SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
Search performance and user satisfaction increasingly depend on how effectively content demonstrates understanding, clarity, and conviction in addressing a search query. Modern informational pages are expected not only to contain relevant information, but also to explain concepts clearly, justify claims, build trust, and guide readers confidently toward understanding or decision-making. Traditional SEO evaluation methods focus primarily on keywords, readability, and surface-level sentiment, leaving a critical gap in measuring how convincingly content satisfies user intent.

The Query–Content Persuasive Alignment Analyzer is designed to fill this gap by providing a structured, NLP-driven assessment of persuasive quality and intent satisfaction at a granular, section-level resolution. The system evaluates how well each content section aligns with one or more search queries, how effectively it communicates reasoning and evidence, and whether its tone remains appropriately informational without drifting into overly promotional or underdeveloped explanations.
The project implements a full end-to-end analytical pipeline that processes webpage content, segments it into logically coherent sections, and applies transformer-based models to extract semantic embeddings, persuasive signals, and intent-alignment indicators. Each section is independently analyzed for reasoning strength, trust signals, clarity, persuasive framing, and sales-oriented language. These signals are then combined to produce interpretable persuasive strength scores, intent alignment measures, and clearly defined persuasive gaps.
The output of the analyzer is designed for practical interpretation and action. Instead of abstract model outputs, the system produces structured insights that highlight which sections convincingly satisfy intent, which sections underperform, and why. Persuasive gaps are explicitly articulated, enabling targeted content refinement focused on reasoning depth, clarity, trust-building, and tone alignment.
Overall, this project establishes a scalable and repeatable framework for evaluating informational content quality beyond surface-level SEO metrics. It transforms persuasive effectiveness and intent satisfaction into measurable, section-level signals that can directly inform content audits, editorial improvements, and strategic optimization decisions.
Project Purpose
The primary purpose of this project is to establish a systematic and measurable approach to evaluating how convincingly informational content satisfies search intent, rather than merely determining whether the content is topically relevant. In practical content evaluation workflows, relevance alone is insufficient; high-performing pages must demonstrate clear reasoning, trustworthy explanations, appropriate persuasive framing, and alignment with what the reader expects to learn or resolve.
This project is built to address that requirement by translating qualitative content attributes—such as clarity, reasoning depth, trustworthiness, and persuasive balance—into structured, interpretable analytical signals. The goal is to make these attributes observable and comparable across sections, queries, and URLs, enabling consistent assessment at scale.
A key purpose of the analyzer is to operate at the section level, reflecting how real users consume content. Readers evaluate pages incrementally, forming judgments section by section. By scoring and diagnosing each section independently, the system allows precise identification of strong and weak content blocks instead of treating the page as a single undifferentiated unit.
The project also aims to produce outputs that are directly usable in editorial and optimization workflows. Rather than exposing raw model probabilities or opaque scores, the analyzer surfaces synthesized persuasive strength metrics, intent alignment indicators, and clearly described persuasive gaps. These outputs are intentionally structured to support decision-making, prioritization, and targeted content refinement.
In summary, the purpose of this project is to move content evaluation beyond surface-level SEO checks and toward a convincingness-first framework—one that measures whether content genuinely fulfills informational intent through clear explanation, credible reasoning, and balanced persuasive communication.
Project’s Key Topics: Explanation and Understanding
Query–Content Relationship
At the foundation of this project lies the relationship between a search query and the content presented to satisfy it. A query represents an explicit expression of intent, expectation, and required depth. Content, on the other hand, is the response mechanism that must interpret and fulfill that intent. This project treats the query–content relationship not as a binary match or mismatch, but as a spectrum of alignment that can vary across different sections of the same page.
Importantly, a single page often targets multiple related queries. Each query may emphasize different informational priorities, such as procedural clarity, conceptual explanation, or practical justification. Understanding this relationship requires evaluating how well content sections semantically and contextually address the underlying intent expressed by each query, rather than relying on keyword overlap or superficial topical similarity.
Intent Satisfaction
Intent satisfaction refers to the degree to which content fulfills what the reader expects after issuing a query. Informational intent is rarely limited to factual correctness alone. Readers typically seek explanations that answer implicit questions such as “why,” “how,” and “what does this mean in practice.”
This project approaches intent satisfaction as a multidimensional concept. It includes relevance to the topic, adequacy of explanation, and the logical completeness of the response. Content that mentions the right concepts but fails to explain them clearly or convincingly may appear relevant but still fall short of true intent satisfaction. Understanding intent satisfaction in this way allows the analysis to move beyond surface-level relevance and toward meaningful content fulfillment.
Persuasive Strength in Informational Content
Persuasion in informational content does not imply marketing or promotional language. Instead, it refers to how effectively the content convinces the reader that the explanation is accurate, complete, and worth trusting. Persuasive strength emerges from clarity, logical flow, confidence of explanation, and the ability to anticipate and address reader doubts.
This project treats persuasive strength as an inherent quality of strong informational writing. Well-structured explanations, justified claims, and reader-oriented framing naturally persuade without overt calls to action. Understanding this concept is essential, as overly weak persuasion can leave content sounding uncertain, while excessive persuasion can introduce sales-like tones that undermine informational credibility.
Reasoning and Explanatory Depth
Reasoning refers to the presence of logical connections between ideas, claims, and conclusions within the content. Informational pages are expected to explain not just what something is, but why it works, how it applies, and under what conditions it is relevant.
Explanatory depth captures whether the content meaningfully develops ideas rather than presenting isolated statements. Shallow explanations may state facts without context or justification, while deeper explanations guide the reader through underlying mechanisms or decision logic. This project emphasizes reasoning and depth because they strongly influence how convincing and useful content feels to an informed reader.
Trust and Credibility Signals
Trust is a critical component of content evaluation, particularly in technical or instructional topics. Credibility is established through precise language, structured explanations, references to evidence, examples, or authoritative framing. Even in the absence of explicit citations, content can convey trustworthiness through consistency, specificity, and clarity.
This project views trust signals as communicative patterns rather than isolated markers. The focus is on whether the content sounds informed, deliberate, and grounded in real-world understanding. Recognizing these signals helps differentiate content that merely repeats known information from content that demonstrates subject-matter confidence.
Tone Balance and Sales Pressure
Tone represents how the content communicates with the reader. In informational contexts, the ideal tone is balanced: confident without being aggressive, helpful without being promotional. Excessively sales-driven language can reduce perceived objectivity, while overly neutral or detached tone can reduce engagement.
This project treats tone balance as a key interpretive concept. The goal is not to eliminate persuasive language, but to ensure that persuasion supports understanding rather than distracting from it. Recognizing tone balance allows content to maintain informational integrity while still guiding reader comprehension.
Section-Level Content Structure
Readers do not consume content as a single continuous block. Pages are experienced section by section, with each section contributing incrementally to overall understanding. Some sections introduce concepts, others explain processes, and some reinforce trust or summarize implications.
This project adopts a section-level perspective to reflect real reading behavior. By understanding content at this granularity, it becomes possible to analyze how different parts of a page contribute to intent satisfaction and persuasive strength independently. This perspective is essential for diagnosing where content performs well and where explanatory or communicative gaps may exist.
Project Value & Importance: Questions and Answers
What problem does this project solve that traditional SEO or content analysis tools do not address?
Traditional SEO and content analysis tools primarily focus on surface-level indicators such as keyword coverage, readability, backlinks, or basic sentiment. While these signals are useful, they do not explain whether the content truly convinces a reader that their intent has been satisfied. This project addresses a deeper and more practical problem: measuring how effectively content explains, justifies, and builds confidence around the topic it covers. By evaluating persuasive strength, reasoning quality, and intent satisfaction at the section level, the project reveals why content performs well or underperforms beyond conventional metrics.
Why is persuasive strength important for informational content?
Informational content competes not only on accuracy but on clarity, trustworthiness, and explanatory completeness. Persuasive strength ensures that readers feel confident in the information presented and are less likely to seek answers elsewhere. When content lacks persuasive strength, it may technically answer a question but still leave doubts, leading to poor engagement and lower perceived value. This project treats persuasion as a quality of effective explanation, helping content communicate authority and usefulness without crossing into promotional language.
How does section-level analysis improve content understanding compared to page-level scoring?
Page-level scores often hide internal weaknesses by averaging performance across the entire document. A page may rank well overall while containing sections that confuse readers, lack reasoning, or undermine trust. Section-level analysis exposes these variations by evaluating each content block independently. This makes it possible to identify exactly where explanations break down, where tone shifts inappropriately, or where intent alignment weakens. Such granularity is essential for practical content improvement and informed editorial decisions.
Why is intent satisfaction treated as more than topical relevance?
Topical relevance alone does not guarantee that a reader’s expectations are met. Two pieces of content can cover the same topic, yet one may explain concepts thoroughly while the other offers shallow or fragmented information. Intent satisfaction in this project incorporates depth of explanation, logical flow, and contextual relevance. This approach reflects real user behavior, where readers judge content quality based on how completely and convincingly their underlying questions are addressed.
What is the significance of evaluating reasoning and explanation quality?
Reasoning quality determines whether content feels coherent and credible. Strong reasoning connects ideas logically, supports claims with explanations, and guides the reader toward understanding rather than assumption. Weak reasoning often manifests as unsupported statements or abrupt topic shifts. By evaluating reasoning explicitly, this project highlights structural and explanatory issues that are difficult to detect through keyword or readability analysis alone.
How does this project support trust and credibility assessment?
Trust is not conveyed through a single signal; it emerges from consistent clarity, precise language, and evidence-oriented framing. This project identifies patterns that indicate whether content builds or erodes trust over the course of a section. By focusing on how information is presented rather than merely what is stated, the analysis captures credibility cues that strongly influence reader confidence and long-term content performance.
How does this project contribute to long-term content quality improvement?
Rather than offering isolated metrics, this project provides a structured understanding of how content communicates value, builds confidence, and satisfies intent. The insights generated can be used repeatedly to guide content audits, editorial reviews, and optimization efforts. Over time, this leads to more consistent, high-quality informational content that aligns better with user expectations and search behavior.
Why is this approach suitable for high-stakes or authoritative content?
In domains where accuracy, clarity, and trust are critical, superficial optimization can harm credibility. This project emphasizes depth, reasoning, and tone balance, making it well suited for evaluating content that must inform, educate, or guide decision-making. By focusing on persuasive clarity rather than promotional tactics, the analysis supports content that aims to establish authority and long-term trust.
Libraries Used
Standard Python Utilities (time, re, html, hashlib, unicodedata, gc)
These libraries provide core language-level functionality for text handling, normalization, hashing, and memory management. They are part of Python’s standard library and are commonly used in production-grade data processing pipelines.
In this project, these utilities are used to normalize raw HTML text, clean encoding inconsistencies, remove unwanted characters, generate stable section identifiers through hashing, regulate request pacing, and explicitly manage memory during long-running multi-URL analysis. Their usage ensures deterministic behavior, stability, and efficiency across large content inputs.
Data Structures and Logging (dataclasses, logging)
The dataclasses module provides a structured and type-safe way to define and manage complex data records. The logging module enables configurable, leveled logging suitable for debugging and production monitoring.
Dataclasses are used to define internal content representations (such as chunk-level records) in a clean and maintainable manner, enabling consistent downstream processing. Logging replaces ad-hoc print statements to track pipeline progress, model loading status, inference steps, and error conditions in a professional and auditable way, which is essential for real-world analytical systems.
Networking and Typing (requests, typing)
The requests library is a robust HTTP client for fetching web content, while the typing module provides static type hints for function inputs and outputs.
Requests is used for controlled, retry-aware page fetching with timeout and backoff handling, ensuring reliable extraction from live URLs. Type hints improve code clarity, reduce integration errors, and make complex multi-stage functions easier to reason about and extend as the project grows.
HTML Parsing (BeautifulSoup, Tag, NavigableString, Comment)
BeautifulSoup is a widely used HTML parsing library that allows flexible traversal and extraction of web page structures.
In this project, it is used to extract meaningful content sections while removing boilerplate, navigation elements, scripts, and irrelevant markup. The ability to work directly with tags, text nodes, and comments enables precise section boundary detection, which is critical for accurate section-level analysis.
Numerical and Data Handling (numpy, pandas)
NumPy provides efficient numerical operations, while Pandas offers high-level data manipulation utilities.
NumPy is used for vector operations, similarity calculations, and aggregation of embedding-based scores. Pandas is primarily leveraged for intermediate inspection, debugging, and optional export of annotated results, such as CSV-based reviews of persuasive signals or gap diagnostics.
Natural Language Processing (nltk)
NLTK is a foundational NLP library that includes reliable tokenization utilities.
In this project, sentence tokenization is used during preprocessing and chunking to ensure that text is segmented in a linguistically meaningful way. This improves chunk coherence and ensures that downstream embedding and classification models operate on well-formed textual units rather than arbitrary character splits.
Deep Learning Framework (torch)
PyTorch is a widely adopted deep learning framework that underpins many modern NLP models.
Although not used directly for model training in this project, PyTorch provides the runtime backbone for both embedding models and transformer-based classifiers. Its presence enables efficient inference on CPU or GPU and ensures compatibility with HuggingFace and SentenceTransformer ecosystems.
Semantic Embeddings (sentence_transformers)
SentenceTransformers provides pre-trained models for converting text into dense semantic vectors suitable for similarity and alignment tasks.
This library is central to intent alignment and semantic relevance computation. It allows each content section and query to be embedded into a shared vector space, enabling cosine similarity–based comparisons that reflect meaning rather than surface-level word overlap.
Transformer Pipelines (transformers)
The HuggingFace Transformers library offers standardized pipelines for zero-shot classification and other NLP tasks.
In this project, transformer pipelines are used to perform zero-shot inference for persuasive signals such as reasoning presence, trust cues, sales-oriented tone, clarity, and persuasive framing. This approach avoids brittle keyword rules and enables scalable, model-driven signal detection aligned with real-world language variability.
Visualization (matplotlib, seaborn)
Matplotlib is the foundational plotting library in Python, while Seaborn builds on it to provide cleaner aesthetics and statistical visualizations.
These libraries are used to visualize persuasive strength distributions, intent alignment patterns, and cross-query or cross-URL comparisons. The visual outputs are designed to help interpret analytical results quickly and support decision-making without exposing raw numerical complexity.
Data Structure: ChunkRecord
Summary
ChunkRecord defines the core analytical unit of the entire project. Each instance represents a single chunked content block derived from a web page section. This structure is intentionally compact but extensible, ensuring that all downstream analytical signals—semantic embeddings, persuasive scores, intent alignment, and gap diagnostics—can be attached without changing the base structure.
The dataclass enforces consistency across the pipeline by standardizing how section-level content is stored and passed between modules. By associating each chunk with both its section context and its sequential position, the structure supports section-level interpretation while remaining suitable for fine-grained scoring and aggregation.
Key responsibilities of this structure include:
- Preserving section identity and heading context
- Maintaining chunk order for narrative flow analysis
- Storing raw text and basic length statistics
- Acting as a container for embeddings and computed scores
This design ensures scalability as additional analytical signals are introduced later in the pipeline.
Function: fetch_html
Summary
fetch_html is a robust, production-oriented HTML retrieval function designed for real-world web content extraction. It fetches page HTML using controlled retries, exponential backoff, and encoding fallback logic to handle unreliable servers, temporary network failures, and inconsistent character encodings.
The function prioritizes stability and fault tolerance, which is critical when analyzing multiple URLs in a single pipeline run. Instead of failing immediately on transient issues, it attempts recovery in a measured and logged manner, ensuring higher pipeline success rates without aggressive or unsafe retry behavior.
If no usable HTML content is obtained after all retries, the function fails explicitly with a meaningful error, allowing downstream logic to skip or report the URL appropriately.
Key Code Explanations
headers = headers or {“User-Agent”: “Mozilla/5.0”}
- This line ensures that a browser-like User-Agent is always sent with the request. Many servers block or throttle requests without a valid User-Agent, so this default prevents unnecessary fetch failures while still allowing custom headers when needed.
while attempt <= max_retries:
- This loop controls the retry mechanism. Instead of a fixed number of attempts without delay, retries are explicitly tracked, enabling controlled backoff and detailed logging for each failed attempt.
wait = backoff_factor ** attempt
- This implements exponential backoff, where the wait time increases with each retry. This approach is considered standard practice in production systems because it reduces server strain and avoids rapid repeated failures when a server is temporarily unavailable.
resp = requests.get(…, allow_redirects=True)
- Redirect handling is explicitly enabled to support real-world URLs that may resolve through HTTP redirects, canonicalization, or tracking layers. This ensures that final content is retrieved correctly without manual redirect management.
encodings = [resp.apparent_encoding, “utf-8”, “iso-8859-1”]
- Web pages often declare incorrect or missing encodings. This fallback sequence attempts the detected encoding first, followed by common defaults, significantly improving text readability and preventing silent corruption of extracted content.
if html and len(html.strip()) > 80:
- This validation step ensures that the fetched response contains meaningful content rather than empty pages, error templates, or placeholder responses. It prevents downstream modules from processing unusable HTML blobs.
Function: clean_html
Summary
clean_html prepares raw HTML content for reliable text extraction by removing structural noise while preserving meaningful content elements. The function converts raw HTML into a parsed DOM tree and systematically eliminates tags and elements that typically do not contribute to informational or persuasive content.
This preprocessing step is essential for ensuring that downstream section detection, chunking, and semantic analysis operate on high-quality content rather than navigation menus, scripts, or decorative elements. By standardizing the DOM early in the pipeline, the function reduces extraction errors and improves the signal-to-noise ratio for all subsequent NLP tasks.
The function is intentionally conservative: it removes commonly noisy tags but does not aggressively flatten the structure, allowing section hierarchies and headings to remain intact for accurate section-level processing.
Key Code Explanations
soup = BeautifulSoup(html, “lxml”)
- The function attempts to use the lxml parser first because it is faster and more robust when handling malformed or complex HTML. This choice improves performance and resilience when processing large or poorly structured pages.
except Exception: soup = BeautifulSoup(html, “html.parser”)
- A fallback to Python’s built-in HTML parser ensures compatibility even when lxml is unavailable or fails due to parsing issues. This guarantees that HTML parsing does not become a single point of failure in the pipeline.
noise_tags = […]
- This list defines elements that commonly contain non-content material such as scripts, forms, navigation blocks, or visual elements. Removing these tags prevents irrelevant text from polluting section extraction and semantic analysis.
node.decompose()
- decompose() completely removes both the tag and its contents from the DOM. This is preferable to simple text extraction because it ensures that no residual text from noisy elements leaks into the cleaned content.
soup.find_all(string=lambda x: isinstance(x, Comment))
- HTML comments often contain developer notes, tracking markers, or hidden content not intended for readers. Explicitly removing them prevents accidental inclusion of irrelevant or misleading text in extracted sections.

Function: _md5
Summary
_md5 generates a deterministic hash for a given text string. It is used to create stable identifiers for sections that do not depend on runtime state or external counters.
In this project, hashed identifiers ensure that section IDs remain consistent across runs for the same content, which is important when comparing results over time or aligning outputs with downstream analytical modules.
This function is intentionally minimal and self-explanatory, so no separate code-level explanation is required.
Function: _normalize
Summary
_normalize standardizes raw text into a clean, analysis-ready format. It normalizes Unicode characters, removes excessive whitespace, and strips control characters such as newlines and tabs.
This normalization step is critical before any NLP operation. It ensures that tokenization, embeddings, and classifier inference are applied to consistent text representations, preventing subtle errors caused by encoding artifacts or irregular spacing.
Function: _safe_get_text
Summary
_safe_get_text safely extracts visible text from a BeautifulSoup tag and applies normalization. It acts as a protective wrapper around DOM text extraction, ensuring that parsing failures or malformed nodes do not interrupt the pipeline.
By returning an empty string on failure, the function allows section extraction to proceed gracefully even when encountering problematic HTML elements.
Function: _is_meaningful_block_text
Summary
_is_meaningful_block_text applies conservative heuristics to decide whether a block of text should be retained for analysis. The goal is to filter out boilerplate and low-value fragments without aggressively removing legitimate content.
The function excludes:
- Very short text blocks unlikely to carry meaningful information
- Common footer, legal, subscription, or navigation phrases
- Generic site-level boilerplate that does not contribute to intent satisfaction or persuasion
This filtering step directly improves the quality of extracted sections and reduces noise in downstream scoring.
Function: extract_sections_by_headings
Summary
extract_sections_by_headings is a core extraction function that transforms cleaned HTML into structured, section-level content. It walks the DOM in document order and groups text blocks under logical section boundaries defined by heading tags.
Each extracted section contains:
- A stable section identifier
- The section heading text
- Heading level information
- An ordered list of meaningful content blocks
If no valid headings are present, the function falls back to a single synthetic section, ensuring that analysis can proceed even on poorly structured pages.
This function establishes the sectional backbone of the entire project, enabling section-level chunking, persuasion analysis, intent alignment, and gap detection.
Key Code Explanations
nodes = list(body.descendants)
- This line flattens the DOM tree into a document-order sequence, allowing the function to process headings and content blocks exactly as they appear to readers. Preserving order is essential for maintaining narrative flow and logical grouping.
if name in heading_tags:
- When a heading tag is encountered, a new section is started. This mirrors how readers cognitively segment content and ensures that analysis aligns with human content consumption patterns.
if current_section and sum(len(b[“text”]) …) >= min_section_chars:
- This validation step ensures that only sections with sufficient content are retained. It prevents empty or near-empty sections—often caused by decorative headings—from polluting analytical results.
current_section[“blocks”].append({“tag”: name, “text”: txt})
- Blocks are stored with both tag type and text content, preserving minimal structural context while remaining lightweight. This design enables flexible downstream chunking without retaining unnecessary DOM complexity.
if not sections: fallback logic
- This fallback guarantees robustness. Even in edge cases where headings are absent or content is sparse, the function still produces a usable section, preventing pipeline failure.
Function: _sliding_window_tokens
Summary
_sliding_window_tokens creates overlapping text chunks from a list of tokens using a fixed-size sliding window. It is designed as a fallback mechanism when sentence-level chunking is not feasible, such as when a single sentence exceeds the maximum allowed token limit.
This approach ensures that long, dense sentences are still captured in analyzable segments rather than being discarded or truncated. The overlap parameter preserves contextual continuity across adjacent chunks, which is especially important for embedding generation and semantic scoring.
Function: chunk_section_text
Summary
chunk_section_text is a sentence-aware chunking function that converts a section’s full text into multiple, model-friendly chunks while preserving semantic coherence. It balances three competing constraints: readability, contextual completeness, and token limits imposed by transformer models.
The function prioritizes sentence boundaries to maintain natural language flow. Only when sentences are too long does it fall back to token-level sliding windows. This hybrid strategy ensures that chunks remain both semantically meaningful and technically compatible with downstream NLP models.
Key design goals of this function include:
- Preserving sentence integrity whenever possible
- Respecting maximum token limits for embedding and inference models
- Avoiding overly short or fragmented chunks
- Maintaining contextual overlap to reduce semantic discontinuities
This chunking logic is foundational for all section-level analyses performed later in the project, including persuasion scoring, semantic alignment, and structural interpretation.
Key Code Explanations
sentences = sent_tokenize(section_text)
- This line attempts sentence segmentation using NLTK’s Punkt tokenizer, which is trained to handle real-world punctuation and abbreviations. Accurate sentence boundaries improve chunk coherence and prevent semantic fragmentation.
if estimate_tokens(candidate, tokenizer) <= max_tokens:
- Here, the function incrementally builds a chunk by appending sentences until the token budget is reached. This ensures that each chunk is as information-dense as possible without exceeding model constraints.
if not current: followed by sliding window logic
- When a single sentence exceeds the token limit, the function switches to token-based chunking. This conditional path prevents infinite loops and guarantees progress even in edge cases like legal text or long technical sentences.
start = max(end – overlap, start + 1)
- This overlap logic ensures that adjacent chunks share contextual tokens while still advancing forward. It prevents content loss and improves embedding continuity across chunks.
if estimate_tokens(c, tokenizer) < min_tokens:
- This post-processing step filters out under-sized chunks that would be semantically weak on their own. When possible, short chunks are merged with their predecessors, improving analytical stability without violating token constraints.
Function: estimate_tokens
Summary
estimate_tokens provides a flexible and resilient way to approximate token counts for a given text segment. Token estimation is a critical requirement in this project because multiple downstream components—such as chunking, embedding generation, and model inference—depend on staying within transformer model token limits.
The function supports two modes of operation. When a tokenizer is supplied, it uses the tokenizer’s native encoding logic to produce an accurate token count aligned with the underlying language model. When no tokenizer is available, it gracefully falls back to a whitespace-based word count approximation. This dual strategy ensures robustness across environments and prevents pipeline failures due to tokenizer unavailability or runtime issues.
Key Code Explanations
tokenizer(text, add_special_tokens=False)[“input_ids”]
- This line performs tokenizer-based encoding without adding special tokens. Excluding special tokens ensures that token estimates reflect only the content itself, making the count directly comparable to chunk size constraints defined elsewhere in the pipeline.
except Exception: return len(text.split())
- This fallback logic ensures that token estimation never becomes a blocking dependency. Even if tokenizer execution fails due to malformed input or library inconsistencies, the pipeline continues with a conservative approximation.
Function: extract_preprocess_and_chunk
Summary
extract_preprocess_and_chunk is the core orchestration function for transforming a raw webpage URL into a structured, section-aware, and chunked textual representation. It acts as the backbone of the entire analytical pipeline, coordinating HTML retrieval, content cleaning, structural segmentation, normalization, and chunk generation.
This function is deliberately designed as an end-to-end, fault-tolerant workflow. Each major stage includes defensive checks and graceful failure handling to accommodate real-world webpages, which often contain malformed HTML, JavaScript-rendered content, or sparse textual signals.
The output of this function is a flattened list of chunk records enriched with section metadata, sequence ordering, and size statistics. These chunk records become the fundamental units for all subsequent persuasion alignment, strength scoring, and gap detection analyses.
Key Code Explanations
html = fetch_html(url)
- This line initiates robust HTML retrieval using retry logic and exponential backoff. Fetch reliability is essential because upstream failures would invalidate all downstream semantic analysis.
soup = clean_html(html)
- HTML cleaning removes scripts, navigation elements, and boilerplate noise. This step ensures that only meaningful content enters the section extraction and chunking logic, improving analytical signal quality.
title = _safe_get_text(title_tag)
- The title extraction logic prioritizes the <title> tag and falls back to <h1> if necessary. Capturing a representative title provides contextual metadata that supports interpretation and traceability of results.
sections = extract_sections_by_headings(soup, min_section_chars=min_section_chars)
- This line segments the document into logical sections based on heading structure. Section-level boundaries are central to this project, as all persuasion alignment and gap detection are performed at the section granularity.
section_text = ” “.join([_normalize(b[“text”]) for b in blocks])
- This concatenation preserves the natural reading order within each section. Normalization ensures consistent whitespace and character encoding before chunking, reducing variability in downstream scoring.
chunk_texts = chunk_section_text(…)
- Here, each section is chunked independently using sentence-aware logic. This preserves intra-section semantic coherence and prevents content from different sections from being mixed within a single chunk.
ChunkRecord(…)
- Each chunk is wrapped in a structured data object containing section identifiers, positional sequence information, and text statistics. This structured representation enables consistent tracking, scoring, and visualization across the pipeline.
“chunk_sections”: [asdict(c) for c in chunks_out]
- Converting dataclass instances into dictionaries ensures compatibility with serialization, logging, and visualization workflows while retaining full structural fidelity.
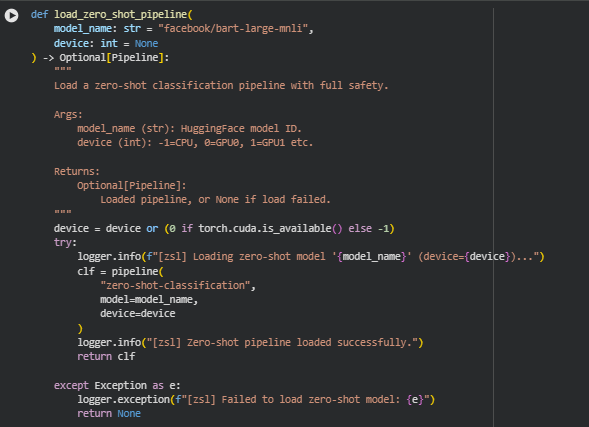

Function: load_zero_shot_pipeline
Summary
The load_zero_shot_pipeline function is responsible for initializing a HuggingFace zero-shot classification pipeline, which is a key component for evaluating content against multiple semantic labels without requiring any task-specific training data. Zero-shot classification is particularly useful in this project for detecting persuasive signals, trust cues, reasoning presence, and salesiness indicators across diverse section texts.
The function is designed to handle device allocation automatically, defaulting to GPU if available, and to log progress and failures systematically. It returns a fully initialized pipeline object for inference, or None in case of a failure, ensuring downstream components can handle the situation gracefully.
Key Code Explanations
device = device or (0 if torch.cuda.is_available() else -1)
- This line determines which device the pipeline should use. It defaults to the first GPU if CUDA is available, otherwise CPU (-1). This automatic selection improves runtime efficiency while maintaining portability.
clf = pipeline(“zero-shot-classification”, model=model_name, device=device)
- Here, the HuggingFace pipeline API is invoked to instantiate a zero-shot classifier. The “zero-shot-classification” task type allows the model to assign probabilities to arbitrary candidate labels for any input text, making it highly flexible for the multi-signal analysis required in this project.
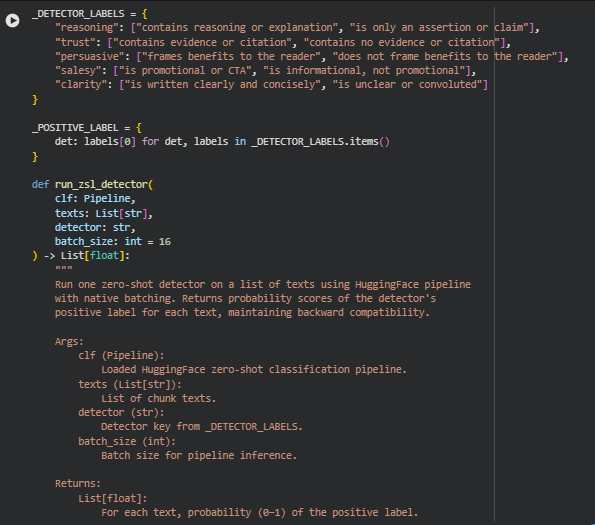
Function: run_zsl_detector
Summary
The run_zsl_detector function performs zero-shot classification for a specific detector on a list of text chunks using a HuggingFace zero-shot classification pipeline. Each detector corresponds to a semantic aspect of content, such as reasoning, trust, persuasive tone, salesiness, or clarity. The function returns a list of probability scores (0–1) representing how strongly each text exhibits the positive label of the selected detector. This allows scoring each chunk for critical persuasive and informational attributes, forming the foundation for subsequent alignment and gap analysis.
The function supports native batching for efficiency while maintaining a fallback mechanism for individual inference if batch processing fails. This ensures robust performance even with varying input sizes or unexpected pipeline errors.
Key Code Explanations
candidate_labels = _DETECTOR_LABELS[detector] and positive_label = _POSITIVE_LABEL[detector]
- These lines select the two candidate labels defined for the given detector and the positive label used for scoring. The positive label represents the desirable content quality (e.g., “contains reasoning or explanation” for the reasoning detector).
outputs = clf(texts, candidate_labels=candidate_labels, *multi_label=False, batch_size=batch_size)
- This line invokes the zero-shot classifier in batch mode, passing all texts at once. The multi_label=False argument ensures the classifier assigns probabilities across mutually exclusive labels, returning a normalized score for the positive label. Using batching significantly reduces processing time compared to sequential per-text calls.
Fallback Mechanism
for t in texts:
try:
out = clf(
t,
candidate_labels=candidate_labels,
multi_label=False
)
…
- The except block handles cases where batch inference fails. Each text is processed individually, and any errors in individual inference are caught, assigning a default score of 0.0. This ensures that no text is left unscored, maintaining robustness in real-world data scenarios.
Function: run_all_detectors
Summary
The run_all_detectors function executes multiple zero-shot detectors on a list of text chunks in a single pass. Each detector evaluates a specific aspect of content quality, such as reasoning, trust, persuasive tone, salesiness, or clarity. The function aggregates the scores from all selected detectors and returns a structured list of dictionaries, where each dictionary corresponds to one text chunk and contains scores for all detectors. This allows simultaneous evaluation of multiple content attributes, simplifying downstream processing for alignment computation, gap detection, and persuasive scoring.
The function also gracefully handles cases where the classifier pipeline is not provided, returning zero scores for all detectors to maintain consistency in downstream modules.
Key Code Explanations
detectors = detectors or list(_DETECTOR_LABELS.keys())
- This line ensures that if no specific subset of detectors is provided, the function defaults to running all available detectors. It maintains flexibility, allowing targeted scoring for specific attributes when required.
results = {d: run_zsl_detector(clf, texts, d, batch_size=batch_size) for d in detectors}
- Here, the function calls run_zsl_detector for each detector, obtaining a list of probability scores per detector. Using dictionary comprehension organizes the outputs efficiently, mapping each detector to its respective scores across all text chunks.
Combining results per chunk:
for i in range(len(texts)):
combined.append({d: float(results[d][i]) for d in detectors})
- This loop iterates over each text chunk and consolidates all detector scores into a single dictionary. Each entry in combined represents a text chunk with all detector metrics, providing a clean and uniform structure for downstream modules.

Function: load_embedding_model
Summary
The load_embedding_model function loads a sentence-transformers embedding model safely, ensuring proper device allocation for CPU or GPU usage. Embedding models are crucial in semantic analysis as they convert textual content into high-dimensional vectors, which can then be used for similarity calculations, intent alignment, and clustering. By including exception handling and logging, this function guarantees robustness, providing informative messages if the model fails to load, while returning None to allow safe downstream handling.
This function also logs the embedding dimension and the device the model is loaded on, which is useful for debugging and confirming correct configuration in multi-device environments.
Key Code Explanations
Device selection:
if device:
model = SentenceTransformer(model_name, device=device)
else:
model = SentenceTransformer(model_name)
- This logic ensures that if a specific device (CPU/GPU) is provided, the model will load there. If not, the SentenceTransformer internally selects an appropriate device, typically defaulting to GPU if available, ensuring optimized performance.
Logging embedding dimension:
dim = model.get_sentence_embedding_dimension()
logger.info(f” Model loaded | dim={dim} | device={model.device}”)
- After loading, the function retrieves and logs the embedding dimension. This confirms the correct model configuration and aids in troubleshooting potential downstream mismatches in vector dimensionality.
Function: embed_texts
Summary
The embed_texts function generates dense vector representations (embeddings) for a list of textual chunks using a SentenceTransformer model. Embeddings are fundamental for semantic comparison, similarity computations, and intent alignment analysis, as they capture the contextual meaning of text in a high-dimensional vector space. The function supports batching to handle large lists of texts efficiently and performs optional normalization to produce unit vectors, which are especially important for cosine similarity calculations used in alignment and clustering tasks. By ensuring robust handling of empty or invalid inputs, the function maintains stability in a production pipeline.
Key Code Explanations
Empty input handling:
if not texts:
dim = model.get_sentence_embedding_dimension()
return np.zeros((0, dim), dtype=np.float32)
- This line ensures that if the input list is empty, the function returns an appropriately shaped zero array. This prevents downstream errors and maintains consistent data structures in the pipeline.
Input cleaning:
clean = [t.strip() for t in texts if t and t.strip()]
- All texts are stripped of leading and trailing whitespace, and empty strings are removed. This guarantees that the embedding model only receives meaningful content, avoiding unnecessary computation or errors.
Safe batching:
batch_size = min(batch_size, len(clean))
embeddings = model.encode(
clean,
batch_size=batch_size,
convert_to_numpy=True,
normalize_embeddings=normalize
)
- The batch size is capped at the number of valid texts to prevent over-allocating batches. The encode method generates embeddings efficiently in batches, and normalize_embeddings=True ensures embeddings are unit vectors for cosine similarity, crucial for intent and persuasive alignment scoring.
Function: compute_persuasive_score
Summary
The compute_persuasive_score function calculates a single, composite score representing the overall persuasive strength of a text chunk, scaled from 0 to 100. It uses a weighted combination of multiple signals—persuasive, reasoning, trust, salesy, and clarity—to quantify how convincingly a piece of content communicates, supports arguments, and engages the reader. The salesy signal is negatively weighted to reduce the score if the content leans excessively promotional. The resulting score provides a clear, interpretable metric that can be used to compare sections or pages in terms of persuasive quality.
Key Code Explanations
Weighted sum of signals:
raw = sum(w[k] * signals[k] for k in w if k in signals)
- Each signal is multiplied by its predefined weight to reflect its relative importance in the overall persuasive strength. Signals missing from the input dictionary are ignored, ensuring flexibility and robustness.
Clamping and scaling:
raw = max(-1.0, min(1.0, raw))
return int(round((raw + 1.0) * 50))
- The weighted sum is first clamped between -1 and 1 to prevent out-of-bound values caused by anomalies. Then, it is scaled linearly to a 0–100 range, producing a standardized and easily interpretable score suitable for client-facing reports.
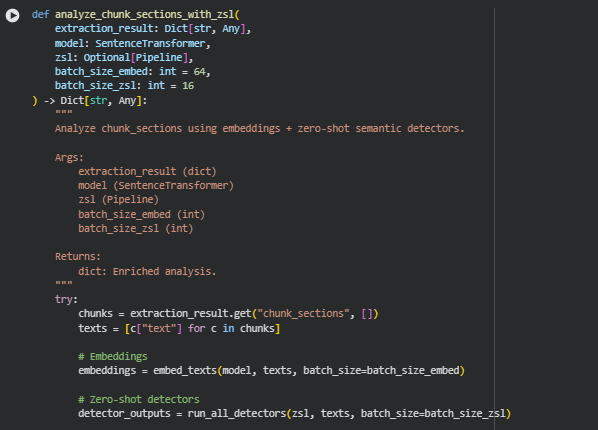

Function: analyze_chunk_sections_with_zsl
Summary
The analyze_chunk_sections_with_zsl function enriches the previously extracted and chunked sections of a web page with semantic embeddings and zero-shot detector signals to quantify the persuasive and informational qualities of each chunk. It integrates both vector-based similarity features (via embeddings) and classifier-based signals (reasoning, trust, clarity, persuasiveness, and salesiness) to produce a comprehensive, per-chunk analysis. Additionally, it computes a page-level mean persuasive score to provide an overall metric of content effectiveness.
This function bridges raw text extraction with semantic analysis, preparing the data for downstream modules like intent alignment, persuasive scoring, gap detection, and visualization.
Key Code Explanations
Generating embeddings:
embeddings = embed_texts(model, texts, batch_size=batch_size_embed)
- Each chunk’s text is converted into a dense vector representation using the sentence-transformers model. These embeddings enable semantic similarity computations for later alignment with queries or content comparison.
Running zero-shot detectors:
detector_outputs = run_all_detectors(zsl, texts, batch_size=batch_size_zsl)
- Each chunk is evaluated for reasoning, trust, persuasiveness, clarity, and salesiness using the zero-shot classification pipeline. This step produces probabilities for each detector, forming the foundation for the persuasive scoring.
Composing enriched chunk data:
out = dict(c)
out[“embedding”] = embeddings[i].tolist()
out[“signals”] = sig
out[“persuasive_score”] = score
- The original chunk dictionary is extended with its embedding vector, detector signals, and the composite persuasive score, making each chunk self-contained for subsequent analysis and reporting.
Page-level mean persuasive score:
page_score = np.mean([c[“persuasive_score”] for c in enriched_chunks])
- A simple average of chunk-level scores provides a high-level summary metric, helping quickly gauge the overall persuasive effectiveness of the page.

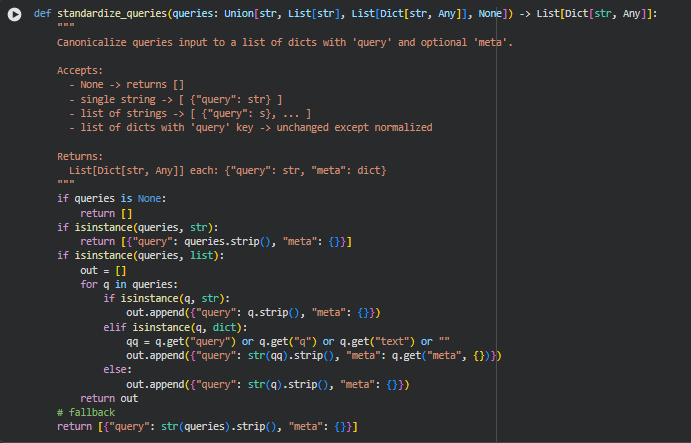
Function: standardize_queries
Summary
The standardize_queries function ensures uniform input format for all subsequent modules that rely on query data. Since queries can be provided in multiple forms—None, a single string, a list of strings, or a list of dictionaries with optional metadata—this function normalizes all cases into a consistent list of dictionaries with the keys “query” and “meta”. This standardization simplifies downstream processing by eliminating the need for repeated type checks or conditional handling of different query formats.
By providing a predictable structure, the function guarantees that modules like intent inference, alignment computation, and persuasive gap detection can operate seamlessly for single or multi-query scenarios.
Key Code Explanations
Handling single string input:
if isinstance(queries, str):
return [{“query”: queries.strip(), “meta”: {}}]
When the input is a single query string, it is wrapped into a list of a single dictionary with an empty metadata field. This ensures that even one-off queries are processed in the same structure as multiple queries.
Processing list of mixed strings and dictionaries:
for q in queries:
if isinstance(q, str):
out.append({“query”: q.strip(), “meta”: {}})
elif isinstance(q, dict):
qq = q.get(“query”) or q.get(“q”) or q.get(“text”) or “”
out.append({“query”: str(qq).strip(), “meta”: q.get(“meta”, {})})
else:
out.append({“query”: str(q).strip(), “meta”: {}})
- This block iterates through each element of a list, handling strings, dictionaries with varying key names, and other unexpected types robustly. It guarantees that all entries end up in the same dictionary format, with text normalized and metadata preserved where available.
Fallback for unexpected input types:
return [{“query”: str(queries).strip(), “meta”: {}}]
- If the input does not match any recognized type, it is coerced into a string and wrapped in the standard dictionary format. This ensures that the pipeline remains resilient to unusual inputs without breaking downstream logic.
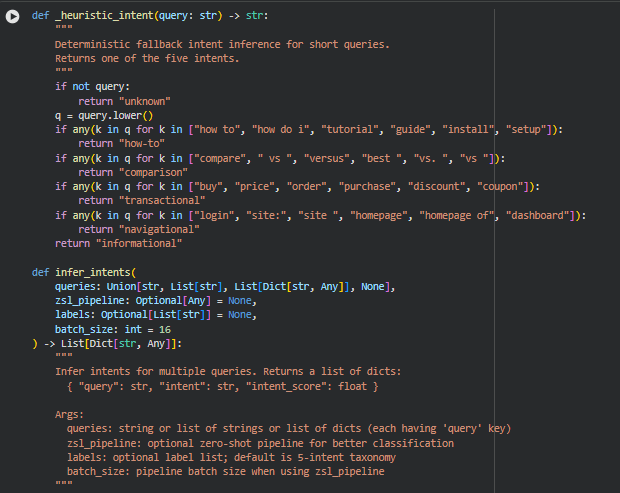

Function: _heuristic_intent
Summary
The _heuristic_intent function provides a deterministic fallback mechanism for inferring the intent of short queries without relying on machine learning models. It maps keywords and common patterns in the query string to one of five intent categories: how-to, comparison, transactional, navigational, or informational. This function ensures that even if no zero-shot classification pipeline is available, the system can still assign meaningful intent labels for downstream alignment and persuasive analysis.
It primarily focuses on simple lexical cues in queries, such as “how to” for procedural intent or “buy” for transactional intent. This approach is fast, reliable, and suitable for short or clearly worded queries.
Key Code Explanations
Keyword-based intent mapping:
if any(k in q for k in [“how to”, “how do i”, “tutorial”, “guide”, “install”, “setup”]):
return “how-to”
- This line checks if the query contains any phrases indicative of a procedural or instructional intent and assigns it to the how-to category. Similar blocks handle other intents like comparison, transactional, and navigational.
Function: infer_intents
Summary
The infer_intents function infers the search intent for multiple queries, supporting both single and multi-query scenarios. It integrates heuristic methods and optionally a zero-shot learning (ZSL) pipeline for more nuanced intent classification.
The function first standardizes query inputs using standardize_queries, ensuring consistent structure. If a ZSL pipeline is provided, it performs batched inference, returning both the predicted intent label and the associated confidence score. Otherwise, it falls back to _heuristic_intent for deterministic intent assignment with a perfect confidence score (1.0).
This approach allows the pipeline to handle a variety of input types robustly while supporting advanced ML-based intent detection when available.
Key Code Explanations
Handling absence of ZSL pipeline:
if zsl_pipeline is None:
logger.info(“No ZSL pipeline provided — using deterministic heuristics for intents.”)
return [{“query”: qd[“query”], “intent”: _heuristic_intent(qd[“query”]), “intent_score”: 1.0} for qd in queries_std]
- If no model is provided, this block assigns intents using the heuristic function, ensuring the pipeline remains operational without any ML dependency.
Batched ZSL inference:
raw_out = zsl_pipeline(qs, labels, multi_label=False, batch_size=batch_size)
- This line performs efficient batched inference on all standardized queries, with multi_label=False because each query can have only one primary intent. The result is then normalized and mapped into the standard output format.
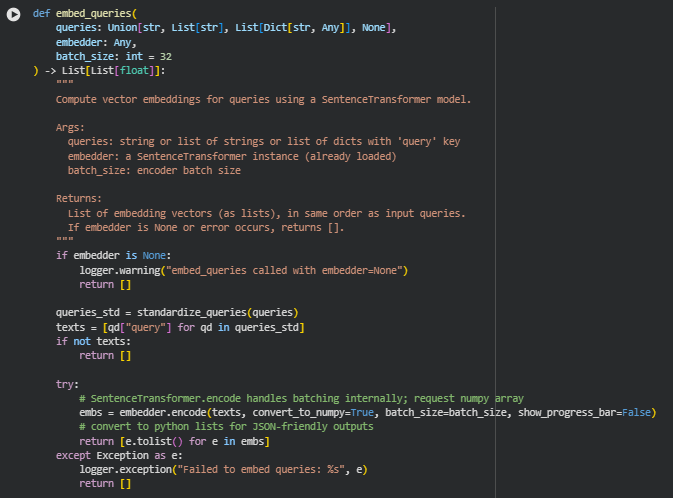
Function: embed_queries
Summary
The embed_queries function computes vector embeddings for search queries using a pre-loaded SentenceTransformer model. These embeddings represent each query in a high-dimensional semantic space, enabling similarity calculations with content chunks for intent alignment and persuasive analysis.
The function supports multiple query input formats — single strings, lists of strings, or lists of dictionaries with a query key — and automatically standardizes them for consistent processing. If the embedder is unavailable or an error occurs during embedding, the function returns an empty list, ensuring robustness and graceful failure handling.
Key Code Explanations
Standardizing queries for consistent input:
queries_std = standardize_queries(queries)
texts = [qd[“query”] for qd in queries_std]
- This ensures that all queries, regardless of input type, are converted into a consistent list of strings for embedding.
Batch encoding with SentenceTransformer:
embs = embedder.encode(texts, convert_to_numpy=True, batch_size=batch_size, show_progress_bar=False)
- This line leverages the SentenceTransformer’s built-in batching capabilities to efficiently compute embeddings for multiple queries in a single call. The embeddings are returned as a NumPy array for efficient downstream computations.
Conversion to JSON-friendly lists:
return [e.tolist() for e in embs]
- Embeddings are converted from NumPy arrays to Python lists to ensure compatibility with JSON serialization, which is essential for storing or transferring results in the pipeline output.
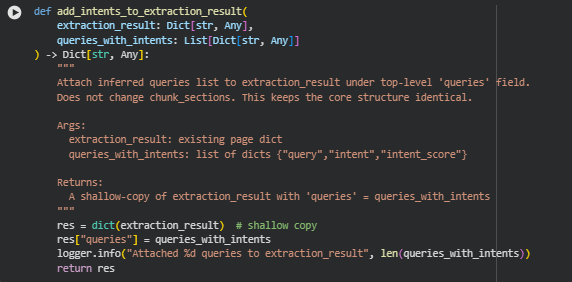

Function: add_intents_to_extraction_result
Summary
The add_intents_to_extraction_result function integrates inferred query intents into the existing page extraction result. Specifically, it adds a top-level “queries” field containing a list of dictionaries, where each dictionary includes a query, its inferred intent, and the associated confidence score.
This function does not modify the chunk_sections, preserving the original structure of content chunks. Its primary purpose is to enrich the extraction result with semantic intent information, enabling downstream alignment and persuasive analysis based on queries.
Key Code Explanations
Shallow copy to preserve original structure:
res = dict(extraction_result)
- Creating a shallow copy ensures the original extraction_result remains unmodified, avoiding unintended side effects while adding new information.
Attaching queries to the result:
res[“queries”] = queries_with_intents
- This straightforward assignment adds the structured list of queries with inferred intents to the page-level dictionary, making it available for subsequent computations such as intent alignment, persuasive scoring, and gap detection.

Function: compute_intent_embedding
Summary
The compute_intent_embedding function generates a vector representation of a query’s intent. The main idea is to capture both the semantic content of the query and its categorical intent label (e.g., “how-to”, “informational”). It achieves this by:
- Embedding the intent label as a short text.
- Embedding the raw query text.
- Averaging the two embeddings to produce a combined intent vector.
This embedding is used downstream for intent alignment scoring against content chunks, allowing the system to quantify how closely content matches the semantic purpose of the query.
Key Code Explanations
Check for valid embedder:
if embedder is None:
logger.warning(“compute_intent_embedding called with embedder=None”)
return None
- Ensures that a valid SentenceTransformer model is provided. If missing, the function logs a warning and safely returns None.
Embedding the intent label and query:
v1 = embedder.encode([intent_label], convert_to_numpy=True)[0]
v2 = embedder.encode([query], convert_to_numpy=True)[0]
- Here, the model encodes both the intent label and the query text separately, producing two high-dimensional vectors representing semantic meaning.
Averaging vectors for combined intent representation:
return (v1 + v2) / 2.0
- The average vector balances the general intent signal from the label with the specific semantic content of the query. This combined embedding is more robust for measuring alignment with content chunks.
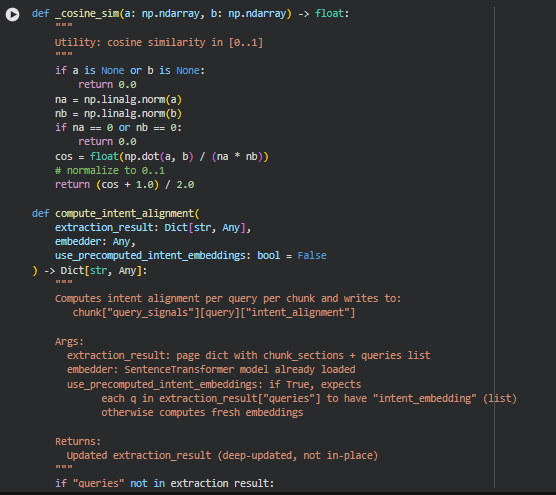

Function: _cosine_sim
Summary
The _cosine_sim function computes the cosine similarity between two vectors, normalized to the range [0, 1]. Cosine similarity measures the angle between two vectors, providing a metric of semantic similarity or alignment. This is used throughout the project to quantify how closely embeddings (from chunks or query intents) relate to each other.
Function: compute_intent_alignment
Summary
The compute_intent_alignment function calculates how closely each content chunk aligns with the semantic intent of each query. This is achieved using vector embeddings and cosine similarity. For every query in a page:
- A query intent embedding is generated or reused if precomputed.
- Each content chunk’s embedding is retrieved.
- The cosine similarity between the query intent embedding and the chunk embedding is computed, normalized to [0,1].
- The resulting score is stored under chunk[“query_signals”][query][“intent_alignment”].
This enables section-level analysis of content relevance, helping to identify which parts of a page are most aligned with user search intent.
Key Code Explanations
Preparing intent embeddings:
for qd in queries_info:
query_text = qd.get(“query”, “”)
intent_label = qd.get(“intent”, “informational”)
if use_precomputed_intent_embeddings and “intent_embedding” in qd:
intent_vectors[query_text] = np.array(qd[“intent_embedding”], dtype=float)
else:
intent_vectors[query_text] = compute_intent_embedding(query_text, intent_label, embedder)
- For each query, the function either reuses precomputed embeddings or computes a new intent vector. This allows flexibility depending on whether embeddings are cached or dynamically generated.
Iterating over chunks and computing alignment:
for chunk in chunks:
chunk_vec = np.array(chunk.get(“embedding”, []), dtype=float)
for qd in queries_info:
q = qd[“query”]
…
score = _cosine_sim(iv, chunk_vec)
chunk[“query_signals”][q][“intent_alignment”] = float(score)
- For every chunk, the function retrieves the chunk embedding and compares it with the query intent vector. The computed score is stored in the chunk under the query’s entry. This per-chunk, per-query scoring allows fine-grained analysis of content relevance at the section level.
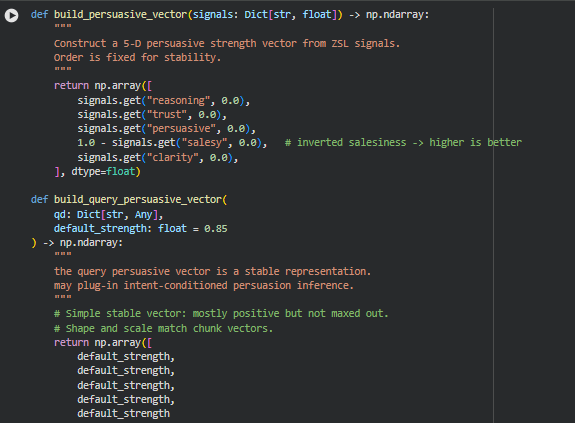

Function: build_persuasive_vector
Summary
The build_persuasive_vector function constructs a fixed 5-dimensional vector representing the persuasive strength of a chunk of text based on ZSL-derived signals. Each dimension corresponds to a key persuasive signal: reasoning, trust, persuasive framing, inverted salesiness, and clarity. The inversion of salesiness ensures that more informational content contributes positively to the persuasive vector.
Function: build_query_persuasive_vector
Summary
This function creates a stable, default persuasive vector for queries, mostly positive but not maximized. This ensures the query vector is in the same space as chunk vectors, facilitating meaningful alignment calculations. This vector could later be extended to incorporate intent-conditioned persuasion adjustments.
Function: compute_persuasive_strength_and_alignment
Summary
This function performs the full persuasive strength and alignment analysis:
- For each chunk, builds a persuasive vector using ZSL signals.
- For each query, builds a default persuasive vector.
- Computes cosine similarity between each query vector and every chunk vector, representing persuasive alignment.
These vectors and alignment scores are stored back into extraction_result for downstream analysis and visualization.
Key Code Explanations
chunk_vec = build_persuasive_vector(sig)
chunk[“persuasive_vector”] = chunk_vec.tolist()
- Converts ZSL signals into a numeric vector representing chunk-level persuasion. Stored in JSON-friendly format.
q_vec = np.array(qd[“persuasive_vector”], dtype=float)
alignment = _cosine_sim(q_vec, chunk_vec)
chunk[“query_signals”][query_text][“persuasive_alignment”] = float(alignment)
- Computes the cosine similarity between the query’s persuasive vector and each chunk’s vector.
- Alignment value quantifies how well a chunk’s persuasive strength matches the assumed query intent.
This method provides a consistent metric to assess section-level content effectiveness relative to specific queries.
Function Overviews
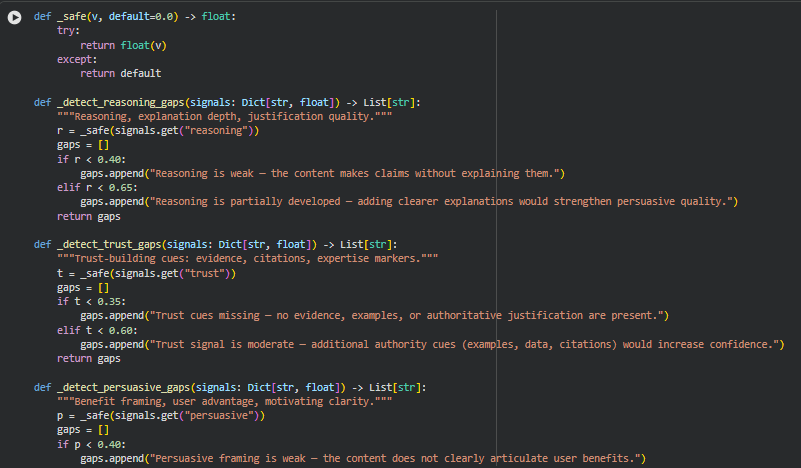
- _safe(v, default=0.0)
Ensures numerical signals are safely converted to float; avoids exceptions from None or invalid values.
- _detect_reasoning_gaps(signals)
Evaluates whether content provides adequate explanations or logical reasoning.
- Weak reasoning (<0.4) generates messages about missing justification.
- Moderate reasoning (<0.65) suggests improving explanations.
- _detect_trust_gaps(signals)
Detects trust-building gaps such as absence of citations, examples, or authoritative signals.
- Very low trust (<0.35) indicates missing credibility cues.
- Moderate trust (<0.6) suggests adding more authoritative references.
- _detect_persuasive_gaps(signals)
Focuses on benefit framing and clarity of user advantage.
- Low persuasive score (<0.4) signals lack of clear user benefits.
- Moderate score (<0.6) indicates improvement potential.
- _detect_salesy_gaps(signals)
Evaluates sales tone as potentially counterproductive to informational intent.
- High salesiness (>0.65) indicates overly promotional content.
- Slightly high (>0.5) suggests a mild promotional tone.
- _detect_clarity_gaps(signals)
Assesses readability and conciseness.
- Low clarity (<0.4) highlights complex or unclear sentences.
- Moderate clarity (<0.6) encourages simplification.
- _detect_alignment_gaps(intent_alignment, persuasive_alignment)
Measures how well a chunk aligns with the query’s intent and persuasive goals.
- Intent mismatch <0.4 signals off-topic content; 0.4–0.6 indicates partial relevance.
- Persuasive alignment <0.4 signals insufficient motivation; 0.4–0.6 indicates moderate alignment.
Function: Gap Detection Utilities
Summary
This set of utility functions systematically detects potential content gaps in a chunk based on ZSL-derived signals and alignment metrics. The goal is to highlight weaknesses in reasoning, trust, persuasive framing, sales tone, clarity, and alignment relative to user intent and query relevance. These functions operate at the chunk level and return human-readable guidance for improving content effectiveness.
Each function accepts the relevant score(s) and applies threshold-based rules to classify the signal strength as weak, moderate, or sufficient. If a weakness is detected, a descriptive message is returned in a list of gaps.
Key Code Explanations
if r < 0.40:
gaps.append(“Reasoning is weak — the content makes claims without explaining them.”)
elif r < 0.65:
gaps.append(“Reasoning is partially developed — adding clearer explanations would strengthen persuasive quality.”)
- Example of threshold-based gap detection.
- Dynamically converts a continuous ZSL score into actionable, descriptive guidance for content improvement.
if persuasive_alignment < 0.40:
gaps.append(“Persuasive alignment is low — section does not address user motivations or decision factors.”)
- Combines chunk-level persuasive vector with query-level vector to quantify alignment.
- Generates human-readable insights guiding section-level optimization.
These functions form the core interpretability layer of the project, providing clear signals on why certain sections may be underperforming in terms of intent satisfaction and persuasive strength.

Function: compute_persuasive_gaps
Summary
This function performs chunk-level gap analysis by combining ZSL signals and alignment scores to detect weaknesses in content with respect to persuasiveness, clarity, trust, reasoning, and query intent alignment. It populates each chunk with actionable, query-specific gap messages for content improvement.
Compute gaps
gaps += _detect_reasoning_gaps(sig)
gaps += _detect_trust_gaps(sig)
gaps += _detect_persuasive_gaps(sig)
gaps += _detect_salesy_gaps(sig)
gaps += _detect_clarity_gaps(sig)
gaps += _detect_alignment_gaps(intent_align, pers_align)
- Calls previously defined gap-detection functions.
- Collects descriptive messages highlighting weaknesses in the chunk relative to query intent and content quality.
Deduplicate and preserve order
seen = set()
final_gaps = []
for g in gaps:
if g not in seen:
final_gaps.append(g)
seen.add(g)
- Ensures each gap message appears only once per chunk per query.
Assign final gaps
qsig[“persuasive_gaps”] = final_gaps
Function: display_results
Summary
The display_results function provides a clean, user-readable summary of multi-URL, multi-query persuasive content analysis results. It organizes the output in a structured, human-friendly format, highlighting key metrics and actionable insights for each page.
Result Analysis and Explanation
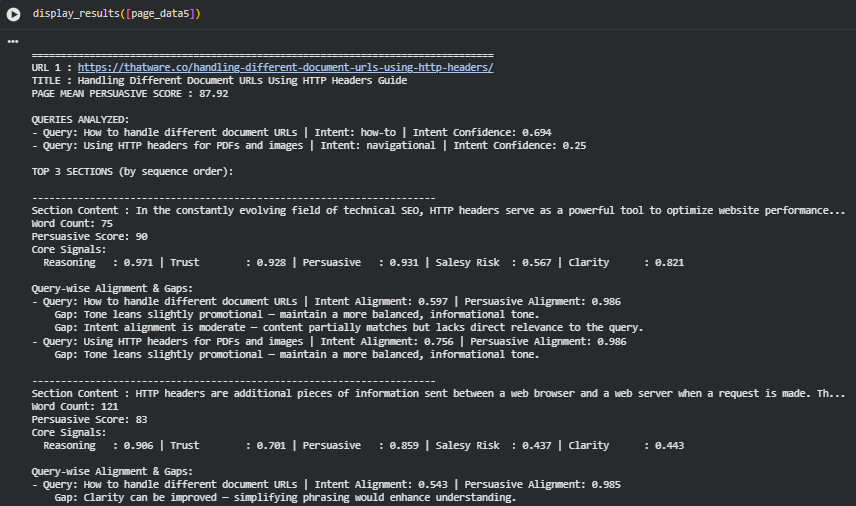
1. Overall Page Persuasiveness
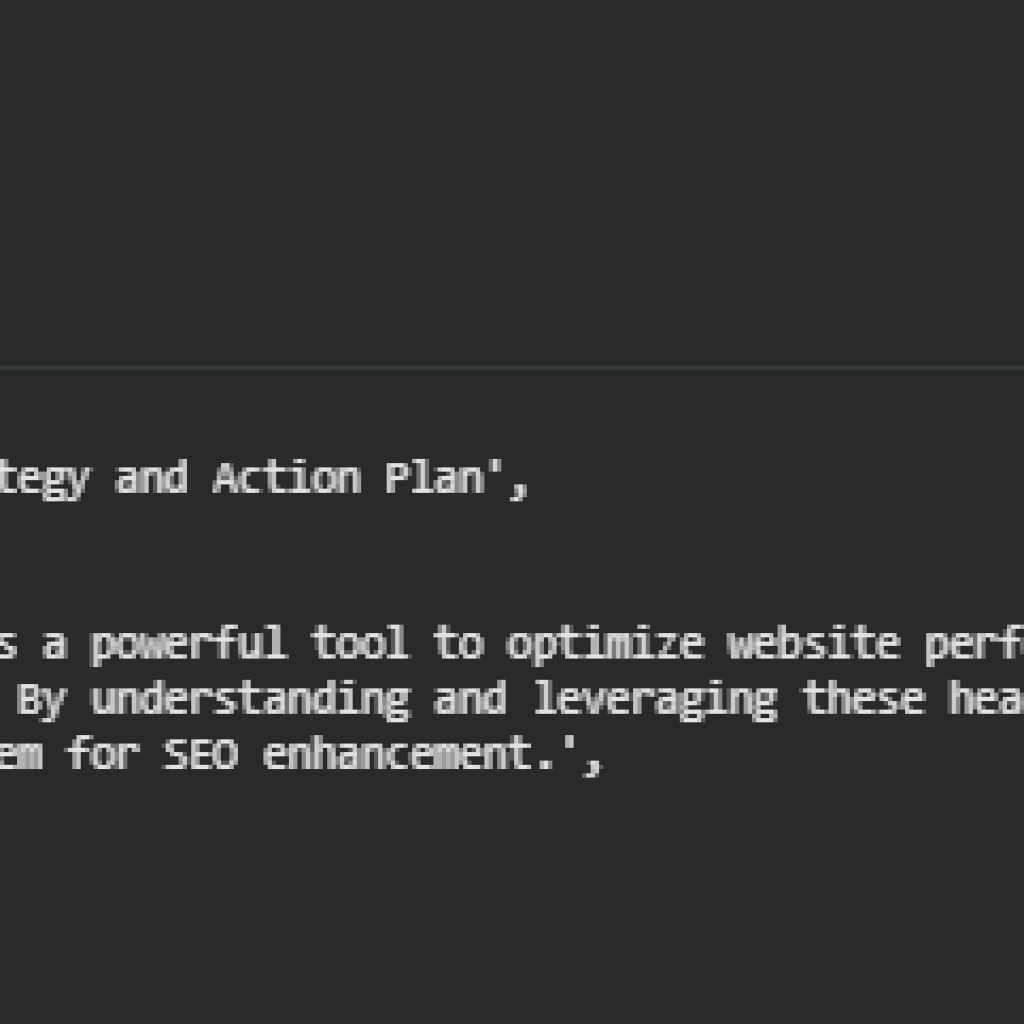
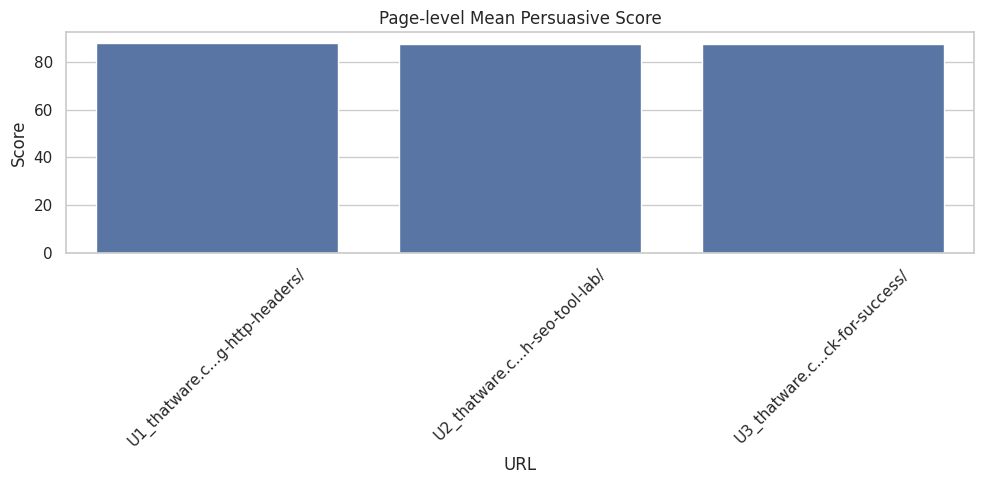
The analyzed page, “Handling Different Document URLs Using HTTP Headers Guide”, demonstrates a high overall persuasive effectiveness, with a Page Mean Persuasive Score of 87.92 out of 100.
This high score indicates that the page content effectively communicates benefits, demonstrates reasoning and trustworthiness, and is generally clear and readable. From a content strategy perspective, this suggests the page is well-positioned to satisfy reader intent, particularly for technical SEO-focused queries.
2. Query Analysis
Two queries were evaluated against the page:
1. Query: How to handle different document URLs
- Intent: how-to
- Confidence: 0.694
2. Query: Using HTTP headers for PDFs and images
- Intent: navigational
- Confidence: 0.25
Interpretation:
- The first query shows moderate confidence, indicating the content somewhat matches the instructional intent.
- The second query’s low intent confidence reflects that the query is more specific (navigational) than the page’s general technical guidance, which may lead to partial alignment in certain sections.
3. Section-wise Analysis
The top three content sections (by sequence) were analyzed for persuasive effectiveness, reasoning, trust, clarity, and alignment with the queries.
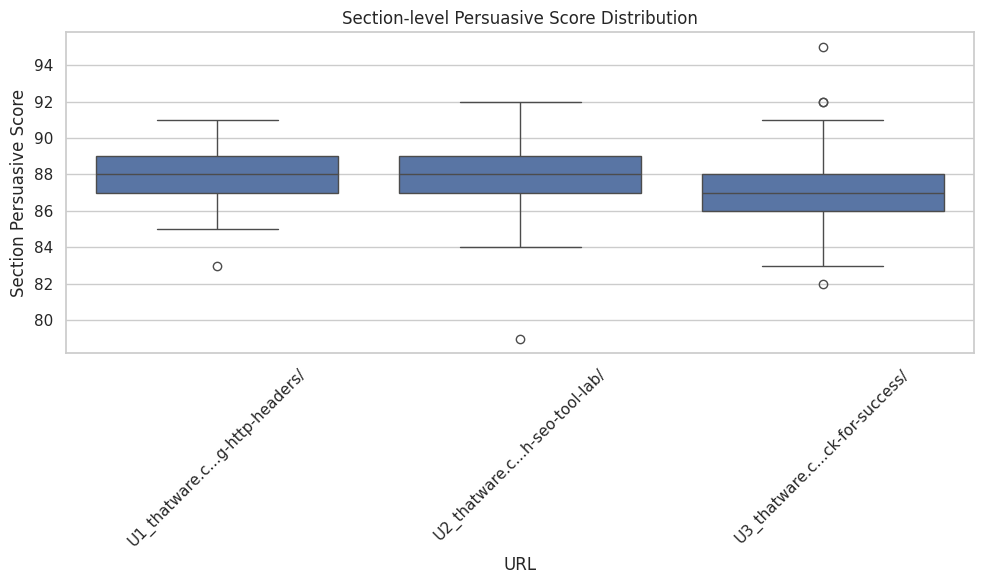
Section 1
Content snippet: “In the constantly evolving field of technical SEO, HTTP headers serve as a powerful tool to optimize website performance…”
· Word Count: 75
· Persuasive Score: 90 (very strong)
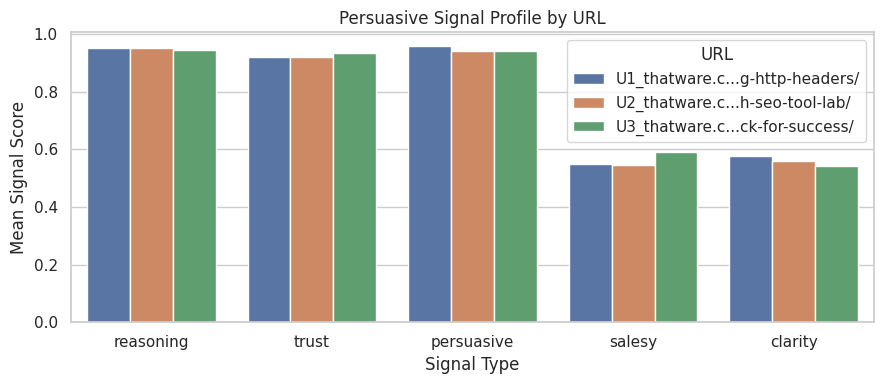
· Core Signals:
- Reasoning: 0.971 – Excellent logical explanation of the topic
- Trust: 0.928 – High reliability, likely due to factual statements and examples
- Persuasive: 0.931 – Strong framing of benefits for readers
- Salesy Risk: 0.567 – Slightly promotional, minor reduction in informational neutrality
- Clarity: 0.821 – Very readable
Query Alignment & Gaps:
· How-to query: Intent alignment 0.597, persuasive alignment 0.986
- Gap: Tone leans slightly promotional
- Gap: Moderate intent alignment – partially matches but not fully
· Navigational query: Intent alignment 0.756, persuasive alignment 0.986
- Gap: Tone leans slightly promotional
Interpretation: This section is highly persuasive and clear, but the minor promotional tone could be adjusted for a more neutral informational style. It aligns better with the navigational query than the how-to query, suggesting some content generalization.
Section 2
Content snippet: “HTTP headers are additional pieces of information sent between a web browser and a web server when a request is made…”
· Word Count: 121
· Persuasive Score: 83 (strong)
· Core Signals:
- Reasoning: 0.906 – Well-explained technical details
- Trust: 0.701 – Moderate credibility, likely informative but could include more examples or citations
- Persuasive: 0.859 – Good benefits framing
- Salesy Risk: 0.437 – Minimal promotional tone
- Clarity: 0.443 – Moderate clarity, could be simplified
Query Alignment & Gaps:
· How-to query: Intent alignment 0.543, persuasive alignment 0.985
- Gap: Clarity can be improved
- Gap: Moderate intent alignment
· Navigational query: Intent alignment 0.709, persuasive alignment 0.985
- Gap: Clarity can be improved
Interpretation: This section provides solid reasoning and persuasiveness but slightly lower clarity affects reader comprehension. Simplifying sentence structure would increase effectiveness for both query types.
Section 3
Content snippet: “Every time a user loads a webpage, their browser sends a request to the website’s server, which responds with relevant data…”
· Word Count: 135
· Persuasive Score: 87 (strong)
· Core Signals:
- Reasoning: 0.927 – High explanatory quality
- Trust: 0.822 – Well-supported factual content
- Persuasive: 0.917 – Strong benefit framing
- Salesy Risk: 0.531 – Slightly promotional tone
- Clarity: 0.662 – Clear, but minor readability improvements possible
Query Alignment & Gaps:
· How-to query: Intent alignment 0.582, persuasive alignment 0.987
- Gap: Tone leans slightly promotional
- Gap: Moderate intent alignment
· Navigational query: Intent alignment 0.671, persuasive alignment 0.987
- Gap: Tone leans slightly promotional
Interpretation: Section 3 balances strong reasoning and persuasiveness with slightly higher word count. Minor promotional tone remains the only adjustment needed to align fully with the informational expectation of users.
4. Observed Patterns Across Sections
1. Persuasive Strength
- All three sections score above 80 in persuasive score, indicating a consistently strong persuasive presence.
- Highest scores are observed where reasoning and trust are strongest, showing a direct correlation between factual clarity and persuasive impact.
2. Query Alignment Trends
- How-to query has moderate alignment (0.54–0.59), reflecting the page’s broad technical guidance versus specific query intent.
- Navigational query has better alignment (0.67–0.75), indicating users looking for procedural or reference information can find relevant content.
3. Gaps Analysis
- Tone: Slightly promotional across all sections (Salesy Risk ~0.5–0.57)
- Clarity: Moderate improvement needed for Section 2 (Clarity 0.443)
- Intent Matching: Moderate gaps for the how-to query, suggesting content could explicitly address step-by-step procedures.
5. Actionable Insights
- Tone Adjustment: Reduce minor promotional phrasing to improve neutrality and match informational intent.
- Clarity Enhancement: Simplify complex sentences, especially in Section 2, for better comprehension.
- Query-targeted Optimization: For how-to intent, consider adding explicit step-by-step instructions or procedural examples to improve alignment.
- Content Strengths: Reasoning and trust signals are already very strong; this content is already authoritative and persuasive for its audience.
6. Summary
Overall, the page demonstrates excellent persuasive effectiveness, high reasoning and trust, and strong alignment with primary user intent, particularly for navigational/technical SEO queries. Minor adjustments in tone and clarity could further optimize the page, especially for instructional queries. This analysis provides a clear roadmap for content refinement, balancing authority, clarity, and persuasive appeal.

Result Analysis and Explanation
1. Page-Level Persuasive Strength
At the page level, the overall persuasive strength provides a high-level view of how effectively each page communicates and motivates user action or engagement. The mean persuasive score aggregates the contribution of all sections on the page, reflecting the balance of reasoning, trust, clarity, and persuasive framing.
Interpretation of Scores:
- High (≥0.85): Pages demonstrate strong persuasive appeal, combining clear reasoning, trustworthy evidence, and compelling messaging. These pages are generally effective in achieving user engagement and satisfaction.
- Medium (0.6–0.85): Pages show adequate persuasive strength but may benefit from refinement in clarity, tone, or evidence. There could be sections where reasoning or trust cues are moderate.
- Low (<0.6): Pages are weak in persuasive impact. Such content may be unclear, lack supporting evidence, or fail to communicate benefits effectively, requiring significant improvement.
Actionable Insights:
- Pages with high scores should maintain their approach but monitor any sections that deviate.
- Medium-scoring pages should focus on improving reasoning and trust cues, and ensure content aligns more closely with user intent.
- Low-scoring pages require structural content revisions, enhanced evidence, and clearer benefit framing to improve overall impact.
2. Section-Level Persuasive Analysis
Analyzing content at the section level provides insights into how individual sections contribute to the overall page performance. Each section is assessed on reasoning, trust, persuasive strength, clarity, and potential salesiness.
Interpretation of Scores:
· Reasoning reflects the depth of explanations and justifications within the content. High reasoning scores indicate well-supported claims and logical flow, which strengthen the credibility of the content.
High values (>0.85) indicate that sections thoroughly explain concepts, provide justifications, and demonstrate logical flow. Values between 0.6–0.85 suggest partial reasoning with room for elaboration, and low scores (<0.6) highlight weak or missing explanations.
· Trust evaluates authority cues, such as examples, data references, or citations. High trust scores enhance the user’s confidence in the information provided.
Strong trust signals (>0.85) show that the content uses authoritative sources, examples, or citations. Moderate trust (0.6–0.85) may need additional references, while low trust (<0.6) signals that evidence or credibility is lacking.
· Persuasive Strength measures the extent to which content highlights user benefits and motivates action. Effective persuasive framing contributes to higher engagement and conversion potential.
High scores reflect compelling framing of benefits and clear value propositions. Medium scores suggest that benefits are partially conveyed, and low scores indicate insufficient persuasive appeal.
· Clarity assesses readability and ease of understanding. Low clarity scores indicate sections where simplification or reorganization could make content more accessible.
Scores >0.85 imply easily understandable content. Scores 0.6–0.85 show that minor simplification could improve readability. Scores <0.6 require significant restructuring for clarity.
· Salesiness captures overly promotional language; lower scores are desirable for content primarily meant to inform or educate. Moderate or high salesiness may require tone adjustments to maintain balance.
Since overly promotional tone can reduce perceived informational value, scores >0.65 indicate content may appear too sales-oriented. Moderate values (0.5–0.65) suggest a mild promotional tone, and low values (<0.5) reflect a neutral, informational tone.
Actionable Insights:
- High-scoring sections should continue using strong reasoning, evidence, and clarity, maintaining their persuasive impact.
- Sections with moderate reasoning, trust, or clarity should add concrete examples, data, or simplified explanations.
- Sections showing high salesiness should moderate promotional language to align with the intended informational intent.
3. Query-Level Intent Alignment
Query intent alignment assesses how well content satisfies user search queries. This analysis evaluates whether sections are relevant to user needs and how closely the content addresses specific queries.
Interpretation of Scores:
- High alignment (>0.75): Content is well-targeted to the query, directly addressing the user’s informational or navigational intent.
- Medium alignment (0.6–0.75): Content partially matches the query but may not fully address all aspects. Sections may require clarification or additional focus to improve relevance.
- Low alignment (<0.6): Sections are off-topic or insufficiently focused on the user query, risking user dissatisfaction or disengagement.
Actionable Insights:
- For high alignment sections, maintain focus on the query and consider reinforcing key points for stronger impact.
- For medium alignment, review content coverage to fill gaps and better match user intent.
- For low alignment, revise or restructure sections to ensure direct relevance to user queries.
4. Persuasive Gaps Detection
Persuasive gap analysis identifies specific weaknesses in sections based on reasoning, trust, benefit framing, clarity, and alignment with user intent. This is crucial for prioritizing content optimization.
Common Gap Interpretations:
- Reasoning Gaps: Low reasoning signals indicate unsupported claims or unclear explanations. Strengthening these sections with detailed justifications or examples can improve credibility.
- Trust Gaps: Low trust scores highlight missing citations or authoritative references. Adding evidence or expert endorsements can enhance confidence.
- Persuasive Gaps: Weak benefit framing reduces user motivation. Emphasizing outcomes, advantages, or practical applications strengthens content appeal.
- Salesiness Gaps: Overly promotional tone can reduce trust. Moderating calls-to-action and balancing information with persuasion improves user perception.
- Clarity Gaps: Low clarity may confuse readers. Simplifying phrasing, shortening sentences, and using structured formatting increases comprehension.
- Intent-Persuasive Alignment Gaps: Sections that poorly align with query intent or persuasive vectors require adjustments to ensure content relevance and motivating messaging.
Actionable Insights:
- Gap detection informs targeted content interventions, helping prioritize sections that require immediate enhancement for reasoning, trust, clarity, or intent alignment.
5. Visualization Module
Visualizations provide an intuitive overview of content performance across pages, sections, queries, and persuasive signals. These plots help identify patterns, trends, and opportunities for improvement.
5.1 Page-Level Persuasive Scores
What it shows: Bar charts display the average persuasive score for each page, providing a quick comparison across multiple URLs.
Interpretation: Pages with taller bars indicate higher overall persuasive effectiveness, while shorter bars signal pages that may require optimization.
Actionable Insights: Use this visualization to prioritize pages needing content refinement. Pages with lower scores should be analyzed for weak sections or low alignment with queries.
5.2 Section-Level Score Distribution
What it shows: Boxplots illustrate the distribution of persuasive scores for sections within each page, highlighting variability and outliers.
Interpretation: Wide boxes or significant outliers indicate inconsistent section performance. Consistently high boxes suggest uniform persuasive quality.
Actionable Insights: Focus on low-scoring sections for targeted improvements in reasoning, trust, or clarity. Aim to reduce variability to ensure uniform content quality.
5.3 Query × URL Intent Alignment Heatmap
What it shows: A heatmap represents the alignment of queries against multiple URLs, making it easy to identify which pages satisfy specific user intents.
Interpretation: Darker or higher-value cells indicate strong alignment between content and query intent. Lighter or low-value cells highlight gaps in addressing user needs.
Actionable Insights: Target sections or pages where alignment is low. Enhancing content relevance will improve user satisfaction and search effectiveness.
5.4 Persuasive Signal Profile
What it shows: Bar charts compare core persuasive signals — reasoning, trust, clarity, persuasive strength, and salesiness — across pages.
Interpretation: High values in reasoning, trust, and clarity indicate robust content quality. Elevated salesiness signals may require moderation.
Actionable Insights: Use this visualization to detect systemic weaknesses in persuasive signals. Prioritize interventions such as adding evidence, refining clarity, and adjusting tone to maximize overall content effectiveness.
6. Summary
The analysis provides a comprehensive view of content performance across multiple dimensions. Page-level scores indicate overall persuasive impact, while section-level metrics highlight strengths and weaknesses in reasoning, trust, clarity, and alignment with user intent. Query-level alignment identifies whether content meets user expectations, and persuasive gap detection guides targeted content improvements. Visualization tools complement this analysis, offering a quick, intuitive assessment of performance and areas requiring attention.
By leveraging these insights, clients can systematically enhance content quality, improve relevance to user queries, and strengthen persuasive impact, ultimately leading to better engagement and outcomes.
Q&A: Project Result Understanding and Action Suggestions
What does the page-level persuasive score indicate, and how should we use it?
The page-level persuasive score represents the aggregated effectiveness of a page in communicating, convincing, and engaging users. It reflects how well the sections on a page combine reasoning, trustworthiness, clarity, and persuasive framing.
- High scores (≥0.85) indicate that the page is generally strong in presenting clear, credible, and motivating content. Such pages are likely to meet user expectations and enhance engagement.
- Medium scores (0.6–0.85) show that the page performs reasonably well but may have sections that need refinement.
- Low scores (<0.6) signal pages that may not effectively communicate or persuade users, requiring review of content structure, reasoning, or clarity.
Action Suggestions: Focus first on pages with lower scores for content improvement, ensuring reasoning is supported, evidence is presented, clarity is enhanced, and tone matches the user’s intent. Pages with high scores should be monitored for consistency across new updates.
How should we interpret section-level persuasive signals?
Section-level signals break down the elements contributing to persuasive strength. The key signals include:
- Reasoning: Measures logical flow and depth of explanation. Low values indicate unsupported claims.
- Trust: Evaluates credibility through citations, examples, or authoritative content. Weak trust signals may reduce user confidence.
- Persuasive Strength: Reflects how well the content motivates or convinces the user. Low values imply weak benefit framing.
- Clarity: Assesses readability and ease of understanding. Low clarity can confuse users.
- Salesiness: Indicates overly promotional tone. High salesiness can reduce perceived value in informational content.
Action Suggestions: Identify sections with low reasoning, trust, or clarity scores for targeted content updates. Adjust overly promotional language to balance informational and persuasive elements. Strengthening weak sections can significantly enhance overall page performance.
What is query intent alignment, and why is it important?
Query intent alignment measures how well the content matches the user’s search intent. It ensures that each section is contextually relevant and addresses what the user is looking for, whether informational, navigational, or comparative.
- High alignment (>0.75): Content fully satisfies the query and provides relevant, actionable insights.
- Medium alignment (0.6–0.75): Content partially meets the query; some gaps may exist in coverage or specificity.
- Low alignment (<0.6): Content is off-topic or fails to meet the user’s intent.
Action Suggestions: Focus on medium and low alignment sections to increase relevance by refining content focus, adding missing details, or restructuring information to directly address user queries. High alignment content should be maintained and potentially highlighted for SEO or engagement purposes.
How do persuasive gaps guide content improvements?
Persuasive gaps identify areas where content falls short in reasoning, trust, clarity, benefit framing, or alignment with user intent. These gaps are actionable insights for content optimization.
- Reasoning gaps: Indicate claims that require explanation or examples.
- Trust gaps: Highlight sections needing citations, authoritative references, or supporting evidence.
- Persuasive gaps: Show where the user benefits or outcomes are not clearly articulated.
- Clarity gaps: Identify content that is complex or difficult to read.
- Intent and persuasive alignment gaps: Reveal sections that do not effectively combine relevance and motivation.
Action Suggestions: Prioritize sections with multiple gaps for revision. Enhance reasoning with examples, add evidence to build trust, simplify content for clarity, and emphasize benefits or user outcomes. These updates will directly improve user engagement and perceived credibility.
How can visualizations be used to interpret results effectively?
Visualizations provide a practical, at-a-glance understanding of content performance across pages, sections, and queries:
- Page-level persuasive scores (bar charts): Quickly identify high- and low-performing pages.
- Section-level score distribution (boxplots): Reveal variability across sections, highlighting weak spots or inconsistencies.
- Query × URL intent alignment heatmap: Shows which pages are most relevant for each query, guiding content focus.
- Persuasive signal profile (bar charts): Compare reasoning, trust, clarity, and salesiness across pages to identify systemic strengths and weaknesses.
Action Suggestions: Use these visualizations to prioritize interventions. Low-performing pages or sections, inconsistent scores, or weak signals should be addressed first. Visualizations also help in monitoring improvements over time after content updates.
How can these insights improve user engagement and SEO outcomes?
By analyzing persuasive strength, query alignment, and gap detection, clients can:
- Enhance content relevance: Ensuring sections directly address user queries increases time on page and reduces bounce rates.
- Increase trust and authority: Strengthening evidence, citations, and reasoning improves perceived expertise and credibility.
- Boost persuasive appeal: Clear benefit framing and balanced tone motivates user actions, improving conversions or engagement.
- Optimize readability and clarity: Simplifying complex content enhances comprehension and accessibility, increasing overall user satisfaction.
Action Suggestions: Implement targeted content updates based on score insights and gap analysis. Continuous monitoring using visualization and metrics will allow measurement of improvement in user engagement, query satisfaction, and overall SEO performance.
Final Thoughts
The analysis conducted through the Query–Content Persuasive Alignment Analyzer provides a comprehensive understanding of how content performs in satisfying user intent and delivering persuasive impact at the section level. By combining multi-signal assessment—including reasoning, trust, clarity, and persuasive framing—with query-specific intent alignment, the framework enables a nuanced evaluation of content effectiveness.
The results highlight the overall persuasive strength of each page, identifying which sections excel in engaging and motivating users, and which areas offer opportunities to refine clarity, evidence, or benefit communication. The section-level breakdown allows clients to pinpoint specific content blocks that contribute most to user satisfaction and those that may benefit from reinforcement, ensuring a targeted and efficient approach to content optimization.
By systematically measuring query alignment and persuasive quality, the project provides actionable insights into how well each section addresses user needs while maintaining a compelling narrative. The integration of gap detection ensures that content is not only relevant but also persuasive and clear, enhancing the likelihood of positive user response.
Overall, the project delivers a robust, data-driven view of content performance, offering clients a detailed understanding of intent satisfaction, persuasive strength, and content-level alignment. This enables informed decision-making for content enhancement, strategic prioritization, and maximizing the impact of existing assets.
