SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
A Gaussian Mixture Model (GMM) is a machine learning technique used for clustering data—in other words, it groups similar pieces of data. In the context of website SEO and analytics, GMM helps businesses and marketers analyze large amounts of data related to user behavior, keyword performance, and traffic patterns to discover hidden patterns, insights, or trends that may not be immediately obvious.

The core purpose of using GMM in SEO and website analytics is to segment data into distinct groups (or clusters) to understand better how different sets of users, pages, or keywords behave. This can help a business optimize its website for better search engine ranking, user engagement, and overall site performance.
How GMM Helps in SEO and Analytics (High-Level Overview):
1. User Behavior Clustering:
- Purpose: GMM can group users based on their behavior, such as how long they spend on the site, how many pages they visit, and whether they engage with the content (e.g., clicking links or making a purchase).
- Example: GMM might identify that one group of users consistently visits your blog, spends a lot of time reading, but doesn’t purchase anything. Another group might be users who quickly visit your product pages and make purchases. By identifying these patterns, you can create targeted marketing campaigns or improve certain parts of your site to boost engagement or sales.
2. Keyword Performance Clustering:
- Purpose: Keywords are the foundation of SEO. GMM can analyze and group keywords based on performance metrics like search volume, rankings, and click-through rates (CTR).
- Example: Suppose you run an SEO campaign and target 100 different keywords. GMM can group these keywords into clusters, where one cluster represents high-performing keywords with high CTR and another represents low-performing keywords. This helps you prioritize which keywords to focus on for better ranking or which to drop.
3. Traffic Source Clustering:
- Purpose: GMM can group different traffic sources, such as organic search, direct visits, or social media referrals, into clusters. This helps you understand which sources drive the most valuable traffic to your site and which need improvement.
- Example: After applying GMM, you might discover that users coming from organic search tend to spend more time on your site and engage more deeply, while users from social media spend less time and bounce quickly. With this knowledge, you can invest more in SEO or refine your social media strategy to improve engagement from those users.
Detailed Breakdown of GMM’s Purpose in SEO and Website Analytics:
1. Uncovering Hidden Patterns:
- GMM doesn’t require the data to be perfectly separated into obvious groups (like some other clustering methods, such as K-Means). It works by assuming that the data comes from a mix of different subgroups (or clusters) and assigning a probability to each data point (user behavior, keyword performance, etc.) belonging to each cluster.
- Example: In the context of SEO, user behavior can often be mixed. One user may come to the site to browse multiple pages, while another might just come for a quick look at a specific product. GMM can identify these subtle differences and group them accordingly.
2. Segmentation for Better Targeting:
- Purpose: Once GMM groups your data into clusters, you can better target your SEO strategies based on these segments. For example, if you know a certain group of users frequently visits a specific section of your website (like the blog), you can focus on SEO strategies that cater to those users.
- Example: If one cluster of users frequently engages with your educational content (like blog posts), you can focus on adding more SEO-optimized articles or improving that section of your site. On the other hand, if a certain group of users is primarily visiting product pages, you might invest more in optimizing those pages for conversions (sales or lead generation).
3. Data-Driven Decision Making:
- Purpose: GMM helps businesses make data-driven decisions by giving them insights into which areas of their site are working and which ones need improvement. Without clustering, you may overlook important differences between user groups or keywords.
- Example: Imagine you run an e-commerce website. GMM might reveal that certain product categories attract high engagement and lead to purchases, while others are rarely visited. With this information, you can heavily promote the high-engagement categories and reevaluate or optimize the underperforming ones.
4. Predictive Insights:
- Purpose: GMM can help predict future behavior based on current patterns. By understanding how different groups of users interact with your site, you can better anticipate their needs and provide them with a more personalized experience.
- Example: If GMM identifies a cluster of users who frequently read blog posts before purchasing, you might focus more on delivering high-quality blog content. This insight can help guide future SEO efforts, ensuring that content continues to drive valuable traffic to your site.
Real-World Example:
Let’s say you run an online business that sells fitness products. You apply GMM to your website’s SEO and analytics data. The model groups your users, keywords, and traffic into different clusters. Here’s what you might find:
- Cluster 1: Users who come through organic search (e.g., through Google) and spend a long time on your product pages. They often purchase fitness accessories like yoga mats. From this insight, you could improve the SEO for product pages related to fitness accessories or create blog content around these products to drive even more traffic.
- Cluster 2: Users who come from social media referrals but tend to leave quickly without purchasing. This suggests your social media campaigns may not be targeting the right audience. You could adjust your strategy to create more engaging social media content or use ads that better align with the interests of your target audience.
- Cluster 3: High-volume but low-ranking keywords that drive traffic to your blog. GMM shows that these keywords are performing well despite not ranking at the top of search results. You might invest more in optimizing these keywords to push them to the first page of search engines, potentially driving even more traffic to your site.
Step-by-Step Explanation:
1. Mount Google Drive to Access Files

Explanation:
- Purpose: Since you are working in Google Colab, you need access to files stored in your Google Drive. This step connects (or “mounts”) your Google Drive to your Colab environment.
- What it does: The code allows you to read files directly from your Google Drive by creating a path to access them. Once mounted, your Drive is accessible under /content/drive.
- Non-tech analogy: Imagine connecting your computer to a cloud storage service (like Google Drive) so you can open and work on files stored there.

2. Load Your CSV Files from Google Drive

Explanation:
- Purpose: After mounting Google Drive, you now want to load specific CSV files that contain your website’s visitor data, traffic data, and keyword performance data.
- What it does: The pd.read_csv() function (from the pandas library) is used to load data from a CSV file into Python, where it can be analyzed. Each dataset is assigned to a variable:
- visitor_behavior_data: Contains information about user behavior on your website (e.g., page views, active users).
- traffic_data: Contains details about your website’s traffic (e.g., where the traffic comes from and user sessions).
- keyword_performance_data: Contains data about keyword performance for SEO (e.g., search volume, traffic generated by keywords).
Non-tech analogy: This is like opening an Excel spreadsheet file in your software so that you can start working with the data.

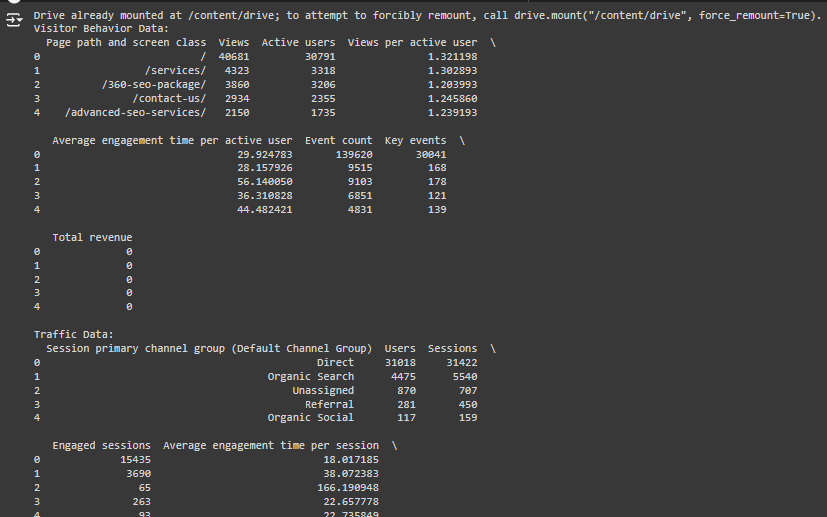
3. Understanding the Data: Printing the First Few Rows
Explanation:
- Purpose: This step previews the first few rows of each dataset. It helps you understand the structure and type of data you are working with before performing any analysis.
- What it does: The .head() function prints out the first 5 rows of the dataset to give you an overview of the content. You’ll see column names, data types (e.g., numbers or strings), and the values in the first few rows.
- For example, in Visitor Behavior Data, you might see columns for “Views”, “Active Users”, and “Average Engagement Time per User”.
- In Traffic Data, you could see columns like** “Users”, “Sessions”, and **”Engagement Rate”.
- In Keyword Performance Data, you might see data like “Keyword”, “Search Volume”, and “Traffic”.
- Non-tech analogy: Imagine quickly scanning the first few lines of a document to get a sense of what information is inside before reading it in full.


Step-by-Step Explanation: Cleaning and Preprocessing the Data
1. Why We Need This Step (Purpose)
Before we can analyze the data or run machine learning models (like GMM), the data must be clean, structured, and usable. Often, data comes with:
· Non-numeric values (e.g., ‘9.9K’, ‘20%’) must be converted to numbers so algorithms can process them.
· Missing values (NaNs) need to be either filled or removed because machine learning models cannot handle them directly.
This step ensures that the data is in a numerical and consistent format, making it ready for further analysis.
2. Converting Strings to Numerical Values

Explanation:
- Purpose: This function is used to convert strings (text values) that represent numbers (like ‘9.9K’ or ‘20%’) into actual numeric values (like 9900 or 20).
- What it does: It processes each value in the dataset to check if it’s a string and then converts it to a number, if needed.
3. Checking if the Value is a String

Explanation:
- Purpose: This checks whether the value is a string (text) using the isinstance() function.
- What it does: If the value is a string (e.g., ‘9.9K’ or ‘25%’), the function will process it. It will skip the conversion step and return the number directly if it’s already a number (like 9900 or 25.5).
- Non-tech analogy: Imagine you’re sorting different types of items (e.g., letters and numbers). This step checks whether the item is a letter, so you know whether it needs to be changed into a number.
4. Handling the ‘K’ Suffix in Numbers (e.g., ‘9.9K’ → 9900)

Explanation:
- Purpose: The letter ‘K’ often represents thousands (e.g., ‘9.9K’ means 9900). This step replaces the ‘K’ with three zeros to convert it into a proper numeric format.
- What it does: If the function encounters a string like ‘9.9K’, it will replace ‘K’ with ‘000’, turning ‘9.9K’ into ‘9.9000’, now ready to be converted into the number 9900.
- Non-tech analogy: Imagine taking a shorthand number like “10K” and expanding it into the full number “10,000.”
5. Handling Percentage Signs (e.g., ‘25%’ → 25)

Explanation:
- Purpose: When percentages (e.g., ‘25%’) are in the data, the % symbol needs to be removed so the remaining number (like 25) can be processed as a numeric value.
- What it does: The function strips out the percentage sign from values like ‘25%’, leaving just the number (25) behind.
- Non-tech analogy: This is like erasing unnecessary symbols from numbers to make them easier to work with.
6. Converting the Cleaned String into a Float (Decimal Number)

Explanation:
- Purpose: This attempts to convert the cleaned string (now free of any ‘K’ or ‘%’ symbols) into a float, a number that can contain decimals (e.g., 9.9).
- What it does: After removing any ‘K’ or ‘%’ symbols, the function uses float() to convert the string (e.g., ‘9900’) into an actual number (like 9900.0).
- Non-tech analogy: *It’s like turning written text *“9.9 thousand” into the actual number 9900.0.



Step-by-Step Explanation: Handling Missing Values (NaNs)
1. Why We Need This Step (Purpose)
· Problem: Missing data is common in real-world datasets. These missing values are typically represented as NaN (Not a Number). Unfortunately, machine learning models, including GMM, cannot work with data that contains missing values.
· Solution: To handle this issue, we use imputation, where missing values are replaced with a meaningful statistic (such as the median). This ensures that the dataset is complete and ready for analysis.
2. Using SimpleImputer to Fill Missing Values

Explanation:
- Purpose: The SimpleImputer is a class from the sklearn.impute module, designed to fill (or “impute”) missing values in a dataset.
- What it does: In this case, we are using the strategy= ‘median’ option, which means that missing values will be replaced with the column’s median. The median is the middle value in a sorted list, and it’s commonly used because it’s less sensitive to extreme values (outliers).
- Non-tech analogy: Think of the imputer as a tool that automatically fills in the blanks in a form with the most reasonable average response.


3. Selecting the Relevant Features for Clustering

Explanation:
- Purpose: This step selects the relevant numerical columns from each dataset that will be used for clustering.
- What it does: It extracts specific columns that contain valuable information for the clustering algorithm. Here’s what is selected:
- Visitor Behavior Data:
- Views: The number of times a page was viewed.
- Active Users: The number of users actively interacting with the page.
- Average Engagement Time per Active User: How much time users spent engaging with the content.
- Traffic Data:
- Users: Number of users who started a session on the site.
- Sessions: Total number of user sessions.
- Engaged Sessions: Number of sessions where users actively engaged (e.g., clicked links or scrolled).
- Keyword Performance Data:
- Position: Keyword ranking in search engine results.
- Volume: Search volume for a specific keyword (how often people search for it).
- Traffic: Estimated traffic generated by each keyword.
- Non-tech analogy: This is like selecting the most important columns of data from a table for the analysis you’re about to perform.


4. Combining All Selected Features into One Dataset

Explanation:
- Purpose: To perform clustering, we need all relevant data in one place, so this step combines (concatenates) all the selected features from the three different datasets (visitor data, traffic data, and keyword data).
- What it does: The pd.concat() function from pandas combines the columns from the three datasets into one large dataset. It appends the columns side by side (because axis=1), creating a single DataFrame that contains all the features we want to use for clustering.
- Non-tech analogy: Imagine you have three different spreadsheets (one for visitor behavior, one for traffic, and one for keywords). This step combines these spreadsheets into one, where all the relevant information is in one table.


5. Applying the Imputer to Fill Missing Values

Explanation:
- Purpose: This step applies the SimpleImputer to the combined dataset, replacing any missing values (NaNs) with the median of the corresponding column.
- What it does:
- imputer.fit_transform(): This function first fits the imputer to the data (calculating the median for each column) and then transforms the dataset by replacing missing values with the respective median.
- The pd.DataFrame() function converts the imputed data back into a pandas DataFrame so that we can work with it as usual. The columns=all_features.columns argument ensures that the columns retain their original names.
- Non-tech analogy: It’s like filling in blank spaces on a form with the most common response from other people. After this step, there are no more blanks (missing values), and the form is complete and ready to be analyzed.


Step-by-Step Explanation: Standardizing the Data
In Step 4, you standardize the data for the machine learning model. This step ensures that all numerical values are on the same scale, which is crucial for clustering algorithms like GMM (Gaussian Mixture Models) to work effectively.
1. Why Standardization is Necessary (Purpose)
· Problem: Different features (columns) in your data can have different ranges. For example:
· “Views” might range from 100 to 100,000.
· “Average Engagement Time” might range from 1 to 60 seconds.
· “Keyword Position” ranges from 1 to 100.
These differences in scale can cause problems for machine learning algorithms like GMM. The algorithm will give more importance to features with larger values, even if they aren’t more important for the task.
- Solution: To prevent this issue, you need to standardize the data. Standardization means adjusting the values of each feature so that they have a mean of 0 and a standard deviation of 1. This puts all features on the same scale, ensuring that no single feature dominates because of its numerical range.
2. Using StandardScaler() for Standardization

Explanation:
- Purpose: This line of code creates an instance of the StandardScaler() class from sklearn.preprocessing. The StandardScaler is a tool used to standardize the data.
- What it does: The scaler will compute the mean and standard deviation for each feature in your dataset. It will then use these values to standardize the data so that each feature has a mean of 0 and a standard deviation of 1.
- Non-tech analogy: Imagine you’re comparing test scores from two different exams—one graded out of 100 and one graded out of 50. Before comparing them fairly, you need to adjust the scores to be on the same scale (e.g., convert everything to a percentage). That’s what standardization does for your data.
3. Fitting and Transforming the Data

Explanation:
· Purpose: This line applies the standardization to the data. It fits the StandardScaler to the dataset and transforms the features so they are all on the same scale.
· What it does:
· fit_transform()* is a method that performs two tasks:
- Fit: The scaler calculates the mean and standard deviation for each feature (column) in the dataset.
- Transform: It then standardizes each feature by subtracting the mean and dividing by the standard deviation.
· The result is that all the numerical features in all_features_imputed are transformed into standardized values (where the mean = 0 and standard deviation = 1).
· This step returns a NumPy array (all_features_scaled) with the standardized values, which will be used for clustering.
· Non-tech analogy: Going back to the test score analogy, after calculating the percentage scores for both exams (fitting), you now have all the scores on the same scale so that they can be compared directly (transformation).
Why This Step is Critical for GMM and Other Algorithms
· Equal Importance to Features: Without standardization, features with larger ranges (like views or sessions) could dominate the clustering process. GMM might give too much importance to these features, even if they aren’t the most important for identifying patterns in the data.
· Better Results: Many machine learning models, including GMM, assume that all features are on a similar scale. Standardizing ensures that the algorithm treats all features fairly, leading to better and more reliable clusters.
What Happens After This Step
- After standardizing the data, your dataset is ready for clustering using GMM. The standardized data will ensure that no single feature unfairly influences the clustering results, leading to more accurate and meaningful clusters.


1. Why Use GMM for Clustering (Purpose)
· Problem: You want to group similar data points based on patterns in your website’s visitor behavior, traffic data, and keyword performance. Manual grouping can be difficult and subjective.
· Solution: GMM is a statistical model that assumes the data comes from a mixture of several Gaussian distributions (also known as normal distributions). Each distribution represents a cluster, and the model will automatically determine which data points belong to each cluster based on their similarities.
2. Creating the GMM Model

Explanation:
- Purpose: This line creates an instance of the GaussianMixture() class from the sklearn.mixture module, which will be used to cluster your data.
- What it does:
- n_components=3: This specifies that you want GMM to divide the data into 3 clusters. You can adjust this number based on how many distinct groups you expect in your data.
- random_state=42: This is a random seed to ensure reproducible results. It helps ensure that you get the same clustering result each time you run the code (useful for consistency when you run the model multiple times).
- Non-tech analogy: Imagine you’re organizing books in a library. You want to sort them into 3 categories (clusters), but you don’t know exactly how to categorize them yet. GMM helps determine the best way to divide the books into 3 groups based on their characteristics.

3. Fitting the GMM Model to the Data

Explanation:
- Purpose: This step trains the GMM model on your standardized data. By “fitting” the model, GMM learns the underlying patterns and structure in the data.
- What it does:
- fit(): This method estimates the parameters (mean, variance, etc.) of the 3 Gaussian distributions (clusters) based on the data you provided. It uses these parameters to determine the probability that each data point belongs to a certain cluster.
- The model will analyze the relationships between the features (e.g., how keyword volume relates to traffic, how user sessions relate to engagement, etc.) and divide the data into 3 distinct groups based on these patterns.
- Non-tech analogy: Consider observing different piles of books to figure out the most logical way to divide them into 3 groups. The model studies the books’ characteristics (e.g., genre, size) and determines how to categorize them.

4. Predicting the Cluster Labels for Each Data Point

Explanation:
- Purpose: This step assigns each data point (e.g., a specific user behavior, traffic pattern, or keyword performance record) to a specific cluster based on the patterns detected by GMM.
- What it does:
- predict(): This method predicts the cluster label for each data point. After the model has learned from the data (through fit()), it assigns each data point to the cluster it most likely belongs to.
- The result is an array of cluster labels (e.g., [0, 1, 2]), each corresponding to one of the 3 clusters.
For example, one data point might be labeled as belonging to Cluster 0 (the first group), another might be assigned to Cluster 1 (the second group), and so on.
- Non-tech analogy: After figuring out the best way to categorize the books, the model now labels each book as belonging to a specific category (e.g., Fiction, Non-Fiction, or Sci-Fi).


5. Adding the Cluster Labels Back to the Original Data

Explanation:
- Purpose: This step appends the cluster labels (predicted in the previous step) to the original dataset so that you can see which cluster each data point belongs to.
- What it does:
- This creates a new column called ‘Cluster’ in your all_features_imputed DataFrame.
- Each row in the DataFrame represents a data point (e.g., a visitor’s session or keyword performance), and the ‘Cluster’ column will indicate which group (or cluster) that data point belongs to (e.g., Cluster 0, Cluster 1, or Cluster 2).
- This makes analyzing the clusters easy and understanding how different data points (pages, keywords, traffic patterns, etc.) are grouped.
- Non-tech analogy: After labeling the books, you now add the category label (e.g., “Fiction” or “Sci-Fi”) next to each book, so it’s clear which group each book belongs to.





Clustered Output.CSV Sample

Understanding the Clustered Output CSV File
Here’s a breakdown of the key columns in the clustered_output.csv file you provided:
1. Views: The number of views a particular page received.
2. Active Users: The number of active users who visited the page.
3. Average Engagement Time per Active User: The average time users interacted with the page.
4. Users: The number of users who initiated sessions on the website.
5. Sessions: The number of sessions users initiate (how often they visited).
6. Engaged Sessions: The number of sessions where users actively engaged (e.g., clicked links, scrolled pages).
7. Position: The search engine rank of a particular keyword (lower is better, e.g., Position 1 means it ranks first).
8. Volume: The search volume of a keyword (how often it is searched).
9. Traffic: The estimated traffic generated by each keyword.
10. Cluster: This is the cluster number assigned by the Gaussian Mixture Model (GMM), representing the group or category to which the data point belongs.
Explanation of the Scatter Plot
The scatter plot you see is a visual representation of the clusters generated by GMM. Each dot represents a data point (either a page or a keyword), and the color of the dot corresponds to which cluster that data point belongs to:
· Cluster 0 (Purple Dots): Represents one group of pages/keywords that are similar in behavior or performance.
· Cluster 1 (Teal Dots): Represents another group of pages/keywords with different behavior or performance patterns.
- Cluster 2 (Yellow Dots): Represents a third distinct group.
Key Insights from the Plot:
· Most of the data points are concentrated near the bottom-left of the graph. This could indicate that the majority of the pages/keywords are performing similarly (low views, traffic, etc.).
· There is one data point far away from the others (Cluster 1, teal dot), indicating an outlier. This could represent a** page or keyword** that is performing exceptionally well compared to the rest.
Understanding the Clusters in the CSV File
Looking at the Cluster column in the CSV:
· Cluster 0 (Purple): Most of the data points belong to this cluster, which includes pages or keywords with moderate views, active users, and traffic. These pages/keywords perform similarly, and this cluster likely represents the “average” or “standard” behavior on the website.
· Cluster 1 (Teal): This contains one high-performing page/keyword. The high values in Views, Active Users, and Traffic show that this cluster represents top-performing pages or keywords.
· Cluster 2 (Yellow): This cluster has data points with higher keyword positions but relatively similar engagement metrics to Cluster 0. It may represent keywords or highly relevant pages but not as highly ranked or searched.
Simple explanation to the Website Owner
1. Cluster Insights:
· Cluster 0: This represents most of the pages or keywords. These pages/keywords have average performance, meaning their views, user engagement, and keyword rankings are similar. The client can consider improving these pages with better SEO strategies to move them to higher-performing clusters.
· Cluster 1: This represents a top-performing page or keyword. The teal dot far from the other data points in the scatter plot shows that this page or keyword is outperforming others in terms of views, traffic, or user engagement. The client can learn from this success and replicate the strategy used on this page for other underperforming ones.
· Cluster 2: This cluster includes keywords with decent search volume but potentially underperforming in terms of user engagement or rankings. The client should consider optimizing these keywords to drive traffic or improve rankings.
2. Scatter Plot:
· Each dot on the scatter plot represents a page or keyword. The color of the dot shows which cluster it belongs to. By looking at the color, you can identify which group the page or keyword falls into (high-performing, average, or underperforming).
· The teal dot far from the rest is an outlier and shows a page/keyword that’s performing much better than others. This could be a major driver of traffic to the website.
Steps to Take After Receiving the GMM Clustering Output
1. Focus on High-Performing Pages and Keywords (Cluster 1):
· What to do: Review the pages or keywords in Cluster 1. These are your best-performing pages or keywords. Look at why these are doing well—maybe they have better SEO, more engaging content, or an easier-to-use layout.
· Next step: Once you understand why these pages are successful, use similar strategies on other pages that aren’t performing as well. For example, if a well-performing product page has high-quality images and detailed descriptions, you could update other product pages with similar content.
2. Optimize Average Pages and Keywords (Cluster 0):
· What to do: Most of your pages or keywords are likely in Cluster 0. These are average performers—neither great nor terrible. You can improve these by making some updates.
· Next step: Improve these pages by adding better content, relevant keywords, and ensuring smooth user experience. For example, you could speed up the page load time or make the design easier to navigate. Updating these areas could move these pages into higher-performing clusters over time.
3. Enhance Underperforming Keywords (Cluster 2):
· What to do: Cluster 2 includes pages or keywords that have potential but are not yet fully optimized. These keywords may have decent search volume (how often people search for them) but are not getting enough clicks or traffic.·
Next step: Focus on improving SEO strategies for these keywords. You can update meta descriptions (the text in search results), improve click-through rates (CTR), or add related keywords to improve visibility. These improvements will help these pages rank higher and attract more visitors.
