SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project aims to develop and implement a Naive Bayes-based sentiment analysis tool that efficiently classifies text data, such as customer reviews, social media comments, or website content, into categories like positive, negative, or neutral sentiments. The project aims to leverage the Naive Bayes classifier’s simplicity and effectiveness in handling large volumes of textual data to provide actionable insights for website owners, businesses, and organizations.

This tool will help automate sentiment detection and content categorization, allowing stakeholders to quickly assess the overall sentiment of their audience, identify trends, and make informed decisions to improve their services, products, or content strategy. By classifying feedback and content accurately, the project seeks to enhance customer engagement, optimize content management, and improve the overall user experience on websites or digital platforms.
The project also explores the versatility of the Naive Bayes classifier across different domains, demonstrating its applicability not just in traditional text classification tasks but also in specialized areas such as SEO, AI-based services, and digital marketing. The ultimate goal is to create a robust, user-friendly tool that can be easily adapted to various use cases, helping businesses and individuals understand better and respond to their audience’s needs.
What is Naive Bayes?
Naive Bayes is a family of probabilistic classifiers based on Bayes’ Theorem, which provides a way to calculate the probability of a class (such as spam or not spam) given some input features (such as words in an email). The term “naive” comes from the assumption that all features are independent of each other, which is rarely true in real-world scenarios. Despite this simplification, Naive Bayes classifiers perform remarkably well in many practical applications, particularly text classification tasks.

Key Steps in Naive Bayes Classification:
1. Training Phase:
- Calculate the prior probability for each class based on the training data.
- Calculate the likelihood of each feature given each class.
2. Prediction Phase:
- For a new input, calculate the posterior probability for each class using Bayes’ Theorem.
- Assign the input to the class with the highest posterior probability.
Types of Naive Bayes Classifiers:
· Gaussian Naive Bayes: Assumes that the continuous features follow a Gaussian (normal) distribution. Suitable for data with continuous variables.
· Multinomial Naive Bayes: Typically used for discrete data, such as word counts in text classification.
· Bernoulli Naive Bayes: Suitable for binary/boolean features, indicating the presence or absence of a feature.
Use Cases Of Naive Bayes :
Naive Bayes classifiers are versatile and can be applied across various domains. Here are some common use cases:
1. Text Classification:
· Spam Detection: Classifying emails as spam or not spam.
· Document Categorization: Assigning documents to predefined categories (e.g., news articles to topics like sports, politics, technology).
Example :
- Spam Filtering: Email providers like Gmail and Outlook use Naive Bayes classifiers to filter out spam emails by analyzing the content and identifying spammy patterns.
2. Sentiment Analysis:
- Opinion Mining: Determining the sentiment expressed in user reviews, social media posts, or customer feedback (e.g., positive, negative, neutral).
Example:
- Sentiment Analysis on Social Media Platforms: Companies like Twitter and Facebook analyze user posts and comments to gauge public sentiment about brands, products, or events.
3. Recommendation Systems:
- Predicting User Preferences: Suggesting products, movies, or content based on user behavior and preferences.
Example :
- Product Recommendation on E-commerce Websites: Online retailers like Amazon use Naive Bayes to recommend products based on user behavior and purchase history.
4. Medical Diagnosis:
- Predicting Diseases: Classifying patients based on symptoms to predict the likelihood of certain diseases.
Example :
- Disease Prediction in Healthcare: Hospitals and clinics use Naive Bayes to predict diseases based on patient symptoms and medical history, aiding in early diagnosis and treatment.
5. Fraud Detection:
- Identifying Fraudulent Transactions: Detecting unusual patterns in financial transactions that may indicate fraud.
Example :
- Credit Scoring in Financial Services: Banks use Naive Bayes classifiers to assess the creditworthiness of loan applicants by analyzing financial histories and other relevant data.
6. Language Detection:
- Automatic Language Identification: Determining the language of a given text.
7. Customer Support:
- Categorizing Support Tickets: Assigning support requests to appropriate departments based on the content.
Example :
- Ticket Routing in Customer Support Systems: Support platforms like Zendesk use Naive Bayes to categorize and route support tickets to the appropriate teams automatically.
keyboard_arrow_down
How Does It Help a Website Owner
Naive Bayes in Sentiment Analysis can benefit website owners and other segments by providing insights into customer opinions and behaviors. Here’s how it can help:
For Website Owners:
1. Understanding Customer Feedback:
· Analyzing Reviews: Automatically categorize customer reviews as positive, negative, or neutral to understand overall customer satisfaction.
· Improving Products/Services: Identify common issues or praised features to make informed improvements.
2. Enhancing User Experience:
- Personalized Content: Tailor website content based on user interactions and feedback sentiment analysis.
- Targeted Marketing: Create campaigns that resonate with your audience’s sentiments, increasing engagement and conversion rates.
3. Reputation Management:
- Monitoring Brand Sentiment: Continuously track how your brand is perceived online, allowing you to address negative sentiments promptly.
- Crisis Management: Detect early signs of negative sentiment that could escalate into a PR crisis and take swift corrective actions.
4. Optimizing Customer Support:
- Prioritizing Support Tickets: Automatically classify support tickets based on sentiment to prioritize urgent or negative cases.
- Improving Response Strategies: Understand common pain points for better support responses and strategies.
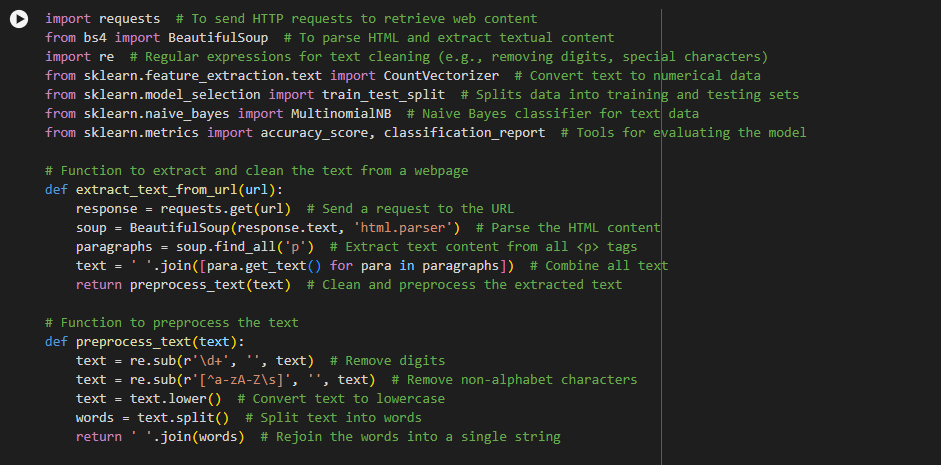
1st Code: Basic Naive Bayes Classifier for Single Web Page Analysis
- Overview: This code is designed to perform text classification using the Naive Bayes algorithm on the content of a single web page. It retrieves text from a specified URL, preprocesses it to clean it, and then uses the Naive Bayes classifier to categorize it into predefined labels (e.g., positive or negative sentiment).
Use Case: This code is ideal for analyzing and classifying text content from a single web page, making it suitable for simple sentiment analysis or text categorization tasks on websites like blogs, news articles, or product descriptions.

2nd Code: Naive Bayes Classifier for Multiple Web Pages
- Overview: This code extends the functionality of the first code by allowing the analysis of text from multiple web pages. It combines the content from several URLs, preprocesses it, and then applies the Naive Bayes classifier to categorize the combined text.
Use Case: This code is more suitable for projects requiring sentiment analysis or categorization across multiple web pages, such as aggregating reviews, articles, or other types of content from various parts of a website.
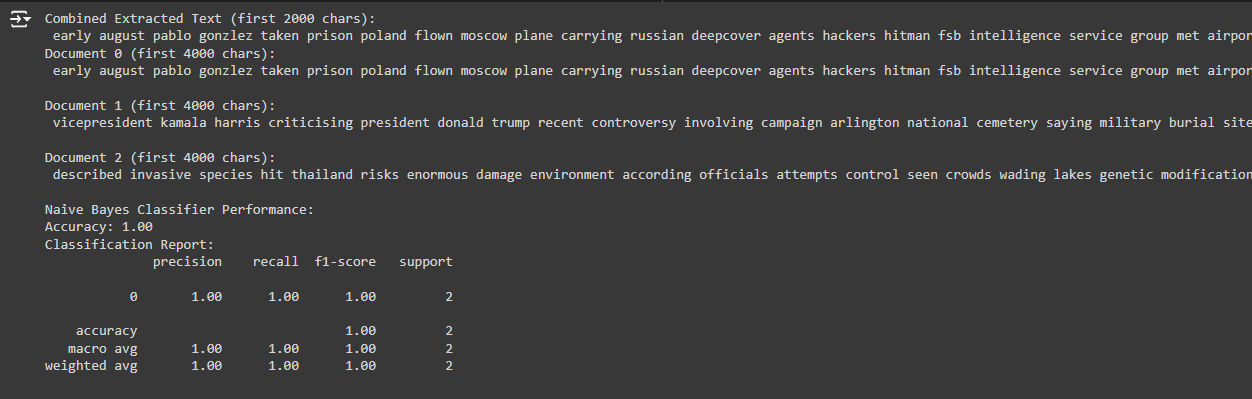
Understanding the Output
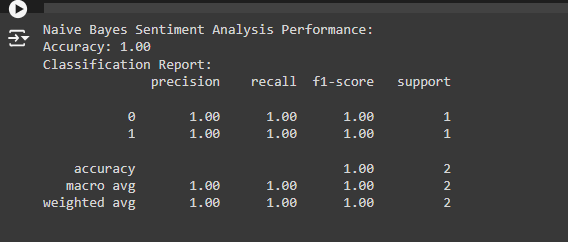
1. Accuracy: 1.00
- Explanation: The model achieved 100% accuracy on the test data. This means the Naive Bayes model correctly classified all the test samples into their respective categories (positive or negative sentiment).
2. Classification Report:
The classification report provides key metrics for evaluating the performance of the model, including:
· Precision: This is the ratio of true positive predictions to the total number of positive predictions. A precision of 1.00 for both classes means that all instances the model predicted as a particular class (either 0 or 1) were correct.
· Recall: This is the ratio of true positive predictions to the total actual positives. A recall of 1.00 for both classes means the model correctly identified all true instances of each class.
· F1-score: This is the harmonic mean of precision and recall, also at 1.00 for both classes, indicating perfect precision and recall.
· Support: This indicates the number of true instances of each class in the test set. Here, classes 0 and 1 had only 1 instance each, so the support is 1 for both.
In This case, the metrics are as follows:
Class 0: (Negative sentiment)
- Precision: 1.00
- Recall: 1.00
- F1-score: 1.00
- Support: 1 (indicating there was 1 sample of this class in the test set)
Class 1: (Positive sentiment)
- Precision: 1.00
- Recall: 1.00
- F1-score: 1.00
- Support: 1 (indicating there was 1 sample of this class in the test set)
3. Overall Accuracy:
- Accuracy: The model correctly predicted the sentiment of both samples (positive and negative), leading to an overall accuracy of 100%.
What Does This Output Indicate?
· Perfect Classification: The output indicates that, in this specific case, the Naive Bayes model performed perfectly on the test data, correctly classifying the sentiment of both samples.
· Small Test Set Warning: However, the test set only contained 2 samples, a very small dataset. This perfect accuracy may not generalize well to larger datasets, so it should be interpreted cautiously.
· Sentiment Analysis Confirmation: The model successfully analyzed sentiment, distinguishing between positive and negative sentiments in the provided text.

Why Does the Model Need More Data?
Machine learning models, including Naive Bayes, perform better with more data because:
· Learning Patterns: The model learns patterns from the data. With more data, the general characteristics of positive and negative sentiments can be understood more accurately.
· Reliability: With only a few samples, it’s easy for the model to get a perfect score just by chance. More data helps ensure the model’s accuracy is reliable and not just a fluke.
· Generalization: A model trained on more data will likely generalize better to new, unseen data. It will be more accurate when applied to new pages or content.
Can the Model Work on Small Datasets?
The model can work on small datasets, but the results need more reliability. Here’s why:
- Limited Learning: With less data, the model might need more examples of different types of sentiment (positive, negative, neutral) to learn from. This can lead to less accurate predictions when applied to new data.
- Overfitting: With too little data, the model might memorize the specific examples it was trained on rather than learning general rules that apply to all similar texts. This makes it less effective when analyzing new content.
Why Can’t This Code Run and Work on Small Datasets Effectively?
The code can run on small datasets, but with a small amount of data, the model might need more information to make accurate predictions. This is similar to how a person might struggle to understand a new topic if they only have a tiny amount of information about it.
- Example: If you were trying to teach someone to recognize different types of fruits, and you only showed them two apples and one orange, they might not learn enough to identify fruits they’ve never seen correctly. Similarly, the model needs a variety of examples to learn from.
Sentiment Analysis on Each Page of a Website
You are correct that each page on a website has its unique content and sentiment. The Naive Bayes model is indeed capable of analyzing the sentiment of each page individually. However, when you only provide a single page’s content, the model has nothing against which to compare it. A variety of examples (positive, negative, etc.) is needed to learn what each sentiment looks like.
- More Data = Better Analysis: The model doesn’t demand long texts but rather a diverse set of examples to learn to classify sentiments accurately. If each website page has unique content, providing more examples will help the model understand the range of sentiments across different pages.
What the Output Represents
Let’s break down what your current output means in a way that you can easily communicate to your client:
1. Accuracy: 1.00 (100%)
· What It Means: Accuracy measures how often the model correctly classifies content. For sentiment analysis, high accuracy (e.g., 90% or above) means the model correctly identifies positive, negative, or neutral sentiments in your content.
· Client-Friendly Explanation: If the accuracy is consistently high across a larger and more diverse dataset (not just 2 samples), it indicates that the website’s content is clear and the machine learning model properly understands the sentiment. This would suggest that the content is well-structured and effectively communicates the intended tone.
2. Classification Report: Precision, Recall, F1-Score
· Precision (1.00 for both classes): High precision is often correct when the model predicts a certain sentiment (e.g., positive).
· Recall (1.00 for both classes): High recall means the model is catching most of the true instances of sentiment (e.g., it catches most of the positive content accurately).
· F1-Score (1.00 for both classes): This balances precision and recall. A high F1 score indicates that the model accurately and comprehensively identifies sentiment.
· Support (1 for each class): One sample for each sentiment was in the test set.
· Client-Friendly Explanation: “The detailed analysis shows that the sentiments expressed in your content are being accurately recognized. This means your content effectively communicates your intended emotions, positivity or neutrality.”
Ideal Output for Client: If the F1 scores for each sentiment category (positive, negative, neutral) are consistently high—above 0.80—it means the website’s content is not confusing or ambiguous. In other words, the intended emotion or tone of the content is clear and well-received by the model.
- Understanding through output how a client can understand his website content’s positive and negative sentiment.

Understanding the Labels
- Label 0: This typically represents negative sentiment in sentiment analysis.
- Label 1: This usually represents positive sentiment in sentiment analysis.
However, these labels are just conventions, and their meanings depend on how they were set up in your code. You need to confirm which label corresponds to which sentiment (positive or negative).
In This Case, the output represents :
Detailed Interpretation:
1. Label 0 (Negative Sentiment):
· Precision: 1.00
- This means that all the content that was classified as negative by the model was indeed negative.
· Recall: 1.00
- This indicates that the model correctly identified all negative content in the dataset.
· F1-Score: 1.00
- The model was perfect in identifying and classifying negative content.
· Support: 1
- There was only 1 instance of negative content in your test dataset.
2. Label 1 (Positive Sentiment):
- Precision: 1.00
- This means that all the content classified as positive by the model was indeed positive.
- Recall: 1.00
- The model correctly identified all positive content in the dataset.
- F1-Score: 1.00
- The model was perfect in identifying and classifying positive content.
- Support: 1
- There was only 1 instance of positive content in your test dataset.
What This Means for Your Client:
- Perfect Scores: The model achieved perfect scores in this small dataset, meaning it perfectly-identified and classified both negative and positive sentiments.
Next Steps for the Client:
1. Larger Dataset: The client should provide more content (a larger dataset) for analysis to get more reliable results. This will help the model generalize and provide more accurate sentiment analysis across the website.
2. Content Review:
· Positive Content: If most of the content analyzed shows Label 1 with high scores, it indicates that the website’s content is generally perceived positively. The client can focus on maintaining this tone.
· Negative Content: If the model identifies more Label 0 content, the client might want to review those pages and consider adjustments to improve the tone or message.
Example to Help the Client Understand:
· If the report had many documents with Label 1 (positive sentiment) and high scores, The client could conclude that their content resonates well with their audience, evoking positive feelings.· If the report had many documents with Label 0 (negative sentiment) and high scores, The client might need to revisit those pages to understand why they elicit negative sentiment.

Thatware | Founder & CEO
Tuhin is recognized across the globe for his vision to revolutionize digital transformation industry with the help of cutting-edge technology. He won bronze for India at the Stevie Awards USA as well as winning the India Business Awards, India Technology Award, Top 100 influential tech leaders from Analytics Insights, Clutch Global Front runner in digital marketing, founder of the fastest growing company in Asia by The CEO Magazine and is a TEDx speaker.
