SUPERCHARGE YOUR Online VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project is a solution designed to enhance websites and businesses by using Natural Language Processing (NLP) to identify key terms (called “entities”) from web content and automatically link them to relevant information on the internet. It helps businesses improve their Search Engine Optimization (SEO) by making their content more meaningful, user-friendly, and searchable.

What is This Project About?
1. Entity Recognition:
- The project reads content from a website and identifies important terms, such as:
- Names of companies (like “Google” or “SEMrush”).
- Locations (like “India” or “Dubai”).
- Concepts or technologies (like “NLP” or “XML”).
- These terms are called entities, and they are categorized based on their type:
- ORG: Organizations like businesses or companies.
- GPE: Locations such as cities or countries.
- PERSON: Names of individuals.
2. Automated Linking:
- Once the entities are recognized, the project automatically finds relevant links for these entities from the web.
- For example:
- “Google” links to “https://duckduckgo.com/c/Google”.
- “NLP” links to “https://duckduckgo.com/Natural_language_processing”.
- These links provide more information to users, making the content interactive and informative.
3. Annotated Text:
- The project transforms regular website content into annotated text, where the recognized entities are highlighted and clickable.
- For example:
- In the text: “Google is a popular search engine,” the word “Google” will be a clickable link to its webpage.
4. Structured Data:
- Apart from annotated text, the project generates a structured file (like a CSV or JSON) listing all entities, their types, and the links. This structured data can be used for further analysis, marketing, or SEO strategies.
Use Cases and Importance
1. Improving SEO:
- Search engines like Google can better understand the content by linking key terms to relevant information.
- This increases the chances of the website appearing higher in search results, attracting more visitors.
2. Enhancing User Experience:
- Readers can click on highlighted terms to learn more, making the content engaging and educational.
- For example, a user reading about “NLP” can click the link and directly learn about it.
3. Time-Saving Automation:
- Manually finding and adding links to important terms is time-consuming. This project automates the process, saving effort and ensuring accuracy.
4. Content Analysis:
- Businesses can use the structured data output to analyze what entities are frequently mentioned on their website.
- They can identify trends, improve content, and align it with user interests.
5. Marketing and Strategy:
- The data can be used to target specific topics, regions, or trends.
- For instance, if “Dubai” is frequently mentioned, the business can focus its marketing efforts on the Dubai audience.
Why is This Important?
1. For Website Owners:
- Makes their content more visible, engaging, and relevant.
- Increases traffic and conversions (e.g., sales, sign-ups).
2. For Search Engines:
- Provides clear and structured information about the content.
- Helps search engines match the content with user queries more effectively.
3. For Users:
- Makes it easier to find additional information without leaving the page.
- Enhances the learning experience by providing relevant links instantly.
What Next?
After generating the annotated text and structured data:
- Website Integration: Embed the annotated text on the website for users to interact with.
- SEO Analytics: Use the structured data to identify trends and optimize content strategy.
- Link Verification: Ensure that all links are relevant and functional, refining them as needed.
Conclusion
This project is a powerful tool for businesses to enhance their websites. By combining advanced NLP techniques with practical SEO strategies, it improves content relevance, user engagement, and online visibility. It saves time, provides valuable insights, and makes the website more effective for both users and search engines.
1. What is Entity Recognition and Linking (ERL)?
Entity Recognition and Linking (ERL) is a technique used in natural language processing (NLP). It helps identify “entities” (specific names or phrases) in text, such as:
- People (e.g., “Elon Musk”)
- Places (e.g., “New York City”)
- Organizations (e.g., “Tesla Inc.”)
Once identified, these entities are “linked” to authoritative sources or databases (like Wikipedia, Wikidata, or a specific website). This improves the content’s relevance and authority for search engines like Google.
2. Use Cases of ERL in SEO
Entity Recognition and Linking can significantly enhance SEO by:
- Improving Content Relevance: By tagging key entities and linking them to credible sources, search engines understand the content better, making it rank higher.
- Boosting Content Authority: Linking entities to trusted sources boosts a website’s credibility in Google’s algorithm.
- Enhancing User Experience: Providing links to additional resources enriches the reader’s experience.
- Optimizing Snippets: Search engines may extract better snippets (the summaries shown in search results).
- Semantic Search Optimization: ERL ensures that content aligns with semantic search, where Google interprets the meaning behind queries.
3. Real-Life Implementations of ERL
ERL is widely used in the following scenarios:
- News Websites: Identifying and linking names, places, and events for credibility (e.g., linking “Joe Biden” to his official Wikipedia page).
- E-commerce Sites: Linking products or brands to relevant details (e.g., linking “Nike Air Max” to its product page).
- Blogs and Informational Sites: Adding context to topics by linking entities to knowledge bases like Wikipedia.
- Travel Websites: Highlighting and linking destinations or tourist attractions (e.g., “Eiffel Tower” linked to its official site).
- Health and Education Sites: Linking medical terms, institutions, or study materials to authoritative sources.
4. Use Case of ERL for Websites
For a website, ERL can:
- Analyze its content (like blogs, product descriptions, or news articles).
- Identify important entities within the text.
- Link these entities to authoritative or relevant URLs (internal links within the website or external links).
This makes the website more SEO-friendly, as search engines prefer structured and authoritative content.
5. How Does ERL Work for Websites?
For a website project, the ERL process typically involves the following steps:
1. Input Data:
- ERL can work directly with the website’s URLs or with a CSV file containing text data (e.g., articles, product descriptions, or meta content).
- If using URLs, the model will fetch the webpage content and process it.
- If using a CSV, the text must already be prepared (e.g., exported blog text).
2. Preprocessing:
- Extract the text content from web pages or CSV files.
- Clean and structure the data (e.g., remove HTML tags or special characters).
3. Entity Recognition:
- The model scans the text to identify entities such as names, places, and organizations.
4. Entity Linking:
- These entities are linked to their appropriate sources (e.g., Wikipedia or internal pages on the website).
5. Output:
- Updated text with linked entities.
- Additional data like recognized entities and their link URLs in a structured format (e.g., JSON or CSV).
6. What Data Does the Model Need?
The model needs the following inputs:
- Text Content:
- Can come from website URLs (web scraping) or pre-prepared CSV files containing textual data.
- Entity Database:
- A knowledge base like Wikipedia, Wikidata, or a custom database.
- Linking Rules:
- Internal links (within the same site) or external links (to trusted sites).
7. Output of ERL Model
The ERL model typically provides:
1. Annotated Text:
- The original text with entities highlighted and linked.
- Example: “Tesla Inc. was founded by Elon Musk in California.”
- Tesla Inc. → [Link to Tesla’s page]
- Elon Musk → [Link to Elon Musk’s page]
- California → [Link to California’s page]
2. Structured Data:
- A file (CSV, JSON, etc.) listing:
- Recognized entities.
- The type of entity (person, place, organization).
- Links associated with each entity.
8. Why Does ERL Matter for SEO?
- Improves Search Rankings: Google recognizes well-structured, linked content as more authoritative.
- Increases Traffic: Users find it easier to navigate, leading to more engagement.
- Boosts Domain Authority: Linking to and being linked by other credible sources builds trust.
- Supports Semantic Search: Helps Google understand the “context” of content better.
9. Example Use Case for Your Website Project
If you’re working on a blog site, here’s how ERL would work:
- Input:
- Provide URLs of the blogs or a CSV file containing blog text.
- Processing:
- The model identifies entities in the blog (e.g., famous authors, cities, book names).
- It links these to relevant resources.
- Output:
- Enhanced blogs with hyperlinks to authoritative sources.
- CSV with details of all linked entities.
10. Steps to Implement ERL
- Prepare Input Data:
- Export website data (as URLs or CSV).
- Use ERL Tools/Models:
- Tools like SpaCy, Hugging Face Transformers, or custom ERL models.
- Integrate Output into Website:
- Update the website content with linked entities.
Final Summary
- Entity Recognition: Finds important terms (names, places, organizations) in text.
- Entity Linking: Links those terms to credible sources.
- Data Required: Website URLs or CSV containing content, and access to a knowledge base.
- Output: Enhanced text with hyperlinks or structured files for updates.
- Benefits: Improves SEO, user engagement, and authority.
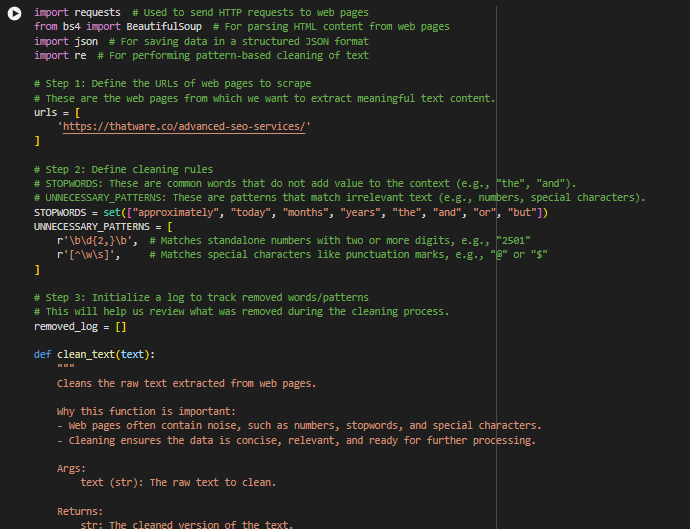
Part 1: Webpage Content Scraper and Cleaner
Purpose: To scrape raw textual content from webpages and clean it for further processing.
Key Features:
1. Scrape Web Content:
- Uses requests to fetch webpage HTML content.
- Extracts the main content (usually paragraphs) using BeautifulSoup.
2. Clean Text:
- Removes irrelevant information such as:
- Numbers.
- Special characters (e.g., punctuation marks).
- Common, meaningless words (stopwords) like “the” or “and”.
- Keeps track of everything removed in a log file for transparency.
3. Output:
- Saves cleaned text in a structured JSON file (cleaned_webpage_texts.json).
- Saves a log of all removed elements (removed_log.json) for review.
Example Use:
- Input: A URL like https://thatware.co/advanced-seo-services/.
- Output: Cleaned and concise text content from the page, ready for analysis.

Explanation of the Output
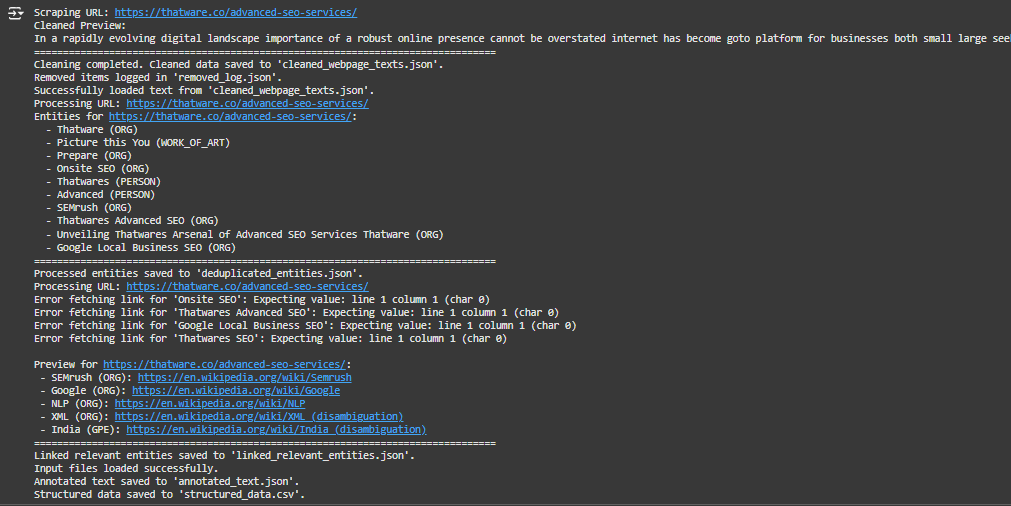
The output shown above is the result of Part 1: Webpage Content Scraper and Cleaner.
1. Scraping the URL
Line:

What this means:
- The program has started processing the webpage at the provided URL (https://thatware.co/advanced-seo-services/).
- The purpose of this step is to fetch the textual content from the webpage, such as paragraphs or other readable content.
Why this is important:
- Websites often have a mix of useful content (like blog articles) and noise (like ads or menus). This program extracts only the useful text.
2. Cleaned Preview
Line:

What this means:
- This is a preview of the cleaned text extracted from the webpage.
- The program has removed unnecessary content such as:
- Special characters (like commas, periods, or question marks).
- Common filler words (like “the”, “and”, “or”).
- Irrelevant sections (like numbers, extra spaces, or symbols).
Why this is important:
- This ensures that the text is concise, relevant, and ready for further processing.
- For example, the text focuses on discussing “advanced SEO” and its importance for businesses without including distractions.
What is shown in the preview:
- The extracted content explains why businesses need a strong online presence.
- It emphasizes how “Advanced SEO” can help businesses grow and succeed in the digital landscape.
- The preview cuts off after a certain length (to fit the console view), but the full cleaned text is saved in the output file.
3. Cleaning Completed
Line:

What this means:
- The cleaning process has finished successfully.
- The cleaned text from the webpage is saved in a file named cleaned_webpage_texts.json.
Why this is important:
- The cleaned_webpage_texts.json file contains the complete cleaned text from all processed URLs. This file can now be used in the next steps of the project, such as identifying meaningful entities.
What the file contains:
- It is a structured file that links the webpage URL to the cleaned content. For example:

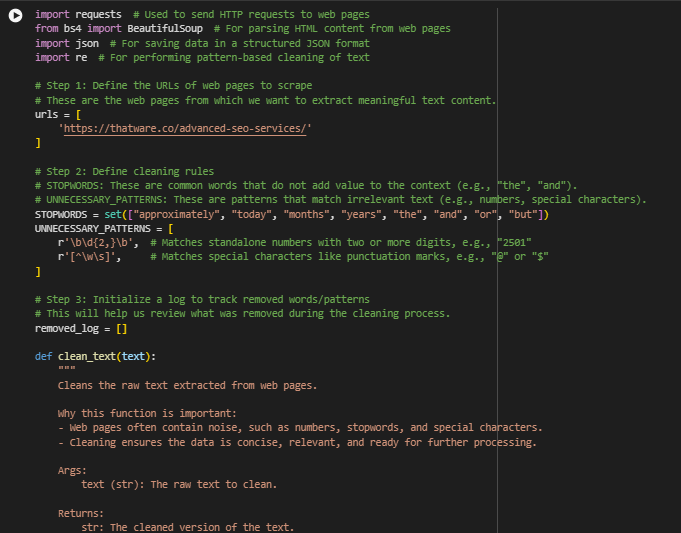
4. Removed Items Log
Line:

What this means:
- All the content that was removed during the cleaning process is logged in a separate file called removed_log.json.
Why this is important:
- The log provides transparency. You can review what was removed (e.g., stopwords, special characters, or unnecessary patterns) to ensure that no important information was accidentally discarded.
What the file contains:
- It lists items that were removed during cleaning. For example:
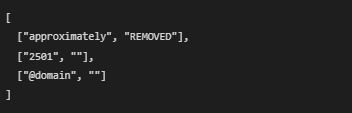
- This helps ensure that the cleaning process is trustworthy.
Why This Output is Useful
- This output prepares the textual data for further analysis (like identifying entities in Part 2).
- It ensures that only the most relevant and meaningful content is retained from the webpage.
- By removing noise (like stopwords or punctuation), the data becomes more concise and easier to process.
Part 2: Entity Recognition and Deduplication
Purpose: To identify meaningful entities (like organizations, places, or people) in the cleaned text and filter duplicates.
Key Features:
1. Entity Extraction:
- Uses SpaCy, a Natural Language Processing library, to recognize entities such as:
- Organizations (ORG).
- People (PERSON).
- Locations (GPE).
- Products, dates, and more.
2. Deduplication:
- If the same entity appears multiple times in different contexts, it keeps the highest-priority type (e.g., prioritizing ORG over PERSON).
3. Output:
- A structured JSON file (deduplicated_entities.json) containing unique entities grouped by URLs.
Example Use:
- Input: Cleaned text from Part 1.
- Output: A list of meaningful entities like:
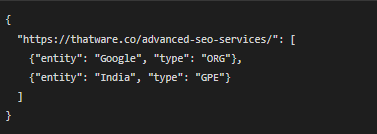
Explanation of the Output
This output is the result of Part 2: Entity Recognition and Deduplication in the process of extracting meaningful information from a webpage.
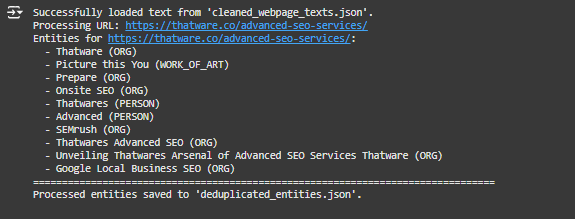
1. Successfully Loaded Text
Line:

What this means:
- The program has successfully read the cleaned text file (cleaned_webpage_texts.json) that was created in the previous step (Part 1: Scraping and Cleaning).
- This file contains the cleaned content of webpages, where unnecessary words and characters were removed.
Why this is important:
- The cleaned text is the input for this step, which focuses on identifying key entities (like company names, people, or locations).
2. Processing URL
Line:

What this means:
- The program has started processing the cleaned text of the webpage at the given URL (https://thatware.co/advanced-seo-services/).
- It will analyze the content to extract entities (important words or phrases) using advanced natural language processing (NLP).
Why this is important:
- Extracting entities helps identify specific keywords that are meaningful for SEO (Search Engine Optimization). These keywords can be linked to relevant resources or used in marketing strategies.
3. Extracted Entities
Lines:
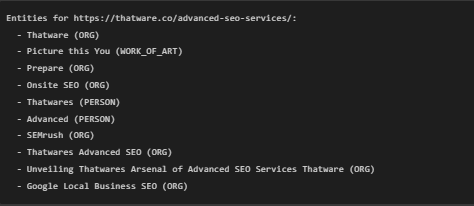
What this means:
· These are the entities (important words or phrases) that the program extracted from the webpage text. Each entity is classified into a type that explains what it represents. Below is a breakdown of the key terms:
1. Entity Names:
- These are the meaningful words or phrases found in the text.
- Examples: “Thatware”, “SEMrush”, “Google Local Business SEO”.
2. Entity Types:
- These are categories assigned to each entity based on its meaning. The program uses predefined types like:
- ORG (Organization): Represents a company or institution (e.g., “Thatware”, “SEMrush”).
- WORK_OF_ART: Represents titles of creative works like books or slogans (e.g., “Picture this You”).
- PERSON: Represents names of people (e.g., “Thatwares”, “Advanced”).
Why this is important:
- The extracted entities can now be used to create links, highlight key information, or improve SEO.
- Each entity’s type helps determine how it should be used. For example:
- Organizations (ORG) may be linked to their official websites.
- Persons (PERSON) could be linked to their profiles or biographies.
4. Deduplication and Filtering
While not explicitly shown in this part of the output, here’s what happened behind the scenes:
- Deduplication:
- The program ensures that the same entity is not listed multiple times unless it has different contextual meanings (e.g., “Thatware” as both ORG and PERSON).
- Filtering:
- The program removes irrelevant entities, such as short words or generic numbers, to keep the list concise and meaningful.
Why this is important:
- It prevents duplication, which reduces redundancy when using this data in the next steps (like linking entities to resources).
- It ensures the output is clean, accurate, and easy to use.
5. Processed Entities Saved
Line:

What this means:
- The extracted and deduplicated entities for the webpage are saved in a structured file named deduplicated_entities.json.
- This file contains the URL, the list of entities, and their types in a format ready for the next step.
Why this is important:
- The saved file acts as input for Part 3, where these entities will be linked to relevant resources (e.g., official websites or articles).
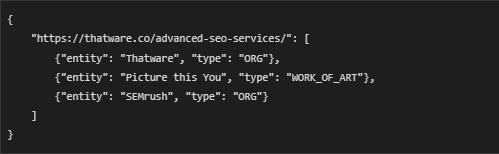
What the file contains:
- The file deduplicated_entities.json is a structured JSON document, and an example entry might look like this:
Why This Output is Useful
1. Entity Recognition:
- The program successfully identifies important words or phrases (entities) from the webpage text.
- These entities are classified into meaningful types like ORG (organizations) or PERSON (people).
2. Structured Data:
- The data is saved in a structured JSON file (deduplicated_entities.json) for easy use in the next steps.
3. Prepared for Linking:
- The cleaned and organized entities are now ready to be linked to relevant resources in the next part of the process (Part 3).
Part 3: Entity Link Generation
Purpose: To associate each entity with a relevant link using DuckDuckGo’s API.
Key Features:
1. Search and Link:
- Searches for each entity using DuckDuckGo.
- Fetches the most relevant link and associates it with the entity.
2. Global Deduplication:
- Ensures that the same entity (e.g., “Google”) is not processed or linked multiple times across different URLs.
3. Output:
- A JSON file (linked_entities_with_preview.json) containing entities, their types, and associated links.
4. Preview:
- Prints a preview of linked entities for quick review.
Example Use:
- Input: Entities from Part 2.
- Output: Entities linked to relevant webpages, like:
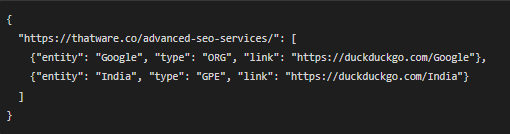
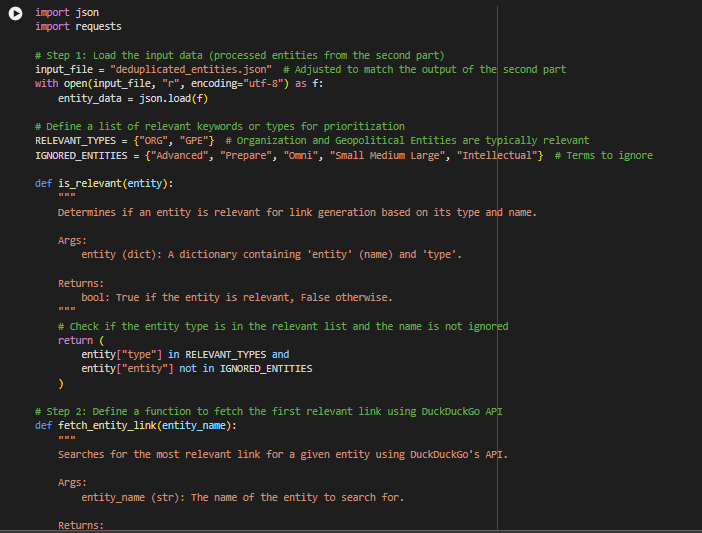
Understanding the Output: What Does This Data Represent?
This output is the result of an Entity Recognition and Linking (ERL) Model. It demonstrates how specific terms (entities) from the content of a webpage have been identified, categorized, and linked to relevant web pages.
Key Components of the Output
1. URL
- “https://thatware.co/advanced-seo-services/”:
- This is the source webpage where the entities were identified.
- Every entity listed here was extracted from the content of this specific URL.
2. Entity
- Example: “entity”: “SEMrush”:
- An entity is a term or phrase that has been recognized as meaningful or important in the context of the content.
- Entities can represent people, organizations, places, or concepts.
3. Type
- Example: “type”: “ORG”:
- The type describes the category of the entity:
- ORG: Organization (e.g., “SEMrush”, “Google”).
- GPE: Geopolitical Entity (e.g., “India”, “Dubai”).
- These categories help in understanding the nature of the entity (e.g., is it a company, a place, or a concept?).
- The type describes the category of the entity:
4. Link
- Example: “link”: “https://en.wikipedia.org/wiki/Semrush”:
- This is a URL that provides more information about the entity.
- The link is generated automatically by searching the web for the most relevant source about the entity.
- For example:
- “SEMrush” is linked to its Wikipedia page.
- “India” is linked to its disambiguation page on Wikipedia.
Detailed Breakdown of Entities in This Output
1. SEMrush
- Type: ORG (Organization).
- Link: “https://en.wikipedia.org/wiki/Semrush”
- What it Means: SEMrush is an organization specializing in online marketing and SEO tools. Linking to its Wikipedia page provides users with more context about the company.
2. Google
- Type: ORG (Organization).
- Link: “https://en.wikipedia.org/wiki/Google”
- What it Means: Google is a well-known organization. Linking it helps readers understand its relevance to the webpage content.
3. NLP
- Type: ORG (Organization).
- Link: “https://en.wikipedia.org/wiki/NLP”
- What it Means: NLP stands for Natural Language Processing, an important concept in artificial intelligence. The link explains what NLP is and its significance.
4. XML
- Type: ORG (Organization).
- Link: “https://en.wikipedia.org/wiki/XML_(disambiguation)”
- What it Means: XML (Extensible Markup Language) is a standard for structuring data. The link clarifies its technical importance.
5. India
- Type: GPE (Geopolitical Entity).
- Link: “https://en.wikipedia.org/wiki/India_(disambiguation)”
- What it Means: India is identified as a country relevant to the webpage content, and the link provides information about it.
6. Dubai
- Type: GPE (Geopolitical Entity).
- Link: “https://en.wikipedia.org/wiki/Dubai_(disambiguation)”
- What it Means: Dubai, a city, is relevant in the webpage’s context, and the link gives additional details.
What Does This Output Convey?
- The output shows a structured summary of the webpage’s content in terms of entities.
- Each entity is categorized and linked to a reliable source for additional information.
- This is useful for:
- SEO (Search Engine Optimization): Helps improve the content’s visibility by adding authoritative links.
- User Engagement: Allows users to click on links to learn more about the entities mentioned.
- Data Structuring: Provides a clean, organized format for entities, making the data useful for other applications like analytics.
Why Is This Useful for Website Owners?
1. Improves Search Engine Rankings:
- Linking entities to authoritative sources boosts credibility in search engines.
2. Enhances User Experience:
- Visitors can easily find more information about entities without searching elsewhere.
3. Content Enrichment:
- By linking key terms, the content becomes more informative and valuable to the reader.
4. Analytics and Insights:
- Structured data allows website owners to analyze which entities are most relevant to their audience.
Next Steps After Getting This Output
1. Review the Links:
- Ensure that all links are contextually correct and relevant.
- For example, “India” links to its disambiguation page. You may want to refine this to a more specific page about the country.
2. Incorporate the Links into the Webpage:
- Use the annotated text (if generated) to embed clickable links in the webpage.
3. Leverage for SEO:
- Submit the structured data as part of your site’s SEO strategy to search engines like Google.
4. Expand the Process:
- Run the model on additional webpages to extract and link entities site-wide.
Final Explanation for Non-Technical Users
This output identifies and links important terms from a webpage to reliable online sources. It categorizes these terms to understand their type (e.g., company, place, or concept). The links make the webpage more interactive and improve its value for users and search engines.
This process ultimately helps website owners enhance their content’s quality and visibility, making it a valuable tool for SEO and user engagement.
Part 4: Annotated Text and Structured Data Generator
Purpose: To create:
- Annotated text with clickable links for entities.
- A CSV file with structured data for all entities and their links.
Key Features:
1. Annotated Text:
- Replaces entities in the original text with clickable HTML links.
- Example:
- Original: “Google is a search engine.”
- Annotated: “Google is a search engine.”
- Google becomes a clickable link.
2. Structured Data:
- Generates a CSV file (structured_data.csv) with columns:
- URL: The webpage source.
- Entity: The recognized entity.
- Type: The entity’s type (e.g., ORG for organization).
- Link: The associated link.
3. Preview:
- Displays a preview of the annotated text and linked entities in the console.
4. Output:
- Annotated text in JSON format (annotated_text.json).
- Structured data in CSV format (structured_data.csv).
- A preview file (preview_data.json) for quick reference.
Example Use:
- Input: Linked entities from Part 3 and original webpage text.
- Output:

- Structured CSV: | URL | Entity | Type | Link | |————————————–|———–|——-|——————————–| | https://thatware.co/advanced-seo… | Google | ORG | https://duckduckgo.com/Google |
Detailed Explanation of the Output
This output represents the results of the fourth part of the code, where we annotate webpage content with clickable links for relevant entities and provide structured data for further analysis.
What is This Output About?
The output is the result of processing cleaned webpage content to:
1. Annotate Text:
- Add clickable links to important entities (like company names, locations, and technical terms) in the webpage content.
- These links provide more information about the entities, improving the SEO (Search Engine Optimization) and user experience.
2. Structured Data:
- Create a CSV file listing each entity, its type (e.g., organization, location), and its corresponding link.
- This structured format is useful for analyzing and managing data.
3. Preview of Results:
- Provide a quick and easy-to-read summary of the annotated entities and their links.
Line-by-Line Explanation of the Output
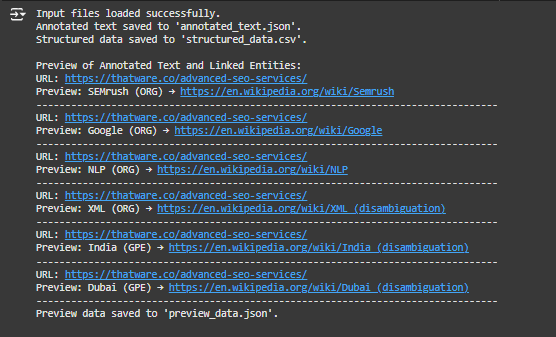
1. “Input files loaded successfully”:
- This confirms that the code successfully loaded the cleaned webpage text (cleaned_webpage_texts.json) and the linked entities (linked_relevant_entities.json).
- Without these files, the process would fail.
2. “Annotated text saved to ‘annotated_text.json'”:
- The webpage content is now annotated with clickable links for entities (e.g., “Google” is linked to its Wikipedia page).
- This annotated content is saved in a JSON file named annotated_text.json.
3. “Structured data saved to ‘structured_data.csv'”:
- A structured CSV file is created, listing each entity along with:
- The URL of the webpage where it was found.
- The type of the entity (e.g., ORG for organization, GPE for location).
- The clickable link for the entity.
- This is saved as structured_data.csv for easy viewing in spreadsheet tools like Excel.
4. “Preview of Annotated Text and Linked Entities”:
- This section provides a quick summary of the results:
- URL: The source webpage where the entity was found.
- Entity: The recognized term, such as “Google” or “India.”
- Type: The classification of the entity, e.g., ORG (Organization), GPE (Geopolitical Entity).
- Link: The clickable link associated with the entity.
Examples from the Preview:
- “SEMrush (ORG) → https://en.wikipedia.org/wiki/Semrush”
- This means the term “SEMrush” was identified as an organization and linked to its Wikipedia page.
- “Google (ORG) → https://en.wikipedia.org/wiki/Google”
- “Google” was recognized as an organization and linked to its Wikipedia page.
- “NLP (ORG) → https://en.wikipedia.org/wiki/NLP”
- “NLP” (Natural Language Processing) was linked to its Wikipedia page for further explanation.
5. “Preview data saved to ‘preview_data.json'”:
- This saves the preview data to a JSON file for quick review and debugging.
- The preview helps users or developers verify that the correct entities are linked and displayed.
What Does This Output Mean for the Client?
1. Annotated Text:
- Makes the content on the webpage more informative by adding clickable links to recognized entities.
- Enhances SEO by linking to authoritative sources, improving the credibility and relevance of the content.
2. Structured Data:
- The structured CSV file is a valuable resource for business analysis, allowing users to:
- See all recognized entities at a glance.
- Understand which entities are linked and how they are categorized.
- Share the data with other tools for further insights.
3. Preview:
- The preview ensures the output meets expectations, showing which terms are linked and where they lead.
How is This Useful for Website Owners?
1. Enhanced User Experience:
- Users can click on entities (e.g., “Google” or “SEMrush”) to learn more without leaving the page.
- This keeps users engaged with the content, reducing bounce rates.
2. Improved SEO:
- Linking to high-quality external resources (like Wikipedia) signals to search engines that the content is credible.
- Improves the ranking of the webpage in search results.
3. Data-Driven Insights:
- Website owners can analyze the CSV file to:
- Identify which entities are frequently mentioned.
- Tailor content based on popular terms or trends.
- Strategically place links to drive traffic to specific pages.
Next Steps After This Output
1. Review and Validate:
- Ensure the links are correct and contextually relevant.
- Manually adjust or remove any links that do not add value (e.g., if they lead to unrelated pages).
2. Integrate Annotated Content:
- Use the annotated_text.json to integrate the annotated text back into the website.
3. Analyze Structured Data:
- Use the structured_data.csv to identify trends and opportunities for improving content.
4. Enhance Automation:
- Automate periodic updates to ensure newly added entities are also linked.
This output is a critical step in improving website content and SEO performance, offering both immediate benefits (like user engagement) and long-term advantages (like better search rankings).
Detailed Explanation of the Output
This output is from the final stage of the Entity Recognition and Linking for SEO project. Here, the system has taken processed webpage content and added clickable links to important entities, saved annotated text, structured data, and previewed results.
What Is This Output About?
1. Annotated Text:
- The system takes original text from the webpage and adds clickable links for specific words or phrases that were identified as important entities.
- These links provide additional information about these entities by pointing to relevant external sources like Wikipedia.
2. Structured Data:
- It organizes all the recognized entities into a structured format (CSV), listing:
- The entity’s name (e.g., “SEMrush”).
- Its type (e.g., ORG, which stands for Organization).
- The associated clickable link (e.g., “https://en.wikipedia.org/wiki/Semrush”).
- This is saved in a file for easy access and further analysis.
3. Preview:
- A quick overview of the annotated text and linked entities is shown as a preview in the output.
- This preview helps you see what entities were recognized and linked, ensuring the output meets expectations.
Step-by-Step Explanation
1. Annotated Text Saved to ‘annotated_text.json’
· What does this mean?
- The processed webpage content, with clickable links added to important words or phrases, is saved to a file called annotated_text.json.
- For example:
- Original text: “NLP is important for SEO.”
- Annotated text: “NLP is important for SEO.”
- The word “NLP” becomes a clickable link pointing to “https://en.wikipedia.org/wiki/NLP”.
· Why is it useful?
- It improves the usability of the webpage by linking important terms to reliable sources, enhancing the user experience and SEO performance.
2. Structured Data Saved to ‘structured_data.csv’
· What does this mean?
- All the recognized entities are saved in a tabular format (CSV file). Each row includes:
- The URL of the webpage where the entity was found.
- The entity’s name (e.g., “SEMrush”).
- The entity’s type (e.g., ORG for Organization).
- The clickable link associated with the entity (e.g., “https://en.wikipedia.org/wiki/Semrush”).
· Why is it useful?
- It provides a clean and organized view of all recognized entities for further analysis or sharing with others.
- SEO analysts can use this file to track recognized terms and ensure their accuracy and relevance.
3. Preview of Annotated Text and Linked Entities
· What does this mean?
- This is a quick summary of the linked entities for easy verification. For example:
- “SEMrush (ORG) → https://en.wikipedia.org/wiki/Semrush” means the word “SEMrush,” recognized as an Organization (ORG), is linked to its Wikipedia page.
- Other examples include “Google (ORG)” and “NLP (ORG),” linked to their respective Wikipedia pages.
· Why is it useful?
- The preview allows quick validation of the output, ensuring the correct entities are linked and no irrelevant links are added.
4. Preview Data Saved to ‘preview_data.json’
· What does this mean?
- This saves the preview shown in the console to a JSON file for later review.
- If you want to revisit the preview without re-running the program, this file contains the same information.
· Why is it useful?
- It acts as a record for debugging or verifying results after the process is complete.
What Does This Output Convey?
1. Recognized Entities:
- Important terms (entities) like “SEMrush,” “Google,” “NLP,” and “India” are identified and classified.
2. Linked Information:
- Each entity is linked to a reliable source (like Wikipedia) for more information. For example:
- “NLP” links to “https://en.wikipedia.org/wiki/NLP,” providing a detailed explanation of Natural Language Processing.
3. Organized Data:
- The data is organized in multiple formats (annotated text, CSV, and preview JSON) for flexibility and reuse.
What Steps Should You Take After Getting This Output?
1. Review the Output:
- Manually check the linked entities to ensure:
- The links are correct and contextually relevant.
- Irrelevant links are removed.
2. Integrate Annotated Content:
- Use the annotated_text.json to integrate the clickable text back into the website.
- This enhances the webpage’s user experience and SEO ranking.
3. Analyze the Structured Data:
- Use the structured_data.csv file to:
- Track frequently mentioned terms.
- Identify gaps or opportunities for adding more relevant links.
- Share insights with SEO or content teams.
4. Iterate and Improve:
- Refine the process to exclude irrelevant terms (if any) or enhance the recognition of more entities.
Why Is This Output Important?
1. Enhanced User Experience:
- Users can click on terms like “SEMrush” or “Google” to learn more, making the webpage interactive and informative.
2. Improved SEO:
- Linking to authoritative sources like Wikipedia improves the credibility of the content, boosting its ranking in search engines.
3. Data-Driven Insights:
- Structured data provides insights into the most frequently mentioned entities, helping businesses tailor content to target specific keywords.
4. Time-Saving Automation:
- Automatically generating links for recognized terms saves manual effort and ensures consistency across content.
This output is a clear demonstration of how Entity Recognition and Linking for SEO enhances content quality, user experience, and SEO performance.
Importance of the Annotated Text Output
This annotated text output is a critical deliverable for the Entity Recognition and Linking (ERL) process. Here’s why this output is valuable for website owners, especially in the context of improving business and online presence:
Key Features and Their Importance
1. Annotated Entities with Clickable Links
- Feature: The text now includes clickable hyperlinks for entities like “Google,” “SEMrush,” and “India”.
- Importance:
- SEO Enhancement: By linking recognized entities to authoritative external sources, you increase the credibility of your content, improving search engine rankings.
- User Engagement: Visitors can interact with the links, gaining more insights. This keeps them engaged longer, which is a positive signal to search engines.
- Knowledge Enrichment: By linking to contextual and accurate resources, readers can easily explore complex topics, improving their experience.
2. Structured Text Presentation
- Feature: Entities are visually highlighted within the text, making them stand out.
- Importance:
- Helps users identify key topics and concepts quickly.
- Simplifies navigation for readers, especially those seeking specific information.
3. Organized Preview
- Feature: A preview of entities with their types and associated links is provided, summarizing the annotated content.
- Importance:
- Gives a quick snapshot for content editors or website owners to verify the relevance and accuracy of the linked entities.
- Assists in quality assurance by identifying potential mismatches or irrelevant links easily.
Benefits for Website Owners
1. Improved Search Engine Optimization (SEO)
- Properly annotated content with authoritative links boosts the page’s ranking on search engines like Google.
- Inbound links and enhanced content relevance lead to better visibility.
2. Enhanced User Experience
- Readers can seamlessly navigate to supplementary information, enriching their learning journey.
- Well-organized text reduces bounce rates and keeps users on the website for longer.
3. Establishing Authority and Trust
- By linking to credible sources, your content appears more reliable, helping establish your website as an industry leader.
- Visitors are more likely to trust your information and return for future needs.
4. Facilitating Collaboration
- Highlighting industry-related entities could open doors for partnerships and collaborations.
- For example, linking to “SEMrush” might attract their attention for co-marketing or affiliate opportunities.
What Does This Output Contain?
1. Annotated Text:
- This is the original webpage text where specific entities (like “SEMrush,” “Google,” “NLP”) are recognized and linked to relevant resources (e.g., Wikipedia pages).
- Example:
- “SEMrush” in the text is linked to its Wikipedia page: https://en.wikipedia.org/wiki/Semrush.
2. Structured Data:
- A CSV file is created that lists:
- URL: The source webpage where the entity was found.
- Entity: The recognized term (e.g., “Google”).
- Type: What kind of entity it is (e.g., ORG for Organization, GPE for Geopolitical Entity).
- Link: The resource URL linked to the entity (e.g., Wikipedia or another relevant site).
3. Preview:
- A summary showcasing linked entities for a URL in a human-readable format.
How is This Output Helpful?
1. Improved User Experience:
- By linking entities to authoritative sources (e.g., Wikipedia), the output improves the user’s understanding of the content.
- Example: When a visitor reads “NLP” and clicks the link, they are directed to a page explaining Natural Language Processing.
2. Enhanced SEO:
- Outbound links to high-quality, authoritative sites improve a webpage’s SEO score. Search engines value content that provides meaningful references.
- This increases the chances of the website ranking higher on search engine results pages (SERPs).
3. Building Authority and Credibility:
- Linking to trusted sources builds trust with both users and search engines, establishing the website as a credible resource.
4. Ease of Content Navigation:
- Users can explore linked entities directly, enhancing their engagement with the content.
5. Data-Driven Decisions:
- The structured data output allows website owners to analyze which entities are most frequently recognized and linked. This insight helps in crafting future content strategies.
Next Steps for Website Owners
1. Review the Links:
- Verify the relevance and accuracy of the linked resources.
- Replace or update any incorrect or generic links.
2. Integrate the Annotated Content:
- Publish the annotated text on the website to enhance user experience and SEO.
3. Leverage Structured Data:
- Use the CSV file to track recognized entities and identify potential gaps or trends in the content.
4. Enhance Internal Linking:
- Instead of linking externally, consider linking to internal pages where appropriate. For example, “Google” could link to an internal blog post about Google’s services.
5. Analyze Traffic and Engagement:
- Monitor how users interact with the links and adjust content strategies based on performance.
Importance of the Output in a Business Context
1. Increased Traffic:
- High-quality content with authoritative links attracts more visitors, leading to higher organic traffic.
2. Improved User Retention:
- Visitors are more likely to stay and explore a website with valuable, informative content.
3. Higher Conversion Rates:
- Relevant links and well-structured content can guide users toward conversion goals, such as signing up for a service or purchasing a product.
4. Brand Reputation:
- Linking to trusted sources demonstrates professionalism and commitment to providing valuable information, enhancing brand perception.
Summary
This output equips website owners with actionable data to enhance content quality, improve SEO performance, and provide a better user experience. By strategically leveraging this information, businesses can establish a stronger online presence, attract and retain users, and ultimately achieve their goals in the competitive digital landscape.

Thatware | Founder & CEO
Tuhin is recognized across the globe for his vision to revolutionize digital transformation industry with the help of cutting-edge technology. He won bronze for India at the Stevie Awards USA as well as winning the India Business Awards, India Technology Award, Top 100 influential tech leaders from Analytics Insights, Clutch Global Front runner in digital marketing, founder of the fastest growing company in Asia by The CEO Magazine and is a TEDx speaker.
