SUPERCHARGE YOUR SEO Strategy & VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project focuses on creating an NLP-powered (Natural Language Processing) dashboard using a technique called Latent Semantic Analysis (LSA). It is specifically designed to improve SEO (Search Engine Optimization) and help website owners or businesses analyze their content in a smarter way. The project combines the power of advanced machine learning and interactive visualization to give clear, actionable insights about the text content of webpages.

In simpler terms, this project is like a smart assistant that reads, analyzes, and suggests improvements for website content, ensuring it performs better on search engines like Google.
What is This Project About?
Imagine you have a website with many pages, like a homepage, blog, about us, or services page. Now, if you want these pages to rank higher on Google, you need to:
- Understand what topics your content is covering.
- Find what’s missing or what needs improvement in your content.
- Get suggestions to make your content more effective for search engines.
This project helps solve these problems by:
- Analyzing content: It reads the text from each webpage and figures out the main topics or themes.
- Providing recommendations: It suggests which pages are similar, so you can link them together or restructure your website.
- Identifying gaps: It highlights topics or ideas that are missing from your website but are important for your target audience.
- Visualizing results: It displays all the insights in an interactive dashboard, so it’s easy to understand even if you’re not a technical expert.
Purpose of the Project
1. Help Businesses Improve SEO
The main purpose of this project is to boost website visibility on search engines by helping businesses optimize their content. SEO is critical because better visibility means more visitors, more sales, and better customer engagement. This project achieves that by:
- Highlighting topics your website is currently strong in.
- Identifying missing or weak topics (content gaps) that need improvement.
- Suggesting better content strategies using data-driven insights.
2. Make Content Analysis Easy and Visual
Analyzing website content manually can be overwhelming, especially for large websites. This project:
- Automates the analysis process using Natural Language Processing (NLP).
- Visualizes complex data like topic distributions and content gaps in a simple dashboard.
- Makes it accessible to non-technical users, so anyone can use the tool to improve their website’s SEO.
3. Support Strategic Decision-Making
This project is not just about identifying problems; it also helps website owners make better decisions. For example:
- If a topic is underrepresented on your website (e.g., “mobile app development”), you can write more blog posts or pages about it.
- If two pages are very similar, you can combine them to avoid redundancy and improve clarity for both users and search engines.
How Does the Project Work?
Here’s how the project operates :
- Collect Website Data:
- The project reads text content from webpages (e.g., blog posts, about us, services pages) using a technique called web scraping.
- It focuses only on the visible text, ignoring unnecessary parts like advertisements or code.
- Preprocess the Text:
- The collected text is cleaned and prepared using Natural Language Processing (NLP).
- This includes removing extra symbols, converting everything to lowercase, and simplifying words (e.g., changing “running” to “run”).
- Analyze Content with LSA:
- Latent Semantic Analysis (LSA) is applied to find the main themes or topics in the text.
- Each webpage is assigned to a topic based on its content, and keywords for each topic are extracted (e.g., for a topic like “SEO,” keywords could be “engine,” “search,” “rank,” etc.).
- Generate Insights:
- A similarity matrix is created to compare all webpages and identify which ones are similar.
- Content gaps are identified by analyzing how well different topics are covered across the website.
- Display Results in an Interactive Dashboard:
- A dashboard is created where users can:
- See content recommendations (e.g., which pages are similar and can be linked together).
- View a word cloud for each topic (a visual representation of important keywords).
- Check a bar chart of content gaps and take action to fill those gaps.
- A dashboard is created where users can:
Key Features of the Project
- Interactive Dashboard:
- A user-friendly dashboard where users can see all the insights visually.
- Easy to navigate, even for non-technical users.
- Topic Modeling:
- Automatically identifies the main topics covered in your website’s content.
- Extracts important keywords for each topic.
- Content Recommendations:
- Suggests which webpages are related, so you can create internal links or group similar content together.
- Content Gap Analysis:
- Shows which topics are not well-covered on your website and need more content.
- Data-Driven SEO Strategy:
- Helps businesses make informed decisions to improve their website’s SEO and user experience.
Why Is This Project Important?
- For Website Owners:
- Helps understand how their content performs.
- Provides actionable insights to improve search engine rankings.
- For SEO Professionals:
- Simplifies the process of analyzing website content.
- Saves time and effort in identifying content gaps and opportunities.
- For Recruiters and Employers:
- Demonstrates expertise in Natural Language Processing (NLP), data analysis, and SEO strategies.
- Shows practical application of advanced machine learning techniques like Latent Semantic Analysis (LSA).
Who Can Use This Project?
- Website Owners and Businesses:
- To improve their content quality and SEO performance.
- Digital Marketers and SEO Experts:
- To analyze and optimize client websites efficiently.
- Students and Developers:
- To learn about NLP techniques like LSA and apply them in real-world projects.
Final Thoughts
This project, “NLP-Powered Dashboard: Latent Semantic Analysis (LSA) for SEO,” is a powerful tool that simplifies the process of analyzing website content and optimizing it for search engines. It combines advanced NLP techniques, data visualization, and actionable insights to make content analysis accessible to everyone. Whether you are a business owner, marketer, or developer, this project provides practical solutions for improving website performance and user experience.
What is Latent Semantic Analysis (LSA)?
LSA is a mathematical method used to analyze and understand relationships between terms (words) and documents in a collection of text data. It helps to uncover hidden (latent) relationships in the data by reducing the complexity of the text using a technique called Singular Value Decomposition (SVD). This method groups words and documents based on their meanings and contexts, even if they don’t share exact terms.
What are its Use Cases?
LSA is widely used in:
- Search Engines: To provide better search results by understanding the context of a query rather than relying only on keyword matching.
- Text Summarization: To summarize large documents into meaningful short text.
- Plagiarism Detection: To find similarities in text while accounting for word rephrasing.
- Recommender Systems: For recommending similar documents, articles, or products.
- Customer Feedback Analysis: Understanding trends or topics in customer reviews or comments.
Real-Life Implementations
- Google Search: Google uses advanced versions of LSA to understand user intent and provide results based on the context of the query.
- Amazon: In recommending products similar to the ones you’ve viewed or purchased.
- Educational Systems: Automatically grading essays or analyzing student responses.
- Social Media: Identifying trending topics by analyzing large amounts of posts or tweets.
How is LSA Useful for Websites?
For a website owner, LSA can:
- Improve SEO: By analyzing the content of the website and identifying terms that are relevant to user searches.
- Content Clustering: Grouping similar articles or blog posts to improve navigation or recommend related content.
- User Behavior Analysis: Understanding what topics are most relevant to visitors based on the content they interact with.
- Keyword Optimization: Discovering keywords and topics that should be emphasized to attract more visitors.
What Does LSA Need to Work?
1. Input Data for LSA
- Text Data: This is essential and can come from:
- A collection of documents or articles.
- The text content of webpages (HTML text processed to remove tags).
- CSV or Excel files containing text data (e.g., blog titles, descriptions).
- Preprocessed Text: Raw text needs to be cleaned (removing stopwords, special characters, etc.) before analysis.
- For Websites*: LSA can either use:
- Webpage URLs: If you want to fetch and analyze live webpage content.
- CSV files: If you already have the webpage content stored in a structured format.
2. Processing Workflow for LSA
Here’s how LSA processes data:
- Text Extraction: Extract text content from URLs or read it from a CSV file.
- Preprocessing:
- Remove HTML tags if working with URLs.
- Remove stopwords, punctuation, and convert text to lowercase.
- Tokenize the text (break it into words).
- Term-Document Matrix Creation:
- Create a matrix where rows represent unique words (terms) and columns represent documents.
- The values in the matrix indicate the frequency of a word in a document.
- Apply Singular Value Decomposition (SVD):
- Reduce the dimensions of the term-document matrix to uncover hidden patterns and relationships.
- Output Generation:
- Clusters of similar terms or documents.
- Semantic structure showing relationships between terms and documents.
3. Output from LSA
- Semantic Similarity: Relationships between words or documents (e.g., which blog posts are similar).
- Topics or Themes: Common themes in the text data (e.g., a website might have themes like “technology,” “health,” or “finance”).
- Rankings: Prioritize content based on relevance to user queries.
Expected Output for a Website
- Related Content Recommendations: Grouping similar blog posts or articles.
- Topic Discovery: Identifying trending topics or underrepresented themes.
- Keyword Analysis: Suggesting keywords for improving SEO.
- Content Gaps: Highlighting areas where new content can be added.
LSA in Website Context:
Imagine you own a blog website with 500 articles. You want to:
- Identify clusters of similar articles.
- Recommend related articles to readers.
- Optimize content for better search rankings.
How it Works:
- Input Data:
- Either provide URLs of all 500 articles or upload their text data in a CSV file.
- Processing:
- Extract the text, clean it, and create a term-document matrix.
- Apply LSA to uncover patterns and relationships.
- Output:
- Clusters showing which articles are related.
- Themes or topics covered across the website.
- Suggestions for new content based on gaps.
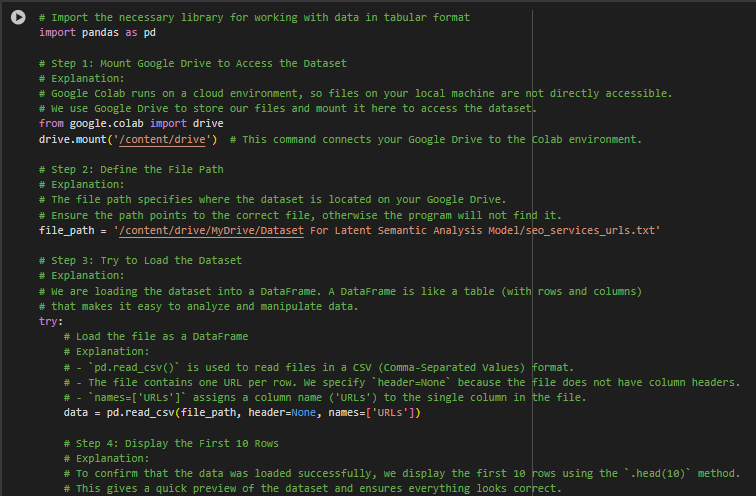
1. Part 1: Scraping Web Content
Purpose:
This part fetches the content of webpages from a list of URLs and saves it into a CSV file.
Steps in this Part:
· Mount Google Drive:
Connects to Google Drive to access the file containing URLs and save the output CSV.
· Define scrape_content Function:
Fetches the HTML content of a webpage and extracts readable text (e.g., paragraphs).
· Read URLs from File:
Loads the list of webpage URLs from a file into memory.
· Loop Through URLs:
Iterates over each URL, scrapes the content using scrape_content, and saves the result in a list.
· Save Scraped Data to CSV:
After scraping all URLs, saves the content to a CSV file for further processing.
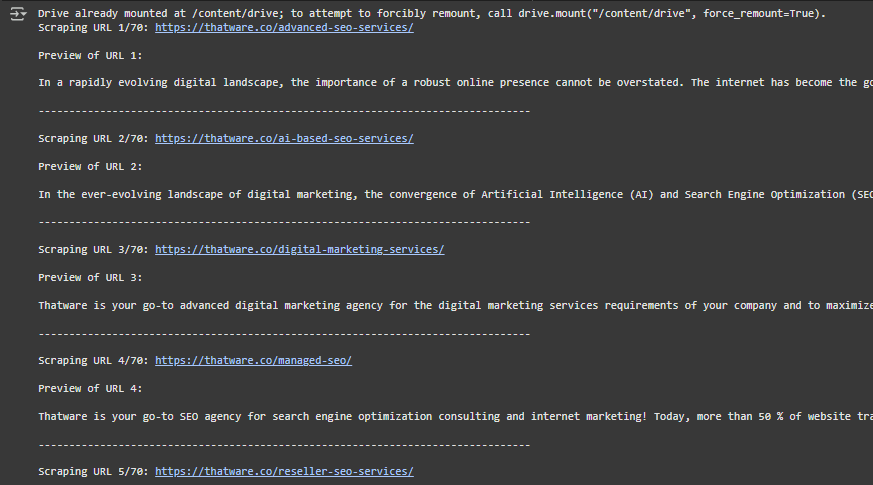
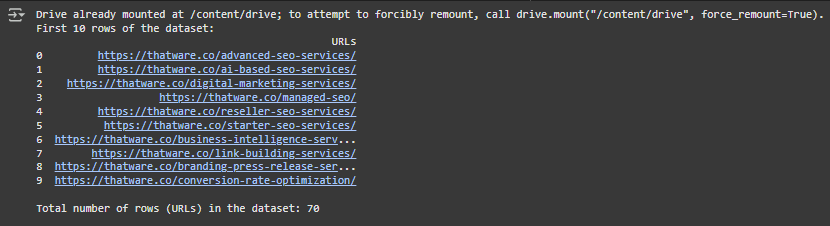
Understanding the Output
The output shows the results of a web scraping script that fetches content from 70 URLs, one by one, and provides a preview of the scraped content.
Output Components
1. Drive Mounting
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(“/content/drive”, force_remount=True).
- What is this? This step shows that Google Drive is already mounted in your Colab environment. Mounting Google Drive allows the script to access files stored in your Drive (like the input file containing URLs or where the scraped data is saved).
- Use case: It ensures that the script can read or save data from/to your Drive.
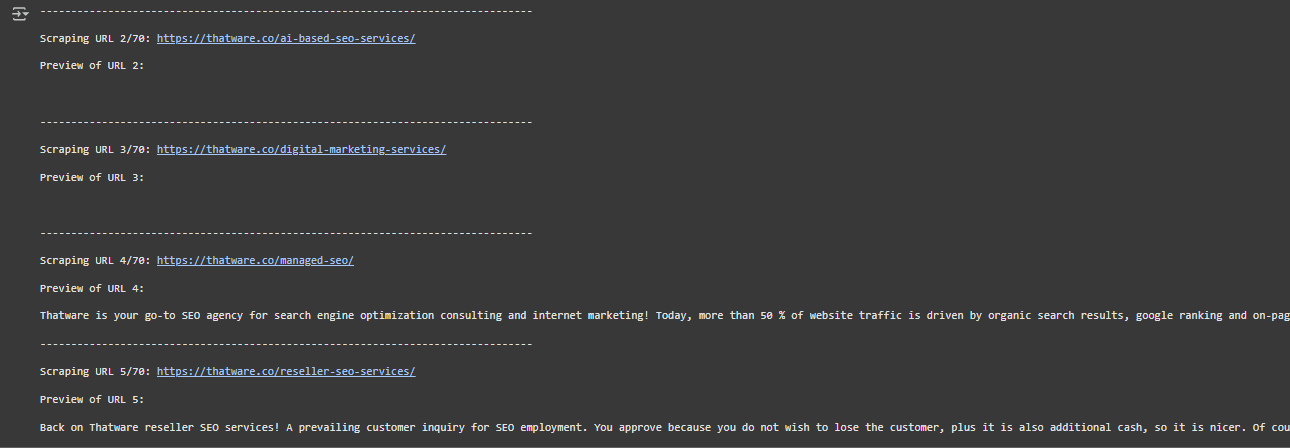
2. Scraping URL 1/70
Scraping URL 1/70: https://thatware.co/advanced-seo-services/
- What is this? The script is processing the first URL (https://thatware.co/advanced-seo-services/) from the list of 70 URLs in your input file.
- Use case: It indicates which webpage the script is currently scraping. This helps you track progress, especially if scraping a large number of URLs.
3. Preview of URL 1
Preview of URL 1:
In a rapidly evolving digital landscape, the importance of a robust online presence cannot be overstated. …
- What is this? This is the preview of the content scraped from the first URL. The script extracts visible text (e.g., paragraphs) from the webpage.
- Use case: The preview allows you to quickly check if the script is scraping relevant content. If the preview matches the webpage’s actual content, the script is working correctly.
4. Separator
——————————————————————————–
- What is this? This separator divides the output for different URLs, making it easier to distinguish between them.
- Use case: It improves readability of the output, especially when scraping multiple URLs.
5. Scraping URL 2/70
Scraping URL 2/70: https://thatware.co/ai-based-seo-services/
- What is this? This indicates that the script has moved on to the second URL in the list.
- Use case: It helps track which URL is currently being processed and the order in which URLs are scraped.
6. Preview of URL 2
Preview of URL 2:
In the ever-evolving landscape of digital marketing, the convergence of Artificial Intelligence (AI) …
- What is this? Similar to the first preview, this is the content scraped from the second URL.
- Use case: Like before, it provides a snapshot of the scraped data, ensuring that the script is extracting meaningful content.
7. Scraping URL 3/70
Scraping URL 3/70: https://thatware.co/digital-marketing-services/
- What is this? This indicates that the script has moved on to the third URL in the list.
- Use case: It continues to show progress in scraping multiple URLs, so you can monitor which URLs have been processed.
8. Preview of URL 3
Preview of URL 3:
Thatware is your go-to advanced digital marketing agency for the digital marketing services requirements …
- What is this? Content scraped from the third URL is displayed as a preview.
- Use case: Like before, the preview validates that the script is successfully fetching content from the specified webpage.
9. Continuing for URLs 4–20
- The output continues in the same pattern for URLs 4 through 20:
- Scraping URL X/Y: Indicates the URL being processed (e.g., URL 4/70, URL 5/70).
- Preview of URL X: Shows the first 500 characters of the scraped content for the corresponding URL.
- Separator: Divides the output for better readability.
Key Use Cases for the Output
- Validation of Scraping Process:
- By showing previews for each URL, the output confirms that the script is correctly extracting content.
- If a URL fails to scrape or returns incorrect content, you can identify and debug it immediately.
- Progress Tracking:
- The numbered format (e.g., URL 1/70) shows how far along the script is in scraping all the URLs.
- Content Analysis:
- The previews provide insights into the type of content available on each URL (e.g., SEO services, AI-based SEO, digital marketing).
2. Part 2: Preprocessing Text Data
Purpose:
This part cleans the raw text data scraped from webpages to prepare it for analysis.
Steps in this Part:
- Mount Google Drive:
Ensures the script can access input and output files stored in your Google Drive. - Download NLTK Data Files:
Downloads stopwords (common words like “the”, “is”) and lemmatization rules to clean the text. - Define preprocess_text Function:
- Removes unwanted characters (e.g., punctuation, numbers).
- Converts text to lowercase.
- Removes stopwords.
- Reduces words to their base form (e.g., “running” → “run”).
- Load Scraped Data:
Reads the scraped text data from the CSV file created in Part 1. - Clean the Text:
Applies the preprocess_text function to clean each webpage’s content. - Save Preprocessed Data to CSV:
Saves the cleaned text data into a new CSV file.
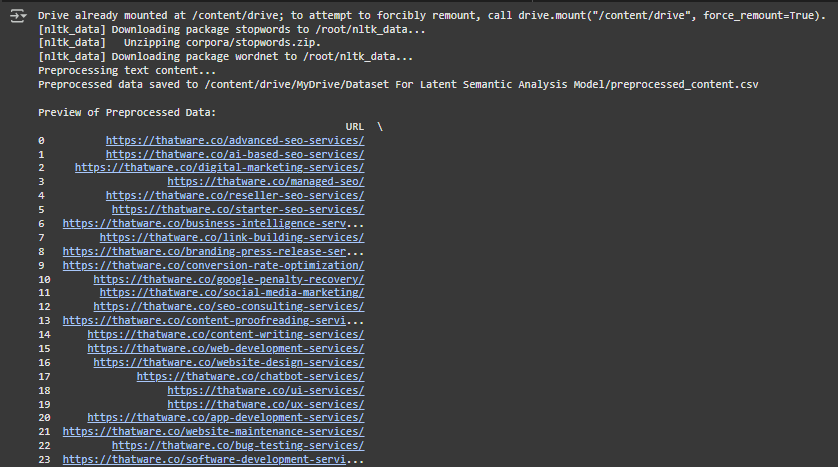
Explanation of the Output
The provided output is the result of text preprocessing performed on content scraped from a set of URLs (webpages). The purpose of this step is to clean and structure raw textual data to prepare it for further analysis, such as Latent Semantic Analysis (LSA).
1. The Header
Preprocessed data saved to /content/drive/MyDrive/Dataset For Latent Semantic Analysis Model/preprocessed_content.csv
- What does it mean?
- This line confirms that the preprocessed data has been successfully saved to a file named preprocessed_content.csv in the specified location in Google Drive.
- The file contains the cleaned content for all the URLs.
- Use case: This file acts as input for the next stages of analysis, such as topic modeling or similarity analysis.
2. The Table Structure
The table contains two columns:
URL Processed_Content
3. Column: URL
0 https://thatware.co/advanced-seo-services/
1 https://thatware.co/ai-based-seo-services/
2 https://thatware.co/digital-marketing-services/
…
- What is this?
- Each row in this column contains a URL corresponding to a webpage that was scraped.
- For example:
- Row 0: https://thatware.co/advanced-seo-services/
- Row 1: https://thatware.co/ai-based-seo-services/
- Use case:
- The URLs serve as identifiers, allowing you to link the processed content back to its source webpage.
- This is important for understanding which content belongs to which webpage.
4. Column: Processed_Content
rapidly evolving digital landscape importance …
everevolving landscape digital marketing conve…
thatware goto advanced digital marketing agenc…
- What is this?
- This column contains the processed and cleaned content extracted from the webpages.
- The raw scraped content from each URL has been transformed through preprocessing steps:
- Lowercasing: Converts all text to lowercase for consistency.
- Removing Special Characters & Numbers: Removes punctuation, numbers, and symbols to retain only text.
- Stopword Removal: Filters out common words like “and”, “the”, “is”, etc., which do not add much value to text analysis.
- Lemmatization: Reduces words to their base form (e.g., “running” → “run”).
- Use case:
- Processed content is structured and cleaned to ensure meaningful analysis in later stages, such as:
- Topic Modeling: Identifying dominant topics in the content.
- Clustering: Grouping similar webpages based on their textual content.
- Semantic Analysis: Understanding relationships between words and phrases.
- Processed content is structured and cleaned to ensure meaningful analysis in later stages, such as:
5. Preview of Preprocessed Data
This preview shows the first 40 rows of data, giving a quick snapshot of the cleaned content for the initial set of URLs.
Key Points to Note in the Output
- Purpose of Preprocessing:
- Raw content scraped from webpages often contains noise, such as HTML tags, special characters, or irrelevant words.
- Preprocessing standardizes and cleans the data, making it suitable for advanced text analysis techniques.
- Why Both Columns Are Necessary:
- URL: Links each row back to its source, providing context.
- Processed_Content: The core data used for analysis, cleaned and optimized for machine learning or natural language processing.
- Example Insight from the Output:
- Row 0 (URL: https://thatware.co/advanced-seo-services/):
- Raw Content: Discusses the importance of advanced SEO services in the digital landscape.
- Processed Content: Focuses on keywords like “digital”, “landscape”, “importance”, “advanced”, and “seo”.
- Row 0 (URL: https://thatware.co/advanced-seo-services/):
What One Can Understand From This Output
- Data Preparation for Analysis: The output represents the cleaned version of text data that will be analyzed to uncover patterns, topics, or relationships.
- Structured Dataset: The table format ensures each piece of data is well-organized and traceable back to its source.
- Next Steps: This data can now be fed into algorithms like TF-IDF, Latent Semantic Analysis (LSA), or clustering for meaningful insights.
3. Part 3: Extracting Topics with LSA
Purpose:
This part performs Latent Semantic Analysis (LSA) to extract topics from the cleaned text data.
Steps in this Part:
- Load Preprocessed Data:
Reads the cleaned text data from the CSV file created in Part 2. - Apply TF-IDF Vectorization:
Converts text into numerical values using TF-IDF (Term Frequency-Inverse Document Frequency), which gives more weight to important words. - Apply LSA (Latent Semantic Analysis):
Reduces the high-dimensional TF-IDF matrix into a smaller set of topics. - Extract Keywords for Topics:
For each topic, identifies the top keywords that define the topic. - Assign Topics to Documents:
Assigns the most relevant topic to each webpage based on the content. - Save LSA Results to CSV:
Saves the topics and their associated documents to a CSV file. - Generate Webpage Mapping:
Maps document IDs to webpage titles for easier reference. - Generate Heatmap:
Creates a visual heatmap of document similarities to identify closely related webpages.
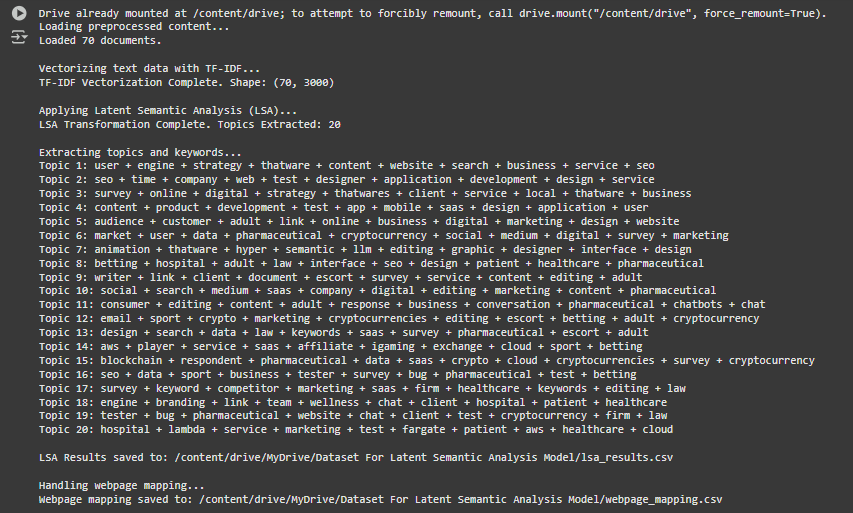
1. Loading Preprocessed Content
Loading preprocessed content…
Loaded 70 documents.
- What happened here?
- The program is loading 70 documents that were cleaned and preprocessed earlier. These documents are likely text content extracted from webpages.
- What are documents?
- A document refers to the text data from a webpage or any piece of written content being analyzed.
- Example: The text content from a webpage like https://thatware.co/advanced-seo-services/ is considered a “document.”
- Why is this step important?
- Preprocessing ensures that the text data is cleaned and ready for further analysis. Without this step, raw data might contain unnecessary characters or noise that could interfere with accurate results.
2. Vectorizing Text Data with TF-IDF
Vectorizing text data with TF-IDF…
TF-IDF Vectorization Complete. Shape: (70, 3000)
- What happened here?
- The program is converting text into numbers using TF-IDF (Term Frequency-Inverse Document Frequency).
- Shape (70, 3000):
- 70 rows: One for each document.
- 3000 columns: Each column represents a unique word or feature chosen by the model.
- What is TF-IDF?
- TF-IDF assigns importance to words based on:
- Term Frequency (TF): How often a word appears in a document.
- Inverse Document Frequency (IDF): How rare the word is across all documents.
- Example: Common words like “the” or “is” get lower importance, while unique words like “strategy” or “SEO” are given more weight.
- TF-IDF assigns importance to words based on:
- Why is this step important?
- Computers can’t directly process text. TF-IDF converts text into a format (numerical matrix) that can be used for further analysis like topic modeling.
3. Applying Latent Semantic Analysis (LSA)
Applying Latent Semantic Analysis (LSA)…
LSA Transformation Complete. Topics Extracted: 20
- What happened here?
- LSA (Latent Semantic Analysis) is applied to the TF-IDF matrix to reduce its dimensionality and extract hidden patterns in the data.
- The model identifies 20 topics based on relationships between words and documents.
- What is LSA?
- Latent Semantic Analysis is a mathematical technique that groups related words into topics. It helps to uncover the underlying themes in a collection of documents.
- For example:
- Documents mentioning “SEO,” “ranking,” and “Google” might belong to a topic about search engine optimization.
- Why is this step important?
- LSA simplifies the dataset by focusing on meaningful patterns and removing noise. Instead of dealing with thousands of words, we now work with a few topics.
4. Extracting Topics and Keywords
Topic 1: user + engine + strategy + thatware + content + website + search + business + service + seo
Topic 2: seo + time + company + web + test + designer + application + development + design + service
…
Topic 20: hospital + lambda + service + marketing + test + fargate + patient + aws + healthcare + cloud
- What happened here?
- For each of the 20 extracted topics, the model lists the top 10 keywords that define the topic.
- Example:
- Topic 1: Keywords like “user,” “engine,” “seo,” and “strategy” suggest this topic is about SEO strategies and user experience.
- What are topics?
- A topic is a cluster of words that frequently occur together in related documents.
- Each topic provides a summary of a theme or concept present in the dataset.
- Why is this step important?
- Keywords help explain what each topic is about. This allows us to:
- Categorize documents.
- Understand the themes present in the dataset.
- Keywords help explain what each topic is about. This allows us to:
5. Saving LSA Results
LSA Results saved to: /content/drive/MyDrive/Dataset For Latent Semantic Analysis Model/lsa_results.csv
- What happened here?
- The results of the LSA analysis, including the topic associations for each document, are saved to a CSV file.
- Why is this step important?
- Saving results ensures that the analysis can be reused without reprocessing the data. It’s helpful for sharing results or using them in dashboards.
6. Handling Webpage Mapping
Handling webpage mapping…
Webpage mapping saved to: /content/drive/MyDrive/Dataset For Latent Semantic Analysis Model/webpage_mapping.csv
- What happened here?
- Each document is linked to its corresponding webpage title or URL. This mapping helps trace back which topic belongs to which webpage.
- Why is this step important?
- Without mapping, it would be difficult to know which document (or webpage) corresponds to a specific topic.
7. Topic Distribution Summary
Topic 0: 62 documents
Topic 3: 2 documents
Topic 10: 1 documents
Topic 5: 1 documents
…
- What happened here?
- The program counts how many documents are associated with each topic.
- Example:
- Topic 0: 62 documents are related to this topic, making it the most dominant.
- Other topics (e.g., Topic 3, Topic 10) have fewer documents.
- Why is this step important?
- Understanding topic distribution helps:
- Identify the most prevalent themes in the dataset.
- Highlight content gaps in underrepresented topics (e.g., Topic 3).
- Understanding topic distribution helps:
Summary of the Output
- The output shows how text data from 70 documents was processed, analyzed, and grouped into 20 topics.
- Key insights:
- Documents: Text content extracted from webpages.
- Topics: Hidden themes identified by grouping related words and documents.
- Distribution: Some topics (e.g., Topic 0) are dominant, while others are niche.
How Can This Output Be Used?
- Content Analysis:
- Understand which themes are covered by the dataset.
- Content Gap Identification:
- Topics with fewer documents (e.g., Topic 3) might require more content creation.
- Keyword Insights:
- Keywords help summarize what each topic is about, aiding SEO and marketing strategies.
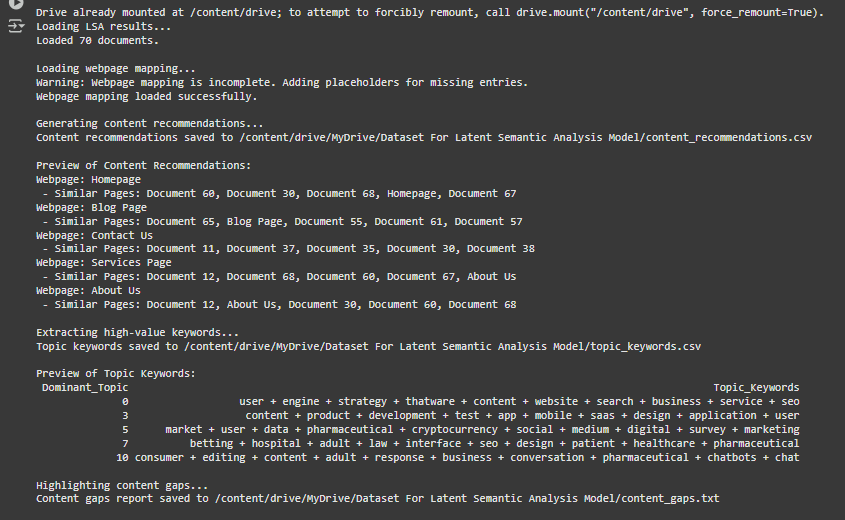
4. Part 4: Content Recommendations and Gap Analysis
Purpose:
This part generates actionable insights, such as related webpage recommendations, high-value keywords, and content gaps.
Steps in this Part:
- Load LSA Results and Webpage Mapping:
Reads the LSA topics and webpage mapping from the files created in Part 3. - Generate Content Recommendations:
Finds similar webpages for each document using a similarity matrix and creates a list of recommendations. - Extract High-Value Keywords:
Identifies the most important keywords for each topic, helping optimize content. - Highlight Content Gaps:
Analyzes the number of documents per topic to find underrepresented topics. Suggests creating more content for these topics. - Save Results to Files:
Saves the recommendations, keywords, and content gaps to separate files.
Understanding What “Documents” Represent
- What is a Document?
- A “document” in this context is a unit of textual content that was processed by the LSA model.
- It could represent:
- The content of a single webpage.
- A blog post.
- An article.
- Or even a specific section of text on a website.
- In simpler terms, think of a “document” as one piece of content that the system is analyzing.
- Why are Document IDs Used?
- Each document is assigned a unique ID (e.g., Document 0, Document 1) for easy identification.
- These IDs are a way for the system to track and reference each piece of content.
- Relation Between Documents and Webpages
- If your input data contains webpage content, then:
- Document 0 could be the “Homepage.”
- Document 1 could be the “Blog Page.”
- And so on.
- In the output, these document IDs are mapped back to their corresponding webpage titles to make the results easier to understand.
- If your input data contains webpage content, then:
Segment 1: Content Recommendations
Preview:
Webpage: Homepage
– Similar Pages: Document 60, Document 30, Document 68, Homepage, Document 67
What This Means:
- The model analyzed the content of the “Homepage” and found other webpages with similar content or themes.
- For example:
- Document 60 might represent a “Services Page” with similar keywords or topics.
- Document 30 could represent a “Contact Us” page that shares overlapping content with the homepage.
Why is This Useful?
- Content Optimization:
- Helps you identify redundancy or overlap in your website’s content.
- For example, if two pages are too similar, you might want to combine or differentiate them.
- Internal Linking:
- Use this data to create internal links between similar pages to improve navigation and SEO.
- Content Expansion:
- If a similar page (e.g., Document 60) has unique keywords not present on the homepage, you could use those keywords to enhance the homepage.
Segment 2: Topic Keywords
Preview:
Dominant_Topic Topic_Keywords
0 user + engine + strategy + thatware + content + website + search + business + service + seo
3 content + product + development + test + app + mobile + saas + design + application + user
What This Means:
- Each “topic” represents a theme or category discovered by the LSA model.
- The keywords listed for each topic are the most important words that define that theme.
Example:
- Topic 0:
- Keywords: user, engine, strategy, seo.
- Meaning: This topic likely relates to SEO (Search Engine Optimization) and business strategy.
- Topic 3:
- Keywords: app, mobile, design.
- Meaning: This topic focuses on mobile app development and related technologies.
Why is This Useful?
- Content Planning:
- Use these topics to decide what kind of content to create or expand on your website.
- For example, if Topic 3 is underrepresented, you might create blog posts about app design or mobile development.
- Understanding Themes:
- Helps you see what your content is about at a high level.
- For example, if Topic 0 dominates your website, your site is heavily focused on SEO.
Segment 3: Content Gaps
Preview:
Average Documents per Topic: 8.75
Topic 3: 2 documents
Suggestion: Add more content for topic 3
What This Means:
- The model calculates the average number of documents per topic (in this case, 8.75).
- Topics with fewer documents than this average are considered content gaps.
- For example:
- Topic 3 only has 2 documents, so it is underrepresented.
- The system suggests creating more content for Topic 3.
- For example:
Why is This Useful?
- Content Strategy:
- Helps you identify topics that need more attention on your website.
- For example, if Topic 10 is about cryptocurrency but has only 1 document, you might create more articles or guides about cryptocurrency to fill the gap.
- Improves Coverage:
- Ensures your website covers all important topics evenly, which can improve user engagement and SEO.
Is This Output Expected?
Yes, the output is functionally correct and aligns with the goals of the LSA model:
- It provides content recommendations based on semantic similarity.
- It extracts key topics from the content.
- It highlights content gaps to guide future content creation.
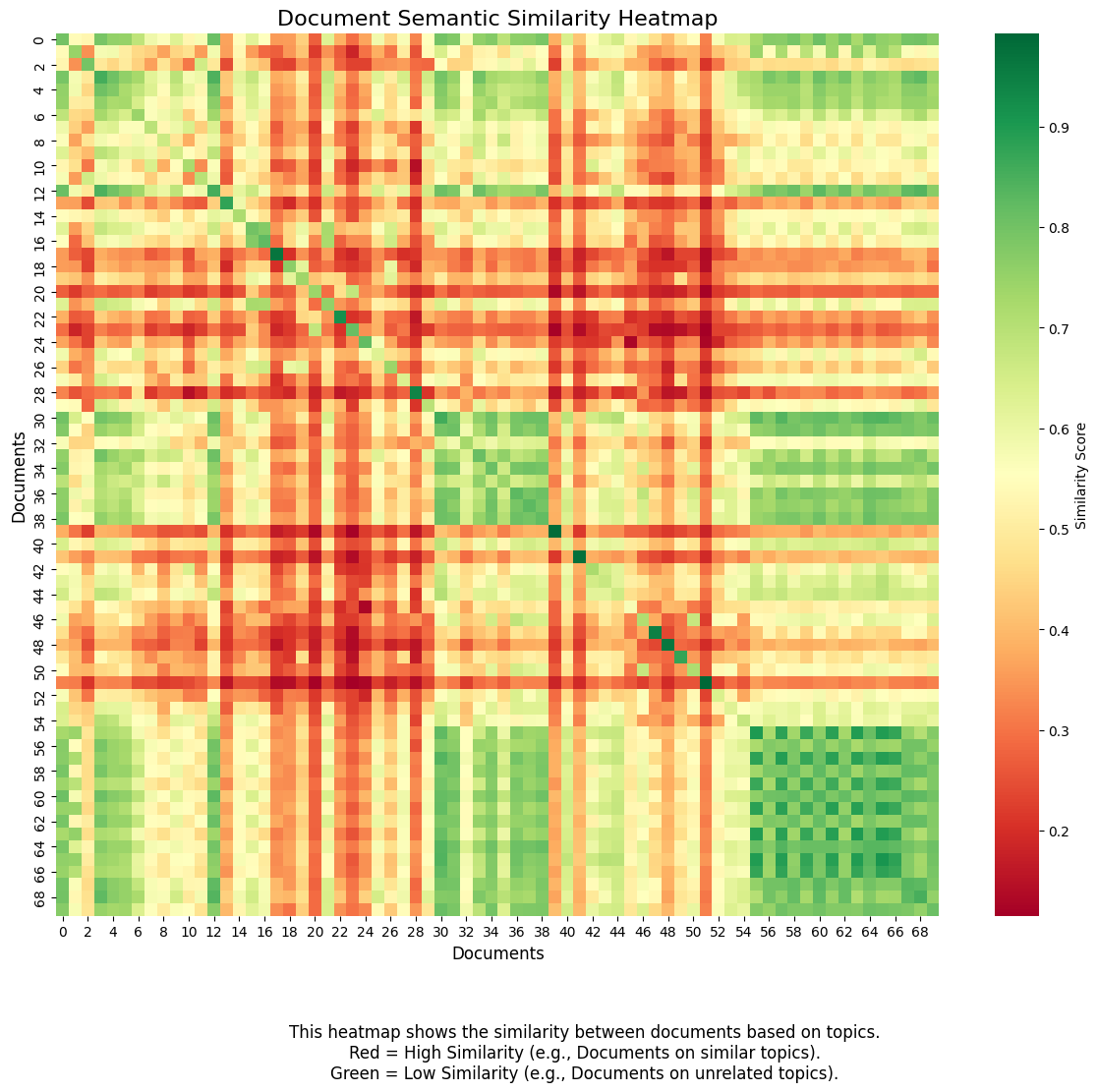
Explanation of the Heatmap Output:
This is a Semantic Similarity Heatmap generated as part of your Latent Semantic Analysis (LSA) model.
What is this Heatmap?
This heatmap is a visual representation of how similar each document in your dataset is to every other document. Here’s what it represents:
- X-axis and Y-axis: Both axes represent the 70 documents in your dataset.
- Each number (e.g., 0, 1, 2…) corresponds to a specific document.
- Example: Document 0 might represent the content of the webpage *”https://thatware.co/advanced-seo-services/”*.
- Color Intensity:
- Red areas: Indicate high similarity between two documents. These documents share a lot of similar topics, ideas, or keywords.
- Green areas: Indicate low similarity between two documents. These documents discuss completely different topics.
- Diagonal line (top-left to bottom-right):
- This represents each document compared to itself. Since a document is always 100% similar to itself, this line is always the reddest.
How to Interpret the Heatmap?
- High Similarity (Red Areas):
- Example: A block of red color between Document 10 and Document 12 (for instance) means these two documents discuss similar topics.
- Use Case:
- You can group these documents together or avoid writing duplicate content.
- This insight can help identify clusters of related content.
- Low Similarity (Green Areas):
- Example: If there’s a green patch between Document 30 and Document 40, it means they have little in common.
- Use Case:
- These documents might belong to completely different topics or audiences. This ensures variety in your content library.
- Clusters of Red/Green:
- Red clusters:
- Groups of documents discussing similar themes (e.g., several articles about SEO services).
- Green clusters:
- Groups of unrelated content, ensuring diversity across your dataset.
- Red clusters:
Key Features in the Heatmap
- Color Legend:
- On the right side of the heatmap, there’s a color bar.
- Dark Red (0.9): Very high similarity.
- Dark Green (0.2): Very low similarity.
- On the right side of the heatmap, there’s a color bar.
- Footnote/Explanation:
- The explanation at the bottom helps users understand the heatmap:
- Red = High similarity (documents discuss similar topics).
- Green = Low similarity (documents discuss unrelated topics).
- The explanation at the bottom helps users understand the heatmap:
- Why is this Useful?
- This helps you:
- Identify similar documents for internal linking or grouping.
- Avoid duplicate topics.
- Find gaps in your content strategy by identifying less-covered topics.
- This helps you:
Practical Use Cases of the Heatmap
- Content Optimization:
- If many documents are similar (red areas), you might merge or rewrite them to avoid redundancy.
- Content Gaps:
- Green areas between many documents suggest diverse topics are being covered, which is a good sign.
- However, green areas in important topics may indicate a need for more content creation.
- Internal Linking Strategy:
- Documents with high similarity (red areas) can be linked internally to boost SEO and user engagement.
- Content Categorization:
- Use this heatmap to group documents into themes (e.g., SEO services, marketing strategies, etc.).
How is the Heatmap Created?
Here’s how this heatmap was generated:
- TF-IDF and LSA:
- The text content of each document was converted into numbers using TF-IDF (to give importance to unique words).
- LSA extracted underlying topics from the dataset, converting documents into a reduced set of numerical features.
- Similarity Matrix:
- The heatmap is based on a similarity matrix, which measures how closely related two documents are in terms of the extracted topics.
- Color Mapping:
- Values from the similarity matrix are mapped to colors (green to red) for visual understanding.
Simplified Example
Let’s imagine we have just 3 documents:
- Document 1: Talks about “SEO strategies for small businesses.”
- Document 2: Talks about “Digital marketing trends.”
- Document 3: Talks about “Health and wellness.”
If we generate a heatmap for these, here’s what we might see:
- Document 1 and Document 2: High similarity (Red), as both are related to marketing.
- Document 1 and Document 3: Low similarity (Green), as SEO and health are unrelated.
What One Can Understand from This Heatmap
- Find Similar Content:
- For example, if you have many red patches, it means you have a lot of related content. This can be used for internal linking or revising similar articles.
- Ensure Content Variety:
- Green patches ensure your content library has variety, appealing to diverse audiences.
- Topic Gaps:
- If a topic is covered by only one or two documents, it’s a potential content gap.
Explanation for Non-Tech Users
- Think of This Heatmap Like a Music Playlist:
- Each document is like a song.
- The heatmap shows which songs are similar (red areas) and which are completely different (green areas).
- Goal:
- Ensure your playlist (content library) has variety while avoiding too much duplication.
5. Part 5: Building an Interactive Dashboard
Purpose:
This part creates a dashboard to visualize the LSA results, content recommendations, and gaps.
Steps in this Part:
- Load LSA Results and Recommendations:
Reads the data files created in previous parts. - Parse Content Gaps:
Processes the content gaps file into a format suitable for visualization. - Set Up Dash App Layout:
Defines the layout of the dashboard, including:- A table for content recommendations.
- A dropdown and word cloud for topic keywords.
- A bar chart for content gaps.
- Define Callback for Word Cloud:
Updates the word cloud dynamically based on the selected topic. - Run the Dashboard:
Launches the web-based dashboard to display the visualizations interactively.
Detailed Explanation of Each Part of the Output
1. Content Recommendations Table
What is it?
This is a table of content recommendations. For each webpage in your dataset, it lists other similar webpages based on their content.
What do the Columns Mean?
- Webpage Title:
- The main page or document you’re analyzing. For example, Homepage or Blog Page.
- These are the primary documents for which you want to find recommendations.
- Similar Webpages:
- A list of other webpages or documents that are semantically similar to the current webpage.
- Example: For the Homepage, it suggests documents like ‘Document 52’, ‘Document 60’, etc. This means these pages discuss similar topics or have related content.
How is this Table Useful?
- Internal Linking:
- You can use this table to create links between similar webpages to boost SEO and improve user experience.
- Example: If the Homepage is related to ‘Document 52’, you can add a link from the Homepage to ‘Document 52’.
- Content Optimization:
- If multiple documents are similar, you might consider merging or differentiating their content to reduce redundancy.
What Can You Learn From It?
- This table helps you understand the relationships between your webpages.
- It identifies clusters of related content and ensures that you don’t have isolated webpages without connections to others.
2. Content Gaps Bar Chart
What is it?
This is a visual representation of how many documents are associated with each topic in your dataset.
What Do the Axes Mean?
- X-axis (Topic): Each bar represents a specific topic identified during the Latent Semantic Analysis (LSA).
- Y-axis (Number of Documents): The height of the bar shows how many documents are related to that topic.
What Does the Chart Show?
- Topic Gaps:
- Topics with fewer documents are considered “gaps” in your content. For example:
- Topic 9 and Topic 3 have 2 documents.
- Topics 8, 17, 12, and 6 each have just 1 document.
- These gaps mean that these topics are underrepresented, and you may want to create more content around them.
- Topics with fewer documents are considered “gaps” in your content. For example:
- Balanced vs. Imbalanced Topics:
- Topics with many documents (not shown in the chart but inferred from Topic 0 having 62 documents) are well-covered.
- Topics with very few documents are areas where you could expand your content.
How is this Chart Useful?
- Content Strategy:
- Use this chart to prioritize which topics need more content. For example:
- Topic 8 has only 1 document, so you might want to create more webpages or blog posts around that topic.
- Use this chart to prioritize which topics need more content. For example:
- Audience Targeting:
- If certain topics align with your audience’s interests, you can focus on filling gaps in those areas.
3. Topic Keywords Word Cloud
What is it?
A word cloud is a visual representation of the most important keywords for a specific topic.
What Do the Words Mean?
- Big Words: These are the most frequently used or most important keywords in the topic.
- Smaller Words: These are less frequently used but still relevant to the topic.
Example for Topic 3:
- Big Words (like “software”, “development”, “mobile”): These are the core focus of Topic 3.
- Smaller Words (like “user”, “design”): These are secondary keywords but still part of the overall topic.
How is this Word Cloud Useful?
- Content Creation:
- Use the keywords to guide the creation of new content or optimize existing content. For example:
- For Topic 3, you might write a blog post titled: “Mobile Software Development Trends for Businesses.”
- Use the keywords to guide the creation of new content or optimize existing content. For example:
- Understanding Audience Needs:
- The keywords tell you what the topic is about. If your audience is interested in “mobile development,” you can focus your efforts on that.
Why is the Dropdown Important?
- The dropdown allows you to switch between topics and view their respective keywords.
- This flexibility lets you analyze multiple topics without cluttering the dashboard.
How All These Parts Work Together
- Content Recommendations Table:
- Helps you understand which webpages are related to each other.
- Useful for improving internal linking and reducing content duplication.
- Content Gaps Bar Chart:
- Shows which topics need more content.
- Guides your content strategy by highlighting underrepresented areas.
- Topic Keywords Word Cloud:
- Gives detailed insights into the focus of each topic.
- Helps you optimize your content for specific keywords.
Simplified Real-Life Example
Imagine you run a website with 70 pages. These pages cover various topics like SEO, mobile development, and digital marketing. This dashboard helps you:
- Find Connections (Recommendations Table):
- If Page A talks about “SEO basics,” and Page B also talks about SEO, you can link them together.
- Fill Gaps (Content Gaps Chart):
- If there’s only one page about “mobile app development,” you know you need to write more content on that topic.
- Optimize Content (Word Cloud):
- If “mobile” and “software” are key keywords for Topic 3, you can ensure those words are prominent in your content.
Why is This Output Valuable?
- Improves Website SEO:
- Internal linking and content gap analysis boost your website’s search engine rankings.
- Enhances User Experience:
- Visitors can navigate easily between related pages, increasing time spent on your website.
- Data-Driven Content Strategy:
- Instead of guessing what content to create, you can make informed decisions based on the data.
Latent Semantic Analysis (LSA) Model Code
What is Latent Semantic Analysis (LSA)?
LSA is a text analysis technique used to:
1. Identify topics in a collection of documents (like webpages).
2. Understand the relationships between these topics and the content in the documents.
3. Group similar documents based on their content.
It works by analyzing the text in all the documents (webpages) and finding patterns, relationships, and hidden meanings (semantics) in the content. This helps create structured insights from unstructured data (like the text on a website).
What Does This Output Mean?
The output is the result of applying LSA to your website’s content.
1. Number of Documents Loaded
· “Loaded 62 documents”:
o This means the model processed 62 pieces of content (webpages or documents) from your website.
o Each “document” here refers to a single webpage or content file.
Why is This Useful?
· The more documents you analyze, the better the understanding of the overall content structure of your website.
· It ensures that all relevant content is included in the analysis for better SEO optimization.
2. TF-IDF Vectorization
· “Vectorizing text data with TF-IDF… Shape: (62, 3000)”:
o TF-IDF stands for Term Frequency-Inverse Document Frequency, which is a technique to identify the most important words in each document.
o The shape (62, 3000) means:
§ 62 documents were analyzed.
§ 3000 unique features (words or phrases) were identified as important across all the documents.
Why is This Step Important?
· TF-IDF ensures the model focuses on the most relevant keywords for each webpage.
· It removes “stopwords” (like “the”, “and”, “is”) and other irrelevant terms, ensuring that only meaningful words are considered.
· This helps improve the accuracy of the topic detection and recommendations.
3. Applying LSA and Extracting Topics
· “Applying Latent Semantic Analysis (LSA)… Topics Extracted: 20”:
o LSA extracted 20 distinct topics from the documents.
o Each topic represents a group of words that frequently appear together and describe a common theme or idea.
· “Extracting topics and keywords”:
o For each topic, the model lists the top 10 keywords that define the topic.
Examples of Extracted Topics:
· Topic 1: user + strategy + thatware + engine + content + website + search + business + service + seo
o This topic is about SEO strategies, users, and business-related content.
· Topic 4: software + development + test + business + app + mobile + design + saas + application + user
o This topic focuses on software development, mobile apps, and SaaS-related content.
Why is This Useful?
· SEO Strategy:
o The topics help you understand the primary themes of your website’s content.
o You can identify if certain important topics (e.g., “SEO services” or “mobile development”) are well-represented or missing.
· Content Clustering:
o The keywords allow you to group related content together. For example, all pages about “software development” (Topic 4) can be linked or organized into a dedicated section on your website.
4. LSA Results Saved
· “LSA Results saved to: /content/drive/MyDrive/Dataset For Latent Semantic Analysis Model/lsa_results.csv”:
o This file contains the processed results:
§ Each document’s dominant topic.
§ Keywords associated with the dominant topic.
Why is This Important?
· This CSV acts as a blueprint of your website’s content structure. It can be used to:
o Identify gaps in your content.
o Plan future content creation.
o Organize your website around key themes.
5. Handling Webpage Mapping
· “Webpage mapping saved to: /content/drive/MyDrive/Dataset For Latent Semantic Analysis Model/webpage_mapping.csv”:
o This file maps each document to its corresponding webpage title.
o Example:
§ Document 1 = Homepage
§ Document 2 = Blog Page
§ Document 3 = About Us
Why is This Useful?
· This mapping allows you to link the analysis results directly to the actual webpages on your site.
· It ensures that actionable insights (like content gaps or topic clusters) can be applied to the correct pages.
6. Topic Distribution Summary
· What Does It Show?
o The summary lists how many documents (webpages) are associated with each topic.
Example:
· Topic 0: 54 documents
o This means most of your website’s content is focused on a single topic.
· Other Topics (e.g., Topic 9, Topic 3, etc.):
o Topics with only 1-2 documents indicate underrepresented areas or content gaps.
Why is This Important?
· Content Gap Analysis:
o Topics with very few documents (e.g., Topic 8, Topic 17, Topic 12) are potential areas where more content is needed.
o For example, if Topic 8 is about “hospital and healthcare” and it’s important for your business, you should create more pages targeting this topic.
· Content Balancing:
o If one topic (e.g., Topic 0) dominates the website, it might indicate an overemphasis on a single theme. This could dilute your website’s ability to rank for other important topics.
How Is This Output Beneficial for SEO?
1. Content Optimization:
o The output highlights the main themes of your website’s content.
o You can use this information to ensure that important topics are well-represented.
2. Internal Linking:
o By grouping similar documents (webpages) under the same topic, you can create internal links. This improves navigation for users and boosts SEO rankings.
3. Content Gaps:
o The topic distribution summary shows areas where content is lacking.
o You can use this to create new content that fills these gaps, making your website more comprehensive and appealing to search engines.
4. Keyword Optimization:
o The topic keywords help you identify the most important terms for each topic.
o You can optimize your webpages by ensuring these keywords are included in the titles, headings, and body text.
What Should the Client Do After Getting This Output?
1. Analyze Topics:
o Look at the extracted topics and identify the ones most relevant to their business.
o Ensure these topics are well-covered with multiple, high-quality pages.
2. Fill Content Gaps:
o Create new content for underrepresented topics.
o For example, if Topic 12 is about “hospital and healthcare” and only has 1 document, they should write blog posts, case studies, or service pages on this theme.
3. Enhance Internal Linking:
o Use the topic clusters to create links between related pages. This improves user navigation and helps search engines understand the structure of the website.
4. Keyword Optimization:
o Ensure that the keywords for each topic are well-represented in the corresponding webpages.
Final Summary
This output is a roadmap for improving the content structure and SEO of the website. It:
· Highlights the primary topics and keywords.
· Identifies content gaps that need to be filled.
· Provides insights for better internal linking and keyword optimization.
What is the Latent Semantic Analysis (LSA) Model?
LSA is a technique used to analyze and extract topics from text data. For example, it looks at all the content on your website (webpages) and identifies:
· The main themes or topics discussed.
· How similar these pages are to each other.
· Any gaps in the content that need to be filled.
This helps in improving SEO (Search Engine Optimization) because:
1. Search engines rank websites higher when they have well-organized and complete content around important topics.
2. Identifying content gaps can help create new pages to attract more traffic.
Breaking Down the Output
The output contains three main sections:
1. Loading and Analyzing Data
· “Loaded 62 documents”:
o Documents refer to webpages or pieces of content from your website.
o The model is analyzing 62 webpages to extract their topics, similarities, and gaps.
· “Webpage mapping is incomplete. Adding placeholders for missing entries”:
o The tool noticed that not all documents (webpages) have been mapped to specific titles. It created placeholder names (e.g., “Document 50”) to make sure no pages are missed in the analysis.
2. Generating Content Recommendations
· What Does It Mean?
o This section identifies similar webpages based on their content.
· Example:
o Webpage: Homepage
§ Similar Pages: Document 52, Document 60, Document 59, Document 50, Homepage
§ The homepage is similar to these documents, meaning these pages likely discuss overlapping topics or ideas.
o Webpage: Blog Page
§ Similar Pages: Document 8, Document 60, Document 59, Document 52, Contact Us
§ The blog page shares content themes with these pages.
· How Is This Useful?
o SEO Benefits:
§ You can create internal links between similar pages to improve navigation for users and increase SEO rankings.
§ For example, on the homepage, you can add links to “Document 52” or “Document 60.”
o Content Organization:
§ It helps organize your website better by grouping related pages under the same category or topic.
3. Extracting High-Value Keywords
· What Does It Mean?
o This section lists the top keywords for each topic (group of related documents).
· Examples:
o Topic 0: user + strategy + thatware + engine + content + website + search + business + service + seo
§ This topic is about SEO, content strategy, and business services.
o Topic 3: software + development + test + business + app + mobile + design + saas + application + user
§ This topic discusses software development, mobile apps, and SaaS solutions.
o Topic 9: betting + phone + answer + consumer + response + conversation + escort + chatbots + chat + adult
§ This topic seems to focus on chatbots, adult content, and customer interaction.
· How Is This Useful?
o Keyword Optimization:
§ You can ensure that these important keywords are well-represented in your webpage titles, headings, and body text.
§ This increases the chance of your website ranking higher for these terms in search engines.
o Content Creation:
§ If a topic (like Topic 9) is important to your business but has few documents, you can create more content using these keywords.
4. Highlighting Content Gaps
· What Does It Mean?
o The tool compares the number of documents (webpages) associated with each topic to the average number of documents per topic (8.86 in this case).
o Topics with fewer documents than the average are flagged as content gaps.
· Examples:
o Topic 9: 2 documents
§ Suggestion: Add more content about chatbots, consumer interaction, or related keywords.
o Topic 3: 2 documents
§ Suggestion: Create more content about software development and SaaS solutions.
o Topic 8: 1 document
§ Suggestion: Write more about proofreading, editing, or content writing.
o Other Topics (17, 12, 6):
§ These topics have only 1 document each and need additional content.
· How Is This Useful?
o Content Gap Analysis:
§ Topics with fewer documents indicate areas where your website is lacking content.
§ Filling these gaps can make your website more comprehensive, attract more traffic, and improve your rankings.
o Actionable Steps:
§ For each topic with gaps, create new blog posts, service pages, or case studies around the keywords listed in the “Topic Keywords” section.
How Is This Output Beneficial for SEO?
1. Improves Internal Linking:
o By linking similar pages together (based on the “Content Recommendations”), you can improve user navigation and help search engines better understand your website’s structure.
2. Boosts Keyword Rankings:
o Optimizing your content with the high-value keywords from the “Topic Keywords” section can help improve your rankings for those terms.
3. Fills Content Gaps:
o Creating content for underrepresented topics ensures your website covers a wide range of relevant topics, making it more appealing to users and search engines.
4. Better Content Organization:
o The analysis helps group related pages together, making it easier to create categories or sections on your website.
What Steps Should the Client Take After Getting This Output?
1. Review Content Recommendations:
o Look at the “Similar Pages” for each webpage.
o Add internal links between these pages to improve navigation and SEO.
2. Fill Content Gaps:
o Identify topics with fewer documents (e.g., Topics 9, 3, 8) and create new content to cover these areas.
o Focus on the keywords provided for each topic to ensure the content is relevant.
3. Optimize Existing Pages:
o Ensure that important keywords from the “Topic Keywords” section are used in your existing content.
4. Create Topic Clusters:
o Organize your website into clusters based on the topics identified by LSA.
o For example, create a section for “SEO Services” (Topic 0) or “Software Development” (Topic 3).
5. Monitor Results:
o After implementing the recommendations, monitor your website’s traffic and rankings to see if there’s improvement.
Final Summary
This output is a blueprint for improving your website’s SEO and content structure. It:
· Groups similar pages together for better organization.
· Identifies high-value keywords to optimize your content.
· Highlights content gaps that need to be filled.
· Provides actionable recommendations to make your website more comprehensive and SEO-friendly.
What is Latent Semantic Analysis (LSA)?
· Purpose of LSA:
LSA is used to understand the main topics/themes of a set of documents (in this case, webpages). It identifies patterns in the content and extracts relationships between documents based on their content.
· SEO Benefits of LSA:
Search engines like Google reward websites that have well-structured, relevant, and comprehensive content around specific topics.
o LSA helps you understand which pages on your website are similar or related.
o It highlights missing content (content gaps), which means you can create new content to fill those gaps and improve your site’s completeness.
o It also shows the keywords associated with each topic, helping optimize your content for SEO.
Explanation of the Output
1. Content Recommendations
This section identifies which webpages are similar to each other based on their content.
· Example:
o Homepage:
Similar Pages: Document 52, Document 60, Document 59, Document 50, Homepage
This means that these pages discuss overlapping topics, which might include SEO strategies, website services, or business content.
o Blog Page:
Similar Pages: Document 8, Document 60, Document 59, Document 52, Contact Us
These pages might all focus on blog-related content, customer engagement, or SEO topics.
· How is this useful for SEO?
1. Internal Linking:
§ You can create internal links between similar pages (e.g., from the Homepage to Document 52). This improves navigation and helps search engines understand your site structure.
§ Example: On the Homepage, add a link to Document 60 if it’s relevant to SEO services.
2. Content Clustering:
§ Use this information to group related pages under a specific section or category.
§ For instance, if the Blog Page and Contact Us are related, you can create a category or menu for “Customer Engagement.”
3. Avoid Content Overlap:
§ If too many similar pages exist, consolidate them to avoid duplicate content issues.
2. Topic Keywords
This section shows the most important keywords for each topic (cluster of documents).
· Example Topics and Keywords:
o Topic 0:
Keywords: user + strategy + thatware + engine + content + website + search + business + service + seo
This topic focuses on SEO, content strategy, and business services.
o Topic 3:
Keywords: software + development + test + business + app + mobile + design + saas + application + user
This topic is about software development, mobile apps, and SaaS solutions.
o Topic 9:
Keywords: betting + phone + answer + consumer + response + conversation + escort + chatbots + chat + adult
This topic relates to chatbots, consumer interaction, and possibly adult content.
· How is this useful for SEO?
1. Optimize Content with Keywords:
§ Ensure that the most important keywords for each topic are included in your webpage content.
§ For example, for Topic 3, make sure your software development pages mention “development,” “test,” “business,” etc.
2. Improve Keyword Rankings:
§ Use these keywords in page titles, headings (H1, H2), and meta descriptions.
3. Focus on Topics with Fewer Pages:
§ If a topic is important but has fewer pages (e.g., Topic 9), create new pages or blog posts to target these keywords.
3. Content Gaps
This section identifies topics that have fewer pages than the average number of pages (8.86 in this case). These are your content gaps.
· Examples of Content Gaps:
o Topic 9:
Only 2 documents exist, but it needs more content.
Suggestion: Create blog posts or service pages about chatbots, consumer interaction, and response systems.
o Topic 3:
Only 2 documents exist.
Suggestion: Add content about software development and SaaS solutions.
o Topic 8:
Only 1 document exists.
Suggestion: Focus on proofreading, editing, and content writing topics.
· How is this useful for SEO?
1. Fill Content Gaps:
§ Creating new content for underrepresented topics ensures your site is more comprehensive. This improves your chances of ranking higher for related keywords.
§ Example: For Topic 9, write a guide on “How Chatbots Improve Customer Experience.”
2. Align Content with Business Goals:
§ If a topic aligns with your business goals (e.g., SaaS solutions in Topic 3), prioritize it when creating new content.
3. Attract More Visitors:
§ Covering diverse topics attracts a broader audience, improving overall website traffic.
How is This Output Beneficial for SEO?
1. Internal Linking Opportunities:
o By linking similar pages together (as shown in the Content Recommendations), you can improve navigation and help search engines index your site more effectively.
2. Keyword Optimization:
o Optimizing your content with the suggested keywords can help you rank higher for relevant searches.
3. Filling Content Gaps:
o Identifying and addressing content gaps ensures your website has comprehensive coverage of all important topics.
4. Better Content Organization:
o The analysis helps group related pages together, making your website more user-friendly.
5. Improved Rankings:
o Search engines reward websites that have well-structured, relevant, and comprehensive content.
What Steps Should the Client Take?
1. Review the Content Recommendations:
o Check which pages are similar and decide whether to link them together or consolidate them.
2. Create New Content for Content Gaps:
o Identify topics with fewer documents (e.g., Topic 9, Topic 3) and create new pages or blog posts.
3. Optimize Existing Pages:
o Use the Topic Keywords to update your existing pages with the most important terms.
4. Monitor Results:
o Track how your website’s traffic and rankings improve after implementing these changes.
Final Summary
This output provides a roadmap for improving your website’s SEO by:
· Identifying related pages (Content Recommendations).
· Highlighting important keywords for each topic (Topic Keywords).
· Pointing out content gaps (Content Gaps) where more content is needed.
By following these recommendations, you can:
· Improve your website’s organization and navigation.
· Optimize for high-ranking keywords.· Attract more visitors and achieve higher search engine rankings.

Thatware | Founder & CEO
Tuhin is recognized across the globe for his vision to revolutionize digital transformation industry with the help of cutting-edge technology. He won bronze for India at the Stevie Awards USA as well as winning the India Business Awards, India Technology Award, Top 100 influential tech leaders from Analytics Insights, Clutch Global Front runner in digital marketing, founder of the fastest growing company in Asia by The CEO Magazine and is a TEDx speaker.
