SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project leverages the Sentence-BERT architecture to evaluate and rank textual content based on semantic closeness to search intent. The approach uses state-of-the-art transformer models to embed both user-intent representations and web page content into a dense vector space, enabling high-accuracy semantic comparison at sentence and page levels.
For each input URL, the system extracts visible textual content, page title, and meta description. These elements are used to derive search intent representations—either from client-provided queries or inferred from title/meta content when queries are unavailable. The content is segmented into individual sentences, which are then semantically compared against the intent representations using cosine similarity over Sentence-BERT embeddings.
The final output includes:
- A ranked list of sentences per query, scored and sorted by semantic similarity.
- An overall page-level similarity score representing average relevance.
- A URL-level ranking sorted by overall semantic alignment with the provided or inferred intent.
- A client-readable report presented inline within the notebook and exported to CSV for downstream use.
All components are implemented using modular, reusable functions with exception handling and performance considerations to ensure robustness, maintainability, and clarity.
Project Purpose
The project is developed to provide an SEO-focused semantic relevance audit of webpage content. The primary objective is to determine how well a page’s content aligns with search intent, using deep semantic matching rather than simple keyword overlap.
Key use cases addressed by this project include:
- Search Intent Matching: Evaluates whether the on-page content effectively reflects the user’s search intent derived from title/meta or external query input.
- Content Quality Assessment: Identifies which sentences contribute most to relevance, enabling targeted improvements in messaging and positioning.
- Page-Level Relevance Scoring: Calculates a unified semantic relevance score for each page to prioritize content optimization across a set of URLs.
- SERP Alignment Strategy: Helps align metadata and on-page text with semantic expectations of users and search engines for higher click-through and ranking potential.
This system supports both manual and automated SEO workflows, offering flexible input handling, scalable similarity ranking, and detailed, structured output suitable for content strategists, technical SEOs, and digital marketing analysts.
Sentence-BERT: Transforming Sentences into Meaningful Vectors
Overview
Sentence-BERT (often abbreviated as SBERT) is a specialized model designed to capture the meaning of entire sentences, rather than individual words or isolated tokens. It builds upon the capabilities of the well-known BERT model but is optimized for tasks where understanding and comparing sentence-level meaning is essential.
In this project, Sentence-BERT plays a central role. It is used to convert both user queries (or inferred queries such as page titles and meta descriptions) and web page content (broken into individual sentences) into numerical representations. These representations are then compared to determine how semantically similar they are. The result is a ranked list of sentences for each page that best match the intended meaning behind the queries.
Why Sentence-BERT Is Needed
Traditional text matching methods rely heavily on word overlap. If a query and a sentence don’t share many of the same words, they are often considered unrelated—even if their meanings are nearly identical. For example:
- Query: “How to boost website visibility?”
- Content Sentence: “Increasing search engine exposure can help attract more visitors.”
Despite different wording, the meaning is closely aligned. Sentence-BERT can recognize this similarity because it doesn’t just look at surface-level words. It understands context, relationships between words, and overall sentence intent.
This kind of understanding is critical in SEO, content relevance assessment, and semantic search—where users phrase their questions in varied ways, and matching content must reflect their intent, not just their keywords.
How Sentence-BERT Works
Sentence-BERT modifies the original BERT architecture to allow comparison between sentences efficiently. In its standard form, BERT requires every sentence pair to be processed together, making it computationally expensive for ranking tasks. Sentence-BERT solves this with a technique known as the bi-encoder architecture.
- Embedding Sentences
Each sentence is independently passed through the Sentence-BERT model, which outputs a dense vector—a list of numbers that represents the sentence’s meaning in a high-dimensional space.
These embeddings capture nuances like:
- Synonyms
- Grammatical structure
- Contextual usage
- Sentence intent
Sentences with similar meanings will be mapped to vectors that are close together in this space.
- Comparing Sentence Meanings
Once each sentence is converted into a vector, they can be compared using a mathematical formula called cosine similarity. This measures how close two vectors are, where:
- A value near 1.0 means the meanings are very similar.
- A value near 0.0 means they are unrelated.
Using this, the system identifies which content sentences are most aligned with the search intent or query.
Model Used in This Project
The model used in this implementation is called all-MiniLM-L6-v2, a lightweight but powerful version of Sentence-BERT. This model was selected because it offers a strong balance of performance and speed—making it capable of processing many pages quickly while maintaining high accuracy in sentence matching.
Key attributes of this model include:
- Based on a distilled version of the BERT architecture called MiniLM
- Uses 6 layers of transformers to encode context
- Outputs 384-dimensional embeddings for each sentence
- Pre-trained on large natural language inference datasets and fine-tuned for semantic similarity tasks
This model allows the system to handle real-time ranking and evaluation of hundreds of sentences from multiple URLs with minimal computational load.
How Sentence-BERT Fits into This Project
In the context of this project, Sentence-BERT is used to:
- Convert both queries and content sentences into comparable vectors
- Compute similarity scores between queries and each sentence
- Rank the content based on how well it matches the meaning of the queries
- Generate an overall score for each page based on the top-ranked matches
This approach ensures that content is not evaluated on keyword presence alone, but on true semantic relevance. It allows businesses to understand how closely their web pages align with user intent, and where adjustments may be needed to improve search performance.
keyboard_arrow_down
Semantic Sentence Similarity: Understanding Meaning Beyond Words
Overview
Semantic Sentence Similarity refers to the process of evaluating how closely the meanings of two sentences align, regardless of the specific words or structure used. Unlike traditional keyword-based matching systems, semantic similarity focuses on understanding the intent, context, and message of a sentence.
This concept is essential for content discovery, SEO, natural language search, and question-answering systems—where different phrases may express the same idea in multiple ways. In this project, semantic sentence similarity enables accurate identification of the most relevant content from a web page, based on the meaning behind queries such as page titles and meta descriptions.
What Makes Semantic Similarity Different?
Traditional text matching techniques—such as term frequency or keyword overlap—compare sentences at the surface level. They count common words or measure overlap but fail to recognize when different phrases mean the same thing.
For example:
- Query: “Tips to improve page speed”
- Content Sentence A: “Ways to enhance website loading time”
- Content Sentence B: “How many images should be on a homepage?”
In keyword-based approaches, Sentence A and B may appear equally similar because of some shared terms. But semantically, Sentence A is closely aligned with the query’s intent, while Sentence B is irrelevant.
Semantic sentence similarity solves this problem by comparing the underlying meanings, not just the surface words.
How Semantic Similarity Is Computed
In this project, semantic similarity is computed using sentence embeddings produced by the Sentence-BERT model. The key steps include:
- Embedding Generation
Each sentence—whether a user query or a sentence from the content—is converted into a fixed-length numerical vector that captures its meaning. These are known as embeddings.
- Sentences with similar meanings result in embeddings that are close in multi-dimensional space.
- This allows unrelated text (even if it shares words) to be clearly separated from truly relevant content.
- Cosine Similarity
To compare two sentence embeddings, cosine similarity is applied. This mathematical method evaluates how close the two vectors are in angle, rather than magnitude. Cosine similarity returns a value between:
- 1.0 -> Perfect semantic match
- 0.0 -> No semantic relation
- < 0.0 -> Opposing meanings (rare for sentence embeddings)
This approach provides a reliable metric to rank sentences based on semantic relevance to a given query.
Role of Semantic Similarity in This Project
Semantic sentence similarity drives two core functions in the system:
Ranking Content Sentences for Each Query
Each page’s text content is broken down into individual sentences. These are ranked based on how semantically close they are to one or more queries (title/meta description).
This enables the system to highlight the most relevant sentences that directly support or respond to the query’s intent—even if those sentences use different vocabulary.
Calculating Overall Page Relevance
The top-ranked sentence similarity scores are averaged to produce a single page-level relevance score. This score reflects how semantically aligned a page’s content is with its own title or metadata. It helps identify strong-performing pages and spot pages that may require optimization.
Why Semantic Similarity Matters in SEO and Content Strategy
Search engines and users are increasingly focused on meaning, not just keywords. Systems like Google’s BERT and MUM evaluate semantic relevance when ranking search results. By aligning content to semantic similarity rather than surface terms:
- Pages are better positioned to match diverse search intents
- Duplicate content detection becomes more meaningful
- Snippets and summaries can be more intelligently extracted
- Internal linking opportunities become clearer
This project leverages semantic sentence similarity to deliver a measurable, practical way to evaluate how well content reflects the intended meaning and how likely it is to satisfy real-world queries.
Libraries Used in the Project
This section outlines the key libraries and modules used in the implementation and explains the specific role each library plays.
requests
The requests library is used for sending HTTP GET requests to fetch the HTML content from a webpage URL. It forms the first step in data acquisition, enabling the system to process real-time content from external sources.
Purpose: Web content extraction
BeautifulSoup from bs4
BeautifulSoup is a Python library for parsing HTML and XML documents. It is used in this project to extract readable, structured text from HTML tags like <p>, <h1>, <h2>, <li>, etc., while ignoring scripts, styles, and non-content elements.
Purpose: HTML parsing and content isolation
nltk.tokenize.sent_tokenize
The sent_tokenize() function from the NLTK library (Natural Language Toolkit) is used to split raw text into a list of sentences. This is a critical step before feeding sentences into the Sentence-BERT model for embedding.
Purpose: Sentence segmentation for semantic comparison
Note: The required tokenizer models (punkt and punkt_tab) are downloaded at runtime to ensure sentence boundaries are accurately identified.
numpy
NumPy is a foundational numerical library used for handling vector operations efficiently. In this project, it assists in computing averages, storing embedding matrices, and handling multidimensional operations during similarity calculations.
Purpose: Numerical computations and matrix handling
pandas
Pandas provides tabular data structures (DataFrames) that are used for organizing and presenting sentence-level and URL-level results. It allows structured manipulation, filtering, and sorting of content similarity scores.
Purpose: Organizing and exporting similarity scores
sentence_transformers
This is the core deep learning library used in the project. It provides pre-trained Sentence-BERT models that convert sentences into dense semantic vectors (embeddings). These embeddings are the foundation for semantic similarity computations.
Purpose: Embedding generation using Sentence-BERT
sklearn.metrics.pairwise.cosine_similarity
This utility function from scikit-learn is used to compute cosine similarity between pairs of sentence embeddings. It returns a similarity score between 0 and 1, indicating the degree of semantic closeness.
Purpose: Semantic similarity calculation between query and content sentences
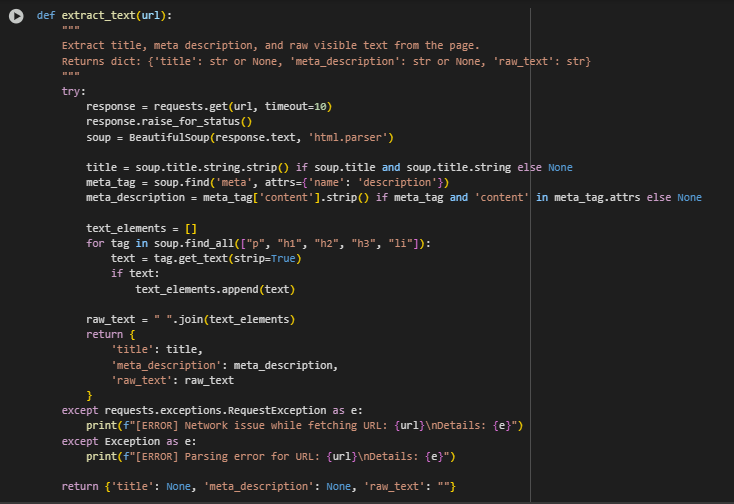
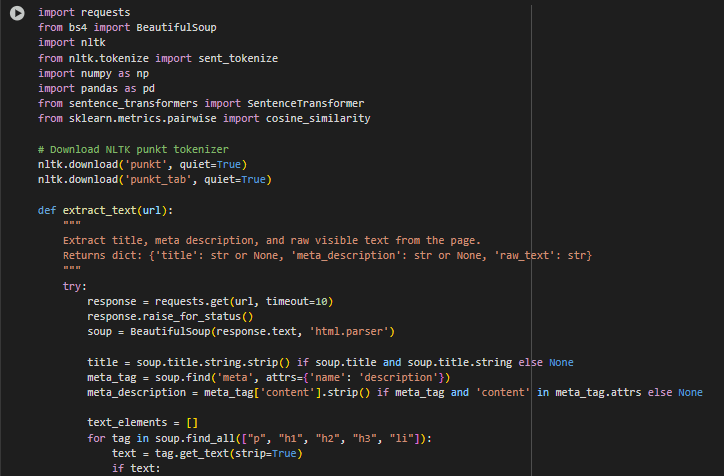
Function Overview: extract_text(url)
This function is responsible for extracting the core textual content from a webpage, including:
- The page’s title
- The meta description
- The main visible text content from common content tags
The output is structured as a Python dictionary containing these three elements, and it serves as the foundational input for the rest of the semantic similarity pipeline.
Objective
To convert a large unstructured text blob into a refined list of well-formed sentences suitable for semantic similarity analysis.
Step-by-Step Explanation
HTTP Request
response = requests.get(url, timeout=10)
- Initiates a web request to the given URL.
- A timeout of 10 seconds is applied to avoid long delays due to unresponsive servers.
response.raise_for_status()
- Ensures that only successful HTTP responses (status code 200) are processed further.
- Raises an exception for any client or server errors (e.g., 404, 500).
HTML Parsing with BeautifulSoup
soup = BeautifulSoup(response.text, ‘html.parser’)
- Parses the entire HTML content of the page using the built-in Python HTML parser.
- Converts the raw HTML into a navigable tree structure for easy content extraction.
Extracting the Title
title = soup.title.string.strip() if soup.title and soup.title.string else None
- Extracts the content within the <title> tag, if available.
- Applies .strip() to remove any leading or trailing whitespace.
- Fallbacks to None if the tag or its content is missing.
Extracting the Meta Description
meta_tag = soup.find(‘meta’, attrs={‘name’: ‘description’}) meta_description = meta_tag[‘content’].strip() if meta_tag and ‘content’ in meta_tag.attrs else None
- Locates the <meta name=”description”> tag, which typically contains a concise summary of the page.
- Extracts the value of the content attribute and cleans it.
- Fallbacks to None if not found.
Extracting Main Visible Content
for tag in soup.find_all([“p”, “h1”, “h2”, “h3”, “li”]): text = tag.get_text(strip=True)
· Iterates through a predefined set of content-rich tags:
- Paragraphs (<p>)
- Headings (<h1> to <h3>)
- List items (<li>)
· Uses .get_text(strip=True) to extract only visible text, ignoring embedded tags or formatting.
if text: text_elements.append(text)
- Ensures that only non-empty content is collected.
- Each block of visible text is appended to a list.
Combining Extracted Text
raw_text = ” “.join(text_elements)
- Joins all cleaned text blocks into a single unified string.
- This text serves as the primary input for sentence segmentation and similarity scoring.
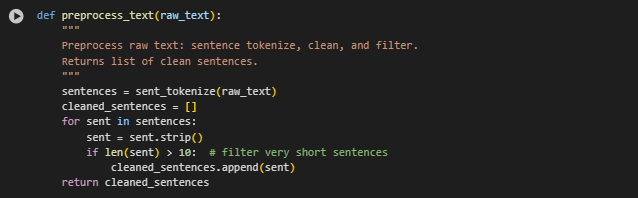
Function Overview: preprocess_text(raw_text)
This function performs essential text preprocessing on the extracted raw content by breaking it down into individual sentences, followed by basic cleaning and filtering. The result is a structured list of clean, contextually meaningful sentences that are ready for semantic embedding using Sentence-BERT.
Objective
To convert a large unstructured text blob into a refined list of well-formed sentences suitable for semantic similarity analysis.
Step-by-Step Explanation
Sentence Tokenization
sentences = sent_tokenize(raw_text)
- Uses NLTK’s sent_tokenize function to segment the input text into individual sentences.
- This tokenizer is trained on a large corpus and handles a wide variety of punctuation and edge cases.
- Sentence-level granularity is critical because Sentence-BERT is designed to work at the sentence (or short text) level for accurate semantic representation.
Note: The use of sent_tokenize() is intentional and important in this project. It ensures that raw text is broken down into linguistically appropriate units, which directly affects the quality of the similarity results.
Whitespace Removal and Filtering
sent = sent.strip()
- Removes leading and trailing whitespace from each sentence to ensure uniformity and avoid embedding discrepancies caused by unnecessary characters.
if len(sent) > 10: cleaned_sentences.append(sent)
- Filters out very short or incomplete sentences (e.g., headers, list bullets, navigation texts) that typically provide little to no semantic value.
- A length threshold of 10 characters is applied to retain only informative and context-rich sentences.
Why This Step Matters
- Preprocessing ensures that only high-quality textual content is passed into the embedding model.
- Poorly segmented or noisy input can significantly degrade the performance of semantic similarity algorithms.
- This step maximizes the relevance and precision of the results produced downstream in the ranking phase.

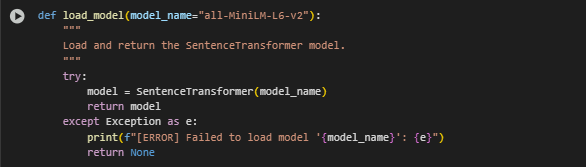
Function Overview: load_model(model_name=”all-MiniLM-L6-v2″)
This function is responsible for loading the pre-trained Sentence-BERT model that powers the semantic similarity engine in this project. The selected model plays a critical role in encoding sentences into dense vector representations suitable for similarity comparisons.
Objective
To initialize and return a pre-trained SentenceTransformer model based on the specified model name, enabling the downstream encoding of sentences into semantic embeddings.
Step-by-Step Explanation
Model Loading
model = SentenceTransformer(model_name)
- Uses the SentenceTransformers library to load a specific pre-trained model. = In this project, the default model is “all-MiniLM-L6-v2”, a lightweight yet powerful variant designed for fast and accurate semantic sentence encoding.
About the Selected Model
· Model Name: all-MiniLM-L6-v2
· Source: Hugging Face Model Hub
· Type: Sentence-BERT variant (Bi-Encoder)
· Characteristics:
- Approximately 22 million parameters.
- Produces 384-dimensional embeddings.
- Trained on 1 billion sentence pairs using contrastive learning.
- Optimized for speed and accuracy, making it ideal for real-time applications and large-scale comparisons.
This model strikes a strong balance between computational efficiency and semantic fidelity, especially in tasks involving dense ranking, search, and clustering.

Function Overview: generate_embeddings(text_list, model)
This function is responsible for converting a list of preprocessed sentences into semantic vector embeddings using the previously loaded Sentence-BERT model. These embeddings serve as the foundation for measuring semantic similarity between content elements.
Objective
To transform each input sentence into a fixed-length vector that captures its semantic meaning, allowing the project to perform similarity comparisons using cosine distance.
Step-by-Step Explanation
Embedding Generation
return model.encode(text_list, convert_to_tensor=True)
- The method model.encode() is provided by the SentenceTransformers library.
- It takes a list of text strings (text_list) and passes each one through the Sentence-BERT model.
- The argument convert_to_tensor=True ensures the output is a PyTorch tensor, making subsequent operations (like cosine similarity) more efficient and compatible with vectorized computation.
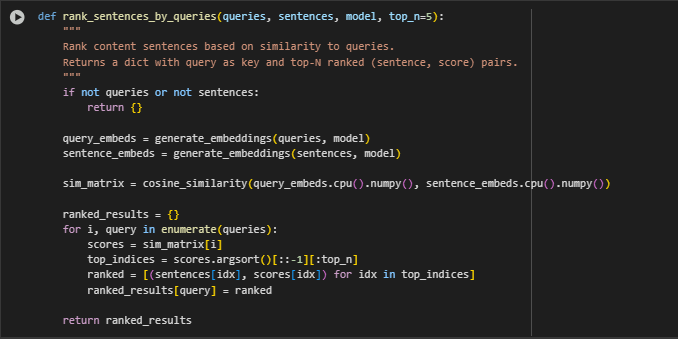

Function Overview: rank_sentences_by_queries(queries, sentences, model, top_n=5)
This function performs semantic sentence matching by comparing each user intent (query) with the content sentences extracted from a web page. It identifies the most relevant content sentences for each query based on semantic similarity, using vector embeddings and cosine similarity.
Objective
To rank content sentences from a webpage based on how semantically similar they are to a set of search-intent-driven queries (e.g., from Google’s “People Also Ask” or editorial keywords).
Step-by-Step Explanation
Input Validation
if not queries or not sentences: return {}
- Ensures that both query list and sentence list are non-empty.
- If either is missing, the function safely returns an empty result.
Embedding Generation
query_embeds = generate_embeddings(queries, model) sentence_embeds = generate_embeddings(sentences, model)
- Converts both the queries and content sentences into their semantic vector representations using the same Sentence-BERT model.
- These embeddings form the basis for all subsequent similarity comparisons.
Cosine Similarity Matrix
sim_matrix = cosine_similarity(query_embeds.cpu().numpy(), sentence_embeds.cpu().numpy())
· Calculates pairwise cosine similarity scores between each query and all content sentences.
· The result is a 2D matrix where:
- Rows = queries,
- Columns = content sentences,
- Each cell = semantic similarity score (range: -1 to 1).
Ranking Sentences
for i, query in enumerate(queries): scores = sim_matrix[i] top_indices = scores.argsort()[::-1][:top_n] ranked = [(sentences[idx], scores[idx]) for idx in top_indices] ranked_results[query] = ranked
For each query:
- Sorts the sentence similarity scores in descending order,
- Selects the top-N most relevant content sentences,
- Returns a list of (sentence, score) tuples for each query.
Why This Step Is Important
- Enables search-intent-driven content evaluation by revealing which sections of the page best match user intent.
- Helps identify opportunities to:
- Improve sentence targeting,
- Reposition or rewrite content,
- Enhance snippet optimization for SERP visibility.
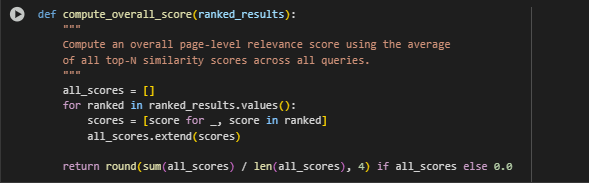

Function Overview: compute_overall_score(ranked_results)
This function calculates a single overall semantic relevance score for an entire webpage based on how well its sentences match a set of predefined intent-driven queries. It condenses sentence-level match quality into a page-level performance indicator.
Objective
To provide an aggregate measure that quantifies how effectively a webpage’s content aligns with multiple user-centric queries using Sentence-BERT semantic similarity scores.
Step-by-Step Explanation
Extract All Similarity Scores
all_scores = [] for ranked in ranked_results.values(): scores = [score for _, score in ranked] all_scores.extend(scores)
- Iterates over the ranked_results dictionary, which contains top-N matching sentences for each query.
- Collects only the similarity scores from each (sentence, score) pair.
- Flattens all scores across all queries into a single list all_scores.
Compute Average Score
return round(sum(all_scores) / len(all_scores), 4) if all_scores else 0.0
- Calculates the average similarity score across all sentence-query matches.
- Rounds the result to four decimal places for consistency.
- If no scores are found (e.g., empty input), returns 0.0 as a fallback.
Why This Step Is Important
- Enables content evaluation at a page level.
- Provides a single numeric metric that can be used to:
- Compare multiple URLs,
- Prioritize pages for optimization,
- Track changes in semantic alignment over time.
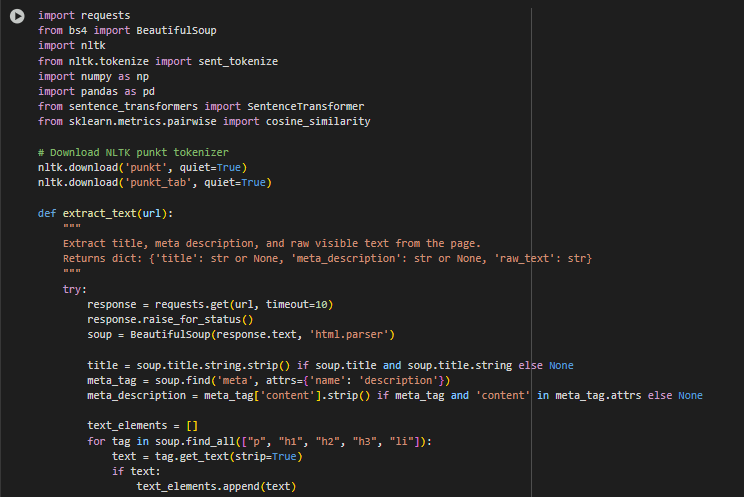
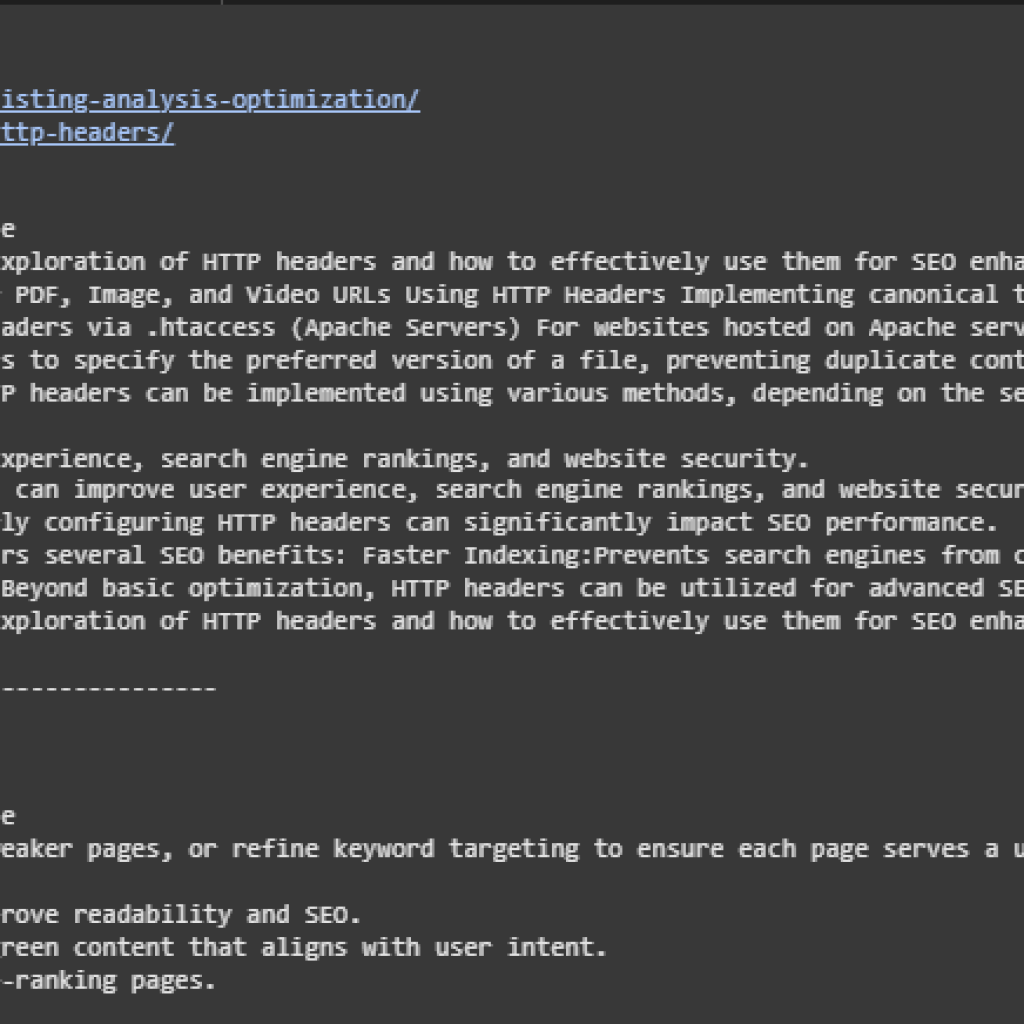
Result Explanation and Analysis
This section presents the analysis of content relevance using semantic similarity scores produced by Sentence-BERT. The evaluation focuses on how effectively the content of a webpage aligns with specific search intents represented by natural language queries. Both sentence-level rankings and an overall page-level score are used to interpret content quality.
Understanding the Scoring System
Each sentence from the content is scored for its semantic similarity with a given intent query using cosine similarity, which ranges between 0.0 and 1.0. A higher score indicates a stronger semantic match.
Score thresholds are interpreted as follows:
- 0.80 – 1.00 -> Highly Relevant: Sentence is directly aligned with search intent.
- 0.60 – 0.80 -> Moderately Relevant: Sentence supports the intent contextually but not perfectly aligned.
- 0.40 – 0.60 -> Somewhat Relevant: Sentence shares partial meaning or theme with the intent.
- < 0.40 -> Low Relevance: Sentence has weak or no meaningful alignment with the query.
The overall page relevance score is calculated as the average of all top-matching sentence scores across all queries.
Analysis of First Page
Overall Page Relevance Score: 0.7205
This score indicates moderate to strong relevance across the evaluated queries. The content consistently aligns with the semantic themes of the queries and includes multiple passages that reflect both technical guidance and SEO-focused explanations.
- Several sentences scored above 0.57, which indicates that the page contains technically relevant insights that contribute meaningfully to search intent.
- One sentence matched perfectly with a query (score 1.0000), demonstrating direct semantic equivalence. The sentence is similar to the meat description of the page.
- Other top-ranked sentences for both queries clustered within the 0.79 to 0.84 range, reinforcing thematic relevance from different angles.
This suggests that the content is well-structured, focused on the topic, and provides coverage from both general and advanced perspectives. Such pages are highly valuable for SEO, especially when optimizing for long-tail or intent-rich search phrases.
Analysis of Second Page
Overall Page Relevance Score: 0.4071
This score reflects weak semantic alignment with the evaluated intents. Most sentences retrieved from the content exhibit only a partial or tangential connection to the underlying search topics.
- The top-ranked sentence in both queries failed to exceed a 0.52 similarity score, indicating the absence of directly aligned content.
- Many sentence scores fell below 0.40, confirming that the majority of the content is off-topic or too generic in the context of the queries.
Although the content may serve general SEO themes, it lacks specific semantic elements related to the targeted topics. Optimization or re-alignment would be necessary to enhance this page’s performance for search intents related to HTTP header strategies or SEO implementations.
Summary of Insights
- Pages with a higher overall relevance score (≥ 0.70) demonstrate a strong alignment with user intent, making them suitable for ranking on intent-specific queries.
- Pages with scores below 0.50 may need content revision or supplementation to target search intents effectively.
- Sentence-level rankings allow deeper inspection into which parts of the content contribute most to intent fulfillment, enabling targeted edits or content expansion strategies.
This relevance scoring framework provides a scalable, explainable, and intent-driven method for evaluating and optimizing content for semantic SEO.
What is this project designed to evaluate?
This project evaluates how well the content of a web page aligns with real-world search intent. It uses natural language queries—similar to how users phrase search engine questions—and compares them to sentences within a page to measure how effectively the page addresses that intent.
How does the system determine “relevance”?
Relevance is determined using Sentence-BERT, a state-of-the-art model for semantic sentence comparison. The model converts each query and sentence into numerical vectors (embeddings), and then calculates cosine similarity between them. A higher similarity score indicates that a sentence is semantically closer to the search intent.
What is the purpose of the sentence ranking?
The sentence ranking highlights the top pieces of content that are most relevant to each query. This helps to:
- Pinpoint which sentences are performing well for a given intent.
- Identify content gaps—areas where no sentence strongly satisfies the query.
- Provide a transparent explanation of why a page received a certain score.
How does this help with SEO in practical terms?
This system bridges the gap between search engine expectations and actual on-page content by:
- Revealing how well a page responds to intent-rich queries.
- Identifying strong sentences that can be used in featured snippets or SERP excerpts.
- Uncovering weak or missing coverage, which can be corrected through content revision or expansion.
Ultimately, it provides actionable SEO guidance based on the semantic quality of content, not just keyword frequency.
A page received a high score (≥ 0.80). What should be done?
- Consider this page a strong performer for the evaluated search intents.
- Identify the top-ranked sentences—these represent high-value content.
- Use them in SERP snippets, featured snippets, or meta descriptions if appropriate.
- Optionally reuse these sentence formats across other similar pages.
A page scored modarate (between 0.60 and 0.79). What next?
- Treat this as a partially optimized page.
- Review the top 5 sentences for each query to see where coverage is strong or weak.
- Look for gaps where important queries lack highly relevant matches.
- Add or revise sentences to more directly answer those intents.
- Consider breaking up long paragraphs or reorganizing sections for clarity.
A page received a low score (< 0.35). Is it underperforming?
- Yes, the page likely does not align well with searcher intent.
- Focus efforts on restructuring or expanding content to better answer the queries.
- Use the top sentences as a reference to identify misaligned content (low-scoring and off-topic).
- Consider creating new sections or rewriting entirely to improve coverage.
specific query consistently shows low-ranked sentences. What should be done?
- This indicates the page does not meaningfully address that query.
- Evaluate whether the query is important to the target audience.
- If yes, create a new paragraph, heading, or section specifically crafted around that topic.
- Use natural phrasing, aiming to semantically mirror the query’s intent.
How should clients use the sentence rankings during content optimization?
- Use high-scoring sentences as anchors or example phrasing for new content.
- Replace or edit weakly aligned sentences that rank low despite being in relevant sections.
- Build content briefs using strong sentences to ensure coverage of core topics.
How is this different from traditional keyword analysis tools?
Traditional tools focus on exact keyword matching, while this project uses semantic analysis, which considers the meaning behind queries. This ensures that content is evaluated based on how well it satisfies user intent, not just how often it uses specific terms.
Final Thoughts
This project demonstrates a structured, data-driven approach to evaluating how effectively content aligns with real-world search intent using Sentence-BERT semantic similarity modeling. By ranking page content against intent-focused queries and computing overall relevance scores, this system offers a clear, quantifiable method to assess and improve SEO performance at both sentence and page levels.
The use of similarity scoring not only highlights content strengths but also exposes coverage gaps and optimization opportunities that might otherwise go unnoticed in manual reviews. High-scoring content can be identified and leveraged strategically, while lower-performing segments can be refined or rewritten to improve alignment with user needs.
Importantly, this solution is flexible and can adapt to any set of target queries or content types, making it highly scalable across editorial pipelines, landing page audits, and ongoing SEO initiatives. It empowers teams to move beyond surface-level metrics and take action based on semantic understanding of how well content answers searchers’ questions.
As search engines continue to evolve toward semantic and intent-based ranking, adopting models like Sentence-BERT provides a meaningful advantage in crafting content that truly resonates. This framework lays a strong foundation for future enhancements such as SERP snippet optimization, internal linking strategies, or content generation recommendations — all informed by the same core principle: aligning content with human intent.

Thatware | Founder & CEO
Tuhin is recognized across the globe for his vision to revolutionize digital transformation industry with the help of cutting-edge technology. He won bronze for India at the Stevie Awards USA as well as winning the India Business Awards, India Technology Award, Top 100 influential tech leaders from Analytics Insights, Clutch Global Front runner in digital marketing, founder of the fastest growing company in Asia by The CEO Magazine and is a TEDx speaker and BrightonSEO speaker.

