SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
Search has fundamentally changed.
Traditional techniques like LDA (Latent Dirichlet Allocation) and keyword-based similarity once powered SEO strategies. But modern search engines (Google, Bing) and Large Language Models (ChatGPT, Gemini, Claude) now rely on semantic understanding, embeddings, and entity relationships rather than simple topic distributions.

If you’re still using LDA + cosine similarity, you’re working with an outdated paradigm.
This guide provides a complete, real-world pipeline for:
- SEO optimization (Google rankings, AI Overviews)
- LLM optimization (RAG, answer engines, citations)
- Content intelligence and automation
1. Why LDA is No Longer Enough
Limitations of LDA
- Bag-of-words (ignores word order)
- Poor handling of short content
- Weak semantic understanding
- Not aligned with transformer-based systems
What replaced it?
Modern systems use:
- Transformer embeddings (BERT, E5, OpenAI)
- Dense retrieval
- Hybrid search (BM25 + embeddings)
- Entity-based ranking
Key shift:
From topics → to meaning, intent, and entities
2. Modern SEO + LLM Architecture Overview
A production-grade system today looks like this:
Content → Cleaning → Chunking → Embeddings → Dual Index
→ Hybrid Retrieval → Reranking → Output Systems
That practical replacement is sentence embeddings.
In this guide, we will simplify the modern approach and focus on two realistic options:
– **SBERT** for a free, local, no-API-key workflow
– **OpenAI text-embedding-3-small** as an optional managed alternative when an API key is available later
The core message is simple:
> If you used LDA to understand topics, compare documents, or improve on-site search, the easiest modern upgrade is to replace LDA vectors with sentence embeddings and keep the rest of the workflow simple.
Why LDA Is No Longer the Best Choice
LDA, or Latent Dirichlet Allocation, was useful when search and content analysis were dominated by keyword frequency and topic distributions. It helped group documents into broad themes, but it has several limitations in modern search scenarios:
– It treats text mostly as a bag of words
– It does not understand meaning well
– It struggles with short queries and short content blocks
– It misses context, phrasing, and semantic similarity
– It does not align with how modern search systems and LLMs interpret content
For example, LDA may treat these as different ideas:
– “best laptop for students”
– “good budget notebook for college”
A modern embedding model understands that both express similar intent.
That is the key shift in modern search:
– **Old approach:** topic probabilities
– **New approach:** semantic meaning
What Should Replace LDA?
For most practical websites, the replacement should be:
– simple to implement
– cheap or free to test
– good enough for search relevance
– understandable without advanced ML knowledge
The best replacement is:
## **Sentence embeddings + cosine similarity**
This means:
1. Convert each page, paragraph, or chunk into a numeric vector
2. Convert the search query into a vector
3. Compare them using cosine similarity
4. Return the most semantically relevant results
That is the modernized version of what many teams once tried to do with LDA.
—
Best Practical Recommendation
Option 1: SBERT
If you want a modern solution that runs without any API key, SBERT is the best recommendation.
SBERT stands for Sentence-BERT. It is designed to turn sentences and paragraphs into embeddings that preserve semantic meaning.
Why SBERT is the best default choice
– Free to use
– Runs locally or in Google Colab
– Easy to implement with Python
– No need for deep ML knowledge
– Excellent for website search, content similarity, clustering, FAQs, and internal linking ideas
A strong beginner-friendly model is:
`all-MiniLM-L6-v2`
It is lightweight, fast, and reliable for many real-world use cases.
Option 2: OpenAI text-embedding-3-small
If later you want a managed API-based setup, `text-embedding-3-small` is a strong option.
Why it is useful
– Very easy API integration
– High quality semantic embeddings
– No model hosting or maintenance
– Good for production workflows when you already use OpenAI services
But for now, it is not your main path
Since you do not have an OpenAI API key, your main implementation should use SBERT. You can still structure your workflow so that switching to OpenAI later is easy.
The Simplified Architecture You Actually Need
A lot of articles overcomplicate this subject. You do not need a large production stack just to replace LDA.
For most sites, the simplified pipeline looks like this:
Step 1: Collect content
Your source can be:
– a webpage URL
– a blog article
– a text file
– a product page
– a group of FAQs
Step 2: Clean the text
Remove unnecessary spacing, scripts, navigation noise, and repeated junk.
Step 3: Split content into chunks
Instead of embedding the full page as one giant block, break it into smaller chunks.
A practical chunk size is around:
– 80 to 200 words for simple websites
– or paragraph-based chunking
Step 4: Generate embeddings
Use SBERT to turn each chunk into a vector.
Step 5: Save the output
At minimum, store:
– chunk text
– chunk id
– source URL or filename
– embedding vector
Step 6: Compare queries using cosine similarity
When a user searches:
– convert the query into an embedding
– compare it with all chunk embeddings
– show the most similar chunks
That is enough to build a good semantic search prototype.
—
What You Do Not Need Right Away
To replace LDA, you do not need the full advanced stack.
You can remove these from the first version:
– vector databases like Pinecone or Qdrant
– cross-encoder rerankers
– knowledge graphs
– entity linking systems
– large hybrid search infrastructure
– advanced RAG pipelines
Those are scaling upgrades, not starting requirements.
—
SBERT Step-by-Step
Here is the practical process.
Step 1: Install dependencies
In Colab, install:
“`python
!pip install sentence-transformers scikit-learn beautifulsoup4 requests matplotlib pandas numpy
“`
Step 2: Load the SBERT model
“`python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(‘all-MiniLM-L6-v2’)
“`
Step 3: Prepare text chunks
Suppose you have these chunks:
“`python
chunks = [
“Semantic search helps match user intent and meaning.”,
“LDA is an older topic modeling method.”,
“SBERT creates dense embeddings for sentences and paragraphs.”
]
“`
Step 4: Generate embeddings
“`python
embeddings = model.encode(chunks)
print(embeddings.shape)
“`
Each chunk now has a numeric vector.
Step 5: Encode a search query
“`python
query = “What can replace LDA for modern website search?”
query_embedding = model.encode([query])
“`
Step 6: Compare query to chunks
“`python
from sklearn.metrics.pairwise import cosine_similarity
scores = cosine_similarity(query_embedding, embeddings)[0]
for chunk, score in zip(chunks, scores):
print(round(score, 4), chunk)
“`
The highest score is your best semantic match.
—
OpenAI text-embedding-3-small Step-by-Step
This section is for future use when you have an API key.
Step 1: Install the SDK
“`python
!pip install openai
“`
Step 2: Set your API key
“`python
import os
os.environ[“OPENAI_API_KEY”] = “your_api_key_here”
“`
Step 3: Request embeddings
“`python
from openai import OpenAI
client = OpenAI()
texts = [
“Semantic search helps match user intent and meaning.”,
“LDA is an older topic modeling method.”
]
response = client.embeddings.create(
model=”text-embedding-3-small”,
input=texts
)
embeddings = [item.embedding for item in response.data]
“`
Step 4: Use cosine similarity the same way
The search logic remains the same. Only the embedding provider changes.
This is why it is smart to design your code in a model-agnostic way.
—
Which One Should You Choose?
Choose SBERT if:
– you want to run everything without an API key
– you want a simple Colab workflow
– you want to learn and test freely
– you need a practical replacement for LDA right now
Choose OpenAI text-embedding-3-small if:
– you later want easy hosted infrastructure
– you are okay with API cost
– you want a managed production option
Final recommendation
For your current situation, the correct recommendation is:
Start with SBERT (`all-MiniLM-L6-v2`)
It gives you the clearest, cheapest, and most practical path away from LDA.
—
Example Use Cases on a Website
Once you generate embeddings for your pages or content chunks, you can use them for:
– semantic site search
– content similarity
– related article suggestions
– FAQ matching
– duplicate or overlapping content detection
– internal linking recommendations
– grouping pages by meaning instead of keyword repetition
This makes SBERT much more flexible than LDA for modern websites.
—
Practical Implementation Advice
To keep the project manageable:
– start with one page or one document
– chunk by paragraphs first
– generate embeddings locally with SBERT
– save them to CSV or JSON
– test query matching using cosine similarity
– add visuals to inspect results
Only after this works should you think about larger systems.
—
Common Mistake to Avoid
A common mistake is replacing LDA with a full enterprise semantic stack immediately. That creates unnecessary complexity.
The better path is:
Beginner path
– SBERT
– paragraph chunking
– cosine similarity
– CSV output
– simple charts
Later upgrade path
– BM25 + embeddings
– better chunking
– metadata filters
– vector database
– reranking
This keeps the transition realistic.
—
Final Conclusion
LDA is no longer the best fit for modern website search because it cannot capture intent and semantic meaning the way modern embedding models can.
But replacing LDA does not require a complicated machine learning stack.
For most practical use cases, the best modern replacement is:
## **SBERT embeddings + cosine similarity**
That gives you a semantic search workflow that is:
– easy to understand
– free to run
– much more useful than LDA
– suitable for blogs, websites, FAQs, and internal content systems
Here is the colab program for the realtime experiment and implementations:
https://colab.research.google.com/drive/1x8G-s2wEznbKcEgNkdUUbsrfFEjcgMA5
Here is the code:
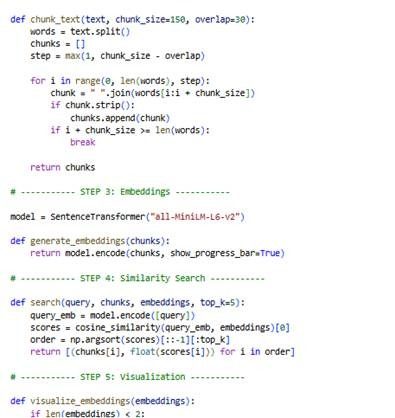
Here is the experimental output:
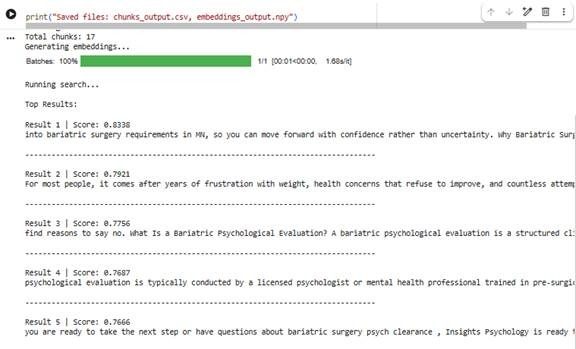
Bottom Line
The shift from LDA to modern semantic retrieval is not just a technical upgrade—it is a fundamental change in how content is understood, ranked, and delivered. By moving to sentence embeddings and cosine similarity, you align your strategy with how search engines and LLMs actually process meaning and intent today. The best part is that this transition does not require complex infrastructure. Starting with a simple SBERT-based workflow allows you to build practical, scalable solutions for SEO, content discovery, and AI-driven search. As your needs grow, you can gradually expand into hybrid search and advanced retrieval systems. In 2026, success in search depends on meaning, not keywords—and this pipeline puts you on the right path.
