SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
BERT is a powerful tool that helps search engines like Google better understand the context of words in a sentence. This means that people are more likely to find exactly what they want when searching for something. For you, as someone creating content or running a website, BERT means you should focus on writing clear, helpful, and natural content. The more your content makes sense in context, the better BERT can help it get found by the right people. This improves your SEO and helps your website perform better in search results.

What is the purpose of this project?
- This project aims to utilize BERT (Bidirectional Encoder Representations from Transformers) to analyze and optimize a website’s content. By generating embeddings that represent the meaning of the website’s content, the project allows for identifying redundant content, uncovering gaps in the content strategy, and improving overall SEO performance. The goal is to ensure the website delivers unique, relevant, and contextually rich content that aligns with search engine algorithms and user intent.
What is BERT?
- BERT stands for Bidirectional Encoder Representations from Transformers. While the name sounds complex, let’s break it down into simple, non-technical terms so you can easily understand what it is and how it helps.
1. Understanding BERT in Simple Terms
· Context Matters: Imagine you’re reading a book, and you come across the word “bank.” Depending on the sentence, “bank” could mean the side of a river or where you keep your money. How do you know which meaning is correct? You look at the words around it to understand the context. BERT works similarly. It reads the entire sentence, both forward and backward, to understand the meaning of each word based on the words around it.
· Bidirectional: Most traditional language models read text in one direction—either from left to right (like how we read English) or right to left. BERT, however, reads the text in both directions at the same time. This allows it to better understand the context because it considers all the words in a sentence together.
· Transformers: This is the type of technology that powers BERT. Think of transformers as a kind of brain that processes and understands language. They help BERT focus on the important parts of a sentence and figure out how words relate to each other.
2. How Does BERT Help with Search Engines and SEO?
· Improving Search Results: When you type a query into Google, BERT helps the search engine understand your request. For example, if you search for “how to catch a cold,” BERT helps Google understand that you’re not asking for tips on getting sick but how people typically get colds. This means you’ll get more relevant results.
· Content Relevance: BERT also helps search engines match your website content to what people are searching for. If your content is well-written and clear, BERT can understand it better and match it to relevant search queries. This makes your website more likely to appear in search results when someone searches for a topic you cover.
3. Why is BERT Important for SEO?
· Understanding User Intent: One of the biggest challenges in SEO (Search Engine Optimization) is ensuring your website content matches what people seek. BERT helps with this by understanding the intent behind search queries. It can differentiate between similar phrases with different meanings and ensure users get results that truly answer their questions.
· Long-Tail Keywords: In SEO, long-tail keywords are longer and more specific search phrases. BERT is especially good at understanding these more complex queries. For example, instead of just understanding “SEO tips,” BERT can help with a search like “how to improve my website’s SEO ranking without technical skills.”
· Better Content Creation: Knowing how BERT works can help you create content that is more likely to rank well on search engines. Since BERT understands context, writing naturally and clearly is important rather than just stuffing keywords into your content.
· Think of BERT as a Smart Assistant: Imagine you have a really smart assistant who understands everything you say, even if it’s complex or vague. BERT is like that assistant for search engines. It helps them understand what you mean and what you’re looking for so they can give you the best possible results.
· Focus on Quality Content: As a website owner or content creator, your job is to write content that answers questions or provides valuable information. You don’t need to constantly worry about cramming in exact keywords. Instead, focus on making your content easy to read and informative, and BERT will help match it to the right searches.
This project improves SEO performance.
- The project improves SEO performance by ensuring that the website’s content is unique, contextually rich, and aligned with user intent. By avoiding redundant content and filling gaps in the content strategy, the website is better positioned to rank higher on search engine results pages (SERPs). Additionally, the use of BERT helps in understanding and targeting long-tail keywords and semantic variations, which are increasingly important in modern SEO.
What is the significance of content similarity in SEO?
- Content similarity is crucial in SEO because search engines aim to provide users with the most relevant and diverse results. A website with multiple pages with highly similar content can lead to content cannibalization, where these pages compete against each other in search rankings. By identifying and addressing content similarity, the project helps to avoid this issue, ensuring that each page on the website has a unique purpose and targets specific keywords or user intents, thereby improving overall site performance.
How does the project help identify content gaps?
- The project can highlight areas where related topics are not well-covered or linked by generating and comparing embeddings for various content pieces on the website. If certain topics that should be related have low similarity in their embeddings, it indicates that the content strategy might be lacking in connecting these topics. The project then suggests creating new content to bridge these gaps, ensuring comprehensive coverage of all relevant topics.
What are the practical benefits of this project for a website owner?
For a website owner, this project offers several practical benefits:
· Improved SEO: Ensuring that the content is unique and contextually relevant makes the website more likely to rank higher in search results.
· Content Strategy Optimization: The project identifies redundant content and gaps, helping the owner create a more effective content strategy.
- Enhanced User Experience: Well-structured, relevant content encourages users to engage with the website, leading to better conversion rates.
1. requests Library
What is it?
- The requests library is a popular Python library for sending HTTP requests to web servers. It allows you to interact with websites programmatically, retrieving web pages, sending data to a server, and more.
Why Do We Need It?
· Web Scraping: In this project, you’re retrieving content from a website to analyze. The requests library sends a GET request to the website’s server, which responds by sending back the HTML content of the page.
· Example Use: When you want to scrape the text content from a webpage (like getting all the paragraphs or headings), requests help you fetch the raw HTML data of that page.
Response = requests.get(URL) # Sends a GET request to the specified URL and retrieves the web page content.
2. BeautifulSoup from bs4
What is it?
- BeautifulSoup is a Python library for parsing HTML and XML documents. It creates a parse tree that makes navigating and searching through the HTML content easy.
Why Do We Need It?
· HTML Parsing: After retrieving the raw HTML content of a webpage using requests, you need to extract useful information from it, such as the text inside paragraph tags (p). BeautifulSoup allows you to do this efficiently by parsing the HTML and providing simple methods to locate elements within it.
· Example Use: If you want to extract all the text inside (p) tags, BeautifulSoup helps you easily find and extract this content.
soup = BeautifulSoup(response.text, ‘html.parser’) # Parses the HTML content retrieved by requests.
paragraphs = soup.find_all(‘p’) # Finds all paragraph tags in the HTML.
3. re (Regular Expressions) Library
What is it?
- The re library in Python works with regular expressions, powerful tools for searching, matching, and manipulating text.
Why Do We Need It?
· Text Preprocessing: When you scrape content from a webpage, the raw text often contains unwanted characters, like punctuation, numbers, or special symbols, that you may want to remove before analysis. Regular expressions allow you to clean and preprocess this text by defining patterns to match and remove or replace unwanted parts.
· Example Use: If you want to remove everything except letters and spaces from the text, make it possible with a simple pattern.
text = re.sub(r'[^a-zA-Z\s]’, ”, text) # Removes all characters that are not letters or spaces.
4. torch Library (PyTorch)
What is it?
- Torch is the core library of PyTorch, a popular open-source deep-learning framework. It provides powerful tools for working with tensors (multi-dimensional arrays) and building neural networks.
Why Do We Need It?
· Running Neural Networks: In this project, you’re using a pre-trained BERT model, a type of neural network. PyTorch provides the infrastructure to load, manipulate, and run this model, allowing you to generate embeddings from text data.
· Example Use: When using BERT to convert text into numerical embeddings, PyTorch manages the entire process, from loading the model to performing the computations needed to generate the embeddings.
Import torch # is required to work with the BERT model implemented in PyTorch.
5. transformers from Huggingface
What is it?
- Transformers is a library provided by Hugging Face that makes it easy to use pre-trained models like BERT, GPT, and others. It includes tools for tokenizing text (converting words into numerical tokens that the model can understand) and loading the models themselves.
Why Do We Need It?
· BERT Model and Tokenization: BERT requires tokenizing text before generating embeddings. The transformers library provides a BertTokenizer to handle this tokenization and a BertModel to load and run the BERT model.
· Example Use: When you input text, the tokenizer converts it into tokens that the BERT model can process. The model then takes these tokens and generates embeddings, which are numerical text representations.
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained(‘bert-base-uncased’) # Loads the BERT tokenizer.
model = BertModel.from_pretrained(‘bert-base-uncased’) # Loads the pre-trained BERT model.

paragraphs = soup.find_all(‘p’)
This line of code uses the BeautifulSoup library in Python to parse HTML content and extract all paragraph elements from a webpage. Here’s what’s happening:
1. soup: This object represents the webpage’s parsed HTML content. It’s created by loading the HTML content into a Python object using the BeautifulSoup library.
2. find_all(): This is a method of the soup object that finds all occurrences of a specific HTML element or elements in the parsed content.
3. (‘p’): This is the argument passed to the find_all() method, specifying that we want to find all paragraph elements (<p) in the HTML content.
So, when we combine them, soup.find_all(‘p’) returns a list of all paragraph elements found in the HTML content.
· The resulting paragraphs variable will be a list of BeautifulSoup Tag objects, each representing a paragraph element. You can then iterate over this list to access the text content of each paragraph like this:
for paragraph in paragraphs: print(paragraph.text)

text_content = ‘ ‘.join([para.get_text() for para in paragraphs])
1. [para.get_text() for para in paragraphs]: This is a list comprehension that iterates over each paragraph element in the paragraphs list.
2. para.get_text(): This method extracts the text content of each paragraph element without any HTML tags.
3. […]: The list comprehension creates a new list containing the text content of each paragraph element.
4. ‘ ‘.join(…): This method takes the list of text content and joins them into a single string, separated by spaces (‘ ‘).
· The resulting text_content variable will be a single string containing the text content of all paragraph elements, separated by spaces.
· For example, if the paragraphs list contains three paragraph elements with the following text content:
[‘This is paragraph 1.’, ‘This is paragraph 2.’, ‘This is paragraph 3.’]
· The text_content variable will be:
‘This is paragraph 1. This is paragraph 2. This is paragraph 3.’

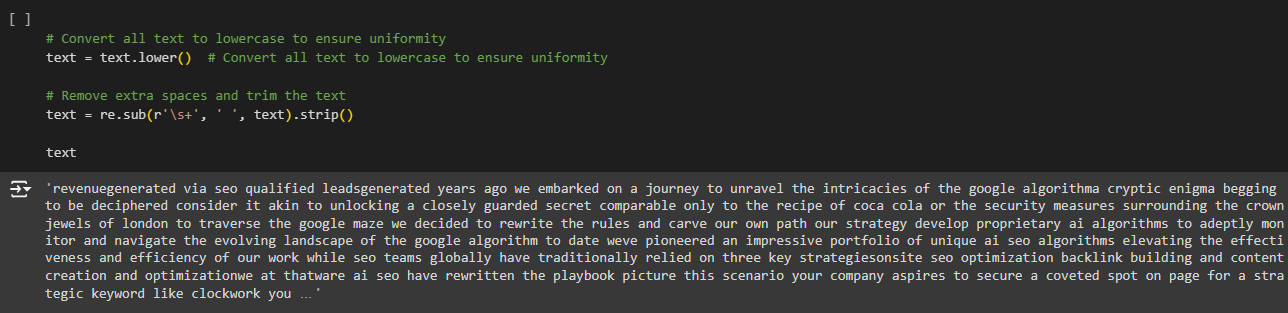
Removing Special Characters, Digits, and Extra Spaces
text = re.sub(r'[^a-zA-Z\s]’, ”, text)
Explanation:
· re.sub(): This function from the re (regular expression) module is used to search for patterns in a string and replace them with something else.
· r'[^a-zA-Z\s]’ is a regular expression pattern. Let’s break it down:
· ^: Means “not” in regular expressions, so [^…] means “anything that is not…”
· a-zA-Z: Represents all uppercase and lowercase letters.
· \s: Represents whitespace characters (like spaces, tabs, and newlines).
· ” (empty string): This tells re.sub() to replace any character that is not a letter or space with nothing, effectively removing it.
Why It’s Useful:
- This step removes anything that isn’t a letter or space from the text. This includes punctuation (like commas and periods), digits (like 123), and special characters (like @, #, and $).
Example:
· Input: “Hello, World! 2023 is the year of AI.”
· Output: “Hello World is the year of AI”

Removing Extra Spaces
text = re.sub(r’\s+’, ‘ ‘, text).strip()
Explanation:
· re.sub(r’\s+’, ‘ ‘, text): This replaces one or more whitespace characters (like spaces, tabs, newlines) with a single space.
· \s+: The + means “one or more”, so this pattern matches any sequence of one or more whitespace characters.
· ‘ ‘` (single space): Replaces the matched sequence with a single space.
· .strip(): This removes any leading or trailing whitespace from the text.
Why It’s Useful:
- This step ensures that the text is neatly formatted with only single spaces between words and no unnecessary spaces at the beginning or end of the text.
Example:
· Input: ” Hello World AI “
· Output: “hello world ai”
Loading the BERT Model and Tokenizer
The load_bert_model function is crucial for preparing the tools to use BERT (Bidirectional Encoder Representations from Transformers) for natural language processing tasks.
Here’s how each step works:
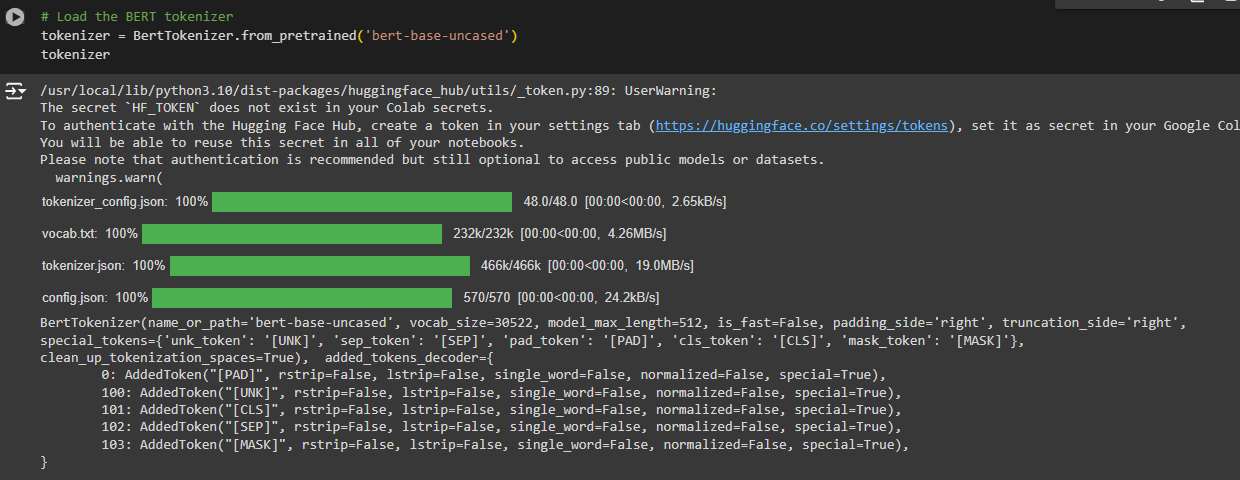
1. Loading the BERT Tokenizer
- tokenizer = BertTokenizer.from_pretrained(‘bert-base-uncased’)
Explanation:
· BertTokenizer: This class is provided by the Hugging Face Transformers library. The tokenizer converts raw text into tokens that the BERT model can process.
· .from_pretrained(‘bert-base-uncased’): This method loads a pre-trained BERT tokenizer from Hugging Face’s model hub.
- ‘bert-base-uncased’: Refers to the specific version of BERT being loaded. “Base” indicates it’s the smaller version of BERT (12 layers, 110 million parameters), and “uncased” means the tokenizer doesn’t differentiate between uppercase and lowercase letters (it converts everything to lowercase).
Why It’s Useful:
BERT cannot directly process raw text. The tokenizer splits the text into smaller units called “tokens,” which can be words, subwords, or even characters. These tokens are then mapped to unique numerical IDs that the model understands.
Example:
· Input Text: “Machine learning is fascinating.”
· Tokenizer Output: [‘machine’, ‘learning’, ‘is’, ‘fascinating’, ‘.’]
· Token IDs: [2535, 4084, 2003, 13136, 1012]
Each word is converted into a token, and then each token is converted into a unique ID.
Loading the Pre-Trained BERT Model
- model = BertModel.from_pretrained(‘bert-base-uncased’)
Explanation:
· BertModel: This class from the Hugging Face Transformers library represents the BERT model itself.
· .from_pretrained(‘bert-base-uncased’): This method loads the pre-trained BERT model corresponding to the tokenizer.
- ‘bert-base-uncased’: This matches the tokenizer version to ensure compatibility between the tokens generated and the model’s expectations.
Why It’s Useful:
- Once loaded, the BERT model can take the token IDs generated by the tokenizer and convert them into embeddings (dense vectors). These embeddings capture the meaning of the words in context.
Example:
· Input Token IDs: [2535, 4084, 2003, 13136, 1012]
· Model Output: A set of vectors (one for each token) representing the meaning of each token in the context of the sentence. These vectors are used for text classification, similarity measurement, or sentiment analysis.
Tokenizing the Input Text
inputs = tokenizer(text, return_tensors=’pt’, max_length=512, truncation=True)
Explanation:
· tokenizer(text, return_tensors=’pt’, max_length=512, truncation=True):
· tokenizer(text): The tokenizer, loaded earlier, processes the input text. It breaks down the text into smaller units (tokens) and converts them into numerical IDs that the BERT model can understand.
· return_tensors=’pt’: This specifies that the tokenizer should return the tokens in the format PyTorch requires (hence ‘pt’). PyTorch is the deep learning framework used by the BERT model.
· max_length=512: BERT models can only process up to 512 tokens simultaneously. If the text is longer, it will be truncated.
· truncation=True: If the input text exceeds the maximum length, it will be cut off at 512 tokens to avoid errors.
Why It’s Useful:
This step converts raw text into a format (tokens) that the BERT model can process. Without tokenization, BERT wouldn’t understand the input text.
Example:
- Input Text: “Machine learning is fascinating.”
Tokenization Output:
· Tokens: [‘machine’, ‘learning’, ‘is’, ‘fascinating’, ‘.’]
· Token IDs: [2535, 4084, 2003, 13136, 1012]
· Tensor Format: The token IDs are returned as a PyTorch tensor, ready for input to the BERT model.
Disabling Gradient Calculation for Efficiency
with torch.no_grad():
Explanation:
· torch.no_grad(): This context manager in PyTorch temporarily turns off gradient calculations. Gradients are used during model training to update weights, but since we’re only interested in using the model for inference (not training it), we don’t need gradients.
· Efficiency: Disabling gradients reduces memory usage and speeds up the computation, making the process more efficient.
Why It’s Useful:
- Calculating gradients is unnecessary and slows down the process when the model is only used for prediction or generating embeddings. This step ensures that the model runs faster and uses less memory.
Example:
· Without no_grad(): The model would perform extra calculations to track gradients, which aren’t needed here.
· With no_grad(): The model runs more efficiently, focusing only on generating the embeddings.
Getting the Output from BERT
outputs = model(**inputs)
Explanation:
- model(*inputs): The tokenized text is fed into the BERT model. The *inputs syntax unpacks the inputs (tokens) into the required format for the BERT model.
- Model Output: BERT produces several outputs, but the one we’re interested in is last_hidden_state, which contains the embeddings for each token in the input.
Why It’s Useful:
- This is where BERT processes the input text and generates the embeddings, which are dense vectors that represent the meaning of the text.
Example:
· Input Tokens: [2535, 4084, 2003, 13136, 1012] (for “Machine learning is fascinating.”)
· Model Output: A set of vectors (one for each token) representing the meaning of each token in the context of the sentence.
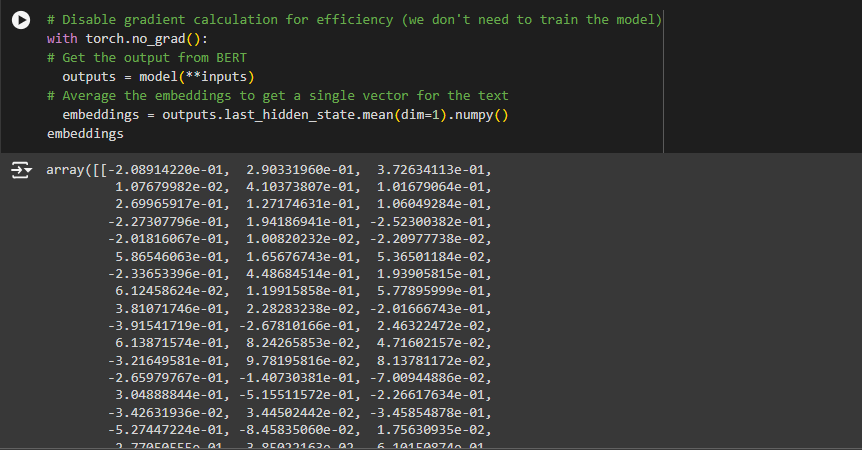
Averaging the Embeddings to Get a Single Vector
embeddings = outputs.last_hidden_state.mean(dim=1).numpy()
Explanation:
· outputs.last_hidden_state: This contains the embeddings for all tokens in the input. It’s a tensor where each token’s embedding is a vector.
· mean(dim=1): This averages the embeddings across the sequence dimension (i.e., it averages the vectors for all tokens in the input). The result is a single vector that represents the entire input text.
· .numpy(): Converts the tensor to a NumPy array for easier manipulation and compatibility with other Python libraries.
Why It’s Useful:
- Averaging the token embeddings gives a single, fixed-size vector that captures the overall meaning of the entire text. This is useful for comparing texts, feeding the vector into another model, or performing tasks like similarity measurement.
Example:
- Token Embeddings: Let’s say the embeddings for the tokens were [v1, v2, v3, v4, v5].
- Averaged Embedding: The function calculates the average of these vectors to get a single vector v_mean, which summarizes the meaning of the whole sentence.
Embeddings Code: While more technical, the embeddings code is powerful for deeper content similarity analysis. It’s useful if the owner or their technical team wants to delve into the granular differences between pages at a semantic level.
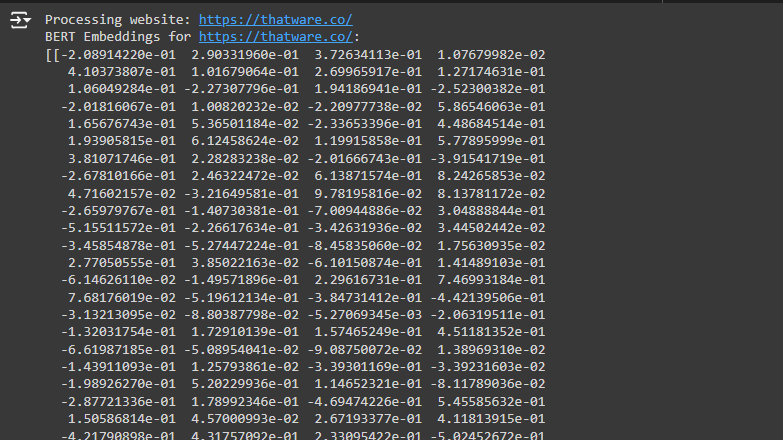
What is the Output?
The output you received is a BERT embedding.
- BERT Embedding: Think of this as a numerical representation of the content on your website. BERT takes the text from your website, processes it, and transforms it into a set of numbers (or vectors). Each number (or set of numbers) in the output represents specific aspects of the meaning and context of the content on your site.
What Does This Output Mean?
· Contextual Understanding: The BERT model has taken all the text on your website and broken it into its core meanings. The embedding (the list of numbers) summarizes that content. Unlike older models that might just count words, BERT understands the relationships between words, the context in which they appear, and the overall meaning of sentences and paragraphs.
· Embeddings: The numbers represent a high-dimensional (complex mathematical space) where similar meanings or contexts are closer together. This means that content that is similar in meaning will produce embeddings that are close together in this space.
Understanding Embeddings and Content Similarity
What Are Embeddings?
· Embeddings: Think of embeddings as a way to represent words, sentences, or entire pieces of content as numbers (specifically, vectors). These numbers capture the meaning of the content in a way that computers can understand.
· Example: Imagine you have two sentences: “I love coffee” and “I enjoy coffee.” While the sentences use different words (“love” vs. “enjoy”), their meanings are very similar. Embeddings for these sentences would be similar because they capture the context and meaning, not just the words themselves.
How Can You Compare Embeddings?
- Similarity of Embeddings: When we compare embeddings, we’re looking at how “close” these numerical representations are to each other in a mathematical space. If two pieces of content have similar embeddings, they are similar in meaning.
· Cosine Similarity: A common way to measure how similar two embeddings are is by calculating the cosine similarity.
This is a number between -1 and 1:
· 1: The two embeddings are very similar.
· 0: The embeddings are neither similar nor dissimilar.
· -1: The embeddings are very dissimilar.
Example of Comparing Embeddings
Step-by-Step:
· Generate Embeddings: First, you generate embeddings for different pages on your website.
· Calculate Similarity: Next, you calculate the cosine similarity between the embeddings of two different pages.
Interpret the Similarity:
· High Similarity: If the cosine similarity is close to 1, the pages are very similar in content.
· Low Similarity: The pages are less similar if it’s closer to 0.
Why This Matters for a Website Owner
· Avoiding Redundancy: If two pages have high similarity, they might be too similar, which could confuse search engines and users. In this case, you might consider merging the content or making one page focus on a different aspect of the topic.
· Identifying Gaps: If two important topics have low similarity, you might find that you’re not covering related content well. This signals an opportunity to create new content that bridges the gap.
Practical Steps to Avoid Redundancy and Identify Gaps
a) Avoiding Redundancy
· Step 1: Generate Embeddings for Your Pages: Use the BERT model to create embeddings for the key pages on your website. This process turns your content into numerical vectors that capture their meaning.
· Step 2: Compare Pages: Calculate the cosine similarity between the embeddings of different pages.
Step 3: Analyze Similarity:
· High Similarity: If two pages are too similar (high cosine similarity), you should review them. Ask yourself:
Are these pages targeting the same keywords or user intent?
Can these pages be combined into one more comprehensive page?
· Action: If two pages are nearly identical in meaning, consider merging them. Differentiate the content by focusing on different aspects or adding unique information to each page.
b) Identifying Content Gaps
· Step 1: Generate Embeddings for Existing Content: As before, create embeddings for all your key pages.
· Step 2: Compare Across Topics: Look at the similarity between different topics or sections of your site.
Step 3: Look for Low Similarity Scores:
· Low Similarity: If two topics that should be related have a low similarity, this might indicate a gap in your content.
· Example: If your site covers “SEO strategies” and “content marketing” but the embeddings show low similarity, it might mean that you’re not effectively linking these two topics. This could be an opportunity to create content that connects these ideas.
· Action: Create new content to bridge these gaps. This could be an article, a guide, or a series of posts that link these topics together.
keyboard_arrow_down
Page Embedding Similarity Code (Cosine Similarity):
- This code plays a critical role in evaluating the similarity between different pages on your website. It is designed to help you identify whether different pages on your site contain similar or redundant content. Understanding the level of similarity between pages is crucial for a number of reasons, particularly in the areas of Search Engine Optimization (SEO) and user experience.

Analyzing the Output and Next Steps for a Website Owner
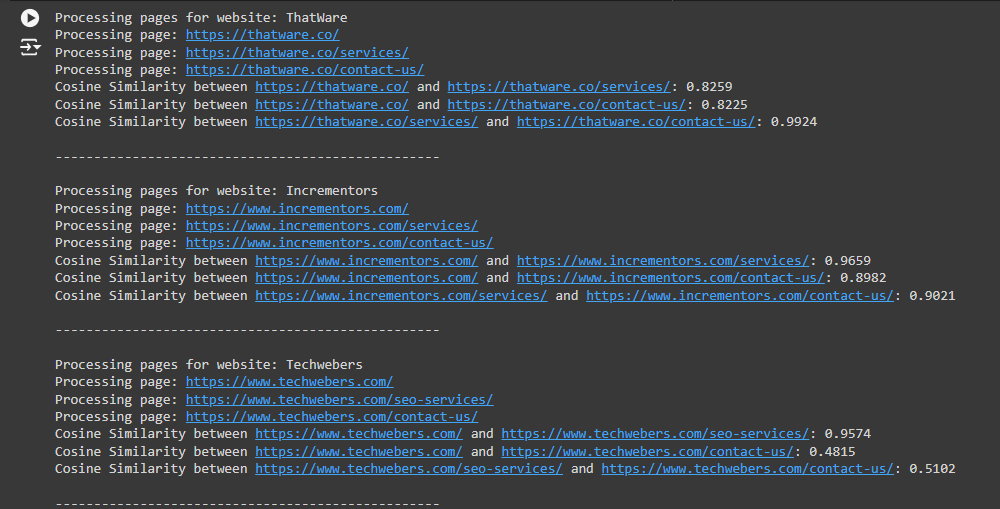
1. Understanding the Cosine Similarity Results:
Cosine Similarity between https://thatware.co/ and https://thatware.co/services/: 0.8258
- This indicates that the content of the homepage and services pages is similar. While they are not identical, they share significant content, which might lead to redundancy.
Cosine Similarity between https://thatware.co/ and https://thatware.co/contact-us/: 0.8225
- The homepage and the contact page also show a high similarity score. Although the contact page should generally contain unique content focused on contact information, a high similarity score suggests that it may contain redundant content similar to the homepage.
Cosine Similarity between https://thatware.co/services/ and https://thatware.co/contact-us/: 0.9924
- This extremely high similarity score indicates that the services and contact pages are almost identical in content, which is problematic as it can confuse both users and search engines.
2. Recommendations for the Website Owner:
Content Differentiation:
· Reduce Redundancy: Given the high similarity scores, it’s important to differentiate the content across these pages. The services and contact pages, in particular, need unique content distinct from each other and the homepage.
· Homepage vs. Services Page: The homepage should provide a broad overview of what the business offers, while the services page should delve into specific services in more detail. Avoid repeating the same content; focus on unique value propositions and service-specific details.
· Contact Page: Ensure that the contact page contains primarily contact information and location-specific details. If additional content is necessary, it should focus on how to reach the company, possibly including a contact form, map, and specific instructions on contacting or visiting.
Understanding Cosine Similarity
Cosine Similarity is a number between 0 and 1 that tells you how similar two pieces of content are.
· 1 means the contents are very similar or almost identical.
· 0 means the contents are completely different.
What the Scores Mean
1. Cosine Similarity between Homepage and Services Page: 0.8258
- What it means: The homepage and the services page have quite a bit of similar content. This isn’t always bad, but if the content is too similar, it might confuse search engines and users.
- Why it matters: You want each page to have unique, focused content. If the services page repeats much of what’s on the homepage, it might be less effective at targeting specific keywords related to your services.
2. Cosine Similarity between Homepage and Contact Page: 0.8225
- What it means: The homepage and the contact page also have a lot of similar content. Usually, the contact page should be more unique, focusing on how users can contact you, rather than repeating what’s on the homepage.
- Why it matters: If your contact page has less content similar to the homepage, it might dilute its purpose. The contact page should provide contact details and a form or information on how to reach you.
3. Cosine Similarity between Services Page and Contact Page: 0.9924
- What it means: The services and contact pages are almost identical in content. This is very high and likely indicates that the content on these pages is nearly the same.
- Why it matters: This is problematic because these pages should serve different purposes. Similar content on both pages could help your SEO (Search Engine Optimization) and confuse visitors who expect different information on each page.
What’s Good and What’s Not
Good Similarity:
- Similar pages can be good if they share common elements and have distinct, focused content. For example, it’s okay if the homepage and services page have overlapping sections (like a brief introduction). Still, most content should be different to target different user intents.
Bad Similarity:
- More similarity between pages is needed because it can lead to content redundancy. Search engines might have difficulty determining which page to show for specific search queries. It can also lead to a poor user experience if visitors see the same information repeated on different pages.
Good Dissimilarity:
· Dissimilarity is good when it reflects that each page has a unique purpose.
For example, the contact page should be quite different from the services page, focusing solely on how to reach the business.

keyboard_arrow_down
What Should You Do?
· Review the Content: Look at the services and contact pages and consider how they can be more distinct from each other and the homepage. Each page should have a clear, unique focus.
· Optimize for SEO: Ensure each page targets different keywords or phrases relevant to its specific content.
· Improve User Experience: Make sure that when users visit different pages, they find unique and relevant information that matches their needs at that point in their journey on your website.
The Keyword Similarity Code is designed to analyze the most important keywords on a website and determine how similar or different they are. This analysis is crucial for website owners and SEO specialists because it helps understand how effectively the top keywords are used across the site, ensuring the content is well-optimized for search engines without unnecessary repetition or redundancy.

Example Output Analysis:
Keywords and Their Similarity Scores:
- Similarity between ‘seo’ and ‘services’: 0.6185 (High Similarity)
- Similarity between ‘ai’ and ‘algorithms’: 0.7945 (High Similarity)
- Similarity between ‘data’ and ‘development’: 0.8101 (High Similarity)
1. Good Keyword Similarity Examples:
SEO’ and ‘Services’ (0.6185):
· Why It’s Good: These keywords are closely related, especially if your business offers SEO services. Content that highlights both keywords is beneficial because it aligns with user intent. When people search for “SEO services,” they expect to find content that discusses both SEO and the services offered. This similarity indicates that your content is focused and relevant to the specific topic.
· How to Leverage It: Ensure your content highlights how your services relate to SEO, and create detailed pages or posts that explore these topics together.
‘AI’ and ‘Algorithms’ (0.7945):
- Why It’s Good: AI and algorithms are naturally linked. If your content discusses AI, it’s logical that algorithms would also be a significant topic. This high similarity is good if your goal is to be seen as an authority on AI technologies, as algorithms are a core component of AI.
- How to Leverage It: Continue creating content that explains the relationship between AI and algorithms, perhaps through case studies, white papers, or technical blogs that explore how algorithms drive AI solutions.
2. Problematic Keyword Similarity Examples:
‘SEO’ and ‘AI’ (0.8150):
· Why It Might Be a Problem: While SEO and AI are important topics, they serve different purposes and appeal to different audiences. If your content is highly similar between these two keywords, it might indicate your content isn’t well differentiated. This could confuse your audience or dilute the focus of your content, especially if you’re trying to target specific user intents.
· What to Do: Consider creating separate content strategies for SEO and AI. While they can intersect (e.g., using AI in SEO), make sure you have distinct content that addresses each topic’s unique aspects.
‘Data’ and ‘Development’ (0.8101):
- Why It Might Be a Problem: If your content heavily overlaps between these two keywords, it could mean that your pages need to be sufficiently distinct. While data is important in development, they are broad topics that should be addressed separately to maximize their SEO potential.
What to Do: Ensure that your “data” content focuses on aspects like data analytics, big data, etc., while “development” content should focus more on software development, web development, etc. By separating these, you avoid competing against yourself in search engine rankings.
3. The Concept of Dissimilarity:
When Dissimilarity is Good:
- Example: If you had a keyword like “SEO” and another like “Customer Support,” you would expect low similarity because they are unrelated topics. This is good as it shows your website covers a broad range of services or topics, catering to different needs without overlapping or confusing content.
When Dissimilarity Might Be Bad:
- Example: If you find a very low similarity between “SEO” and “Search,” it could indicate a missed opportunity to connect closely related topics. If your content doesn’t link these two well, you might miss out on better keyword targeting and user engagement.
Final Thoughts:
· High Similarity is generally good when it indicates that related keywords are well-integrated into your content. However, too much similarity between unrelated keywords might suggest your content is not focused enough, potentially confusing users or search engines.· Dissimilarity is expected and beneficial when dealing with unrelated keywords, ensuring your content strategy is diverse and comprehensive.
Hiring ThatWare provides businesses with strategic expertise, affordable pricing, extensive experience in digital marketing, and access to a full team capable of implementing successful search marketing campaigns. The company’s adaptability and commitment to experimentation are key advantages for businesses seeking effective SEO solutions.

Thatware | Founder & CEO
Tuhin is recognized across the globe for his vision to revolutionize digital transformation industry with the help of cutting-edge technology. He won bronze for India at the Stevie Awards USA as well as winning the India Business Awards, India Technology Award, Top 100 influential tech leaders from Analytics Insights, Clutch Global Front runner in digital marketing, founder of the fastest growing company in Asia by The CEO Magazine and is a TEDx speaker.
