SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
The Content Sequence Integrity Analyzer evaluates how effectively a page’s sections progress from one idea to the next, identifying where the narrative flow strengthens understanding and where it breaks down. The system analyzes each section of a webpage, determines the semantic relationship between consecutive topics, and measures how smoothly the content transitions across the entire page. Using transformer-based semantic representations and section-level scoring, it uncovers issues such as abrupt jumps, regressions to earlier topics, fragmented discussion patterns, and inconsistency in information flow.

The project transforms raw webpage content into structured segments, extracts semantic signals, and evaluates the sequence using coherence scoring, adjacency similarity, topic drift, and disruption indicators. These combined signals provide a detailed picture of the page’s logical structure, exposing areas where content may confuse readers, dilute topical authority, or hinder search engine crawlers from interpreting the page’s purpose and hierarchical organization.
The Analyzer delivers actionable, visually supported insights. It highlights strong and weak transition points, identifies sections contributing to fragmentation, and surfaces the specific areas of the page most in need of reordering or rewriting. By measuring structural cohesion at both local and page-wide levels, the system enables content and SEO teams to make informed improvements that enhance clarity, user experience, and the semantic reliability of the page for search engines.
Project Purpose
The purpose of the Content Sequence Integrity Analyzer is to evaluate and improve the logical structure of long-form webpages by analyzing how effectively their sections progress from one concept to the next. Well-ordered, semantically coherent content plays a critical role in user comprehension, engagement, and search engine interpretation. When sections follow a natural, meaningful sequence, readers can absorb information more easily and search engines can interpret the topical hierarchy with higher confidence. Conversely, poorly ordered sections—such as abrupt topic shifts, regressions to earlier themes, or fragmented transitions—can weaken clarity, reduce trust, and limit the page’s ability to demonstrate strong topical authority.
This project provides a systematic and data-driven method to detect and quantify these structural issues. It applies transformer-based semantic models to assess the relationship between consecutive sections, measure topical drift across the entire document, and identify disruptions where the narrative flow breaks. These signals form the basis of a comprehensive evaluation of sequence integrity, enabling precise identification of structural weaknesses that would otherwise remain hidden during manual content reviews.
The system’s purpose extends beyond simply highlighting problem areas. It enables content teams to understand why a sequence issue occurs, where it impacts the user journey, and how to correct it. The insights generated guide decisions such as reorganizing sections, adding transitional sentences, merging highly similar passages, or rewriting isolated blocks to align with the surrounding context. The output ensures that the final document not only reads more naturally but also communicates its topical focus more effectively to search engines.
Through this structured approach, the project aims to support the creation of content that is clear, cohesive, authoritative, and semantically aligned from start to finish.
Project’s Key Topics Explanation & Understanding
Conceptual Sequence Integrity
Conceptual Sequence Integrity represents how well a piece of content progresses from one idea to the next in a clear, coherent, and purposeful manner. In high-quality content, concepts unfold in a structured flow—introductory sections lead into explanations, which transition into deeper insights, examples, and applications. When this chain breaks, readers experience confusion and search engines detect irregularities in topic development.
Why Sequence Integrity Matters
A strong sequence keeps the reader oriented, reduces cognitive load, and improves the interpretability of the content. Search engines also evaluate internal coherence to understand topical focus, thematic density, and content readiness for ranking. A page with disjointed ordering often signals poor editorial structure, which can negatively influence engagement signals and ranking evaluations.
How the Analyzer Measures Sequence Integrity
The project evaluates sequence integrity using semantic comparisons between consecutive and historically earlier sections, looking for irregularities such as large jumps or regressions. These insights allow an assessment of whether the page follows an optimal progression or whether restructuring could enhance clarity and topic retention.
Logical Flow Analysis
Logical flow captures how smoothly the content transitions across ideas. Beyond simple structural placement, it examines semantic continuity—whether two adjacent sections meaningfully relate, build upon each other, or drift into unrelated domains.
Adjacency Consistency
A core component is adjacency similarity, which quantifies how closely one section semantically relates to the next. Stable progression indicates high consistency, while sudden drops indicate potential breaks in the narrative. These disruptions can mislead readers and fragment search engine understanding.
Topic Progression Behavior
The Analyzer identifies natural conceptual evolution—moving from broad concepts to specifics, from explanations to examples, and from background to recommendations. Detecting deviations helps determine whether restructuring or added transitional content may be necessary.
Concept Regressions
A concept regression occurs when a section reverts to a topic previously discussed in an earlier (but not immediately preceding) area of the content. This often indicates a misplaced or poorly sequenced block.
How Regressions Affect Interpretation
Regressions confuse readers, create loops in topic progression, and weaken the cumulative narrative structure. For search engines, these regressions resemble discontinuities that reduce interpretive confidence in the topical hierarchy.
How Regressions Are Detected
The system compares each section not only with its immediate predecessor but also with historically earlier sections. When similarity to an earlier section is significantly higher than similarity to the adjacent one, it is flagged as a regression. The margin of difference indicates severity, which informs prioritization for restructuring.
Local Drift
Local drift quantifies how far a section moves from the established topical trajectory. Even when not severe enough to be considered a regression, notable drift may indicate disorganization or lack of continuity.
Interpreting Drift
High drift values often point to:
- abrupt change in focus,
- introduction of unrelated subtopics, or
- insufficient bridging context.
Low drift reflects stable narrative development, which improves both readability and machine interpretability.
Role of Drift in Identifying Weak Transitions
Drift values help pinpoint where transitional sentences or restructuring may be required to maintain a coherent conceptual chain.
Fragmentation
Fragmentation measures how often a page breaks into unrelated conceptual clusters. High fragmentation means the content jumps between themes without sufficient connective structure.
Why Fragmentation Matters
Fragmentation increases cognitive strain on readers and complicates the semantic interpretation for search engines. Section clusters become harder to map to a unified topic, which may dilute authority signals.
How Fragmentation Is Calculated
Using semantic similarity and cluster distribution, the Analyzer detects how many distinct conceptual segments form within the content. A fragmented structure usually suggests that content may benefit from merging related sections or reorganizing topic ordering.
Semantic Adjacency Similarity
Adjacency similarity is a direct measure of conceptual relatedness between consecutive sections. It is a foundational metric for understanding whether content follows a meaningful narrative thread.
High vs. Low Similarity
- High similarity indicates smooth conceptual development.
- Low similarity highlights potential structural issues, transitions requiring strengthening, or sections that may be misplaced.
Importance in SEO Content
Consistent adjacency helps search engines infer hierarchical structure and improves contextual alignment, strengthening relevance and topic authority.
Cluster Transitions
Clustering groups sections based on semantic closeness. Transitions between clusters represent conceptual shifts within the content.
Interpreting Cluster Behavior
A healthy page shows predictable transitions—moving from introduction to explanation, then deeper analysis, and finally conclusion. Excessive inter-cluster jumps indicate erratic topic flow.
Using Cluster Insights for Structure Optimization
Cluster sequences help identify where sections should be merged, reordered, or rewritten to form a more consistent thematic timeline.
Embeddings for Semantic Representation
Embeddings convert text into dense numerical representations that encode meaning. This project uses embedding vectors to measure semantic relationships across sections.
Why Embeddings Are Essential
Embeddings allow the Analyzer to quantify conceptual similarity rather than relying on keyword matching. This enables deeper detection of actual meaning alignment, topic continuity, and conceptual drift.
Behavior in SEO Context
Embedding-based analysis mirrors how modern search engines interpret content, making these measurements aligned with real ranking evaluation signals.
Q&A: Understanding Project Value, Purpose, and Importance
Why is evaluating the logical flow of content important for performance?
Logical flow determines how smoothly a reader can move from one idea to the next. When concepts are arranged in a natural, progressive order, it reduces cognitive effort, improves comprehension, and increases the likelihood that readers will stay engaged. Search engines interpret this structural clarity as a signal of expertise and authority, especially for pages intended to explain, guide, or instruct. Strong sequence integrity enhances user satisfaction and strengthens the page’s ability to meet search intent more effectively.
What problems typically arise when content has weak sequence integrity?
Weak sequence integrity often leads to disrupted reading experiences. Sudden topic jumps, missing transitions, repetitive regressions to earlier concepts, and poor grouping of related ideas make the page feel scattered. This causes readers to lose context, skim excessively, or abandon the page. From an SEO perspective, these structural weaknesses reduce perceived content depth, topical authority, and alignment with search expectations. As a result, the page may underperform even when the underlying information is strong.
What does the project measure that traditional content reviews usually miss?
Traditional audits rely heavily on manual review and rely on the reviewer’s subjective interpretation of the page structure. This project adds an objective layer through semantic modeling and sequence-based analysis. It detects hidden structural issues, identifies concept jumps that are not visible through basic reading, calculates the coherence strength between consecutive ideas, and tracks concept drift throughout the page. These are nuanced signals that cannot be reliably spotted unless measured quantitatively.
How does understanding “concept drift” support better content decisions?
Concept drift refers to how far the content moves away from the main theme as it progresses. Controlled drift helps pages introduce advanced or supportive ideas without losing coherence. Excessive drift causes the narrative to scatter into unrelated or loosely connected directions. By quantifying this drift, the project helps identify where content begins to lose its topical focus. This allows restructuring of sections, removal of unnecessary digressions, or repositioning of advanced concepts to preserve clarity and thematic depth.
Why does the project compare section sequences instead of only analyzing text quality?
Quality alone is insufficient if the information is delivered in a confusing order. A page may be written well at the sentence level yet fail to guide users through a logical knowledge progression. The sequence-aware approach analyzes how concepts evolve, how each idea builds on the previous one, and whether the page forms a structured knowledge pathway. This mirrors how real readers and search engines interpret content, providing a more complete evaluation of content effectiveness.
How does topic clustering improve understanding of content structure?
Topic clustering groups semantically related sections together so that the content’s thematic architecture becomes visible. This allows deeper structural assessment—detecting whether related ideas appear in one continuous block or are scattered across the page. It also helps identify mispositioned topics, sections breaking the narrative flow, and the relative strength or weakness of concept groupings. This level of understanding supports precise restructuring and sequencing improvements.
Why does the analysis focus on “progression” and “regression” between sections?
Progression indicates that the content is moving forward—expanding the idea, introducing new layers of explanation, or advancing the reader’s understanding. Regression occurs when the content returns to a previously covered concept without strategic purpose, which disrupts flow and interrupts comprehension. Tracking both allows the project to identify structural inefficiencies. Once detected, these issues can be corrected by repositioning sections, merging repetitive ideas, or reorganizing transitions to preserve momentum.
How does improving sequence integrity impact SEO outcomes?
Search engines aim to surface content that answers user queries clearly, comprehensively, and in a well-structured form. When a page maintains strong concept continuity, it signals topic mastery, reduces semantic noise, and ensures that the content aligns tightly with search intent. This improves the perceived authority of the page. Additionally, a logically ordered content structure enhances crawl interpretation, helping search engines understand which components of the page play primary roles and how they relate to the target query.
What strategic advantages does this analysis offer for large or complex content pages?
Long-form or multi-section guides often suffer from structural drift, uneven pacing, and sequence inconsistencies. The analysis systematically identifies where conceptual load becomes too dense, where explanations are abrupt, or where transitions are missing. This provides clear direction for restructuring without requiring extensive manual auditing. The result is improved readability, more coherent narratives, and stronger alignment with conversion paths and informational expectations.
How does the project support decision-making for content restructuring?
The visualizations and metrics highlight exactly where structural issues exist, making the decision-making process more efficient and less subjective. Instead of guessing where readers may get confused, the analysis shows where sequence coherence weakens, where drift peaks, and where concept clusters break. This allows targeted improvements—moving specific sections, re-ordering topic flows, merging content, or enhancing transitions. These actions directly enhance clarity, engagement, and search signaling.
Libraries Used
time
The time library is a standard Python utility used for measuring durations, delays, and timestamps. It provides functions for tracking execution time and managing time-based controls during processing.
In this project, it is used to monitor and optimize runtime during key operations such as content extraction, embedding generation, and clustering steps. Tracking execution time helps ensure the system performs efficiently, especially when processing long-form pages or multiple URLs.
re
The re library enables pattern matching and text manipulation through regular expressions. It allows flexible detection, cleaning, and restructuring of text patterns.
In this project, regular expressions are used to clean noisy HTML-derived text, normalize content structure, filter unwanted characters, and detect section boundaries. This ensures that only clean, meaningful text is passed into further processing stages like tokenization and embedding.
html (html_lib)
The html library provides utilities for handling common HTML entities and encoding/decoding operations.
It is used to decode escaped characters (e.g., &, ), clean HTML-based noise, and ensure that extracted page content is readable and accurately represented before further analysis.
hashlib
hashlib offers secure hashing functions that generate unique identifiers based on text input.
The project uses hashing to assign stable, collision-resistant IDs to content sections. These IDs help maintain consistent referencing throughout the analysis pipeline, especially when evaluating sequences, mapping clusters, and visualizing content flows.
unicodedata
The unicodedata module provides tools to normalize and standardize Unicode text.
It is used to clean and normalize text extracted from pages—removing diacritics, standardizing character formats, and improving consistency for downstream NLP processing.
gc
Python’s gc (garbage collection) interface helps manage memory usage by explicitly clearing unused objects.
This project handles long texts, multiple embeddings, and large intermediate arrays. Using gc ensures that memory-intensive steps such as embedding generation and clustering remain stable and efficient.
logging
The logging library allows structured reporting of events, warnings, and debugging information.
Custom logging is used throughout the project to monitor pipeline execution, track content extraction progress, log errors, and ensure transparency during complex operations like clustering or model inference. This supports reliability and easier maintenance.
requests
requests is the standard Python library for performing HTTP requests in a simplified and reliable way.
It is used to fetch webpage content for each URL. Since the project relies on real webpage extraction, this library ensures stable retrieval, correct handling of response encodings, and error management for failed or redirected URLs.
typing
The typing module provides advanced type annotations for Python code.
In this project, it improves code readability, ensures type safety across complex inputs such as section lists and similarity matrices, and supports maintainability when handling mixed data structures throughout the pipeline.
BeautifulSoup (bs4)
BeautifulSoup is a widely used library for parsing and cleaning HTML documents. It can navigate tags, remove unwanted elements, and extract meaningful content.
The project uses BeautifulSoup to extract clean text from webpage HTML, remove scripts, style tags, comments, and decorative elements. It ensures the content sections fed into the analysis are accurate and free from formatting noise.
numpy (np)
NumPy is the foundational numerical computation library in Python, offering arrays, vectorized operations, and mathematical utilities.
It is used for embedding handling, similarity matrix construction, cluster computation, and numerical transformations throughout the project. NumPy ensures efficient processing of the high-dimensional data generated by the embedding model.
pandas (pd)
Pandas provides robust data structures for tabular data manipulation, joining, grouping, and cleaning.
This project uses pandas to organize extracted sections, store embeddings, structure cluster outputs, and prepare data for visualization. It helps maintain data integrity across different steps of the analysis pipeline.
sklearn.cluster (AgglomerativeClustering)
Agglomerative Clustering is part of scikit-learn’s hierarchical clustering suite.
It is used to group content sections based on semantic similarity. This clustering exposes the hidden topic structure of the page, identifies conceptual groupings, and helps evaluate whether related ideas appear together or are scattered across the content sequence.
sklearn.metrics (pairwise_distances)
This module computes pairwise distance matrices for vectors.
The project uses it to calculate semantic distances between section embeddings. These measurements are critical for detecting concept jumps, regressions, and identifying the proximity of ideas throughout the page.
nltk (Natural Language Toolkit)
NLTK provides tokenization tools, corpus utilities, and preprocessing methods for natural language text.
Here, it is used for sentence tokenization within sections, enabling better segmentation and refinement of content units. This supports clearer analysis and more precise embedding generation.
sentence_transformers (SentenceTransformer)
SentenceTransformer enables easy loading and inference of high-quality transformer-based embedding models.
It is used to generate semantic embeddings for each content section. These embeddings power the core analysis: logical flow detection, topic clustering, drift tracking, and coherence evaluation. Without embeddings, the project cannot assess semantic relationships effectively.
transformers.utils.logging
This utility controls logging verbosity for the transformer model.
It is used to suppress unnecessary output from the embedding model during inference, keeping the notebook environment clean and improving readability during reporting.
matplotlib.pyplot (plt)
Matplotlib is the fundamental plotting library in Python for creating detailed visualizations.
It is used to build the project’s visual outputs—including coherence plots, disruption maps, cluster flows, and drift heatmaps. These visualizations translate complex structural insights into intuitive, actionable graphics.
seaborn (sns)
Seaborn is a statistical visualization library built on Matplotlib that enables cleaner, more aesthetic charts.
It is used to enhance plot styling, ensure visual consistency, and produce interpretable charts that help highlight sequence patterns, topic flows, and structural imbalances. Seaborn settings improve clarity for clients reviewing the results.
Function: fetch_html
Summary
The fetch_html function is responsible for reliably retrieving the raw HTML content of a webpage. Since the entire analysis pipeline—section extraction, embedding generation, sequence evaluation, and conceptual flow detection—depends on accurate page content, this function forms the foundation of the project’s data ingestion process.
This function implements a robust retrieval mechanism with retry logic, exponential backoff, configurable headers, and encoding fallback strategies. These capabilities ensure stability against temporary network failures, slow servers, rate limitations, or inconsistent character encodings commonly observed across the web. By guaranteeing consistent, valid HTML output, the function ensures that all subsequent analytical steps operate on reliable, clean data without interruptions.
Key Code Explanations
1. Exponential Backoff for Retry Logic
wait = backoff_factor ** attempt
time.sleep(wait)
This implements exponential backoff, where the waiting period grows as retries increase. For example, with a backoff factor of 2.0, retry delays become: 2s → 4s → 8s. Exponential backoff prevents overwhelming a server with rapid repeated requests and improves the success probability when the failure is due to temporary network congestion or server-side issues.
2. Multiple Encoding Attempts
enc_choices = [getattr(resp, “apparent_encoding”, None), “utf-8”, “iso-8859-1”]
Webpages often use different character encodings, and some servers fail to declare them correctly. This line defines a priority list of encodings to test. The function tries each encoding until it obtains a sufficiently long and valid HTML body. This avoids corrupted characters and ensures the extracted text retains accuracy during NLP analysis.
3. Usability Check for HTML Content
if html and len(html.strip()) > 80:
return html
A sanity threshold is used to prevent returning empty or malformed pages that contain only boilerplate or error messages. A minimum length ensures that the fetched page is substantial enough to proceed with content parsing and section extraction.
Function: clean_html
Summary
The clean_html function prepares raw webpage HTML for downstream text extraction by removing noise, clutter, and non-content elements. Webpages typically contain numerous dynamic scripts, interface components, tracking modules, advertisements, and multimedia elements that do not contribute to the conceptual flow of the written content. If these elements are not removed, they interfere with section segmentation, inflate token counts, distort embeddings, and degrade the accuracy of sequence integrity analysis.
This function converts the incoming HTML into a parsed BeautifulSoup object and then performs structured cleaning. It removes irrelevant tags, strips away inline scripts and non-textual elements, and eliminates embedded comments. The result is a cleaner, more text-focused DOM structure, ensuring that subsequent steps—such as identifying logical sections or computing semantic similarities—operate on high-quality content rather than structural noise.
Key Code Explanations
1. Dual Parser Initialization
try:
soup = BeautifulSoup(html_content, “lxml”)
except Exception:
soup = BeautifulSoup(html_content, “html.parser”)
The function first attempts to parse the HTML using lxml, a fast and robust parser. If lxml is unavailable or the HTML is malformed, it falls back to Python’s built-in html.parser. This ensures dependable parsing across a wide range of webpage formats and encoding qualities without disrupting the workflow.
2. Removal of Non-Content and Noisy Tags
remove_tags = [
“script”, “style”, “noscript”, “iframe”, “svg”, “canvas”,
“header”, “footer”, “nav”, “form”, “input”, “figure”, “img”,
“video”, “audio”, “source”, “picture”, “aside”, “advertisement”
]
This list targets tags that typically introduce noise:
- Scripting and styling (script, style, noscript)
- Layout and structure components (header, footer, nav, aside)
- Interactive and media elements (iframe, video, audio, img, canvas)
- Advertisement placeholders
These components do not contribute meaningful semantics to the textual narrative. Removing them eliminates unnecessary distraction and avoids irrelevant content influencing the semantic embeddings used for conceptual flow analysis.
3. Tag Decomposition Loop
for node in soup.find_all(tag):
node.decompose()
.decompose() fully removes the tag and its children from the DOM. By directly decomposing the elements, the cleaned HTML retains only meaningful content blocks—primarily headings, paragraphs, and textual containers. This step significantly boosts the precision of sequence-level analysis and clustering.
4. Comment Removal
for c in soup.find_all(string=lambda x: isinstance(x, Comment)):
c.extract()
HTML comments often contain template metadata, tracking placeholders, dynamic instructions, or backend-generated fragments. Removing these prevents non-visible text from being mistakenly processed as part of the content.
Function: _md5_hex
Summary
The _md5_hex function generates a stable MD5 hash for any given string. This hashing utility is essential for creating unique identifiers for sections extracted from the webpage. By converting text into a fixed-length hexadecimal string, the system ensures consistency when referencing, comparing, or caching section-level content. Hashing also avoids storing long or sensitive text fragments while still enabling reliable linkage between components of the analysis pipeline.
Because section boundaries and text contents can vary widely across pages, using hashed representations ensures robust and collision-resistant identification without exposing raw text directly in intermediate data structures.
Key Code Explanations
1. MD5 Hash Generation
return hashlib.md5(text.encode(“utf-8”)).hexdigest()
This line encodes the input text into UTF-8 and computes its MD5 digest. The hexdigest() method produces a readable hex string representation, making it usable as a clean and stable identifier. This approach is lightweight, deterministic, and sufficiently unique for section-level hashing.
Function: _safe_normalize
Summary
The _safe_normalize function cleans and normalizes raw text extracted from HTML. Webpage text often contains HTML escape characters, inconsistent unicode representations, unnecessary whitespace, and newline artifacts. Without normalization, these issues can distort section boundaries, reduce embedding quality, and introduce noise into semantic similarity calculations.
This function standardizes textual content through HTML unescaping, unicode normalization, and whitespace consolidation. The resulting text is cleaner, more consistent, and better aligned with NLP preprocessing expectations.
Key Code Explanations
1. HTML Entity Decoding
txt = html_lib.unescape(text)
Many webpages encode characters like &, , or accented letters using HTML entities. This step converts them into their actual readable characters, ensuring that text embeddings represent genuine content rather than encoded symbols.
2. Unicode Normalization
txt = unicodedata.normalize(“NFKC”, txt)
Unicode characters can have multiple equivalent forms, such as precomposed or decomposed accents. NFKC normalization harmonizes these forms into a consistent representation. This avoids unnecessary distinctions in the embedding space and improves text similarity scoring.
3. Cleanup of Line Breaks and Excess Whitespace
txt = re.sub(r”[\r\n\t]+”, ” “, txt)
txt = re.sub(r”\s+”, ” “, txt).strip()
This removes newline clusters, tabs, and repeated spaces, replacing them with single spaces. Clean, linearized text reduces noise and ensures better segmentation during the section extraction stage.
Function: extract_sections
Summary
The extract_sections function identifies, extracts, and structures meaningful textual sections from the cleaned HTML. Since this project evaluates conceptual sequencing and logical progression across a page, accurate segmentation is essential. This function prioritizes heading-based segmentation (H1–H4), as headings are the most reliable indicators of topical boundaries on well-structured pages. When headings are insufficient or missing, it falls back to grouping paragraphs into approximate thematic blocks based on word count.
Each extracted section includes a unique identifier, heading text, the raw textual content beneath the heading, its sequential position on the page, and a DOM reference path. This structured representation serves as the foundation for semantic embedding, cluster assignment, sequence coherence scoring, and visualization.
The logic is robust enough to handle blogs, guides, category pages, documentation, and other SEO-relevant content formats.
Key Code Explanations
1. Heading-Based Sectioning
headings = body.find_all(heading_tags)
This identifies all heading elements (e.g., <h1>, <h2>, etc.) in the page. Headings act as strong semantic boundaries, enabling the system to capture discrete concepts and topic transitions that reflect the logical structure intended by the page author.
2. Iterative DOM Walk for Boundary Detection
for node in body.descendants:
if name in heading_tags:
# finalize previous section
# start a new section
Instead of scanning headings alone, the function walks through document descendants in actual DOM order. This allows sequential capture of all text associated with each heading, making the segmentation reflect real page structure rather than relying on linear lists or heuristics.
3. Section Validation and ID Generation
if len(current[“raw_text”].strip()) >= min_section_chars:
src = f”{current[‘heading’]}_{current[‘position’]}_{_md5_hex(current[‘raw_text’][:120])}”
current[“section_id”] = _md5_hex(src)
Sections must meet a minimum size threshold to ensure they represent meaningful conceptual content. Short or empty text blocks are automatically excluded. For valid sections, a unique identifier is generated based on the heading, position, and snippet of text—ensuring stable identity even across similar sections.
4. Paragraph-Based Fallback
if not sections:
paras = [p for p in body.find_all([“p”, “li”]) …]
Many modern pages rely on JavaScript-based rendering or custom block structures without clear heading tags. The fallback mechanism groups paragraphs or list items into blocks around a target word count (e.g., 250 words). This ensures that even minimally structured pages still yield analyzable sections.
5. Section Structuring
sections.append({
“section_id”: …,
“heading”: f”Section {position}”,
“raw_text”: raw,
“position”: position,
“dom_path”: …
})
Each section is stored with all metadata required for later stages:
- heading: serves as a conceptual label
- raw_text: used for embeddings, coherence scoring, and drift analysis
- position: grounds the section in page order
- dom_path: supports traceability in editor interfaces
Function: _is_boilerplate
Summary
The _is_boilerplate function is a conservative detector for identifying boilerplate content within a section of text. Boilerplate refers to text that appears repeatedly across pages and typically does not contribute meaningful conceptual content for analysis, such as copyright statements, privacy policies, footers, or navigation instructions. Removing such content ensures that subsequent semantic analysis, embedding, clustering, and coherence scoring focus only on conceptually relevant text.
This function is particularly useful in SEO and content sequence evaluation projects, as boilerplate text can otherwise skew similarity scores, falsely trigger regressions, and interfere with sequence integrity metrics.
Key Code Explanations
1. Boilerplate Keyword List
_REDUCED_BOILERPLATE = [
“privacy policy”, “cookie policy”, “terms of service”, …
]
A curated list of common boilerplate phrases is defined. These phrases represent content that appears frequently on webpages but is not conceptually meaningful.
2. Text Matching Logic
for bp in bps:
if bp in lower and len(lower.split()) < max_words_for_drop:
return True
The function checks if any boilerplate phrase exists in the lowercase version of the section text. To avoid false positives on longer text that may include similar words in meaningful context, only sections below a certain word threshold (max_words_for_drop) are treated as boilerplate.
3. Short Repetitive Text Detection
if len(lower.split()) < 6 and len(lower) < 120:
return True
Very short and repetitive text sections are also classified as boilerplate. This captures ultra-short lines that provide no conceptual value, such as disclaimers or navigational cues.
Function: preprocess_section_text
Summary
The preprocess_section_text function prepares raw section text for downstream semantic analysis. It applies normalization, filtering, and optional content cleaning steps to ensure the text is meaningful, clean, and consistent. The preprocessing includes HTML unescaping, unicode normalization, removal of URLs and inline references, boilerplate filtering, and optional preservation of code blocks. Very short or conceptually empty sections are automatically filtered out.
This preprocessing step is crucial in content sequence analysis projects, as it ensures that embeddings, cluster assignments, drift detection, and regression events reflect the actual conceptual flow rather than noise, links, or boilerplate.
Key Code Explanations
1. Normalization
text = _safe_normalize(raw_text)
Initial normalization ensures that HTML entities, unicode inconsistencies, and excessive whitespace are cleaned. This guarantees consistency in semantic embedding and similarity calculations.
2. URL and Inline Reference Removal
if remove_urls:
text = re.sub(r”https?://\S+|www\.\S+”, ” “, text)
if remove_inline_refs:
text = re.sub(r”\[\d+\]|\(\d+\)”, ” “, text)
URLs and numeric inline references (commonly citations or footnotes) are removed if configured. These elements typically do not add conceptual value and can interfere with text similarity and clustering.
3. Boilerplate Filtering
if _is_boilerplate(text, boilerplate_terms=boilerplate_terms):
return “”
Sections identified as boilerplate by _is_boilerplate are removed. This prevents legal, navigational, or repeated text from affecting the logical sequence analysis.
4. Minimum Word Count Enforcement
if len(text.split()) < min_word_count:
return “”
Sections with insufficient word count are dropped. This ensures that only meaningful, conceptually rich content contributes to downstream evaluation.
This function acts as the gatekeeper for all section-level text before embeddings, coherence scoring, and regression analysis. Proper preprocessing ensures high-quality analysis and actionable insights.
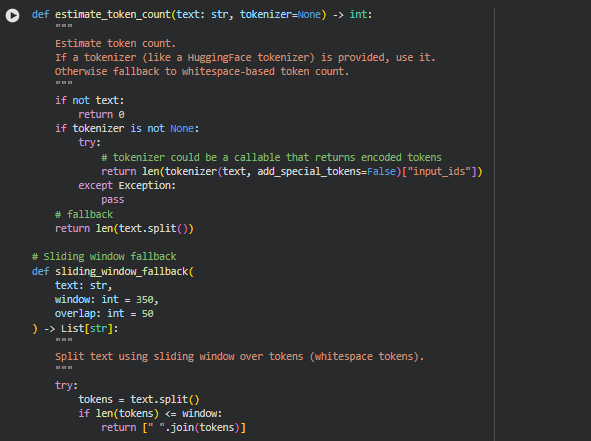
Function: estimate_token_count
Summary
The estimate_token_count function provides an estimate of the number of tokens in a given text segment. Tokens are units of text used by NLP models, such as words or subwords. Accurate token estimation is critical for ensuring sections can be processed by transformer models without exceeding model token limits.
The function supports the use of an external tokenizer, such as a HuggingFace tokenizer, for precise token counts. If no tokenizer is provided, it falls back to a simple whitespace-based count, providing a reasonable approximation for sentence or section lengths.
Key Code Explanations
1. Optional Tokenizer Usage
if tokenizer is not None:
return len(tokenizer(text, add_special_tokens=False)[“input_ids”])
When a tokenizer is provided, the function uses it to calculate the exact number of tokens. This ensures compatibility with transformer models, where tokenization may not match simple word counts.
2. Fallback Logic
return len(text.split())
If no tokenizer is provided, a basic whitespace-based count is returned. This serves as a lightweight and fast approximation when precise token counts are not critical.
Function: sliding_window_fallback
Summary
The sliding_window_fallback function is a simple method to split a long text into smaller, overlapping chunks based on a sliding window of tokens. It ensures that every part of the text is captured, and overlapping tokens maintain contextual continuity between chunks.
This function is particularly useful when a single sentence or section exceeds the maximum token limit for processing, providing a fallback mechanism for large blocks of text.
Key Code Explanations
1. Token Windowing
start = 0
while start < len(tokens):
end = start + window
chunk_tokens = tokens[start:end]
chunks.append(” “.join(chunk_tokens).strip())
start = max(end – overlap, start + 1)
The function iterates over tokens, creating chunks of size window with an overlap of overlap tokens. This overlap ensures that the context between adjacent chunks is preserved for semantic analysis.
Function: hybrid_chunk_section
Summary
The hybrid_chunk_section function provides a sentence-aware approach for splitting text into manageable chunks suitable for transformer models. It combines sentence-level splitting with token estimation and a sliding window fallback. This ensures that sections fit within a maximum token limit while preserving sentence integrity. Very small or overly large chunks are handled gracefully using fallback strategies.
This function is essential for concept sequence analysis, enabling large sections to be processed in chunks while maintaining the logical flow for semantic embedding, adjacency similarity, and drift calculations.
Key Code Explanations
1. Sentence Tokenization
sentences = sent_tokenize(text)
The text is split into sentences using NLTK’s sent_tokenize. Sentence-level segmentation ensures semantic coherence is preserved when forming chunks.
2. Token Estimate Check
token_est = estimate_token_count(temp, tokenizer=tokenizer)
if token_est <= max_tokens:
current_chunk.append(sent)
Sentences are accumulated into a chunk until the estimated token count exceeds the maximum allowed. This prevents chunks from exceeding model input limits.
3. Sliding Window Fallback
if estimate_token_count(sent, tokenizer=tokenizer) > max_tokens:
chunks.extend(sliding_window_fallback(sent, window=max_tokens, overlap=sliding_overlap))
If a single sentence itself exceeds the maximum token limit, the function falls back to the sliding window approach. This ensures even unusually long sentences are split for processing.
4. Minimum Token Filtering
cleaned = [c.strip() for c in chunks if estimate_token_count(c.strip(), tokenizer=tokenizer) >= min_tokens]
Chunks smaller than the minimum token threshold are discarded. This ensures that only meaningful content is included in downstream embeddings, preventing noise from overly short chunks.
The hybrid approach allows the project to handle sections of varying lengths efficiently, preserving sentence boundaries where possible while still accommodating transformer token limits. This is critical for accurate semantic representation and subsequent sequence integrity analysis.
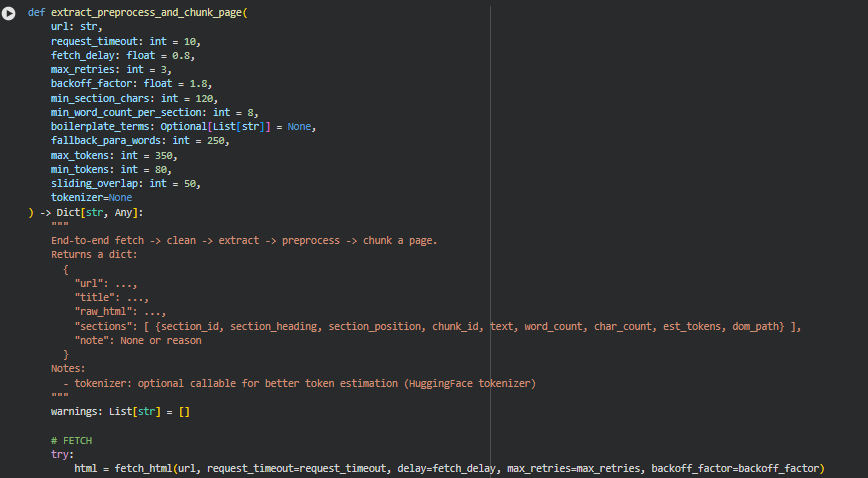
Function: extract_preprocess_and_chunk_page
Summary
The extract_preprocess_and_chunk_page function provides an end-to-end pipeline for processing a web page. It handles the complete workflow of fetching, cleaning, extracting sections, preprocessing text, and generating chunks suitable for semantic analysis. The function returns a structured dictionary containing the URL, page title, raw HTML, and processed sections. Each section includes metadata such as section ID, heading, position, chunk ID, token estimates, word count, and character count.
This function is central to the project as it transforms raw web content into structured, clean, and semantically meaningful units. These units are then used for adjacency similarity analysis, drift detection, regression identification, and cluster sequencing. By handling retries, fallback strategies, and boilerplate filtering, it ensures robustness across diverse web pages.
Key Code Explanations
1. HTML Fetching with Retries and Exponential Backoff
html = fetch_html(url, request_timeout=request_timeout, delay=fetch_delay, max_retries=max_retries, backoff_factor=backoff_factor)
The function uses fetch_html to retrieve the HTML content. It implements retries with exponential backoff to handle transient network issues. A delay before the first request and incremental waits on retries ensures responsible crawling behavior and reduces the chance of server overload.
2. HTML Cleaning and Parsing
soup = clean_html(html)
clean_html parses the HTML using BeautifulSoup and removes noisy tags such as scripts, styles, iframes, and boilerplate content. This ensures that only the meaningful content, typically article text or main sections, is retained for subsequent processing.
3. Title Extraction
title_tag = soup.find(“title”)
title = _safe_normalize(title_tag.get_text()) if title_tag else “Untitled Page”
The function extracts the page title, prioritizing the <title> tag. If absent or empty, it falls back to the first <h1> tag. A robust title extraction provides context for each page and allows better labeling of subsequent sections.
4. Section Extraction
raw_sections = extract_sections(soup, min_section_chars=min_section_chars, fallback_para_words=fallback_para_words)
Sections are extracted using heading boundaries (H1–H4) or, as a fallback, paragraph-based grouping. Each section is assigned a unique ID, heading, position, and DOM path. This structured approach ensures accurate segmentation for further semantic analysis.
5. Text Preprocessing
cleaned = preprocess_section_text(sec.get(“raw_text”, “”), min_word_count=min_word_count_per_section, boilerplate_terms=boilerplate_terms)
Each section’s text is normalized, URLs and inline references are optionally removed, and short or boilerplate-like content is filtered out. This ensures that only meaningful content contributes to downstream analysis, improving the quality of embeddings and similarity measurements.
6. Sentence-Aware Chunking
chunks = hybrid_chunk_section(text=sec[“text”], max_tokens=max_tokens, min_tokens=min_tokens, sliding_overlap=sliding_overlap, tokenizer=tokenizer)
Sections are further split into chunks using a hybrid, sentence-aware chunker. This respects sentence boundaries while ensuring that each chunk remains within a token limit suitable for transformer models. Overlapping tokens preserve semantic continuity between chunks.
7. Section and Chunk Metadata Construction
final_sections.append({
“section_id”: sec[“id”],
“section_heading”: sec[“heading”],
“section_position”: sec[“position”],
“dom_path”: sec.get(“dom_path”),
“chunk_id”: cid,
“text”: chunk,
“word_count”: len(chunk.split()),
“char_count”: len(chunk),
“est_tokens”: est_tokens
})
For each chunk, metadata including word count, character count, token estimate, section ID, heading, and chunk ID is recorded. This metadata is essential for downstream visualization, regression detection, drift computation, and sequence integrity scoring.
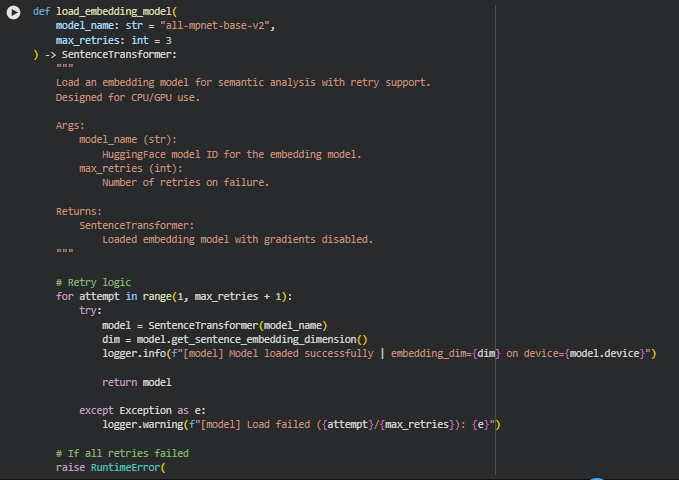
Function: load_embedding_model
Summary
The load_embedding_model function is responsible for loading a pre-trained sentence embedding model from HuggingFace using the SentenceTransformer framework. This embedding model converts textual content into high-dimensional vectors that capture semantic meaning. These embeddings form the foundation for multiple analyses in the project, including adjacency similarity, local drift, regression detection, cluster sequencing, and overall sequence integrity evaluation.
The function includes retry logic to handle transient loading failures, ensuring robustness when accessing remote model repositories or initializing large models. Once loaded, the model is ready for CPU or GPU execution, enabling efficient vector computation across all page sections and chunks.
Key Code Explanations
1. Retry Logic for Model Loading
for attempt in range(1, max_retries + 1):
try:
model = SentenceTransformer(model_name)
dim = model.get_sentence_embedding_dimension()
logger.info(f”[model] Model loaded successfully | embedding_dim={dim} on device={model.device}”)
return model
except Exception as e:
logger.warning(f”[model] Load failed ({attempt}/{max_retries}): {e}”)
The function attempts to load the model multiple times if the first attempt fails, logging warnings on each failure. This ensures robustness in scenarios where network issues or temporary repository unavailability could interrupt the model initialization.
Function: embed_texts
Summary
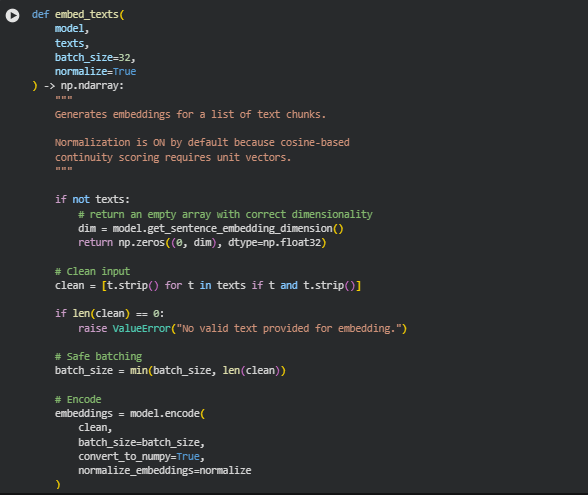
The embed_texts function converts a list of textual sections or chunks into high-dimensional semantic vectors using a pre-loaded SentenceTransformer embedding model. These embeddings capture the semantic meaning of the text, allowing downstream calculations such as adjacency similarity, local drift, regression detection, and cluster sequence analysis. By default, the embeddings are normalized to unit vectors, which is essential for cosine similarity calculations used extensively in sequence integrity analysis.
This function supports batching to efficiently process large numbers of text chunks while maintaining performance and memory management.
Key Code Explanations
1. Handling Empty Input
if not texts:
dim = model.get_sentence_embedding_dimension()
return np.zeros((0, dim), dtype=np.float32)
If the input list of texts is empty, the function returns an empty array with the correct embedding dimensionality. This ensures that downstream computations do not fail due to missing data and maintains consistent array shapes.
2. Input Cleaning
clean = [t.strip() for t in texts if t and t.strip()]
All text entries are stripped of leading and trailing whitespace, and empty strings are filtered out. This step guarantees that only meaningful content is passed to the embedding model, preventing unnecessary computation or errors.
3. Safe Batching
batch_size = min(batch_size, len(clean))
The batch size is dynamically adjusted to not exceed the number of valid text chunks. This prevents batch-related errors during model encoding and optimizes performance.
4. Encoding and Normalization
embeddings = model.encode(
clean,
batch_size=batch_size,
convert_to_numpy=True,
normalize_embeddings=normalize
)
The cleaned texts are passed to the model’s encode method. Embeddings are returned as a NumPy array. Normalization ensures that all embeddings are unit vectors, which is critical for cosine similarity-based scoring, such as calculating adjacency similarity or local drift between sequential sections.
Function: compute_adjacent_similarity
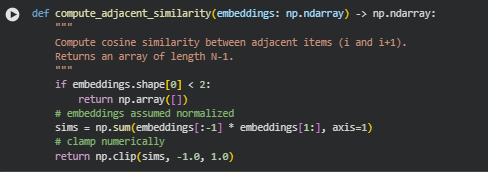
Summary
The compute_adjacent_similarity function calculates the semantic continuity between consecutive sections or chunks of a page. Using the embeddings generated for each section, the function computes the cosine similarity between each pair of adjacent items (i.e., between section i and section i+1). The resulting values quantify how semantically related each pair of neighboring sections is, forming the basis for evaluating content flow and detecting sudden regressions or disruptions in the logical sequence.
This metric is critical for the project, as it allows identification of potential breaks in conceptual flow that may confuse readers or affect perceived authority of the content.
Key Code Explanations
1. Early Exit for Insufficient Sections
if embeddings.shape[0] < 2:
return np.array([])
If the input contains fewer than two sections, there are no adjacent pairs to compare, so the function returns an empty array. This prevents unnecessary computations and avoids errors in downstream processing.
2. Cosine Similarity Computation
sims = np.sum(embeddings[:-1] * embeddings[1:], axis=1)
Assuming embeddings are normalized to unit vectors, the dot product between consecutive embeddings directly computes the cosine similarity. Each value represents the semantic similarity between a section and its immediate next section, forming a sequence of continuity scores.
3. Numerical Clamping
return np.clip(sims, -1.0, 1.0)
Clamping ensures that any minor floating-point arithmetic errors do not produce values outside the valid cosine similarity range [-1, 1]. This maintains numerical stability and reliability for subsequent calculations, such as local drift, regression scoring, and visualization.
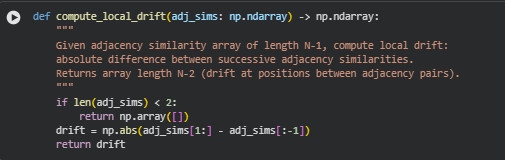
Function: compute_local_drift
Summary
The compute_local_drift function measures sudden changes in semantic continuity between consecutive sections. Using the adjacency similarity scores computed for each pair of neighboring sections, the function calculates the absolute difference between successive adjacency similarities. These differences, referred to as local drift, indicate where the content flow changes sharply, potentially signaling regressions, logical jumps, or disruptions in the conceptual sequence.
Local drift values are essential for evaluating the coherence and structural integrity of content. High local drift can highlight areas that may confuse readers or reduce perceived expertise.
Key Code Explanations
1. Early Exit for Insufficient Data
if len(adj_sims) < 2:
return np.array([])
If there are fewer than two adjacency similarity values, it is impossible to compute a drift between them. Returning an empty array prevents downstream errors and ensures only valid drift values are processed.
2. Absolute Difference Computation
drift = np.abs(adj_sims[1:] – adj_sims[:-1])
This line computes the element-wise absolute difference between successive adjacency similarities. Each resulting value quantifies the magnitude of change in continuity between neighboring section pairs, effectively capturing local inconsistencies in logical flow.
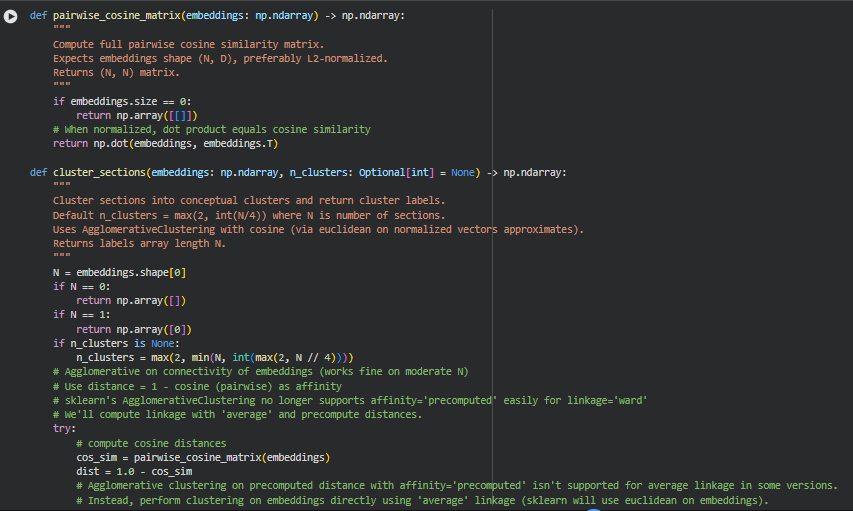
Function: pairwise_cosine_matrix
Summary
The pairwise_cosine_matrix function computes the full pairwise cosine similarity matrix for a set of embeddings. Cosine similarity measures how semantically aligned two vectors are, which in this context corresponds to the conceptual similarity between sections of content. A value closer to 1 indicates high semantic similarity, while values closer to 0 or negative indicate low similarity or conceptual divergence.
This matrix is fundamental for tasks like clustering, regression detection, or sequence coherence analysis, as it provides a global view of inter-section relationships.
Key Code Explanations
1. Handle Empty Input
if embeddings.size == 0:
return np.array([[]])
Ensures that the function gracefully handles empty input by returning an empty 2D array instead of causing computation errors.
2. Cosine Similarity via Dot Product
return np.dot(embeddings, embeddings.T)
Assuming embeddings are L2-normalized, the dot product directly yields cosine similarity. This operation produces an N x N matrix where each element [i, j] represents the similarity between section i and section j.
Function: cluster_sections
Summary
The cluster_sections function groups sections into conceptual clusters based on semantic embeddings. Sections within the same cluster are closely related in meaning, while sections in different clusters are conceptually distinct. This clustering aids in identifying topic boundaries, repeated themes, and fragmentation within the content. The function defaults to a sensible number of clusters based on content length but allows manual specification.
Key Code Explanations
1. Determine Number of Clusters
if n_clusters is None:
n_clusters = max(2, min(N, int(max(2, N // 4))))
Automatically selects a reasonable number of clusters based on the number of sections (N). This heuristic ensures at least two clusters while preventing excessive fragmentation.
2. Compute Cosine Distances
cos_sim = pairwise_cosine_matrix(embeddings)
dist = 1.0 – cos_sim
Transforms similarity into a distance metric suitable for clustering. Agglomerative clustering uses these distances to determine which sections are grouped together.
3. Agglomerative Clustering
model = AgglomerativeClustering(n_clusters=n_clusters, linkage=”average”)
labels = model.fit_predict(embeddings)
Performs hierarchical clustering using the average linkage method. Each section is assigned a cluster label, which later informs visualizations like the Cluster Sequence Flow and sequence coherence analysis.
4. Fallback Handling
labels = np.repeat(np.arange(n_clusters), N // n_clusters + 1)[:N]
In case of unexpected errors with AgglomerativeClustering, a simple deterministic fallback assigns sections evenly across clusters, ensuring downstream processes can continue without failure.
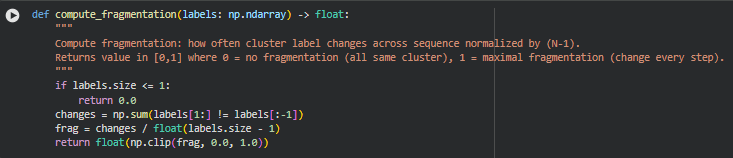
Function: compute_fragmentation
Summary
The compute_fragmentation function quantifies the structural coherence of a sequence of content sections by measuring how frequently the conceptual cluster changes from one section to the next. Each section has an associated cluster label obtained from semantic clustering. Fragmentation is calculated as the proportion of adjacent sections that belong to different clusters.
A low fragmentation score (close to 0) indicates that the content flows consistently within the same conceptual theme, while a high score (close to 1) suggests frequent topic jumps or abrupt transitions, signaling potential issues in logical flow. This metric is crucial for evaluating content sequence integrity, as it directly reflects structural consistency across a page.
Key Code Explanations
1. Handle Short Sequences
if labels.size <= 1:
return 0.0
For sequences with one or zero sections, fragmentation is undefined in practice, so the function returns 0, assuming no fragmentation occurs.
2. Count Cluster Changes
changes = np.sum(labels[1:] != labels[:-1])
Computes the number of times adjacent sections have differing cluster labels. This identifies points in the sequence where the content shifts to a different conceptual topic.
3. Normalize Fragmentation
frag = changes / float(labels.size – 1)
Normalizes the count of changes by the total number of possible transitions (N-1), producing a value between 0 and 1 that is comparable across sequences of different lengths.
4. Clamp to Valid Range
return float(np.clip(frag, 0.0, 1.0))
Ensures the final fragmentation score remains within the valid range [0, 1], providing robustness against numerical errors or unexpected inputs.
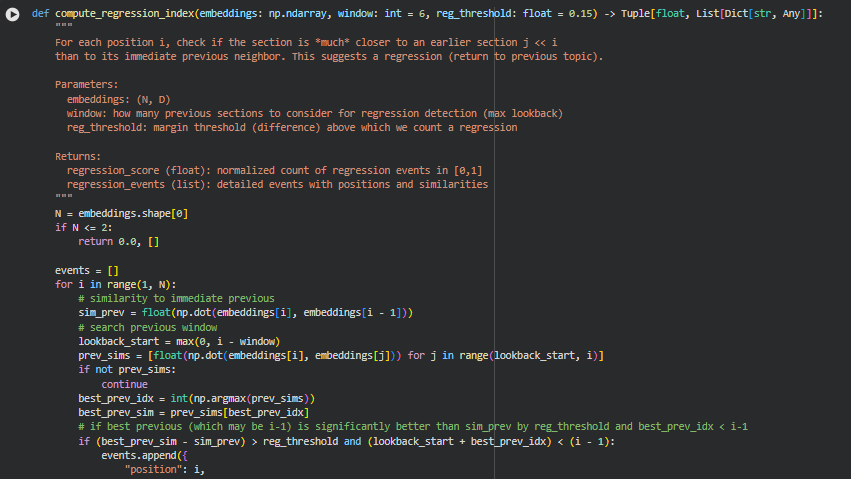
Function: compute_regression_index
Summary
The compute_regression_index function identifies sections in a content sequence that exhibit a regression—where a later section conceptually returns to a topic discussed much earlier, rather than progressing naturally from its immediate predecessor. Such regressions can indicate lapses in logical flow or redundant topic revisits, which may reduce the overall coherence of the content.
The function evaluates each section against a window of preceding sections and compares cosine similarities of embeddings. If a section is significantly closer to a previous section outside the immediate predecessor, it is marked as a regression. The function outputs a normalized regression score between 0 and 1 and a detailed list of regression events, allowing for both quantitative and qualitative assessment of sequence integrity.
Key Code Explanations
1. Early Exit for Short Sequences
N = embeddings.shape[0]
if N <= 2:
return 0.0, []
For sequences with two or fewer sections, regression detection is meaningless. The function returns a zero score and an empty events list.
2. Compute Similarity to Immediate Previous Section
sim_prev = float(np.dot(embeddings[i], embeddings[i – 1]))
Calculates the cosine similarity between the current section i and its immediate predecessor i-1. This serves as a baseline to detect regressions.
3. Lookback Window and Similarity Evaluation
lookback_start = max(0, i – window)
prev_sims = [float(np.dot(embeddings[i], embeddings[j])) for j in range(lookback_start, i)]
best_prev_idx = int(np.argmax(prev_sims))
best_prev_sim = prev_sims[best_prev_idx]
Examines the previous window sections for each current section. Computes cosine similarity with each of these earlier sections and identifies the one with the highest similarity, which may indicate a regression if it is significantly higher than the immediate predecessor similarity.
4. Detect Regression Events
if (best_prev_sim – sim_prev) > reg_threshold and (lookback_start + best_prev_idx) < (i – 1):
events.append({
“position”: i,
“nearest_prev_index”: lookback_start + best_prev_idx,
“sim_to_prev”: sim_prev,
“sim_to_nearest_prev”: best_prev_sim,
“margin”: best_prev_sim – sim_prev
})
Marks a regression event if the similarity to the earlier section exceeds the similarity to the immediate predecessor by reg_threshold and the earlier section is not the immediate previous one. Detailed information including positions, similarities, and margin is stored for later analysis or visualization.
5. Normalize Regression Score
score = len(events) / float(max(1, N – 1))
return float(np.clip(score, 0.0, 1.0)), events
Computes a normalized regression score by dividing the number of regression events by the total possible transitions (N-1), and ensures the score remains in the valid range [0,1]. This provides a quantitative measure of the sequence’s regression frequency.
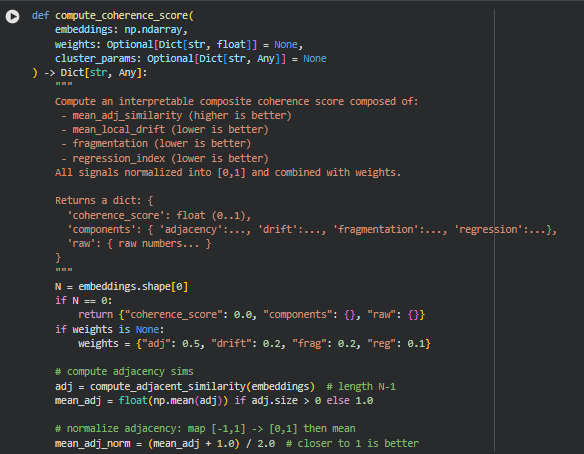
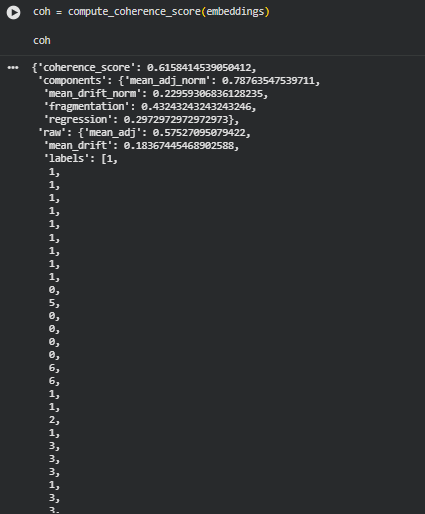
Function: compute_coherence_score
Summary
The compute_coherence_score function calculates a comprehensive, interpretable score that quantifies the logical flow and conceptual consistency of a sequence of content sections. It integrates multiple semantic signals—including adjacency similarity, local drift, fragmentation, and regression—into a single coherence metric normalized between 0 and 1. Each component captures a distinct aspect of sequence integrity: high adjacency similarity indicates smooth transitions, low local drift signals minimal abrupt changes, low fragmentation reflects coherent conceptual clusters, and a low regression index shows minimal backward jumps in topic coverage. The function is highly configurable with weighting and clustering parameters, allowing tailored coherence evaluation.
This score is particularly valuable for evaluating SEO content, instructional materials, or long-form articles, as it provides both a quantitative measure and detailed insights into the structural and semantic organization of the text.
Key Code Explanations
1. Early Exit for Empty Embeddings
N = embeddings.shape[0]
if N == 0:
return {“coherence_score”: 0.0, “components”: {}, “raw”: {}}
Ensures that sequences without any sections return a zero coherence score, avoiding further computation errors.
2. Adjacency Similarity Calculation
adj = compute_adjacent_similarity(embeddings)
mean_adj = float(np.mean(adj)) if adj.size > 0 else 1.0
mean_adj_norm = (mean_adj + 1.0) / 2.0
Computes cosine similarity between consecutive sections. This reflects the smoothness of transitions. The score is normalized to the range [0,1], where higher values indicate stronger continuity.
3. Local Drift Computation
drift = compute_local_drift(adj)
mean_drift = float(np.mean(drift)) if drift.size > 0 else 0.0
mean_drift_norm = float(np.clip(mean_drift / 0.8, 0.0, 1.0))
Measures abrupt changes in similarity between adjacent sections. Larger drift indicates sudden topic changes. The normalization uses a practical heuristic to bound values between 0 and 1.
4. Fragmentation via Clustering
labels = cluster_sections(embeddings, **(cluster_params or {}))
frag = compute_fragmentation(labels)
Sections are grouped into conceptual clusters, and the fragmentation metric quantifies how often the cluster assignment changes in the sequence. Frequent cluster changes indicate low coherence.
5. Regression Index
reg_score, reg_events = compute_regression_index(embeddings)
Calculates regressions, where sections revisit earlier topics. Both the normalized score and detailed event information are returned for interpretation and visualization.
6. Composite Coherence Calculation
coherence = (
weights[“adj”] * mean_adj_norm
– weights[“drift”] * mean_drift_norm
– weights[“frag”] * frag
– weights[“reg”] * reg_score
)
coherence_clipped = float(np.clip(coherence, -1.0, 1.0))
coherence_norm = (coherence_clipped + 1.0) / 2.0
Integrates all components using specified weights. Positive contributions come from adjacency similarity, while drift, fragmentation, and regression reduce the score. The final value is clipped and normalized to [0,1], providing an interpretable metric of sequence coherence.
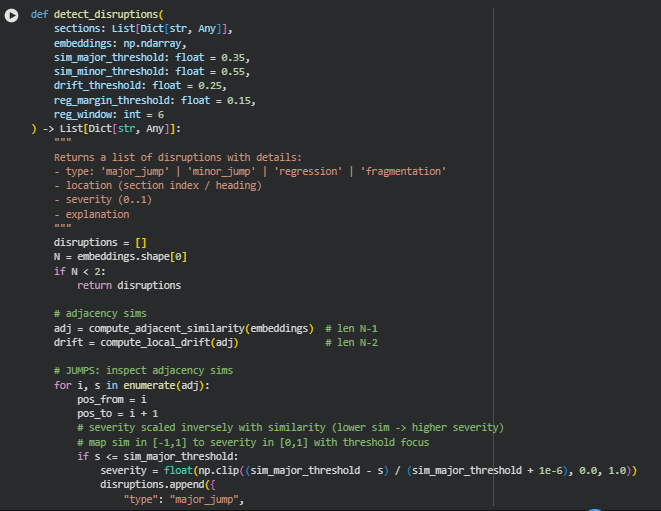
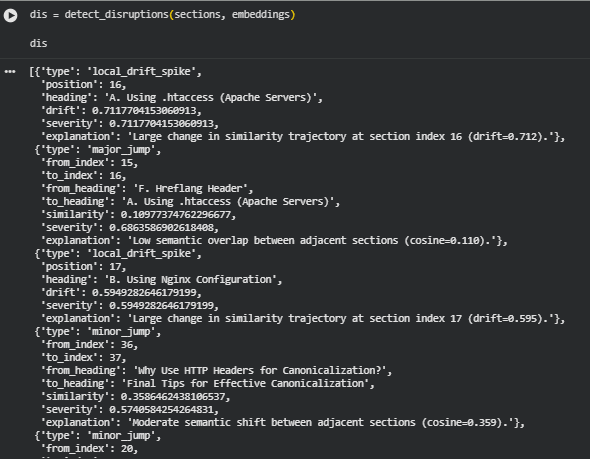
Function: detect_disruptions
Summary
The detect_disruptions function identifies structural and semantic inconsistencies within a sequence of content sections. It analyzes embeddings of sections to detect major or minor semantic jumps, abrupt local drift spikes, regressions to previous topics, and non-contiguous conceptual clusters (fragmentation). Each disruption is quantified with a severity score and accompanied by detailed contextual information, such as section headings, positions, and explanatory notes. This function enables actionable insights for improving content flow, logical sequencing, and overall coherence in long-form articles, tutorials, or SEO-focused pages.
The function integrates multiple aspects of content integrity, allowing a nuanced understanding of where readers might encounter abrupt topic changes or inconsistencies, and highlighting areas that may require reorganization.
Key Code Explanations
1. Adjacency Similarity Jumps
adj = compute_adjacent_similarity(embeddings)
for i, s in enumerate(adj):
if s <= sim_major_threshold:
…
elif s <= sim_minor_threshold:
…
Calculates cosine similarity between consecutive sections to identify semantic jumps. Sections with similarity below sim_major_threshold are flagged as major jumps, and those between sim_major_threshold and sim_minor_threshold as minor jumps. Severity is scaled inversely with similarity.
2. Local Drift Spikes
drift = compute_local_drift(adj)
for j, d in enumerate(drift):
if d >= drift_threshold:
…
Measures abrupt changes in similarity between adjacent sections. A high drift indicates a sudden turn in topic or content trajectory. The severity is proportional to the magnitude of the drift, providing insight into sections that disrupt smooth progression.
3. Regressions to Earlier Sections
reg_score, reg_events = compute_regression_index(embeddings, window=reg_window, reg_threshold=reg_margin_threshold)
for ev in reg_events:
…
Detects cases where a section is semantically closer to an earlier section than its immediate predecessor, signaling a regression or return to a prior topic. This highlights potential backward jumps that reduce logical sequence integrity.
4. Fragmentation Detection
labels = cluster_sections(embeddings)
unique_labels = np.unique(labels)
for lab in unique_labels:
idxs = np.where(labels == lab)[0]
if len(idxs) > 1:
gaps = np.diff(idxs)
mean_gap = float(np.mean(gaps)) if gaps.size else 0.0
if mean_gap >= 3:
…
Analyzes conceptual clusters across the sequence to detect non-contiguous occurrences. Clusters appearing in separated positions are flagged as fragmentation events, with severity based on mean separation and cluster size. This identifies sections that break the conceptual flow.
5. Sorting by Severity
disruptions = sorted(disruptions, key=lambda x: x.get(“severity”, 0.0), reverse=True)
All detected disruptions are sorted by severity in descending order, prioritizing the most impactful inconsistencies. This ensures that critical disruptions are highlighted first for review and potential corrective action.
Function: generate_recommendations
Summary
The generate_recommendations function translates detected content disruptions into actionable, editor-friendly suggestions for improving logical flow and coherence. Each recommendation is conservative, offering options rather than deterministic changes, and includes actionable guidance such as inserting transitions, considering section moves, reviewing regressions, or consolidating fragmented clusters. By mapping semantic analysis to practical editorial advice, this function bridges the gap between automated coherence detection and human content optimization. Recommendations include rationales, suggested skeleton text for transitions, and estimated editorial cost, providing an intuitive guide for content improvement.
This approach allows content editors to prioritize the most critical structural issues and implement improvements that enhance reader experience, maintain SEO value, and reduce semantic inconsistencies.
Key Code Explanations
1. Transition Skeleton for Jumps
def transition_skeleton(prev_text, next_text, n_words=12):
prev_kw = ” “.join(prev_text.split()[:n_words//2])
next_kw = ” “.join(next_text.split()[:n_words//2])
return f”To bridge from the previous section to the next, briefly recap: ‘{prev_kw}…’ and explain how it leads into ‘{next_kw}…’.”
Generates a simple template to suggest a bridging transition between sections. It uses the first few words from both the preceding and following section to create an editor-friendly recap prompt, helping reduce abrupt semantic jumps.
2. Handling Major and Minor Jumps
if typ == “major_jump”:
recs.append({“action”: “insert_transition”, …})
recs.append({“action”: “consider_move”, …})
elif typ == “minor_jump” or typ == “local_drift_spike”:
recs.append({“action”: “insert_transition”, …})
For significant semantic jumps, the function suggests inserting a transition to improve flow, and optionally moving the “to” section to a more contextually appropriate position. Minor jumps or drift spikes only trigger transition suggestions. The rationale is always tied to the detected disruption.
3. Regression Recommendations
elif typ == “regression”:
recs.append({
“action”: “review_regression”,
“position”: i,
“suggested_merge_candidate”: nearest,
…
})
Flags sections that regress to earlier topics, recommending review or potential merging with their nearest previous semantically similar section. This helps prevent content redundancy or illogical topic jumps.
4. Fragmentation Recommendations
elif typ == “fragmentation”:
recs.append({
“action”: “consolidate_fragmented_cluster”,
“cluster_label”: d.get(“cluster_label”),
“indices”: indices,
…
})
Identifies scattered clusters that appear non-contiguously. Suggestions include consolidating scattered subsections under a single heading or moving repeated material together, improving content cohesion and readability.
5. Deduplication and Prioritization
seen = set()
dedup = []
for r in recs:
key = (r.get(“action”), tuple(r.get(“between”, [])) if “between” in r else r.get(“position”, None), r.get(“action”))
if key in seen:
continue
seen.add(key)
dedup.append(r)
Ensures that recommendations are unique and avoids redundant suggestions, prioritizing clarity and editor usability.

Function: run_sequence_integrity_pipeline
Summary
The run_sequence_integrity_pipeline function orchestrates the full Sequence Integrity Analysis of a page, integrating semantic embeddings, coherence evaluation, disruption detection, and actionable recommendations. It accepts either precomputed embeddings or a model for on-the-fly embedding generation. The function annotates each section with adjacency similarity, local drift, cluster labels, regression events, and disruption flags, and aggregates these into a page-level sequence_integrity block. By combining multiple semantic and structural signals, it provides editors and SEO analysts with a holistic view of content flow, logical consistency, and potential areas for improvement.
This pipeline allows users to identify major and minor topic jumps, regressions to earlier sections, and fragmentation of conceptual clusters, while also offering editor-friendly guidance to improve readability, flow, and semantic integrity.
Key Code Explanations
1. Embedding Generation
if embeddings is None:
if model is None:
raise ValueError(“Either provide embeddings or model”)
embeddings = embed_texts(model, texts, normalize=True)
else:
embeddings = np.asarray(embeddings)
if embeddings.shape[0] != N:
raise ValueError(f”Embeddings length ({embeddings.shape[0]}) != number of sections ({N})”)
Generates or validates embeddings for each section. If no precomputed embeddings are provided, the function uses the supplied model. Ensures alignment between embeddings and sections for accurate downstream analysis.
2. Section-Level Metrics Annotation
adj_sim = compute_adjacent_similarity(embeddings)
local_drift = compute_local_drift(adj_sim)
labels = cluster_sections(embeddings)
reg_score, reg_events = compute_regression_index(embeddings, window=reg_window, reg_threshold=reg_margin_threshold)
Calculates core signals for each section:
- Adjacency similarity between consecutive sections.
- Local drift, highlighting abrupt changes in semantic trajectory.
- Cluster labels for conceptual grouping.
- Regression events, flagging sections that revert to earlier topics.
These signals are stored within individual sections for precise tracking.
3. Section-Level Flagging and Regression Attachment
for ev in reg_events:
pos = int(ev[“position”])
sections[pos].setdefault(“regression_events”, []).append({…})
sections[pos][“regression_flag”] = True
Attaches regression events to the relevant sections, marking them for editorial review. Each regression includes similarity margins and nearest previous section indices, enabling context-aware recommendations.
4. Coherence Score Computation
coherence = compute_coherence_score(embeddings)
coherence_clean = {
“coherence_score”: float(coherence.get(“coherence_score”, 0.0)),
“components”: coherence.get(“components”, {}),
“raw”: coherence.get(“raw”, {})
}
Aggregates adjacency, drift, fragmentation, and regression signals into a single interpretable coherence score. Provides both normalized components and raw metrics for detailed inspection.
5. Disruption Detection and Annotation
disruptions = detect_disruptions(sections=sections, embeddings=embeddings, …)
for d in disruptions:
# Annotate sections and build page-level disruptions
sections[idx].setdefault(“disruptions”, []).append(d)
sections[idx][“disruption_flag”] = True
Detects semantic discontinuities including major/minor jumps, drift spikes, regressions, and fragmentation. Each section is annotated with relevant disruption flags, and all detected disruptions are collected for page-level analysis.
6. Recommendations Generation
recommendations = generate_recommendations(sections, embeddings, disruptions, max_recs=max_recs)
Translates detected disruptions into editor-friendly recommendations, such as:
- Inserting transition text to bridge major or minor jumps.
- Considering reordering of disconnected sections.
- Reviewing regressions to previous sections.
- Consolidating fragmented clusters.
Recommendations include rationales and suggested skeleton text, providing actionable guidance for improving content sequence.
7. Page-Level Aggregation
page_data[“sequence_integrity”] = {
“coherence”: coherence_clean,
“fragmentation_score”: float(fragmentation_score),
“cluster_labels”: labels_list,
“section_level”: {…},
“disruptions”: page_disruptions,
“recommendations”: recommendations
}
Compiles all signals, disruptions, and recommendations into a single page-level structure, allowing easy access to both section-specific and overall sequence integrity metrics. This provides a complete semantic and structural overview for editorial decision-making.
Function: truncate
Summary
The truncate function produces clean, concise previews of section text or headings for display and labeling. It ensures long text blocks are shortened to a fixed maximum length while maintaining readability. By adding an ellipsis when content exceeds the limit, it preserves context while keeping outputs UI-friendly. This supports downstream functions that need compact representations of sections, especially in reports, logs, and disruption summaries.
Function: find_section_by_position
Summary
The find_section_by_position function retrieves a section dictionary based on its sequential position within a page. It provides a simple, reliable lookup for functions that need to map regression events, disruptions, or recommendations back to the specific section they reference. This ensures accurate contextual reporting, especially when generating explanations or displaying structural issues to users.
Function: section_label
Summary
The section_label function creates human-readable identifiers for sections by prioritizing preview text, then headings, and falling back to generic names when needed. It ensures every section can be displayed cleanly in summaries, disruptions, recommendations, and regression reports. By using the truncate utility, it produces compact labels that are informative without overwhelming the interface.
Function: display_results
Summary
The display_results function provides a clean, user-friendly console display for multi-URL sequence integrity analysis. It translates raw metrics, disruption signals, and recommendations into an interpretable output format tailored for analysts and content editors. The function presents coherence scores, fragmentation, section-level metrics, disruptions, regression events, and actionable recommendations in an organized and intuitive structure. This creates a readable, at-a-glance overview of sequence integrity performance across pages, enabling effective troubleshooting and editorial decision-making.
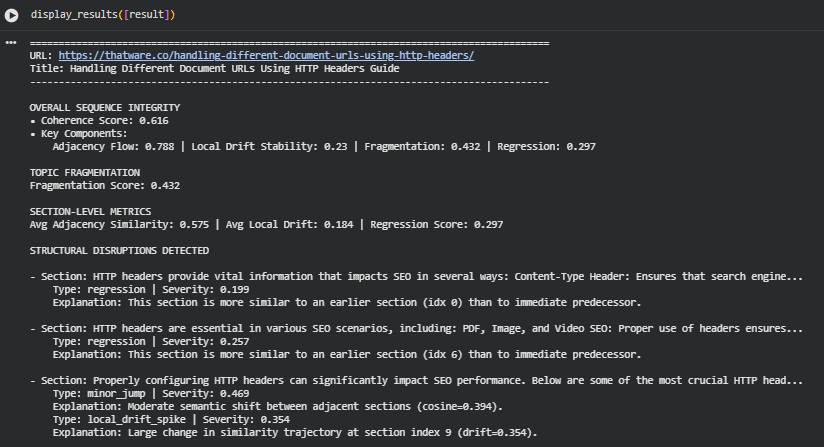
Result Analysis and Explanation
This section provides a detailed interpretation of the sequence-integrity results generated for the page “Handling Different Document URLs Using HTTP Headers Guide.” The goal is to help understand how well the content progresses, where structural disruptions occur, and what corrective actions are advisable for improving clarity, user experience, and SEO interpretability.
Overall Sequence Integrity
The content achieves a Coherence Score of 0.616, indicating a moderately stable conceptual flow. This score suggests that the general structure maintains a recognizable order, but notable inconsistencies appear across multiple sections.
Interpretation of Key Components
Adjacency Flow (0.788) This score reflects how smoothly each section transitions into the next. A value close to 0.8 indicates that most consecutive sections share conceptual continuity. This is generally positive for both users and search engines, as the narrative rarely changes abruptly.
Local Drift Stability (0.23) This value evaluates how predictable the similarity trend is across the sequence. A relatively low value here indicates fluctuations in semantic direction. These fluctuations point to sudden shifts in context or topic emphasis, which may affect readability.
Fragmentation (0.432) A fragmentation score around 0.43 signals that the content shifts clusters nearly half the time as the reader progresses. This indicates moderate topical fragmentation—sections occasionally change focus before a cluster is complete or fully explained.
Regression (0.297) Regression indicates how often the content refers back to earlier topics instead of continuing the logical sequence. A score of ~0.30 indicates regular backward jumps, suggesting that concepts reappear after unrelated topics, disrupting flow.
When Action Is Needed
Action becomes necessary when a coherence score falls into the 0.45–0.65 range alongside mid-level fragmentation and regression. This combination indicates that the structure is functioning but not optimally. Improving section ordering, transitions, and cluster continuity can significantly enhance clarity and SEO understanding.
Topic Fragmentation Analysis
The Fragmentation Score of 0.432 indicates that nearly half of all section-to-section movements involve a change in topical cluster. This level of fragmentation suggests that the article alternates between different themes—basic explanation, use cases, SEO impacts, and implementation details—without completing one cluster before moving into another.
Interpretation and Action Steps
A score near 0.40–0.45 represents medium fragmentation. This is acceptable for broad, multi-step guides but may weaken narrative clarity if transitions are not handled well.
Corrective measures include:
- Merging short, closely related sections into a single cohesive block
- Adding contextual bridges where necessary
- Grouping advanced topics after foundational topics have been completed
These adjustments help maintain logical continuity for readers and support search engine understanding of topic hierarchy.
Section-Level Metrics
Average Adjacency Similarity (0.575)
This indicates moderate similarity between consecutive sections. While not poor, it reflects uneven transitions, where some sections connect well while others fall short.
Average Local Drift (0.184)
Drift represents how sharply the content shifts from one point to the next. A value below 0.2 is manageable but suggests that certain sections deviate sharply from the established direction. These deviations typically require transition sentences or reordering.
Regression Score (0.297)
This matches the overall regression measure and reinforces that backward jumps occur frequently enough to impact flow. Regression is commonly triggered when implementation details appear earlier than conceptual explanations or when examples appear before the underlying rule is introduced.
Structural Disruptions
Structural disruptions highlight areas where the content deviates significantly from expected progression. Three major patterns appear in this analysis.
Regression Events
Multiple regression events were identified, each signaling that the section resembles content from earlier positions rather than continuing forward.
Examples include:
- A section discussing SEO impacts of HTTP headers regresses toward the initial introduction.
- A section on SEO scenarios aligns more closely with a prior section on advanced header usage.
Impact: These regressions cause the narrative to feel repetitive or disordered. Search engines may interpret such patterns as unclear topical hierarchy, which weakens semantic signals.
Topic Jumps (Minor Jumps)
One section shows a moderate semantic jump (severity 0.469). This jump implies a shift to a topic not sufficiently prepared by the preceding section. Jumps of this magnitude interrupt reading flow and may reduce user comprehension.
Local Drift Spikes
A drift spike of 0.354 indicates a sharp shift in similarity direction. This typically occurs when the content abruptly changes from one conceptual category (e.g., definitions) to another (e.g., advanced settings). Drift spikes often require transition sentences to maintain continuity.
Interpretation of Regression Events
The regression breakdown shows three sections where semantic reversal is substantial enough to impact structure:
- The first regression indicates that foundational explanations reappear after several intermediate topics, making the content feel repetitive.
- The second regression shows a shift back toward an advanced optimization section, suggesting poor placement of either the earlier or later segment.
- The third regression reflects misalignment between implementation details and conceptual explanation orders.
onable Implications
Content should be reorganized so that conceptual foundations appear first, then use cases, then implementation specifics, followed by advanced-level material. Realigning in this sequence minimizes backward jumps and improves interpretability.
Recommendations and Practical Guidance
Three corrective action types were suggested: transition insertion, section reordering, and contextual reinforcement.
Transition Insertions
Two areas require transitions due to sharp semantic shifts or low similarity. Transitions help maintain the reader’s mental model and reduce fragmentation.
These should be inserted when:
- Consecutive sections exhibit low cosine similarity (<0.20)
- Drift spikes exceed ~0.30
- A new subtopic begins abruptly without introductory context
Section Reordering
A segment is identified as potentially misplaced, showing patterns of advanced explanation positioned before baseline concepts. Reordering such sections ensures that readers receive foundational understanding before deeper implementation details.
When Corrections Have High Impact
Corrections should be prioritized when:
- Coherence falls between 0.55 and 0.65
- Fragmentation exceeds 0.40
- Regression surpasses 0.25
- Drift spikes appear repeatedly
The current analysis meets these thresholds, meaning the suggested actions will materially improve structure, clarity, and SEO interpretability.
Summary Interpretation for User Decisions
The page demonstrates moderate structural strength with clear opportunities for improvement. The primary issues stem from regressions and medium fragmentation, indicating that the content occasionally circles back to earlier concepts or changes topic clusters prematurely.
Addressing the recommended areas—transition insertion and targeted reordering—will strengthen the linear flow, enhance user comprehension, and consolidate semantic signals for search engines. These improvements directly support higher engagement quality and improved crawl interpretation.
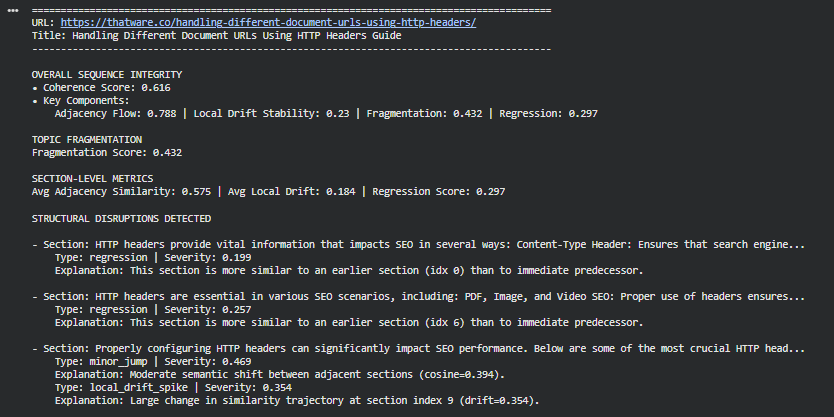
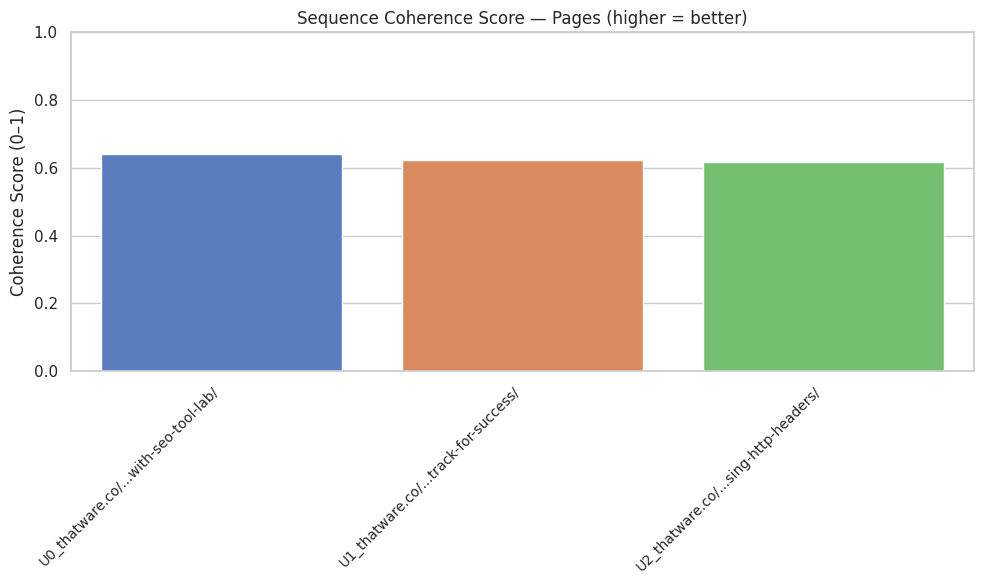
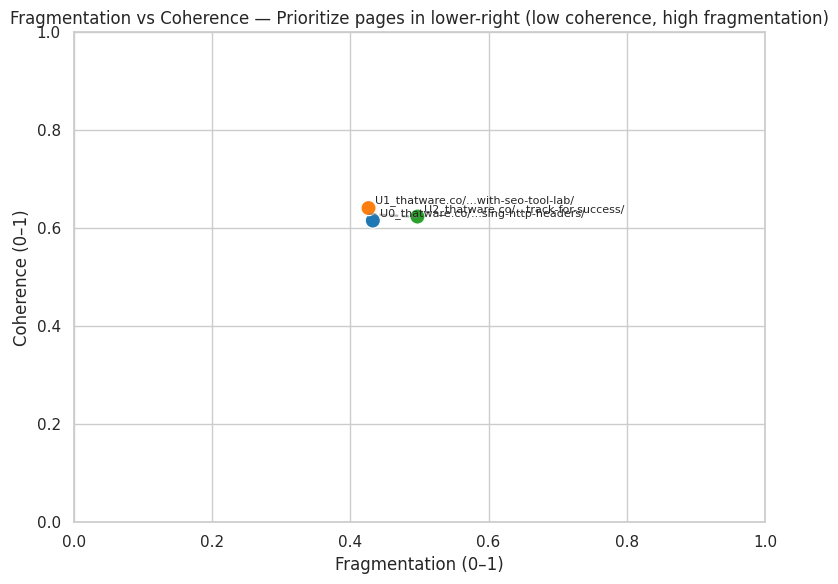
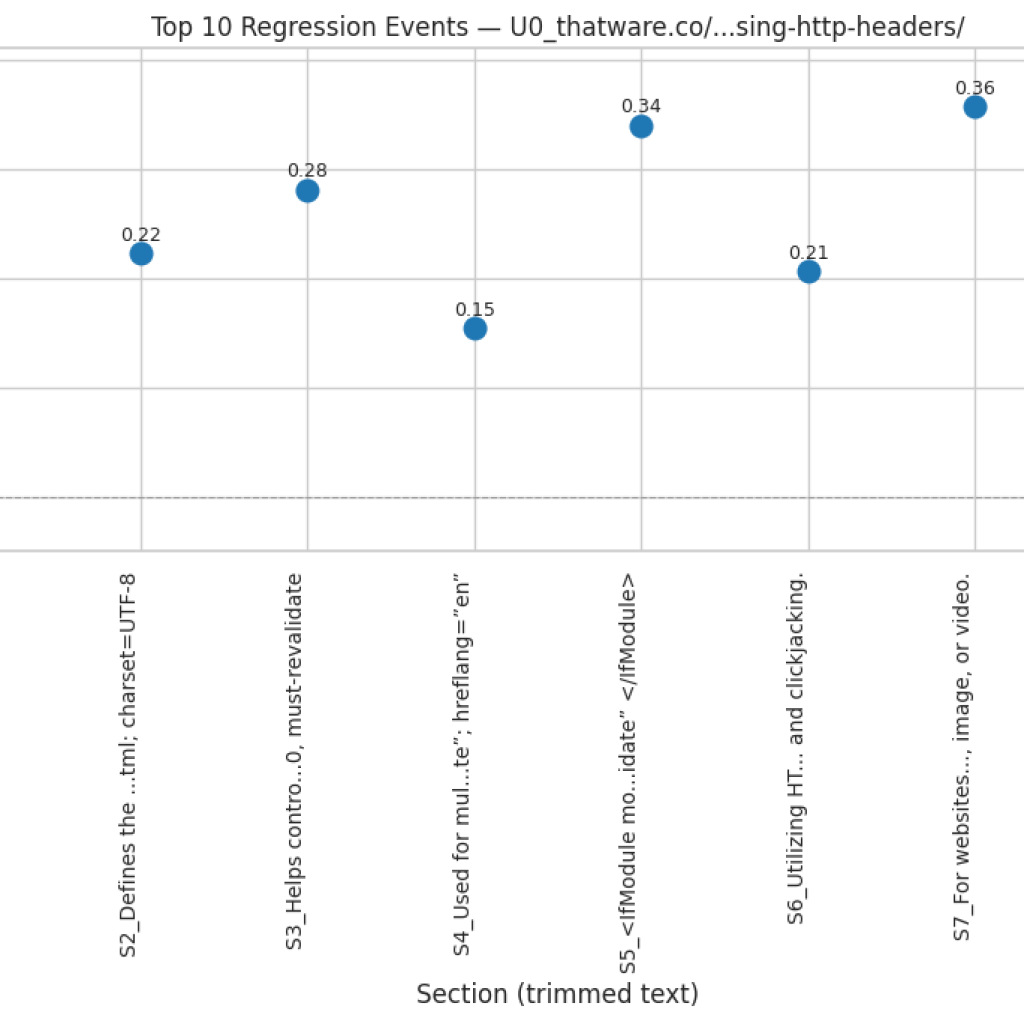
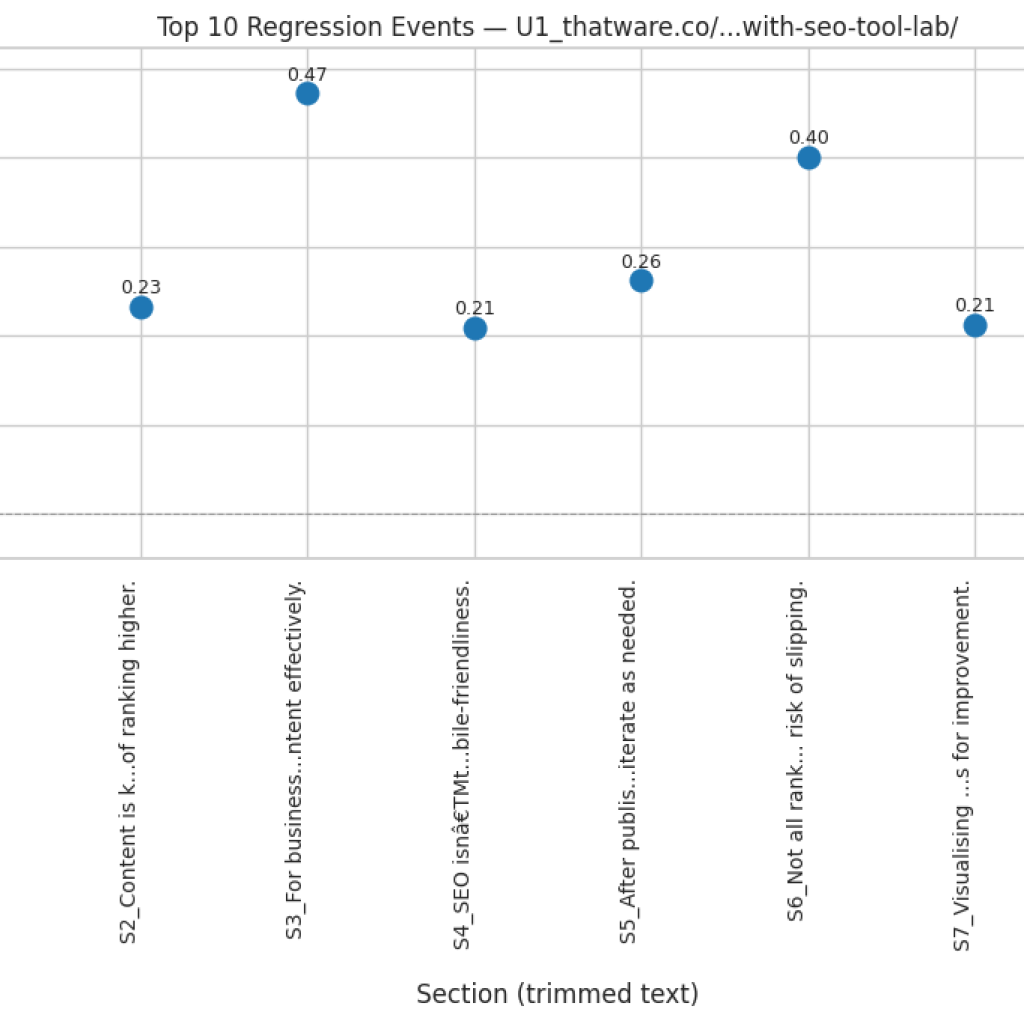
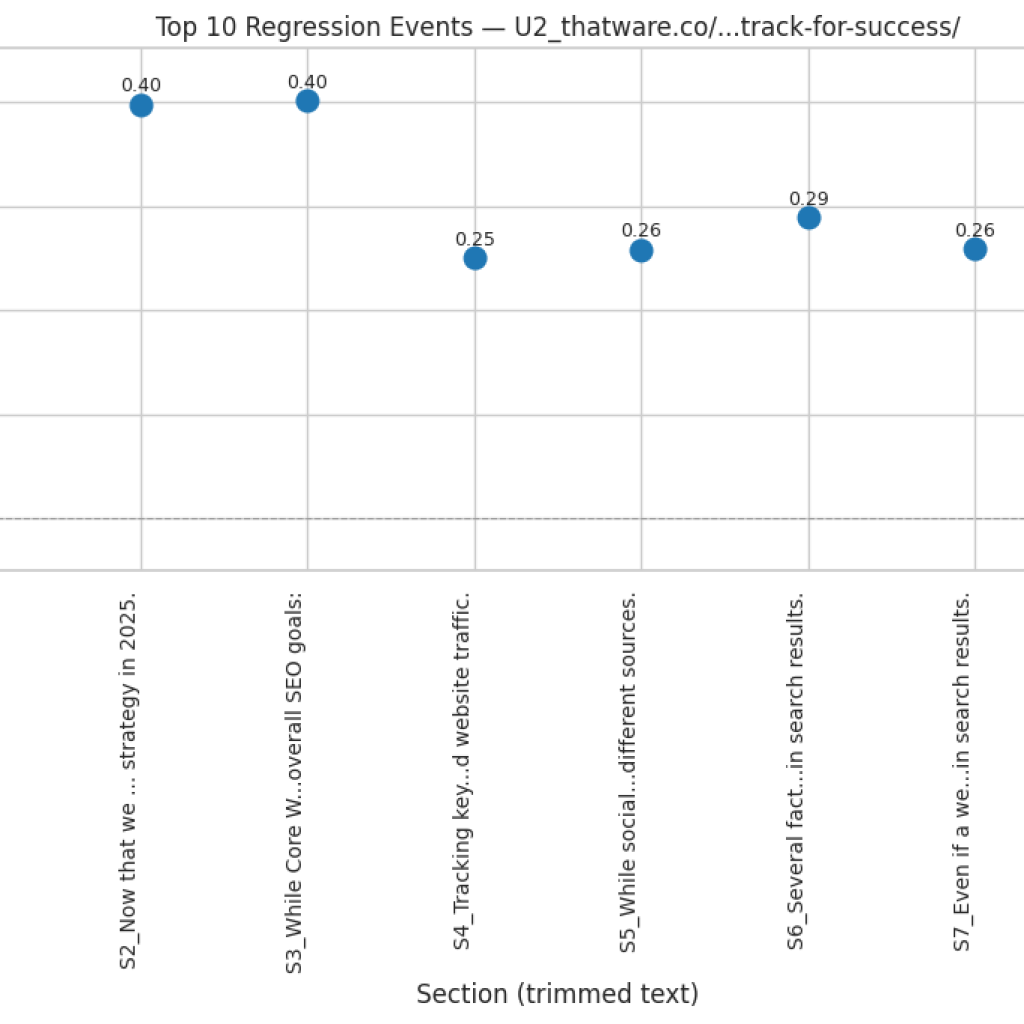
/tmp/ipython-input-162265401.py:1738: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_xticklabels(labels, rotation=75, ha=”right”, fontsize=”small”)
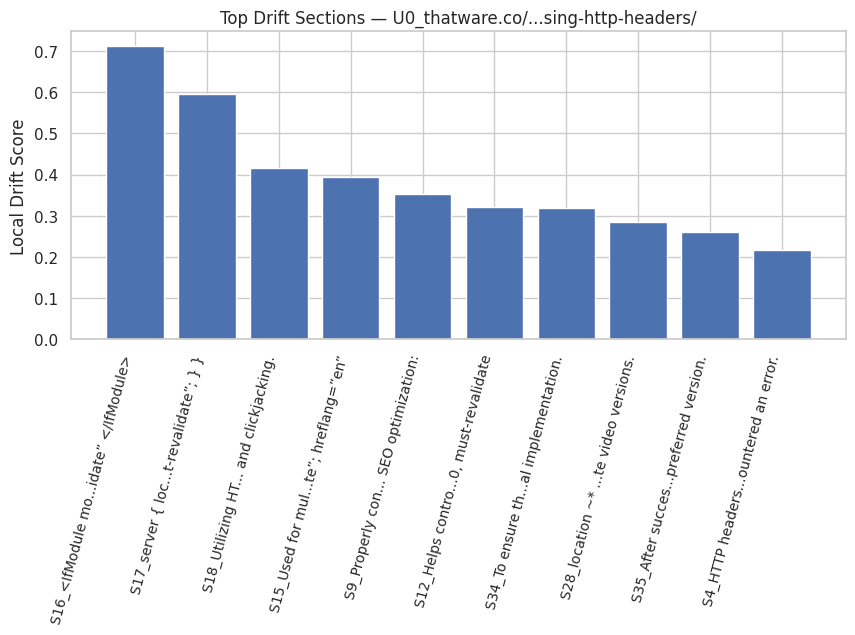
/tmp/ipython-input-162265401.py:1738: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_xticklabels(labels, rotation=75, ha=”right”, fontsize=”small”)
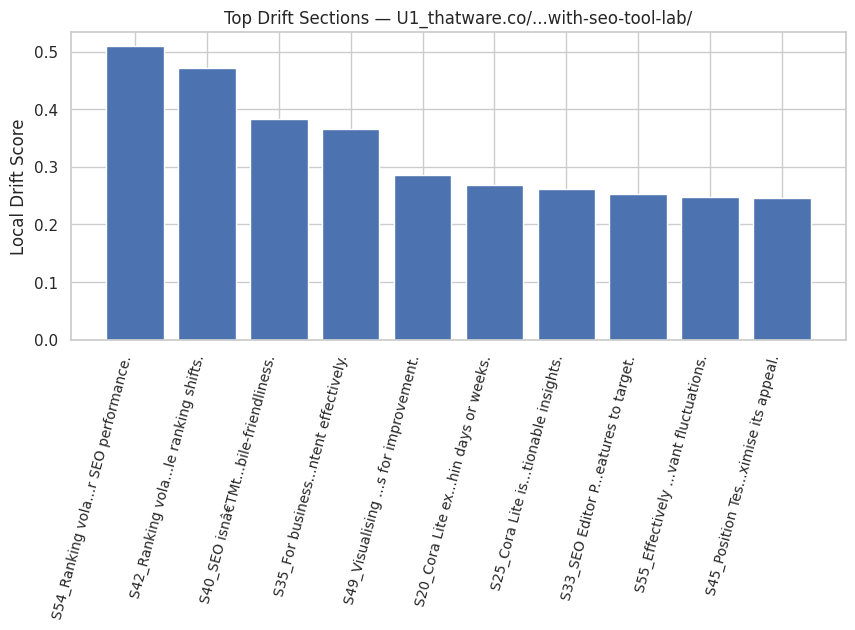
/tmp/ipython-input-162265401.py:1738: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_xticklabels(labels, rotation=75, ha=”right”, fontsize=”small”)
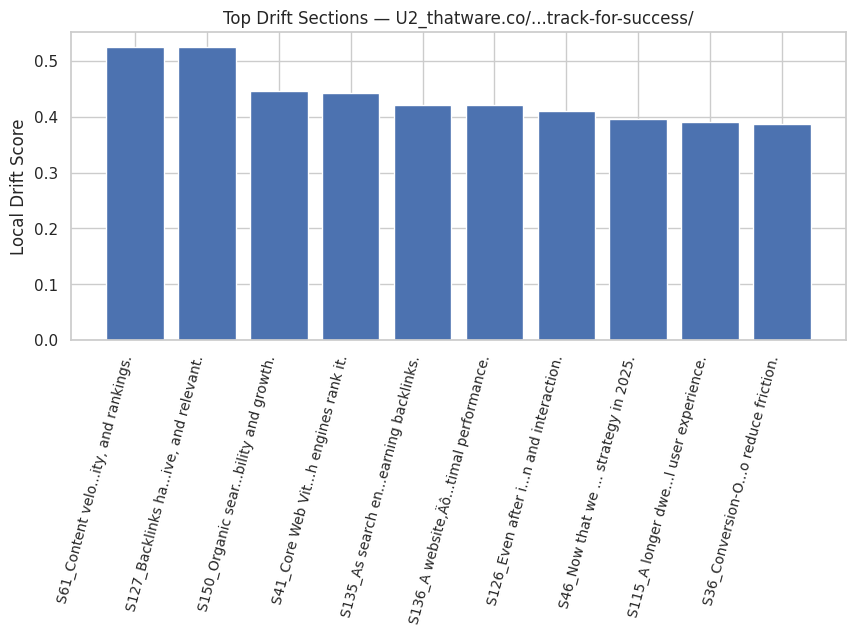
Result Analysis and Explanation
This section provides a comprehensive interpretation of the sequence-integrity evaluation results. All metrics, structural signals, and visualization trends are explained in detail to support practical decision-making. Each subsection describes what the metric represents, how to interpret score ranges, when action is required, and what type of action is typically beneficial in real-world SEO content optimization.
Overall Sequence Integrity
The sequence integrity score reflects the extent to which the document maintains an orderly progression of ideas from beginning to end. A consistently high score indicates that concepts evolve logically, whereas a depressed score suggests structural interruptions, regressions, or fragmenting shifts in topic development.
A value in the 0.60–0.70 range generally indicates mixed sequence reliability. This means the document forms a meaningful flow in several portions but also contains notable segments where concept ordering weakens. Such cases typically arise when explanatory blocks, examples, or deep-dive technical segments are positioned without sufficient contextual preparation.
Interpretation Thresholds
· 0.80–1.00 (Strong Integrity) Content follows a coherent conceptual path. Only minor refinements are required.
· 0.65–0.79 (Moderate Integrity) Content remains understandable, but noticeable fluctuations in topic proximity may impair smooth reading and crawl predictability.
· 0.40–0.64 (Mixed Integrity) Logical progression is inconsistent. Reordering, transition strengthening, or the integration of bridging context is recommended.
· Below 0.40 (Weak Integrity) Sequential disruptions, regressions, and topic jumps frequently interrupt comprehension. Re-structuring of multiple sections may be needed.
The assessed score falls within the mixed integrity range, indicating recognizable flow but also recurring interruptions in conceptual progression. These interruptions frequently require structured transitions rather than major re-writing.
Component-Level Structural Indicators
The system analyzes individual structural dimensions that contribute to the overall sequence score. Each component provides a different lens on how concepts evolve from section to section.
Adjacency Flow
Adjacency flow captures the similarity between consecutive sections. High scores imply that each new section extends or complements the preceding one. A value close to the 0.75–0.80 range normally reflects adequate immediate continuity.
When adjacency flow is high while other dimensions are low, the issue often stems from larger-scale structural decisions (e.g., misplaced blocks) rather than sentence-level transitions.
Local Drift Stability
Local drift measures how sharply the semantic direction changes at each step. Stability (drift below 0.15–0.20) indicates linear movement through related concepts. Larger drift spikes imply sudden pivots that may confuse or slow a reader.
A drift average in the 0.18–0.25 region indicates moderate fluctuation. This typically occurs when explanatory lists, examples, or specialized concepts interrupt a broader conceptual storyline.
Fragmentation
Fragmentation represents the presence of semantically isolated sections. Values between 0.35–0.50 indicate mild to moderate fragmentation, meaning certain sections do not strongly connect to nearby segments. This impacts crawler interpretation by breaking topical consistency.
Fragmentation in this range often suggests the existence of standalone segments that need bridging context.
Regression
Regression measures how similar a section is to earlier content rather than to its immediate predecessor. Elevated values (above 0.25) imply backward semantic jumps. These jumps may create repeated explanations or return to earlier concepts without signalling the shift.
A regression profile in this range usually highlights misplaced summary blocks, repeated explanations, or concept loops.
Topic Fragmentation
Topic fragmentation indicates the proportion of content that behaves as isolated topic units rather than contributing to a central narrative. A score in the 0.40–0.45 range reflects moderate fragmentation.
Such cases often arise when technical sections, examples, multi-role headers, or specialized subsections appear in rapid succession without contextual framing. Fragmentation of this magnitude reduces clarity for readers and affects how search engines evaluate topical authority and contextual cohesion.
Interpretation Guidelines
- Below 0.20 – Strong thematic unity
- 0.20–0.35 – Mild fragmentation
- 0.35–0.55 – Moderate fragmentation (action recommended)
- Above 0.55 – Strong fragmentation (restructuring required)
Section-Level Behavior and Localized Disruptions
Section-level metrics detect fine-grained disruptions in continuity. These signal where the content diverges from expected logical development.
Minor or Moderate Semantic Jumps
A semantic jump occurs when the conceptual distance between two consecutive sections exceeds typical variance. Such jumps do not always indicate incorrect structure, but frequent occurrences suggest missing transitions or abrupt topic introductions.
When similarity falls notably below the document’s average adjacency band, the shift becomes visible to the reader and can interrupt comprehension.
Local Drift Spikes
A drift spike represents a sharp deviation from the evolving trend. Even if the section is relevant, its placement may not reflect the surrounding narrative. Drift spikes often correspond to:
- Introduction of advanced concepts before foundational ones
- Switches between example-heavy and theory-heavy content
- Sudden return to operational details after conceptual framing
Regression Events
Regression events indicate backward movement in conceptual space. These are particularly important because they reveal unintentional revisiting of earlier ideas. Regressions of mild severity generally require transition reinforcement; higher-margin regressions may require section repositioning.
Recommendations Interpretation
The system produces recommended corrective actions:
Transition Insertion
Transition insertion is recommended when continuity weakens but the section order remains fundamentally valid. This is usually a low-cost, high-impact remedy appropriate when:
- Moderate jumps exist
- Drift spikes occur
- Fragmentation is localized rather than structural
A transition typically includes contextual framing, a brief recap, or a short connector that ties the previous and next topics.
Section Reordering
Section moves are suggested when a section aligns more closely with earlier or later segments, implying structural misplacement. This requires medium effort and is essential when regressions repeatedly surface around the same conceptual cluster.
When Reordering Is Necessary
Reordering becomes necessary if:
- Multiple regressions emerge around similar conceptual regions
- Fragmentation rises above 0.50
- The document oscillates between advanced and introductory concepts without logical escalation
Visualization & Interpretation of Structural Signals
The visualization suite provides a multi-angle view of the document’s structural integrity. Each plot isolates a specific behavioural pattern within the content—coherence progression, fragmentation behaviour, regression severity, and drift concentration—allowing structural inconsistencies to be diagnosed visually rather than inferred solely from numerical metrics. Together, these charts highlight where the narrative flow weakens, where conceptual transitions become inconsistent, where the document loops back unnecessarily, and where abrupt topic shifts break continuity.
Sequence Coherence Bar Chart (Combined Across All URLs)
This visualization presents the coherence score of each page as a bar chart, enabling a comparative assessment of how well each page maintains logical progression from start to finish. The chart uses trimmed labels for readability, ensuring that even long URLs remain identifiable.
The bars reveal the overall smoothness of conceptual movement. Higher bars represent pages with stronger structural consistency and fewer abrupt transitions. Lower bars indicate pages requiring attention, particularly where conceptual jumps, regressions, or topic fragmentation interrupt the natural flow. The visual ranking makes prioritization straightforward: pages with the weakest structure appear immediately noticeable, directing optimization efforts toward the highest-impact areas first.
Interpretation becomes clearer when scores fall into meaningful ranges.
- 0.75–1.00: Strong sequence integrity, predictable narrative development.
- 0.50–0.75: Moderately coherent, may contain uneven transitions.
- 0.00–0.50: Weak coherence, closer examination recommended.
The bar chart therefore serves as a high-level entry point for identifying where deeper structural diagnosis is needed.
Fragmentation vs Coherence Scatter Plot (Combined)
This scatter plot positions each page along two structural dimensions—fragmentation and coherence—offering a combined view of thematic stability versus narrative smoothness. Fragmentation measures how frequently a document introduces isolated or disconnected topics, while coherence measures overall conceptual flow.
The visual relationship between these dimensions often reveals patterns not immediately evident from individual scores. For example, pages appearing in the lower-right zone combine low coherence with high fragmentation. This zone represents the most structurally unstable content, where concepts appear scattered and transitions lack contextual grounding. Conversely, pages in the upper-left quadrant demonstrate both strong cohesion and minimal fragmentation.
A trend line further supports interpretation by highlighting the relationship between both metrics. When the line slopes downward, high fragmentation correlates with low coherence, reinforcing the need for structural tightening where scatter points drift rightward. The visualization helps prioritize pages that require re-grouping of concepts, enhanced contextual framing, or restructuring of thematic clusters.
Regression & Disruption Event Map (Per URL)
The regression map visualizes the sections that exhibit the strongest backward alignments—areas where a segment aligns more closely with earlier content rather than its immediate predecessor. These backward pulls often indicate conceptual regressions, repeated explanations, or misplaced details.
For each URL, the plot highlights the top regression margins, focusing on events with the highest structural impact. Each point on the chart represents a section producing a regression signal, with the vertical position reflecting the severity of the regression margin. Higher positive values indicate stronger backward jumps, suggesting that the section disrupts the logical forward progression.
Understanding the map involves examining both severity and distribution.
- Isolated spikes suggest localised issues, often fixable with transition insertion.
- Clustered spikes across consecutive sections imply deeper architectural misplacement.
- Large positive margins point toward sections that require reordering or reframing.
The trimmed labels beneath each point allow rapid identification of offending sections without overwhelming the axis. This makes the regression map an essential tool for diagnosing narrative loops and structural reversals.
Top Drift Sections Bar Chart (Per URL)
Local drift measures the absolute change in adjacency similarity between consecutive sections—essentially how sharply the content shifts from one step to the next. The bar chart surfaces the sections with the most significant drift values, enabling focused attention on abrupt topic transitions.
High drift values typically correspond to conceptual leaps, where a section introduces a theme, technical detail, or example that diverges significantly from the preceding context. These abrupt transitions can disrupt both reader comprehension and crawler interpretation, creating a sense of thematic inconsistency.
The plot highlights the top N drift-heavy sections, sorted in descending order for clarity. Interpretation follows natural thresholds:
- Drift below 0.15 generally indicates smooth, contextually supported transitions.
- 0.15–0.30 reflects moderate shifts that may benefit from added context.
- Above 0.30 identifies abrupt jumps where restructuring or transition reinforcement becomes necessary.
By examining the bar heights, editors can pinpoint exactly which sections weaken continuity and should be prioritized for smoothing or repositioning.
Integrated Value of the Visualization Suite
Together, these plots form a comprehensive diagnostic framework that reveals structural weaknesses from multiple angles. The coherence bar chart provides cross-page ranking; the fragmentation–coherence scatter contextualizes thematic balance; the regression map exposes backward jumps and disruptions; and the drift bar chart highlights abrupt transitions.
This visual ecosystem supports a practical optimization workflow:
- Identify weak pages using coherence bars.
- Understand thematic imbalance using the scatter plot.
- Trace structural regressions via the regression map.
- Pinpoint abrupt transition zones using drift bars.
Such a layered approach ensures that content refinement is guided by precise, data-driven structural insights rather than subjective evaluation, improving both user comprehension and SEO interpretability.
Conclusion of the Result Analysis Section
The results reveal a document with foundational coherence but noticeable inconsistencies in flow, topic clustering, and semantic progression. The analysis highlights the importance of reinforcing transitions, smoothing conceptual pivots, and addressing regression-prone regions. Proper application of transition design, structural refinement, and context-based positioning significantly improves clarity, user experience, and SEO interpretability.
Q&A for Result Interpretation, Action Suggestions, and Practical Value
What does a mixed sequence integrity score indicate about the page’s current structural performance?
A mixed sequence integrity score reflects a document that maintains meaningful flow in several areas but displays noticeable breaks in logical progression. These breaks often occur when advanced topics appear before foundational context, when lists or examples interrupt the narrative path, or when sections revisit earlier concepts without signalling the return. Such inconsistencies create uneven reading momentum and reduce the clarity of topical development. Search engine crawlers, which interpret content semantically, may register these inconsistencies as unclear topic transitions. A mixed score therefore indicates a need for structural refinement rather than a complete rewrite. Improvements typically involve repositioning sections, adding contextual framing, and reorganizing concept clusters so the document reads as a steadily advancing explanation rather than a set of loosely connected segments.
How should topic fragmentation be interpreted, and what actions become necessary when fragmentation reaches moderate levels?
Topic fragmentation represents the degree to which sections behave as standalone thematic units rather than contributing to a unified progression. Moderate fragmentation values imply that certain portions diverge from the surrounding narrative or introduce topics with insufficient grounding. This can lead to a disjointed user experience, where segments feel “inserted” rather than woven into the main storyline.
Actions appropriate for moderate fragmentation focus on restoring thematic continuity. Transitional statements can explain why an isolated concept is relevant at that specific point. Supporting context can be added before introducing technical details or examples that otherwise feel abrupt. When fragmentation clusters appear across multiple sections with related topics, those sections benefit from being grouped together or positioned after introductory context. Addressing fragmentation reinforces semantic coherence, strengthens SEO topical alignment, and improves both human and crawler interpretability.
What do regression events reveal about the content flow, and when is reordering necessary?
Regression events highlight instances where a section aligns more strongly with earlier content than with its immediate predecessor. These events often indicate conceptual looping, repeated explanations, or misplaced sections. When regression margins remain mild and infrequent, localized adjustments—such as inserting clarifying transitions—are usually sufficient.
Reordering is recommended when regression events form clusters, align with drift spikes, or appear across adjacent regions of the document. In such cases, sections may be positioned too early or too late relative to supporting content. Moving these sections restores the natural evolution of ideas. This adjustment benefits SEO interpretation by reducing semantic oscillation and creating a more predictable information structure. Human reading experience also improves as concepts begin to appear in the order required for comprehension, reducing effort spent reconciling backward shifts.
How can visualization outputs guide corrective actions in a practical optimization workflow?
Visualization outputs translate complex structural signals into observable patterns, making it easier to identify where thematic issues occur. A sequence coherence plot highlights whether concept development follows a smooth path or contains repeated dips. A local drift chart reveals sudden direction shifts that may require additional context. Regression timelines pinpoint where the narrative jumps backward. Fragmentation heat maps show which sections stand out as semantic outliers.
In practice, these visual patterns help prioritize edits. Deep troughs or repeated drift spikes indicate high-impact zones where even small refinements can significantly improve readability. Fragmentation hotspots suggest where reinforcing relevance or restructuring groups of concepts may be necessary. By following these visual cues, optimization becomes targeted rather than broad, saving editorial effort and ensuring improvements directly address measured weaknesses. This structured approach enhances reader experience and strengthens topical authority signals for search engines.
When should transition insertion be used instead of full restructuring?
Transition insertion is appropriate when the section order is fundamentally correct but the content moves from one topic to another too abruptly. A transition helps prepare the reader by summarizing what was just covered and signalling what will follow. This approach is ideal when adjacency similarity dips slightly or when local drift spikes appear without corresponding regressions.
Full restructuring is necessary only when the order of concepts disrupts comprehension or when several sections consistently align with earlier content. Transition insertion is a low-effort, high-impact solution that improves flow, reduces abrupt semantic shifts, and supports clearer narrative movement without altering the document’s architecture. This makes it the preferred remedy for most moderate-level issues.
How should actionability thresholds be understood when deciding whether to revise content?
Actionability thresholds determine when a metric represents a meaningful structural issue instead of natural variation. For example, drift averages below 0.15 typically reflect stable progression, while averages above 0.25 indicate inconsistent topic transitions. Fragmentation above 0.35 begins to impair central topic development. Regression margins above 0.25 suggest that a section’s placement may disrupt narrative flow.
Understanding these thresholds allows editors to avoid unnecessary adjustments. When scores fall into mild ranges, simple enhancements such as adding context or tightening phrasing may be sufficient. When metrics surpass moderate thresholds, more deliberate intervention—such as reordering or re-framing sections—is warranted. Using thresholds ensures that optimization efforts focus on the areas that most influence user experience and SEO interpretation.
What benefits can be expected after addressing the identified structural issues?
Addressing structural issues strengthens both human readability and crawler interpretation. Improved sequence integrity enables readers to move through the content with less cognitive friction, reducing information overload and increasing engagement. Well-placed transitions and consistent topic progression help readers understand how concepts relate, leading to higher perceived authority and trust.
Search engines benefit from clearer thematic organization, which supports better topic categorization, improved semantic understanding, and enhanced ranking signals for expertise and content comprehensiveness. Lower fragmentation and minimized regressions help crawlers identify the content’s main subject more distinctly, improving performance for relevant queries. Overall, structural refinement enhances discoverability, usability, and the perceived quality of the page.
What types of content typically cause sequence instability, and how can they be managed?
Sequence instability often emerges when the document alternates between conceptual explanation, technical details, and operational examples without adequate framing. Lists of advanced techniques or deep technical subsections introduced too early can disrupt the expected flow. Similarly, revisiting earlier concepts while discussing later topics causes regressions and breaks continuity.
These issues can be managed by organizing content hierarchically: foundational concepts first, practical applications next, and specialized variations last. Each segment benefits from introductory framing that explains its relevance and summarizes preceding context. Grouping related ideas into clusters prevents fragmentation and reduces drift. This structured approach encourages predictable conceptual development that supports both readability and SEO clarity.
Final Thoughts
The Content Sequence Integrity Analyzer provides a structured, data-driven framework for evaluating how effectively a document progresses from one idea to the next. Through semantic similarity modelling, transition diagnostics, fragmentation measurement, regression detection, and detailed visualization, the system delivers a clear and actionable understanding of a page’s structural behaviour.
The analytical pipeline establishes how well each section contributes to a coherent narrative, how consistently topics evolve across the document, and where disruptions weaken the overall flow. By quantifying coherence, identifying fragmentation patterns, and detecting backward thematic shifts, the system outlines a comprehensive structural profile for any content asset. The visualization suite further enhances interpretability by presenting coherence levels, thematic stability, regression intensity, and drift concentration in intuitive, decision-friendly formats.
Taken together, the insights enable precise refinement of content architecture. Strong coherence signals validate effective sequencing, while localized drift, fragmentation, or regression indicators highlight sections that benefit from improved transitions or repositioning. This empowers teams to enhance clarity, ensure smoother user experience, and strengthen search engine understanding of the page’s structural intent.
The Content Sequence Integrity Analyzer therefore serves as a practical, performance-oriented tool for maintaining and improving content quality. Its metrics and visual diagnostics support confident editorial decisions, reinforce structural consistency, and help ensure that each document communicates its ideas in a logically connected, reader-aligned, and SEO-friendly manner.
