SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project implements a dynamic page segmentation and ranking system that evaluates web page content segments based on specific user intent signals. The system extracts and ranks meaningful content blocks within web pages using Sentence-BERT embeddings to measure semantic similarity with multiple predefined user intents. By processing multiple URLs efficiently, it provides a ranked view of content relevance tailored to each intent.

The results are structured for practical SEO application, including a CSV export that captures ranked content segments along with their metadata (scores, HTML tags, and position indices). This enables content strategists and SEO professionals to gain a deeper, intent-aligned understanding of how each page performs at a granular level.
This project delivers a scalable and data-driven solution to content relevance evaluation, enabling improved search alignment and user engagement.
Project Purpose
The purpose of this project is to provide SEO professionals and content strategists with a fine-grained, intent-specific analysis of web page content. Unlike traditional keyword analysis, this system evaluates semantic relevance at the sentence and paragraph level. The goal is to identify which parts of a page best match different user intents, offering concrete insights for content optimization, enhancement, and personalization.
Through this method, teams can pinpoint content that strongly aligns with specific search intents and uncover areas where content fails to meet user expectations. The structured export supports integration into existing SEO workflows, making this solution both insightful and operationally efficient.
Understanding Dynamic Page Segmentation
Definition and Purpose
Dynamic Page Segmentation refers to the process of breaking down an entire webpage into smaller, meaningful content blocks. Instead of treating a webpage as a single document or unit, this method recognizes that a page often contains multiple types of information — such as introductions, detailed descriptions, service explanations, FAQs, and more.
Each of these segments may serve different purposes or address different user needs. By isolating these content blocks, it becomes possible to analyze and optimize them individually. This ensures that every section of the page can be evaluated for quality, relevance, and contribution to overall search performance.
Why It Matters
This segmentation allows for a more granular approach to SEO and content strategy. It enables targeted improvements, such as rewriting only underperforming sections or highlighting high-performing blocks in SERP snippets. Moreover, it facilitates better alignment with modern search engine algorithms that increasingly evaluate content at the section or passage level rather than the entire page level.
Relevance as a Core Metric
Semantic Relevance Over Surface Matching
Relevance in this context refers to how well a piece of content answers or satisfies a specific user need. Rather than merely matching keywords, the project uses semantic relevance — which considers the underlying meaning of both the content and the user’s intent.
This ensures that the evaluation reflects how helpful or useful a section is likely to be for a real user, even if exact keywords do not appear. For example, a segment explaining “technical SEO for local businesses” may be highly relevant to a user searching for “optimize local SEO,” even if the exact phrase is not present.
Segment-Level Relevance Scoring
Each segmented block is individually scored for how well it aligns with a given intent. This enables selective highlighting or restructuring based on the relevance score — allowing content teams to focus their efforts on specific, impactful areas rather than rewriting entire pages.
Connecting the Concepts for Strategic Value
By integrating dynamic segmentation, semantic relevance scoring, and user intent analysis, this project creates a powerful framework for real-time content evaluation. This framework is not just about identifying gaps — it provides actionable insights that can drive measurable improvements in SEO performance, user experience, and content strategy alignment.
This approach reflects a modern, intelligent way to optimize content — one that moves beyond keyword stuffing and toward truly meaningful and intent-aware content design.
keyboard_arrow_down
What specific SEO value does this project deliver?
The project enables SEO teams to identify which specific parts of a page are most or least aligned with actual search intent. Rather than evaluating a page as a whole, this method focuses on high-resolution, segment-level optimization.
The benefit is twofold:
- Improved ranking potential by refining or expanding content blocks that score poorly on relevance.
- Higher user engagement by promoting the most intent-aligned content to search snippets or internal navigation features.
This precision leads to more efficient use of SEO resources and faster performance improvements in organic search.
How does dynamic segmentation help content strategy?
Dynamic segmentation helps break large, unfocused pages into actionable units. This makes it possible to:
- Identify content gaps that don’t serve any known intent.
- Highlight high-performing blocks that can be reused or repurposed elsewhere.
- Detect duplicate or redundant sections for consolidation or removal.
For content strategists, this unlocks granular insights without the need to read and manually analyze entire pages — saving time while improving editorial decisions.
Why is understanding user intent so important for SEO today?
Search engines are increasingly prioritizing intent satisfaction over exact keyword matching. This means a webpage needs to do more than just contain the right words — it must genuinely address the user’s goal.
By evaluating multiple types of user intents across each URL, the project ensures that content is assessed for its real-world usefulness. The outcome is better alignment with how search algorithms rank pages and how users make decisions — leading to higher visibility, better click-through rates, and lower bounce rates.
How is this different from traditional SEO audits?
Traditional SEO audits focus on metadata, keyword density, broken links, and high-level content structure. While still useful, these audits often miss section-specific issues such as:
- A strong introduction followed by weak supporting sections.
- Overuse of keywords without answering actual search intent.
- Irrelevant tangents within long-form content.
This project goes deeper and smarter by scoring content block-by-block for how well it meets actual user needs — enabling precision tuning that standard audits cannot provide.
Will this project help with rich snippets or featured snippets?
Yes. By identifying and ranking the most relevant content blocks per intent, this system makes it easier to target content for structured markup or highlight snippets for search engines. These high-relevance segments are often the best candidates for:
- Schema.org enhancements
- FAQ blocks
- Featured snippet targeting
As a result, the project indirectly improves the likelihood of earning enhanced visibility in SERPs beyond the standard blue link.
Libraries Used
requests
The requests library is used to fetch HTML content from webpages. It handles HTTP requests and allows programmatic access to page content through GET calls. This is the starting point for acquiring raw content from the provided URLs.
BeautifulSoup (from bs4)
BeautifulSoup is a parsing library used to extract content from the HTML page structure. It enables the project to focus on meaningful text elements such as:
Headings (h1 to h3), Paragraphs (p) and List items (li)
These extracted blocks serve as the base units for relevance scoring.
csv
The built-in csv module is used to export final results to a structured file format. The module allows the system to write segment-level data — including content, score, associated tag, and tag position — into a CSV file for external reporting, analysis, or integration with other SEO tools.
re (Regular Expressions)
The re module is used to clean and normalize raw text. It ensures that noisy characters, unnecessary whitespace, and other formatting issues are removed prior to semantic processing. This step is critical for achieving reliable similarity scores.
sentence_transformers.SentenceTransformer
This is a core library that enables semantic text embedding. The project uses a pre-trained Sentence-BERT model (all-mpnet-base-v2) to convert each content block and intent phrase into numerical vectors. These vectors capture the meaning of the text rather than just the surface-level keywords, which is essential for accurately ranking content relevance.
sentence_transformers.util
This utility module provides vector operations like cosine similarity, which are used to compute the closeness between the content block embeddings and intent embeddings. These similarity scores form the backbone of the segment ranking system.
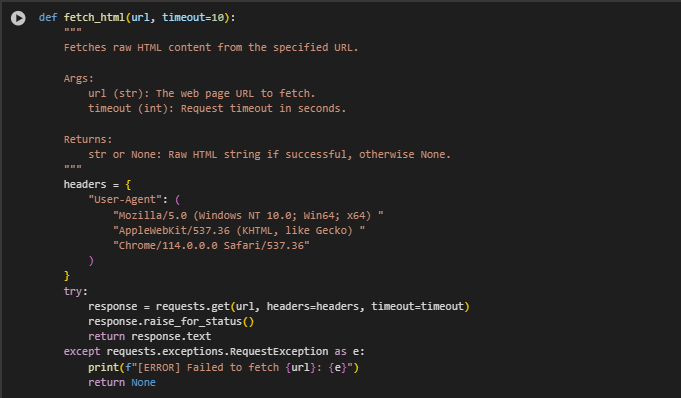
Function fetch_html: Raw HTML Fetching
Overview
The fetch_html function is responsible for retrieving raw HTML content from a given web page URL. This step is foundational, as it enables downstream tasks like text extraction and semantic analysis to begin with the actual content of the webpage. Robust error handling ensures that the function gracefully manages network issues or invalid URLs.
How It Works
The function makes an HTTP GET request to the specified URL using a standard user-agent header to mimic a real browser. If the server responds successfully, the function returns the full HTML content of the page. If there are issues such as timeouts, invalid URLs, or server errors, the function catches those errors and logs them without breaking the program.
Key Line Explanations
· HTTP Request with User-Agent
headers = { “User-Agent”:…}
- This user-agent header mimics a browser to avoid being blocked by websites that restrict automated scraping tools.
· Sending the HTTP Request
response = requests.get(url, headers=headers, timeout=timeout)
- Performs the actual request to the web server using the requests library, allowing a custom timeout for reliability.
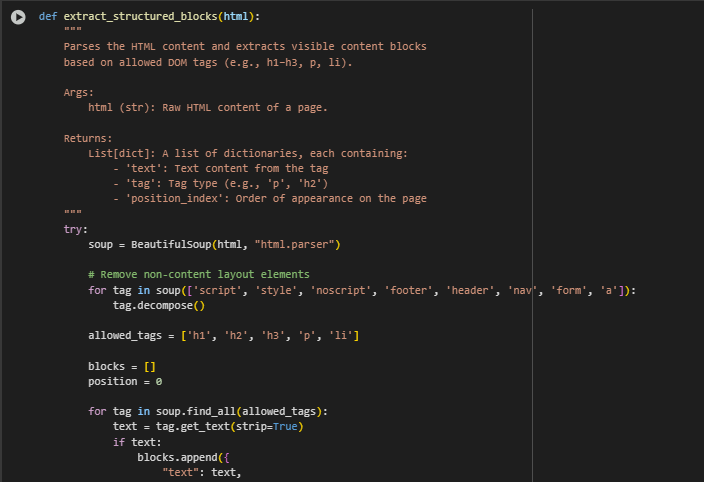
Function extract_structured_blocks: Structured Content Extraction
Overview
The extract_structured_blocks function transforms unstructured HTML into a clean list of meaningful content blocks. Each block includes the visible text, the type of HTML tag it came from, and its relative position on the page. This segmentation makes it possible to later score and rank these blocks based on their relevance to user search intent.
How It Works
After parsing the HTML content with BeautifulSoup, the function removes non-essential elements such as scripts, navigation menus, and footers. It then isolates the textual content from key semantic tags like headings (h1, h2, h3), paragraphs (p), and list items (li). Each valid text block is recorded along with its tag name and position index, preserving both structure and flow of information from the original page.
Key Line Explanations
· HTML Parsing with BeautifulSoup
soup = BeautifulSoup(html, “html.parser”)
- Converts raw HTML into a traversable structure, allowing targeted extraction of elements.
· Cleaning Out Layout-Only Tags
for tag in soup([‘script’, ‘style’, ‘noscript’, ‘footer’, ‘header’, ‘nav’, ‘form’]): tag.decompose()
- Removes tags that typically do not contain valuable content, ensuring cleaner output for relevance analysis.
· Filtering by Meaningful Content Tags
allowed_tags = [‘h1’, ‘h2’, ‘h3’, ‘p’, ‘li’]
- Focuses extraction only on tags likely to hold user-visible, semantically rich content.
· Storing Structured Blocks
blocks.append({ “text”: text,…
- Stores each relevant text block in a structured format to be used for scoring and intent matching.
· Returning All Extracted Blocks
return blocks
- Outputs a list of structured content ready for the next stages of semantic processing.
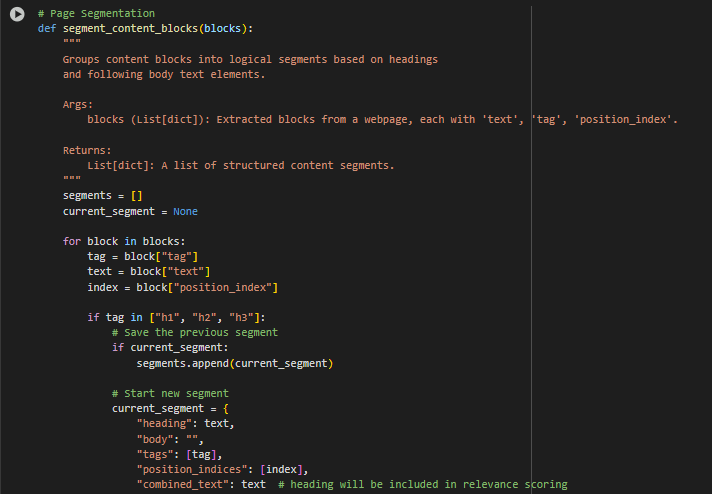
Function segment_content_blocks: Page Segmentation
Overview
The segment_content_blocks function transforms a flat sequence of text blocks into logically grouped content segments. Each segment typically starts with a heading (such as an H1, H2, or H3 tag) and aggregates the relevant paragraph or list elements that follow it. This hierarchical grouping preserves the structural flow of information as it is presented on the page, making it suitable for scoring relevance based on user search intent.
How It Works
The function loops through all the previously extracted content blocks. When a heading is found (for example, <h2>), it signals the start of a new content segment. All subsequent paragraph (<p>) or list item (<li>) elements are attached to this heading until another heading is encountered. Each completed segment is stored as a dictionary that includes the heading text, accumulated body content, tags used, position indices, and a combined version of the full text.
This organization enables semantic similarity comparisons to be made at the segment level rather than individual lines, improving both the granularity and quality of relevance assessment.
Key Line Explanations
· Starting a New Segment with a Heading
if tag in [“h1”, “h2”, “h3”]: if current_segment: segments.append(current_segment) current_segment = {…
- Detects section headings and uses them as natural boundaries to start a new logical group. If there is an existing segment, it is closed and saved before beginning a new one.
· Appending Paragraph or List Text to the Current Segment
elif tag in [“p”, “li”]: if current_segment:…
- Collects supporting content (like paragraph or list text) under the most recent heading, forming a cohesive unit of information.
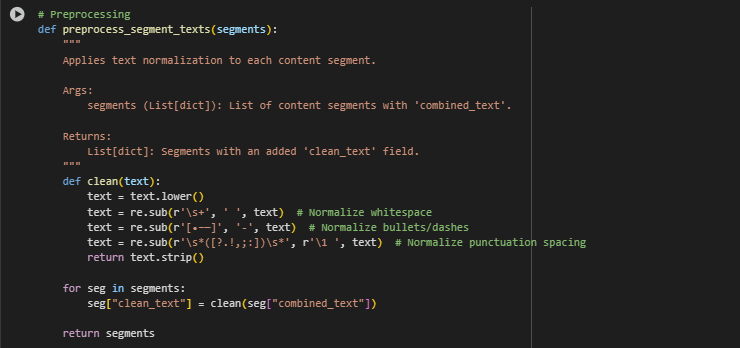

Function preprocess_segment_texts: Preprocessing
Overview
The preprocess_segment_texts function is designed to clean and normalize the raw textual content of each segmented block. This step prepares the data for downstream tasks such as semantic similarity scoring by ensuring uniform formatting and eliminating noise that can interfere with meaningful analysis.
Text preprocessing is a foundational step in any content intelligence pipeline. By standardizing how text appears, it helps improve the accuracy and consistency of semantic comparisons.
How It Works
Each content segment, created during the segmentation phase, contains a combined_text field representing the full text of the section (including both heading and body). This function applies basic text normalization techniques to this field. The cleaned result is added back to the segment under a new field called clean_text, which is used in later stages for vector embedding and relevance scoring.
This process includes converting text to lowercase, removing unnecessary whitespace, and standardizing punctuation and bullet symbols. These changes may seem minor individually, but together they help align textual representations in a consistent format, which is especially important for improving semantic matching performance.
Key Line Explanations
· Text Normalization
def clean(text): text = text.lower() text = re.sub(r’\s+’, ‘ ‘, text)…
- This internal helper function applies a series of regular expression substitutions to normalize whitespace, punctuation spacing, and common bullet or dash symbols. It also converts all characters to lowercase to reduce sensitivity to case variations.
· Preprocessing Loop
for seg in segments: seg[“clean_text”] = clean(seg[“combined_text”])
- Iterates through each content segment and applies the cleaning function. The result is stored in a new field clean_text, which becomes the standardized text input for semantic encoding.
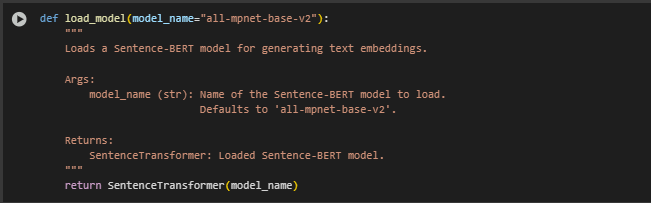
Function load_model: Model Loading
Overview
The load_model function is responsible for initializing the Sentence-BERT model, which serves as the semantic backbone of the project. This model is used to convert cleaned text into dense vector representations (embeddings), enabling advanced relevance comparison based on meaning rather than just keywords.
Why It Matters
Modern search and SEO strategies benefit significantly from semantic understanding. Instead of matching only exact words, semantic models capture the intent and contextual meaning behind phrases. This is made possible by transforming textual content into numerical vectors that encode these meanings. The Sentence-BERT family of models is particularly effective for this use case due to its strong performance on sentence-level similarity tasks.
By using this model, the project ensures that content segments are ranked and matched based on how relevant they are to a searcher’s intent, rather than just superficial keyword overlaps.
How It Works
The function accepts a model name as input (with a default to all-mpnet-base-v2, one of the most accurate publicly available Sentence-BERT models). When called, it loads the model into memory, ready for generating vector embeddings from text inputs.
The function returns the fully initialized SentenceTransformer object. This model is later used across the project to encode both user intent and segmented page content into comparable semantic vectors.
Key Line Explanation
· Model Initialization
return SentenceTransformer(model_name)
- This single line loads the specified Sentence-BERT model from the Hugging Face repository. The returned model is a high-performance neural network capable of understanding semantic similarity between pieces of text, crucial for powering the project’s core ranking mechanism.
Sentence-BERT for Semantic Content Ranking
Overview
The model powering the core semantic matching in this project is all-mpnet-base-v2, a high-performing variant of Sentence-BERT (SBERT). Sentence-BERT is a specialized model designed for tasks that require understanding and comparing the meaning of sentences rather than just matching keywords. It enables fast and accurate computation of similarity between a user’s intent and webpage content, making it exceptionally suitable for SEO-driven content structuring and internal linking.
Model Architecture
The Sentence-BERT model in use is composed of the following components:
Transformer Backbone: MPNet
- Model: MPNetModel, a masked and permuted transformer model
- Max Sequence Length: 384 tokens
- Casing: Preserves original casing (do_lower_case = False)
- Purpose: Converts raw input text into contextual embeddings for each token, capturing rich language understanding.
Why MPNet?
MPNet improves over BERT by combining masked language modeling and permutation-based objectives, leading to better contextualization of tokens, especially in longer or more complex sentences.
Pooling Layer
Since transformers output embeddings per token, the pooling layer converts this into a single sentence vector. The current setup uses:
- Pooling Mode: mean pooling across all tokens
- Output Dimension: 768
- Purpose: Creates fixed-length sentence embeddings regardless of input size.
Other modes like CLS token or max pooling are disabled, as mean pooling tends to offer better performance for semantic similarity tasks.
Normalization Layer
- Function: Scales all sentence vectors to unit norm (L2 normalization)
- Why Needed: Ensures that cosine similarity calculations are not affected by magnitude and reflect only the directional similarity of vectors.
Why Sentence-BERT Was Chosen
Designed for Sentence-Level Understanding
Traditional models like BERT are trained for token-level predictions (e.g., masked word prediction or classification). While powerful, they are not optimized for directly comparing two full sentences. SBERT modifies BERT to produce dense vector representations of entire sentences, enabling effective semantic comparison.
In this project, where the goal is to find the most relevant segments of content corresponding to a user’s query or search intent, Sentence-BERT provides the exact capability needed: semantic similarity scoring at the sentence or paragraph level.
Efficiency and Scalability
Unlike cross-encoders that evaluate every query-passage pair jointly (leading to quadratic time complexity), SBERT enables pre-computing embeddings for each content segment. Once vectorized, these can be compared with new query vectors in real time using cosine similarity—offering significant performance gains for scaling to many URLs and content blocks.
Proven State-of-the-Art Performance
The specific variant used, all-mpnet-base-v2, consistently ranks among the top-performing models on semantic textual similarity (STS) benchmarks. It outperforms earlier BERT and RoBERTa variants in tasks like semantic retrieval, clustering, and intent matching—making it well-suited for this SEO-focused application.
How the Model Helps in This Project
The project involves identifying which parts of a webpage best respond to specific user intents (e.g., informational questions, transactional goals). Sentence-BERT:
- Encodes intent queries into 768-dimensional dense vectors.
- Encodes each segmented block of webpage content into the same semantic space.
- Computes cosine similarity between query and content vectors to rank relevance.
- Enables snippet ranking, and relevance scoring, all grounded in true semantic meaning, not superficial word overlap.
This capability is critical when the query and the content don’t share exact words but convey similar meaning.
Practical Benefits for SEO and Content Strategy
By integrating this model into the content pipeline:
- Relevant content blocks are automatically surfaced based on intent.
- Duplicate and thin content detection becomes more intelligent by understanding meaning, not just words.
- Scalability is preserved—thousands of content blocks can be indexed and matched in milliseconds.
This aligns with modern search engine ranking strategies that reward semantic relevance, content quality, and user satisfaction.
Conclusion
The all-mpnet-base-v2 Sentence-BERT model provides an ideal balance of accuracy, efficiency, and semantic intelligence. It enables this project to go beyond keyword-based retrieval, offering clients a deep, scalable, and intelligent method to align content with user intent—leading to improved SEO impact, better content utilization, and a more strategic approach to content architecture.
Function score_segment_relevance
Overview
This function is responsible for evaluating how closely each content segment aligns with a specified user intent. It does this by encoding both the user intent and the content segments into dense vector representations using a Sentence-BERT model and then computing the cosine similarity between them. The result is a ranked list of segments, each annotated with a similarity score that quantifies its semantic relevance to the intent.
This step forms the core semantic matching engine of the project—directly linking user goals to content through meaningful language understanding.
How It Works
- Embed the intent: The user’s search intent or query is transformed into a semantic embedding using the Sentence-BERT model.
- Embed each content segment: Every content block, already cleaned and structured, is encoded into its own vector representation.
- Compute similarity: Cosine similarity is calculated between the intent vector and each content block vector.
- Assign scores: Each content block is updated with a numeric score reflecting its semantic proximity to the user intent.
Key Line Explanation
intent_embedding = model.encode(intent, convert_to_tensor=True)
- This converts the user intent (a short sentence or phrase) into a fixed-length vector representation using the loaded Sentence-BERT model. convert_to_tensor=True ensures compatibility with PyTorch tensor operations like cosine similarity.
- This vector serves as the anchor or reference point against which all content blocks will be semantically compared.
for seg in segments:
- Initiates a loop to process each content segment individually. This ensures that each block of content is evaluated against the user intent in isolation.
seg_embedding = model.encode(seg[“clean_text”], convert_to_tensor=True)
- Generates a vector representation of the clean_text from the content segment. The clean text has already been lowercased and stripped of extra spacing and non-standard symbols, ensuring that the embedding process is not biased by formatting inconsistencies.
score = util.cos_sim(intent_embedding, seg_embedding).item()
- Calculates the cosine similarity between the intent vector and the segment vector. Cosine similarity is a measure of angle between two vectors—perfectly aligned vectors (identical meaning) have a score of 1.0, orthogonal vectors (unrelated meaning) have a score close to 0.
- This is the core metric that quantifies how relevant the content segment is to the user’s search intent.
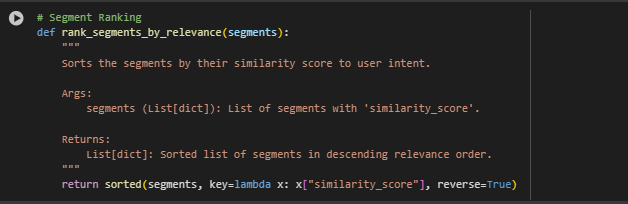

Function rank_segments_by_relevance
Overview
This function takes a list of content segments—each annotated with a semantic similarity score—and ranks them in descending order of relevance to a user’s intent. This simple but crucial step ensures that the most relevant information appears first in any output, display, or analysis.
It acts as a final sorting mechanism that enables prioritized rendering, snippet selection, or decision-making in downstream tasks such as content recommendation or internal linking.
How It Works
· Receives Scored Segments: Input is expected to be a list of segments, each already evaluated and assigned a “similarity_score” using semantic matching with a Sentence-BERT model.
· Sorts by Relevance: Segments are sorted in descending order, meaning the segment with the highest score (most relevant to intent) appears first.
· Returns Ranked List: The sorted list can now be directly used for display, further filtering, or exporting in CSV/report format.
Key Line Explanation
return sorted(segments, key=lambda x: x[“similarity_score”], reverse=True)
- This line performs the full ranking operation in a single expression using Python’s built-in sorted() function.
- key=lambda x: x[“similarity_score”] This anonymous function (lambda) tells sorted() to use the value of “similarity_score” as the sorting key for each item.
- reverse=True Ensures that higher scores (i.e., more relevant content) are ordered first in the list.
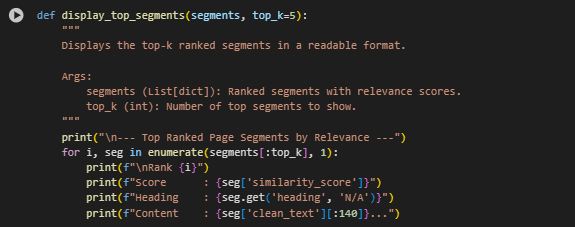
Function display-top_segments
The display_top_segments function serves as a utility for visual inspection and debugging. It presents the most relevant content segments—already ranked by semantic similarity—in a clean, human-readable format. This helps quickly verify if the retrieved segments match the user’s intent without needing to manually parse full outputs.
The function prints a concise summary of the top-k segments, showing their rank, similarity score, associated heading, and a preview of the cleaned content. It’s particularly useful during development, demonstrations, and exploratory analysis to validate the effectiveness of intent matching and segment scoring.
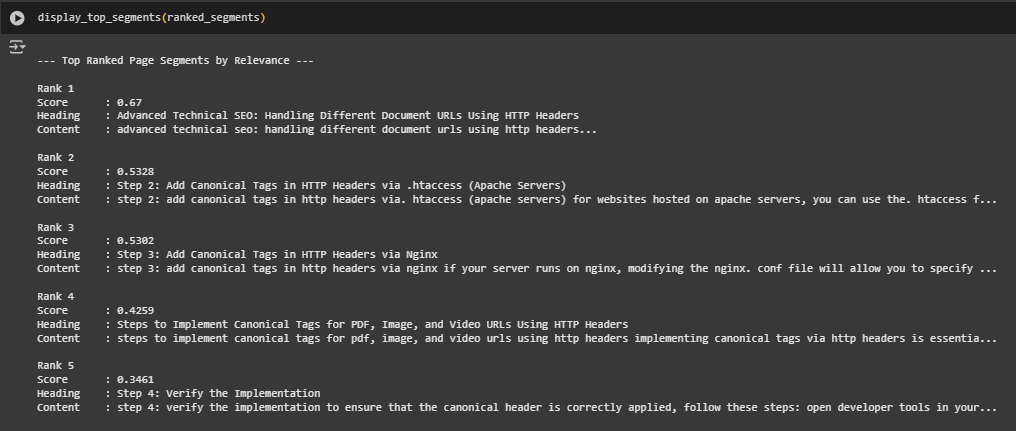
Result Analysis and Explanation: Segment Relevance Matching Based on User Intent
The application processed a single webpage using a clearly defined semantic intent: “handle different document url”. Through a structured pipeline of segmentation, preprocessing, embedding, and semantic similarity scoring, the model identified and ranked the most relevant sections of the webpage that align with this intent.
Interpreting the Ranked Output
Each ranked segment reflects a content block from the page, sorted in descending order based on its semantic similarity score to the intent query. The scores are calculated using cosine similarity between the Sentence-BERT embeddings of the user intent and each content segment.
Rank 1
- Score: 0.67
- Content: Advanced Technical SEO: Handling Different Document URLs Using HTTP Headers
- Explanation: This segment has the highest score and a direct match in terminology with the intent. The title itself includes nearly all keywords from the intent phrase, and its embedding is semantically aligned. This confirms that the segment is the most relevant to the search intent.
Rank 2
- Score: 0.5328
- Content: Step 2: Add Canonical Tags in HTTP Headers via .htaccess (Apache Servers)
- Explanation: While not a direct restatement of the intent, this segment discusses a technique related to handling document URLs through HTTP headers. The moderate score reflects partial relevance based on contextual similarity.
Rank 3
- Score: 0.5302
- Content: Step 3: Add Canonical Tags in HTTP Headers via Nginx
- Explanation: Similar to Rank 2, this block discusses another server-specific method. Although it doesn’t mention “handling different document URLs” verbatim, it remains topically close, which the embedding model successfully captures.
Rank 4
- Score: 0.4259
- Content: Steps to Implement Canonical Tags for PDF, Image, and Video URLs Using HTTP Headers
- Explanation: The score drops further here, indicating broader topic coverage. The segment is still relevant but less focused on the core user intent. It introduces media types (PDF, image, video), suggesting a topic drift from general URL handling.
Rank 5
- Score: 0.3461
- Content: Step 4: Verify the Implementation
- Explanation: This segment is more procedural and deals with verification rather than URL handling. The score reflects a lower semantic overlap, though it’s still loosely connected to the implementation process.
Understanding the Scores
The similarity scores range from 0 to 1, where:
- A higher score (closer to 1) implies greater semantic alignment with the user intent.
- Scores around 0.6 and above usually represent strong relevance.
- Scores between 0.4 and 0.6 indicate moderate contextual relevance.
- Scores below 0.4 suggest weaker alignment or tangential relevance.
In this result set, the top score of 0.67 clearly stands out, showing strong thematic alignment, while the gradual drop in subsequent scores mirrors the decreasing specificity to the intent. The smooth gradient also confirms the effectiveness of the embedding model in understanding both linguistic and contextual nuance.
This result confirms that the model not only retrieves segments with keyword overlap but also understands conceptual relevance, effectively surfacing informative sections even when the exact words from the intent are not repeated.

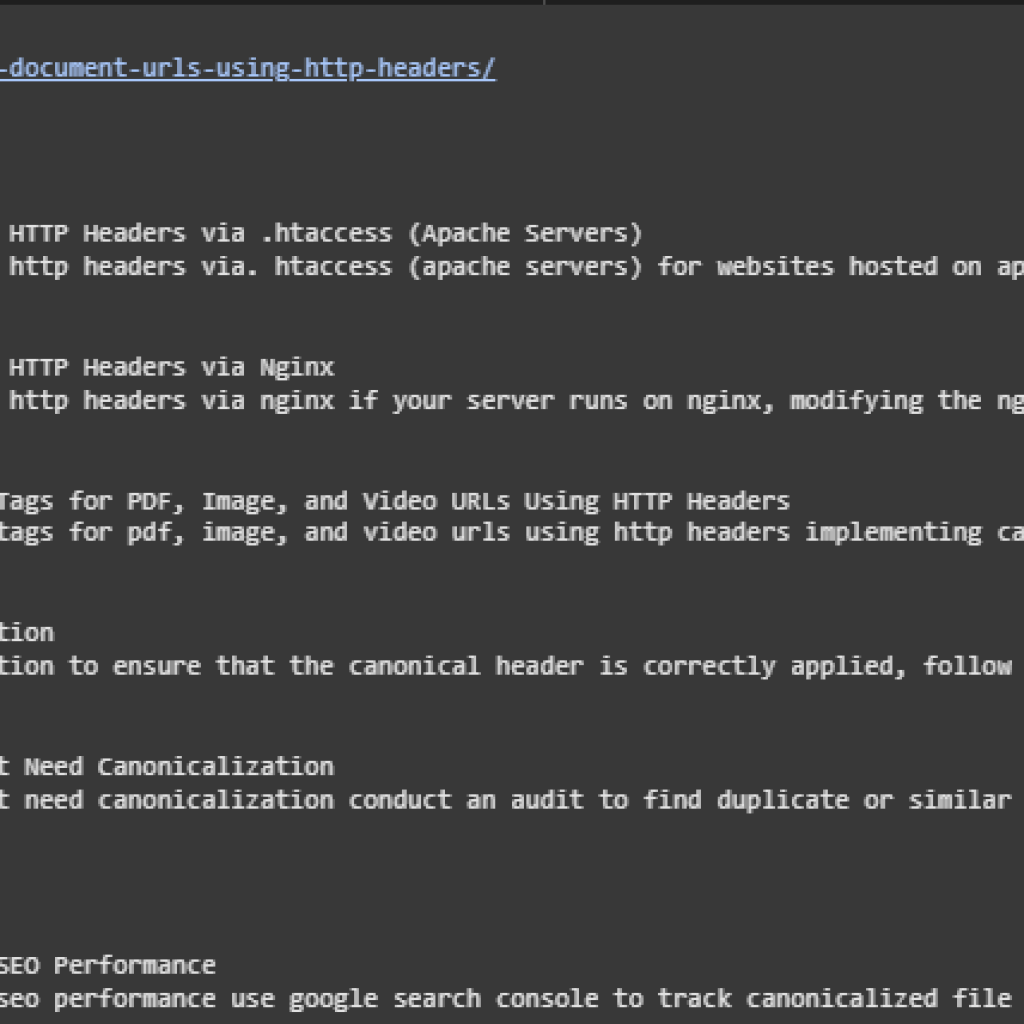
Result Analysis and Explanation
The final output showcases how the semantic similarity scoring system effectively matches user-defined intents with the most relevant content segments from a collection of webpages. Each intent is mapped to multiple ranked content blocks, each scored based on its semantic closeness to the intent. These scores range between 0 and 1, where a higher score indicates a stronger semantic match between the user’s query and the corresponding content.
Interpreting the Scores
· High Scores (e.g., > 0.7): Indicate very strong alignment between the user intent and the content. The heading and body text directly address the underlying concept or action described in the intent.
· Moderate Scores (0.4 to 0.7): Suggest relevant but possibly broader or partially aligned content. These segments might touch on the topic but not cover all details directly.
· Lower Scores (< 0.4): Typically represent marginal relevance. While the content may contain related keywords or concepts, it might not fully satisfy the intent without additional context.
This scoring allows for clear prioritization. For example, a content snippet scoring 0.75 should be considered more aligned with the user’s needs compared to one scoring 0.35. When selecting internal linking targets or content blocks to highlight, the scores guide both automation and manual review.
Content Relevance Across Multiple Intents
Each webpage was evaluated for multiple intents. It is notable that the same content block may appear in different intents with varying scores, depending on how closely its semantics match the specific query. This indicates the model’s capacity to distinguish fine-grained contextual differences even within a single document.
For instance:
- A heading about “Optimize Website for Local SEO” scores highest when the intent relates to local SEO.
- The same or similar sections receive lower scores when evaluated against an unrelated intent like “handle different document URL”, despite potentially sharing technical SEO terminology.
Practical Benefits in Real-World Use
From a business and SEO strategy standpoint, this output facilitates several key applications:
- Content Highlighting and Rewriting: By identifying segments with weak alignment, teams can rewrite or augment them to better match high-priority search intents.
- Internal Linking Opportunities: Top-scoring content blocks can be used as anchor targets for internal links, ensuring that related content is surfaced where users (and search engines) expect it.
- Search Intent Coverage Assessment: The presence or absence of high-scoring content for each intent helps determine whether a webpage adequately addresses the intended topic. This aids in content audits and editorial planning.
- Cross-Page Semantic Navigation: Since the same intent can be evaluated across multiple pages, it becomes possible to semantically cluster or guide users across different but related articles, improving content discoverability and dwell time.
keyboard_arrow_down
Final Thoughts
The implementation of this semantic scoring and intent-matching system marks a significant advancement in aligning website content with real-world user behavior. By leveraging sentence-level semantic similarity, the model provides clear, interpretable output that reflects how well each section of content addresses specific user intents.
This approach goes beyond surface-level keyword optimization, offering actionable insights into which content blocks are performing, where gaps exist, and how internal linking and content structuring can be improved. The score-driven framework not only enhances search visibility but also supports long-term strategic content planning.
Ultimately, this system equips stakeholders—across SEO, content strategy, and UX—with the tools needed to make data-backed decisions that drive engagement, search performance, and user satisfaction.
Click here to download the full guide about Dynamic Page Segmentation for Relevance.
