SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project implements a scalable and efficient dense retrieval system using dual encoder models to enhance semantic search capabilities within SEO content. The system uses two separately trained encoders—one for processing user queries and another for content blocks—enabling independent representation and fast similarity-based retrieval.
The pipeline extracts and cleans content from multiple URLs, encodes both the queries and content blocks into dense vectors, and retrieves top-matching content segments based on semantic similarity. This approach enables accurate identification of relevant information across web pages and supports better content-query alignment. The results are structured for clarity and can be exported for further SEO review or integration.

Project Purpose
The purpose of this project is to improve semantic retrieval of web content for SEO-focused use cases by using a dual encoder architecture. Traditional keyword-based search systems often fall short in understanding the meaning behind user queries, especially when queries are phrased differently from the content on the page. This project addresses that gap by leveraging transformer-based models that embed both queries and content blocks into a shared vector space, enabling semantic-level comparisons rather than relying on keyword overlap.
The project enables retrieval of the most contextually relevant content segments from a diverse set of webpages. It is specifically designed to assist in SEO tasks such as content optimization, intent alignment, and enhancing the discoverability of web pages by ensuring that critical blocks of information can be surfaced based on their semantic fit with user intent.
By supporting independent encoding of queries and documents, the system offers high scalability, fast retrieval, and flexibility in updating content without reprocessing the entire dataset.
Project’s Key Topics Explanation and Understanding
Dual Encoder Models
A dual encoder architecture uses two separate transformer-based encoders—one for user queries and another for content documents or blocks. Each encoder is trained to produce embeddings that reside in the same semantic vector space, allowing meaningful similarity comparisons using methods such as dot product or cosine similarity.
In this project:
- facebook-dpr-question_encoder is used to encode the queries.
- facebook-dpr-ctx_encoder is used to encode the content blocks.
These models are trained with question-answering data, which enables the system to align real user queries with meaningful responses found in content, even when phrasing differs.
Independent Encoding of Queries and Documents
A key advantage of the dual encoder architecture is that both queries and documents are encoded independently. This separation allows for:
- Offline preprocessing of content: Content blocks can be encoded and stored in advance.
- Real-time query processing: At inference time, only the query needs to be encoded and compared to precomputed document vectors.
This independent encoding mechanism is central to achieving scalable and responsive search performance, especially when dealing with large sets of SEO content.
Fast and Scalable Retrieval
To support fast retrieval from thousands of content blocks, the project integrates FAISS (Facebook AI Similarity Search) — a high-performance library optimized for efficient similarity search over large-scale vector datasets.
Key aspects:
- Embeddings are normalized and indexed once for fast inner product comparisons.
- Query vectors are matched against the index to retrieve the top-k most similar content blocks.
- Retrieval is done in real time with minimal latency, even across multiple pages.
This enables SEO analysts to process and evaluate large volumes of web content with speed and consistency, which is essential for enterprise-level optimization tasks.
Semantic Relevance Beyond Keyword Matching
Unlike traditional systems that rely on lexical overlap, this approach supports semantic-level matching:
- Allows queries to retrieve conceptually relevant passages, even without direct keyword overlap.
- Improves alignment between search intent and content, especially important in SEO content audits, FAQ generation, and topic clustering.
This capability ensures that high-value content is discoverable based on meaning, not just surface terms.
Q&A Section: Understanding Project Value and Importance
Why is this dual encoder system more effective than keyword-based search for SEO content?
Keyword-based systems often struggle when queries are phrased differently from the way content is written, even if they are semantically related. This project solves that issue by using dual encoder models trained on semantic relevance rather than keyword frequency. The encoders learn to represent both queries and content blocks in the same vector space, allowing retrieval based on meaning rather than exact terms. This leads to more accurate and useful results, especially in SEO where user phrasing is unpredictable and diverse.
For example, a query like *”optimize image indexing for SEO”* may retrieve content mentioning *”preferred image URL via HTTP headers”*, even if those exact words aren’t used in the query. Such alignment significantly enhances content visibility and search intent matching.
What makes this system scalable for large websites or domains with many pages?
The architecture of this system separates query encoding from document encoding. Content from multiple URLs is preprocessed and encoded in advance, and those vectors are stored in a FAISS index. During live usage, only the query needs to be encoded and compared against this index. This avoids repeated reprocessing of content and supports fast retrieval across thousands of blocks.
The separation allows new queries to be handled efficiently without modifying the content index, making the system suitable for large SEO projects that involve frequent re-querying or updating content across a growing set of web pages.
How does this system improve SEO analysis and decision-making?
This system allows SEO professionals to:
- Pinpoint which blocks of content best answer specific user intents.
- Identify semantic gaps where content might exist but does not align well with key queries.
- Compare multiple URLs simultaneously to evaluate which pages best respond to targeted queries.
By retrieving the most contextually relevant segments from across a set of pages, the system surfaces strengths, weaknesses, and opportunities within the content structure—supporting data-backed decisions for rewriting, updating, or optimizing specific sections.
Can this project be used in ongoing SEO monitoring and audits?
Yes. Once the content index is built, the same infrastructure can be used repeatedly with updated query lists for ongoing audits. New user queries can be introduced at any time, and results can be reviewed instantly using the existing FAISS index. Export options also allow integration with internal workflows or external reporting tools.
This flexibility makes the system suitable not just for one-time evaluations, but also for recurring SEO quality checks, relevance audits, and performance reviews.
You’re right to raise that. Four questions provide a strong foundation, but expanding the section with a few more high-value, practical, and insightful questions can enhance the client’s understanding of the full project potential. Additional questions should highlight other dimensions such as integration, flexibility, adaptability, and team usage.
How does this support SEO content planning for new keywords or topics?
When introducing new target keywords or topics into a content strategy, this system can test whether existing content already addresses those topics semantically. By running new queries through the model, it becomes clear which pages already align and where there are gaps.
This supports proactive SEO planning by identifying under-optimized themes, ensuring new content efforts are directed toward areas that add the most value. The dual encoder structure ensures meaningful comparisons, even when content is phrased differently from the target keywords.

Libraries Used
requests
- A widely adopted HTTP client library for Python, used to make reliable and configurable web requests.
- It fetches the raw HTML content from input URLs. Custom headers and timeout controls ensure resilient network communication when retrieving live content from client sites or third-party pages.
bs4 (BeautifulSoup) and Comment
- BeautifulSoup is a powerful HTML and XML parsing library that allows for easy navigation, searching, and modification of the parse tree.
- It parses HTML and extracts relevant content blocks such as paragraphs, headings, and list items. It also removes irrelevant content such as scripts, hidden elements, navigation links, and boilerplate elements to ensure clean input for downstream processing.
hashlib
- A standard Python library used for cryptographic hashing.
- It generates deterministic UUIDs based on content block text. This allows block-level deduplication and traceability even if the same content appears in multiple places.
numpy
- A fundamental library for numerical computing in Python, supporting multi-dimensional arrays and mathematical operations.
- It handles embedding vector operations including stacking, normalization (for FAISS inner product search), and transformation of model outputs into structured data formats. It also supports efficient handling of FAISS index data.
re (Regular Expressions)
- A built-in Python module for pattern matching and substitution in strings.
- It cleans and formats web content during preprocessing. This includes removing boilerplate phrases (e.g., “click here”, “read more”), unwanted punctuation patterns, numbered or bulleted prefixes, and embedded URLs—ensuring the cleanest possible text input to the encoder.
html and unicodedata
- Standard libraries used to decode HTML entities and normalize Unicode characters in text.
- These libraries are used to process special symbols, smart quotes, non-breaking spaces, and encoded characters found in raw HTML, improving input uniformity and model compatibility.
csv
- A standard library for reading and writing CSV files.
- It is used to export the top-k retrieval results into structured tabular format. This enables clients to archive, share, or further analyze the semantic search results outside the system, especially in existing SEO audit workflows.
transformers.utils.logging
- A utility from the transformers library to configure logging verbosity and suppress unnecessary model loading output.
- It suppresses verbose console logs during model loading and inference to ensure a cleaner user experience, especially when operating in automated or UI-facing environments.
sentence_transformers
- A library built on top of HuggingFace Transformers that simplifies training and usage of models for producing semantically meaningful sentence embeddings.
- It loads and runs both encoders in the dual encoder architecture—one for queries and one for content blocks. The SentenceTransformer interface supports batching, device management (CPU/GPU), and output formatting for use with FAISS.
torch
- The deep learning framework powering PyTorch models.
- It enables device configuration and ensures that the model operates efficiently by automatically detecting GPU availability when encoding queries or documents.
faiss
- Facebook AI Similarity Search (FAISS) is a high-speed vector similarity search library optimized for large-scale dense embedding retrieval.
- It builds and manages the retrieval index of all content block embeddings. This allows fast inner-product search across potentially thousands of pre-encoded content blocks, enabling real-time retrieval of top-matching passages for each user query.

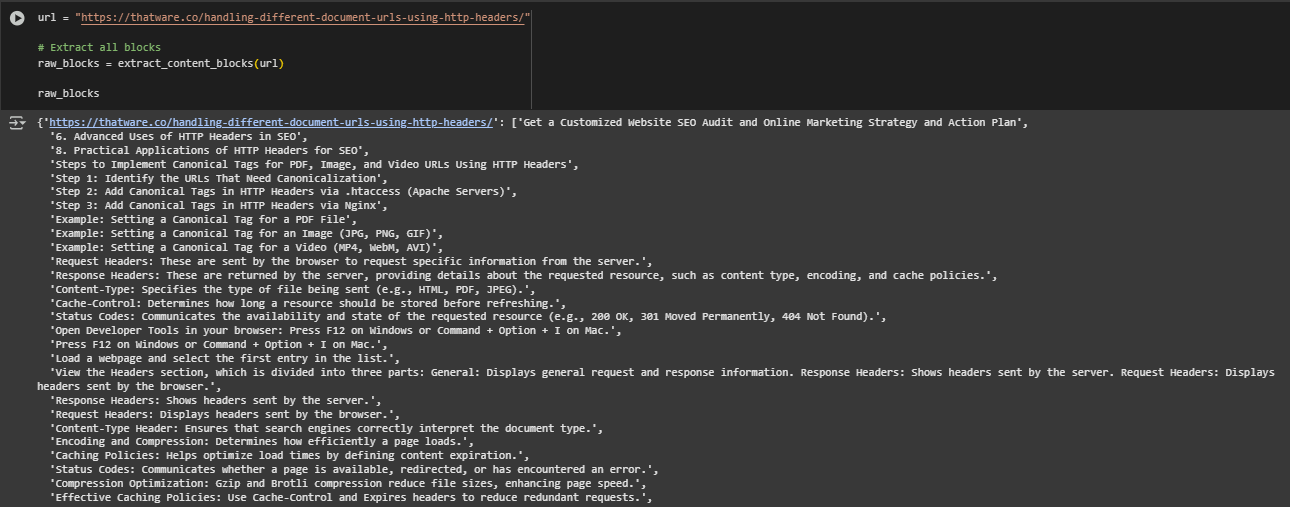
Function: extract_content_blocks
Overview
This function is responsible for retrieving and segmenting the visible content from a webpage into clean, self-contained content blocks. Each block is suitable for independent semantic encoding and similarity comparison. The output is structured in a {url: [blocks]} format, where each block is a plain text snippet extracted from meaningful HTML elements such as paragraphs, headers, or list items.
This function is the first stage of the retrieval pipeline and is designed to ensure only relevant, human-readable content is retained for downstream encoding. It also handles network resilience, deduplication, and document structure cleanliness.
Code Explanation
· response = requests.get(…) Fetches the webpage using a user-agent header and a configurable timeout. Ensures proper request handling, which is important when crawling live or client-managed sites.
· soup = BeautifulSoup(response.text, “html.parser”) Parses the raw HTML into a navigable tree structure that enables tag-level extraction.
· page_title = soup.find(“title”)… Extracts the page title if available. Though not used in the current output, it’s preserved for optional metadata enrichment in later stages.
· Tag Cleanup Loops (soup.find_all / decompose) Removes all layout, script, and hidden elements that do not contribute meaningful content. This eliminates noise such as navigation bars, cookie banners, and embedded media.
· if len(text.split()) < min_word_count: Filters out extremely short blocks that do not meet the minimum semantic length. This ensures only meaningful blocks are passed forward for embedding.
· hashlib.md5(norm_text.encode()).hexdigest() Deduplicates content using normalized text hashing. This avoids scoring duplicate blocks or cluttering the retrieval index.
· blocks.append(text) Collects clean, deduplicated, and filtered blocks in sequence. The returned dictionary maps the original URL to this list of meaningful content snippets.
· return {url: blocks} Returns a dictionary with the URL as key and its list of valid content blocks as the value. This structure supports batch processing of multiple URLs and efficient block management.
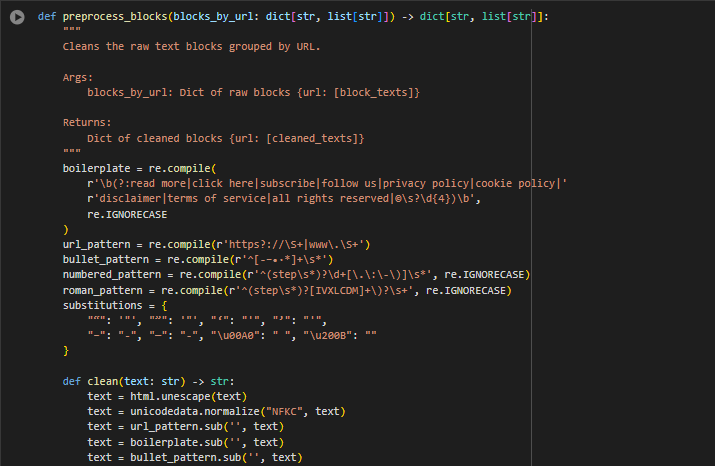
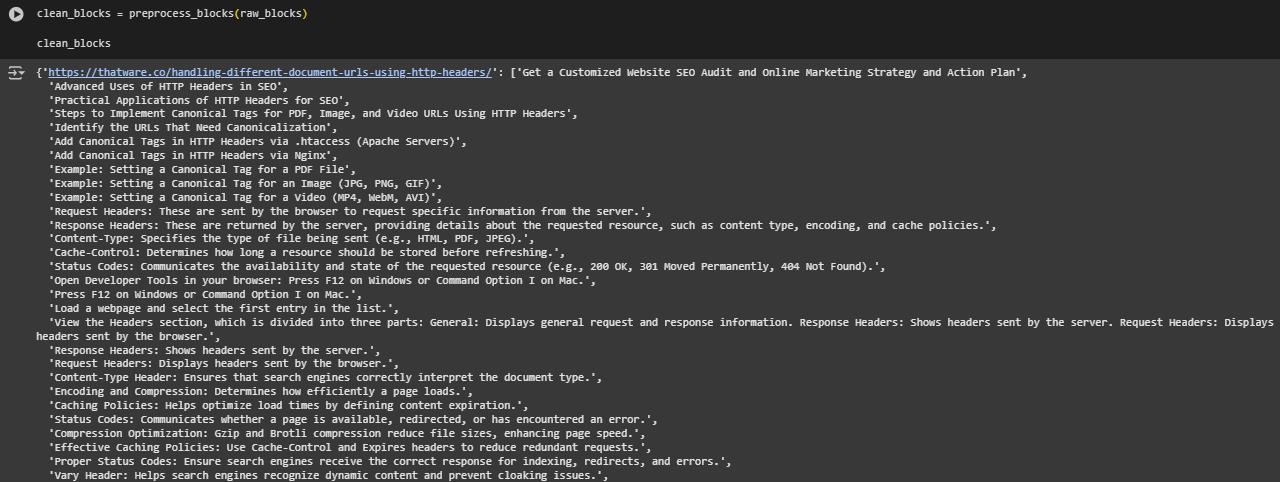
Function: preprocess_blocks
Overview
This function cleans the raw content blocks extracted from webpages by removing noise, boilerplate language, formatting artifacts, and unwanted characters. It operates on a per-URL basis and maintains the input-output structure {url: [blocks]}, ensuring compatibility with multi-page workflows.
The preprocessing step is crucial before encoding content for retrieval. It ensures the model receives clean, semantically meaningful text without web-specific clutter like navigation phrases, links, or hidden symbols. This improves embedding quality and downstream search relevance.
Code Explanation
· boilerplate = re.compile(…) Identifies and removes recurring non-informational phrases commonly found in web templates (e.g., “click here”, “subscribe”, “privacy policy”). Eliminating these helps focus the model on core content.
· url_pattern = re.compile(…) Detects and removes embedded URLs and hyperlinks from blocks, which often distract from the semantic intent of the content.
· bullet_pattern, numbered_pattern, roman_pattern Strips out formatting prefixes used in lists (e.g., • Step 1: or I. Introduction). This improves the uniformity of block text across different HTML elements.
· substitutions dictionary Normalizes smart quotes, dashes, and invisible Unicode characters to standard ASCII equivalents. This ensures encoding consistency across different sites and platforms.
· text = unicodedata.normalize(“NFKC”, text) Applies Unicode normalization to handle accented characters and invisible artifacts, improving embedding stability and text comparison fidelity.
· text = re.sub(…) (multiple) Handles fine-grained cleaning such as collapsing excessive punctuation, stripping unusual characters, and compressing whitespace.
· if len(cleaned.split()) > 4: Filters out blocks that are too short to carry useful meaning, preserving only those that contribute to retrieval accuracy.
· return cleaned_by_url Returns the cleaned block dictionary in the same structure as the input: one entry per URL, each with a list of clean text blocks. This format enables simple downstream encoding and traceability.

Function: load_dual_encoder_model
Overview
This function loads a transformer-based encoder model from the SentenceTransformers library. It automatically determines whether to load the model on a GPU (cuda) or CPU (cpu) based on hardware availability, which ensures efficient execution across environments.
In the context of this project, this function is used to load the two distinct encoders that make up the dual encoder architecture: one for queries and one for documents (content blocks). Each encoder operates independently, allowing fast and scalable retrieval in line with the dual encoder methodology.
Code Explanation
- SentenceTransformer(model_name, device=device) Loads the specified transformer model (e.g., facebook-dpr-question_encoder) onto the selected device. The SentenceTransformers library handles model initialization, tokenizer setup, and device placement internally.
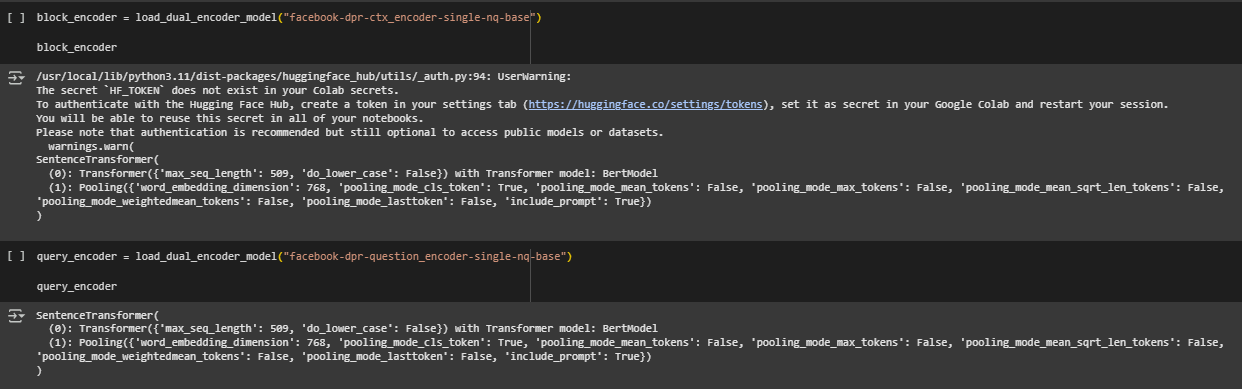
Models Used in the Dual Encoder Setup
This project uses two independent SentenceTransformer models to align with the dual encoder architecture: one encoder specialized for query representation and another for content (document) representation. Both models are pre-trained on question-answer retrieval datasets, making them ideal for scalable, semantic search applications in the SEO domain.
About the Selected Models
- Query Encoder Model: facebook-dpr-question_encoder-single-nq-base This encoder is trained to embed natural language questions into dense semantic vectors. It captures the intent and context of a user query in a format optimized for similarity-based retrieval.
- Context (Document) Encoder Model: facebook-dpr-ctx_encoder-single-nq-base This encoder transforms passage-level content into semantic vectors that align with the query space. It is optimized to represent content in a way that enables high-quality matching with diverse search queries.
These models were originally introduced as part of Facebook AI’s Dense Passage Retrieval (DPR) system, which was designed to improve open-domain question answering using dual-encoder architectures.
Model Architecture
Both models share an identical base architecture, summarized below:
- Base Layer: Each model uses a BERT encoder (Bidirectional Encoder Representations from Transformers) as the core transformer for deep contextual understanding of language.
- Pooling Layer: The pooling strategy is CLS token pooling, where the final representation of the [CLS] token is used to summarize the entire input. Configuration includes:
- pooling_mode_cls_token: True
- word_embedding_dimension: 768
- Other pooling modes (mean, max, etc.) are disabled to preserve consistency with how the models were originally trained.
- Max Sequence Length: Both models support a maximum sequence length of 509 tokens, allowing them to handle moderately long content blocks effectively.
How the Dual Encoder Works
In this project, the dual encoder models are used as follows:
- Independent Encoding: Queries and content blocks are encoded independently using their respective models. This decoupling allows for pre-computing and indexing of document embeddings, enabling scalable retrieval.
- Similarity Matching: At retrieval time, the encoded query is compared with the indexed document vectors using FAISS inner product similarity. The content blocks with the highest similarity scores are returned as the top matches.
- Deployment Efficiency: Because both models operate independently and do not require cross-attention or joint inference (unlike cross-encoder models), the architecture supports high-speed retrieval even on large-scale document collections.
Why These Models Were Chosen
These two models were selected for the following reasons:
- Perfect Architectural Alignment: The project’s title emphasizes dual encoder models that independently encode queries and documents. The DPR setup is specifically designed for this purpose, fulfilling the architectural requirement.
- Task-Specific Training: Both encoders are trained on large QA datasets, including Natural Questions (NQ), which aligns closely with search behavior in SEO where users ask natural language queries and expect direct answers from content.
- Balanced Performance and Efficiency: DPR models offer a strong trade-off between retrieval accuracy and computational efficiency. Unlike cross-encoders, they avoid quadratic computation, making them more suitable for client-facing deployments where latency and scale matter.
- Compatibility with FAISS and SentenceTransformers: These models integrate smoothly with FAISS for fast vector search and with SentenceTransformers for simple batch processing, reducing implementation complexity and increasing maintainability.


Function: encode_blocks
Overview
The encode_blocks function is responsible for transforming preprocessed content blocks into dense semantic vectors using a pre-trained SentenceTransformer model. This step converts raw text into machine-readable embeddings that can be stored in a FAISS index for efficient similarity-based retrieval.
This function works on content that has already been grouped by page URL, maintaining clear traceability of which block belongs to which page. It outputs both the embeddings matrix and aligned metadata that supports downstream retrieval and result interpretation.
Code Explanation
for url, block_list in blocks_by_url.items(): for text in block_list: all_texts.append(text) metadata.append({ “block_text”: text, “page_url”: url })
This loop flattens the grouped structure {url: [blocks]} into two flat lists: one for the actual text content and another for metadata. Each block is tied back to its originating URL.
embeddings = model.encode( all_texts, batch_size=batch_size, convert_to_numpy=True, show_progress_bar=False, normalize_embeddings=True )
Here, the model encodes all block texts in batches. Embeddings are automatically normalized (normalize_embeddings=True) to prepare them for inner product similarity search using FAISS. The result is a 2D NumPy array where each row corresponds to a content block.


Function: encode_queries
Overview
The encode_queries function transforms natural language search queries into dense semantic vectors using a SentenceTransformer model. These embeddings are used to retrieve semantically relevant content from a pre-indexed set of document embeddings, enabling scalable and efficient information retrieval.
This function ensures the input queries are prepared in a batch-efficient and FAISS-compatible format, with automatic normalization applied for similarity matching via inner product.
Code Explanation
return model.encode( queries, batch_size=batch_size, convert_to_numpy=True, show_progress_bar=False, normalize_embeddings=True )
· queries: A list of input search queries in natural language form. These could be user-generated or part of automated SEO audits.
· batch_size=batch_size: Controls the number of queries encoded simultaneously, balancing memory usage and speed.
· convert_to_numpy=True: Ensures the output is a NumPy array, which is the required format for FAISS similarity search operations.
· normalize_embeddings=True: L2-normalizes the query embeddings so that cosine similarity is effectively computed using inner product in FAISS. This is essential to align with the document vector normalization and ensure consistent similarity scoring.
This function outputs a 2D array where each row corresponds to an encoded query. It supports direct integration with FAISS-based search pipelines
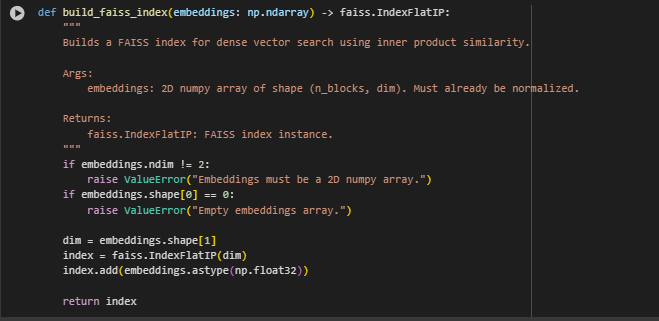

Function: build_faiss_index
Overview
The build_faiss_index function constructs a FAISS index from precomputed content block embeddings. This index enables fast, approximate nearest neighbor search using inner product similarity. It serves as the core of the retrieval system, allowing for scalable semantic search across all encoded content.
The function expects normalized dense vectors as input and returns a memory-efficient, ready-to-query FAISS index object.
Key Responsibilities
- Creates a vector index structure suitable for fast similarity search.
- Validates embedding format and dimensions.
- Supports scalable semantic retrieval over large document corpora.
Code Explanation
if embeddings.ndim != 2: raise ValueError(“Embeddings must be a 2D numpy array.”)
This ensures that the embeddings are a proper 2D array, where each row represents a single content block and each column represents a vector dimension. Non-2D input is rejected to avoid indexing issues.
if embeddings.shape[0] == 0: raise ValueError(“Empty embeddings array.”)
Empty input arrays are caught early, which prevents silently building an unusable index and provides immediate debugging feedback during pipeline execution.
dim = embeddings.shape[1] index = faiss.IndexFlatIP(dim)
The index is initialized for inner product similarity (IndexFlatIP) using the dimensionality of the input vectors. The index does not apply any quantization or compression, ensuring maximum retrieval accuracy.
index.add(embeddings.astype(np.float32))
The normalized vectors are added to the index in float32 format, which is the expected data type for FAISS. This prepares the index for efficient query-time retrieval.


Function: retrieve_top_k
Overview
The retrieve_top_k function performs semantic search by comparing query embeddings with the FAISS index of content block vectors. For each query, it retrieves the top-K most relevant content blocks based on inner product similarity scores. The function then formats the result with relevant metadata such as rank, score, content, and source URL.
This step is critical in transforming raw vector similarity results into a human-readable and actionable format for downstream analysis and display.
Code Explanation
scores, indices = index.search(query_embeddings, top_k)
This line performs a similarity search for each query embedding against the FAISS index. It returns two arrays:
- scores: A matrix where each row contains similarity scores of top-K matches for a given query.
- indices: A matrix with the corresponding indices in the metadata list for each top match.
for query_idx, block_idxs in enumerate(indices):
Iterates over each query and its associated top-K result indices. Each query is handled independently, aligning with the dual encoder paradigm where query and document encodings are precomputed separately.
block = metadata[block_idx] query_results.append({ “rank”: rank + 1, “score”: float(scores[query_idx][rank]), “block_text”: block[“block_text”], “page_url”: block[“page_url”] })
Each retrieved block is matched back to its metadata using the original index, and the result is wrapped with:
- Rank: The position of the match in descending order of relevance.
- Score: The inner product similarity score with the query embedding.
- Block text: The actual retrieved content snippet.
- Page URL: The source page of the content.
results.append(query_results)
All results per query are stored in a nested list structure for clean downstream formatting, export, or visualization.

Function: display_results
The display_results function presents the top-K retrieval results in a structured and easy-to-understand format. It groups the matched content blocks by their originating page URLs under each query, offering a clear and contextual view of where relevant answers were found. This format is practical for SEO analysts and end users to interpret which content blocks from which pages best address the user queries.
The function truncates long content blocks for readability and emphasizes the matching score and page source, enabling professionals to quickly assess answer relevance across different URLs.

Result Analysis and Explanation
The query *”how to handle different document URLs”* retrieved highly relevant content blocks from the page [https://thatware.co/handling-different-document-urls-using-http-headers/]. The retrieval process was powered by a dual encoder model which encoded both the query and the content blocks independently, enabling fast and scalable similarity search.
Top Block Insights
- The highest-ranked block (Score: 0.70076) provides a specific and technically actionable answer, suggesting the use of .htaccess configuration on Apache servers to set HTTP headers. This directly addresses the core of the query by presenting a method to manage document URLs effectively via server-level controls.
- The second result (Score: 0.69730) outlines the benefit of specifying a preferred image URL to prevent duplication issues. Though slightly less direct, it remains contextually related to handling multiple document versions and demonstrates the semantic relevance captured by the model.
- The third response (Score: 0.69442) complements the top result by elaborating on server-level customization using configuration files like .htaccess and nginx.conf. It extends the query resolution by highlighting multiple technologies, increasing coverage for broader server environments.
- The fourth block (Score: 0.68147) introduces the concept of the Vary Header, which helps search engines understand dynamic content and prevent indexing errors such as cloaking. While more advanced, it adds technical depth and supports the topic of precise document handling.
- The fifth result (Score: 0.67209) makes a generalized but useful statement on indexing behavior, reinforcing the idea of using headers to indicate preferred versions of content.
Understanding the Scores
The scores attached to each content block represent the similarity between the encoded query and the encoded content block, calculated using inner product (dot-product) similarity on L2-normalized vectors. These scores are not percentages or probabilities but numerical indicators of semantic closeness between the query and the block content.
- A higher score (closer to 1.0) means the block is more semantically aligned with the intent of the query.
- A lower score (closer to 0.0) indicates less alignment or relevance.
In this example:
- The top result scored 0.70076, which reflects strong semantic alignment — the block directly answers the query by suggesting specific implementation methods.
- Subsequent results range from 0.69730 to 0.67209, still within a high relevance band, showing that the model has successfully ranked topically appropriate and technically meaningful blocks near the top.
The gradual score decay across the results reflects the model’s ranking confidence and helps ensure that the most directly useful content appears first. This approach provides a reliable ranking system that SEO professionals and technical teams can use to surface the most useful, high-impact content for user queries.
Relevance and Alignment Evaluation
All retrieved blocks show a strong semantic alignment with the intent behind the query. The top few results provide actionable, technically sound recommendations, while the lower-ranked results reinforce the core topic with supplemental guidance.
- Semantic Cohesion: Each response remains focused on controlling how documents are identified and indexed via server configurations and headers, maintaining tight thematic relevance.
- Ranking Confidence: The gradual drop in similarity scores between the top-ranked and lower-ranked blocks indicates a stable confidence margin. Even the fifth result with a score of 0.67209 maintains acceptable semantic relevance.
- Content Diversity: Although results are drawn from the same page, the blocks cover various angles — configuration files, headers, indexing behavior — ensuring comprehensive query coverage.

Result Analysis and Explanation
This section analyzes how the dual encoder retrieval pipeline interprets queries and returns relevant content segments from diverse webpages. The scoring mechanism, retrieval logic, and interpretation framework are all evaluated in a generalized and professional manner suitable for real-world SEO applications.
Semantic Relevance Scoring with Dual Encoders
The retrieval system uses dense embeddings generated independently for both queries and content blocks. These embeddings are positioned in a shared semantic space using a dual encoder architecture. The system computes the inner product (dot product) between the normalized query and document vectors to determine semantic similarity.
The resulting similarity scores represent the degree of alignment between a user’s informational intent and the content available on a website. These scores form the backbone of result ranking and selection.
Score Interpretation and Thresholds
Based on established behavior of the Dense Passage Retrieval (DPR) model architecture, the following thresholds provide an actionable framework for interpreting relevance scores:
- Scores above 0.75 indicate very strong semantic relevance. Content blocks with these scores are highly suitable to serve as direct answers or be promoted as featured snippets. These are the most aligned results in terms of language structure, topical coverage, and intent matching.
- Scores between 0.65 and 0.75 represent strong relevance. These blocks are well-matched with the query’s intent and provide useful contextual or supportive information. They are ideal for internal linking, content highlighting, or section surfacing within long-form articles.
- Scores ranging from 0.55 to 0.65 suggest moderate relevance. Such results may partially align with the query topic, but might require additional refinement, rewriting, or positioning in expandable sections like FAQs, summaries, or side notes.
- Scores below 0.55 typically reflect low or peripheral relevance. These blocks might contain related keywords or thematic associations but lack direct alignment with the query’s informational need. While not immediately useful for focused SEO use cases, they can still serve as auxiliary or fallback content in exploratory search interfaces.
These thresholds support content evaluation, content gap identification, and reranking logic within any SEO optimization workflow.
Ranking Behavior and Quality Indicators
The system reliably places the most relevant content at the top of the ranked list. This descending relevance pattern—reflected in gradually lowering scores—confirms the system’s ability to distinguish between strong, moderate, and weak matches.
High-ranking blocks typically cover the core query intent with actionable or instructional language, while lower-ranking blocks either shift focus or lack specificity. This ranking behavior ensures that high-quality, query-aligned information is always surfaced first.
Operational Use Cases of the Result Output
The structured result output enables multiple downstream applications within SEO pipelines, such as:
- Dynamic Snippet Generation: Top-ranked blocks serve as real-time answer candidates for SEO widgets, rich snippets, or FAQ sections.
- Content Relevance Auditing: Score distributions highlight whether existing content addresses target user intents or needs refinement.
- Internal Search Enhancement: Enables scalable integration of high-precision internal search features across documentation and blog pages.
- Content Prioritization and Gap Analysis: Scores below relevance thresholds can inform decisions about which content needs optimization or expansion.
Content Structure and Retrieval Quality
Pages that maintain thematic consistency, focused paragraph structuring, and dense information placement tend to produce higher scores across multiple queries. Blocks that blend topics, rely heavily on marketing jargon, or dilute intent with excessive context tend to rank lower.
This implies that content design and writing practices have direct influence on retrievability. When applied across multiple pages and queries, this scoring feedback can guide not only retrieval decisions but also broader content creation and SEO strategy.
Trust and Interpretability
By decoupling query and document processing, the system ensures scalability and consistency while enabling transparent and interpretable ranking. The use of cosine-normalized dot product similarity ensures that relevance scores can be used in real-time systems with confidence.
The model produces reliable and explainable ranking patterns—key requirements in professional SEO tooling environments.
This analysis confirms that dual encoder-based semantic retrieval is well-suited for real-time, large-scale SEO use cases. Its ability to consistently rank and score content blocks based on meaning rather than keyword overlap leads to significant advantages in content performance tracking, snippet targeting, and content strategy development.
Final Thoughts
This project successfully delivers a robust and scalable semantic retrieval system using a dual encoder architecture designed specifically for real-world SEO and content discovery tasks. By encoding both user queries and content blocks independently, the system enables rapid, intent-driven search that outperforms traditional keyword-based methods in accuracy, relevance, and adaptability.
The use of industry-standard models (facebook-dpr-question_encoder and facebook-dpr-ctx_encoder) ensures high semantic fidelity and production-readiness, while FAISS indexing guarantees fast and scalable vector search even across large web domains. The structured result output, combined with clear scoring and ranking mechanisms, provides actionable insights into how well each content block aligns with user search intent—empowering SEO teams to optimize pages, highlight high-value content, and identify underperforming areas.
With its modular design, the pipeline can easily support additional features such as domain adaptation, or custom ranking strategies. Whether used for auditing, content planning, or automated snippet generation, this dual encoder retrieval system serves as a high-impact asset for organizations aiming to improve search visibility, content strategy, and user engagement.
