SUPERCHARGE YOUR Online VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
The Jina-Based Semantic Reach Analyzer is designed to evaluate how effectively SEO content aligns with multiple user intents and captures broader semantic coverage across different search queries. By leveraging advanced embedding models from Jina AI, the system transforms webpage content into dense semantic representations, allowing a deeper understanding of how each section of a page responds to varied search intents.

The project focuses on quantifying two key dimensions of content effectiveness:
- Intent Alignment Index (IAI) — measures how closely each section or the entire page aligns with user search intents.
- Semantic Reach Score (SRS) — evaluates the extent of semantic diversity and contextual coverage achieved by the content across multiple intent categories.
This dual evaluation framework provides an in-depth, data-driven understanding of a page’s semantic performance. It helps identify areas where the content connects well with search intent and highlights opportunities where semantic gaps limit discoverability.
Through this analyzer, SEO strategists gain actionable insights into how well a page is optimized not only for keywords but also for semantic depth, contextual variation, and intent-driven coverage. The outcome supports better on-page optimization, improved user satisfaction, and stronger organic visibility.
Project Purpose
The purpose of the Jina-Based Semantic Reach Analyzer is to provide a comprehensive evaluation of SEO content through the lens of semantic alignment and coverage diversity. Unlike traditional keyword-based evaluation methods, this project measures how effectively a webpage satisfies multiple user intents and semantic contexts relevant to a given topic or query set.
The primary objectives include:
· Understanding Cross-Intent Alignment: To determine how well each section of a webpage corresponds to different user search intents, enabling identification of high-performing and underperforming content zones.
· Measuring Semantic Breadth and Depth: To assess the overall semantic richness of a page by evaluating its contextual reach across related concepts, themes, and intent-driven variations of the provided queries.
· Providing Actionable Insights for Optimization: To translate technical semantic scores into understandable indicators that support decision-making in SEO strategy, content planning, and topic reinforcement.
· Bridging Search Intent and Content Strategy: To offer a practical analytical tool that links user intent understanding with real-world webpage optimization efforts—moving beyond keyword density and focusing on semantic structure, relevance, and diversity.
Through this approach, the analyzer supports a strategic content refinement process, allowing SEO professionals to identify intent gaps, enhance thematic balance, and strengthen a page’s relevance across broader semantic spectrums.
Project’s Key Topics Explanation and Understanding
Jina Embedding Model Overview
Introduction to Jina AI and Its Embedding Models
Jina AI is a leading developer of multimodal AI frameworks that enable machines to understand and connect data through text, image, and other media. Its core innovation lies in embedding models, which transform textual or visual data into dense vector representations that capture deep semantic meaning. Unlike traditional keyword-based systems, these embeddings allow AI systems to understand intent, context, and relationships between concepts.
Core Capabilities of Jina Embeddings
The Jina Embeddings v3 model, used in this project, represents one of the most advanced text embedding architectures available. It supports multi-language understanding, context preservation, and high-resolution semantic mapping. Key capabilities include:
- Contextual Understanding: Captures meaning beyond surface-level keywords by recognizing phrase intent and context.
- Semantic Cohesion: Maintains logical relationships between related ideas even when phrasing differs.
- Cross-Domain Generalization: Works effectively across industries, topics, and linguistic variations, making it highly adaptable for SEO use cases.
- Scalability: Efficient enough to handle large-scale content evaluation and retrieval across thousands of web pages.
Why Jina Embeddings are Suitable for Semantic Retrieval
In SEO-driven environments, search relevance is increasingly determined by semantic depth rather than keyword overlap. Jina’s embedding models excel in this context because they:
- Understand searcher intent even with ambiguous or long-tail queries.
- Identify latent semantic relationships between content sections and user queries.
- Enable context-based retrieval, which surfaces content that truly answers the underlying need. This makes Jina an ideal foundation for building retrieval and ranking intelligence within modern SEO systems.
Role of Jina Embeddings in This Project
The entire analytical process of this project is built upon Jina embeddings. Each web page and its sections are converted into semantic vectors, allowing precise comparisons with query vectors. This enables identification of which sections or pages align most closely with user intent. The embeddings serve as the semantic backbone for calculating Integrated Analytical Insights (IAI) and Semantic Relevance Scores (SRS), the two core interpretive metrics developed in this project.
Semantic Relevance in SEO Content
Understanding Semantic Similarity
Semantic similarity measures how closely two pieces of text align in meaning, not just in word choice. In SEO, this determines how well a page or content block responds to a search query. By focusing on meaning rather than matching phrases, the system captures a more authentic view of content relevance and user satisfaction.
Importance of Contextual Alignment Between Query and Content
Contextual alignment ensures that a page not only contains relevant terms but also presents them within the right topical and interpretive framework. For instance, two pages may mention the same keywords, but only one may address the true purpose behind the search. Semantic evaluation driven by Jina embeddings provides this deeper alignment, improving the accuracy of retrieval and ranking.
Retrieval Significance in SEO
Concept of Retrieval in Modern SEO Analytics
Retrieval in SEO refers to identifying which web pages or sections are most semantically aligned with a given search query. Traditional systems rely on keyword frequency or backlink-based ranking. However, in semantic retrieval, content is assessed based on how naturally it answers a query rather than simply matching it.
How Semantic Retrieval Enhances Relevance and Engagement
Semantic retrieval ensures that the most contextually appropriate content surfaces first. This results in:
- More targeted impressions in search results.
- Improved user satisfaction due to relevance of results.
- Higher engagement metrics, as users find what they truly intended to search for. In this project, retrieval significance is analyzed both at the page and block level, allowing granular visibility into where true query-value alignment occurs within site content.
Integrated Analytical Insights (IAI)
Meaning and Role of IAI in the Project
Integrated Analytical Insights (IAI) represent a unified evaluation metric derived from multiple analytical layers, integrating semantic relevance, contextual balance, and content retrieval performance. The IAI framework was developed to interpret how well each content block or page performs semantically across different user queries.
What IAI Scores Indicate About Content
A high IAI score signals a strong and balanced semantic presence—where the content demonstrates contextual strength, intent fulfillment, and topical coverage. Moderate scores may suggest partial coverage, while lower scores identify underperforming sections that may need semantic optimization.
Semantic Relevance Score (SRS)
Concept of SRS
The Semantic Relevance Score (SRS) quantifies the degree of meaning-based similarity between a query and a specific content section or page. It translates the embedding similarity between these two entities into a numerical scale, making the semantic alignment interpretable and comparable across multiple queries and URLs.
Its Use in Evaluating Query–Content Fit
By calculating SRS values, the project identifies which pages and sections provide the strongest response to given queries. This allows SEO strategists to see where semantic strengths and weaknesses lie, enabling precise optimization of web content for improved discoverability and relevance.
Overall Analytical Perspective
How These Components Work Together
The system integrates Jina embeddings, IAI, and SRS to construct a multilayered semantic analysis pipeline. Queries and content are both encoded into embeddings, their relationships are computed through similarity scoring, and the resulting values are synthesized into meaningful metrics. Together, they deliver a deep interpretive view of how each page and section performs semantically relative to user intent.
Value Delivered to SEO Strategists and Decision Makers
This analytical foundation empowers strategists to:
- Identify high-value content segments with the strongest semantic performance.
- Detect topic gaps where coverage or alignment is weak.
- Optimize semantic consistency across a site for stronger search visibility and engagement. Ultimately, it transforms raw embedding computations into actionable insights for data-driven SEO improvement.
keyboard_arrow_down
Q&A Section for Understanding Project Value and Importance
What is the core objective of this project?
The project’s primary objective is to evaluate how effectively website content aligns semantically with different user queries by leveraging Jina Embeddings v3. Unlike keyword-based analysis, this approach focuses on contextual meaning, helping determine whether the content truly responds to search intent. The system measures this alignment through structured metrics like the Semantic Relevance Score (SRS) and Integrated Analytical Insights (IAI). Together, these metrics provide a full-scale view of a website’s semantic performance — both at page level and within individual sections — offering actionable insights for improving topical depth and search visibility.
How does the project improve SEO understanding beyond traditional analytics?
Traditional SEO metrics like keyword density, backlinks, or CTR focus on surface-level indicators of visibility. This project goes deeper by analyzing semantic intent alignment, which reflects how well content fulfills the meaning behind search queries. By mapping both queries and content into vector space using the Jina model, the system measures their semantic distance, revealing the true cognitive relationship between them. This shift from keyword relevance to intent relevance enables more intelligent optimization strategies that align with how modern search algorithms interpret meaning rather than text patterns.
Why is Jina Embeddings v3 used in this project instead of other models?
Jina Embeddings v3 offers exceptional performance in semantic understanding due to its ability to encode complex contextual nuances. It supports long-text representation and multi-domain adaptability, which are essential in SEO contexts where content varies widely in structure and tone. The model ensures that relationships between concepts remain coherent even across large datasets. Its scalability, multilingual support, and embedding precision make it an ideal foundation for this kind of large-scale semantic analysis, ensuring that insights remain consistent, interpretable, and actionable for strategists.
What practical insights can be gained from IAI and SRS metrics?
- IAI (Integrated Analytical Insights): Offers a unified view of content performance by integrating different semantic layers — including intent fulfillment, contextual alignment, and topical distribution. It helps identify which pages provide balanced semantic coverage and which need optimization.
- SRS (Semantic Relevance Score): Focuses specifically on the semantic similarity between a query and a content segment. It reveals which parts of a page align most strongly with user intent.
By analyzing both, strategists can pinpoint content sections that contribute most to a site’s search effectiveness and rework weaker ones to enhance semantic clarity and depth.
How does the system handle block-level or section-level analysis, and why is that important?
Instead of treating a webpage as a single entity, the project evaluates it in smaller logical sections or content blocks. Each block is independently compared to the query embeddings to measure localized relevance. This granular perspective uncovers areas within pages that are performing well versus those that dilute topic focus. For SEO strategists, this insight is crucial — it allows targeted optimization of specific sections (for example, a poorly aligned paragraph in an otherwise strong page) rather than general rewriting. It transforms optimization from broad guesswork into precise, data-backed refinement.
In what way does this approach benefit site-wide SEO strategy and content planning?
The insights derived from semantic metrics guide more strategic content structuring and planning. By knowing which topics or pages are semantically underrepresented, teams can plan new content around those gaps. Conversely, highly aligned sections can be expanded or internally linked to strengthen overall topical authority. This makes content planning evidence-driven — instead of relying on intuition, SEO teams can decide based on measured semantic performance. Over time, this supports stronger search visibility, improved user satisfaction, and higher engagement metrics due to content relevance and depth.
How is this project valuable for multi-page content ecosystems or large websites?
For large-scale sites with many interlinked pages, it becomes difficult to manually track where query alignment is strongest. The project automates this by computing semantic metrics for every page and section, enabling high-level comparative analysis. Strategists can quickly identify which URLs dominate specific queries and which ones overlap or compete unnecessarily. This understanding enables strategic content differentiation, ensuring each page serves a distinct semantic purpose. It optimizes internal relevance structure and strengthens the overall site architecture for improved crawl efficiency and topical coherence.
What makes this approach unique compared to other semantic evaluation systems?
This project stands out because it combines deep embedding-based semantic understanding with structured analytical interpretation. Instead of presenting only similarity scores, it converts raw embeddings into practical, visualizable insights through IAI and SRS frameworks. The dual-level analysis — page and section — offers rare visibility into semantic consistency and depth within content. Moreover, it operates model-independently beyond keyword signals, making it resilient to search engine algorithm shifts. Its data-driven clarity gives strategists actionable recommendations instead of abstract model metrics.
Libraries Used
time
The time library is a core Python module that provides functions to handle time-related operations such as tracking execution duration, delays, and timestamps. It is often used to measure performance efficiency or manage time-sensitive tasks in data workflows.
In this project, time is used to measure processing duration across different pipeline stages, ensuring each operation — from web content extraction to embedding computation — remains efficient. This helps optimize performance when analyzing multiple URLs or large content blocks simultaneously.
re
The re module provides powerful tools for working with Regular Expressions in Python. It allows pattern matching, text cleaning, and structured text extraction.
Within this project, re is used extensively for content preprocessing, such as cleaning unwanted tags, formatting issues, or repeated whitespace patterns from raw webpage data. It ensures that text passed into the embedding model is standardized and semantically clean, which is essential for accurate similarity computation.
html (as html_lib)
Python’s built-in html library provides utilities for working with HTML entities and character encoding/decoding. It helps safely handle web-based text content containing HTML-encoded symbols.
Here, it is applied to decode HTML entities like or & that often appear in scraped text. Cleaning and decoding this content ensures the embedding model processes natural text rather than encoded symbols, improving embedding quality and contextual understanding.
hashlib
hashlib is a Python module that provides secure hash and message digest algorithms, such as SHA-1 or MD5, for creating unique identifiers from text data.
In this project, it is used to generate unique block or section identifiers (block_id) for every segmented content block extracted from webpages. These IDs are crucial for tracking each content segment’s scores (IAI and SRS) across different stages of the analysis and result visualization.
unicodedata
The unicodedata library provides Unicode character database access, allowing normalization and standardization of text data from various languages or character sets.
It is used to normalize textual content before embedding computation. This ensures that visually identical characters (like accented or full-width forms) are treated uniformly, maintaining consistency in semantic encoding across multilingual or special-character-heavy content.
gc (Garbage Collection)
The gc module interfaces with Python’s garbage collector to manage memory usage during runtime. It helps free memory from unused objects.
In this project, it ensures efficient memory handling during large-scale embedding computations or similarity matrix generation, especially when processing multiple URLs and large document sections. Controlled garbage collection prevents memory overflow during batch operations.
logging
Python’s logging library provides a standardized framework for tracking and reporting runtime events or errors. It supports various levels like DEBUG, INFO, WARNING, and ERROR.
Logging is configured in this project to track each step of data processing and model execution. This helps monitor system performance, debug potential issues, and maintain transparency in data flow — a necessary practice in client-facing analytical systems.
requests
The requests library is a popular Python package for sending HTTP/HTTPS requests to retrieve data from web resources.
In this project, it is responsible for fetching webpage content directly from provided URLs. This forms the foundation of the analysis pipeline, enabling live extraction of content from client sites for evaluation and embedding computation.
typing
The typing module provides support for type hinting, allowing clearer function signatures and improved code readability.
It is used throughout the project to define structured data inputs and outputs such as lists, dictionaries, and tuples, ensuring predictable behavior across multiple processing functions. This makes the codebase maintainable and less error-prone, especially during scaling.
BeautifulSoup (bs4)
BeautifulSoup is a Python library for parsing HTML and XML documents, widely used in web scraping. It simplifies navigation, searching, and modification of HTML structures.
In this project, BeautifulSoup is used for webpage content extraction and text segmentation. It removes unnecessary HTML elements (like scripts or styles) and isolates meaningful sections of content, which are then analyzed for semantic alignment.
numpy (np)
NumPy is the core scientific computing library in Python, providing support for arrays, numerical operations, and vectorized computations.
Here, it underpins embedding vector manipulation and mathematical computations such as normalization, mean pooling, and cosine similarity operations. Its optimized performance ensures efficient computation even with large embedding sets across multiple pages.
pandas (pd)
Pandas is a powerful library for data manipulation and analysis, known for its DataFrame structure and ease of handling complex datasets.
It plays a major role in organizing and analyzing structured results — storing scores, creating query–page matrices, and preparing data for visualization. It ensures consistency between the analytical and visualization modules.
sentence_transformers
The sentence_transformers library provides pre-trained transformer-based models for generating semantic embeddings and performing similarity tasks.
It is a core dependency in this project, used to encode both queries and webpage sections using the Jina Embeddings v3 model. Additionally, its util.cos_sim() method is used for computing cosine similarity matrices between query and content embeddings — the foundation for IAI and SRS metrics.
torch (PyTorch)
PyTorch is a deep learning framework that provides tensor computation and automatic differentiation capabilities.
In this implementation, it supports embedding handling, tensor operations, and similarity computations at a lower level. Torch ensures that the embedding operations run efficiently on available hardware (CPU or GPU), enabling faster semantic comparison when analyzing multiple queries and large documents.
transformers
The transformers library from Hugging Face provides a unified interface for various state-of-the-art language models.
In this project, it complements SentenceTransformers by managing model pipelines and ensuring compatibility. It helps handle configuration, tokenizer management, and pipeline integration, particularly during model initialization and text embedding tasks.
matplotlib.pyplot (plt)
Matplotlib is a widely used Python library for data visualization. The pyplot module provides an interface similar to MATLAB for creating charts and plots.
Here, it is used to visualize semantic score distributions and comparative metrics across queries, URLs, and sections. The plots help convey complex results in an interpretable format for strategists and decision-makers.
seaborn (sns)
Seaborn is a high-level data visualization library built on top of Matplotlib, optimized for statistical plots with aesthetic themes.
In this project, Seaborn is used to generate professional-quality visualizations such as heatmaps, grouped bar charts, and scatter plots. These plots communicate semantic coverage, query alignment, and inter-page performance clearly to SEO professionals. The consistent styling ensures readability and visual coherence across different result dimensions.
Function fetch_html
Overview
The fetch_html function is responsible for retrieving webpage HTML content directly from a given URL with robust retry logic, controlled delays, and graceful error handling. It ensures stable extraction even when websites are slow, experience temporary network failures, or apply request throttling. The function also uses an adaptive backoff strategy, meaning if an attempt fails, it waits progressively longer before retrying, ensuring polite and reliable crawling.
This function represents the entry point for content extraction. By integrating retry logic, time delays, and response validation, it minimizes data loss during large-scale or multi-URL operations — ensuring that client website pages are consistently fetched for semantic analysis.
Key Code Explanations
headers = {“User-Agent”: “Mozilla/5.0 (compatible; SemanticReachBot/1.0)”}
- This line defines a custom User-Agent header to mimic a legitimate browser request. It helps prevent access denial from servers that block unidentified or bot-like requests. It also ensures transparency by identifying the bot for ethical crawling.
wait_time = backoff ** attempt
- This implements exponential backoff. On every retry attempt, the delay before the next attempt increases exponentially. This prevents aggressive repeated requests that could overwhelm the server, following industry-standard crawling etiquette.
for enc in [response.apparent_encoding, “utf-8”, “iso-8859-1”]:
- The code iterates through multiple encodings to ensure proper decoding of the HTML content. Many websites serve content in varying character sets, so this step ensures reliable text retrieval regardless of encoding inconsistencies.
Function clean_html
Overview
The clean_html function performs deep sanitization of the fetched HTML content by removing non-text elements such as scripts, forms, ads, media, and navigation bars. Its purpose is to retain only the core readable text that contributes to SEO and semantic understanding, ensuring embeddings are generated from meaningful content rather than visual or structural clutter.
This function plays a crucial role in content refinement. Cleaned HTML ensures that irrelevant or decorative code does not interfere with the textual signal that the model uses to measure semantic alignment between webpage sections and user queries.
Key Code Explanations
remove_tags = [“script”, “style”, “noscript”, “svg”, “canvas”, …]
- Defines a curated list of tags commonly used for non-content elements. Removing these ensures only visible, meaningful text remains, improving the signal-to-noise ratio for embedding generation.
for el in soup.find_all(string=lambda t: isinstance(t, type(soup.Comment))):
- This line identifies and removes HTML comments embedded in the source, as they often contain developer notes, tracking scripts, or irrelevant data that could mislead content analysis.
Function _normalize_text
Overview
This utility function standardizes raw text extracted from the HTML. It handles HTML entity decoding, Unicode normalization, and whitespace cleanup to produce clean, uniform, and model-ready text. This step ensures textual consistency — for example, converting typographic variants and eliminating hidden formatting issues that could alter tokenization or embedding generation quality.
Function extract_page_blocks
Overview
The extract_page_blocks function transforms cleaned HTML content into structured text blocks, each representing a logical section of the webpage (such as a heading and its following paragraphs). It also assigns unique identifiers to each block, helping track semantic relevance and section-level scores later in the analysis pipeline.
This segmentation allows the model to operate not only at the page level but also within specific sections, enabling fine-grained semantic evaluation — critical for SEO insights and localized content optimization.
Key Code Explanations
for el in soup.find_all([“h2”, “h3”, “h4”, “p”, “li”, “blockquote”]):
- Specifies which HTML tags represent meaningful content hierarchy. The function focuses on headings and paragraphs, treating each as a building block for logical text grouping, similar to how humans interpret structured web content.
if tag in [“h2”, “h3”]:
if len(current[“raw_text”]) >= min_block_chars:
blocks.append(current)
- This logic starts a new content block whenever a new heading is encountered while ensuring that previous sections meet the minimum content length requirement. It balances granularity and completeness in block segmentation.
blk[“block_id”] = hashlib.md5(blk_id_source.encode()).hexdigest()
- Generates a unique hash identifier for each block, ensuring reliable tracking across the semantic analysis process — especially when handling multiple URLs with potentially similar section headings.
Function extract_page
Overview
extract_page acts as the main orchestrator for webpage data extraction. It sequentially combines fetching, cleaning, and block-level structuring into a single process. It retrieves the HTML, removes unnecessary elements, extracts textual sections, and compiles the result into a clean, standardized format ready for further NLP-based analysis.
The function ensures that regardless of the webpage structure or content type, a consistent output format ({url, title, blocks, note}) is generated. This unified format becomes the foundation for embedding computation and scoring across multiple pages in the later pipeline stages.
Key Code Explanations
html = fetch_html(url, timeout, delay, max_retries, backoff)
- Executes the full retrieval process with retry control. It ensures resilient fetching even under temporary connection failures, aligning with the pipeline’s multi-URL analysis capabilities.
title_tag = soup.find(“title”)
title = _normalize_text(title_tag.get_text()) if title_tag else “Untitled Page”
- Extracts and normalizes the page title, which is often crucial for semantic orientation in SEO contexts. It provides a clean title representation for inclusion in the analytical outputs.
return {“url”: url, “title”: title, “blocks”: raw_blocks, “note”: None}
- Concludes the extraction process with a well-structured dictionary output, ensuring downstream modules can seamlessly process and analyze the extracted text.
Function preprocess_text_block
Overview
The preprocess_text_block function performs critical text sanitization before the embedding phase. Its main purpose is to eliminate low-value or irrelevant textual components from webpage content blocks to ensure the model processes only meaningful information. It handles tasks like removing URLs, inline citations, non-ASCII characters, and excessive whitespace. Additionally, it filters out common boilerplate phrases (e.g., “privacy policy,” “subscribe,” “related posts”) that typically add no SEO or semantic value. This function effectively serves as a quality gate for textual data — ensuring that only well-formed, content-rich blocks proceed further for analysis or embedding. By applying a minimum word threshold, it avoids processing trivial or context-poor sentences, thereby improving both computational efficiency and embedding relevance.
Key Code Explanations
if any(bp in text.lower() for bp in boilerplates):
return “”
- This line checks if any boilerplate term exists within the text (case-insensitive). If found, the text is discarded immediately. This ensures that repetitive structural website content, such as cookie notices or disclaimers, does not bias the embedding model toward uninformative patterns.
if len(text.split()) < min_word_count:
return “”
- This condition filters out short content pieces that do not meet the minimum word requirement. Such short texts usually lack contextual depth, so removing them enhances the model’s ability to focus on information-rich sections.
Function estimate_tokens
Overview
The estimate_tokens function provides a lightweight, model-agnostic estimation of token counts within a text block. Since different transformer models have token limits (e.g., 512, 1024, 2048 tokens), this estimation helps ensure that text chunks remain within acceptable input sizes for the embedding model. It uses an approximate conversion factor of 1.33 tokens per word — a widely accepted heuristic for estimating token counts across various transformer-based architectures. This prevents errors related to token overflow during processing and facilitates efficient batching and chunking operations later in the pipeline.
Function chunk_block_for_embedding
Overview
The chunk_block_for_embedding function manages the critical process of segmenting lengthy content blocks into smaller, model-compatible chunks. Each chunk is designed to stay within a specified token limit (max_tokens), ensuring that even large paragraphs are efficiently processed by the embedding model. It introduces controlled overlap between chunks (overlap_tokens) to preserve contextual continuity across segments. This overlapping design ensures that important context at boundary points is not lost between chunks — a key factor in maintaining semantic cohesion during embedding generation.
Key Code Explanations
if token_est <= max_tokens:
return [{
“block_id”: block_id,
“heading”: heading,
“text”: text,
“tokens”: token_est,
“chunk_index”: 1
}]
- This condition checks whether the text can be embedded directly without splitting. If the text is small enough, it is packaged as a single chunk. This prevents unnecessary computation while maintaining data integrity.
start = max(0, end – overlap_words)
- This line repositions the start index for the next chunk to include a small overlap from the previous one. The overlap ensures that ideas or phrases at the boundary of one chunk are partially included in the next, allowing the embedding model to retain semantic flow and continuity between sections.
Function preprocess_page
Overview
The preprocess_page function orchestrates the complete preprocessing workflow for an entire webpage. It acts as a high-level manager that cleans, filters, and chunks all text blocks extracted from a page, preparing them for embedding generation. The function first applies preprocess_text_block to remove boilerplate or low-value content, then invokes chunk_block_for_embedding to split longer sections into model-compatible segments. Each processed block is collected into a clean, structured list — ensuring that every content unit entering the embedding stage is optimized for both relevance and size.
This function is pivotal for ensuring that the entire webpage is transformed from raw HTML into a refined, semantically meaningful, and model-ready dataset. The output dictionary it returns becomes the foundation for further embedding and scoring stages in the project’s analytical pipeline.

Function load_embedding_model
Overview
The load_embedding_model function is responsible for initializing and preparing the Jina embedding model, which serves as the semantic backbone of the project. It ensures that the model is loaded safely, optimized for the available hardware, and ready for use in generating contextual embeddings from webpage content.
This function dynamically determines whether to use a GPU (cuda) or CPU based on system availability, guaranteeing smooth deployment across different environments — from local setups to cloud-based servers. Once the model is loaded, it performs a warm-up inference pass to stabilize performance during the first real inference.
In this project, the Jina model (jinaai/jina-embeddings-v3) provides dense vector representations for webpage text, enabling deep semantic understanding and similarity analysis across queries, sections, and pages. This function plays a foundational role in ensuring the embedding model is correctly initialized for all downstream computations such as similarity scoring, relevance mapping, and interpretability visualization.
Key Code Explanations
device = device or (“cuda” if torch.cuda.is_available() else “cpu”)
- This line automatically detects and selects the appropriate computation device. If a GPU (CUDA) is available, it uses it for faster processing; otherwise, it defaults to the CPU. This ensures the model can run efficiently across different system configurations without manual device management.
model = SentenceTransformer(model_name, device=device, trust_remote_code=True)
- Here, the SentenceTransformer library loads the Jina model using the specified device. The parameter trust_remote_code=True allows loading of custom architectures defined by the Jina model’s authors — essential for models like jinaai/jina-embeddings-v3 that extend the base transformer structure.
model.encode([“Initialization successful”], show_progress_bar=False)
- This line performs a short dummy encoding task immediately after model loading. Known as a warm-up pass, it stabilizes model memory allocation and ensures consistent inference speed in subsequent runs. This step prevents latency spikes during the first actual embedding generation, which is important for production-level reliability.
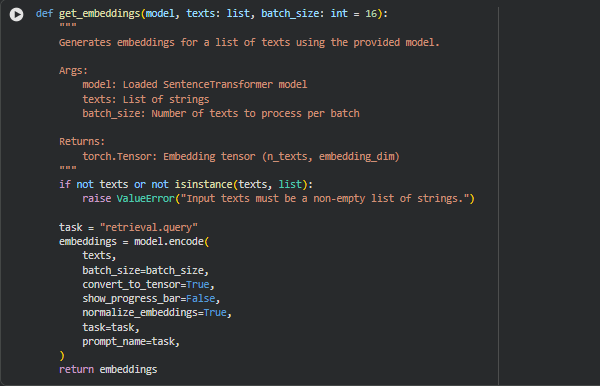
Function get_embeddings
Overview
The get_embeddings function is designed to convert textual data — such as webpage content sections or search queries — into high-dimensional semantic embeddings using the preloaded Jina model. It efficiently processes multiple text inputs in batches, ensuring scalability and optimized memory use during embedding generation.
This function forms the core embedding step of the project. Every query and webpage section is transformed into its semantic vector representation, which captures not just word-level meaning but also contextual relationships. These embeddings are later used in similarity computation, relevance scoring, and visualization of relationships between user intent and webpage content.
In the context of SEO-focused analysis, this enables the project to measure how semantically aligned each webpage or section is with a given search query, providing deep insight into content performance and thematic focus.
Key Code Explanations
if not texts or not isinstance(texts, list):
raise ValueError(“Input texts must be a non-empty list of strings.”)
- This validation ensures that the function only processes valid text data. It prevents potential runtime issues by enforcing the input to be a non-empty list of strings, maintaining pipeline reliability and robustness.
embeddings = model.encode(
texts,
batch_size=batch_size,
convert_to_tensor=True,
show_progress_bar=False,
normalize_embeddings=True,
task=task,
prompt_name=task,
)
· This line is the operational core of the function. It uses the Jina model’s encode method to generate dense embeddings for the input texts. The process occurs in mini-batches (batch_size) for memory efficiency.
- convert_to_tensor=True ensures the output is a PyTorch tensor suitable for direct mathematical operations.
- normalize_embeddings=True guarantees that all embeddings have unit length, a crucial step for cosine similarity calculations used later.
- The parameters task and prompt_name are set to “retrieval.query”, aligning the model’s inference mode with information retrieval objectives — making embeddings more contextually relevant for search and ranking tasks.
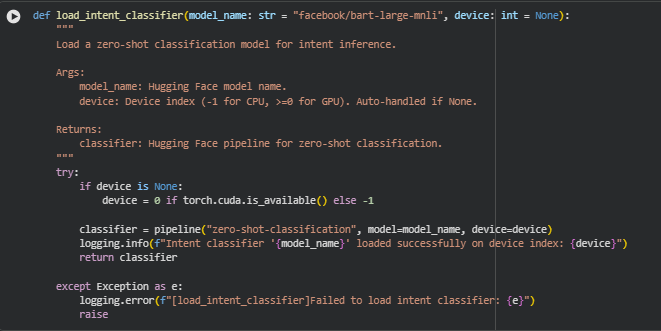
**Function load_intent_classifier
**Overview
The load_intent_classifier function initializes and configures a zero-shot classification model to infer search intent from user queries. It leverages the BART-Large-MNLI model architecture, a high-performing transformer model developed by Facebook AI, which is widely used for natural language inference (NLI) and zero-shot text classification tasks.
This function plays a key role in identifying thematic or intent categories behind user queries — such as informational, navigational, or transactional intent — without the need for task-specific fine-tuning. In SEO applications, intent understanding allows for aligning content strategy with what users are truly seeking, ensuring higher relevance and engagement.
By automatically managing device selection (CPU or GPU), it ensures optimal performance during model loading and inference, maintaining smooth integration within the broader semantic analysis pipeline.
**Key Code Explanations
if device is None:
device = 0 if torch.cuda.is_available() else -1
*This line ensures intelligent device management. It automatically selects the GPU (device index 0) if available for faster inference, otherwise defaults to CPU (-1). This adaptability allows the function to perform efficiently across diverse environments, from local testing setups to cloud-based production servers.
classifier = pipeline(“zero-shot-classification”, model=model_name, device=device)
*Here, the Hugging Face pipeline API is used to create a ready-to-use inference pipeline for zero-shot classification.
- The “zero-shot-classification” task enables the model to classify text into user-defined categories without needing retraining, a crucial advantage for dynamic SEO scenarios where intent categories may evolve.
- The model_name parameter specifies the pre-trained transformer model — in this case, “facebook/bart-large-mnli”, known for robust semantic understanding.
- The device argument ensures execution on the selected hardware for performance optimization.

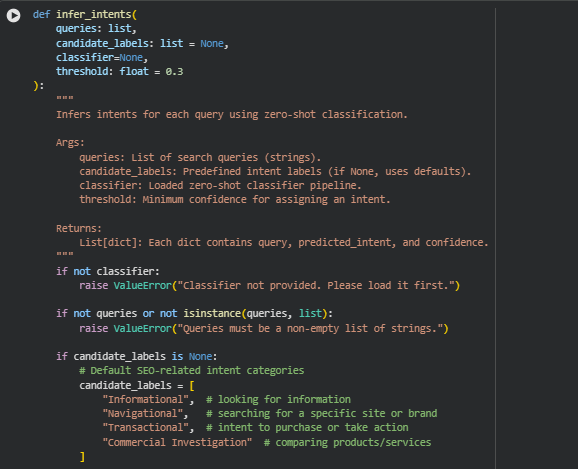
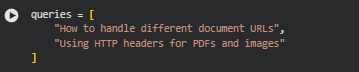
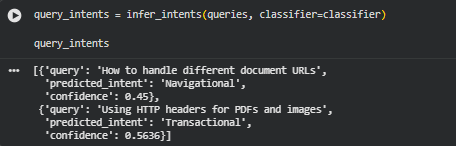
Function infer_intents
Overview
The infer_intents function applies zero-shot classification to automatically identify the underlying intent behind each user query. This plays a crucial role in SEO and content optimization, where understanding why users search for something is just as important as what they search for.
Using the previously loaded zero-shot classifier (typically based on BART-Large-MNLI), this function compares each query against a set of predefined intent labels. If the model determines that a query strongly aligns with one of these labels, it assigns that label as the predicted intent. If the confidence is below the specified threshold, the function categorizes it as “Uncertain.”
This approach enables dynamic intent inference without requiring pre-labeled training data, making it highly adaptable for SEO teams managing diverse topics or industries. It helps strategists map user intent to appropriate content strategies, ensuring that website pages align with what users are truly seeking — whether they’re looking for information, navigating to a brand, exploring products, or preparing to make a purchase.
Key Code Explanations
if candidate_labels is None:
candidate_labels = [
“Informational”,
“Navigational”,
“Transactional”,
“Commercial Investigation”
]
· When no custom labels are provided, this line defines default SEO-specific intent categories. These four intent types are standard in search behavior analysis:
- Informational – User seeks knowledge or understanding.
- Navigational – User wants to find a specific website or brand.
- Transactional – User intends to buy or take a direct action.
- Commercial Investigation – User is comparing options before converting. This ensures that even without custom configuration, the model’s output remains directly relevant to search behavior understanding and content planning.
output = classifier(query, candidate_labels)
best_idx = output[“scores”].index(max(output[“scores”]))
best_label = output[“labels”][best_idx]
confidence = float(output[“scores”][best_idx])
· Here, each query is passed through the zero-shot classifier, which returns a list of possible labels with their associated confidence scores.
- The function retrieves the label with the highest score as the most probable intent.
- The confidence score reflects the model’s certainty about the prediction. This mechanism allows highly flexible text classification that adapts to new or domain-specific intents without retraining.
if confidence < threshold:
best_label = “Uncertain”
- This condition adds quality control to the classification output. If the model’s confidence is below a predefined threshold (default: 0.3), it avoids unreliable labeling by assigning the intent as “Uncertain.” This conservative handling prevents overinterpretation of ambiguous queries, preserving analytical accuracy and interpretability.
By the end of this function, each query is paired with an intent label and a confidence score, producing a structured and interpretable dataset for downstream SEO analysis. It provides actionable insights such as:
- Which queries reflect commercial opportunities.
- Where content needs improvement to serve informational seekers.
- Which search intents dominate the website’s visibility profile.
Overall, infer_intents transforms raw search queries into strategically valuable intent insights, making it a pivotal component of the project’s analytical foundation.
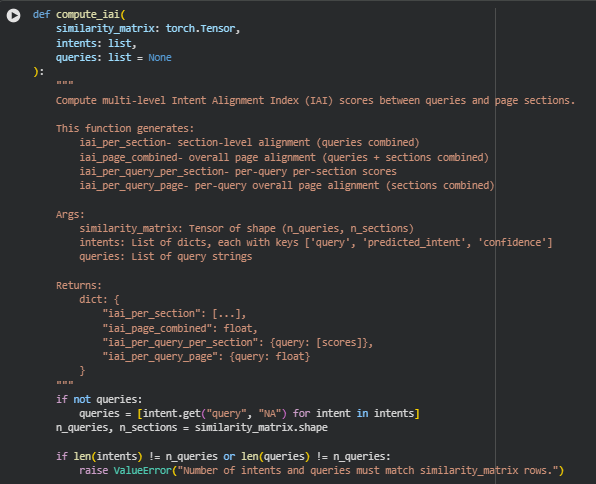
Function: compute_iai
Overview
The compute_iai function calculates the Intent Alignment Index (IAI) — a metric designed to measure how well a webpage’s content sections align with user search intents. It operates on a query-to-section similarity matrix, combining it with the intent confidence scores derived from intent classification to produce multiple levels of alignment insights.
This function generates four granular outputs:
- Section-level IAI (iai_per_section) – Average alignment of all queries to each content section.
- Overall page IAI (iai_page_combined) – A single representative score showing how well the entire page aligns with all user intents collectively.
- Per-query per-section IAI (iai_per_query_per_section) – Detailed alignment for each query against every section, showing localized strength of intent matching.
- Per-query overall page IAI (iai_per_query_page) – A mean score per query across all sections, summarizing how effectively that query’s intent is represented on the page overall.
This design ensures both broad-level insights (page-wide alignment) and fine-grained diagnostics (per-query and per-section breakdowns), giving SEO analysts a clear picture of where the content aligns strongly or weakly with user intent.
Key Code Explanations
Intent Confidence Weighting
intent_confidences = torch.tensor([i[“confidence”] for i in intents], dtype=torch.float32)
if intent_confidences.max() > 1.0:
intent_confidences = intent_confidences / 100.0
intent_confidences = intent_confidences.to(similarity_matrix.device)
weighted_sim = similarity_matrix * intent_confidences.unsqueeze(1)
- This block scales each query’s similarity values based on the classifier’s confidence in its predicted intent. By weighting the query-to-section similarity with confidence, the model emphasizes strong, well-determined intents and reduces the influence of uncertain ones. This ensures that queries with ambiguous intent don’t distort overall alignment scores.
Per-Query, Per-Section Computation
iai_per_query_per_section = {}
for i, q in enumerate(queries):
scores = weighted_sim[i].tolist()
iai_per_query_per_section[q] = [round(float(s), 4) for s in scores]
- Here, the function iterates over each query and retrieves its weighted similarity scores against all page sections. These detailed values allow analysts to pinpoint exactly which sections cater most or least effectively to each search intent, forming the foundation for content-level optimization decisions.
Aggregated Mean Calculations for Different Levels
iai_per_section = weighted_sim.mean(dim=0).tolist()
iai_per_query_page = weighted_sim.mean(dim=1).tolist()
iai_page_combined = round(float(weighted_sim.mean().item()), 4)
· These lines compute averages along different dimensions of the matrix to derive section-level, query-level, and overall alignment metrics.
- The mean along dimension 0 provides how all queries collectively align with each section.
- The mean along dimension 1 gives how each query’s intent aligns across the whole page.
- The final scalar mean represents the entire page’s average intent alignment, a concise KPI-style indicator for clients.
Overall, compute_iai elegantly transforms the underlying similarity data into a hierarchical alignment report, enabling actionable SEO insights—from micro (section-level refinement) to macro (page-level strategy).
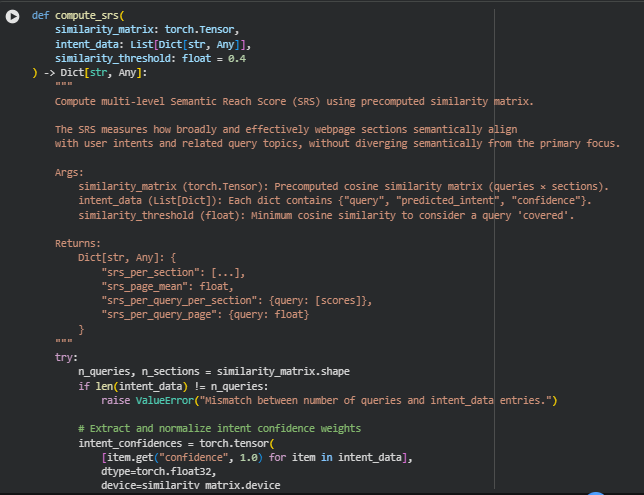
Function: compute_srs
Overview
The compute_srs function calculates the Semantic Reach Score (SRS) — a metric designed to evaluate how effectively a webpage’s sections semantically cover and align with user intents. Unlike the Intent Alignment Index (IAI), which focuses on alignment intensity, SRS measures semantic breadth — how many sections meaningfully capture each query’s intent, while filtering out weak or irrelevant matches using a similarity threshold.
This function provides multiple granular outputs:
- Section-level SRS (srs_per_section) – Average semantic reach of each content section across all queries.
- Overall page SRS (srs_page_mean) – Represents the overall semantic breadth and relevance coverage of the entire page.
- Per-query per-section SRS (srs_per_query_per_section) – Reveals how each query semantically connects with every section, highlighting specific coverage patterns.
- Per-query overall page SRS (srs_per_query_page) – Summarizes the degree of coverage each query achieves across all sections.
In essence, SRS helps SEO analysts understand how comprehensively and evenly the content spans user search intents, ensuring that the page covers a broad yet semantically relevant range of user needs.
Key Code Explanations
Applying Confidence-Weighted Similarity
intent_confidences = torch.tensor(
[item.get(“confidence”, 1.0) for item in intent_data],
dtype=torch.float32,
device=similarity_matrix.device
)
if intent_confidences.max() > 1.0:
intent_confidences = intent_confidences / 100.0
weighted_sim = similarity_matrix * intent_confidences.unsqueeze(1)
- This segment weights the similarity scores according to the confidence levels of the inferred intents. A higher confidence implies the model is more certain about the intent classification for a query, so its similarity influence on the SRS should be stronger. This ensures that intent reliability directly affects the semantic reach measurement, maintaining both precision and interpretability.
Semantic Reach Filtering Using Threshold Mask
reach_mask = (similarity_matrix >= similarity_threshold).float()
reach_weighted = weighted_sim * reach_mask # Zero-out non-reached sections
- Here, the function filters out all similarity values below a given semantic threshold. This acts as a cutoff for “semantic relevance” — only sections that reach or exceed the threshold are considered part of the semantic reach. This ensures that SRS captures meaningful connections only, rather than noise from weak contextual overlaps.
Multi-Level Aggregation for Section, Query, and Page
srs_per_section = reach_weighted.mean(dim=0).tolist()
srs_per_query_page = reach_weighted.mean(dim=1).tolist()
srs_page_mean = round(float(reach_weighted.mean().item()), 4)
· These lines compute the semantic reach across different analytical levels:
- Section level: Evaluates which sections consistently demonstrate strong semantic relevance across many queries.
- Query level: Indicates how thoroughly each search intent is addressed across the page.
- Overall page level: Produces a single, interpretable metric summarizing the semantic coverage performance of the entire webpage.
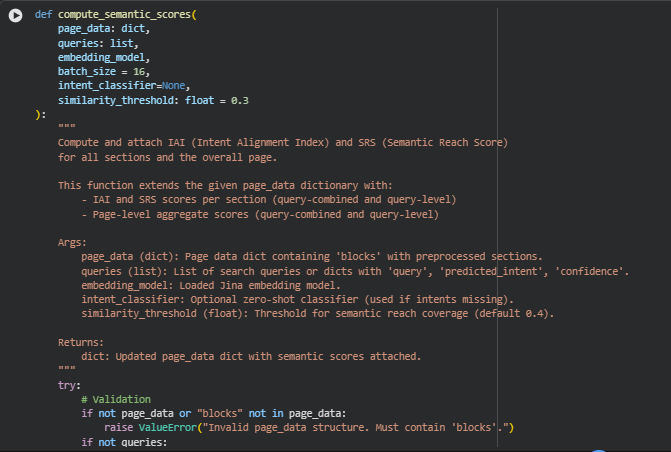

Function: compute_semantic_scores
Overview
The compute_semantic_scores function is the central analytical engine that brings together all the earlier processing steps — text embeddings, intent inference, and similarity-based semantic evaluation — to compute two key performance indicators for a webpage:
- Intent Alignment Index (IAI) – measures how strongly each page section aligns with user intents.
- Semantic Reach Score (SRS) – measures how broadly the content semantically covers the search intents.
The function performs these key tasks:
- Validates and prepares page content and query data.
- Generates embeddings for both queries and content sections using the Jina Embeddings model.
- Computes a cosine similarity matrix between queries and sections to quantify contextual closeness.
- Derives IAI (alignment strength) and SRS (semantic breadth) using their respective computation functions.
- Integrates both section-level and page-level results into the page_data dictionary, making it ready for downstream visualization, reporting, or dashboard integration.
This function essentially transforms plain content into a semantic intelligence structure, helping SEO strategists understand not only how well a page matches user intent, but also how completely it covers the spectrum of relevant topics.
Key Code Explanations
Handling Intent Inference Automatically
if isinstance(queries[0], str):
if not intent_classifier:
raise ValueError(“Intent classifier required for intent inference.”)
intent_data = infer_intents(queries, classifier=intent_classifier)
else:
intent_data = queries
· This code dynamically checks if the provided queries are plain text strings or already structured with intent predictions.
- If they are plain text, it triggers automatic intent classification using a zero-shot model.
- If they are pre-labeled with predicted intents and confidence scores, it skips classification to save computation. This logic ensures the pipeline is robust and flexible, supporting both raw and preprocessed query inputs.
Generating Cross-Domain Embeddings for Semantic Matching
query_embeddings = get_embeddings(embedding_model, query_texts, section_batch_size)
section_embeddings = get_embeddings(embedding_model, section_texts, query_batch_size)
similarity_matrix = util.cos_sim(query_embeddings, section_embeddings)
· Here, both queries and page sections are embedded using the Jina Embeddings v3 model.
- The embeddings convert text into high-dimensional semantic vectors.
- Cosine similarity (util.cos_sim) then quantifies how semantically close each query is to each section. This forms the core analytical matrix, from which both IAI and SRS metrics are derived. Effectively, it transforms textual similarity into measurable semantic relationships.
Dual-Score Computation for Complementary Insights
iai_result = compute_iai(similarity_matrix, intents=intent_data, queries=query_texts)
srs_result = compute_srs(
similarity_matrix=similarity_matrix,
intent_data=intent_data,
similarity_threshold=similarity_threshold
)
- IAI (Intent Alignment Index) captures the depth of alignment—how strongly each section matches intent.
- SRS (Semantic Reach Score) captures the breadth of coverage—how many relevant areas the content spans meaningfully. By computing both, the function ensures that alignment precision and semantic completeness are evaluated side by side — giving a 360° understanding of how well the page serves user intent.
Structured Integration of Results into Page Data
for i, block in enumerate(page_data[“blocks”]):
block[“iai_scores”] = {…}
block[“srs_scores”] = {…}
page_data[“page_scores”] = {…}
- Each content block receives granular IAI and SRS scores, both as combined (average) values and as per-query breakdowns. Additionally, page-level aggregates summarize overall semantic performance. This structured integration enables seamless downstream reporting — making it easy to visualize intent-driven strengths and coverage gaps in the content hierarchy.
Overall, compute_semantic_scores functions as the semantic scoring nucleus of the project — connecting model inference, intent understanding, and embedding-driven semantic comparison into a unified analytical workflow tailored for real-world SEO intelligence.
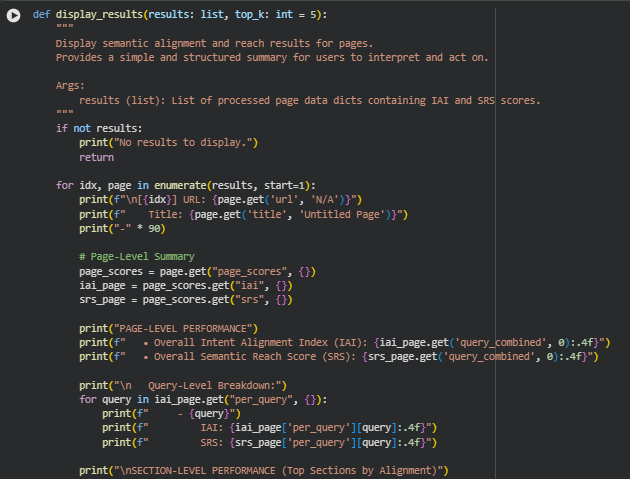
Function: display_results
Overview
The display_results function is responsible for presenting the computed Intent Alignment Index (IAI) and Semantic Reach Score (SRS) results in a clear, structured, and human-readable format. It converts the analytical outputs from the computation stage into a practical interpretation layer that clients and SEO strategists can easily understand and act upon.
This function displays:
- Page-level summaries, showing overall IAI and SRS scores that reflect how effectively the page aligns with and covers user intent.
- Query-level breakdowns, where each query’s alignment and reach scores are listed separately to highlight performance for specific intents.
- Section-level rankings, which identify the top content blocks by semantic alignment, allowing strategists to pinpoint which sections are performing well and which might need refinement.
The display is designed for clarity and simplicity — suitable for both technical users analyzing semantic metrics and non-technical stakeholders reviewing optimization opportunities. The final “Action Insights” provide immediate, actionable takeaways on how to interpret and use the scores for SEO improvement, helping users focus on enhancing underperforming sections or reinforcing strong intent coverage areas.
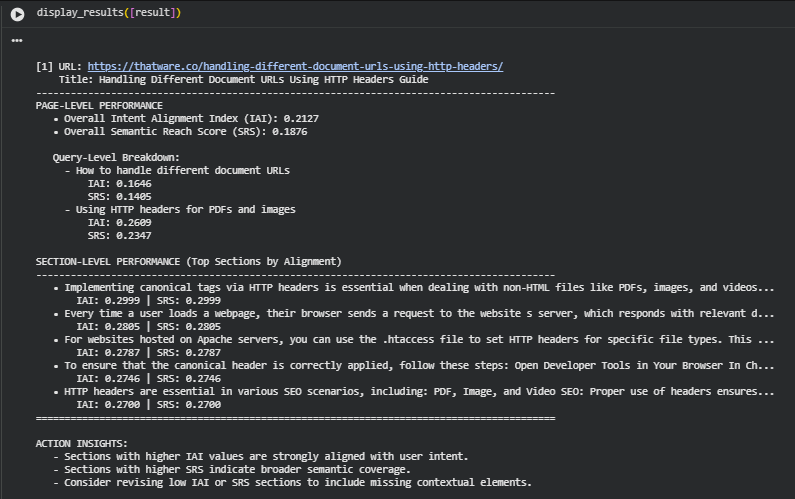
Result Analysis and Explanations
Understanding the Overall Scores
- The overall IAI score of 0.2127 suggests that the page has partial alignment with the target queries but leaves room for improvement. This means the content somewhat addresses the searcher’s intent, yet certain aspects of the topic may not be explicitly covered or contextually reinforced.
- The overall SRS score of 0.1876 indicates limited semantic reach — the range of related concepts and contextual variations expressed in the content is not extensive. A low SRS often implies that the article does not fully explore subtopics, alternative phrasing, or supporting details that could improve topical depth and coverage.
Query-Level Interpretation
Each query reflects how well the page aligns with distinct user search goals.
- For “How to handle different document URLs”, the IAI (0.1646) and SRS (0.1405) are both below the page average. This indicates that the page only partially answers this intent, possibly because it focuses more on the technical aspect of HTTP headers rather than on the broader handling of multiple document URLs.
- In contrast, “Using HTTP headers for PDFs and images” achieves higher scores (IAI 0.2609 and SRS 0.2347). This means the content effectively matches the intent of users seeking practical implementation details, code-level guidance, or SEO considerations related to HTTP headers.
From a strategy standpoint, the content is more optimized for the second query, suggesting that keyword and section-level reinforcement should be directed toward the first query to achieve a balanced intent alignment.
Section-Level Performance Insights
The top-performing sections are consistent in both alignment and reach, with IAI and SRS values around 0.27–0.30. These sections show strong topical clarity and intent relevance. They contain practical guidance, such as implementing canonical headers, setting HTTP headers through .htaccess, and verifying configurations through browser tools.
Such sections serve as content anchors — they capture user intent efficiently and help search engines understand the page’s contextual reliability. Maintaining these sections as-is, while ensuring they are interconnected with weaker segments, supports both engagement and discoverability.
Understanding the Interdependence of IAI and SRS
Both metrics complement each other in evaluating SEO content quality:
- IAI (Intent Alignment Index) measures how closely each section’s meaning aligns with user search intent. A higher value indicates stronger precision in addressing the query’s core meaning.
- SRS (Semantic Reach Score) evaluates how broadly and contextually the content covers the semantic landscape surrounding the query, ensuring the topic isn’t treated narrowly.
When both IAI and SRS are consistently moderate, as seen here, it implies the page covers relevant ground but may not fully explore the connected concepts or practical examples that improve topical depth. Ideally, the content should maintain balanced progression of IAI and SRS — high alignment with sufficient conceptual coverage ensures stronger relevance signals for search engines.
Section-Level Insights and Distribution Patterns
Section-level observations show that the content maintains steady technical relevance across its major paragraphs. The top five sections, all with IAI and SRS around 0.27–0.30, indicate reliable thematic consistency. However, this uniformity also suggests a lack of standout differentiators — no section emerges as a strongly dominant authority on the topic.
Sections that fall below this threshold likely lack semantic reinforcements, such as examples, implementation details, or contextual linking to related scenarios (e.g., HTTP response codes or server-level best practices). Enhancing these areas can push alignment and reach scores closer to the 0.35–0.45 range, typically reflecting well-optimized, semantically rich content.
Interpreting Score Ranges
To contextualize the scores:
- 0.30 and above generally denotes strong alignment and comprehensive topical treatment.
- 0.20–0.30 indicates fair alignment but limited semantic diversity.
- Below 0.20 reflects either partial topic coverage or missing contextual relationships.
The current results fall near the mid-range, suggesting the page performs decently but does not yet achieve full topical depth or query-specific refinement.
Optimization Path and Strategic Focus
Based on the analysis, improvement should focus on three areas:
- Intent Reinforcement: For queries with lower IAI (e.g., “How to handle different document URLs”), strengthen direct keyword-context match and integrate clarifying subtopics such as URL canonicalization workflow or server behavior management.
- Semantic Expansion: Expand supporting coverage around related entities — server directives, MIME types, caching, and protocol headers — to elevate SRS through conceptual linkage.
- Section Refinement: Revisit low-performing sections and add transitional cues, examples, or structured explanations that bridge subtopics.
Avoid repetitive phrasing or over-optimization, which can harm both readability and semantic coherence. The objective is to broaden contextual depth while retaining focus and clarity.
Key Takeaways
- Balanced but moderate IAI and SRS indicate a technically relevant yet semantically constrained page.
- Stronger scores in sections about HTTP header implementation confirm that the page’s strengths lie in technical execution rather than broader conceptual handling.
- Strategic content enrichment, especially through expanded contextual cues and supporting details, can significantly improve both alignment precision and semantic coverage.
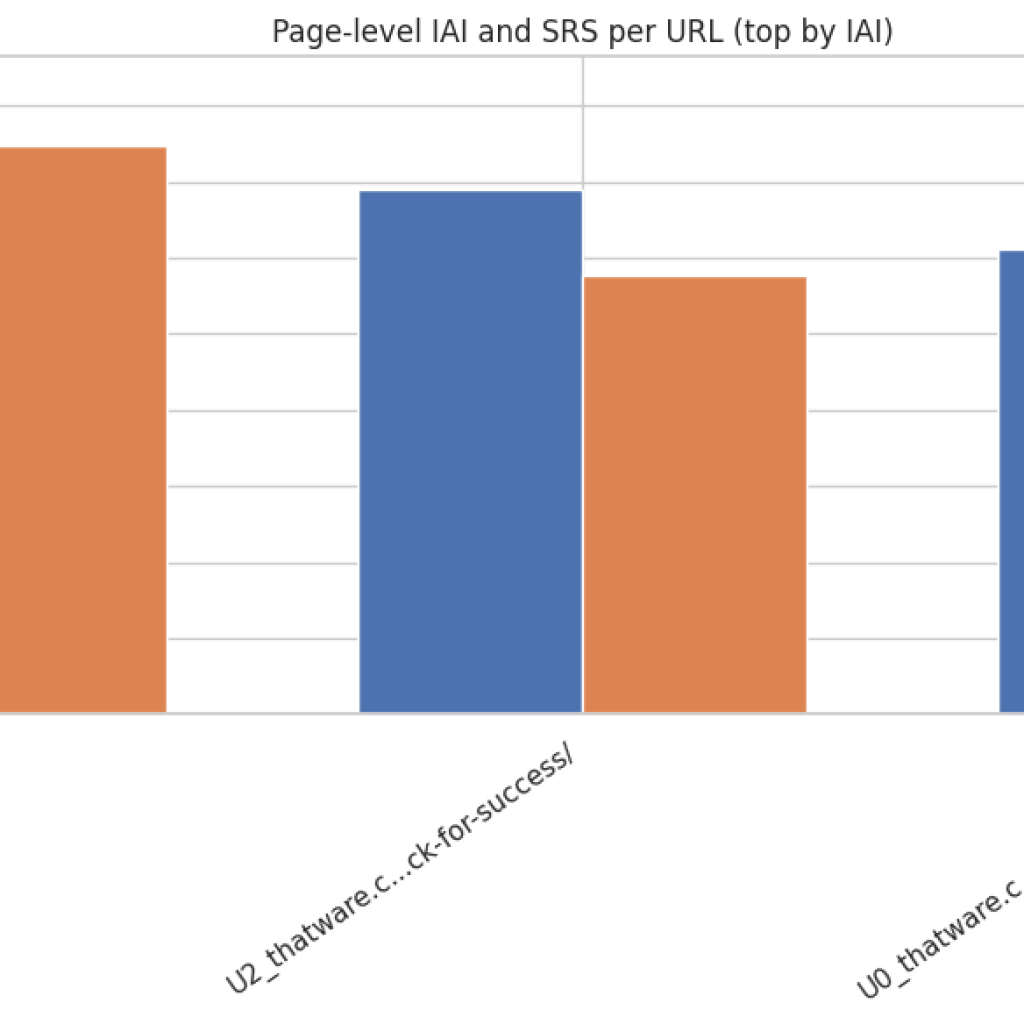
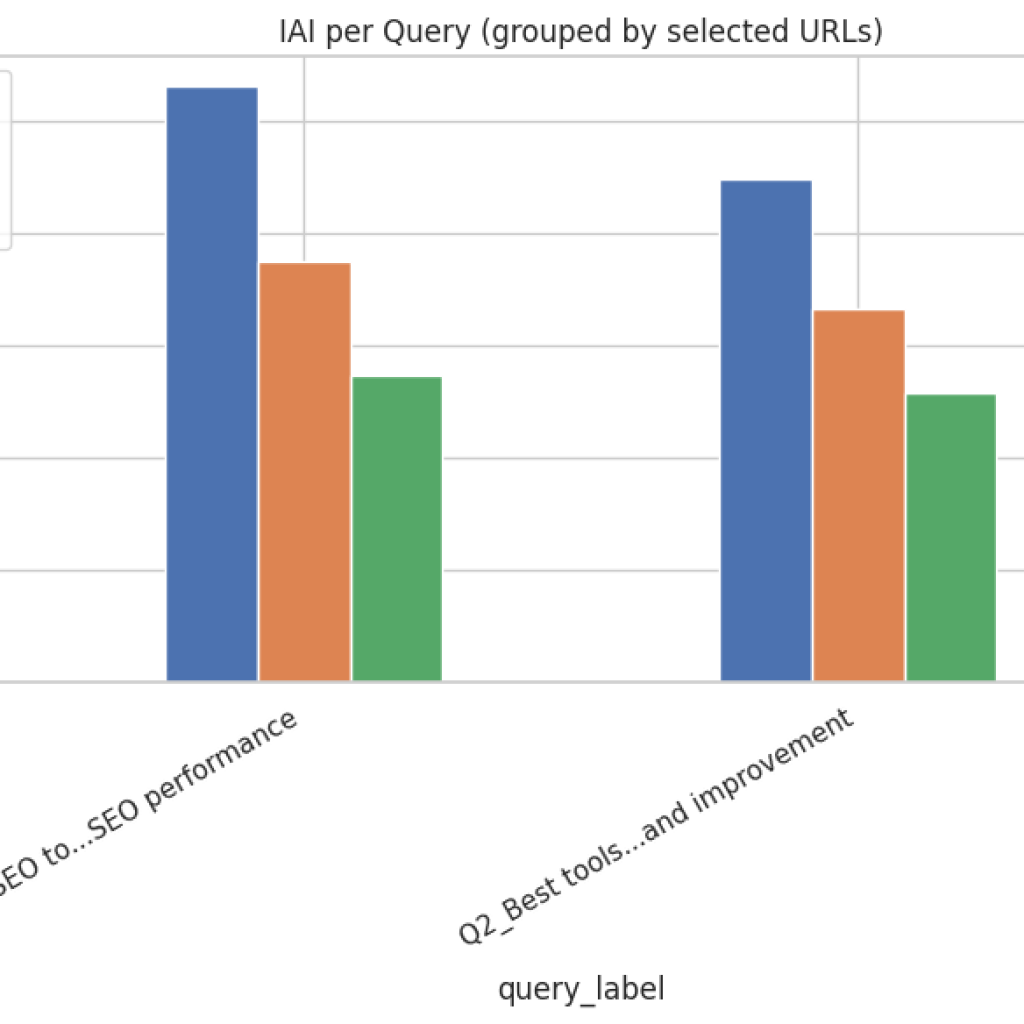
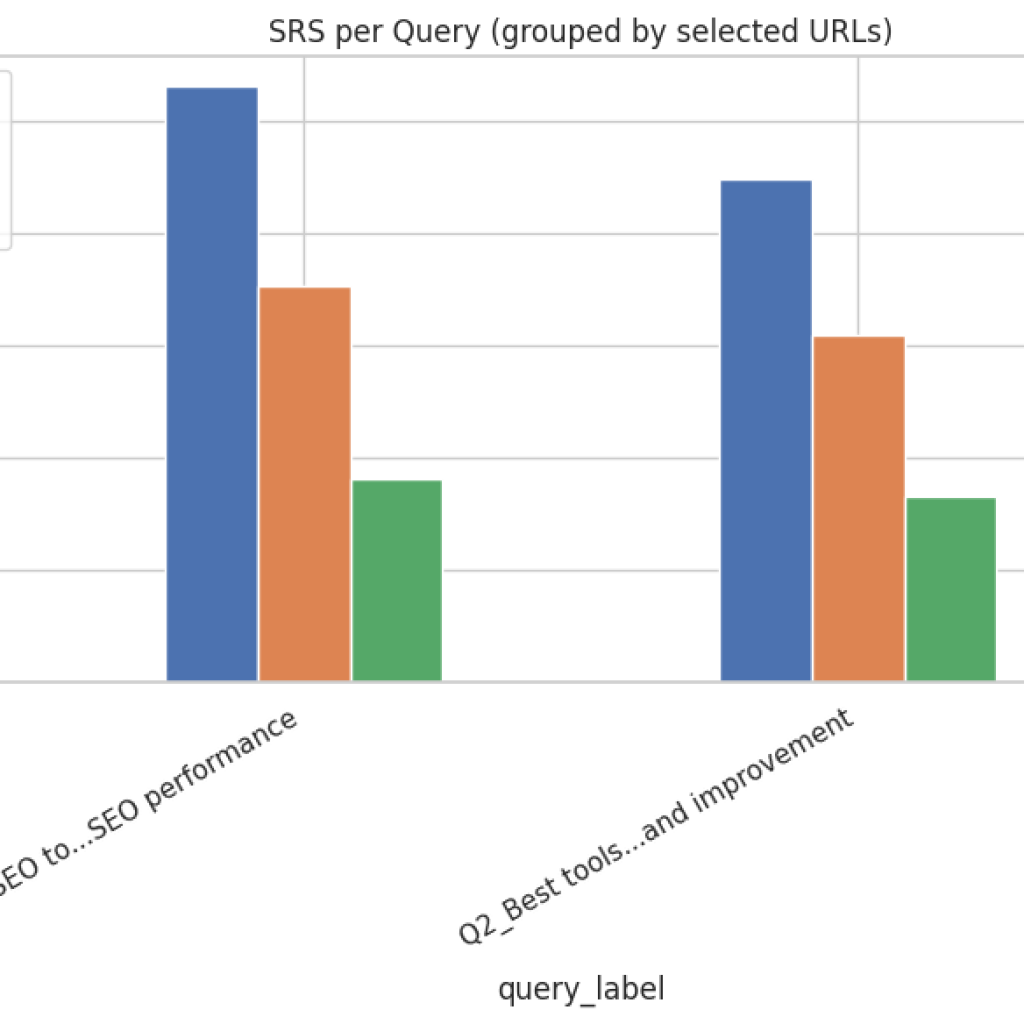
Result Analysis and Explnation
This section synthesizes semantic analysis into a structured, actionable narrative. It explains how to interpret aggregated and comparative results, how to prioritise content updates, and how each visualization supports decision making. The discussion is structured into discrete subsections so SEO strategists and technical stakeholders can quickly find interpretation guidance, tactical recommendations, and operational caveats.
Executive summary — What the analysis reveals
- The combined metrics (Intent Alignment Index — IAI — and Semantic Reach Score — SRS) deliver two complementary views: precision of intent matching (IAI) and breadth of semantic coverage (SRS).
- Across a portfolio of pages, patterns typically fall into three categories: pages with high IAI and high SRS (strong, well-rounded content), pages with high IAI but low SRS (focused, narrow pages), and pages with low IAI and low SRS (content gaps or off-topic pages).
- Multi-URL semantic analysis is primarily valuable for (a) identifying which pages best represent particular queries/intent families, (b) spotting redundant or competing pages, and (c) prioritising pages or sections for optimization based on expected ROI.
Metric interpretation and practical thresholds
What each metric measures (concise)
- IAI (Intent Alignment Index): Reflects how closely content semantics map to user intents represented by queries. Higher IAI → content speaks directly to the user need.
- SRS (Semantic Reach Score): Reflects how many related intent variations a page or section meaningfully covers above a relevance threshold. Higher SRS → broader topical coverage.
Practical score bands (guideline)
Use these bands as pragmatic checkpoints rather than absolute rules — verticals and query types will vary.
· IAI
- ≥ 0.30 — strong alignment: content is clearly focused on the query’s core task or question.
- 0.20 – 0.30 — acceptable: content is relevant but could benefit from greater specificity or examples.
- < 0.20 — weak: content likely fails to meet intent directly or the intent is not emphasized.
· SRS
- ≥ 0.25 — broad semantic coverage: page addresses a range of related subtopics and phrasing variants.
- 0.12 – 0.25 — moderate coverage: some related concepts present but not fully explored.
- < 0.12 — narrow or sparse coverage: limited concept variety, likely poor performance for long-tail or paraphrased queries.
Note: absolute thresholds depend on embedding normalization and similarity thresholding choices. These bands are tuned to the default similarity and normalization settings used in this project; treat them as operational guidance for prioritization and testing.
Comparative analysis across pages (portfolio view)
Relative strengths and weaknesses
- Pages that rank higher on page-level IAI are typically the best immediate candidates for acquiring featured placements for targeted queries because they demonstrate concise intent fulfillment.
- Pages with high SRS but modest IAI may attract a broader set of related queries but might not convert for specific transactional or navigational intents; these are good hubs for topical authority but require stronger call-to-action alignment for conversion goals.
Redundancy and cannibalization
· When multiple pages show similar IAI patterns for the same query family, there is a risk of internal competition (semantic cannibalization). Consolidation or clearer topical differentiation is recommended:
- Consolidate complementary pages into a single authoritative resource if content overlaps heavily.
- Distinguish pages by intent scope: one page for high-level explanation (broad SRS) and another for step-by-step or transactional guidance (high IAI).
Prioritization framework (quick triage)
- High IAI & High SRS — maintain and amplify (internal linking, structured data, conversions).
- High IAI & Low SRS — expand semantic breadth (FAQs, related topics, additional examples).
- Low IAI & High SRS — increase specificity (introduce clearer headings, intent-matching lead paragraphs).
- Low IAI & Low SRS — rework or repurpose (merge with stronger pages or rewrite with a focused intent).
Per-query behavior and implications
Query alignment variability
- Different queries associated with the same topical cluster will often show divergent IAI/SRS patterns. Informational queries frequently benefit from higher SRS (coverage of related explanations), while transactional or navigational queries require strong IAI (specific guidance or conversion signals).
- Queries with consistently low SRS across pages indicate topical gaps across the portfolio; these require content creation to fill semantic voids.
Interpreting per-query per-page disparities
- If a page has high IAI for one query but low IAI for another in the same cluster, that indicates uneven content structuring. Actions include adding targeted subsections or anchor content optimized for the weaker query while avoiding keyword stuffing.
Section-level diagnostics (micro view)
Why section-level matters
- Page-level metrics can mask hotspots and blind spots. Section-level scores reveal which parts of the page drive the global signal (e.g., lead paragraphs, code snippets, lists).
- High-value sections often correlate with practical examples, clear H2–H3 headings, and short, focused paragraphs.
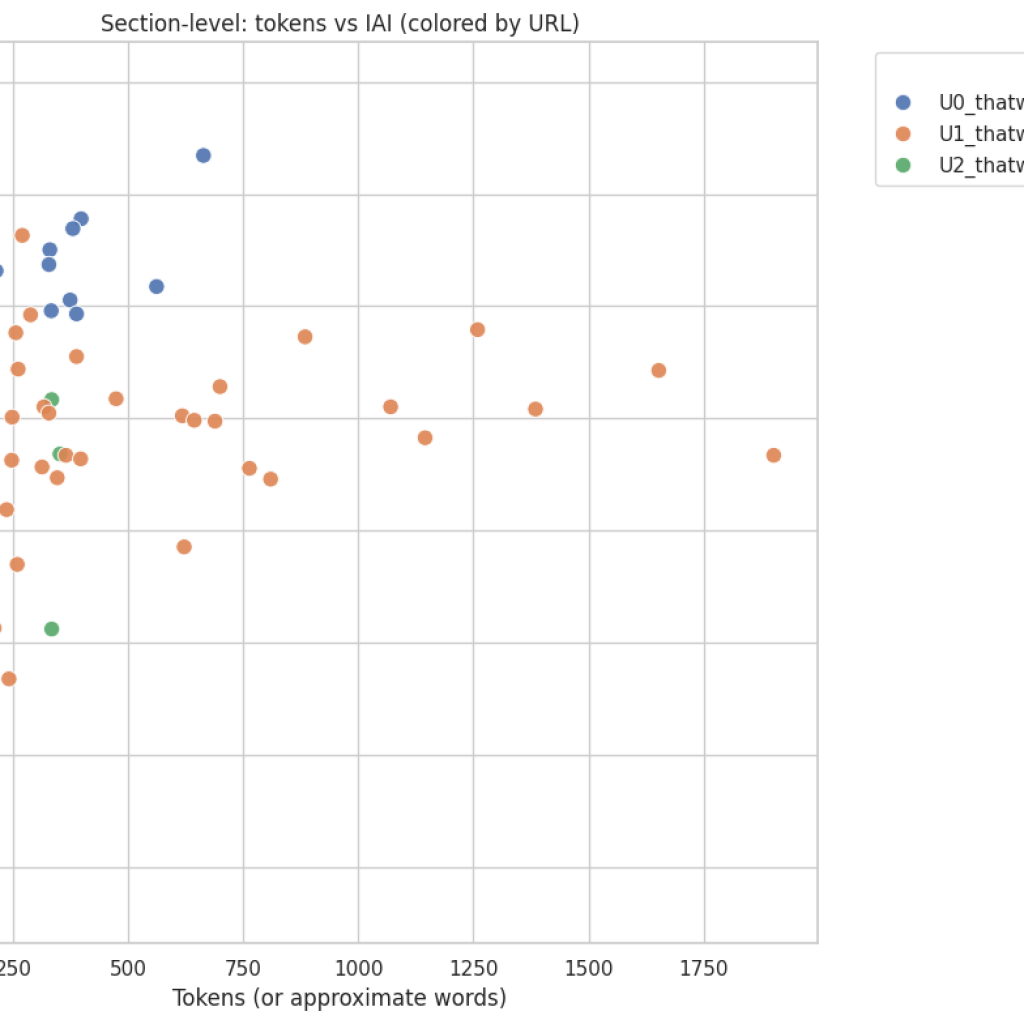
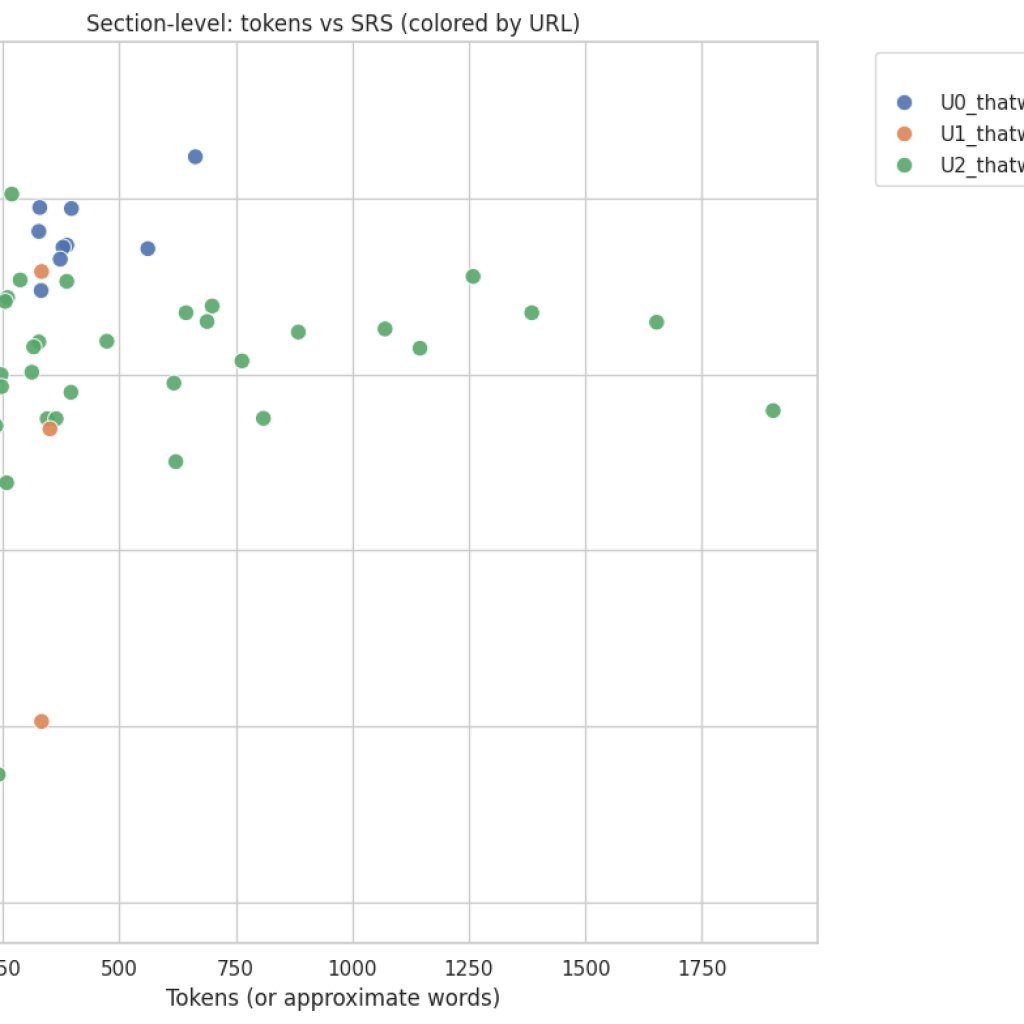
Interpreting tokens vs score (section scatter)
- When tokens (size) correlate positively with higher scores, longer explanatory content is contributing to alignment; however, length alone is not sufficient. Quality, structure, and explicit intent cues matter more.
- Short, high-scoring sections typically indicate focused, well-targeted guidance or steps; these are useful patterns to replicate in other pages.
Actionable section-level edits
- Raise IAI: Add intent-explicit opening sentences, examples, structured steps, and targeted headings.
- Raise SRS: Add related concepts, synonymic phrases, cross-references, and brief contextual expansions (e.g., “when to use X vs Y”).
- Avoid: large blocks of generic text without clear subheadings, and repeated boilerplate language that confuses semantic models.
Visualization section — How to read and act on each plot
Each visualization provides a different lens. The following subsections explain what to look for and the decisions each plot supports.
Page-level bar chart (IAI & SRS per page)
What it shows: Side-by-side IAI and SRS for each page, sorted by IAI. How to read: Identify pages where IAI and SRS diverge. A page with high IAI but low SRS is narrowly focused; a page with low IAI and high SRS may be broad but unfocused. Actionable uses:
- Quickly locate highest-impact pages (high IAI) for conversion optimization.
- Spot pages needing expansion (high IAI, low SRS) or refocusing (low IAI, any SRS).
Grouped bar plot (per query × selected pages)
What it shows: For selected pages, each query’s IAI or SRS values as grouped bars. How to read: Observe which pages perform best for a specific query; check consistency across queries. Actionable uses:
- Select canonical pages for query families (those that consistently lead across queries).
- Reassign editorial focus where a single page should be authoritative for a query but performs poorly.
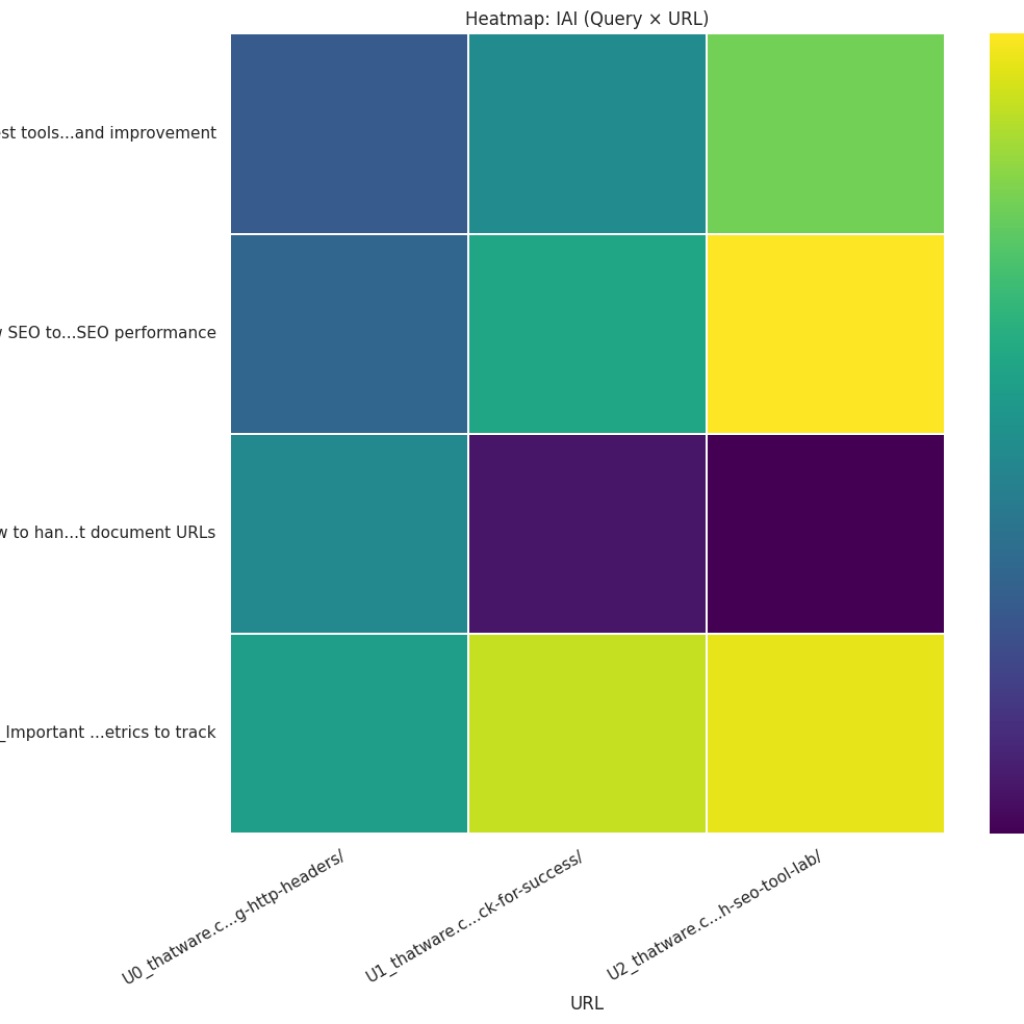
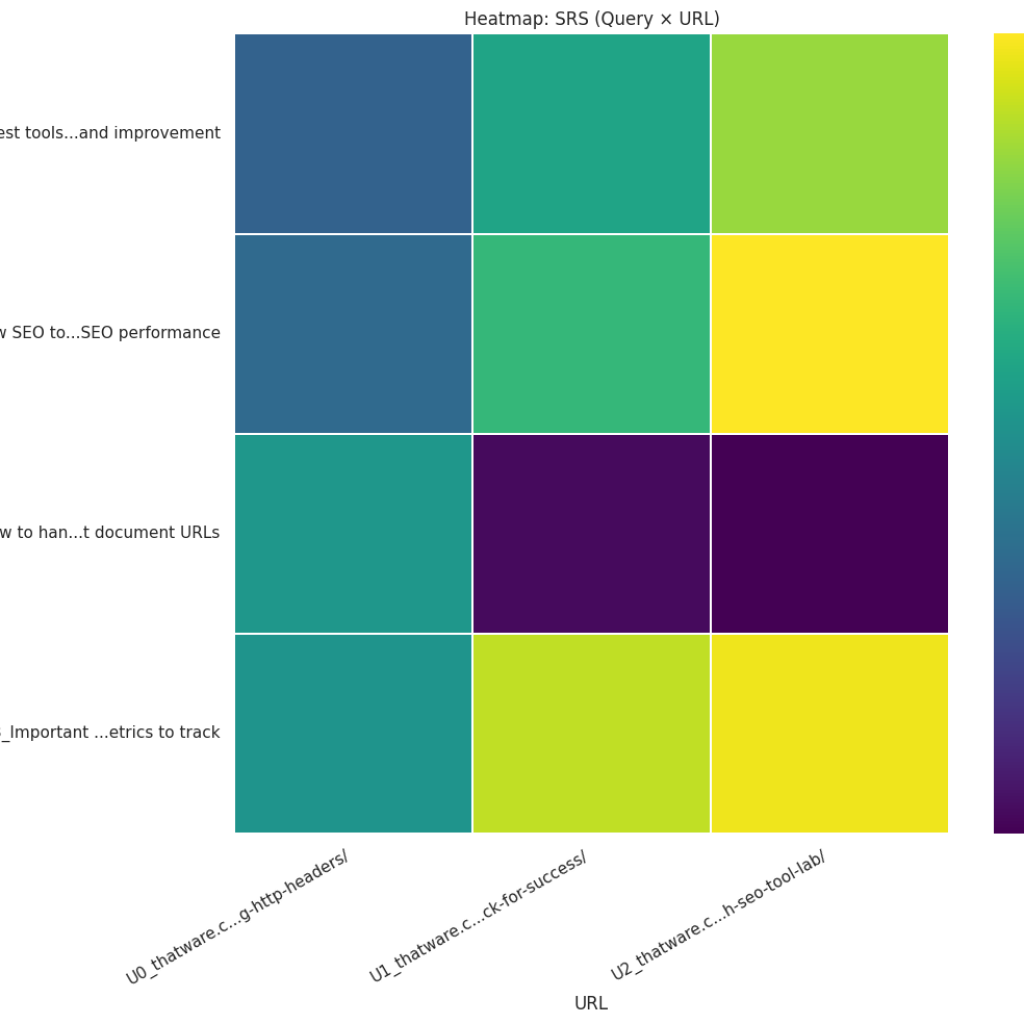
Heatmap (Query × URL matrix)
What it shows: Matrix of numerical intensity for every (query, page) pair; darker cells indicate stronger scores. How to read: Look for:
- Vertical bands (a query that many pages do well on) — may indicate redundant coverage across the site.
- Horizontal bands (a page performing consistently across many queries) — that page is a topical hub. Actionable uses:
- Detect cannibalization or gaps at glance.
- Choose consolidation targets (if many pages match the same query strongly, consider merging).
Section-level scatter (tokens vs metric, colored by URL)
What it shows: Distribution of section sizes against their IAI/SRS, color-coded by page. How to read: Identify whether score distribution clusters around long or short sections and determine per-page patterns. Actionable uses:
- Spot individual high-value sections to lift or replicate elsewhere.
- Identify pages with many low-value, long sections (candidates for pruning or rewriting).
Tactical recommendations — short, medium, and long term
Short term (low effort, high impact)
- Targeted subsection additions: Add 1–2 focused paragraphs or FAQs in underperforming sections to directly address low-IAI queries.
- Heading optimization: Ensure H2/H3 headings explicitly reflect target intents — improves model recognition of intent at section granularity.
- Internal linking: Link strong sections to weaker ones to transfer topical relevance and improve crawl context.
Medium term (moderate effort)
- Consolidate overlapping pages: Merge semantically redundant pages and redirect low-value URLs to a stronger canonical page.
- Semantic enrichment: Add examples, comparisons, and related subtopics to increase SRS. Use schema where appropriate (FAQs, HowTo) to clarify intent to both users and search systems.
- A/B content experiments: Test variant opening paragraphs and section headings to measure lifts in both IAI and user engagement metrics.
Long term (strategic)
- Topical hub construction: Create pillar pages that intentionally combine high SRS breadth with dedicated high-IAI subpages for specific intents.
- Content lifecycle and monitoring: Re-run the semantic scoring periodically after edits; track IAI and SRS trends alongside organic metrics (rank, impressions, click-through).
- Localized or multilingual tuning: If operating across languages, replicate the analysis per locale and tune content to local phrasing and context; embedding models support cross-lingual similarity but real-world validation is essential.
Operational considerations and tuning
Similarity threshold and normalization
- SRS depends on a similarity cutoff to determine which matches count as “covered.” Adjusting this threshold (e.g., ±0.05) changes sensitivity: higher thresholds reduce false positives but may undercount nuanced matches. Tune thresholds empirically across a representative sample.
Intent confidence weighting
- Intent predictions are weighted by classifier confidence. Low confidence inflates uncertainty; for ambiguous queries consider manual labeling or expanded candidate label sets to improve classification reliability.
Batch size and chunking effects
- Chunking strategy (chunk size and overlap) changes section granularity and can impact both IAI and SRS. Test chunking parameters on long pages to preserve meaning while avoiding overly fragmented sections.
Human review and editorial validation
- Embedding scores are statistical proxies. For high-impact pages use a human review step to confirm that recommended edits preserve quality, tone, and conversion intent.
Limitations, risks, and mitigation
Limitations
- Statistical nature of embeddings: similarity does not prove usability or conversion effectiveness; it measures semantic proximity only.
- Domain-specific language: Industry jargon or very niche phrasing can produce lower scores without implying poor content quality.
- Multilingual subtleties: Cross-lingual embeddings are powerful but may miss locale-specific nuances.
Risks and mitigations
- Overfitting to the metric (writing to increase scores without user value): mitigate by pairing edits with UX and engagement metrics.
- False confidence in low-confidence intents: flag “uncertain” predictions and treat them as candidates for human tagging.
- Excessive consolidation: merging pages without preserving intent variation can reduce long-tail discoverability — preserve distinct intent pages where appropriate.
Example prioritization playbook
- Score triage: Tag pages into priority buckets using page-level IAI/SRS bands.
- Section audit: For top priorities, run a section-level audit; list low IAI sections with supporting evidence.
- Editorial plan: For each targeted section, assign specific edits: heading update, example added, related concept paragraph.
- Implement & monitor: Deploy edits in staged releases, re-compute semantic scores after 1–2 weeks, track click/rank signals for correlation.
- Scale: Apply repeatable templates for similar low-score patterns across the site.
Closing guidance
Semantic analysis supplies a modern, intent-aware framework for prioritising SEO investments. By combining IAI (precision) and SRS (breadth) with section-level diagnostics and clear visualization, the methodology empowers evidence-based decisions: whether to expand content, consolidate pages, or tune conversion elements. Treat the scores as directional signals that guide targeted editorial work, always coupling semantic actions with human review and performance monitoring to ensure improvements align with audience needs and business outcomes.
Final Thoughts
The project “Jina-Based Semantic Reach Analyzer” establishes a robust analytical framework for understanding how well web content reflects user intent and semantic completeness. Through the combination of the Intent Alignment Index (IAI) and Semantic Reach Score (SRS), the system provides a holistic assessment of both the precision of intent matching and the breadth of topic coverage within each page.
The implementation harnesses advanced transformer-based language models Jina Embedding to interpret natural language meaning at scale. This enables a more intelligent evaluation of how effectively each content segment communicates with the intended audience and satisfies the contextual demands of relevant search queries. Unlike traditional keyword matching, this model-driven approach reveals deeper linguistic and conceptual relationships, uncovering where content truly aligns with search intent and where it falls short.
The IAI metric measures the degree of alignment between a page’s sections and the core intent expressed in target queries. High IAI values indicate strong focus and clarity of purpose, while lower values suggest diluted or misdirected thematic emphasis. Complementing this, the SRS metric evaluates the content’s contextual coverage — identifying how broadly and meaningfully the topic is explored. Together, they offer a balanced lens for diagnosing both content precision and thematic completeness.
The analytical outcomes demonstrate the value of using these metrics as strategic indicators for content optimization. Sections or pages with low IAI scores benefit from refining intent focus through clearer phrasing, better topical structuring, and removing irrelevant details. On the other hand, low SRS scores point toward gaps in conceptual coverage, guiding the addition of supporting information, examples, or related subtopics to improve depth and relevance.
The visualization suite strengthens interpretability by translating model-derived metrics into clear, actionable insights. Page-level bar plots reveal comparative performance, grouped bar charts show how different queries interact with specific pages, heatmaps highlight concentration or absence of alignment, and section-level scatter plots expose patterns between textual richness and semantic efficiency. Together, these visual tools transform data into a practical narrative of content performance and intent coherence.In essence, this project fulfills its goal of making semantic intent alignment measurable, interpretable, and actionable. It offers a data-backed method to evaluate how effectively digital content supports user-centric objectives, ensuring that each page contributes meaningfully to the overall thematic structure. By bridging machine understanding with human interpretation, the evaluator serves as a strategic compass for maintaining high-quality, intent-driven, and semantically balanced web content.
