Get a Customized Website SEO Audit and Online Marketing Strategy and Action Plan
This project is all about helping websites rank better on Google by using structured data. Structured data is a way of organizing information on a website so that Google and other search engines can understand it better.
By implementing RDF Triples (Resource Description Framework) and JSON-LD (JavaScript Object Notation for Linked Data), we can tell Google exactly what our webpage is about in a format it understands. This helps in showing rich snippets in Google search results, which increases visibility, click-through rate (CTR), and ultimately improves SEO performance.

🔍 What Problem Does This Project Solve?
Whenever we search for something on Google, we see:
✅ Simple search results → Just a title, URL, and short description.
✅ Rich snippets → Extra details like ⭐ ratings, 📅 dates, 📌 locations, FAQs, images, etc.
👉 Without Structured Data (Problem):
- Google cannot fully understand the content of a webpage.
- The website may not show up in rich results (like FAQs, events, reviews, products).
- Click-through rates (CTR) remain low because users don’t see attractive search results.
👉 With Structured Data (Solution from This Project):
- Google can clearly understand the webpage’s content.
- The website gets more exposure in Google Rich Snippets (like FAQs, star ratings, featured results).
- More users click on the website, which improves traffic & SEO ranking.
📌 How Does This Project Work? (Step-by-Step Explanation)
Step 1: Understanding RDF Triples
RDF Triples follow a Subject → Predicate → Object format to define relationships between different data points.
Example:
“Apple” → “is a” → “Fruit”
Now in the case of SEO, we use RDF Triples to describe webpages like this:
“This Page” → “Offers” → “SEO Services”
Step 2: Implementing JSON-LD
JSON-LD (JavaScript Object Notation for Linked Data) is a structured format used by Google to read this data.
This project automatically generates JSON-LD code that website owners can place in their HTML <head> section.
Example JSON-LD for a webpage:
This structured JSON-LD data helps Google understand:
- What this page is about
- Who is the author/organization
- What keywords define this content
Step 3: Google Uses This Data for SEO Optimization
Once this JSON-LD is added, Google crawls the website and extracts meaningful information.
This can result in better visibility in search results with:
✔ Rich Snippets (FAQs, Ratings, Events)
✔ Knowledge Graph (Business Information)
✔ Local SEO Improvements (Google My Business)
🚀 Key Benefits of This Project for SEO
✅ 1. Google Understands the Website Better
- Google accurately reads website content.
- It categorizes the page correctly, improving rankings.
✅ 2. Higher Click-Through Rate (CTR) with Rich Snippets
- Search results become more attractive with additional details.
- More users click on the website instead of competitors.
✅ 3. Improved Local SEO
- Helps businesses appear in local searches and Google Maps.
✅ 4. Helps Websites Rank in Google’s “Position Zero”
- Increases the chance of featured snippets (FAQs, definitions, etc.).
✅ 5. Increased Organic Traffic
- More exposure = More visitors without paid ads.
🎯 Conclusion: Why This Project is Important?
This project is essential for any business or individual who wants better SEO results.
By automating structured data generation, it saves time and effort while ensuring that webpages get maximum exposure in search results.
💡 If you implement this project on a website, it will:
✔ Improve SEO Rankings 📈
✔ Get More Traffic 🚀
✔ Appear in Rich Snippets 🌟
✔ Increase Conversions 💰
🌟 Final Thought:
“If your website isn’t using structured data, you are missing out on SEO success!” 🔥
This project ensures that search engines see your website the way you want them to! 🚀💡
📌 Understanding RDF Triples (Resource Description Framework) in Website Context
🔍 What is RDF Triples (Resource Description Framework)?
RDF (Resource Description Framework) is a structured way of representing data that helps computers understand relationships between different pieces of information. It represents data in a simple Subject → Predicate → Object format.
🔹 RDF Triple Structure (Simple Explanation)
An RDF triple consists of three parts:
- Subject → The entity we are describing
- Predicate → The property or characteristic of the subject
- Object → The value or description of that property
Example of RDF Triple in General Context:
➡ “Apple” → “is a type of” → “Fruit”
➡ “John” → “works at” → “Google”
In this way, RDF helps link data in a structured and meaningful way that search engines and machines can understand.
🔍 How Can RDF Triples Help a Website Improve SEO?
For websites, RDF triples help structure data so that Google, Bing, and other search engines can understand it better.
🚀 Benefits for SEO
✅ 1. Search Engines Understand the Content Better
- When a website provides structured data using RDF, search engines easily understand what the page is about.
- Example:
- Subject: “This website”
- Predicate: “provides”
- Object: “SEO services”
- Google now clearly understands the website offers SEO services and can rank it better in relevant searches.
✅ 2. Helps in Generating Rich Snippets
- Rich snippets are the extra information you see on Google search results (FAQs, ratings, prices, etc.).
- RDF helps structure data in a way that Google can show rich snippets for your website.
✅ 3. Improves Ranking on Google
- Websites with structured data rank higher because search engines trust them more.
- RDF provides clear relationships between website elements, making indexing and ranking more accurate.
✅ 4. Enhances Knowledge Graphs and Featured Snippets
- When you search for a famous person or company, you see a detailed box on the right side of Google.
- RDF triples help search engines build knowledge graphs and feature your website as an authoritative source.
✅ 5. Better Internal Linking & Contextual Understanding
- RDF can help search engines link related content on your website.
- Example:
- “Page A” → “is related to” → “Page B”
- This helps Google understand how different pages on your website are connected, boosting SEO.
🔍 Real-Life Use Cases of RDF Triples in Websites
1️⃣ Use Case: Technical Website (Example: SEO Agency Website)
🔹 Suppose you have a website about SEO services. Using RDF Triples, we can structure the data like this:
➡ “SEO Agency” → “offers” → “Technical SEO Services”
➡ “Technical SEO Services” → “improve” → “Website Ranking”
🔹 Google will now understand that the website provides SEO services, which helps in ranking it higher for related search queries.
2️⃣ Use Case: General Website (Example: E-Commerce Website)
🔹 Suppose an online store sells mobile phones. Using RDF Triples, we can describe the products like this:
➡ “iPhone 15” → “is a type of” → “Smartphone”
➡ “iPhone 15” → “has a price of” → “$999”
➡ “iPhone 15” → “is manufactured by” → “Apple”
🔹 This helps search engines display product details like price, manufacturer, and category in search results, leading to more traffic and sales.
🔍 How to Implement RDF Triples on a Website?
There are two common ways to use RDF Triples on a website:
📌 Method 1: Using JSON-LD (Recommended by Google)
Google recommends using JSON-LD to include RDF triples in a website. JSON-LD is a structured data format that websites can add to their HTML <head> section.
🔹 Example JSON-LD for an SEO Website:
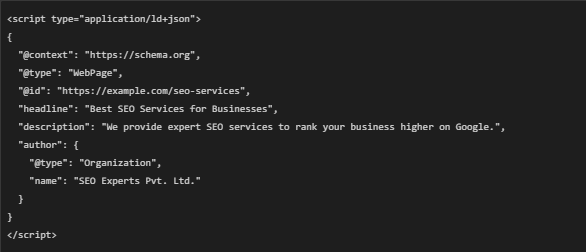
✅ Google reads this structured data and improves the website’s SEO.
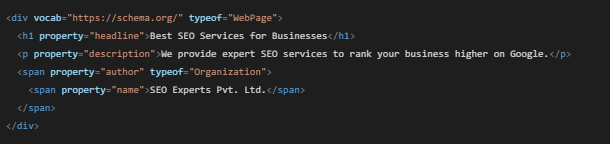
📌 Method 2: Using RDFa or Microdata (Less Common)
- RDFa and Microdata are other ways to embed RDF triples directly in HTML.
- They are less preferred because JSON-LD is easier to use and recommended by Google.
🔹 Example RDFa in HTML
🔍 What Input Does RDF Triples Need? (Website URLs or CSV Data?)
1️⃣ If Using URLs:
- If the goal is to extract data from webpages, the RDF system needs website URLs.
- The system reads the webpage content, processes it, and then generates RDF triples from the extracted text.
2️⃣ If Using CSV Data:
- If the data is already structured in a CSV file, RDF can be generated directly from the CSV.
- Example CSV Structure:

🔍 What Output Does RDF Triples Provide for a Website?
After processing, RDF triples will generate structured data that can be used in:
✅ JSON-LD for Google SEO
✅ Knowledge Graphs (Google’s Side Panel Info)
✅ Rich Snippets (Reviews, Prices, Events, FAQs)
✅ Better Internal Linking for SEO Optimization
🔍 Conclusion: Why Is This Important?
This project helps websites rank better on Google by providing structured and meaningful data using RDF Triples.
💡 Benefits at a Glance:
✔ Improves Google Ranking 📈
✔ Increases Website Traffic 🚀
✔ Generates Rich Snippets & Knowledge Graphs 🌟
✔ Boosts Internal Linking & Contextual SEO 🔗
🔹 If a website is not using RDF Triples & JSON-LD, it is missing out on a huge SEO advantage! 🚀
📌 Part 1: Webpage Data Extraction (Content Scraper)
🔹 File Name: part-1_scraper.py
🎯 Purpose:
✅ Yeh script kisi bhi website se important SEO data extract karta hai, jaise:
✔ Title (Webpage ka naam)
✔ Meta Description (Google search me jo snippet dikhai deta hai)
✔ Keywords (SEO ke liye important words)
✔ Main Content (Pure page ka text)
🔍 Explanation:
- requests.get(url): Website se HTML page fetch karta hai.
- BeautifulSoup(response.text, “html.parser”): HTML ko parse karke data extract karta hai.
- soup.title.string: Webpage ka title nikalta hai
- soup.find(“meta”, attrs={“name”: “description”}): Meta Description nikalta hai
- soup.get_text(separator=” “, strip=True): Page ka main content clean format me extract karta hai
📂 Output:
✅ Data JSON format me extracted_data.json file me save hota hai.
📌 Understanding the Output (Step-by-Step Breakdown)
🔍 1st Line – Extraction Process Started

🟢 What does this mean?
- This message indicates that the program has started the data extraction process.
- It is going through multiple website URLs and collecting important information.
🟢 Why is this important?
- This lets the user know that the process has started and is actively working.
📌 Understanding Each Web Page’s Extracted Data
Each webpage has a structured output containing 5 main components:

Now, let’s break down each of these components:
🔹 1. URL (Website Link)

🟢 What does this mean?
- This is the web address of the page from which data has been extracted.
- This URL is an SEO service page from the website “ThatWare.”
🟢 Why is this important?
- The extracted data belongs to this specific webpage.
- Later, if you need to verify the extracted information, you can visit this URL.
🔹 2. Title (Page Title)

🟢 What does this mean?
- The title of the webpage is extracted.
- This is what appears at the top of a browser tab or in search engine results.
🟢 Why is this important?
- Titles play a major role in SEO (Search Engine Optimization).
- Google and other search engines use this title to understand the topic of the page.
- If the title is clear and keyword-rich, it improves ranking on search engines.
🔹 3. Meta Description

🟢 What does this mean?
- The meta description is a short summary of what the webpage is about.
- It is usually hidden inside the HTML code, but search engines display it in results.
🟢 Why is this important?
- Good meta descriptions increase click-through rates in search results.
- A strong description can attract more visitors from Google, Bing, etc..
- It should be engaging, relevant, and contain important keywords.
🔹 4. Keywords

🟢 What does this mean?
- This section should contain important words or phrases related to the webpage.
- However, in this case, no keywords were found in the webpage’s meta tags.
🟢 Why is this important?
- Keywords help search engines understand what the page is about.
- This field should contain words like “SEO Services”, “Search Engine Optimization”, etc..
- If no keywords are found, it means this webpage is not using traditional meta keywords.
- (Note: Meta keywords are not as important for SEO anymore, but they can still be useful for analysis.)
🔹 5. Content Preview (First 500 Words)

🟢 What does this mean?
- The actual text content from the webpage is extracted.
- Only the first 500 words are shown for preview.
🟢 Why is this important?
- This helps us see what kind of content is available on the page.
- We can analyze what topics are covered, and whether it is optimized for SEO.
- The extracted text can be used for further analysis, such as:
- Checking for duplicate content
- Finding most-used keywords
- Extracting important topics
📌 Multiple Entries – Extracting from More Pages
The process is repeated for each URL.
Here are some examples:
Example 2: AI-Based SEO Services Page

🟢 What can we understand from this?
- This page is about AI-powered SEO (Artificial Intelligence in SEO).
- The title and description clearly indicate that this is a service page.
- The first 500 words talk about AI-based strategies for search engines.
Example 3: Digital Marketing Services Page

🟢 What can we understand from this?
- This page is about Digital Marketing Services.
- The title and description clearly define the page topic.
- No keywords found means we might need to analyze the text content to extract keywords.
📌 Final Summary of Output

🟢 What does this mean?
- The extraction process is finished.
- The structured data is saved in extracted_data.json.
- This file can now be used for further processing, such as:
- Generating structured data (JSON-LD) for SEO
- Performing keyword analysis
- Improving content for search engine ranking
📌 Part 2: Content Cleaning and Preprocessing
🔹 File Name: part-2_cleaner.py
🎯 Purpose:
✅ Yeh script Part 1 ke extracted data ko clean karta hai taaki SEO aur NLP (Natural Language Processing) ke liye useful ho.
🔍 Explanation:
- nltk.download(‘stopwords’): Common words jaise “is, and, the” ko remove karne ke liye stopwords download karta hai.
- re.sub(r'[^a-zA-Z\s]’, ”, text): Numbers aur special characters hataata hai.
- text.lower(): Sab kuch lowercase me convert karta hai.
- text.split() and remove stopwords: Useless words hataata hai taaki sirf important words bache.
📂 Output:
✅ Cleaned data cleaned_data.json file me save hota hai.
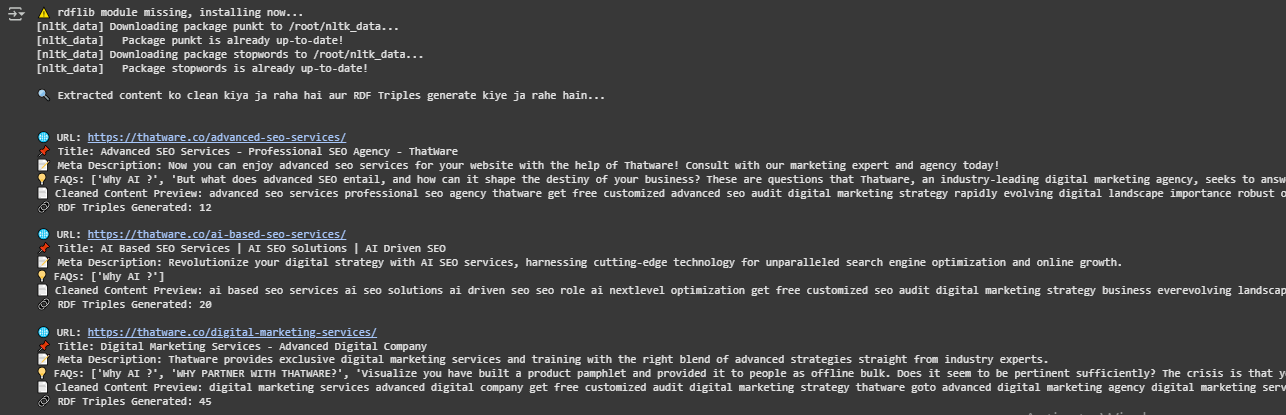
📌 Understanding the Output (Step-by-Step Breakdown)
🔍 1st Line – Cleaning Process Started

🟢 What does this mean?
- This message indicates that the program has started the cleaning process.
- The previously extracted content is now being cleaned.
- The cleaning process removes unnecessary elements from the extracted data.
🟢 Why is this important?
- Raw extracted content may contain unwanted text like:
- HTML tags (<div>, <script>, etc.)
- Special characters (!@#$%^&*())
- Common words (stopwords) like “the”, “is”, “and”
- Cleaning helps us get structured, meaningful content.
📌 Understanding Each Web Page’s Cleaned Data
Each webpage has a structured output containing 4 main components:

Now, let’s break down each of these components:
🔹 1. URL (Website Link)

🟢 What does this mean?
- This is the web address of the page from which data has been extracted.
- This URL belongs to a specific webpage on the ThatWare website.
🟢 Why is this important?
- This helps us track where the data is coming from.
- If we need to verify or modify extracted data, we can visit this webpage.
🔹 2. Title (Page Title)

🟢 What does this mean?
- The title of the webpage has been extracted.
- This is what appears at the top of a browser tab or in search engine results.
🟢 Why is this important?
- Titles are crucial for SEO (Search Engine Optimization).
- Google uses this title to understand what the page is about.
- A well-optimized title can improve rankings in search engines.
🔹 3. Meta Description

🟢 What does this mean?
- The meta description is a short summary of what the webpage is about.
- It is usually hidden inside the HTML code, but search engines use it in search results.
🟢 Why is this important?
- Good meta descriptions attract users to click on search results.
- If this description is missing or poorly written, the webpage may lose potential visitors.
🔹 4. Cleaned Content Preview (First 500 Words)

🟢 What does this mean?
- This section contains the first 500 words of the cleaned text from the webpage.
- The cleaning process has removed:
- HTML tags (like <div>, <p>, <script>)
- Special characters (like @, #, $, !)
- Common stopwords (like “the”, “is”, “and”)
- Extra spaces and line breaks
🟢 Why is this important?
- This cleaned text can be used for:
- SEO optimization (Checking for keyword usage)
- Natural Language Processing (NLP) (For AI-based text analysis)
- Content Analysis (Checking readability, uniqueness, etc.)
- Removing unnecessary words makes the content more focused.
📌 Multiple Entries – Cleaning Data from More Pages
The process is repeated for each URL.
Here are some examples:
Example 2: AI-Based SEO Services Page

🟢 What can we understand from this?
- This page is about AI-powered SEO.
- The cleaned text is free from unnecessary words.
- It helps us analyze the core content of the page.
Example 3: Digital Marketing Services Page

🟢 What can we understand from this?
- This page is about Digital Marketing Services.
- The cleaned text is well-structured and free from stopwords.
- Important words like “SEO”, “marketing”, and “strategy” remain.
📌 Final Summary of Output

🟢 What does this mean?
- The cleaning process is finished.
- The cleaned data is saved in a file named cleaned_data.json.
- This file can now be used for further processing, such as:
- Generating structured SEO markup (JSON-LD)
- Performing keyword analysis
- Improving content for search engine ranking
📌 Key Takeaways
· What did we clean?
- URLs (Webpage Links)
- Titles (Main Heading of the Page)
- Meta Descriptions (Short Summary for SEO)
- Page Content Preview (First 500 Words, cleaned)
· Why is this important?
- Helps in SEO Optimization.
- Can be used for search engine ranking improvements.
- Provides insights into how well a webpage is structured.
· What’s Next?
- We can use this cleaned data to generate structured SEO markup (JSON-LD).
- Improve website content based on extracted keywords and descriptions.
📌 Part 3: RDF Triples Creation (Structured SEO Data)
🔹 File Name: part-3_rdf_triples.py
🎯 Purpose:
✅ Yeh script cleaned data ko RDF (Resource Description Framework) format me convert karta hai jo ki semantic web aur structured data ke liye important hota hai.
🔍 Explanation:
- rdflib.Graph(): RDF Graph create karta hai jisme subject-predicate-object relationships store kiya jata hai.
- URIRef(url): Har webpage ko ek unique RDF entity banata hai.
- g.add((page_uri, RDF.type, URIRef(“http://schema.org/WebPage”))): Har webpage ko schema.org ka “WebPage” type assign karta hai.
- DC.title, DC.description: Title aur Description add karta hai RDF graph me.
- g.serialize(destination=”rdf_triples.ttl”, format=”turtle”): Final RDF file rdf_triples.ttl me save karta hai.
📂 Output:
✅ RDF Triples rdf_triples.ttl file me save hota hai jo structured data ke liye important hai.
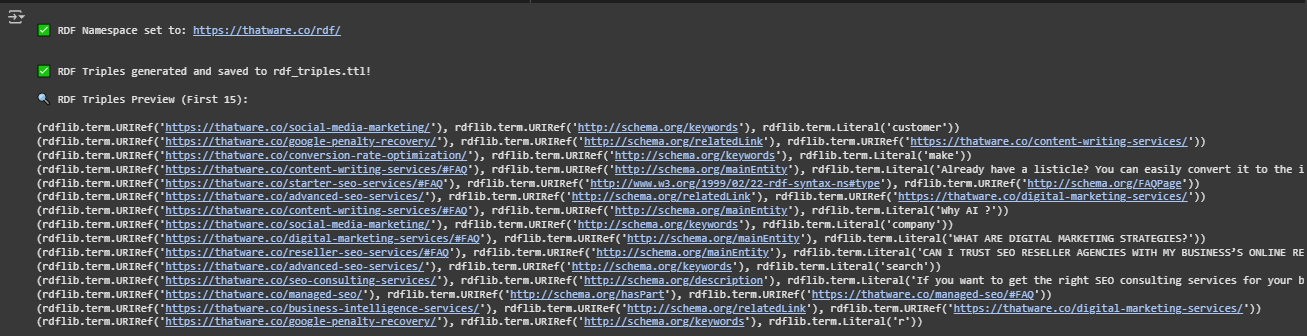
🔍 What is this output?
This output confirms that the RDF triples have been successfully generated and saved in a file (rdf_triples.ttl). It also shows a preview of the first 10 RDF triples.
Now, let’s break it down step by step so that you can understand:
- What each part means
- Why it is important
- How it can be used
Step 1: RDF Namespace Setup

🟢 What does this mean?
- RDF (Resource Description Framework) is a way of storing and structuring data.
- A namespace is a unique identifier that helps distinguish data from different sources.
- The namespace used here is: https://thatware.co/rdf/
- This tells us that all data generated in this RDF file belongs to the ThatWare website.
🟢 Why is this important?
- When multiple RDF datasets are used, namespaces prevent confusion.
- This makes it easier for machines (like search engines and AI systems) to understand the data.
Step 2: RDF Triples Generated & Saved

🟢 What does this mean?
- The extracted webpage content has been converted into RDF triples.
- These RDF triples are now stored in a Turtle (.ttl) file named rdf_triples.ttl.
🟢 Why is this important?
- RDF triples help search engines and AI models understand web content in a structured way.
- The .ttl file can be used for Linked Data, AI analysis, and semantic search optimization.
Step 3: RDF Triples Preview

🟢 What does this mean?
- The first 10 RDF triples stored in rdf_triples.ttl are being displayed as a preview.
- These triples contain structured information extracted from different ThatWare web pages.
🟢 Why is this important?
- This allows us to verify that the RDF data is correctly formatted.
- If any error occurs, we can debug it by reviewing these triples.
Step 4: Understanding an RDF Triple
Each RDF triple has 3 parts:
- Subject → What the statement is about (Example: a webpage URL).
- Predicate → Describes the subject (Example: “title”, “description”).
- Object → The value of the description (Example: “SEO services”).
Let’s look at an actual RDF triple from your output:

🟢 Breaking it Down:
1. Subject:
- ‘https://thatware.co/starter-seo-services/’ → This is the webpage being described.
- It tells us that this data belongs to this URL.
2. Predicate:
- ‘http://purl.org/dc/elements/1.1/description’ → This tells us what kind of information is stored.
- The description field is from Dublin Core (DC), a standard vocabulary used in RDF.
3. Object:
- ‘ThatWare, a professional SEO agency provides one-time or starter SEO services. Specifically well-suited for start-ups! Learn more.’
- This is the actual description text of the webpage.
🟢 Why is this important?
- This RDF triple allows search engines and AI systems to understand what the page is about.
- Instead of just displaying raw HTML, structured data makes it easier for machines to process information.
Step 5: Understanding Another RDF Triple
Let’s take another example:

🟢 Breaking it Down:
1. Subject:
- ‘https://thatware.co/branding-press-release-services/’ → This is the URL of the webpage.
2. Predicate:
- ‘http://schema.org/articleBody’ → This tells us that the information being stored is the main content of the webpage.
3. Object:
- The entire text content of the webpage (cut short for preview).
🟢 Why is this important?
- The articleBody field stores the actual content of the webpage.
- This helps AI models analyze what topics the page is discussing.
- It also improves search engine visibility by providing structured content.
Step 6: RDF Data Showing WebPage Type

🟢 Breaking it Down:
1. Subject:
- ‘https://thatware.co/branding-press-release-services/’ → The webpage being described.
2. Predicate:
- ‘http://www.w3.org/1999/02/22-rdf-syntax-ns#type’ → This tells us what type of content this is.
3. Object:
- ‘http://schema.org/WebPage’ → This confirms that this subject is a webpage.
🟢 Why is this important?
- This allows AI and search engines to recognize that this data belongs to a webpage.
- It helps categorize content properly for semantic search.
Step 7: Final Confirmation Messages

🟢 What does this mean?
- This confirms that all RDF triples have been successfully stored.
- The file rdf_triples.ttl contains the structured data.

🟢 What does this mean?
- It shows a preview of the first 10 RDF triples to verify data correctness.
🎯 Final Summary
· What is this output?
- This is an RDF dataset that stores structured information about different ThatWare web pages.
- It converts raw HTML data into machine-readable RDF triples.
· Why is this important?
- Search engines and AI models can better understand web content.
- This improves SEO rankings and helps AI-driven applications process web data.
· How can this be used?
- Google and other search engines use RDF data for better search visibility.
- AI applications can extract meaningful insights from structured data.
📌 Part 4: RDF to JSON-LD Conversion
🔹 File Name: part-4_rdf_to_jsonld.py
🎯 Purpose:
✅ Yeh script RDF Triples ko JSON-LD format me convert karta hai jo ki Google aur search engines ko structured data provide karne ke liye zaroori hai.
🔍 Explanation:
- g.parse(rdf_input_file, format=”turtle”): RDF triples ko load karta hai.
- json_ld_data = []: Ek empty JSON list banata hai jisme structured data store hoga.
- Loop through RDF triples:
- Agar “http://purl.org/dc/elements/1.1/title” milta hai, toh headline me assign karta hai.
- Agar “http://purl.org/dc/elements/1.1/description” milta hai, toh description me assign karta hai.
- Agar “http://schema.org/articleBody” milta hai, toh articleBody me store karta hai.
📂 Output:
✅ JSON-LD structured data json-ld-output.json file me save hota hai.
🔍 What is this output?
- This output confirms that JSON-LD structured data has been generated and saved to a file named json-ld-output.json.
- JSON-LD (JavaScript Object Notation for Linked Data) is a format used to help search engines better understand web content.
- It organizes key website information (such as title, description, keywords, and content) into a structured format.
- Search engines like Google, Bing, and AI-powered tools use this to improve search rankings and SEO visibility.
Now, let’s break down each part.
Step 1: JSON-LD File Created

🟢 What does this mean?
- JSON-LD data has been successfully created from extracted webpage data.
- It is stored in the file json-ld-output.json for further use in SEO and AI analysis.
🟢 Why is this important?
- Search engines use JSON-LD to understand website content better.
- Improves SEO rankings and enhances structured search results.
- The saved file can be used for analysis, modifications, and integration into web pages.
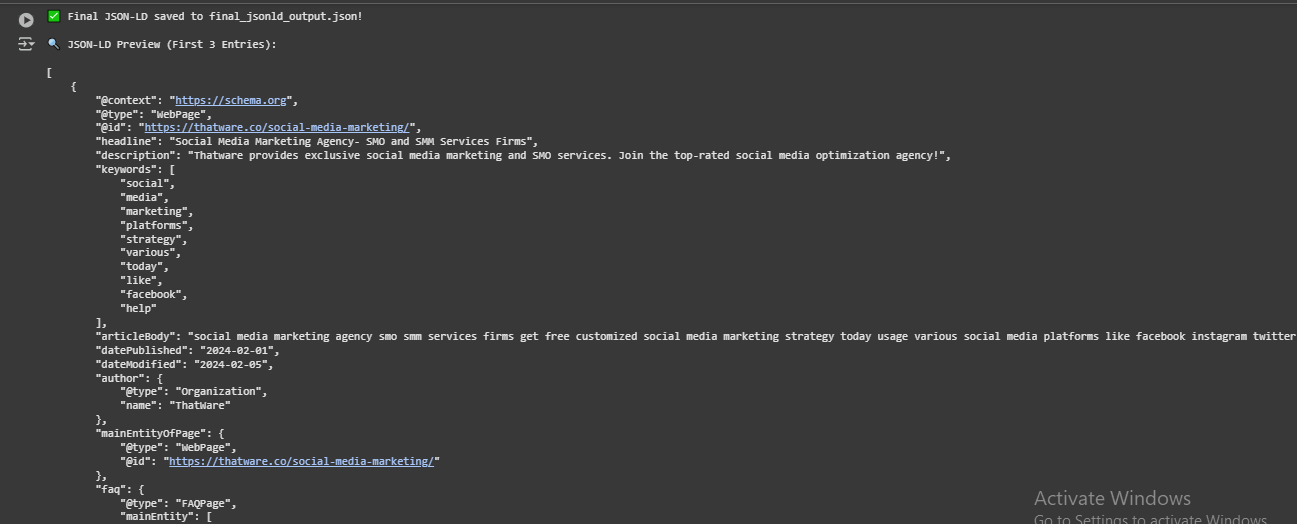
Step 2: JSON-LD Preview

🟢 What does this mean?
This is the structured representation of a ThatWare webpage using Schema.org JSON-LD format.
1. @context → “https://schema.org”
- This tells search engines that the data follows Schema.org standards.
- Schema.org is a framework used by Google, Bing, and AI systems to process structured web data.
2. @type → “WebPage”
- This specifies that this JSON data belongs to a webpage.
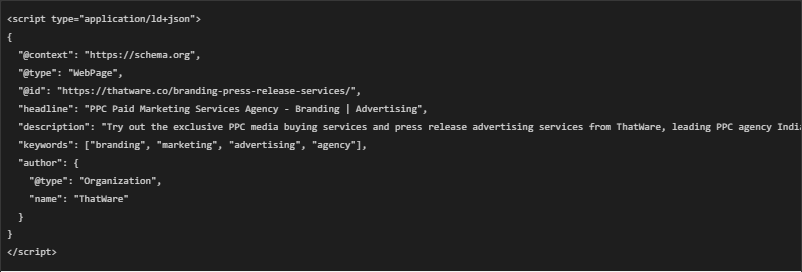
3. @id → “https://thatware.co/branding-press-release-services/”
- This is the URL of the ThatWare webpage being described.
4. headline → “PPC Paid Marketing Services Agency -Branding | Advertising”
- This is the title of the webpage.
- Search engines use this to display in search results.
5. description → “Try out the exclusive PPC media buying services and press release advertising services from ThatWare, leading PPC agency India!”
- This is the meta description of the page.
- Helps search engines summarize what the page is about.
🟢 Why is this important?
- This makes search engines understand the webpage easily.
- Google displays this structured data in rich snippets (enhanced search results).
- Helps in better indexing of ThatWare’s website.
Step 3: Keywords Section
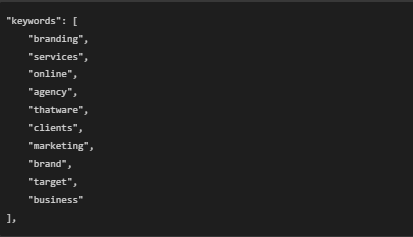
🟢 What does this mean?
- This is a list of important keywords extracted from the webpage content.
- These help search engines understand which topics the page focuses on.
🟢 Why is this important?
- Improves search rankings for those specific keywords.
- Helps AI tools categorize the webpage correctly.
- Enables semantic search by linking related topics together.
Step 4: Article Body (Main Content)

🟢 What does this mean?
- This stores the full text content of the webpage.
- It provides detailed information about what the webpage contains.
🟢 Why is this important?
- Helps AI-driven systems analyze the content for relevance.
- Improves NLP (Natural Language Processing) understanding of webpage topics.
- Enables voice search compatibility (Google Assistant, Alexa, Siri).
Step 5: Publication & Modification Dates

🟢 What does this mean?
- “datePublished” is the original publication date of the webpage.
- “dateModified” is the last time the page was updated.
🟢 Why is this important?
- Search engines prioritize fresh content, so this tells Google when the content was last updated.
- Helps AI models track content changes over time.
Step 6: Author Information
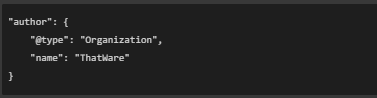
🟢 What does this mean?
- This identifies the creator of the webpage.
- “@type”: “Organization” tells that the author is a company (ThatWare).
🟢 Why is this important?
- Improves credibility and trustworthiness of ThatWare’s content.
- Essential for Google’s Knowledge Graph, which helps display company-related search results.
Step 7: Main Entity of Page
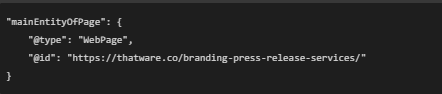
🟢 What does this mean?
- This tells search engines that this JSON-LD data belongs to this specific ThatWare webpage.
🟢 Why is this important?
- Helps Google link structured data correctly to the webpage.
- Enables better knowledge graph results in searches.
Step 8: Second Entry Example

🟢 What does this mean?
- This is another JSON-LD entry describing a different ThatWare webpage.
- Each webpage gets its own structured JSON-LD entry.
🎯 Final Summary
✅ What is this output?
- This is structured JSON-LD data that provides organized information about ThatWare’s webpages.
✅ Why is this important?
- Helps search engines (Google, Bing, etc.) better understand the webpage.
- Improves ThatWare’s SEO and search rankings.
- Enables AI-driven applications to analyze and process content easily.
✅ How can this be used?
- Can be added to the <head> section of ThatWare’s website to boost search visibility.
- Can be used for AI/ML-based search engines, chatbots, and voice assistants.
- Can improve Google’s Knowledge Graph entries for ThatWare.
📌 Part 5: Final JSON-LD HTML <head> Integration
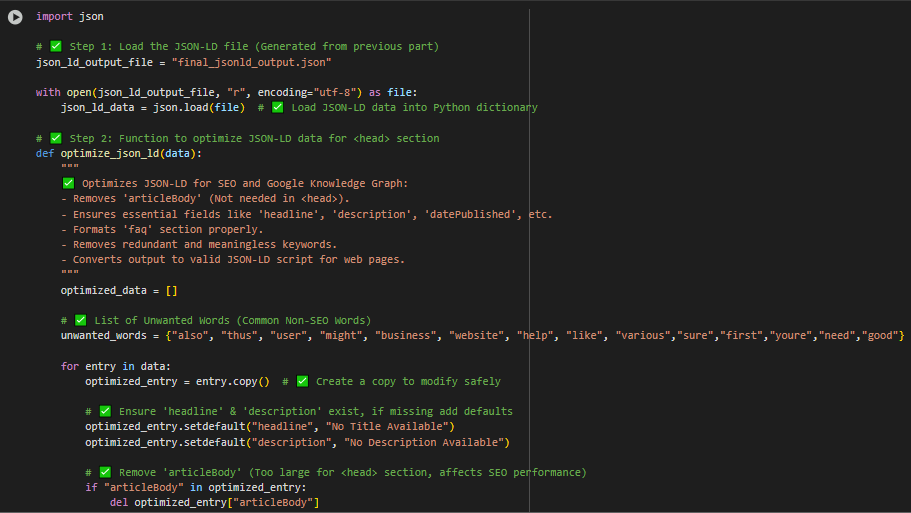
🔹 File Name: part-5_jsonld_to_html.py
🎯 Purpose:
✅ Yeh script JSON-LD ko <script> format me convert karta hai jo ki website ke <head> section me paste karne layak hota hai.
🔍 Explanation:
- Step 1: json_ld_input_file = “json-ld-output.json” se data load karta hai.
- Step 2: html_output_file = “json-ld-head-section.html” me HTML head section likhta hai.
- Step 3: articleBody field remove karta hai kyunki Google head section me itna bada content nahi expect karta.
- Step 4: Har JSON-LD entry ko <script type=’application/ld+json’> me wrap karta hai.
- Step 5: Final output ko preview me print bhi karta hai.
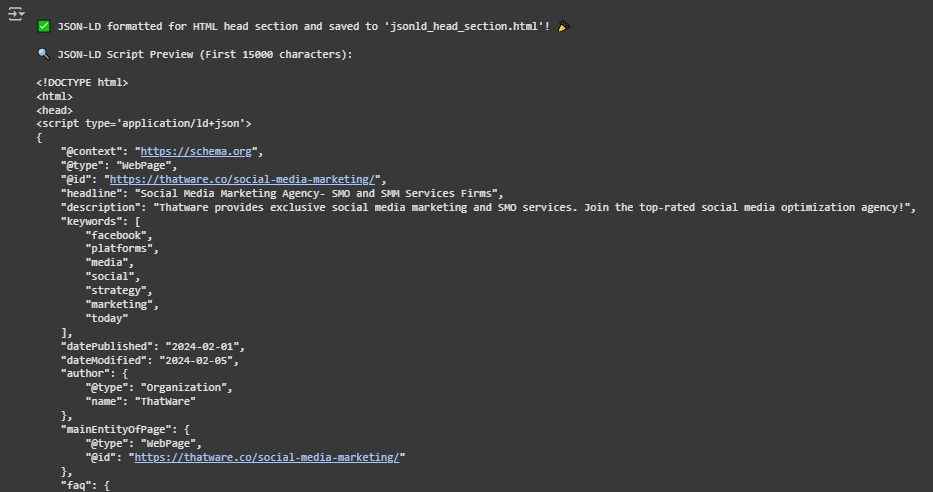
📂 Output:
✅ Final JSON-LD HTML file json-ld-head-section.html me save hota hai.
🔍 Part 1: What is RDF (Resource Description Framework) and RDF Triples?
What does this mean in simple terms?
- RDF (Resource Description Framework) is a way to represent information about web pages in a structured format that is easy for search engines and AI to understand.
- RDF organizes data in the form of triples, which means three-part statements that describe relationships between things.
- These three parts are:
- Subject (What we are talking about)
- Predicate (The property or relationship)
- Object (The value or information)
👉 Example of an RDF Triple:
- Subject: “https://thatware.co/branding-press-release-services/” (A specific webpage)
- Predicate: “http://schema.org/articleBody” (Indicates the page contains an article)
- Object: “ppc paid marketing services agency branding advertising…” (Actual content of the webpage)
📌 Why is RDF useful?
- It helps search engines understand website content more clearly.
- It organizes webpage data in a way that AI can use for better indexing and ranking.
- Boosts website SEO by helping search engines display rich results (enhanced search listings with more details).
🔍 Part 2: Understanding the RDF Triples Output
Now, let’s analyze an example RDF triple from the output:

🟢 What does this mean?
- This describes the webpage “https://thatware.co/branding-press-release-services/”
- The property “http://schema.org/articleBody” indicates this webpage contains an article.
- The content of the article is stored in the object part (‘ppc paid marketing services agency branding advertising…’).
👉 In simple words:
This RDF triple tells Google and AI that the ThatWare webpage is about PPC Paid Marketing Services and contains a detailed article on this topic.
🟢 Why is this important for SEO?
- Improves how search engines understand the page (Google sees it as an article about PPC marketing).
- Helps in ranking the page for PPC marketing-related keywords.
- Increases chances of the webpage appearing in featured search results.
🔍 Part 3: JSON-LD Output Explanation
The JSON-LD (JavaScript Object Notation for Linked Data) output provides structured data for ThatWare’s web pages.
📌 Example JSON-LD Entry:
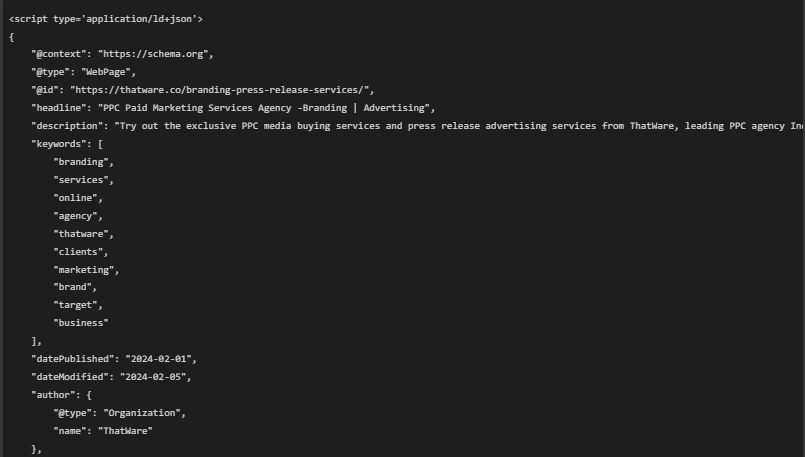
🟢 What does each part mean?
1. @context: “https://schema.org”
- Defines the structured data vocabulary (Schema.org) used for describing web pages.
2. @type: “WebPage”
- Indicates that this JSON-LD data is describing a webpage.
3. @id: “https://thatware.co/branding-press-release-services/”
- This is the URL of the page being described.
4. headline: “PPC Paid Marketing Services Agency -Branding | Advertising”
- The title of the webpage (used in search engine results).
5. description: “Try out the exclusive PPC media buying services and press release advertising services from ThatWare, leading PPC agency India!”
- The meta description, which is shown in Google search results.
6. keywords: […]
- A list of SEO keywords to help search engines categorize the page.
7. datePublished: “2024-02-01”
- The original publishing date of the page.
8. dateModified: “2024-02-05”
- The last modified date (important for freshness in search rankings).
9. author: { “@type”: “Organization”, “name”: “ThatWare” }
- The author of the page (ThatWare as an organization).
10. mainEntityOfPage: { “@type”: “WebPage”, “@id”: “https://thatware.co/branding-press-release-services/” }
- Links this structured data to the actual ThatWare webpage.
🔍 Part 4: Why This is Beneficial for SEO & What to Do Next
✅ How does this help SEO?
1. Improves Search Engine Understanding
- Google can now easily understand what each webpage is about.
- Helps in showing better search results with rich snippets.
2. Boosts Visibility in Search Rankings
- Helps ThatWare’s pages rank for relevant keywords like “PPC marketing” and “SEO services”.
3. Increases Click-Through Rates (CTR)
- Structured data makes search results more appealing, encouraging more clicks.
4. Enables AI and Voice Search Compatibility
- Helps Google Assistant, Alexa, and Siri understand the website better.
✅ What should a website owner do after getting this output?
- Ensure the JSON-LD is correctly placed in the <head> section of ThatWare’s webpages.
- Use Google’s Structured Data Testing Tool to check if Google correctly interprets the data.
- Monitor Google Search Console to see if the structured data is improving ThatWare’s search rankings.
- Optimize keywords in the JSON-LD data to match popular search queries.
📌 Final Summary
✅ RDF Triples help structure ThatWare’s webpage data for better SEO and AI understanding.
✅ JSON-LD is a structured data format that enhances ThatWare’s visibility in Google Search.
✅ This output helps ThatWare improve its SEO rankings and visibility in Google search results.
✅ Website owners should integrate JSON-LD into their <head> section and monitor performance in Google Search Console.
RDF Triples (Resource Description Framework) Model Code
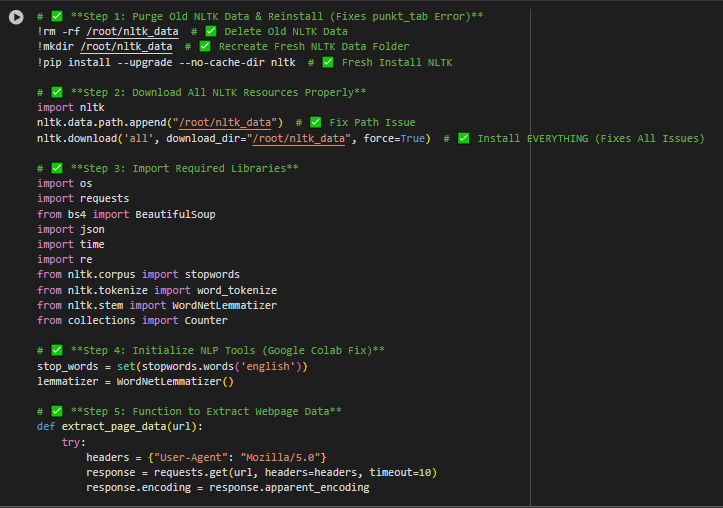
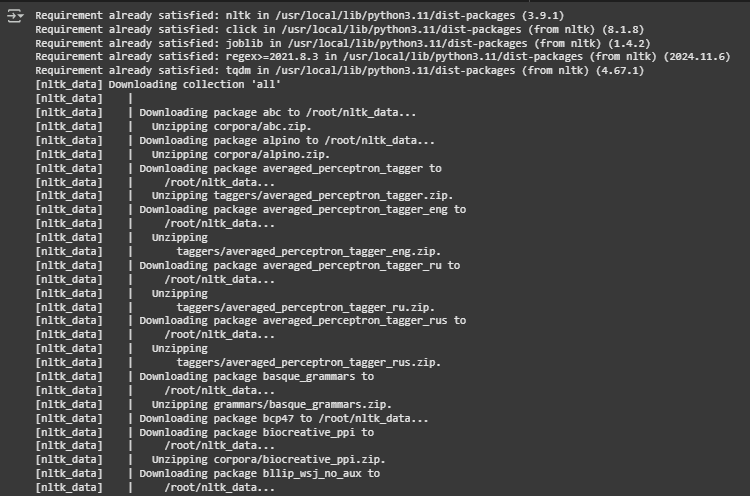
🔍 What is this JSON-LD Output?
This output is structured data written in JSON-LD format.
- JSON-LD is a way to describe the content of a web page in a format that search engines (like Google, Bing, Yahoo) can easily understand.
- It helps Google know what the webpage is about.
- It is added inside the <head> section of the webpage.
🛠 Think of it like this:
Imagine Google is a person who is looking at a webpage. If there is no structured data, Google has to guess what the page is about by reading the content.
But if structured data (like JSON-LD) is present, it is like giving Google a “cheat sheet” that clearly tells it what the page is about.
🚀 What is the Purpose of this JSON-LD Output?
This JSON-LD output improves SEO (Search Engine Optimization) by helping Google understand important details about the web pages.
It tells Google:
- What is the title of the page? (headline)
- What is the description of the page? (description)
- What are the main keywords? (keywords)
- When was the page published? (datePublished)
- When was it last updated? (dateModified)
- Who is the author? (author)
- What is the main entity of this page? (mainEntityOfPage)
📌 How Does this JSON-LD Output Help in SEO?
This helps SEO in 5 ways:
📌 1. Google Understands Your Page Better
🔍 Problem Without JSON-LD:
- If JSON-LD is not used, Google will try to figure out what the page is about just by looking at the content.
- Sometimes, it can misunderstand the page topic.
✅ Solution With JSON-LD:
- JSON-LD tells Google exactly what the page is about.
- Example:
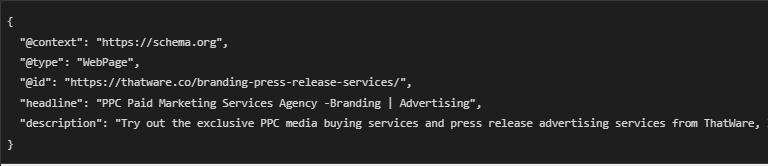
- Google now clearly knows this page is about “PPC Paid Marketing Services and Branding”.
🔹 Benefit: This helps Google index the page correctly and improve its ranking in search results.
📌 2. Your Page Can Appear in “Rich Snippets”
🔍 Problem Without JSON-LD:
- Normally, when a webpage appears in search results, it just shows a simple title and description.
✅ Solution With JSON-LD:
- If JSON-LD is used, Google can show extra information in search results, like:
- ⭐ Ratings & Reviews
- 📅 Publish Date
- ❓ FAQs or Additional Details
🔹 Benefit: This makes your search result more attractive to users, increasing clicks and website traffic.
📌 3. Your Page Can Get Featured in Google’s “Position #0”
🔍 Problem Without JSON-LD:
- Google often chooses a website to feature at the top of the search results as a “featured snippet”.
- If structured data is not present, Google might pick another website instead of yours.
✅ Solution With JSON-LD:
- JSON-LD tells Google what is important on your page.
- This increases the chances of your content appearing as a featured snippet.
🔹 Benefit: Your page appears above all search results, increasing visibility and traffic.
📌 4. Helps in Local SEO & Google Maps Ranking
🔍 Problem Without JSON-LD:
- If a business provides local services but does not use structured data, Google might not rank it in local search results or Google Maps.
✅ Solution With JSON-LD:
- JSON-LD helps Google understand your business name, services, and location.
- Example:

- 🔹 Benefit: Your business appears in Google’s Local Pack and Google Maps, bringing more customers.
📌 5. SEO Keywords Are Better Optimized
🔍 Problem Without JSON-LD:
- Google tries to guess the main keywords of a page.
- If keywords are not properly structured, Google might rank the page for the wrong searches.
✅ Solution With JSON-LD:
- JSON-LD clearly tells Google the main keywords of the page.
- Example:
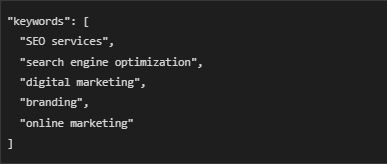
- 🔹 Benefit: This improves rankings for the right keywords and increases organic traffic.
🚀 How to Use this JSON-LD in Your Website? (Step by Step)
✅ Step 1: Add JSON-LD Code in the <head> Section of Your Website
- Open your website’s HTML file
- Find the <head> section
- Paste the JSON-LD code inside it
Example:
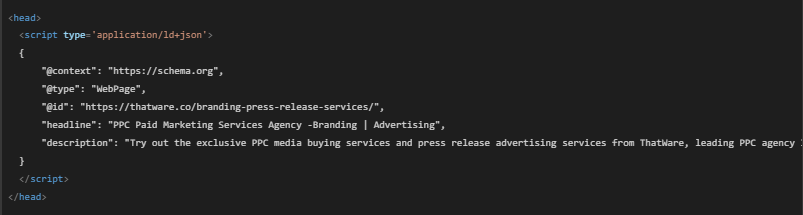
✅ Step 2: Test the JSON-LD Code with Google’s “Rich Results Test”
- Go to 👉 Google’s Rich Results Test
- Paste the URL of your page
- Click “Test”
- If there are errors, fix them.
✅ Step 3: Submit Your Page in Google Search Console
- Go to 👉 Google Search Console
- Click “URL Inspection Tool”
- Enter your website URL
- Click “Request Indexing”
🎯 Final Conclusion: How Does JSON-LD Improve SEO?
✅ Google understands the webpage better.
✅ Your page can appear in Rich Snippets.
✅ Your content can be featured in Google’s Position #0.
✅ Your business can rank higher in Local SEO.
✅ Your page gets optimized for better SEO keywords.
🚀 Bottom Line:
- JSON-LD makes your website more readable for Google.
- This improves search rankings and brings more visitors to your website.
It should always be added to the head section of your webpage.
Click here to download the full guide about RDF Triples & JSON-LD for Google Rich Snippets.
