2. SEO Optimization:
· For pages in Cluster 2 (long engagement but low views), focus on improving their SEO so they show up higher in search engine results.
· Example: If your /advanced-seo-services/ page is in this cluster, you can add more relevant keywords, optimize the page title, and improve the meta descriptions to make it more visible in Google search results.
3. Internal Linking:
· Increase traffic to low-traffic pages (Cluster 0 and 2) by linking to them from high-traffic pages (Cluster 1). For example, if your home page is in Cluster 1, add links to services, blogs, or product pages from it to guide visitors to other parts of your website.
4. Promotions and Marketing:· Consider running marketing campaigns (e.g., email newsletters, social media posts) to promote the pages in Cluster 2 that people spend a long time on but don’t visit much.

Thatware | Founder & CEO
Tuhin is recognized across the globe for his vision to revolutionize digital transformation industry with the help of cutting-edge technology. He won bronze for India at the Stevie Awards USA as well as winning the India Business Awards, India Technology Award, Top 100 influential tech leaders from Analytics Insights, Clutch Global Front runner in digital marketing, founder of the fastest growing company in Asia by The CEO Magazine and is a TEDx speaker.
