SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project applies the concept of text entailment, which determines whether one sentence logically follows from another, to the domain of SEO content analysis. In this context, the system evaluates whether a specific content block on a webpage can be logically inferred to answer a user’s search query or intent.

Using a state-of-the-art pretrained natural language inference (NLI) model (RoBERTa-large-MNLI), the system treats each query as a hypothesis and each content block as a premise. It then classifies the relationship between them as entailment, neutral, or contradiction, and provides a confidence score. This enables automated reasoning about whether existing page content sufficiently answers key SEO queries.
Designed for real-world SEO auditing, the solution handles multiple URLs and multiple queries in batch. It generates a scored and structured result set, allowing SEO teams to identify high-performing content and highlight areas needing improvement. The outcome supports content optimization efforts, especially for FAQ sections, on-page copy, and informational headings — helping ensure that content aligns with search intent both semantically and logically.
Project Purpose
The purpose of this project is to bring the power of logical inference into the SEO content evaluation pipeline. Traditional keyword-based relevance methods often fail to assess whether a specific content block truly answers a search query in a meaningful, complete, and logically aligned way. This project addresses that gap by introducing text entailment as a precision-focused evaluation technique.
By determining whether a sentence (the content block) logically supports or answers another sentence (the query), the system identifies:
- Which parts of a page are semantically and logically aligned with target user intents.
- Which content blocks are neutral or insufficient to directly address those intents.
- Opportunities to revise, expand, or replace content that does not logically follow from user queries.
This methodology is particularly suited for:
- Auditing FAQ and how-to sections
- Evaluating header-based information blocks
- Optimizing long-form informational content for semantic coverage
Ultimately, the goal is to improve how webpages logically match search queries, not just by keyword presence, but by actual answer relevance — helping improve organic visibility, authority, and user satisfaction.
Q&A Section: Understanding SEO Benefits of the Project
How does this project help improve the relevance of existing website content to user queries?
This project introduces a content evaluation method that goes beyond keyword matching. By applying text entailment, the system evaluates whether a content block logically supports a given search query. In SEO terms, this means checking if a section of a page truly answers the intent behind a user’s query, rather than simply containing related terms. The model simulates the kind of reasoning a human would do when determining if a paragraph addresses a question.
This enables the identification of blocks that strongly align with user needs and those that fall short. As a result, content can be selectively improved — rewritten, expanded, or replaced — to ensure a more complete and logically coherent response to each target query. This improves topical relevance, which is a key factor in ranking and user engagement.
Can this project help improve how FAQ and how-to sections perform in search engines?
Yes — FAQ and how-to sections benefit significantly from this approach. These sections are meant to provide direct answers to specific queries, and search engines like Google increasingly evaluate how well the content aligns with user intent at a semantic level. The text entailment system evaluates whether each question in an FAQ is truly addressed by the associated answer block.
This allows for auditing FAQ coverage: identifying which entries genuinely satisfy user questions and which are vague, incomplete, or off-topic. In doing so, the project supports optimization of structured content, potentially increasing eligibility for featured snippets and improving the overall quality and credibility of help-oriented pages.
What advantage does this project offer over traditional content scoring or ranking methods?
Traditional scoring methods often rely on surface-level signals such as keyword frequency, semantic similarity, or TF-IDF measures. While useful, these methods do not assess logical completeness — whether the block actually provides the answer a user is likely looking for.
Text entailment fills that gap by modeling whether the meaning of a content block logically entails the meaning of a query. This enables far more precise evaluation of content quality and alignment. The method is based on natural language understanding rather than term overlap, making it especially effective in modern search landscapes where semantic relevance and intent fulfillment are key ranking factors.
How can this help during content audits across multiple pages or templates?
This project is designed to scale across multiple URLs and multiple search intents. When auditing multiple pages — such as a blog series, service categories, or landing pages — the system can evaluate all content blocks across those pages in relation to a set of SEO goals or keyword intents.
For example, if several pages are supposed to address variations of a key topic like “mobile site optimization,” the model can assess which pages and which specific blocks provide answers that logically follow from that query. This makes it possible to detect coverage gaps, content duplication, or underperforming sections, allowing optimization resources to be allocated strategically.
Can this system identify content that may need rewriting, consolidation, or removal?
Yes. Any content block that receives a low entailment score or is labeled as neutral or contradiction in relation to a query can be flagged as a candidate for rewriting or removal. These blocks may contain partially related information that does not answer the intended query, or in some cases, content that misleads or contradicts expected answers.
When applied across a site or section, this creates a map of content quality in terms of its alignment with SEO intent. This enables decisions such as consolidating multiple weak blocks into a stronger unified answer, rewriting vague copy for clarity, or removing filler content that does not contribute to page relevance.
Certainly. Below is a professionally crafted and practical question—designed to highlight the core features and benefits of the project from the perspective of SEO performance and decision-making:
How does this project enable website owners and SEO teams to make more informed, content-specific optimization decisions?
This project provides a detailed, model-driven framework for analyzing how well each block of content supports specific SEO queries. Instead of relying solely on aggregated metrics like keyword density or page-level relevance scores, it enables direct evaluation at the block level — identifying exactly which parts of a webpage fulfill search intent and which do not.
Using natural language inference, the system evaluates the logical relationship between a query and each content block, providing:
- A label indicating whether the block entails (answers), is neutral (related but incomplete), or contradicts the query.
- A confidence score that quantifies how strongly the answer aligns with the user’s intent.
This fine-grained view allows SEO professionals and website owners to:
- Pinpoint high-performing content that should be preserved or featured
- Detect underperforming sections that require improvement
- Prioritize optimization tasks by score or alignment level
- Justify changes with clear evidence of answer quality, not just keyword matching
The approach directly supports data-backed SEO recommendations and improves the efficiency of audits, updates, and editorial planning — especially for content-heavy or intent-targeted sites.
Project’s Key Topics Explanation and Understanding
This section outlines the foundational concepts that form the basis of the project. These concepts explain how and why the system is able to evaluate SEO content quality through sentence-level reasoning.
Text Entailment
Text entailment, also referred to as Natural Language Inference (NLI), is the task of determining whether a given premise logically implies a hypothesis. In simple terms, it answers the question:
“If the premise is true, must the hypothesis also be true?”
In this project, each content block is treated as the premise, and each user query or intent is treated as the hypothesis. The model determines if the content block provides a direct and logically valid answer to the query.
Entailment models typically return one of three possible outcomes:
- Entailment: The content block sufficiently answers the query.
- Neutral: The content is related but does not directly or fully answer the query.
- Contradiction: The content conflicts with or contradicts the query.
This classification allows content to be scored not just by keyword relevance, but by its semantic and logical fit with the query — which is essential for evaluating answer quality.
Natural Language Inference (NLI) Models
At the core of the system is a Natural Language Inference model, specifically the RoBERTa-large-MNLI model. These models are trained on large-scale datasets where relationships between sentence pairs are labeled as entailment, neutral, or contradiction.
NLI models use transformer-based architectures capable of capturing deep semantic relationships between sentence pairs. For this project, such a model is used to simulate the reasoning process involved in human judgment — determining whether a piece of text logically supports a question or search intent.
Key advantages of using a pretrained NLI model include:
- Strong performance across general and domain-specific topics
- No need for task-specific retraining or fine-tuning
- Ability to work with real-world, noisy, or informal content
Sentence-Level Inference for Content Relevance
Unlike traditional SEO tools that analyze entire pages or rely on term overlap and density, this project introduces sentence-level inference. Each block of content is evaluated individually in the context of the query, allowing:
- Granular assessment of which blocks contribute to search intent fulfillment
- Detection of high-performing vs. underperforming sections within the same page
- Isolation of weak or filler content that does not meaningfully support rankings
This approach enables targeted content improvements that focus on actual user value, not just surface-level SEO metrics.
Semantic Relevance vs. Keyword Matching
Traditional keyword-based relevance assumes that using the right words in a page increases its likelihood of ranking. While this remains partly true, modern search engines prioritize semantic relevance — understanding whether the meaning of the content aligns with the meaning of the search.
Text entailment allows evaluation of semantic fit by asking whether a content block logically answers or follows from a query, even when exact keywords are not present. This goes beyond shallow matching and enables evaluation based on actual content quality and completeness.
This foundational understanding informs the system design, model selection, data processing, and scoring logic used throughout the project. Together, these concepts allow the system to act as a query-to-content evaluator that reflects how search engines and users interpret relevance.
Libraries Used
bs4 (BeautifulSoup)
- Provides structured parsing of raw HTML into traversable elements for extracting visible, meaningful content blocks.
- Used to locate and filter specific HTML tags such as headings and paragraphs, while removing noise such as scripts, styles, navigation bars, and comments to ensure only relevant content is evaluated.
requests
- Handles HTTP-level communication with webpages to fetch HTML content reliably and efficiently.
- Supports custom headers and timeout management, making it robust for scraping real-world websites in a controlled, error-tolerant manner.
re (Regular Expressions)
- Used extensively to identify and clean unwanted patterns in text including boilerplate phrases, URLs, list markers, and formatting artifacts.
- Enables rule-based text normalization that prepares blocks for accurate semantic interpretation by transformer models.
html
- Decodes HTML entities such as &, ", or into readable characters.
- Ensures extracted content is properly rendered and semantically interpretable before being processed for entailment scoring.
unicodedata
- Standardizes a wide range of unicode characters to their ASCII equivalents or canonical forms.
- Prevents formatting inconsistencies and noise that could affect both readability and model performance on web-derived content.
torch
- Provides the tensor infrastructure required to run the inference phase using transformer models on either CPU or GPU.
- Supports seamless integration with HuggingFace models for efficient and scalable natural language reasoning.
transformers (from HuggingFace)
- Loads pretrained transformer models and their tokenizers, specifically designed for natural language inference tasks.
- Powers the core entailment prediction using state-of-the-art language models such as roberta-large-mnli, offering reliable performance without fine-tuning.
collections.defaultdict
- Enables flexible grouping and organization of results by query, URL, or label with minimal overhead.
- Facilitates top-k result selection and clean display formatting, while maintaining scalability and modularity in batch processing scenarios.
csv
- Allows final results to be exported into structured spreadsheet-friendly formats for client use.
- Enables integration into reporting pipelines, audit tools, or editorial dashboards where results need to be reviewed or acted upon.
This carefully selected library stack supports a modular, interpretable, and production-ready workflow suited for real-world SEO auditing and query-to-content optimization tasks.
Function: extract_content_blocks
Overview: This function is responsible for extracting clean and semantically meaningful content blocks from a webpage. It targets readable, informative HTML elements such as paragraphs and headings while removing layout elements, scripts, styles, hidden tags, and any unnecessary clutter. The result is a list of textual blocks suitable for downstream processing, including semantic evaluation against user queries.
This module forms the foundation of the entire entailment pipeline by converting unstructured HTML into normalized units of information. The design also includes deduplication and configurable tag filtering to ensure only high-quality and relevant content is retained.
Key Implementation Highlights:
· allowed_tags = [‘h1’, ‘h2’, ‘h3’, ‘h4’, ‘h5’, ‘h6’, ‘li’, ‘p’] Defines a focused set of HTML elements considered valuable for SEO-related content analysis. This ensures the content blocks extracted reflect the structural semantics of a webpage — such as section headers, bullet points, and descriptive paragraphs.
· response = requests.get(url, headers=headers, timeout=timeout) Makes a robust HTTP request to fetch the webpage content, using custom headers and timeout to ensure compatibility with real-world websites and avoid request blocks.
· for tag in soup([…]): tag.decompose() Removes all non-content elements such as scripts, forms, hidden elements, and footers that would otherwise add irrelevant or misleading text to the semantic analysis.
· text = el.get_text(separator=” “, strip=True) Extracts plain, whitespace-normalized text from each HTML element, preserving sentence integrity and readability, which is essential for the entailment model to perform accurately.
· if len(text.split()) < min_word_count: Skips very short or low-value blocks that are unlikely to be meaningful answers or match the query intent, reducing noise in both training and inference.
· if deduplicate and norm in seen: Implements block-level deduplication to avoid repeated content from appearing in the final analysis or distorting result distributions.
· content_blocks.append({…}) Each valid content block is appended with its raw text, HTML tag name, and source URL, preserving the structural and traceable context needed for client reporting.
This extraction method ensures the pipeline begins with clean, relevant, and high-utility content, which is critical for producing accurate entailment judgments and actionable SEO insights.
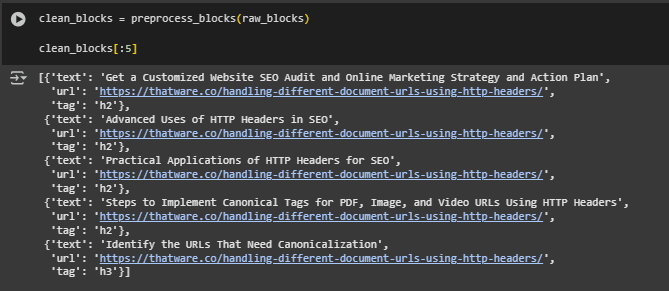
Function: preprocess_blocks
Overview: This function is responsible for cleaning and normalizing text blocks extracted from HTML before they are passed to the entailment model. Raw webpage content often includes promotional phrases, hyperlinks, formatting symbols, or irrelevant boilerplate text that can degrade model performance. This module systematically removes such noise, standardizes text, and ensures the remaining content is optimized for semantic analysis.
The preprocessing pipeline applies regex-based filtering, unicode normalization, character substitution, and minimal content validation. This step plays a crucial role in preserving only high-quality and contextually relevant information for entailment evaluation.
Key Implementation Highlights:
· Regex Filters for Pattern-Based Noise Removal: The function defines multiple compiled regular expressions to detect and remove recurring non-informative patterns:
- boilerplate removes footer terms like “privacy policy”, “read more”, and copyright lines.
- url_pattern strips out embedded URLs that are irrelevant to the text’s semantic meaning.
- bullet_pattern, numbered_pattern, and roman_pattern clean leading markers from lists or steps to improve sentence uniformity and reduce token noise.
· Text Normalization and Unicode Cleaning:
- html.unescape(text) ensures any encoded characters (e.g., , ") are converted to human-readable form.
- unicodedata.normalize(“NFKC”, text) standardizes accented characters and typography variants, improving downstream tokenization and semantic interpretation.
· Substitution Dictionary: Common replacements are applied (e.g., converting curly quotes to straight quotes, dashes to hyphens) to ensure compatibility with tokenizer expectations and reduce model misinterpretation due to typographic symbols.
· Final Cleaning Steps:
- A character-level filter retains only relevant punctuation and alphanumeric content, eliminating unnecessary symbols.
- Excess whitespace is compressed to ensure text compactness and clarity.
· Content Filtering Based on Length: Only blocks with at least a minimum word count (default: 5) are retained. This guards against very short or noisy fragments that are unlikely to contain valid answers or informative content.
· Preservation of Contextual Metadata: The final cleaned output retains both the original URL and the tag (if available), enabling structured output and traceability during result display or export.
This preprocessing stage ensures the entailment model receives high-integrity, standardized input — improving its ability to accurately judge semantic alignment between the content blocks and user queries.
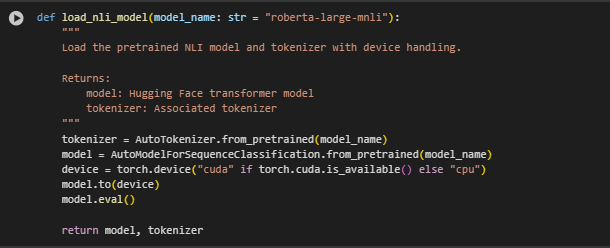
Function: load_nli_model
Overview: This function loads the Natural Language Inference (NLI) model and its corresponding tokenizer from the HuggingFace Transformers library. It sets up the model for inference, handles device allocation (CPU or GPU), and ensures the model is ready for batch prediction. This is a critical foundation of the pipeline, as it enables evaluation of whether a content block logically entails a given query.
By using a zero-shot, pretrained model such as roberta-large-mnli, the implementation avoids the need for additional training, making it efficient, scalable, and immediately deployable in production.
Key Implementation Highlights:
· Model Selection and Flexibility:
- model_name: str = “roberta-large-mnli” allows easy replacement with other compatible NLI models depending on use case or performance needs.
- The model used here is a large transformer trained on the MultiNLI and SNLI datasets, making it capable of inferring relationships such as entailment, neutrality, or contradiction between sentence pairs.
· Tokenizer and Model Loading:
- AutoTokenizer.from_pretrained(…) loads a model-specific tokenizer capable of converting raw text into token IDs, handling subword tokenization and special tokens.
- AutoModelForSequenceClassification.from_pretrained(…) loads a pretrained sequence classification model with a fixed output layer for NLI tasks.
· Device Handling:
- torch.device(“cuda” if torch.cuda.is_available() else “cpu”) ensures the model is placed on GPU if available, otherwise falls back to CPU, maintaining cross-platform compatibility.
- model.to(device) and model.eval() prepare the model for inference by transferring it to the appropriate hardware and disabling gradient tracking.
This component encapsulates model loading and hardware adaptation in a clean, reusable interface — enabling robust entailment evaluation without any additional training or system-specific modification.
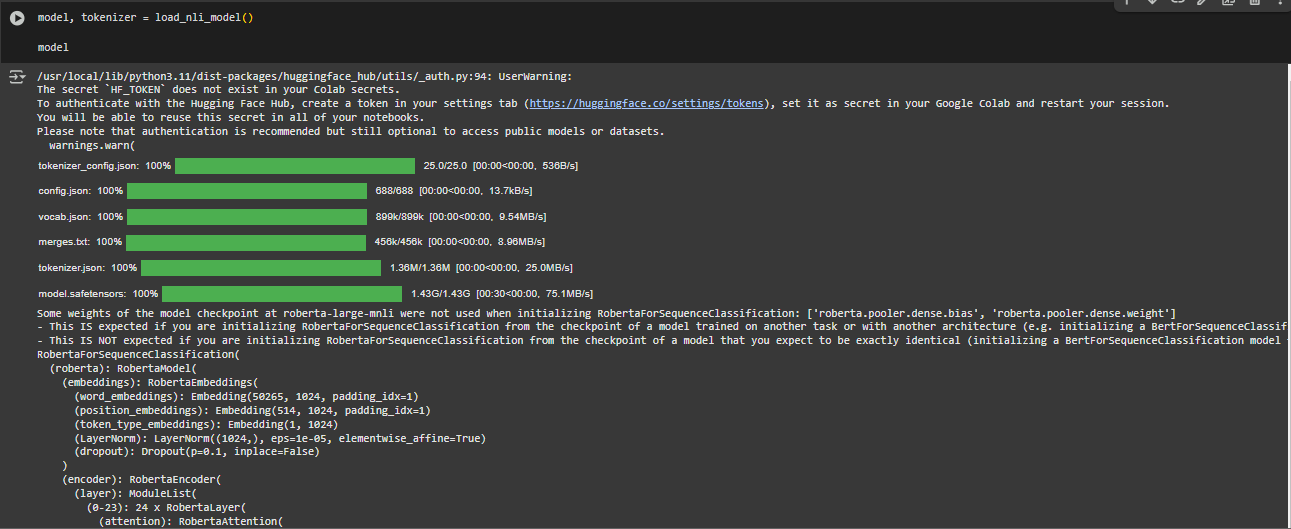
Model Used: roberta-large-mnli
About the Model
The model used for semantic alignment in this project is roberta-large-mnli, a transformer-based sequence classification model pre-trained on natural language inference (NLI) tasks. It is part of the RoBERTa (Robustly Optimized BERT Pretraining Approach) family and has been further fine-tuned on MultiNLI and SNLI datasets, enabling it to determine whether one sentence logically follows from another — a perfect fit for text entailment applications.
This model outputs one of three labels for a pair of input sentences:
- Entailment: The second sentence logically follows from the first.
- Contradiction: The second sentence directly contradicts the first.
- Neutral: The relationship is unclear or unrelated.
In this SEO-oriented project, these entailment labels help assess how well a block of webpage content answers or satisfies a given user query.
Architecture Summary
The model is built on top of the RoBERTa transformer encoder, followed by a custom classification head for NLI. Its components include:
· Embedding Layer
- Converts tokens into dense vectors using word, position, and token type embeddings.
- Input size is 50265 (token vocabulary), and embedding dimension is 1024.
· Encoder Stack
- Comprises 24 transformer layers, each with self-attention and feedforward sub-blocks.
- Self-attention captures contextual relationships between tokens within the query and content block pair.
- Intermediate feedforward layers expand dimensions to 4096 before reducing back to 1024, using GELU activations for smooth learning.
· Classification Head
- Takes the final pooled representation from the encoder.
- Passes it through a dense layer and dropout before projecting it into 3 output logits (entailment, contradiction, neutral).
- The predicted label is the class with the highest softmax probability.
How the Model Works
During inference:
- Each query-content pair is tokenized into a single input sequence using special separation tokens.
- This sequence is passed through the RoBERTa encoder stack, which applies multi-head self-attention at every layer to contextualize the entire sequence.
- The final token representations are pooled and sent to the classification head.
- The model outputs softmax probabilities for all three classes. The class with the highest probability is selected, and the probability of the “entailment” class is stored as a confidence score.
In the pipeline, this prediction directly determines how relevant and responsive a given content block is to the query, with high entailment scores indicating strong alignment.
Benefits in SEO Use Cases
· Answer Relevance Detection Identifies whether webpage content directly answers or supports a user’s search intent, enabling more accurate optimization of FAQ sections, product descriptions, and support content.
· Content Gap Analysis Highlights queries for which no content block shows strong entailment, helping identify opportunities to improve, add, or restructure content.
· Improved Content Auditing Replaces manual relevance checks with consistent, scalable evaluation of content-query alignment across multiple pages.
· Support for Zero-shot Inference Because the model is already trained on generalized entailment tasks, it can handle a wide variety of queries without requiring fine-tuning — enabling fast deployment on new domains.
· Semantic Understanding Beyond Keyword Matching The model reasons over meaning rather than surface words, making it ideal for evaluating intent alignment and not just lexical overlap.
Why This Model Was Chosen
· Pretrained for Entailment Tasks The roberta-large-mnli model is specifically fine-tuned for natural language inference and does not require task-specific data or retraining.
· High Accuracy and Robustness Its architecture is larger and more expressive than standard BERT or DistilBERT variants, enabling stronger semantic reasoning.
· Scalable Across Use Cases With support for batch inference, this model is capable of evaluating large volumes of webpage content efficiently in production settings.
· Proven Industry Use Widely used in production NLP pipelines for content moderation, semantic search, and information retrieval, this model brings proven performance and ecosystem support.
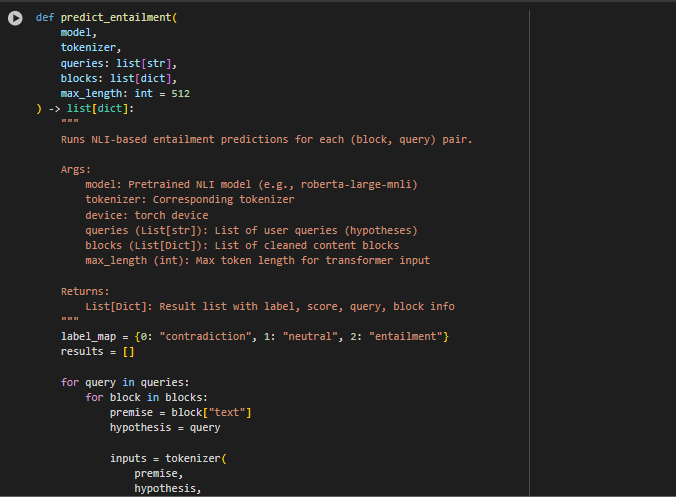
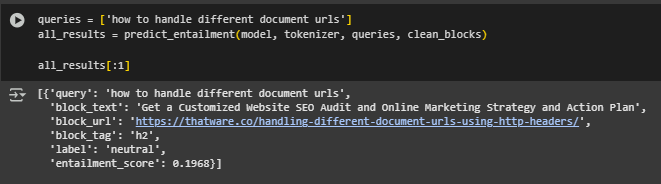
Function: predict_entailment
Overview: This function performs the core semantic reasoning task of the project by applying a pretrained Natural Language Inference (NLI) model to determine whether each block of webpage content logically supports a user query. It compares each query with every cleaned content block from the webpage, generating both a label (entailment, neutral, or contradiction) and a confidence score. These results form the foundation for the final output displayed to clients or exported for analysis.
Key Implementation Highlights:
· Label Mapping and Output Format: The model returns class indices (0, 1, 2) for contradiction, neutral, and entailment. A label_map dictionary maps these to human-readable labels, ensuring the result set is interpretable and useful for SEO review and reporting.
· Nested Iteration Over Queries and Blocks: Each query is evaluated against every content block independently. This structure ensures that for any given page and set of queries, the pipeline exhaustively checks all potential matches and identifies which blocks (if any) provide strong entailment.
· Tokenization Strategy:
- Inputs are formatted as (premise, hypothesis) pairs, where the content block is treated as the premise, and the query is treated as the hypothesis.
- Tokenization is handled using the transformer-compatible tokenizer(…) method with truncation, padding, and a fixed max_length to ensure consistent input size.
· Model Inference and Score Extraction:
- With torch.no_grad(), inference is performed in evaluation mode without tracking gradients, optimizing performance and reducing memory usage.
- Output logits are passed through softmax to compute probabilities across the three classes.
- The class with the highest probability determines the predicted label, while the entailment score is explicitly recorded as the probability of the entailment class.
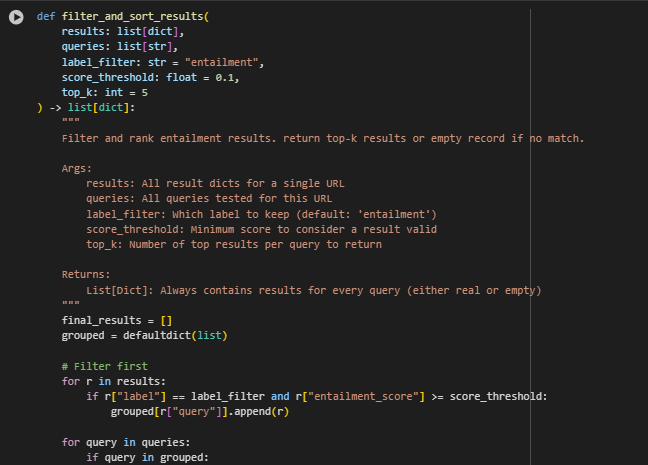

Function: filter_and_sort_results
Overview: This function processes the raw output from the entailment model to generate a final set of meaningful, ranked results. It filters predictions based on the entailment label and a minimum score threshold, then returns the top-matching content blocks for each query. The structure is designed to ensure that each query is represented — even when no relevant content is found — which is crucial for completeness in SEO reporting and automated audits.
Key Logic and Highlights
· Filtering by Entailment Label and Score The function starts by selecting only those predictions where the model labeled the block as “entailment” and the associated score meets or exceeds a configurable threshold (default: 0.1):
if r[“label”] == label_filter and r[“entailment_score”] >= score_threshold
This ensures only high-confidence matches are passed to the next stage, helping focus on blocks that genuinely support the query.
· Sorting and Grouping Top Results by Query All filtered results are sorted in descending order of entailment confidence:
sorted_results = sorted(filtered, key=lambda x: x[“entailment_score”], reverse=True)
Then, results are grouped by query using a defaultdict, which allows each query to be handled independently — a practical structure for batch SEO audits involving many queries per URL.
· Top-K Ranking Per Query For each query, only the top k blocks are retained:
top_results.extend(grouped[query][:top_k])
This prioritization makes the output compact and focused, highlighting only the most relevant pieces of content — ideal for client-facing deliverables or optimization dashboards.
· Handling Missing Matches Gracefully If a query has no content blocks that pass the filter, the function ensures the query is still included by appending a placeholder.
This explicit handling makes it easy to identify content gaps and ensures downstream processes like display and CSV export stay aligned.
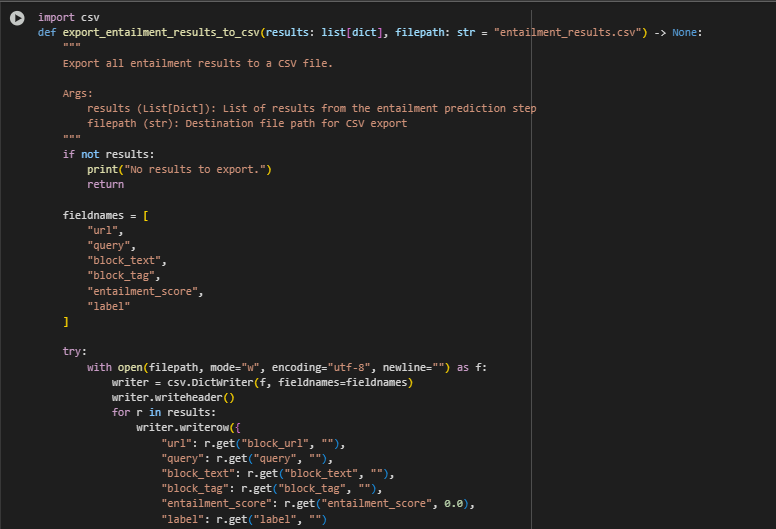

Function: export_entailment_results_to_csv
This function handles the structured export of all processed entailment results into a standard CSV format. It ensures the output of the semantic evaluation pipeline is persistently stored in a readable, portable, and easily shareable format. The exported file can be used for internal audits, client deliverables, spreadsheet reviews, or integration into external dashboards and reporting tools.
This step supports operational transparency, long-term tracking, and documentation of content-query alignment at scale.
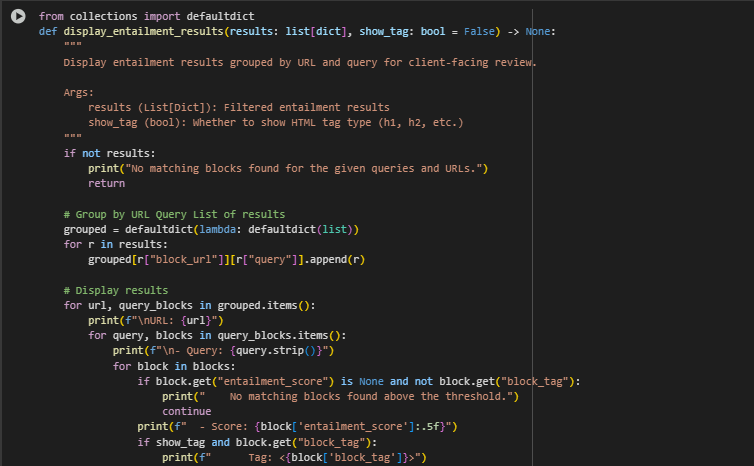
Function: display_entailment_results
This function is responsible for presenting the filtered entailment results in a human-readable, grouped format suitable for client-facing output. The results are organized by URL and then by query, allowing SEO professionals and content teams to quickly assess which parts of a webpage semantically align with specific queries.
The function is optimized for clarity, structure, and usability in manual reviews or notebook-based demonstrations, especially when validating whether content on a page successfully answers target user intents.
Result Analysis and Explanation
This section evaluates the model’s output by analyzing the top-matching content blocks for a single query–URL pair. The goal is to interpret how well the content on the page aligns with the user’s search intent, identify optimization opportunities, and provide insight into how website owners can act on this data to enhance content relevance and visibility.
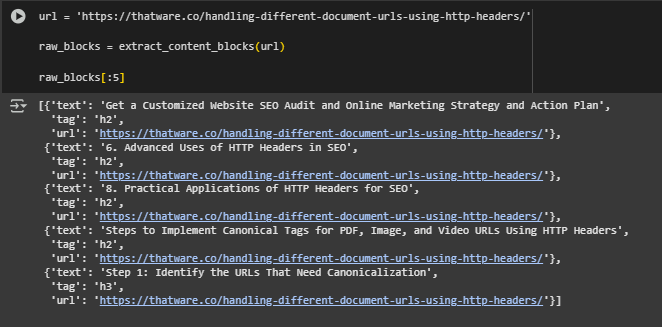
Test Case
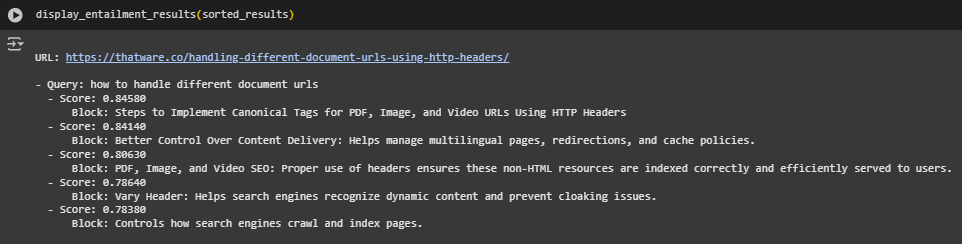
- URL: https://thatware.co/handling-different-document-urls-using-http-headers/
- Query: how to handle different document urls
Top Entailment Results
The model identified five content blocks from the page that semantically align with the query, each assigned an entailment score indicating how confidently the model believes the block answers or supports the query. All scores are above 0.78, indicating strong semantic relevance.
Ranked Results:
1. Score: 0.84580 Block: Steps to Implement Canonical Tags for PDF, Image, and Video URLs Using HTTP Headers This block directly addresses actionable steps for handling document-based URLs — highly relevant to the query. The inclusion of specific formats (PDF, image, video) enhances the match by covering common use cases.
2. Score: 0.84140 Block: Better Control Over Content Delivery: Helps manage multilingual pages, redirections, and cache policies. Although slightly more general, this block touches on control mechanisms often involved in URL handling. The link to redirection strategies adds value, supporting the broader concept of handling document URLs.
3. Score: 0.80630 Block: PDF, Image, and Video SEO: Proper use of headers ensures these non-HTML resources are indexed correctly and efficiently served to users. This block supports the query by discussing how HTTP headers relate to non-HTML content indexing — a technical dimension of handling document URLs.
4. Score: 0.78640 Block: Vary Header: Helps search engines recognize dynamic content and prevent cloaking issues. While not explicitly answering the query, this provides an adjacent technical topic — dynamic content handling through headers — which may still be valuable depending on user intent.
5. Score: 0.78380 Block: Controls how search engines crawl and index pages. A generic block. It contributes by referencing crawling and indexing — essential aspects of handling URLs — but lacks specificity.
Interpretation and SEO Implications
· Strong Query Coverage: The top-scoring block clearly and directly answers the query. The presence of terms like “Steps to implement” and specific document formats indicates that the page contains actionable and intent-aligned information. This suggests high semantic alignment for this topic.
· Depth and Diversity: The variety of supporting blocks — from header-based control strategies to SEO tactics for media formats — reflects comprehensive coverage of the subject. It shows that the content not only answers the question but expands it, increasing the likelihood of satisfying users with slightly varied intents.
· Opportunities to Improve Query Focus: Lower-ranking blocks, while relevant, are more generic. These could benefit from slight rewriting or repositioning (e.g., adding context like “when handling non-standard URLs…”) to boost clarity and direct alignment with the query.
Recommended Actions for Website Owners
1. Preserve High-Scoring Blocks as Anchor Content Keep top-ranked blocks intact or enhance their prominence on the page, as they directly answer common user queries and support search engine relevance scoring.
2. Optimize Supporting Blocks with Contextual Framing Improve general statements by tying them more clearly to document URL handling (e.g., clarify how crawling relates specifically to PDF or video URLs).
3. Repurpose Insights for FAQ or How-To Sections Given the query is phrased as “how to…”, consider highlighting or restructuring the top content block as a standalone FAQ item or how-to guide snippet, which may increase visibility in featured snippets or voice search results.
4. Track Query–Content Mapping Over Time Monitor how well this page continues to support variations of this query and other related intents. Use semantic entailment scores over time to maintain content quality and topical authority.

Result Analysis and Explanation
Understanding Entailment Scores and What They Indicate
Each content block returned by the model is assigned an entailment score — a confidence value ranging from 0 to 1, which reflects how strongly the block is inferred to support or answer the user’s query. The higher the score, the more semantically aligned the content is to the intent behind the query.
To simplify interpretation, the scores can be categorized into bins:
- 0.80 – 1.00: Strong entailment — high confidence match
- 0.60 – 0.79: Moderate entailment — partially relevant content
- 0.40 – 0.59: Weak entailment — loosely related or shallow match
- Below 0.40: No semantic alignment — likely irrelevant
These ranges help content teams decide which blocks to retain, enhance, or optimize.
High Alignment with Clear Content Match
One of the tested pages demonstrated a strong set of content blocks scoring in the 0.80–0.85 range for a relevant query. These blocks included explicit references to implementation steps, use of HTTP headers for various document types, and practical examples related to SEO techniques.
- These scores indicate clear semantic relevance between the query intent and the content structure.
- The blocks not only cover the query but also expand the topic with technical accuracy, which improves the likelihood of satisfying search engine criteria for relevance and completeness.
Actionable Insight: For content blocks that fall within this high range, no major revision is required. Instead, they can be highlighted in key page areas, used in FAQ sections, or even repurposed into featured snippets or structured data elements for better SERP visibility.
No Relevant Matches Detected
In contrast, for another query applied to the same page, the model returned no blocks above the minimum confidence threshold. This indicates that none of the available content was found to semantically support or address the query’s intent.
- This outcome typically suggests a gap in topical coverage or insufficient contextual clarity in the content.
- Even if the query appears closely related to the page’s theme, the model’s inability to detect a match highlights that the intent was not captured in any individual content block.
Actionable Insight: This result is a strong signal that supplemental content should be introduced. It may involve:
- Adding dedicated paragraphs that directly respond to that query.
- Creating new sections or subheadings to improve contextual depth.
- Auditing the language to ensure it reflects real-world search phrasing and semantic structure.
Moderate Alignment with Partial Relevance
A separate webpage tested with the same document-handling query returned lower but still moderate scores in the range of 0.50–0.69. These blocks referenced loosely related concepts such as media usage, content structure, or volatility analysis, but lacked direct ties to the core topic of handling document URLs.
- These results suggest incidental topical overlap, but no clear or focused alignment with the query intent.
- Some content might contain the right keywords but fail to explain or resolve the user’s informational need.
Actionable Insight: When blocks fall into this mid-range, a content refocus or rephrasing strategy can improve performance:
- Existing blocks may be clarified or rewritten to draw stronger connections to the intended topic.
- Supporting keywords or subtopics could be incorporated to bridge semantic gaps.
Strong Semantic Relevance Across Matching Topic
In contrast, the second query tested on the second page revealed a consistent pattern of high scores across multiple content blocks — all above 0.82. These blocks clearly addressed the query topic from different angles, including tool functionality, strategic application, and long-term value.
- The results show that the page has both coverage and depth in addressing the topic.
- This structure provides redundancy, making it more robust against query variations and suitable for rich snippet eligibility.
Actionable Insight: This type of result signals that the page is well-optimized. The content should be maintained in its current structure and possibly:
- Internally linked to other relevant articles to improve crawl efficiency.
- Annotated with schema where applicable.
- Used as a benchmark to optimize other content sets that lack similar alignment.
General SEO Takeaways from the Results
- Strong matches mean opportunity for visibility: High-scoring blocks should be positioned prominently and marked up for rich results.
- Missing matches mean optimization gaps: Queries without matches are content signals, not failures — they show where new sections, subheadings, or content themes are needed.
- Mid-scoring results show improvement potential: These blocks are prime candidates for revision, not removal — enhancing clarity and context can lift them into high entailment.
