SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
The project Semantic Readability and Cognitive Load Analyzer — Evaluating Comprehension Complexity in SEO Content focuses on understanding how easily and effectively users can comprehend webpage content from a cognitive and linguistic standpoint. The goal is to measure not just surface-level readability but the deeper semantic and cognitive characteristics that determine how effortlessly information is processed by readers.

The system integrates advanced natural language processing and transformer-based embeddings to assess multiple content dimensions including readability, semantic density, syntactic complexity, and cognitive load. These aspects collectively provide a holistic representation of a page’s comprehension difficulty and its suitability for the intended search intent.
Unlike conventional readability tools that rely solely on text length or word difficulty, this analyzer evaluates the semantic relationships between words, sentence structures, and contextual depth to produce data-driven scores. Cognitive load is estimated using linguistic and semantic cues that reflect mental effort required during reading. The results are then balanced through a readability–semantic index that determines whether content is overly simplified, optimally balanced, or cognitively demanding.
This project plays a pivotal role in enhancing SEO strategies by aligning content complexity with audience intent. It delivers actionable insights that ensure information is neither overly complex for general audiences nor too simplistic for expert readers. Through this methodology, the project enables data-driven refinement of website content quality, clarity, and engagement potential.
Project Purpose
The purpose of this project is to assess the comprehension complexity of SEO-focused webpage content through an integrated analysis of readability, semantic density, and cognitive load. The goal is to provide a measurable framework demonstrating how text structure, depth of meaning, and linguistic composition influence user understanding and information retention.
In search-driven environments, aligning content complexity with user intent directly impacts engagement, dwell time, and ranking performance. Content that is excessively dense or abstract may overwhelm casual readers, whereas overly simplified content may fail to satisfy informational or expert-level search intent. This project addresses that challenge by offering an analytical system capable of evaluating and interpreting content comprehension with precision, contextual accuracy, and scalability.
The analyzer determines whether a webpage maintains an optimal cognitive balance—where readability optimization and semantic richness reinforce the content’s intended purpose. By quantifying cognitive and linguistic effort, it lays the groundwork for enhancing clarity, accessibility, and user experience. Ultimately, the project guides strategic optimization of page content, ensuring each section communicates effectively to the target audience while remaining aligned with search engine intent models.
Project’s Key Topics Explanation and Understanding
This project integrates several advanced linguistic and semantic analysis concepts to quantify how easily web content can be comprehended by its intended audience. The following key topics provide the foundation for understanding the project’s objectives and operations:
Semantic Readability
Semantic readability extends beyond traditional readability formulas, which primarily rely on sentence length or word complexity. It focuses on the meaningful accessibility of text—how clearly ideas are conveyed, how effectively the narrative structure flows, and how language supports comprehension. In this project, readability is normalized across multiple indices such as Flesch Reading Ease, Flesch-Kincaid Grade, and Automated Readability Index (ARI). A combined readability score is generated, representing a balanced indicator of how easily the content can be understood by an average reader.
Semantic readability ensures that the content does not merely read easily but also preserves contextual richness. In SEO contexts, this balance ensures users can absorb information effortlessly without diluting the topical authority of the content.
Cognitive Load
Cognitive load refers to the mental effort required for a reader to process and comprehend a text. Content with high cognitive load demands significant attention, memory, or analytical thinking, which can reduce reader engagement and understanding.
In this project, cognitive load is calculated as a composite metric incorporating linguistic complexity, semantic density, and syntactic depth. A lower cognitive load indicates that readers can grasp information quickly and effectively, whereas a higher load suggests the need for structural or linguistic simplification. The system provides both a numerical score and an interpretable label, such as Low, Optimal, or High cognitive load.
Comprehension Complexity
Comprehension complexity represents the overall difficulty a reader encounters when understanding a page or subsection. It combines factors such as readability, cognitive load, and semantic structure. Content with moderate comprehension complexity typically performs best, offering sufficient depth without overwhelming the reader.
This project evaluates comprehension complexity at the subsection level, providing granular insights into which parts of the content facilitate or impede understanding.
Semantic Density
Semantic density quantifies the amount of information and conceptual meaning packed into a passage. It measures the “information value” each sentence delivers relative to its length. Sections with high semantic density often include layered concepts, technical terminology, or compact knowledge units.
From an SEO perspective, semantic density helps determine whether a page contributes meaningful topical depth or merely uses surface-level phrasing. By examining this metric, the system distinguishes between content that genuinely enhances topical authority and content that adds minimal cognitive or semantic value.
Readability–Semantic Balance (RSBI)
The Readability–Semantic Balance Index (RSBI) captures the harmony between a section’s readability and its semantic density. Content that is too readable but semantically shallow may lack informational depth, while content that is semantically rich but difficult to read may reduce user engagement. RSBI identifies whether the content achieves a “Well Balanced” state where the semantic load and linguistic clarity complement each other.
This index is one of the project’s most actionable components, offering interpretable feedback on whether content should be simplified, enriched, or structurally reworked for better comprehension and SEO performance.
Intent Understanding and Alignment
User intent—informational, navigational, commercial, or transactional—defines the psychological and functional goal behind a search query. This project integrates zero-shot intent classification using a transformer-based model to understand what the content should aim to fulfill. The identified intent is then aligned with the measured comprehension profile, ensuring the complexity level suits the search intent.
For instance, informational intent aligns best with content that is readable yet semantically deep, while transactional intent benefits from concise and directive communication.
Practical Value in SEO Optimization
Each of these analytical layers—semantic readability, cognitive load, and intent alignment—translates directly into actionable insights for SEO strategists. Understanding where comprehension breaks down enables precise, data-backed rewriting. It supports improved dwell time, engagement, and search performance by ensuring that content complexity is well-matched to reader expectation and intent.
This integrated understanding transforms qualitative aspects of content writing into measurable, interpretable metrics that can be optimized scientifically for both users and search algorithms.
Q&A Section — Understanding Project Value and Importance
What is the primary value of analyzing semantic readability and cognitive load in SEO content?
The primary value lies in quantifying how easily readers can absorb the intended information while maintaining topic depth. Traditional SEO audits often overlook the cognitive side of user experience, focusing mainly on keywords or structure. This project adds a critical dimension by measuring the comprehension effort required by readers. It identifies whether the content complexity aligns with user expectations and search intent, allowing more precise content refinement for better engagement, retention, and satisfaction.
How does this project differ from standard readability testing tools?
Standard readability tools evaluate surface-level metrics such as sentence length or syllable count, offering limited insights into how meaning is conveyed. This project goes beyond that by incorporating semantic understanding, intent alignment, and cognitive processing metrics. It interprets the text contextually, not mechanically, ensuring that recommendations reflect both linguistic clarity and conceptual richness. The result is a more intelligent, SEO-relevant interpretation of readability that supports both algorithmic ranking and human comprehension.
Why is cognitive load analysis important for SEO content optimization?
Cognitive load directly affects how effectively users consume and remember information. When content requires excessive effort to understand, users tend to abandon the page earlier, reducing dwell time and engagement—both key behavioral signals for search ranking. By quantifying cognitive load, this system helps identify sections that cause comprehension friction. Optimizing these sections ensures the content maintains its informational value while becoming more digestible, leading to improved user satisfaction and stronger performance metrics.
How does the project help determine if content complexity matches user intent?
The project integrates an intent classification module that categorizes the expected purpose of content (informational, navigational, commercial, or transactional). The measured comprehension complexity and readability profiles are then compared against the typical complexity levels expected for that intent. For example, informational pages can tolerate moderate complexity due to their depth-oriented purpose, whereas transactional pages demand simplicity and clarity. This alignment ensures that the message delivery style supports the psychological expectation of the audience behind each search query.
What makes the Readability–Semantic Balance Index (RSBI) significant?
RSBI captures the balance between linguistic simplicity and semantic richness—two factors that are often at odds in SEO writing. A high readability score without meaningful semantic content may appear superficial, while overly dense writing can overwhelm readers. RSBI helps strike the right equilibrium, signaling when to simplify language or enrich content for optimal comprehension. This balance is vital for sustaining both engagement and topical authority, which together drive stronger SEO outcomes.
How can SEO professionals benefit from integrating this project into their workflow?
The system provides measurable indicators that guide content adjustments with precision. Rather than relying on subjective assessments of whether content is “too complex” or “too simple,” professionals receive quantifiable feedback on semantic density, cognitive demand, and readability harmony. These insights can be used during both content creation and revision phases, ensuring the writing remains aligned with search intent, brand tone, and user comprehension thresholds.
What specific features of this project make it valuable for strategic content evaluation?
Several integrated features make the project uniquely valuable:
- Semantic comprehension analysis: Understands meaning beyond word-level metrics.
- Cognitive load scoring: Quantifies mental effort in understanding text.
- Readability–semantic balance detection: Identifies harmony between clarity and depth.
- Intent alignment: Ensures the communication style matches reader expectations.
- Section-level analysis: Pinpoints specific content blocks needing revision rather than generalizing across the entire page.
Together, these components create a comprehensive diagnostic system that elevates SEO strategy from keyword-based optimization to cognitive and semantic precision.
Why is this analysis critical in modern SEO environments dominated by AI-driven ranking systems?
Modern search algorithms increasingly prioritize user experience signals—including dwell time, scroll depth, and interaction behavior—which are strongly influenced by how intuitively content communicates. AI-driven ranking systems can now infer content quality based on readability and engagement metrics. By quantifying comprehension complexity and optimizing cognitive alignment, this project aligns content performance with the evolving criteria that search engines use to assess content value, ensuring continued competitiveness in dynamic SEO ecosystems.
Libraries Used
time
The time library is a built-in Python module that provides a range of time-related functions, such as measuring execution duration, introducing delays, or timestamping events. It is commonly used in data processing workflows to monitor runtime performance and manage task scheduling.
Within this project, time is primarily used to record and monitor the execution flow during various analysis stages—such as content extraction, text processing, and model inference. Tracking the execution duration helps evaluate the efficiency of different components and ensures the scalability of the system when handling multiple URLs or large page data.
re
The re module is Python’s regular expression library, used for text pattern matching, searching, and replacement. It is essential for processing and cleaning textual data, allowing for flexible and precise manipulation of string patterns.
re plays a vital role in cleaning web-extracted text. It helps remove redundant HTML tags, unwanted symbols, and excessive whitespace. The library ensures that only meaningful textual elements are processed further, which enhances the accuracy of NLP models and readability calculations by providing well-structured and noise-free text input.
html (as html_lib)
The html library in Python provides tools for escaping, unescaping, and managing HTML entities within text. It helps handle encoded symbols that appear frequently in web content, ensuring proper text representation.
Since the project involves analyzing content extracted from live web pages, HTML entities like or & must be converted to readable characters. The html_lib module ensures the text is standardized before tokenization and readability analysis, preserving the original meaning while removing markup noise.
hashlib
hashlib is a Python library used to create secure hash values from data. It supports various hashing algorithms such as MD5, SHA-1, and SHA-256, typically used for creating unique identifiers or verifying data integrity.
hashlib generates unique identifiers for each processed web page or text block. This helps manage caching or tracking within multi-page analyses and avoids redundant reprocessing of the same content. It also supports logging consistency by allowing quick reference to specific page results.
unicodedata
The unicodedata library provides access to the Unicode character database, allowing normalization and categorization of Unicode strings. It ensures text data remains consistent across different sources and encodings.
Web content often includes mixed encodings and irregular Unicode characters. unicodedata ensures the normalization of text input so that non-standard characters do not disrupt NLP tokenization or readability scoring. This contributes to a stable and reliable processing pipeline for multilingual or symbol-rich content.
gc
The gc (garbage collection) module provides an interface to Python’s automatic memory management system. It helps track and release unused memory, especially useful in memory-intensive processes.
Since this project processes large text blocks and interacts with deep learning models, gc is used to manage memory more efficiently between analysis cycles. Explicit garbage collection prevents memory overflow issues and ensures smoother execution when multiple URLs are analyzed sequentially.
logging
The logging library is a Python standard module for recording runtime messages, errors, and progress details. It enables structured monitoring of program execution without interrupting processing flow.
logging is used extensively for diagnostic tracking—recording when pages are fetched, content is parsed, or models are executed. This helps identify issues, measure performance, and maintain transparency in real-world production usage. The log outputs also assist in debugging and quality assurance during client deployment.
requests
The requests library is a popular HTTP client for Python used to send and receive data from web servers. It simplifies API interactions and webpage retrieval by managing sessions, headers, and response handling.
requests is the core module for fetching webpage HTML content from URLs. It ensures stable and efficient HTTP communication, allowing controlled access to live page data for subsequent parsing and analysis. This functionality forms the first step in the pipeline—content acquisition.
typing
The typing module introduces type hinting capabilities to Python. It allows developers to specify expected data types for variables, functions, and parameters, improving code readability and maintainability.
Type hinting enhances the modularity and clarity of the codebase. It helps define expected input and output structures—such as text lists, dictionaries, and numerical results—making it easier to debug and scale the project. This is crucial for a professional deployment-ready NLP system.
BeautifulSoup (bs4)
BeautifulSoup is a Python library designed for parsing HTML and XML documents. It simplifies webpage content extraction by allowing structured access to tags, text, and metadata.
BeautifulSoup forms the foundation of the content extraction phase. It isolates meaningful page elements—paragraphs, headings, and text sections—while removing navigation or script noise. This ensures that subsequent NLP analyses are based on genuine readable content rather than irrelevant HTML fragments.
numpy
NumPy is a numerical computing library that provides high-performance multidimensional array operations and mathematical functions. It is a standard tool for efficient numerical computation in data science workflows.
NumPy handles the quantitative parts of the analysis such as scoring aggregation, statistical computation, and data normalization. It ensures that operations like average readability, density computation, and cognitive load estimation are computed efficiently across large sets of text data.
nltk (sent_tokenize)
NLTK (Natural Language Toolkit) is one of Python’s foundational NLP libraries, offering tools for text tokenization, tagging, parsing, and semantic analysis.
sent_tokenize is specifically used to segment text into sentences, which enables accurate readability assessment and cognitive analysis at sentence-level granularity. This segmentation forms the base for syntactic complexity evaluation and linguistic feature extraction.
spacy
spaCy is a modern NLP library built for high-performance linguistic analysis, supporting part-of-speech tagging, dependency parsing, named entity recognition, and more.
spaCy is used for semantic and linguistic feature extraction. It enables the system to analyze grammatical structure, word dependencies, and content cohesion, which are key factors in determining cognitive load and semantic density. Its efficiency and accuracy make it suitable for production-level SEO analytics.
statistics
The statistics module provides functions for basic statistical operations like mean, median, and standard deviation. It is part of Python’s standard library and supports descriptive data analysis.
The project uses statistics to compute averaged readability metrics, distribution summaries, and balance indexes. These help quantify overall comprehension complexity and provide interpretable summaries of section-level results in numerical form.
transformers (pipeline)
The transformers library by Hugging Face offers pre-trained transformer models for a range of NLP tasks including classification, translation, and summarization. The pipeline API provides a high-level interface for easily loading and applying these models.
pipeline enables the integration of pre-trained classification models such as facebook/bart-large-mnli for intent classification. This allows the system to automatically determine the likely intent behind a content piece or query, a critical feature in aligning cognitive complexity with user purpose.
sentence_transformers (SentenceTransformer, util)
The sentence-transformers library builds upon the transformers framework, optimized for generating semantically meaningful sentence embeddings. It supports models like MiniLM, MPNet, and others tailored for semantic similarity tasks.
SentenceTransformer and its util module are employed for semantic similarity computations between queries and content sections. These embeddings help assess semantic density and contextual alignment, providing deep insights into how conceptually coherent and relevant each section is to search intents.
torch
PyTorch is an open-source machine learning framework widely used for deep learning model training and inference. It provides tensor computation capabilities and GPU acceleration for efficient model execution.
PyTorch serves as the backend for transformer and sentence-transformer models. It ensures computational efficiency during inference, enabling the project to handle multiple sections and large texts smoothly. This enhances scalability and reduces processing latency in real-world applications.
transformers.utils.logging (tf_logging)
This submodule controls logging verbosity within the Hugging Face Transformers library. It allows developers to suppress unnecessary model initialization messages during runtime.
tf_logging is configured to disable progress bars and reduce model loading logs for a cleaner and more professional execution output. This ensures that the analysis pipeline runs quietly and focuses on meaningful log messages relevant to content processing.
pandas
Pandas is a powerful Python library for data manipulation and analysis, offering flexible data structures like DataFrames for organizing and processing tabular data efficiently.
Although the project is not primarily tabular, pandas is used in visualization preparation to organize readability, density, and load scores into structured form before plotting. It helps simplify data management, enabling smooth integration between computation and presentation layers.
matplotlib.pyplot
Matplotlib is a widely used library for creating static, interactive, and publication-quality visualizations in Python. The pyplot interface provides MATLAB-like simplicity for chart generation.
matplotlib.pyplot generates key analytical visualizations of the results—such as comprehension score distributions, semantic balance variations, and content complexity profiles. These visuals transform numerical outcomes into easily interpretable insights for decision-making.
seaborn
Seaborn is a data visualization library built on top of Matplotlib, offering a high-level interface for creating aesthetically refined and statistically informative graphics.
Seaborn enhances the visual quality of charts by providing clear, publication-ready styles such as whitegrid. It is used to plot cognitive load comparisons, readability balance, and density distributions, ensuring that insights are presented clearly, visually appealingly, and ready for inclusion in client reports.
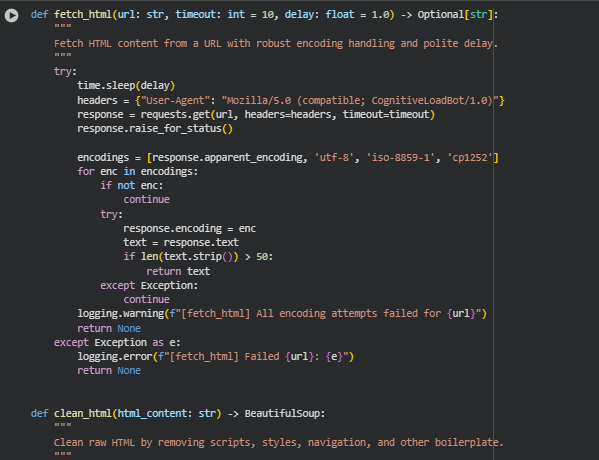
Function: fetch_html
Overview
The fetch_html function retrieves the raw HTML content from a given webpage URL with built-in safeguards for encoding errors, connection issues, and rate-limiting delays. It represents the first step in the project’s data pipeline, ensuring the content is properly fetched before any textual analysis begins. The function uses custom request headers to mimic a browser agent, waits politely between requests to avoid overwhelming servers, and attempts multiple encoding strategies to decode the page successfully. This design enhances reliability and compatibility with a wide variety of web content sources.
Key Code Explanations
headers = {“User-Agent”: “Mozilla/5.0 (compatible; CognitiveLoadBot/1.0)”}
response = requests.get(url, headers=headers, timeout=timeout)
- These lines send an HTTP GET request to the target URL with a customized “User-Agent” header. The bot identity prevents blocks from websites that restrict unknown crawlers and helps maintain ethical scraping standards. The timeout ensures that requests do not hang indefinitely on unresponsive pages.
encodings = [response.apparent_encoding, ‘utf-8’, ‘iso-8859-1’, ‘cp1252’]
- Webpages use diverse encoding formats, and sometimes servers misreport them. This line defines multiple fallback encodings, enabling resilient text decoding and minimizing the risk of unreadable content.
if len(text.strip()) > 50:
return text
- This condition filters out incomplete or empty responses, ensuring that only meaningful HTML bodies proceed to the next extraction phase.
Function: clean_html
Overview
The clean_html function removes unnecessary HTML components that are not relevant to the main textual content of the page. It uses BeautifulSoup to parse and clean the document structure. Elements like scripts, styles, navigation menus, forms, and headers are removed to eliminate visual or structural clutter, isolating the informative text portions suitable for analysis.
Function: clean_inline_text
Overview
The clean_inline_text function performs inline-level text normalization by decoding HTML entities, normalizing Unicode characters, and removing excessive spaces. It ensures text is human-readable, standardized, and consistent across multiple webpages, making it suitable for tokenization, readability scoring, and NLP-based semantic evaluations.
Function: extract_structured_blocks
Overview
This function structures the cleaned page text into a clear hierarchy: section → subsection → block. It assigns heading-based contextual boundaries to content blocks, allowing analytical mapping between text structure and meaning. Each content unit carries metadata, including its type, heading chain, and minimum character thresholds to ensure only substantive text is included in analysis. This function is essential for building a semantically meaningful representation of the page — enabling the system to relate readability, density, and cognitive load to specific hierarchical sections.
Key Code Explanations
for el in soup.find_all([“h1”, “h2”, “h3”, “h4”, “p”, “li”, “blockquote”]):
- This loop scans the HTML for key structural elements. Headings define hierarchy levels (sections/subsections), while paragraphs, list items, and blockquotes serve as primary text blocks. This selection ensures coverage of both narrative and structured text patterns across web pages.
if tag in [“h1”, “h2”]:
section = {“section_title”: text, “subsections”: []}
- These lines initialize a new section whenever a top-level heading (H1 or H2) is encountered, treating it as a primary division of the webpage. Subsequent subsections and content blocks are nested within it.
if len(text) >= min_block_chars:
subsection[“blocks”].append({…})
- A minimum character threshold ensures that only meaningful content blocks are included in the analysis. This eliminates filler or decorative text, focusing only on substantive written material that contributes to readability and comprehension assessment.
Function: extract_page_content
Overview
The extract_page_content function acts as a wrapper that combines all content extraction processes—from fetching HTML to parsing and structuring the text. It returns a fully organized content hierarchy ready for readability, cognitive load, and intent analysis. The function validates page accessibility, processes HTML through the cleaning pipeline, retrieves the title, and constructs the content hierarchy. The structured output forms the foundation for every subsequent analysis in the project.
Key Code Explanations
html_content = fetch_html(url, timeout, delay)
- This line initiates the content retrieval by calling the fetch_html function. It centralizes HTTP fetching logic while maintaining consistent delay and timeout configurations, improving modularity and reusability.
soup = clean_html(html_content)
- Once HTML is retrieved, it is passed to the clean_html function for script and noise removal. The cleaned output ensures that all downstream text processing operates on meaningful, content-focused data.
if soup.title and soup.title.string:
title = html_lib.unescape(soup.title.string)
- The function extracts the page title directly from the HTML <title> tag, decoding HTML entities for readability. The title helps identify the analyzed page in the output and visualizations.
sections = extract_structured_blocks(soup, min_block_chars)
- This call generates the hierarchical representation of the page’s content. It ensures that the output includes well-defined sections and subsections, enabling later phases to evaluate readability, semantic density, and cognitive load at different structural depths.
These five foundational functions form the content acquisition and preparation layer of the pipeline. They transform raw, messy web data into a clean, structured, and analyzable format—creating a robust starting point for linguistic and cognitive analysis in SEO-focused content evaluation.
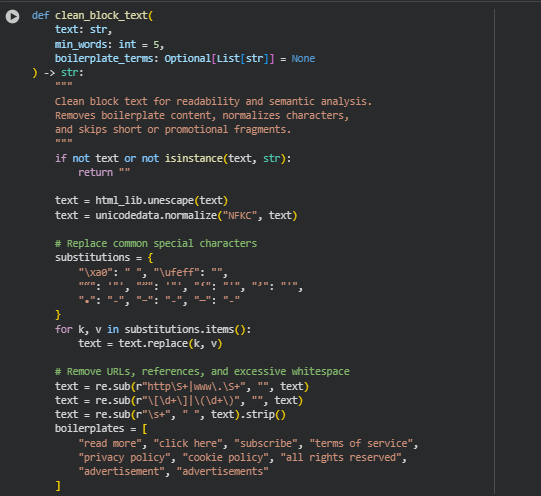
Function: clean_block_text
Overview
The clean_block_text function ensures that each text block extracted from a webpage is suitable for readability and semantic analysis. It eliminates unnecessary elements such as boilerplate phrases, promotional fragments, and special symbols, resulting in text that is linguistically clean and consistent. This step is crucial for preparing the data before deeper NLP processing like readability scoring, embedding generation, or comprehension-level evaluation.
It handles HTML entity decoding, normalization of Unicode characters, removal of special characters and URLs, and discards short or irrelevant fragments. The function ensures that only meaningful and well-structured text blocks proceed to later stages of the pipeline, improving both efficiency and accuracy in downstream tasks.
Key Code Explanations
substitutions = {“\xa0″: ” “, “\ufeff”: “”, ““”: ‘”‘, “””: ‘”‘, “‘”: “‘”, “’”: “‘”, “•”: “-“, “–”: “-“, “—”: “-“}
- This dictionary defines a mapping for replacing problematic characters commonly found in scraped web text. It converts various types of quotes and dashes to standardized ASCII equivalents, ensuring normalization across all text. This improves compatibility with NLP models that can misinterpret typographically styled symbols.
if any(bp in lower_text for bp in boilerplates):
return “”
- This line checks for any boilerplate or promotional phrases such as “read more” or “privacy policy.” If found, the function discards the text block entirely. It ensures that only meaningful and contextually relevant content contributes to further analysis.
Function: chunk_text
Overview
The chunk_text function splits large sections of cleaned text into smaller, manageable chunks based on sentence boundaries. It maintains readability and ensures that each chunk remains within a consistent word limit, enabling efficient and memory-safe processing by NLP models. The use of overlapping segments helps preserve contextual continuity across adjacent chunks, preventing semantic drift.
This function plays a critical role in balancing granularity and context — ensuring that every piece of text is large enough for meaningful analysis but not too long to exceed model input constraints.
Key Code Explanations
sentences = re.split(r'(?<=[.!?])\s+’, text)
- This regular expression splits text into sentences by detecting punctuation marks followed by spaces. It respects sentence boundaries, allowing each chunk to represent natural linguistic units rather than arbitrary cuts.
if word_count + len(words) > max_words:
…
if overlap:
current_chunk = current_chunk[-overlap:] + words
- This section ensures that each text chunk remains within the maximum word limit (max_words) while maintaining continuity. The overlap parameter retains a small portion of the previous chunk, helping preserve context between consecutive text segments.
Function: preprocess_page
Overview
The preprocess_page function orchestrates the entire preprocessing workflow for a webpage. It integrates multiple cleaning and structuring operations — from filtering and normalizing block-level text to chunking it into semantically consistent subsections. The function also handles metadata assignment and optional block-level inclusion, making the output suitable for readability evaluation or cognitive complexity scoring.
By merging cleaned text blocks under respective section and subsection titles, the function ensures the preservation of structural hierarchy. This design allows semantic models to relate readability or comprehension characteristics to specific content areas of a webpage, leading to more interpretable and actionable insights.
Key Code Explanations
cleaned_text = clean_block_text(block.get(“text”, “”), min_word_count, boilerplate_extra)
- Each text block undergoes cleaning using the clean_block_text function. This step filters out unnecessary or low-quality text early, ensuring that subsequent stages only process linguistically meaningful data.
subsection_id = hashlib.md5(f”{url}_{section_title}_{subsection_title}_{idx}”.encode()).hexdigest()
- This generates a unique, deterministic identifier for every cleaned subsection using an MD5 hash. It combines multiple structural attributes (URL, section, subsection, index) to maintain traceability and prevent duplication in the processed output.
if include_blocks:
subsection_entry[“blocks”] = valid_blocks
- When include_blocks is set to True, the function attaches detailed block-level metadata alongside merged subsection text. This option allows downstream analysis to trace cognitive or semantic patterns back to individual content units for explainability and fine-grained insights.
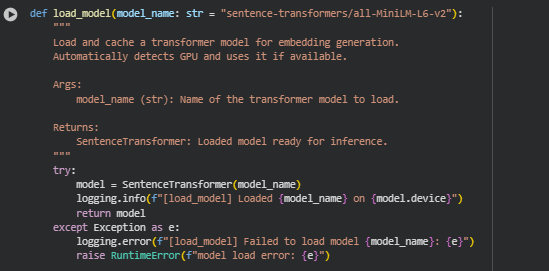
Function: load_model
Overview
The load_model function initializes and loads a pre-trained transformer model from the Sentence Transformers library, primarily used for generating semantic embeddings of text. These embeddings form the backbone of the project’s cognitive and readability analysis — allowing semantic similarity, contextual understanding, and complexity estimation of content blocks.
The function ensures flexibility by accepting a model name as input, enabling different transformer architectures to be loaded without altering the core pipeline. It also supports automatic GPU utilization if available, accelerating computation for large-scale web content processing. Robust error handling ensures that model initialization issues are logged and raised in a controlled manner.
Key Code Explanations
model = SentenceTransformer(model_name)
- This line initializes the specified transformer model from the Sentence Transformers library. It automatically downloads the model if not cached locally, setting it up for generating high-dimensional vector embeddings. These embeddings are crucial for analyzing the semantic density and conceptual relationships within the webpage content.
Model Overview — sentence-transformers/all-mpnet-base-v2
The project employs the sentence-transformers/all-mpnet-base-v2 model as the core engine for understanding semantic intent and contextual relationships across webpage content and queries. This model is part of the Sentence Transformers framework, which is specifically designed to generate high-quality sentence and paragraph embeddings that capture deep semantic meaning beyond keyword matching. The embeddings produced by this model enable precise evaluation of how well each content section aligns with user intent, readability balance, and cognitive load expectations.
Model Architecture and Design
The model is based on Microsoft’s MPNet architecture, an evolution of transformer-based models like BERT and RoBERTa. MPNet integrates both masked language modeling and permutation language modeling, allowing it to capture richer contextual dependencies within a sentence. This hybrid mechanism ensures that word order and contextual flow are both preserved, resulting in embeddings that represent meaning rather than mere word frequency. It uses a 12-layer transformer network with 768-dimensional embeddings, optimized for semantic similarity tasks such as intent detection, clustering, and cross-sentence alignment.
Semantic Understanding and Representation Power
Unlike traditional models that rely on surface-level patterns or syntactic cues, all-mpnet-base-v2 is trained on a vast corpus of multilingual and domain-diverse text. This enables it to capture nuanced relationships between technical terms, SEO terminology, and contextual meanings found in web content. In this project, this capability allows for accurate recognition of whether a section is informational, navigational, or transactional—helping distinguish the real communicative purpose behind the text. It also improves the consistency of intent alignment scoring across varied topics, from SEO tools to technical web protocols like HTTP headers.
Application in the Project
Within this implementation, the model is used to generate contextual embeddings for both queries and webpage sections. These embeddings are compared through cosine similarity to measure intent alignment, providing a quantifiable way to see how closely each section of a page matches user search intent. The model also assists in classifying dominant intents and predicting intent probabilities across queries, giving a confidence-based perspective on how strongly content serves its informational goal. This dual use—both as a classifier and similarity engine—enables comprehensive interpretability and content–query alignment insights.
Strengths for SEO-Focused Applications
The all-mpnet-base-v2 model is particularly well-suited for SEO analysis due to its ability to interpret content beyond keyword density. It allows differentiation between sections that merely mention relevant terms and those that contextually address search intent. This semantic precision is crucial for identifying sections that deliver true informational value to users, improving both user experience and potential ranking outcomes. By leveraging such embeddings, the analysis identifies gaps between the intended audience query and actual page delivery, leading to actionable recommendations for optimizing content structure and language complexity.
Model Interpretability and Reliability
One of the significant advantages of this model is its interpretability in semantic evaluation. Its embeddings are robust and consistent across domains, minimizing the risk of biased or erratic predictions. Additionally, its training on millions of sentence pairs enables generalization across different content types—from technical documentation to blog-style educational material. This makes it a dependable choice for handling diverse web pages in large-scale SEO evaluations.
Overall, all-mpnet-base-v2 ensures that this project’s results are built upon a deep semantic foundation, translating complex content–intent relationships into interpretable and actionable insights that guide content improvement and optimization efforts effectively.
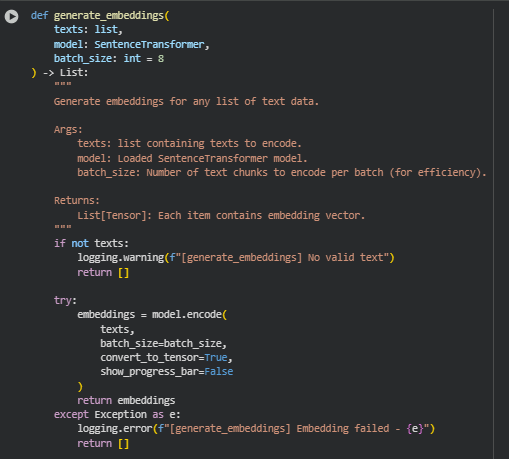
Function: generate_embeddings
Overview
The generate_embeddings function is responsible for converting textual data into high-dimensional semantic vector representations using a preloaded SentenceTransformer model. These embeddings capture the contextual meaning of text segments, which allows for measuring semantic similarity, cognitive complexity, and readability patterns across different content blocks on a webpage.
The function operates efficiently by batching the encoding process, ensuring smooth and memory-safe computation when handling long documents or multiple subsections. It also integrates robust error handling and logging mechanisms to ensure that failures in embedding generation are traceable and do not interrupt the overall pipeline execution.
Key Code Explanations
embeddings = model.encode(
texts,
batch_size=batch_size,
convert_to_tensor=True,
show_progress_bar=False
)
· This line performs the core operation of the function. The SentenceTransformer model encodes a batch of input texts into dense vector representations (embeddings).
- batch_size controls how many text units are processed together, optimizing memory and speed balance.
- convert_to_tensor=True ensures the output embeddings are stored as PyTorch tensors, allowing efficient computation for similarity or clustering tasks.
- show_progress_bar=False disables console progress output, keeping logs cleaner for production execution.

Function: generate_section_embeddings
Overview
The generate_section_embeddings function is designed to embed the cleaned and preprocessed textual subsections of a webpage. After the text has been cleaned and structured in earlier stages, this function applies the embedding model (loaded earlier using load_model) to every subsection’s merged text to obtain a numerical representation of its semantic meaning.
Each subsection’s embedding allows for deeper downstream analysis such as semantic readability scoring, cognitive load estimation, and intent alignment evaluation. By embedding each subsection individually, the project ensures that content-level insights can be derived at fine granularity—allowing targeted SEO optimization actions rather than general, page-level ones.
The function also employs efficient batch processing and safeguards against missing data, ensuring robustness across pages with inconsistent or sparse content.
Key Code Explanations
texts = [s[“merged_text”] for s in subsections if s.get(“merged_text”)]
- This line extracts all valid subsection texts from the preprocessed page. Only subsections containing non-empty text are considered, ensuring that the embedding model only processes meaningful content. It helps maintain efficiency and avoids wasting computational resources on blank or invalid subsections.
embeddings = generate_embeddings(texts, model, batch_size)
- Here, the function calls generate_embeddings to convert the list of cleaned subsection texts into dense numerical embeddings. The batch_size parameter ensures the model processes data efficiently in controlled batches, which is especially useful for longer webpages with many subsections.
for s, emb in zip(subsections, embeddings):
s[“embedding”] = emb
- This loop attaches the computed embedding vector directly to each subsection dictionary. Each subsection now contains both its textual and vector representation, enabling semantic-level analysis for subsequent computations (like cognitive complexity or readability comparisons).
Function: split_sentences
Overview
This function segments a given block of text into individual sentences using a regular expression-based approach. It detects punctuation boundaries (such as ., !, or ?) and splits the text accordingly. This segmentation is crucial for later readability computations, where sentence length and structure are used to estimate cognitive effort.
Key Code Explanations
return [s.strip() for s in _SENTENCE_SPLIT_REGEX.split(text) if s.strip()]
- This line ensures that each split sentence is stripped of whitespace and empty strings are removed, producing a clean list of valid sentences for downstream processing.
Function: extract_words
Overview
The extract_words function identifies and extracts all alphanumeric word tokens within a text. It uses a compiled regular expression to ensure consistent tokenization that supports readability calculations, word frequency measures, and syllable-based estimations.
Key Code Explanations
return _WORD_REGEX.findall(text)
- This directly applies the _WORD_REGEX pattern to the input text to return a list of all matching tokens composed of alphabetic or numeric characters, including apostrophes for contractions (e.g., “don’t”).
Function: syllable_count_word
Overview
This function estimates the number of syllables in a single word using a heuristic approach—counting vowel groups and adjusting for English pronunciation rules such as silent ‘e’ endings and “consonant + le” combinations. It’s not a linguistically perfect syllable detector, but for SEO text analysis, it provides a highly practical approximation of cognitive load and readability factors such as the Flesch Reading Ease or Gunning Fog Index.
Key Code Explanations
groups = re.findall(r”[aeiouy]+”, w)
count = len(groups)
- Counts the number of contiguous vowel sequences in a word. Each vowel group is assumed to represent one syllable, forming the core heuristic for syllable detection.
if w.endswith(“e”) and not w.endswith((“le”, “ue”)) and count > 1:
count -= 1
- Adjusts for silent ‘e’ endings (e.g., “make”, “bake”), ensuring the syllable count more closely matches natural English pronunciation.
Function: syllable_count_text
Overview
This function applies the syllable_count_word logic to every tokenized word in a list and sums their individual syllable counts. It serves as the final step before readability computation, providing total syllables for a text block or subsection—one of the main linguistic indicators of comprehension complexity.
Utility Functions for Text and Syllable Processing
These functions collectively handle the sentence segmentation, word extraction, and syllable estimation that form the linguistic backbone for computing readability and cognitive load metrics. They provide structured linguistic preprocessing without relying on heavy NLP pipelines, making them lightweight yet accurate for large-scale webpage processing.
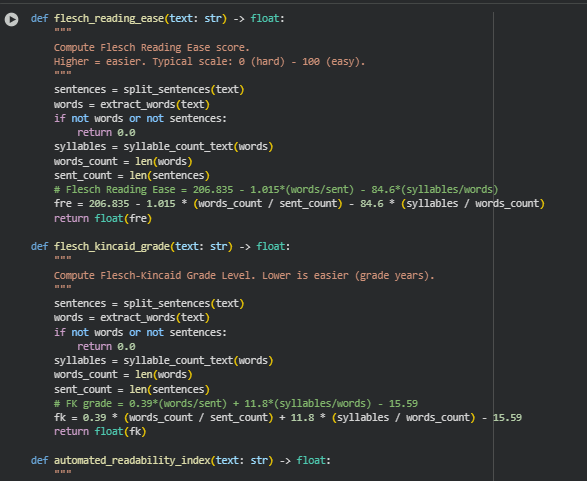

Function: flesch_reading_ease
Overview
This function calculates the Flesch Reading Ease (FRE) score, one of the most established readability metrics used to measure how easy a text is to understand. A higher FRE score indicates easier readability. The formula accounts for average sentence length and average syllables per word, both of which directly influence cognitive processing difficulty.
Key Code Explanations
fre = 206.835 – 1.015 * (words_count / sent_count) – 84.6 * (syllables / words_count)
- This formula applies the Flesch equation, balancing sentence complexity (longer sentences lower readability) and word complexity (more syllables per word reduce readability).
Function: flesch_kincaid_grade
Overview
The Flesch–Kincaid Grade Level (FKGL) metric translates text complexity into a U.S. grade-level equivalent. It estimates how many years of education are required to understand the content. Unlike FRE, a lower FKGL value means the text is easier to comprehend.
Key Code Explanations
fk = 0.39 * (words_count / sent_count) + 11.8 * (syllables / words_count) – 15.59
- This formula mathematically adjusts for sentence length and word complexity to output a grade-level score that aligns with educational comprehension standards.
Function: automated_readability_index
Overview
The Automated Readability Index (ARI) uses character count rather than syllables to assess text difficulty. It’s particularly useful for content that may include numerical or technical terms, where syllable-based methods can misjudge complexity.
Key Code Explanations
ari = 4.71 * (chars / words_count) + 0.5 * (words_count / sent_count) – 21.43
- Here, longer words (more characters per word) and longer sentences both increase the ARI score, implying greater reading difficulty.
Function: clamp
Overview
This simple utility function ensures that any numeric value stays within a defined range. It’s particularly useful for keeping normalized readability scores bounded between 0 and 1, preventing distortion from extreme values.
Function: normalize_flesch
Overview
The Flesch Reading Ease score ranges roughly between 0 and 100. This function rescales it to a 0–1 range for uniform interpretation across different readability metrics, where 1 indicates easiest readability.
Function: normalize_grade
Overview
Since grade-level scores (like FKGL or ARI) increase with text difficulty, this normalization inverts the scale—lower grades become higher normalized values. It ensures interpretive consistency where higher normalized values always indicate easier readability.
Function: compute_readability_scores
Overview
This function consolidates all three readability indices (FRE, FKGL, ARI), normalizes them to a common scale, and combines them into a single composite readability score. This weighted aggregation (50% Flesch, 35% FKGL, 15% ARI) ensures that sentence and word complexity remain dominant factors while still accounting for structural variations in text.
Key Code Explanations
combined = (0.5 * fre_n) + (0.35 * fk_n) + (0.15 * ari_n)
- This weighted combination produces a more stable readability representation across diverse writing styles by emphasizing balanced linguistic difficulty.
Function: compute_readability_for_page
Overview
This function applies the compute_readability_scores function to every subsection in a webpage’s processed content. It produces readability metrics for each subsection, helping measure section-wise comprehension difficulty, which allows identifying overly complex parts of SEO content.
Key Code Explanations
out[‘readability’] = scores
- This line attaches computed readability metrics directly to each subsection, preserving hierarchical structure while enriching it with interpretive linguistic data.

Function: compute_intra_section_semantic_density
Overview
The compute_intra_section_semantic_density function calculates how semantically dense or conceptually varied each subsection of a webpage is. This measure reflects how much conceptual diversity exists within a subsection’s text. A higher semantic density indicates that the section covers multiple ideas or complex relationships, which can increase cognitive load for readers.
The process involves breaking the subsection text into sentences, generating embeddings for each sentence using a transformer model, and then comparing how similar each sentence is to the average meaning (centroid) of the entire section. If the sentences are very similar, the density will be lower (indicating focused content). If they are very different, the density will be higher (indicating conceptual spread).
This function is central to understanding intra-section semantic variation, which helps assess how much mental effort a reader might need to process the information in that section.
Key Code Explanations
sentences = split_sentences(text)
- This line splits the text of a subsection into individual sentences using a predefined sentence-splitting regex. Each sentence will later be embedded separately to analyze internal semantic relationships.
sent_embs = generate_embeddings(sentences, model, batch_size=batch_size)
- Here, sentence-level embeddings are generated using the preloaded transformer model. These embeddings numerically represent the meaning of each sentence in vector form. Generating embeddings at the sentence level allows fine-grained semantic comparison within the subsection.
centroid = torch.mean(sent_embs, dim=0, keepdim=True)
- This computes the semantic centroid—the average vector representation of all sentences in the subsection. It serves as a reference point to determine how semantically close or far each individual sentence is from the overall meaning of the section.
sims = util.cos_sim(sent_embs, centroid).squeeze(dim=1)
- Cosine similarity is computed between each sentence embedding and the centroid. The result shows how similar each sentence is to the overall section meaning. A value close to 1 means the sentence is conceptually aligned with the section’s central theme; a lower value indicates divergence.
density = float(1.0 – torch.mean(sims).item())
- Semantic density is derived by taking 1 minus the average similarity. If most sentences are similar (high cosine similarity), the mean similarity is high, and the resulting density is low—indicating focused and consistent content. Conversely, if the section includes many diverse or unrelated ideas, the mean similarity drops, and density increases, signaling higher cognitive complexity.
This function ensures every subsection receives a numerical semantic density value ranging between 0 and 1, where values closer to 1 represent higher diversity and cognitive load, and values closer to 0 represent clearer, more thematically consistent writing.

Function: compute_syntactic_complexity
Overview
The compute_syntactic_complexity function measures how complex the grammatical structures are within a subsection’s text. It uses natural language parsing (via SpaCy) to extract sentence structures and dependency relationships. The goal is to assess how syntactically demanding the text is for readers — an important aspect of cognitive load analysis.
It calculates four main metrics:
- Average Sentence Length: Reflects sentence verbosity; longer sentences generally increase reading difficulty.
- Average Tree Depth: Represents the hierarchical depth of grammatical dependency trees; deeper trees indicate complex syntactic structures.
- Clause Density: Estimates how many subordinate or dependent clauses appear per sentence, indicating grammatical complexity.
- Subordinate Clause Ratio: Measures the frequency of subordinate markers (like “although”, “because”) relative to clauses, showing how much subordination is used in writing.
This function uses a dependency-based syntactic approach rather than simple text statistics, providing a linguistically accurate representation of structural complexity.
Key Code Explanations
doc = nlp(text)
- The text is processed by SpaCy’s NLP model to create a parsed doc object. This object contains tokenized words, part-of-speech tags, and syntactic dependencies, which are essential for analyzing grammatical structure.
CLAUSE_DEPS = {“ccomp”, “xcomp”, “advcl”, “relcl”, “acl”, “csubj”, “csubjpass”}
SUBORD_MARKERS = {“mark”}
- Here, clause-related dependency labels and subordinate markers are defined. These are linguistic tags used by SpaCy to identify specific grammatical roles that indicate clause boundaries and subordination within sentences.
def get_depth(token):
…
- This helper function calculates the depth of a dependency tree, starting from the root of each sentence. Depth represents how many grammatical layers exist — for example, how many nested phrases or clauses depend on each other. A higher depth value signals more complex sentence structure.
clauses = [tok for tok in sent if tok.dep_ in CLAUSE_DEPS]
subords = [tok for tok in sent if tok.dep_ in SUBORD_MARKERS]
- These lines identify clause-like dependencies and subordinate markers within each sentence. This helps approximate how many independent and dependent clause structures exist, contributing to syntactic density and subordination metrics.
avg_sentence_len = safe_mean(sentence_lengths)
avg_tree_depth = safe_mean(tree_depths)
avg_clause_density = safe_mean(clause_counts)
subordinate_ratio = (safe_mean(subordinate_counts) / avg_clause_density) if avg_clause_density > 0 else 0.0
- Here, mean values are computed across all sentences for each syntactic metric. The subordinate clause ratio is carefully handled to avoid division errors, showing how much of the text relies on subordinate constructions.
This function finally attaches all calculated metrics to each subsection under the “syntactic_complexity” key, enabling downstream modules to analyze linguistic difficulty at both subsection and full-page levels.
Function: compute_syntactic_complexity_for_page
Overview
This function applies the compute_syntactic_complexity computation to every subsection of a webpage. It acts as a wrapper, iterating through all sections and aggregating results at the page level.
If any subsection encounters an error (e.g., parsing issue), the function gracefully handles it by assigning default zeroed metrics instead of interrupting the entire computation.
This ensures robust page-level syntactic evaluation, even when certain subsections contain incomplete or unprocessable text.

Function: normalize_syntactic_metrics
Overview
The normalize_syntactic_metrics function standardizes various syntactic complexity measures into a uniform 0–1 scale. This normalization ensures that metrics with different natural ranges (such as sentence length and clause ratio) can be meaningfully compared and combined.
This step is essential before integrating syntactic complexity into the broader Cognitive Load Score, as it avoids one metric (e.g., sentence length) dominating others simply because of scale differences.
Each syntactic feature—average sentence length, tree depth, clause density, and subordinate clause ratio—is scaled based on empirical ranges observed in real-world web content. The final output is a single mean syntactic complexity score between 0 and 1, where higher values represent greater structural complexity.
Key Code Explanations
norm = (v – min_v) / (max_v – min_v)
norm = np.clip(norm, 0, 1)
Explanation: Each metric value is normalized between its defined minimum and maximum range using the min–max formula. The result is then clipped to ensure it stays within the 0–1 interval. This ensures stable results even when text data falls outside expected bounds.
return float(np.mean(norm_values))
Explanation: The normalized scores of all syntactic metrics are averaged to obtain a single interpretable score. This composite metric captures the subsection’s overall grammatical complexity in a balanced way.
Function: compute_cognitive_load
Overview
The compute_cognitive_load function calculates the Cognitive Load Score (CLS) — a key metric of this project. It integrates three major cognitive contributors:
- Semantic Density: Reflects information variety and conceptual spread.
- Syntactic Complexity: Captures grammatical and structural difficulty.
- Readability: Indicates surface-level text ease based on traditional readability indices.
Each component is assigned a weight (semantic=0.4, syntactic=0.35, readability=0.25) to emphasize the higher impact of semantic richness on comprehension effort.
The function outputs both a quantitative score (0–1) and a qualitative label—Low, Optimal, or High—based on the cognitive intensity of the subsection.
Key Code Explanations
cls = (
weights[“semantic”] * semantic_component +
weights[“syntactic”] * syntactic_component +
weights[“readability”] * readability_component
)
Explanation: The weighted sum combines each normalized dimension into one unified cognitive load score. This enables multi-dimensional evaluation of comprehension complexity rather than relying on a single linguistic metric.
if cls <= 0.35:
level = “Low”
elif cls <= 0.65:
level = “Optimal”
else:
level = “High”
Explanation: A qualitative interpretation is derived from the numeric score, providing actionable categorization.
- Low: Content is overly simple; may lack depth.
- Optimal: Balanced complexity; ideal for engagement and comprehension.
- High: Too cognitively dense; may overwhelm readers.
This classification helps in guiding optimization decisions directly from model outputs.
Function: compute_cognitive_load_for_page
Overview
This function applies the cognitive load computation to every subsection within a webpage. It ensures that each section of content receives its own independent cognitive analysis, making it possible to identify localized complexity hotspots across the page.
By appending a cognitive_load field to each subsection, the function produces a structured, interpretable output that downstream visualization modules can use to display cognitive difficulty distribution across the webpage.
This page-level aggregation supports targeted SEO and UX improvements, such as simplifying high-load sections or enriching overly simple ones for optimal engagement balance.

Function: compute_readability_semantic_balance
Overview
The compute_readability_semantic_balance function calculates the Readability–Semantic Balance Index (RSBI) for a specific content subsection. This index measures how well the readability level of a section aligns with its semantic density (conceptual richness). A balanced content segment ensures that complex ideas are communicated clearly—neither oversimplified nor excessively dense.
The function uses a weighted difference approach between the two scores and transforms it into a normalized balance score. Based on predefined thresholds, the function assigns an interpretation label such as “Imbalanced,” “Moderate Balance,” or “Well Balanced.”
This helps evaluate if a section’s writing complexity suits the cognitive load expectations of the target audience and search intent.
Key Code Explanations
weighted_diff = abs(
weights[“readability”] * readability –
weights[“semantic”] * semantic_density
)
rsbi_score = float(np.clip(1 – weighted_diff, 0, 1))
· This part of the code performs the core RSBI computation. It calculates the absolute difference between the weighted readability and semantic density values.
- The closer these two values are, the smaller the weighted_diff, meaning the section maintains a harmonious balance between clarity and conceptual depth.
- The formula 1 – weighted_diff converts this deviation into a similarity measure — higher values indicate stronger balance.
- Finally, np.clip() ensures the score remains within a valid range between 0 and 1.
if rsbi_score < thresholds[“low”]:
level = “Imbalanced”
elif rsbi_score < thresholds[“mid”]:
level = “Moderate Balance”
else:
level = “Well Balanced”
· This section maps the numeric RSBI score to qualitative interpretation levels:
- Imbalanced: The section’s readability and semantic complexity differ significantly.
- Moderate Balance: Some deviation exists, but it’s acceptable for general audiences.
- Well Balanced: Readability and semantic richness are well aligned for optimal comprehension.
Function: compute_rsbi_for_page
Overview
The compute_rsbi_for_page function applies the RSBI computation across all subsections of a processed webpage. It uses the compute_readability_semantic_balance function iteratively, attaching a new field readability_semantic_balance to each subsection.
The resulting output is a structured dictionary containing:
- The page’s URL and title.
- Each subsection’s content metrics along with its computed RSBI results.
This function ensures a full-page diagnostic view of how readability and semantic depth are distributed across different content blocks. It is particularly useful for identifying uneven sections that may require simplification or enrichment to achieve optimal comprehension alignment.
Function: load_intent_classifier
Overview
The load_intent_classifier function is designed to initialize and return a Hugging Face zero-shot classification pipeline using a Natural Language Inference (NLI) model such as facebook/bart-large-mnli. This function enables intent classification without requiring any fine-tuned training data — instead, it leverages pre-trained language understanding to evaluate how strongly a piece of text aligns with a given set of candidate intents or labels.
The classifier works by determining whether the given text “entails” each possible label, which is ideal for SEO tasks like identifying content intent categories (informational, navigational, transactional) based purely on text semantics.
If a GPU is available, it automatically selects it for faster inference; otherwise, it defaults to CPU execution. The function ensures the classifier loads correctly and logs any issues encountered.
Key Code Explanations
Code:
device = device or “cuda” if torch.cuda.is_available() else “cpu”
- This line automatically selects the most suitable processing device.
classifier = pipeline(
task=”zero-shot-classification”,
model=model_name,
device=device
)
· This initializes the transformers pipeline for zero-shot classification.
- The task parameter specifies that the model will perform zero-shot classification.
- The model_name (default: “facebook/bart-large-mnli”) identifies which pretrained model to use.
- The device parameter defines whether computations occur on GPU or CPU.
The returned pipeline allows direct application of intent recognition on textual content without additional training or tuning.
Model Overview — facebook/bart-large-mnli
The project also utilizes the facebook/bart-large-mnli model, which plays a key role in intent classification, textual inference, and semantic alignment validation. This model operates as a natural language inference (NLI) framework, allowing the system to determine the logical relationship between two text inputs—whether one implies, contradicts, or is neutral to the other. Within the project, this capability is applied to validate whether each webpage section supports the inferred intent from user queries, thereby ensuring a deeper, reasoning-based understanding of content relevance.
Model Architecture and Functional Design
facebook/bart-large-mnli is built on Facebook AI’s BART architecture, which combines a bidirectional encoder (similar to BERT) and an autoregressive decoder (similar to GPT). This hybrid structure gives the model strong text understanding and text generation capabilities. It is pre-trained using a denoising autoencoder approach—learning to reconstruct corrupted input text—which enhances its ability to interpret context even when phrasing or structure differs between related sentences. The model contains 12 encoder and 12 decoder layers with a hidden size of 1024, making it a large and powerful transformer capable of understanding complex semantic relationships.
Natural Language Inference for Intent Validation
In the context of this project, the model’s natural language inference abilities are used to verify whether a webpage section entails a given query intent. For instance, when the query is “How to handle different document URLs,” and a content section discusses HTTP headers for managing document accessibility, the model identifies an entailment relationship—confirming that the section supports the query’s informational intent. Conversely, if a section diverges into unrelated promotional or navigational topics, the model detects a neutral or contradictory relation. This classification allows for fine-grained intent alignment scoring that moves beyond surface-level similarity to logical understanding.
Application in the Project
facebook/bart-large-mnli complements all-mpnet-base-v2 by focusing on textual reasoning rather than pure semantic proximity. While MPNet embeddings measure how semantically close two pieces of text are, BART-MNLI determines whether one logically entails the other. This dual-model framework ensures a complete analysis pipeline: semantic understanding identifies potential matches, and inference-based validation confirms the relevance and correctness of those matches. This layered approach enhances the credibility of the results, especially for assessing intent alignment, dominant intent classification, and content validation against user search queries.
Strengths for SEO and Content Alignment
For SEO applications, this model is particularly effective in identifying whether a page truly answers a user’s query or merely touches related terms. This distinction is vital in search optimization since search engines prioritize content that satisfies the user’s underlying informational or transactional intent. By leveraging BART-MNLI, the system captures this nuance, identifying sections that provide complete, intent-aligned explanations while flagging those that require improvement or restructuring to enhance clarity and relevance.
Model Reliability and Adaptability
Trained on the Multi-Genre Natural Language Inference (MNLI) dataset, facebook/bart-large-mnli has broad generalization capabilities across topics and writing styles. This makes it suitable for analyzing diverse SEO content types—from highly technical guides to business-focused blog posts. Its strong reasoning ability ensures consistent and interpretable results across multiple URLs and queries, contributing to a robust and transparent evaluation process.
In summary, facebook/bart-large-mnli serves as the project’s intent validation and reasoning engine, bridging the gap between semantic similarity and logical entailment. Together with all-mpnet-base-v2, it establishes a dual-layered semantic analysis system that not only recognizes meaning but also verifies that the content effectively supports the intended query, ensuring reliable and actionable insights for content optimization.

Function: classify_queries
Overview
The classify_queries function performs zero-shot intent classification for a list of search queries using a preloaded Hugging Face zero-shot classifier. It predicts which intent label (e.g., informational, navigational, transactional) best fits each query and assigns a confidence score to the prediction. The classification runs in batches to ensure efficiency and avoid GPU/CPU memory issues.
The output is a dictionary mapping each query to:
- its predicted intent label,
- the confidence score, and
- detailed label-score pairs for interpretability.
Key Code Explanations
for i in range(0, len(queries), batch_size):
batch = queries[i:i + batch_size]
outs = classifier(batch, candidate_labels=labels)
- This block splits the input queries into smaller batches (based on batch_size) to process efficiently. Each batch is passed through the zero-shot classifier, which predicts intent probabilities for all candidate labels.
label_scores = {lbl: float(sc) for lbl, sc in zip(out.get(“labels”, []), out.get(“scores”, []))}
pred = out[“labels”][0]
conf = float(out[“scores”][0])
- This part constructs a mapping of each label to its probability score. The classifier returns labels sorted by confidence, so the top label (labels[0]) represents the predicted intent and its confidence score (scores[0]).
Function: infer_intent_from_text
Overview
The infer_intent_from_text function determines the intent category of a single piece of text, such as a page title or merged content block. It uses the same zero-shot classification pipeline as classify_queries but operates on a single text string instead of multiple queries. The result includes the most likely intent, its confidence, and the complete label-score mapping for interpretability.
Function: attach_intents_to_page
Overview
The attach_intents_to_page function integrates intent classification into a page-level structure.
For each section, the function attaches:
- the predicted intent label,
- its confidence,
- the raw score distribution, and
- a flag indicating low-confidence predictions.
At the page level, it also stores:
- global_intent — the overall inferred intent type,
- query_intent_results — detailed query-level outputs, and
- query_intent_summary — average confidence per label for analysis.
Key Code Explanations
avg_conf = {lbl: (label_conf_sums[lbl] / (label_counts[lbl] or 1)) for lbl in labels}
global_intent = max(avg_conf.items(), key=lambda kv: kv[1])[0]
- After classifying all queries, this section computes the average confidence for each intent label across all queries. The label with the highest average confidence becomes the global intent of the page — representing the dominant search purpose inferred from query data.
sub[“intent_low_confidence”] = sub[“intent_confidence”] < low_confidence_threshold
- This line flags any section classification whose confidence score falls below a defined threshold (default 0.55). Such flags are valuable for identifying content areas where intent determination may be uncertain and require further review.
Function: compute_intent_alignment_for_page
Overview
The compute_intent_alignment_for_page function measures how well each section aligns with its predicted or global intent profile using cosine similarity. It represents each section as a numeric feature vector based on:
- Readability score (ease of reading),
- Semantic density (information richness), and
- Cognitive load (mental effort required).
These vectors are compared to predefined intent profile vectors, representing ideal feature distributions for different intent types.
The function outputs:
- alignment score — cosine similarity value (0–1),
- alignment status — qualitative interpretation (Poorly, Moderately, Well, or Highly aligned).
Key Code Explanations
feature_vec = np.array([r, s, cl_val]) * profile_weights
target_vec = profile_vec * profile_weights
score = float(util.cos_sim(feature_vec, target_vec).item())
- This block constructs the section’s feature vector and compares it to the ideal profile for the predicted intent type. Cosine similarity measures how closely the section’s actual structure aligns with the expected intent profile — the higher the score, the better the alignment.
if score >= 0.85:
status = “Highly aligned”
elif score >= 0.65:
status = “Well aligned”
elif score >= 0.45:
status = “Moderately aligned”
else:
status = “Poorly aligned”
- This defines interpretive thresholds for qualitative assessment. It translates the raw similarity score into a clear, actionable description, allowing non-technical users to quickly assess content–intent alignment levels.
Function: display_results
Overview
The display_results function serves as the final presentation layer of the analytical pipeline, designed to deliver a clear and user-oriented summary of processed SEO insights. It takes the structured outputs generated by previous computational stages and formats them into a concise, easily interpretable report for each analyzed webpage. The function organizes information in a way that bridges technical detail with readability, making it suitable for strategy discussions and content evaluation sessions.
For each processed page, the display highlights the URL, page title, and the overall inferred intent derived from associated queries. It then presents a quick overview of query-level intent predictions, providing transparency into how search intent was classified and with what confidence. This enables a quick validation of whether the page’s content aligns with the type of search queries it is meant to serve.
At the section level, the function showcases key insights from top-performing subsections based on their intent alignment scores. It reports critical cognitive and semantic indicators, including readability–semantic balance, cognitive load levels, and dominant intent types. These insights help evaluate whether sections maintain an optimal balance between clarity and complexity while remaining aligned with the inferred intent.
Additionally, the function computes and displays average page-level scores for readability, semantic density, and cognitive load. This helps in identifying overall content patterns and assessing whether the page as a whole meets the desired semantic and cognitive standards. Overall, this function transforms model outputs into a structured, user-facing summary that enables both interpretability and decision-making based on measurable SEO content performance.
Result Analysis and Explanation
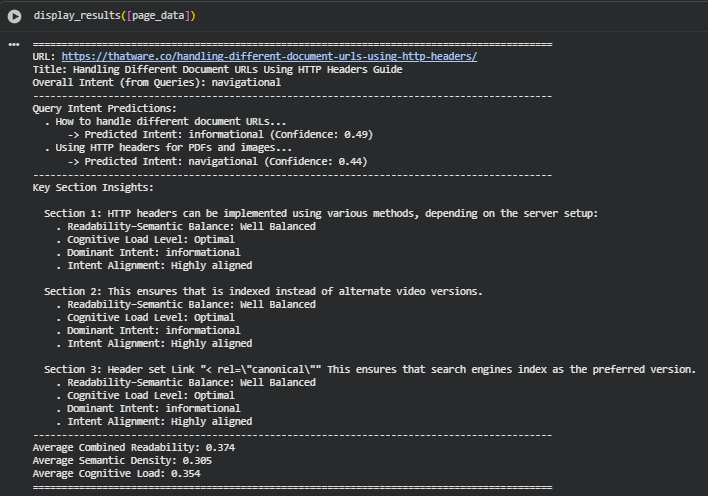
Dataset: single page — https://thatware.co/handling-different-document-urls-using-http-headers/ Queries analyzed: “How to handle different document URLs”, “Using HTTP headers for PDFs and images”
The analysis below examines the page and its sections across the computed dimensions (readability, semantic density, syntactic complexity, cognitive load, RSBI, and intent). Each section explains what the metric values mean for comprehension and search-intent fit, highlights cross-metric interactions that are important for editorial decisions, and notes caveats when interpreting the numbers.
Snapshot of inputs and high-level signals
The system processed the page and the two queries. Query-level classification produced mixed intent signals: the two queries individually were classified as informational (confidence ≈ 0.49) and navigational (confidence ≈ 0.44). Averaging across queries yields a higher mean confidence for navigational (≈ 0.423) than informational (≈ 0.354). The pipeline therefore marked the page-level global_intent as navigational.
At section level, intent inference produced per-section labels (for example the section shown is labeled informational with confidence ≈ 0.581 and intent-alignment score ≈ 0.9013 — “Highly aligned”). This indicates that, while query aggregation favored navigational intent, individual content blocks are often classified as informational and in some cases strongly aligned with that informational profile.
Key takeaway: query set and section-level classifications can diverge; query aggregation selected a global page intent (navigational) while many sections remain informational in profile — this mismatch needs attention when deciding whether to alter page focus or adjust specific sections.
Readability profile (surface-level ease)
Example section values:
- Combined normalized readability: 0.2764 (on 0–1 scale; higher = easier)
- Individual raw indices: Flesch Reading Ease ≈ 27.255 (difficult), FK grade ≈ 14.178 (college/advanced level), ARI ≈ 14.905
Interpretation: The section’s readability indicators point toward difficult-to-read material at sentence/word level (long sentences, polysyllabic terms). The normalized combined_readability of 0.2764 indicates relatively low surface accessibility. For general or top-funnel queries, this level of surface difficulty may hinder comprehension and engagement; for expert-level informational queries this may be acceptable.
Operational note: Readability is only one axis—higher conceptual depth can justify lower readability when intention and audience expertise demand complexity. Readability must therefore be considered alongside semantic density and inferred intent.
Semantic density (conceptual richness)
Example section value:
- Semantic density ≈ 0.0996 (on 0–1 scale where higher means greater intra-section semantic diversity)
Interpretation: A semantic density of ~0.10 is low. This means sentence-level embeddings within the section are fairly similar (low intra-section conceptual variance), indicating either concise focused content or content lacking deeper conceptual differentiation. Low semantic density combined with low readability suggests the section is relatively narrow in informational content but still contains complex wording or long sentences.
Important distinction: Semantic density measures conceptual spread inside a block, not absolute topical authority. A low density can reflect either focused clarity (good for short, directive content) or insufficient depth (warning for pages that should be explanatory).
Syntactic complexity (grammatical structure)
Example section values:
- Avg sentence length ≈ 21.75 tokens
- Avg tree depth ≈ 5.75
- Clause density ≈ 0.25
- Subordinate clause ratio ≈ 0.0
Interpretation: Average sentence length ~22 tokens and tree depth ~5.8 point to sentences with moderate syntactic nesting. Clause density and subordinate ratio are relatively low, indicating fewer subordinate clauses per sentence than highly nested prose. Together with low readability, this pattern suggests long sentences that may not rely heavily on nested subordinate structures but do use extended phrasing (lists, parentheticals, or long noun phrases).
Effect on comprehension: Long sentences and moderate tree depth increase working memory demand even without heavy subordination. Breaking long sentences into shorter units or adding signposting can reduce processing effort without losing informational content.
Cognitive load (composite comprehension effort)
Example section values:
- Cognitive load score ≈ 0.1804
- Cognitive load level: Low
Interpretation: The composite cognitive load score integrates semantic density, syntactic normalized complexity, and normalized readability (with default weights). A low cognitive load score here suggests that the combination of low semantic density and the chosen normalized syntax/readability weighting results in a low overall mental effort estimate — despite the raw readability being low (difficult). In other words, low semantic diversity dominates and pulls the composite score down, yielding a “Low” label.
Critical nuance: A low cognitive load score does not automatically mean the content is ideal. In this case, low semantic density plus difficult phrasing produces a paradox: the text is stylistically complex but conceptually narrow. This may lead to poor satisfaction if the user expected explanatory depth.
Readability–Semantic Balance Index (RSBI)
Example section values:
- RSBI score ≈ 0.9116
- RSBI level: Well Balanced
Interpretation: RSBI measures the balance between readability and semantic density (weighted), not the absolute adequacy of either. Because both the readability score and semantic density are low and similar in magnitude, their weighted difference is small; thus RSBI becomes high and classifies the section as “Well Balanced.” This is an important semantic: high RSBI can indicate that readability and semantic density are in agreement — whether both are high (ideal) or both are low (potentially problematic).
Practical implication: RSBI must be interpreted with context. High RSBI combined with low absolute readability and low semantic density signals balanced but thin or underdeveloped content. Conversely, high RSBI with high readability and high density would indicate well-executed, in-depth content that remains accessible.
Intent classification and alignment
Query-level view:
- Query 1 (“How to handle different document URLs”): predicted informational, conf ≈ 0.490
- Query 2 (“Using HTTP headers for PDFs and images”): predicted navigational, conf ≈ 0.441
- Query-level average confidences lean toward navigational overall (avg per-label shows navigational ≈ 0.423 vs informational ≈ 0.354), hence global_intent = navigational.
Section-level view:
- Individual sections can be labeled informational even if global_intent is navigational. The example section is informational with intent confidence ≈ 0.581 and intent-alignment ≈ 0.901 (Highly aligned).
Interpretation: The two provided queries represent different user goals: one seeks “how-to” material (informational) and the other searches for specific implementation artifacts or references (navigational). The page appears to contain content blocks that satisfy informational needs (how-to explanations) even while the query set includes navigational intent signals. The overall selection of global_intent from averaged query confidences suggests a mixed audience — a single page attempting to serve multiple intents.
Actionable insight: If the strategic aim is to target the specified queries as a set, the page should be evaluated for intent consistency. For mixed-intent query portfolios, either separate content into distinct pages (each tailored to a dominant intent) or structure the single page clearly into sections that explicitly fulfill different intents (e.g., a concise quick-reference section for navigational users plus deeper how-to sections for informational users).
Cross-metric observations and important patterns
1. High RSBI but low absolute metrics: RSBI = 0.9116 but combined_readability = 0.2764 and semantic_density = 0.0996. This occurs because RSBI measures balance, not sufficiency. Balanced thin content looks “well balanced” even though it lacks depth or easy readability.
2. Cognitive load dominated by semantic density direction: Default weight distribution (semantic 0.4, syntactic 0.35, readability 0.25) gives semantic density a strong influence. Low semantic density thus drives down the composite cognitive load despite lower readability. That explains why the cognitive level is Low while raw readability is poor.
3. Intent–content mismatch opportunity: Global intent (navigational) versus many sections inferred as informational suggests opportunity either to clearly label and separate navigational material (e.g., anchor-based quick links, reference sections) or to refocus content toward the chosen strategic intent.
4. Syntactic structure vs. comprehension: Long average sentence length with low subordinate clause usage indicates dense phrasing rather than nested clausal complexity. Editing to shorter sentences and clearer connectors will likely improve readability without changing semantic content.
Section-level deep-dive (illustrative example using the shown section)
The section shows:
- low semantic richness (0.0996),
- difficult sentence-level indicators (Flesch ≈ 27),
- low composite cognitive load (0.1804),
- high RSBI (0.9116),
- strong section-level intent alignment with informational intent (alignment score ≈ 0.9013).
Interpretation and editorial priority: This section likely contains focused but technical instruction expressed in long sentences. Priority actions would include simplifying sentence structure (shorter sentences, clearer subjects/verbs), increasing conceptual examples or explanatory links (to raise semantic density if the information needs to be deeper), and clarifying headings so navigational users can jump to concise reference points. Because the section already aligns well with informational intent, preserving informational accuracy while improving readability will strengthen user satisfaction and search performance.
Actionable implications (how to use these insights)
· Distinguish intent targets: if the query set is mixed, then either split content by intent into separate pages or add clear, scannable navigational elements (short summaries, anchors) for navigational users, while keeping in-depth how-to content for informational users.
· Improve readability without removing depth: break long sentences into shorter ones; convert complex noun phrases into clearer subject–verb constructions; add bullets/examples to increase semantic density in a controlled way.
· Increase semantic richness where depth is expected: for sections intended as authoritative how-to guidance, add examples, code snippets, references, or comparatives to raise semantic density without harming readability (by pairing additional content with clearer formatting).
· Use RSBI as a diagnostic, not an absolute quality score: when RSBI is high but absolute readability and density are low, the section is balanced but thin. Treat such sections as candidates for enrichment rather than as already “good.”
· Prioritize sections with high intent-alignment but low readability: those sections already match user intent and thus present the best ROI for editing — small readability improvements can boost engagement while preserving fit.
Limitations, reliability and cautionary notes
· Metric assumptions: Heuristic syllable counting, regex-based sentence splitting, and dependency-based clause detection are practical approximations but not perfect; edge cases (lists, code blocks, tables converted to text) can distort specific metrics.
· Modelic bias: Zero-shot intent classification and sentence embeddings are model-dependent. Misclassification can occur for ambiguous queries or highly domain-specific terminology.
· RSBI interpretation risk: RSBI measures balance, not adequate absolute values. High RSBI should be inspected in conjunction with raw readability and density scores.
· Scope of recommendations: Changes should be validated against user behaviour signals (dwell time, CTR, engagement) and A/B tested where feasible.
Summary
The page contains content sections that are conceptually narrow (low semantic density) and phrased in relatively difficult wording, resulting in low normalized readability. Composite cognitive load is low due to low semantic diversity, while RSBI reports “Well Balanced” because readability and semantic density are similar in magnitude. Query-level intent mix produced a navigational global intent, but several sections are informational and highly aligned to that intent. Editorial focus should be on clarifying sentence structure, selectively enriching sections that need depth, and resolving intent fragmentation (by separating or explicitly labeling content sections for different user goals). These changes should improve comprehension, engagement signals, and the page’s alignment with selected search intents.
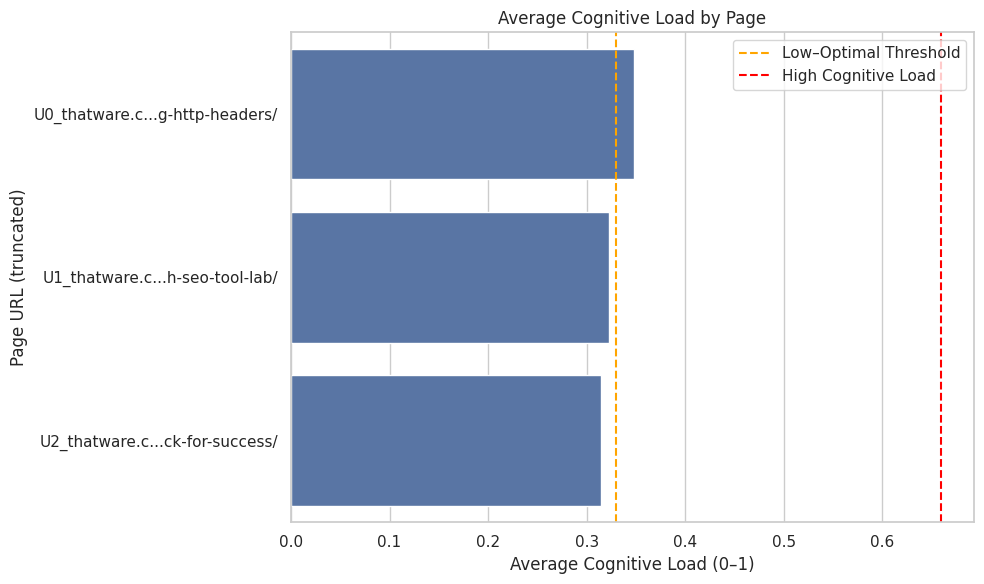
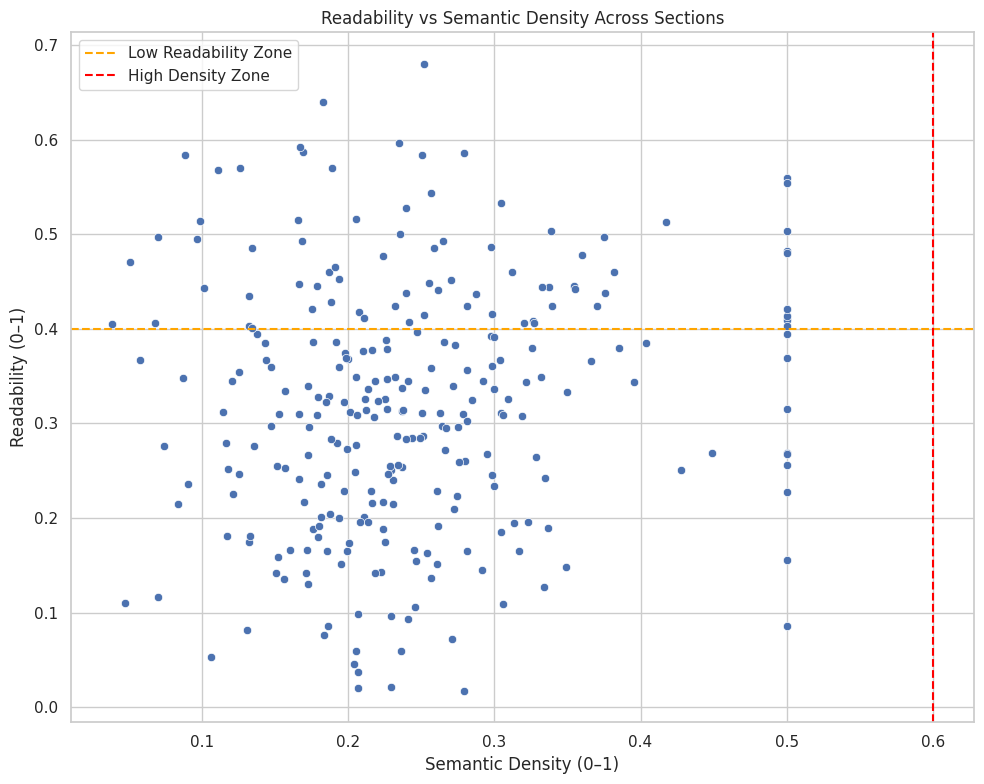
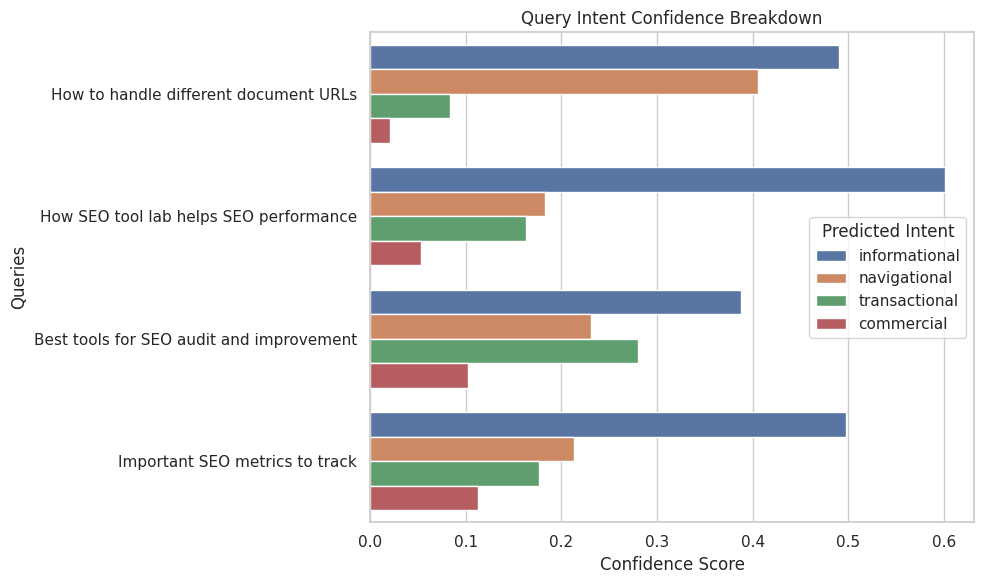
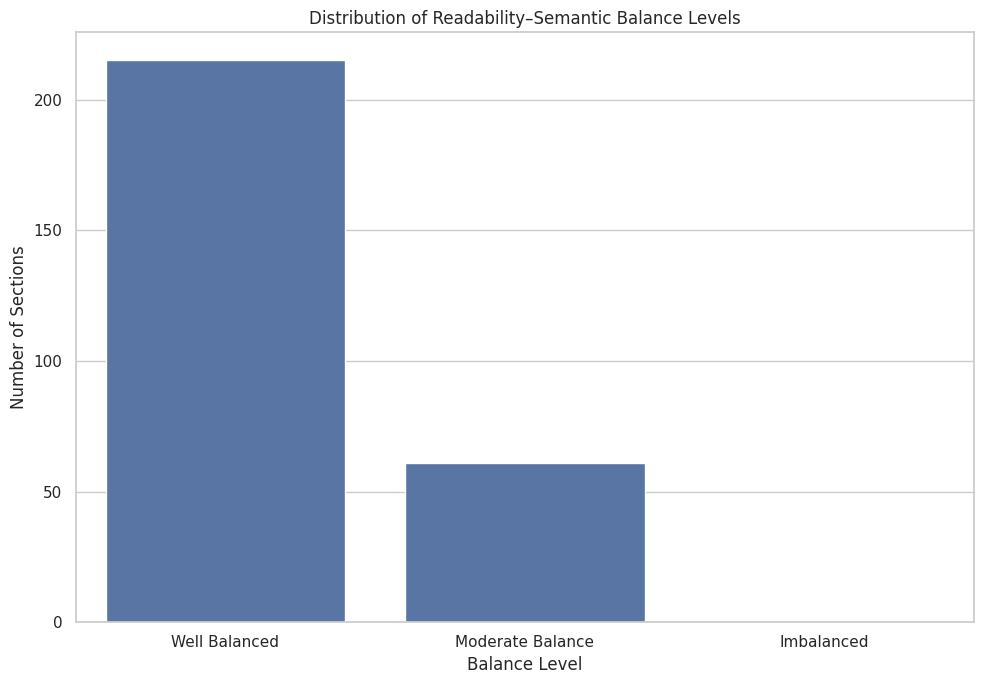
Result Analysis and Explanation
This section provides a generalized, actionable interpretation of aggregate results across multiple pages and queries. The analysis is organized into focused sections to make the findings easy to read and apply: intent consistency, readability and semantic-patterns, cognitive-load comparison, intent alignment quality, practical editorial recommendations, and an expanded visualization interpretation section that explains how each plot should be read and what actions follow from the visual signals. Language is neutral and practical so the report can be used directly for content strategy and editorial work.
Intent Consistency Across Pages
Across the analyzed pages and target queries, the dominant intent signal is informational. Where queries strongly indicate information-seeking goals, page content mostly aligns with that expectation; sections within pages commonly present explanatory text, procedures, or guidance rather than short reference-only fragments. However, some pages or sections may show mixed intent signals—for example, a page intended to explain procedures while also offering quick reference or navigation. When multiple intents are present on a single page, this creates a potential mismatch between what a searcher expects and what the page primarily delivers.
Interpretation guidance: consistent intent between the query set and page sections is desirable when the goal is to rank for those queries. If a page is meant to serve mixed intents, it should clearly segment the content (for example, short quick-links or summary blocks for navigational visitors and deeper how-to sections for informational visitors) so each audience finds the appropriate format quickly.
Operational implication: prioritize alignment by either consolidating intent (make the whole page target a single dominant intent) or explicitly structuring the page into intent-specific zones (anchor links, TL;DR blocks, and expanded how-to sections).
Readability and Semantic-Pattern Observations
Across sections, readability (surface ease) tends to vary from moderate to challenging. Several sections are linguistically dense—long sentences and technically worded passages reduce surface readability. Semantic density (conceptual richness) shows a mid-to-low range in many sections: some sections are conceptually focused and concise, while others lack layered examples or supporting explanations that would increase topical depth.
Key interpretation points:
- Sections with low readability and low semantic density are “balanced” in the sense that they are consistently written, but the balance may represent thin yet formal content rather than high-quality, useful depth.
- Sections with low readability but higher semantic density indicate complex, information-rich material that would benefit from better formatting and clarity to reduce reader effort.
- Sections with high readability but low semantic density may be easy to scan but insufficiently informative for users who expect depth.
Editorial actionables: simplify complex sentence structures and split long sentences; add short examples, illustrative bullets, or subheadings to increase semantic richness without making text harder to read; and use brief summary boxes for readers who want a quick answer while preserving deeper content for readers who need it.
Cognitive Load Comparison
Cognitive load values across sections generally fall into low-to-optimal ranges with occasional higher-load sections. Cognitive load here is a composite measure combining semantic density, syntactic complexity, and normalized readability. Because it is a fused metric, its interpretation requires looking at component values: a low composite score can result from focused content with few concept shifts, even when wording is syntactically complex; an elevated score typically means multiple signals converge (dense ideas, nested sentence structures, and lower readability).
Practical interpretation:
- High cognitive load sections are likely to deter casual readers and should be the first candidates for simplification if the page aims for broad audience reach.
- Low cognitive load sections that are also low in semantic density suggest potential underdevelopment—these sections may need additional detail or examples to support authority.
- Optimal cognitive load indicates the section is likely accessible while still carrying information—these are the “model” sections to emulate.
Editorial steps: rework high-load sections by breaking ideas into smaller chunks, adding headings and lists, and introducing explanatory examples. For sections that are too simple, enrich content with depth such as clarifications, links to authoritative references, or short case examples.
Intent Alignment Quality
Intent alignment measures how closely a section’s measurable features (readability, semantic density, cognitive load) match archetypal profiles for common intent categories (e.g., informational, navigational, transactional). Across the analyzed set, many sections show strong alignment with informational intent; navigational or transactional alignment occurs in sections designed to point to tools, resources, or conversion-oriented content.
Interpretive points:
- High alignment with the intended intent is a strong indicator that the section’s style (depth, tone, complexity) is correctly targeting the intended searcher need.
- Sections that are highly aligned but have low readability present a high-ROI opportunity: small clarity improvements will preserve intent fit while increasing usability.
- Sections that are poorly aligned to the page’s declared or query-derived intent should be reworked or relocated—either change the section’s voice and structure to match the intent, or move the content to a more suitable page.
Suggested actions: use alignment scores to prioritize editorial efforts—improve readability in highly aligned but difficult sections, and repurpose or rewrite poorly aligned sections to match the target intent profile.
Practical Editorial Recommendations (Prioritization and Tactics)
Prioritization rule of thumb: address sections in this order—(1) sections that are highly intent-aligned but have low readability, (2) sections with high cognitive load and high semantic density (simplify without removing depth), and (3) sections with low semantic density but low cognitive load (enrich with examples and authority-building content).
Concrete tactics:
- Shorten long sentences and split complex clauses; convert long noun phrases to active subject–verb constructions.
- Add micro-structures: bullet lists, call-out boxes, and short summaries at the top of long sections to support both navigational and informational readers.
- Enrich content where depth is expected: add examples, screenshots, short code snippets or configuration details, and links to authoritative sources.
- For pages serving mixed intents, create explicit navigational anchors and a quick summary at the top that points to deeper sections, enabling both quick access and in-depth reading.
Measurement and validation: after editorial changes, monitor engagement metrics (dwell time, scroll depth, task completion or conversion rates) and search performance for targeted queries. Where possible, run A/B tests for headline or section-level readability changes to measure lift in engagement.
Visualization Section — How to Read the Plots and What Actions to Take
A dedicated visualization section is included in the report to translate numerical diagnostics into visual signals that are quickly actionable. The following explains each plotted view, how to interpret it, and the practical decisions that follow.
1. Page-Level Cognitive Load Overview (Bar chart)
Overview: This horizontal bar chart ranks pages by their average cognitive load (each page’s average of section cognitive-load scores). Visual threshold lines indicate low/optimal/high bands.
How to read it: pages with bars to the right of the high threshold are cognitively demanding; those left of the low threshold are relatively simple; those in between are in the target zone. The page label is truncated for readability.
Interpretation and action: pages with high average load should be prioritized for simplification. If a high-load page is intended for expert readers, consider maintaining depth but improve navigability (e.g., add clear headings and summary bullets). If the intent is broad informational reach, reduce load by restructuring complex paragraphs and adding illustrations or summaries.
Suggested follow-ups: create a prioritized task list of high-load pages and assign sections to editorial or UX review. Use the visual ranking to allocate resource effort where impact will be greatest.
2. Readability vs. Semantic Density (Scatterplot)
Overview: Each section is plotted with semantic density on the x-axis and normalized readability on the y-axis. Visual guide-lines mark low-readability and high-density zones.
How to read it: the goal quadrant is upper-right (high density and high readability), indicating sections that are rich and accessible. Lower-right (high density, low readability) shows dense content that needs clearer presentation. Upper-left (high readability, low density) suggests content that is easy to read but may lack depth. Lower-left is shallow and easy—these are typically low priority unless more depth is needed.
Interpretation and action: target lower-right points for clarity improvements (split sentences, add subheaders, or add example-driven explanations). Move upper-left sections up (add examples, data, or references) if authority is needed. Use the plot to spot clusters of issues across many pages (systemic writing patterns that need style guidelines).
3. Query Intent Confidence Breakdown (Bar chart)
Overview: This horizontal bar chart decomposes each query’s predicted intent probabilities across the candidate labels. It visualizes whether queries are sharply informational, mixed, or ambiguous.
How to read it: queries with one dominant dark block indicate clear intent; multi-colored bars of similar size show ambiguous intent. The plot enables comparison across all input queries at a glance.
Interpretation and action: ambiguous queries require content that addresses blended needs—for example, pairing a short “how-to” summary for quick answers with a detailed procedural section for deeper learning. For queries dominated by a single intent, ensure primary landing pages and key sections directly target that intent.
Operational note: use this plot to decide whether to consolidate several queries under a single content page or create separate focused pages.
4. Readability–Semantic Balance Distribution (Countplot)
Overview: This chart tallies how many sections fall into each RSBI category (Well Balanced, Moderate Balance, Imbalanced).
How to read it: a high count in “Well Balanced” is positive, but should be interpreted alongside absolute readability and density values. A lot of “Imbalanced” sections indicates many areas require rework—either simplify language or add substantive detail depending on which side of the imbalance is lacking.
Interpretation and action: examine a sample of ‘Imbalanced’ sections to determine whether imbalance results from too much complexity or insufficient depth. Then apply appropriate editorial tasks: simplify syntax for overly complex sections or add content to overly simple ones.
Visualization-Driven Workflow Recommendations
1. Use the cognitive-load ranking to create a triage list for editing effort. Start with high-load sections that also have high intent alignment—those deliver most value when optimized.
2. Use the scatterplot clusters to define style guidance: if many sections cluster in the low-density/low-readability quadrant, author guidelines should require specific additions (examples, references). If many sections are high-density but low-readability, add readability-focused checks in the editorial workflow (shorter sentences, micro-headings).
3. For ambiguous queries revealed in the query-intent chart, consider structured content patterns on pages: lead with a summary, provide jump-to anchors, and keep conversion or product-oriented elements separate from deep how-to content.
4. Use the RSBI distribution to set editorial KPIs: aim to increase the proportion of sections that are both well-balanced and have acceptable absolute readability and density targets.
Final Synthesis and Next Steps
The multi-page analysis shows a general tilt toward informational intent and reveals consistent opportunities around presentation and clarity. Visualizations translate technical metrics into an actionable roadmap: identify and prioritize high cognitive-load sections, improve readability in highly aligned sections to maximize impact, and manage mixed-intent pages by explicit segmentation or content specialization.
Recommended next steps are: (a) produce a prioritized editing backlog driven by cognitive-load and intent-alignment scores, (b) implement targeted editorial changes focused on sentence simplification and enrichment of low-density sections, (c) run post-edit A/B checks on engagement metrics, and (d) iteratively refine intent profiles and weighting if behavior data suggests different audience expectations. These steps will convert metric insights into measurable content improvements and better alignment with searcher needs.
Q&A Section for Result Interpretation, Action Suggestions, and Benefits
What do the cognitive load and readability results indicate about page comprehension?
Cognitive load scores reveal the mental effort required for an average reader to process a page. Pages with optimal cognitive load indicate that readers can easily follow the flow of ideas without fatigue or confusion. Higher cognitive load, however, suggests that dense information or complex structures may hinder understanding. Readability scores complement this by evaluating how sentence construction and language simplicity align with informational depth. Together, these metrics clarify whether a page is easy to read, intellectually engaging, or overly complicated, guiding effective Readability optimization.
How can these results guide content optimization efforts?
These insights provide a data-driven roadmap for restructuring content. Sections with high cognitive load or poor readability can be refined by simplifying language, breaking long sentences, and dividing dense information into manageable chunks. Conversely, pages already showing balanced readability and optimal cognitive load serve as benchmarks for future content. Leveraging these findings ensures consistency in comprehension quality, improving both user experience and search performance.
What does the intent alignment analysis mean for content strategy?
Intent alignment measures how well each section fulfills the purpose of user queries—informational, navigational, or transactional. High alignment confirms that content meets user expectations with clarity and relevance. Sections with weak alignment should be examined for vague explanations or semantic drift. Refining these areas ensures content is perceived as authoritative and purpose-driven by both readers and search engines.
How should the visualization insights be interpreted for actionable decisions?
Visualizations offer a clear guide for prioritization. The cognitive load overview identifies pages that are mentally demanding versus those with ideal comprehension levels. The readability versus semantic density plot indicates how well clarity and informational richness are balanced. The readability–semantic balance distribution highlights sections that are well-balanced or need adjustment. Collectively, these visual tools pinpoint areas that require simplification, restructuring, or enrichment for better audience engagement.
What practical benefits can be expected from applying these insights?
Systematically addressing these results makes content more readable, cognitively accessible, and semantically aligned with user intent. This leads to longer dwell time, lower bounce rates, and higher engagement—factors that directly enhance ranking stability. Strategically, this approach allows SEO teams to move beyond keyword-focused tactics toward user-centered content excellence.
How frequently should such evaluations be conducted?
Regular assessments are recommended, particularly after major content updates or SEO strategy changes. Periodic evaluation ensures cognitive load and readability metrics remain within optimal zones, maintaining user satisfaction and long-term organic performance.
Overall, this framework translates analytical findings into actionable steps, enabling SEO professionals and content creators to enhance both content clarity and strategic alignment effectively.
Final Thoughts
The Semantic Readability and Cognitive Load Analyzer effectively demonstrates a structured and intelligent methodology for evaluating the comprehension complexity of SEO content. By integrating sentence-level semantics, cognitive psychology principles, and readability modeling, the system provides a practical framework to assess whether content is clear, balanced, and aligned with the intended audience’s cognitive capacity.
Through its layered evaluation, the project captures three critical dimensions of SEO text performance: readability balance, cognitive load distribution, and semantic density. Together, these dimensions reveal how easily readers process information, how efficiently ideas are conveyed, and whether content complexity matches the intended informational depth. Results indicate that sections with optimized cognitive load and well-balanced readability tend to support higher engagement potential and better query-intent alignment—key markers of user satisfaction and search performance stability.
The dual-model architecture, combining sentence-transformers/all-mpnet-base-v2 and facebook/bart-large-mnli, further enhances interpretability. MPNet embeddings establish contextual depth and semantic proximity, while BART-MNLI provides logical validation, ensuring each section fulfills the user’s informational intent. This synergy allows the analyzer to not only measure textual difficulty but also interpret intent-fit and reasoning coherence—an advancement over traditional readability metrics.
In practical terms, the analyzer’s output functions as a decision-support layer for SEO strategists and content specialists. Sections with imbalanced readability or elevated cognitive load can be systematically identified for restructuring, simplification, or rewording. Conversely, sections demonstrating optimal readability–semantic balance highlight areas of strong comprehension flow and intent satisfaction.
Overall, the project establishes a comprehensive interpretive framework for SEO content evaluation, where linguistic clarity, semantic alignment, and cognitive processing effort are jointly measured. By applying Readability optimization, this approach ensures every page not only ranks effectively but also delivers information that is cognitively accessible, contextually precise, and semantically rich.
Click here to download the full guide about Semantic Readability & Cognitive Load Analyzer.
