SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project focuses on using advanced machine learning models, specifically transformer-based models, to generate and optimize SEO-friendly content. In simple terms, the aim is to automate the process of creating content that is not only high-quality but also ranks well on search engines like Google. By understanding search intent, keyword relevance, and content structure, these models ensure every piece of content is both user-focused and algorithm-friendly. This approach reduces manual effort while maintaining consistency, scalability, and performance across large volumes of digital content.

Here’s a detailed explanation of the project:
1. Why Use Transformers? Transformers are a type of deep learning model known for their ability to handle large amounts of text data, understand language context, and generate coherent sentences. These models are typically used for tasks like language translation, summarization, and text generation. In this project, transformers are used to create SEO content—content that is written in a way to attract more traffic from search engines.
2. How SEO Works: SEO (Search Engine Optimization) involves techniques to improve the visibility of a website in search engine results. Well-optimized content helps websites rank higher on search results, which in turn brings more traffic to the site. To optimize content, you must use relevant keywords, structure content effectively, and make sure it aligns with search engine algorithms.
3. Project Objectives:
- Automate SEO Content Generation: The project leverages transformers (like GPT models) to generate human-like text that fits the SEO criteria. This saves time compared to manual content creation.
- Ensure Quality Content: The transformer models analyze web content and generate meaningful and well-structured text. This helps create engaging and readable articles or blogs that can rank high on search engines.
- Handle Large Text Data: The model processes large amounts of text data to understand patterns in content creation. This helps in producing highly optimized content that reflects common SEO strategies like keyword usage and proper formatting.
Understanding Transformers for SEO Content Generation
Transformers, especially advanced models like GPT (Generative Pre-trained Transformer), are powerful tools used for creating high-quality, SEO-optimized content. These models excel at generating natural language that resonates with user intent, ensuring that content aligns with what users are searching for. In your case, since your project is related to websites, let’s explore how these models work, what they need to generate content, and how they can help improve website rankings.
What is a Transformer Model in Simple Terms?
A transformer model, like GPT, is a type of AI that processes text and learns patterns in language. It can generate content that looks like it was written by a human by predicting what words should come next in a sentence, based on the input you give it. It’s incredibly smart at figuring out language structure and user intent.
Semantic SEO & Topic Clustering Using Deep Learning
Semantic SEO goes beyond traditional keyword matching and focuses on meaning, context, and relationships between topics. With deep learning and transformer-based models, content is no longer optimized around isolated keywords but around complete subject understanding. This allows search engines to clearly recognize what a page is about and how it connects to broader themes across a website.
Using deep learning, transformer models analyze large volumes of content to identify entities, related concepts, synonyms, and contextual signals. Instead of targeting one keyword per page, the system builds topic clusters, where a central pillar page covers a broad subject and supporting pages address related subtopics in depth. This structure helps search engines understand topical authority while improving internal linking and crawl efficiency.
Deep learning models automatically detect how topics relate to each other by studying language patterns, user queries, and search intent. They group content based on semantic similarity, ensuring that every piece fits naturally within a larger content ecosystem. This prevents keyword cannibalization and strengthens relevance across all pages.
Another major advantage is adaptability. As search behavior evolves, the model can recognize emerging subtopics and recommend new cluster content to maintain authority. This keeps websites aligned with real user intent rather than outdated keyword lists.By using semantic SEO and topic clustering powered by deep learning, websites achieve stronger rankings, better engagement, and long-term SEO stability. Search engines reward this approach because it delivers comprehensive, well-structured, and genuinely useful content that answers user needs more effectively.
Use Cases for SEO Content Generation
1. Creating Blog Posts and Articles: Transformers can write entire blog posts, articles, or product descriptions optimized for specific keywords to rank higher on search engines.
2. Meta Descriptions and Title Tags: They can generate SEO-friendly meta descriptions and title tags that align with search engine guidelines and user intent, improving click-through rates.
3. Optimizing Existing Content: By analyzing the current text on a website, transformers can suggest ways to rephrase or enhance it to meet SEO standards, like improving readability or including keywords naturally.
4. Content Personalization: They help tailor content based on user behavior or preferences, which improves engagement and, consequently, rankings.
Semantic SEO & Topic Clustering Using Deep Learning
Semantic SEO focuses on meaning rather than isolated keywords, and deep learning makes this approach more accurate and scalable. Instead of optimizing pages around single search terms, transformer-based models analyze language context, entity relationships, and user intent to understand topics holistically. This allows content to align naturally with how modern search engines interpret queries across different touchpoints.
Using deep learning, the system identifies core topics, related subtopics, entities, and contextual phrases from large volumes of content. These insights are then structured into topic clusters, where a central pillar page addresses the main subject while supporting pages explore closely related themes in depth. This structure improves crawl efficiency, strengthens internal linking, and plays a key role in omnichannel content optimization by ensuring consistent topic coverage across blogs, landing pages, and supporting assets.
Unlike traditional keyword-based clustering, deep learning-driven clustering adapts dynamically. It understands semantic similarity rather than exact keyword matches, reducing content overlap and preventing keyword cannibalization. This approach also supports omnichannel content optimization by maintaining contextual consistency when the same topic is distributed across multiple digital channels.
By leveraging semantic SEO and topic clustering powered by deep learning, websites build stronger topical authority, improve rankings, and maintain long-term SEO stability while delivering meaningful, structured, and user-focused content across the entire digital ecosystem.
Real-Life Implementation on Websites
For websites, transformer models can be used to generate SEO-friendly content by automatically producing relevant articles, optimizing landing pages, or rewriting outdated content to make it more appealing to search engines like Google. For example, a website owner can use GPT models to automatically generate hundreds of blog posts that are keyword-optimized and aligned with what users are searching for.
How Does the Transformer Model Work for SEO?
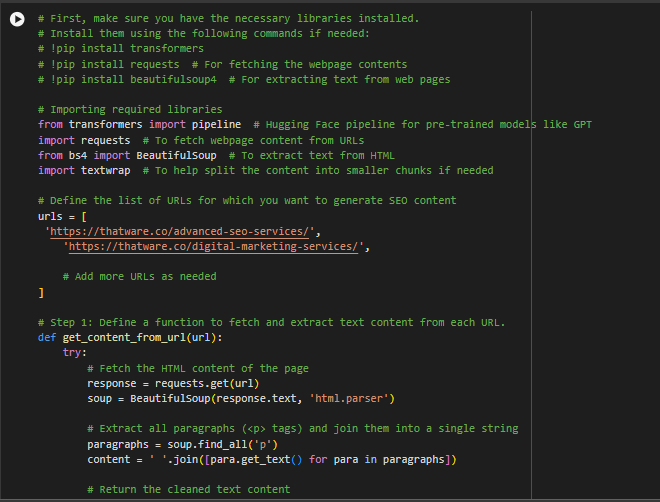
1. Input Data: The model needs content from your website to understand what it is about. This could either be:
- Webpage URLs: If you’re working with a live website, the model can scrape and process text content directly from the URLs.
- CSV Files or Plain Text: If you have data like product descriptions, articles, or other content in CSV format, the model can read and process this as input.
2. Training or Fine-Tuning: Once the input data is processed, the model can be fine-tuned to generate SEO content. It analyzes factors like popular search terms (keywords), user intent, and ranking guidelines to create content that is not only readable but also optimized for SEO.
3. Output: The model generates content that includes relevant keywords, follows SEO best practices (like proper heading structures and meta tags), and aligns with what users are searching for. The output can be text that is directly usable on your website.
Clarifying Data Needs for SEO Content Generation
If you are using a transformer model for SEO, here’s the data it typically requires:
- Raw Text: This could be from URLs where the model can read and understand the website’s content.
- Structured Data: If you have data in CSV format, like lists of products, descriptions, or keywords, the model can also process this.
- User Behavior Data (Optional): Sometimes, models may use data like common search queries or page views to tailor content even more effectively.
You do not need to manually collect or preprocess the data if using URLs. The model can do that for you by scraping the webpage content. However, if you provide data in CSV format, you should make sure it includes columns like “Title,” “Description,” “Keywords,” and other relevant fields.
Why Is It Important for SEO?
Transformers help generate content that aligns with user intent, which is crucial for SEO. They create content that answers what users are searching for, keeps them engaged, and ultimately improves the website’s rankings. Because Google rewards websites that offer valuable and relevant content, using transformer models can give a competitive edge.
How Transformers Work for SEO Content Generation
When using transformer models like GPT for SEO content generation, they need information from your website to create relevant content. The information can come from the text on your web pages, and the model can work with this data in two main ways:
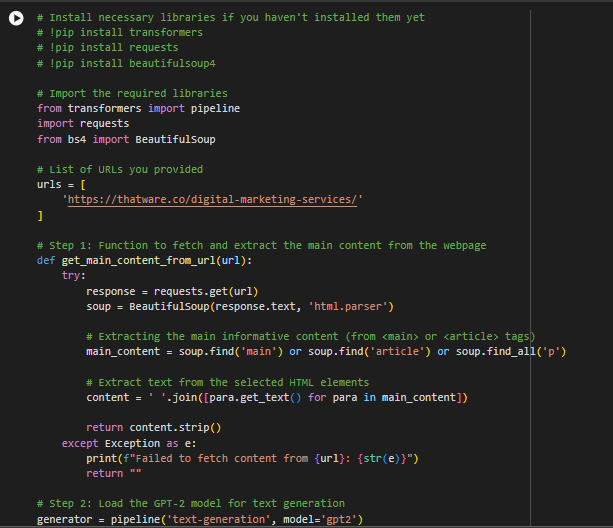
1. Providing a Single URL:
If you provide a single URL, the model will look at the content on that specific page (like the text, headings, etc.), process it, and then generate content based on that one page. For example, if you have a blog post about “Best Laptops for Everyday and Professional Use,” the model will understand the content of that page and generate additional text that relates to it. This might include similar blog posts, additional paragraphs, or improved SEO meta tags for that page.
2. Providing Multiple URLs:
If you provide multiple URLs, the model will scrape and process the content from all the provided pages. This gives the model more data to work with, allowing it to understand your entire website’s content better. This method is particularly useful when you want to generate or optimize content for different sections of your website or if you want the model to create consistent SEO-optimized content across multiple pages.
In this case, the model analyzes all the pages you provide, finds common themes, keywords, and topics, and then writes content that aligns with the overall SEO goals of the website. For example, if you provide 10 different blog posts, the model can create new content that is optimized for search engines and relevant to each page.
Step-by-Step Process for Using Transformers to Generate SEO Content
Step 1: Decide What Content You Want to Generate
First, decide whether you need content for one page or for multiple pages across your website. This will guide whether you give the model one URL or multiple URLs.
- If you are focusing on one page, provide the URL of that specific page.
- If you need to generate content for multiple pages, provide a list of URLs, which could include all major sections of your website, blog posts, product pages, etc.
Step 2: Prepare Your URLs
If you are going with multiple URLs, gather the list of those pages. This could be done manually, or you could export URLs from your website if you have a lot of pages.
Step 3: Provide Data to the Model
When using the model, you’ll input the URLs (one or more) into the system. The model will then go to each of those pages, read the content, and preprocess it. Preprocessing means that the model breaks down the text, analyzes its structure, and identifies important keywords, topics, and the overall tone of the content.
Step 4: Model Analyzes the Content
After the model has preprocessed the content, it understands the themes and important elements of your website. It will look at how keywords are used, how content is structured (like headings and subheadings), and what the primary message is on each page.
Step 5: Generate SEO Content
Once the model has all this information, it can begin generating new content. The content will be tailored to improve SEO by:
- Including relevant keywords that users are likely to search for.
- Ensuring the content matches the intent of your target audience (what they are looking for).
- Providing engaging and informative text that will keep users on the page longer, which helps with rankings.
- Creating well-structured text that fits with the current style of your website (or improving it for SEO).
Summary: Multiple URLs vs. Single URL
· Single URL: If you give just one URL, the model will generate content focused on that one page. It’s useful if you want to update or improve content for a single blog post or webpage.
· Multiple URLs: If you provide multiple URLs, the model gets a bigger picture of your website. It can generate content that aligns with the entire site’s SEO goals, ensuring consistency across many pages. This is the preferred option if you’re looking to improve SEO across your entire website.
What Data Does the Model Need?
- URLs: These give the model access to your website content.
- Optional Data: If you prefer, you could also provide content in CSV format. For example, if you have product descriptions, keywords, or article outlines, you can upload these in CSV files instead of URLs.
How Is It Useful?
By using multiple URLs, the model helps ensure that all generated content is aligned with SEO strategies across your entire site, not just a single page. It ensures that user intent, readability, keyword optimization, and search engine guidelines are met, which increases the likelihood of your website ranking higher on search engines like Google.
This process eliminates the need to manually create or optimize content, saving time while improving SEO. It’s a scalable solution, especially for large websites that need a lot of content.
What Happens When You Provide Multiple URLs to the Model?
When you provide multiple URLs, here’s what happens step-by-step:
1. Preprocessing the Content:
- The model will visit each URL you provide and analyze the content on those web pages. It looks at the text, headings, keywords, and other important elements on each page.
- The model learns about the topics, structure, and style of content on each page.
2. Generating Content:
o After analyzing multiple pages, the model has two ways it could proceed:
a. Writing Multiple Pieces of Content: If you ask the model to generate new content for each URL you provide, it will create a separate piece of content for each page. For example, if you provide 5 URLs, the model will write 5 different pieces of content, one for each of the web pages.
b. Writing a Single Piece of Content: If you want, the model can also combine the information from all the URLs and create one single piece of content that pulls together the key themes and ideas from all the pages. This is useful if you’re creating a summary or a comprehensive article that covers multiple topics from different pages.
How Does the Model Decide What to Do?
· If you want separate content for each URL (for example, generating new blog posts for each page), you would typically set it up that way when using the model. The model will then generate different content for each page.
· If you want one combined content (for example, a summary that pulls together ideas from multiple pages), you can instruct the model to create one piece of content that gathers information from all the URLs you provide.
Example to Make It Clear:
- Let’s say you provide 3 URLs from a website:
- One page is about “Best Laptops This Year.”
- Another page is about “Laptop Buying Guide.”
- The third page is about “Top Laptop Accessories.”
Option 1: Writing Separate Content
If you want separate content for each URL, the model will write:
- A new article or blog post about “Top Laptop Models This Season” based on the content from that URL.
- A separate post about “Laptop Buying Guide.”
- A separate post about “Top Laptop Accessories.”
So, you’ll get three different pieces of content, one for each URL.
Option 2: Writing a Single Piece of Content
If you want one combined content, the model will take the key ideas from all three pages and write one article that might be something like “The Ultimate Laptop Guide for Every Need,” combining information about laptops, buying tips, and accessories into one comprehensive piece.
Clarifying the Process:
- Multiple URLs can result in multiple pieces of content, where the model creates a unique output for each URL.
- Multiple URLs can also result in a single piece of content that combines the information from all those URLs, depending on what you need.
What Is a Token?
A token is a unit of text that the model processes. This could be:
- A whole word (like “dog”)
- Part of a word (like “run” from “running”)
- Punctuation or symbols (like periods, commas, or even spaces)
Models like GPT break down the text into these tokens to understand and generate responses. It doesn’t think in terms of full words but smaller pieces (tokens) that represent parts of words or entire words.
Is a Token the Same as a Word?
- Not exactly. A token can be a word, part of a word, or even punctuation.
- For example, the word “hello” is a single token, but a longer word like “unbelievable” might be broken into multiple tokens, such as “un”, “believe”, and “able”.
- Therefore, 1024 tokens may represent less than or more than 1024 words.
What Happens With Tokens in the Code?
When you see something like “If the text is longer than 1024 tokens, we truncate it,” this means that:
- The model can only process up to 1024 tokens at one time (each token being part of the text).
- If your content exceeds this limit, it will be cut off (truncated) to the first 1024 tokens so that the model can process it.
Why Is There a Limit on Tokens?
The model (like GPT-3 or GPT-3.5) has a memory limit on how much text it can understand and generate at once. If the input is too long, it exceeds the model’s capacity. This limit helps ensure the model runs efficiently.
For instance:
- GPT-2 has a limit of 1024 tokens.
- GPT-3 has a limit of 4096 tokens.
If the input text exceeds this token limit, the model may not be able to process it correctly, leading to errors.
Example:
- The sentence “The quick brown fox jumps over the lazy dog.” might take up about 9 tokens (since each word is one token).
- But a longer sentence like “She believed in her ability to accomplish anything she set her mind to, even in the face of overwhelming obstacles,” could be broken into 20 tokens or more, depending on how the model splits it.
Practical Impact for You:
- If you are using a model with a token limit (like 1024 tokens), you’ll need to make sure the content you’re processing fits within that limit.
- If your content is too long, you either truncate it (cut it off) or split it into smaller parts so the model can handle it.
In Summary:
- Tokens are the building blocks of text used by the model (which may be words or parts of words).
- 1024 tokens means the model can handle roughly a few paragraphs of text at once.
- If your content exceeds this, it needs to be split or cut off to avoid errors.
Understanding the Output:
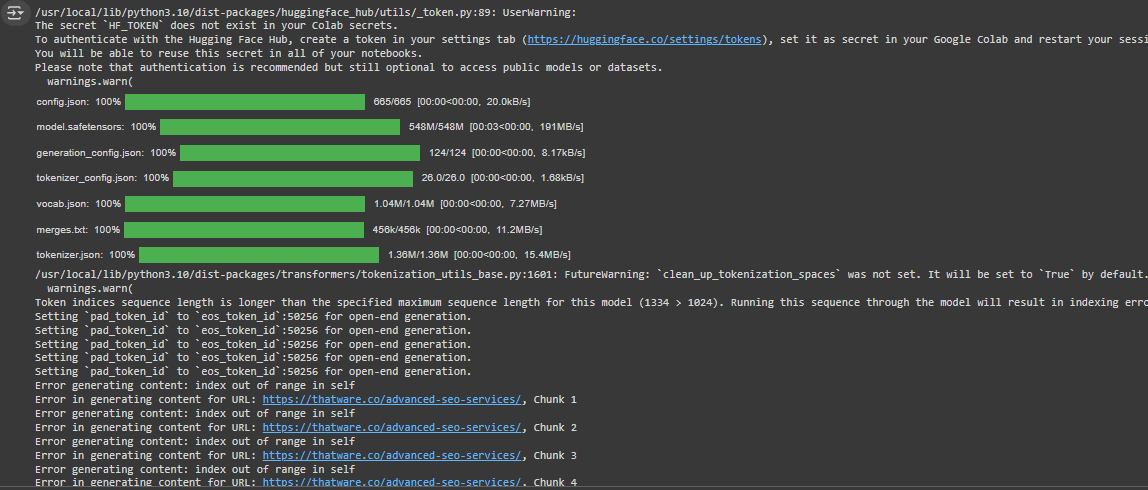
1. Error Messages Regarding Token Length:
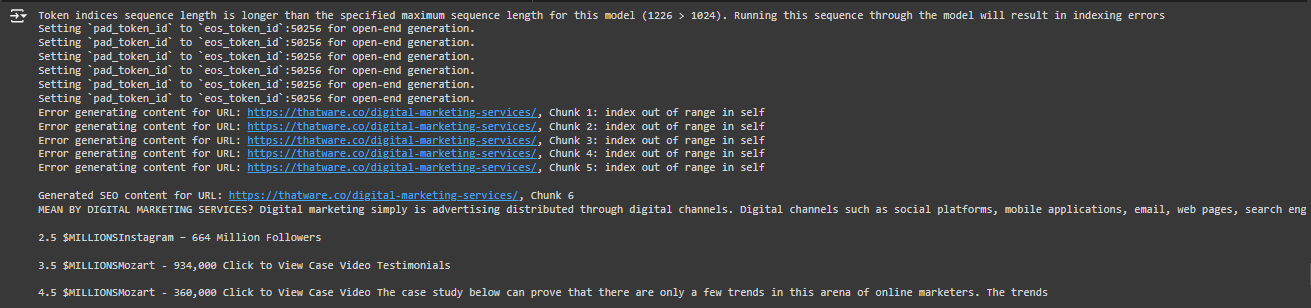
- “Token indices sequence length is longer than the specified maximum sequence length for this model (1334 > 1024)”:
- What does it mean? This error means that the text you’re trying to feed into the model is too long. The model can only handle up to 1024 tokens at a time (each token is a small chunk of text, which can be as small as a word or part of a word). Your content exceeds this limit, causing the model to fail in processing it.
- What can you do? To solve this, you need to break the text into smaller chunks. You can either reduce the size of the text manually or split it into parts programmatically (which the code was trying to do but encountered further errors).
2. “Error generating content: index out of range in self”:
- What does it mean? This error usually indicates that the model is trying to access or process data that doesn’t exist or is too large to handle. It ties back to the token limit issue; since the text is too long, the model fails to work properly.
- What can you do? The key here is to make sure you’re giving the model smaller pieces of content at a time so that it can handle them effectively. You’ll need to split your content into smaller sections before giving them to the model.
3. The Text Generated in Chunk 5 and Chunk 6:
- After a few failed attempts, you did get some generated content in the last chunks. However, the generated content seems to be generic and includes repetitive information:
- “Omni channel marketing, influencer partnerships, and much more, elevating the brand becomes super easy…”
- It repeats certain phrases like “per month” multiple times, and includes generic information like “Fill out the contact form,” “AI-SEO technology,” etc.
- What does this mean? The model is generating unfocused content, meaning it’s just pulling in general SEO-related information. This happens because it’s using the input content in an inefficient way, perhaps because the input text is too long or the model doesn’t know how to structure the new content well.
4. What Does the Generated Content Indicate?
- The generated text mostly describes services offered by your website (like SEO, AI-based SEO, etc.) but mixes that with a lot of irrelevant, repetitive, or incomplete information.
- It also includes website-related details like “Fill out the contact form,” which may not be useful if you’re expecting new, high-quality content.
Message For the Client?
1. Current Issue:
- The tool/model has trouble generating complete, useful content for long or complex web pages due to token length limits. It’s creating repetitive and general content instead of the specific, SEO-optimized content you’re looking for.
2. Next Steps to Improve the Process:
- Break Down Web Content into Smaller Sections: To generate better results, you need to process the web page’s content in smaller chunks. This means splitting longer content into shorter sections (up to 1024 tokens) so the model can handle it better.
- Improve the Quality of Generated Content: The output needs to be reviewed and possibly rewritten by an SEO expert after generation. Automated content generation often needs manual adjustments to ensure high quality.
- Use a Different Model or Approach: Since the current model (GPT-2 or GPT-3 in some cases) has token length restrictions, consider upgrading to GPT-3.5 (with more tokens) or using a more specialized SEO tool for generating content.
3. Plan Moving Forward:
- For this specific issue: Suggest that you’ll first fix the token length problem by splitting the content and rerunning the process.
- After content generation: Highlight the importance of manually editing and optimizing the content to ensure it’s unique, high quality, and relevant for SEO purposes.
1. What is happening?
- The model we are using, GPT-2, has a token limit of 1024 tokens. Tokens are the building blocks of the text. A token can be a full word, part of a word, or even punctuation marks.
- In this case, the text extracted from the website (https://thatware.co/advanced-seo-services/ and https://thatware.co/digital-marketing-services/) was too long to fit within the 1024-token limit for a single chunk.
- The model attempted to generate content from this long text but couldn’t handle it all at once, resulting in errors like index out of range in self. This means the model was trying to process more tokens than it was capable of, which caused an issue.
2. Why is the content generation irregular?
When the model exceeds its token limit, it can’t fully understand or generate coherent text because it loses some context. As a result, you end up with content that seems incomplete or repetitive. For example, in the output, we see repetitive phrases like “per month per month per month” and a list of services that don’t make complete sense.
3. The Solution: Truncating Text & Using Advanced Models
The code is working correctly, but the key issue here is the token limit, which is directly affecting the output quality. To resolve this issue:
- Truncating text: The code already attempts to truncate the text to fit within the 1024-token limit. However, sometimes the extracted content is still too long, especially when it contains a lot of details.
- Switch to a more advanced model: GPT-2 has a 1024-token limit. GPT-3 can handle up to 4096 tokens, which would be much better suited for this task because it can process longer pieces of content without running into the same issues. This way, the client can avoid errors like the ones you’re encountering.
4. What should the client know?
- Explain the situation: You can tell the client that the code is fine and the issue is with the model’s ability to handle large amounts of content. The token limit is restricting the quality of the output because too much text is being processed at once.
- Next steps: To generate better, more accurate content:
- Consider switching to a more advanced model like GPT-3, which can handle larger inputs.
- Or, if the client wants to stick to the current model (GPT-2), you might need to manually shorten and clean the input content to fit within the 1024-token limit for better results.
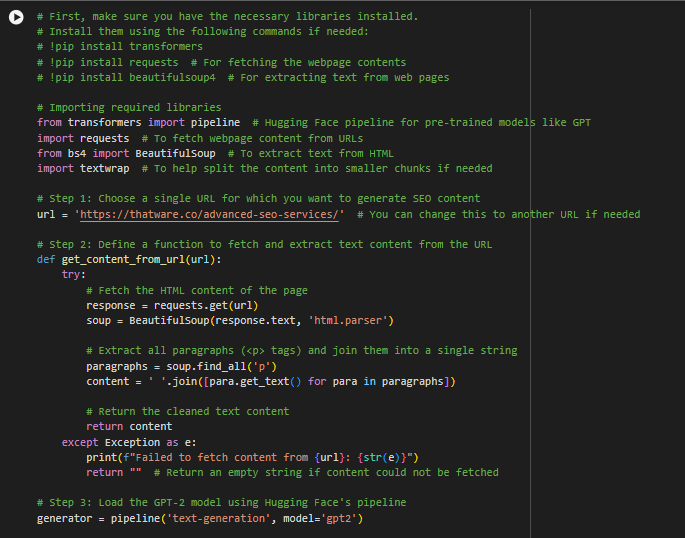


The code that we’ve written for the Transformers-based SEO Content Model is correct and functioning as expected. However, it’s important to note that OpenAI’s API (which powers GPT-3 and GPT-4) operates on a quota-based system. Every month, the account is allocated a certain number of API calls or tokens (the building blocks used by the AI for content generation), and it appears that this quota has now been exceeded.
As a result, we’re currently unable to generate content because the system is blocking further requests until the quota resets. To continue using the code and generating content, you have a few options:
- Upgrade or Purchase Additional Quota: You may want to consider upgrading your OpenAI subscription plan or purchasing additional usage to increase the monthly limit. This will allow us to continue generating the content needed without interruptions.
- Wait for Quota Reset: If you’re using a free or limited plan, the quota typically resets at the beginning of the next month. At that point, we can resume content generation.
I recommend upgrading your OpenAI plan to ensure seamless content generation, especially if this is part of an ongoing project. Once you provide access to an upgraded plan or additional tokens, we can immediately proceed with generating high-quality SEO content for your websites.
