Get a Customized Website SEO Audit and Online Marketing Strategy and Action Plan

Semantic SEO refers to search engine optimization strategies that help search queries deliver meaningful results to users by understanding the intent behind their questions. Semantic search goes beyond matching exact keywords, providing users with contextualized information that is relevant and linked to the broader topic.
To achieve maximum visibility and higher search rankings for your website, it’s essential to optimize your landing pages and overall site using AI-driven modules related to semantic search, natural language processing (NLP), information retrieval, and more.The reality is that implementing AI can be challenging for most people, as it demands advanced coding skills and sophisticated technology. At ThatWare, we simplify AI with clear, step-by-step processes, making it accessible for anyone to optimize their pages effectively according to semantic SEO best practices. Without further delay, let’s dive in:
1.COSINE SIMILARITY
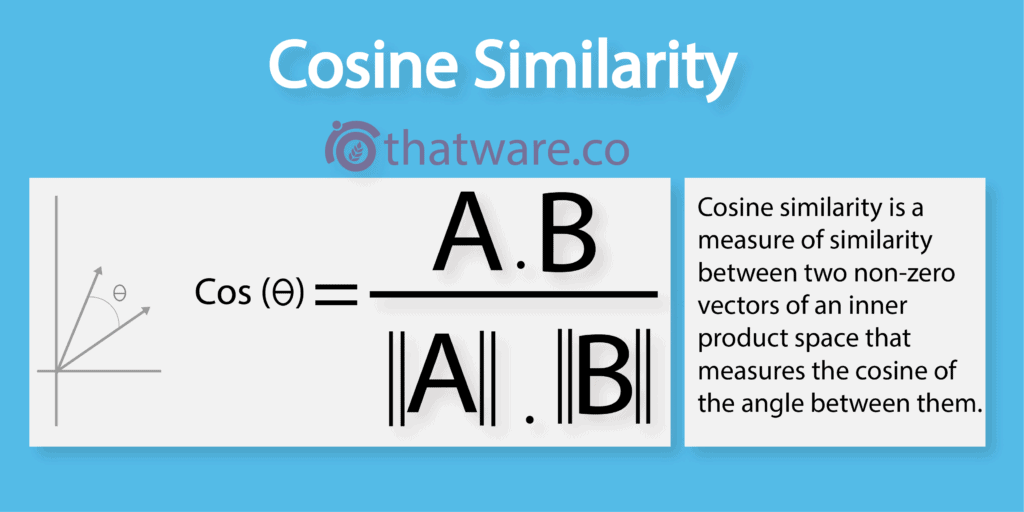
Cosine similarity measures the angle between two non-zero vectors to determine how closely they are related. When the angle between vectors is small, the similarity is high; when the angle reaches 90 degrees, the vectors are considered completely unrelated.
Search engines like Google apply cosine similarity to evaluate how closely a webpage’s content aligns with a user’s search query. To optimise a page for a specific keyword, one effective approach is to analyse the cosine similarity scores of top-ranking pages and use them as a benchmark. The closer your content vector aligns with those high-performing pages, the stronger the relevance signal becomes—leading to improved ranking potential.
2.LATENT DIRICHLET ALLOCATION (LDA)
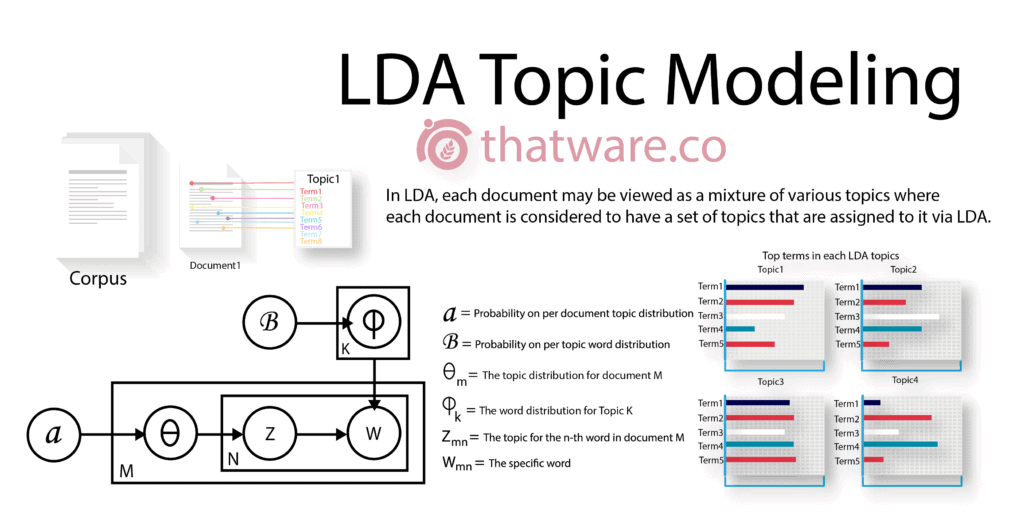
Latent Dirichlet Allocation (LDA) is a topic modelling algorithm that calculates two key distributions: document-to-topic and topic-to-word. Topics are hidden (latent), and each word is assigned a probability of belonging to one or more topics.
In simpler terms, LDA evaluates how contextually relevant a document is when compared to a search query or competing content. Google and other search engines use LDA extensively to assess topical depth. If a competitor ranks highly for a competitive keyword, analysing their page using LDA metrics can guide optimisation. A stronger topic relevance score significantly increases ranking probability.
3.PROBABILISTIC LSA
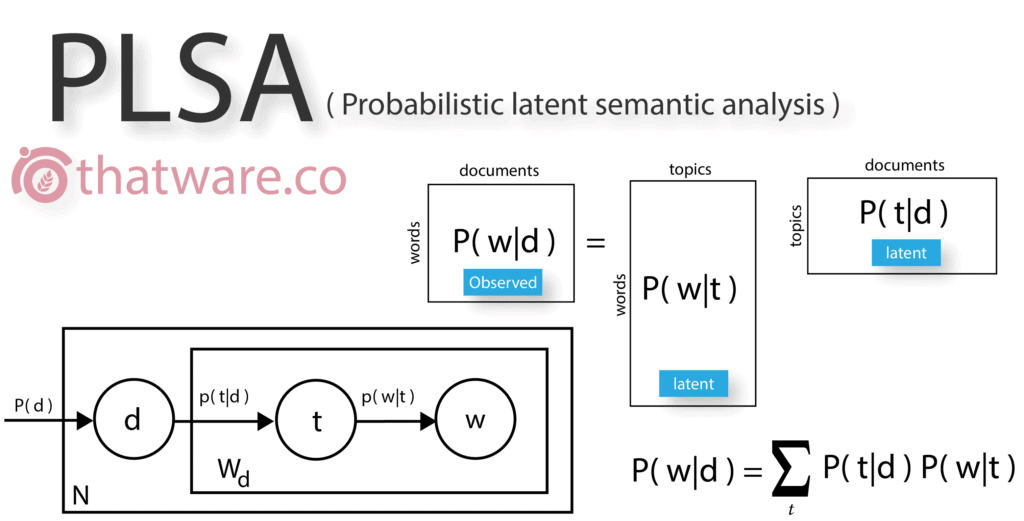
Probabilistic Latent Semantic Analysis, also referred to as probabilistic latent semantic indexing, is widely used in modern information retrieval and text mining. PLSA builds a latent vector space where every word in a document is assigned a probability within a hidden topic.
This approach enables search engines to understand semantic relationships between words beyond simple keyword matching, improving the accuracy of content relevance evaluation.
4.JACCARD INDEX

Unlike cosine similarity, the Jaccard Index operates without binary vectors, making its output more refined for certain similarity calculations. It compares two document sets by dividing the intersection of shared elements by their combined union.
In SEO applications, the Jaccard Index is particularly useful for tag optimisation. Excessive tagging can generate unnecessary pages and waste crawl budget. By clustering similar tags using the Jaccard similarity ratio, SEO professionals can consolidate redundant tags into a single representative tag—thereby improving crawl efficiency and site structure.
5.KAPPA COEFFICIENT

The Kappa coefficient originates from Cohen’s Kappa and measures agreement versus disagreement between two evaluators. It calculates how much consensus exists beyond random chance.
In digital marketing and SEO decision-making, Kappa plays a vital role in identifying strong agreement patterns. Research indicates that over 80% of successful recommendations stem from high agreement scores, making this metric critical for validating optimisation strategies.
6.TOPIC MODELING

Topic modelling is used to identify thematic clusters across a collection of documents within a corpus. This process primarily relies on algorithms such as LDA and PLSA.
In SEO, topic modelling is essential for determining user intent behind content. This becomes especially important for algorithms like Google’s RankBrain, which prioritise semantic understanding over exact keyword matching.
7.VECTOR SPACE MODELING

In a vector space model, each document is represented as an m-dimensional vector, where each dimension corresponds to a unique term in the corpus. Here, m represents the total vocabulary size across all documents.
This model allows search engines to mathematically compare search queries with landing pages, enabling precise relevance scoring and more accurate ranking decisions.
8.LINK INTERSECT USING R
Link intersect is a programmatic technique used to identify common backlinks across multiple websites. It relies on vector intersection methods to determine shared link sources.
This approach helps SEO professionals uncover backlink opportunities, analyse competitor link strategies, and prioritise high-value domains for outreach.
9.ROCCHIO ALGORITHM

According to the Rocchio algorithm, every webpage has a TF-IDF score relative to a specific search query. This score dynamically changes based on the keyword being evaluated.
The PageRank or relevance score of a page is therefore not static—it shifts depending on how closely the content aligns with the search term intent, reinforcing the importance of query-focused optimisation.
10.BAG OF WORDS (BOW)

Every document or corpus contains its own cluster of terms. When processed through a document-term matrix, the output is transformed into a structured data frame organised by term frequency. This enables the creation of word clusters based on prominence.
In SEO, the Bag of Words model is highly valuable for identifying priority keyword groups and tag clusters. These clusters can then be strategically used for content optimisation, internal linking, and semantic expansion.
11.BEST MATCHES CORRELATION (BM25)

Basically, this algorithm stands for best matches pair, if you compare and correlate between ‘n’ pairs or components then it will be represented as BMn.
The main principal formula is based on the probabilistic retrieval (part of modern information retrieval) which is a ranking function used by search engine crawlers to rank matching documents according to their relevance for a given search query.
12.HIERARCHICAL CLUSTERING

This is a special type of clustering which is performed by a cluster process algorithm within the same document set. The output is generally is in the form of a dendrogram. The principal mechanism uses a distance algorithm.
This technique is an advanced technique and can be utilized for multiple operations for a complete SERP experience. For example, HC can be used to classify pages based on selective sets of keywords and tags and which can be later utilized for optimizing your main landing page.
13.DOCUMENT HEAT MAP
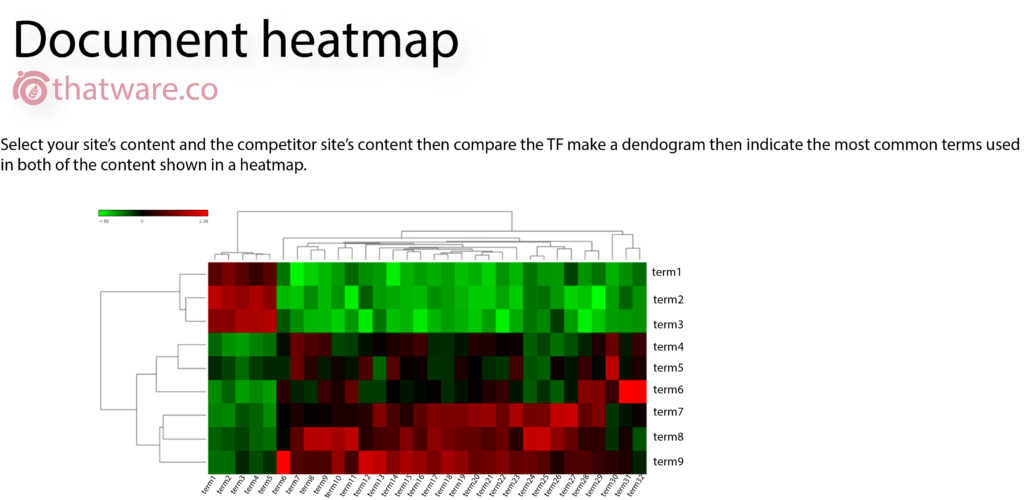
It is basically a creation of a heatmap module which will indicate two websites TF while comparing to each other. The main benefit of this process is that – one can compare the heatmap of the landing pages of competitors and then optimize the changes based on the output.
14.SENTIMENT ANALYSIS
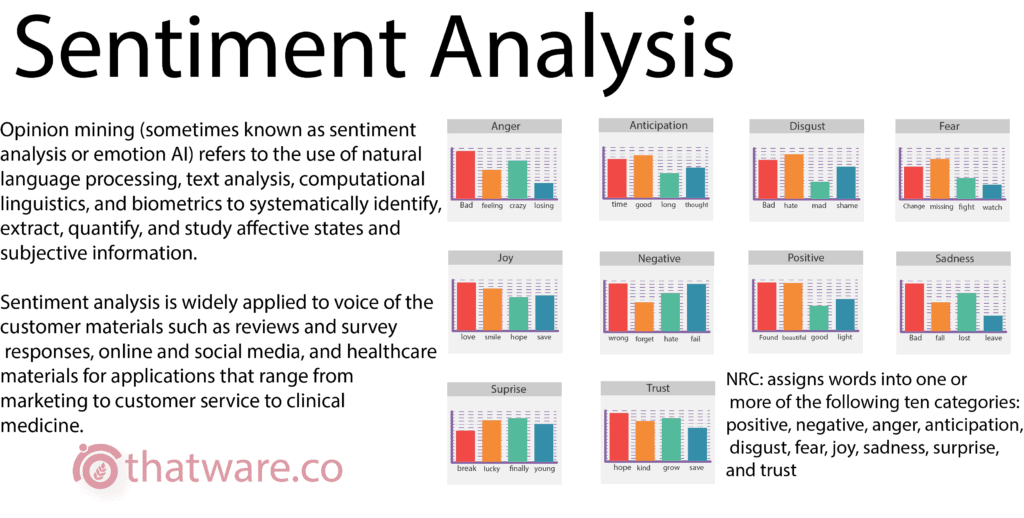
Sentiment analysis is an AI algorithm which is used to get an idea about the percentage of positiveness and negativeness of a particular data or a document set. The process uses AFFIN, NRC, bing dataset.
Furthermore, it can also be used to subdivide the positiveness and negativeness based on anger, joy, trust, disappoint, and etc. In the seo world, sentiment analysis is very important in many ways. One of the ways is to check on the user comments and behavioral pattern as for whether it is leading to a negative sense or positive sense.
15.DOCUMENT VS. DOCUMENT SIMILARITY

Document-to-document similarity applies cosine similarity to measure how closely two documents relate to each other. A smaller angle between document vectors indicates higher similarity. In most optimisation scenarios, an ideal similarity score typically falls between 0.3 and 0.5.
From a ranking perspective, the closer your landing page aligns technically and contextually with the top-ranking page, the greater the potential ranking advantage.
16.ANCHOR TEXT SIMILARITY
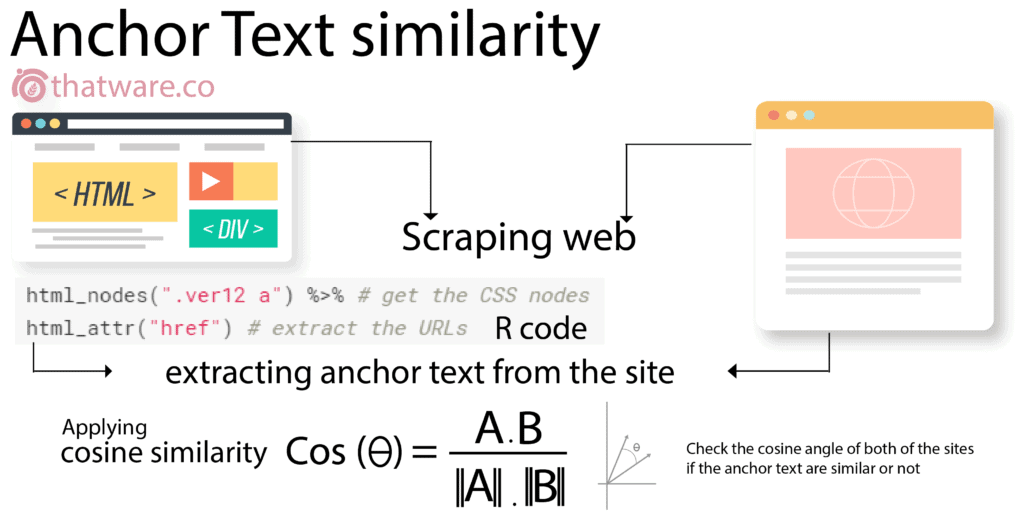
Anchor text similarity involves using AI-driven scripts to extract anchor texts from both your website and competing domains. These anchor datasets are then intersected to identify common anchor patterns.
This method is especially useful when designing anchor text strategies inspired by competitors that already rank at the top of search results.
17.CO-OCCURRENCE

Co-occurrence analysis identifies how frequently specific terms appear together within one or more documents. This technique is also applicable in image recognition systems.
In SEO, co-occurrence helps optimise page content by identifying related terms that naturally belong together, thereby strengthening contextual relevance.
18.K-MEAN CLUSTERING
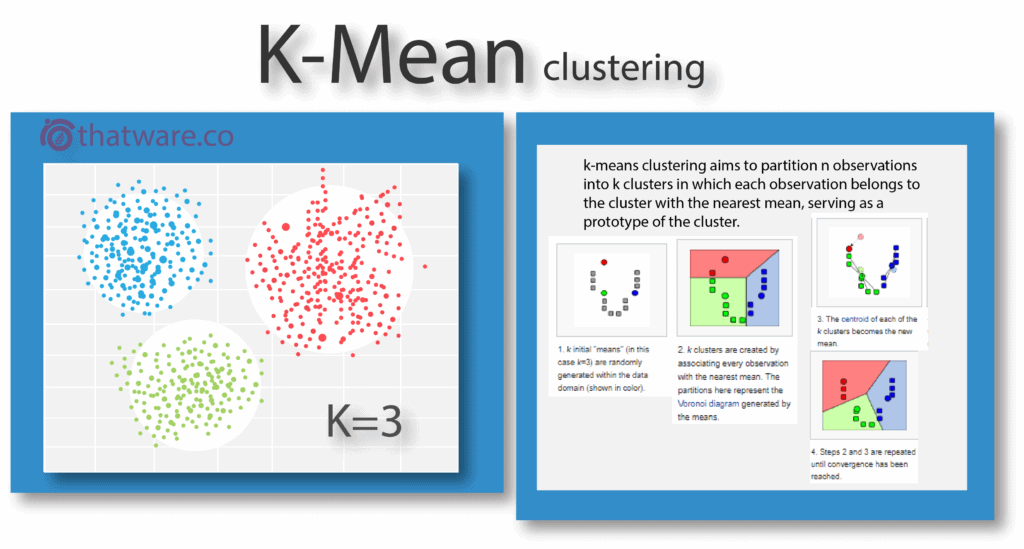
The K-means algorithm groups data points into clusters based on distance metrics such as Euclidean distance. Each cluster is represented by a centroid, and the value of K determines the total number of clusters created.
This approach is highly effective for semantic optimisation, allowing pages to be structured around meaningful topic clusters rather than isolated keywords.
19.FLAT CLUSTERING

Flat clustering algorithms organise documents into non-hierarchical groups where items within a cluster are highly similar, while items across different clusters remain distinctly different.
This clustering logic ensures clear topical separation, improving content categorisation and semantic clarity across large document sets.
20.NAIVE BAYES
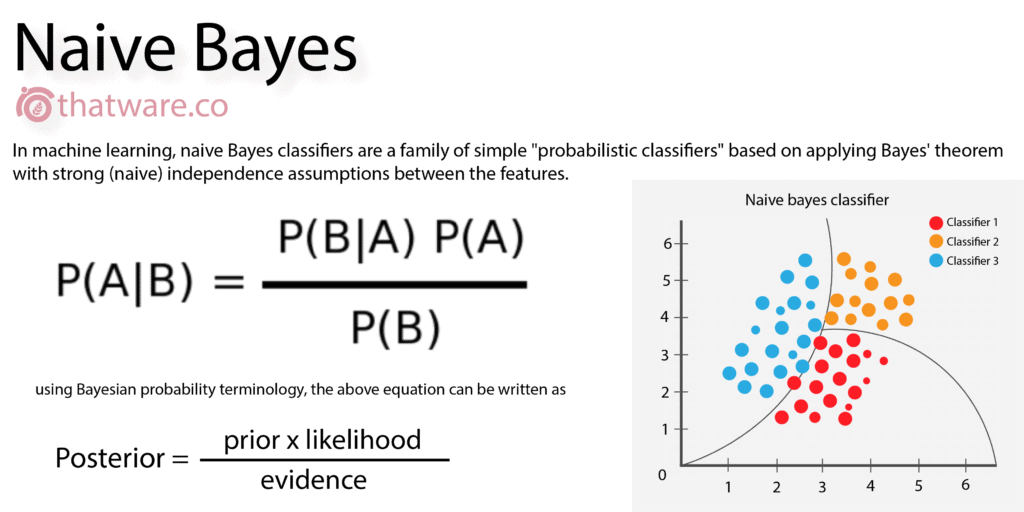
Naive Bayes is based on Bayes’ theorem and is primarily used for predictive modelling using historical data. Despite its simplicity, it delivers reliable predictions across multiple analytical scenarios.
In SEO and digital marketing, Naive Bayes can be applied to forecast ranking outcomes by analysing current KPIs and historical performance trends.
21.PREDICTIVE ANALYSIS USING MARKOV CHAIN
Markov Chain is a multi-state transition model designed for predictive analysis with high accuracy and minimal noise. It evaluates future states based solely on current conditions.
In digital marketing applications, this model is often used to predict market behaviour, including stock and share movement patterns.
22.SEMANTIC PROXIMITY
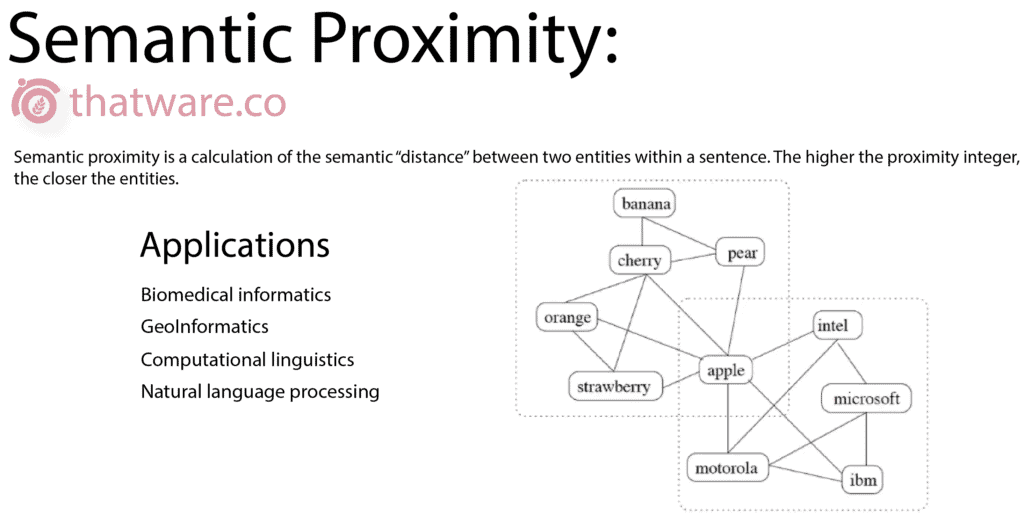
Semantic proximity measures the distance between related words or search terms within a document set. It relies on algorithms such as Euclidean cosine to calculate contextual closeness.
In SEO, maintaining balanced semantic spacing is critical—related keywords should be evenly distributed throughout the content to ensure natural relevance.
23.ADABOOST ALGORITHM

AdaBoost strengthens weak classifiers by combining them into a single, highly accurate model. It also helps reduce computational complexity by optimising learning efficiency.
For large-scale eCommerce websites with millions of pages, AdaBoost significantly speeds up optimisation processes while maintaining accuracy.
24.PREDICTION OF TRENDS
For every search query, certain result patterns and trending subtopics emerge over time. At ThatWare, a proprietary machine learning module has been developed to identify and predict these trends based on entered query datasets.
This enables proactive content optimisation aligned with future demand rather than reactive ranking adjustments.
25.FUZZY C
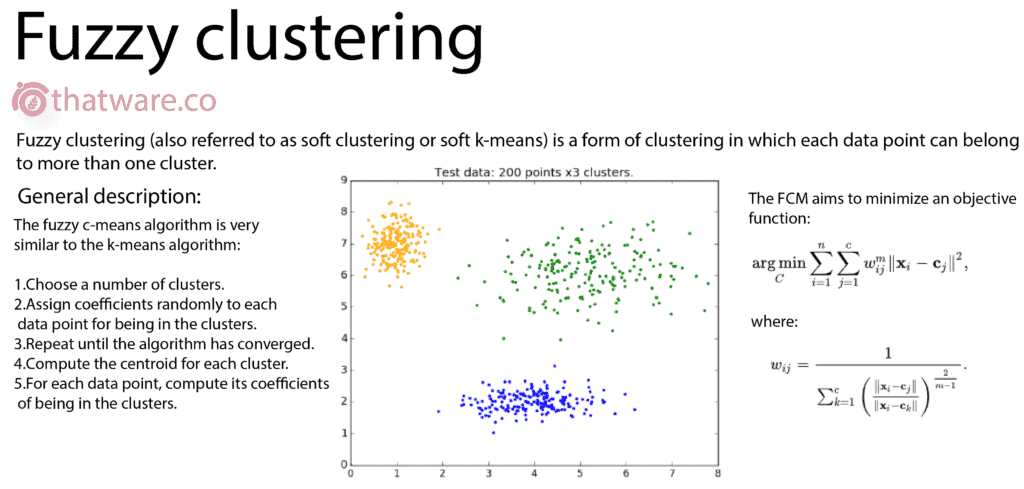
Fuzzy C-Means clustering allows each data point to belong to multiple clusters with varying degrees of membership.
This flexible clustering model is particularly useful in complex business intelligence scenarios where rigid classification is impractical.
26.LEARNING VECTOR QUANTIZATION (LVQ)

Learning Vector Quantization is a supervised extension of vector quantization. It uses labelled class data to fine-tune the placement of Voronoi vectors for improved classification accuracy.
LVQ has advanced applications in specialised SEO use cases, though its implementation involves complex coding and falls beyond basic optimisation discussions.
27.TF-IDF
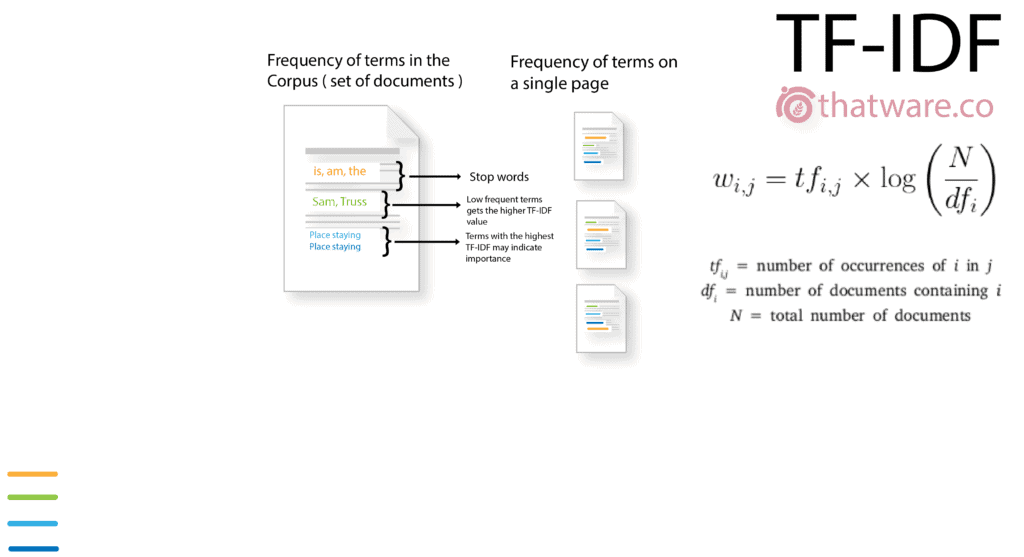
TF-IDF measures how relevant a term is within a document relative to the entire corpus. Term Frequency reflects how often a word appears, while Inverse Document Frequency evaluates its uniqueness.
A strong TF-IDF score has a well-established correlation with improved search engine rankings.
28.PRECISION

In information retrieval, precision refers to the proportion of retrieved documents that are relevant to the search query. It is also known as positive predictive value.
This metric indicates how accurately a system returns meaningful results in response to a query.
29.RECALL

Recall measures the proportion of relevant documents that are successfully retrieved from the total available set. It is often referred to as sensitivity.
Higher recall indicates better coverage of relevant content, which positively influences ranking performance.
30.F-MEASURE

The F-measure is a combined metric that balances both precision and recall. When these two values are close, the F-measure effectively represents their average.
This metric provides a more holistic view of retrieval performance than evaluating precision or recall independently.
31.CHAMPION LIST (IR)

A vector space model to avoid computing relevancy rankings for all documents each time a document collection is queried. The champion list contains a set of n documents with the highest weights for the given term. It is frequently used for ranking pages based on semantic engineering.
32.MANUAL CORA

Website correlation, or website matching, is a process used to identify websites that have similar content or similar tags or similar structure.
The main idea of semantic engineering is to incorporate language tags and meta-data that are interrelated to the main topic into the text so that the search engine can react to the specified query semantically for a particular question even if does not correlate to same keyword. This methodology utilizes artificial intelligence (AI) technologies to create a vocabulary cloud around a specific topic depending on the meaning and intent behind a search query to improve the central theme and user experience.
What is Semantic Engineering? Is Semantic SEO is the New SEO?
Semantic engineering is the process of search engine optimized content creation around a particular topic rather than the same keywords.
Compared with traditional media, the digital world is changing quite quickly and emerging technologies and strategies are being introduced to establish the most attractive experience for users. In 2011, Google and other large search engines begin utilizing semantic SEO Natural Language Processing Techniques (NLP) and Artificial Intelligence (AI) tools and techniques to classify users’ search purpose.
The goal of the consumer is enhanced by their previous searches to offer the semantic quest for the UI a meaning. AI tools and techniques are innovated and implemented contributing to the introduction of Semantic SEO in the software industry. The semantic SEO resources often detect some stuffing of black hat keywords whose immoral approaches drive traffic to the website.
Another major trend is the use of keywords from LSI (Latent Semantic Indexing), which is a collection of keywords that are correlated semantically with each other and can help to improve content by semantic SEO. There are many LSI keyword finders and LSI keyword generators that recommend you apply keywords to the content to help it organically creep up to the top SERP ranks on the website.
How Does Semantic Search Impact SEO?
1. Users switching to Voice Search
Semantic search has grown primarily because of expanded voice search. According to research from Stone Temple Consulting, mobile voice commands have become increasingly common, with 33 percent of high-income households using voice commands on smartphones beyond just “regularly” or “quite frequently.”
Optimizing for voice search differs significantly from traditional SEO. You need to provide concise, purpose-driven answers to make your content more conversational. Create material that directly addresses a typical question at the top of the page, before moving into detailed explanations. To help search engines understand the context and meaning, implement structured data wherever possible.
2. Emphasis moves from Keywords to Topics
Content should no longer focus solely on individual keywords. Instead, cover broad topics within your niche in depth. The goal is to create extensive, original, and high-quality content that delivers real value.
Rather than producing hundreds of small, scattered pages on isolated topics, consider building “ultimate guides” and comprehensive content pieces that your audience will find genuinely useful. Incorporating semantic relevance keywords naturally can also help reinforce context and improve search visibility.
3. Searcher intent becomes a Priority
Targeting keywords is no longer just about the words themselves—it’s about understanding purpose. By analyzing the questions that lead users to your page, you can identify themes and topics ideal for developing meaningful content.
Start by listing relevant keywords, then organize them based on user intent. This approach ensures your content aligns with the needs and expectations of your audience, rather than simply focusing on ranking for isolated search terms.
When you grasp the purpose of the searcher, start creating content that discusses their intent explicitly, rather than creating content around specific keywords or broad topics.
4. Focus shifts to User Experience
User satisfaction in an era of semantic engineering should be guiding all of our SEO activities. Google cares for user satisfaction and their software is constantly fine-turned to better understand and satisfy the searchers. SEO practitioners, too, will rely on UX.
For this, boost page speed as much as possible, maintain consistency of your mobile site (especially now that Google gives priority to indexing mobile sites), and keep an eye on metrics such as bounce rate and session duration.
5. Technical SEO matters just as much as Content
Even with Google’s shift from “strings to things,” the algorithm cannot fully interpret meaning on its own. Your website must be structured to help Google understand your content clearly.
Keywords – Keywords still hold relevance. For common queries and related long-tail keywords, use a content analysis approach. Naturally integrate them into title tags, URLs, body text, header tags, and meta tags without forcing them.
Link Building – Authoritative backlinks continue to be a critical ranking signal. Focus on creating content that naturally attracts links. Also, implement a solid internal linking structure to connect your valuable pages and strengthen your site architecture.
Site Speed – Optimize your site by minifying resources, compressing files, enabling browser caching, and following Google’s speed guidelines. A fast-loading site enhances both user experience and SEO performance.
It’s surprising that traditional SEO techniques—backlinks, keywords, and guest blogging—still cost thousands per month yet are less effective for modern search. These methods no longer align with Semantic Search and Conversational AI.
Growth Hacking with AI in Semantic SEO is the emerging trend. Instead of wasting resources on outdated tactics, focus on creating relevant, high-quality content that directly addresses the searcher’s intent. Google now evaluates content through machine understanding and conversational AI. Today, your essential tools are simply Google Analytics and CrawlQ Business Analytics, aligned with semantic SEO best practices.
