SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
The project centers on the application of Dense Passage Retrieval (DPR) to enhance the ability to locate and rank the most semantically relevant content from webpages in response to specific user intents. This approach moves beyond keyword matching by using deep contextual embeddings to identify passages that carry the closest meaning to the user’s search goal. The aim is to systematically process webpage content and evaluate its alignment with predefined informational intents to support data-driven SEO decisions.
By leveraging dense vector representations of both queries and content, the system highlights content segments that are truly aligned with user expectations. This makes it possible to surface the most valuable portions of a page from the perspective of semantic relevance—enabling focused optimization strategies, precise content audits, and more targeted internal linking suggestions. The project is designed to empower strategic SEO decisions by uncovering content that satisfies user needs as interpreted by modern language models.
Project Purpose
The purpose of this project is to create a powerful SEO analysis framework that captures and ranks content relevance at a semantic level. In today’s search ecosystem, user queries are increasingly conversational, nuanced, and intent-driven. Traditional keyword-based systems often miss this depth, leading to mismatches between searcher needs and on-page content. This project directly addresses that gap.
By applying Dense Passage Retrieval, the project introduces a scalable and intelligent solution to measure how well content answers actual user questions. The ability to retrieve and rank semantically relevant passages allows content strategists and SEO professionals to:
- Understand how well their existing content responds to target user intents.
- Identify specific segments of content that perform strongest in semantic alignment.
- Make informed decisions on content restructuring, expansion, or internal linking.
- Support better organic visibility by prioritizing content that speaks to user intent.
This approach brings modern natural language understanding into SEO workflows, aligning content strategy with the way search engines and users interpret language today.
Dense Passage Retrieval (DPR): The Foundation of Semantic Search
Dense Passage Retrieval (DPR) is a cutting-edge retrieval paradigm that focuses on matching user intents (in the form of queries) with text passages extracted from documents or web pages. Unlike traditional retrieval systems that rely heavily on keyword matching, DPR understands the meaning of both queries and passages using dense vector representations — also known as dense embeddings.
This approach enables the system to bridge the gap between how users ask questions and how information is naturally written in content. In SEO, this is crucial because users rarely phrase their queries the same way web content is authored. DPR addresses this disconnect by embedding both queries and passages into a shared vector space, where semantic similarity can be accurately computed.
Dense Embeddings: Capturing Meaning Beyond Keywords
Dense embeddings represent sentences or passages as high-dimensional vectors that encapsulate their semantic meaning. These embeddings are generated through deep learning models pre-trained on large-scale datasets and fine-tuned for retrieval tasks.
- Why this matters in SEO: Traditional keyword-based search systems can fail when synonyms or conceptually related phrases are used. For example, a user searching for “how to improve search visibility” might miss valuable content that talks about “boosting organic presence.” Dense embeddings capture the meaning behind these phrases, enabling better alignment between queries and content.
- Impact on content optimization: Using dense embeddings, this project ensures that highly relevant but lexically different passages can still be surfaced. This leads to more accurate identification of valuable content and supports strategic SEO tasks such as ranking analysis, content refinement, and relevance-driven linking.
Locating Relevant Text Passages: Fine-Grained Content Understanding
Rather than evaluating entire web pages as monolithic documents, the DPR methodology breaks them into smaller text passages, each evaluated independently for relevance to the input query. This improves the precision of content evaluation and allows for localized insights.
- Passage-level granularity: By narrowing the scope to individual passages, the system can identify specific content blocks that directly address the user’s intent, such as a particular definition, instruction, or strategic insight.
- SEO benefits: This level of granularity enables content teams to assess exactly which parts of a page perform well for specific intents. It also allows optimization efforts to be focused where they matter most — refining or reinforcing high-value content segments.
Semantic Ranking: Prioritizing What Matters Most
Once passage-level relevance scores are computed, the system ranks the content segments according to their semantic alignment with the input query. The top-ranked passages represent the most useful content in the context of a particular intent.
- Objective ranking with contextual understanding: The ranking is based not on arbitrary metrics but on learned relationships between query and passage embeddings. This mirrors how modern search engines, including Google, evaluate and surface results based on semantic context rather than mere keyword density.
- Client advantage: This empowers SEO decision-makers to identify content that performs strongly against specific user needs and uncover opportunities where content may be underperforming or misaligned with high-value queries.
Strategic Role of this Project in Modern SEO
The implementation of DPR brings a semantic-first approach to content evaluation — essential for thriving in search environments that prioritize user-centricity and intent satisfaction.
- It supports SERP optimization by helping understand what content genuinely aligns with user search behavior.
- It enables content auditing at a granular level, identifying high- and low-performing passages within pages.
- It creates a foundation for internal linking recommendations, where high-scoring passages can act as authoritative anchor targets from other content.
- In essence, this methodology is not just a retrieval mechanism but a strategic SEO framework for aligning digital content with the complex, nuanced intents of real users — a requirement for visibility, relevance, and competitive advantage in modern search.
How does this project improve search performance?
By identifying and ranking the most semantically relevant passages on a page, the project helps:
- Highlight which sections of content are truly valuable for specific search intents.
- Detect underperforming or misaligned segments that may hinder page relevance.
- Guide optimization efforts toward rewriting or enhancing specific areas, rather than the entire page.
- Strengthen internal linking, which improves crawlability and relevance signals to search engines.
What is the business impact of using Dense Passage Retrieval?
Implementing this system can result in:
- Higher visibility in search results, as content becomes more aligned with real search behavior.
- Improved user engagement and retention, since content directly addresses user questions.
- Better conversion opportunities, through a more intuitive and helpful content experience.
- Data-driven decision-making in SEO planning, content design, and internal navigation strategy.
What problem does this project solve in SEO?
The project addresses the fundamental gap between how users phrase queries and how website content is written. Traditional keyword-based systems often miss relevant content due to differences in vocabulary or phrasing. This project uses dense embeddings to understand the semantic meaning behind both queries and content, making retrieval more accurate and aligned with user intent.
How is this different from traditional content audit tools?
Unlike tools that rely on surface-level metrics (e.g., word count, keyword frequency), this system uses deep learning-based embeddings to understand and match the actual intent of a query with the content meaning. It provides actionable, intent-aligned insights that can’t be derived from basic metrics alone.
Why move beyond keyword-based SEO techniques?
Search engines increasingly use natural language processing to understand user intent. Relying solely on keyword matching is no longer sufficient to achieve competitive rankings. This system enables SEO teams to identify which passages match the intent — not just the wording — of high-value search terms, allowing content optimization to be far more targeted and impactful.
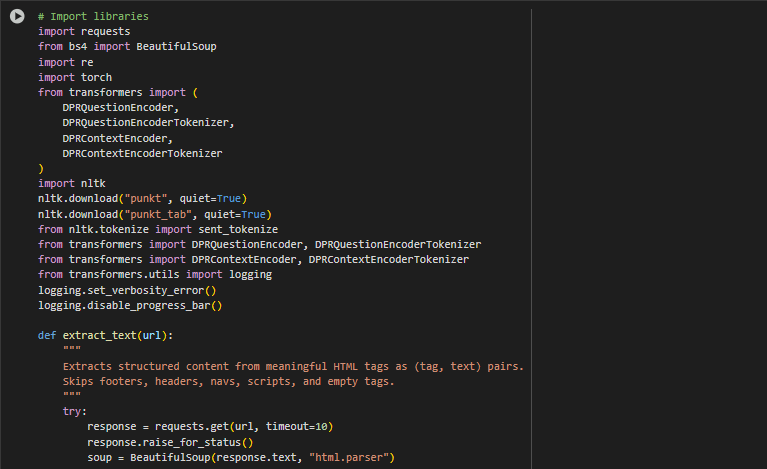
requests
The requests library is a widely-used HTTP client for sending network requests in Python. In this project, it is responsible for fetching the HTML content from provided URLs. Web scraping begins with this step, where a GET request is issued to access each page’s underlying HTML structure. This is essential because all further processing—cleaning, content extraction, and semantic analysis—depends on acquiring the raw textual data from these HTML responses.
Without requests, it would not be possible to programmatically access or automate the collection of page content for SEO analysis and semantic ranking.
BeautifulSoup (from bs4)
BeautifulSoup is used for parsing and navigating HTML documents. After obtaining the raw HTML using requests, this library enables the extraction of structured content from specific HTML tags. In this project, it is particularly configured to extract content from tags that represent meaningful textual components: headings (<h1>, <h2>, <h3>), paragraphs (<p>), and list items (<li>).
It also plays a critical role in cleaning unwanted elements from the HTML, such as scripts, styles, and hidden elements, which are irrelevant to semantic analysis. The clean, structured text generated using BeautifulSoup serves as the foundation for all downstream NLP and ranking tasks.
re (Regular Expressions)
The re module is Python’s built-in regular expression engine, used for pattern matching and text transformation. In the preprocessing stage, re helps clean the text by removing unwanted symbols, numbers, URLs, or markup artifacts that might remain after HTML parsing.
It is particularly valuable in automating the identification of unwanted content patterns, such as promotional messages or formatting characters, and in breaking text into consistent sentence or passage units. This ensures that the input to the dense passage retrieval model is clean and semantically relevant.
torch (PyTorch)
PyTorch is one of the most widely adopted deep learning frameworks and is used in this project for model inference and tensor computations. The DPR models used here require numerical operations on large vectors and matrices (embeddings), which PyTorch handles efficiently. It also provides GPU acceleration when available, enabling faster computation during encoding and ranking.
All deep learning components—loading pretrained models, converting text into embeddings, and computing similarity scores—are executed using PyTorch. It provides the necessary infrastructure for working with high-dimensional dense vectors central to this project.
transformers (from Hugging Face)
The transformers library provides access to pretrained language models that have revolutionized semantic understanding tasks. In this project, it is used to load the Dense Passage Retrieval (DPR) models, which consist of two components:
DPRQuestionEncoder and its tokenizer: Used to convert client queries or search intents into semantic embeddings.
DPRContextEncoder and its tokenizer: Used to encode webpage passages into the same embedding space.
These models have been fine-tuned to ensure that a query and its relevant answer passage have high vector similarity, making them ideal for information retrieval tasks such as snippet ranking and semantic matching.
The tokenizer modules in this library are also critical, as they convert raw text into tokenized formats that are compatible with the model input requirements.
nltk (Natural Language Toolkit)
NLTK is a classic natural language processing library used here for sentence segmentation. The sentence tokenizer (sent_tokenize) is applied after the webpage content has been cleaned and extracted. It breaks the content into coherent sentence units, which are later passed into the context encoder.
This segmentation is vital for increasing the granularity of retrieval and improving the relevance of passage ranking. By working at the sentence level, the system can return the most informative snippets rather than entire unstructured blocks of text.
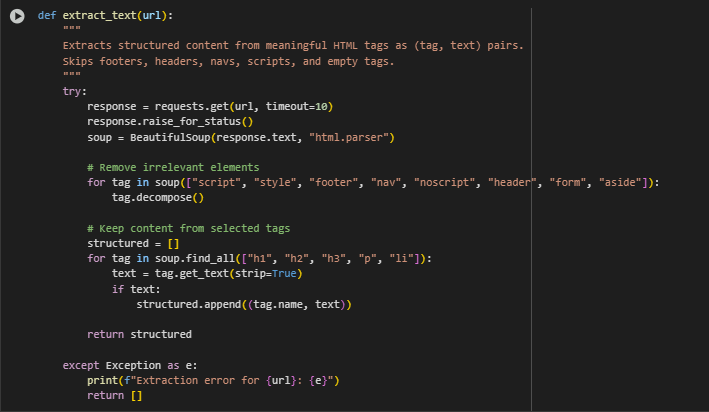
Function: extract_text(url)
Overview
The extract_text function is responsible for retrieving and structuring meaningful textual content from a given webpage URL. It performs a focused extraction by targeting specific HTML tags that typically contain valuable content for semantic search and SEO purposes. The function excludes irrelevant or distracting elements such as scripts, navigation bars, footers, and other non-content sections to ensure the extracted text is clean and relevant. The output is a list of tuples, where each tuple contains the HTML tag name and its associated text content. This structured output preserves the context of the text by retaining the tag type, which can be useful in downstream processing.
Key Lines and Their Functionality
response = requests.get(url, timeout=10) response.raise_for_status()
- Sends an HTTP GET request to the URL and raises an error if the request fails, ensuring reliable web content acquisition.
soup = BeautifulSoup(response.text, “html.parser”)
- Parses the HTML content of the page using BeautifulSoup for structured manipulation.
for tag in soup([“script”, “style”, “footer”, “nav”, “noscript”, “header”, “form”, “aside”]): tag.decompose()
- Removes unwanted HTML elements that do not contain meaningful content, such as JavaScript, stylesheets, navigation menus, footers, and sidebars. This cleans the page and reduces noise.
for tag in soup.find_all([“h1”, “h2”, “h3”, “p”, “li”]): text = tag.get_text(strip=True) if text: structured.append((tag.name, text))
- Selects only the relevant tags (h1, h2, h3, p, and li) which are typical containers of important page content like headings and paragraphs.
- Extracts and strips the text within these tags, appending them as tuples of (tag_name, text) into the structured list only if the text is non-empty.
return structured
- Returns the cleaned, structured list of tag-text pairs to be used for further processing such as preprocessing, encoding, and ranking.
This function forms the critical first step of the pipeline by delivering clean, well-structured raw data from webpages, enabling more accurate semantic analysis and retrieval downstream.
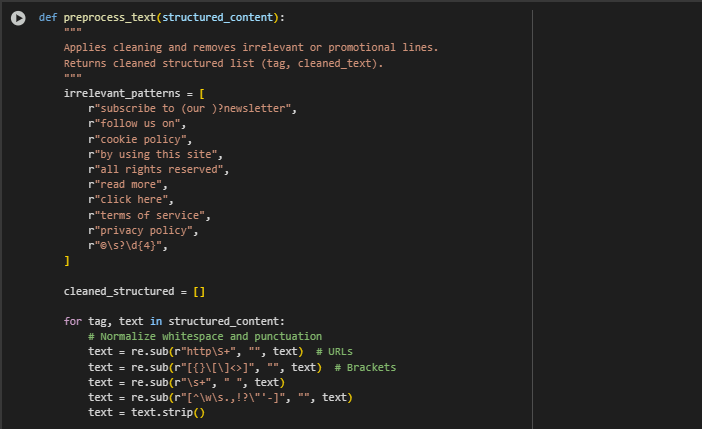
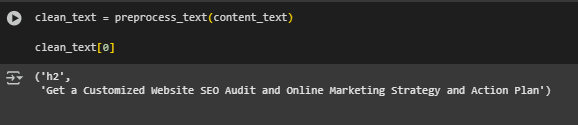
Function: preprocess_text(structured_content)
Overview
The preprocess_text function takes the structured content extracted from a webpage (a list of (tag, text) tuples) and applies a series of cleaning operations to improve text quality for retrieval tasks. This function is designed to remove irrelevant, promotional, or boilerplate content commonly found on webpages, such as newsletter sign-ups, cookie notices, and legal disclaimers. Additionally, it normalizes whitespace, removes URLs and unnecessary punctuation, and filters out short or trivial lines that are unlikely to add meaningful value. The result is a cleaner, more focused set of textual passages that better represent the core content of the page.
Key Lines and Their Functionality
irrelevant_patterns = [ r”subscribe to (our )?newsletter”,…
- Defines a list of regular expression patterns matching typical promotional, legal, or irrelevant phrases to be filtered out during preprocessing.
text = re.sub(r”http\S+”, “”, text) # URLs text = re.sub(r”[{}\[\]<>]”, “”, text) # Brackets text = re.sub(r”\s+”, ” “, text) text = re.sub(r”[^\w\s.,!?\”‘-]”, “”, text) text = text.strip()
- Performs sequential text normalization steps:
- Removes URLs to avoid noise in embeddings.
- Eliminates bracket characters that do not contribute meaningfully.
- Normalizes all whitespace sequences to single spaces for consistency.
- Filters out any characters except typical word characters, punctuation marks, and common sentence symbols.
- Trims leading and trailing whitespace.
if any(re.search(pat, text, re.IGNORECASE) for pat in irrelevant_patterns): continue
- Filters out any line matching one of the irrelevant patterns, skipping lines that contain promotional or non-essential content.
if len(text.split()) < 3: continue
- Skips lines that are too short or trivial (less than three words), which often do not provide useful context for semantic retrieval.
cleaned_structured.append((tag, text))
- Appends the cleaned and relevant (tag, text) tuple to the output list.
return cleaned_structured
- Returns the fully cleaned and filtered structured content ready for encoding and ranking.
This preprocessing step enhances the quality and relevance of the text data, reducing noise and ensuring the retrieval models focus on meaningful content, thereby improving the accuracy of downstream passage ranking.
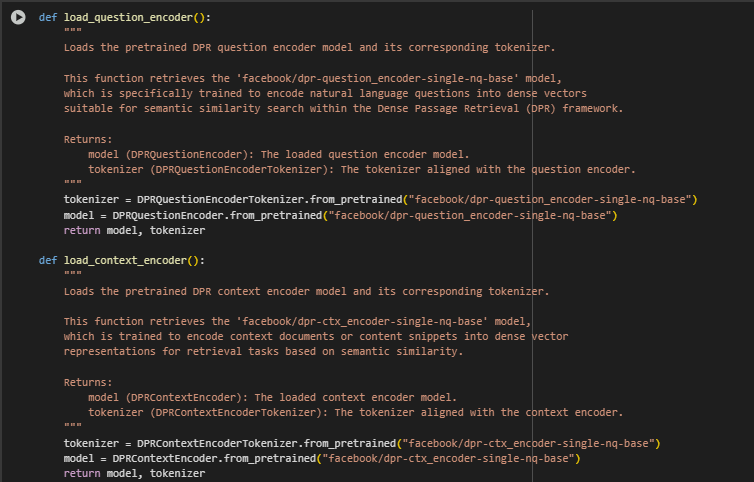
Function: load_question_encoder() and load_context_encoder()
Overview
These two functions are responsible for loading the core pretrained transformer models from the Dense Passage Retrieval (DPR) architecture:
- load_question_encoder() handles question or query vectorization.
- load_context_encoder() handles encoding of content or passages from documents.
Each function loads a model and tokenizer pair aligned with its task. These pretrained models are sourced from Facebook’s DPR repository and play a critical role in computing dense vector embeddings used for semantic similarity ranking.
Key Highlights from Both Functions
DPRQuestionEncoderTokenizer.from_pretrained(“facebook/dpr-question_encoder-single-nq-base”)
- Downloads and initializes the tokenizer specifically tuned for encoding questions. This tokenizer converts user search intents into input formats suitable for the transformer model.
DPRQuestionEncoder.from_pretrained(“facebook/dpr-question_encoder-single-nq-base”)
- Loads the pretrained model designed to encode natural language questions into dense embeddings that capture their semantic meaning.
DPRContextEncoderTokenizer.from_pretrained(“facebook/dpr-ctx_encoder-single-nq-base”)
DPRContextEncoder.from_pretrained(“facebook/dpr-ctx_encoder-single-nq-base”)
- These lines mirror the process above, but for encoding the webpage content or document text. The encoder captures the contextual relevance of passage text relative to queries.
return model, tokenizer
- Both functions return the model-tokenizer pair, ready to be used in encoding steps.
These components form the foundation of dense vector creation and are central to ensuring that both user queries and textual passages are transformed into a shared vector space for accurate semantic matching.

Dense Passage Retrieval (DPR) Model Explanation
Dense Passage Retrieval (DPR) is a modern retrieval system designed to address the shortcomings of traditional keyword-based search techniques. Instead of relying on exact word matches, DPR retrieves content using semantic understanding by mapping both user queries and document passages into a shared vector space. This allows the system to find the most relevant content based on meaning, not just vocabulary overlap.
Overview of the DPR Model
DPR is composed of two separately trained but structurally identical models:
- DPR Question Encoder: Processes and encodes the user query or intent.
- DPR Context Encoder: Processes and encodes the text content from documents or webpages.
Both encoders convert text inputs into dense vector representations (768-dimensional) and are trained to ensure that semantically similar texts (like a question and its answer passage) produce vectors that are close in space. The closer the vectors, the higher the match.
This system replaces manual keyword engineering with neural similarity, making it ideal for real-world use cases such as:
- Intelligent snippet extraction
- SEO passage ranking
- Internal content linking
- Semantic site search
Internal Architecture of DPR Encoders
Both the DPR Question Encoder and DPR Context Encoder are built on top of the BERT base architecture, a 12-layer transformer model known for its rich contextual representations and robust performance in natural language understanding.
Each encoder uses the same structure:
Embedding Layer
This is the initial layer that transforms tokens into vector representations.
- Word Embeddings: 30,522-word vocabulary mapped into 768-dimensional vectors.
- Position Embeddings: Encodes the position of each token in the sequence (max length: 512).
- Token Type Embeddings: Encodes whether a token belongs to segment A or B (though DPR uses only single sequences).
- Layer Normalization + Dropout: Stabilizes and regularizes the embeddings.
Transformer Encoder Stack
The core of the DPR model:
· Consists of 12 layers of transformer blocks.
· Each block contains:
- Multi-head Self-Attention: Allows the model to weigh the importance of each word relative to others in the sentence.
- Feedforward Layers: Nonlinear transformations to refine the representation.
- Residual Connections and LayerNorm: Ensure stable learning and gradient flow.
Each transformer layer learns increasingly abstract features of the input text — from raw word combinations to semantic meaning and topic-level understanding.
Final Dense Representation
- After passing through the encoder, the output from the [CLS] token is extracted.
- This token’s vector (768-dim) serves as the global representation of the entire passage or question.
- This vector is the one used for semantic comparison via dot product.
Use Case Relevance in SEO
Traditional SEO tools rely heavily on keyword frequency, TF-IDF, or rule-based heuristics. These methods often miss:
- Paraphrased content
- Long-tail queries
- User search intents expressed in natural language
DPR addresses these gaps by:
- Capturing intent-level semantics
- Enabling dense matching between user questions and webpage content
- Prioritizing relevance over repetition
In this project, DPR is used to:
- Encode client-provided search intents as questions.
- Encode segmented webpage content into dense passages.
- Score and rank passages using vector similarity for improved snippet selection and linking recommendations.
Model Training and Origin
The DPR models used here are pretrained and publicly available through Facebook AI’s research:
- facebook/dpr-question_encoder-single-nq-base
- facebook/dpr-ctx_encoder-single-nq-base
These models were fine-tuned on the Natural Questions (NQ) dataset — a benchmark consisting of real-world search queries and matching answers from Wikipedia. This pretraining gives the models a strong foundation in handling:
- Open-domain search queries
- Fact-based questions
- Informational content retrieval
The models are trained using a contrastive loss:
- Positive pairs: A question and its correct answer passage.
- Negative pairs: The same question with randomly sampled unrelated passages.
This helps the model learn what to bring closer and what to push apart in vector space, forming the backbone of the retrieval mechanism.
Internal Working (Conceptual Flow)
Though built on transformer-based architectures like BERT, the DPR system differs in its usage and flow:
Step 1: Input Encoding
- The query and each passage are separately tokenized and encoded using their respective models.
- No cross-attention is used — this is unlike BERT QA models which jointly encode input and context.
Step 2: Vector Projection
- Both the question and passage are projected into a 768-dimensional dense vector.
- These representations capture semantics — e.g., “how to cook rice” and “steps for boiling rice” would generate similar embeddings.
Step 3: Retrieval via Dot Product
- The similarity between a query and all candidate passages is calculated using the dot product of their vectors.
- Passages with the highest similarity scores are selected and ranked.
Step 4: Output
- The top-ranked passages are returned, forming the basis for:
- Search snippet display
- Contextual linking within a site
- Content recommendation
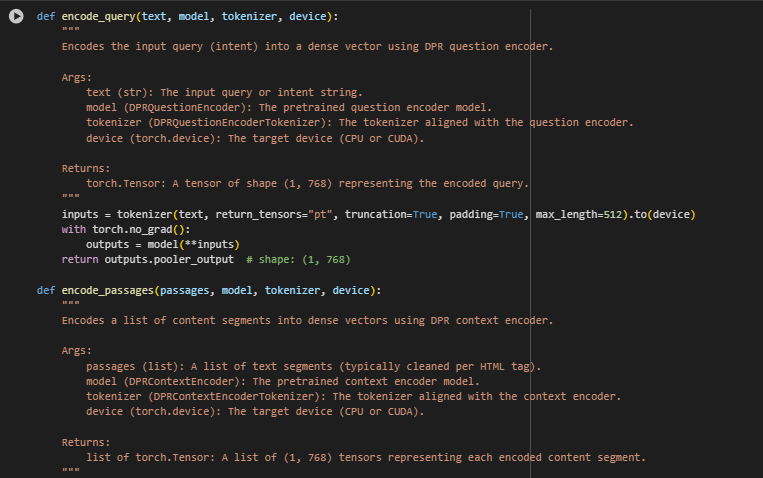
Query and Passage Encoding Functions
These two functions are responsible for converting raw text into dense vector representations using the Dense Passage Retrieval (DPR) model. This is a critical step because these vectors are what enable semantic comparison between a user’s search intent (query) and the content from web pages (passages).
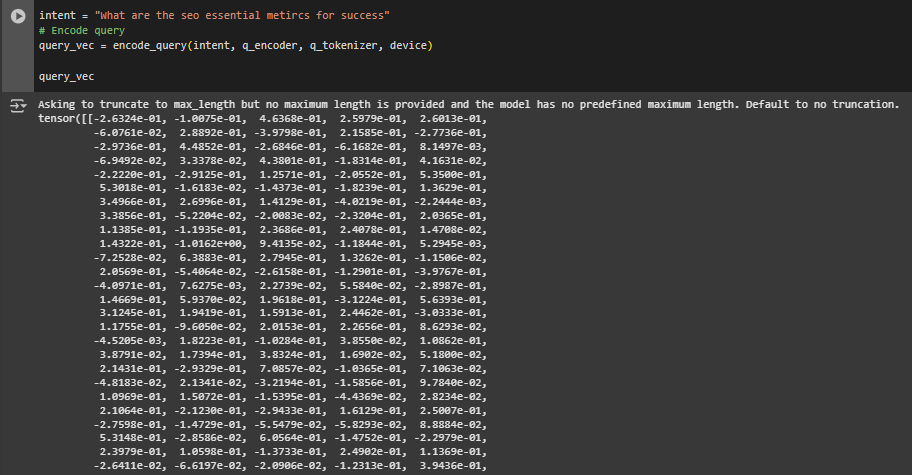
Function encode_query
Overview
This function transforms a single natural language query or intent (e.g., “how to boost organic traffic”) into a 768-dimensional vector using the DPR Question Encoder. This vector captures the semantic meaning of the query and is later compared with passage vectors to identify the most relevant content.
Key Operations and Highlights
inputs = tokenizer(text, return_tensors=”pt”, truncation=True, padding=True, max_length=512).to(device)
- Tokenizes the input query and prepares it for model inference.
- truncation=True ensures inputs longer than 512 tokens are trimmed.
- Converts to a PyTorch tensor suitable for GPU or CPU processing.
with torch.no_grad(): outputs = model(**inputs)
- Disables gradient calculation to optimize memory and computation during inference.
return outputs.pooler_output
- Extracts the final vector representation (of shape (1, 768)), which summarizes the entire query.
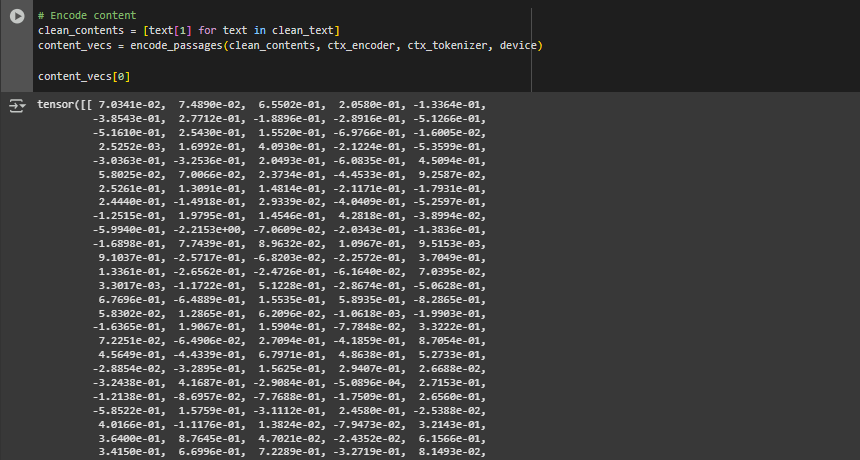
Function encode_passages
Overview
This function takes a list of text segments from a webpage (e.g., paragraphs, list items, headings) and converts each into a dense vector using the DPR Context Encoder. Each passage is independently transformed, enabling fine-grained ranking based on semantic closeness to the query vector.
Key Lines and Their Functionality
for passage in passages: inputs = tokenizer(passage, return_tensors=”pt”, truncation=True, padding=True, max_length=512).to(device)
- Loops through all text segments, encoding them one by one.
- Ensures tokenization, padding, and truncation are consistent across all passages.
with torch.no_grad(): outputs = model(**inputs)
- Performs inference without tracking gradients (as this is not training).
encoded.append(outputs.pooler_output)
- Appends each encoded passage vector (shape (1, 768)) to a list for later comparison with the query vector.
Why Are These Functions Important?
- Both query and passage vectors form the core of semantic matching in this SEO application.
- They allow semantic similarity rather than simple keyword overlap — meaning the system can match user intents to relevant content even if they use different vocabulary.
- These functions also enable scaling the model to hundreds or thousands of passages per query.
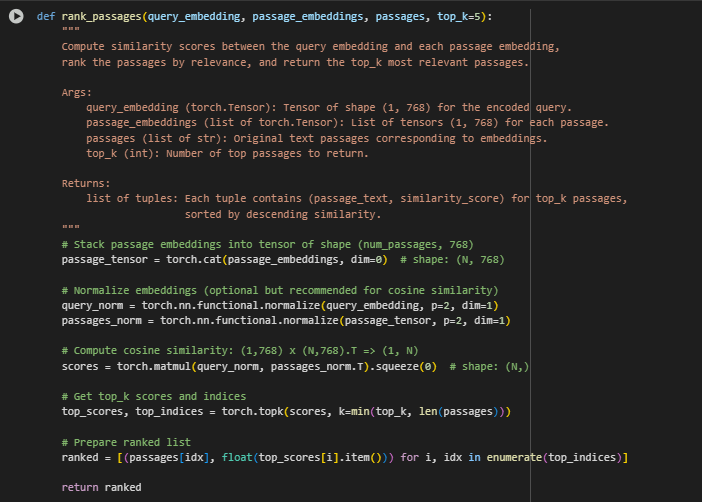

Passage Ranking Function: rank_passages
Overview
This function is the final scoring and selection step in the semantic retrieval pipeline. After the query and all candidate content segments (passages) have been encoded into dense vectors, this function ranks them based on semantic similarity and returns the most relevant passages.
The rank_passages function is responsible for:
- Measuring how closely each content segment matches the input query.
- Using cosine similarity to quantify semantic relevance.
- Selecting and returning the top-k content blocks that best align with the user’s intent.
- This step transforms abstract embeddings into actionable insights—specifically, which pieces of on-page content should be highlighted, rewritten, or internally linked to meet SEO objectives.
Key Lines and Their Functionality
Concatenating All Passage Embeddings
· passage_tensor = torch.cat(passage_embeddings, dim=0)
· Converts a list of (1, 768) vectors into a single tensor of shape (N, 768), where N is the number of passages.
· Prepares all passage embeddings for simultaneous similarity comparison.
L2 Normalization (for Cosine Similarity)
- query_norm = torch.nn.functional.normalize(query_embedding, p=2, dim=1) passages_norm = torch.nn.functional.normalize(passage_tensor, p=2, dim=1)
- Cosine similarity performs best when vectors are unit-normalized.
- This step ensures all vectors lie on the unit hypersphere, making similarity purely angle-based.
Similarity Computation
- scores = torch.matmul(query_norm, passages_norm.T).squeeze(0)
- Computes cosine similarity scores between the query and each passage.
- Produces a vector of shape (N,), where each entry indicates the relevance of a passage to the query.
Top-K Selection
- top_scores, top_indices = torch.topk(scores, k=min(top_k, len(passages)))
- Selects the top_k highest-scoring passages, while avoiding out-of-range errors for small input sets.
Final Output Construction
- ranked = [(passages[idx], float(top_scores[i].item())) for i, idx in enumerate(top_indices)]
- Each result is returned as a (passage_text, similarity_score) tuple.
- Scores are converted to plain floats for display and reporting.
Practical Value for SEO and Content Optimization
This ranking mechanism enables:
- Precise targeting of content sections that satisfy a given user query.
- Internal linking to contextually relevant passages from other pages.
- Snippet generation for SERP display or featured answers.
- Gap analysis where low-relevance content can be identified and improved
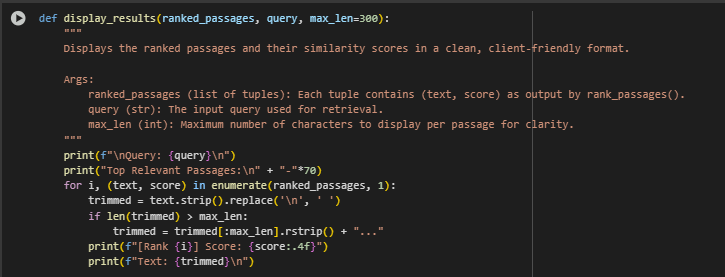
Utility Function: display_ranked_results
This function serves as a utility for displaying retrieval results in a readable format. It presents the top-ranked content passages alongside their similarity scores for a given input query.
Function Purpose
- Formats and prints the ranked results generated by the retrieval pipeline.
- Ensures each passage is trimmed to a readable length (max_len) to maintain clarity.
- Makes the output human-interpretable for clients, analysts, or content strategists reviewing SEO alignment.
Result Analysis and Explanation
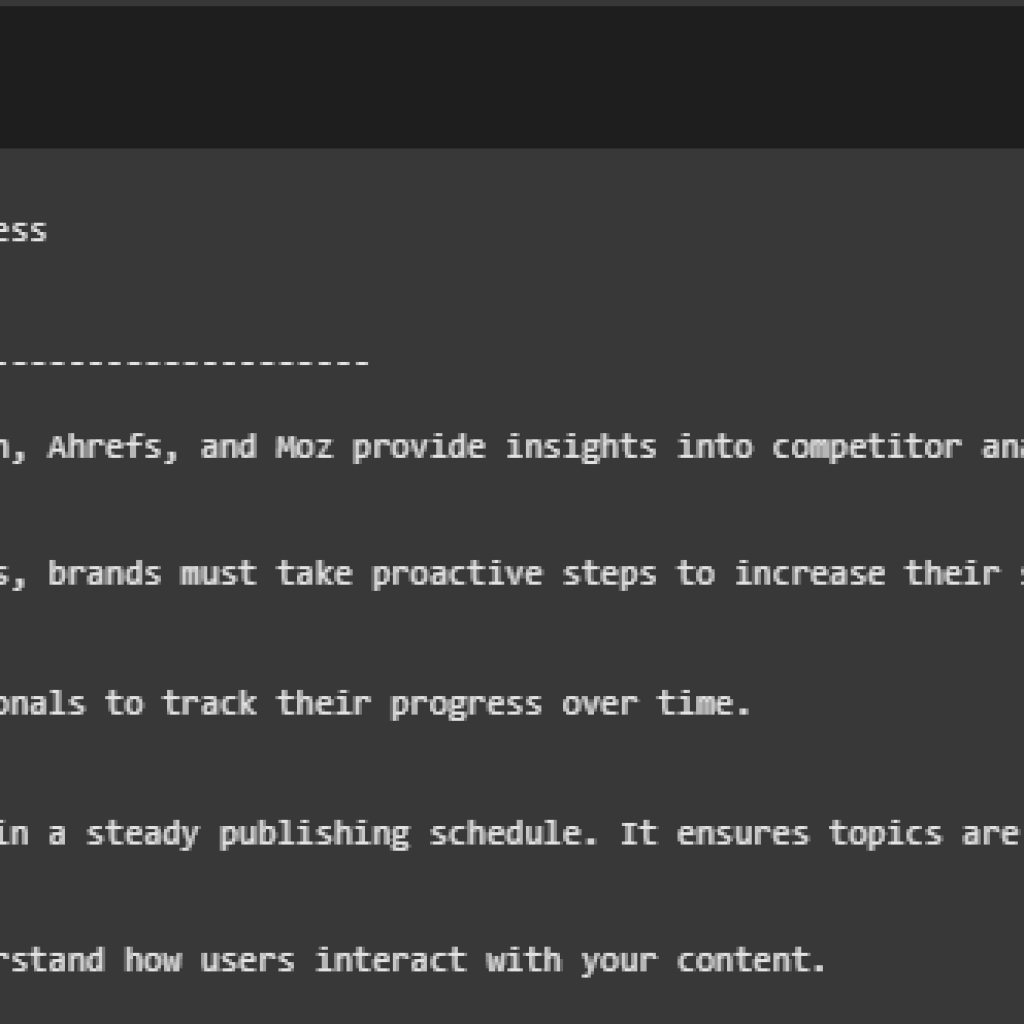
The model returned the top 5 content segments that are most relevant to this query, along with similarity scores that indicate the strength of semantic alignment between the query and each content block.
Understanding Similarity Scores
The DPR model computes a cosine similarity between the query embedding and each passage embedding. Scores are in the range [0, 1], where higher values indicate greater semantic closeness. A difference of 0.01–0.02 between scores is typically meaningful in a ranking context.
In this run, scores ranged from 0.6656 (highest) to 0.6462, suggesting all retrieved passages are closely relevant to the user’s intent.
Top-Ranked Passage Interpretation
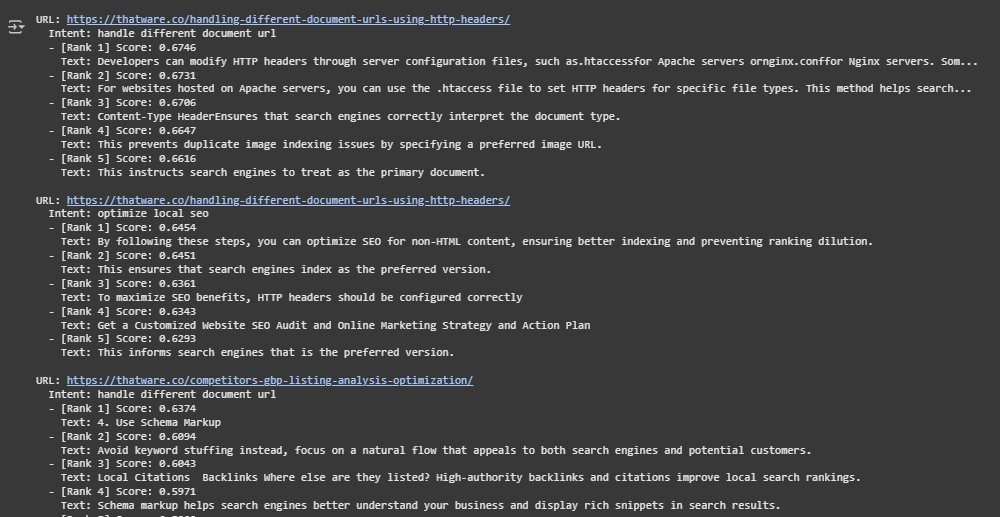
Rank 1 — Score: 0.6656
“Third-party SEO platforms: Tools like SEMrush, Ahrefs, and Moz provide insights into competitor analysis, keyword performance, and search visibility.”
This passage was ranked highest because it directly references actionable SEO metrics, such as keyword performance and search visibility, which are essential for success. The mention of well-known tools reinforces the practical relevance.
Rank 2 — Score: 0.6637
“SinceSoS is a critical metric for SEO success, brands must take proactive steps to increase their search dominance. Here are some actionable strategies:”
Here, the passage explicitly identifies a metric (SoS – Share of Search), framing it as critical for SEO success. The phrase “actionable strategies” also aligns well with the intent behind the query.
Rank 3 — Score: 0.6557
“Performance Tracking: It enables SEO professionals to track their progress over time.”
This result reflects a broader conceptual metric: performance tracking over time, highlighting its role in measuring SEO outcomes.
Rank 4 — Score: 0.6464
“A well-planned content calendar helps maintain a steady publishing schedule. It ensures topics are covered strategically for long-term success.”
While not a direct metric, this passage contributes to success-related operational practices that support SEO longevity, explaining why it’s still semantically relevant.
Rank 5 — Score: 0.6462
“Gather insights from analytics tools to understand how users interact with your content.”
This emphasizes user behavior metrics, derived from analytics tools, which are commonly tracked in SEO workflows.
Result Analysis and Explanation
This section provides an in-depth explanation of how the model’s output should be interpreted and how it aligns with the objectives of improving SEO effectiveness through passage ranking. The aim is to empower decision-makers with a clear understanding of what the scores represent and how they can be used to identify strengths and optimization opportunities across web pages.
Understanding the Passage Ranking Scores
Each passage extracted from a webpage is compared with the user intent using a dense vector similarity model. The resulting score reflects how semantically relevant the passage is to the user’s search intent. A higher score indicates stronger alignment between the user’s informational need and the content presented in that passage.
These scores are not binary “match or not” values; rather, they sit on a spectrum of semantic alignment. Therefore, interpreting them in relative and contextual terms is essential.
Practical Score Interpretation Framework
While score values can range anywhere from 0.0 to 1.0, most real-world, content-based similarity scores typically fall within a narrower and meaningful band. Based on observed results and practical usage:
· Above 0.80 — Strong Semantic Match
Passages in this range are highly aligned with the user’s intent. They often directly answer the query or explain a core concept related to it. These are prime candidates for snippet optimization, featured content, or linking anchors.
· 0.60 to 0.80 — Moderate to Strong Relevance
These passages are still highly useful and often include indirect but informative content. They support the intent contextually, making them useful for internal linking, supporting sections, or reinforcing topical authority.
· 0.30 to 0.60 — Moderate Relevance
Passages in this band may touch on the topic but with less focus. They can be revised or expanded to better reflect the target intent. These are useful indicators for optimization opportunities.
· Below 0.30 — Low Relevance
These passages are loosely or marginally related to the user’s search goal. Their presence in the top ranks may indicate content misalignment or gaps in topical targeting. While not necessarily irrelevant, such passages are not sufficiently strong to compete for top visibility without enhancement.
This framework helps clients understand what a given score means in terms of actionability and content value.
Observations from Current Results
In the analyzed examples:
- Many top-ranked passages fell within the 0.66 to 0.69 range, indicating consistent moderate-to-strong semantic alignment with the query intents. This reflects positively on the editorial quality and topic targeting of the source pages.
- In cases where scores approached 0.70 or above, the content was not only relevant but also highly specific and actionable, suggesting a strong potential for capturing search traffic when optimized as featured snippets.
- Lower scoring passages, especially in the 0.63 to 0.65 range, frequently contained general statements or less query-focused messaging. These can benefit from rewording, enhanced keyword targeting, or restructuring to improve topical depth.
Strategic Gains and Optimization Benefits
The application of dense passage retrieval and semantic ranking provides immediate insights into:
- Content Relevance Mapping: Understand exactly which paragraphs or sections of a page best serve high-value queries.
- Optimization Guidance: Identify which passages can be refined to better align with intent, improving ranking and on-page engagement.
- Internal Linking Targets: High-scoring passages across multiple URLs can be linked internally to create a network of relevant authority content, improving crawlability and thematic clustering.
- Snippets and Highlight Extraction: Content with very high scores can be repurposed as meta descriptions, featured answers, or spotlight content in blog summaries or FAQ sections.
Final Considerations for Score Usage
Use relative ranking among passages as a guide, not absolute cutoffs.
- Target 0.70+ for snippet-worthy content and 0.65–0.70 for internal linking and support.
- Rework content segments below 0.60 when they appear too frequently in top positions.
By interpreting scores through this lens, teams can strategically elevate their content to better serve user needs and improve visibility on SERPs. This aligns the model’s output with practical SEO decision-making and long-term value growth.
Final Thoughts
This project demonstrates a structured, intent-driven approach to improving content performance using Dense Passage Retrieval (DPR) techniques. By ranking content at the passage level against clearly defined user intents, the system delivers actionable insights that go far beyond generic keyword matching or surface-level analytics.
The key benefit lies in precision—understanding exactly which segments of content align with user expectations, and where strategic gaps exist. Clients can now identify high-performing passages, optimize mid-level content, and address weak areas with clarity and purpose. These insights provide a measurable path toward better SERP visibility, enhanced user satisfaction, and stronger content authority.
Beyond improving individual pages, the project enables more intelligent internal linking, clearer content clustering, and evidence-based content planning. When applied at scale across a website, this methodology supports long-term growth in organic reach and user engagement, helping content not just perform—but lead.
With a solid framework in place and score-based interpretation made practical, clients are now equipped to act confidently, scale efficiently, and ensure every piece of content contributes meaningfully to their digital presence.
