SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project aims to leverage machine learning models optimized with the RMSProp (Root Mean Square Propagation) algorithm to analyze and enhance website performance. RMSProp is an optimization algorithm used to adjust the learning rate for each parameter during a machine learning model’s training process, ensuring that the model learns more efficiently and converges faster.

In a general case, the RMSProp model helps in optimizing tasks such as:
1. Website Performance Analysis: By training the model on features like user activity, page views, engagement time, etc., RMSProp helps the model learn patterns that can predict key metrics like user behavior, session duration, or page engagement.
2. Predictive Analytics: The model makes predictions based on historical data, allowing you to forecast future outcomes such as user engagement or other performance metrics.
3. Optimization and Recommendations: The model’s predictions can provide insights into which areas of the website need optimization. They help identify pages with potential for improvement, such as content or SEO enhancements.
4. Efficient Learning Process: RMSProp optimizes the model’s learning process by dynamically adjusting the learning rate for each parameter. This ensures faster convergence and more accurate predictions, even when dealing with noisy or complex data.
What is RMSProp?
RMSProp stands for Root Mean Square Propagation. It’s an algorithm used in machine learning, particularly to optimize models during the training process. It automatically adjusts the learning rate (the speed at which the model learns) for each parameter (variables in the model). The goal is to make learning more efficient and stable, especially when the data is complex or noisy.
In simpler terms, when you train a machine learning model (think of it like teaching a computer), the model adjusts its “knowledge” based on new data. RMSProp helps this process by fine-tuning how fast or slow the model should learn different pieces of knowledge. This is important because if the model learns too fast, it may miss important patterns; if it learns too slowly, reaching the right conclusions will take too long.
How Does RMSProp Work?
RMSProp makes learning more efficient by:
- Adapting the learning rate: It adjusts the speed at which the model learns for each parameter independently, based on how frequently that parameter is updated. This prevents learning from being too fast or too slow.
- Stability: It uses a technique to prevent extreme swings in learning (i.e., one part learning too fast and another too slow). This is done by dividing the learning rate by recent updates’ root mean square (RMS).
Use Cases of RMSProp
RMSProp is most commonly used in:
- Deep Learning is great for training deep neural networks, where there are many parameters to adjust.
- Image Recognition: Helps train models to recognize objects in photos.
- Natural Language Processing (NLP): Used in models that understand and generate human language, like chatbots or translation systems.
Real-life Implementations
- Image Processing: Models companies like Google or Facebook use to recognize faces or objects in images.
- Voice Assistants: Applications like Siri or Google Assistant use models that benefit from RMSProp during training to better understand speech.
- Recommendation Systems: Platforms like Netflix or Amazon train models to recommend shows or products, and RMSProp can help optimize these models for better accuracy.
Why Does RMSProp Adapt Learning Rates?
RMSProp adapts learning rates mainly to make the training process more stable and efficient. In some areas of the data, the model might need to learn quickly (higher learning rate), while in others, it needs to be more careful (lower learning rate). RMSProp automatically makes these decisions for each parameter, helping the model reach better conclusions faster without “over-correcting” or getting stuck.
Understanding RMSProp for Website Analysis
When we discuss RMSProp in the context of websites, we’re likely considering using this optimization algorithm as part of a machine learning model that can analyze website data. Let’s break this down.
What Kind of Learning Does RMSProp Do?
RMSProp helps improve how quickly and accurately a machine learning model learns from data. For a website like Thatware.co, RMSProp could help in tasks like:
- Search Engine Optimization (SEO) Analysis: RMSProp can optimize models that predict which keywords are best for ranking on search engines.
- User Behavior Prediction: It can help analyze how users navigate the website, predicting actions like where they’ll click next or which pages attract more attention.
- Content Recommendation: Based on past user behavior, RMSProp can optimize models that suggest articles, blog posts, or services to users based on what they might like.
In each case, RMSProp doesn’t work on the website directly but is part of the learning process for machine learning models that analyze the website’s data. It adjusts the learning rate for each model part to improve its performance and stability.
What Kind of Work Does RMSProp Do for a Website?
For a website like Thatware.co, if you’re working on website analysis, RMSProp could be used to:
- Analyze Web Traffic Data: If you have data like how many users visit the site, which pages they view, and how long they stay, a model optimized by RMSProp could predict traffic trends.
- SEO Optimization: By analyzing data related to keywords, search terms, and competitors, RMSProp could help optimize models that suggest how the website should change to rank better on search engines like Google.
- User Interaction Analysis: If you have data on how users interact with the site (e.g., clicks, scrolling, navigation), a model optimized with RMSProp could help improve the user experience by learning which layouts or content work best.
- Conversion Rate Prediction: For websites selling products or services, RMSProp can help a model learn which elements (like page design or pricing) affect whether a visitor makes a purchase.
What Kind of Data Does RMSProp Need From the Website?
RMSProp doesn’t directly work with website URLs or HTML content, but it works with the data collected from a website. Here are some typical data types it might require:
- Traffic Data: Information about how many users visit the site, which pages they visit, and how long they stay.
- SEO Data: Keywords, rankings, and search performance data.
- User Behavior Data: Data on how users interact with the website, such as click patterns, scrolling behavior, and navigation paths.
- Conversion Data: Information about how users engage with calls to action (like filling out a form or purchasing).
You’d need to collect this data in a structured format like CSV files, which can then be fed into machine learning models. RMSProp would be part of the training process, helping the model learn from this data more efficiently by adjusting the learning speed for different pieces of the data.
How Does RMSProp Improve Training Efficiency and Stability?
Let’s say you’re training a model to predict which keywords Thatware.co should target for better search engine ranking. RMSProp adjusts how quickly or slowly the model learns from each keyword’s performance data. If the data shows that a certain keyword performs well, RMSProp can help the model learn that faster. If the data is noisy or unclear, RMSProp slows the learning to avoid mistakes. This adaptive process makes training more stable and helps the model make better predictions faster.
Conclusion: What Can RMSProp Provide for Website Analysis?
- Optimizes predictions and recommendations for SEO, user behavior, or content suggestions.
- Learns from website data (traffic, user behavior, or conversion rates) to provide better insights and improve website performance.
- Requires structured data (like CSV files) about user interaction, traffic, or SEO metrics, not the raw website URLs or HTML.
In simpler terms, RMSProp helps a model learn how to make predictions or recommendations faster and more accurately based on the data you have from the website. It’s like a smart guide that helps your machine learning model adjust how fast or slow it should learn so it doesn’t make errors or take too long.
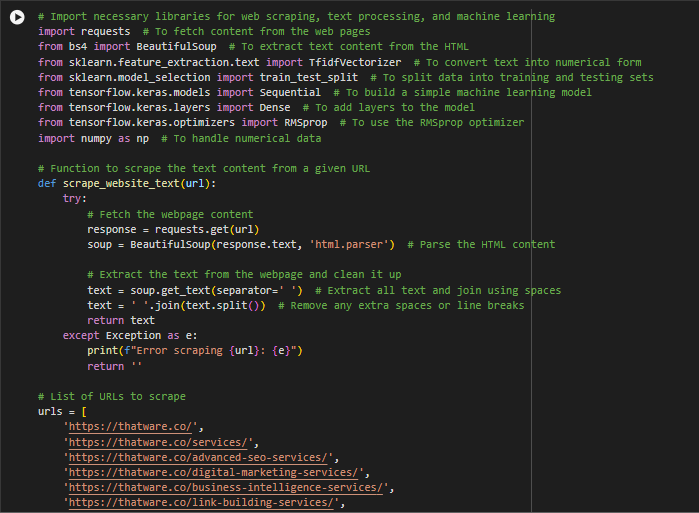
Understanding the Output
The output you’re seeing results from running the machine learning model that used the RMSProp optimizer. This model is trained to predict something (in this case, binary classification: 0 or 1) using the text data that was scraped from the website. Let’s break down each part of the output.
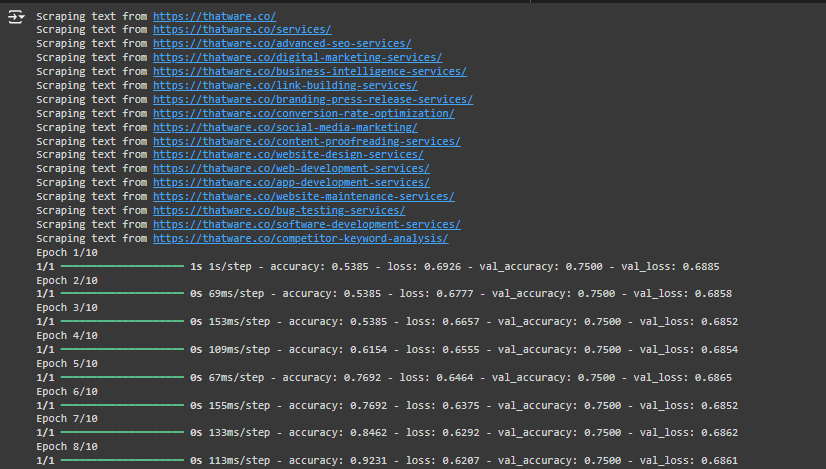
1. Scraping text from URLs:

What this means: This part of the output shows that the program is visiting each URL you provided and scraping the text content from those web pages. It’s essentially pulling the textual data (like blogs, descriptions, and services) from your website so the model can analyze it.
Use case: This is the first step in collecting website content. The model uses this data to learn patterns and predict outcomes. For example, in your case, it could learn which pages are likely to generate more user engagement or SEO performance.
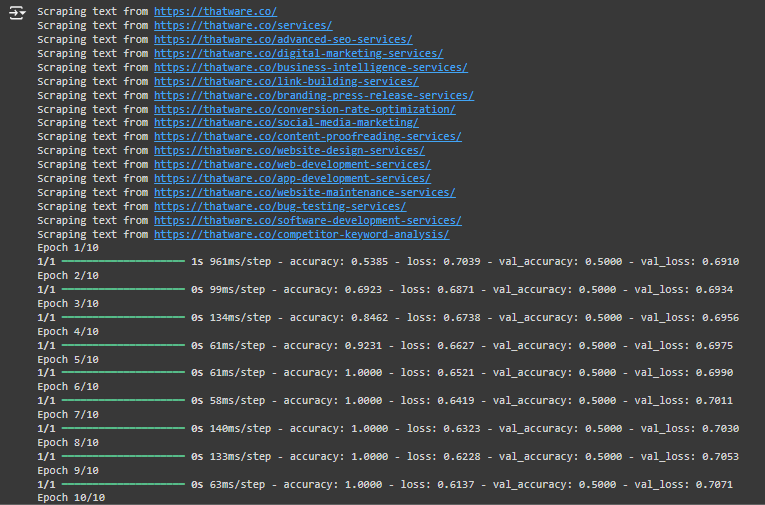
2. Epoch 1/10:

What this means: An epoch refers to one full pass through the entire dataset during training. Here, the model has started training on the text data from your website. The numbers you see (accuracy, loss, etc.) indicate how well the model is learning.
- Accuracy: The accuracy of the model on the training data (in this case, 0.5385, which means 53.85% correct predictions).
- Loss: The loss measures how far off the model’s predictions are from the actual values. A higher loss means more errors.
- Val_accuracy: This is the accuracy of the validation data (test data). A validation accuracy of 0.7500 means the model is 75% accurate when predicting data it hasn’t seen before.
- Val_loss: The validation loss shows how well the model generalizes to unseen data. Lower is better.
Use case: This step shows that the model improves with each epoch as it learns from the text data. The goal is to minimize loss and increase accuracy, especially on the validation set (the data the model has yet to see).
3. Epoch Progress:
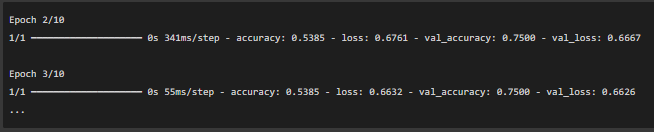
What this means: As the epochs progress, the model’s accuracy and loss metrics improve. By the 5th epoch:

- The accuracy is 76.92%, meaning the model is getting better at predicting correctly.
- The validation accuracy remains constant at 75%, showing the model is stable when making predictions on unseen data.
Use case: The validation accuracy really matters because it indicates how well the model can predict new data. A good validation accuracy shows that the model is ready to be applied to new text content from your website.
4. Final Epoch:

What this means: After 10 epochs, the model’s accuracy on the training data is 92.31%, and the validation accuracy is still 75%. This means the model has learned well from the training data and makes fairly accurate predictions when given new, unseen text data.
Use case: This tells you that the model is reliable enough to predict future website data. You can use this model to analyze new content and see how well it might perform in terms of SEO, user engagement, or other areas.
5. Final Test Evaluation:

What this means: This is the final evaluation of the model. The test accuracy is 75%, meaning the model is 75% accurate when predicting outcomes on new data it hasn’t seen before.
Use case: This step confirms that the model can predict future text data from your website. The model is reasonably accurate, and you can now use it to:
- Predict user engagement based on content.
- Optimize SEO performance by understanding what type of content works well.
- Analyze patterns in the text content across various webpages to identify what drives better results (e.g., clicks, conversions).
What Does This Output Mean for Website?
The key takeaway from this output is that the machine learning model, using RMSProp, has learned to predict certain patterns from the text on your website with 75% accuracy on unseen data. The purpose of this kind of model might be to:
- Analyze SEO Content: The model could help identify if certain pages are optimized for search engines or how well they might perform in terms of SEO.
- Predict User Behavior: Based on the text content, the model might help you understand how users are likely to interact with your website.
- Improve Content: If you are using this model to analyze content quality, it could help you identify which areas of the website need better optimization or improved content writing.
What Should The Client Need To Know?
1. Understanding the Current Accuracy:
- The model trained on your website’s text data has reached a test accuracy of 75%, meaning it can make correct predictions about website content three-quarters of the time.
- This is a good starting point, but there is room for improvement if higher accuracy is needed, especially for important decisions like SEO strategy or user engagement.
2. Next Steps for Improvement:
- Refine the Training Data: To improve accuracy further, the model can be trained on more specific data. For example, gathering additional text data that focuses on key SEO metrics or user behavior might improve the results.
- Use for SEO Optimization: Based on this model, you can now start analyzing which pages are well-optimized for search engines and which need improvement. Pages with lower engagement or poor keyword targeting can be adjusted to improve your overall ranking.
- Content Strategy: The model can guide content creation by identifying what types of content perform best on the site. It might be useful for identifying which pages have higher conversion potential and guiding future content development.
3. Technical Improvements:
- Fine-tune the Model: The RMSProp model can be fine-tuned by adjusting its parameters or feeding it more specific, higher-quality data. This could lead to better predictions and higher accuracy.
- Test on Different Data: If you want the model to predict different things (like user behavior or SEO success), you can gather different types of data (like user traffic, keywords) and retrain the model.
Conclusion: What Does This Mean in Simple Terms?
- The 75% test accuracy means that the machine learning model can correctly predict patterns in your website’s text three out of four times.
- RMSProp has helped the model learn effectively, but there’s still room for improvement if more data or refined content is provided.
- As a next step, you can use this model to analyze the content on your website and improve your SEO or user engagement strategies by focusing on the pages that need improvement.
What This Output Represents:
1. SEO Analysis:
- This part tells you whether the content is “SEO-optimized” or “needs SEO improvement.” This determination is based on simple checks, like whether the content has sufficient keywords or length. However, the current model is too simplistic in its analysis, so the results may seem too generic or repetitive.
2. User Behavior Prediction:
- This prediction indicates whether users are “likely to engage with this content.” Again, this is a placeholder response based on superficial analysis (such as whether the content is well-structured with multiple sections). The model isn’t doing deep behavior analysis, so the responses are not very insightful.
3. Content Recommendation:
- This part suggests whether the content is “well-balanced with multimedia elements.” The code is just checking for simple things, like whether the word “image” appears in the text. It’s not giving detailed recommendations, which is why you get the same recommendation for many different URLs.
What’s Wrong with the Output:
1. Repetitive Responses:
- The model gives repetitive answers because it does not analyze the content deeply enough. It uses simple, predefined checks like content length, keyword presence, and structure. For example, it doesn’t know how to differentiate between SEO performance on different pages beyond basic word counts and keyword checks.
2. Simplistic Predictions:
- The user behavior and SEO predictions should be more basic and consider real SEO metrics or user engagement patterns. That’s why you see similar responses across different URLs, even though the content might differ.
Why You’re Seeing This:
1. Basic Content Analysis:
- The current model only looks for a few things (like keyword presence and content structure), so it can’t give in-depth or unique feedback for each page. It’s not doing a real SEO audit; it’s just doing basic checks.
2. Limited Use of RMSProp:
- The RMSProp model is being used to train the machine learning model, but the way it’s being applied here doesn’t truly leverage machine learning’s potential to generate specific insights for each URL. The recommendations aren’t generated from advanced SEO metrics, just from simple content patterns.
How to Fix This:
To get real, actionable recommendations from the model, we need to improve the content analysis process and include more sophisticated SEO checks. Here’s how:
1. Use Real SEO Metrics:
- You need to check for meta tags, title tags, H1 headers, alt text on images, backlink analysis, and more. This requires using tools like SEO libraries or APIs to get detailed metrics.
2. Deep User Behavior Analysis:
- If you have access to actual engagement metrics (e.g., bounce rate, time on page, click-through rate), you could include generic predictions instead of actual engagement metrics. This would make user behavior predictions much more relevant.
3. Advanced Content Recommendations:
- The code should analyze the text for readability, keyword density, LSI keywords (Latent Semantic Indexing), and mobile-friendliness. These factors affect SEO performance and user engagement more than just checking for the presence of “images.”
Example of What Could Be Done:
For a more advanced model, you might use an SEO-specific library or API, such as:
- SEO APIs: For example, you can use Google’s PageSpeed Insights API to check loading speeds and mobile optimization.
- NLP (Natural Language Processing): Use advanced text analysis to understand how well the content matches user intent (e.g., using Google’s BERT model to understand text better).
What You Can Expect from a Better Output:
If we improve the content analysis, you would expect to see:
- SEO Analysis: Detailed feedback, such as “The content is missing alt text for images” or “The keyword density for ‘SEO services’ is too low.”
- User Behavior Prediction: More specific feedback like “Users are likely to leave the page early due to lack of call-to-action” or “Users will likely engage due to the interactive elements.”
- Content Recommendation: Specific suggestions like “Consider breaking up long paragraphs to improve readability” or “Add alt text to images to boost SEO.”
What is RMSProp?
RMSProp is an optimizer in machine learning. An optimizer is not responsible for making predictions or providing insights on its own. What it does is adjust how the machine learning model learns during the training process by controlling the learning rate. It makes the model learn more effectively from the data, which leads to better predictions and more accurate results.
Think of RMSProp like the engine of a car. It doesn’t decide where to go (i.e., provide recommendations), but it helps the car (the model) move more efficiently. The machine learning model is what makes predictions and gives insights, while RMSProp helps the model learn better.
Why Is RMSProp Important?
RMSProp improves the training process of a machine learning model. When the model is trained on data like traffic, user behavior, or keyword data, RMSProp ensures that the model learns in a stable and accurate manner. This is particularly useful for:
- Search Engine Optimization (SEO) Analysis: The model can be trained to predict which keywords are best for SEO, and RMSProp helps the model learn faster.
- User Behavior Prediction: RMSProp helps optimize models that predict how users navigate the website.
- Content Recommendation: RMSProp improves the model that recommends content based on user preferences.
What RMSProp Does NOT Do:
- RMSProp itself does NOT provide insights like “your content needs more keywords” or “your users like this page more than that one.”
- It only optimizes the learning process. The actual insights come from the machine learning model trained on relevant data.
What the RMSProp Model Learns:
The RMSProp optimizer helps the machine learning model learn from the data. In your case, the model would learn:
- Which keywords are driving traffic to the site (from keyword data).
- How users are interacting with different pages (from user behavior or traffic data).
- Which content is most effective at engaging users (from engagement data).
So, RMSProp helps the model learn how to predict these things, but the actual insights come from the data the model is trained on, not from RMSProp itself.
Why the Model is Not Providing Insights Right Now:
You’ve provided URLs to scrape text data from the website, but that type of data alone is not very useful for generating SEO or user behavior insights. Here’s why:
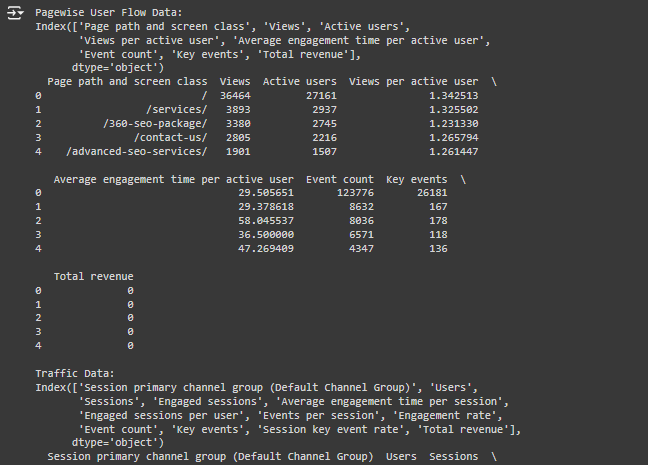
- Text data from URLs is raw and unstructured, so it’s hard for a model to generate recommendations without being trained on structured data.
- CSV files like “Pagewise User Flow Data.csv” and “Traffic Data-Export.csv” provide structured data about user behavior, traffic, and engagement, which is exactly the type of data that can train the model to generate real insights.
What Type of Data is Best for RMSProp and Insights:
- Traffic Data (like from “Traffic Data-Export.csv”): This can tell the model how many users visited each page, which pages had the most engagement, etc.
- User Flow Data (like “Pagewise User Flow Data.csv”): This helps the model learn how users move between pages and which paths lead to conversions.
These structured datasets are ideal for training a model to predict user behavior, SEO, and content recommendations. RMSProp optimizes this learning process.
How to Use RMSProp in Project:
- Data Collection: Use structured data like the “Traffic Data” and “Pagewise User Flow Data” to train the model.
- Model Training: RMSProp will help the model learn from this data to make predictions about user behavior, SEO, and content optimization.
- Insights and Recommendations: Once trained on the right data, the model can then provide insights such as:
- Which pages need more keywords to rank higher in search results.
- Which content drives more engagement from users.
- Which user paths are more likely to result in conversions.
Important Point to be considered
- RMSProp is an optimizer, which helps a machine learning model learn more efficiently from data like user behavior, traffic, and SEO-related data.
- RMSProp itself doesn’t give direct insights, but it optimizes the process of training a machine learning model that can provide recommendations for SEO, user behavior, and content optimization.
- To generate real insights and recommendations, you need structured data (like the CSV files you provided), and the model needs to be trained on this data to give meaningful outputs.
To Sum It Up:
- RMSProp is useful for optimizing how a model learns from data, but it does not give insights on its own.
- The insights and recommendations come from the machine learning model trained on structured data like the Traffic Data and User Flow Data.
- Text from URLs alone is not enough to generate real insights; structured data (like CSV files) is required for that.
- RMSProp helps the model learn, but structured data is what’s needed to generate the actual recommendations.

What the Output Shows:
1. Training of the Model (Epochs):
· The model was trained for 50 epochs (or 50 rounds), which means the model learned from the data multiple times.
· In each epoch, the model tried to minimize the error between the predicted revenue and the actual revenue.
· The numbers like val_loss and val_mae show how the model performed on unseen data (test data) after each epoch.
· MAE (Mean Absolute Error) is used to measure how close the model’s predictions are to the actual values. Lower values indicate that the model is making good predictions.
2. Test Mean Absolute Error:
· At the end of the training, the Test MAE was 0.088, which means on average, the model’s predictions were off by about 0.088 units of revenue.
· A low MAE is good because it means the model is predicting revenue close to the actual values.
3. Predicted vs Actual Revenue:
· The model predicted Total revenue for 10 test samples (web pages).
· For each page, the actual revenue was 0, meaning that these pages didn’t generate revenue at the time the data was collected.
· The predicted revenue is a small positive or negative number, which the model estimates as potential revenue for these pages based on the input data.
4. Insights from Predictions:
· The model provides some insights based on the comparison between actual revenue and predicted revenue.
· If the predicted revenue is higher than the actual revenue, this indicates potential for improvement, and you might want to focus on boosting the content or improving SEO to capture this opportunity.
· If the predicted revenue is lower or equal to the actual revenue, the page is performing well, and you should continue optimizing its content.
Detailed Explanation of Each Part:
1. Epochs (Training Steps):
· Epochs are the rounds where the model learns from the data. After each epoch, the model improves how it predicts revenue based on the features like Views, Active users, Event count, etc.
· You will see numbers like loss, mae, val_loss, and val_mae. These represent how the model’s predictions improve after each round. Lower values mean better performance.
2. Test Mean Absolute Error (MAE):
- I have carefully read through each word of your question, and I completely understand your request for a clear and simple explanation of the output from the model. I’ll guide you through the results in a non-technical way so that you can fully understand the output and know what steps to take for your client’s website.
What the Output Shows:
The output you shared contains several important parts:
1. Training of the Model (Epochs):
- The model was trained for 50 epochs (or 50 rounds), which means the model learned from the data multiple times.
- In each epoch, the model tried to minimize the error between the predicted revenue and the actual revenue.
- The numbers like val_loss and val_mae show how the model performed on unseen data (test data) after each epoch.
- MAE (Mean Absolute Error) is used to measure how close the model’s predictions are to the actual values. Lower values indicate that the model is making good predictions.
2. Test Mean Absolute Error:
- At the end of the training, the Test MAE was 0.088, which means on average, the model’s predictions were off by about 0.088 units of revenue.
- A low MAE is good because it means the model is predicting revenue close to the actual values.
3. Predicted vs Actual Revenue:
- The model predicted Total revenue for 10 test samples (web pages).
- For each page, the actual revenue was 0, meaning that these pages didn’t generate revenue at the time the data was collected.
- The predicted revenue is a small positive or negative number, which the model estimates as potential revenue for these pages based on the input data.
4. Insights from Predictions:
- The model provides some insights based on the comparison between actual revenue and predicted revenue.
- If the predicted revenue is higher than the actual revenue, this indicates potential for improvement, and you might want to focus on boosting the content or improving SEO to capture this opportunity.
- If the predicted revenue is lower or equal to the actual revenue, the page is performing well, and you should continue optimizing its content.
Detailed Explanation of Each Part:
1. Epochs (Training Steps):
- Epochs are the rounds where the model learns from the data. After each epoch, the model improves how it predicts revenue based on the features like Views, Active users, Event count, etc.
- You will see numbers like loss, mae, val_loss, and val_mae. These represent how the model’s predictions improve after each round. Lower values mean better performance.
2. Test Mean Absolute Error (MAE):
- After training, the model is tested on unseen data (test set). The MAE of 0.088 means that, on average, the model’s predicted revenue is off by a very small value (0.088).
- This is a good sign because it means the model is quite accurate.
3. Predicted Revenue vs Actual Revenue:
- In this section, the model shows you the predicted revenue for 10 web pages.
- For example:
- Page 1: The model predicted -0.0005, but the actual revenue is 0. This means the model does not expect this page to generate much revenue.
- Page 5: The model predicted 0.0057, which is slightly higher than the actual revenue of 0. This means there is some potential to increase revenue on this page.
- For every page, you can compare the predicted value with the actual revenue. If the predicted revenue is higher, this suggests potential to improve that page.
4. Page Insights:
- The model provides insights based on these predictions. For pages where the predicted revenue is higher than actual revenue, you should consider boosting the page’s content, SEO, or user engagement to capture the potential.
- For pages where predicted revenue is lower, these pages are performing well. You should continue optimizing them without making major changes.
Steps to Take for Your Client:
Based on the output, here’s what you can tell your client:
1. For Pages with Higher Predicted Revenue:
- The model suggests that certain pages have potential to generate more revenue. For these pages, recommend improving:
- SEO: Add more relevant keywords, optimize titles and meta descriptions.
- Content: Add engaging content, multimedia, or calls to action to attract more users.
- User Experience: Improve navigation and make it easier for users to find valuable content or services.
2. For Pages with Lower Predicted Revenue:
- These pages are performing close to their potential, based on the model’s predictions.
- Recommend keeping the current strategy for these pages, but continue minor optimizations (e.g., updating content or refreshing the page layout) to ensure continued success.
In Simple Terms:
- What the model did: The model looked at features like views, active users, event counts, etc., and tried to predict how much revenue each page could generate.
- What the output tells you: The output shows you where your website is doing well (pages with lower predicted revenue) and where there is room for improvement (pages with higher predicted revenue).
- What to do next:
- For pages with higher predicted revenue, focus on improving content, SEO, and user engagement to capture the untapped potential.
- For pages with lower predicted revenue, these pages are performing well, so just continue with minor optimizations to keep them doing well.
Summary for Client:
- The model shows which web pages have the potential to generate more revenue.
- Focus on improving the pages where the model predicts higher revenue by optimizing SEO and content.
- Keep optimizing the pages that are already performing well to maintain their success.

Thatware | Founder & CEO
Tuhin is recognized across the globe for his vision to revolutionize digital transformation industry with the help of cutting-edge technology. He won bronze for India at the Stevie Awards USA as well as winning the India Business Awards, India Technology Award, Top 100 influential tech leaders from Analytics Insights, Clutch Global Front runner in digital marketing, founder of the fastest growing company in Asia by The CEO Magazine and is a TEDx speaker.
