SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
What is XPath?
XML Path (XPath) is a query language developed by W3 to navigate XML documents and select specified nodes of data. This definitive XPath SEO guide will help you understand the entire architecture in terms of SEO.
XPath (XML Path Language) is a query language used for navigating and selecting nodes in XML (Extensible Markup Language) documents. Developed by the World Wide Web Consortium (W3C), XPath provides a standardized way to locate and retrieve specific elements or attributes within an XML document.
In the context of Search Engine Optimization (SEO), Custom Extraction Screaming Frog plays a crucial role in data extraction and analysis from web pages. SEO professionals utilize XPath to pinpoint relevant elements within HTML documents, such as meta tags, headings, URLs, and structured data markup. This allows them to gather valuable insights into a website’s structure, content organization, and metadata, which are vital for optimizing the site’s visibility in search engine results.
XPath expressions consist of a combination of axes, node tests, and predicates, allowing users to traverse the hierarchical structure of XML documents and target specific nodes based on their properties or relationships with other nodes. This flexibility enables precise data extraction and manipulation, facilitating tasks like competitor analysis, content auditing, and keyword research in the field of SEO.
Overall, XPath serves as a powerful tool for SEO practitioners, enabling them to extract, analyze, and interpret data from web pages effectively, thereby informing strategic decisions to improve search engine rankings and enhance online visibility.

Use of XPath in SEO
This option allows you to scrape data by using XPath selectors, including attributes. XPath (XML Path Language) is a powerful tool in the realm of Search Engine Optimization (SEO), primarily employed for web scraping and data extraction. SEO professionals leverage XPath selectors to precisely locate and extract specific elements from HTML or XML documents, facilitating in-depth analysis of websites, competitor research, and content optimization.
One of the key applications of Custom Extraction Screaming Frog is in the extraction of critical SEO elements such as meta tags, headings, URLs, and structured data markup. By targeting these elements with XPath selectors, SEO practitioners can gather valuable insights into a website’s structure, content hierarchy, and semantic markup, which are crucial factors in search engine ranking algorithms.
Moreover, XPath enables the extraction of attributes associated with HTML elements, providing additional context and metadata for SEO analysis. For instance, extracting the “alt” attribute from image tags helps assess the optimization of images for search engines, while gathering “href” attributes aids in evaluating the quality of backlinks.
In summary, XPath is an indispensable tool in the SEO toolkit, offering precise data extraction capabilities essential for comprehensive website analysis, competitive intelligence, and strategic optimization efforts. By harnessing XPath selectors effectively, SEO professionals can gain deeper insights into website performance, enhance visibility in search results, and drive organic traffic growth.
How to Find XPath For a Website
Easiest way to find XPath is using Chrome’s Inspect Tool. Here’s how:
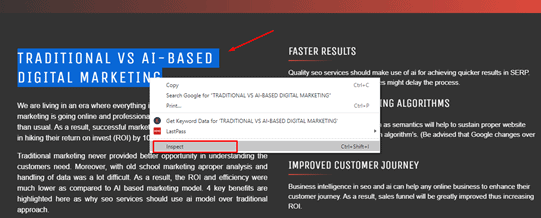
Select desired section of the website for which you want to find the XPath, then right click on it and select Inspect.
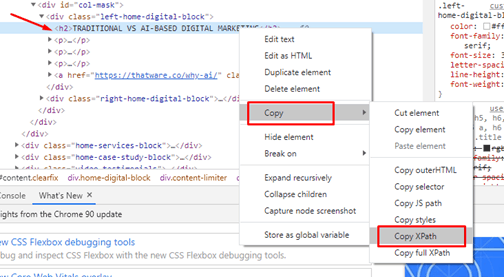
Once you have the source, then you can right click an element and select Copy > Copy XPath.
🔶 Then Run Screaming Frog Tool
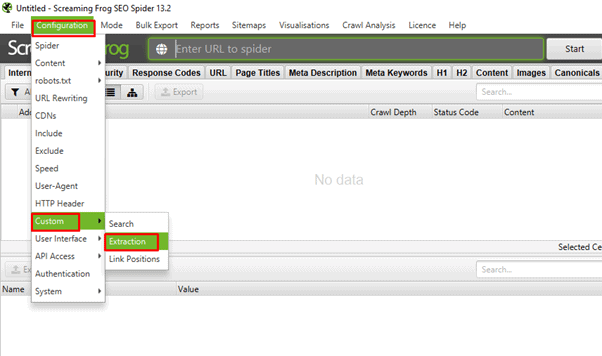
From the top menu navigation, select Configuration > Custom > Extraction
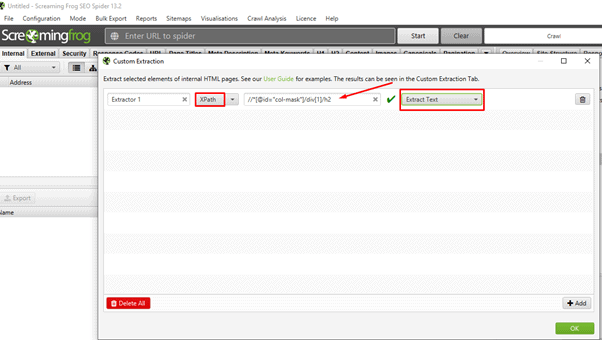
🔶 Then paste the copied element in the XPath section as shown in the above screenshot and make sure the option should be selected as Extract Text.
🔶 Next, crawl the website on Screaming Frog.
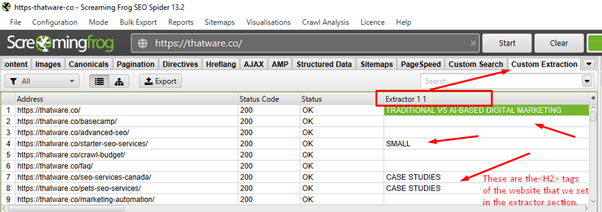
After that, view the scraped data under the Custom Extraction Tab which we set on the previous section in the Extractor 1. We picked the <H2> section of the site to get the details of scrapped data.
X Path Cheat Sheet
Basic Xpaths
| ELEMENT | XPATH FOR SCREAMING FROG | EXTRACTION |
| Any element | //* | Extract Text |
| Any <p> element | //p | Extract Text |
| Any <div> element | //div | Extract Text |
| Any element with class “example” | //*[@class=’example’] | Extract Text |
| The whole webpage | /html | Extract Inner HTML |
| All webpage body | /html/body | Extract Inner HTML |
| All text | //text() | Extract Text |
| All links | //@href | Extract Text |
| Links with specific anchor text “example” | //a[contains(., ‘example’)]/@href | Extract Text |
| Email Addresses | //a[starts-with(@href, ‘mailto’)] | Extract Text |
Elements can have different classes and IDs, however, there are usually some basic XPaths you can scrape that account for most site formatting.
XPath for SEO
| ELEMENT | XPATH | EXTRACTION |
| H3 | //h3 | Extract Text |
| H3 with specific text “example” | //h3[contains(text(), “example”)] | Extract Text |
| Count of H3s | count(//h3) | Function |
| Full hreflang (link + value) | //*[@hreflang] | Extract Text |
| Hreflang values | //*[@hreflang]/@hreflang | Extract Text |
| Types of Schema | //*[@itemtype]/@itemtype | Extract Text |
| Schema itemprop rules | //*[@itemprop]/@itemprop | Extract Text |
XPath offers several benefits for SEO practitioners:
- Precise Data Extraction: XPath allows precise targeting of specific elements and attributes within HTML documents, enabling SEO professionals to extract relevant data such as meta tags, headings, URLs, and structured data markup with accuracy.
- Competitor Analysis: XPath facilitates the extraction of competitor website data, including keywords, content structure, and metadata. This information helps SEO professionals benchmark their strategies against competitors and identify areas for improvement.
- Content Auditing: With XPath, SEO professionals can audit website content to ensure it aligns with SEO best practices, including keyword optimization, heading structure, and metadata completeness. This enables them to identify content gaps and opportunities for optimization.
- Structured Data Markup: Screaming Frog Web Scraping is instrumental in extracting structured data markup, such as Schema.org markup, from web pages. This data provides search engines with additional context about the content, improving the chances of rich snippets and enhanced search results.
- Custom Data Collection: XPath allows for custom data collection tailored to specific SEO analysis needs. Whether it’s extracting backlink URLs, image alt text, or internal linking structure, XPath provides the flexibility to gather the required data efficiently.
- Automation: XPath can be integrated into automated scraping and data analysis tools, streamlining repetitive SEO tasks and saving time for SEO professionals. Automation enhances efficiency and scalability in managing SEO campaigns and projects.
- Insights for Optimization: By extracting and analyzing data using XPath, SEO professionals gain valuable insights into website performance, user experience, and search engine visibility. These insights inform optimization strategies aimed at improving rankings, increasing organic traffic, and enhancing overall website visibility.
In summary, XPath for SEO offers precision, efficiency, and customization in data extraction and analysis, empowering SEO professionals to make informed decisions and drive tangible improvements in search engine performance.
Future Trends and Developments in XPATH SEO Data Scraping
A. Emerging technologies and tools for advanced data extraction
With the rapid evolution of technology, data extraction techniques are also advancing to meet the growing demands of SEO professionals. Several emerging technologies and tools are poised to revolutionize the field of data scraping, offering more efficient and precise methods for extracting valuable insights from websites.
- Headless Browsers: Headless browsers like Puppeteer and Selenium WebDriver are gaining popularity for their ability to interact with web pages like a real user. These browsers can execute JavaScript, render dynamic content, and navigate through complex website structures, making them ideal for data scraping tasks that involve dynamic content.
- Natural Language Processing (NLP): NLP technologies are being integrated into data scraping tools to enhance their ability to understand and interpret textual content. By employing NLP algorithms, these tools can extract semantic meaning from web pages, enabling more accurate analysis of content and context.
- API-Based Scraping Solutions: As websites become more sophisticated in their design and implementation, traditional scraping methods may encounter limitations or obstacles. API-based scraping solutions offer an alternative approach by directly accessing structured data through APIs provided by websites, bypassing the need for HTML parsing and XPATH extraction.
- Distributed Scraping Systems: To handle large-scale data scraping tasks efficiently, distributed scraping systems are being developed to distribute the workload across multiple servers or nodes. These systems can parallelize data extraction processes, significantly reducing the time and resources required for scraping large volumes of data.
B. Impact of AI and machine learning on automated data scraping
AI and machine learning technologies are transforming the landscape of automated data scraping, enabling more intelligent and adaptive scraping algorithms that can learn from data patterns and user interactions. The impact of AI and machine learning on data scraping extends to various aspects of the process, including data extraction, preprocessing, analysis, and interpretation.
- Enhanced Data Extraction Accuracy: AI-powered data scraping algorithms can leverage machine learning models to improve the accuracy of data extraction from web pages. By training on large datasets of labeled examples, these algorithms can learn to recognize and extract relevant information more effectively, even in the presence of noise or variability in the data.
- Dynamic Content Handling: Machine learning techniques enable data scraping tools to adapt to changes in website layouts and structures. These tools can learn to identify and parse dynamic elements such as AJAX-loaded content, infinite scrolling, and single-page applications, ensuring robust data extraction capabilities across a wide range of websites.
- Semantic Data Analysis: AI-driven data scraping solutions can perform semantic analysis on extracted data to uncover deeper insights and patterns. By applying natural language processing (NLP) and machine learning algorithms, these solutions can extract entities, sentiments, and relationships from textual content, enabling more sophisticated data analysis and interpretation.
- Automated Error Handling and Optimization: Machine learning algorithms can be utilized to automatically detect and handle errors or anomalies encountered during the scraping process. These algorithms can learn from past experiences and adjust scraping parameters dynamically to optimize performance and reliability.
C. Predictions for the future of XPATH in SEO and web data analysis
XPATH, as a powerful tool for data extraction and manipulation, is expected to remain a fundamental component of SEO and web data analysis workflows in the future. While advancements in technology and methodologies may introduce new approaches to data scraping, XPATH is likely to continue playing a crucial role in extracting structured data from web pages for SEO purposes.
- Integration with Advanced Technologies: XPATH is likely to be integrated with emerging technologies such as AI, machine learning, and natural language processing to enhance its capabilities for SEO and web data analysis. By combining XPATH with these advanced technologies, SEO professionals can unlock new possibilities for extracting, analyzing, and leveraging web data.
- Continued Relevance in Complex Web Environments: Despite the emergence of alternative data scraping techniques, XPATH is expected to remain relevant for extracting structured data from complex web environments. Its ability to navigate through HTML documents and identify specific elements based on their hierarchical relationships makes it well-suited for scraping data from diverse websites.
- Standardization and Best Practices: As the field of web scraping continues to evolve, standardization efforts and best practices for using XPATH in SEO and web data analysis are likely to emerge. SEO professionals may develop standardized XPATH patterns and conventions for common scraping tasks, facilitating collaboration and knowledge sharing within the community.
- Adaptation to Evolving Web Technologies: XPATH is expected to evolve in response to changes in web technologies and practices, such as the adoption of new HTML standards, JavaScript frameworks, and content delivery mechanisms. SEO professionals will need to stay abreast of these developments and adapt their XPATH strategies accordingly to ensure effective data extraction and analysis.
Therefore, the future of XPATH in SEO and web data analysis looks promising, with ongoing advancements in technology, methodologies, and best practices expected to further enhance its capabilities and relevance. By embracing emerging technologies, leveraging AI and machine learning, and staying informed about evolving web trends, SEO professionals can harness the full potential of XPATH for extracting valuable insights and driving success in their SEO efforts.
Conclusion
When the progress bar reaches ‘100%’, the crawl has finished and you can choose to ‘export’ the data using the ‘export’ buttons.
Here in this XPath SEO guide analysis, we have extracted the headings (H2) of the site as shown in the exported excel screenshot:

