SUPERCHARGE YOUR Online VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
Project Summary
The Concept Reinforcement Analyzer evaluates how effectively a webpage maintains and reinforces its central topic throughout its content sections. The project measures the semantic consistency of a core idea — ensuring that the main concept introduced at the beginning remains strong, relevant, and contextually aligned across the entire page.

This analytical framework identifies where the content supports the central theme with clarity and where the reinforcement weakens, allowing precise visibility into the strength of conceptual focus. By examining the distribution and intensity of concept-related expressions, the system highlights whether the content maintains thematic continuity or drifts into unrelated areas.
The project is built as a real-world analytical tool designed for SEO and content strategy applications. It leverages natural language processing (NLP) models to extract, analyze, and quantify conceptual reinforcement across web content, translating semantic depth into measurable insights. The output helps determine the effectiveness of topic retention, revealing how consistently a page communicates its primary idea to search engines and readers alike.
Project Purpose
The purpose of the Concept Reinforcement Analyzer is to measure how consistently a webpage upholds and strengthens its primary concept across different content sections. The project aims to transform conceptual alignment — traditionally a qualitative aspect of writing — into quantifiable insights that reveal how effectively each part of the page reinforces the main idea.
This initiative addresses a key SEO and content optimization challenge: ensuring that the thematic core of a page remains coherent from introduction to conclusion. Pages that maintain strong conceptual reinforcement tend to achieve better search relevance, user engagement, and comprehension, as both search algorithms and readers can easily interpret the content’s intent.
By providing measurable indicators of reinforcement strength, the analyzer supports informed optimization decisions. It allows identification of sections where conceptual consistency fades, helping strengthen narrative flow and topical focus. The overall objective is to make semantic coherence measurable, actionable, and aligned with content quality standards that enhance topical authority and visibility.
Project’s Key Topics Explanation and Understanding
The Concept Reinforcement Analyzer centers around understanding how well a page’s main idea is repeated, supported, and strengthened throughout its various content sections. To evaluate this, the project integrates multiple conceptual and linguistic principles from modern Natural Language Processing (NLP) and SEO-focused content analysis. The following are the core topics and concepts that define the analytical foundation of this project.
Concept Reinforcement
Concept reinforcement refers to how consistently a specific theme or main idea is expressed across a document. In high-quality content, the central concept is not merely introduced once but is subtly restated, elaborated, and semantically connected throughout the text. This reinforces comprehension for readers and signals topical authority to search engines.
Reinforcement strength can vary depending on word choice, contextual phrasing, or semantic relation between sections. Strong reinforcement implies the content maintains focus and thematic clarity, while weak reinforcement may indicate digressions, topic shifts, or sections that do not contribute meaningfully to the main topic. Measuring this reinforcement allows for an objective evaluation of how tightly each part of the page aligns with its intended concept.
Main Topic Consistency
Main topic consistency assesses whether all sections of a page collectively support a unified conceptual direction. It ensures that the content remains centered on the primary idea and avoids fragmentation. This concept forms the structural foundation of semantic coherence — an essential aspect of content that drives readability, comprehension, and SEO strength.
Maintaining topic consistency across sections prevents semantic drift, where the focus of the text gradually shifts away from its main objective. For SEO, this consistency enhances the likelihood that search engines will correctly interpret the page’s intent, improving topical authority and relevance.
Section-Level Semantic Representation
Each webpage is divided into logical content blocks or sections, such as headings, paragraphs, or topic clusters. Each section carries its own semantic meaning but must still align with the overarching theme. To measure this relationship, the project utilizes section-level semantic embeddings, which numerically represent the meaning of text using transformer-based language models.
By comparing these section embeddings to the main topic representation, it becomes possible to quantify conceptual closeness between the section and the central idea. This creates a measurable signal of how well each section reinforces or diverges from the topic.
Semantic Similarity and Contextual Alignment
Semantic similarity is the quantitative measure of how close in meaning two pieces of text are. The project relies on advanced transformer models that map sentences into high-dimensional semantic spaces, where similar concepts appear close together. Contextual alignment extends this idea by focusing on meaning within context — not just lexical overlap.
For example, two sentences might use different words but still express the same concept. Measuring this contextual similarity helps determine reinforcement beyond simple keyword repetition, ensuring that the analysis captures true conceptual coherence rather than surface-level similarity.
Reinforcement Distribution Across Page
Conceptual reinforcement is not uniform throughout a document. It can vary by section depending on how ideas are developed, supported, or concluded. The reinforcement distribution identifies where conceptual strength rises or falls across a page. Understanding this distribution highlights strong segments that effectively reinforce the topic and weak sections that may dilute thematic focus. This insight is essential for actionable optimization — improving sections that underperform without disrupting overall structure or narrative flow.
SEO and Topical Authority Implications
From an SEO perspective, concept reinforcement directly impacts topical authority — a search engine’s perception of how comprehensively and consistently a page covers a subject. Pages with high reinforcement scores typically demonstrate better content coherence, which aligns with search engine preferences for semantically rich and well-structured text.
Conceptual consistency also supports user experience. Readers naturally follow a logical and focused narrative when each section contributes meaningfully to the same idea, improving retention and trustworthiness of the information.
This combination of concept reinforcement measurement, semantic similarity analysis, and section-level consistency evaluation provides a structured approach to quantify and visualize how effectively a webpage sustains its primary topic. It transforms abstract content quality factors into measurable, interpretable metrics, laying the foundation for data-driven content optimization.
Q&A — Understanding Project Value, Features, and Strategic Importance
What business and SEO benefits does Concept Reinforcement Analyzer deliver?
Concept Reinforcement Analyzer converts qualitative aspects of content—topic focus, thematic consistency, and narrative coherence—into quantitative metrics that directly inform optimization decisions. From an SEO perspective, pages that consistently reinforce a clear central concept are more likely to be interpreted as topically authoritative by search engines, improving relevance signals for targeted queries. From a content strategy perspective, reinforced pages reduce reader confusion, increase dwell time, and improve conversion paths because each section purposefully supports the page’s main idea. Operational benefits include prioritized editing (high-impact sections are surfaced), reduced editorial guesswork, measurable tracking of content improvements over time, and better alignment between keyword strategy and content execution.
What is the core purpose of the Concept Reinforcement Analyzer?
The core purpose of the Concept Reinforcement Analyzer is to evaluate how consistently a page reinforces its main topic across all content sections. In SEO-focused content, maintaining a strong thematic connection throughout the page is critical for signaling authority and topical depth. This project measures that connection in a structured, data-driven manner, helping determine where the page maintains or weakens its core message. It transforms what was once a subjective editorial judgment into quantifiable insight for optimization and content planning.
Why is concept reinforcement important for SEO and user comprehension?
Search engines interpret consistent topical reinforcement as a sign of expertise and clarity. Pages that continuously align their subtopics, examples, and supporting details with the main concept tend to rank better because they present a coherent knowledge structure. For readers, consistent reinforcement enhances comprehension, minimizes topic drift, and improves information retention. The analyzer bridges both needs — technical SEO alignment and improved content readability — by identifying exactly how the page maintains thematic focus from start to end.
What distinguishes this project from conventional content optimization tools?
Traditional tools focus on surface-level indicators such as keyword frequency or readability scores. The Concept Reinforcement Analyzer goes beyond that by using semantic similarity modeling to capture deeper conceptual relationships. Instead of counting keyword occurrences, it measures the semantic distance between content blocks and the main concept. This makes it far more adaptive to natural language, synonyms, and rephrased concepts, which aligns with how modern search engines interpret meaning. The system focuses on meaning-level consistency rather than mechanical repetition.
How does the system identify and analyze conceptual reinforcement?
The system divides the page into meaningful content blocks and uses transformer-based embeddings to assess how closely each block aligns with the target concepts or queries. Each block receives a similarity score, allowing the system to measure thematic strength section by section. Through aggregated evaluation, the analyzer determines overall conceptual consistency, identifying strong and weak reinforcement zones. This approach ensures that the assessment reflects both linguistic and contextual understanding of the page rather than keyword matching alone.
What are the main features of the Concept Reinforcement Analyzer?
Key features include:
- Block-level semantic evaluation: Measures contextual reinforcement at the paragraph or section level.
- Query-based flexibility: Allows analysis across multiple main concepts or topics simultaneously.
- Reinforcement mapping: Detects where the core idea weakens or shifts within the content structure.
- Multi-query aggregation: Highlights overlapping weak areas across multiple themes, showing where overall topical integrity declines.
- Visualization and interpretability: Offers easy-to-read visual summaries that communicate conceptual balance and weakness points for quick decision-making.
What underlying model or technology powers this analysis?
The project is built on transformer-based sentence embedding models capable of capturing contextual semantic meaning in natural language. These models transform text into high-dimensional vector representations that reflect conceptual relationships rather than surface-level patterns. This ensures the analyzer can interpret linguistic variations, paraphrases, and domain-specific phrasings while maintaining reliable concept detection. By relying on this embedding-based understanding, the analyzer can quantify conceptual reinforcement with a degree of accuracy that keyword-driven tools cannot achieve.
How does the analyzer ensure scalability and adaptability for different domains?
The design is modular and domain-agnostic. By adjusting the target query list or concept set, the analyzer can adapt to different industry verticals or content strategies — whether technical, educational, or commercial. Because the underlying models capture generalized semantics, it can be applied to multiple page types without re-engineering. Domain adaptation is possible through custom query sets or fine-tuning if needed, making the tool suitable for agencies handling large, multi-domain SEO portfolios.
What role does this project play in the larger SEO optimization process?
The Concept Reinforcement Analyzer acts as a diagnostic intelligence layer within a content optimization pipeline. Before publishing or auditing content, it identifies structural and topical gaps that weaken page relevance. Post-analysis, its findings guide writers, strategists, and SEO teams to focus on sections where conceptual strength is low. It integrates naturally with topic modeling, content scoring, and internal linking strategies — effectively functioning as a reinforcement assurance mechanism that ensures every section of the content contributes meaningfully to the page’s search intent.
What types of content benefit most from this analysis?
Long-form, informational, and high-competition content benefit the most — such as guides, blog posts, landing pages, and documentation. In such content types, maintaining conceptual continuity is vital for both ranking and user understanding. However, the analyzer can also be applied to commercial or product pages where thematic alignment between features, benefits, and primary topics determines conversion quality. Any content that aims to build authority around a focused idea gains measurable value from reinforcement assessment.
How does this project contribute to long-term content quality assurance?
By establishing measurable benchmarks for conceptual consistency, the project enables long-term tracking of content health. Pages can be periodically re-analyzed to detect thematic drift over time — a common issue after multiple content updates. This ensures that ongoing optimization aligns with the original strategic theme. The tool effectively becomes part of a sustainable content governance system, maintaining alignment between SEO goals, editorial intent, and user relevance.

Libraries Used
time
The time library is a standard Python module that provides functions to track, measure, and manage time-related operations such as delays, timestamps, and performance monitoring. It is often used in automation and network-related processes to ensure that requests or computations are properly spaced and executed at controlled intervals.
In this project, time is used to introduce controlled delays between consecutive webpage requests. This ensures that multiple URLs can be processed responsibly without overwhelming the target server, maintaining good web scraping etiquette and preventing potential request blocking. The delay mechanism also adds a level of reliability to the extraction process by avoiding simultaneous network load during multi-page execution.
re
The re (regular expressions) library provides tools for string pattern matching, text parsing, and extraction. It is an essential component in text processing workflows, enabling efficient detection, substitution, and validation of patterns within large bodies of text.
Here, it is used for text cleaning, URL simplification, and structured extraction of relevant patterns from raw HTML content. It supports functions like trimming redundant prefixes, normalizing section titles, and sanitizing extracted text for analysis. This ensures that preprocessing steps are consistent and the data passed to the model is clean and uniform.
html (as html_lib)
The built-in html library offers tools for escaping and unescaping HTML entities. It helps convert encoded HTML characters back into readable text, ensuring that textual data extracted from webpages remains meaningful and human-readable.
In this project, it is used to decode special characters like &, <, or " into their original forms. This decoding is crucial when processing textual content for embedding generation, as it prevents semantic distortion caused by unprocessed HTML encodings and ensures the embeddings reflect true linguistic content.
hashlib
The hashlib library provides secure hash and message digest algorithms. It is used to generate unique, fixed-length identifiers for arbitrary data using algorithms like MD5, SHA1, or SHA256.
Here, hashlib is applied to generate unique IDs for content blocks using a hash of the text. This ensures each block can be tracked consistently throughout the pipeline without relying on positional indices or content strings, which might change. It creates a stable, collision-resistant mapping mechanism for referencing each content section.
unicodedata
The unicodedata module provides access to the Unicode Character Database, allowing standardization and normalization of text representations. It ensures consistent handling of characters from different scripts, accent marks, and other special characters.
In this project, it is used to normalize all extracted text to a uniform encoding format (typically NFC normalization). This ensures consistent embedding computation and prevents discrepancies in model input when dealing with international or multi-language pages that may contain varied Unicode representations.
gc (Garbage Collection)
The gc library provides an interface to Python’s garbage collector, which manages memory cleanup for objects no longer in use. Manual garbage collection can be particularly useful in projects dealing with large data structures or models.
Here, it helps maintain memory efficiency when processing multiple URLs or embedding large text blocks. After each page’s analysis, unused variables are cleared from memory, and the garbage collector is invoked to prevent memory buildup, ensuring stable and efficient multi-page execution.
logging
The logging module enables structured recording of runtime information such as warnings, errors, and process flow messages. It is widely used in production-grade systems for debugging, monitoring, and audit trails.
In this project, logging provides traceable feedback during extraction, preprocessing, embedding generation, and analysis phases. It captures and reports any warnings or exceptions with clear contextual messages, ensuring operational transparency and easier debugging in real-world deployments or batch runs.
requests
The requests library simplifies HTTP requests in Python, providing user-friendly methods for sending GET and POST requests and handling responses. It is a foundational library for any web content extraction or API-based project.
Within this project, it powers the webpage fetching mechanism in the extraction module. It handles URL requests, manages timeouts, and processes response encoding. Its robust error handling and flexible configuration make it ideal for large-scale URL extraction with reliability and control over network interactions.
typing
The typing module provides support for type hints and annotations, enabling more readable, structured, and error-resistant code. It helps define expected input and output types for functions, promoting maintainability and reducing logical errors.
In this project, typing annotations ensure that each function communicates its expected data structure clearly — such as List[str], Dict[str, Any], or Optional[float]. This makes the codebase cleaner, easier to debug, and more maintainable for long-term collaborative development or extension.
BeautifulSoup (from bs4)
BeautifulSoup is a powerful HTML and XML parsing library used to extract and navigate document elements. It enables selective access to tags, text, attributes, and nested content within a webpage’s HTML structure.
Here, it plays a crucial role in the extraction stage by cleaning the fetched HTML, removing boilerplate elements like scripts, ads, or navigation items, and segmenting meaningful content. It helps form a structured and text-oriented representation of the page suitable for downstream semantic analysis.
numpy
NumPy is the foundational numerical computation library in Python, providing array-based data structures and optimized operations for mathematical and matrix calculations. It is extensively used in machine learning and data science applications.
In this project, it is primarily used for statistical computations during the reinforcement analysis phase. Operations like averaging similarity scores, calculating quantiles, and normalizing data rely on NumPy’s optimized array operations, ensuring numerical accuracy and efficiency across large-scale text similarity computations.
sentence_transformers
The sentence_transformers library builds on transformer-based models to generate dense vector embeddings for sentences or text blocks. It provides pre-trained models capable of capturing rich semantic meaning beyond surface-level text similarity.
This project uses sentence_transformers to convert content sections and queries into embeddings. The cosine similarity between these embeddings quantifies how well each section aligns with the target concept. Its efficiency and contextual accuracy make it ideal for evaluating conceptual reinforcement at a deep semantic level.
torch (PyTorch)
PyTorch is a leading deep learning framework offering tensor computation, automatic differentiation, and GPU acceleration. It forms the computational foundation for most modern NLP and transformer-based models.
In this project, torch underpins the embedding operations within the SentenceTransformer models. It manages tensor processing and ensures that large embedding computations run efficiently on available hardware, supporting scalable multi-block and multi-query analysis without manual optimization.
transformers.utils.logging
This is a logging utility module from the transformers library used to control verbosity and progress output of transformer models. It helps in managing runtime logs during model loading and inference.
Here, it is used to suppress unnecessary logs and progress bars that can clutter the notebook environment during model initialization and encoding operations. This ensures a clean, professional output suited for client-facing notebooks where clarity and presentation are prioritized.
matplotlib.pyplot
Matplotlib is a widely-used data visualization library for creating static, interactive, and publication-quality charts. It provides precise control over figure design and supports a wide range of plot types.
In this project, it is used to visualize reinforcement scores, distribution of similarity, and query-level reinforcement trends. These visualizations help interpret the conceptual structure and performance of each content section, providing interpretable insights for optimization and reporting.
seaborn
Seaborn builds upon Matplotlib to provide a high-level interface for visually appealing statistical plots. It automates color schemes, layouts, and styling while maintaining compatibility with Matplotlib.
Within this project, Seaborn enhances the clarity and aesthetics of visualizations such as reinforcement distribution and block similarity comparisons. Its consistent and clean design ensures that plots are easily interpretable by non-technical audiences, making analytical results more accessible and client-friendly.
Function: fetch_html
Summary
This function retrieves the raw HTML content of a given webpage URL while maintaining reliability and politeness in access. It includes a delay before each request to avoid overwhelming web servers, applies custom request headers to mimic real browsers, and uses multiple encoding strategies to ensure the correct interpretation of text from diverse web pages. Its error handling and fallback mechanisms help maintain consistent data retrieval even when encoding issues or network interruptions occur.
Key Code Explanations
encodings = [response.apparent_encoding, ‘utf-8’, ‘iso-8859-1’, ‘cp1252’]
- This line prepares a prioritized list of encoding formats. It attempts to decode the HTML content in several common character encodings to handle variations across websites. This prevents data corruption caused by misinterpreted character sets.
Function: clean_html
Summary
This function removes unnecessary or non-content HTML elements, such as scripts, styles, navigation bars, and other structural components that do not contribute to textual meaning. The goal is to isolate meaningful textual data for NLP-based analysis by stripping elements that can distort or pollute the semantic representation of the page content.
Key Code Explanations
for tag in soup([“script”, “style”, “noscript”, “iframe”, “svg”, “canvas”, “nav”, “header”, “footer”, “form”, “aside”]):
tag.decompose()
- This code iterates through unwanted HTML elements and removes them completely from the document tree. This ensures only meaningful and visible textual content remains, allowing for accurate downstream text processing.
Function: clean_inline_text
Summary
This utility function standardizes and sanitizes inline text data extracted from HTML elements. It decodes HTML entities, normalizes Unicode characters for consistent text representation, and removes redundant spaces or special characters. It ensures all textual data follows a consistent, machine-readable format suitable for semantic similarity and reinforcement analysis.
Function: extract_structured_blocks
Summary
This function organizes webpage content into structured text blocks while preserving the contextual relationship between headings and their associated paragraphs or list items. Each block includes metadata such as section title, tag type, and sequence position to help interpret the logical flow of the page.
Key Code Explanations
if tag in [“h1”, “h2”, “h3”, “h4”]:
current_section = text
continue
- This part identifies section titles within the document. Headings are stored separately and used as contextual markers to group subsequent paragraphs under their relevant section headers.
if tag in [“p”, “li”, “blockquote”] and len(text) >= min_block_chars:
- This ensures only meaningful blocks of text are captured by filtering out overly short or insignificant content, such as small labels or single-line elements.
Function: extract_page_content
Summary
This high-level function orchestrates the entire process of fetching, cleaning, and structuring webpage content into meaningful data blocks. It begins by downloading the page, removes non-essential HTML components, extracts the title, and segments the content into coherent sections ready for semantic analysis. It also includes status indicators to track extraction success or identify failure reasons.
Key Code Explanations
html_content = fetch_html(url, timeout, delay)
if not html_content:
return {“url”: url, “title”: None, “blocks”: [], “status”: “fetch_failed”}
- Before processing, this step ensures the HTML was successfully retrieved. If fetching fails, the function returns a structured error response without interrupting the workflow, improving robustness across multiple URLs.
if soup.title and soup.title.string:
title = html_lib.unescape(soup.title.string)
- This extracts the page title if available, cleaning it for display or identification purposes. The title provides a quick reference for reports and visualizations later in the project.
if not blocks:
return {“url”: url, “title”: title, “blocks”: [], “status”: “no_blocks_found”}
- This condition checks whether meaningful content was identified. It prevents empty or structurally broken pages from contaminating the analysis, marking them with a descriptive status for diagnostic tracking.
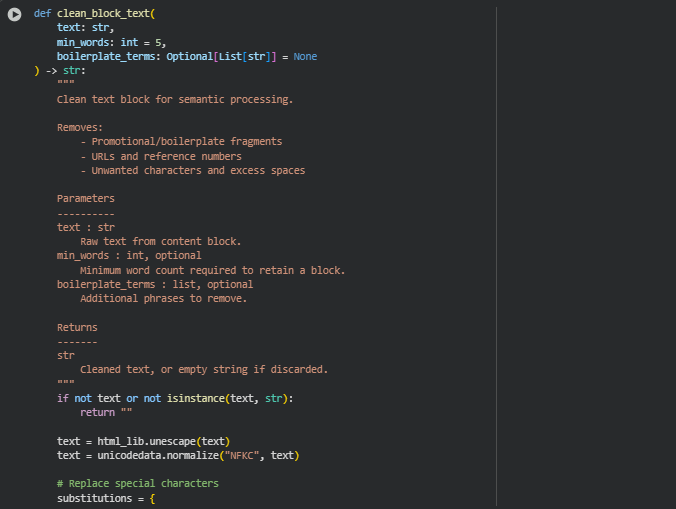
Function: clean_block_text
Summary
This function refines and filters textual content within a block before it enters the semantic modeling pipeline. It removes promotional or irrelevant language, strips URLs, reference markers, and special characters, and filters out low-quality or meaningless text fragments. This ensures that the model receives only coherent, context-rich information that accurately reflects the web page’s meaningful content.
Key Code Explanations
substitutions = {“\xa0″: ” “, “\ufeff”: “”, ““”: ‘”‘, “””: ‘”‘, “‘”: “‘”, “’”: “‘”, “•”: “-“, “–”: “-“, “—”: “-“}
- This dictionary replaces special or non-standard characters with normalized equivalents. It helps maintain text uniformity and prevents misinterpretations by embedding models that may treat such characters as distinct tokens.
boilerplates = [“read more”, “click here”, “subscribe”, “terms of service”, …]
- A predefined list of boilerplate terms helps eliminate repetitive and non-informative language commonly found on webpages, such as promotional prompts and policy statements. This prevents such fragments from skewing semantic similarity scores.
if len(lower_text.split()) < min_words:
return “”
- This validation ensures that only content-rich text blocks are retained. Very short segments, such as single words or small labels, are discarded to avoid noise in semantic analysis.
Function: split_block
Summary
This function divides large text blocks into smaller, contextually consistent chunks suitable for transformer-based embedding models. Since most transformer models have a limited input context window (e.g., 512 tokens), this function estimates token counts and splits the text accordingly, preserving sentence boundaries to maintain readability and contextual continuity.
Key Code Explanations
estimated_tokens = len(text.split()) * avg_token_per_word
- An approximate token count is calculated using an average token-to-word ratio. This avoids processing text that exceeds model limits while optimizing for performance without needing actual tokenization at this stage.
sentences = re.split(r'(?<=[.!?])\s+’, text)
- The text is segmented based on sentence boundaries rather than arbitrary character or word limits. This approach keeps logical meaning intact and prevents context loss between split parts.
if token_count + sent_tokens > max_tokens:
if current:
sub_blocks.append(” “.join(current))
current = words
- This condition ensures that each resulting sub-block remains within the token limit. Once a block reaches the threshold, it is finalized and a new block begins, allowing flexible segmentation aligned with model constraints.
Function: preprocess_page
Summary
This function orchestrates the preprocessing of a webpage’s structured content before semantic embedding and reinforcement analysis. It cleans, validates, and splits each text block into smaller segments while preserving metadata such as section title and content order. This stage transforms raw HTML-derived content into a high-quality, analysis-ready format compatible with transformer models.
Key Code Explanations
cleaned_text = clean_block_text(block.get(“text”, “”), min_words=min_word_count, boilerplate_terms=boilerplate_extra)
- Each block is first passed through the cleaning function to remove boilerplate, URLs, and meaningless fragments. This ensures only relevant, high-quality text is processed further.
split_blocks = split_block(cleaned_text, max_tokens=max_tokens, avg_token_per_word=avg_token_per_word)
- This step ensures compliance with transformer input limits by dividing large text sections into smaller, context-preserving parts.
block_id = hashlib.md5(f”{url}_{block.get(‘section_title’, ”)}_{position_counter}_{idx}”.encode()).hexdigest()
- A unique hash-based identifier is generated for every processed block. This allows precise traceability of each content segment across preprocessing, embedding, and analysis stages while avoiding collisions across URLs or sections.
if not processed_blocks:
logging.warning(f”[preprocess_page] No valid blocks found for {url}”)
- This warning mechanism records instances where a page lacks meaningful text, ensuring visibility into data quality issues without breaking the analysis flow.
Function: load_model
Summary
This function initializes and loads a pre-trained SentenceTransformer model used for generating high-quality semantic embeddings of content blocks and search queries. The model converts text into numerical vector representations that capture contextual meaning, enabling the comparison of how strongly each content section reinforces the main topic. By centralizing model loading, the function ensures consistent use of embeddings throughout the pipeline and minimizes redundant model initialization for efficiency.
Key Code Explanations
model = SentenceTransformer(model_name)
- This command loads the transformer model architecture and weights from the specified pre-trained model repository. The default “sentence-transformers/all-mpnet-base-v2” is a highly optimized model for semantic similarity and contextual understanding—ideal for measuring reinforcement of core concepts across page content.
Model Overview — all-mpnet-base-v2
The project utilizes the sentence-transformers/all-mpnet-base-v2 model, a transformer-based architecture developed for high-precision semantic understanding. It plays a central role in identifying how strongly each section of the content aligns with the target concept, enabling the measurement of conceptual reinforcement, stability, and semantic coherence across multiple queries and pages.
Model Foundation and Objective
The model is built on MPNet (Masked and Permuted Pre-training for Language Understanding), a transformer framework designed to capture bidirectional context with enhanced efficiency. Unlike traditional transformer models that process text sequentially, MPNet combines the strengths of masked language modeling and permutation-based training, allowing it to understand word dependencies in a more flexible and contextually aware way.
This capability is crucial for analyzing SEO content, where meaning often depends on subtle contextual shifts, phrasing variations, and topic continuity rather than direct keyword repetition.
Embedding and Semantic Representation
In this project, the model converts both content blocks and query phrases into dense vector representations (embeddings). These embeddings encode the semantic meaning of text, not just its literal words. By computing cosine similarity between the embeddings of a content block and a query, the model quantifies how conceptually close or distant the two pieces of text are.
This numerical similarity score forms the foundation of key project metrics:
- Reinforcement Index: Measures the average semantic similarity of content blocks to the target concept.
- Stability Index: Reflects how consistent this similarity remains across different sections.
- Weak Section Identification: Highlights blocks with low similarity, signaling conceptual drift or insufficient reinforcement.
Strengths and Suitability for SEO Context Analysis
The all-mpnet-base-v2 model is well-suited for this type of analysis due to several strengths:
- Contextual Precision: Accurately captures subtle meaning differences between semantically related phrases (e.g., “SEO audit” vs. “search optimization review”).
- Language Flexibility: Handles both technical and natural language effectively, making it adaptable for various SEO content formats such as guides, blogs, and landing pages.
- Robust Generalization: Pre-trained on a wide corpus, the model effectively interprets domain-agnostic content and adapts to SEO-specific terminology without additional fine-tuning.
These properties ensure reliable reinforcement scoring that mirrors human-like understanding of contextual relevance — essential for assessing conceptual strength across diverse topics and writing styles.
Model Integration in the Project Pipeline
Within the project workflow, the model operates as the semantic engine that powers all reinforcement metrics. Each page’s text is divided into blocks, embedded, and compared with each target query’s embedding. The resulting similarity scores are aggregated and normalized to produce reinforcement-related indices and weak-section maps.
This structured approach transforms subjective topic relevance into measurable, data-driven insights — enabling objective evaluation of how effectively content sustains its central idea.
Practical Value in Real-World SEO Evaluation
By leveraging all-mpnet-base-v2, the project bridges linguistic intelligence with performance analysis. It provides content strategists with quantifiable evidence of conceptual depth, consistency, and topical coverage. Unlike keyword density or rule-based metrics, this model-driven approach measures semantic reinforcement, ensuring that content not only includes the right terms but also communicates the right meaning consistently throughout.
This combination of interpretability, accuracy, and real-world applicability makes all-mpnet-base-v2 a powerful choice for evaluating and optimizing conceptual strength in SEO-driven content.
Function: generate_embeddings
Summary
This function converts a list of text segments into dense numerical embeddings using the loaded SentenceTransformer model. Each embedding captures the contextual and semantic meaning of the text, enabling accurate comparison between content sections and queries. The process ensures text data is transformed into a machine-understandable format while maintaining linguistic relationships, which is essential for evaluating concept reinforcement across page sections.
Key Code Explanations
embeddings = model.encode(
texts,
batch_size=batch_size,
convert_to_tensor=True,
show_progress_bar=False,
normalize_embeddings=True
)
· This line performs the core embedding generation.
- batch_size controls how many text samples are processed simultaneously, balancing speed and memory efficiency.
- convert_to_tensor=True ensures outputs are in tensor format for optimized mathematical operations during similarity computation.
- normalize_embeddings=True standardizes the vector magnitudes, ensuring that similarity scores reflect true semantic closeness rather than vector scale differences.
- show_progress_bar=False keeps runtime output clean, suitable for production and client-oriented usage.


Function: compute_block_similarities
Summary
The compute_block_similarities function performs the core analytical task of this project — measuring how strongly each page block reinforces the target concept or query. It evaluates semantic similarity between each query and every content block using embeddings generated by the SentenceTransformer model. The resulting similarity scores represent how closely each section of content aligns with the core topic, offering quantifiable reinforcement metrics for SEO analysis.
Key Code Explanations
blocks = preprocessed_page.get(“blocks”, [])
if not blocks:
logging.warning(f”[compute_block_similarities] No content blocks found for {url}”)
return preprocessed_page
- This ensures the function only proceeds when valid content blocks exist. If none are found, it logs a warning and safely returns the unmodified structure. This safeguard prevents unnecessary computation and potential runtime issues from empty inputs.
query_embeddings = generate_embeddings(queries, model, batch_size)
block_embeddings = generate_embeddings(block_texts, model, batch_size)
- Both queries and content blocks are converted into dense semantic embeddings. By representing them in the same vector space, the function can directly compare their meanings. The consistent use of batch_size maintains memory efficiency, especially for longer pages.
similarity_matrix = util.cos_sim(query_embeddings, block_embeddings)
- This step computes cosine similarity between every query and every block embedding. The result is a matrix where each value (ranging from -1 to 1) indicates how semantically aligned a content block is with a query. High scores reflect stronger conceptual reinforcement.
block_scores = {q: float(similarity_matrix[q_idx][idx]) for q_idx, q in enumerate(queries)}
avg_score = float(torch.mean(similarity_matrix[:, idx]))
block[“similarity_scores”] = block_scores
block[“avg_reinforcement_score”] = avg_score
· This loop updates each block with two key metrics:
- similarity_scores — individual similarity values for each query, allowing fine-grained analysis of how each block supports different core ideas.
- avg_reinforcement_score — the overall average reinforcement value of the block across all queries, offering a single interpretable strength metric for that section.
This dual-layer approach enables both detailed and summarized evaluation of conceptual alignment within the content.

Function: _find_contiguous_zones
Summary
The _find_contiguous_zones function is a utility helper that identifies continuous stretches (zones) of weakly reinforcing blocks on a webpage. Given a sorted list of block positions that are marked as weak, it groups adjacent positions into contiguous ranges. Each range (zone) represents an uninterrupted sequence of weak sections, helping to visually and analytically locate areas where the core concept reinforcement weakens across the page.
This segmentation aids later visualization and interpretation by transforming scattered weak points into structured “zones of weakness,” allowing strategic focus on regions rather than isolated blocks.
Function: analyze_reinforcement_per_query
Summary
The analyze_reinforcement_per_query function performs the quantitative analysis of topic reinforcement for each query across all content blocks of a page. It uses the previously computed semantic similarity scores to measure the strength, consistency, and stability of conceptual reinforcement in different content segments.
The function calculates several core reinforcement metrics for each query, including:
- Overall Reinforcement Index (ORI): Measures the average degree of alignment between the content and the query.
- Reinforcement Stability Index (RSI): Evaluates the consistency of reinforcement strength throughout the page.
- Weak Threshold (Quantile-based): Dynamically determines the cutoff below which blocks are considered weakly reinforcing.
- Weak Zones: Groups consecutive weak blocks to highlight conceptually underperforming regions.
- Reinforcement Frequency: Percentage of blocks that strongly reinforce the main concept.
- Consensus Weak Blocks: Identifies sections that remain weak across multiple queries, signaling systemic conceptual gaps.
This comprehensive structure ensures that both per-query and aggregated insights are produced, enabling accurate evaluation of topic coherence and reinforcement across the entire page.
Key Code Explanations
blocks_by_position = sorted(blocks, key=lambda x: x.get(“position”, 0))
positions = [b.get(“position”) for b in blocks_by_position]
- This arranges the content blocks based on their structural order in the page. By maintaining sequential ordering, subsequent analyses can identify where weak reinforcements appear contextually—allowing pattern detection, such as whether weaknesses cluster toward specific sections (e.g., middle or end of the page).
mean_score = float(np.mean(scores_arr))
std_score = float(np.std(scores_arr))
stability = 1.0 – (std_score / mean_score) if mean_score > 0 else 0.0
· These computations quantify overall reinforcement and its stability.
· mean_score indicates the general strength of concept alignment.
· std_score measures variation—how unevenly reinforcement appears across blocks.
· stability represents uniformity: a higher stability value means the concept is reinforced evenly throughout the content, a key SEO metric for maintaining reader and search engine coherence.
weak_indices = [i for i, s in enumerate(scores_arr) if s <= weak_threshold]
weak_zones = _find_contiguous_zones(weak_positions_sorted)
- This identifies all blocks that fall below the calculated weak threshold and groups them into continuous “weak zones.” These zones provide structured insights into where reinforcement dips consistently rather than sporadically—vital for understanding content flow and narrative breaks in topic relevance.
reinforcement_frequency = round(strong_count / len(scores_arr), 4)
- This metric measures how often the page sections exhibit strong conceptual reinforcement relative to the total content. A high frequency value indicates robust topic alignment and content uniformity, reflecting positively on the page’s SEO relevance and conceptual clarity.
consensus_weak_blocks = [bw for bw in block_weak_counts if bw[“weak_count”] >= consensus_weak_k]
- This step identifies blocks that are weak across multiple queries, signaling recurring topical weaknesses. By applying a consensus rule (based on majority or specified threshold), it isolates core sections that dilute the page’s main theme regardless of query, offering actionable insights for improving concept focus.
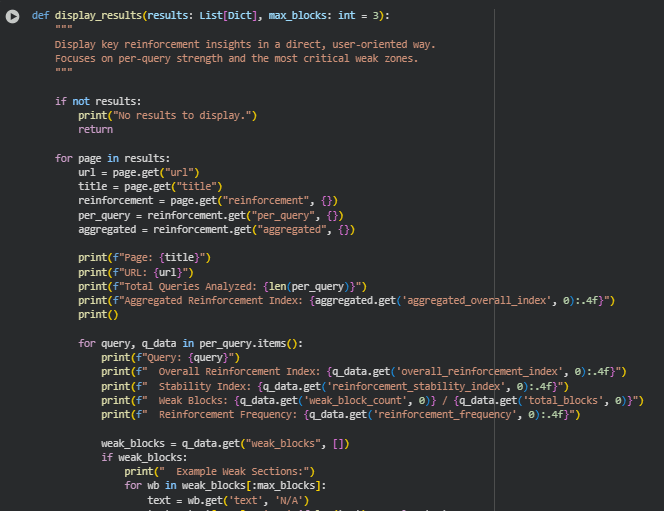
Function: display_results
Summary
The display_results function serves as a presentation layer that converts the complex analytical outputs of reinforcement metrics into a clear, human-readable format. It is primarily designed for client or user interaction, enabling a quick understanding of page-level reinforcement behavior without delving into code or data structures.
This function prints summarized results for each analyzed page, covering essential metrics such as the number of queries evaluated, overall reinforcement index, stability index, weak block counts, and reinforcement frequency. It also highlights example weak sections to help users identify which areas of content require attention. In addition, the function provides consensus weak blocks—those consistently weak across multiple queries—helping in pinpointing the most critical conceptual weaknesses.
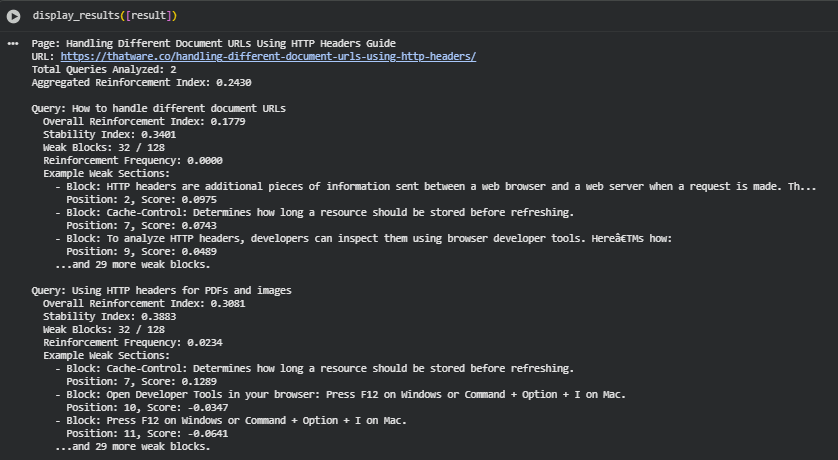
Result Analysis and Explanation
Executive overview
The analysis quantifies how consistently the page reinforces two target concepts: “How to handle different document URLs” and “Using HTTP headers for PDFs and images.” The aggregated reinforcement index for the page is 0.2430, indicating that, overall, the page provides only modest semantic alignment with the selected concepts. Both queries show substantial numbers of weak sections (32 of 128 blocks flagged weak for each query), which indicates that large portions of the page do not closely align with the intended thematic focus. The findings reveal specific content areas where editing or structural adjustments would deliver the most value in improving topical clarity and search relevance.
Overall page-level assessment
Aggregated Reinforcement Index (0.2430): This metric summarizes the mean semantic alignment across queries and blocks. A value near 0.24 indicates low-to-moderate topical reinforcement overall. Such a level typically reflects partial coverage of the intended topics, with notable gaps in how the page’s sections echo the core concepts.
Distributional insight: The presence of 32 weak blocks per query out of 128 total blocks reveals a substantial tail of underperforming content. The reinforcement frequency values (near 0.00 and 0.0234 for the two queries) show that very few blocks pass the “strong reinforcement” threshold; most blocks either weakly support the topics or do not support them at all.
Practical implication: The current page structure and copy provide limited continuous reinforcement for the selected concepts. This suggests the need for targeted content edits and re-structuring to make key ideas more pervasive and consistent across the article flow.
Per-query analysis
Query — How to handle different document URLs
· Overall Reinforcement Index (0.1779): Very low mean alignment. Sections generally do not semantically match the core concept in a meaningful way.
· Stability Index (0.3401): Low stability implies high variability in how well different sections align with this query. A few sections may be somewhat relevant, but reinforcement is inconsistent across the page.
· Weak Blocks (32 of 128): Substantial count of underperforming segments. These weak blocks are spread through the content and are not isolated to a single, small area.
· Reinforcement Frequency (0.0000): Essentially no blocks meet the “strong reinforcement” threshold for this query, indicating a lack of consistently concentrated coverage.
· Representative weak examples:
- Position 2 — short definition-style or general statement about HTTP headers scored ~0.0975 (weak).
- Position 7 — single-line technical note (Cache-Control) scored ~0.0743.
- Position 9 — a procedural line about using developer tools scored ~0.0489.
Interpretation: The content contains factual or technical fragments that reference headers or tools but do not frame them in terms of handling different document URLs specifically. The page may include relevant facts, but these are not connected into an instructive or consolidated narrative aligned to the query.
Query — Using HTTP headers for PDFs and images
· Overall Reinforcement Index (0.3081): Moderate but still limited alignment; stronger than the first query but far from robust.
· Stability Index (0.3883): Moderate variability—some sections support this concept better than others, but inconsistency remains.
· Weak Blocks (32 of 128): Same count as the first query, indicating overlapping gaps and scattered weaknesses.
· Reinforcement Frequency (0.0234): A small fraction of blocks are strongly aligned; most content remains weak or peripheral.
· Representative weak examples:
- Position 7 — Cache-Control snippet scored ~0.1289 (weak-to-moderate).
- Positions 10–11 — short instructional lines about pressing F12 scored near zero or negative (indicating semantic irrelevance or noise for this query).
Interpretation: The page contains technical details relevant to headers and caching, which can relate to resource handling for PDFs and images. However, many micro-instructions or short fragments do not frame these technical details in a way that demonstrates how headers should be applied to PDF/image resource handling, limiting semantic reinforcement for the query.
Weak-zone and block-level patterns
- Spread and clustering: Weak sections are numerous and distributed through the page rather than concentrated in a single location. The sample weak blocks at early positions (2, 7, 9, 10, 11) suggest that both the introduction and certain technical detail areas contain weakly aligned text fragments.
- Nature of weak content: Many weak blocks are either short procedural instructions (single-line commands or keystroke hints), terse technical notes (single-line Cache-Control definitions), or general statements that lack explicit connection to the selected queries. Short, decontextualized lines frequently score poorly because embeddings find low semantic overlap with the targeted, applied concepts.
- Negative or near-zero similarity values: A few blocks show negative scores. Negative values indicate semantic divergence rather than mere weak alignment; these blocks may be off-topic, contain noisy scraping artifacts, or include phrasing that the model interprets as unrelated to the queries.
Practical consequence: Sections composed of many small fragments or isolated instructions dilute overall reinforcement. Remediation that merges or elaborates these fragments into explanatory, query-aligned paragraphs will increase both mean scores and stability.
Consensus weak-blocks and cross-query implications
- Consensus signals: Some blocks are weak across both queries (for example, the Cache-Control line at position 7 is weak for both queries). These consensus weak blocks are high-priority targets: improving them can yield gains for multiple concepts simultaneously.
- Inter-query overlap: The shared weak-block count indicates overlap in where the page fails to reinforce conceptually. This suggests systemic issues—either the content is too fragmented, or the editorial framing does not tie technical details back to the main topics.
Implication for optimization strategy: Prioritize blocks that are weak across multiple queries. Edits that recontextualize a Cache-Control example into an explanation of how caching affects serving of PDFs and images and how to handle document URLs will benefit both query dimensions.
Prioritized remediation recommendations (practical, action-oriented)
- Consolidate and expand fragmentary lines into explanatory sections. Short, instruction-only lines (e.g., keystroke hints, brief headers) should be combined into short paragraphs that explain purpose and relevance to handling document URLs or to header usage for images/PDFs. Example: convert “Cache-Control: …” into a short explanation of how cache policies affect serving different document URLs and image/PDF behavior, and include a short example showing header values for PDFs and images.
- Add explicit linking sentences to tie technical details back to the target concept. For blocks that mention headers or tools, prepend or append a sentence that contextualizes the technical detail in relation to document URL handling (e.g., “This header’s cache policy is important for ensuring correct PDF delivery when serving multiple document URLs because…”).
- Rework early content to set clear intent. The early blocks (positions 1–5) should explicitly define the problem (document URL handling scenarios) and preview how headers and caching relate to the solution set. An improved introduction that states the scope will improve alignment for downstream sections.
- Group related technical content into thematic sub-sections. For example, create a sub-section “Headers for static assets (images, PDFs)” that collects cache-control, content-type, and content-disposition guidance and explains their role for document URL handling.
- Use examples and short code snippets with context. Where code or commands are shown (developer tools or header examples), include a brief explanation about how the example maps to the problem—this converts isolated fragments into reinforced, high-value content.
- Address consensus weak blocks first. Edit blocks that are weak across queries (e.g., position 7) because these offer the highest ROI. These edits will improve reinforcement indices for multiple target concepts simultaneously.
Measurement and validation plan
- Immediate re-evaluation: After applying edits to targeted blocks (start with consensus weak blocks and early introduction), re-run the analyzer and compare per-query ORI and Stability Index. Successful remediation should show an increase in ORI, a rise in reinforcement frequency, and reduced weak-block counts.
- Controlled comparison: For pages with measurable traffic, deploy edits to a subset (or A/B versions) and monitor search impressions, clicks, and ranking signals for target queries over subsequent weeks. Use analyzer metrics as intermediate checkpoints to confirm that content changes improved conceptual coverage before waiting for ranking signals.
- Iterative tuning: If stability remains low after initial edits, expand focus to contiguous weak zones (multiple adjacent weak blocks) and reframe or restructure these areas rather than applying single-line fixes.
Limitations, caveats, and data-quality considerations
- Extraction noise: Some low or negative scores may result from HTML extraction artifacts (broken encoding characters, truncated sentences). Manual review of flagged weak blocks should first verify content quality before editing.
- Short fragment bias: Very short lines, menus, or instruction snippets frequently score poorly despite being functionally useful. Some fragments may be intentionally off-topic (e.g., legal notices or UI instructions). Mark such blocks for exclusion from reinforcement edits if they are intentionally unrelated.
- Model sensitivity to wording and domain-specific terms: Semantic models interpret meaning probabilistically; specialized domain language or shorthand might require rephrasing to more standard terminology for the embeddings to properly register conceptual alignment.
- No direct causation guarantee: Improvements in reinforcement metrics indicate stronger conceptual coverage, which is expected to support SEO outcomes. However, ranking and traffic are influenced by broader site, competitive, and technical factors; metrics should be combined with real-world SEO tracking to validate business impact.
Suggested immediate action checklist
- Edit the introduction to explicitly state document URL handling goals and how headers affect PDFs/images.
- Rework or expand position 7 (Cache-Control) into a short, explanatory subsection that ties caching policies to document-serving considerations.
- Combine short procedural lines (F12 instructions) into one concise “inspect headers” paragraph that explains purpose and how it relates to URL handling.
- Address the top 5 consensus weak blocks first (priority editing).
- Re-run the analyzer and compare ORI, Stability, weak-block counts, and reinforcement frequency for each query.
These analyses and recommendations provide a clear roadmap to increase the page’s thematic clarity and topical reinforcement. Applying prioritized edits to consensus weak sections and improving the contextual framing of technical details should yield measurable improvements in the page’s semantic alignment with the target concepts.
Result Analysis and Explanation
This section presents a comprehensive interpretation of the analysis results, explaining how the metrics reflect the overall strength of concept reinforcement across page content. Each subsection outlines the analytical perspective, interpretive meaning, and practical recommendations for improvement.
Overall Reinforcement Performance
The analysis reveals varying levels of concept reinforcement consistency across multiple pages and targeted queries. The Aggregated Reinforcement Index represents the average semantic strength with which key concepts are echoed through the content. Pages with higher aggregated values demonstrate stronger alignment with their core topics, while lower scores indicate that the main ideas are not reinforced evenly across sections.
In practical SEO terms, a higher reinforcement index implies that the page maintains topical coherence throughout, supporting both search engine understanding and user retention. Conversely, a lower index points to scattered or diluted topic focus, suggesting that parts of the content may deviate from the intended theme or fail to connect key ideas effectively. This understanding allows strategists to pinpoint where reinforcement is insufficient and refine those segments to achieve a more unified topical message.
Aggregated Reinforcement Index — Evaluating Conceptual Strength
The Aggregated Reinforcement Index represents how effectively the analyzed content reinforces its core topics across all sections.
· Interpretation:
- Below 0.3: Indicates weak conceptual reinforcement — the main ideas are mentioned but not supported consistently throughout the page.
- 0.3–0.6: Suggests moderate reinforcement — the page maintains some conceptual focus but may have gaps or uneven distribution of supporting content.
- Above 0.6: Reflects strong reinforcement — the target concepts are repeatedly supported with semantically aligned content.
· Insight: A lower index typically signals that the core topic is diluted across sections, often due to unrelated or overly general content blocks. Higher values signify well-structured content that stays aligned with the intended theme.
· Recommended Action: Strengthen low-performing areas by revisiting weaker sections and reintroducing concept-related keywords, semantic variations, and contextually relevant examples that maintain the page’s topical integrity.
Stability Index — Measuring Consistency of Reinforcement
The Stability Index measures how consistently the reinforcement level is maintained across the page. It evaluates whether the concept’s strength fluctuates or remains stable.
· Interpretation:
- Below 0.4: High inconsistency — the content contains scattered relevance, indicating topic drift.
- 0.4–0.7: Moderate consistency — some sections are strong, while others weaken the overall message.
- Above 0.7: Stable and well-structured content — the reinforcement remains even throughout.
· Insight: Inconsistent stability indicates that while certain parts of the page perform well semantically, others deviate from the main concept. High stability shows effective alignment between topic intent and execution across all sections.
· Recommended Action: For low-stability results, standardize topic framing within subheadings, paragraph intros, and supporting details. Each section should reference or logically connect to the core concept to ensure continuity of reinforcement.
Reinforcement Frequency — Assessing Spread of Concept Mentions
This metric indicates how frequently the target concept or its contextual equivalents appear across different content blocks.
· Interpretation:
- Low (< 0.05): The concept appears infrequently, reducing overall topical strength.
- Moderate (0.05–0.15): Adequate presence but limited contextual coverage.
- High (> 0.15): Strong spread — the concept and its related terms are integrated throughout the content.
· Insight: Frequency acts as a signal of topical density. Low frequencies may result in reduced relevance in search systems and weaker message retention for readers. Balanced repetition with contextual variation ensures reinforcement without overuse.
· Recommended Action: Identify sections with minimal or no concept presence and integrate semantic synonyms or contextual expansions of the main query to improve conceptual reach.
Weak Block Distribution — Identifying Vulnerable Sections
Weak blocks represent sections where the semantic similarity between the content and the target query falls below acceptable thresholds. These sections weaken the page’s reinforcement strength.
In practice, this information highlights areas of the page that fail to reinforce the main idea effectively. These sections might contain generic, tangential, or overly technical information that dilutes topical strength. Identifying such blocks allows content teams to revise or rewrite them using clearer, query-aligned phrasing. Reducing weak section density directly improves the page’s semantic coherence and helps strengthen the overall topical reinforcement signal.
· Interpretation:
- High Weak Block Ratio (> 30%): Indicates that a large portion of the page lacks alignment with the core topic.
- Moderate (15–30%): Partial alignment — key ideas appear inconsistently.
- Low (< 15%): Strong topic focus and consistent reinforcement.
· Insight: Pages with high weak-block density usually suffer from off-topic explanations or overly technical sections that fail to tie back to the main concept. Addressing these ensures a coherent and focused narrative.
· Recommended Action: Review weak sections to either reframe them with contextually related content or remove irrelevant portions. Strengthen them by embedding concept-specific phrasing and supporting subtopics.
Consensus Weak Sections — Overlapping Gaps Across Concepts
This analysis identifies content areas that appear weak across multiple target queries, highlighting structural or thematic blind spots.
· Insight: Overlapping weak sections often reveal general-purpose text (e.g., tool instructions, setup details) that fails to reinforce any of the key themes. Such sections reduce overall conceptual depth and SEO value.
· Recommended Action: Rewrite these recurring weak sections to introduce bridging language that connects procedural or descriptive content back to the main topics. This ensures every section contributes to the reinforcement objective.
Visualization Analysis and Insights
Visualizations provide an accessible overview of how reinforcement behaves across different pages and queries, making it easier to interpret complex metrics into actionable SEO insights.
The visualizations used in this analysis help decode multiple aspects of reinforcement behavior:
Query-Wise Reinforcement Comparison
This bar chart compares overall reinforcement strength across multiple pages for each query. It helps identify which topics are most strongly supported on each page and where significant imbalances exist. Strategically, pages with lower scores for specific queries may need targeted optimization to integrate those themes more naturally.
This plot compares how strongly different pages or queries reinforce their associated concepts. A balanced pattern indicates uniform conceptual focus, while steep differences suggest content imbalances.
Stability vs. Strength Relationship
This scatter plot visualizes the relationship between the Reinforcement Stability Index and Overall Reinforcement Index. Points clustered in the upper-right region represent topics that are both strong and consistent — the ideal scenario. Lower or scattered points suggest instability or inconsistent reinforcement. By studying this pattern, content teams can determine whether weak performance is due to uneven topic coverage or inherently low conceptual focus.
This plot shows whether high reinforcement corresponds to stable concept representation. Ideally, points should cluster in the upper-right quadrant, reflecting both strength and consistency.
Weak Section Density Map
The heatmap highlights the proportion of weak blocks per query per page, offering a structural view of where reinforcement is most inconsistent. Higher density values mark areas that require more attention, such as sections with excessive off-topic content. This visualization helps prioritize content cleanup efforts by showing which page-query combinations contribute most to the dilution of topical strength.
The heatmap helps pinpoint specific URLs or query contexts where weak block density is highest. It provides a clear view of where targeted content optimization is required.
Reinforcement Score Distribution
The boxplot illustrates the spread of reinforcement scores across all analyzed sections for each query. Narrow distributions centered around higher values indicate uniform and effective reinforcement, while wider or lower distributions signal uneven conceptual representation. This view helps identify queries where content quality varies sharply between sections, suggesting a need for normalization and consistency improvements.
The plot visualizes score spread across all queries, showing whether reinforcement is concentrated (stable and strong) or scattered (unstable and weak). Narrow distributions are ideal, as they indicate controlled consistency.
Holistic Interpretation and Practical Takeaways
Collectively, these metrics reveal the semantic health of the content.
- High reinforcement with stability signals strong topic focus and a high-quality semantic structure.
- Low reinforcement with high weak-block density reflects content fragmentation and poor topical cohesion.
- Moderate ranges typically indicate improvement potential — either by deepening concept integration or reducing tangential content.
Actionable Summary:
- Strengthen concept presence in weak or under-reinforced blocks.
- Rebalance uneven reinforcement by connecting loosely related sections back to the primary concept.
- Maintain contextual diversity to avoid keyword redundancy while ensuring strong semantic alignment.
- Use reinforcement visualizations as continuous monitoring tools to validate improvements in future content revisions.
Q&A Section — Understanding Project Results, Actions, and Strategic Benefits
This section provides practical clarity on interpreting the project’s analytical outputs. It is structured around real-world questions that help decision-makers understand what the results signify, what actions to take, and how those actions translate into measurable SEO and content quality improvements.
What does a low Aggregated Reinforcement Index indicate about the page content, and what should be done to improve it?
A low Aggregated Reinforcement Index signifies that the page does not consistently reinforce its core idea across all sections. While certain paragraphs may touch upon the main topic, others deviate or become generic, leading to a diluted conceptual focus. This weakens both user comprehension and topical authority in search systems.
Action Steps:
- Identify underperforming content blocks using the weak-section analysis.
- Rephrase or expand these sections to directly connect them to the central concept.
- Use semantically related phrases and supporting context instead of repetitive keyword insertions to enhance conceptual richness.
Benefit: Improving the reinforcement index creates more coherent and topically aligned content, leading to stronger SEO visibility and more effective message delivery for users.
How should the Stability Index be interpreted, and why does it matter for optimization planning?
The Stability Index reveals how uniformly the main idea is maintained throughout the page. A stable page sustains consistent topic relevance, while a low-stability score reflects fluctuating alignment — strong in some areas but weak or unrelated in others.
Action Steps:
- Review sections with abrupt topic shifts or unrelated discussions.
- Use subheadings and structured internal transitions to maintain continuity.
- Align content tone, examples, and context within each section to ensure smooth conceptual flow.
Benefit: High stability not only strengthens thematic focus but also improves user retention and readability, creating a seamless narrative that sustains engagement.
Why is Reinforcement Frequency important even if other scores are moderate or strong?
Reinforcement Frequency reflects how often and how widely the key concept and its related terms appear. Even with moderate reinforcement strength, low frequency can signal poor distribution, meaning the concept appears in only a few parts of the content. This uneven representation prevents the main topic from being adequately recognized by both readers and algorithms.
Action Steps:
- Identify sections where the concept is missing or minimally referenced.
- Introduce topic-relevant keywords, examples, and analogies without overstuffing.
- Balance repetition by varying phrasing (e.g., using contextual synonyms and secondary concepts).
Benefit: A balanced frequency ensures that the topic remains visible and reinforced throughout, leading to improved topical authority and enhanced discoverability.
What do weak blocks represent, and how should they be addressed for better semantic performance?
Weak blocks are portions of the content where the alignment with the target concept falls below acceptable thresholds. They signal where the topic weakens, typically due to unrelated information, overly broad explanations, or lack of semantic linkage to the main idea.
Action Steps:
- Review weak blocks identified across queries to locate recurring weak spots.
- Restructure those sections with clearer references to the target concept.
- Add connecting context that bridges off-topic segments with the primary idea.
Benefit: Strengthening weak blocks not only enhances topical cohesion but also boosts the page’s semantic reliability — a key factor in consistent search visibility and reader comprehension.
What insights do Consensus Weak Sections offer, and how can they be leveraged for broader optimization?
Consensus Weak Sections reveal which parts of the content repeatedly underperform across multiple query analyses. This overlap indicates deeper content-level issues rather than query-specific weaknesses.
Action Steps:
- Prioritize these overlapping weak sections for immediate rewriting.
- Replace generic or repetitive lines with content that ties back to multiple target topics simultaneously.
- Maintain logical connections between related subtopics to enhance semantic cross-coverage.
Benefit: Addressing consensus weak sections ensures comprehensive optimization — the content becomes equally relevant for multiple target topics, improving coverage breadth and content efficiency.
How should the results guide future content structuring and editorial strategies?
The metrics and visualizations serve as a blueprint for strategic content planning. They highlight where reinforcement is strong, where stability falters, and how topic focus changes throughout the text.
Action Steps:
- Use the visualizations (e.g., reinforcement distribution and weak-section maps) to pinpoint structural inconsistencies.
- Build future content outlines around stable, high-performing sections identified in the analysis.
- Adopt reinforcement consistency as a measurable editorial quality metric for upcoming content cycles.
Benefit: Embedding reinforcement analysis into content workflows establishes an evidence-based editorial process, improving both writing quality and SEO alignment over time.
How can this analysis be used to maintain ongoing SEO and content quality assurance?
Beyond one-time optimization, the analysis offers a sustainable monitoring framework. By tracking changes in reinforcement and stability indices over time, teams can measure the effect of edits and determine whether content updates truly strengthen conceptual clarity.
Action Steps:
- Re-run reinforcement evaluations periodically after implementing updates.
- Compare trend shifts in indices to validate optimization efforts.
- Use findings to refine content strategies and identify best-performing semantic structures.
Benefit: Continuous measurement ensures that SEO and content strategies evolve based on quantifiable performance, maintaining competitive strength and thematic precision across the content portfolio
Final Thoughts
The project “Concept Reinforcement Analyzer — Measuring Strength of Key Idea Reinforcement Across Page” successfully establishes a structured, data-driven approach to understanding how consistently a web page reinforces its central ideas across content sections. By leveraging advanced transformer-based language understanding through the all-mpnet-base-v2 model, the analysis transforms abstract concepts such as topic consistency and contextual relevance into quantifiable, interpretable measures.
Through metrics such as the Aggregated Reinforcement Index, Stability Index, and Weak Section Density, the project identifies how well each page sustains its main concepts in alignment with target search intents. The approach not only detects semantic gaps but also clarifies where and how conceptual weakening occurs within the content flow. This allows optimization efforts to focus precisely on areas where reinforcement is low, ensuring greater topical alignment, improved content cohesion, and stronger contextual signals to search engines.
The inclusion of visualization-based insights further enhances interpretability, providing a clear comparative understanding of reinforcement strength, stability, and section-level weaknesses across multiple pages. These graphical analyses translate technical scores into actionable insights, enabling more strategic editorial decisions for on-page content improvement. Overall, the project delivers a comprehensive analytical framework that empowers SEO strategists and content specialists to evaluate and enhance the semantic integrity of digital content. It bridges linguistic intelligence with SEO performance metrics, ensuring that every piece of content consistently supports its core idea — a crucial factor in driving both reader comprehension and search relevance.
