SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
What are Striking Distance Keywords?
We define Striking Distance Keywords as those ranking keywords for which our Website is ranking anywhere between the 2nd to 20th page. The name “Striking Distance” is chosen since targeting these keywords will be relevantly easier than targeting any other keyword types.

Normally these are the potential keywords that are improperly mapped and implemented in the target url.
To find these keywords manually for every page is time-consuming and almost impossible for a large enough site. Hence it makes much sense to automate the task using a little bit of python code.
Why use Python?
Python is an excellent tool that can be used to automate tasks that are repetitive and perhaps its greatest benefit is that it’s customizable. Which allows us to get more unique insights from our data set.
In today’s article, we will be talking about how to find striking distance keyword ranking from the 3rd page to the 20th page for each page and also advise whether these keywords are eligible to be optimized.
Here’s a Snapshot of the Output we generated for our site: thatware.co
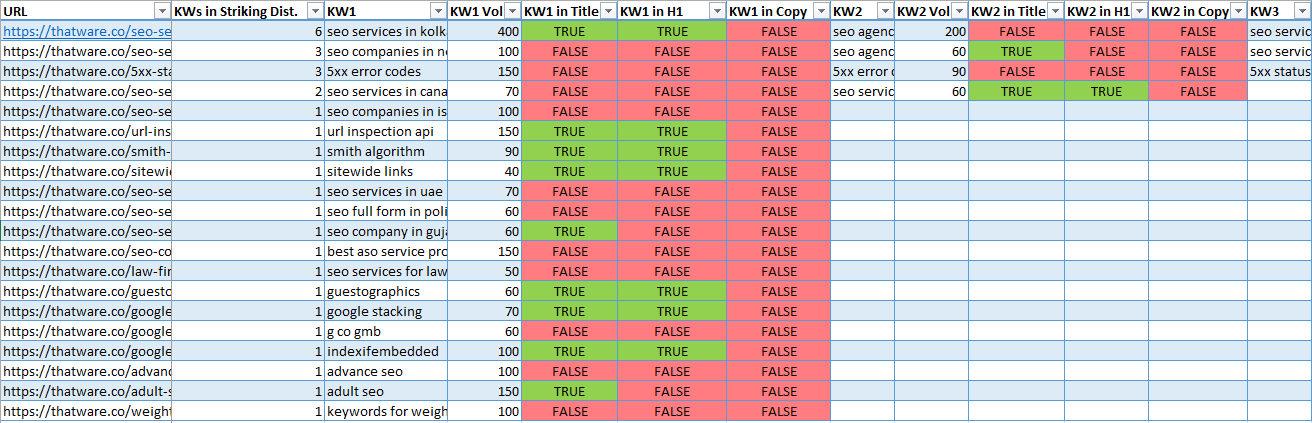
Now, I understand most SEOs might not know coding and those people might get frightened only by the mention of the word in this post. However, I wanted to assure you that we will be using a pre-built script to obtain this output using a Google Collaboration Sheet.
The Google Collaboration Sheet will also be useful for those code-savvy guys who are looking to play around and customize the data according to their needs.
The above keywords are specified along with information regarding their placement, either in the Title, Headline or content copy.
How to Find Striking Distance Keywords?
The setup process is quite simple. It involves the following steps.
- Crawl the website along with a custom extraction with the web copy, and export the data in CSV format.
- Upload the Ranking keywords data for HTML pages.
- Feed these two data in the Google Collaboration Sheet and obtain the desired Output.
Crawling the Website
Setting Up Crawl
I will be using Screaming frog to crawl the website and gather the requisite data.
- Go to Configuration > Spider > Crawl. Keep the following configuration.

- Go to Extraction Tab on the same Spider Configuration.
In this, we need some basic information like Page Title, Meta description, H1, and Indexability. You can choose the options below.
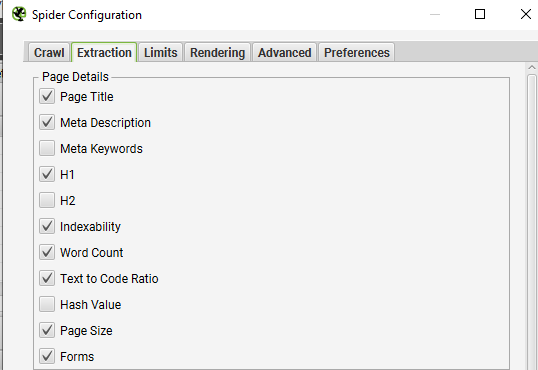
The Indexability Report is important as it helps the Google script to understand which URLs to drop instantly when generating the Report.
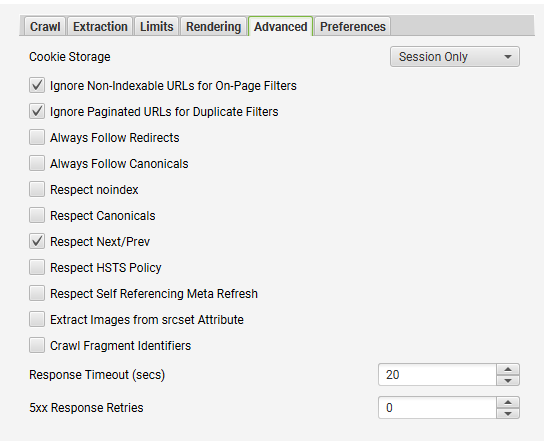
- Filter out Paginated Pages
We would want to filter out paginated pages from the range of our crawl. We can do this by selecting “Respect Next/Prev” from Configuration > Spider > Advanced.
- Set Up Custom Extraction for the Page Copy
In order for the script to check whether a particular keyword is present in the page copy or not, we need to implement a custom extraction for the page copy.
Configuration > Custom > Extraction
Name the extractor as shown below

- The script uses “Copy” as the extractor name so keep it the same.
- Share the relevant Xpath or CSS path for the home page element of your website.

- Make sure Extract Text is selected to extract the copy as text rather than HTML.
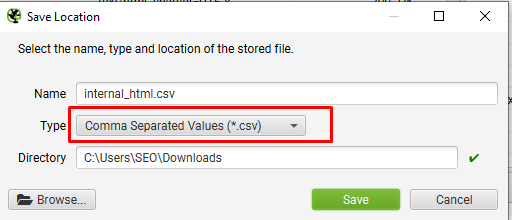
With that, the crawler is all set. Now, all we have to do is to export all the internal HTML in “CSV” format.

Gather all Ranking Keywords Data from any Keyword Tool
For this example, I will be using the Ahrefs tool to find all the organic ranking keywords. The same would work for any Keyword Tool.
- Go to Ahref > Site Explorer > Enter domain url.
- Go to the organic rankings report, then export all the organic keywords which are ranking for HTML pages.
- Make sure to export all keywords as below in UTF – 8 formats.
Note: By default the script works with Ahrefs and SEMRush keyword exports. However, it can work with any keyword file in CSV format as long the column names are the same as expected in the code.
Run the Code!
Congratulations on reaching this far. Now all that is left is to run the code in the Google Collaboration Sheet.
Here is the link to the Collaboration Sheet where we will find a premade executable to run your program.
- Select Runtime > Run all from the Top Bar Menu.
- The program will expect you to upload the organic ranking keyword file in the CSV format that you just downloaded.
- Similarly, the Code will prompt us to upload the HTML Crawl Report that we exported from Screaming Frog Earlier.
- Finally, after the rest of the code is processed you will get an output with all the Striking Distance Keywords. Here’s the output we received for ThatWare.
With a few design skills, you can format the report to look like the above.
Enhanced Python Workflow for Striking Distance Keywords Discovery
Python’s flexibility and power make it an ideal choice for SEO tasks like identifying striking distance keywords. In this section, we delve into an enhanced Python workflow that simplifies the process of discovering these keywords while adding layers of efficiency and customization. From selecting libraries to handling large datasets, the workflow can be tailored to your specific needs.
1. Setting Up the Environment
Before starting, ensure that your Python environment is properly configured. Here are the steps to get started:
Install Necessary Libraries:
Python’s ecosystem is rich with libraries that streamline data processing and web scraping. Use the following libraries:
pip install pandas numpy requests beautifulsoup4 selenium matplotlib seaborn openpyxl
Choose Your IDE:
Select an IDE that supports data visualization and debugging, such as Jupyter Notebook, PyCharm, or Visual Studio Code.
Set Up a Virtual Environment:
Isolate your project dependencies to avoid conflicts by creating a virtual environment:
python -m venv seo_env
source seo_env/bin/activate # For Linux/Mac
seo_env\Scripts\activate # For Windows
2. Automating Website Crawling
Crawling a website is the first step in discovering striking distance keywords. While tools like Screaming Frog are effective, Python’s Selenium and BeautifulSoup libraries offer custom crawling capabilities.
Using Selenium for Dynamic Pages:
For websites with JavaScript-heavy content, Selenium can be employed to render pages and extract data:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get(‘https://example.com’)
# Extract page title and meta description
title = driver.find_element(By.TAG_NAME, ‘title’).text
meta_desc = driver.find_element(By.NAME, ‘description’).get_attribute(‘content’)
print(f”Title: {title}, Meta Description: {meta_desc}”)
driver.quit()
Scraping Static Pages with BeautifulSoup:
BeautifulSoup is efficient for extracting HTML elements from static pages:
from bs4 import BeautifulSoup
import requests
url = ‘https://example.com’
response = requests.get(url)
soup = BeautifulSoup(response.text, ‘html.parser’)
# Extract title and H1 tags
title = soup.title.string
h1 = soup.find(‘h1’).text
print(f”Title: {title}, H1: {h1}”)
3. Processing Large Datasets with Pandas
Handling the data exported from tools like Screaming Frog and Ahrefs requires robust data manipulation. Pandas is a go-to library for this purpose.
Reading and Cleaning Data:
Import the exported CSV files and clean the data:
import pandas as pd
crawl_data = pd.read_csv(‘screaming_frog_output.csv’)
keyword_data = pd.read_csv(‘ahrefs_keywords.csv’)
# Remove unnecessary columns
crawl_data = crawl_data[[‘URL’, ‘Title’, ‘Meta Description’, ‘Indexability’]]
keyword_data = keyword_data[[‘Keyword’, ‘Position’, ‘Volume’, ‘URL’]]
# Filter indexed pages
crawl_data = crawl_data[crawl_data[‘Indexability’] == ‘Indexable’]
Merging Datasets:
Combine the crawl data with keyword rankings to create a unified dataset:
merged_data = pd.merge(keyword_data, crawl_data, on=’URL’, how=’inner’)
4. Analyzing and Filtering Keywords
Once the datasets are merged, filter and analyze the keywords to identify striking distance opportunities.
Filter by Position:
Identify keywords ranking between the 3rd and 20th pages:
striking_distance = merged_data[(merged_data[‘Position’] >= 30) & (merged_data[‘Position’] <= 200)]
Prioritize by Volume and Intent:
Focus on keywords with higher search volumes and transactional or navigational intent:
prioritized_keywords = striking_distance[striking_distance[‘Volume’] > 500]
5. Keyword Presence Analysis
Check whether striking distance keywords are present in key on-page elements (Title, H1, Meta Description, and Body).
Automated Checks:
Add a flag to indicate whether a keyword is present in these elements:
def check_keyword_presence(row, keyword):
return keyword.lower() in row[‘Title’].lower() or \
keyword.lower() in row[‘Meta Description’].lower()
striking_distance[‘Keyword in Elements’] = striking_distance.apply(
lambda row: check_keyword_presence(row, row[‘Keyword’]), axis=1
)
Visualizing Results:
Use Seaborn or Matplotlib to create visualizations of the keyword distribution:
import matplotlib.pyplot as plt
import seaborn as sns
sns.countplot(data=striking_distance, x=’Keyword in Elements’)
plt.title(‘Keyword Presence in On-Page Elements’)
plt.show()
6. Advanced Enhancements
Batch Processing:
For larger datasets, use Python’s multiprocessing library to speed up keyword checks:
from multiprocessing import Pool
def process_batch(batch):
return batch.apply(lambda row: check_keyword_presence(row, row[‘Keyword’]), axis=1)
with Pool(processes=4) as pool:
results = pool.map(process_batch, np.array_split(striking_distance, 4))
striking_distance[‘Keyword in Elements’] = pd.concat(results)
Incorporating Backlink Analysis:
Use APIs from tools like Ahrefs or SEMRush to integrate backlink data for target pages:
import requests
ahrefs_api = ‘https://api.ahrefs.com?your_api_key’
response = requests.get(f'{ahrefs_api}&target_url=https://example.com’)
backlinks = response.json()
print(f”Backlinks: {backlinks[‘total’]}”)
7. Automating Reporting
Generate a user-friendly report to share insights with your team or clients.
Exporting Data:
Save the filtered dataset to an Excel file:
striking_distance.to_excel(‘striking_distance_keywords.xlsx’, index=False)
Creating Dashboards:
Use libraries like Plotly or Dash to create interactive dashboards:
import plotly.express as px
fig = px.bar(
striking_distance, x=’Keyword’, y=’Volume’, color=’Keyword in Elements’,
title=’Striking Distance Keyword Opportunities’
)
fig.show()
8. Scheduling Regular Updates
Set up a cron job or task scheduler to automate the workflow at regular intervals.
Using Python’s Schedule Library:
import schedule
import time
def run_workflow():
print(“Running Striking Distance Workflow”)
# Add your complete workflow script here
schedule.every().week.do(run_workflow)
while True:
schedule.run_pending()
time.sleep(1)
9. Troubleshooting Common Issues
Handling Missing Data:
Fill or drop missing values to ensure the workflow runs smoothly:
merged_data.fillna(‘N/A’, inplace=True)
Performance Bottlenecks:
Optimize the code by limiting unnecessary iterations or using efficient libraries like Numpy for numerical operations.
Common Pitfalls to Avoid
While implementing Python-based workflows for discovering striking distance keywords, there are several pitfalls that can hinder success. Avoiding these common mistakes ensures smoother processes and better outcomes. Below, we delve into some critical pitfalls and offer actionable solutions.
1. Overlooking Data Accuracy
One of the most frequent errors is using inaccurate or outdated data. Crawling websites and extracting keyword data can yield incomplete or incorrect results if not done meticulously.
What to avoid:
Failing to verify the correctness of data extracted from tools like Screaming Frog or Ahrefs.
Using outdated keyword data that doesn’t reflect current search trends.
Solution:
Regularly update your keyword datasets and ensure they align with the latest metrics.
Cross-verify extracted data with other sources or tools for accuracy.
Conduct periodic audits of your workflows to identify and fix inconsistencies in the data.
2. Improper Configuration of Crawling Tools
Crawling tools such as Screaming Frog require precise settings to extract relevant data efficiently. Misconfigurations can lead to incomplete crawls or irrelevant data.
What to avoid:
Neglecting to adjust crawl settings for your website’s unique structure.
Failing to exclude irrelevant pages (e.g., paginated pages or duplicate URLs).
Solution:
Customize crawl configurations to suit the specific needs of your website.
Exclude non-indexable or irrelevant pages by using filters like “Respect Next/Prev.”
Conduct test crawls to ensure configurations are optimized before executing full-scale processes.
3. Ignoring Keyword Context
Extracting keywords without considering their context within the page can result in missed optimization opportunities.
What to avoid:
Treating keywords in isolation without analyzing their relevance to the content.
Overlooking synonyms or related terms that could enhance keyword mapping.
Solution:
Analyze the placement and context of keywords in titles, headers, and body content.
Use tools like NLP (Natural Language Processing) to understand keyword intent and relationships.
Map keywords to pages based on their thematic relevance and user intent.
4. Inconsistent File Formats and Structures
When integrating data from different tools, inconsistency in file formats and column names can disrupt workflows and cause errors in the script.
What to avoid:
Uploading files with mismatched formats or corrupted data.
Using files that do not adhere to the expected column structure of your Python script.
Solution:
Standardize file formats before uploading by converting them to CSV in UTF-8 format.
Ensure column headers match the specifications of your Python script.
Test small sample files to validate compatibility before running full datasets.
5. Misinterpreting Output Data
Even when scripts run successfully, misunderstanding the output can lead to incorrect decisions and strategies.
What to avoid:
Misreading keyword rankings or incorrectly identifying striking distance keywords.
Overlooking flagged errors in the output.
Solution:
Familiarize yourself with the output structure of your Python script.
Double-check results manually to confirm accuracy.
Use visualization tools like Excel or Google Sheets to interpret data more effectively.
6. Over-Reliance on Automation
While Python scripts can automate repetitive tasks, over-reliance on them without human intervention can limit flexibility and creativity.
What to avoid:
Assuming the script will account for all variables without manual oversight.
Ignoring the need for periodic updates to the script as workflows evolve.
Solution:
Combine automated workflows with manual analysis for a balanced approach.
Regularly review and refine Python scripts to align with updated SEO practices.
Train team members to interpret and modify scripts when necessary.
7. Neglecting Site-Specific Customization
Every website has unique characteristics that generic Python scripts may not address. Without customization, the results may not fully align with your site’s structure or goals.
What to avoid:
Using pre-built scripts without tailoring them to your specific needs.
Failing to account for unique URL structures or meta tag formats.
Solution:
Modify scripts to include custom extraction paths (XPath or CSS selectors) based on your site’s design.
Identify and address site-specific challenges, such as dynamic content or JavaScript rendering.
8. Underestimating Processing Time and Resources
Large-scale crawls and keyword analysis can be resource-intensive, and underestimating their demands can lead to inefficiencies.
What to avoid:
Running extensive crawls on low-resource systems.
Expecting instantaneous results from complex processes.
Solution:
Use cloud-based platforms like Google Colab for resource-heavy operations.
Break down large datasets into smaller batches for processing.
Schedule crawls during off-peak hours to reduce server strain.
9. Failing to Prioritize Keywords
Not all striking distance keywords are equally valuable. Failing to prioritize can lead to wasted effort on low-impact optimizations.
What to avoid:
Treating all identified keywords as equally important.
Ignoring metrics like search volume, competition, and click-through rates.
Solution:
Prioritize keywords based on their potential impact on traffic and conversions.
Focus on optimizing keywords with moderate competition and high relevance.
Use ranking difficulty scores to determine the feasibility of targeting specific keywords.
10. Lack of Collaboration and Communication
SEO workflows often involve multiple team members. Poor communication can lead to misaligned efforts and inefficiencies.
What to avoid:
Working in silos without sharing progress or findings.
Overlooking input from content creators or developers.
Solution:
Establish clear communication channels and workflow documentation.
Collaborate with content and technical teams to ensure seamless execution.
Regularly update stakeholders on progress and insights.
11. Disregarding User Intent
Optimizing for keywords without understanding user intent can lead to irrelevant or poorly performing content.
What to avoid:
Targeting keywords solely based on ranking potential.
Creating content that doesn’t align with user needs or expectations.
Solution:
Conduct intent analysis for all target keywords.
Align keyword optimization strategies with the type of content users expect (e.g., informational, transactional, or navigational).
12. Neglecting Mobile and Voice Search Optimization
With the growing prevalence of mobile and voice searches, failing to optimize for these mediums can hinder your SEO efforts.
What to avoid:
Ignoring mobile-friendly keyword strategies.
Overlooking long-tail and conversational keyword opportunities.
Solution:
Optimize content for mobile-first indexing.
Incorporate natural language phrases and questions to capture voice search traffic.
13. Lack of Post-Optimization Monitoring
SEO is an ongoing process, and failing to monitor the impact of your optimizations can result in missed opportunities for improvement.
What to avoid:
Assuming keyword rankings will remain stable after optimization.
Ignoring changes in competitor strategies or search engine algorithms.
Solution:
Continuously track keyword rankings and organic traffic metrics.
Use tools like Google Search Console to monitor the performance of optimized pages.
Stay updated on SEO trends and adjust strategies as needed.
Advanced Customization and Tips
When working with striking distance keywords and Python-based automation tools, achieving advanced customization is crucial for optimizing results and tailoring insights to your specific needs. This section delves into tips, techniques, and strategies to enhance your workflow and output.
1. Customizing XPath and CSS Selectors
To extract precise elements from your website, refine the XPath or CSS selectors used in the crawler configuration. This allows for targeted data extraction, ensuring the script focuses on relevant content such as titles, meta descriptions, headers, and body text. A few tips for customization include:
Analyze Website Structure: Use browser developer tools (Inspect Element) to understand the structure of your website.
Refine Selectors: Ensure your selectors are neither too broad (leading to irrelevant data) nor too narrow (missing vital information).
Test Incrementally: Validate your selectors on a small subset of pages before applying them to the entire crawl.
2. Tailoring Keyword Export Settings
When exporting keywords from tools like Ahrefs or SEMrush, customize your settings to include only the most relevant data. Focus on:
Keyword Segmentation: Filter keywords by search intent, relevance, or ranking position.
Format Adjustments: Ensure the exported CSV aligns with the column headers expected by your Python script.
Frequency Optimization: Schedule periodic exports to monitor changes in rankings and identify new opportunities.
3. Leveraging Python Libraries for Data Enrichment
While the script handles basic keyword and content alignment, you can integrate additional Python libraries to enrich your data further:
Pandas: For advanced data manipulation and cleaning.
Matplotlib/Seaborn: To visualize keyword performance trends.
NLTK/Spacy: For natural language processing tasks such as sentiment analysis or keyword clustering.
4. Enhancing Output Reports
To make reports more actionable and visually appealing, consider customizing the output with:
Conditional Formatting: Highlight keywords based on metrics like search volume, click-through rates, or ranking difficulty.
Summary Metrics: Add aggregates, such as the total number of optimized keywords or their cumulative search volume.
Interactive Dashboards: Use tools like Google Data Studio or Tableau to create interactive reports based on the output CSV.
5. Automating Post-Processing Steps
The output from your script can serve as a foundation for further automation. For example:
Content Management Integration: Automatically flag pages requiring content updates in your CMS.
Backlink Campaigns: Identify pages to target for backlink building based on keyword opportunities.
Performance Tracking: Feed results into a monitoring tool to track improvements in keyword rankings over time.
6. Advanced Collaboration Features
Using platforms like Google Colab, you can enable collaboration and customization among team members:
Shared Scripts: Allow multiple contributors to edit and refine the code.
Version Control: Use Git integration to track changes and maintain a version history.
Notebook Annotations: Add comments and explanations directly in the code cells to enhance understanding.
7. Integrating Machine Learning Models
For those seeking to go beyond standard optimizations, integrating machine learning models can provide deeper insights. Consider:
Predictive Modeling: Use machine learning to predict which keywords are most likely to improve rankings with minimal effort.
Clustering Algorithms: Group similar keywords to inform content creation strategies.
Ranking Analysis: Train models to analyze ranking trends and recommend actionable strategies.
8. Adapting to Different Website Architectures
Not all websites are created equal, and customization is often needed based on architecture. For instance:
E-commerce Sites: Focus on extracting product-specific keywords and integrating them into product descriptions.
Blogs: Prioritize aligning high-ranking keywords with engaging headlines and subheadings.
Local Businesses: Incorporate location-based keywords and map schema enhancements.
9. Testing and Iteration
Advanced customization requires iterative testing to refine your setup. Follow these steps:
Run Small-Scale Tests: Apply changes to a limited number of pages and evaluate results.
Monitor Metrics: Track KPIs such as ranking improvements, traffic increases, and conversion rates.
Iterate Quickly: Make adjustments based on findings and repeat the testing cycle.
10. Documentation and Knowledge Sharing
Ensure all customizations and processes are well-documented to facilitate replication and scaling. Key aspects to document include:
Selector Customizations: Share XPath and CSS modifications.
Script Changes: Detail any adjustments made to the original code.
Learnings: Record insights gained during the process for future reference.
Preview of Output
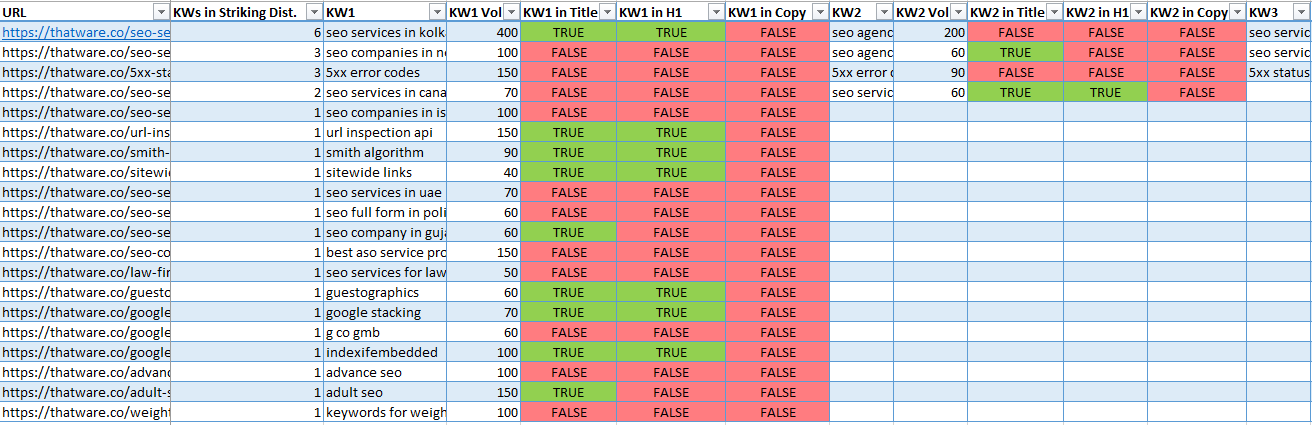
The output report shows all the top 5-6 keyword opportunities and places them in horizontal order along with their search volumes.
Then the presence of the Keywords is determined either in Title, H1, or the Body and accordingly is flagged TRUE or FALSE.
The Striking Distance Keywords obtained are ranking within the 3rd – 20th Page and are useful to pick some easy keyword wins, by simply optimizing the placement of the keyword. (Also some backlinks to the landing page might be useful too.)

Thatware | Founder & CEO
Tuhin is recognized across the globe for his vision to revolutionize digital transformation industry with the help of cutting-edge technology. He won bronze for India at the Stevie Awards USA as well as winning the India Business Awards, India Technology Award, Top 100 influential tech leaders from Analytics Insights, Clutch Global Front runner in digital marketing, founder of the fastest growing company in Asia by The CEO Magazine and is a TEDx speaker and BrightonSEO speaker.
