SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project implements an advanced content analysis solution using Latent Dirichlet Allocation (LDA) to identify dominant topics across web pages and uncover opportunities for internal linking and topic gap optimization. By leveraging LDA-based topic modeling, the project systematically evaluates how each web page aligns with underlying thematic structures and provides actionable insights to enhance on-site SEO strategy. It further outputs suggested internal links between contextually similar pages and flags topics that are underrepresented, which could indicate gaps in content coverage.

The entire implementation is designed to scale for real-world SEO campaigns, especially for content-heavy websites seeking strategic improvements in topic relevance and search engine visibility.
Project Purpose
The primary purpose of this project is to equip content and SEO teams with data-driven insights into how existing pages contribute to topic coverage and to identify untapped or weakly covered topics for strategic content creation. Specifically, the project delivers:
- Internal Linking Suggestions: Automatically identifies thematically similar pages that can be internally linked to enhance content discoverability, reduce bounce rates, and improve PageRank flow.
- Topic Gap Detection: Highlights topics that are not dominantly represented by any current content. These represent potential opportunities for new content that aligns with the domain’s topical authority.
- Keyword Clarity per Topic: Surfaces the top keywords associated with each topic cluster, helping teams understand how content is thematically organized.
This provides not only a snapshot of current topic coverage but also a forward-looking roadmap for content optimization.
Project’s Key Topics Explanation and Understanding
This section explores the two main technical pillars of the project — Latent Dirichlet Allocation (LDA) and Topic Modeling — providing a deep dive into their functionality, rationale, and relevance to the goals of SEO and content optimization. These methods form the analytical backbone of the project and explain how abstract semantic information can be extracted and leveraged from web content.
Latent Dirichlet Allocation (LDA)
Overview
Latent Dirichlet Allocation (LDA) is a generative probabilistic model developed to identify abstract topics within a collection of textual documents. Each document is viewed as a blend of various topics, and each topic is a probability distribution over words. Unlike manual tagging or keyword-based classification, LDA learns these topics unsupervised — meaning without prior labels or categories.
This makes LDA especially effective in scenarios where content is abundant and human-curated topic labeling is infeasible.
How LDA Works
LDA operates under the assumption that there are hidden (latent) semantic structures in a large corpus of documents. Its mechanism can be summarized as follows:
- For each document in the corpus:
- Assume a fixed number of topics exist across all documents.
- Each document has its own unique mix of these topics, defined by certain proportions (e.g., 40% Topic A, 60% Topic B).
- Each topic is characterized by a certain probability of containing specific words.
- The model tries to infer these hidden structures by iteratively guessing and adjusting the assignment of words to topics until it reaches a distribution that best explains the observed data.
- This results in:
- A topic distribution per document (which topics are present and how prominently).
- A word distribution per topic (which words best represent each topic).
Why LDA Was Used in This Project
LDA was chosen for this project due to its ability to uncover dominant themes in a completely unsupervised and scalable way. When analyzing a set of blog or content pages, manually reviewing every article to understand its thematic focus is inefficient and error-prone.
Instead, LDA:
- Automatically identifies key discussion areas across all pages.
- Quantifies the relevance of each topic to each page, enabling deeper analytical insights.
- Supports content clustering, allowing similar pages to be grouped without relying on metadata or manual input.
This helps clients make data-backed decisions on internal linking, content silos, and topic coverage expansion.
Why LDA Was Chosen Over Alternatives
There are several topic modeling approaches available — such as Non-negative Matrix Factorization (NMF), Latent Semantic Analysis (LSA), and even neural embeddings-based methods.
LDA was chosen because:
- It is interpretable: Topics are easy to explain in terms of keyword distributions.
- It is domain-agnostic: It works across industries and niches without retraining or customization.
- It is efficient for small to mid-sized corpora: Ideal for sets of 10–100 pages, such as those found on business or informational websites.
- It has wide support: Extensive libraries, research backing, and proven reliability in SEO and content applications.
Topic Modeling
Overview
Topic modeling is the broader task of discovering abstract “topics” that occur in a collection of documents. A topic is typically defined as a group of words that tend to co-occur across documents, suggesting a shared subject or theme. The process is unsupervised, meaning it does not require pre-defined labels or categories.
In essence, topic modeling extracts semantic structure from text, providing insights into what a collection of documents is truly about — far beyond surface-level keyword counts.
How Topic Modeling Works
- The technique takes in a collection of documents (such as blog pages).
- It processes and converts them into a format where words and their frequencies are mapped.
- An algorithm like LDA then infers latent topics by identifying patterns in how words appear across different documents.
- The result is:
- A topic distribution per document.
- A list of eywords per topic, often representing a concept.
For example, if multiple documents mention words like “index”, “crawl”, “robots.txt”, and “server”, topic modeling might group them into a topic labeled “Technical SEO”.
Why Topic Modeling Was Used in This Project
The primary goals of this project are:
- To understand the main themes discussed on each page.
- To group pages with similar topics to suggest internal linking opportunities.
- To identify content gaps and underrepresented topics for future content planning.
Topic modeling provides a scalable and objective way to achieve all three.
Rather than relying on vague assumptions or manual tagging, topic modeling gives:
- Clear topic identities that characterize each document.
- Quantitative relevance scores that indicate how strongly a document is associated with a topic.
- A bird’s eye view of the content ecosystem — which areas are over-served, under-served, or missing altogether.
Why Topic Modeling Was Chosen Over Simpler Keyword-Based Approaches
While keyword frequency and TF-IDF can identify prominent terms in documents, they fall short in understanding context, co-occurrence, and topic overlap. They also fail to capture multi-word topics and can’t handle synonyms or conceptual proximity.
Topic modeling, especially when powered by LDA:
- Captures deeper semantic meaning.
- Groups content by conceptual themes, not just surface terms.
- Allows for rich content analysis, internal link planning, and optimization that aligns with search engine understanding of content clusters.
What problem does this project solve?
This project addresses the common challenge of content fragmentation and lack of thematic clarity across website pages. As content grows, it becomes difficult to manually assess whether topics are sufficiently covered, over-represented, or missing. Without this insight:
- Internal linking becomes arbitrary or inconsistent.
- Some valuable pages may remain buried or disconnected.
- Content silos are difficult to manage or align with user intent.
This project provides a scalable, data-driven solution by automatically uncovering the main themes in each page and showing how content aligns or diverges across the site.
Why is this important for SEO and content strategy?
Search engines now evaluate websites based on topical authority and how well different content pieces relate to each other. Pages are no longer ranked purely by keywords but by semantic relevance and site architecture.
This project enables:
- Stronger internal linking between topically similar pages.
- Improved content clustering to align with search engine expectations.
- Identification of topic gaps where additional content should be developed.
- Reduction of redundancy, preventing similar pages from cannibalizing each other’s rankings.
The result is a more structured, efficient, and search-friendly website, which can improve both crawlability and user experience.
How does the project improve internal linking opportunities?
By identifying which pages belong to the same topic clusters, the system suggests meaningful internal links. These links:
- Help search engines crawl and index related content efficiently.
- Distribute page authority (PageRank) more effectively across relevant articles.
- Improve user navigation by connecting content with shared themes.
Unlike manual linking, which can be biased or inconsistent, this approach ensures internal links are based on semantic similarity, not guesswork.
What makes this approach different from traditional SEO audits?
Traditional audits focus on technical SEO elements like meta tags, schema, and backlinks. While important, they often overlook the semantic relationships between pages — a critical factor in modern SEO.
This project uses advanced machine learning (LDA and topic modeling) to reveal hidden thematic structures that technical audits cannot uncover. It complements existing audits by:
- Adding a layer of content intelligence.
- Supporting strategic decisions about editorial planning and linking.
- Offering actionable insights based on actual semantic data.

Libraries Used in the Project
The following libraries were used to build and execute the topic modeling system. Each library was chosen to address specific needs in text processing, topic modeling, and result visualization.
Text Preprocessing Libraries
- BeautifulSoup
Used to parse and extract raw text from HTML content. This ensures that only meaningful, visible content from the page is analyzed, excluding scripts, navigation, and other non-content elements.
- requests
Facilitates downloading HTML content from each URL. It serves as the interface to collect the raw data from the web pages under analysis.
- nltk (Natural Language Toolkit)
Provides essential tools for text cleaning, including:
- stopwords: A list of common English words (like “the”, “and”) that do not contribute to the semantic value of the content.
- punkt: A tokenizer for breaking text into sentences and words.
- wordnet + WordNetLemmatizer: Converts words to their base or dictionary form, improving the quality of topic modeling by grouping similar terms (e.g., “running”, “ran”, and “runs” are converted to “run”).
- re (Regular Expressions)
Used for low-level pattern-based cleaning of noisy characters, symbols, and non-alphabetic tokens.
- numpy and collections.defaultdict
Support numerical operations and structured storage of results respectively. numpy enables efficient vector calculations, while defaultdict organizes related data into accessible groupings.
Topic Modeling Libraries
- gensim
A robust library for natural language processing, specifically optimized for topic modeling and similarity retrieval. The two key components used are:
- corpora.Dictionary: Builds a mapping of unique words to numerical IDs, which is required for transforming documents into a bag-of-words format.
- LdaModel: Implements Latent Dirichlet Allocation to identify latent topics in the text. It generates a set of topics by analyzing how words co-occur across documents.
Visualization Library
- pyLDAvis
A specialized visualization tool that helps interpret LDA results through interactive, web-based plots. It provides:
- Visual clusters of topics in two-dimensional space.
- Keyword relevance for each topic.
- Document-topic relationships.
The gensim_models module under pyLDAvis ensures compatibility with the gensim LDA implementation, and enable_notebook() activates inline visualization for Jupyter Notebooks.
Each of these libraries contributes a distinct layer of functionality — from fetching data and preprocessing, to modeling hidden topics and finally, presenting the results in an interpretable format. Their seamless integration supports a smooth and accurate analysis pipeline tailored for real-world SEO content optimization and thematic discovery.
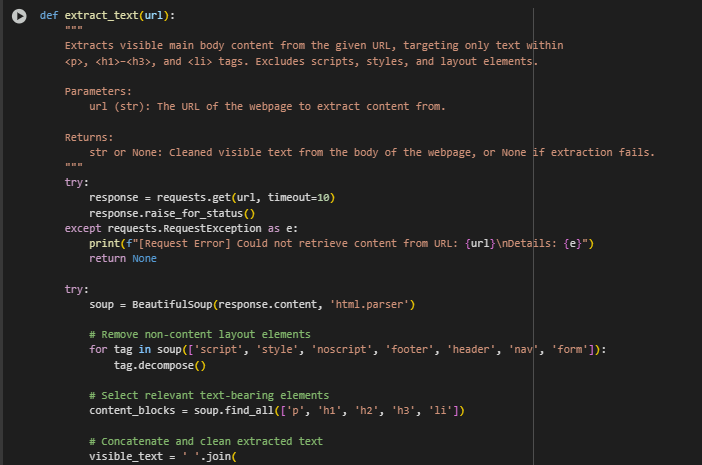
Web Content Extraction Function: extract_text(url)
Function Summary
This function retrieves and extracts the main visible textual content from a webpage. It specifically targets content relevant to search engines and human readers by focusing on informative HTML elements such as paragraphs, headers, and list items. The purpose is to collect only valuable semantic content for topic modeling while filtering out navigational or decorative elements like menus, ads, and scripts.
This is a foundational step in the project, ensuring that only meaningful and analyzable content is passed forward for topic detection and analysis.
Key Implementation Highlights
· URL Retrieval with Error Handling
response = requests.get(url, timeout=10) response.raise_for_status()
This ensures the web page is successfully fetched within a 10-second window. If the request fails due to issues like network errors or a non-responsive server, it will raise an informative exception and skip that URL.
· Tag-Based Content Filtering
for tag in soup([‘script’, ‘style’, ‘noscript’, ‘footer’, ‘header’, ‘nav’, ‘form’]): tag.decompose()
This step removes non-informative or layout-based sections of the webpage (such as JavaScript, menus, forms, etc.), ensuring that only actual content contributes to the topic analysis.
· Targeted Extraction of Text Elements
content_blocks = soup.find_all([‘p’, ‘h1’, ‘h2’, ‘h3’, ‘li’])
By focusing on paragraphs (<p>), headers (h1> to <h3>), and list items (<li>), the function captures core textual information typically used in articles, blog posts, or documentation.
· Text Aggregation and Final Cleanup
visible_text = ‘ ‘.join( block.get_text(separator=’ ‘, strip=True) for block in content_blocks if block.get_text(strip=True) )
All selected content blocks are merged into a single text string. This step ensures that only visible and non-empty text is retained, ready for further preprocessing and analysis.
This function serves as the entry point for raw data ingestion in the project pipeline and is crucial for ensuring that topic modeling operates on clean, high-quality input that reflects the actual value of each web page.
`
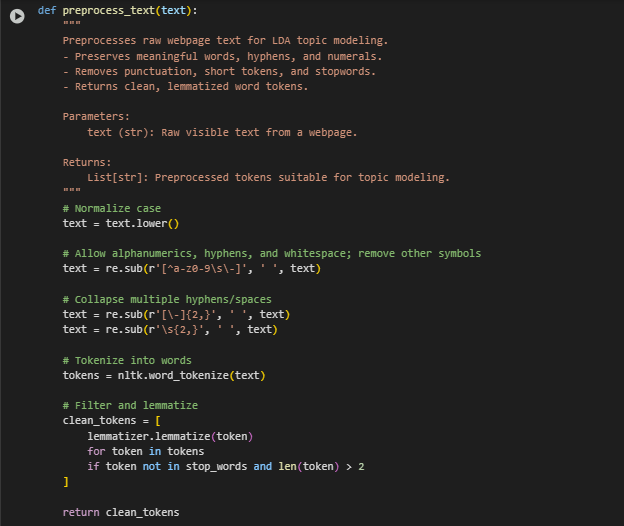
Text Preprocessing Function: preprocess_text(text)
Function Summary
This function prepares the raw extracted web content for topic modeling by cleaning and transforming the text into a structured and analyzable format. It ensures that only meaningful, relevant words are retained, which enhances the accuracy and interpretability of the topic modeling results.
Preprocessing is a critical stage in natural language processing (NLP) as it removes noise and standardizes the data for better computational performance and clarity of insights.
Key Implementation Highlights
· Text Normalization
text = text.lower()
Converts all characters to lowercase to ensure consistency. This prevents the same word in different cases (e.g., “SEO” vs “seo”) from being treated as separate tokens.
· Symbol and Punctuation Cleaning
text = re.sub(r'[^a-z0-9\s\-]’, ‘ ‘, text)
Retains only letters, digits, spaces, and hyphens, removing all other special characters (e.g., punctuation or symbols) that are not useful for topic analysis.
· Whitespace and Hyphen Normalization
text = re.sub(r'[\-]{2,}’, ‘ ‘, text) text = re.sub(r’\s{2,}’, ‘ ‘, text)
Cleans up excess hyphens or spaces that may have resulted from formatting in the original HTML, ensuring uniform token separation.
· Tokenization
tokens = nltk.word_tokenize(text)
Breaks down the cleaned text into individual word units, making the content machine-readable for subsequent analysis.
· Filtering and Lemmatization
clean_tokens = [ lemmatizer.lemmatize(token) for token in tokens if token not in stop_words and len(token) > 2 ]
- Removes stopwords (e.g., “the”, “and”, “in”) which do not contribute meaningfully to topic differentiation.
- Ignores very short tokens (less than 3 characters) to reduce noise.
- Uses lemmatization to convert words to their base or root form (e.g., “running” becomes “run”), improving generalization in topic recognition.
This function ensures that only valuable, normalized textual elements remain from each web page, creating a clean foundation for the LDA model to identify meaningful semantic patterns across content. It is essential for maintaining reliability and interpretability in the final topic assignments.
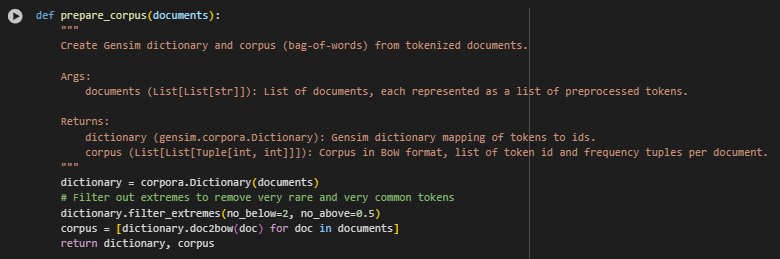
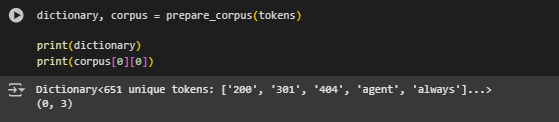
Corpus Preparation Function: prepare_corpus(documents)
Function Summary
This function transforms preprocessed text data into a numerical format that is compatible with the Latent Dirichlet Allocation (LDA) model. Specifically, it generates a dictionary and a corpus using the Bag-of-Words (BoW) representation. This step is fundamental for enabling the model to learn topic patterns based on word frequencies across documents.
Key Implementation Highlights
· Dictionary Creation
dictionary = corpora.Dictionary(documents)
Constructs a Gensim dictionary, which maps each unique token (word) in the corpus to a unique integer ID. This mapping is used to convert word-based data into an efficient numerical form.
· Vocabulary Filtering
dictionary.filter_extremes(no_below=2, no_above=0.5)
Removes tokens that are:
- Too rare (appear in fewer than 2 documents)
- Too common (appear in more than 50% of documents)
- This filtering eliminates noisy or uninformative words, such as typos or overly generic terms, which can dilute the topic clarity.
· Bag-of-Words Corpus Creation
corpus = [dictionary.doc2bow(doc) for doc in documents]
Converts each document into a Bag-of-Words (BoW) format—a list of tuples where each tuple contains:
o A token ID (from the dictionary)
o The frequency of that token in the document
This representation preserves how often each term appears, which is essential for topic modeling to weigh word importance.
This function produces two essential components:
Dictionary – Defines the vocabulary space for the model.
Corpus – Provides a frequency-based numerical representation of each document.
Together, they serve as the input foundation for training the LDA model, enabling it to detect thematic patterns and organize documents according to their content topics. These elements are critical for achieving accurate, scalable, and interpretable topic modeling outcomes.
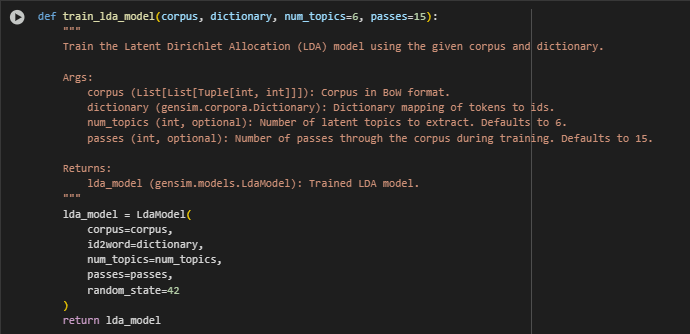
Model Training Function: train_lda_model(corpus, dictionary, num_topics=6, passes=15)
Function Summary
This function trains the Latent Dirichlet Allocation (LDA) model using the prepared numerical representations of documents. The model learns to uncover latent topics—patterns of word usage that frequently co-occur in the dataset—across the content corpus. These topics serve as the foundation for understanding, grouping, and aligning content based on thematic relevance.
Key Implementation Highlights
· Model Initialization and Training
lda_model = LdaModel( corpus=corpus, id2word=dictionary, num_topics=num_topics, passes=passes, random_state=42 ) This block configures and trains the LDA model with the following core components:
- corpus: The bag-of-words matrix representing the frequency of terms in each document.
- id2word: The token-to-ID dictionary used to interpret model results in human-readable terms.
- num_topics=6: Specifies that the model should extract six distinct latent topics. This value is adjustable based on the content diversity and client needs.
- passes=15: The number of times the model iterates over the entire dataset. More passes allow the model to better converge on coherent topics, especially useful when documents are complex or the corpus is small.
- random_state=42: Sets a consistent seed for reproducibility of results.
What This Function Delivers
· Trained LDA Model
The result is a fully trained topic model that has learned to categorize documents by detecting statistically significant patterns of word usage. These patterns are represented as probability distributions over the defined topics.
· Semantic Structuring of Content
The model enables downstream actions such as:
- Determining which topics are present in each document
- Ranking content based on topical relevance
- Identifying topic overlaps or gaps across web pages
This trained LDA model acts as the core engine for the entire topic modeling framework, allowing client websites to be programmatically analyzed for content alignment, SEO structuring, and internal linking potential based on actual semantic signals.
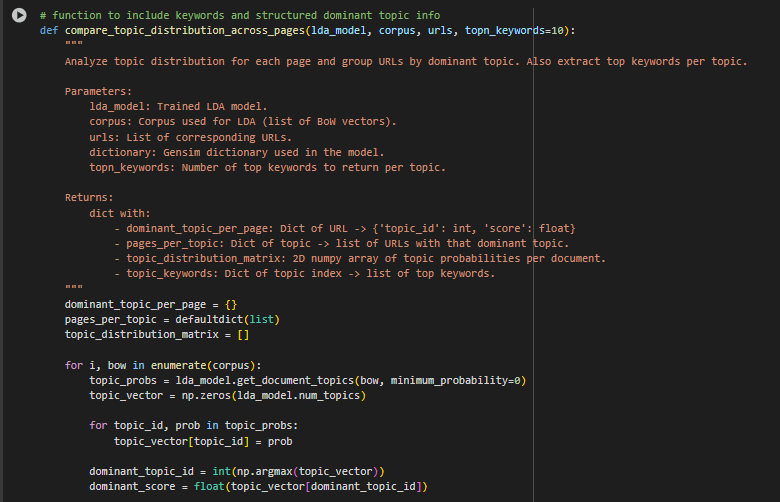
Function: compare_topic_distribution_across_pages(lda_model, corpus, urls, topn_keywords=10)
Function Summary
This function analyzes how topics—extracted by the trained LDA model—are distributed across each individual webpage. For every page, the function identifies the most dominant topic and organizes URLs based on their primary thematic alignment. Additionally, it provides a list of representative keywords for each topic and constructs a matrix of topic probabilities for further interpretation or visualization.
This stage serves as the semantic interpretation layer of the project—where raw model output is translated into structured insights for client decision-making.
Key Implementation Highlights
· Mapping Pages to Their Most Relevant Topic
topic_probs = lda_model.get_document_topics(bow, minimum_probability=0) … dominant_topic_id = int(np.argmax(topic_vector)) … dominant_topic_per_page[url] = { ‘topic_id’: dominant_topic_id, ‘score’: round(dominant_score, 4) }
- For each webpage (document), the function retrieves the full topic probability distribution (i.e., how much each topic contributes to the page).
- It then selects the most dominant topic (the one with the highest score) and records the confidence score for that selection.
- This creates a clear mapping of each URL to its strongest topical category—forming the basis for clustering and internal optimization.
· Grouping Pages by Shared Dominant Topic
pages_per_topic[dominant_topic_id].append(url)
o Pages that share the same primary topic are grouped together.
o This grouping directly supports SEO strategies such as:
- Thematic clustering for internal linking
- Identifying redundant content areas
- Detecting content silos or topic gaps
· Constructing the Topic Distribution Matrix
topic_distribution_matrix.append(topic_vector) … topic_distribution_matrix = np.array(topic_distribution_matrix)
- A 2D matrix is generated, where each row corresponds to a webpage and each column represents a topic.
- Values in this matrix indicate how strongly each topic is expressed in each page.
- This structure enables quantitative comparisons and visual diagnostics using heatmaps, clustering, or UMAP/t-SNE.
· Extracting Top Keywords for Each Topic
top_words = lda_model.show_topic(topic_id, topn=topn_keywords) topic_keywords[topic_id] = [word for word, _ in top_words]
- The function surfaces the top N keywords for each topic, which act as semantic labels or descriptors.
- These keywords help non-technical stakeholders understand what each topic represents, enhancing transparency and strategic alignment.
· Outputs Returned
The function returns a structured dictionary containing four crucial elements:
- dominant_topic_per_page A mapping of each URL to its most dominant topic and the corresponding confidence score.
- pages_per_topic A grouping of URLs by their dominant topic, facilitating thematic analysis.
- topic_distribution_matrix A document-topic matrix for heatmap or clustering visualizations.
- topic_keywords Keywords defining each topic, aiding interpretability for clients and strategists.
This function transforms the raw model output into actionable insight—allowing SEO teams, content managers, and strategists to understand content alignment, reorganization opportunities, and gaps to fill. It is one of the most crucial pieces in realizing the real-world business impact of LDA-based topic modeling.
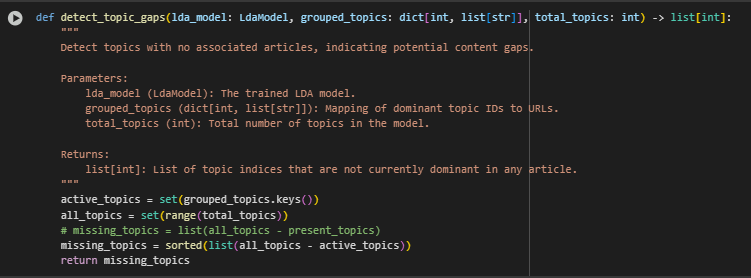
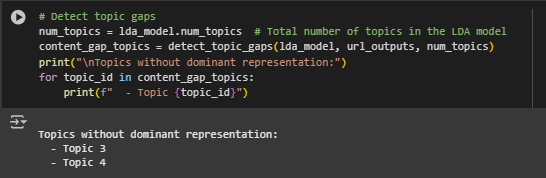
Function: detect_topic_gaps(topic_data, total_topics)
Function Summary
This utility function identifies latent topics that are not prominently featured in any of the analyzed webpages. These absent topics are referred to as topic gaps—important indicators of missing content coverage within the site’s overall structure.
By pinpointing topics that are not dominant on any page, this function enables content planning and expansion strategies designed to improve topical authority, search coverage, and internal coherence.
Key Implementation Highlights
· Extracting Topics Represented on Existing Pages
present_topics = set(topic_data[‘pages_per_topic’].keys())
- The function first identifies which topics are already represented as dominant on at least one webpage.
- It uses the pages_per_topic dictionary (generated by the earlier topic distribution function) to extract all observed dominant topics.
· Calculating the Set of All Topics Modeled
all_topics = set(range(total_topics))
- Here, a complete set of all topics extracted by the LDA model is created—using topic indices from 0 to total_topics – 1.
· Finding Gaps by Set Difference
return list(all_topics – present_topics)
- The function computes the difference between all modeled topics and the set of present dominant topics.
- The result is a list of topic indices that have no dominant presence on any webpage—these are the topic gaps.
Output Returned
List of gap topic indices (e.g., [2, 5]): Each entry corresponds to a topic that, while modeled by LDA, is not the dominant topic on any document.
Strategic Value
Identifying topic gaps is essential for:
- Creating new content to fill missing thematic areas
- Improving semantic coverage for broader SEO impact
- Aligning with user intent by ensuring all key themes are addressed
By surfacing unrepresented topics, this function drives targeted content expansion and strengthens a website’s overall topical authority within its domain.
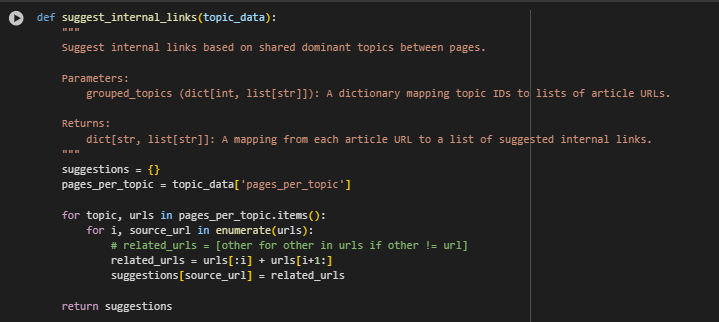
Function: suggest_internal_links(topic_data)
Function Summary
This function automatically generates internal linking suggestions between pages that share the same dominant topic, as identified by the LDA model. By creating logical internal links based on topical similarity, the function helps strengthen:
- Semantic structure
- Topical authority
- Crawling efficiency
- User navigation experience
It returns a mapping from each page to a list of other pages that cover the same primary topic, enabling relevant and meaningful internal connections.
Key Implementation Highlights
· Extract Pages Grouped by Dominant Topic
pages_per_topic = topic_data[‘pages_per_topic’]
- This retrieves a dictionary mapping each topic ID to a list of URLs where that topic is dominant.
- It serves as the foundation for generating internal linking suggestions within each topical group.
· Suggest Links to Other Pages Within the Same Topic Group
for topic, urls in pages_per_topic.items(): for i, source_url in enumerate(urls): related_urls = urls[:i] + urls[i+1:] suggestions[source_url] = related_urls
For each topic cluster:
- Every URL is treated as a source page.
- The other pages within the same cluster are treated as potential internal link targets.
- This ensures all pages link to semantically related content based on topic alignment.
Output Returned
Dictionary of Internal Linking Suggestions:
{ ‘url_1’: [‘url_2’, ‘url_3’], ‘url_4’: [‘url_5’], … } Each key is a source page, and the value is a list of other pages that share its dominant topic and are good candidates for internal linking.
Strategic Value
Internal linking suggestions generated by this function support several core content and SEO objectives:
- Improved topical clustering: Strengthens the semantic network around key topics.
- Enhanced crawlability and indexation: Helps search engines discover and understand related content.
- Better user journey: Guides visitors through thematically linked content, increasing session duration.
- Authority flow optimization: Passes page rank and contextual relevance across similar pages.
This automated system simplifies the traditionally manual process of identifying internal links and ensures that connections are content-driven and contextually valid.
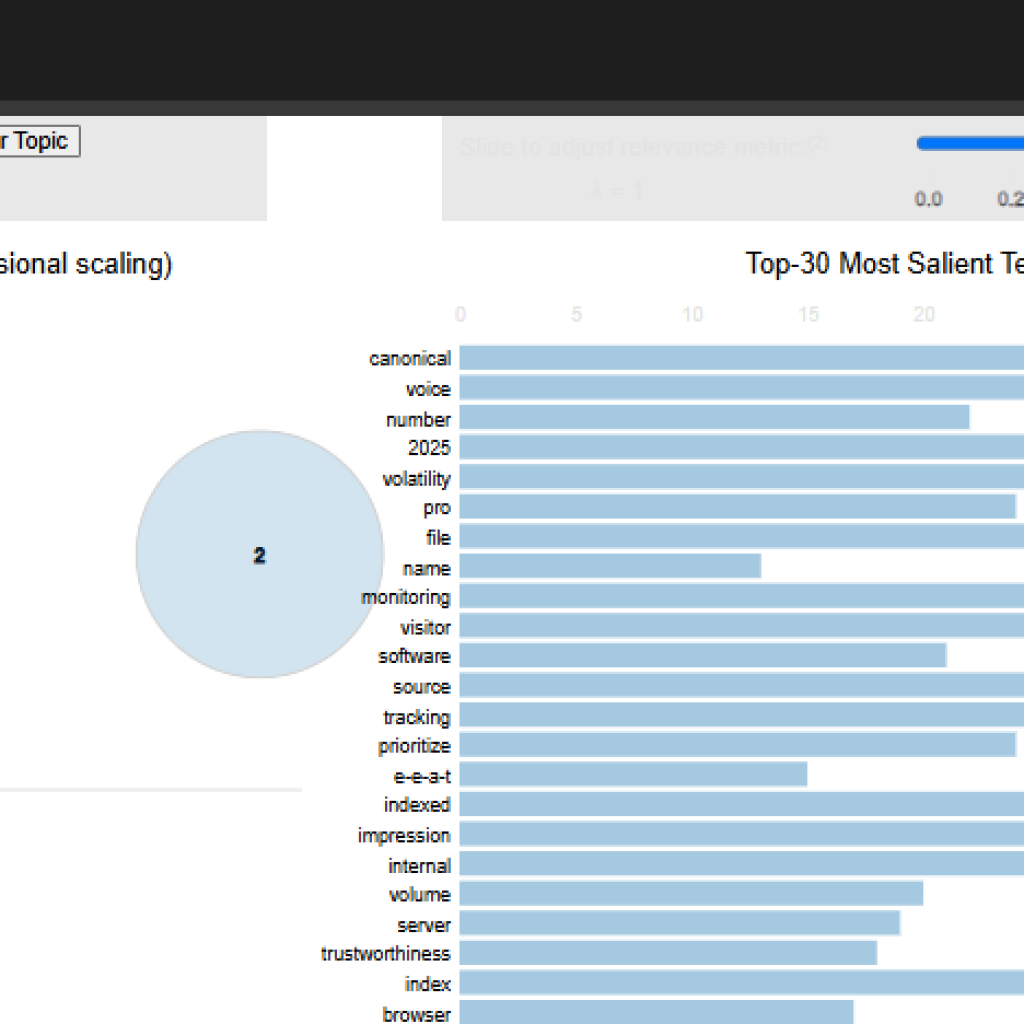
Interpreting the pyLDAvis Topic Visualization
The pyLDAvis.display(vis_data) output generates an interactive visual map of topics identified by the LDA model. This visualization serves as a practical interface for understanding how topics are distributed, how distinct they are, and what words define them.
Left Panel: Topic Circles on the Inter-topic Distance Map
- Each circle in the left panel represents one of the six topics discovered by the model.
- The size of each circle reflects the prevalence of that topic across the corpus.
- The distance between circles indicates semantic distinctiveness:
- Closer circles suggest overlapping or related content.
- Distant circles suggest well-separated topical themes.
Based on the keyword similarity, some overlap or clustering may be observed between:
- Topic 0, 1, 2, and 4, which all emphasize terms like search, content, user, seo, page, google, ranking.
- This suggests a group of topics that focus on general SEO and search engine strategies.
Topic 3 might appear slightly more isolated:
- Contains unique terms such as header, tool, cora, http, indicating focus on technical SEO tools or audit techniques.
Right Panel: Keyword Bar Chart for Selected Topic
When hovering or selecting a topic from the left panel:
- The right panel shows a horizontal bar chart of the top keywords for that topic.
- The bars distinguish:
- Red (saliency): Words frequently used across the corpus.
- Blue (relevance): Words most unique to the selected topic.
For example:
- Selecting Topic 1 might reveal “core” and “update” as high-relevance keywords, indicating content about Google core updates and their impact on SEO.
- Topic 3’s bar chart would highlight keywords like cora, tool, header, strongly pointing to on-page SEO audit tools or technical analysis content.
Topic Summary from Visualization
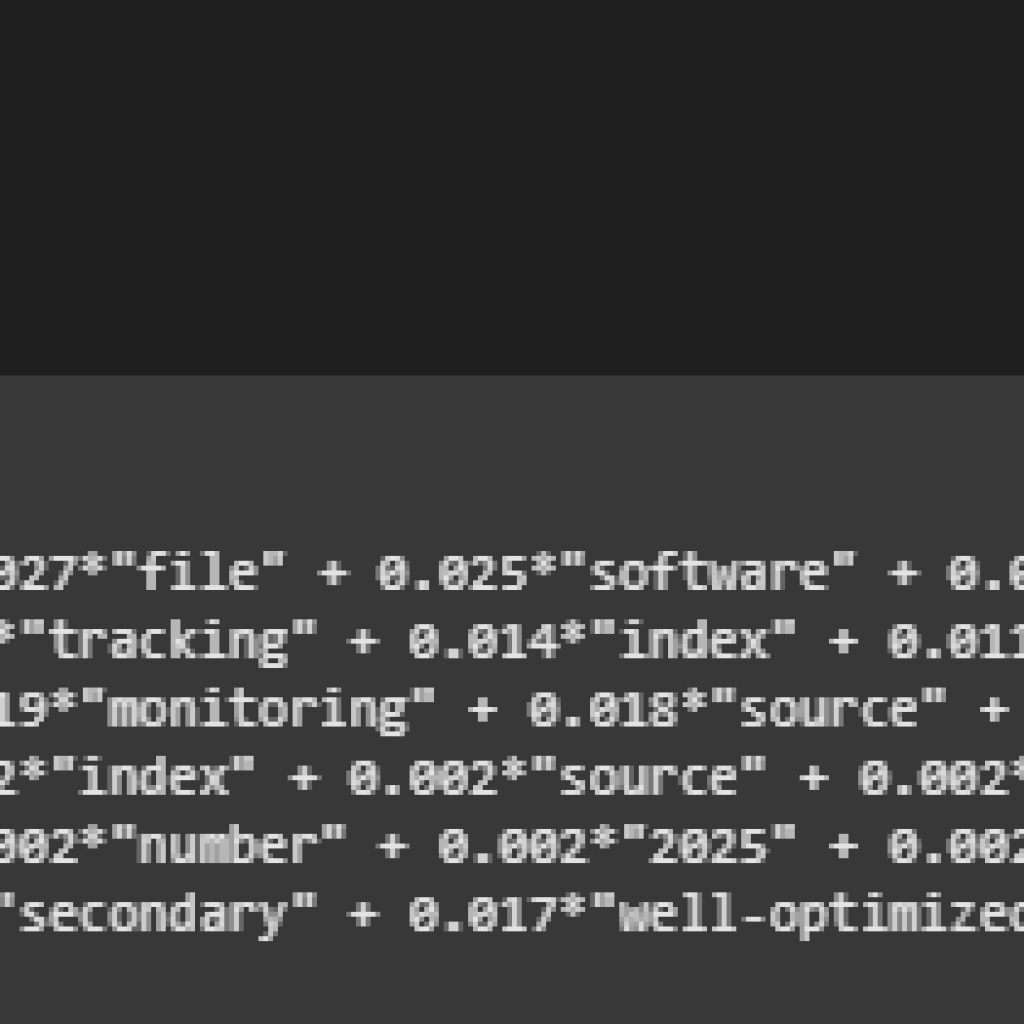
Topic 0: SEO strategy and business impact (search engine strategies)
Topic 1: Core updates and user experience focus (Google updates, UX in SEO)
Topic 2: Traffic and performance strategies (ranking, search performance)
Topic 3: Technical tools and audit practices (headers, tools, technical elements)
Topic 4: General SEO strategies for websites and businesses
Topic 5: Visibility and conversion-focused content (business and traffic visibility)

Final Output Analysis and Explanation
This section provides a comprehensive breakdown of the topic modeling results using Latent Dirichlet Allocation (LDA). The findings are derived from analyzing the semantic distribution of themes across multiple web content pages. These insights are intended to guide decisions related to internal linking, content gap identification, and thematic alignment across the site.
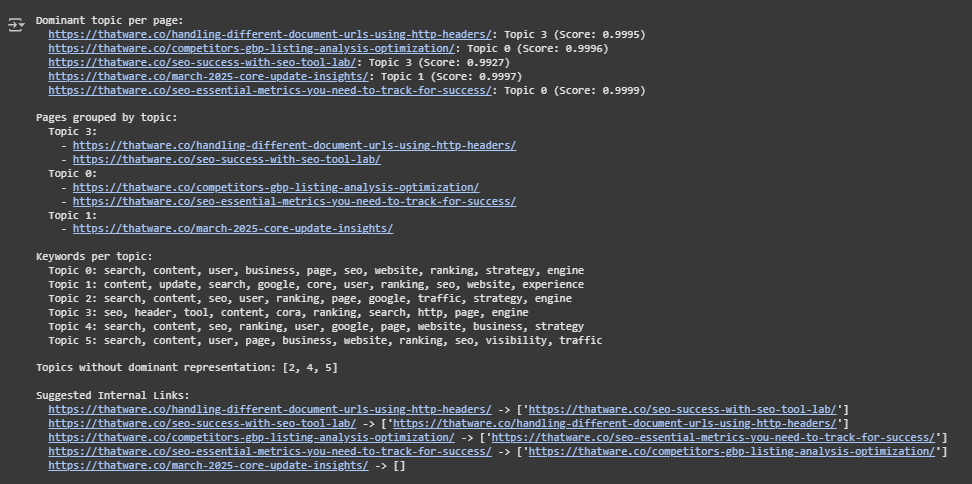
Dominant Topics Across Pages
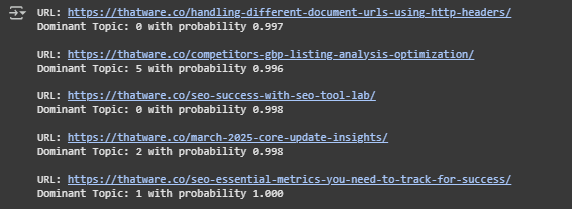
Each content page has been evaluated to determine which latent topic it most strongly represents. The model computes a topic probability distribution for every page, and the topic with the highest score is assigned as the dominant topic for that page. The scores indicate high topic coherence, with values approaching 1.0, signifying strong alignment between the content and the identified theme.
For instance, several pages are almost entirely aligned with Topic 0, Topic 1, or Topic 3. These dominant assignments suggest that the content on each of those pages is highly focused around a specific thematic area, allowing for confident categorization and targeted content actions.
Grouping of Pages by Shared Themes
Pages have been grouped based on their dominant topic to uncover clusters of semantically related content. This grouping is foundational for discovering how well the current content architecture supports thematic consistency:
- Topic 0 represents a common theme focused on SEO strategy and user-centered content, featuring keywords such as search, content, user, business, website, and strategy. Pages grouped here likely discuss broad SEO planning, performance tracking, or user behavior optimization.
- Topic 1 centers around algorithmic updates and their SEO implications, as evidenced by terms like core, update, google, experience, and ranking. Content in this group likely provides insights into recent search engine changes and best practices for adaptation.
- Topic 3 is more technically oriented, highlighting tools and structural elements through keywords like header, tool, cora, http, and engine. Pages under this topic probably focus on on-page SEO, technical audits, or implementation techniques.
These groupings allow for structured content architecture and enable better internal linking strategies, as related topics are now programmatically identified.
Identification of Underrepresented Topics
An essential part of the analysis involves detecting topic gaps—themes that exist in the LDA model but are not dominantly represented by any content. Topics 2, 4, and 5 fall into this category.
- Topic 2 shares overlapping keywords with both Topics 0 and 1 but is uniquely positioned to explore traffic generation strategies and deeper keyword optimization.
- Topic 4 may reflect a blend of SEO fundamentals and competitive strategy, useful for onboarding or beginner-level educational material.
- Topic 5 introduces terms like visibility and traffic, which could support content focused on conversion rate optimization and SERP visibility.
The absence of content dominantly aligned with these topics presents opportunities for content expansion. These gaps indicate thematic areas that are relevant but under-addressed, and filling them would help create a more balanced and comprehensive content strategy.
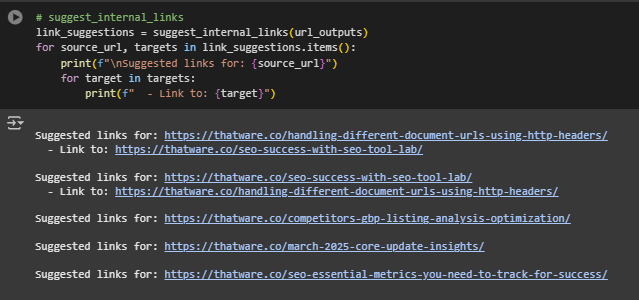
Internal Linking Recommendations
The model also outputs a list of suggested internal links based on topic alignment. For each page, other content items within the same dominant topic group are recommended as potential linking candidates. This approach strengthens the topical structure of the website and enhances user navigation.
- Pages that share the same dominant topic are ideal candidates for interlinking, as they cater to similar user intents and reinforce thematic authority.
- Internal linking suggestions have been automatically generated by excluding self-references and only including other pages that belong to the same topic.
- In cases where a topic group contains only one page, no internal linking recommendations are made, as no related page exists within the same theme cluster. This further reinforces the content gap and can help prioritize content creation efforts.
These internal link suggestions are not only useful for improving SEO crawlability and link equity flow, but they also contribute to better user engagement by guiding visitors through semantically related content.
Final Thoughts
The LDA-based topic modeling system offers a data-driven approach to understanding how content aligns with strategic themes, reveals content gaps, and enhances internal linking opportunities. By evaluating the dominant topics per page and analyzing the overall distribution across the site, this project provides practical insights into how well the current content structure supports discoverability, authority, and user intent alignment.
Three key outcomes are immediately actionable:
- Content Focus Analysis: Identifying which pages are strongly aligned with specific topics helps determine which content assets are best positioned as authority pieces within their thematic area. These pages serve as ideal candidates for cornerstone content and targeted internal linking.
- Topic Gap Detection: Uncovered topic gaps highlight critical areas where new content is needed to capture untapped search demand. This insight enables the site to grow strategically and cover broader semantic territory.
- Internal Link Structuring: Suggested internal links based on shared dominant topics offer a high-confidence way to improve crawlability and semantic connectivity, both of which support ranking strength and user navigation.
Together, these capabilities not only improve on-page SEO performance but also support the broader goal of building a semantically cohesive and search-optimized site architecture. This approach moves beyond keyword targeting, embracing a thematic content strategy that is sustainable, measurable, and aligned with modern search engine behaviors.
As search algorithms continue to prioritize topic authority and semantic relevance, implementing the insights from this analysis can play a pivotal role in achieving long-term organic growth.
