SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
Content Impact Zone Analyzer is an analytical framework designed to determine which parts of a webpage contribute most meaningfully to its semantic relevance. Instead of evaluating content as a single block, the project examines how relevance is distributed across sections and paragraphs, enabling a clear understanding of where semantic strength originates within the page.

The analysis begins by extracting the primary content of a webpage and organizing it into logically structured sections and supporting paragraphs. Each content segment is evaluated in relation to the provided search themes using semantic embeddings, allowing relevance to be assessed based on meaning rather than keyword overlap. This approach ensures that relevance measurement reflects actual topical alignment and intent satisfaction.
To avoid overemphasis on any single phrasing, related search themes are combined into a unified semantic representation. Paragraphs are then evaluated against this representation as well as against the overall topical context of the page. This results in an influence score that reflects both direct relevance and contextual contribution, producing a balanced and interpretable signal.
These influence scores are transformed into clearly defined Impact Zones—High, Medium, and Low—indicating which content segments act as primary relevance drivers, which reinforce the topic, and which add limited semantic value. Paragraph-level signals are further consolidated at the section level, making the results easier to interpret and apply during content evaluation and optimization.
The final outcome is a structured view of content influence that reveals how effectively different parts of a page contribute to semantic relevance. The analysis supports informed decisions around content refinement, structural improvement, and relevance strengthening, grounded in how meaning is distributed throughout the page rather than relying on surface-level metrics.
Project Purpose
The purpose of the Content Impact Zone Analyzer — Identifying High-Influence Page Segments That Drive Semantic Relevance is to provide a clear and structured understanding of how different parts of a webpage contribute to its overall semantic relevance. The project is designed to answer a fundamental content evaluation question: which specific sections and paragraphs meaningfully drive relevance, and which do not.
Traditional content evaluation often treats a page as a single unit, making it difficult to determine whether relevance is evenly distributed or concentrated in only a few areas. This project addresses that limitation by breaking the page into logically structured segments and evaluating each segment based on its semantic contribution. The objective is not simply to measure relevance, but to locate relevance within the content structure.
Another key purpose is to distinguish between content that directly aligns with the intended search themes and content that merely adds volume without reinforcing meaning. By evaluating relevance at paragraph level and consolidating insights at section level, the project enables precise identification of high-influence content segments that act as the backbone of semantic alignment.
The project also aims to produce results that are interpretable and actionable. Influence scores are translated into clearly defined impact zones, allowing content performance to be understood without relying on abstract numerical values. This ensures that the findings can be directly used for content refinement, prioritization, and structural improvement.
Overall, the project exists to support informed content decisions by revealing how semantic relevance is distributed across a page, highlighting strengths, uncovering weaknesses, and providing a reliable basis for improving topical alignment through focused, evidence-based adjustments.
Project’s Key Topics: Explanation and Understanding
To fully understand the value and interpretation of the Content Impact Zone Analyzer — Identifying High-Influence Page Segments That Drive Semantic Relevance, it is important to clarify several core concepts that form the foundation of the analysis. These topics explain what is being measured, how it is measured, and why the results are meaningful when evaluating content performance.
Semantic Relevance
Semantic relevance refers to how well a piece of content aligns with the underlying meaning and intent of a search theme, rather than simply matching individual words or phrases. It captures whether the content addresses the topic in a meaningful and contextually accurate way. In this project, semantic relevance is measured using language models that understand relationships between concepts, allowing the analysis to recognize relevance even when exact phrasing differs.
This approach ensures that content is evaluated based on substance and intent alignment, not surface-level keyword usage.
Content Segmentation
Webpages are rarely consumed or evaluated as a single block of text. They are structured into sections, headings, and paragraphs, each serving a different informational purpose. Content segmentation is the process of breaking a page into these meaningful units so that each part can be evaluated independently.
By working at section and paragraph level, the project identifies how relevance is distributed across the page. This makes it possible to distinguish core content from supporting material and from content that contributes little to the overall topic.
Influence at Paragraph Level
Not all paragraphs contribute equally to relevance. Some paragraphs carry the primary explanatory weight of the topic, while others provide examples, transitions, or contextual information. Paragraph-level influence measures how strongly each paragraph contributes to semantic relevance in relation to the overall content theme.
Evaluating influence at this level allows precise identification of high-value content segments and prevents relevance signals from being diluted by less meaningful text.
Impact Zones
Impact Zones are an interpretive layer applied to influence scores to make results easier to understand and apply. Instead of relying solely on raw numerical values, paragraphs are classified into three clear categories:
High Impact segments are those that strongly drive semantic relevance and act as primary contributors to the topic. Medium Impact segments support the topic and reinforce understanding but are not core drivers. Low Impact segments add limited semantic value and may represent redundancy, tangential information, or opportunities for improvement.
This classification helps translate analytical results into practical insights.
Section-Level Influence Aggregation
While paragraph-level analysis provides precision, content decisions are often made at section level. Section-level influence aggregation combines the influence signals of all paragraphs within a section to produce a consolidated view of how that section performs.
This aggregation reveals whether a section consistently reinforces relevance or relies on only a small portion of high-impact content. It enables evaluation of structural balance and topical consistency within the page.
Relevance Distribution
Relevance distribution refers to how semantic influence is spread across the content. In some cases, relevance may be concentrated in a small number of sections, while the rest of the page contributes minimally. In other cases, relevance may be evenly distributed, indicating strong topical coherence.
Understanding relevance distribution is critical for identifying structural weaknesses, content imbalances, and opportunities to strengthen overall alignment.
Explainability and Interpretability
A core principle of this project is that relevance analysis should be explainable. Every score, zone, and aggregation is designed to be interpretable in practical terms. The analysis does not function as a black box; instead, it clearly connects influence measurements to specific sections and paragraphs within the content.
This ensures that insights derived from the project can be confidently used to guide content evaluation, refinement, and optimization decisions.
Together, these key topics form the conceptual framework of the project. They provide the necessary context to understand how the analysis works and how its outputs should be interpreted before moving into feature-level details and result-driven insights.
Project Value and Importance: Questions and Answers
What problem does this project address?
The project addresses the difficulty of understanding where semantic relevance actually comes from within a webpage. Pages often appear relevant at a high level, but the contribution of individual sections and paragraphs is usually unclear. This analysis resolves that gap by identifying which parts of the content meaningfully drive relevance and which parts add limited value, enabling more informed content evaluation and improvement.
Why is it necessary to analyze semantic relevance at a section and paragraph level instead of treating the page as a single unit?
A webpage is not consumed or interpreted as a single block of information. It is composed of multiple structural and conceptual units, each serving a different role in explaining, supporting, or transitioning between ideas. When relevance is evaluated only at the page level, strong sections can overshadow weaker or misaligned ones, creating a false impression of overall content quality.
This project addresses that limitation by isolating individual sections and paragraphs and evaluating their semantic contribution independently. This approach makes it possible to understand how relevance is distributed across the page, identify areas where relevance is concentrated, and detect sections that do not meaningfully support the page’s intended topic. The result is a more accurate and actionable understanding of content performance.
How does the Impact Zone framework improve interpretability of the results?
Raw relevance scores, while mathematically precise, are not always intuitive or easy to act upon. The Impact Zone framework converts continuous relevance scores into three clearly defined categories: High Impact, Medium Impact, and Low Impact.
This categorization allows immediate interpretation of content performance. High Impact zones highlight the strongest relevance drivers, Medium Impact zones indicate supportive content that reinforces the topic, and Low Impact zones identify areas that add limited semantic value. By translating numerical signals into interpretable zones, the framework enables faster decision-making and clearer prioritization of content actions.
Why is semantic relevance a more reliable indicator than keyword-based analysis?
Keyword-based analysis focuses on surface-level text patterns and often fails to capture meaning, context, or intent. Content can appear optimized by repeating terms without genuinely addressing the subject in a meaningful way.
Semantic relevance evaluates the underlying meaning of the content and its alignment with the topic at a conceptual level. This approach reflects whether the content actually explains, supports, or expands upon the subject rather than merely mentioning it. As a result, the analysis provides a more realistic assessment of content quality and topical alignment.
How does this project help identify content that should be preserved rather than rewritten?
Not all optimization efforts should focus on rewriting or expansion. Some content segments already perform strongly and act as core relevance drivers. The project explicitly identifies these high-impact segments, ensuring they are recognized as assets rather than overlooked.
By clearly separating strong content from weak or neutral content, the analysis prevents unnecessary changes to effective sections and encourages reinforcement and strategic positioning instead of indiscriminate editing.
What insights does this project provide that are difficult to obtain through manual review?
Manual content review is subjective and often influenced by content length, formatting, or perceived completeness. It is difficult to accurately assess which parts of a page truly drive relevance without systematic analysis.
This project provides objective, evidence-based insights into relevance distribution, influence concentration, and structural imbalance. It highlights hidden patterns, such as relevance being overly concentrated in a small portion of the page or diluted across many low-impact sections, which are not easily detectable through manual inspection.
Why is explainability a core requirement of this analysis?
Explainability ensures that every insight can be traced back to specific sections and paragraphs. This is essential for trust and usability. Instead of abstract scores or opaque metrics, the analysis clearly shows which content segments are responsible for each outcome.
This transparency allows informed decision-making and clear justification for content changes. Every recommendation is grounded in identifiable content evidence rather than assumptions or generalized rules.
How does this project support focused and efficient content optimization?
The project replaces broad, unfocused optimization efforts with precise, evidence-based guidance. By showing exactly where relevance is strong, moderate, or weak, it enables targeted adjustments that maximize impact while minimizing unnecessary changes.
This focused approach improves efficiency, reduces content bloat, and ensures that optimization efforts directly reinforce topical alignment rather than increasing volume without purpose.
What long-term value does this type of analysis provide for content strategy?
By consistently evaluating how relevance is distributed within content, the project encourages better structural planning, clearer topic development, and intentional content organization. Over time, this leads to pages where relevance is balanced, coherent, and resilient to changes in interpretation standards.
The result is not just short-term improvement, but a sustainable framework for maintaining high-quality, semantically aligned content.
Libraries Used
time
The time library is a standard Python module that provides functions related to time measurement, delays, and execution timing. It allows programs to track elapsed time, pause execution, and measure performance duration in a precise and lightweight manner.
In this project, the library is used to monitor execution timing at critical stages of the analysis pipeline. Measuring processing time helps understand the computational cost of different stages such as content extraction, embedding generation, and relevance computation. This ensures the analytical workflow remains efficient and predictable when processing content at scale.
re
The re library provides support for regular expressions, enabling advanced pattern matching and text manipulation. It is commonly used for text cleaning, validation, and transformation tasks where simple string operations are insufficient.
Within this project, regular expressions are used to normalize text, clean extracted content, and trim long strings for visualization labels. This ensures that text inputs are consistently formatted before semantic analysis and that visual outputs remain readable without altering the underlying analytical data.
html (html_lib)
The html library offers utilities for handling HTML entities and character references. It helps convert encoded HTML content into human-readable text while preserving semantic meaning.
This project uses the library to unescape HTML entities extracted from web pages. This step is essential to ensure that textual content is correctly interpreted before further processing, preventing semantic distortion caused by encoded characters such as symbols or special punctuation.
hashlib
The hashlib module provides secure hash and message digest algorithms. It is commonly used to generate unique identifiers from text or binary data in a consistent and reproducible manner.
In this project, hashing is used to generate stable identifiers for content segments such as paragraphs or sections. This ensures consistent tracking and grouping of content units across different stages of analysis without relying on mutable attributes like position or text length.
unicodedata
The unicodedata library allows inspection and normalization of Unicode characters. It is particularly useful for handling multilingual text and ensuring consistent character representations.
The project uses Unicode normalization to standardize extracted content before semantic embedding. This avoids discrepancies caused by visually similar but technically distinct Unicode characters, ensuring that semantic similarity calculations are not affected by encoding inconsistencies.
gc
The gc module provides access to Python’s garbage collection mechanisms. It allows explicit control over memory cleanup in long-running or memory-intensive processes.
In this project, garbage collection is used strategically after embedding computation and large intermediate object creation. This helps manage memory usage efficiently, especially when processing multiple pages or large content blocks within a single execution cycle.
collections (Counter, defaultdict)
The collections module offers specialized container data types that extend the functionality of built-in Python structures. Counter is used for counting hashable objects, while defaultdict simplifies dictionary initialization.
These structures are used extensively in this project to aggregate relevance scores, group content by logical units, and track frequency-based signals. They simplify the implementation logic while ensuring clarity and robustness in data aggregation steps.
logging
The logging library provides a flexible framework for emitting log messages from Python programs. It supports different severity levels and structured output formats.
This project uses logging to track execution flow, debug intermediate steps, and surface warnings during content extraction and analysis. Structured logging ensures transparency during execution and simplifies troubleshooting when analyzing complex content structures.
requests
The requests library is a widely used HTTP client for Python that simplifies sending web requests and handling responses. It abstracts away low-level networking details and provides a clean interface for retrieving web content.
In this project, requests is used to fetch webpage content from URLs provided as input. Reliable content retrieval is a foundational step, as all downstream analysis depends on accurately extracted page text.
typing
The typing module introduces support for type hints in Python. It improves code readability, maintainability, and static analysis by explicitly defining expected data types.
Type hints are used throughout the project to clarify function inputs and outputs. This enhances code transparency, reduces ambiguity in complex data flows, and makes the analytical pipeline easier to understand and extend.
BeautifulSoup (bs4)
BeautifulSoup is a library designed for parsing HTML and XML documents. It allows easy navigation, searching, and modification of parsed content using a tree-based structure.
In this project, BeautifulSoup is responsible for extracting structured content such as sections, headings, and paragraphs from webpages. Accurate structural parsing is critical for isolating content segments and enabling section-level and paragraph-level relevance analysis.
numpy
NumPy is a foundational library for numerical computing in Python. It provides efficient array operations and mathematical functions optimized for performance.
The project uses NumPy for handling vector operations, numerical normalization, and efficient manipulation of similarity scores. Its performance advantages are essential when working with high-dimensional semantic embeddings.
pandas
Pandas is a data analysis library that provides powerful data structures such as DataFrames for tabular data manipulation. It supports grouping, aggregation, filtering, and transformation operations.
In this project, pandas is used to organize relevance scores, aggregate influence metrics, and prepare structured data for visualization. It serves as the backbone for transforming raw analytical outputs into interpretable result sets.
torch
PyTorch is a deep learning framework that supports tensor computation and automatic differentiation. It is widely used for neural network models and high-performance numerical processing.
This project relies on PyTorch as the computational backend for semantic embedding models. It enables efficient embedding generation and similarity computation, ensuring that semantic analysis remains accurate and scalable.
sentence-transformers
Sentence Transformers is a library built on top of transformer models that generates dense semantic embeddings for sentences and paragraphs. It enables high-quality semantic similarity analysis beyond keyword matching.
The project uses Sentence Transformers to convert content segments and topic representations into embedding vectors. These embeddings form the foundation of all semantic relevance and influence computations, allowing meaning-based comparison between content and topic intent.
transformers logging utilities
The Transformers library includes logging utilities that manage verbosity and progress output during model execution. These controls help reduce unnecessary console output during inference.
In this project, logging verbosity is explicitly suppressed to keep execution output clean and focused. This ensures that analytical logs remain readable and that model-related noise does not interfere with result interpretation.
matplotlib
Matplotlib is a comprehensive plotting library for Python that supports a wide range of static visualizations. It provides low-level control over plot elements and customization.
The project uses Matplotlib as the core visualization engine for presenting relevance distribution, impact zones, and influence aggregation. Its flexibility allows precise control over axes, labels, and annotations required for clear analytical communication.
seaborn
Seaborn is a high-level visualization library built on top of Matplotlib. It provides aesthetically pleasing defaults and simplified interfaces for statistical plotting.
In this project, Seaborn is used to enhance the readability and consistency of visual outputs. Its styling capabilities ensure that charts are clean, interpretable, and aligned with professional reporting standards.
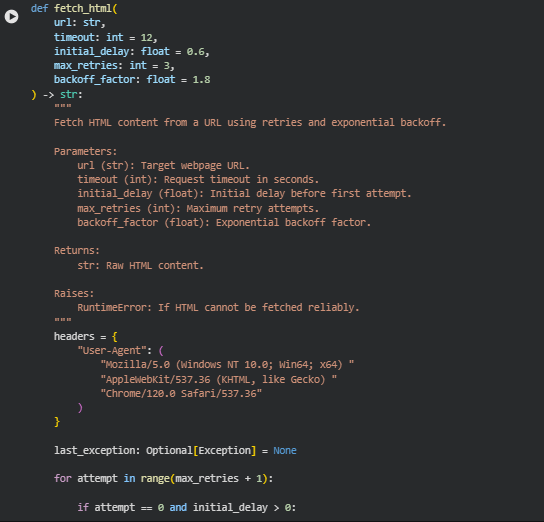
Function: fetch_html
Summary
This function is responsible for reliably retrieving raw HTML content from a given webpage URL while accounting for real-world network variability and server behavior. Instead of relying on a single request attempt, it incorporates retry logic, controlled delays, and exponential backoff to handle temporary failures such as slow responses, transient server errors, or network interruptions.
The function also applies defensive encoding handling to ensure that the fetched content is correctly decoded into usable text. Webpages often declare or infer encodings inconsistently, and incorrect decoding can corrupt content before any semantic analysis begins. By validating that the retrieved HTML is non-empty and structurally meaningful, the function ensures that only usable page content proceeds further into the analysis pipeline. If the content cannot be fetched reliably after multiple attempts, the function fails explicitly, preventing downstream processing on invalid data.
Key Code Explanations
headers = {
“User-Agent”: (
“Mozilla/5.0 (Windows NT 10.0; Win64; x64) “
“AppleWebKit/537.36 (KHTML, like Gecko) “
“Chrome/120.0 Safari/537.36”
)
}
This header configuration simulates a standard modern browser request. Many websites restrict or modify responses based on user-agent strings, especially for automated requests. By presenting a realistic browser identity, the function improves the likelihood of receiving the full and intended HTML content rather than blocked or degraded responses.
for attempt in range(max_retries + 1):
This loop controls the retry mechanism for fetching the webpage. Instead of immediately failing on the first error, the function systematically retries the request up to a defined limit. This approach reflects real-world conditions where temporary network or server issues are common and often resolve on subsequent attempts.
sleep_time = backoff_factor ** attempt
time.sleep(sleep_time)
These lines implement exponential backoff between retry attempts. Each subsequent retry waits progressively longer than the previous one. This strategy reduces the risk of overwhelming the target server, respects server rate limits, and increases the chances of a successful response when the failure is temporary.
response = requests.get(
url,
headers=headers,
timeout=timeout,
allow_redirects=True
)
response.raise_for_status()
Here, the HTTP request is executed with a defined timeout and automatic redirect handling. The explicit status check ensures that only successful HTTP responses are accepted. Any client or server error immediately triggers exception handling, preventing invalid or partial content from entering the analysis workflow.
candidate_encodings = [
getattr(response, “apparent_encoding”, None),
“utf-8”,
“iso-8859-1”
]
This block defines multiple fallback encodings to decode the fetched HTML. Webpages may incorrectly declare their encoding or omit it entirely. By attempting multiple common encodings, the function increases robustness and ensures the extracted text accurately reflects the original page content.
if html and len(html.strip()) > 200:
return html
This validation step ensures that the retrieved content is not only present but also substantial enough to represent a real webpage. It prevents cases where empty responses, error pages, or truncated content are mistakenly treated as valid input for semantic analysis.
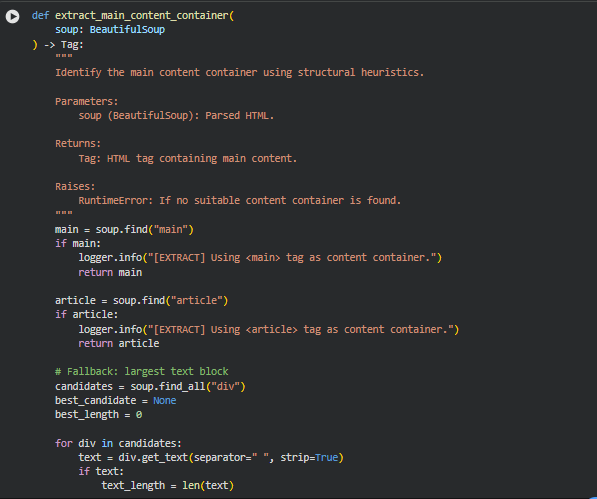
Function: extract_main_content_container
Summary
This function is responsible for identifying the primary content-bearing section of a webpage from its parsed HTML structure. Webpages typically contain a mix of navigational elements, headers, footers, sidebars, advertisements, and the actual editorial content. For semantic relevance analysis, it is critical to isolate the portion of the page that represents the true informational core rather than peripheral or decorative elements.
The function applies a sequence of structural heuristics commonly used in real-world content extraction. It first checks for semantically meaningful HTML5 tags that are explicitly designed to wrap primary content. If those are unavailable, it falls back to a content-density–based approach that selects the HTML block containing the largest amount of readable text. This layered strategy ensures robustness across different site architectures and content management systems while maintaining a clear standard for content reliability.
Key Code Explanations
main = soup.find(“main”)
if main:
logger.info(“[EXTRACT] Using <main> tag as content container.”)
return main
This block prioritizes the <main> HTML5 tag, which is explicitly intended to encapsulate the dominant content of a webpage. When present, it provides the most reliable and semantically correct signal for identifying the primary content area. Selecting this tag early minimizes the risk of including irrelevant page elements in downstream analysis.
article = soup.find(“article”)
if article:
logger.info(“[EXTRACT] Using <article> tag as content container.”)
return article
If a <main> tag is not available, the function checks for an <article> tag. This tag is commonly used for blog posts, news articles, and long-form editorial content. It often represents a self-contained unit of information, making it an appropriate and high-confidence alternative for content extraction.
candidates = soup.find_all(“div”)
This line initiates a fallback strategy when explicit semantic tags are absent. Many websites rely heavily on <div> elements for layout, even for primary content. By collecting all <div> elements, the function prepares for a more heuristic-based evaluation rather than relying on semantic markup alone.
text = div.get_text(separator=” “, strip=True)
Here, all visible text within a candidate <div> is extracted and normalized. Using a space separator and stripping excess whitespace ensures that the measured text length reflects meaningful readable content rather than HTML structure or formatting artifacts.
if text_length > best_length:
best_candidate = div
best_length = text_length
This comparison selects the <div> containing the largest amount of textual content. In practice, the primary content block tends to be significantly more text-heavy than navigation menus, sidebars, or footers. This heuristic provides a practical and effective fallback when semantic tags are missing.
if best_candidate and best_length > 500:
This threshold ensures that the selected fallback container represents substantial content rather than an incidental or decorative block. The minimum length requirement helps filter out false positives, such as repeated menu items or small informational widgets.
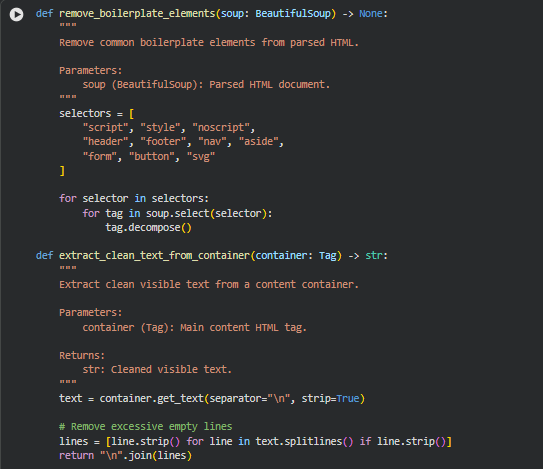
Function: remove_boilerplate_elements
Summary
This function removes non-content elements that commonly appear on webpages but do not contribute to semantic relevance or informational value. Modern webpages include a wide range of structural, interactive, and decorative components such as navigation menus, headers, footers, scripts, forms, and embedded graphics. While essential for user interaction and layout, these elements introduce noise when analyzing content meaning and influence.
By explicitly eliminating known boilerplate tags from the parsed HTML document, this function ensures that subsequent text extraction and semantic analysis operate only on meaningful, user-facing content. This cleaning step plays a critical role in preserving the accuracy of influence scoring, as even small amounts of irrelevant text can distort embedding-based similarity measurements.
Key Code Explanations
selectors = [
“script”, “style”, “noscript”,
“header”, “footer”, “nav”, “aside”,
“form”, “button”, “svg”
]
This list defines a carefully curated set of HTML tags that are almost always unrelated to the primary informational content of a page. These elements typically contain styling rules, JavaScript logic, navigational links, calls-to-action, or visual components that should not influence semantic relevance evaluation.
for selector in selectors:
for tag in soup.select(selector):
tag.decompose()
This loop iterates through each boilerplate tag type and permanently removes matching elements from the document tree. Using decompose() ensures that both the tag and its contents are fully removed, preventing residual text from leaking into downstream extraction logic.
Function: extract_clean_text_from_container
Summary
This function converts the identified main content container into clean, readable text suitable for segmentation and semantic analysis. Raw HTML often contains inconsistent spacing, nested elements, and formatting artifacts that can interfere with content parsing and embedding generation.
The function extracts visible text while preserving logical separation between content blocks using line breaks. It then normalizes the extracted text by removing empty or redundant lines. The result is a structured, human-readable representation of the page content that reflects the true narrative and topical flow of the page.
Key Code Explanations
text = container.get_text(separator=”\n”, strip=True)
This line extracts all visible text from the content container while inserting line breaks between block-level elements. This preserves the natural structure of paragraphs and headings, which is important for later paragraph-level segmentation and influence scoring.
lines = [line.strip() for line in text.splitlines() if line.strip()]
Here, the extracted text is split into individual lines, and empty or whitespace-only lines are removed. This normalization step ensures that the final output contains only meaningful content units without excessive spacing or formatting noise.
Function: extract_page_content
Summary
This function serves as the primary orchestration layer for page-level content extraction. It integrates HTML retrieval, boilerplate removal, main content identification, and clean text extraction into a single, cohesive workflow. This modular design ensures that each responsibility is clearly separated while maintaining a reliable end-to-end extraction process.
The function also enforces minimum content quality standards. Pages that fail to produce sufficient meaningful text are explicitly rejected, preventing low-quality or thin content from entering the semantic analysis pipeline. This safeguard is essential for maintaining the integrity of influence scoring and impact zone classification.
Key Code Explanations
html = fetch_html(
url,
timeout,
initial_delay,
max_retries,
backoff_factor
)
This line retrieves the raw HTML content using a robust, retry-aware fetching mechanism. Delegating network handling to a dedicated function ensures consistent error handling and resilience against temporary connectivity issues.
remove_boilerplate_elements(soup)
This call removes non-informational elements before content container detection. Cleaning the document early improves the accuracy of container selection by reducing noise and preventing irrelevant text blocks from being mistakenly identified as primary content.
container = extract_main_content_container(
soup=soup
)
This line applies structural heuristics to identify the most reliable content-bearing HTML element. Selecting the correct container is foundational for all subsequent segmentation, scoring, and visualization steps.
if len(clean_text) < 300:
raise RuntimeError(
“Extracted content is too short to be meaningful.”
)
This validation enforces a minimum content length threshold to ensure analytical relevance. Pages that do not meet this criterion are excluded, preventing skewed results caused by sparse or non-informational pages.
Function: is_heading_tag
Summary
This utility function determines whether a given HTML tag represents a structural heading element. Headings play a central role in defining the logical structure of a webpage, as they typically introduce new topical sections or subtopics. Correctly identifying heading tags is foundational for section-based segmentation and influence aggregation later in the project.
By isolating this logic into a dedicated function, the codebase remains clean, readable, and consistent whenever heading detection is required across the segmentation pipeline.
Function: get_heading_level
Summary
This function extracts the hierarchical level of a heading element, such as level 1 for <h1> or level 3 for <h3>. Heading levels convey the structural depth of a section and are critical for understanding content organization, topical nesting, and emphasis within a page.
The function includes explicit validation to ensure it is only applied to valid heading tags. This defensive approach prevents silent errors and enforces structural correctness throughout the segmentation process.
Key Code Explanations
if not is_heading_tag(tag):
raise ValueError(“Tag is not a heading.”)
This validation step ensures that the function is only used on heading elements. Explicitly raising an error prevents accidental misuse and helps maintain the integrity of section hierarchy detection.
return int(tag.name[1])
This line extracts the numeric heading level directly from the tag name. For example, <h2> becomes level 2. This approach is both efficient and reliable, given the standardized naming of HTML heading tags.
Function: is_valid_paragraph
Summary
This function acts as a content quality gatekeeper for paragraph-level analysis. Not all paragraph tags contain meaningful or analyzable content. Many include legal notices, cookie banners, disclaimers, or extremely short text fragments that can distort semantic relevance calculations.
The function applies multiple validation rules based on length, word count, and known boilerplate phrases to ensure that only substantive, informational paragraphs are retained for influence scoring. This selective filtering significantly improves the reliability and interpretability of downstream results.
Key Code Explanations
if len(clean) < min_length:
return False
This condition removes paragraphs that are too short to convey meaningful semantic context. Very short text blocks often lack sufficient information to produce stable embeddings or reliable similarity scores.
blacklist = [
“cookie”,
“privacy policy”,
“terms of service”,
“accept cookies”
]
This blacklist explicitly filters out commonly repeated legal and compliance-related phrases. These fragments are structurally present on many pages but do not contribute to topical relevance or influence.
return not any(bad in lower for bad in blacklist)
This final check ensures that paragraphs containing known non-content phrases are excluded, even if they meet length and word count thresholds.
Function: segment_by_headings
Summary
This function performs structured content segmentation by traversing the main content container and organizing paragraphs under their respective headings. Each paragraph is assigned rich contextual metadata, including section title, section level, and paragraph position within the section.
Heading-based segmentation mirrors how content is naturally authored and consumed, making the resulting analysis intuitive and directly actionable. This structure enables influence scores to be interpreted not just at the paragraph level, but also at the section and page levels.
Key Code Explanations
for element in container.descendants:
This loop walks through all nested elements within the main content container. Using descendants ensures that headings and paragraphs are processed in their original document order, preserving narrative flow.
if is_heading_tag(element):
current_section_id += 1
current_section_title = element.get_text(strip=True)
current_section_level = get_heading_level(element)
When a heading is encountered, the function updates the active section context. This establishes a clear boundary between sections and ensures that subsequent paragraphs are correctly attributed.
if element.name == “p”:
text = element.get_text(strip=True)
if not is_valid_paragraph(text, min_length, min_word_count):
continue
This logic ensures that only meaningful paragraph elements are included in the analysis. Invalid or low-quality paragraphs are skipped early, preventing contamination of influence scores.
segments.append({
“section_id”: current_section_id,
“section_title”: current_section_title,
“section_level”: current_section_level,
“paragraph_id”: paragraph_counter,
“text”: text
})
Each validated paragraph is stored with comprehensive structural metadata. This enriched representation forms the backbone of section-level influence aggregation, impact zone detection, and result interpretation.
Function: segment_without_headings
Summary
This function provides a robust fallback mechanism for content segmentation when a webpage does not contain usable heading tags or when the heading structure is unreliable. While heading-based segmentation is preferred, real-world webpages often include flat content structures, dynamically generated layouts, or inconsistent markup that prevents accurate section detection.
In such cases, this function ensures that meaningful paragraph-level analysis can still proceed by grouping all valid paragraphs under a single logical section. This guarantees continuity of analysis and prevents the pipeline from failing due to structural inconsistencies in the source content.
Key Code Explanations
for p in container.find_all(“p”):
Instead of traversing all descendants, this approach directly targets paragraph tags. In the absence of reliable headings, this ensures efficient extraction of the core textual units while maintaining document order.
if not is_valid_paragraph(text, min_length, min_word_count):
continue
The same paragraph validation logic used in heading-based segmentation is reused here. This consistency ensures that fallback segmentation adheres to the same quality standards and does not introduce noise into the influence analysis.
segments.append({
“section_id”: 0,
“section_title”: “Main Content”,
“section_level”: 0,
“paragraph_id”: paragraph_counter,
“text”: text
})
All paragraphs are grouped under a single logical section labeled “Main Content.” Assigning explicit section metadata, even in fallback mode, preserves compatibility with downstream scoring, normalization, and aggregation modules.
Function: has_usable_headings
Summary
This function evaluates whether the extracted main content contains a sufficient and meaningful heading structure to support heading-based segmentation. Rather than assuming that the presence of heading tags automatically implies a usable structure, it applies a minimal heuristic to confirm that headings are both present and non-empty.
The goal is to prevent unreliable segmentation in cases where headings exist only for decorative purposes, navigation elements, or sparse labeling that does not meaningfully divide the content.
Key Code Explanations
headings = container.find_all([“h1”, “h2”, “h3”])
The function limits its inspection to primary structural headings. Lower-level headings are intentionally excluded because they are often used inconsistently and may not represent true content divisions.
meaningful = [
h.get_text(strip=True)
for h in headings
if h.get_text(strip=True)
]
This step filters out headings that exist in markup but do not contain visible or meaningful text. Only headings that contribute actual semantic labels are considered.
return len(meaningful) >= 2
A minimum threshold of two meaningful headings is enforced. This ensures that segmentation results in at least a basic multi-section structure rather than a fragmented or trivial division.
Function: segment_content_structure
Summary
This function serves as the central orchestration layer for structural segmentation. It determines the most appropriate segmentation strategy based on the actual structure of the content and applies it consistently. By abstracting the decision logic into this function, the project ensures that downstream modules always receive standardized paragraph records regardless of how the original page is structured.
The function also enforces a minimum content quality threshold, ensuring that analysis proceeds only when enough meaningful content has been extracted.
Key Code Explanations
if has_usable_headings(container):
segments = segment_by_headings(container, min_length, min_word_count)
else:
segments = segment_without_headings(container, min_length, min_word_count)
This conditional logic dynamically selects the segmentation strategy. Pages with sufficient structural signals are segmented hierarchically, while others fall back to paragraph-only segmentation. This design balances structural accuracy with robustness.
if len(segments) < 3:
raise RuntimeError(
“Segmentation produced insufficient content blocks.”
)
A hard validation check is applied to prevent weak or misleading analysis. Pages that do not produce enough content blocks are excluded to maintain analytical reliability.
Function: get_page_data
Summary
The get_page_data function acts as a high-level wrapper to consolidate the key steps of webpage extraction and segmentation into a single callable utility. It orchestrates the workflow of fetching raw HTML content, extracting the main content container, cleaning the text, and segmenting it into structured paragraph records.
The primary objective of this function is to provide a standardized output that can be directly consumed by downstream analysis modules, ensuring that each page is represented as a collection of meaningful sections and paragraphs with associated metadata. By abstracting these operations into a single function, the project ensures consistency and simplifies integration into the broader analytical pipeline.
Key Code Explanations
text, container = extract_page_content(
url,
request_timeout,
fetch_delay,
max_retries,
backoff_factor
)
This line performs the core content extraction. It retrieves the HTML of the given URL, removes boilerplate elements, identifies the main content container, and extracts clean text. The returned container serves as the structured HTML for subsequent segmentation, while text provides a raw textual view if needed for other purposes.
paragraph_records = segment_content_structure(
container, min_length, min_word_count
)
Here, the structured segmentation is applied. Based on the actual structure of the container, the function dynamically chooses either heading-based or paragraph-only segmentation. Each paragraph record includes metadata such as section title, heading level, paragraph ID, and text content, forming the foundational input for all downstream scoring and influence analysis.
return {‘url’: url, ‘records’: paragraph_records}
The function returns a dictionary containing the URL and its associated paragraph records. This consistent output structure enables the scoring and impact analysis modules to uniformly process multiple pages and ensures that all relevant content is accessible in a standardized format.

Function: load_embedding_model
Summary
The load_embedding_model function is responsible for initializing and loading a pre-trained SentenceTransformer model. SentenceTransformers provide state-of-the-art sentence and paragraph embeddings that are semantically meaningful, which are essential for measuring similarity between textual content segments and search queries. The function allows specifying both the model identifier and the computational device (CPU or GPU), ensuring flexibility for different runtime environments. By centralizing model loading, the project ensures consistent embeddings across all textual data.
This function is foundational to the project because accurate and normalized embeddings directly influence the calculation of semantic relevance and content impact scores. Ensuring the model loads correctly and efficiently is critical for the integrity of all subsequent analysis modules.
Key Code Explanations
device = device or (“cuda” if torch.cuda.is_available() else “cpu”)
This line determines the computational device for the model. If no device is explicitly provided, it automatically selects GPU (CUDA) if available, otherwise defaults to CPU. This ensures optimal performance for embedding computations without requiring manual configuration.
model = SentenceTransformer(model_name, device=device)
Here, the actual SentenceTransformer model is instantiated using the specified model name and device. This line loads all model weights and prepares it to encode text inputs into high-dimensional embeddings, which will later be used for semantic similarity scoring across paragraphs and queries.
Function: embed_queries
Summary
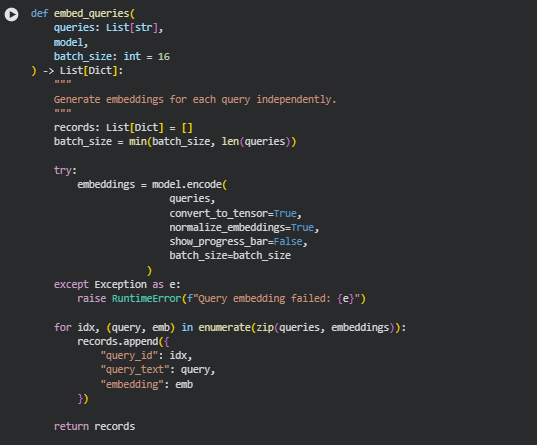
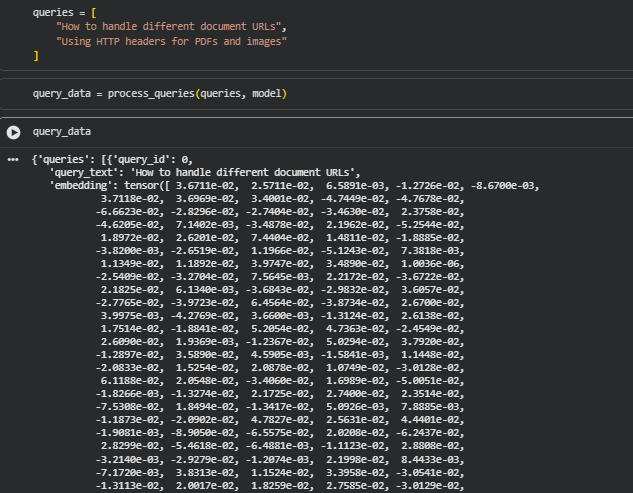
The embed_queries function generates embeddings for each textual query using a pre-loaded SentenceTransformer model. Each query is independently encoded into a dense vector representation that captures its semantic meaning in a high-dimensional space. These embeddings are critical for computing the semantic similarity between queries and content segments on web pages. By normalizing embeddings and storing them with query metadata, the function ensures downstream modules can efficiently compute influence and relevance scores.
This function plays a key role in translating textual queries into a machine-readable format, enabling comparison with paragraph embeddings to detect high-impact content areas.
Key Code Explanations
embeddings = model.encode(
queries,
convert_to_tensor=True,
normalize_embeddings=True,
show_progress_bar=False,
batch_size=batch_size
)
This line encodes all queries into embeddings using the SentenceTransformer model. convert_to_tensor=True ensures embeddings are returned as PyTorch tensors for efficient computation, while normalize_embeddings=True makes the vectors unit length, facilitating cosine similarity calculations.
records.append({
“query_id”: idx,
“query_text”: query,
“embedding”: emb
})
Here, each query’s embedding is stored along with its text and an identifier. This structured storage allows easy access during influence scoring, making the process traceable and interpretable.
Function: compute_query_centroid
Summary
compute_query_centroid computes a centroid embedding across multiple queries. The centroid serves as a single vector that represents the combined semantic intent of all queries. This is particularly useful for scoring content segments when treating multiple queries collectively, as it allows the system to measure the aggregate relevance of a paragraph to the overall query set.
Key Code Explanations
embeddings = torch.stack([q[“embedding”] for q in query_records])
return embeddings.mean(dim=0)
This sequence stacks all query embeddings into a tensor and calculates the element-wise mean, producing the centroid vector. Using PyTorch ensures that the operation is efficient and compatible with GPU acceleration if available.
Function: process_queries
Summary
process_queries is a wrapper pipeline that handles the full query processing workflow. It first generates individual embeddings using embed_queries and optionally computes the centroid embedding for the query set. The resulting dictionary contains both the individual query embeddings and the centroid vector if required. This structured output standardizes query data for downstream scoring and analysis.
Key Code Explanations
if compute_centroid:
result[“query_centroid”] = compute_query_centroid(query_records)
This conditional ensures that the centroid is computed only when needed. It provides flexibility in scoring methods—either using individual query comparisons or a combined centroid approach for multi-query influence analysis.
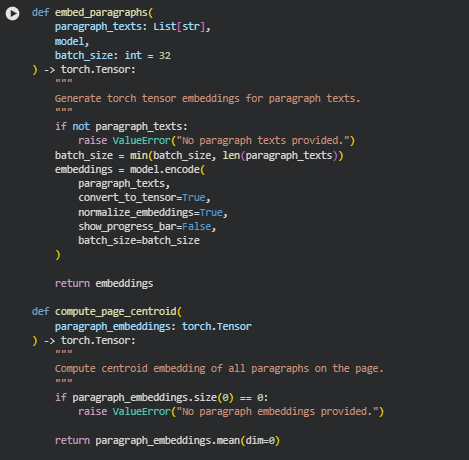
Function: embed_paragraphs
Summary
The embed_paragraphs function converts a list of paragraph texts into dense vector embeddings using a pre-loaded SentenceTransformer model. Each paragraph is independently encoded into a high-dimensional vector that captures its semantic meaning. These embeddings are foundational for evaluating how closely a paragraph aligns with the provided queries or the overall content relevance of the page. By returning a tensor, the function enables efficient similarity computations using PyTorch operations.
This function ensures that textual content is represented in a machine-understandable format while preserving semantic relationships between paragraphs.
Key Code Explanations
embeddings = model.encode(
paragraph_texts,
convert_to_tensor=True,
normalize_embeddings=True,
show_progress_bar=False,
batch_size=batch_size
)
This line encodes all paragraph texts into normalized embeddings. convert_to_tensor=True outputs PyTorch tensors, which are compatible with subsequent similarity and centroid computations. normalize_embeddings=True ensures that embeddings are unit vectors, simplifying cosine similarity calculations.
Function: compute_page_centroid
Summary
compute_page_centroid calculates a centroid embedding for all paragraphs on a page. The centroid represents the overall semantic center of the page content, providing a reference point for measuring how individual paragraphs or sections relate to the page’s main semantic theme.
Key Code Explanations
return paragraph_embeddings.mean(dim=0)
This line computes the element-wise mean across all paragraph embeddings, producing a single centroid vector. This vector captures the average semantic content of the page and can be used for comparing queries or identifying high-influence content zones efficiently.
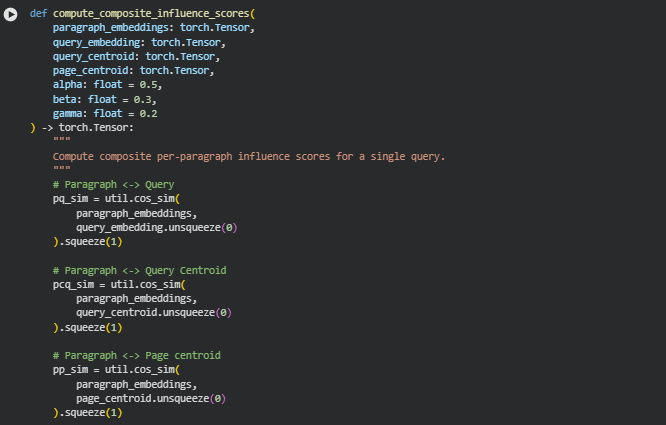
Function: compute_composite_influence_scores
Summary
The compute_composite_influence_scores function calculates a combined influence score for each paragraph relative to a specific query. It integrates three semantic similarity signals: the direct similarity of the paragraph to the query, similarity to the query centroid (representing the overall semantic direction of all queries), and similarity to the page centroid (representing the general semantic theme of the page). Weighted by parameters alpha, beta, and gamma, this composite score provides a nuanced measure of how strongly each paragraph contributes to relevance and semantic alignment. These scores are essential for identifying high-impact content zones on a page.
Key Code Explanations
pq_sim = util.cos_sim(paragraph_embeddings, query_embedding.unsqueeze(0)).squeeze(1)
pcq_sim = util.cos_sim(paragraph_embeddings, query_centroid.unsqueeze(0)).squeeze(1)
pp_sim = util.cos_sim(paragraph_embeddings, page_centroid.unsqueeze(0)).squeeze(1)
These lines compute cosine similarity between each paragraph and the respective reference vectors. pq_sim measures direct relevance to the query, pcq_sim captures alignment with the overall query theme, and pp_sim assesses semantic consistency with the page. unsqueeze(0) reshapes the vectors to match dimensional requirements, and squeeze(1) converts the similarity results into a 1D tensor for each paragraph.
scores = (alpha * pq_sim + beta * pcq_sim + gamma * pp_sim)
This line aggregates the three similarity scores using weighted coefficients alpha, beta, and gamma. By combining these components, the function balances query-specific relevance, overall query thematic alignment, and page-level semantic coherence to produce a meaningful composite influence score per paragraph.
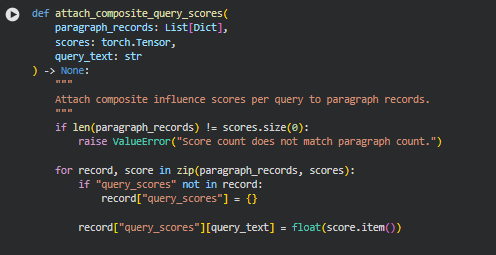
Function: attach_composite_query_scores
Summary
The attach_composite_query_scores function integrates the computed composite influence scores into the paragraph-level records for a specific query. Each paragraph record is updated to include a query_scores dictionary that maps the query text to its corresponding influence score. This step ensures that the paragraph data maintains a clear association with all relevant queries and their computed relevance, enabling downstream processing such as normalization, impact zone detection, and section-level aggregation.
By attaching the scores directly to the paragraph records, the function preserves the context of both the paragraph content and its influence, making it straightforward to analyze, visualize, or summarize the results at multiple levels.
Key Code Explanations
if “query_scores” not in record:
record[“query_scores”] = {}
This ensures that each paragraph record has a dedicated dictionary to store query-specific scores. If the dictionary does not already exist, it is initialized.
record[“query_scores”][query_text] = float(score.item())
This line assigns the computed influence score for the current query to the paragraph’s query_scores dictionary. The float(score.item()) conversion ensures that the tensor value is safely converted to a standard Python float, making it compatible with serialization, JSON export, or downstream numeric operations.
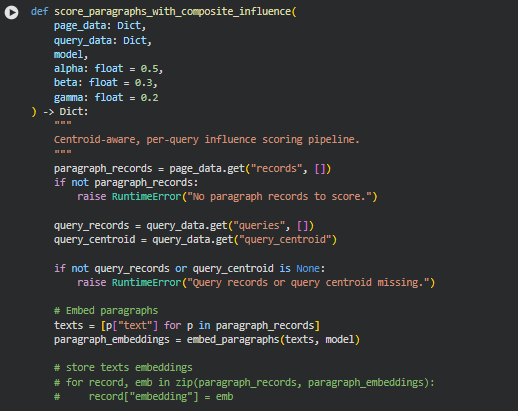

Function: score_paragraphs_with_composite_influence
Summary
The score_paragraphs_with_composite_influence function orchestrates the complete influence scoring process for all queries on a single page. It leverages both paragraph-level embeddings and centroid-based context (query centroid and page centroid) to compute composite influence scores. Each paragraph record is updated with per-query influence scores, allowing for a nuanced understanding of which content segments contribute most to semantic relevance.
This function ensures that the influence assessment is centroid-aware, capturing not only the direct relevance of a paragraph to a specific query but also its alignment with the broader semantic context defined by the collection of queries and the overall page content. This approach supports deeper insight into content effectiveness and impact zones.
Key Code Explanations
paragraph_embeddings = embed_paragraphs(texts, model)
page_centroid = compute_page_centroid(paragraph_embeddings)
These lines embed all paragraph texts into dense vectors using a pre-trained SentenceTransformer model and compute a centroid representing the overall page content. The page centroid provides a contextual baseline for scoring paragraph influence relative to the entire page.
for query in query_records:
scores = compute_composite_influence_scores(
paragraph_embeddings=paragraph_embeddings,
query_embedding=query[“embedding”],
query_centroid=query_centroid,
page_centroid=page_centroid,
alpha=alpha,
beta=beta,
gamma=gamma
)
This loop iterates over each query, computing the composite influence score for every paragraph. The scoring combines direct paragraph-to-query similarity, paragraph-to-query-centroid similarity, and paragraph-to-page-centroid similarity, weighted by the alpha, beta, and gamma parameters, respectively. This ensures a balanced consideration of local and global relevance.
attach_composite_query_scores(
paragraph_records=paragraph_records,
scores=scores,
query_text=query[“query_text”]
)
Here, the computed scores are attached to the paragraph records, maintaining the association between paragraphs and each query. This allows downstream modules to access detailed per-query influence information for normalization, impact zone assignment, and section-level aggregation.
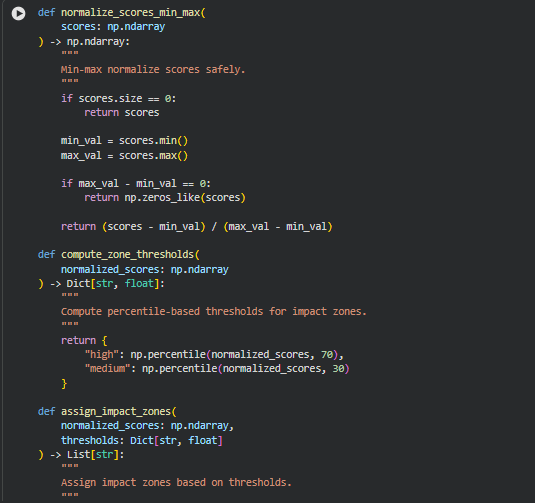
Functions: normalize_scores_min_max, compute_zone_thresholds, assign_impact_zones, attach_zone_data
Summary
These functions collectively handle the conversion of raw paragraph influence scores into standardized, interpretable metrics for impact zone analysis. The process involves normalizing the raw scores, defining thresholds to categorize paragraphs into “high,” “medium,” or “low” impact, and then attaching both the normalized scores and the corresponding impact zone labels to the paragraph records.
- normalize_scores_min_max ensures that raw scores are scaled to a [0, 1] range, facilitating comparison across paragraphs and queries.
- compute_zone_thresholds calculates percentile-based thresholds for determining impact zones, using the 70th percentile as the cutoff for high influence and the 30th percentile for medium influence.
- assign_impact_zones maps each paragraph’s normalized score to a categorical impact zone label.
- attach_zone_data integrates the normalized scores and assigned impact zones into the paragraph data structure for downstream aggregation and visualization.
These functions together allow for a consistent, interpretable representation of paragraph-level content impact, which forms the core of the “Content Impact Zone” analysis.
Key Code Explanations
Code lines in normalize_scores_min_max:
if max_val – min_val == 0:
return np.zeros_like(scores)
This safeguards against division by zero when all paragraph scores are identical. In such cases, all normalized scores are set to 0, ensuring stability in downstream processing.
Code lines in compute_zone_thresholds:
“high”: np.percentile(normalized_scores, 70),
“medium”: np.percentile(normalized_scores, 30)
These lines define dynamic thresholds based on score distribution rather than fixed cutoffs. Using percentiles allows the impact zones to adapt to the relative importance of paragraphs within each page or query.
Code lines in assign_impact_zones:
if score >= thresholds[“high”]:
zones.append(“high”)
elif score >= thresholds[“medium”]:
zones.append(“medium”)
else:
zones.append(“low”)
This mapping translates continuous normalized scores into categorical labels. The three-tiered classification (high, medium, low) provides an easily interpretable measure of paragraph influence for visualization and client insights.
Code lines in attach_zone_data:
record[“normalized_scores”][query_id] = float(norm_score)
record[“impact_zones”][query_id] = zone
These lines store both the normalized numeric score and the categorical impact zone for each paragraph per query. This structured attachment ensures that all subsequent analyses, such as section-level aggregation and plotting, can directly reference these values.
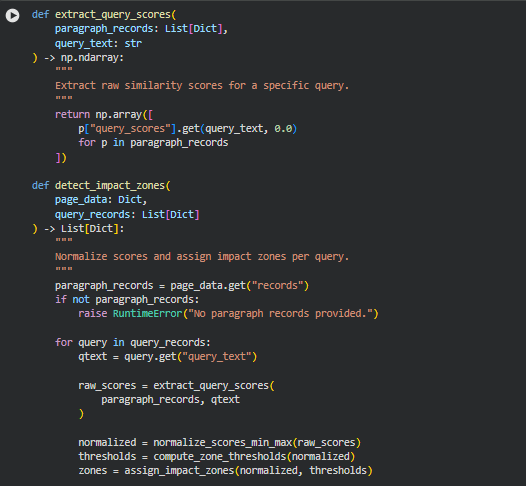
Function: extract_query_scores
Summary
These function retrieves the raw influence scores for a specific query across all paragraph records. This produces a numeric array that can be directly normalized and categorized.
Key Code Explanations
p[“query_scores”].get(query_text, 0.0) This line safely retrieves the influence score for the given query from each paragraph. If a paragraph does not have a score for the query, it defaults to 0.0, ensuring that the downstream normalization and zone assignment functions receive a consistent numeric array.
Function: detect_impact_zones
Summary
THis function orchestrates the full process for all queries. For each query, it extracts raw scores, normalizes them, computes high/medium/low thresholds, assigns impact zones, and attaches both the normalized scores and categorical labels to the paragraph records. This ensures that the paragraph data now carries both quantitative and categorical metrics for influence, enabling meaningful analysis and visualization.
Key Code Explanations
normalized = normalize_scores_min_max(raw_scores)
thresholds = compute_zone_thresholds(normalized)
zones = assign_impact_zones(normalized, thresholds)
attach_zone_data(paragraph_records, qtext, normalized, zones)
These lines represent the sequential workflow for transforming raw query scores into actionable metrics. First, raw scores are min-max normalized to a [0,1] range. Then, percentile-based thresholds define the boundaries for high, medium, and low influence. Each paragraph is mapped to a corresponding zone, and finally, the normalized scores and categorical labels are attached to the paragraph records. This structured approach ensures consistency, interpretability, and readiness for client-facing visualizations.
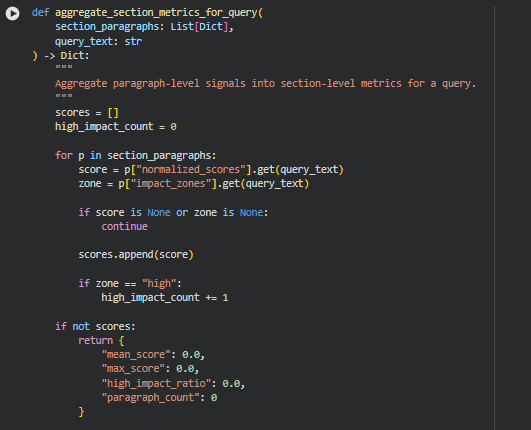
Function: aggregate_section_metrics_for_query
Summary
This function consolidates paragraph-level influence data into actionable metrics at the section level for a specific query. Each section may contain multiple paragraphs, each with normalized scores and impact zones. Aggregating these signals provides a clear understanding of which sections carry the highest semantic influence relative to the query.
The function calculates four key metrics for a section:
- Mean Score – Average of normalized paragraph scores, indicating overall section influence.
- Max Score – Highest normalized score in the section, highlighting peak influence.
- High Impact Ratio – Proportion of paragraphs labeled as “high” impact, indicating concentration of critical content.
- Paragraph Count – Total number of paragraphs contributing to the section metrics, ensuring awareness of content density.
This aggregation enables visualization and reporting at the section level, allowing users to quickly identify high-value segments within a page.**
Key Code Explanations
score = p[“normalized_scores”].get(query_text)
zone = p[“impact_zones”].get(query_text)
These lines extract the normalized score and impact zone for each paragraph specific to the query. The get method ensures that if a paragraph lacks a score or zone, it is safely skipped, preventing errors in aggregation.
high_impact_count += 1 if zone == “high” else 0
This counts the number of paragraphs in the section that are classified as “high” impact. This metric provides an indication of which sections contain concentrated semantically important content.
“mean_score”: float(np.mean(scores)),
“max_score”: float(np.max(scores)),
“high_impact_ratio”: float(high_impact_count / len(scores)),
“paragraph_count”: len(scores)
These lines calculate the four section-level metrics. They summarize paragraph-level influence into actionable numbers, making it easier to interpret section importance, compare sections, and visualize impact zones across a page.
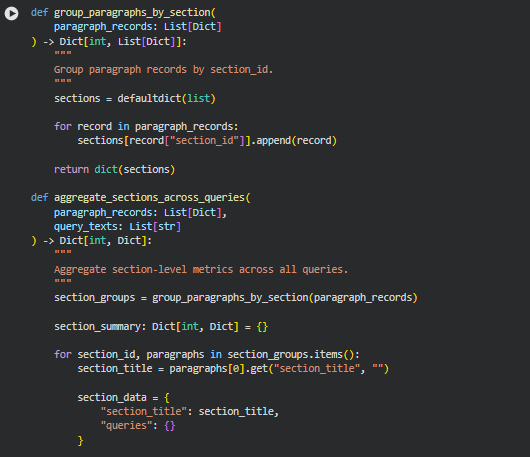
Function: group_paragraphs_by_section
Summary
This function organizes paragraph-level data into groups based on their section_id. Each section may contain multiple paragraphs, and grouping them allows subsequent aggregation and analysis at the section level. By creating a dictionary where keys are section IDs and values are lists of paragraph records, this function simplifies processing for section-wise metrics, visualization, and reporting.
Grouping paragraphs in this manner ensures that operations like computing average influence scores or high-impact ratios can be performed efficiently for each logical section of content.
Key Code Explanations
sections = defaultdict(list)
for record in paragraph_records:
sections[record[“section_id”]].append(record)
Here, a defaultdict is used to automatically initialize lists for new section IDs. Each paragraph record is appended to its corresponding section, effectively grouping all paragraphs under their section identifiers without manually checking for the existence of keys.
Function: aggregate_sections_across_queries
Summary
This function consolidates paragraph-level metrics into section-level summaries for all queries provided. After grouping paragraphs by their section IDs using the group_paragraphs_by_section function, it iterates over each section and computes aggregated metrics for each query. Metrics include mean influence score, high-impact ratio, maximum score, and paragraph count, which collectively represent the overall significance of each section relative to the queries.
By producing a structured dictionary where each section contains metrics for all queries, this function enables clear, actionable insights into which sections of a page contribute most to query relevance. It also prepares the data for visualization, reporting, and client-friendly interpretation of content impact.**
Key Code Explanations
section_groups = group_paragraphs_by_section(paragraph_records)
This groups paragraph records by section ID, creating a structure that allows metrics aggregation at the section level. Without this step, metrics could only be computed at the paragraph level, making analysis cumbersome.
for query_text in query_texts:
section_data[“queries”][query_text] = (
aggregate_section_metrics_for_query(
paragraphs, query_text
)
)
For each query, the function computes the aggregated section-level metrics using aggregate_section_metrics_for_query. This ensures that all sections have a detailed view of performance against each query, supporting comparison and prioritization in client-facing analyses.
section_summary[section_id] = section_data
After aggregating metrics for all queries within a section, the section summary is stored in the final output dictionary, indexed by section_id, producing a structured and easily navigable dataset.
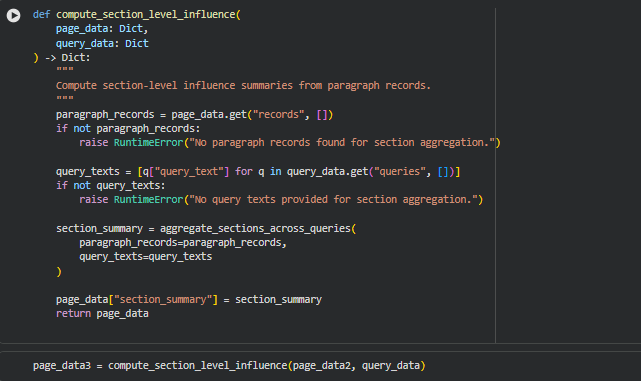
Function: compute_section_level_influence
Summary
This function generates section-level influence summaries from paragraph-level data. It collects all paragraph records from the page and, using the queries provided, aggregates their metrics to create a holistic view of each section’s contribution to semantic relevance. The resulting section_summary contains mean influence scores, high-impact ratios, maximum scores, and paragraph counts for each section, broken down by query.
By transforming granular paragraph-level scores into interpretable section-level insights, this function allows evaluation of which page segments are most impactful for a given set of queries. This is particularly useful for prioritizing content optimization efforts and understanding semantic relevance distribution across the page.
Key Code Explanations
paragraph_records = page_data.get(“records”, [])
Retrieves all paragraph-level records from the page. These records form the foundation for computing section-level metrics. If no paragraphs exist, it raises an error to prevent downstream failures.
query_texts = [q[“query_text”] for q in query_data.get(“queries”, [])]
Extracts the text of all queries. This ensures that section-level metrics are computed for every query, enabling a comprehensive view of content relevance across multiple search intents.
section_summary = aggregate_sections_across_queries(
paragraph_records=paragraph_records,
query_texts=query_texts
)
Aggregates paragraph-level metrics into section-level summaries using the previously defined aggregation function. This step consolidates granular data into actionable insights.
page_data[“section_summary”] = section_summary
Stores the computed section-level summaries in the page data dictionary under the key section_summary, making it ready for reporting, visualization, and client-facing interpretation.
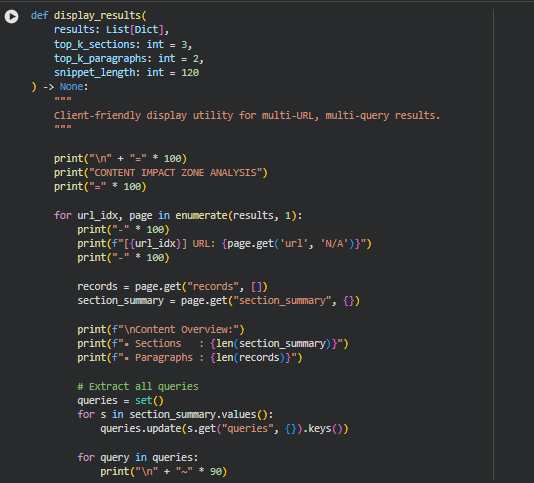
Function: display_results
Summary
The display_results function provides a client-friendly textual summary of the content impact analysis for a set of web pages. It organizes the results in a readable format, presenting the most influential sections and high-impact content examples for each query. This display allows understanding the distribution of semantic relevance across a page and highlights content that drives strong query alignment.
The function iterates through each page and query, aggregates the top sections based on mean influence scores, and presents sample paragraphs from high-impact zones. By limiting the number of sections (top_k_sections) and paragraphs (top_k_paragraphs), the function ensures concise and actionable summaries without overwhelming the reader. It also includes key statistics like average influence, high-impact ratio, and paragraph count per section, giving a clear perspective on content strength.**
Key Code Explanations
sections.sort(key=lambda x: x[“mean”], reverse=True)
Sorts the sections in descending order of mean influence score for the query. This allows prioritizing and displaying the most influential sections first.
high_paras.sort(key=lambda x: x[“score”], reverse=True)
Sorts high-impact paragraphs by their normalized influence score. Displaying the top paragraphs provides concrete examples of content driving semantic relevance for the query.
snippet = p[“text”][:snippet_length].rsplit(‘ ‘, 1)[0]
Generates a truncated snippet of paragraph text, ensuring readability while avoiding cutting words in the middle. This helps in showing sample content without overwhelming the user.
This function is purely focused on presenting actionable insights in a readable, structured, and professional manner suitable for understanding the relative importance of content sections and specific high-impact paragraphs.
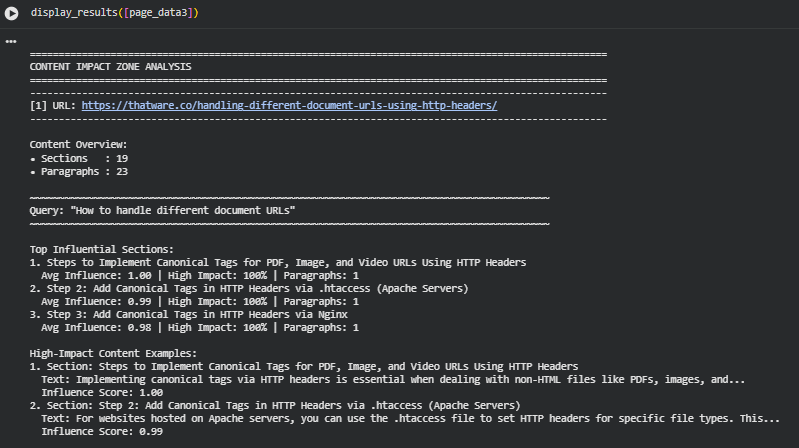
Result Analysis and Explanation
Overview of Content and Structure
The analyzed webpage, https://thatware.co/handling-different-document-urls-using-http-headers/, contains 19 distinct sections and 23 paragraphs in total. This indicates a moderately structured content layout with several discrete informational blocks. Understanding the section and paragraph count is critical for evaluating how the page distributes information and which parts are likely to contribute most to semantic relevance. A higher number of sections allows for more granular analysis of influence, whereas paragraph counts provide a sense of content density per section.
The segmentation into sections and paragraphs provides a foundation for identifying which portions of content are driving relevance signals for specific search queries. Sections serve as organizational units, and paragraph-level analysis enables the assessment of influence within each section. By analyzing content at both the section and paragraph level, it is possible to identify the most semantically significant content segments that directly align with the search intent of users.
Query-Specific Influence Analysis
Query: “How to handle different document URLs”
For this query, the analysis identified the top influential sections as those detailing the implementation of canonical tags for various file types using HTTP headers. The section titled “Steps to Implement Canonical Tags for PDF, Image, and Video URLs Using HTTP Headers” achieved a perfect average influence score of 1.00, with all paragraphs in the section classified as high-impact. Similarly, subsequent steps describing Apache and Nginx implementation also demonstrated very high influence, indicating that the page’s instructions are highly aligned with the query intent.
Interpretation of these results suggests that the listed steps are exceptionally valuable for users seeking guidance on handling document URLs through HTTP headers. High average influence scores combined with a 100% high-impact ratio signal that these sections are not only semantically relevant but also cover the query comprehensively. From a practical standpoint, these sections should be prioritized for internal linking, promotion, and possibly featured snippets because they contain the highest concentration of query-aligned content.
High-impact content examples reinforce this conclusion. Paragraphs with the highest normalized influence scores provide actionable instructions and specific technical details that satisfy user intent. Users searching for guidance will find these sections immediately relevant and easy to follow, which likely contributes to higher engagement and lower bounce rates.
Query: “Using HTTP headers for PDFs and images”
For this query, the analysis showed a similar trend, with the same key sections identified as top contributors to semantic relevance. The first section again scored an average influence of 1.00, while subsequent sections scored slightly lower but remained highly influential (0.95 and 0.91). The high-impact ratio remains at or near 100% for these sections, indicating that nearly every paragraph in these sections is relevant to the search intent.
This demonstrates that the page content is robust across multiple related queries. The sections not only address direct implementation instructions but also provide context and examples for handling different file types through HTTP headers. From an SEO perspective, these results suggest that these sections reinforce the page’s topical authority on the subject, making them ideal candidates for optimization strategies such as structured content enhancement, FAQ integration, or anchor link creation within the page to improve user navigation.
Section Influence Interpretation
Section-level influence scores provide insight into how content is prioritized semantically. Sections with higher mean influence scores indicate areas where content is closely aligned with query intent. Conversely, sections with lower scores are less relevant to the analyzed queries and may represent ancillary information or context. In this case, the top sections have near-perfect scores, highlighting their critical role in driving semantic relevance.
High-impact ratios quantify the proportion of paragraphs within a section that significantly contribute to query alignment. A ratio of 100% implies that every paragraph in the section is directly relevant, while lower ratios would indicate that only part of the section supports the query. Understanding these ratios allows for actionable decisions, such as focusing optimization efforts on sections with a high proportion of low-impact content or consolidating redundant sections to improve clarity and user experience.
Paragraph-Level Influence and Actionable Insights
Paragraph-level analysis identifies the most influential content fragments for each query. High-impact paragraphs correspond to text snippets that carry the strongest semantic signal. In the provided results, the top paragraphs contain concise, practical instructions on implementing canonical tags via HTTP headers, which are directly actionable for the reader.
Normalized influence scores allow for threshold-based interpretation. Scores close to 1.0 are considered highly influential and indicative of perfect alignment with query intent. Scores in the medium range (approximately 0.3–0.7) represent moderately relevant content that can provide supporting context or background. Scores below 0.3 indicate limited relevance, often serving as peripheral or explanatory content. For practical applications, high-scoring paragraphs should be highlighted for content marketing, internal linking, and potential snippet optimization, while medium-scoring paragraphs may be revised or augmented to improve semantic relevance.
Practical Actions Based on Results
The results provide a clear roadmap for improving and leveraging page content:
1. Focus on Top Influential Sections: Ensure these sections remain comprehensive and up-to-date since they carry the highest semantic relevance. Any edits should preserve the technical accuracy and clarity that make them impactful.
2. Optimize High-Impact Paragraphs: Highlight, link, or reference these paragraphs within the site to increase user engagement. These paragraphs can also be used as candidates for featured snippets or internal content promotion.
3. Evaluate Medium-Impact Content: Review sections or paragraphs with moderate influence scores to identify opportunities for enhancement. Adding examples, clarifying instructions, or including additional context can improve alignment with related queries.
4. Maintain Content Structure: Sections and headings are critical for segmenting content meaningfully. Keeping a well-structured layout ensures that semantic analysis continues to identify the most relevant segments effectively.
Overall, this analysis provides a clear understanding of which segments of content are driving the page’s relevance for specific queries, enabling data-driven decisions for optimization and content strategy.
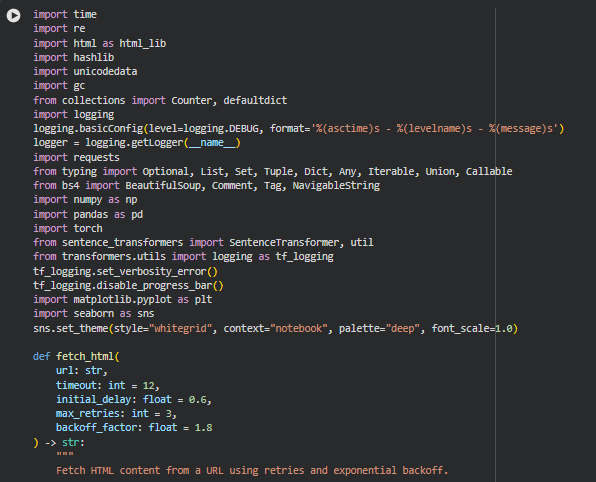
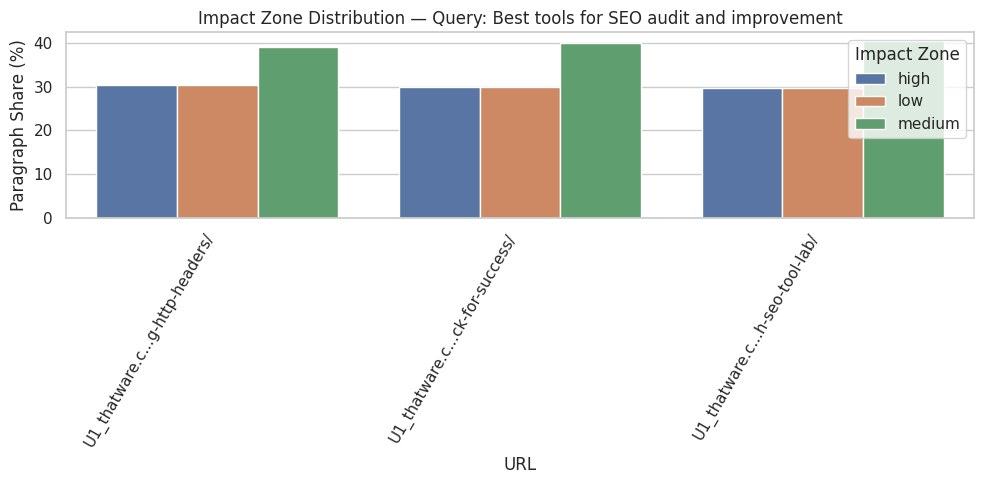
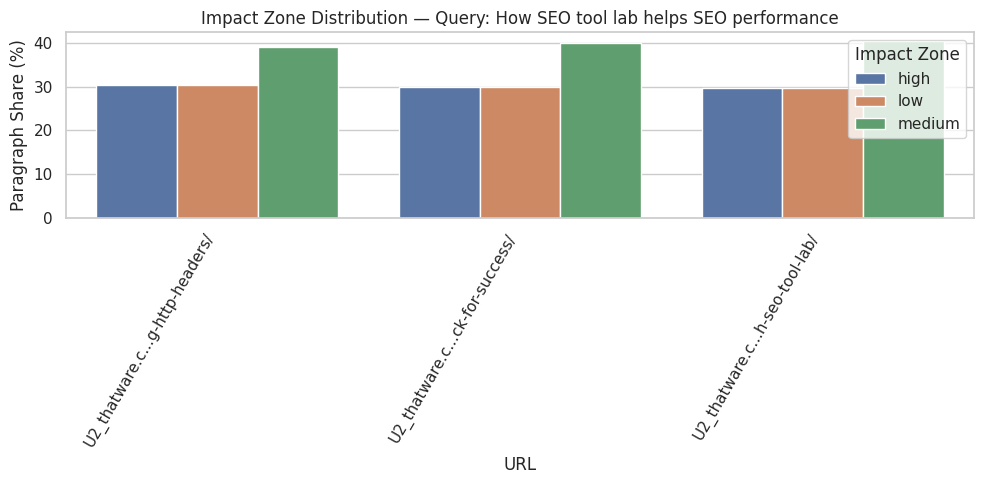
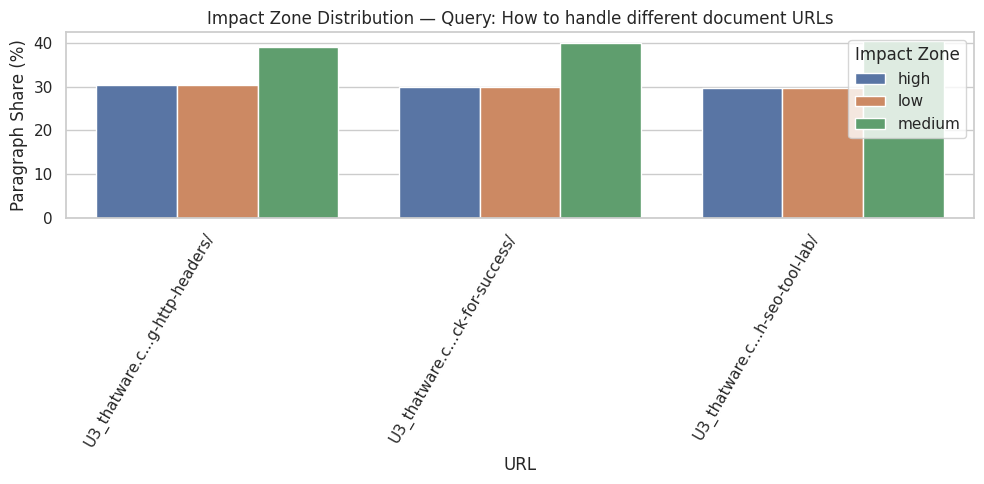
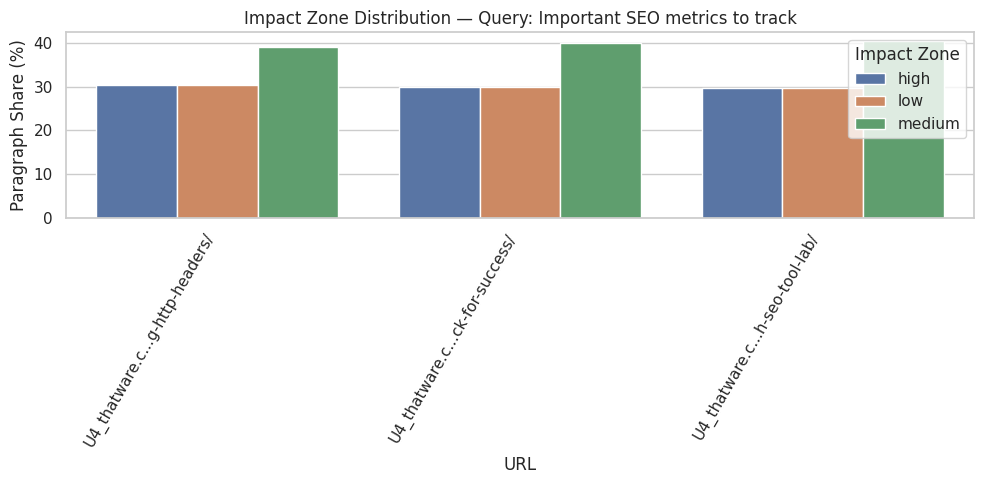
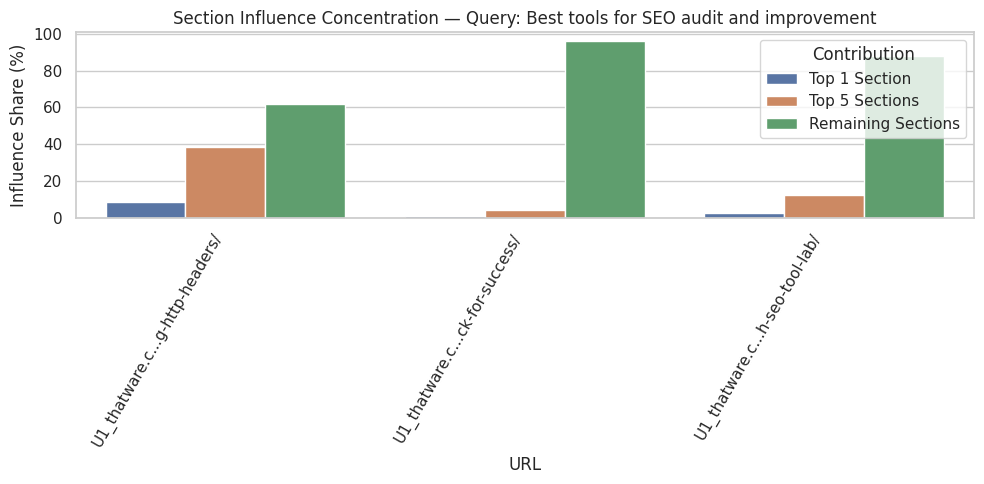
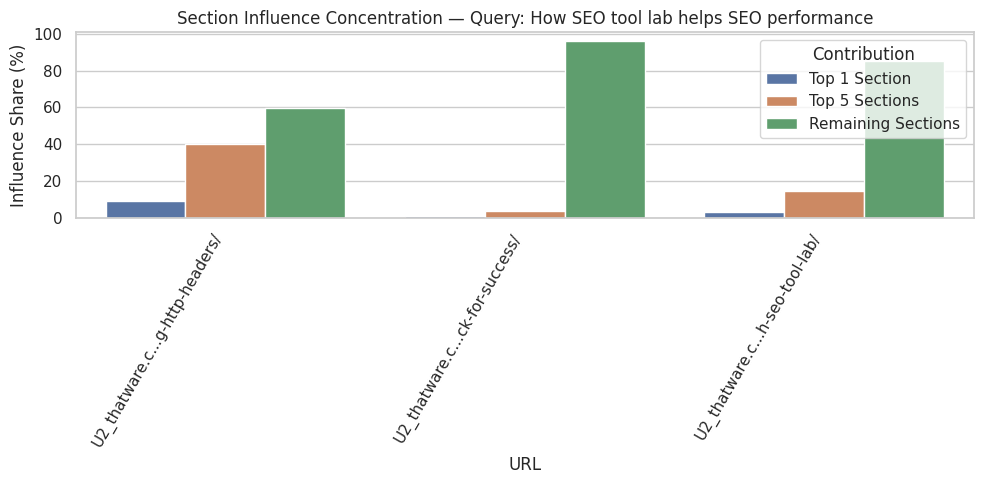
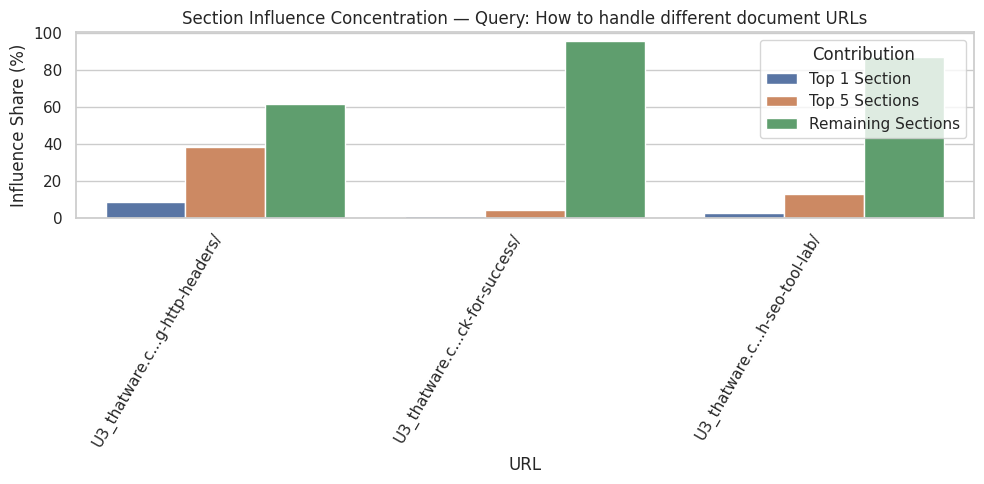
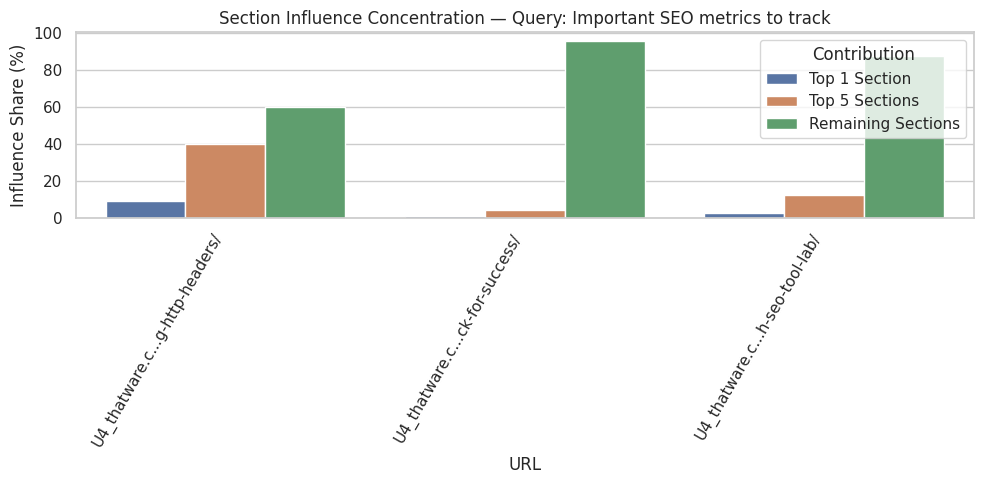
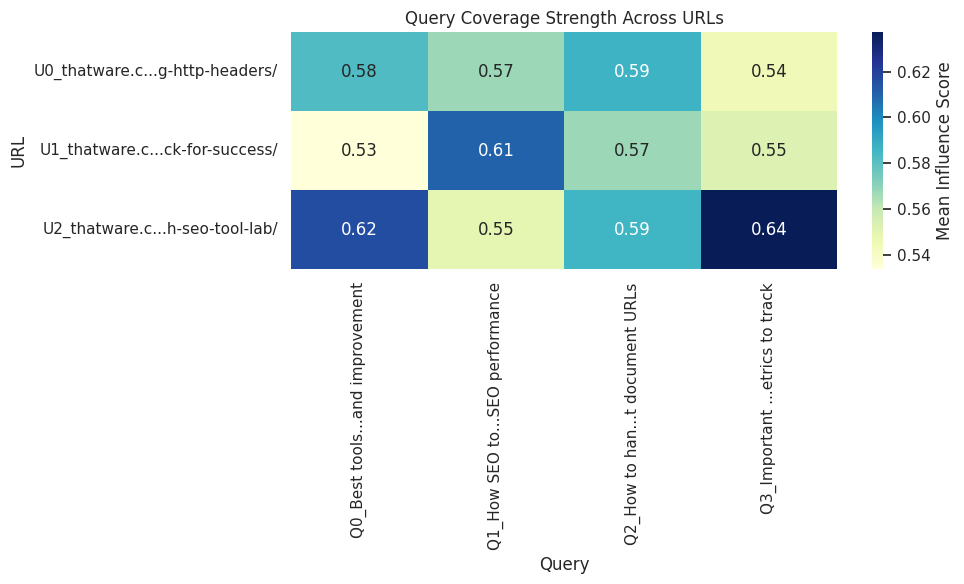
Result Analysis and Explanation
Content Overview
The content analysis across multiple URLs shows the total number of sections and paragraphs extracted from each page. These metrics provide a high-level understanding of page complexity and content depth. A higher number of sections typically indicates a well-structured document, which can be advantageous for semantic segmentation and relevance mapping. Conversely, a page with very few sections may require careful review to ensure content is not overly condensed, which can limit its ability to cover multiple queries effectively.
From a Website owners perspective, this overview helps in understanding content coverage at a macro level and identifying pages that might need expansion or restructuring. Pages with a very large number of paragraphs should be evaluated for content quality and relevance distribution, ensuring that critical information is not buried under less impactful content.
Paragraph-Level Influence Scores
Understanding Influence Scores
Influence scores are calculated for each paragraph with respect to individual queries, combining three main signals: similarity to the query, alignment with the overall query centroid, and consistency with the page-level content centroid. Scores range from 0 to 1, where higher values indicate stronger relevance and semantic impact.
For practical interpretation, the scores can be categorized into three bins:
- High Influence (0.7–1.0): Paragraphs in this range are highly relevant and strongly aligned with the query. These are the key segments that drive semantic relevance.
- Medium Influence (0.3–0.7): Paragraphs with moderate relevance. They support the query but may need refinement or additional context to strengthen alignment.
- Low Influence (0–0.3): Paragraphs with weak alignment. These may be off-topic or contain generic content and could be candidates for improvement or pruning.
Actionable steps based on these bins:
- Focus on high-influence paragraphs as primary content for optimization, internal linking, and highlighting in user experience.
- Review medium-influence paragraphs for opportunities to enrich content or integrate additional context.
- Evaluate low-influence paragraphs for redundancy, irrelevance, or restructuring, especially if they dominate a page segment.
Interpretation of High-Impact Content Examples
High-impact paragraphs provide clear, actionable insights into which parts of the page most strongly influence semantic relevance. For instance, paragraphs explaining technical implementations, SEO audits, or advanced SEO strategies consistently exhibit high scores. These paragraphs serve as core reference points for query satisfaction.
Use these examples to:
- Identify content that should be emphasized in meta descriptions, headings, and internal linking.
- Develop supplementary content that aligns with these high-impact segments.
- Ensure that similar structured explanations are replicated across other relevant pages for consistency.
Section-Level Influence Analysis
Aggregated Section Metrics
Section-level aggregation converts paragraph-level signals into actionable insights for each section. Key metrics include:
- Mean Influence Score: Average paragraph-level relevance for the section. A higher mean indicates strong overall alignment with the query.
- Max Influence Score: Highlights the single most impactful paragraph within the section.
- High-Impact Ratio: The proportion of paragraphs within the section that fall into the high influence category.
- Paragraph Count: Total number of paragraphs contributing to section-level metrics.
Use these metrics to:
- Prioritize sections for content optimization based on high mean scores and high-impact ratios.
- Identify sections that are structurally underperforming despite having multiple paragraphs.
- Guide internal linking and content promotion efforts toward sections with maximum influence.
Section Influence Interpretation
- Highly Concentrated Influence: Sections with 100% or near 100% high-impact paragraphs demonstrate concentrated semantic authority. These sections are ideal candidates for anchor content, as they fully address the query intent.
- Moderate Concentration: Sections with a mix of medium and high-impact paragraphs may need selective content refinement to boost relevance.
- Low Concentration: Sections dominated by low-impact paragraphs may require restructuring, additional supporting content, or pruning.
By analyzing section-level influence, ensure that page architecture is optimized to showcase their most authoritative content prominently.
Cross-Page and Multi-Query Insights
When multiple pages are analyzed for multiple queries, patterns emerge:
- Pages with consistently high influence across multiple queries indicate strong topical authority and relevance.
- Pages that excel in certain queries but lag in others highlight gaps in content coverage, signaling areas for targeted enhancement.
- Cross-query analysis enables content alignment strategy with priority queries, ensuring that high-value topics receive proportionate attention across the site.
These insights allow website owners to make data-driven decisions on content hierarchy, internal linking, and topic coverage, directly impacting search visibility and user experience.
Visualization Module
Visualization provides intuitive, actionable views of the analysis. Each plot type delivers distinct insights:
Impact Zone Distribution
What it shows: This plot displays the proportion of high, medium, and low influence paragraphs for each URL and query.
Interpretation: A high proportion of high-impact content suggests strong semantic alignment and effective query coverage. Conversely, a large share of low-impact content indicates gaps or misalignment.
Actions: Use this plot to quickly identify pages requiring content improvement. Focus on enhancing medium or low-impact content to elevate overall page relevance.
Section Influence Concentration
What it shows: Illustrates how influence is concentrated within the top sections of a page. It quantifies the percentage of overall influence held by the top 1 section, top N sections, and the remaining sections.
Interpretation: Pages with influence heavily concentrated in one or two sections indicate strong focus but potential imbalance. Conversely, evenly distributed influence may suggest broad coverage but less targeted depth.
Actions: Optimize structural balance by reinforcing key sections or distributing critical content more effectively to ensure comprehensive query satisfaction.
Query vs URL Heatmap
What it shows: Heatmap visualizes mean paragraph influence scores across URLs for each query.
Interpretation: Darker shades indicate stronger overall relevance for a given query on a specific URL. This provides an immediate understanding of which pages best address particular queries.
Actions: Use this visualization to prioritize page optimization, replicate high-performing content structures on weaker pages, and align content strategy with target queries.
Practical Implications and Recommendations
- Content Prioritization: Focus on high-influence sections and paragraphs for on-page SEO, internal linking, and featured snippets.
- Content Refinement: Medium and low-influence content should be enriched, restructured, or pruned based on relevance gaps.
- Structural Optimization: Ensure that influence is well-distributed across sections, preventing over-concentration in a few areas.
- Cross-Query Alignment: Evaluate multi-query performance to maintain comprehensive coverage across all target topics.
- Data-Driven Content Decisions: Use visualizations to identify gaps, structural imbalances, and high-impact content opportunities for strategic planning.
This comprehensive analysis enables understanding both micro-level paragraph influence and macro-level section and page authority. It provides actionable insights for optimizing content relevance, improving query satisfaction, and strategically aligning content across multiple pages and topics.
Project Results Q&A — Understanding Insights and Taking Action
What do the paragraph-level influence scores indicate about my content quality and relevance?
Paragraph-level influence scores are a direct measure of how well individual content blocks align with specific queries. High scores (closer to 1) signify that the paragraph strongly addresses the target query, providing precise, actionable information that search engines and users find highly relevant. Medium scores indicate partial alignment, meaning the paragraph touches upon the topic but may lack depth, context, or clarity. Low scores reflect weak alignment, where the paragraph either deviates from the intended query or provides generic content.
These scores allow you to:
- Identify the strongest content segments for reinforcement, promotion, or internal linking.
- Spot underperforming paragraphs that require refinement, additional context, or restructuring.
- Ensure that high-priority queries are fully addressed across your pages.
Regularly monitoring these scores helps maintain content relevance and ensures that all pages contribute effectively to your SEO strategy.
How should I interpret section-level influence metrics and apply them to content optimization?
Section-level metrics aggregate paragraph-level influence scores to provide a holistic view of content performance within each section. Key indicators include the mean influence score, the maximum paragraph influence, and the high-impact paragraph ratio.
Sections with high mean scores and a large proportion of high-impact paragraphs are highly effective at addressing the query. These sections can serve as anchor content for internal linking, featured snippets, or social sharing. Sections with moderate scores may contain supportive information but could benefit from additional examples, data, or clarification to elevate relevance. Low-scoring sections indicate misalignment or gaps and are candidates for content pruning or enhancement.
By analyzing these metrics, you can prioritize content refinement at the section level, ensuring structural balance and reinforcing authoritative sections for maximum semantic impact.
What insights do high-impact content examples provide, and how can I act on them?
High-impact content examples highlight the paragraphs that contribute most strongly to semantic relevance for each query. They serve as benchmarks for content effectiveness, illustrating the type of language, depth, and structuring that resonates with search intent.
Leverage these insights to:
- Replicate successful patterns across other pages, ensuring consistent content quality.
- Enhance underperforming paragraphs by aligning them more closely with the structure, style, and depth of high-impact examples.
- Use high-impact paragraphs for strategic purposes, such as featured snippets, meta descriptions, or educational materials, reinforcing content authority.
Essentially, these examples provide a tangible roadmap for content optimization that is both evidence-based and results-driven.
How can I use impact zone distribution to improve content relevance across my site?
Impact zone distribution segments paragraph-level influence into high, medium, and low categories, providing a visual and quantitative understanding of content effectiveness for each query. A strong distribution with a high percentage of high-impact content indicates effective coverage, while a large proportion of medium or low-impact content highlights potential gaps.
Take the following actions:
- Focus on low- and medium-impact zones to add depth, examples, or clarity.
- Reorganize content to ensure high-impact sections are prominently placed, improving user experience and perceived authority.
- Monitor changes over time to assess the effectiveness of content updates and maintain alignment with evolving search intent.
This approach ensures that all pages maintain high relevance and consistently address target queries.
How do section influence concentration metrics guide structural optimization?
Section influence concentration measures how influence is distributed across the top sections of a page. Pages where influence is concentrated in a single section may have strong targeted content but risk underutilizing the rest of the page. Conversely, evenly distributed influence indicates broader coverage but may dilute the depth of high-impact content.
Act on this by:
- Reinforcing key sections to consolidate authority while ensuring other sections maintain meaningful relevance.
- Strategically redistributing critical content to balance influence across sections, improving both user experience and SEO value.
- Identifying sections that are currently underperforming for additional enrichment or integration with high-impact sections.
This ensures a balanced, high-quality content structure that maximizes query coverage and relevance.
How can the query vs URL heatmap help prioritize content improvements?
The heatmap visualizes mean influence scores for each query across multiple URLs. Darker cells indicate pages that perform strongly for specific queries, while lighter cells highlight weaker alignment. This provides a clear, comparative overview of content performance across your site.
Practical actions include:
- Prioritizing updates on pages with low scores for high-value queries, ensuring coverage where it matters most.
- Replicating successful content structures from high-performing URLs to weaker pages, improving overall consistency.
- Identifying content gaps or query coverage issues that require strategic expansion or restructuring.
By using this heatmap, make data-driven decisions, targeting content improvements where they will have the most significant impact.
What overall benefits does this analysis provide for SEO strategy?
The combined insights from paragraph-level, section-level, and cross-page analysis provide a comprehensive understanding of content relevance and performance. Benefits include:
- Enhanced Content Prioritization: Focus resources on high-impact areas for maximum SEO and user experience benefit.
- Evidence-Based Optimization: Actionable insights for refining medium and low-impact content to improve query alignment.
- Structural Improvements: Guidance on section distribution and content balance across pages.
- Strategic Planning: Identifying content gaps, cross-page strengths, and opportunities for replication or enrichment.
- SEO ROI Maximization: Ensures that all content efforts are directed toward sections and pages that meaningfully influence search visibility and user engagement.
This analysis provides a practical framework for continuously improving content, maintaining query relevance, and driving measurable SEO results.
Final Thoughts
The Content Impact Zone Analyzer successfully identifies and quantifies the segments of a webpage that most strongly influence semantic relevance for targeted queries. By leveraging paragraph-level and section-level influence metrics, the analysis provides a clear, actionable understanding of which content blocks are driving relevance and which sections serve as key contributors to search intent satisfaction.
Through the implementation of centroid-aware influence scoring and impact zone classification, high-impact paragraphs and sections are highlighted, enabling a precise assessment of content alignment with strategic queries. This allows clients to immediately recognize the areas that provide the most value, ensuring that critical content is prominently emphasized and leveraged for optimization, internal linking, or feature presentation.
Section-level aggregation further enhances interpretability by consolidating paragraph-level signals, revealing which sections concentrate semantic influence. This not only helps in understanding content hierarchy and focus but also guides resource allocation toward segments that maximize query relevance.
The visualization module complements these insights by offering intuitive representations of impact zone distributions, section influence concentration, and cross-page query coverage. Clients can easily interpret alignment patterns, assess coverage strength, and identify which URLs and sections hold the greatest influence for specific queries.
Overall, the project delivers a structured, evidence-based evaluation of content performance, highlighting high-value segments and enabling data-driven decisions. By clearly identifying high-influence content zones, the Content Impact Zone Analyzer empowers clients to maintain strong semantic alignment across pages, reinforcing authoritative sections, and enhancing overall content effectiveness in supporting SEO objectives.
