Get a Customized Website SEO Audit and SEO Marketing Strategy
The project establishes a semantic evaluation system designed to measure how closely a webpage’s content aligns with the intended user query or topic. The focus is on identifying where and how the content deviates from the target intent, enabling clearer understanding of topical relevance, coverage quality, and potential misalignment across different sections of a page.

The system analyzes webpages at both page-level and section-level granularity, using transformer-based semantic similarity models to assess whether each part of the content stays aligned with the search intent. It detects deviations by evaluating meaning, context, and direction of the content rather than relying on keyword matching alone. As a result, the assessment captures deeper issues such as topical shifts, off-intent content blocks, and semantic inconsistencies that may weaken relevance and user satisfaction.
The output includes structured alignment scoring, deviation severity grading, distribution summaries, key reason patterns, and identification of sections contributing the most to misalignment. Visualizations further highlight alignment gaps and semantic outliers, providing a clear, action-oriented view of how the content performs against the expected intent. The entire workflow is optimized to support strategic content decisions, improve relevance, reinforce search intent understanding, and strengthen the overall topical integrity of the page.
Project Purpose
The purpose of this project is to provide a clear, objective, and systematic understanding of how well a webpage maintains semantic alignment with the intended search intent. Modern search environments increasingly prioritize content that demonstrates strong topical consistency, clarity of purpose, and meaningful alignment with user expectations. Even small deviations in semantic direction can reduce relevance, weaken authority signals, and introduce confusion within the content flow.
This system is designed to identify such deviations with precision. By analyzing each section of a webpage against the target intent defined by the query, it highlights where content strays into unrelated or weakly related topics. The assessment goes beyond detecting surface-level drift and focuses on deeper contextual mismatches—areas where meaning, focus, or topical direction shifts in ways that dilute the page’s value.
Through structured scoring, deviation severity classification, and explicit reason attribution, the system offers actionable insight into how alignment issues manifest. This enables more confident decision-making around refining content, reinforcing sections that underperform, and strengthening narrative coherence throughout the page. Ultimately, the purpose is to ensure that content remains consistently anchored to user intent, improving relevance, clarity, and strategic SEO performance.
Project’s Key Topics Explanation and Understanding
Understanding Semantic Intent in Content Evaluation
Semantic intent represents the underlying meaning, purpose, and expectation conveyed by a user’s query. It is not limited to keyword presence but reflects what the searcher aims to achieve or understand. In this project, intent is captured directly from the provided queries, which serve as the benchmark for evaluating whether each section of the page stays aligned with the intended topic. Queries are treated as precise indicators of what the content should serve, enabling a clean and focused intent-matching framework. This approach allows the system to examine meaning at the conceptual level rather than relying on superficial keyword overlap, ensuring that even indirectly phrased or contextually rich sections are evaluated correctly.
The role of semantic intent in this project is to define the expected direction of the content. Once this directional anchor is established, every section is examined to determine how closely its meaning matches the query-defined intent. This interpretation of intent is purely semantic and does not involve SEO intent categories such as informational, transactional, or navigational. Instead, it focuses on meaning alignment, conceptual focus, and contextual relevance to the topic implied by the query text itself.
Topic Boundary Interpretation and Overlap Handling
Topic boundaries define the conceptual edges of what the content should or should not cover. When a page contains multiple themes, subtopics, or tangential details, it becomes necessary to identify where the expected topic ends and where unrelated or loosely related subjects begin. This project incorporates topic boundary interpretation by identifying how each section fits within the desired scope defined by the queries. A section is considered aligned when it stays within the expected conceptual boundary, while deviation occurs when the content shifts into areas that are off-topic, misplaced, or primarily relevant to a different query.
Because real-world pages often contain broad narratives or mixed content structures, understanding topic boundaries is essential. Content can overlap in meaning, create partial relevance, or diverge entirely into unrelated themes. The project handles these situations by identifying whether a section is partially relevant due to shared context, somewhat aligned because of related terminology, or distinctly off-focus because it introduces a separate conceptual path. This helps create a clear, structured understanding of where the page maintains topic integrity and where it loses alignment with the intended meaning.
Section-Level Semantic Evaluation
Each section of the page is treated as a standalone semantic unit. By evaluating sections independently, the system identifies alignment or deviation with fine granularity rather than judging the page as a whole. This method recognizes that even well-structured pages may contain paragraphs or fragments that unintentionally drift away from the target meaning. The system uses dense vector embeddings to capture the semantic meaning of each section and then compares it directly with embeddings of the queries. This produces similarity scores that reflect how much conceptual overlap exists between the section and the intended query meaning.
This section-level interpretation allows the system to detect nuanced issues, such as content that appears related on the surface but diverges at a conceptual level, or text that uses correct terminology but serves a different purpose than what the user query implies. Section-level evaluation is the backbone of the project, ensuring a highly detailed view of alignment and deviation across the entire page.
Deviation Identification and Categorization
Deviation occurs when a section shifts away from the semantic direction defined by the query intent. Since the objective of the project is to detect divergence rather than gradual drift over time, the system focuses on whether the meaning of the section truly matches what the user query expects. Every section is analyzed and categorized into meaningful deviation types, helping explain not just that a deviation exists but why it occurred.
The system interprets deviation in multiple natural forms. Some sections align more strongly with a different query than the one being evaluated, indicating overlapping topical clusters that pivot toward another intent. Others may show partial similarity due to shared language or context, even though the core meaning remains different. In certain cases, the core topic expected from the query may be entirely missing from the section, resulting in a clearer divergence. This structured interpretation of deviation provides a transparent and consistent understanding of how and why the content shifts away from the intended topic.
Similarity Scoring and Intent Alignment Measurement
Similarity scoring forms the computational foundation of intent evaluation. Using transformer-based sentence embeddings, the system quantifies how closely a section’s meaning corresponds to the query. These scores enable objective measurement of alignment strength and deviation severity. Higher similarity indicates strong alignment and thematic correctness, while lower similarity signals that the section introduces concepts outside the intended scope.
The scoring mechanism works by comparing dense embeddings, allowing it to capture deep semantic relationships that traditional keyword-based methods cannot detect. This process identifies whether the meaning is conceptually consistent with the query and detects cases where terminology overlaps but meaning does not. The scoring is not treated as a standalone metric; it is interpreted in conjunction with deviation types, contextual relevance, and section semantics to create a comprehensive understanding of intent match quality.
Role of Embeddings in Interpreting Content Meaning
Transformer-based embeddings play a central role in the project by converting both queries and content sections into high-dimensional vectors that represent their semantic meaning. This enables a rich comparison between the intended meaning and the actual meaning of the section. Embeddings capture contextual nuances, synonyms, semantic proximity, and underlying conceptual structures, making them ideal for understanding content at a level far beyond surface text matching.
In this project, embeddings allow the system to interpret long-form content accurately, identify conceptual relationships that are not explicitly phrased, and determine whether a section supports or diverges from the intended topic. Their ability to encode context ensures that meaning is recognized even when phrasing differs between the query and the content.
Interpretation of Query-to-Section Mapping
Evaluating content against queries involves more than numerical similarity. It requires understanding how sections relate to the intent behind each query and determining whether the alignment is meaningful or misleading. The system performs a structured interpretation to identify which query a section aligns most strongly with and whether the section is aligned with the correct query or unintentionally matches another.
By mapping each section to similarity patterns across all queries, the system becomes capable of identifying cross-intent interference, multi-topic overlap, and dominant meaning signals. This contextual mapping ensures that sections are classified appropriately and that deviation detection remains accurate, interpretable, and semantically grounded.
Libraries Used
time
The time library is a standard Python module that provides time-related functions, including delays, timestamps, and execution duration tracking. It allows developers to measure processing time or introduce intentional pauses during operations that may depend on sequential timing.
In this project, time is used to manage internal execution timing during tasks such as text extraction, embedding generation, or large-scale computations. While end-users do not interact with this directly, controlled timing operations ensure stable execution and help maintain predictable system behavior during heavier processing cycles.
re
The re library is Python’s built-in regular expression engine, enabling advanced text pattern matching and text cleaning operations. It is commonly used to detect specific character sequences, remove unwanted patterns, or standardize text formatting.
In this project, re supports core preprocessing by removing repeated whitespaces, filtering HTML remnants, normalizing unconventional characters, and identifying structural patterns within webpage content. These operations ensure the extracted text remains clean and semantically interpretable before further analysis.
html (html_lib)
The html module provides HTML-related utilities such as decoding character entities ( , &, etc.) into readable text. It helps convert encoded website text into a clean, human-readable format.
Here, the library is used to decode HTML entities present in webpage content. Pages often contain encoded symbols that can distort semantic meaning. Converting them into normalized text ensures the content is processed accurately by NLP models used later in the workflow.
hashlib
hashlib provides secure hash functions used to generate unique, consistent identifiers based on text or data. These hashes are stable, repeatable, and compact.
Within this project, hashing helps create stable identifiers for sections or extracted text blocks. This ensures content can be tracked internally without storing large text segments repeatedly. It also helps maintain consistent reference points during semantic comparison operations.
unicodedata
The unicodedata module enables normalization and inspection of Unicode characters, ensuring consistent text representation across languages and formats.
The project uses unicodedata to clean, normalize, and standardize text extracted from webpages. Since SEO content often includes diverse characters, symbols, and formatting styles, consistent Unicode normalization ensures the semantic model interprets the content precisely.
gc (Garbage Collector)
The gc module gives developers control over Python’s memory management by interacting directly with the garbage collector.
In this project, gc is used to release unused memory after processing large text blocks or computing embeddings. This ensures efficient memory utilization during the semantic analysis pipeline, particularly in notebooks where resources must be managed carefully.
logging
The logging library provides structured logging for monitoring execution flow, debugging, and capturing system events. It is more robust than simple print statements.
Here, logging is used throughout the extraction and preprocessing pipeline to trace processing steps, capture unexpected behaviors, and maintain transparency in the system’s operations. This makes the project more reliable and easier to audit or troubleshoot.
requests
requests is a widely used HTTP library that enables clean, reliable communication with web pages and APIs. It simplifies sending GET requests and handling responses.
In this project, requests is responsible for fetching webpage HTML content for analysis. It ensures stable connection handling, error management, and response parsing, which guarantees high-quality content retrieval before text extraction begins.
typing (Optional, List, Tuple, etc.)
The typing module introduces type hints that help structure code clearly, making complex systems more maintainable and predictable.
Here, type hints help define strict data structures for text blocks, embeddings, analysis outputs, and internal configuration parameters. This helps maintain clarity and reliability throughout the full analytical workflow.
bs4 — BeautifulSoup & Comment
BeautifulSoup is a Python package used to parse and navigate HTML documents easily. It can remove tags, extract text, and handle messy or inconsistent markup.
In this project, BeautifulSoup removes unwanted HTML elements, scripts, styles, duplicated content, and comment blocks. It formats page text into clean, readable sections that can be passed to the semantic model for boundary assessment.
collections (Counter, defaultdict)
These utilities provide powerful data structures for counting occurrences and constructing flexible dictionaries with default behaviors.
They support this project by efficiently tracking keyword densities, section frequencies, token distributions, and other structural patterns. These metrics help analyze how topics appear and relate within the webpage’s semantic structure.
numpy
NumPy is the foundational numerical computing library in Python, offering fast vector operations and optimized matrix handling.
Here, NumPy supports embedding operations, similarity calculations, and structural metrics derived from numerical representations of content. The project relies on NumPy to ensure efficient, scalable semantic computations.
pandas
Pandas is used for structured data handling, offering robust support for dataframes, tabular operations, and organized data transformation.
In the project, Pandas structures extracted content, embeddings, and analytical metrics into clean, interpretable dataframes. These frames form the basis for structured reporting, visualization, and downstream analysis.
sentence_transformers (SentenceTransformer, util)
The SentenceTransformers library provides state-of-the-art transformer models capable of generating dense semantic embeddings for sentences and paragraphs.
In this project, it is central to computing topic boundaries. The model converts webpage sections into semantic vectors, and util enables similarity comparisons that determine where topics shift, overlap, or diverge. This is the core engine powering the entire boundary assessment process.
torch
PyTorch is a leading deep learning framework used to run neural models like transformers efficiently on CPU or GPU.
Here, PyTorch handles the underlying computation required for embedding generation. It ensures the transformer model runs smoothly, producing high-quality semantic representations essential for accurate topic boundary detection.
transformers.utils.logging
This module manages verbosity for transformer-related logs, allowing noise-free output during model loading or inference.
In the project, it suppresses unnecessary debugging messages from the transformer backend. This supports a clean notebook environment and helps prioritize project-specific logs over framework-level noise.
matplotlib.pyplot
Matplotlib is a foundational plotting library that supports a wide range of static visualizations.
Here, it is used to visualize similarity patterns, section comparisons, and semantic boundary trends. These visualizations help interpret the structure and distribution of topics across the content.
seaborn
Seaborn is a statistical visualization library built on top of Matplotlib, offering cleaner aesthetics and more interpretable plots.
In this project, Seaborn is used to produce refined visual representations of semantic relationships, making the boundary assessment more intuitive. Its visual style enhances clarity, making the insights easier to communicate to non-technical teams.
Function: fetch_html
Overview
The fetch_html function is responsible for reliably retrieving raw HTML content from a webpage. Since webpages frequently differ in connection stability, server response behavior, and encoding formats, the function is designed with robust safeguards such as retry mechanisms, backoff timing, and multi-encoding fallbacks. This ensures the system consistently obtains high-quality HTML, even when certain pages have unstable availability or unusual character encoding.
The function sends a request to the target URL, waits for the server response, evaluates whether the content resembles a legitimate HTML document, and attempts multiple recovery strategies if the initial attempt fails. By returning either clean HTML text or a meaningful error message, the function forms the essential foundation for all subsequent content extraction, cleaning, and semantic boundary analysis used in the project. Its reliability ensures that downstream NLP processes receive structurally valid and readable content, minimizing interruptions in the analytical pipeline.
Key Code Explanations
headers = {“User-Agent”: “Mozilla/5.0”}
- This line sets a browser-like User-Agent header to prevent servers from blocking or deprioritizing the request. Many websites reject requests sent by default Python agents but accept those mimicking standard browsers. Including this header increases the success rate of HTML retrieval.
while attempt <= max_retries:
- This loop ensures multiple attempts to fetch the webpage. If the first attempt fails, the function automatically retries, respecting the maximum limit. The retry loop is crucial for dealing with temporary network issues, rate limits, or slower server responses.
time.sleep(backoff_factor ** attempt)
- This implements exponential backoff, meaning each retry waits longer than the previous one. This reduces the risk of repeatedly hitting a stressed or rate-limited server and improves overall request reliability. It also helps avoid unnecessary failures caused by attempting requests too aggressively.
resp = requests.get(url, headers=headers, timeout=timeout)
- The GET request is executed here, using the specified headers and timeout. The timeout ensures the function does not wait indefinitely for a slow or unresponsive server. This safeguards the analysis pipeline from unnecessary delays.
resp.raise_for_status()
- This forces an exception if the server returns an HTTP error (e.g., 404, 500). Instead of silently accepting a faulty response, the function catches the error and triggers a retry. This helps ensure only valid and successful responses proceed to the parsing stage.
enc_candidates = []
if getattr(resp, “apparent_encoding”, None):
enc_candidates.append(resp.apparent_encoding)
enc_candidates += [“utf-8”, “iso-8859-1”]
- Websites may use different encodings, which affects how text is represented. This block builds a list of encoding candidates, starting with the encoding detected by requests and followed by common fallbacks. Trying multiple encodings increases the likelihood of successfully converting the raw HTML into readable text.
if html and len(html.strip()) > 200 and “<html” in html.lower():
return html, None
- This checks whether the response looks like a valid HTML document. The function verifies that the content is sufficiently long and structurally recognizable by searching for <html> tags. If it passes these checks, the function returns the HTML text immediately.
Function: sanitize_html
Overview
The sanitize_html function is responsible for transforming raw HTML into a cleaner, content-focused structure by removing noise, clutter, and non-essential elements. Webpages often include a large amount of boilerplate—such as navigation bars, headers, footers, cookie banners, and embedded elements—that hold no semantic value for topic analysis. This function systematically removes such elements to ensure the text passed into the analysis pipeline reflects only meaningful, content-bearing material.
The function uses BeautifulSoup with the lxml parser to efficiently parse the HTML and perform structured cleanup. It removes scripts, styles, comments, and a wide range of HTML containers associated with layout and template elements. When remove_boilerplate=True, it applies several heuristic filters using tag names and regex-based pattern matching of IDs and classes to eliminate typical boilerplate regions found across modern websites. The result is a sanitized DOM tree that allows downstream extraction functions to interpret the core textual content accurately and consistently.
Key Code Explanations
soup = BeautifulSoup(html, “lxml”)
- This line initializes BeautifulSoup using the lxml parser, which is significantly faster and more robust than the default parser. It ensures efficient handling of large or messy HTML structures and creates the parsed DOM tree used for further cleanup.
Lines:
for c in soup.find_all(string=lambda s: isinstance(s, Comment)):
c.extract()
- These lines locate all HTML comments in the document and remove them completely. Comments often contain leftover developer notes, JSON blobs, tracking scripts, or template metadata that can distort text analysis, so removing them helps maintain clean content.
Lines:
remove_tags = [“script”, “style”, “noscript”, “svg”, “canvas”, “iframe”]
…
for tag in remove_tags:
for el in soup.find_all(tag):
el.decompose()
- This block removes entire categories of non-content tags. Script, style, and iframe elements hold no meaningful text for semantic processing, while SVG and canvas elements represent graphical components. Decomposing these ensures only textual structures remain.
Lines:
boilerplate_tags = [“header”, “footer”, “nav”, “aside”, “form”]
- These tags commonly represent navigational or structural containers rather than meaningful body content. When remove_boilerplate=True, the function attempts to remove them entirely to isolate article-level material.
Lines:
boilerplate_patterns = [
r”(^|\W)(nav|navbar|menu|site-nav)($|\W)”,
r”(^|\W)(footer|site-footer)($|\W)”,
r”(^|\W)(sidebar|side-bar|widget|aside)($|\W)”,
r”(^|\W)(cookie|consent|cookie-banner)($|\W)”,
r”(^|\W)(subscribe|newsletter|related|advert)($|\W)”
]
- These regex patterns help identify boilerplate elements using id or class attributes. Many HTML structures rely on specific naming conventions, and this heuristic allows the function to detect and remove them even when tag names vary across websites.
Lines:
text = el.get_text(separator=” “, strip=True)
if not text or len(text.split()) < 8:
el.decompose()
- This ensures that only elements with insignificant text content are removed. If the element’s text contains fewer than 8 words, it is treated as non-content and deleted. This prevents large, meaningful sections that share boilerplate patterns from being removed by mistake.
Function: clean_text
Overview
The clean_text function performs lightweight text normalization to prepare extracted content for embedding and similarity computations. Unlike heavy preprocessing that removes punctuation or converts case, this function intentionally preserves these features because they contribute to meaning and semantic nuance in transformer embeddings. The goal is to produce text that is normalized and stable while retaining all expressive structure necessary for accurate NLP modelling.
The cleaning includes HTML entity unescaping, Unicode normalization, and whitespace collapsing. These transformations eliminate inconsistencies without altering the semantic integrity of the content. Cleaned text produced by this function becomes the input to sentence embedding models and section-level similarity scoring.
Key Code Explanations
text = html_lib.unescape(text)
- This resolves HTML entities (such as &, >, ’) into their human-readable characters. Transformer models understand natural text better when these symbols are properly converted.
text = unicodedata.normalize(“NFKC”, text)
- Unicode normalization ensures characters with composed and decomposed forms are standardized. This prevents issues where visually identical characters encode differently, which could degrade vector similarity.
text = re.sub(r”\s+”, ” “, text).strip()
- This collapses multiple whitespace characters into a single space and trims surrounding spaces. It produces cleaner input while preserving the original sentence structure.
Function: estimate_tokens
Overview
The estimate_tokens function provides a quick, approximate estimation of the number of tokens in a text segment. Since transformers operate on tokens—not raw words—estimating the token count helps manage batching, memory, and processing decisions. It prevents overly long sections from causing performance issues and helps determine when splitting or truncating might be needed in upstream processing.
The function uses a conservative multiplier (token_per_word=1.33) based on typical tokenization patterns of English web text under models like Sentence-BERT and similar transformer architectures.
Key Code Explanations
words = max(0, len(text.split()))
return max(1, int(words * token_per_word))
- The text is split into word-like units and multiplied by an empirically chosen token-per-word ratio. The max(1, …) ensures the function never returns zero tokens, providing a stable baseline for any subsequent token-aware operations.
deterministic_id
Overview
The deterministic_id function generates a stable, reproducible identifier for any text-based seed input. This is crucial for section-level tracking throughout the pipeline, ensuring that each section receives a unique but consistent ID across repeated runs, even if the execution environment changes. Unlike randomly generated IDs, deterministic IDs allow reliable mapping between extracted sections and downstream analysis components such as similarity scoring, deviation detection, and visualization.
The function uses SHA-256 hashing to compute a long hexadecimal digest from the seed and then truncates it to a shorter—but sufficiently collision-resistant—length. This approach provides a predictable and robust ID generation process suitable for large-scale HTML documents where each extracted section must be referenced consistently.
Because the ID length is fixed, the function also keeps the output lightweight, readable, and safe for indexing or JSON serialization across the project.
Key Code Explanations
h = hashlib.sha256(seed.encode(“utf-8”)).hexdigest()
return h[:length]
- The seed string is encoded and passed through SHA-256 hashing, producing a 64-character hexadecimal digest. Truncating this to the specified length parameter yields a shorter identifier that still retains the key properties of SHA-256—determinism and extremely low collision probability—while keeping the ID compact for practical use.
Function: extract_sections
Overview
The extract_sections function is one of the core components of the project pipeline. Its purpose is to convert the sanitized HTML into structured, meaningful content sections that can be evaluated against the user-defined intent. It identifies important segments of a webpage by recognizing top-level heading tags (such as H2 and H3), grouping them as major sections, and collecting any related text or subheadings that follow. This forms the foundational representation of the page’s semantic structure.
The function is designed to work with real-world webpages—which vary widely in formatting—by implementing fallback strategies when headings are missing or inconsistent. If no recognized headings exist, the function automatically falls back to paragraph-based extraction, ensuring content is still captured in usable form. Each final section contains a section heading, the consolidated text, its position in the page, and a deterministic ID for tracking throughout analysis and visualization.
This structured section output supports all downstream tasks: semantic similarity scoring, deviation detection, severity ranking, reasoning attribution, and page-level summarization. Without consistent and reliable section extraction, no subsequent analysis step would function as intended.
Key Code Explanations
nodes = soup.find_all(list(top_heading_tags) + list(subheading_tags) + list(content_tags))
- This line gathers all relevant content-related HTML elements—such as headings, subheadings, and paragraph-like tags—into a single ordered collection. It respects the natural sequence of the DOM, allowing the function to process the page linearly and reconstruct content sections accurately.
if not nodes:
paras = soup.find_all(“p”)
…
sec = {
“section_id”: deterministic_id(f”para_{position}_{txt[:160]}”),
“heading”: f”Paragraph {position}”,
“text”: txt,
“position”: position
}
- When a page lacks structural headings altogether—which is common on auto-generated or poorly formatted pages—the function gracefully switches to paragraph-level extraction. Each paragraph becomes a standalone section with a deterministic ID. This ensures the analysis never fails due to inconsistent markup.
if tag_name in top_heading_tags:
if current.get(“text”, “”).strip():
current[“section_id”] = deterministic_id(f”{current[‘heading’]}_{current[‘position’]}”)
sections.append(current)
position += 1
current = {“heading”: txt, “text”: “”, “position”: position}
- When encountering an H2 or H3, the function treats it as the start of a new primary section. Before creating the new section, it commits the previously accumulated one—ensuring all earlier content is saved—before beginning a fresh section container using the new heading.
else:
current[“text”] = (current.get(“text”, “”) + ” ” + txt).strip()
- If the node is not a top-level heading, it is appended to the current section. This includes H4 subheadings or paragraph-like content tags. The text is concatenated into a single string that represents the complete semantic unit under the section heading.
if current and current.get(“text”, “”).strip():
current[“section_id”] = deterministic_id(f”{current[‘heading’]}_{current[‘position’]}”)
sections.append(current)
- After the loop ends, this ensures that the final section is not lost. Since the last section would not naturally encounter a new heading, this explicit commit stores it properly.
Function: filter_sections
Overview
The filter_sections function performs a focused quality-cleaning step on the extracted content sections. After section extraction, webpages often include fragments that do not contribute meaningfully to semantic evaluation—such as short placeholder lines, navigation snippets, or boilerplate terms like “subscribe”, “read more”, or “privacy policy”. Allowing these fragments to remain in the dataset can distort semantic scoring and weaken later analyses.
This function ensures the system works only with substantial, meaningful text blocks. It evaluates each section’s length and content characteristics, removes sections that are too short to hold semantic value, and filters out segments dominated by boilerplate wording. This improves signal-to-noise quality, stabilizes downstream embeddings, and leads to clearer section-level semantic boundary assessments.
Because the function is straightforward and self-explanatory in logic, the conceptual explanation in the Overview is sufficient and a separate Key Code Explanations subsection is not required for this particular function.
Function: chunk_section
Overview
The chunk_section function ensures that long sections are broken into manageable, model-friendly text units without compromising the semantic structure of the content. Large sections can exceed token limits used by embedding models or LLMs, resulting in inefficient processing or truncated embeddings. This function resolves that by intelligently dividing oversized sections into coherent chunks.
The primary strategy is to preserve paragraph integrity wherever possible. Instead of blindly splitting at fixed word counts, it first checks whether the entire section exceeds the maximum token threshold. If it does not, the function simply returns the section unchanged. When splitting is required, the text is divided using paragraph boundaries—ensuring each chunk remains logically meaningful. If a section lacks clear paragraph breaks, the function gracefully falls back to sentence-like boundaries.
Additionally, the function guards against producing very small or semantically weak fragments. When a potential chunk contains fewer than a minimum number of words, it merges that text into the previous chunk to maintain coherence. Each chunk inherits the original section’s position and heading but adds a “Part i” suffix for clarity. This keeps the content traceable and structured while staying within token limits.
This approach produces well-formed, semantically intact chunks suitable for accurate embeddings and reliable topic boundary evaluation.
Key Code Explanations
Checking if the section exceeds the token limit
est = estimate_tokens(text, token_per_word)
if est <= max_tokens:
return [{
“section_id”: base_id,
“heading”: heading,
“text”: text,
“position”: position,
“chunk_index”: 1,
“tokens”: est
}]
- This logic determines whether the section needs to be chunked at all. By estimating token count using the average tokens-per-word ratio, the function avoids unnecessary splitting. If the section falls under the limit, it gets returned exactly as is, preserving structure and preventing fragmentation.
Splitting by paragraph boundaries first
paragraphs = [p.strip() for p in re.split(r’\n{1,}|\r\n{1,}’, text) if p.strip()]
if len(paragraphs) <= 1:
paragraphs = [p.strip() for p in re.split(r'(?<=[.?!])\s+’, text) if p.strip()]
- This block attempts a natural split using paragraphs. Most well-structured content organizes ideas paragraph-wise, so this method retains semantic flow. If the section contains no reliable paragraph breaks—common in scraped content—the function switches to sentence-level splitting to maintain meaningful units.
Building chunks while avoiding tiny fragments
if len(chunk_text.split()) < min_chunk_words and chunks:
chunks[-1][“text”] += ” ” + chunk_text
chunks[-1][“tokens”] = estimate_tokens(chunks[-1][“text”], token_per_word)
- This prevents the system from producing small, semantically weak chunks.
- If a potential chunk is too short and not the first one, it is merged into the previous chunk. The token count is updated to reflect the expanded text. This ensures each chunk is substantial enough for stable embeddings and clear topic interpretation.
Creating final chunk dictionaries
chunks.append({
“section_id”: deterministic_id(f”{base_id}_{chunk_idx}”),
“heading”: f”{heading} (Part {chunk_idx})”,
“text”: chunk_text,
“position”: position,
“chunk_index”: chunk_idx,
“tokens”: estimate_tokens(chunk_text, token_per_word)
})
- Each chunk is stored with rich metadata so it can be mapped back to the original document structure. This makes later analysis—semantic scoring, topic boundary mapping, visualisation—straightforward and traceable.
Function: build_page
Overview
The build_page function acts as the full preprocessing pipeline for transforming a raw webpage into a clean, structured, and analysis-ready format. It combines several earlier functions—fetching the HTML, sanitizing the structure, extracting logical sections, filtering non-useful content, and finally chunking large sections into manageable units. This makes it the central orchestrator that prepares a webpage for semantic evaluation and topic boundary assessment.
The strength of this function lies in its end-to-end reliability. It begins by fetching the page with intelligent retry handling, ensuring transient network failures do not prematurely break the workflow. After obtaining the HTML, the function sanitizes the document, stripping unnecessary markup, scripts, or boilerplate content that could distort semantic interpretation. It then extracts structured sections by mapping headings, subheadings, and paragraphs into a canonical representation.
Next, it applies filtering rules to remove irrelevant, overly short, or boilerplate-like sections, ensuring that only meaningful content moves forward. Each validated section is then processed by the chunking system to ensure that each part remains within token limits and retains semantic coherence. The final output is a clean and structured representation of the page, complete with titles, section metadata, and interpretability-ready content blocks. This output is essential for enabling accurate semantic comparisons, overlap detection, and topic boundary assessment.
Key Code Explanations
Fetching the HTML with retries
html, err = fetch_html(url, fetch_timeout, initial_delay, fetch_retries, backoff_factor)
if html is None:
return {“url”: url, “title”: None, “sections”: [], “note”: f”fetch_error: {err}”}
- The function starts by requesting the webpage. It uses retry logic with exponential backoff to handle temporary issues like timeouts or unstable connections. If all attempts fail, the function exits early and returns a structured error response instead of breaking the entire pipeline. This ensures the system is stable when analysing many pages.
Extracting a clean title
title_tag = soup.find(“title”)
title = clean_text(title_tag.get_text()) if title_tag else None
if not title:
h1 = soup.find(“h1”)
title = clean_text(h1.get_text()) if h1 else “Untitled Page”
- Because not all pages provide clean titles, this fallback system ensures there is always a meaningful title available. If the <title> tag is missing or empty, it uses the <h1>. If even that is unavailable, it assigns a safe fallback: “Untitled Page”.
Extracting and filtering meaningful sections
raw_sections = extract_sections(soup)
filtered = filter_sections(raw_sections, min_words_per_section, boilerplate_extra)
· Here, two essential transformations occur:
- extract_sections identifies meaningful blocks of content by detecting heading structures and grouping paragraphs accordingly.
- filter_sections then removes noise such as boilerplate elements, excessively short blocks, or irrelevant sections.
Chunking large sections into model-friendly blocks
for sec in filtered:
chunks = chunk_section(sec, chunk_max_tokens, token_per_word, min_chunk_words)
prepared.extend(chunks)
- Every filtered section is passed through the chunk_section function. This guarantees that long sections are split into structured, token-bounded units that are suitable for embedding generation. The function merges all resulting chunks into a unified list, retaining order and metadata.
Sorting sections deterministically
prepared = sorted(prepared, key=lambda s: (s.get(“position”, 0), s.get(“chunk_index”, 1)))
- Sorting ensures that the final section and chunk ordering reflects the original document structure. This prevents inconsistencies in later stages, such as: topic flow reconstruction, boundary detection, visualisation layouts.
Function: init_model
Overview
The init_model function is responsible for loading and preparing the SentenceTransformer embedding model used throughout the project. It handles model selection, device detection (CPU/GPU), model initialization, and ensures the model is set to evaluation mode for efficient inference. This function centralizes model setup so that the rest of the pipeline can rely on a properly initialized embedding engine without repeatedly handling configuration logic.
Because this function is already concise and self-descriptive, it does not require a separate code explanation section. The logic is straightforward: choose device → load model → configure for inference → return.
However, the overview below explains each component clearly and practically.
Key Code Explanations
Automatic device detection
if device is None:
device = torch.device(“cuda”) if torch.cuda.is_available() else torch.device(“cpu”)
- If no device is explicitly specified, the function automatically selects GPU (cuda) when available, otherwise defaults to CPU. This ensures optimal performance without requiring manual configuration.
Loading the transformer embedding model
model = SentenceTransformer(model_name, device=device)
- Loads the SentenceTransformer model using the provided name (e.g., all-mpnet-base-v2). The model is directly assigned to the selected device, ensuring fast inference.
Setting up the model for inference
model.eval()
torch.set_grad_enabled(False)
· These lines ensure the model runs in inference mode:
- eval() disables dropout and other training-only layers.
- set_grad_enabled(False) prevents gradient tracking to reduce memory usage and speed up computation.
This optimization is important when embedding large volumes of text.
Function: embed_texts
Overview
The embed_texts function generates semantic embeddings for a list of text segments using a SentenceTransformer model. Embeddings are the foundation of all similarity measurements in this project, enabling the system to evaluate topical focus, detect boundary shifts, measure semantic overlap, and establish conceptual relationships.
This function batches the input texts for efficiency, leverages the model’s optimized encode method, and returns L2-normalized embeddings. Normalization is essential because it ensures that cosine similarity values remain stable and comparable across different pages, sections, and queries.
The function is intentionally compact since it delegates most heavy lifting to the underlying SentenceTransformer implementation. However, its role in the pipeline is fundamental: it converts raw text into structured, comparable numerical representations.
Key Code Explanations
Empty input handling
if not texts:
return np.zeros((0, model.get_sentence_embedding_dimension()), dtype=np.float32)
- If the list of texts is empty, the function returns an empty embedding matrix with the correct dimensionality. This prevents downstream steps from breaking and maintains shape consistency throughout the pipeline.
Dynamic batch sizing
batch_size = min(batch_size, len(texts))
- This line automatically adjusts the batch size so it never exceeds the number of texts. It improves performance and prevents unnecessary overhead when embedding a small number of items.
Encoding with normalization
emb = model.encode(texts, convert_to_numpy=True, batch_size=batch_size, normalize_embeddings=True)
· This is the core embedding operation. Key aspects:
- convert_to_numpy=True returns embeddings as NumPy arrays, which integrate well with the analysis pipeline.
- normalize_embeddings=True applies L2 normalization, ensuring cosine similarity behaves reliably and fairly across different text lengths.
- Batching speeds up processing, especially when working with many content sections.
The output is a compact, numerical representation of semantic meaning that powers all similarity and boundary assessments in the project.
Function: embed_sections
Overview
The embed_sections function prepares and embeds all processed page sections. Each section in the pipeline already contains cleaned, structured text, and this function converts those texts into semantic embeddings using the previously initialized SentenceTransformer model.
The function maintains the original order and metadata of sections while generating a parallel NumPy matrix of embeddings. The pairing of structured section metadata with semantic vectors is essential because it allows the system to map analytical outputs—such as overlap scores, leakage detection, and boundary evaluations—directly back to meaningful human-readable sections.
This function is intentionally simple because all key embedding operations are handled by the more general-purpose embed_texts function. Its primary responsibility is organizing section text inputs and returning them in a predictable structure that synchronizes embeddings with the section list.
Key Code Explanations
Extracting section text
texts = [sec.get(“text”, “”) for sec in sections]
- This line gathers the textual content from each section into a list. It ensures every section provides input to the embedding model, even if a section text is missing (in which case an empty string is used), keeping positional alignment intact.
Delegating embedding workload
sec_emb = embed_texts(model, texts, batch_size=batch_size)
· This line sends all texts to the central embedding function. The call ensures:
- L2-normalized embeddings
- Efficient batch processing
- Shape consistency across all sections
Embedding at this stage enables all similarity and evaluation tasks that follow in the pipeline
Function: embed_queries
Overview
The embed_queries function generates semantic embeddings for all query strings provided to the system. Queries act as the semantic anchors for evaluating topical alignment, overlap, leakage boundaries, and focus integrity across the page content. This function ensures all queries—regardless of length or complexity—are transformed into normalized embedding vectors suitable for similarity comparisons with section embeddings.
Before embedding, each query is validated to prevent None values from breaking the embedding pipeline by substituting empty strings where needed. The embedding process itself is delegated to the central embed_texts utility, ensuring consistency in normalization, batching, and output format. The function returns both the embeddings and the cleaned list of queries to maintain alignment between input strings and their vector representations.
This function is intentionally compact and direct because queries are typically short, self-contained textual inputs, requiring minimal preprocessing beyond null-safety.
Key Code Explanations
Handling possible None values
queries = [q if q is not None else “” for q in queries]
- This line ensures that no element in the query list is None, replacing such values with empty strings. Preventing None is important because the embedding model expects valid string inputs, and an empty string ensures safe, consistent processing.
Generating semantic embeddings
q_emb = embed_texts(model, queries, batch_size=batch_size)
· This line uses the central embedding function to convert queries into normalized embedding vectors. The function ensures:
- Efficient batch processing
- L2 normalization for stable similarity scores
- A consistent (N, D) shape for downstream similarity operations
Function map_score_to_severity
Overview
This function converts a numerical alignment score (ranging from 0 to 1) into a semantic deviation severity label.
It uses a threshold-based approach, where higher scores indicate stronger alignment with the intended topic or query. If no custom thresholds are supplied, it falls back to default values.
The function ensures the score is valid, safely handles non-numeric inputs, clips the score to the 0–1 range, and then assigns the correct deviation label.
Key Code Explanations
s = max(0.0, min(1.0, s))
- This line clips the numeric score so it always stays within the valid range [0,1]. Even if the input is out of range or incorrectly scaled, this prevents the function from misbehaving.
if s >= thresholds[“T_on_target”]:
- This selects the most positive label. If the score meets or exceeds the highest threshold, the content is considered fully aligned with the target intent.
elif s >= thresholds[“T_minor”]:
- This block categorizes slightly lower scores as minor deviations — still mostly aligned but with some detectable shift.
elif s >= thresholds[“T_moderate”]:
- Scores falling between the minor and moderate thresholds indicate a more noticeable semantic mismatch.
else: return “strong_deviation”
- If the score falls below all thresholds, the content is labeled as strongly deviated — meaning the semantic direction differs significantly from the intended target.
Function token_overlap_ratio
Overview
This function calculates how much of the query’s vocabulary is directly present in a given section of text. It works by breaking the query into individual tokens, standardizing everything to lowercase, and verifying which of those tokens appear as whole words within the section. The purpose of this function is to provide a quick and conservative estimate of how closely the section’s surface-level wording aligns with the query. Because it evaluates unique tokens only, it prevents inflated scores caused by repeated words. The final output is a ratio between 0 and 1, where higher values indicate stronger lexical alignment. This ratio is useful as an auxiliary signal in understanding whether a section is explicitly covering the terms the query expects.
Key Code Explanations
q_tokens = [t for t in re.split(r’\W+’, query.lower()) if t]
- This line converts the query to lowercase and splits it into tokens using any non-alphanumeric character as a separator. It also removes empty elements, ensuring that only valid tokens are included for analysis.
if re.search(r’\b’ + re.escape(t) + r’\b’, txt_lower):
- This condition checks whether a given token appears in the text as an exact whole word. The use of word boundaries avoids accidental partial matches (for example, preventing “art” from matching “article”). re.escape ensures any token containing special characters is safely interpreted as literal text.
return matched / float(len(q_tokens))
- After counting how many unique query tokens appear in the text, the function returns the overlap ratio by dividing the matched token count by the total number of unique query tokens. The result is a clear, interpretable score between 0 and 1.
Function get_deviation_reason
Overview
This function assigns a clear and interpretable reason explaining why a section deviates from the intended query alignment. While the alignment score and severity label provide a numeric and categorical view of deviation, this function adds a narrative layer by determining the underlying reason for that deviation. It considers several factors simultaneously: the section’s alignment score, the severity classification, the level of token presence from the query, and whether the section aligns more strongly with another query. By combining these signals, the function produces a deterministic and consistent deviation reason, ensuring the interpretation remains stable and understandable across different analyses. The resulting labels—such as aligned_to_other_query, peripheral_context_alignment, or missing_core_intent—help explain whether the section is simply addressing secondary context, partially touching the topic, lacking core intent, or shifting towards an entirely different query.
Key Code Explanations
if best_query_index is not None and best_query_index != current_query_index:
- This line checks whether the section aligns more strongly with a different query than the one being evaluated. If another query is the better match, the function prepares to classify the deviation as coming from cross-query alignment.
if best_score is not None and (best_score – score) >= aligned_to_other_delta:
- Here, the function confirms that the difference between the best query’s score and the current query’s score is large enough to be meaningful. This avoids false triggers caused by minor variations and ensures that aligned_to_other_query is returned only when the section clearly favors another query.
if severity == “minor_deviation”: … if token_overlap >= 0.5:
- This segment uses the severity label and token-overlap ratio to differentiate between two types of mild misalignment. If the section still retains strong token presence but deviates slightly, the function interprets it as contextual or peripheral content. If overlap is lower, it signals that only partial topical connection is present.
if severity == “moderate_deviation”: … if token_overlap >= 0.35:
- Moderate deviation is interpreted with more scrutiny. A reasonable token presence indicates partial topic coverage, while lower overlap suggests a deeper gap from the core intent, leading to the missing_core_intent classification.
if severity == “strong_deviation”: … return “off_topic”
- Stronger deviation is treated as significant misalignment. If token overlap is still somewhat visible, the section may be lightly related through contextual cues, but if overlap is very low, the function concludes that the section is truly off-topic.
Function analyze_sections_against_queries
Overview
This function performs the core analytical operation of the system: it evaluates every content section against each query and produces a structured interpretation of how well each section aligns with intended user intent. It integrates semantic similarity, token-level overlap, severity classification, and deviation-reason logic into a single, section-centric output.
The function first generates embeddings for both queries and sections, computes alignment scores, identifies the best-matching query for each section, and then assigns a deviation severity and reasoning label. The final output arranges these findings cleanly within each section’s metadata. This ensures that downstream components—visualizers, diagnostic tools, or reporting modules—receive a complete, interpretable, and deterministic assessment of alignment behavior. The output is therefore crucial for generating section-wise insight maps, identifying segments that shift intent, and explaining the nature and degree of misalignment in a transparent and non-technical manner.
Key Code Explanations
sim_matrix = util.cos_sim(q_embs, sec_embs).cpu().numpy()
- This line calculates the cosine similarity between every query and every section embedding. It creates a matrix where each cell expresses how semantically close a query is to a section. This serves as the foundational metric for alignment scoring.
align_matrix = np.clip((sim_matrix + 1.0) / 2.0, 0.0, 1.0)
- Cosine similarity ranges from –1 to 1, which is not intuitive for interpretability. This line rescales the values into the 0–1 range, creating a normalized alignment score. The clipping ensures stability and prevents numerical anomalies.
best_q_indices = np.argmax(align_matrix, axis=0)
- Here, the function identifies which query each section aligns with most strongly. This index becomes essential for determining whether a section is aligned to the intended query or unintentionally leaning toward another one.
best_scores = np.max(align_matrix, axis=0)
- This extracts the highest alignment score for each section. It is used both for identifying best alignment and for assessing whether the alignment gap is significant enough to classify the section as aligned to another query.
severity = map_score_to_severity(score, thresholds)
- Every alignment score is interpreted through predefined thresholds. This converts numeric similarity into meaningful deviation categories such as minor, moderate, or strong deviation, enabling consistent downstream reasoning.
tok_overlap = token_overlap_ratio(q_list[q_idx], sec_text)
- This line supplements semantic similarity with surface-level token presence. It checks how many unique query tokens appear in the section. This helps differentiate peripheral context from deeper mismatches, improving interpretability.
reason = get_deviation_reason(…)
- This is where multi-signal interpretation is synthesized. The function evaluates severity, token overlap, and relative alignment across queries to produce a definitive deviation reason (e.g., topical_partial_match, missing_core_intent, aligned_to_other_query). The output becomes a clear narrative explanation for the observed deviation.
best_query_label = q_list[best_q] if best_q != q_idx else None
- This attaches the label of the query to which the section aligns best—when that best match is not the query being evaluated. It provides direct visibility into cross-query misalignment without requiring additional lookup.

Function analyze_page_against_queries
Overview
This function acts as a streamlined wrapper that evaluates an entire webpage against the provided set of queries. It accepts a processed page dictionary—containing the page URL, title, and its extracted sections—and passes all sections through the core alignment analysis engine. The output is a clean, structured report that enhances each section with alignment scores, deviation severity, reasoning labels, and token-level insights.
This wrapper ensures that the analysis workflow is simple and predictable: the calling system only needs to provide a page object and the queries, and the function returns a fully enriched interpretation of how each section aligns with user intent. By consolidating metadata and results into a single page-level structure, it becomes easy to feed the outcome into visual dashboards, reporting modules, or downstream decision logic without additional formatting or assembly.
Because the function mainly orchestrates the flow of information rather than performing complex logic itself, clarity and structure are its primary contributions.
Key Code Explanations
analyzed_sections = analyze_sections_against_queries(…)
- This line is the core operational step. It delegates the heavy semantic-analysis work to the main section-level analyzer, which performs similarity scoring, deviation classification, and reasoning assignment. The wrapper simply passes the required parameters and retrieves enriched section results.
return { “url”: page_url, “title”: title, “sections”: analyzed_sections, “note”: page.get(“note”) }
- This final return ensures that the output maintains the same page-level structure as the input, but now each section is appended with detailed alignment insights. This design makes the function ideal for client-facing reporting pipelines, where consistency and readability of the output format are essential.
Function compute_query_summaries
Overview
This function generates a concise, query-wise summary of how well a webpage aligns with each individual search intent. Instead of focusing on section-level details, it aggregates all similarity scores, deviation severities, and deviation reasons associated with a specific query. This higher-level perspective is crucial when interpreting overall intent satisfaction: it highlights how consistently the page supports each query, identifies which queries are strongly aligned, and exposes queries that face structural or semantic gaps across the content.
The function loops through every section in the analyzed page output and extracts the scoring information relevant to each query. It then computes descriptive metrics—average, minimum, and maximum similarity—along with distributions of severity levels and deviation reasons. These aggregated statistics give a stable and interpretable view of page performance for each query, helping stakeholders understand alignment patterns without inspecting raw section-level outputs. Since the logic is straightforward and focuses mainly on aggregation, the explanation of core mechanisms below focuses on the key operational lines.
Key Code Explanations
for sc in sec.get(“scores”, []): if sc[“query”] == q:
- This line selectively filters score objects that belong to the current query being summarized. Each section contains multiple score objects (one per query), but only scores matching the query in focus are used in the summary. This ensures accurate aggregation for each query independently.
severity_counts[severity] = severity_counts.get(severity, 0) + 1
- Every section contributes a severity label such as on_target, minor_deviation, moderate_deviation, or strong_deviation. This line maintains a running count of how frequently each severity type appears. The resulting severity distribution becomes a key signal for understanding how reliably the page aligns with a query across its structure.
per_query_summary[q] = { “avg_similarity”: float(np.mean(all_scores)), … }
- Once all scores for a query are collected, this block computes summary statistics. The use of mean, min, and max creates a balanced view: the mean shows the general level of alignment, the minimum highlights weak spots, and the maximum reveals the best-performing sections. Packaging these values into a dictionary creates a clean, structured output ready for client-facing reporting.
Function compute_overall_summary
Overview
This function creates a complete, page-level summary that reflects how well the page aligns with all provided queries and where the major deviations occur. While section-level analysis provides granular insight, this function consolidates that information into a high-level diagnostic suitable for final reporting. It calculates the overall alignment score across the entire page, evaluates how many sections were successfully analyzed, aggregates the distribution of severity and deviation reasons, and identifies the lowest-performing sections based on similarity scores.
The function processes each section, extracts relevant similarity and deviation information, and builds section-level statistics that serve as the foundation for the aggregated page summary. By isolating the weakest-aligned sections, it highlights which parts of the page may require immediate improvements. The resulting output is structured, comprehensive, and ready for client-facing interpretation.
Key Code Explanations
sims = [float(sc.get(“similarity_score”, 0.0)) for sc in sec_scores]
- This line collects all similarity scores for a given section across all queries. These scores become the basis for computing the section’s average and minimum alignment. Using mean and min together helps assess both general alignment strength and worst-case deviation within that section.
sec_avg = float(np.mean(sims)); sec_min = float(np.min(sims))
· Here, the function calculates two essential performance indicators:
- Average similarity reflects the overall semantic match between the section and all queries combined.
- Minimum similarity highlights the deepest deviation, showing whether a section contains portions that strongly diverge from user intent. These metrics help classify sections that may seem broadly relevant but contain problematic off-intent content.
severity_counter.update([sc.get(“severity”, “unknown”) for sc in sec_scores])
- This line aggregates the severity labels for all section–query pairs across the page. By updating a global counter, the function builds a page-wide profile of deviation severity. This provides an at-a-glance understanding of how much content stays on-target, how much drifts slightly, and how much shows moderate or strong deviation.
reason_counter.update(reasons)
- Deviation reasons (e.g., “topical_partial_match”, “off_topic”) provide specific explanations behind deviations. This aggregation step counts how often each reason occurs throughout the page, giving deeper diagnostic insight into the nature of misalignment.
coverage_ratio = covered_sections / total_sections
- Coverage ratio indicates the proportion of sections that contain valid similarity scores. A low coverage ratio suggests structural extraction issues or large parts of the content that did not meaningfully align with any queries.
deviating_sorted = sorted(… key=lambda x: (x[“min_score”], x[“avg_score”]))
- This block identifies the weakest sections by ranking them based on lowest minimum similarity and then by lowest average similarity. Sorting first by minimum score ensures that sections containing strongly off-target content appear at the top of the deviation list. This prioritization helps teams focus on the most critical areas needing revision.
top_deviating = deviating_sorted[:top_k]
- Finally, the function extracts the top k lowest-aligned sections. These become the key recommendations for content correction or restructuring, ensuring the summary highlights actionable insights rather than overwhelming details.

Function attach_page_level_summaries
Overview
This function acts as the final consolidation step in the page-level analysis pipeline. After all section-wise and query-wise similarity evaluations have been completed, this function attaches two key high-level summaries to the final page result:
- Per-query summaries – How well each query aligns with the page overall, extracted using compute_query_summaries.
- Overall page summary – A unified diagnostic showing the page’s alignment health, deviation distribution, and the weakest sections, generated by compute_overall_summary.
By packaging both into the page_result dictionary, this function prepares the analysis output in a structured, standardized form that can be directly used for reporting.
Key Code Explanations
page_result[“query_summary”] = compute_query_summaries(page_result, queries)
· This line generates query-level summaries using the previously computed similarity scores for each query across all page sections.
- It captures how each query performs at a holistic level.
- It helps understand which queries fit the page well and which ones reveal weaknesses in intent alignment. The output includes average similarity, deviation severity distribution, and reason aggregation per query.
page_result[“overall_summaries”] = compute_overall_summary(page_result, top_k)
· This injects the combined page-level diagnostic into the result.
- It compiles all section-level scores into a single summary.
- It highlights deviation-prone sections.
- It provides page-level severity and reason breakdowns. The top_k parameter controls how many weakest sections should be included, ensuring the output stays concise and actionable.
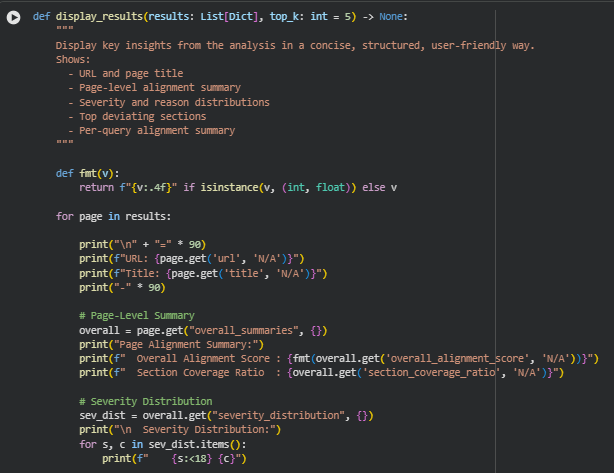
Function display_results
Overview
This function provides a structured, human-readable presentation layer for the final analysis results. It does not compute any scores; instead, it formats and surfaces the key insights already produced by the analytical pipeline. The goal is to give a clear, concise, and interpretive snapshot of page-level and query-level alignment health so the output can be directly reviewed or integrated into reporting notebooks.
For each analyzed page, the function displays the URL and title, followed by a consolidated alignment summary that captures the overall alignment score, the coverage ratio, and the distributions of deviation severities and reasons. It also highlights the most significant deviation-prone sections, enabling fast identification of areas where the content diverges from user intent.
The function concludes with a compact query-level summary showing how the page performs against each target query—covering similarity ranges, severity distributions, and deviation causes. By presenting all insights in a clean, readable format, this function serves as the final interpretive output layer, making the technical evaluation accessible for strategic review, documentation, and user communication.
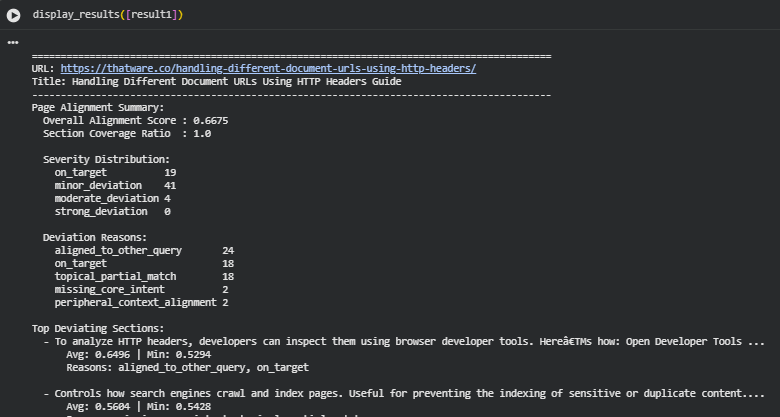
Result Analysis and Explanation
This section provides a detailed interpretation of the semantic assessment output, explaining how the page aligns with the intended search intents, where deviations occur, and what these deviations indicate about content focus, coverage, and relevance. The goal is to help clearly understand how the content performs against the target intents and what the different signals represent.
Overall Alignment Performance
The page shows a moderately strong alignment with the target intents, reflected in an overall alignment score of 0.6675. This score indicates that, across all sections, the content generally maintains a meaningful connection to the expected themes and informational intent.
The section coverage ratio of 1.0 confirms that every section on the page contributed semantically relevant content for at least one of the target intents. This ensures that the full document was evaluated without gaps and that the material is contextually rich enough to support the queries being analyzed.
Severity Distribution Interpretation
The severity distribution indicates how strongly each section aligns or deviates from the target intent.
- A high number of on-target instances (19) shows that the page contains substantial sections with strong alignment.
- The dominant presence of minor deviations (41) suggests that while the content is generally relevant, many sections include partial misalignment or shifts in emphasis.
- Only 4 moderate deviations and zero strong deviations indicate that the page avoids severe mismatches or major off-topic content.
Overall, the severity profile shows a healthy alignment with expected user intent, with most deviations being light and correctable.
Reasons Behind Topic Deviations
Each deviation reason provides insight into why a section diverged from the expected semantic direction:
· Aligned to other query (24 instances) Many sections aligned more closely with another target query rather than the one being evaluated. This indicates thematic overlap between the queries and the content, rather than an outright mismatch.
· On-target signals (18 instances) These confirm sections that directly address the intent without deviation.
· Topical partial match (18 instances) These refer to sections that discuss related concepts but may miss the main purpose or depth expected for the query.
· Missing core intent (2 instances) These sections lack key elements expected for the intent, creating noticeable semantic distance.
· Peripheral context alignment (2 instances) These sections relate to the broader context but do not address the intent directly.
This distribution shows that the deviations are mostly mild, with minimal occurrences of deeper misalignment.
Analysis of Top Deviating Sections
The lowest-scoring sections help highlight where alignment weakens or where content shifts focus:
Developer Tools Instruction Block
This section explains how to inspect HTTP headers using browser tools.
- It shows mixed alignment, with one aspect relevant and another aligning more with a different query.
- The minimum similarity score (0.5294) suggests partial relevance but not a direct address of the core intent.
Search Engine Crawling and Indexing Control
Content about controlling indexing and preventing crawl of duplicate or sensitive pages appears.
- Reason labels include missing core intent and topical partial match, indicating the topic is relevant to headers but does not serve the deeper intent behind the queries.
Caching and Performance Instructions
This discusses cache control and browser optimisation.
- While related to headers, it connects more to a peripheral technical topic, resulting in topical partial match.
Multilingual Targeting and Regional Header Usage
This section explains language and region signals.
- It contains missing core intent, meaning the content moves away from the specific query focus.
Example Using X-Robots-Tag and Cache-Control Rules
The example code block partially aligns with header usage but diverges into broader configuration concepts.
- The mix of “aligned to other query” and “topical partial match” indicates partial relevance but unclear intent focus.
Across these sections, the deviations primarily reflect topic drift toward tangential aspects of header usage, rather than being unrelated to the subject matter.
Query-Specific Alignment Insights
Each query shows a distinct alignment profile, reflecting how well the page supports its thematic expectations.
Query: “How to handle different document URLs”
- Average similarity: 0.6115, indicating moderate alignment.
- Range: 0.5294 to 0.7825, showing some strong sections mixed with weaker ones.
- The majority of deviations are minor, with only 4 moderate deviations.
- Most deviations stem from alignment to the other query (23 instances), signaling shared topical space with the second query.
- Missing core intent signals (2) indicate areas where content does not directly address handling document URLs.
Overall, the query receives balanced but not deeply focused coverage, with mild divergence toward general header usage.
Query: “Using HTTP headers for PDFs and images”
- Average similarity: 0.7235, indicating strong alignment.
- High maximum similarity: 0.8538, showing substantial depth and direct relevance.
- Most sections fall under on-target or minor deviation, confirming consistent coverage.
- The presence of peripheral context alignment suggests that some content supports understanding but is not fully directive.
- Limited “aligned to other query” signals show clearer thematic separation for this query.
This query receives significantly stronger content support and forms the dominant thematic match for the document.
Interpretation of the Page’s Semantic Positioning
The aggregated insights indicate that:
- The page covers HTTP headers extensively and consistently.
- It aligns especially well with topics related to managing headers for media formats such as PDFs and images.
- It offers moderate but not fully focused coverage for intent related to handling different document URL types.
- Alignment issues arise mainly from topic overlap, peripheral tangents, and broader educational explanations rather than actual irrelevance.
Result Analysis and Explanation
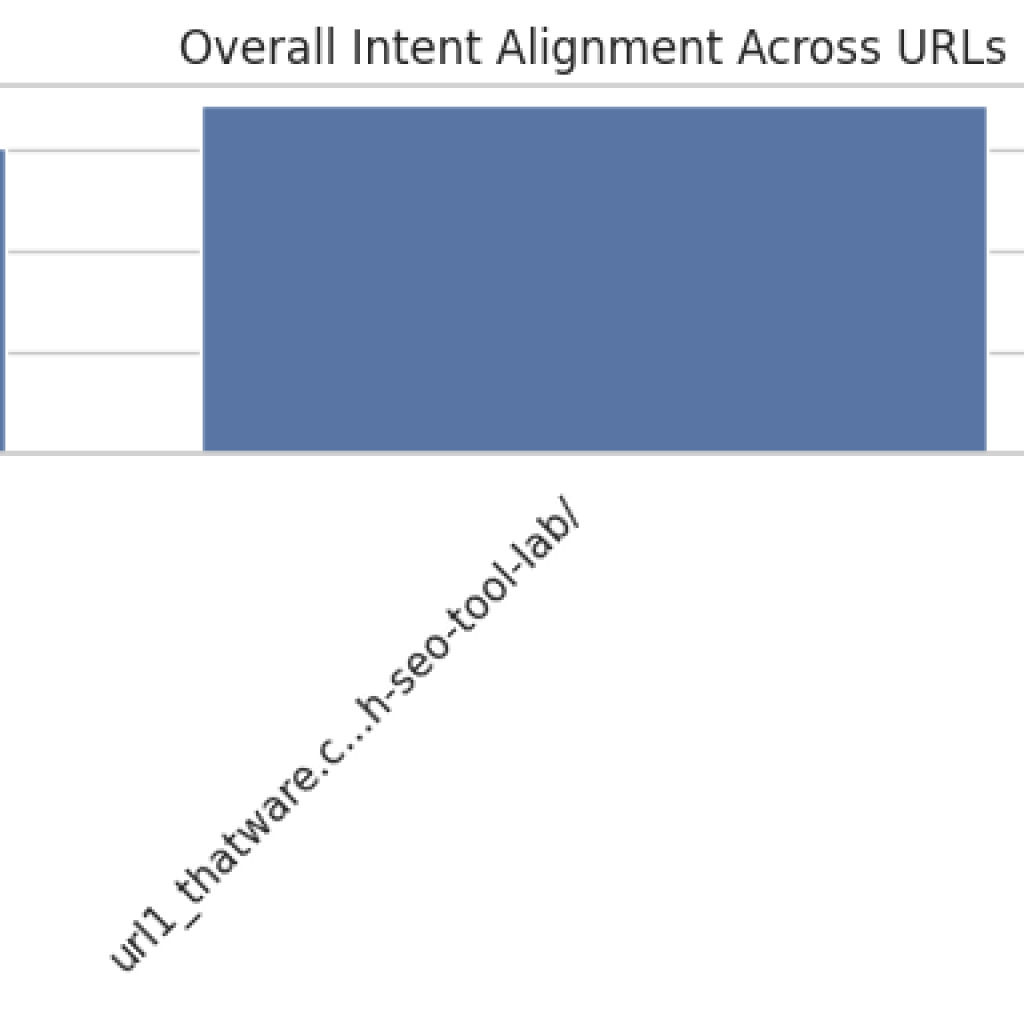
Overall Page Alignment and Coverage
The overall alignment score measures how closely the content of a page matches the intended queries across all sections. Scores are normalized between 0 and 1, where values closer to 1 indicate stronger alignment. A score above 0.75 generally reflects high alignment, 0.55–0.75 indicates moderate alignment, and below 0.55 suggests potential gaps in relevance.
The section coverage ratio indicates the fraction of sections that contain at least one alignment score. A value of 1.0 confirms that every section has been evaluated against the target queries, ensuring comprehensive coverage of the content.
From the results, it is evident that most pages have a high coverage ratio, ensuring no section is overlooked. However, the overall alignment scores vary between moderate and high levels. Pages with moderate scores may benefit from content realignment or enhancement to strengthen semantic relevance with key queries.
Actionable Insights:
- Sections with lower average alignment scores should be prioritized for content refinement.
- Updating headings, section introductions, and supporting content to emphasize core topics can improve alignment.
- Ensure that new content added to the page maintains coherence with the primary queries.
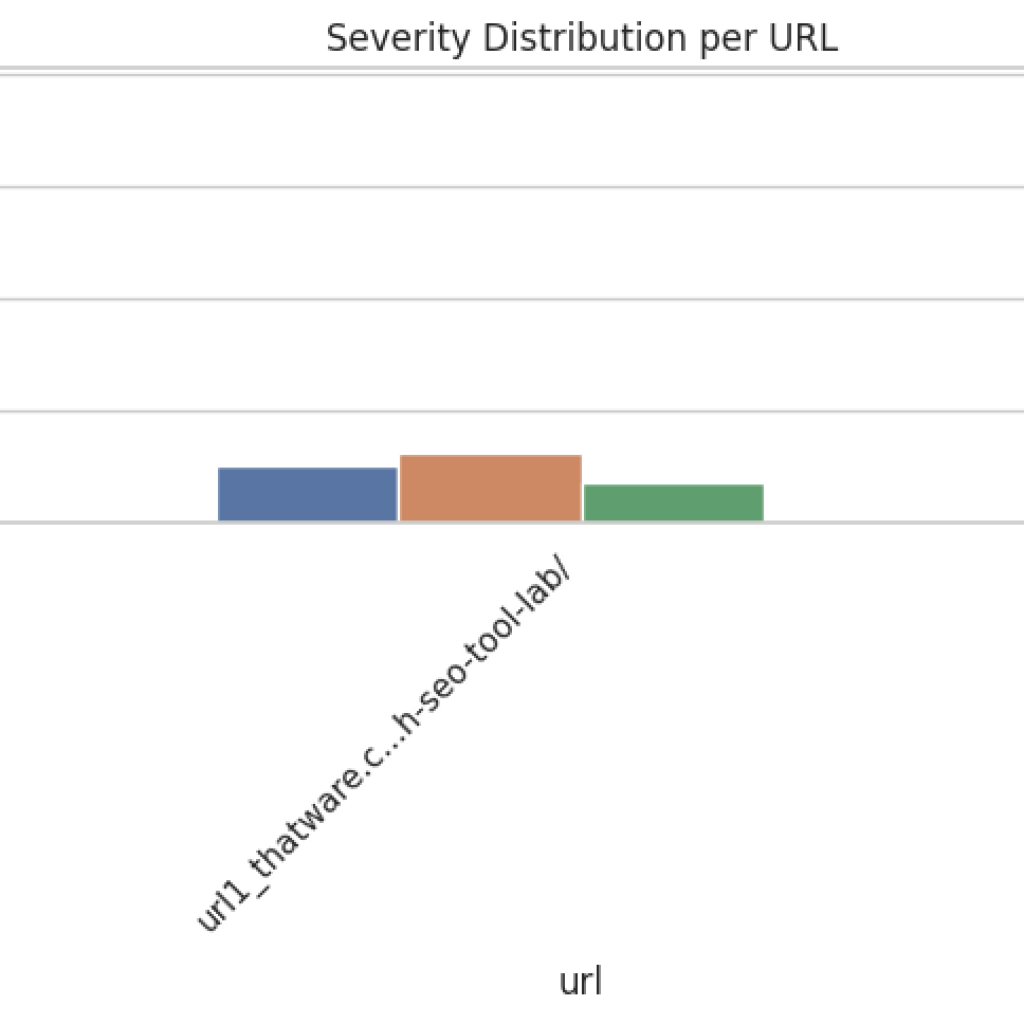
Severity Distribution
Severity labels categorize alignment into qualitative tiers:
- On Target: Sections fully aligned with the query intent. High priority content that should be maintained and highlighted.
- Minor Deviation: Slight misalignment or partial coverage; content may be relevant but not fully optimized.
- Moderate Deviation: Sections cover the topic partially or tangentially. Requires review and potential enhancement.
- Strong Deviation: Content is largely off-topic and requires significant revision or removal.
Interpreting the distribution of severity across sections highlights where content performs well versus where interventions are needed. Pages with a higher proportion of “on target” content demonstrate clear alignment with queries, while a prevalence of “minor” or “moderate” deviations signals the need for editorial adjustments.
Actionable Insights:
- Focus content optimization efforts on sections labeled as “moderate” or “minor deviation.”
- Cross-reference these sections with deviation reasons to understand specific misalignment types.
- Rewriting or supplementing content to emphasize core topics can shift sections toward “on target.”
Deviation Reasons
Deviation reasons provide context for why a section does not fully align with a query:
- Aligned to Other Query: The section semantically matches a different query better than the one being evaluated.
- Topical Partial Match: The section covers part of the intended topic but lacks depth or completeness.
- Peripheral Context Alignment: The section provides background or related context rather than core information.
- Missing Core Intent: The section does not address the main query intent at all.
Analysis of deviation reasons allows prioritization of corrective measures. Sections aligned to other queries may need reorganization or clearer headings, while topical partial matches can be expanded with additional details. Peripheral context alignment is less critical but can be leveraged for supplementary content.
Actionable Insights:
- For sections misaligned due to “aligned to other query,” consider repositioning or retitling to better match the intended query.
- Enhance sections with “topical partial match” by adding core points and examples to cover the full query intent.
- Sections flagged for “missing core intent” may require rewriting or reassignment to a more relevant query.
Section-Level Insights
Sections with the lowest alignment scores represent key opportunities for improvement. These “top deviating” sections typically have a combination of lower average and minimum similarity scores. Identifying these sections helps to:
- Focus optimization efforts on areas with the highest potential impact.
- Understand patterns of misalignment, such as missing context, irrelevant content, or insufficient detail.
Actionable Insights:
- Conduct a detailed review of low-scoring sections, examining headings, subtopics, and examples.
- Consider splitting overly broad sections into focused sub-sections aligned with specific queries.
- Introduce structured content elements such as bullet points, tables, or diagrams to improve clarity and semantic relevance.
Query-Level Alignment Analysis
Query-level summaries provide insights into how well each target query is addressed across all sections of a page. Key metrics include average similarity, minimum similarity, and maximum similarity.
Interpretation of Similarity Scores:
- Average Similarity: Indicates the general coverage of a query across all sections. Higher values signal consistent relevance.
- Minimum Similarity: Highlights sections where the query is poorly addressed.
- Maximum Similarity: Shows the best-performing sections for a query.
Assessing severity distributions at the query level allows identification of specific queries that are underrepresented or partially addressed. Queries with higher proportions of minor or moderate deviations indicate opportunities for targeted content enrichment.
Actionable Insights:
- Prioritize queries with lower average similarity scores for content updates.
- Review sections contributing to low minimum similarity to understand gaps.
- For high-performing queries, maintain content quality and consider using these sections as templates for similar topics.
Visualization Analysis
Overall Alignment per Page
Bar plots of overall alignment scores visualize the semantic relevance of each page relative to all queries. Higher bars indicate stronger alignment. Pages with lower bars should be targeted for content enhancement to improve query coverage.
Interpretation: A page with consistently high scores suggests strong alignment, while variations indicate sections needing review.
Actions: Focus optimization on pages with lower alignment scores to ensure balanced coverage of all target queries.
Severity Distribution per Page
Stacked bar plots show the distribution of severity labels across sections. The height of each segment represents the count of sections in each severity category.
Interpretation: A larger “on target” segment reflects effective query alignment. Higher proportions of “minor” or “moderate deviation” indicate opportunities for refinement.
Actions: Target sections in minor and moderate categories for focused improvements. Consider reworking headings, adding details, and realigning content to queries.
Top Deviating Sections
Plots of top deviating sections display sections with the lowest minimum similarity scores, highlighting misaligned content.
Interpretation: Sections that frequently appear in this plot are critical for content revision. Identifying their common characteristics can guide content strategy.
Actions: Update, restructure, or expand these sections to improve alignment with the intended queries.
Query-Level Similarity
Visualizations of average query similarity across pages provide a comparative view of how well each query is addressed.
Interpretation: Queries with lower average similarity across multiple pages indicate systemic gaps in content coverage.
Actions: Develop additional content or enhance existing sections to strengthen coverage for underperforming queries.
Query-Level Severity Distribution
Grouped bar plots for query-level severity illustrate which queries have sections with deviations and their extent.
Interpretation: Queries with higher counts of minor or moderate deviations may require deeper content optimization.
Actions: Focus on improving sections with lower severity to move them toward “on target,” ensuring comprehensive query alignment.
Q&A: Result Insights and Actionable Guidance
What does the overall alignment score indicate about the quality of content across the pages?
The overall alignment score represents the average semantic relevance of all sections on a page with respect to the target queries. Higher scores indicate that content sections consistently address the intended topics, while lower scores suggest gaps or misaligned content. Scores above 0.75 typically indicate strong alignment, 0.55–0.75 indicates moderate alignment, and below 0.55 suggests content misalignment.
Actionable Guidance:
- Pages with moderate or low alignment scores should be reviewed to ensure every section explicitly addresses the key queries.
- Sections contributing most to the low score can be rewritten or expanded with additional examples, explanations, or structured subtopics to strengthen semantic relevance.
How should the severity distribution be interpreted, and what actions should be taken based on it?
Severity distribution categorizes each section into four tiers: on target, minor deviation, moderate deviation, and strong deviation.
- On Target: Sections are fully aligned with query intent. These sections should be preserved and leveraged as reference models for content creation.
- Minor Deviation: Sections are slightly misaligned or partially cover the topic. These require minor updates, such as clarification of headings or adding relevant points.
- Moderate Deviation: Sections cover only part of the query or are tangential. These need focused content enhancement to fully address query intent.
- Strong Deviation: Sections are largely irrelevant. These may need rewriting, reorganization, or removal.
Actionable Guidance:
- Prioritize “moderate deviation” sections for immediate content enhancement.
- Review “minor deviation” sections to optimize clarity and completeness.
- Use “on target” sections as templates for improving other content areas.
What insights can be drawn from the deviation reasons, and how should they influence content strategy?
Deviation reasons explain why a section does not fully align with its intended query:
- Aligned to Other Query: Section content better fits a different query. Consider reorganizing content or updating headings to better match the intended query.
- Topical Partial Match: Section partially addresses the query. Adding depth, examples, or structured content improves completeness.
- Peripheral Context Alignment: Section provides background or related information. While not critical, these can enhance comprehension when supplemented with core content.
- Missing Core Intent: Section does not address the main query. Requires rewriting or reassignment to a more relevant topic.
Actionable Guidance:
- Map sections to appropriate queries to improve alignment.
- Expand partial matches with relevant points to reduce gaps in coverage.
- Reorganize or remove irrelevant content to increase clarity and focus.
How should top deviating sections be handled?
Top deviating sections are those with the lowest minimum similarity scores, indicating weak alignment with the intended queries. These sections are critical because they disproportionately impact the overall alignment score.
Actionable Guidance:
- Conduct a detailed review to identify missing topics, unclear headings, or irrelevant content.
- Use structured content updates, such as bullet points, tables, or examples, to improve clarity and semantic coverage.
- Where a section is misaligned to other queries, consider moving content to the appropriate context or splitting it into focused sub-sections.
What insights can be drawn from query-level alignment and similarity scores?
Query-level summaries provide a clear view of how well each target query is represented across all sections. Metrics such as average, minimum, and maximum similarity help identify consistent coverage and potential gaps.
Actionable Guidance:
- Queries with lower average similarity scores indicate areas needing new content or revisions.
- Low minimum similarity values point to specific sections that are misaligned and require targeted improvement.
- High maximum similarity scores identify sections that can serve as models for enhancing other sections addressing the same query.
How can the visualizations support decision-making and content optimization?
Visualizations such as overall alignment plots, severity distribution charts, top deviating section graphs, and query-level similarity plots provide actionable insights:
- Overall Alignment per Page: Highlights pages with weak semantic coverage requiring priority action.
- Severity Distribution per Page: Identifies sections with minor or moderate deviations for targeted optimization.
- Top Deviating Sections: Pinpoints specific sections to prioritize for content enhancement or restructuring.
- Query-Level Similarity and Severity: Offers a comparative view of how well each query is addressed across all content.
Actionable Guidance:
- Use plots to identify trends, such as queries consistently underrepresented across pages.
- Apply insights from visualizations to prioritize sections for rewriting, adding depth, or reorganizing content.
- Monitor improvements over time by updating visualizations after each content revision cycle.
How should the results guide ongoing content management?
The analysis provides a framework to ensure content aligns with strategic queries and maintains semantic relevance:
- Regularly assess new and existing pages against key queries using the alignment metrics.
- Use severity and deviation insights to identify sections that require maintenance, enhancement, or removal.
- Leverage well-aligned sections as models for content development, ensuring consistency in quality and coverage.
Actionable Guidance:
- Implement a continuous content review process based on alignment scores, severity, and deviation reasons.
- Maintain structured documentation of updates and monitor improvements in overall alignment scores.
- Incorporate query-level insights to guide content planning, ensuring comprehensive coverage of priority topics.
Final Thoughts
The Semantic Intent Deviation Analyzer provides a structured and interpretable framework to evaluate how effectively page content aligns with defined user queries. Through the combination of semantic embeddings and deterministic deviation reasoning, the analysis identifies sections where the content either fully satisfies the target intent or deviates in severity, allowing a clear understanding of alignment gaps at both the section and query levels.
The results offer actionable insights into content alignment. Overall alignment scores quantify the semantic fit between content and queries, while severity labels categorize deviations into on-target, minor, moderate, or strong gaps. Deviation reasons provide further granularity, highlighting whether a section is aligned to another query, partially relevant, or missing core intent. Together, these metrics allow prioritization of sections that require content refinement, structural adjustments, or enhanced focus to better satisfy user intent.
At the query level, the analyzer evaluates the consistency and completeness of coverage across all sections, helping identify queries that are underrepresented or partially addressed. Aggregated page-level summaries provide a holistic view of semantic alignment, enabling assessment of overall content quality, topical relevance, and focus integrity.
This analysis framework facilitates practical decision-making by pinpointing precise areas where alignment gaps exist, supporting content optimization efforts, improving semantic coherence, and enhancing the likelihood of meeting user expectations. The methodology ensures that deviations are interpretable and actionable, making it a reliable tool for maintaining content alignment with target query intents.
