SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
“SemanticWeb” is a project integrating advanced Natural Language Processing (NLP) techniques, particularly the GloVe model, into a website’s infrastructure to optimize content. The project focuses on improving how a website understands, organizes, and presents its content to users, enabling better search results, personalized recommendations, and overall user experience.

What exactly does GloVe do in this project?
- GloVe (Global Vectors for Word Representation) is used to create word embeddings, mathematical representations of words that capture their meanings based on their usage in large datasets. In this project, GloVe helps the website understand the relationships between words and concepts, allowing it to organize content better and improve search functionality by recognizing synonyms and related terms.
What is GloVe (Global Vectors for Word Representation)
- GloVe, short for “Global Vectors for Word Representation,” is a technique in Natural Language Processing (NLP) used to understand the meaning of words based on their usage in large amounts of text. Imagine you have a huge text collection (like all the books in a library). GloVe looks at how often words appear together in this text. For example, the word “king” often appears with words like “queen,” “crown,” and “royal.” GloVe captures these relationships and turns each word into a list of numbers (a vector), where similar words have similar lists of numbers. This way, GloVe helps computers understand the meanings and relationships between words, even if the computer doesn’t “speak” our language.
What Are Its Uses in the Case of a Website?
GloVe can be incredibly useful for a website in improving how content is organized, searched, and presented to users. Here are some specific uses:
- Content Optimization: GloVe can help understand the context of words within a website’s content. This allows the website to automatically group similar content, suggest related articles, or improve the internal search functionality, making it easier for users to find relevant information.
- Semantic Search: Traditional search engines on websites might look for the exact words a user types. However, with GloVe, the search can understand the meaning behind the words. For example, if someone searches for “cheap flights,” the website can also return results for “affordable air travel,” even if the exact words don’t match.
- Personalization: GloVe can help personalize content recommendations. By understanding the user’s preferences and the semantic relationships between words, the website can suggest content that the user is more likely to find interesting or useful.
How Is It Going to Benefit Website Owners in Terms of Business?
For website owners, especially those running businesses, GloVe offers several key benefits:
- Improved User Experience: By offering more relevant content and better search results, users are more likely to stay longer on the website, leading to higher engagement, lower bounce rates, and increased loyalty.
- Increased Conversions: For e-commerce websites, GloVe can help match products with user searches more accurately, leading to higher chances of sales. If users find exactly what they are looking for quickly, they are more likely to purchase.
- Increased Conversions: For e-commerce websites, GloVe can help match products with user searches more accurately, leading to higher chances of sales. If users find exactly what they are looking for quickly, they are more likely to purchase.
- Insightful Analytics: By analyzing the semantic content of user searches and interactions, website owners can gain deeper insights into what their audience is looking for. This data can inform content strategies, marketing campaigns, and product development.
Real-Life Implementation of GloVe
GloVe is used in various real-world applications across different industries:
- E-Commerce: Online stores like Amazon use advanced NLP techniques like GloVe to improve product recommendations, search results, and customer service chatbots. When a user searches for a product, the system can understand related terms and suggest relevant items.
- Social Media Platforms: Platforms like Twitter and Facebook use GloVe to analyze the vast text data users generate. This helps in understanding trends, filtering spam, and even sentiment analysis, where the platform can gauge users’ general mood or opinions.
- News Aggregators: Websites that gather news from various sources, like Google News, use GloVe to categorize articles and suggest related news stories. This helps users discover content they are interested in, even if they didn’t explicitly search for it.
- Voice Assistants: Devices like Amazon’s Alexa or Google Home use NLP techniques, including GloVe, to better understand user commands. When you ask a question, the assistant uses these models to understand what you mean and to provide accurate responses, even if you phrase things differently.
Real Life Example:
- A real-life example would be an e-commerce site that uses GloVe-based NLP to enhance its product search. For instance, if a user searches for “running shoes,” the site could return results that include related terms like “athletic footwear” or “sports sneakers,” even if those exact words weren’t in the original query. This improves the user experience and increases the likelihood of a purchase.
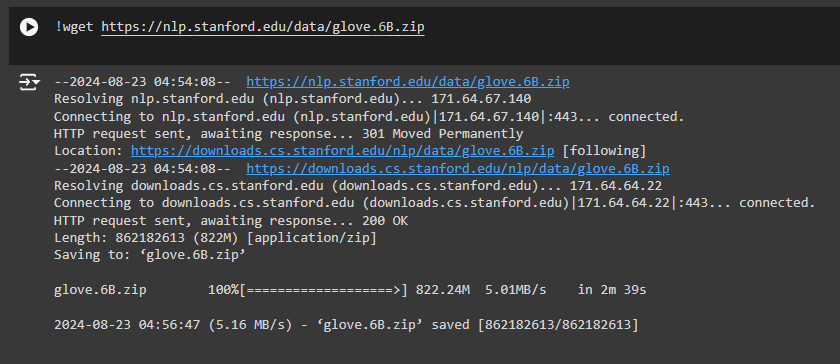
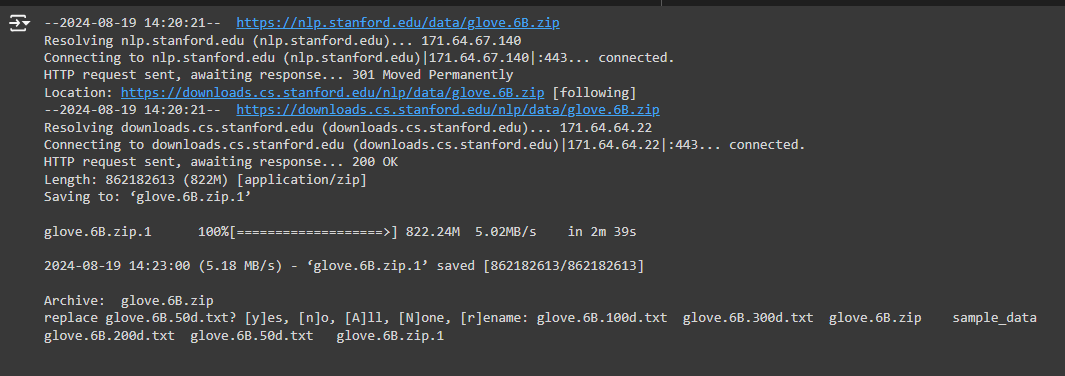
Step 1: Download the GloVe Embeddings
!wget https://nlp.stanford.edu/data/glove.6B.zip
- What This Does: This command downloads a file called glove.6B.zip from the internet. This file contains “GloVe embeddings,” like pre-built maps that help a computer understand the meaning of words based on how often they appear together in large amounts of text.
- Why It’s Necessary: Imagine you’re trying to teach a computer to understand language. Instead of making the computer learn from scratch, we give it a head start using these pre-built maps (GloVe embeddings). Downloading this file is like getting a toolkit to help us understand the meaning of words.
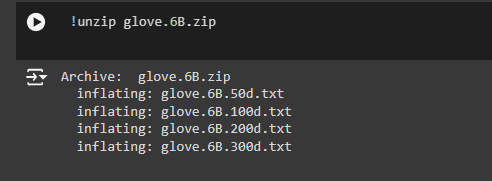
Step 2: Unzip the Downloaded File
!unzip glove.6B.zip
· What This Does: This command unzips (or unpacks) the glove.6B.zip file. After unzipping, you get several text files, each containing different versions of the word maps (embeddings) with varying levels of detail.
· Why It’s Necessary: The downloaded file is like a compressed package (imagine a zipped suitcase). Before we can use the tools inside, we need to unzip (unpack) it. This step is crucial because it makes the data accessible and ready to use.
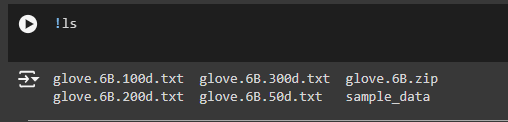
Step 3: Verify the Files Are Unzipped
!ls
· What This Does: This command lists all the files in the current folder, allowing you to check that the unzipping process worked correctly and that the necessary files are now available.
· Why It’s Necessary: Consider this step as checking that all the tools you unpacked are in good condition. Listing the files ensures that everything you need is available and ready for the next steps.
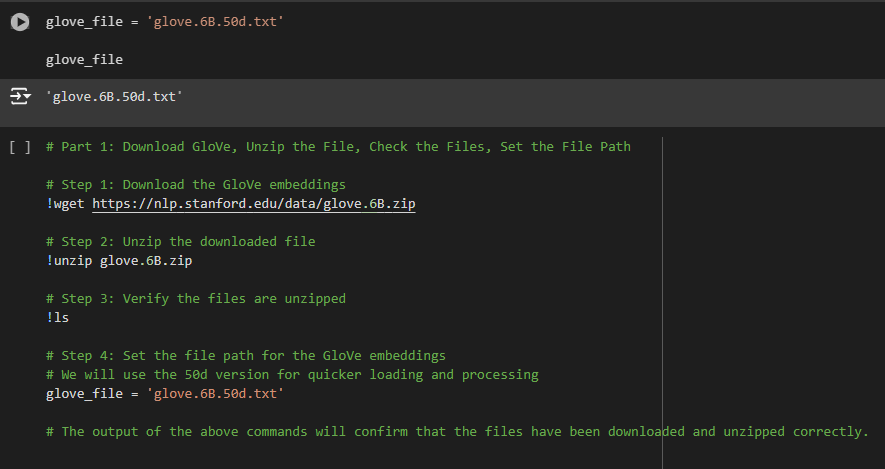
Step 4: Set the File Path for the GloVe Embeddings
glove_file = ‘glove.6B.50d.txt’
· What This Does: You are selecting one of the unzipped files. The file glove.6B.50d.txt contains a 50-dimensional version of the word maps. This means each word is represented by 50 numbers, which is a good balance between detail and speed.
· Why It’s Necessary: This step is like picking the right tool from your toolkit. The 50-dimensional file was chosen because it provides enough detail to be useful while still being fast enough to work with quickly. By setting this file path, you tell the computer which file to use in the project.
Explanation of Each Library:
1) requests:
· Purpose: This library sends HTTP requests, like when you want to fetch data from a website.
· Example: Imagine you want to read an article online. The requests library allows your program to “go online” and “read” the content of that article.
2) from bs4 import BeautifulSoup:
· Purpose: BeautifulSoup is a library that helps you parse (understand and extract) the HTML content of a webpage. After using requests to fetch a webpage, BeautifulSoup helps you navigate and find specific parts of the page, like paragraphs or links.
· Example: If you visit a website and want to extract all the text inside the paragraphs (
tags), BeautifulSoup is like a tool that digs into the webpage and pulls out just the text you’re interested in.
3) import re:
· Purpose: This is the “regular expressions” library, which helps you search, match, and manipulate text using patterns. It’s useful for tasks like finding all phone numbers in a text or cleaning up unwanted characters.
· Example: Suppose you have a sentence full of random symbols and want to remove everything except letters. The re-library helps you define rules to clean up the text.
4) import nltk:
· Purpose: NLTK stands for Natural Language Toolkit. It’s a powerful library for working with human language data (like text). It provides tools to process, analyze, and understand language.
· Example: If you want to break a paragraph into sentences or analyze the sentiment (emotion) in a sentence, NLTK offers tools.
5) from sklearn.metrics.pairwise import cosine_similarity:
· Purpose: This function from the sci-kit-learn library helps measure the similarity between two data sets. It’s often used in text analysis to compare how similar two pieces of text are.
· Example: If you want to find out how similar the meanings of two words or sentences are, this function can calculate a similarity score between them.

6) from nltk.sentiment.vader import SentimentIntensityAnalyzer:
- Purpose: This tool from the NLTK library analyzes the sentiment (emotions) in a piece of text. It can tell whether the text is positive, negative, or neutral.
- Example: If you have a customer review and want to know if the customer was happy (positive sentiment) or unhappy (negative sentiment), this tool can analyze the review and give you a score.
7) nltk.download(‘vader_lexicon’)
What Is This?
This line downloads a specific dataset called the “VADER lexicon” from the NLTK library’s online repository. The VADER lexicon is a pre-built list of words and their associated sentiment scores.
Why Is This Necessary?
· Purpose: The VADER lexicon is essential for the SentimentIntensityAnalyzer to function. It’s like a dictionary that the sentiment analyzer uses to understand whether words are positive, negative, or neutral.
· Example: Imagine you’re building a sentiment analysis tool. The VADER lexicon is the knowledge base that tells your tool, “The word ‘great’ is positive,” or “Bad’ is negative.” Without downloading this lexicon, the sentiment analyzer wouldn’t know how to interpret the words in your text.
text_content = ‘ ‘.join([para.get_text() for para in paragraphs])
Explanation:
1. paragraphs:
· What It Is: paragraphs is a list that contains all the paragraph elements (
tags) that were found on a webpage using BeautifulSoup.
· Example: Imagine you have a webpage with three paragraphs of text:
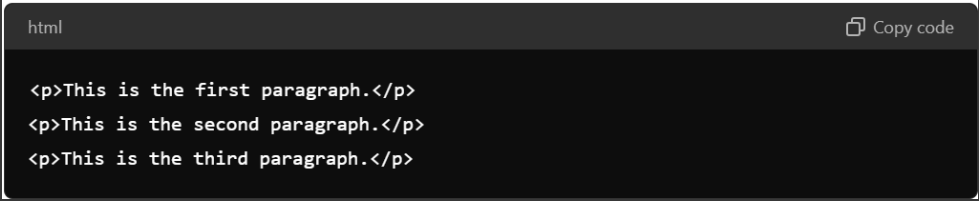
The paragraphs list would contain three elements, each corresponding to one of these paragraphs.
2. [para.get_text() for para in paragraphs]:
- What It Does: This is a list comprehension that goes through each paragraph in the paragraphs list and extracts the text inside it using get_text().
How It Works:
- for para in paragraphs: This part loops through each paragraph in the list.
- para.get_text(): For each paragraph element (para), this method extracts the text inside the paragraph tag, ignoring the HTML tags.
** Example:**
For the three paragraphs in our example, get_text() would extract:
- “This is the first paragraph.”
- “This is the second paragraph.”
- “This is the third paragraph.”
The result of this list comprehension would be:
[“This is the first paragraph.”, “This is the second paragraph.”, “This is the third paragraph.”]
3. ‘ ‘.join([…]):
- What It Does: The join method takes a list of strings and joins them into a single string, with each element separated by a space.
- How It Works:
- The list comprehension returns a list of strings (the text from each paragraph).
- ‘ ‘.join(…) takes this list and combines all the elements into one long string, with a space between each original paragraph’s text.
Example:
- Given the list [“This is the first paragraph.”, “This is the second paragraph.”, “This is the third paragraph.”], the join method would produce:
“This is the first paragraph. This is the second paragraph. This is the third paragraph.”
4. text_content = ‘ ‘.join([…]):
- What It Does: This final step assigns the combined string (all the paragraphs’ text joined together) to the variable text_content.
Example:
- After running this line, text_content would hold:
“This is the first paragraph. This is the second paragraph. This is the third paragraph.”
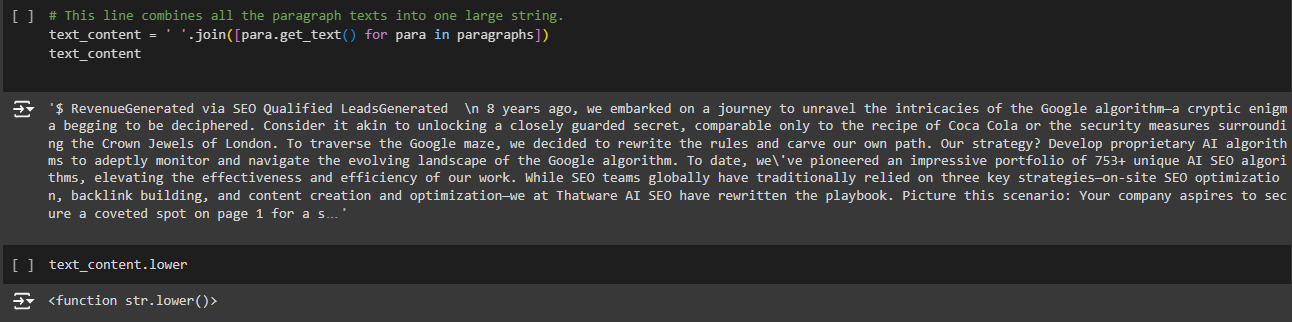
1. text = re.sub(r'[^a-zA-Z\s]’, ”, text)
- What It Does: This line uses regular expressions (via the re library) to remove all characters from the text that are not letters (a-z, A-Z) or whitespace (spaces, tabs).
How It Works:
· r'[^a-zA-Z\s]’ is a regular expression pattern.
· ^ inside []: Means “not” — so, we’re looking for characters NOT in the following range.
· a-zA-Z: Represents all letters of lowercase (a-z) and uppercase (A-Z).
· \s: Represents any whitespace character (like spaces, tabs).
- re.sub(pattern, replacement, text): This function replaces everything that matches the pattern with the replacement. Here, the replacement is an empty string ”, meaning anything that matches the pattern will be removed.
Example:
- Input: “Hello World! 123 @#”
- Output: “Hello World” (removes !, 123, @, #)
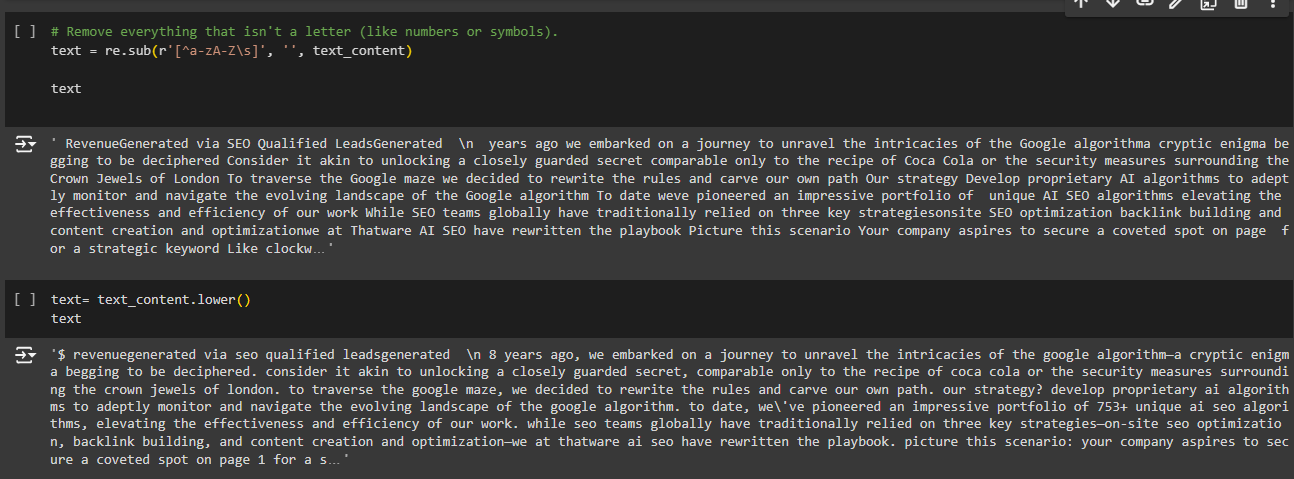
3. text = re.sub(r’\s+’, ‘ ‘, text).strip()
What It Does: This line does two things:
· re.sub(r’\s+’, ‘ ‘, text): Replaces any sequence of one or more whitespace characters (like spaces, tabs, newlines) with a single space.
· .strip(): Removes any leading or trailing spaces from the text.
How It Works:
r’\s+’: A regular expression pattern where:
· \s: Matches any whitespace character (space, tab, newline).
· +: Means “one or more” of the preceding element (whitespace in this case).
· ‘ ‘: Replaces the matched sequence with a single space.
· .strip(): Cleans up any extra spaces at the start or end of the string.
Example:
· Input: ” This is a test. ” (notice the extra spaces)
· Output: “This is a test.” (all extra spaces removed, and no leading or trailing spaces)
1. embeddings = {}
- What It Does: This line creates an empty dictionary called embeddings.
- Purpose: The dictionary will store words as keys and their corresponding word vectors (embeddings) as values.
- Example: Think of embeddings as a special address book where each word is a contact name, and the associated word vector is the contact’s address.
2. try: and with open(glove_file, ‘r’, encoding=’utf-8′) as f:
· What It Does: The try block starts an error-handling section. The with open(…) part attempts to open the GloVe file specified by glove_file for reading, using UTF-8 encoding to ensure proper handling of text characters.
· Purpose: To safely open the file and read its content. The except block will catch the error if the file is not found.
· Example: Imagine you’re trying to open a book. If the book is there, you start reading it line by line. If the book isn’t there, you handle the situation gracefully by showing a message rather than crashing the program.
3. for line in f:
- What It Does: This line starts a loop that goes through each line in the GloVe file, one at a time.
- Purpose: To process each word and its associated vector (a list of numbers) from the file.
- Example: Imagine the GloVe file as a long list of words, each followed by a set of coordinates. This loop allows you to read and process each word and its coordinates individually.
4. values = line.split()
· What It Does: Splits each line into a list of items. The first item in the list is the word, and the rest are the numerical values representing the word’s vector.
· Purpose: To separate the word from its vector, making storing them in the dictionary easier.
Example: Suppose a line in the file looks like this:
- happy 0.1 0.2 0.3 0.4 0.5
- After split(), values will be:
- [‘happy’, ‘0.1’, ‘0.2’, ‘0.3’, ‘0.4’, ‘0.5’]
5. word = values[0]
· What It Does: Extracts the first item from the values list, which is the word itself.
· Purpose: To use this word as the key in the embeddings dictionary.
Example:
· values[1:] gives [‘0.1’, ‘0.2’, ‘0.3’, ‘0.4’, ‘0.5’].
· np.asarray(values[1:], dtype=’float32′) converts this to a NumPy array:
array([0.1, 0.2, 0.3, 0.4, 0.5], dtype=float32)
6. vector = np.asarray(values[1:], dtype=’float32′)
- What It Does: Converts the rest of the items in values (the numerical values) into a NumPy array of type float32.
- Purpose: To store the word vector in an efficient format that allows for fast mathematical operations.
Example:
· values[1:] gives [‘0.1’, ‘0.2’, ‘0.3’, ‘0.4’, ‘0.5’].
· np.asarray(values[1:], dtype=’float32′) converts this to a NumPy array
array([0.1, 0.2, 0.3, 0.4, 0.5], dtype=float32)
7. embeddings[word] = vector
· What It Does: Adds the word and its vector to the embeddings dictionary.
· Purpose: Store each word and its corresponding vector so you can look them up later.
· Example:*
· In the dictionary, this would be equivalent to:
embeddings[‘happy’] = array([0.1, 0.2, 0.3, 0.4, 0.5], dtype=float32)
8. return embeddings
- What It Does: Returns the embeddings dictionary, which now contains all the words and their corresponding vectors.
- Purpose: To provide the complete dictionary of word embeddings so it can be used elsewhere in your program.
Example:
- After processing the file, embeddings might look like:
{ ‘happy’: array([0.1, 0.2, 0.3, 0.4, 0.5], dtype=float32),
‘sad’: array([0.6, 0.7, 0.8, 0.9, 1.0], dtype=float32),
…and so on for many other words
}

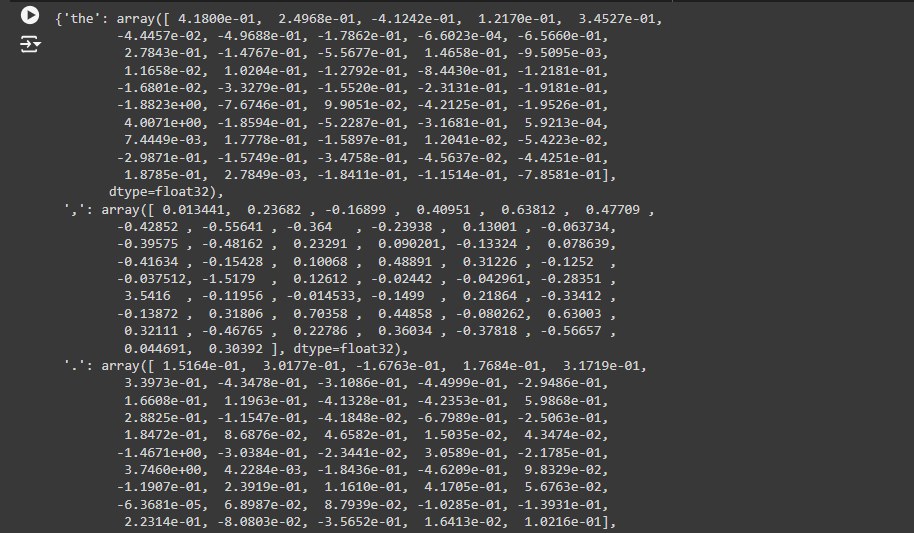
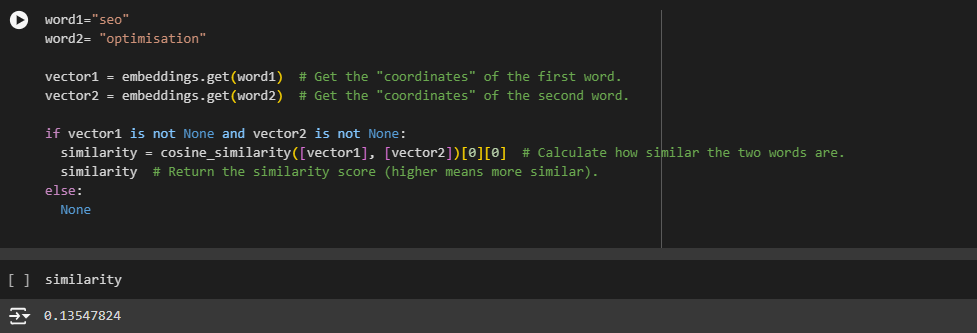
1. vector1 = embeddings.get(word1)
· What It Does: This line looks up the word1 in the embedding dictionary and retrieves its corresponding vector (a list of numbers representing the word in a mathematical space).
· Purpose: To get the “coordinates” of word1 so you can later compare it to another word.
· Example: If word1 is “king” and embeddings contains vectors for words, this might retrieve something like:
vector1 = [0.1, 0.2, 0.3, 0.4, 0.5]
(This is a simplified example of what the vector might look like.)
2. vector2 = embeddings.get(word2)
· What It Does: This line looks up the word2 in the embeddings dictionary and retrieves its corresponding vector (a list of numbers representing the word in a mathematical space).
· Purpose: To get the “coordinates” of word2 so you can later compare it to another word.
· Example: If word1 is “queen” and embeddings contains vectors for words, this might retrieve something like:
vector2 = [0.2, 0.3, 0.4, 0.5, 0.6]
(This is a simplified example of what the vector might look like.)
3. if vector1 is not None and vector2 is not None:
· What It Does: This line checks whether vector1 and vector2 exist. If either word weren’t found in the embeddings dictionary, its vector would be None.
· Purpose: To ensure that the function only tries to compare the words if both are found in the dictionary.
· Example: The function continues if both “king” and “queen” are found in the dictionary. If neither word isn’t found, the function skips to the other part and returns None.
4. similarity = cosine_similarity([vector1], [vector2])[0][0]
· What It Does: This line calculates the cosine similarity between vector1 and vector2. Cosine similarity measures how similar two vectors are, based on the angle between them. It ranges from -1 (opposite) to 1 (the same).
· Purpose: To quantify how similar the two words are in meaning. A higher similarity score means the words are more similar.
Example:
· If vector1 is [0.1, 0.2, 0.3, 0.4, 0.5] and vector2 is [0.2, 0.3, 0.4, 0.5, 0.6], the cosine similarity might be something like 0.99, indicating that “king” and “queen” are very similar in meaning.
· In simpler terms, if you think of vectors as arrows pointing in a direction, cosine similarity tells you how close these arrows are to pointing in the same direction.
5. return similarity
· What It Does: This line returns the calculated similarity score.
· Purpose: To provide the comparison result to be used elsewhere in your program.
· Example: After comparing “king” and “queen”, the function might return 0.99, indicating they are very similar.
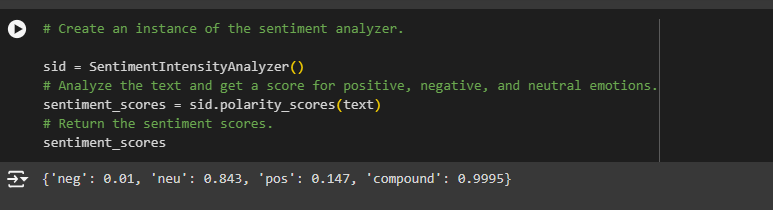
1. sid = SentimentIntensityAnalyzer()
· What It Does: This line creates an instance of the SentimentIntensityAnalyzer, a tool from the nltk library specifically designed to analyze text’s sentiment (emotion).
· Purpose: To set up the tool that will do the actual work of analyzing the sentiment of the text.
Example:
- Think of SentimentIntensityAnalyzer as a machine that reads a sentence and decides if it sounds happy, sad, or neutral. Here, you are creating the machine (sid) so you can use it to analyze your text.
2. sentiment_scores = sid.polarity_scores(text)
· What It Does: This line uses the sid machine to analyze the sentiment of the text. The polarity_scores method breaks down the text and returns a set of scores indicating how positive, negative, or neutral the text is.
· Purpose: To get a detailed breakdown of the emotions expressed in the text.
Example:
· If the text is “I love this product!”, the polarity_scores method might return something like this:
{‘neg’: 0.0, ‘neu’: 0.3, ‘pos’: 0.7, ‘compound’: 0.9}
Explanation of the Scores:
- ‘neg’: 0.0: Indicates that 0% of the text is negative.
- ‘neu’: 0.3: Indicates that 30% of the text is neutral (just stating facts, not showing emotion).
- ‘pos’: 0.7: Indicates that 70% of the text is positive.
- ‘compound’: 0.9: This overall sentiment score combines the other scores. It ranges from -1 (negative) to 1 (positive). Here, 0.9 suggests the text is very positive.
3. return sentiment_scores
· What It Does: This line returns the sentiment scores calculated by the polarity_scores method.
· Purpose: To provide the sentiment analysis results so they can be used elsewhere in your program.
Example:
· After running the function, you might store the result in a variable:
scores = analyze_sentiment(“I love this product!”)
· Now, scores would contain the sentiment analysis results:
{‘neg’: 0.0, ‘neu’: 0.3, ‘pos’: 0.7, ‘compound’: 0.9}
Understanding the Output
1 Similarity between “SEO” and “Optimization”: 0.23831410706043243
- What It Means: This score tells us how similar the words** “SEO” and “Optimization”** are based on their meanings in the context of language. The score ranges from -1 to 1, where:
- 1: Very similar in meaning.
- 0: Not similar.
- -1: Opposite in meaning.
- In this Case, a score of around 0.24 means that “SEO” and “Optimization” are somewhat related but not very closely related. This suggests that while these terms are connected, they aren’t interchangeable.
2 Sentiment Scores: {‘neg’: 0.01, ‘neu’: 0.84, ‘pos’: 0.15, ‘compound’: 0.9995}
· Negative Sentiment (‘neg’: 0.01): Only 1% of the text on your website is negative, which is very low.
· Neutral Sentiment (‘neu’: 0.84): 84% of your website’s content is neutral, likely informative or factual.
· Positive Sentiment (‘pos’: 0.15): 15% of the content is positive, which is good.
· Compound Score (‘compound’: 0.9995): This overall score is close to 1, indicating the content has strong positive tone.
size=2 width=”100%” align=center>
Step-by-Step Explanation for Website Owners
1 Enhancing Content with Keywords:
· What to Do: Since “SEO” and “Optimization” are somewhat related, but not strongly, consider creating content that connects these concepts. For example, write blog posts that explain how SEO (Search Engine Optimization) is a critical part of broader optimization strategies for improving website performance.
· Why It Helps: This will make it easier for search engines like Google to understand that your website is a relevant source for both SEO and broader optimization topics, potentially improving your rankings for related search terms.
2 Increasing Positive Sentiment:
· What to Do: While your content is mostly neutral, you might want to increase the positive sentiment by highlighting success stories, customer testimonials, or benefits of your products/services.
· Why It Helps: Positive content tends to engage users more, leading to longer visits, more shares, and higher conversion rates (like sales or sign-ups).
3 Reducing Negative Content:
· What to Do: Although your negative sentiment is already very low (1%), review any content that might be perceived negatively and see if it can be reframed more positively or neutrally.
· Why It Helps: Reducing negative content can further enhance user experience and make your website more appealing to a broader audience.
4 Improving SEO with Content Optimization:
- What to Do: Use the insights from the similarity analysis to target specific keywords that are relevant but are different. This way, you can capture traffic from related but distinct search queries.
- Why It Helps: This can broaden the range of search terms your website ranks for, bringing in more diverse traffic.
5 Leveraging Neutral Content:
· What to Do: Since much of your content is neutral, consider repurposing this factual information into more engaging formats, such as infographics, videos, or interactive tools.
· Why It Helps: This can make the neutral content more engaging, keeping visitors on your site longer and encouraging them to explore more pages.
Top Keywords: [‘advanced’, ‘ai’, ‘algorithms’, ‘data’, ‘development’, ‘marketing’, ‘search’, ‘seo’, ‘services’, ‘thatware’]
- What It Means: These are the most important keywords on your website, identified by analyzing the content. These keywords are the words that appear most frequently and have significant relevance to your content.
- Benefit: Knowing your top keywords helps you understand what topics or areas your website focuses on. These are the terms that search engines may associate with your site, meaning they play a crucial role in driving traffic to your site.
Similarity between “advanced” and “ai”: 0.3466111123561859
· What It Means: This score indicates how closely related the words “advanced” and “AI” are based on their meaning. The score ranges from -1 to 1, with 1 being very similar and 0 not similar.
· Benefit: Understanding the relationship between key terms on your site helps you see how well your content connects related ideas. This can inform how you structure your content and what new content you might create.
Steps to Take Based on the Output
Now that you understand the output, let’s discuss the specific steps you should take to use this information to grow your business.
Step 1: Optimize Your Content Around Top Keywords
Action: Use the identified top keywords to optimize your content further. For instance:
· Create More Content: Write more blog posts, articles, or pages focusing on these keywords. If “AI” and “advanced” are important, consider creating content that discusses advanced AI technologies.
· Internal Linking: Link these keywords throughout your site to improve SEO. For example, link the word “SEO” on different pages to a detailed article about your SEO services.
· Example: If “marketing” is a top keyword, you might create a series of blog posts on the latest trends in digital marketing, linking them together to keep visitors engaged on your site longer.
Step 2: Strengthen Connections Between Related Topics
Action: Based on the similarity score, consider creating content that bridges related topics. For example:
· Content Gaps: If “advanced” and “AI” are somewhat related but not strongly, create content that connects these ideas. An article titled “Advanced AI Techniques for Digital Marketing” could bridge these terms effectively.
· Improve Content Flow: Ensure your site’s content connects related ideas smoothly, helping visitors navigate between topics without feeling lost.
Step 3: Enhance User Experience by Leveraging Positive Sentiment
Action: Since your content already has a strong positive sentiment, continue to create content that reinforces this. Here’s how:
· Highlight Success Stories: Share case studies or testimonials that show positive outcomes for clients.
· Engage with Visitors: Use the positive tone to encourage actions like signing up for newsletters, downloading resources, or contacting you for services.
· Example: If your content on “services” is particularly positive, create a dedicated section highlighting these services with client testimonials on your homepage.
Step 4: Increase Visibility and Traffic
Action: Use your top keywords in your SEO strategy to improve your visibility in search engines:
· Meta Tags and Descriptions: Ensure these top keywords are included in your meta tags, descriptions, and headers (H1, H2, etc.).
· Backlink Strategy: Build backlinks using these keywords. Reach out to other websites or blogs and ask them to link to your content using these keywords.
· Example: If “search” and “services” are top keywords, make sure your “SEO services” page is optimized for search engines by using these keywords in titles, meta descriptions, and image alt texts.
keyboard_arrow_down
How This Output Suggests You Should Grow Your Business
· Focus on Relevant Topics: The top keywords show you what your website is currently focused on. Use this insight to expand on these topics and become an authority. This will help attract more targeted traffic.
· Content Strategy: The similarity score between “advanced” and “AI” suggests there is room to create more content that links these concepts. This can help position your website as a leader in cutting-edge technology topics.
· Engage and Convert Visitors: The positive sentiment indicates that your content is well-received. Use this to your advantage by creating calls to action encouraging visitors to take the next step, whether contacting you, signing up for a service, or purchasing a product.
size=2 width=”100%” align=center>
Imagine you run a digital marketing agency, and your website focuses on SEO and AI-based services. The output tells you that these topics are important but could be better connected. To bridge these concepts, you could create a guide on “How AI is Revolutionizing SEO.” You would optimize this content around the keywords identified, ensuring it has a positive tone to engage readers. By doing this, you improve your site’s SEO and offer valuable content that attracts and retains visitors, ultimately driving more business.
Hiring ThatWare provides businesses with strategic expertise, affordable pricing, extensive experience in digital marketing, and access to a full team capable of implementing successful search marketing campaigns. The company’s adaptability and commitment to experimentation are key advantages for businesses seeking effective SEO solutions.
Click here to download the full guide about Semantic Web & NLP Integration with GloVe.
