SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project delivers a robust solution to detect and assess the presence of AI-generated content within webpages. By analyzing text blocks extracted from client-provided URLs, the system evaluates how much of the page content is likely generated by automated tools rather than human authorship.
Using a high-accuracy pretrained transformer model specialized in AI-content detection, each content block is individually scored for its likelihood of being machine-generated. The system then aggregates these scores to provide overall metrics, including the percentage of AI-generated content per page, average detection confidence, and a ranked list of the most suspicious text segments.

Designed for SEO professionals and digital content teams, the solution helps prioritize content audits, maintain originality standards, and improve search engine credibility. The full implementation is modular, scalable, and built using industry-standard data science practices, with results accessible in both visual summaries and downloadable JSON reports.
Project Purpose
The purpose of this project is to provide SEO-focused organizations with an automated, reliable, and scalable method to detect AI-generated content across their websites. As generative AI becomes increasingly common in content creation workflows, distinguishing between original human-written material and machine-generated text has become critical for maintaining trust, editorial standards, and organic search performance.
Search engines are continuously advancing their ability to assess content quality and authenticity. Websites that unknowingly publish high volumes of AI-generated or low-authenticity material may face penalties in search rankings, reduced user trust, and damage to brand credibility. SEO teams need clear visibility into which pages are at risk and where automated content is concentrated.
This system addresses that need by analyzing content block by block, identifying likely AI-generated segments, and quantifying the ratio of automated content per page. It enables SEO managers, content leads, and compliance teams to prioritize audits, flag suspicious content, and take corrective action to preserve content originality across digital properties.
By making AI-content detection operationally scalable, this solution supports broader initiatives in content quality assurance, search optimization, and editorial governance.
Key Topics Explanation and Understanding
This project is centered around the automated detection and ranking of webpage content based on its origin — whether it is human-written (original), AI-generated, or algorithmically composed. The project addresses several critical technical and strategic topics relevant to digital content management and SEO performance:
AI-Generated Content Detection
AI-generated content refers to text written by large language models or automated writing tools rather than by human authors. While these tools can increase content production speed, they also introduce risks such as reduced originality, factual inaccuracies, and lowered editorial quality. The system implemented in this project uses a specialized transformer-based model that evaluates each content block and assigns a confidence score indicating the likelihood that the text was generated by AI. This detection capability enables content teams to audit and monitor where generative models have been used, intentionally or otherwise.
Original Content Identification
Original content is critical for domain authority, audience engagement, and compliance with search engine guidelines. Unlike duplicate or AI-generated material, original content reflects unique viewpoints, context-aware phrasing, and editorial judgment. This project helps surface and preserve original content by identifying and separating it from blocks that appear to be automatically generated. The identification process is based on content structure, linguistic patterns, and model-based scoring, enabling precise and scalable evaluation across large websites.
Content Authenticity Scoring
To support meaningful analysis, each block of text is evaluated independently, and scores are aggregated to determine an overall content authenticity profile for each page. This includes metrics such as the proportion of AI-generated blocks (AI Ratio), the average AI detection score across all content, and a ranked list of the most suspicious content segments. These scores help quantify content risk and guide targeted remediation efforts.
Web-Scale Auditing of SEO Content
The solution is designed to process multiple webpages in a single workflow, enabling scalable content integrity audits. Whether used across entire domains or on high-priority sections such as landing pages, blogs, or product descriptions, the system delivers structured outputs that support decision-making for SEO optimization, quality control, and policy enforcement.
Q&A: Understanding the Project Value and Importance
What specific business problem does this project solve?
This project addresses the growing challenge of identifying AI-generated content within large websites. As generative tools become more common in content production, organizations face increasing difficulty in verifying whether published material reflects original, human-authored input. This system automates that verification process, helping SEO teams maintain content authenticity and reduce reliance on manual review.
How does this project support SEO and content quality strategies?
The system provides SEO teams with a scalable method to assess whether webpage content is human-authored or AI-generated. This insight is crucial because search engines continue to emphasize original, high-quality, and expertise-driven content in their ranking algorithms. By flagging pages with higher proportions of AI-generated text, the system enables focused editorial review and helps maintain compliance with best practices that impact search visibility and authority.
How does this solution fit into the SEO content lifecycle?
The system integrates naturally into multiple stages of the SEO workflow. It can be applied to newly published content as a pre-launch quality check, used in scheduled content audits to flag existing pages, or applied during SEO remediation efforts to isolate low-trust content. Its ability to process multiple URLs and extract meaningful blocks allows SEO managers and editors to gain block-level visibility without requiring full manual review.
What features make this system useful across large content portfolios?
The implementation supports batch processing of multiple pages, auto-extraction of structured content blocks, and automatic scoring and ranking of potentially AI-generated text. Outputs are presented in a client-friendly summary format and can be exported in JSON for integration into internal tools. These features make it scalable for large domains, microsites, or segmented audits based on site priority.
How can different roles within a client’s team benefit from this tool?
- SEO professionals gain page-level indicators of AI content risk, helping prioritize which URLs require human intervention.
- Editorial teams can review highlighted content blocks for rewriting or approval.
- Content compliance and governance leads can use the data to ensure adherence to originality policies across web properties.
- Digital marketing managers can align messaging and tone by ensuring content reflects brand-authored standards.
How does this system reduce manual workload?
Manual review of content for authenticity across hundreds of URLs is resource-intensive and often inconsistent. This system automates the block extraction and detection process, delivering ready-to-review summaries and surfacing the most suspicious content segments. It enables teams to focus only on content that shows high risk, saving time while improving audit coverage.
Can this project be used repeatedly or integrated into long-term workflows?
Yes. The implementation is modular, lightweight, and export-ready. It can be run as needed for one-time audits or integrated into recurring quality control cycles. Because the code is designed to be maintainable and adaptable, organizations can scale or modify it based on content volume, site structure, or evolving editorial policies.
Libraries Used
The implementation uses a set of well-established Python libraries for web crawling, HTML parsing, content normalization, and AI-based text classification. These libraries form the technical foundation of the detection pipeline, enabling reliable and scalable processing of client URLs.
requests
The requests library is a widely used HTTP client for Python, enabling programmatic interaction with web servers through simple and reliable HTTP requests. It supports features such as custom headers, timeouts, and status checks, which are essential when dealing with varied page types and network conditions.
In this project, requests is used to fetch the raw HTML content of webpages directly from the provided client URLs. Proper headers and timeouts are configured to simulate browser-like access and ensure stable retrieval. This serves as the first step in the pipeline, providing the base input for downstream content extraction.
bs4 (BeautifulSoup, Comment)
BeautifulSoup from the bs4 package is a robust and flexible HTML/XML parser. It allows structured navigation and filtering of HTML elements, making it ideal for isolating readable content from markup-heavy webpages.
In this implementation, BeautifulSoup is used to parse the HTML DOM and extract visible content blocks based on tag-level filtering (e.g., <p>, <div>, <section>). It also removes irrelevant or hidden elements such as <script>, <style>, <footer>, and user-invisible components. The Comment object is used to eliminate HTML comments that can otherwise be mistaken as text during parsing.
urllib.parse.urlparse
The urlparse function from Python’s standard urllib.parse module provides structured decomposition of URLs into their constituent parts like scheme, netloc, path, and query parameters.
This utility is used in the project to assist with domain parsing, input validation, and logging. While not central to content scoring, it plays a supportive role in maintaining URL integrity and ensuring correct mapping of results to source pages.
hashlib
hashlib provides cryptographic hash functions for generating unique digests from input strings. It is widely used in data deduplication, caching, and integrity verification.
In this project, hashlib is used to generate MD5 hashes for normalized content blocks. These hashes are stored and checked to ensure that repeated content is only processed once. This helps avoid redundancy when similar or identical blocks appear multiple times on a single page, especially within common layout sections like menus or repeated banners.
logging
Python’s logging module enables configurable logging for tracking application behavior, errors, and execution status in a structured way. It is preferred over print statements in production systems.
Here, logging is used to track critical runtime events such as failed URL fetches, empty page content, or skipped blocks. These logs can assist developers or operational teams in identifying crawl issues, debugging unexpected behavior, and improving audit coverage.
re
The re module provides regular expression operations for pattern matching, text filtering, and substitution. It is a powerful utility for content preprocessing in NLP workflows.
In this context, re is used to clean up raw text extracted from HTML. It standardizes spacing, removes non-textual characters, and filters out blocks containing menu symbols or layout fragments. This ensures that only clean, semantically meaningful content is passed to the detection model for classification.
html and unicodedata
The html module provides tools to handle HTML entities, such as converting & into &, which are commonly found in rendered content. unicodedata offers functions for Unicode normalization, ensuring consistency across text encoding and display.
Both are used in the preprocessing step to clean and normalize the extracted content. By unescaping entities and flattening Unicode characters, the system ensures that the model receives linguistically clean inputs that reflect how a human reader would interpret the page.
transformers
The transformers library by HuggingFace provides state-of-the-art tools for loading and working with pre-trained NLP models. It supports thousands of transformer-based models including BERT, RoBERTa, T5, and others across a range of tasks.
In this project, transformers is used to load the fakespot-ai/roberta-base-ai-text-detection-v1 model and run AI-content classification on each content block. It provides the tokenizer, model architecture, and pipeline utilities needed to score the likelihood that a block is AI-generated. This forms the core detection logic of the system.
transformers.utils.logging
This submodule allows developers to suppress unnecessary logs from the transformer models, especially during batch inference or notebook execution.
The project disables model-level verbosity and progress bars to keep notebook output clean and focused on client-relevant results. This helps improve usability and makes the report easier to navigate for SEO professionals reviewing the outputs.
json
The json module is part of Python’s standard library for working with structured data formats. It supports reading, writing, and formatting JSON files, which are commonly used in APIs, reporting, and data storage.
Here, it is used to export the final AI detection summaries into a single, structured JSON file. The export includes per-URL statistics, top suspicious blocks, and scoring metrics in a format that can be shared with clients or imported into downstream tools for further analysis or dashboard integration.
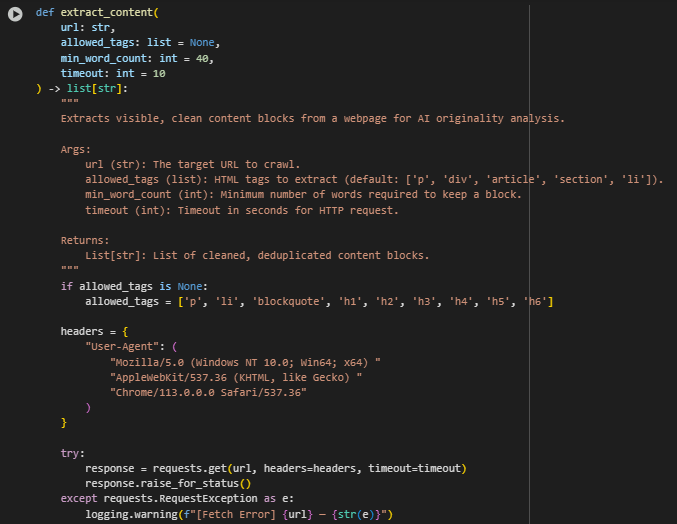
Function: extract_content
Overview
The extract_content function is responsible for extracting visible, meaningful content blocks from a given webpage URL. It fetches the HTML content, filters out hidden or non-informational elements, and then extracts readable text based on allowed HTML tags. The function is designed to return clean, deduplicated content blocks that are representative of what a user would actually see on the page.
This content is used as the input to the AI content detection model. Ensuring quality and relevance at this stage is critical to achieving accurate and useful results.
Key Code Explanations
· requests.get(…) Used to fetch the raw HTML of the target webpage. A custom User-Agent header is added to simulate a browser request and improve reliability when accessing public-facing websites.
· BeautifulSoup(response.text, “lxml”) Parses the HTML content using the lxml parser, which allows efficient navigation and manipulation of the page structure.
· for tag in soup([…]): tag.decompose() Removes script, style, form, and other non-content elements that do not contribute to the main body of the webpage. This step ensures that only user-visible text is processed.
· if “display:none” in tag[‘style’] and if tag.has_attr(“hidden”) Identifies and excludes elements hidden via inline CSS or HTML attributes. This ensures that content intended to be invisible is not included in the detection process.
· allowed_tags = [‘p’, ‘li’, ‘blockquote’, ‘h1’, ‘h2’, ‘h3’, ‘h4’, ‘h5’, ‘h6’] Specifies which tags to extract text from. These tags are chosen because they typically contain the main content, such as paragraphs, headings, and list items.
· if len(text.split()) < min_word_count Filters out very short content blocks that likely don’t carry useful semantic meaning. This helps remove fragments like navigation links or short labels.
· hashlib.md5(norm_text.encode()).hexdigest() Generates a hash for each cleaned text block to detect and skip duplicate content. This prevents repeated sections (e.g., footer links or repeated sidebar content) from skewing the results.
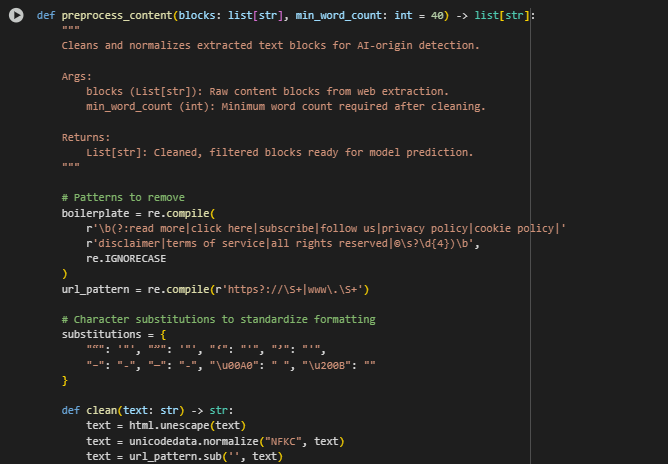
Function: preprocess_content
Overview
The preprocess_content function is responsible for cleaning and normalizing the raw content blocks extracted from web pages. This is a crucial intermediary step before running content blocks through the AI-origin detection model. It ensures that noisy, irrelevant, or boilerplate text is removed, and that the remaining text is consistent, readable, and semantically meaningful. The output is a list of well-structured content blocks ready for classification.
Key Code Explanations
· boilerplate = re.compile(…) Defines a regular expression pattern to identify and remove common low-value phrases such as “read more”, “privacy policy”, or “click here”. These phrases often occur in website footers or templates and do not carry informational value relevant to content quality.
· url_pattern = re.compile(…) Captures and removes hyperlinks from the content. Removing embedded URLs helps avoid bias in model scoring, particularly when dealing with templated or navigational text.
· substitutions = {…} Maps visually similar but inconsistent characters (e.g., curly quotes, long dashes, non-breaking spaces) to standard equivalents. This improves model compatibility and avoids irregularities caused by text encoding issues.
· text = html.unescape(text) and unicodedata.normalize(“NFKC”, text) Unescapes HTML entities and normalizes Unicode formatting. This step ensures that characters appear as a human reader would see them and that linguistic patterns are cleanly interpreted by the detection model.
· re.sub(r”\s+”, ” “, text).strip() Collapses multiple whitespace characters into a single space and trims leading/trailing whitespace. This standardizes the text formatting and ensures block-level consistency.
· if len(cleaned.split()) >= min_word_count Filters out content blocks that are too short after cleaning. This threshold ensures only substantial text is passed to the AI model, avoiding noise from short fragments like buttons, labels, or legal disclaimers.
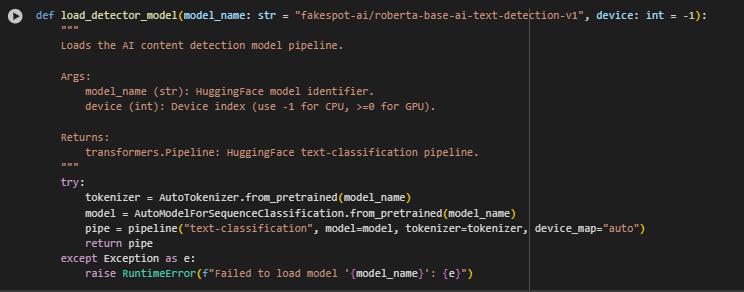
Function: load_detector_model
Overview
The load_detector_model function initializes and returns the pre-trained AI content detection model from HuggingFace. It wraps the model and tokenizer in a standardized inference pipeline, enabling streamlined text classification of content blocks. This function encapsulates model loading into a modular and reusable component, ensuring clean separation of concerns between model setup and downstream processing.
The model used in this project—fakespot-ai/roberta-base-ai-text-detection-v1—is designed to classify whether input text is likely AI-generated or human-authored, making it suitable for the objective of detecting non-original content across client web pages.
Key Code Explanations
· AutoTokenizer.from_pretrained(model_name) and AutoModelForSequenceClassification.from_pretrained(model_name) These lines load the tokenizer and model architecture based on the provided model identifier. This setup ensures that tokenization and model encoding are aligned with the fine-tuned parameters of the detection model.
· pipeline(“text-classification”, …) Creates a HuggingFace pipeline that simplifies the prediction process. The pipeline abstracts away tokenization, batching, and model evaluation steps, allowing content blocks to be passed directly for scoring. This improves readability and maintainability of the overall detection system.
· device_map=”auto” Automatically assigns the model to a GPU if available, falling back to CPU otherwise. This ensures optimal performance during inference, particularly when processing content from many pages in batch mode.

Model Overview: fakespot-ai/roberta-base-ai-text-detection-v1
What Is This Model?
This project utilizes a pre-trained language classification model called fakespot-ai/roberta-base-ai-text-detection-v1, available via the HuggingFace Model Hub. It is a fine-tuned variant of the widely used roberta-base transformer architecture, purpose-built for detecting AI-generated text.
The model is trained to classify whether a given input passage is human-authored or generated by a language model. For each input, it produces probability scores across two classes—commonly labeled as REAL (human-written) and FAKE (AI-generated). These confidence scores form the core signal used to assess content originality at the block level across webpages.
Model Architecture and Operational Logic
Transformer-Based Foundation (RoBERTa)
At its core, the model is built on RoBERTa (Robustly Optimized BERT Pretraining Approach), a transformer-based language model developed by Facebook AI. RoBERTa improves upon the original BERT architecture by:
- Training on larger and more diverse datasets
- Removing the next-sentence prediction objective
- Applying dynamic token masking
- Extending training duration for stronger contextual understanding
These enhancements allow RoBERTa to capture deeper linguistic and contextual relationships within text.
Inference Workflow in This System
Within this project, the model operates as follows:
- Tokenization:
Each extracted content block is passed through a tokenizer that converts raw text into token IDs suitable for transformer inference. - Contextual Encoding:
The transformer encoder processes the tokenized input, capturing semantic, syntactic, and stylistic patterns across the entire block. - Binary Classification:
A classification head applies a softmax layer over the final transformer representations, assigning probabilities to the two output classes: AI-generated or human-written. - Confidence Scoring:
The model returns both a label and an associated confidence score, enabling downstream systems to rank and prioritize content blocks by AI-generation likelihood.
This classification is context-aware and relies on learned linguistic, stylistic, and statistical features commonly associated with machine-generated text.
Why This Model Was Selected
Task-Specific Optimization
Unlike general-purpose NLP models designed for sentiment analysis or topic classification, this model is explicitly fine-tuned for AI-text detection. Its narrow specialization makes it well-suited for content originality analysis and editorial quality control.
Production-Ready and Reliable
Sourced from Fakespot AI and distributed via HuggingFace, the model is production-ready and does not require additional fine-tuning to deliver reliable results. This enables rapid deployment while maintaining stability and reproducibility across environments.
Seamless Pipeline Integration
The model integrates cleanly with HuggingFace’s transformers inference pipelines, allowing consistent scoring with minimal configuration. This compatibility ensures straightforward incorporation into automated content analysis workflows.
Efficient and Scalable Performance
Powered by the roberta-base backbone, the model strikes a practical balance between performance and efficiency. It is capable of processing multiple content blocks per page at scale without requiring specialized hardware, making it suitable for enterprise SEO audits and large content inventories.
Summary
The fakespot-ai/roberta-base-ai-text-detection-v1 model provides a robust, context-aware foundation for AI-content detection. Its transformer-based architecture, task-specific fine-tuning, and production readiness make it a strong choice for scalable content authenticity analysis within modern SEO and editorial intelligence systems.
Importance in SEO Context
Search engines place growing emphasis on content originality, authoritativeness, and human relevance. Over-reliance on AI-generated text can reduce page quality scores, increase the risk of content devaluation, or even trigger penalties if discovered at scale.
By embedding this model into the SEO audit pipeline:
- Editorial teams gain visibility into which content may be AI-generated or need review.
- SEO professionals can maintain content trustworthiness, ensuring alignment with evolving quality guidelines.
- Brands preserve authenticity by confirming that key messaging and expertise are not overly automated or diluted.
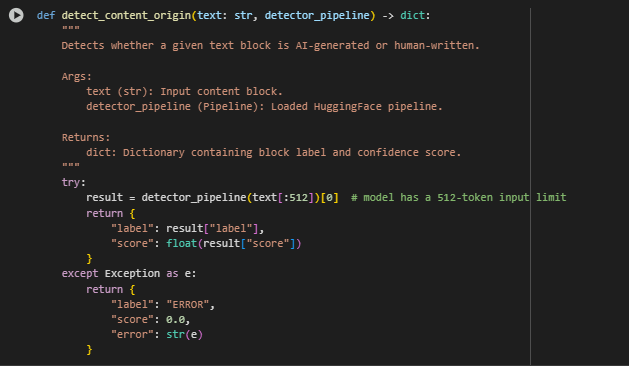
Here is the detailed explanation for the function detect_content_origin, written in the same structured and professional format used previously:
Function: detect_content_origin
Overview
The detect_content_origin function classifies a single content block as either AI-generated or human-written. It uses the previously loaded HuggingFace detection pipeline to score each block and returns a structured result containing the prediction label and confidence score. This function is essential for applying the AI content detection model at the block level, allowing granular evaluation across a page.
This modular approach makes the scoring logic reusable, cleanly separating model inference from content extraction and result summarization.
Key Code Explanations
· result = detector_pipeline(text[:512])[0] Applies the AI detection pipeline to the content block. Because transformer models like RoBERTa have a token limit (typically 512 tokens), the input is truncated to the first 512 characters to prevent overflow. This ensures compatibility without degrading model performance.
· return {“label”: result[“label”], “score”: float(result[“score”])} Constructs a dictionary that contains the classification result — either “REAL” (human-written) or “FAKE” (AI-generated) — along with the model’s confidence score. This format standardizes the output for downstream processing and result display.
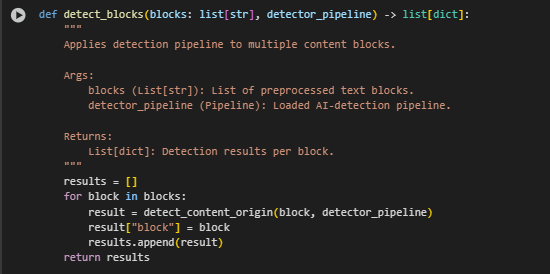
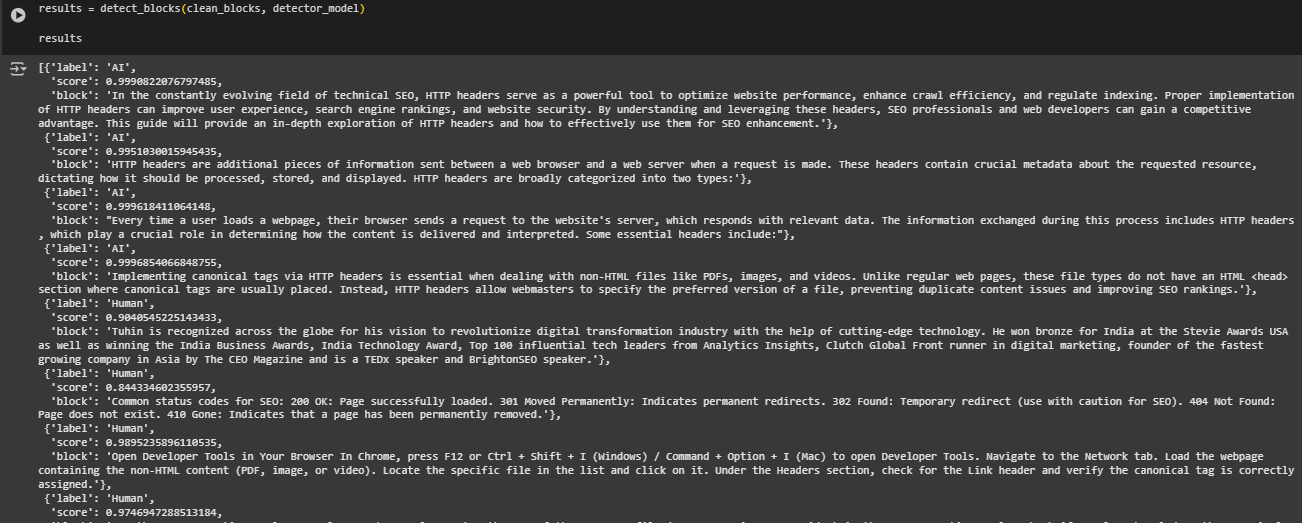
Function: detect_blocks
Overview
The detect_blocks function performs AI-origin classification on a list of content blocks from a single web page. It iterates through each block, applies the detection model, and stores the individual results along with their corresponding text. This enables block-level granularity in assessing content authenticity, which is essential for identifying specific areas within a page that may have been AI-generated.
The function operates as a lightweight wrapper around the detect_content_origin function and is designed for reusability within the broader pipeline.
Key Code Explanations
· for block in blocks: Iterates over the list of cleaned and preprocessed content blocks extracted from a page. Each block is considered independently to ensure accurate classification and per-block visibility.
· result = detect_content_origin(block, detector_pipeline) Calls the single-block classification function using the pre-loaded detection pipeline. This allows for consistent scoring across all blocks with centralized model logic.
· result[“block”] = block Attaches the original block text to the result dictionary. This step is critical for later stages of the workflow where both the model score and the associated text are needed for display, ranking, or export.
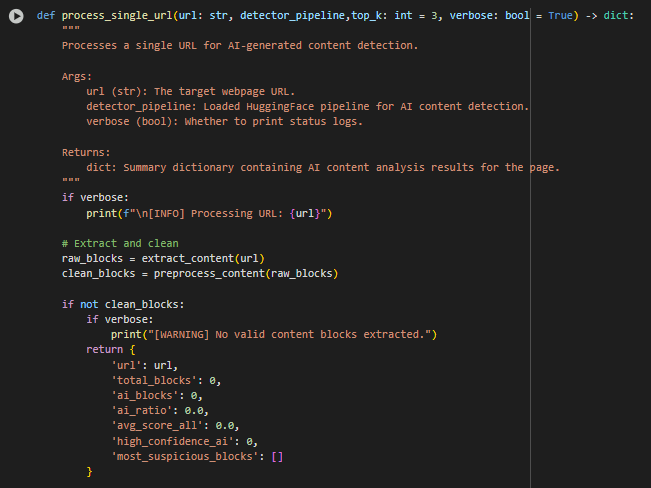
Function: process_single_url
Overview
The process_single_url function performs a complete end-to-end AI-origin analysis for a single webpage. It integrates content extraction, preprocessing, AI-based detection, and score aggregation into one cohesive workflow. Designed to be modular and reusable, this function acts as the core analytical unit for evaluating content originality at a granular, block-level resolution.
The function returns a structured summary containing actionable metrics such as total AI-classified blocks, average AI probability score, high-confidence AI detections, and the most suspicious content segments. These outputs are directly applicable to content audits, editorial governance, quality assurance, and advanced SEO decision-making.
Key Workflow Components and Code Explanations
1. Webpage Content Extraction
raw_blocks = extract_content(url)
This step crawls the target webpage and extracts visible HTML content blocks. The extraction process focuses on semantically meaningful, user-facing text, ensuring that only content relevant to real readers is evaluated, while ignoring non-visible or non-informational elements.
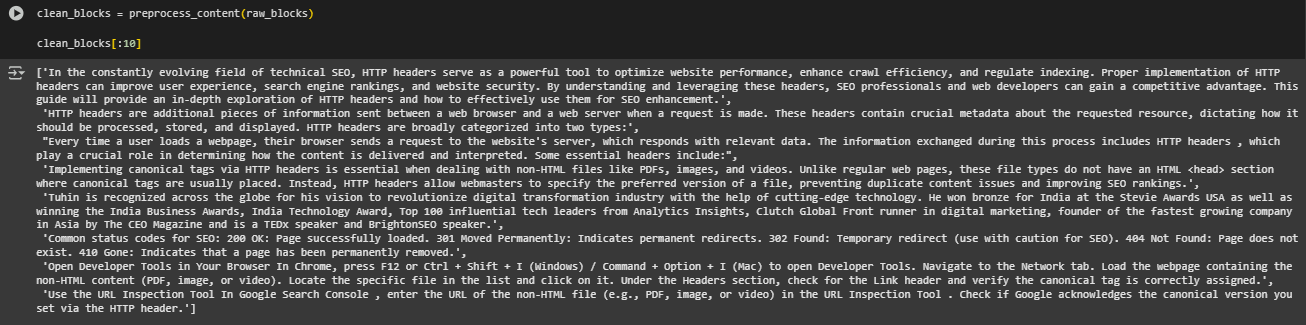
2. Content Preprocessing and Normalization
clean_blocks = preprocess_content(raw_blocks)
The preprocessing stage cleans and standardizes the extracted blocks by removing boilerplate text, formatting noise, navigation fragments, and low-signal content. This normalization ensures that the AI detection model receives high-quality, contextually relevant text, improving detection accuracy and reducing false positives.
3. Empty or Edge-Case Handling
if not clean_blocks:
return {…}
This conditional handles scenarios where a webpage contains no meaningful content after preprocessing. In such cases, the function returns a structured zero-output response, with all metrics set to 0.0 or empty arrays. This guarantees consistent downstream behavior and prevents failures in pipelines that depend on standardized output formats.
4. Block-Level AI Detection
results = detect_blocks(clean_blocks, detector_pipeline)
Each preprocessed content block is passed through a transformer-based AI detection pipeline. The output consists of per-block classification results, including a label (AI or Human) and an associated confidence score, enabling fine-grained content origin analysis.
5. Identification of AI-Classified Content Blocks
ai_blocks = [r for r in results if r[“label”] == “AI”]
This step filters the detection results to isolate blocks classified as AI-generated. These blocks form the primary basis for computing all content authenticity and risk metrics associated with the page.
6. High-Confidence AI Detection Filtering
high_conf_ai = [r for r in ai_blocks if r[“score”] > 0.9]
To improve actionability, AI-classified blocks are further filtered using a high-confidence threshold (default: 0.9). These blocks represent strong AI-generation signals and are typically prioritized for editorial review, compliance checks, or SEO risk flagging.
7. Ranking the Most Suspicious Content Blocks
top_blocks = sorted(ai_blocks, key=lambda x: -x[“score”])[:3]
AI-classified blocks are sorted in descending order based on confidence score, and the top N blocks (default: 3) are selected. These represent the most suspicious content segments and are surfaced in the output for rapid inspection and remediation.
8. Page-Level AI Probability Scoring
avg_score_all = round(sum(r[“score”] for r in results) / len(results), 5)
This cilculation computes the average AI-detection score across all analyzed blocks. While coarse, this metric provides a useful page-level signal indicating the overall likelihood of AI-generated content presence and helps prioritize pages for deeper audits.
Summary
The process_single_url function delivers a robust, interpretable, and SEO-ready AI content analysis pipeline. By combining block-level detection with structured aggregation, it enables scalable content authenticity evaluation while maintaining transparency and editorial control—making it particularly valuable for enterprise SEO teams, publishers, and quality-focused content operations.
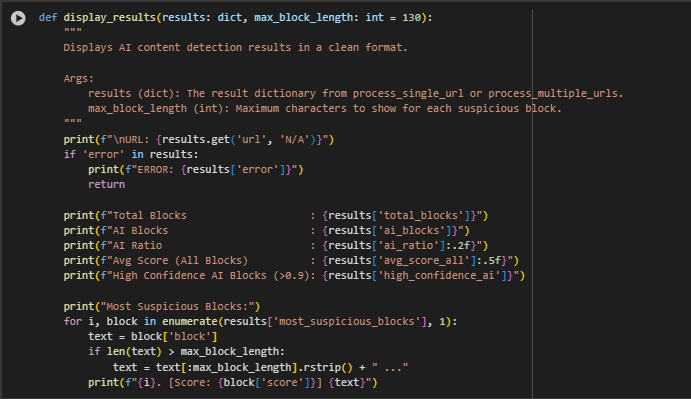
Function: display_results
The display_results function provides a concise, readable summary of AI-content detection results for a single webpage. It prints key statistics such as the total number of content blocks, the number and ratio of AI-classified blocks, average model confidence score, and the count of high-confidence AI detections. Additionally, it presents a shortened preview of the most suspicious content blocks, ranked by their AI score. The function is designed to improve usability for SEO professionals and content auditors by making complex model output quickly understandable in a notebook setting. It is particularly helpful when reviewing multiple URLs interactively, allowing teams to assess content quality and risks at a glance.
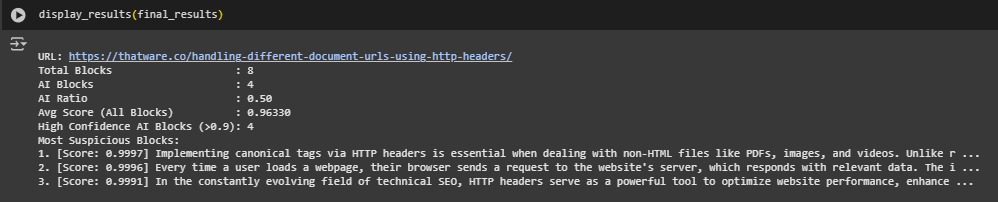
Result Analysis and Explanation
This section explains the AI-origin detection result for one webpage. The content from the page was extracted, cleaned, and analyzed block by block to assess how much of it is likely AI-generated. Below is a breakdown of each output field and what it represents.
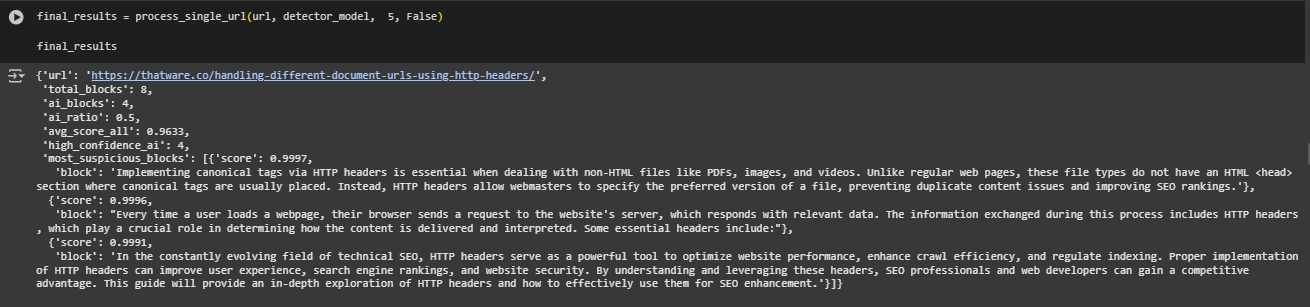
Total Blocks: 8
This indicates that eight distinct content blocks were extracted from the page. Each block generally corresponds to a visible paragraph, heading, or list item that holds meaningful user-facing information.
AI Blocks: 4
Out of the total 8 blocks, four were classified by the AI-origin detection model as likely AI-generated. This means 50% of the content on this page is potentially non-original or produced with assistance from AI systems. This may raise quality concerns depending on how the content is positioned and its role on the page.
AI Ratio: 0.50
The AI Ratio is the proportion of blocks detected as AI-generated relative to the total number of blocks. A 0.50 value means that half of the page’s content is potentially machine-authored. In SEO-focused audits, a ratio near or above 0.5 often warrants closer inspection, especially on key informational pages where human expertise is expected.
Average Score (All Blocks): 0.96330
This is the average of the model’s confidence scores across all blocks — both AI and human-labeled. A high average score (close to 1.0) suggests that the model is consistently confident in its classifications. In this case, the score indicates strong AI-likeness across the board, even for blocks labeled as human.
High Confidence AI Blocks (> 0.9): 4
This metric reflects the number of AI-classified blocks with a confidence score above 0.90. A high count in this range implies that not only are many blocks flagged as AI-generated, but the model is also highly certain of those classifications. From a content governance and SEO compliance perspective, this level of certainty should be taken seriously.
Most Suspicious Blocks (Top 3 by Score)
The three highest-scoring AI-labeled blocks are presented here as representative samples of potentially non-original content. These blocks received scores close to or above 0.999, indicating near-certain AI-origin. Their wording, structure, or tone may resemble common patterns found in auto-generated text, despite their correctness or grammatical quality.
These top blocks help identify specific areas of concern within the page, allowing SEO teams or content managers to perform deeper qualitative reviews and decide whether rewriting or editorial oversight is necessary.
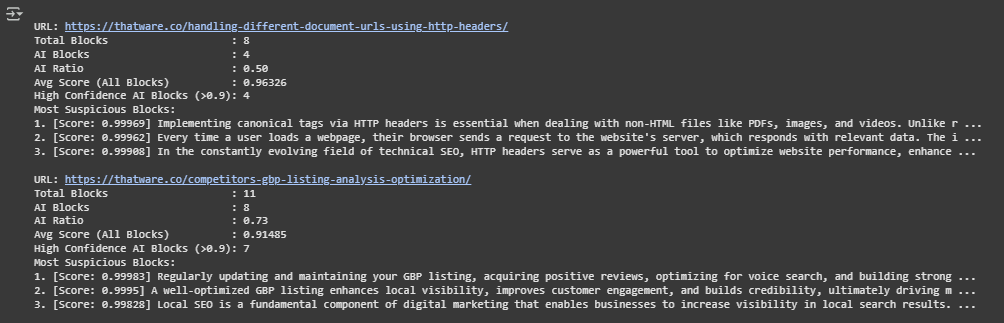
Result Analysis and Explanation
This section provides a practical understanding of how to interpret the AI-origin detection outputs when applied across multiple webpages. Each result includes a set of metrics that collectively describe the degree of AI-generated content and its confidence level. These insights help SEO teams and content strategists identify where automation may have been overused and take informed action to improve content originality.
Total Blocks
- Indicates the number of visible content segments extracted from a page.
- A higher count suggests a longer, content-rich page, while lower counts are typical for product pages or short landing content.
- When comparing pages, total block count helps normalize AI-related metrics across different content lengths.
Actionable Considerations:
- Pages with unusually low block counts should be reviewed for content depth and completeness.
- Pages with high block counts may benefit from focused sampling of high-confidence blocks for efficiency.
AI Blocks
- This represents the number of blocks classified as likely AI-generated by the model.
- It is an absolute value showing how much AI content appears within a page.
Interpretation:
- A small number of AI blocks is expected in modern editorial workflows.
- A high number of AI blocks suggests automation is playing a central role in content creation.
Actions to Consider:
- For pages with 5 or more AI blocks, especially on service, FAQ, or educational content, editorial teams should review and consider rewriting parts for tone, accuracy, or originality.
- Cross-reference with traffic and keyword ranking to prioritize high-value pages.
AI Ratio
- AI Ratio is the percentage of blocks flagged as AI-generated out of the total blocks.
- It is a high-level metric used to gauge the overall dependency on automated text generation.
Interpretation Guidelines:
- 0.00 – 0.20 -> Very low AI presence. Content appears highly original.
- 0.21 – 0.49 -> Mixed origin content. Likely some light automation or assistance.
- 0.50 – 0.74 -> Moderate to high AI presence. May signal template use or bulk-generated content.
- 0.75 – 1.00 -> Very high AI presence. Content is largely machine-generated or synthetic.
Actions to Take:
- Pages above 0.50 should be flagged for editorial review, especially if positioned for SEO-critical keywords or topics requiring expertise.
- For ratios above 0.75, prioritize rewriting or content enrichment to improve quality and trustworthiness.
- Pages with ratios under 0.20 can generally be considered editorially safe unless flagged by other systems.
Average Score (All Blocks)
- This is the average of model confidence scores across all blocks on a page, whether labeled AI or human.
- A consistently high average score often indicates a uniform, AI-like tone even if not all blocks are classified as AI.
Score Ranges and Interpretation:
- Below 0.60 -> Natural human writing with little to no AI signal.
- 0.60 – 0.85 -> Possible assisted writing or light templating.
- 0.86 – 0.95 -> Strong AI tone present. Often indicates optimization or rewriting tools.
- Above 0.95 -> Highly AI-characteristic writing across most of the page.
Recommended Actions:
- For scores above 0.85, review content tone for over-optimization or repetitiveness.
- High scores combined with high AI ratio should trigger full editorial audit.
- Pages with average scores under 0.60 can be treated as authentic unless manually flagged.
High Confidence AI Blocks (> 0.90)
- This is the number of blocks where the AI label was assigned with a confidence score greater than 0.90.
- These blocks are statistically the most reliable indicators of machine-written content.
What It Means:
- Even if AI ratio is moderate, a high count of high-confidence AI blocks points to specific parts of the page needing attention.
Client Actions:
- 3 or more high-confidence AI blocks on a page should be reviewed immediately.
- Focus rewriting or human review effort on these blocks first for efficiency.
- For category or templated pages, this can also signal a need to update the underlying content generation approach.
Most Suspicious Blocks
- For each page, the top 3 highest-scoring AI blocks are shown.
- These blocks represent the content most likely to be flagged by search engines or content evaluators as automated.
How to Use:
- Use these blocks as entry points for manual editorial review.
- Even if they appear grammatically correct, consider their structure, tone, and semantic originality.
- Replace with expert-written, context-rich alternatives when possible.
This generalized result interpretation helps clients assess content health at scale. The scoring system is designed to be used not just for evaluation but for directing real editorial actions that improve content quality, SEO performance, and compliance with evolving search standards.
Final Thoughts
This project delivers a complete, production-ready solution for detecting AI-generated content across webpages with precision, transparency, and scalability. By combining targeted web content extraction, robust text preprocessing, and a domain-specialized transformer model, the system identifies AI-origin content at a granular level and translates technical outputs into clear, actionable insights.
From block-level classification to AI ratio analysis and high-confidence detection, each component of the implementation has been purposefully designed to support SEO professionals and content managers in evaluating originality, maintaining editorial quality, and safeguarding ranking integrity. The modular architecture allows seamless scaling across large content inventories, while the result summaries and exportable outputs ensure efficient integration into existing content workflows.
As search engines continue to prioritize authentic, human-centric content, this system empowers clients to stay ahead of compliance demands and deliver trustworthy digital experiences — with measurable control over how content is authored, presented, and evaluated.
