SUPERCHARGE YOUR Online VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project aims to help website owners organize, optimize, and enhance their web content to make it more search engine friendly and user-focused. Using Latent Semantic Indexing (LSI), the project aims to identify the main topics or themes in a website’s content and improve its visibility and relevance on search engines like Google. Here’s a breakdown of what that means in simple terms.

What is Latent Semantic Indexing (LSI)?
Latent Semantic Indexing (LSI) is a technique for analyzing and understanding relationships between words in a body of text. In this case, we’re using it to examine the words and topics on a website and then group them into specific themes or topics. Think of it as having a tool that can read through all the web pages on a site and then summarize the main ideas, grouping similar content together.
Why is LSI Important for SEO?
Search engines like Google don’t just look for individual keywords on a page—they want to understand what the page is truly about. By understanding the broader topics and related words on each page (rather than isolated keywords), the search engine can show the website to users searching for relevant information. In other words, LSI helps make the content more relevant and understandable, which can improve search engine rankings, making it easier for people to find the website.
How the Project Works
The project uses the following steps to achieve content and SEO optimization for a website:
1. Content Collection: The project gathers text from each website page. This means it goes to each URL (webpage) and collects the words that appear on the page, especially focusing on meaningful content rather than random or filler words.
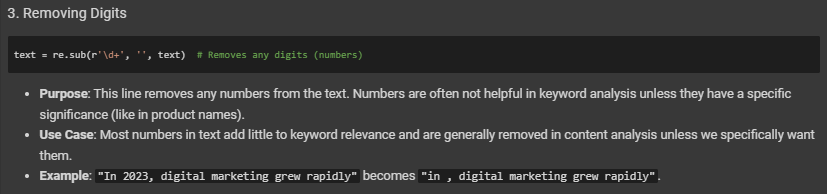
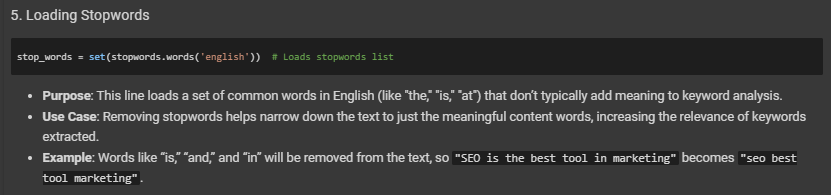
2. Text Processing and Cleaning: Before analyzing, the project cleans the text to remove any unnecessary words (like “and” or “the”) and characters (like punctuation or numbers). This helps focus only on the words that matter for identifying themes.
3. Grouping by Themes (Components): Using LSI, the project organizes the content into themes or components. Each component represents a main topic found across the website. For example, if the website has pages about “SEO services,” “app development,” and “digital marketing,” each of these topics might become a separate component.
4. Assigning Keywords and URLs to Each Theme:
- Keywords: Each component is given a set of keywords that best describe it. These keywords are the most relevant words that represent that specific topic. For example, the “SEO services” theme might have keywords like “digital marketing,” “SEO strategy,” and “search engine.”
- URLs: Each theme also lists the URLs of the pages that match that topic. This way, the website owner knows which pages discuss which themes.
5. Output Generation: Finally, the project creates an output that shows the themes, their keywords, and the URLs that match each theme. This output is structured to be easy for a website owner to read and use.
What the Output Shows
The project output is a list of themes (components) with their relevant keywords and associated URLs. Here’s what each part of the output means:
- Component: This is the main topic or theme, such as “SEO services” or “software development.” Each component represents a topic that the website covers in its content.
- Keywords: These are important words related to that theme. They help define what the theme is about.
- Related URLs: These pages on the website match the theme and keywords of that component. It shows where each topic is covered on the website.
Why This is Useful for a Website Owner
The LSI-Powered Content and SEO Optimization project provides website owners a clear view of their content structure. Here’s why this is beneficial:
- Content Organization: The website owner can see which main topics the website covers, helping them understand the structure and focus areas of the site.
- SEO Improvement: By focusing on relevant keywords for each topic, the website owner can ensure the pages are optimized for search engines. This increases the chances of the pages ranking higher in search results.
- Content Gaps Identification: The project output may show areas where certain topics have fewer pages. This information can guide the website owner to create more content in those areas if needed.
- User-Friendly Content: When themes organize content, it’s easier for users to navigate and find relevant information. For example, users looking for “app development” can easily find pages specifically about that.
- Targeted SEO Strategy: The output helps the website owner target specific keywords on each page, making SEO efforts more focused and effective.
What is Latent Semantic Indexing (LSI)?
Latent Semantic Indexing (LSI) is a technique used in search engines to understand the relationships between words in a piece of content. Instead of just matching exact keywords, LSI identifies related terms and concepts that help search engines figure out the broader context of the content. For example, if a webpage is about “cars,” LSI might also understand that words like “vehicles,” “automobiles,” and “engine” are related.
Use Cases of LSI Optimization:
- Improving Search Engine Optimization (SEO): LSI helps make content more relevant for search engines by incorporating semantically related keywords. This increases the chance of ranking higher in search results.
- Content Relevance: It helps search engines understand your content’s context, ensuring users are directed to the right pages.
- Topic Discovery: LSI can identify and suggest related topics for content creation, helping websites cover a subject more thoroughly.
Real-life Implementation of LSI:
- Google Search: Although Google no longer directly uses LSI, it still uses similar techniques (like machine learning) to understand content beyond just keywords. This improves results by understanding the meaning behind a user’s search.
- Website SEO Optimization: LSI is useful for website owners to ensure that all relevant terms connected to the main topic are used, making content more likely to appear in related searches.
How LSI Optimization Helps Websites:
For a website, LSI optimization means using related keywords throughout the content to ensure search engines understand the page’s topic better. This makes it easier for the site to appear in more relevant search results. For instance, if your client’s website sells sports shoes, using LSI will ensure that terms like “athletic footwear,” “running shoes,” and “sneakers” are part of the content to signal relevance to search engines.
Data Requirements for LSI Optimization:
The LSI algorithm analyzes large amounts of text data and finds patterns between terms. To optimize LSI for a website:
- Webpage URLs: If you’re optimizing an existing website, you would need the URLs of all the pages that contain content. The LSI model will crawl these pages, process the text content, and identify related terms.
- CSV Data: If the content is not directly available through URLs, you can collect it in a CSV (Comma-Separated Values) format, which might include columns like “Page Title,” “Main Content,” “Keywords,” etc. The LSI model will then analyze this data to find patterns and recommend related keywords.
How LSI Works in Practice:
- Preprocessing Text: The content (either from URLs or a CSV file) is analyzed, and unnecessary words (like “and,” “the,” “of”) are removed.
- Term-Document Matrix: The algorithm then creates a matrix of all the words and how often they appear across different documents (web pages).
- Singular Value Decomposition (SVD): This step reduces the data to identify patterns between terms, finding which words are most related.
- Output: The output is a list of related keywords or topics that should be included in your content to improve relevance.

1. Import Necessary Libraries
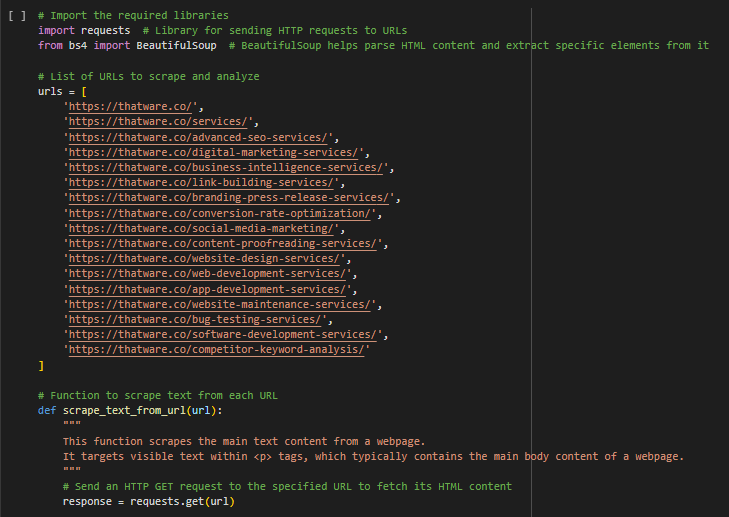
Explanation Of Each Step:
Explanation:
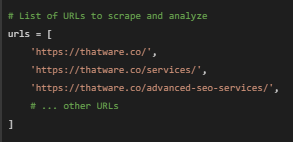
This list of URLs includes all the webpage links from which we want to extract text. Each URL links to a page with specific content.
· Use Case: By creating a list of URLs, we can easily loop through each webpage link one at a time. This is useful if we extract similar information (like main text) from multiple pages.
· Example: If a website owner wants to gather text from all major service pages for keyword analysis, listing each URL in this format makes it easy to collect data from all pages.
Explanation:
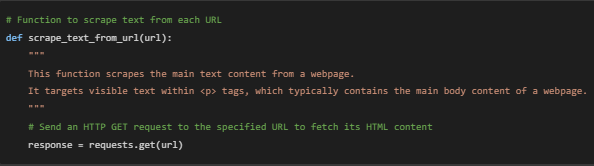
1. Defining the Function: scrape_text_from_url(url) is a custom function we created to simplify extracting text from each webpage.
- Use Case: Instead of writing the same code multiple times, we define this function once and can call it for each URL. This saves time and keeps our code organized.
2. Sending an HTTP Request: response = requests.get(url)
- This line sends an HTTP request to the given url, asking the server to return the HTML content of that page.
- Example: When the code encounters https://thatware.co/, it sends a request to that URL, and the server responds with the full HTML code of that page.

Explanation:
1. Parsing HTML Content: soup = BeautifulSoup(response.text, ‘html.parser’)
- This line takes the HTML content from the response and breaks it down for easy analysis. The html.parser argument tells BeautifulSoup to interpret the content as HTML.
2. Use Case: Parsing with BeautifulSoup makes it easy to find and extract specific HTML tags, like <p> for paragraphs, <a> for links, etc.
3. Example: Suppose the webpage contains several sections, but you only want the main body text within <p> tags. Parsing with BeautifulSoup allows us to select only the paragraph tags and ignore other parts, like navigation menus or footers.
Explanation:
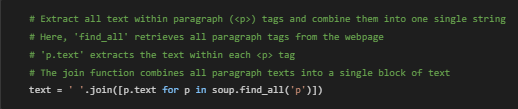
1. Finding Paragraph Tags: soup.find_all(‘p’)
- This function finds all <p> tags on the page, which usually contain the article’s or webpage’s main content.
2. Extracting Text: [p.text for p in soup.find_all(‘p’)]
- This code extracts the text inside each <p> tag, ignoring the HTML itself.
3. Combining Text: ‘ ‘.join([…])
- We use ‘ ‘.join(…) to combine all the paragraphs into one large block of text, separated by spaces. This makes it easier to read and analyze as a single piece of text.
4. Use Case: This process helps collect the main written content from each page without other code elements. It’s particularly useful for gathering content for keyword analysis or summarizing the main points.
5. Example: If a page has three paragraphs, like “Welcome to our services page,” “We offer advanced SEO,” and “Contact us for more information,” this line would combine them into: “Welcome to our services page We offer advanced SEO Contact us for more information”

Explanation:
This line returns the combined paragraph text from the webpage. When the function is called, it outputs the text content of the URL that was provided as input.
- Use Case: Returning the content lets us store, display, or analyze it later in our main code.
- Example: If you call scrape_text_from_url(‘https://thatware.co/’), this line will return all the main text content of that URL.

Explanation:
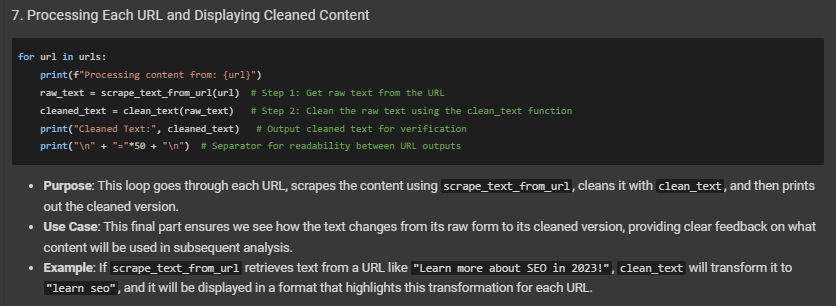
1. Looping Through URLs: for url in urls:
- This loop goes through each URL in our list, one by one, calling the scrape_text_from_url function for each one.
2. Printing Each URL’s Content:
- print(f”Content from {url}:”) prints a label showing which URL’s content is being displayed.
- print(scrape_text_from_url(url)) calls our function to retrieve the text for each URL and prints it.
3. Adding Separators: print(“\n” + “=”*50 + “\n”)
- This line adds a line of equal signs to visually separate each page’s output, making reading multiple outputs in sequence easier.
4. Use Case: This loop allows us to display the content from each URL in a structured way, helping the user verify and understand what text data has been extracted from each page.
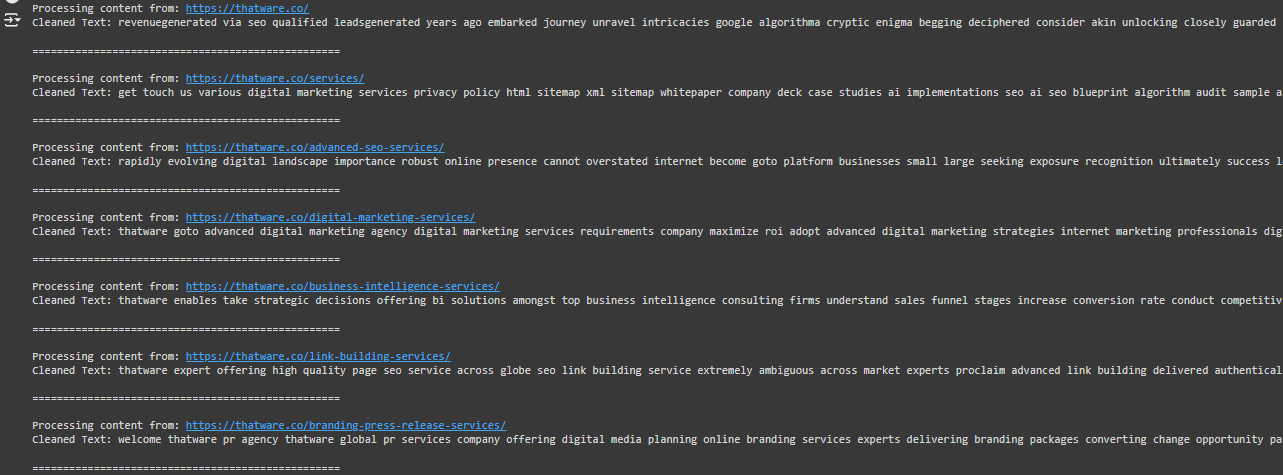
Example of Expected Output:
The output will look like this, showing the main content from each URL in a clear format:

Here’s a detailed breakdown of each part of this code, including the purpose and examples for each step:
Code Walkthrough and Explanation
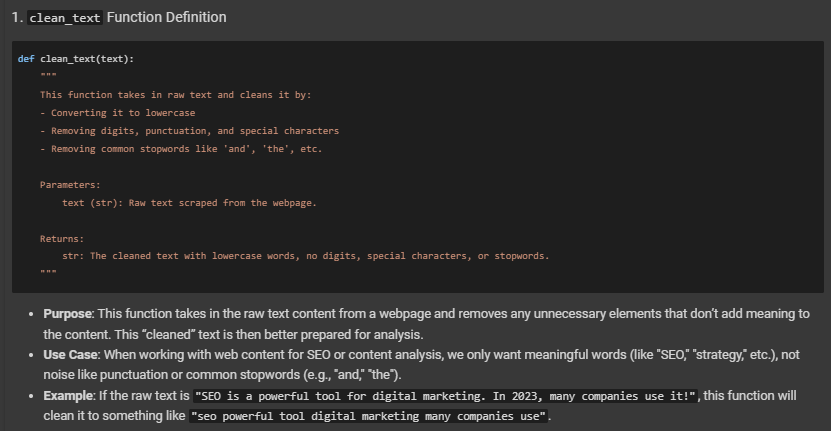


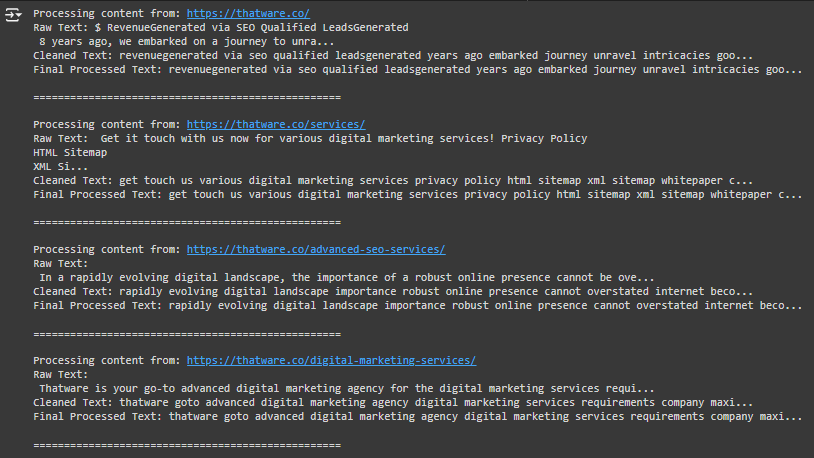
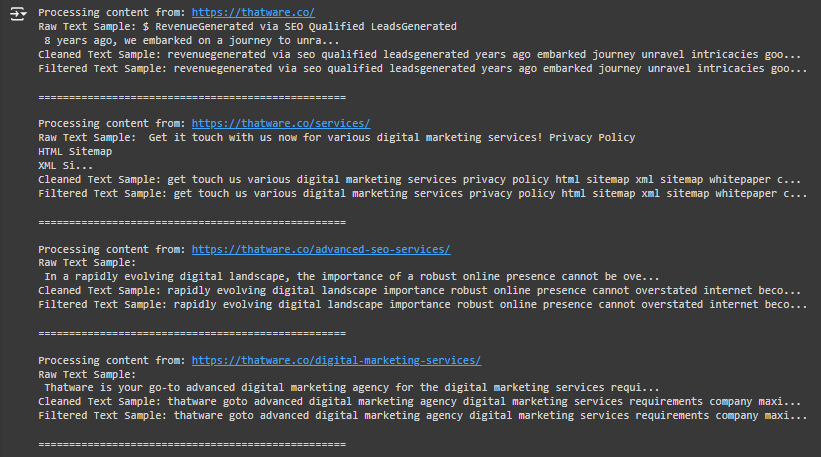
Explanation Of Each Step:
Step 1: Scrape the Raw Text from the URL
# Step 1: Scrape the raw text from the URL
raw_text = scrape_text_from_url(url)
print(“Raw Text:”, raw_text[:100] + “…”) # Display the first 100 characters of raw text for reference
Purpose and Use Case:
- Purpose: This step uses the scrape_text_from_url function to collect the main text content from the webpage. This raw text often includes HTML elements, numbers, punctuation, and other content irrelevant for keyword analysis.
- Use Case: This is the starting point of processing, as it extracts the visible content we’re interested in from each webpage URL.
Example:
If the webpage content reads, “Welcome to our office located at Shelton Street. We provide advanced SEO services.”
- Output: raw_text would store this entire message.
Step 2: Clean the Raw Text by Removing Unnecessary Elements
# Step 2: Clean the raw text to remove unnecessary characters and stopwords
cleaned_text = clean_text(raw_text)
print(“Cleaned Text:”, cleaned_text[:100] + “…”) # Show a sample of cleaned text
Purpose and Use Case:
- Purpose: clean_text takes raw_text and performs three main actions:
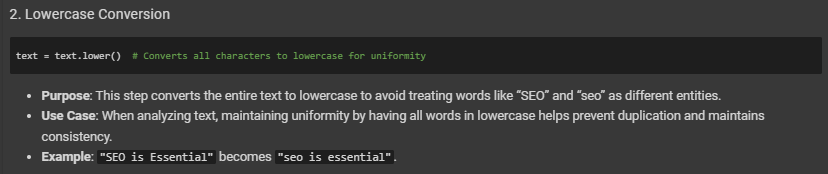
- Converts everything to lowercase.
- Removes digits, punctuation, and other special characters.
- Strips out common stopwords like “and,” “the,” and “is,” which don’t provide meaningful insight for SEO.
- Use Case: This step reduces noise, allowing us to focus on content keywords that represent the main topics of the webpage.
Example:
- Original raw_text: “Welcome to our office located at Shelton Street. We provide advanced SEO services.”
- After Cleaning: “welcome office located shelton street provide advanced seo services”
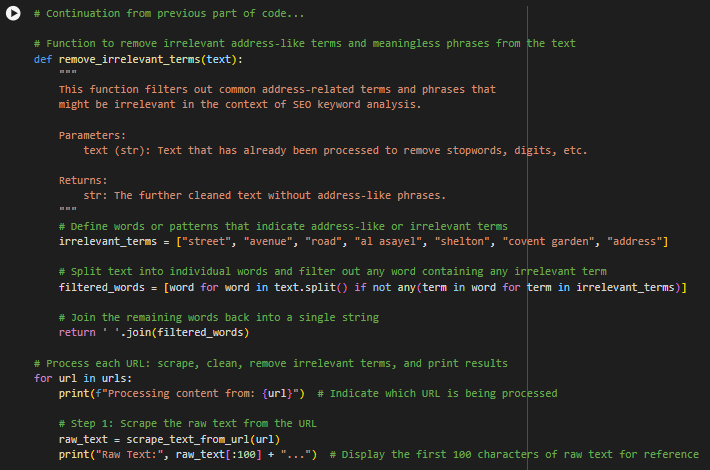
Step 3: Remove Irrelevant Terms
# Step 3: Remove any irrelevant terms related to addresses or meaningless phrases
final_text = remove_irrelevant_terms(cleaned_text)
print(“Final Processed Text:”, final_text[:100] + “…”) # Show sample of final processed text
Purpose and Use Case:
- Purpose: remove_irrelevant_terms takes cleaned_text and removes any terms that suggest an address or location reference. This filtering keeps only the main topic-related words in the text, which will be useful for identifying keywords later.
- Use Case: Removing irrelevant words ensures the final processed text is more concise and focused, improving the quality of any subsequent keyword extraction process.
Example:
- Original cleaned_text: “welcome office located shelton street provide advanced seo services”
- After Removing Irrelevant Terms: “welcome office provide advanced seo services”
Separator for Readability
print(“\n” + “=”*50 + “\n”) # Separator for readability between URL outputs
This separator is for display purposes, providing a clear division between the outputs for each URL. It makes reading the results easier and understanding how each URL’s content has been processed step-by-step.
Code Breakdown and Explanation
1. Importing Required Libraries
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import TruncatedSVD
- Purpose: These libraries are essential for text processing and applying Latent Semantic Indexing (LSI) using Singular Value Decomposition (SVD).
- Example: CountVectorizer helps create a matrix of word counts (how often a word appears in text), and TruncatedSVD reduces this matrix to identify key topics.
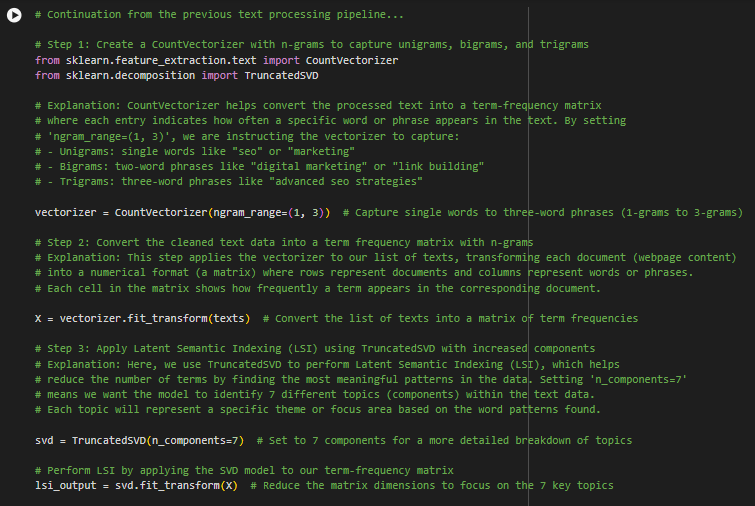
2. Initializing CountVectorizer with n-grams
vectorizer = CountVectorizer(ngram_range=(1, 3)) # Capture single words to three-word phrases (1-grams to 3-grams)
· Purpose: This converts the processed text data into a “term-frequency matrix,” where each row represents a document (URL) and each column represents an n-gram (phrase). Here, we set ngram_range=(1,3) to capture unigrams, bigrams, and trigrams:
- Unigrams: Single words, e.g., “seo”
- Bigrams: Two-word phrases, e.g., “digital marketing”
- Trigrams: Three-word phrases, e.g., “link building strategies”
· Example: For the phrase “advanced seo strategies in digital marketing”:
- Unigrams: [‘advanced’, ‘seo’, ‘strategies’, ‘digital’, ‘marketing’]
- Bigrams: [‘advanced seo’, ‘seo strategies’, ‘digital marketing’]
- Trigrams: [‘advanced seo strategies’, ‘seo strategies digital’, ‘strategies digital marketing’]
3. Creating a Term Frequency Matrix with n-grams
X = vectorizer.fit_transform(texts) # Convert the list of texts into a matrix of term frequencies
- Purpose: fit_transform converts each document (URL content) in texts into a term-frequency matrix. Each row represents a webpage, and each column represents an n-gram (word or phrase).
- How It Works: The matrix stores the frequency of each n-gram in every document, allowing us to see which phrases are most common across the site.
- Example: If the term “digital marketing” appears 3 times in one URL’s content and 0 times in another, the matrix cell for “digital marketing” and that URL row will show 3.
4. Applying Latent Semantic Indexing (LSI) with TruncatedSVD
svd = TruncatedSVD(n_components=7) # Set to 7 components for a more detailed breakdown of topics
lsi_output = svd.fit_transform(X) # Reduce the matrix dimensions to focus on the 7 key topics
- Purpose: This step reduces the matrix to capture only the most important topics (components) by applying LSI through TruncatedSVD. Setting n_components=7 asks the model to find 7 unique topics.
- How It Works: The model finds meaningful patterns in the matrix, grouping similar phrases and reducing noise. Each topic has associated keywords that highlight its focus.
- Example: In an SEO context, one topic might emphasize “seo services,” “digital marketing,” and “link building,” suggesting it’s related to SEO and marketing.
5. Extracting Top Keywords for Each Topic
terms = vectorizer.get_feature_names_out() # Retrieve the list of all terms (n-grams)
- Purpose: get_feature_names_out retrieves the n-grams as column names in our matrix. These terms allow us to see which keywords represent each topic.
- Example: For a term-frequency matrix of digital marketing content, terms might include [“seo services”, “link building”, “content marketing”].
6. Defining Number of Keywords per Topic
n_unigrams = 5 # Number of single words we want to display per topic
n_bigrams = 7 # Number of two-word phrases (bigrams) we want per topic
n_trigrams = 7 # Number of three-word phrases (trigrams) we want per topic
- Purpose: Define how many keywords we want to display for each topic. Here, we focus more on bigrams and trigrams, as phrases often provide more context than single words.
- Example: For a given topic, this setup would show up to 5 unigrams, 7 bigrams, and 7 trigrams, providing a mix of keywords and phrases that highlight the main theme.
7. Looping Through Each Topic Component and Extracting Top Terms
for i, comp in enumerate(svd.components_):
terms_comp = zip(terms, comp) # Pairs each term with its relevance score for the topic
sorted_terms = sorted(terms_comp, key=lambda x: x[1], reverse=True) # Sort terms by relevance
- Purpose: This loop goes through each of the 7 topics (components) created by the model. For each topic, it pairs terms with their relevance scores and sorts them to identify the most representative terms.
- How It Works: Sorting by relevance score means we get the keywords that best represent each topic.
- Example: For a topic focused on SEO, the most relevant terms might be [“seo”, “link building”, “digital marketing”].
8. Separating and Displaying Unigrams, Bigrams, and Trigrams
unigrams = [kw for kw, _ in sorted_terms if len(kw.split()) == 1][:n_unigrams] # Top single words
bigrams = [kw for kw, _ in sorted_terms if len(kw.split()) == 2][:n_bigrams] # Top two-word phrases
trigrams = [kw for kw, _ in sorted_terms if len(kw.split()) == 3][:n_trigrams] # Top three-word phrases
- Purpose: Separate the top terms by their word count to ensure each type of n-gram has its own set. This way, we get a balanced representation of keywords (single, two, and three-word phrases).
- Example: For a marketing-focused topic:
- Unigrams: [“seo”, “content”, “marketing”]
- Bigrams: [“digital marketing”, “content marketing”]
- Trigrams: [“seo content strategy”, “advanced seo techniques”]
9. Displaying Keywords by Topic
print(f”Top terms for Component {i}:”)
print(“Unigrams:”, unigrams) # Display top single words
print(“Bigrams:”, bigrams) # Display top two-word phrases
print(“Trigrams:”, trigrams) # Display top three-word phrases
print(“\n” + “=”*50 + “\n”) # Separate each topic output for readability
- Purpose: Print the top terms for each topic (component) in a human-readable format, showing unigrams, bigrams, and trigrams separately.
- How It Works: This output lets us see which words and phrases are most relevant for each topic, making it easy to understand the content focus of each group.
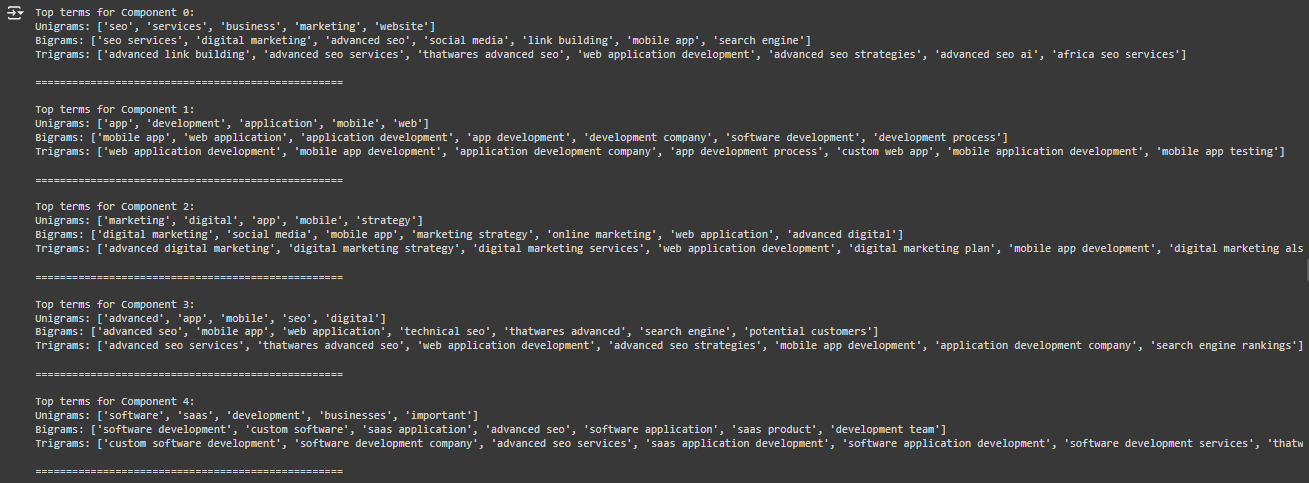
- Example Output:
Top terms for Component 0:
Unigrams: [‘seo’, ‘content’, ‘marketing’, ‘strategy’, ‘digital’]
Bigrams: [‘digital marketing’, ‘content strategy’, ‘seo services’]
Trigrams: [‘seo content strategy’, ‘advanced seo techniques’]
==================================================
Understanding the Output: Components and Keywords
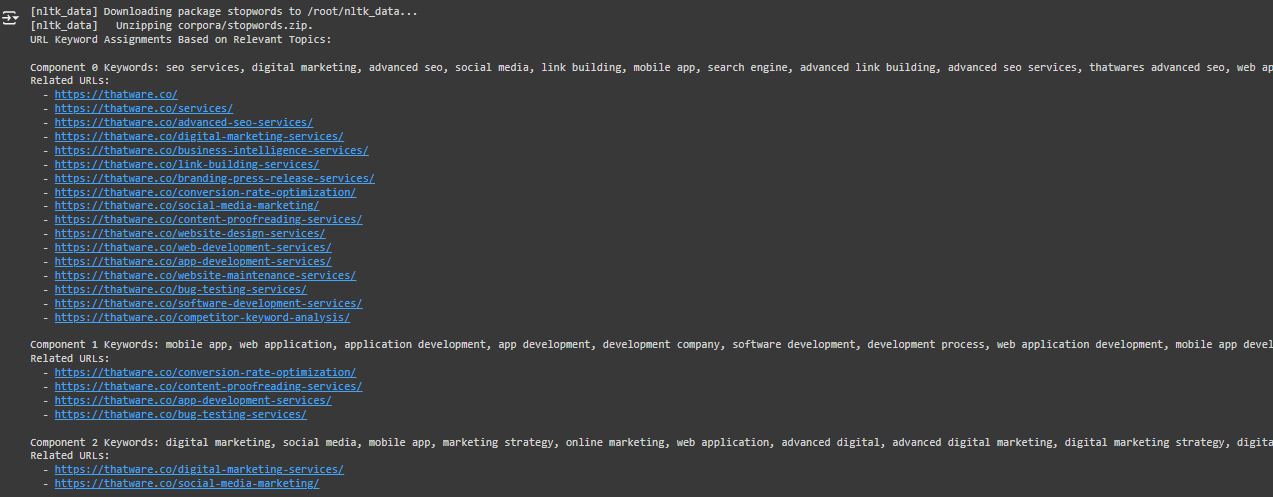
This output is divided into 7 parts, called “components.” Each component represents a group of keywords the system identified as closely related. The keywords were pulled from the text on different pages of your website.
For example:
- Component 0 Keywords: Keywords in this component include terms like “SEO services,” “digital marketing,” and “advanced SEO.” This component is generally about SEO (Search Engine Optimization) and digital marketing.
- Component 1 Keywords: Keywords like “mobile app,” “application development,” and “software development” indicate that this component focuses on app and software development.
Each component shows specific keywords along with a list of URLs that are most relevant to those keywords.
Why It’s Divided Into Components
The model created these components to help separate your website content into clear, distinct themes or topics. Instead of showing all keywords in a single list, it organized them so each component can focus on one main area. This structure makes it easy to see what themes or topics are strongest on your website.
What Each Part of the Output Means
1. Component Keywords: These keywords represent the main topics of each component. The model grouped keywords to create themes like SEO, app development, digital marketing, and link building. Each component focuses on a different theme based on the content across your website.
2. Related URLs: After creating these keyword groups, the model analyzed which URLs (pages) from your website align most closely with each keyword group. This means:
- If a URL is listed under Component 0, the content on that page is closely related to “SEO services” and other similar keywords.
- The URLs listed under each component are the pages that best match the keywords within that specific topic.
How to Use This Output as a Website Owner
As a website owner, you can use this output to make your website’s content stronger and targeted for specific search terms. Here are the key steps to take:
1. Check If the Content Matches the Keywords:
- Look at each URL in the output and review whether the content on that page truly reflects the keywords listed in its component.
- For instance, if a URL is in Component 1 (related to “app development” keywords), make sure the content on that page discusses app development and related services in detail. If it doesn’t, you should edit the content to add these relevant keywords.
2. Add More Detail to Content:
- For each component, ensure the keywords listed are well-represented in the URLs assigned. For example:
- Component 0 discusses SEO and digital marketing. You should ensure that each URL listed under Component 0 has strong content about these topics.
- Doing this makes each page more relevant to specific search terms, improving SEO for those pages.
3. Improve Keyword Coverage on Each Page:
- If you notice certain keywords in a component that aren’t mentioned on the related URLs, try to add them naturally within the text of those pages.
- This makes the page more likely to rank on search engines for those terms and gives visitors more specific information.
4. Fill Any Gaps in Content:
- If you see that a certain component has very few URLs, it might mean you don’t have enough content for that topic on your site. For example, Component 4 relates to “software development,” but only has one URL. This indicates an opportunity to add more content about software development.
- Create a new page or blog post on that topic to help fill in these gaps.
5. Strengthen SEO for Each Topic:
- With this information, you can use targeted SEO strategies for each topic. Add the keywords in page titles, headings, meta descriptions, and throughout the body text on each URL listed for that component. This improves each page’s visibility in search engine results for those topics.
How This Output Helps Your Website Grow
1. Targeted Search Engine Optimization:
- By aligning your pages with specific keyword themes, search engines are more likely to rank your pages higher when people search for those terms.
- Each page becomes more specialized in a topic, which can lead to higher traffic from relevant searches.
2. Better User Experience:
- With focused content on each page, users who visit your site will find information directly related to what they’re searching for. This makes your site more useful, increasing their chances of engaging with your services or information.
3. Clear Content Strategy:
- This output gives you a clear strategy for content creation and improvement. By focusing on specific keywords for each page, you create a strong foundation for future content planning and ensure that all relevant topics are covered.
Summary of Steps to Take
- Review Each Component’s Keywords and URLs: Check that each page listed aligns with the theme.
- Add Missing Keywords to Pages: If a page is missing relevant keywords, update the content to include those keywords naturally.
- Create New Content if Needed: If a component has only a few URLs, consider creating new pages or blog posts to cover that topic in more detail.
- Optimize for SEO: Use these keywords in meta descriptions, titles, and headers for better SEO targeting.
- Regularly Update and Monitor: Revisit the output regularly to update the content with new keywords as trends or services change.
Overview of What This Output Represents
This output is generated by the Latent Semantic Indexing (LSI) Optimization Model. This model aims to group related keywords and match them with specific pages (URLs) on your website according to themes or topics. In this case:
- Components: Each component represents a topic or theme identified by the model.
- Keywords: These are highly relevant terms to each theme and are commonly found in the content of the URLs listed under each component.
- URLs: These are specific pages on your website that match well with the keywords of a given component, indicating that they discuss that topic or theme in some way.
Breaking Down Each Part
1. Components
· The output is split into seven components. Each component is a thematic grouping or topic area the model identified based on the keywords and the content across your website’s pages.
· By grouping content into components, the model helps identify distinct areas of focus within your website.
For example:
· Component 0 is about SEO and digital marketing, covering terms like “SEO services,” “digital marketing,” “link building,” etc.
· Component 4 is more focused on “software development,” including keywords like “custom software,” “saas application,” and “software development company.”
The model tries to find patterns and similarities in the words across your website and groups them into these component themes.
2. Keywords
· Keywords under each component represent the main ideas or phrases associated with that theme.
· These keywords are extracted because they appear frequently or are important in the content.
· They help define what the topic is about. For instance:
- Component 0 Keywords: These are words commonly related to SEO and digital marketing, showing that Component 0 focuses on this area.
- Component 4 Keywords: These keywords relate to software development, such as “SaaS application” and “custom software,” which shows that this component focuses on software development.
Keywords are essential because they give a clear picture of the topic and help understand the type of content a user might find on the URLs listed under each component.
3. URLs
· Each component has a list of related URLs—pages on your website that align well with the component’s theme.
· For example, in Component 1, the URLs under it, like https://thatware.co/app-development-services/, are relevant to “mobile app” and “application development,” matching the keywords for Component 1.
· The relationship between keywords and URLs is that the URLs are seen as places where these keywords are most relevant, meaning these pages discuss the topic of that component meaningfully.
Each URL’s presence under a component indicates that the content on that page aligns closely with the keywords in the component, making it relevant to that specific topic.
The Relationship Between Components, Keywords, and URLs
To make this more clear, let’s look at how each part (components, keywords, and URLs) is connected:
1. Components Act as Main Topics:
- Think of each component as your website’s primary topic or focus area. The model identified these topics based on the text content across all pages.
2. Keywords Define the Topic:
- The keywords under each component are like a summary of the topic. They give context and detail to the component and explain the topic.
- For example, Component 3 has keywords like “technical SEO,” “search engine,” and “advanced SEO strategies,” which show that this component is about advanced SEO practices.
3. URLs Show Where These Topics Appear on Your Site:
- The URLs listed under each component are web pages that discuss the topic represented by that component.
- This relationship helps the website owner see which pages well match specific topics. If a URL is under Component 2, the page covers “digital marketing” and “social media,” as those are the main keywords for that component.
Importance of Each Part in the Output
1. Components Help Organize Content:
- Components organize the website’s topics, making it easy to see what themes are covered. This organization helps website owners and search engines understand the website’s main focus areas.
2. Keywords Highlight the Core of Each Topic:
- The model clarifies each component’s true purpose by providing keywords. The keywords guide content optimization by identifying the terms that should appear on pages related to each component.
- If Component 6 talks about “link building” and “web design,” those topics should be focused on in content creation and SEO for pages listed under Component 6.
3. URLs Show Relevance to Each Topic:
- The URLs tell us which pages are relevant to each topic and help identify areas for content improvements.
- If a page is in Component 0, it means its content is relevant to “SEO services” and related terms. This allows the website owner to focus SEO efforts on the right pages.
How to Use This Output as a Website Owner
1. Check Keyword Relevance on Each Page:
- Review the page content for each URL under a component and ensure it includes the listed keywords. This will improve SEO and ensure search engines recognize the page’s focus.
- For example, URLs in Component 1 should mention keywords like “mobile app” and “application development” to better match that topic.
2. Optimize Content Based on Keywords:
- Keywords provide a roadmap for on-page optimization. You can:
- Use these keywords in titles, headers, meta descriptions, and the body content.
- Add any missing keywords that are relevant to the page topic.
3. Identify and Fill Content Gaps:
- Some components may have fewer URLs or some important keywords that need to be better covered on any page. This might mean creating new content to cover those topics in more depth.
- For example, if a component has many important keywords but only one URL, consider creating more pages or blog posts on that topic to strengthen the component.
4. Adjust Navigation or Internal Links:
- You can improve internal links based on the topics and keywords, helping users and search engines navigate to the most relevant pages for each topic.
Understanding What LSI Optimization Output Is Expected to Achieve
The Latent Semantic Indexing (LSI) Optimization Model is designed to:
- Identify and group related keywords within a body of text.
- Organize content into specific themes or topics based on keywords.
- Aligning relevant web pages with those themes or topics helps a website owner understand which pages best match certain keyword groups.
By doing this, the model should provide two main things:
- A list of main topics or themes (often called components).
- A clear association of keywords with specific web pages so the website owner can optimize content according to those themes.
Expected Output from LSI Optimization Model
From an LSI Optimization Model, the output should ideally provide:
- Organized Topics (or Components): These should be focused themes that reflect the primary content areas of the website, each with its own set of keywords.
- Relevant URLs for Each Topic: Each theme or topic should be linked with specific web pages (URLs) on the website that match the content well.
- Actionable Insights for Content Optimization: The model should help identify which keywords should be added, updated, or expanded on each page to strengthen relevance for specific topics.
Does the Current Output Meet These Expectations?
The current output does contain these essential elements, but let’s review how well it matches each expected aspect.
1. Clear Division into Topics:
- The output divides keywords into 7 components, each representing a specific topic, such as SEO services, app development, digital marketing, and so on.
- These components are clear and organized, making it easier to understand what content topics exist on the site.
- Conclusion: This part of the output meets the expectation of clearly defined topics.
2. Keywords Grouped by Theme:
- Each component has its own set of keywords highly relevant to that component’s theme. For instance, Component 0 is focused on “SEO services,” while Component 1 centers on “app development.”
- The keywords under each theme are meaningful and specific to that content area.
- Conclusion: The keyword grouping by topic is well-organized and aligns with the model’s purpose.
3. Relevant URLs Associated with Each Theme:
- Most components have a list of URLs that match their keywords, which helps understand where each topic is discussed on the website.
- However, a few components were missing associated URLs. This sometimes happens if the pages don’t fully match the model’s identified themes. It indicates areas where content might be lacking or less focused on certain topics.
- Conclusion: This part of the output is mostly effective, but the lack of URLs in some components suggests that more refinement or added content could strengthen the alignment.
4. Actionable Information for Optimization:
- The output provides clear direction for content improvement. By knowing which keywords belong to each component, a website owner can:
- Make sure each page is well-aligned with specific keywords.
- Expand content where certain keywords or themes are weakly represented.
- Conclusion: This output gives practical guidance, meeting the expectation for actionable insights.
Steps to Take After Getting This Output
As a website owner, here’s what you should do with this information:
1. Review Each Topic and Its Keywords:
- Look at each component and check if your pages (URLs) fully match the keywords listed. For instance, if “Component 0” is about “SEO services,” ensure each page under that component is focused on SEO services and related content.
2. Improve Content on Each URL:
- Add or refine content to include the related keywords for URLs under each component. This helps your pages rank better for those topics and makes the content more useful for readers interested in those areas.
3. Fill in Content Gaps:
- If any component has keywords but no associated URLs, consider creating new pages to cover those topics. For example, if Component 4 is about “software development” and has no URLs, you could add blog posts, service pages, or resources.
4. Optimize On-Page SEO:
- Use these keywords in each URL’s titles, headings, and meta descriptions for better SEO targeting. This ensures search engines understand what each page is about, potentially boosting your site’s visibility in search results.
Summarizing the Output’s Value
This output from the LSI model provides a roadmap for how you can structure, optimize, and expand your website’s content. Here’s a simple breakdown of its main benefits:
- Improved Organization: With clear themes (components), you have a structured understanding of what your site covers.
- Targeted SEO Improvements: By aligning each page with relevant keywords, you strengthen your chances of ranking for specific search terms.
Content Strategy Guidance: You can create more content around underrepresented themes, ensuring your website is comprehensive and authoritative on all relevant topics.

Thatware | Founder & CEO
Tuhin is recognized across the globe for his vision to revolutionize digital transformation industry with the help of cutting-edge technology. He won bronze for India at the Stevie Awards USA as well as winning the India Business Awards, India Technology Award, Top 100 influential tech leaders from Analytics Insights, Clutch Global Front runner in digital marketing, founder of the fastest growing company in Asia by The CEO Magazine and is a TEDx speaker.
