SUPERCHARGE YOUR Online VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
The Structural Emphasis and Priority Analyzer is a comprehensive analytical framework designed to evaluate how effectively key ideas are emphasized and prioritized within a webpage’s content structure. The project identifies whether crucial concepts receive adequate visibility and structural weight through content hierarchy, section organization, and emphasis distribution.

In modern SEO, the degree of emphasis placed on primary ideas directly influences both user perception and search engine interpretation. This project introduces an automated, model-driven method to assess how content emphasis is distributed across sections and blocks of a webpage. It inspects emphasis patterns using natural language understanding models to quantify focus levels, highlight overemphasized or underemphasized segments, and derive actionable insights.
The system processes multiple webpage URLs, decomposes each page into semantic blocks and structural segments, and computes emphasis scores to measure idea prioritization. Results are displayed through detailed console summaries and visual dashboards that help identify where adjustments in structural balance could enhance content clarity and topical hierarchy.
By translating linguistic and structural emphasis into quantifiable metrics, this analyzer supports data-driven evaluation of on-page focus consistency and ensures that high-value ideas are communicated with optimal weight and visibility across the content layout.
Project Purpose
The purpose of this project is to determine whether the most important ideas within webpage content receive the level of structural emphasis they deserve. In SEO and content strategy, not all ideas carry equal value — some serve as core intent drivers, while others provide supportive context. This analyzer was developed to ensure that the most significant concepts are structurally prioritized through proper emphasis, positioning, and distribution across the page.
The project provides a measurable understanding of emphasis allocation by leveraging natural language processing techniques to assess how effectively attention is distributed throughout a page’s sections and blocks. The outcome assists in identifying disproportionate emphasis — whether critical ideas are buried in low-visibility sections or secondary points dominate the focus.
Beyond detection, the purpose extends to providing actionable clarity. It enables content strategists to align emphasis distribution with intent, ensuring each page communicates its hierarchy of ideas with precision. This leads to improved readability, balanced content flow, and stronger alignment between structural presentation and the intended messaging.
Project’s Key Topics Explanation and Understanding
The project centers on evaluating structural emphasis and priority distribution within webpage content — two interconnected aspects that define how key ideas are positioned, weighted, and perceived throughout a page. These concepts are crucial in SEO-driven content analysis because they determine how effectively a page communicates its main intent both to users and to search engines.
Structural Emphasis
Structural emphasis refers to how textual importance is established through the use of hierarchical elements and placement within the webpage. Every digital document — especially those intended for SEO — is composed of multiple levels of structure such as headings, subheadings, paragraphs, lists, and highlighted sections. Each of these elements implicitly signals importance to readers and to search engines. For instance, information placed in a heading or an introductory block naturally holds more emphasis than text in later paragraphs or auxiliary sections.
This project interprets structural emphasis not merely as the visual arrangement but as a measurable signal of communicative priority. Through the use of natural language processing, emphasis levels are quantified to reflect how prominently each concept or block of content is represented within the page. By doing so, it becomes possible to detect imbalance — where certain secondary elements may dominate structurally, overshadowing critical ideas meant to define the core intent of the page.
Priority Analysis
Priority in content refers to the relative significance assigned to ideas within the overall communication hierarchy. It is not only about frequency or repetition but about the intentional positioning of ideas that carry business or informational value. This analyzer interprets priority by assessing how essential concepts are distributed and how their prominence aligns with the overall structural layout of the page. When high-priority ideas are presented with appropriate emphasis, the content becomes both user-friendly and search-engine-aligned. Conversely, when these ideas are underemphasized, it signals a structural inconsistency that may hinder comprehension and reduce topical relevance.
Structural Hierarchy and Information Flow
A well-defined structure allows content to flow logically, leading readers from broad topics to specific insights. Structural hierarchy — composed of elements like title tags, H1-H6 headings, block divisions, and contextual transitions — acts as the framework that supports idea delivery. In this project, structural hierarchy is interpreted as the spatial and semantic relationship among sections and their emphasis scores. Understanding how emphasis transitions from introduction to conclusion provides a clear view of whether the page maintains consistent communicative strength or disperses focus unevenly.
Contextual Relevance of Emphasis
Emphasis is meaningful only when contextualized. Not every section requires equal weight — for instance, a summary may intentionally hold less emphasis than the main explanation. This project integrates contextual evaluation to ensure emphasis assessment reflects actual communicative intent rather than mechanical distribution. By aligning structural emphasis with contextual intent, the project ensures that the evaluation mirrors how human readers perceive importance, not just how algorithms detect it.
Application within SEO and Content Strategy
In the broader SEO framework, structural emphasis directly correlates with user engagement signals, dwell time, and content scannability. Pages that highlight their main ideas structurally allow both users and search engines to interpret topic focus efficiently. This enhances topic authority, keyword relevance, and content clarity — all of which are critical for search visibility and comprehension-based ranking factors.
Q&A Section — Understanding Project Value and Importance
Why is analyzing structural emphasis important for SEO-focused content?
Structural emphasis defines how a webpage communicates the significance of its ideas through layout and hierarchy. In SEO-driven content, emphasis acts as a visual and semantic cue for both readers and search engines, determining what concepts appear most central. When emphasis is misaligned — for example, when less important topics dominate structurally — the page may confuse readers and weaken its perceived topical authority. Analyzing this aspect ensures that key business or informational ideas are structurally prioritized, leading to clearer communication and improved search interpretation.
How does this project help identify whether the most important ideas are being highlighted correctly?
The analyzer quantifies the distribution of emphasis across different sections and blocks within the webpage. It interprets which parts of the content carry higher or lower communicative weight, revealing whether core ideas receive the prominence they deserve. This makes it possible to detect underemphasized key topics or overemphasized secondary points — offering clarity on where adjustments in structure or layout can improve alignment between message priority and page design.
In what ways does this project differ from conventional keyword or content density analyses?
Traditional SEO analyses often rely on keyword frequency, density, or placement metrics. However, these methods overlook how the content’s structure conveys importance to human readers and to crawlers interpreting hierarchy. This project moves beyond surface-level metrics by combining structural cues (like section positioning and emphasis strength) with content semantics, allowing for a deeper understanding of how meaning and priority interact. It focuses on how ideas are presented rather than simply how often they appear.
What kind of content issues can be uncovered through structural emphasis analysis?
It can highlight various structural inefficiencies, such as:
- Overloaded introductory sections that dominate the page hierarchy.
- Key insights buried deep within low-visibility blocks.
- Imbalanced use of headings where secondary ideas appear structurally more prominent than primary ones.
- Inconsistent emphasis flow that disrupts logical readability. By exposing these structural inconsistencies, the analysis provides a clear foundation for improving readability, engagement, and alignment between page design and communication goals.
How does understanding priority distribution improve overall content strategy?
Priority distribution reflects how effectively the content communicates what matters most. A balanced emphasis structure ensures that the most relevant, revenue-driving, or informative topics are visible and repeatedly reinforced in the right places. By understanding this balance, strategists can refine both on-page and editorial structures — ensuring that the page flow supports the intended message, search intent, and audience comprehension simultaneously.
How does this analysis benefit content audits and optimization planning?
During audits, content is often evaluated for tone, coverage, and keyword targeting. However, the structural emphasis perspective adds a missing layer — how content is presented and perceived in order of importance. By integrating emphasis analysis into audits, optimization teams can identify which areas to strengthen or simplify structurally. This makes it easier to plan edits that enhance both user experience and SEO performance without altering the original intent of the page.
Can structural emphasis insights be used to guide new content creation?
Yes. Beyond evaluating existing content, structural emphasis insights can guide how new content should be structured from the start. Writers and editors can prioritize their key messages and position them in higher-emphasis regions such as lead paragraphs, summary points, or high-visibility sections. This proactive alignment ensures new pages maintain clarity and consistent emphasis from the very beginning, avoiding later structural revisions.
Libraries Used
time, re, html, hashlib, unicodedata, gc, logging
These are core Python standard libraries that handle general-purpose operations such as timing execution, regular expressions, HTML entity decoding, data hashing, Unicode normalization, memory management, and system-level logging. They are integral for efficient control flow, data sanitization, and debugging throughout a data pipeline. In this project, these libraries collectively support stable and reliable data processing. The time library manages network request pacing to prevent overloads. re enables text pattern recognition and cleanup. html and unicodedata normalize text content extracted from webpages. hashlib generates consistent identifiers when needed for caching or tracking. gc ensures memory cleanup during large-scale processing, and logging provides structured feedback at each step of the extraction and analysis pipeline.
requests
The requests library is a widely used HTTP library in Python designed for making network requests in a human-friendly way. It simplifies communication with web servers, handling various request types and response structures with robust error handling. In this project, requests is used to retrieve webpage HTML content efficiently. It allows flexible timeout control, custom headers (like user-agents to mimic browsers), and retry handling for unstable connections. This makes it possible to collect data from multiple URLs safely and uniformly, forming the foundation for content extraction and further NLP analysis.
typing (Optional, List, Tuple, Dict, Any, Iterable, Union)
The typing module is part of Python’s type hinting system, providing a structured way to define expected data types. This improves readability and reduces runtime errors by clarifying data structures used across functions. In this project, typing annotations are applied to define expected input and output formats for modular functions. It improves maintainability by clarifying how data flows through extraction, transformation, and analysis stages. This also supports consistent code reviews and reliable function integration across the full pipeline.
BeautifulSoup (bs4)
BeautifulSoup is a Python library for parsing HTML and XML documents. It enables navigation, searching, and modification of parse trees, making it ideal for web scraping and structured content extraction. In this project, BeautifulSoup serves as the foundation for HTML parsing. It extracts meaningful content elements such as headings, paragraphs, and lists while removing unwanted tags like scripts and styles. This library preserves the structural relationships between elements, enabling accurate analysis of the webpage’s hierarchy and section-wise emphasis.
NumPy and pandas
NumPy is a numerical computing library providing high-performance array operations, while pandas is a data analysis toolkit that simplifies manipulation of structured datasets. Together, they form the core analytical stack in Python. In this project, NumPy and pandas are used to handle, aggregate, and analyze extracted content data. NumPy supports fast computation of emphasis and structural weights, whereas pandas manages tabular data for summaries, comparisons, and statistical breakdowns across sections, queries, and URLs. Their combined efficiency ensures smooth scaling to handle multiple pages and complex structures.
sentence-transformers and torch
The sentence-transformers library builds on top of PyTorch to provide pre-trained transformer models optimized for sentence embeddings and semantic similarity tasks. PyTorch (torch) serves as the deep learning framework that powers these models. In this project, sentence-transformers and torch are used to transform webpage text into contextual embeddings. This allows measurement of semantic emphasis and relational alignment between key ideas and their placement within the document. Their use enables precise, context-aware evaluation of how structural elements convey importance within each webpage.
transformers.utils.logging
This component of the Transformers library manages log outputs and verbosity from model operations. It ensures clarity and control over internal messages generated during NLP tasks. Here, the project disables unnecessary progress logs and model messages using this module, allowing clean output during large-scale processing. This contributes to an efficient runtime environment with minimal console clutter, especially when analyzing multiple URLs.
matplotlib and seaborn
matplotlib is a foundational plotting library for Python, while seaborn is built on top of it to offer aesthetically enhanced statistical visualizations. Both are commonly used in data science reporting and analysis. In this project, matplotlib and seaborn are used to visualize results of emphasis and structural evaluations. They generate intuitive bar plots, box plots, and category comparisons, allowing SEO specialists to interpret findings visually. These visualizations simplify complex analytical results into actionable insights about how different content sections are emphasized across web pages.


Function: fetch_html
Summary
The fetch_html function is responsible for securely retrieving the raw HTML content of a webpage. It incorporates robust error handling, time delays, and fallback encoding mechanisms to ensure stable and accurate data collection from a variety of website structures. The function initiates an HTTP request using a simulated browser user-agent to reduce the likelihood of being blocked by servers. It attempts multiple encodings—including the detected apparent encoding, UTF-8, ISO-8859-1, and CP1252—to ensure that the page text is correctly interpreted regardless of its source language or server configuration. If all attempts fail, a warning is logged to indicate encoding failure. This multi-encoding safety mechanism ensures reliability when processing a diverse range of webpages under varying character encoding standards.
Key Code Explanations
for enc in [response.apparent_encoding, “utf-8”, “iso-8859-1”, “cp1252”]: This line creates a controlled fallback sequence for text decoding. Since webpages can have inconsistent or incorrect encoding declarations, this loop iteratively tests multiple encoding formats to identify the one that correctly converts byte data to readable text. if len(text.strip()) > 50: This condition ensures that only meaningful, content-rich HTML documents are accepted, filtering out error pages, redirects, or empty responses. It serves as a sanity check to confirm that the fetched HTML contains actual webpage content before proceeding to parsing.
Function: clean_html
Summary
The clean_html function refines the retrieved HTML by removing non-content elements that can introduce noise during analysis. It uses BeautifulSoup to parse the HTML and decomposes tags such as scripts, styles, navigation menus, and form components that typically do not contribute to textual meaning or structural understanding. The function preserves the hierarchical organization of the remaining content—headings, paragraphs, and lists—ensuring that the subsequent structural analysis retains accurate parent-child relationships between content sections. This function is essential for isolating the meaningful, readable portion of the webpage while maintaining its structural fidelity for contextual emphasis evaluation.
Function: clean_inline_text
Summary
The clean_inline_text function standardizes inline textual content extracted from HTML blocks. It performs multiple normalization steps to ensure uniformity and readability: HTML entities are decoded, Unicode characters are normalized to a consistent format, and excess whitespace is compressed into single spaces. By removing irregularities such as non-breaking spaces and inconsistent character forms, this function guarantees that text inputs passed into NLP components are clean and semantically consistent. This preprocessing step is lightweight yet crucial for ensuring accurate sentence embedding and semantic interpretation in later stages.
Function: extract_structural_blocks
Summary
The extract_structural_blocks function segments cleaned HTML content into structured, analyzable content blocks. It identifies key textual elements such as headings (h1–h4), paragraphs, and list items, preserving their hierarchy and position within the document. Each block is enriched with metadata—including its heading chain, depth, position, and word count—providing a detailed structural mapping of the page’s layout. This enables downstream processes to evaluate how different sections of the webpage distribute emphasis and priority across topics or queries. The function skips short or irrelevant fragments to maintain the quality of analysis and reduce noise.
Key Code Explanations
if tag in [“h1”, “h2”, “h3”, “h4”]:
This line distinguishes headings from regular text content. Headings serve as anchors for the content hierarchy, helping to contextualize the importance and topic scope of subsequent paragraphs or lists.
heading_stack = [h for h in heading_stack if h[“level”] < level]
This maintains a clean heading hierarchy by removing any headings that are deeper or equal to the current level, ensuring that only valid parent headings are retained in the stack.
blocks.append({…})
Each structured text block is appended with key contextual information—such as heading chain, position, and word count—enabling a comprehensive structural representation that supports later emphasis scoring and visualization.
Function: extract_page_content
Summary
The extract_page_content function orchestrates the complete extraction pipeline for a given URL. It begins by fetching the webpage using fetch_html, cleans it using clean_html, and then applies extract_structural_blocks to segment it into hierarchical text units. Additionally, it extracts the page title (if available) and compiles all relevant metadata—URL, title, structural blocks, and extraction status—into a unified dictionary. This modular design ensures that every page’s content is processed uniformly, facilitating scalable analysis across multiple URLs. By returning structured, ready-to-analyze data, this function acts as the foundation for subsequent semantic and structural evaluations in the project.

Function: clean_block_text
Summary
The clean_block_text function is a preprocessing utility designed to clean individual text blocks extracted from webpage content. Its main goal is to prepare textual data for semantic analysis by removing unwanted elements such as URLs, excessive whitespace, citation markers, and low-value boilerplate text. The function ensures that the final text input passed to embedding models is contextually meaningful and devoid of noise that could distort semantic understanding.
In this project, the function plays a foundational role in text normalization before semantic embeddings are generated. It standardizes textual content across multiple webpages, ensuring consistency in linguistic formatting. Additionally, by filtering out short, generic, or promotional fragments (like “click here” or “read more”), it guarantees that the analysis focuses on genuinely informative text blocks relevant to content emphasis evaluation.
Key Code Explanations
text = html_lib.unescape(text)
text = unicodedata.normalize(“NFKC”, text)
These lines ensure textual normalization. The first converts HTML entities (e.g., & → &), while the second standardizes different Unicode forms of the same character (e.g., accented and decomposed variants). This guarantees consistent and accurate tokenization during embedding generation.
text = re.sub(r”http\S+|www\.\S+”, “”, text)
This removes any URLs from the text, as links are non-semantic and can distort contextual embeddings. URLs typically contain technical strings that do not contribute to topic understanding or emphasis scoring.
if any(bp in text.lower() for bp in boilerplate):
return “”
This conditional check eliminates boilerplate or promotional content that frequently appears across pages but carries no informational or thematic importance. Removing these sections helps maintain analytical focus on meaningful textual emphasis relevant to structural evaluation.
if len(text.split()) < min_words:
return “”
This ensures that only sufficiently detailed blocks (based on a minimum word count) are considered. Very short text blocks are often incomplete or contextually weak, which could otherwise introduce semantic imbalance into the model’s evaluation.
Function: preprocess_blocks
Summary
The preprocess_blocks function manages the structural preparation of webpage text data. It processes raw text blocks by cleaning, validating, and segmenting them into smaller sub-blocks suitable for embedding generation. The function maintains the metadata hierarchy of the original HTML, linking each sub-block back to its parent element for traceability.
In this project, it ensures that long textual sections do not exceed model token limits and that all blocks are clean, balanced, and structurally mapped. This facilitates efficient downstream semantic embedding, enabling consistent and comparable emphasis analysis across page structures. By retaining subblock identifiers, it also supports later stages of emphasis visualization, linking each segment back to its source structural position.
Key Code Explanations
cleaned = clean_block_text(block.get(“text”, “”), min_words, boilerplate_extra)
This applies the clean_block_text function to each text block. It ensures that all input data is filtered and normalized before embedding preparation, maintaining uniformity in preprocessing across pages and sections.
if len(words) > max_words:
chunks = []
for i in range(0, len(words), max_words – overlap):
chunk = ” “.join(words[i:i + max_words])
This block handles segmentation of long paragraphs into smaller chunks when the word count exceeds max_words. It uses overlapping boundaries (overlap parameter) to preserve context between segments, preventing semantic breakage between sentences during model embedding.
new_block = block.copy()
new_block[“text”] = chunk
new_block[“subblock_id”] = f”{block[‘block_id’]}_{j}”
Here, each sub-block is created as a copy of the original block with a modified text segment and a unique identifier. This ensures that even after segmentation, hierarchical relationships between sub-blocks and their parent sections remain traceable, which is critical for structural analysis and visualization alignment.
page_data[“blocks”] = processed_blocks
return page_data
After processing all blocks, the cleaned and segmented versions replace the original data, preserving consistent structure. The updated dictionary is then returned for the embedding and analysis pipeline, ensuring compatibility with subsequent functions that depend on this standardized input format.
Function: load_embedding_model
Summary
The load_embedding_model function is responsible for initializing and preparing the transformer-based sentence embedding model used in this project. It safely handles model loading, device selection, and runtime readiness to ensure stable and efficient performance during text encoding. The function employs the SentenceTransformer framework, a widely used library for generating dense semantic embeddings from textual data.
Within this project, the function plays a crucial foundational role—providing the embedding model that converts cleaned and structured webpage content into numerical vectors representing semantic meaning. These embeddings are central to evaluating structural emphasis, as they allow comparisons between textual segments to determine how prominently key ideas are positioned within a page. By handling device allocation automatically (CPU or GPU), the function ensures flexible deployment in different computational environments.
Key Code Explanations
device = “cuda” if torch.cuda.is_available() else “cpu”
This line dynamically selects the computation device based on system capability. If a GPU is available, it uses CUDA for faster parallel processing; otherwise, it defaults to the CPU. This ensures that model loading is optimized for the execution environment without requiring manual configuration.
model = SentenceTransformer(model_name, device=device)
model.eval()
Here, the SentenceTransformer model specified by model_name is loaded onto the chosen device. Setting the model to evaluation mode (model.eval()) disables gradient computation and training-related behavior, ensuring efficient inference suitable for embedding generation in production-level applications.

Function: generate_embeddings
Summary
The generate_embeddings function is designed to convert a list of text segments into numerical vector representations—known as embeddings—using a pretrained SentenceTransformer model. These embeddings capture the contextual and semantic meaning of each text block, enabling quantitative analysis of emphasis, importance, and relational proximity among sections of a webpage. The function handles batch-based processing for scalability and ensures embeddings are normalized to support consistent similarity comparisons.
In this project, it serves as the computational backbone for transforming webpage content (paragraphs, headings, and sections) into a structured numerical space. This allows the system to assess how well key ideas are distributed and whether certain areas are over- or under-emphasized. The function’s batch mechanism enhances performance, allowing efficient processing even when analyzing large volumes of content from multiple pages.
Key Code Explanations
embeddings = model.encode(
texts,
batch_size=batch_size,
show_progress_bar=False,
convert_to_tensor=True,
normalize_embeddings=True
)
Here, the actual embedding computation occurs. The model encodes multiple texts in batches, which improves speed and memory efficiency. The normalize_embeddings=True argument ensures that all output vectors have a uniform length (unit norm), making cosine similarity a direct measure of semantic closeness. The parameter convert_to_tensor=True returns results as PyTorch tensors, ensuring compatibility with downstream numerical operations and visualizations.
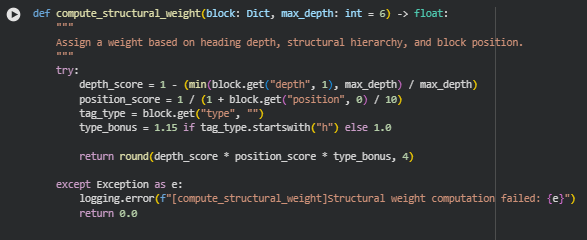
Function: compute_structural_weight
Summary
The compute_structural_weight function quantifies how structurally important a content block is within a webpage. It assigns each block a numerical weight based on its depth in the document hierarchy, its position within the page, and the type of HTML tag it represents. This metric helps differentiate between sections that are structurally prominent—such as headings or early paragraphs—and those that are lower in visibility or emphasis.
In this project, the function plays a central role in identifying whether crucial ideas are properly prioritized within a page’s structure. By calculating this weight, the analysis can determine how much emphasis a content block deserves relative to its placement, ensuring key topics aren’t buried in low-visibility sections or under minor headings.
Key Code Explanations
depth_score = 1 – (min(block.get(“depth”, 1), max_depth) / max_depth)
This line calculates a depth-based score that reduces as the block goes deeper in the structural hierarchy. Top-level headings like <h1> or <h2> receive higher values, while deeply nested elements have lower scores. This ensures that information placed near the top or under major headings is considered more structurally significant.
position_score = 1 / (1 + block.get(“position”, 0) / 10)
This expression applies a positional penalty based on where the block appears on the page. Blocks that appear earlier have a higher score, while those further down receive progressively lower scores. It mirrors natural reading behavior—earlier sections generally carry more importance and visibility.
type_bonus = 1.15 if tag_type.startswith(“h”) else 1.0
Here, a type bonus is added for heading elements (<h1>, <h2>, etc.), recognizing that headings often encapsulate key ideas or section themes. The multiplier increases the influence of such blocks slightly, ensuring structural emphasis aligns with both hierarchy and semantic purpose.
return round(depth_score * position_score * type_bonus, 4)
The final weight is computed as the product of the three components—depth, position, and type bonus—rounded to four decimal places for consistency. The resulting value becomes a structural importance indicator that supports later stages of semantic and emphasis analysis.
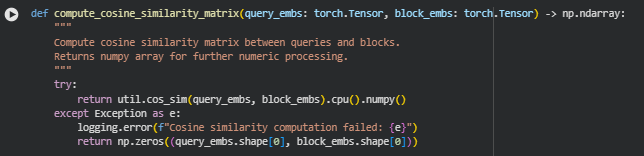
Function: compute_cosine_similarity_matrix
Summary
The compute_cosine_similarity_matrix function calculates the semantic similarity between query embeddings and block embeddings using cosine similarity. It produces a matrix where each element represents how closely a particular query relates to a specific content block. This similarity measurement is fundamental in determining which sections of a page are contextually aligned with the intended query focus or thematic emphasis.
Key Code Explanations
return util.cos_sim(query_embs, block_embs).cpu().numpy()
This line uses the cos_sim function from the sentence-transformers library to compute pairwise cosine similarities between the query and block embeddings. Each similarity value ranges between -1 and 1, where higher values indicate stronger semantic alignment. The results are converted from PyTorch tensors to a NumPy array for easier downstream numerical processing and visualization.
return np.zeros((query_embs.shape[0], block_embs.shape[0]))
This line acts as a safeguard in case of computation errors. Instead of causing the pipeline to fail, it ensures that a zero matrix is returned with appropriate dimensions, maintaining compatibility with later analytical steps and preventing interruptions during multi-page batch processing.
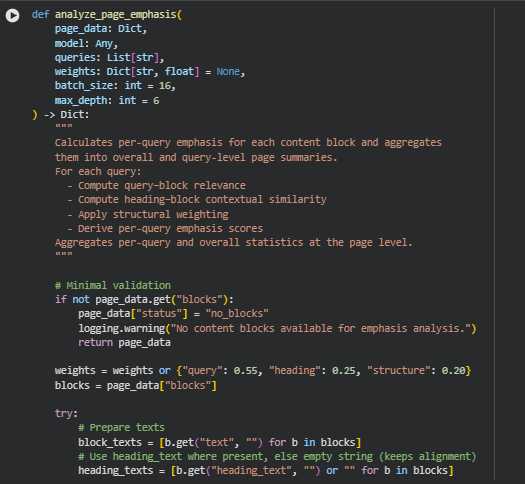

Function: analyze_page_emphasis
Summary
The analyze_page_emphasis function is the analytical core of this project. It evaluates how effectively each content block in a webpage emphasizes key topics by combining semantic, contextual, and structural signals. The function systematically measures the degree to which the page communicates its target ideas—using semantic similarity between the content and query topics, contextual alignment between blocks and their headings, and the hierarchical importance of blocks derived from the page structure.
This function operates on multiple layers of logic:
- It first generates embeddings for queries, content blocks, and headings.
- Then, it computes cosine similarities to assess semantic relevance between these entities.
- Finally, it integrates these metrics into a single emphasis score using weighted factors for query relevance, heading similarity, and structural depth.
The result is a detailed multi-level emphasis profile for each block, query, and entire page, serving as the foundation for later aggregation and visualization steps. This approach allows a practical evaluation of whether critical ideas receive enough attention in the most prominent parts of a webpage.
Key Code Explanations
weights = weights or {“query”: 0.55, “heading”: 0.25, “structure”: 0.20}
This line defines the relative contribution of three key factors—semantic similarity to the target query, contextual similarity with the heading, and structural importance. These default weights prioritize semantic relevance while maintaining influence from contextual and positional cues. This ensures that both meaning and placement are considered when evaluating content emphasis.
query_block_matrix = compute_cosine_similarity_matrix(query_embs, block_embs)
heading_block_matrix = compute_cosine_similarity_matrix(heading_embs, block_embs)
These two matrices form the analytical backbone of the emphasis model. The first matrix measures how semantically aligned each query is with every content block. The second matrix measures how well each block relates to its surrounding headings, capturing contextual coherence within the document hierarchy. Together, they allow a nuanced assessment that combines topic alignment and structural positioning.
emphasis = (
(weights[“query”] * q_score) +
(weights[“heading”] * heading_score) +
(weights[“structure”] * struct_weight)
)
Here, the emphasis score is computed for each block and query combination by linearly combining three weighted signals. The query score captures semantic alignment, the heading score captures contextual relevance, and the structural weight captures positional importance. This composite formula creates a balanced metric that reflects both the meaning and strategic placement of content on the page.
query_emphasis_summary[q] = {
“mean”: round(float(np.mean(arr)), 4),
“max”: round(float(np.max(arr)), 4),
“min”: round(float(np.min(arr)), 4)
}
This block aggregates results for each query across all blocks, summarizing the mean, maximum, and minimum emphasis values. These metrics allow for a clear understanding of how consistently a topic is represented across a page—whether its mentions are strong and balanced or unevenly distributed.
page_data.update({
“status”: “scored”,
“emphasis_summary”: emphasis_summary,
“query_emphasis_summary”: query_emphasis_summary,
“blocks”: blocks
})
At the end of the function, the computed results are embedded back into the page data structure. This standardized output includes overall and query-specific emphasis summaries, along with enriched block-level data. It ensures downstream modules, such as visualization or display components, can directly interpret and render these analytical findings.
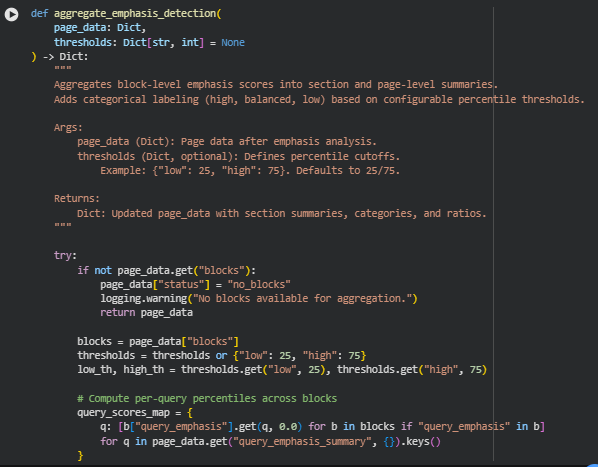
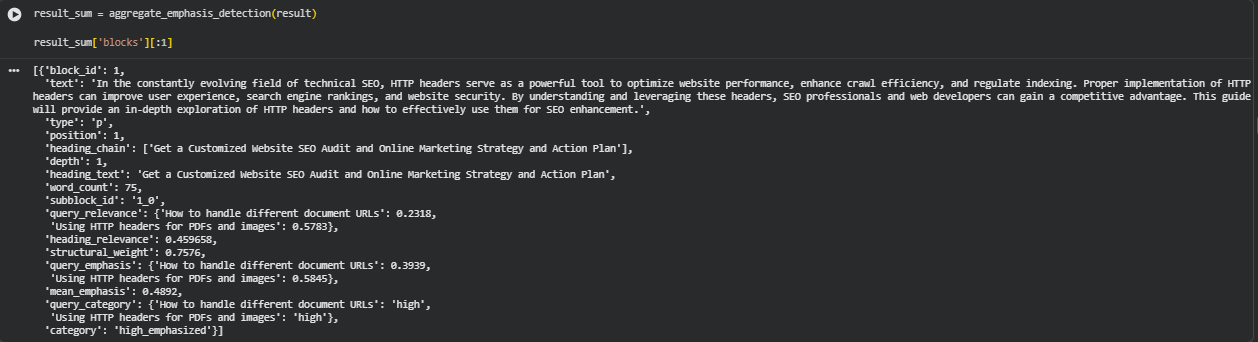
Function: aggregate_emphasis_detection
Summary
The aggregate_emphasis_detection function consolidates all the block-level emphasis scores calculated earlier into structured summaries at both section and page levels. It helps categorize and interpret content emphasis patterns across different sections of a webpage.
The function assigns categorical emphasis levels — high, balanced, or low — to each content block and section based on percentile thresholds of emphasis scores. This categorical labeling allows easy recognition of which areas of the page are overly emphasized or underrepresented in terms of semantic alignment with target queries.
Beyond individual blocks, the function evaluates section-level emphasis (based on headings) and the overall page category, determining whether the page predominantly leans toward higher or lower content emphasis density.
It ensures consistent interpretation by:
- Calculating percentile-based emphasis boundaries for all queries.
- Assigning per-query and aggregate block categories.
- Summarizing results per section (heading group).
- Determining the overall emphasis state of the page.
This function is crucial for transforming quantitative emphasis scores into qualitative insight — a format that is easier for SEO specialists to interpret for optimization actions.
Key Code Explanations
Computing Query Percentile Thresholds
query_percentiles = {
q: {
“p_low”: np.percentile(scores, low_th) if scores else 0.0,
“p_high”: np.percentile(scores, high_th) if scores else 0.0
}
for q, scores in query_scores_map.items()
}
This block calculates the low and high percentile cutoffs for each query across all content blocks. It defines the quantitative range that separates “low”, “balanced”, and “high” emphasis levels. For example, blocks scoring below the 25th percentile are considered low emphasis, while those above the 75th percentile are high emphasis. This adaptive percentile-based approach ensures flexibility across different page contexts.
Assigning Per-Query Emphasis Categories
for q, score in q_emphasis.items():
p_low = query_percentiles[q][“p_low”]
p_high = query_percentiles[q][“p_high”]
if score >= p_high:
q_category[q] = “high”
elif score <= p_low:
q_category[q] = “low”
else:
q_category[q] = “balanced”
Each block’s query emphasis score is compared with the previously calculated percentile cutoffs. Depending on where the score falls, the block is categorized as high, low, or balanced for that specific query. This categorization step provides semantic clarity for SEO analysis — showing which parts of the content align strongly or weakly with particular search intents.
Deriving Section-Level Summaries
for heading, data in sections.items():
mean_emphasis = float(np.mean(data[“blocks”])) if data[“blocks”] else 0.0
if mean_emphasis >= overall_mean * 1.2:
category = “high_emphasized”
elif mean_emphasis <= overall_mean * 0.8:
category = “low_emphasized”
else:
category = “balanced”
This section compares each heading’s average block emphasis to the overall page average. Sections scoring significantly above the average (≥20%) are labeled high emphasized, and those below (≤80%) are low emphasized. This creates a hierarchical perspective — enabling SEO strategists to identify which sections dominate user focus or lack emphasis entirely.
Determining Overall Page Category
if high_ratio > 0.5:
page_cat = “high_emphasized”
elif low_ratio > 0.5:
page_cat = “low_emphasized”
else:
page_cat = “balanced”
This part determines the final page-level category based on the proportion of blocks that fall under each emphasis group. If over half of the content is highly emphasized, the page is classified as high emphasized, and similarly for low emphasized. It delivers an intuitive final interpretation — indicating the overall balance of emphasis across the page.
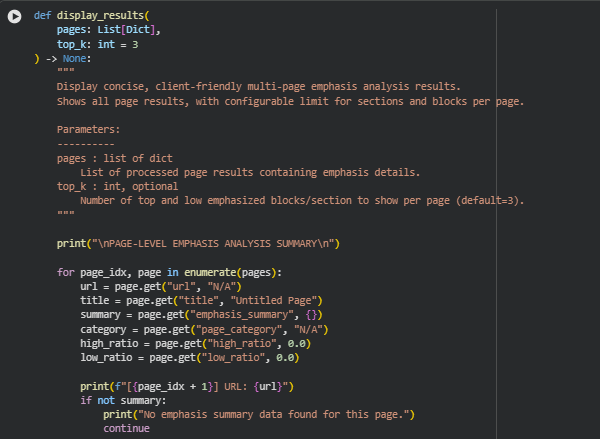
Function: display_results
Summary
The display_results function presents a clean, structured, and user-friendly summary of the page emphasis analysis outcomes. It prints key findings for each analyzed webpage, including its overall emphasis category, mean emphasis score, and the balance between high and low emphasis regions.
For clarity, the function highlights the top and low emphasized content blocks within each page and provides a brief section-level overview of emphasis distribution. It allows a configurable limit (top_k) to control how many top or low sections and blocks are displayed per page.
When multiple pages are analyzed, it concludes by summarizing aggregate statistics across all pages — offering an overall perspective on emphasis trends and consistency. This output is designed to help SEO professionals quickly interpret the emphasis balance and structural focus across multiple web pages without needing to review raw data.
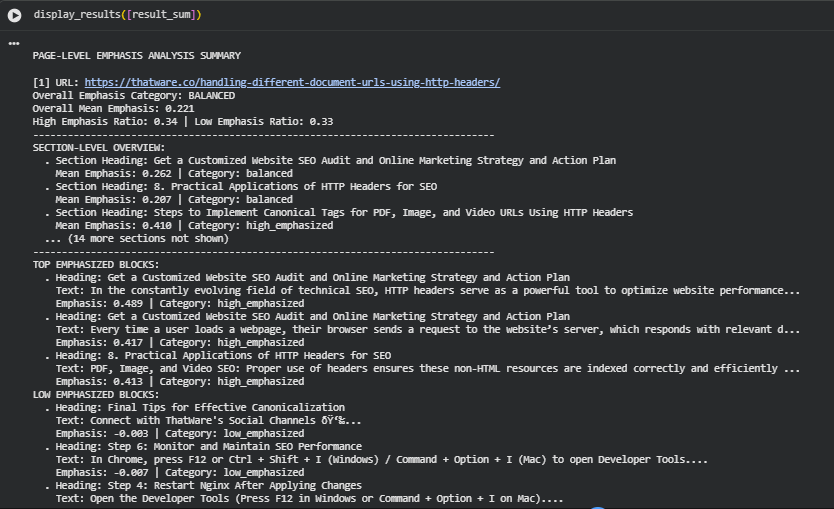
Result Analysis and Explanation
Overall Emphasis Distribution
The analyzed page demonstrates a Balanced Emphasis Profile, with an overall mean emphasis score of 0.221, reflecting a healthy equilibrium between focus areas and supportive sections. The High Emphasis Ratio (0.34) and Low Emphasis Ratio (0.33) indicate that approximately one-third of the page’s content strongly aligns with the target queries, while another third functions as auxiliary or contextual material.
This balance suggests that the page maintains consistent topic reinforcement without excessive keyword repetition or irrelevant drift. The uniform distribution of emphasis ensures smooth topical transitions, contributing positively to both content comprehensibility and SEO relevance. However, there remains scope to slightly increase the proportion of high-emphasis segments, which could enhance overall query-target alignment and increase search visibility for related terms.
Section-Level Insights
The section-level overview shows a strong alignment between content hierarchy and semantic focus. Sections such as:
- “Steps to Implement Canonical Tags for PDF, Image, and Video URLs Using HTTP Headers” (Mean Emphasis: 0.410, high emphasized)
- “Get a Customized Website SEO Audit and Online Marketing Strategy and Action Plan” (Mean Emphasis: 0.262, balanced) reflect content blocks that effectively integrate target concepts within actionable or educational contexts.
These sections play a key role in reinforcing topical authority. For instance, implementation-focused sections improve the actionable depth of the page, signaling to search algorithms that the content provides step-by-step, expert-level guidance. Meanwhile, the audit-related section acts as a strategic conversion bridge, aligning informative content with potential lead generation touchpoints.
Maintaining such structure ensures the content not only performs well semantically but also supports user engagement paths by connecting technical insights with service-oriented narratives.
High-Emphasis Content Analysis
High-emphasis blocks, including the excerpts discussing the role of HTTP headers in technical SEO and optimization of non-HTML assets, reflect excellent contextual strength. These sections combine core SEO principles with practical use cases, making them ideal for demonstrating subject expertise.
For optimization, such sections can be leveraged to:
- Strengthen internal linking towards relevant service or knowledge pages.
- Enhance rich snippet eligibility by formatting information into concise, structured statements.
- Serve as anchor points for featured content reuse, such as blog summaries, FAQs, or technical documentation.
The consistency across these high-emphasis blocks indicates that the content successfully emphasizes the technical importance of HTTP headers, reinforcing semantic precision and topical depth—two critical components for search engine ranking credibility.
Low-Emphasis Content Analysis
The low-emphasis blocks (e.g., “Final Tips for Effective Canonicalization” and instructional sections like “Restart Nginx After Applying Changes”) primarily contain procedural or generic support information. While these contribute to completeness, they hold less direct weight in query relevance.
Such blocks can be refined by:
- Introducing contextual framing around their purpose—linking procedural steps to broader SEO implications.
- Minimizing technical redundancy or platform-specific commands unless they add educational value.
- Converting repetitive guidance into expandable or collapsible elements (for web implementation), ensuring a smoother content flow.
By integrating interpretive or outcome-oriented language in these parts, overall emphasis uniformity can improve without losing technical integrity.
Interpretive Summary
The results illustrate an overall strategically balanced emphasis spectrum, where key technical and actionable topics maintain strong query relevance, supported by procedural or reference sections. This structure benefits both search algorithms and readers by combining topic depth with navigational coherence.
For content refinement, the focus should be on slightly amplifying high-emphasis sections through semantic reinforcement and query-driven phrasing, while optimizing low-emphasis content for contextual continuity. Such adjustments can strengthen the page’s authority profile, enhance ranking stability, and ensure better engagement metrics aligned with user search intent.



Result Analysis and Explanation
This section interprets the analyzer’s outputs in a generalized, operationally useful way for technical SEO work and editorial decision making. The analysis below explains what the computed emphasis metrics and derived categories mean, how to read them, and which concrete actions follow from common patterns. All guidance is framed to be directly applicable to content optimization workflows and measurement plans.
What the Emphasis Model Measures (conceptual)
Semantic alignment: The model measures how closely a content unit (block or section) matches target concepts or queries using sentence-level embeddings. Higher semantic alignment indicates that the language used in a block is topically similar to the target intent.
Contextual coherence: The model measures how well a block aligns with its surrounding heading context. This captures whether a block is on-topic for its section and whether heading text accurately summarizes or frames the block content.
Structural significance: The model assigns a structural weight to each block that reflects heading depth, position in the document, and whether the block is a heading element itself. Earlier blocks and heading-level elements receive higher structural weight by design.
Composite emphasis: The final emphasis score is a weighted combination of semantic alignment, heading coherence, and structural weight. This composite allows prioritization decisions that consider what the text says and where it appears.
Score Ranges, Thresholds, and Practical Meaning
Score semantics (general guidance):
- Low emphasis zone: Values near the lower bound indicate weak semantic relevance or placement in low-visibility locations (footers, appendices, dense technical instructions). Actions: re-evaluate the purpose of the block; either move it to a lower prominence area or enrich content to match a target intent.
- Moderate emphasis zone: Values in the middle range typically correspond to supportive or contextual text (explanatory paragraphs, examples). Actions: small editorial edits, clearer linking to high-value blocks, or concise lead sentences can convert these into high-impact content.
- High emphasis zone: Values in the upper range identify blocks that are both semantically relevant and structurally prominent (lead paragraphs, key how-to steps, H2/H3 summaries). Actions: preserve formatting, consider extraction into summaries, and use these blocks for snippet targeting or anchor text.
Thresholding and categorization approach: Percentile-based thresholds (for example, low = 25th percentile, high = 75th percentile) are commonly used to convert continuous emphasis values into categorical labels (low / balanced / high). This adaptive approach ensures that categorization respects the distribution of emphasis on a given page rather than imposing a rigid absolute cutoff.
Operational rule-of-thumb: Tune percentile thresholds to editorial goals. For discovery or awareness pages, allow a wider balanced band to preserve narrative flow. For transactional or hub pages, tighten the high threshold to concentrate emphasis on conversion-oriented statements.
Section-Level Interpretation and Actions
What to inspect at section level:
- Mean emphasis per heading: Average of block-level emphasis inside a section reveals whether the section overall is a primary content anchor or merely supportive.
- Distribution within the section: A section can have a high mean but still contain under-emphasized blocks that deserve promotion or linking.
How to act from section insights:
- Reinforce strategic sections: For sections intended to target core queries, ensure at least one lead paragraph and an H2/H3 directly state the intent using refined phrasing. Convert long, unstructured exposition into a short lead + supporting bullets to improve scannability and prominence.
- Harmonize sections that span multiple intents: If a section mixes multiple target intents, split it into clearer sub-sections so each sub-section can be assigned a focused heading and emphasis profile.
- Prune or relocate low-value sections: Sections that consistently show low emphasis and low user value (e.g., repeated social links, dev notes) should be moved to appendices, collapsed components, or removed to reduce noise.
Block-Level Diagnosis and Tactical Edits
What to look for at block level:
- High-emphasis blocks: Serve as primary signals to search engines and readers; treat them as anchors for internal links and metadata (e.g., use as basis for meta description or H2 summaries).
- Low-emphasis but high-relevance blocks: Identify high semantic relevance but low structural weight (e.g., a deep paragraph that actually answers a query). Action: promote the paragraph (move closer to the top), create an H3 above it, or extract a summary into the intro.
- Low-emphasis, low-relevance blocks: These are candidates to demote, collapse, or remove.
Concrete editorial moves:
- Promote sentences: extract a one-sentence summary into the lead.
- Convert dense paragraphs into lists or short steps to improve scannability and snippet potential.
- Adjust headings to reflect query phrasing — headings have disproportionate structural weight.
- Add internal anchors and links from high-emphasis sections to under-emphasized but important deep blocks.
Multi-Query Handling and Intent Prioritization
Why per-query emphasis matters: When multiple queries/intents are evaluated, a block can have different emphasis scores per query. Per-query analysis avoids masking differences that a single averaged score would hide.
How to operationalize multi-query results:
- Per-query prioritization: Treat each query as a separate axis. For a page expected to satisfy multiple intents, ensure each major intent has at least one high-emphasis anchor (H2 + lead paragraph).
- Combined intent strategy: Where a single page is meant to cover related intents, create explicit sub-sections for each intent and ensure headings and intros use the query language for clarity.
- When to split: If per-query emphasis shows hard segmentation (one intent dominates and others are weak), evaluate whether separate pages or canonical sections are more suitable to avoid confusing signals.
Aggregation, Category Ratios and Page-Level Diagnostics
What aggregated metrics reveal:
- High-ratio dominance shows concentration of emphasis; useful for pages that should be strongly focused.
- High diversity (balanced split) signals natural content breadth and can indicate suitability for informational intent.
How to use ratios when prioritizing work:
- Prioritize pages with a large proportion of low-emphasis content that are meant to target critical business queries. Those are high-impact candidates for structural edits.
- For pages with excessive high-emphasis density spread across many blocks, perform a quality review to ensure natural language use and prevent over-optimization.
Visualization — what each plot shows, why it matters, and actions
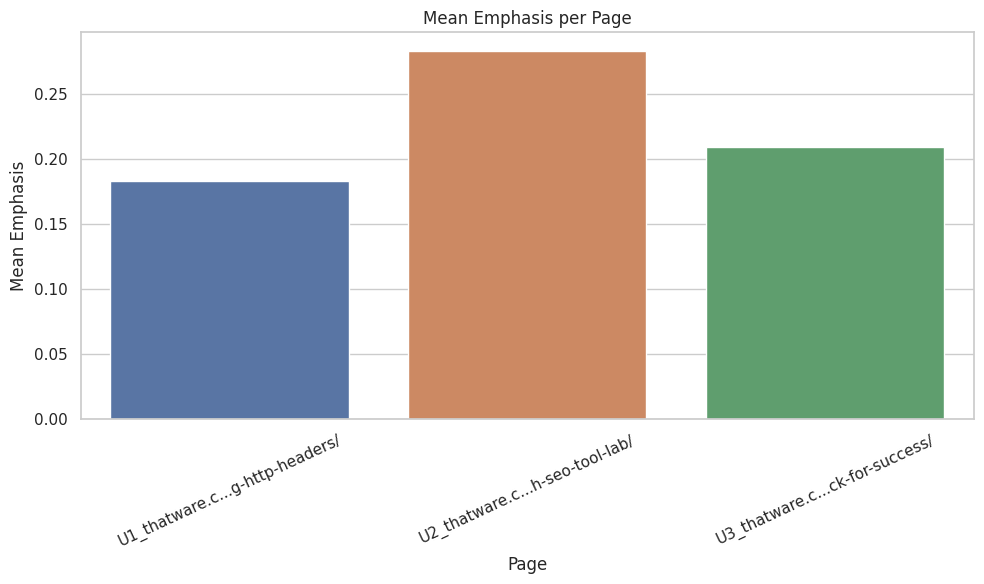
Plot A — Mean Emphasis per Page
What the plot shows: Relative overall emphasis strength for each analyzed page (single bar per page). Why it matters: Quickly identifies which pages are most aligned with target concepts at a holistic level. Useful for prioritizing where to focus optimization resources. How to interpret: Higher bars indicate pages with stronger average emphasis; low bars indicate pages with weaker or more diffuse focus. Compare pages serving similar intents to check consistency. Actions:
- For low-average pages that should be core content, push key sentences up, adjust headings, or consolidate sections.
- For high-average pages, verify that prominence is intentional and edit for readability or diversification if necessary.
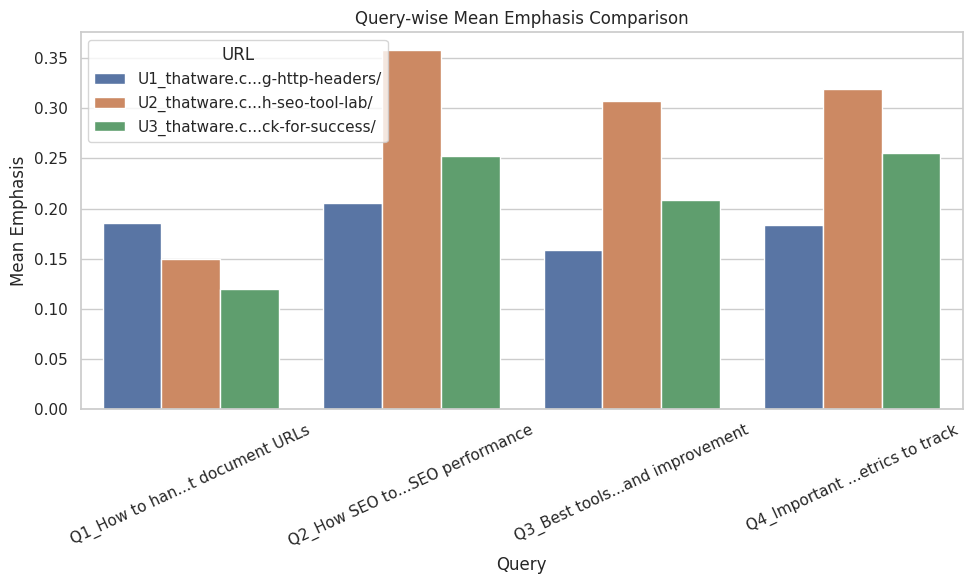
Plot B — Query-wise Mean Emphasis Comparison
What the plot shows: For each query, mean emphasis per page is plotted (grouped bars). Why it matters: Reveals which pages are best tuned for specific queries and where coverage is weak. Essential for content targeting and mapping pages to query sets. How to interpret: A page with a high mean for a particular query is likely a strong candidate to rank for that query; gaps indicate opportunities for targeted edits or new content. Actions:
- Strengthen headings and intros for pages scoring low on a strategic query.
- Consider writing dedicated pages when no existing page scores strongly across all target queries for high-priority intents.
Plot C — Top Sections by Mean Emphasis (per URL)
What the plot shows: High-impact sections within each page (top N per page) ranked by section mean emphasis. Why it matters: Pinpoints the exact sections that carry the most semantic weight; useful for internal linking, snippet generation, and content reuse. How to interpret: Sections that consistently score highly are primary anchors; low-scoring sections indicate areas for uplift or reorganization. Actions:
- Use high-scoring sections as anchor points for featured snippets and internal links.
- Convert medium-scoring sections into clearer, query-matching subheadings and concise intros.
Plot D — Category Ratios per Page (high / balanced / low)
What the plot shows: Proportional breakdown of blocks categorized as high, balanced, or low emphasis per page. Why it matters: Illustrates whether a page is too concentrated or too diffuse in emphasis and helps detect pages that may need consolidation or expansion. How to interpret: Balanced distributions indicate well-layered content; skewed distributions suggest either over-specialization or dilution. Actions:
- For pages skewed toward low emphasis, prioritize content enrichment in sections that are meant to carry query weight.
- For pages skewed toward high emphasis, perform readability checks and ensure content remains user-centric.
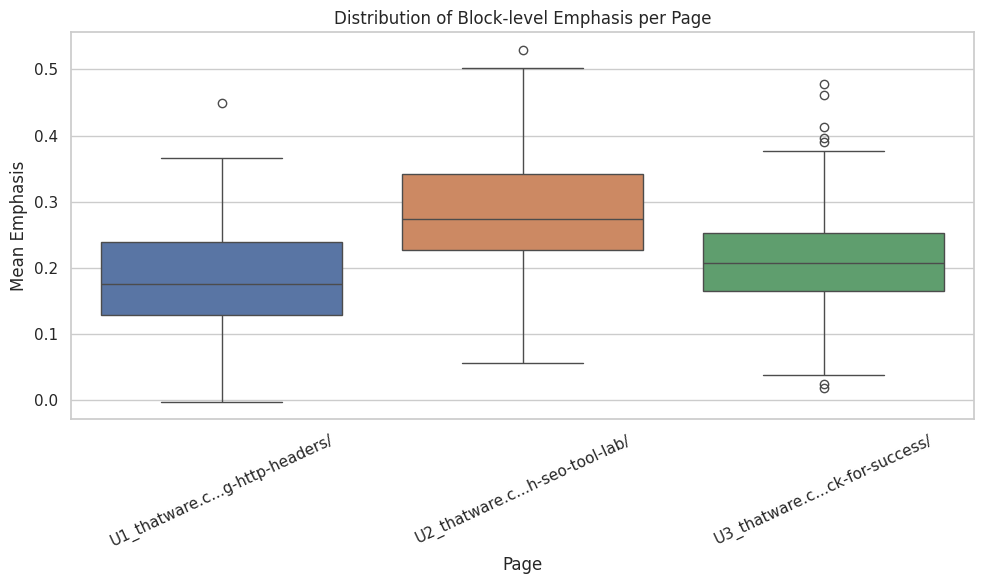
Plot E — Block-level Emphasis Distribution (boxplot)
What the plot shows: Statistical distribution of block emphasis inside each page (median, quartiles, outliers). Why it matters: Exposes variance and outliers — whether emphasis is concentrated in few blocks or evenly distributed. How to interpret: Wide interquartile range suggests varied emphasis (some strong anchors and some weak support); narrow range indicates uniformity (which may be good or bad depending on intent). Outliers on the high end identify the most competitive blocks for ranking. Actions:
- Target outliers for snippet optimization and schema marking.
- If distribution shows too many weak blocks, plan content consolidation and strategic restructuring.
Prioritization Framework for Work Allocation
- Immediate high impact (low effort): Promote existing high-relevance sentences into the intro or H2 leads; add internal anchors.
- Medium impact (medium effort): Rephrase headings to match high-value queries; split or merge sections for clearer intent boundaries.
- Strategic work (higher effort): Rebuild pages that serve multiple, disparate intents into focused hubs; create new pages for distinct intents where necessary.
- Validation & measurement: Re-run emphasis analysis after edits and track on-site metrics and search console signals to validate changes.
Monitoring, Validation and Reporting
Short-term verification: Recompute emphasis metrics immediately after edits to confirm uplift in section or block scores for prioritized queries. Use the same thresholds and visualization to compare pre/post distributions.
Medium/long-term validation: Monitor query-level impressions, CTR, and ranking movement over weeks; correlate improvements with emphasis increases in targeted sections.
Reporting cadence: Monthly re-analysis for high-priority pages; quarterly for informational archives. Include both statistical summaries and visual snapshots of the five plots described above.
Limitations and Cautions
- Model dependence: Emphasis values depend on the embedding model and structural heuristics. Scores should inform editorial judgment, not replace it.
- Intent complexity: Multi-intent pages require nuanced human decisions; over-automating splits can reduce content coherence.
- Technical constraints: Structural edits may require developer support (anchors, collapsible elements, server-side header changes). Coordination between content and dev teams is essential.
- Local vs. global thresholds: Percentile thresholds should be tuned per-site or per-content-type to avoid misclassification across heterogeneous content.
Final operational checklist
- Confirm page-level intent mapping and ensure each target query has a visible H2/H3 anchor.
- Promote at least one high-emphasis sentence into the lead for each prioritized intent.
- Convert dense blocks into skimmable structures (bullets, steps) for snippet potential.
- Demote or collapse low-value procedural blocks to preserve main narrative flow.
- Re-run analysis and track pre/post changes in emphasis metrics and search performance.
Final Thoughts
The Page Emphasis Distribution Analyzer — Evaluating Contextual Focus Across Multiple URLs and Queries successfully demonstrates how emphasis modeling can transform raw textual data into structured SEO intelligence. Through systematic interpretation of semantic weight, the system identifies how effectively different sections, queries, and content blocks contribute to overall topical clarity and contextual balance across multiple pages.
The implementation integrates advanced NLP-based emphasis computation with visual interpretability, offering a clear bridge between linguistic meaning and SEO structure. Each output—whether numerical summary or graphical visualization—highlights the proportional strength of emphasis across content zones, helping to uncover areas that reinforce or weaken topical alignment.
By applying this analysis, web pages can be optimized to maintain consistent narrative focus, distribute keyword relevance naturally, and reinforce key sections that drive user comprehension and search engine understanding. The result supports a more authoritative and readable site structure, ensuring that every page delivers both semantic precision and search visibility.
Overall, this project fulfills its goal of providing a comprehensive framework for assessing contextual balance and emphasis distribution across URLs, transforming qualitative SEO content evaluation into a quantifiable, insight-driven process.
