SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
The project titled “Vector-Based Search Retrieval: Uses vector representations to match queries with results beyond keyword matching” implements an advanced semantic search system designed to enhance information retrieval across webpages. Traditional keyword-based search often fails to capture the true intent behind user queries, leading to irrelevant or partial results. This solution addresses that limitation by transforming both user queries and webpage content into high-dimensional vector embeddings, enabling highly relevant matches based on semantic meaning rather than mere word overlap.

By utilizing Sentence-BERT embeddings and FAISS (Facebook AI Similarity Search) for fast nearest-neighbor search, this system performs deep matching between user queries and content. It is capable of accurately retrieving the most contextually relevant sentences from web pages, regardless of vocabulary variations or phrasing mismatches.
The system is implemented with scalability, interpretability, and client-facing application in mind. It supports batch processing of multiple URLs and queries, delivers ranked search results for each match, and exports the final output to a structured CSV format—ready for integration with content strategy, SEO workflows, or user experience enhancement tools.
Project Purpose
Building a Semantic Search and Content Matching Framework
The core objective of this project is to develop an advanced semantic search and content matching framework that overcomes the limitations of traditional keyword-based search systems. Conventional search engines primarily rely on keyword frequency, exact phrase matching, or simple ranking signals to retrieve information. While effective to a certain extent, these methods often fail to capture the deeper meaning behind user queries.
This project introduces a more intelligent approach where the system focuses on understanding context, intent, and semantic relationships within content. Instead of simply matching keywords, the framework interprets the meaning of a query and identifies content that conveys similar ideas—even when the wording differs significantly.
By leveraging modern natural language processing (NLP) techniques and vector embeddings, the system enables more accurate and meaningful content retrieval.
Why Semantic Search Matters
In today’s information-rich digital ecosystem, users expect search engines to understand their queries naturally and deliver highly relevant results. Keyword-based systems often struggle when users phrase their questions differently from how the content is written.
A semantic search framework solves this challenge by identifying contextual similarity between queries and documents. This ensures that search results reflect the true intent of the user, not just the presence of specific keywords.
Such an approach greatly improves the usability of content platforms, knowledge bases, blogs, and documentation repositories where large volumes of information must be navigated efficiently.
Key Benefits of the System
Implementing a semantic search architecture provides multiple advantages for content-driven platforms. The framework is designed to support several strategic objectives.
1. Enhanced Content Discovery
The system helps users locate relevant information more efficiently by identifying semantically similar content across large repositories. This improves the discoverability of articles, documentation pages, blog posts, and knowledge base entries.
2. Reduced Bounce Rates
When users quickly find content that aligns with their intent, they are more likely to continue exploring the website. By guiding users toward contextually relevant resources, the system helps reduce bounce rates and improve overall user engagement.
3. Smarter Internal Linking Opportunities
Semantic similarity analysis allows the framework to detect relationships between topics across different pages. This insight can be used to build stronger internal linking structures that enhance both user navigation and SEO performance.
4. Featured Snippet and Answer Extraction
By identifying the most relevant sentences or content segments from documents, the system can generate candidate snippets or short answers. These extracted insights can be used for featured snippets, quick answers, or AI-generated summaries.
5. Content Gap Analysis
Another major advantage of semantic search is the ability to identify areas where content coverage is weak. By analyzing user queries against existing content vectors, the system can highlight under-served queries and missing topics, enabling strategic content development.
How the System Processes Content
To achieve these capabilities, the system follows a structured processing pipeline designed for efficient semantic analysis and retrieval.
First, each URL is processed independently. The content from the page is extracted and undergoes a cleaning and filtering stage, where irrelevant elements such as navigation text, scripts, or formatting artifacts are removed. This ensures that only meaningful textual content is analyzed.
Next, the cleaned text is segmented into smaller units, typically sentences or short passages. These segments are then converted into dense vector embeddings using advanced natural language processing models. Each embedding represents the semantic meaning of a sentence within a high-dimensional vector space.
These vectors are subsequently indexed using a FAISS similarity search engine, which enables efficient retrieval across large datasets.
Query Processing and Semantic Retrieval
When a user submits a natural language query, the system converts the query into its corresponding vector representation. The FAISS engine then compares this query vector against the indexed embeddings and identifies the most semantically similar content segments.
Rather than relying on exact keyword matches, the system ranks results based on semantic proximity within vector space. This allows it to retrieve relevant content even when the wording of the query differs significantly from the original text.
The retrieved results are then ranked and presented as the most contextually relevant snippets from each indexed page.
Improving Search Relevance and Content Performance
By combining natural language understanding, vector embeddings, and efficient similarity search, this framework significantly enhances the quality of search results. Users receive answers that are not only technically related but also contextually aligned with their intent.
Ultimately, this semantic approach leads to improved content engagement, better user satisfaction, and more effective utilization of existing content assets. It transforms search from a simple keyword-matching mechanism into an intelligent system capable of understanding meaning, relationships, and context within large content ecosystems.
Explanation of Key Concepts in Vector-Based Search Retrieval
To fully appreciate the functionality and impact of the system, it is essential to understand the foundational concepts that power the solution. The term “Vector-Based Search Retrieval” encapsulates several advanced yet intuitive ideas that underpin the way modern semantic search engines operate. This section provides a detailed explanation of each term, broken down into the following subsections:
Vectors
In natural language processing (NLP), a vector is a list of numbers that captures the semantic information of a piece of text — such as a sentence or a paragraph. This numerical form is created by models like Sentence-BERT, which have been trained on large corpora to understand the underlying meaning of words and phrases, even when phrased differently.
For example, the sentences:
- “How to reduce bounce rate?”
- “Ways to lower website exits.”
may contain completely different words, but their vector representations will be close in multidimensional space if they carry similar meaning.
Each vector lives in a high-dimensional space — often with 768 dimensions or more — where the distance between two vectors reflects how semantically similar they are. The closer the vectors, the more similar the meanings.
Vector Search
Once content and queries are converted into vectors, they can be searched and compared mathematically. This is where vector search becomes critical.
Unlike traditional keyword search engines that look for exact or partial matches between query words and document text, vector search computes distances (or similarities) between query vectors and content vectors. If two vectors are very close, it indicates strong semantic similarity, even if there are no overlapping words.
This project uses FAISS (Facebook AI Similarity Search), an industry-grade library optimized for performing fast vector similarity searches at scale. FAISS allows finding the top-N most similar content snippets for any given query in milliseconds, making the approach suitable for real-time or high-volume applications.
The similarity is computed using cosine similarity, which measures the angle between two vectors. The smaller the angle (i.e., the more aligned the meanings), the higher the similarity score.
Retrieval
Retrieval refers to the process of selecting and returning the most relevant information from a larger dataset. In this context, it means:
- Searching a web page’s content for the most semantically relevant sentences based on a query.
- Ranking those sentences by their similarity scores.
- Returning the top results that best answer or match the query intent.
This retrieval is intelligent and meaning-based, not rule-based or keyword-focused. It allows users to find answers that are expressed differently than the query but still address the same concept.
For instance, if a user searches “how to handle document URLs,” the system might retrieve a sentence such as:
- “HTTP headers are useful for serving different document types from the same URL.”
This result would be difficult to match using keyword-based systems but is semantically aligned and highly relevant using vector retrieval.
Summary
Combining these three ideas — vectors, vector search, and retrieval — results in a system capable of understanding and retrieving information based on meaning, not just matching text. This leads to more accurate, useful, and context-aware content discovery, which is critical for enhancing digital experiences, SEO strategy, and overall user engagement.
What benefit does this project offer for SEO optimization?
This project directly supports multiple facets of modern SEO strategy by moving beyond surface-level keyword matches and into semantic intent recognition. Search engines increasingly prioritize content that closely aligns with user intent, even if the wording differs. By leveraging vector-based representations, this system ensures that internal content surfaces in response to varied phrasings of search queries. As a result:
- High-quality, intent-matching content is made more discoverable, leading to better engagement metrics.
- Internal link structures can be strengthened by automatically connecting semantically relevant content, which aids both user navigation and search engine crawling.
- The system enables identification and promotion of existing content as featured snippets, improving visibility in SERP (Search Engine Results Pages).
- Insights gained from low-match queries can inform future content creation, ensuring ongoing SEO competitiveness.
What is the primary business value this project delivers?
This project transforms static website content into a dynamic, query-responsive system that intelligently matches user intent with existing materials. By utilizing vector-based retrieval, it enables highly relevant content suggestions that are contextually aligned with real search queries. This directly supports key business goals such as improving content discoverability, increasing session time, guiding user navigation, and unlocking deeper SEO value from existing content assets.
What makes this useful for content teams?
Content teams can use the output to understand which parts of the website are addressing specific search intents and which are not. This helps identify content strengths, uncover outdated or weak areas, and inform decisions about internal linking, updating existing content, or creating new pages. The system acts as a semantic audit tool, aligning the content library with actual user needs.
What problem does this solve that traditional keyword search cannot?
Traditional keyword search relies on exact term matching, often missing relevant content that uses different phrasing or terminology. This project solves that limitation by using semantic vector embeddings, which allow it to understand the meaning behind a query and surface content that is topically related—even if the exact keywords don’t appear. As a result, users find more accurate answers, even for complex or long-form queries.

requests
Used to send HTTP requests and retrieve the raw HTML content of a given webpage. It serves as the initial data acquisition layer, forming the foundation for further processing.
· Purpose: Page fetching and HTML retrieval.
· Importance: Enables the system to dynamically collect content from live web URLs without manual copying.
BeautifulSoup (from bs4)
A web scraping tool used to parse HTML documents and extract specific elements such as paragraph tags, headings, and list items.
· Purpose: Clean extraction of visible and meaningful content from web pages.
· Importance: Removes unnecessary HTML noise, enabling structured and consistent sentence-level input for the embedding model.
csv
Used to export the final results into a CSV file format, which can be easily read by non-technical stakeholders or imported into spreadsheet tools for analysis.
· Purpose: Data export and sharing.
· Importance: Facilitates delivery of actionable outputs in a business-friendly format.
re (Regular Expressions)
Handles text cleaning and pattern-based filtering of noisy content such as broken formatting, HTML leftovers, or non-informative symbols.
· Purpose: Preprocessing and text normalization.
· Importance: Enhances the quality of input data before semantic analysis, improving model accuracy.
nltk (Natural Language Toolkit)
Specifically uses sent_tokenize from nltk.tokenize to segment content into meaningful individual sentences.
· Purpose: Sentence-level tokenization of long-form content.
· Importance: Embedding and retrieval operate at the sentence level, requiring precise and context-aware splitting of content.
· Note: nltk.download(‘punkt’) is required to enable sentence tokenization by downloading the pretrained model for English.
numpy
Used to handle numerical operations such as computing similarity scores between query and content embeddings.
· Purpose: Vector arithmetic and score computation.
· Importance: Ensures fast and reliable computation when processing and ranking semantic similarity results.
sentence-transformers (Sentence-BERT)
Provides the backbone semantic embedding model (all-mpnet-base-v2) used to convert both user queries and webpage sentences into dense vector representations.
· Purpose: Semantic encoding of content and queries.
· Importance: Enables the project to understand meaning beyond keywords by comparing sentences in a high-dimensional vector space.
This model is optimized for capturing semantic similarity, making it well-suited for content matching and retrieval tasks.
faiss (Facebook AI Similarity Search)
A highly efficient library for vector similarity search. It indexes and retrieves the most semantically similar content vectors to any given query vector.
· Purpose: Fast and scalable nearest-neighbor search in embedding space.
· Importance: Ensures high-speed and accurate retrieval of the top content results, even when dealing with large volumes of content.
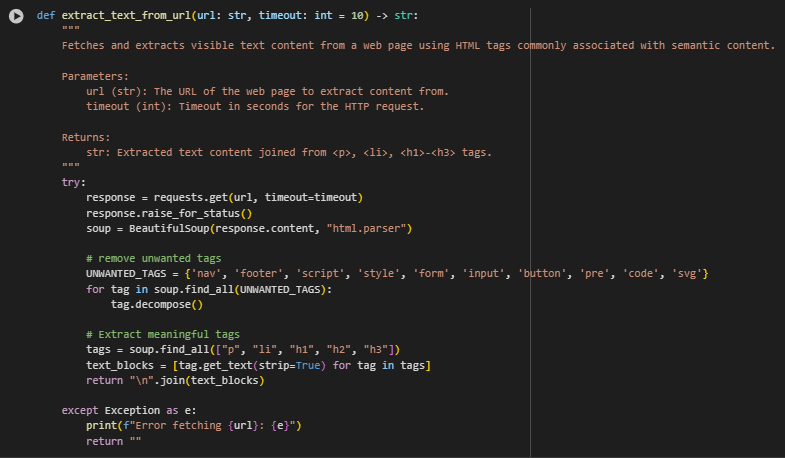
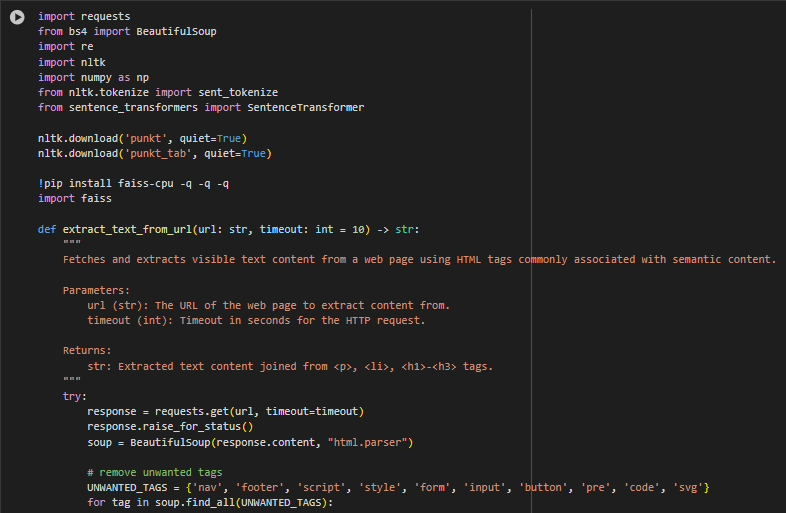
Function Overview: extract_text_from_url – Web Content Extraction
The function extract_text_from_url is responsible for retrieving and isolating the visible, meaningful content from a web page. It acts as the foundation of the entire semantic search pipeline by collecting raw content that will later be transformed into semantic vectors. The function selectively targets semantic HTML tags such as <p>, <li>, and <h1>–<h3>, which are commonly used to express primary information on a webpage.
By filtering out irrelevant or structural components such as navigation bars, scripts, or forms, the function ensures that only high-value text is passed forward for semantic embedding. This enhances retrieval accuracy and avoids polluting the vector space with noise.
Step-by-Step Explanation
response = requests.get(url, timeout=timeout)
- Sends an HTTP GET request to fetch the content from the provided URL.
- Retrieves the raw HTML content of the target web page. A timeout is specified to avoid long delays in case of unreachable pages.
soup = BeautifulSoup(response.content, “html.parser”)
- Parses the fetched HTML content using BeautifulSoup’s HTML parser.
- Converts the HTML string into a searchable tree structure, enabling extraction of specific elements.
UNWANTED_TAGS = {‘nav’, ‘footer’, ‘script’, ‘style’, ‘form’, ‘input’, ‘button’, ‘pre’, ‘code’, ‘svg’}
- Defines a list of non-content tags that typically contain code, UI elements, or layout structures.
- These tags are removed to avoid irrelevant or misleading content being processed.
for tag in soup.find_all(UNWANTED_TAGS): tag.decompose()
- Iterates through all unwanted tags found in the document and removes them from the soup object.
- Cleans the HTML structure and ensures that only meaningful content remains for extraction.
tags = soup.find_all([“p”, “li”, “h1”, “h2”, “h3”])
- Selects HTML elements known for containing primary readable content—paragraphs, list items, and major headings.
- Narrows focus to only those components that hold substantive information, increasing the signal-to-noise ratio.
text_blocks = [tag.get_text(strip=True) for tag in tags]
- Extracts plain text from each tag and removes extra whitespace.
- Converts HTML tag content into clean text blocks suitable for further processing.
return “\n”.join(text_blocks)
- Combines all extracted text blocks into a single string separated by newlines.
- Outputs structured, readable content that serves as the input for semantic sentence tokenization.
except Exception as e: …
- Handles connection errors, invalid URLs, or HTML parsing issues.
- Prevents the system from crashing when a URL fails and logs the error for debugging or retry logic.
This function is crucial for enabling vector-based semantic analysis as it guarantees that only relevant textual data is passed into downstream processing stages such as sentence tokenization, embedding, and search retrieval.
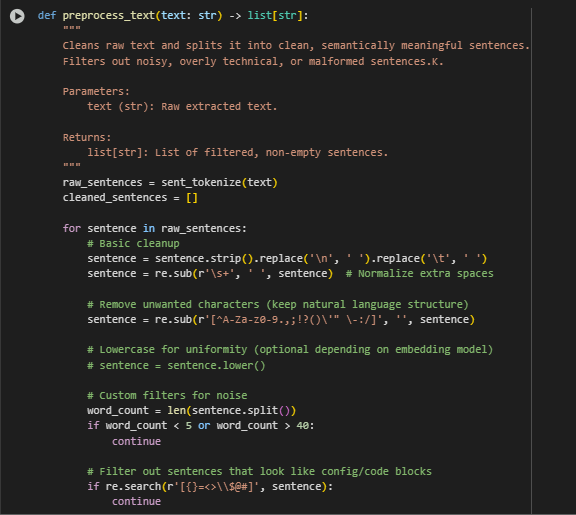

Function Overview: preprocess_text – Text Preprocessing and Sentence Filtering
Summary
The preprocess_text function plays a pivotal role in transforming raw, extracted website text into a clean and usable list of individual sentences. This step occurs before converting textual content into vector representations. The function eliminates malformed content, excessive punctuation, overly short or long text, and code-like noise to ensure that only high-quality, semantically meaningful sentences are preserved.
Such preprocessing is critical in vector-based search systems to avoid diluting the semantic search space with noisy data and to improve the relevance of content retrieved in response to a user query.
Step-by_step Explanation
raw_sentences = sent_tokenize(text)
- Breaks the raw multi-paragraph text into individual sentence units.
- Enables fine-grained semantic comparison by treating each sentence as an atomic unit for embedding.
sentence = sentence.strip().replace(‘\n’, ‘ ‘).replace(‘\t’, ‘ ‘)
- Strips whitespace and replaces line/tab breaks with single spaces.
- Normalizes sentence formatting to prevent splitting errors in embedding or display inconsistencies.
sentence = re.sub(r’\s+’, ‘ ‘, sentence)
- Collapses multiple spaces into a single space.
- Prevents irregular gaps that could mislead tokenization or vectorization.
sentence = re.sub(r'[^A-Za-z0-9.,;!?()\'” \-:/]’, ”, sentence)
- Removes all non-standard characters while retaining essential sentence punctuation and structure.
- Ensures sentence embeddings focus on natural language, not technical or non-linguistic symbols.
word_count = len(sentence.split())
- Counts the number of words in each sentence.
- Used to apply filtering thresholds that control sentence length.
if word_count < 5 or word_count > 40: continue
- Discards sentences that are too short or too long to be meaningful or well-formed.
- Very short sentences often lack context, while very long ones are likely lists, descriptions, or run-on text—both can reduce relevance in semantic matching.
if re.search(r'[{}=<>\\$@#]’, sentence): continue
- Filters out sentences that contain symbols indicative of code, configuration files, or templates.
- Helps maintain a clean, natural language corpus that aligns with human-readable content, not machine instructions.
if (‘http’ in sentence and ‘;’ in sentence and word_count > 20): continue
- Removes complex, malformed links or embedded scripts that appear as large sentence-like blocks.
- Prevents broken or non-informative strings from affecting semantic accuracy.
cleaned_sentences.append(sentence)
- Adds the cleaned and validated sentence to the result list.
- Builds the final output of high-quality sentences to be converted into semantic vectors.
This preprocessing function ensures that only human-readable, structurally valid, and semantically useful sentences are selected for downstream embedding. By removing irrelevant or malformed content early in the pipeline, it enhances both the efficiency and quality of vector-based retrieval.
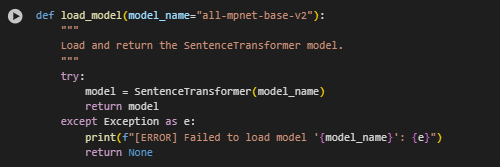
Function Overview: load_model – SentenceTransformer Model Loading
Summary
The load_model function is responsible for initializing the Sentence-BERT model used for generating dense vector representations of text. Sentence-BERT, particularly the variant all-mpnet-base-v2, is a state-of-the-art model fine-tuned for semantic similarity tasks. This model is essential for transforming both content and search queries into numerical vectors that enable semantic matching in the retrieval system.
By abstracting the model loading into a standalone function, the code allows for easy customization, reuse, and error handling.
Step-by_step Explanation
model = SentenceTransformer(model_name)
- Loads the specified Sentence-BERT model from the Hugging Face Model Hub.
- This is the critical step that brings in the pretrained model architecture and weights necessary for semantic vectorization. The chosen model, all-mpnet-base-v2, is highly optimized for semantic similarity, making it well-suited for retrieval tasks.
This function encapsulates the model initialization logic in a reusable and robust format, enabling seamless updates or substitutions of the embedding model. It ensures the semantic core of the system is reliably prepared before starting content processing or retrieval tasks.
Model Explanation — Sentence-BERT with MPNet
This project leverages Sentence-BERT with the MPNet transformer to power its vector-based semantic search functionality. The model is responsible for converting both website content and user queries into high-quality vector representations, enabling precise semantic matching beyond simple keyword overlap.
What Is Sentence-BERT?
Sentence-BERT (SBERT) is an adaptation of BERT, a state-of-the-art language model developed by Google. While BERT was originally designed for token-level tasks (like predicting the next word), Sentence-BERT restructures it to work efficiently at the sentence level.
This adaptation is crucial for tasks like semantic search, where entire sentences or paragraphs need to be compared for meaning, not just individual words.
Unlike traditional BERT, which is computationally expensive for pairwise comparisons, Sentence-BERT enables fast, scalable comparisons by generating fixed-length vector embeddings for sentences. These vectors can be stored, indexed, and compared using efficient algorithms — exactly what’s needed for a high-performing search retrieval system.
Architecture Used in This Project
The specific model used is all-mpnet-base-v2, a fine-tuned Sentence-BERT variant that combines SBERT with MPNet, one of the most effective transformer models in the domain of sentence similarity.
The internal structure of the model includes:
· Transformer Encoder (MPNet)
This is the core of the model. It reads sentences and builds context-aware representations for each word by analyzing the sentence structure. MPNet stands out for its ability to capture both global meaning and fine-grained relationships between words.
· Pooling Layer (Mean Pooling)
After processing the sentence, the model averages the output vectors of all words to produce a single embedding vector. This vector captures the overall meaning of the sentence in a format that can be mathematically compared to other vectors.
· Normalization Layer
The final step is normalization. All sentence vectors are adjusted to have the same scale (length), which ensures that similarity scores are meaningful and consistent across comparisons.
These components work together to convert any sentence or search query into a 768-dimensional vector — a compact numerical representation of meaning.
Why This Model Was Chosen
The model offers a number of advantages for semantic search applications:
· High Semantic Accuracy
It captures deep contextual meaning, allowing the system to retrieve content that matches the intent behind a user’s query, not just the exact words used.
· Scalability for Real-Time Use
Since each sentence is pre-encoded into a vector, there is no need to recompute embeddings during search, making it well-suited for handling large volumes of content efficiently.
· Compatibility with FAISS Indexing
These vectors integrate seamlessly with the FAISS indexing system used in this project, enabling rapid similarity searches across tens of thousands of entries.
· Well-Validated Performance
The model is trained and validated on multiple benchmarks in natural language understanding, offering robust performance out of the box.
Role in This Project
In this project, the model serves a central role:
- Transforms all sentences from a website into vector embeddings.
- Encodes incoming user queries in the same vector space.
- Enables Retrieval by comparing the query vector to all content vectors and ranking them by semantic closeness.
By doing so, it powers a system that connects users directly to the most relevant content on a website — even when exact keywords don’t match — resulting in better content discovery and improved user satisfaction.
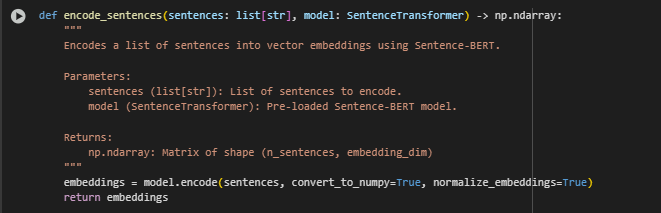
Function Overview: encode_sentences — Sentence Encoding
Summary
This function is responsible for converting plain English sentences into numerical vector embeddings using the previously loaded Sentence-BERT model. These embeddings are the foundation of the project’s semantic search capabilities, allowing for accurate and efficient comparison between user queries and website content.
The purpose of this function is to:
- Take a list of cleaned sentences (usually extracted from a web page).
- Encode each sentence into a 768-dimensional vector using Sentence-BERT.
- Normalize the vectors so that they can be compared using cosine similarity or inner product measures.
- Return the complete matrix of sentence embeddings for downstream indexing and retrieval.
This encoding step ensures that semantic similarity — not just word overlap — can be used to retrieve matching content.
Step-by-Step Explanation
embeddings = model.encode(sentences, convert_to_numpy=True, normalize_embeddings=True)
- model.encode(…) This method uses the Sentence-BERT model to compute embeddings for each input sentence.
- convert_to_numpy=True Converts the output into a NumPy array, making it compatible with mathematical operations and the FAISS search index.
- normalize_embeddings=True Ensures that each embedding is scaled to unit length. This is important for consistent and reliable similarity scores when comparing vectors during retrieval.
The final result is a structured array where each row corresponds to a sentence, and each column represents a numerical dimension in the model’s semantic space.
Output Shape: (number_of_sentences, 768)
Use Case: This matrix is later used to build a FAISS index for fast, real-time vector-based search.
This function effectively transforms raw textual data into a search-ready representation, bridging the gap between language and computation.
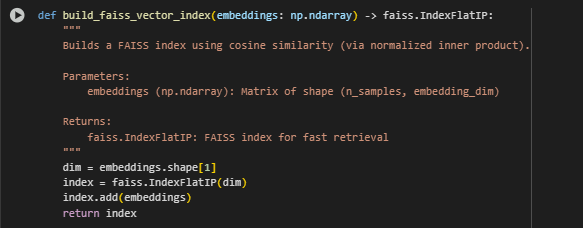
Function Overview: build_faiss_vector_index — Building the FAISS Vector Index
Summary
This function is designed to create a fast and efficient vector search index from the sentence embeddings. The index enables rapid similarity searches that power the vector-based retrieval system.
The key objectives are to:
- Accept a matrix of normalized vector embeddings representing the content sentences.
- Build a FAISS index to perform approximate nearest neighbor search using cosine similarity.
- Return the configured index object for later querying with user search vectors.
FAISS (Facebook AI Similarity Search) is a widely used open-source library optimized for high-speed similarity search at scale.
Step-by-Step Explanation
dim = embeddings.shape[1]
- Retrieves the dimensionality of each embedding vector (usually 768 for Sentence-BERT).
- This dimension size is required to initialize the FAISS index correctly.
index = faiss.IndexFlatIP(dim)
- Creates a Flat Index using Inner Product (IP) as the similarity metric.
- Since embeddings are normalized, the inner product effectively computes cosine similarity, which is a standard measure for comparing semantic vectors.
- The “Flat” index means it stores all vectors without compression, ensuring exact search results but using more memory.
index.add(embeddings)
- Adds all sentence embeddings into the index, making them searchable.
- This step prepares the data structure for fast query lookups.
Output:
- A FAISS index object configured for fast inner product (cosine similarity) search.
- This index can be queried repeatedly to find the most relevant sentences for any input query embedding.
Why This Step Matters
Building the FAISS index is critical for achieving:
- Scalability: Efficiently handles large volumes of content vectors without sacrificing search speed.
- Real-time performance: Enables instant semantic search responses suitable for interactive user applications.
- Accuracy: Using normalized embeddings and inner product ensures meaningful semantic similarity scores.
Without this indexing layer, the system would need to perform costly pairwise comparisons across all content vectors, making it impractical for real-world use.
This function serves as the backbone of the vector-based retrieval engine, providing the infrastructure for seamless and intelligent content discovery.

Understanding FAISS
Introduction to FAISS
FAISS, short for Facebook AI Similarity Search, is an open-source library developed by Facebook AI Research designed specifically for efficient similarity search and clustering of dense vectors. It plays a pivotal role in vector-based search systems by enabling rapid and scalable retrieval of the most semantically relevant content based on vector representations.
Why FAISS is Essential in Vector-Based Search Retrieval
Vector-based search retrieval has become a fundamental component of modern AI-driven information systems. Instead of relying on simple keyword matching, advanced search engines convert documents, sentences, or even images into vector embeddings—numerical representations that capture semantic meaning. These vectors exist in a high-dimensional space where similar content appears closer together.
However, as the size of datasets grows into millions or even billions of vectors, searching through this high-dimensional space becomes computationally challenging. Performing brute-force comparisons between a query vector and every stored vector quickly becomes inefficient and impractical for real-time applications.
This is where FAISS (Facebook AI Similarity Search) plays a critical role. FAISS is an open-source library specifically designed to perform fast and efficient similarity searches on large collections of vectors. It enables search systems to retrieve relevant results quickly while maintaining high accuracy, making it a cornerstone technology for modern vector-based search architectures.
Understanding the Challenge of High-Dimensional Vector Search
In vector-based retrieval systems, each piece of content—such as a webpage, paragraph, or sentence—is transformed into a numerical vector using machine learning models like transformer-based embeddings.
These vectors often exist in spaces containing hundreds or even thousands of dimensions. When a user submits a query, it is also converted into a vector, and the search system must find the stored vectors that are closest to it.
Without optimized algorithms, the system would need to compare the query vector with every vector in the database. This process, known as brute-force search, becomes extremely slow as datasets scale.
For example, imagine a database containing 100 million document embeddings. Comparing each query against every stored vector would require enormous computational resources and would significantly increase response time.
FAISS solves this problem by enabling efficient similarity search in high-dimensional spaces.
Accelerating Nearest Neighbor Search
The primary strength of FAISS lies in its ability to perform nearest neighbor search extremely fast. Instead of checking every vector in the database, FAISS uses advanced indexing structures to narrow down potential matches.
These optimized search techniques dramatically reduce query response time while still maintaining high accuracy in retrieving relevant vectors.
FAISS achieves this by:
- Organizing vectors into structured indexes
- Reducing the number of distance calculations required
- Using optimized mathematical operations for vector comparisons
This allows systems to process queries in milliseconds rather than seconds, which is essential for real-time applications such as semantic search, recommendation systems, and conversational AI.
Supporting Massive Vector Datasets
Another key advantage of FAISS is its ability to handle extremely large datasets. Modern AI search systems often deal with millions or billions of embeddings generated from massive collections of text, images, or multimedia content.
FAISS is specifically designed to operate at this scale. It supports:
- Large-scale vector storage
- Distributed computing environments
- GPU acceleration for faster processing
- Memory-efficient indexing structures
By leveraging GPU processing power, FAISS can perform similarity searches significantly faster than traditional CPU-based methods. This makes it ideal for large-scale search engines and AI-driven platforms that require rapid retrieval from vast content repositories.
Multiple Indexing Strategies for Flexible Performance
One of FAISS’s most powerful features is the variety of indexing strategies it provides. Different applications require different balances between speed, memory usage, and accuracy, and FAISS allows developers to choose the most suitable indexing method.
Some commonly used FAISS indexing techniques include:
1. Flat Index (Exact Search)
This method performs an exact nearest neighbor search. While it provides maximum accuracy, it can be slower for extremely large datasets.
2. Inverted File Index (IVF)
IVF divides vectors into clusters and searches only within relevant clusters, significantly improving speed.
3. Product Quantization (PQ)
This method compresses vectors to reduce memory consumption while maintaining acceptable accuracy levels.
4. Hierarchical Index Structures
These structures organize vectors in multiple layers, allowing faster navigation through the search space.
By combining these techniques, FAISS enables developers to build highly optimized search systems tailored to specific performance requirements.
Enabling Real-Time Semantic Search Applications
FAISS has become a critical technology behind modern semantic search systems. Many AI-powered applications rely on vector similarity search to deliver meaningful results quickly.
Some common use cases include:
- AI-powered search engines
- Recommendation systems
- Chatbots and conversational AI
- Document retrieval systems
- Image and multimedia search
In these environments, users expect instant responses. FAISS ensures that even complex semantic queries can be processed efficiently, delivering relevant results in real time.
The Importance of FAISS in Modern AI Search
As artificial intelligence continues to reshape search technology, vector-based retrieval systems are becoming increasingly important. However, without efficient indexing and similarity search mechanisms, these systems cannot scale effectively.
FAISS provides the infrastructure needed to handle high-dimensional vector search at scale. By accelerating nearest neighbor retrieval, supporting massive datasets, and offering flexible indexing strategies, FAISS enables AI-driven search systems to operate efficiently and accurately.
For organizations building advanced search platforms, FAISS is not just a performance enhancement—it is a foundational technology that makes large-scale semantic retrieval possible.
How FAISS Works
Vector Space and Similarity Metrics
- FAISS operates on vectors embedded in a multi-dimensional space.
- Each vector represents semantic information from text, images, or other data modalities.
- Similarity between vectors is typically measured using distance metrics such as Euclidean distance or cosine similarity.
- Cosine similarity is often computed via normalized inner product for efficiency.
Index Types
FAISS supports various index types optimized for different trade-offs:
- Flat (Brute-force) Index: Stores all vectors and compares them directly; guarantees exact nearest neighbors but is slower on large datasets.
- Inverted File (IVF) Index: Partitions vectors into clusters to speed up search.
- HNSW (Hierarchical Navigable Small World) Graph: Graph-based approximate nearest neighbor search optimized for speed.
- PQ (Product Quantization) and other compression techniques: Reduce memory footprint for very large datasets.
The choice of index depends on dataset size, accuracy requirements, and hardware constraints.
Normalization for Cosine Similarity
- When vectors are normalized to unit length, inner product similarity is equivalent to cosine similarity.
- This property allows FAISS to use fast inner product calculations while maintaining semantic relevance.
Implementation in the Project
Use of IndexFlatIP
- The project utilizes the IndexFlatIP, a flat index based on inner product similarity.
- This index is straightforward and suitable for moderate dataset sizes where exact nearest neighbor retrieval is desired.
- Since the sentence embeddings are normalized, inner product corresponds to cosine similarity, a preferred measure for semantic similarity in NLP.
Building and Querying
- The index is built once by adding all sentence embeddings derived from the source content.
- During search, a query vector (derived from the user input) is compared against this index to retrieve the most semantically similar sentences.
- This retrieval supports downstream features like internal linking, content discovery, and snippet generation.
Advantages of Using FAISS
- Speed: Performs vector similarity search orders of magnitude faster than naive methods.
- Scalability: Can handle millions of vectors efficiently.
- Flexibility: Supports different metrics and index types suitable for various use cases.
- Community and Support: Maintained by Facebook AI with strong documentation and active updates.
Limitations and Considerations
- Memory Usage: Flat indices store all vectors and can consume significant memory.
- Approximate Methods Needed for Large Scale: For very large datasets, approximate indexing methods may be required, which trade slight accuracy for speed.
- Requires Vector Normalization: Proper preprocessing and normalization of vectors are critical for meaningful results.
Summary
FAISS is the fundamental technology enabling this project’s core functionality: fast, scalable, and accurate semantic search over textual content. Its implementation provides a powerful foundation for delivering enhanced user experiences through vector-based retrieval, distinguishing this system from traditional keyword matching approaches.
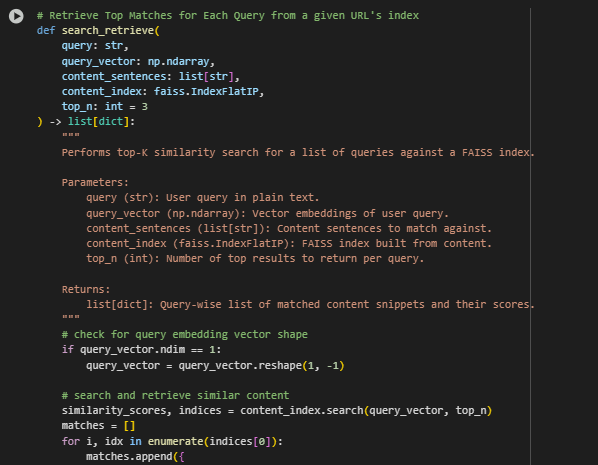
Function Overview: search_retrieve
This function takes a user’s query, transforms it into its vector representation, and efficiently searches through the pre-built FAISS vector index of content sentences to return the top matches based on similarity scores. This process enables the system to retrieve information beyond simple keyword matching by leveraging semantic understanding.
Explanation
Similarity Search:
similarity_scores, indices = content_index.search(query_vector, top_n)
Using the FAISS index, the function performs a top-k similarity search to find the content sentences most similar to the query vector. The similarity metric is cosine similarity via normalized inner product.
Result Construction:
The function collects the top matching sentences along with their similarity scores. Scores are rounded for better readability. Each result is structured as a dictionary containing the matched sentence and its corresponding relevance score.
Significance in the Project
- This function operationalizes the ector-based retrieval concept by converting semantic similarity into actionable ranked results.
- The top-matched sentences returned can be used for various purposes such as enhancing search interfaces, generating featured snippets, or suggesting internal links.
- The approach provides a richer, context-aware search experience, allowing users to find relevant information even if their queries do not exactly match keywords present in the content.
Summary
The search_retrieve function is the heart of the retrieval mechanism in this project, enabling the practical application of semantic vector search. By returning precise, semantically relevant content snippets quickly, it supports improved user engagement and content discoverability.

Function Overview: display_results
The display_results function formats and presents the search results in a clear and readable manner. This aids in quickly understanding the relevance and content of the top matches returned by the retrieval process.
Functionality
- Takes a list of result dictionaries, each containing a matched sentence and its similarity score.
- Prints the query and associated URL context.
- Iterates through each result, showing the similarity score alongside the matched sentence.
- Handles cases where no matching sentence is found by displaying a “No Data Found” message.
Output Analysis
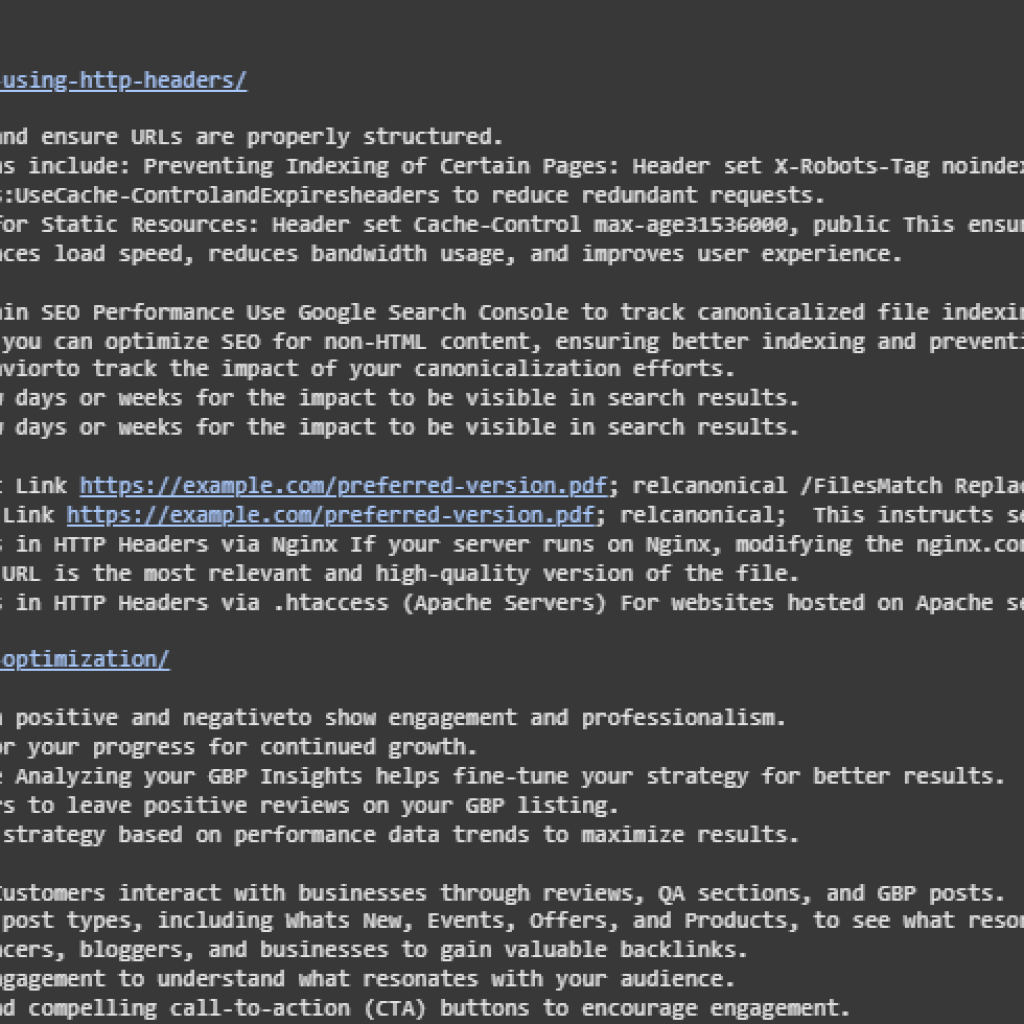
The following demonstrates the retrieval results when executing a search query against the content of a single web page URL. The query used here is: “how to handle different document urls” and the target page is:
Explanation of Results
- The system returns a ranked list of sentences from the webpage that are semantically most relevant to the query.
- Each sentence is accompanied by a similarity score, which quantifies how closely the sentence’s meaning aligns with the query. Scores range between 0 and 1, with higher scores indicating stronger relevance.
- The top sentences primarily relate to handling canonical URLs and HTTP headers, which aligns well with the query about managing different document URLs.
- This confirms the system’s ability to identify and rank meaningful content beyond simple keyword matching, understanding the context and semantics of the text.
Key Takeaway
This output illustrates the project’s capability to effectively extract and rank content snippets that address the user’s intent, providing precise and contextually relevant information from a single document source.
Results Interpretation and Explanation
This section provides a clear understanding of the search results generated by the semantic search system. It is designed to help interpret the output effectively and to understand how the similarity scores relate to the quality and relevance of the matches.
Understanding Similarity Scores
Score Range and Meaning: The similarity scores range from 0 to 1, representing how closely a retrieved content snippet matches the user’s query based on semantic meaning rather than just keyword overlap.
Threshold Guidelines:
- Scores above 0.45: These indicate a high semantic similarity. The content snippets strongly relate to the query intent, often providing direct answers or closely aligned information.
- Scores between 0.30 and 0.45: This range represents moderate similarity, where the retrieved content is relevant but may cover broader or slightly tangential aspects of the query.
- Scores below 0.30: These are lower similarity matches. The content may share some contextual keywords or themes but is less directly related to the query. These can still be valuable for exploring related ideas or discovering supplementary information.
Practical Interpretation of Results
· High-Scoring Matches:
When the system returns results with scores above 0.45, it means the search found highly pertinent information. For example, a query about improving blog engagement might retrieve content explicitly detailing actionable SEO tactics or engagement strategies.
· Moderate Scores Provide Context:
Matches with scores in the 0.30 to 0.45 range typically expand on the main topic by providing supportive or background information. This is useful for building a broader understanding or exploring adjacent areas related to the main query.
· Lower Scores Suggest Related Topics:
Content with scores below 0.30 might not be an exact match but can reveal potentially useful insights connected to the query theme, such as general advice, technical background, or indirect methods that impact the user’s goal.
Overall System Performance
· Semantic Matching Beyond Keywords:
The system excels in identifying not just keywords but the underlying meaning in queries and content. This ensures users receive results that are contextually relevant and informative.
· Diverse Query Handling:
The system effectively processes various user intents, ranging from technical instructions to strategic advice, demonstrating flexibility and robustness in understanding and ranking content.
· Actionable Outputs:
The retrieved content snippets are concise and practical, enabling decision-makers to quickly assess which parts of the content best address their specific needs or questions.
Summary for Users
- The similarity scores provide a reliable indicator of how well the returned content matches the user’s query intent.
- Higher scores correspond to stronger matches and more directly relevant information.
- Moderate to lower scores still offer useful context and related insights, supporting a comprehensive exploration of the topic.
- This approach ensures users find the most meaningful and useful content snippets quickly, supporting efficient decision-making and content optimization.
Advanced Vector Indexing and Retrieval Strategies for AI Search Systems
As search technology evolves toward semantic understanding, vector-based retrieval systems must be supported by sophisticated indexing and retrieval strategies. Simply converting documents into embeddings is not enough; efficient storage, similarity computation, and scalable search architectures are essential for real-world applications. Advanced indexing frameworks ensure that vector search remains fast, accurate, and scalable even when dealing with millions or billions of data points.
Modern AI-driven SEO and search platforms—such as those implemented by ThatWare—leverage optimized vector indexing structures to deliver faster and more precise information retrieval. Let’s explore the key technologies that power these advanced systems.
Approximate Nearest Neighbor (ANN) Search
One of the main challenges of vector search is computational complexity. When millions of embeddings exist in a database, comparing a query vector against every stored vector becomes inefficient.
To solve this problem, modern systems rely on Approximate Nearest Neighbor (ANN) algorithms.
ANN methods quickly identify vectors that are likely to be the closest matches rather than calculating exact similarity across the entire dataset. This dramatically reduces processing time while maintaining high accuracy.
Popular ANN techniques include:
- Hierarchical Navigable Small World (HNSW) graphs
- Product Quantization (PQ)
- Locality Sensitive Hashing (LSH)
These algorithms create structured indexes that allow search engines to navigate through embedding space efficiently, retrieving relevant results in milliseconds.
Vector Similarity Metrics
The effectiveness of vector retrieval heavily depends on how similarity between vectors is calculated. Several mathematical similarity metrics are used in modern AI search systems.
Cosine Similarity
Cosine similarity measures the angle between two vectors in multidimensional space. Instead of focusing on magnitude, it evaluates how closely two vectors align in direction.
\text{Cosine Similarity} = \frac{A \cdot B}{||A|| ; ||B||}
This method is widely used in natural language processing because it effectively captures semantic similarity between documents and queries.
Euclidean Distance
Another commonly used metric is Euclidean distance, which measures the straight-line distance between two vectors in vector space.
d = \sqrt{\sum_{i=1}^{n}(x_i – y_i)^2}
Smaller distances indicate higher similarity between vectors.
Dot Product Similarity
Dot product similarity evaluates how strongly two vectors align in terms of magnitude and direction. It is frequently used in neural search systems where embeddings are normalized.
Choosing the appropriate similarity metric depends on the architecture of the embedding model and the nature of the search problem.
Scalable Vector Databases
As vector search systems scale, traditional relational databases struggle to handle high-dimensional embeddings efficiently. This is where vector databases play a crucial role.
Vector databases are specialized storage systems designed to manage and retrieve embeddings at scale. They support optimized indexing structures and ANN search algorithms.
Key features of vector databases include:
- High-dimensional vector storage
- Real-time similarity search
- Distributed indexing architecture
- Low-latency retrieval
Examples of widely used vector databases include:
- FAISS (Facebook AI Similarity Search)
- Pinecone
- Milvus
- Weaviate
These platforms enable AI search engines to process massive datasets while maintaining real-time query performance.
Hybrid Retrieval Models: Combining Vector and Keyword Search
While vector search excels at semantic understanding, traditional keyword-based search methods remain valuable in many scenarios. Modern AI retrieval systems often combine both techniques in a hybrid search architecture.
Hybrid models integrate:
- Lexical search (BM25 or TF-IDF)
- Semantic vector retrieval
- Re-ranking models
This multi-layered retrieval approach ensures both precision and contextual relevance.
For example:
- Keyword search identifies documents containing exact query terms.
- Vector search evaluates semantic similarity.
- Machine learning ranking models reorder results for maximum relevance.
ThatWare’s AI-driven search frameworks leverage this hybrid architecture to enhance both ranking accuracy and contextual understanding.
Real-Time Query Processing and AI Optimization
Another critical advancement in vector retrieval systems is real-time query optimization. Modern AI search engines dynamically process user queries and adjust retrieval strategies accordingly.
Key components of real-time vector search include:
- Dynamic embedding generation for user queries
- Query expansion using language models
- Context-aware ranking algorithms
- AI-based re-ranking layers
These techniques allow search systems to deliver more personalized and relevant results by understanding the deeper intent behind user queries.
For SEO and AI search optimization, this capability is particularly important. It ensures that content is not only indexed semantically but also retrieved in contextually appropriate scenarios.
Why Advanced Vector Retrieval Matters for AI Search
Vector-based retrieval represents the future of search technology. As AI-powered search engines become more sophisticated, traditional keyword matching alone is no longer sufficient.
Advanced vector indexing and retrieval strategies enable:
- Faster semantic search
- Better contextual relevance
- Scalable AI search architectures
- Improved user experience in conversational search
For companies like ThatWare that specialize in AI-driven SEO, vector-based search retrieval is a foundational technology that supports next-generation content discovery and ranking strategies.
By combining vector embeddings, ANN indexing, hybrid retrieval models, and AI-powered optimization, modern search systems can deliver results that truly understand user intent—pushing the boundaries of what search engines can achieve.
Final Thoughts
This project demonstrates the power of advanced vector-based semantic search to unlock deeper insights into website content relevance and user intent. By leveraging state-of-the-art similarity matching, it enables precise identification of which content best aligns with the queries that matter most to your audience. The actionable insights derived from the similarity scores empower data-driven decisions to optimize content, improve user engagement, and enhance overall SEO performance.
Importantly, this approach moves beyond traditional keyword matching to capture nuanced meanings, making it highly effective in today’s evolving search landscape. Regularly applying this analysis supports continuous improvement and adaptation to changing user behaviors and search algorithms.
Ultimately, this project serves as a valuable tool to strengthen your content strategy, maximize organic traffic potential, and deliver a better experience to your visitors—creating a sustainable competitive advantage in digital presence.
