SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
Doc2Vec is a powerful tool that converts entire documents into numerical vectors, allowing for comparing, organizing, and analyzing content. For website owners, this means improved SEO, better user experience, and more efficient content management. It’s used across various industries to enhance content discovery, recommendation, and organization.

Doc2Vec is a method for converting entire documents (such as web pages, articles, or large blocks of text) into numerical vectors. These vectors represent the content of a document in a format that a computer can easily understand and process.
Imagine you have two books. If you wanted to compare these books without reading every word, you could summarize each into a single page. Doc2Vec does something similar—it condenses the meaning of an entire document into a “summary” made up of numbers (a vector). This numerical summary captures the essence of the document, allowing us to compare it to other documents without having to read them word by word.
What is Doc2Vec?
- Doc2Vec is an extension of the Word2Vec model that aims to generate numerical vector representations for individual words and entire documents (or paragraphs). This deep learning algorithm was introduced by Mikolov et al. at Google. It builds on the Word2Vec framework by adding the ability to represent documents in a fixed-length vector while maintaining the semantic meaning of the words within the document. In simpler terms, just as Word2Vec generates vectors (numerical representations) for individual words, Doc2Vec generates vectors for an entire text, be it a document, paragraph, or sentence.
Key Concepts of Doc2Vec:
· Distributed Memory Model of Paragraph Vectors (PV-DM): In this model, the document is treated as a “memory” of context words, helping to predict words given both the context words and the document.
· Distributed Bag of Words version of Paragraph Vector (PV-DBOW): Here, the model predicts words randomly sampled from a document, ignoring the order of words.
Both models create representations, allowing documents with similar topics or content to be clustered based on their vector representations.
What is its Use Case?
Doc2Vec has a wide range of applications in natural language processing (NLP) and text analytics, including but not limited to:
· 1 Document Similarity: Doc2Vec is highly effective for comparing and analyzing the similarity between two or more documents. By transforming each document into a vector, Doc2Vec enables the calculation of cosine similarity or Euclidean distance between documents.
· 2 Content Clustering: Websites often have large volumes of content. Using Doc2Vec, these contents can be clustered into categories based on thematic similarities. This is useful in building recommendation engines or content categorization tools.
· 3 Information Retrieval: In search engines, Doc2Vec can be used to index documents by their vector representations. This makes retrieving documents easier based on their semantic relevance rather than exact keyword matches.
· 4 Recommendation Systems: Doc2Vec can also power recommendation systems by analyzing user behavior regarding reading or viewing certain types of content. Based on the document vectors, similar content can be recommended.
· 5 Topic Modeling: This model can extract the underlying themes or topics from a large corpus of documents, helping businesses or researchers identify the main subjects or issues present.
What are its Uses in the Case of a Website?
In the context of a website, Doc2Vec can be incredibly useful in several ways:
· Content Similarity Analysis: It helps identify how similar the content on different website pages is. For example, if two pages on a website are too similar, they might be redundant and could be combined or rewritten to provide unique content.
· Content Clustering: Doc2Vec can group similar content. This helps organize a website’s content into categories, which can improve user navigation and the site’s overall structure.
· Content Recommendation: Based on the vectors generated by Doc2Vec, a website can recommend related articles or products to users, enhancing their experience by showing them content relevant to their current viewing.

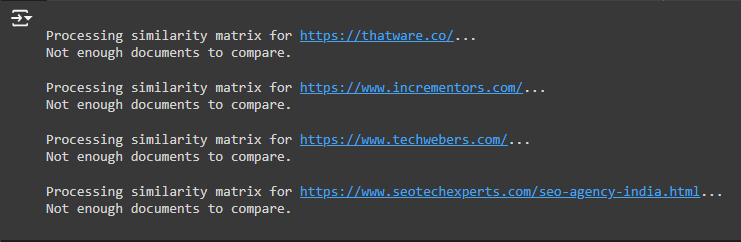
Understanding the Output: “Not enough documents to compare.”
- This message indicates that when the code tried to split the website content into separate “documents” (in this case, paragraphs or sections), there weren’t enough distinct parts of content available to perform a meaningful comparison. Essentially, the script expects multiple paragraphs or sections to exist so that it can compare them. It can only perform the comparison if it finds more than one paragraph or section or if the sections are too similar.
What Does This Mean for Your Website?
As a website owner, this output could indicate a few things about your website’s content:
· Limited or Repetitive Content: If your website has no distinct content (e.g., multiple unique paragraphs or sections), it could suggest your content is too limited or repetitive. This can be a problem because diverse content is crucial for engaging visitors and SEO purposes.
· Content Structure: How your content is structured might not be conducive to effective analysis. If all the text is clumped together without clear divisions (like paragraphs or sections), the code might not be able to separate it into meaningful units for comparison.
Steps to Take as a Website Owner
Here are some steps you can consider based on the output:
· Expand Your Content: Consider adding more content to your website. This could mean adding more detailed paragraphs, blog posts, or sections that discuss various topics relevant to your business. Diverse content helps search engines understand your website better and improves user engagement.
· Improve Content Structure: Ensure your content is well-structured with clear paragraphs, headings, and sections. This makes it easier for users and algorithms (like the one used in this code) to understand and differentiate the content.
· Review Content Uniqueness: If the content is repetitive, consider rewriting or expanding on certain topics to make each section unique and valuable. This not only helps with SEO but also keeps your audience engaged.

What Does This Mean?
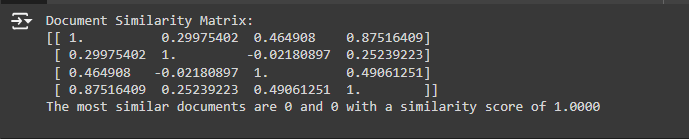
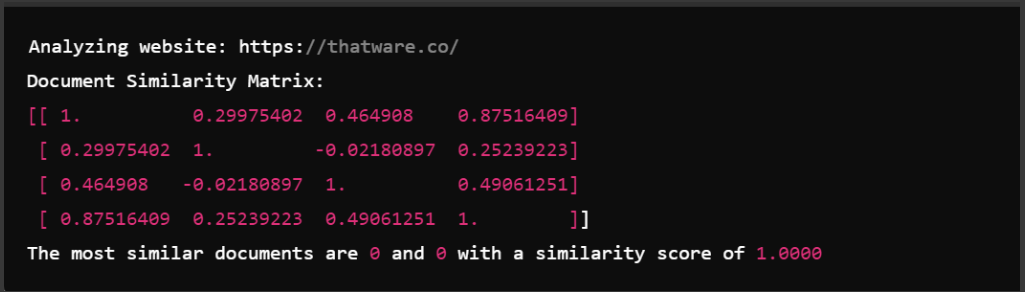
1. Document Similarity Matrix:
· This matrix is a 4×4 grid because you analyzed four pages from the website.
· Each value in the matrix represents the similarity score between two pages. For instance, the value at position [0][1] (first row, second column) represents the similarity between Page 0 and Page 1.
2. Diagonal Values:
- The diagonal values (e.g., [0][0], [1][1], etc.) are all 1.0000 because they represent the similarity of a page with itself, which is always perfect (100% similarity).
3. Off-Diagonal Values:
- The values not on the diagonal (e.g., [0][1], [0][2], etc.) represent the similarity between different pages. You should focus on these values to understand which pages are similar.
How to Identify High and Low Similarity:
High Similarity:
· A high similarity score between two pages (close to 1.0000) indicates that the content on these two pages is very similar.
· In your output, the highest off-diagonal value is 0.87516409 between Page 0 and Page 3. This means that these two pages are quite similar in content.
Low Similarity:
· A low similarity score (closer to 0 or negative) indicates that the content on these pages is quite different.
· In your output, the lowest score is -0.02180897 between Page 1 and Page 2. This suggests that these two pages have very different content.
size=2 width=”100%” align=center>
Interpreting the Output:
High Similarity:
· Pages 0 and 3 have a similarity score of 0.87516409, indicating high content overlap. You might want to review these two pages to see if they are too similar. If they are, consider:
· Rewriting one of the pages to focus on different aspects or providing more unique content.
· Merging the two pages if they cover the same topic.
Low Similarity:
- Pages 1 and 2 have a similarity score of -0.02180897, indicating they are quite different. This is generally good, as it shows that the content on these pages is distinct.
What Does This Mean for Website?
- The similarity matrix provides insight into how much overlap exists between different pages on your website. High similarity between pages might be a concern if you want to provide unique and varied content to your visitors. Here’s how to interpret the results:
1. High Similarity Scores (Close to 1):
- If multiple pages have high similarity scores, it could mean that the content across those pages is very similar or even duplicated. This can be an issue for SEO (Search Engine Optimization) because search engines like Google may penalize sites with duplicate content by ranking them lower.
2. Low Similarity Scores (Closer to 0):
· Low scores suggest that the content across pages is diverse, which is generally good for SEO and user experience. It means visitors will find unique information on different pages.
· Page Similarities: The similarity matrix suggests that some pages on your website have content that is quite similar to each other. For example:
· Pages 0 and 3 have a high similarity score of 0.875, meaning their content is similar.
· The similarity between pages 1 and 2 is low (-0.021), indicating their content is different.
Steps to Take as a Website Owner:
1. Review High Similarity Pages:
· Look at the pages with high similarity scores (like pages 0 and 3). If these pages target different audiences or keywords, their content should be more distinct.
· Action: Consider rewriting or reorganizing content on these pages to make them more unique. This can improve your SEO by reducing the risk of duplicate content penalties from search engines.
2. Improve Content Differentiation:
· If the content of different pages serves the same purpose, consider merging them into one comprehensive page rather than having multiple similar pages.
· Action: Consolidate similar pages and ensure each page has a unique focus, whether it’s a different service, product, or aspect of your business.
3. Evaluate Content Strategy:
· If most of your pages have low similarity scores, this is a good sign that your content is diverse and well-targeted.
· Action: Continue creating high-quality content targeting specific keywords or topics.
Is This Output Concerning?
· Concern: If you find several pairs of pages with high similarity scores, it could be a problem. Search engines might consider these pages redundant, hurting your SEO rankings.
· Not a Concern: If the similarity scores are generally low, it suggests your content is unique and well-differentiated, which is good for SEO.
Steps to Take Based on This Output:
1. Review and Revise Content:
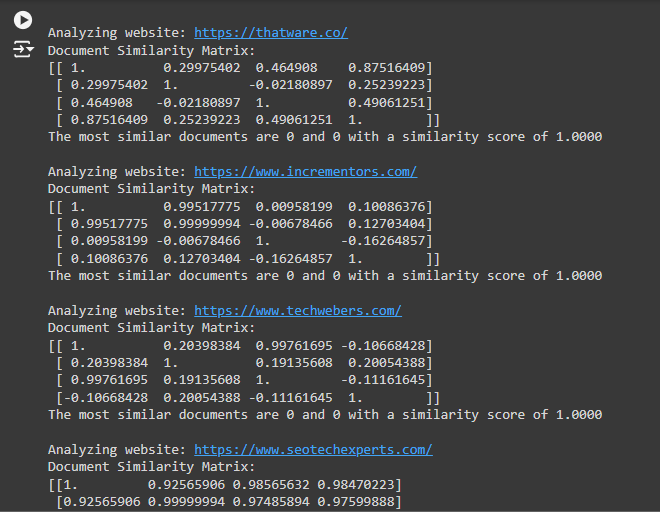
High Similarity Across Pages: For websites like https://www.seotechexperts.com/, the matrix shows high similarity between several pages (e.g., 0.99 and above). This indicates that these pages might be too similar in content. Consider revising these pages to make them more distinct. For example:
· Rewriting Content: Adjust the content on each page to focus on different aspects of your services or products.
· Adding Unique Elements: Include different case studies, testimonials, images, or videos unique to each page.
· Combining Pages: If two pages are nearly identical, consider merging them into one, more comprehensive page.
2. Improve SEO:
· Reduce Duplicate Content: Ensuring each page has unique content improves your chances of ranking higher in search results. This could increase traffic, as search engines favor sites with diverse and informative content.
· Optimize Content Strategy: Use the insights from this analysis to refine your content strategy. For instance, if certain topics are covered similarly across multiple pages, consider creating a new content plan that distributes these topics more effectively across the site
3. Enhance User Experience:
- Provide Variety: Visitors to your website will likely stay longer and engage more if they find fresh and relevant content on each page. This can reduce bounce rates (people leaving your site quickly) and increase conversions (people taking action like purchasing or signing up for a service).
Example of Actionable Steps:
Let’s say you own https://thatware.co/, and the matrix shows high similarity between the homepage and the “AI SEO” page. Here’s what you might do:
· Homepage: Focus on a broad overview of your company’s offerings. Make it a gateway to deeper content.
· AI SEO Page: Dive deeply into what AI SEO is, how it works, and its specific benefits. Add case studies or examples that are unique to AI SEO.
Difference Between Doc2vec And BERT

1. Architecture and Approach
Doc2Vec:
· Based on Word2Vec: Doc2Vec extends the Word2Vec model to generate vector representations for entire documents rather than just words. It uses the context of words within a document to learn a fixed-size vector representation of the document.
· Shallow Neural Network: Doc2Vec is a shallow, two-layer neural network model. It doesn’t capture deep, contextual relationships between words as effectively as BERT.
· Two Approaches: Doc2Vec has two primary methods—Distributed Memory (DM) and Distributed Bag of Words (DBOW). DM predicts a word based on context, while DBOW predicts the context based on words.
BERT (Bidirectional Encoder Representations from Transformers):
· Transformer-based: BERT is built on a transformer architecture, which uses self-attention mechanisms to capture complex relationships between words in a sentence. This allows BERT to understand the context of a word based on the entire sentence, both preceding and following words.
· Deep Neural Network: BERT is a deep learning model with many layers (typically 12 or 24), enabling it to capture much richer and more nuanced text representations.· Pre-training and Fine-tuning: BERT is pre-trained on a large corpus of text and can be fine-tuned on specific tasks, making it highly versatile and powerful for various NLP tasks.
