SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
The Knowledge Granularity Evaluator is an advanced analytical framework designed to assess the informational structure and conceptual balance of web content. It determines how comprehensively a page covers its primary topics and related ideas, offering an evidence-based view of topical authority and semantic precision.

By integrating transformer-based semantic modeling with intelligent content segmentation, the system evaluates multiple dimensions of content quality, including conceptual depth, topical breadth, and semantic coverage. These evaluations highlight strengths and gaps in knowledge presentation across a webpage.
In addition, the framework measures how effectively the content aligns with specific search queries, enabling precise evaluation of content relevance and topical match strength.
This approach transforms raw web content into interpretable, data-backed insights that guide SEO professionals and strategists in enhancing topic coverage, improving content structure, and reinforcing authority signals.
Project Purpose
The purpose of the Knowledge Granularity Evaluator is to establish a systematic framework for measuring how effectively web pages convey, expand, and relate key concepts within a topic. Conventional SEO analysis often focuses on keyword density or surface-level relevance, but this project extends beyond those measures by evaluating conceptual granularity—how deeply and broadly a topic is developed within content.
This project aims to:
- Quantify the depth of information to determine how comprehensively a concept is discussed.
- Measure the breadth of topical expansion to understand how widely related subtopics are covered.
- Compute a granularity index that balances these two perspectives for an overall measure of topic strength.
- Assess query alignment, evaluating how closely each content segment semantically aligns with the provided search queries.
The outcome enables objective, data-driven evaluation of content structure and coverage quality. It provides clear, interpretable indicators to identify which sections of a page deliver strong topic coverage and which areas require refinement to achieve balanced conceptual representation.
Project’s Key Topics Explanation and Understanding
Knowledge Granularity in Web Content
Knowledge granularity refers to the level of conceptual detail and coverage density within digital content. In SEO and semantic analysis, granularity determines how comprehensively and meaningfully a page addresses the central topic and its related concepts. Fine-grained knowledge indicates deep exploration of specific subtopics, detailed explanations, and strong contextual interconnections. Coarse-grained knowledge, by contrast, signifies broader but shallower coverage—where topics are introduced but not elaborated in depth. Granularity thus acts as a bridge between content depth and content breadth, providing a quantitative perspective on how well a page communicates topic-level expertise.
Conceptual Depth
Conceptual depth measures the richness and density of information around a particular concept or idea. It reflects how thoroughly content elaborates on a topic by analyzing:
- The level of semantic specificity within each subsection or chunk.
- The variety and intensity of related terms and contextual details.
- The internal conceptual cohesion of content segments.
A higher depth score indicates that a page or subsection contains detailed explanations, multiple concept layers, and clear semantic progression. In SEO strategy, this metric is crucial for identifying sections that demonstrate expertise and depth of understanding—key indicators of high-quality, authoritative content.
Conceptual Breadth
Conceptual breadth evaluates the extent of topic coverage by measuring how many distinct but relevant subtopics are addressed within a page. While depth focuses on how much is said about a topic, breadth focuses on how many related ideas are meaningfully included. This involves assessing semantic diversity across sections and the range of unique conceptual clusters identified in the embedding space.
Balanced breadth indicates a well-rounded page that connects multiple related themes, supports user comprehension, and enhances topic authority. However, excessive breadth without sufficient depth can lead to diluted topical focus, whereas low breadth limits contextual scope.
Granularity Index
The granularity index combines conceptual depth and breadth into a single, interpretable score. It quantifies how effectively a page balances in-depth coverage with broad conceptual expansion. Formally, this index is a weighted aggregation of the normalized depth and breadth scores for each page. A higher granularity index represents pages that not only go deep into core topics but also establish relevant conceptual relationships across sections. This index serves as the central metric for identifying content that achieves both specialization and topical comprehensiveness—characteristics typically associated with high-quality, semantically authoritative pages.
Semantic Coverage
Semantic coverage measures the representational completeness of content within its conceptual space. It evaluates whether the combined page sections collectively capture the essential semantic territory of a topic, as reflected in embedding-based clustering and similarity patterns. High semantic coverage suggests that the content successfully spans the core and peripheral areas of meaning associated with the target topic, minimizing conceptual gaps.
Query Alignment
Query alignment measures how closely the meaning of a content segment matches the provided search queries. Unlike keyword matching, this measure is embedding-based and operates at the semantic level. Each query and content subsection is encoded into vector representations, and their cosine similarity provides an alignment score. High alignment indicates strong topical relevance to the query, showing that the content addresses the same conceptual intent represented by the search input. This enables precise evaluation of whether individual sections within a page meaningfully correspond to the themes users search for.
Integration of Depth, Breadth, and Alignment
Together, depth, breadth, granularity, and query alignment provide a holistic, multidimensional understanding of content quality.
- Depth ensures detailed knowledge presence.
- Breadth ensures topical inclusivity.
- Granularity Index balances both.
- Query Alignment connects content representation to real-world search semantics.
This integrated approach provides actionable insight into how web content performs conceptually, guiding optimization efforts toward balanced, semantically strong, and query-aligned pages.
Q&A Section for Understanding Project Value and Importance
How does evaluating knowledge granularity improve SEO strategy?
Evaluating knowledge granularity helps determine how effectively a webpage communicates expertise and topic mastery. SEO performance today is influenced not only by keyword relevance but also by the semantic strength and informational quality of content. By measuring conceptual depth and breadth, this project identifies whether a page goes beyond surface-level coverage to deliver substantive, expert-level information. This enables content strategists to pinpoint areas that need deeper elaboration or broader topical expansion. Pages with optimized granularity tend to perform better in competitive search environments, as search engines increasingly reward well-structured, semantically rich content that demonstrates topic authority and relevance.
Why is it important to measure both conceptual depth and breadth instead of focusing on one aspect?
Depth and breadth represent two complementary dimensions of high-quality content. Depth captures the detailed understanding of a specific concept, while breadth ensures coverage of all important subtopics within a theme. Focusing on only one dimension can result in imbalance—content may become too narrow and repetitive or too broad and unfocused. By quantifying both dimensions, this project offers a balanced analysis of how thoroughly and comprehensively a page covers its main subject. The combination of these metrics allows for precise optimization strategies—strengthening detailed sections while also filling in conceptual gaps to ensure complete topic representation.
What makes this project different from traditional SEO content evaluation methods?
Traditional SEO assessments often rely on keyword density, meta-tag optimization, or readability scores, which offer limited insight into the semantic structure of content. This project, however, introduces an advanced, concept-level evaluation framework built on semantic embeddings and contextual modeling. It measures not only what topics are mentioned but also how concepts are connected, expanded, and contextualized throughout the page. This approach goes beyond surface indicators, providing a structural understanding of content quality that aligns more closely with how modern search algorithms interpret meaning. As a result, it offers a more intelligent, data-driven foundation for improving content relevance and authority.
How can businesses use these insights to strengthen their online authority?
By analyzing content through granularity and semantic coverage metrics, businesses can directly identify gaps in expertise or topic coverage. The insights reveal which areas of content exhibit strong conceptual understanding and which lack sufficient depth or connectivity. This enables targeted enhancement—such as expanding underdeveloped sections, integrating related subtopics, and improving internal consistency. Over time, this structured refinement helps establish greater topical authority, leading to improved search visibility, stronger domain expertise recognition, and a more trustworthy presence in competitive niches.
How does query alignment contribute to improving content effectiveness?
Query alignment provides a semantic bridge between what users search for and what the webpage actually communicates. By mapping query vectors to section-level embeddings, the system identifies how well each segment corresponds to real search queries. This ensures that content not only maintains high conceptual quality but also directly addresses the specific questions, problems, or informational needs represented by user searches. Such alignment improves both relevance and engagement—readers find what they are seeking more quickly, and search engines interpret the content as highly responsive to user intent, improving visibility and ranking potential.
How does this analysis help optimize content for future-proof SEO performance?
As search algorithms evolve, they increasingly emphasize understanding meaning and context rather than relying on exact keyword matches. This project aligns with that evolution by focusing on semantic structure and conceptual quality. By quantifying the relationships between depth, breadth, and semantic coverage, it ensures that content remains adaptable to future search updates that favor contextual expertise. Businesses can continuously refine their pages using these insights to maintain strong rankings even as SEO standards shift toward meaning-driven evaluation.
Libraries used
time
The time library in Python provides functionality to work with time-related tasks, including measuring execution durations, adding delays, and timestamping events. It is widely used for performance monitoring and controlling the flow of execution in applications where timing is important.
In this project, time is used to manage network requests to webpages and control delays between requests. This prevents server overload and ensures a stable, responsible extraction of page content. Additionally, time can be leveraged to measure execution time of key pipeline stages, which helps monitor efficiency and optimize preprocessing for large-scale SEO analysis.
re
The re module provides regular expression support in Python, allowing for advanced pattern matching, searching, and text substitution. It is commonly used to clean, parse, and validate textual data efficiently.
Within this project, re is crucial for preprocessing extracted HTML content. It is used to remove unwanted elements like URLs, numeric references, extra whitespace, or specific boilerplate patterns from text blocks. This ensures that content processed for embeddings is clean, relevant, and free from noise that could skew semantic analysis.
html (as html_lib)
The html library in Python provides utilities to handle HTML-specific data, including escaping and unescaping HTML entities. It helps convert encoded characters into readable text and vice versa.
Here, html_lib is used to normalize HTML content extracted from web pages. Many web pages encode special characters (e.g., , &) which need to be converted back to standard text for accurate tokenization and embedding generation. This ensures semantic analysis receives meaningful textual data.
hashlib
hashlib is a Python module that provides secure hashing functions like MD5, SHA-1, and SHA-256. Hashing is often used to generate unique identifiers or verify data integrity.
In this project, hashlib is employed to create unique identifiers for content blocks, subsections, and chunks. By combining page URL, section, and subsection titles into MD5 hashes, each content segment receives a consistent and collision-resistant ID, enabling reliable tracking and referencing throughout preprocessing, embedding, and analysis stages.
unicodedata
The unicodedata module provides access to the Unicode Character Database, allowing normalization and categorization of text. It is commonly used to handle accented characters, diacritics, and non-standard Unicode representations.
In this project, unicodedata ensures that textual content extracted from web pages is normalized into a standard Unicode form. This step prevents inconsistencies in semantic embeddings caused by visually similar but differently encoded characters, supporting accurate downstream NLP computations.
gc
The gc (garbage collector) module allows explicit control of memory management in Python, particularly for cleaning up unreferenced objects. It is useful when working with large datasets or memory-intensive operations.
In the pipeline, gc is used to free memory after processing large pages or batches of embeddings. This helps maintain efficient RAM usage, especially during preprocessing and embedding generation for multiple URLs, preventing memory overflow in long-running SEO analyses.
logging
The logging module provides a standardized way to capture messages, warnings, and errors during program execution. It offers multiple severity levels and supports flexible output formatting.
Here, logging is used to track key events, warnings, and errors during extraction, preprocessing, and embedding. Detailed logs help monitor pipeline execution, detect failed page fetches, and troubleshoot issues without interrupting the process, making the workflow robust and reliable.
requests
The requests library simplifies making HTTP requests in Python. It supports GET/POST requests, headers, timeouts, and error handling, making it the de-facto standard for web scraping or API interaction.
In this project, requests is used to fetch webpage content for analysis. It allows controlled network calls with timeouts and error handling, enabling stable extraction of HTML content from multiple URLs for subsequent preprocessing and semantic evaluation.
typing (Optional, List, Tuple, Dict, Any, Iterable, Union)
The typing module provides type hints for Python functions, improving code clarity, readability, and maintainability. It allows developers to specify expected data types, supporting safer and more structured coding practices.
Here, type hints are used extensively throughout the pipeline to define expected input and output types of functions. For instance, lists of URLs, optional query lists, and dictionaries of subsections are explicitly typed, making the code more readable and easier to maintain in real-world client projects.
BeautifulSoup (from bs4)
BeautifulSoup is a Python library for parsing HTML and XML documents. It provides simple methods to navigate, search, and modify parse trees, making it an essential tool for web scraping.
In this project, BeautifulSoup is used to parse raw HTML content extracted from URLs. It allows structured extraction of sections, subsections, and text blocks while removing unwanted tags, scripts, and style elements. This structured output forms the foundation for clean preprocessing and embedding generation.
numpy
numpy is a foundational library for numerical computing in Python, providing efficient array operations, linear algebra routines, and mathematical functions. It is widely used in data processing and machine learning pipelines.
Within this project, numpy handles vectorized operations on embeddings, similarity calculations, and aggregation of metrics. Its high-performance arrays enable fast computations over large volumes of semantic vectors, supporting depth, breadth, and query alignment analyses efficiently.
sklearn.cluster.AgglomerativeClustering
AgglomerativeClustering is a hierarchical clustering algorithm from scikit-learn. It groups similar items based on distance metrics and forms nested clusters without requiring a pre-specified number of clusters.
Here, it is used to cluster semantically similar content subsections within a page. By identifying overlapping or redundant sections, the algorithm supports more accurate computation of breadth and granularity, ensuring each conceptual cluster contributes meaningfully to the overall metrics.
sentence_transformers (SentenceTransformer, util)
The sentence-transformers library enables the generation of dense, semantically meaningful embeddings for sentences or text blocks. The util module provides functions such as cosine similarity for measuring semantic closeness.
In this project, SentenceTransformer encodes each subsection’s merged text into embeddings, which form the basis for measuring depth, breadth, and query alignment. Cosine similarity functions from util support clustering and query relevance computations, integrating seamlessly with the knowledge granularity evaluation framework.
torch
PyTorch (torch) is a widely used machine learning library for tensor computations, deep learning model implementation, and GPU acceleration.
In this project, PyTorch underpins the sentence-transformers embedding model. It allows efficient tensor operations for encoding text and computing similarities, leveraging GPU acceleration where available. This ensures fast and scalable semantic analysis across multiple pages and queries.
** transformers.utils.logging (tf_logging)**
The transformers logging utility manages verbosity and progress display for HuggingFace transformers. It allows suppression of excessive logs or progress bars during model inference.
Here, it is configured to reduce console clutter and suppress warnings from the underlying transformer models. This keeps pipeline output clean and professional while focusing on important logging messages relevant to page extraction and embedding.
pandas
pandas is a data manipulation and analysis library in Python, providing DataFrames for tabular data and extensive functionality for aggregation, filtering, and grouping.
In this project, pandas is used to organize and manipulate results for visualization. DataFrames facilitate aggregation of subsection metrics, computation of mean query similarities, and preparation of structured datasets for plotting and reporting.
matplotlib.pyplot
matplotlib.pyplot is a plotting library for creating static, interactive, and animated visualizations in Python. It supports bar charts, scatter plots, histograms, and custom figure styling.
It is used here to visualize page-level metrics (depth, breadth, granularity), correlations, and distributions of query similarities. Clear visualizations help communicate analysis results in a concise and interpretable manner, making complex semantic evaluations actionable.
seaborn
seaborn is a high-level statistical data visualization library built on top of matplotlib. It simplifies plotting complex distributions and relationships with enhanced aesthetics and integrated support for pandas DataFrames.
In this project, seaborn is used to generate aesthetically appealing barplots, scatterplots, and boxplots for query alignment and knowledge metrics. Its statistical plotting capabilities highlight trends and patterns across URLs and queries, aiding understanding and decision-making.
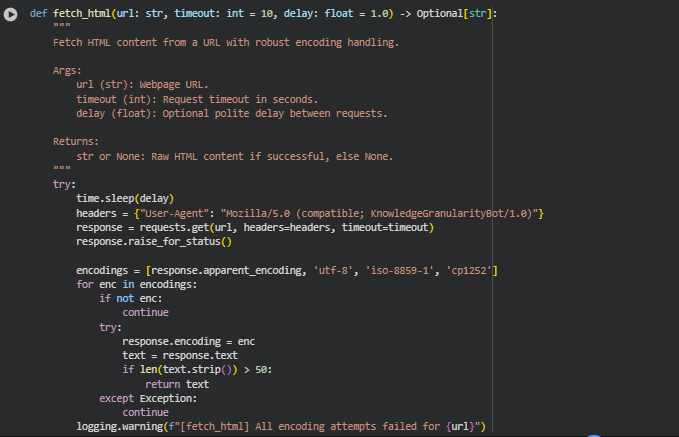
Function: fetch_html
Overview
The fetch_html function retrieves raw HTML content from a given URL while handling network errors, timeouts, and encoding issues. It includes a polite delay between requests to avoid overloading web servers. This function forms the foundation of the extraction stage, ensuring that subsequent preprocessing and semantic analysis receive complete and valid HTML content.
Key Code Explanations
· time.sleep(delay) Introduces a delay before the request. This is essential for responsible web scraping, preventing server overload and reducing the risk of being blocked.
· headers = {“User-Agent”: “Mozilla/5.0 (compatible; KnowledgeGranularityBot/1.0)”} Sets a custom user agent to simulate a standard browser and avoid being blocked by anti-bot mechanisms.
· response.raise_for_status() Ensures that only successful HTTP responses are processed. Any HTTP errors raise exceptions, which are caught and logged.
· Encoding handling loop:
· encodings = [response.apparent_encoding, ‘utf-8’, ‘iso-8859-1’, ‘cp1252’]
for enc in encodings:
response.encoding = enc
text = response.text
if len(text.strip()) > 50:
return text
Iterates over common encodings to correctly decode page content, ensuring reliable handling of multi-language pages and non-standard characters.
Function: clean_html
Overview
clean_html removes unwanted HTML elements such as scripts, styles, navigation menus, footers, and forms. The output is a cleaned BeautifulSoup object containing only meaningful content suitable for structured extraction. This prepares pages for hierarchical section and subsection parsing.
Key Code Explanations
· soup = BeautifulSoup(html_content, “lxml”) Parses the raw HTML into a BeautifulSoup object using the fast and robust lxml parser.
· for tag in soup([…]): tag.decompose() Iterates over non-content tags (scripts, styles, headers, footers, etc.) and removes them from the DOM. This reduces noise in downstream block extraction and ensures semantic embeddings focus on meaningful content.
Function: clean_text
Overview
Normalizes inline text by unescaping HTML entities, standardizing Unicode characters, and collapsing multiple whitespaces. This ensures that extracted content is clean and consistent for tokenization and embedding.
Key Code Explanations
· text = html_lib.unescape(text) Converts HTML-encoded characters like or & into human-readable text.
· text = unicodedata.normalize(“NFKC”, text) Normalizes Unicode characters to a standard form, preventing inconsistencies that could affect semantic similarity calculations.
· text = re.sub(r”\s+”, ” “, text).strip() Collapses consecutive whitespace into single spaces and trims leading/trailing spaces, ensuring clean and uniform content for embeddings.
Function: extract_structured_blocks
Overview
Extracts content from the cleaned HTML into a hierarchical structure: sections → subsections → blocks. Each block retains its heading chain and tag type, enabling granular analysis of depth, breadth, and semantic coverage.
Key Code Explanations
· for el in soup.find_all([…]): Iterates over headings and content elements (h1–h4, p, li, blockquote) to build a hierarchical structure.
· Section and subsection creation:
· if tag in [“h1”, “h2”]:
section = {“section_title”: text, “subsections”: []}
sections.append(section)
subsection = None
if tag in [“h3”, “h4”]:
subsection = {“subsection_title”: text, “blocks”: []}
section[“subsections”].append(subsection)
Dynamically assigns headings to sections or subsections based on HTML tag level. Ensures that each subsection belongs to its correct section.
· Content block appending:
· if len(text) >= min_block_chars:
block_idx += 1
subsection[“blocks”].append({
“block_id”: block_idx,
“text”: text,
“tag_type”: tag,
“heading_chain”: [section[“section_title”], subsection[“subsection_title”]]
})
Only blocks exceeding the minimum character count are included. Each block stores its heading chain, tag type, and unique ID, supporting hierarchical analysis and embeddings later.
Function: extract_page
Overview
The top-level extraction function that combines HTML fetching, cleaning, and structured block extraction. Returns a page dictionary with URL, title, sections, subsections, blocks, and status. It provides a ready-to-process structure for the preprocessing and embedding stages.
Key Code Explanations
· html_content = fetch_html(url) Retrieves the raw HTML. If fetch fails, the function returns a minimal dictionary with status: fetch_failed.
· soup = clean_html(html_content) Cleans HTML by removing scripts, styles, and navigation elements, preparing the content for structured parsing.
· Title extraction and normalization:
· if soup.title and soup.title.string:
title = html_lib.unescape(soup.title.string)
title = unicodedata.normalize(“NFKC”, title).strip()
Ensures the page title is correctly extracted and standardized for consistent reporting and downstream analysis.
· sections = extract_structured_blocks(soup, min_block_chars) Generates a hierarchical structure of sections, subsections, and blocks, which becomes the input for preprocessing, embedding, and knowledge granularity computations.
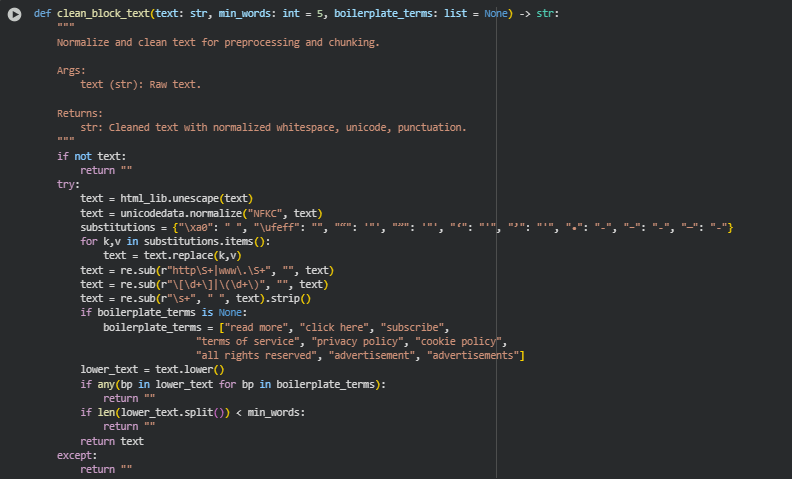
Function: clean_block_text
Overview
The clean_block_text function normalizes and cleans raw text from HTML blocks. It removes boilerplate content, unwanted characters, and short or irrelevant text segments. This ensures that only meaningful content is retained for further chunking and embedding, improving semantic analysis quality.
Key Code Explanations
· text = html_lib.unescape(text) Converts HTML entities like or & into standard characters, making text human-readable.
· text = unicodedata.normalize(“NFKC”, text) Standardizes Unicode characters to a consistent form, avoiding encoding inconsistencies.
· substitutions = {…} and loop over replacements Replaces common symbols (e.g., different dash types, quotes, bullets) with normalized characters for consistent text representation.
· re.sub(r”http\S+|www\.\S+”, “”, text) Removes URLs from the text to avoid noise in embeddings.
· Boilerplate removal check:
if any(bp in lower_text for bp in boilerplate_terms): return “”
Filters out promotional or repetitive content (like “read more” or “subscribe”) which does not contribute to semantic richness.
· Minimum word count check:
if len(lower_text.split()) < min_words: return “”
Ensures that very short or insignificant text blocks are ignored to maintain quality.
Function: chunk_text
Overview
chunk_text splits cleaned text into smaller segments suitable for embedding models. Each chunk contains a maximum number of words, with optional overlap to preserve context across adjacent chunks. This allows processing of long sections without exceeding model input limits.
Key Code Explanations
· words = text.split() Converts text into a list of words for easy slicing into fixed-size chunks.
· Chunking loop:
· while start < len(words):
end = min(start + max_words, len(words))
chunk_words = words[start:end]
chunks.append(” “.join(chunk_words))
start = end – overlap
Iteratively creates chunks of max_words size, maintaining an overlap to preserve semantic continuity between consecutive chunks.
Function: preprocess_extracted_page
Overview
This function transforms extracted page blocks into embedding-ready chunks while minimizing memory usage. It performs incremental cleaning and streaming chunking, avoiding full-text merges and redundant storage. The output is a flat list of subsections with unique IDs and chunked text, ready for embedding computation.
Key Code Explanations
· text_buffer = [] and word_count = 0 Maintains a temporary buffer of words to create chunks incrementally without merging all text at once. This reduces RAM consumption on long pages.
· cleaned_text = clean_block_text(block.get(“text”, “”), …) Applies text normalization and boilerplate removal on each block before chunking, ensuring only meaningful content is processed.
· Incremental chunking:
· while len(text_buffer) >= max_words:
chunk_words = text_buffer[:max_words]
chunk = ” “.join(chunk_words)
…
text_buffer = text_buffer[max_words – overlap:]
Generates chunks of fixed size, maintaining a small overlap window for semantic continuity. Processed words are immediately removed from the buffer to save memory.
· Handling final partial chunk: Ensures leftover words at the end of a subsection are still included as a smaller chunk, preventing content loss.
· gc.collect() Explicitly triggers garbage collection after each subsection, freeing memory and keeping the pipeline stable for large pages.
· Unique subsection IDs:
sub_id = hashlib.md5(f”{subsection_id_base}_{len(cleaned_subsections)+1}”.encode()).hexdigest()
Generates consistent and unique identifiers for each chunk, supporting tracking and linking in downstream embedding and analysis stages.
Function: load_model
Overview
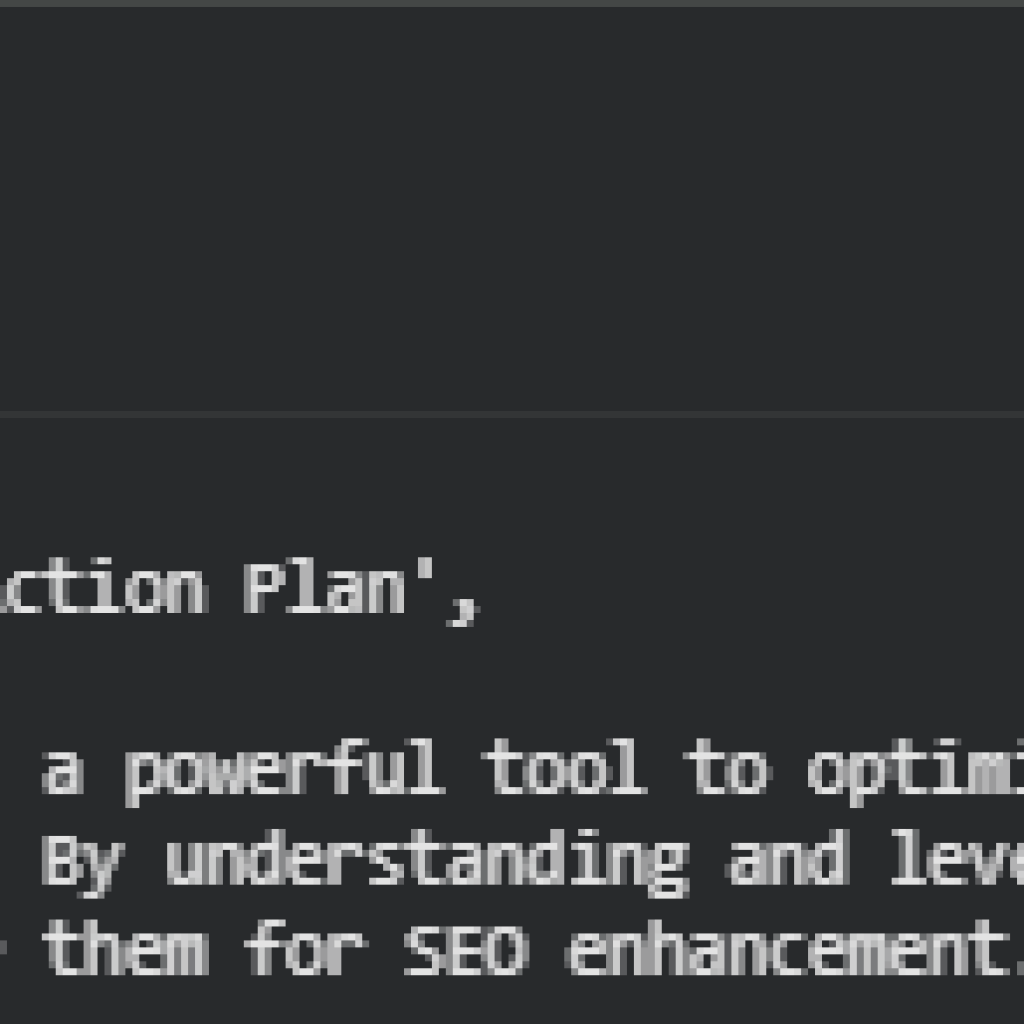
The load_model function loads a pre-trained embedding model from HuggingFace using the Sentence-Transformers library. It allows selection of any model by name (defaulting to “all-mpnet-base-v2”), which is used to generate semantic embeddings for web page subsections and search queries. The function ensures the model is initialized on the appropriate device (CPU or GPU) for efficient inference.
Key Code Explanations
· model = SentenceTransformer(model_name)
Loads the requested Sentence-Transformers model. These models convert text into dense vector embeddings that capture semantic meaning, enabling similarity computation and clustering in later stages.

Model Overview: sentence-transformers/all-mpnet-base-v2
Overview
The all-mpnet-base-v2 model belongs to the Sentence-Transformers family of transformer-based models designed for producing high-quality sentence and paragraph embeddings. It is optimized for semantic similarity, clustering, and information retrieval tasks. Unlike traditional word embeddings, this model generates dense vector representations of full sentences or paragraphs, capturing contextual meaning, semantic relationships, and subtle nuances in language.
Architecture and Key Features
- Built on MPNet (Masked and Permuted Pretraining for Language Understanding), a transformer-based architecture combining advantages of BERT and XLNet.
- Produces 768-dimensional embeddings for each input text.
- Pretrained on large-scale datasets for capturing general semantic knowledge.
- Fine-tuned for sentence-level similarity tasks using datasets such as STS (Semantic Textual Similarity) and NLI (Natural Language Inference), ensuring high alignment with human judgments.
Why This Model Was Used in the Project
- Semantic Accuracy: The model provides embeddings that capture the semantic content of text blocks and subsections, crucial for evaluating conceptual depth and breadth.
- Query Alignment: Embeddings generated by this model allow robust cosine similarity calculations with search or analysis queries, enabling accurate assessment of query relevance per subsection.
- Scalability: The model can process multiple text chunks efficiently with batch encoding, supporting large pages without significant memory overhead.
- Integration: Seamlessly integrates with the Sentence-Transformers Python library and PyTorch, simplifying preprocessing, embedding, and similarity computations across the full knowledge granularity pipeline.
Practical Impact on Project Results
Using all-mpnet-base-v2 ensures that the embeddings capture true semantic relationships, allowing the pipeline to:
- Cluster subsections into meaningful concept groups, reflecting topic coverage.
- Compute depth by measuring intra-cluster similarity.
- Compute breadth based on distinct conceptual clusters.
- Evaluate query relevance per subsection accurately.
This model forms the core semantic understanding engine for the project, making all downstream metrics—depth, breadth, granularity, and query alignment—both reliable and actionable.
Function: generate_embeddings
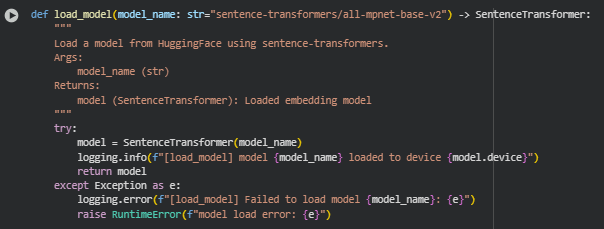
Overview
The generate_embeddings function converts a list of text strings into dense vector representations using a pre-loaded Sentence-Transformer model. These embeddings capture semantic meaning, enabling similarity comparisons, clustering, and relevance scoring across subsections or queries. The function supports batch processing to improve efficiency when encoding large volumes of text.
Key Code Explanations
· if not texts: … return []
Early exit for empty input lists. Prevents unnecessary computation and logs a warning if no valid text is provided.
· embeddings = model.encode(texts, batch_size=batch_size, convert_to_tensor=True, show_progress_bar=False)
- Uses the loaded Sentence-Transformer model to encode all input texts.
- batch_size controls the number of texts processed simultaneously, balancing speed and memory usage.
- convert_to_tensor=True ensures embeddings are returned as PyTorch tensors, compatible with later cosine similarity calculations.
- show_progress_bar=False suppresses visual progress, keeping logs clean in production pipelines.

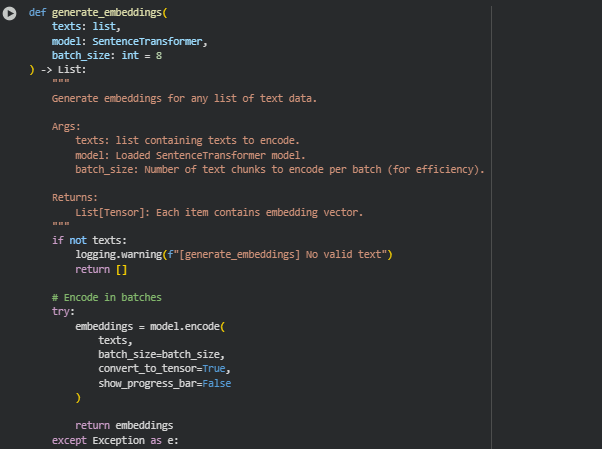
Function: generate_section_embeddings
Overview
The generate_section_embeddings function computes embeddings for each subsection in a preprocessed web page. It takes the merged text from each subsection, encodes it using a Sentence-Transformer model, and attaches the resulting embedding vector back to the corresponding subsection. These embeddings are crucial for downstream similarity calculations, clustering, and query alignment.
Key Code Explanations
· texts = [s[“merged_text”] for s in subsections if s.get(“merged_text”)]
- Collects only subsections with valid text for embedding generation.
- Ensures empty or invalid subsections are skipped, reducing unnecessary computation.
· embeddings = generate_embeddings(texts, model, batch_size)
- Calls the generic embedding function to transform text into vector representations.
- Batch processing improves efficiency and prevents memory overload when handling multiple subsections.
· for s, emb in zip(subsections, embeddings): s[“embedding”] = emb
- Assigns the generated embedding back to the original subsection dictionary.
- Maintains the structured format (section -> subsection -> blocks) with embeddings integrated for downstream analyses such as query relevance or clustering.
Function: generate_query_embeddings
Overview
The generate_query_embeddings function converts a list of search or analysis queries into their corresponding embedding vectors using the same Sentence-Transformer model as used for page subsections. These query embeddings allow direct comparison between user queries and subsection embeddings for relevance scoring and alignment analysis. By reusing the generic generate_embeddings function, it ensures consistent vector representation and batching efficiency.
Key Code Explanations
· embs = generate_embeddings(queries, model, batch_size)
- Encodes all queries into dense vector representations.
- Supports batch processing to handle multiple queries efficiently without memory overload.
· for q, emb in zip(queries, embs): q_embs[q] = emb
- Maps each query string to its corresponding embedding in a dictionary.
- Enables quick lookup of embeddings for similarity calculations in downstream functions like query alignment.

Function: cluster_subsections
Overview
The cluster_subsections function groups subsections of a webpage into concept-based clusters by comparing their embeddings. Subsections with similar semantic content are assigned the same cluster label. This enables the analysis of conceptual breadth, helps detect redundant content, and provides a structure for computing granularity metrics.
Key Code Explanations
· embeddings = [s[“embedding”] for s in page.get(“subsections”, []) if s.get(“embedding”) is not None]
- Collects all subsection embeddings from the page.
- Ensures that only valid embeddings are considered, avoiding errors during clustering.
· embeddings = np.vstack([emb.cpu().numpy() if hasattr(emb, “cpu”) else emb for emb in embeddings])
- Converts embeddings to NumPy arrays, handling PyTorch tensors if needed.
- Stacking enables vectorized computation of pairwise similarities.
· similarity_matrix = util.cos_sim(embeddings, embeddings).cpu().numpy()
- Computes cosine similarity between all pairs of subsections.
- Represents how semantically close each subsection is to the others.
· distance_matrix = 1.0 – similarity_matrix
- Converts similarity into distance (required by clustering algorithm).
- A distance of 0 indicates identical content, and higher values indicate lower similarity.
· clustering = AgglomerativeClustering(…); cluster_labels = clustering.fit_predict(distance_matrix)
- Performs hierarchical agglomerative clustering using the precomputed distance matrix.
- distance_threshold=1 – similarity_threshold determines the granularity of clusters based on the similarity threshold.
· for s, label in zip(page[“subsections”], cluster_labels): s[“concept_cluster”] = int(label)
- Assigns a unique integer cluster label to each subsection.
- Enables downstream calculations such as breadth score and concept-level grouping.

Function: compute_depth
Overview
The compute_depth function calculates the depth score of a webpage, which reflects how semantically cohesive the content is within each concept cluster. A high depth score indicates that subsections within the same concept cluster are highly similar, representing detailed coverage of specific concepts.
Key Code Explanations
· cluster_groups = {}; for s in subsections: label = s.get(“concept_cluster”, -1); cluster_groups.setdefault(label, []).append(s[“embedding”])
- Groups subsection embeddings by their assigned concept cluster labels.
- Enables measuring intra-cluster similarity for depth computation.
· emb_stack = np.vstack([e.cpu().numpy() if hasattr(e, “cpu”) else e for e in embeddings])
- Converts subsection embeddings to a NumPy array for vectorized similarity calculations.
- Handles PyTorch tensors if used for embeddings.
· sim_matrix = util.cos_sim(emb_stack, emb_stack).cpu().numpy()
- Computes pairwise cosine similarity between all subsections in the same cluster.
- Captures semantic cohesion within a concept cluster.
· mask = np.triu(np.ones_like(sim_matrix), k=1).astype(bool); intra_similarities.extend(sim_matrix[mask])
- Selects only the upper triangular values (excluding diagonal) to avoid self-similarity duplicates.
- Aggregates all pairwise similarities across clusters.
· depth_score = float(np.mean(intra_similarities)) if intra_similarities else 0.0
- Calculates the average intra-cluster similarity as the depth score.
- Assigns 0 if no meaningful intra-cluster similarity exists.
· page[“depth_score”] = depth_score
- Stores the computed depth score in the page dictionary for downstream analysis.

Function: compute_breadth
Overview
The compute_breadth function calculates the breadth score of a webpage, which measures how many distinct concepts or topics are covered relative to the total number of subsections. A high breadth score indicates diverse coverage across multiple concepts rather than repetition of the same concept.
Key Code Explanations
· cluster_labels = [s.get(“concept_cluster”) for s in page.get(“subsections”, [])]
- Extracts the concept cluster labels assigned to each subsection.
- These labels represent distinct concept groups identified during clustering.
· num_clusters = len(set(cluster_labels))
- Counts the number of unique clusters (distinct concepts) on the page.
- Key metric for measuring content diversity.
· num_subsections = len(cluster_labels)
- Determines total subsections present.
- Used to normalize breadth relative to content size.
· breadth_score = min(1.0, num_clusters / num_subsections)
- Computes normalized breadth score between 0 and 1.
- Ensures that breadth cannot exceed 1 even if every subsection is unique.
· page[“breadth_score”] = breadth_score
- Stores the computed breadth score in the page dictionary for downstream use.
· page[“num_concepts”] = len(set(cluster_labels))
- Captures the absolute number of distinct concept clusters.
- Useful for understanding the variety of topics covered.
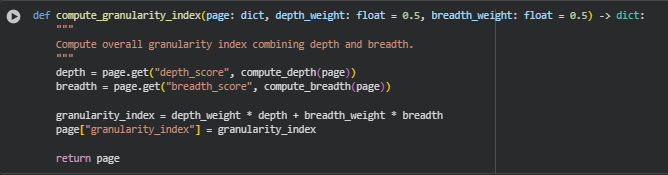

Function: compute_granularity_index
Overview
The compute_granularity_index function calculates a single granularity index for a webpage by combining its depth and breadth scores. This index provides a unified metric that reflects both the conceptual depth (detailed exploration within topics) and breadth (diversity of topics) of content. Weighting factors allow flexible emphasis on either dimension depending on analysis goals.
Key Code Explanations
· depth = page.get(“depth_score”, compute_depth(page))
- Retrieves the depth score from the page if already computed.
- If not present, it calls compute_depth(page) to calculate it.
- Ensures granularity can be computed even if depth hasn’t been precomputed.
· breadth = page.get(“breadth_score”, compute_breadth(page))
- Retrieves the breadth score or calculates it if missing.
- Guarantees that both dimensions are available for granularity computation.
· granularity_index = depth_weight * depth + breadth_weight * breadth
- Combines depth and breadth into a single weighted index.
- depth_weight and breadth_weight are tunable parameters to prioritize depth or breadth as required.
- Produces a continuous score reflecting overall content granularity.
· page[“granularity_index”] = granularity_index
- Stores the final granularity index in the page dictionary for downstream analysis and visualization.
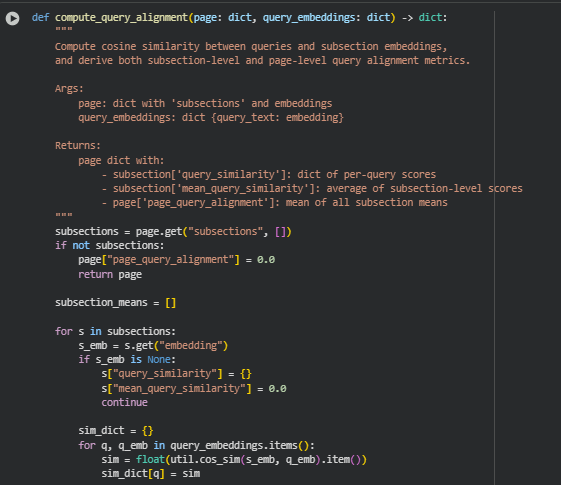

Function: compute_query_alignment
Overview
The compute_query_alignment function evaluates how well the content of a webpage aligns with a set of search or analysis queries. It computes cosine similarity between each query and the embeddings of subsections, generating metrics at both the subsection level and page level. This provides insight into which parts of the content are most relevant to the queries and the overall alignment of the page.
Key Code Explanations
· s_emb = s.get(“embedding”)
- Retrieves the embedding of the subsection.
- If no embedding exists, initializes empty query similarity metrics for that subsection.
· sim = float(util.cos_sim(s_emb, q_emb).item())
- Computes cosine similarity between the subsection embedding and each query embedding.
- Provides a relevance score ranging from 0 (no similarity) to 1 (high similarity).
· s[“query_similarity”] = sim_dict
- Stores per-query similarity scores for the subsection.
- Allows later visualization or analysis to identify which queries are best addressed by which subsections.
· s[“mean_query_similarity”] = sum(sims) / len(sims) if sims else 0.0
- Calculates the average similarity across all queries for this subsection.
- Provides a concise measure of how well the subsection content aligns overall with the set of queries.
· page[“page_query_alignment”] = sum(subsection_means) / len(subsection_means) if subsection_means else 0.0
- Computes the mean of all subsection averages to produce a page-level query alignment metric.
- Summarizes the overall relevance of the page to the query set in a single score.

Function display_results
Overview
The display_results function provides a concise, user-facing summary of the processed page results. It takes the fully processed pipeline output and prints key page-level metrics—Depth Score, Breadth Score, Granularity Index, Page Query Alignment, and Concept Clusters—in a clear format. It also highlights the top n subsections based on their mean query similarity, showing a snippet of each subsection and the corresponding query relevance scores.
This function does not perform any computation. All metrics and similarity values are precomputed in the pipeline, ensuring that the display step is lightweight and memory-efficient. Sorting of subsections by mean query similarity is applied solely for presentation purposes to highlight the most relevant content.
The function is useful for quickly understanding which parts of a page contribute most to its knowledge depth and alignment with specified queries, providing an actionable, easily interpretable overview without exposing raw data or requiring further analysis.
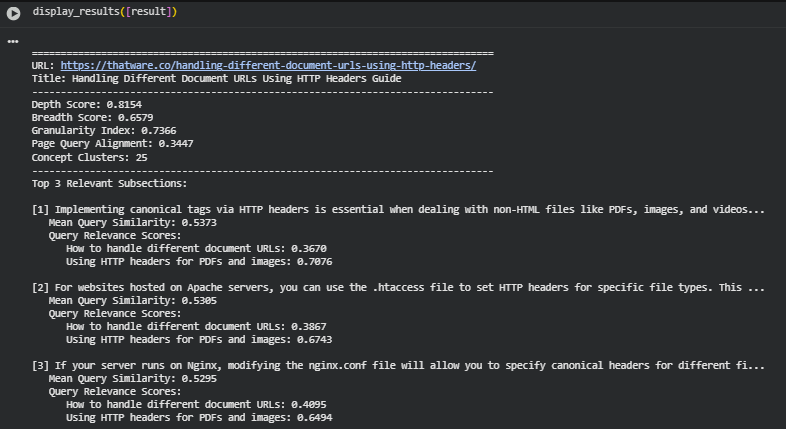
Result Analysis and Explanation
The following analysis is based on a single-page evaluation with two search queries. Each section focuses on a specific aspect of the results, providing actionable interpretation and guidance.
Page-Level Granularity Metrics
Depth Score (0.8154):
· Definition: Measures the semantic cohesion within clusters of sections. A higher score indicates that sections within a concept cluster are highly related, reflecting well-developed content on specific topics.
· Interpretation: With a depth score above 0.8, this page demonstrates strong conceptual depth, meaning it covers topics thoroughly with consistent information across related sections.
· Threshold Guidelines:
- 0.0 – 0.5: Low depth, content may be superficial.
- 0.5 – 0.7: Moderate depth, some concept areas may lack detail.
o 0.7: High depth, well-developed and focused coverage.
Breadth Score (0.6579):
· Definition: Represents the coverage of distinct concept clusters, normalized by the number of sections. High breadth suggests diverse topic coverage within the page.
· Interpretation: A score of ~0.66 indicates that the page covers multiple concept clusters reasonably well but may have some clusters with multiple related sections, showing moderate diversity of topics.
· Threshold Guidelines:
- 0.0 – 0.4: Limited topic coverage, mostly repetitive content.
- 0.4 – 0.7: Moderate breadth, several unique concepts are addressed.
o 0.7: High breadth, extensive conceptual coverage.
Granularity Index (0.7366):
- Definition: Weighted combination of depth and breadth (default weights: 0.5 each), reflecting overall knowledge granularity.
- Interpretation: A value of ~0.74 indicates a balanced page with strong conceptual depth and moderately diverse topic coverage. This score can be used to compare pages on a website to identify the most content-rich or detailed resources.
Page Query Alignment (0.3447):
· Definition: Average alignment of sections with search or analysis queries, reflecting relevance of content to specific queries.
· Interpretation: A score of ~0.34 suggests moderate relevance, indicating that some sections are aligned with the queries, while others may require refinement to improve query-specific coverage.
· Threshold Guidelines:
- 0.0 – 0.3: Low relevance; most content does not match queries.
- 0.3 – 0.6: Moderate relevance; a significant portion of content aligns with queries.
o 0.6: High relevance; content is well-targeted to queries.
Concept Clusters (25):
- Definition: Number of distinct semantic clusters identified across sections.
- Interpretation: A total of 25 clusters indicates a diverse set of concepts addressed, allowing granular analysis of section-level focus areas.
Top Relevant Sections
This section highlights the sections most aligned with the queries, providing insight into which content is most effective in addressing search intents.
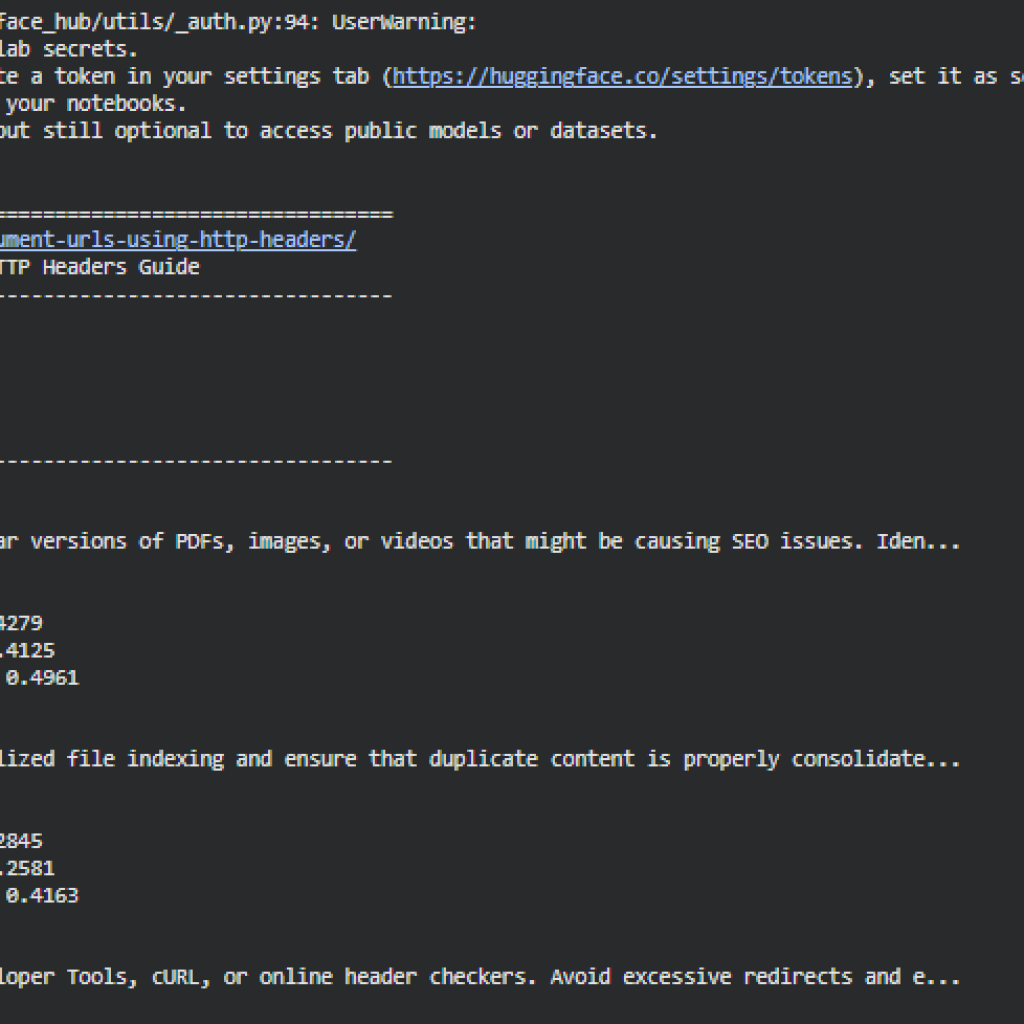
Section 1: “Implementing canonical tags via HTTP headers is essential when dealing with non-HTML files like PDFs, images, and videos…”
· Mean Query Similarity: 0.5373 (moderate to high relevance)
· Query-Specific Alignment:
- “How to handle different document URLs”: 0.3670 → Moderate alignment; content partially addresses this query.
- “Using HTTP headers for PDFs and images”: 0.7076 → Strong alignment; content is highly relevant to this query.
· Interpretation: This section is particularly strong for query-specific content on HTTP headers and file-type handling but may only partially satisfy broader document URL handling queries.
Section 2: “For websites hosted on Apache servers, you can use the .htaccess file to set HTTP headers for specific file types…”
· Mean Query Similarity: 0.5305
· Query-Specific Alignment:
- “How to handle different document URLs”: 0.3867
- “Using HTTP headers for PDFs and images”: 0.6743
· Interpretation: Provides practical server-level guidance. Slightly lower relevance to the general query compared to Section 1 but still significant for PDF and image handling guidance.
Section 3: “If your server runs on Nginx, modifying the nginx.conf file will allow you to specify canonical headers for different files…”
· Mean Query Similarity: 0.5295
· Query-Specific Alignment:
- “How to handle different document URLs”: 0.4095
- “Using HTTP headers for PDFs and images”: 0.6494
· Interpretation: Demonstrates platform-specific guidance for Nginx servers, slightly lower alignment than Section 2 for the second query but still among the top relevant content.
Practical Insights:
- These sections indicate strong technical coverage for specific scenarios (Apache, Nginx, canonical headers).
- Sections can be prioritized for query-focused SEO optimization, highlighting content that addresses highly relevant queries while identifying gaps for less-aligned topics.
Actionable Takeaways
1. Strengths:
- High depth indicates well-developed, cohesive content.
- Multiple clusters ensure diverse topics are addressed.
- Top sections show clear alignment to key queries, particularly for file-type handling with HTTP headers.
2. Opportunities:
- Page-level query alignment (~0.34) suggests that overall query coverage can be improved, possibly by linking more sections to broader document URL handling topics.
- Breadth is moderate; some concepts might be overrepresented, while others may require expansion.
3. SEO Guidance:
- Highlight and structure sections with high query relevance to strengthen query-targeted SEO signals.
- Consider expanding content in clusters with lower mean query similarity to improve alignment with other important queries.
Result Analysis and Explanation
This section provides an in-depth analysis of multi-page content using the Knowledge Granularity Evaluator framework. It focuses on understanding conceptual depth, breadth, granularity, and query alignment across multiple web pages. The section is structured to give practical insights into each metric, subsections’ relevance, and the visual interpretation of results.
Page-Level Knowledge Metrics
Depth Score
Definition: Depth measures the internal semantic coherence of content clusters within a page. Higher depth indicates that a page explores individual topics thoroughly, with consistent and detailed content across subsections.
Interpretation:
· Thresholds for evaluation:
- Depth > 0.75 → Strong, detailed conceptual coverage.
- Depth 0.50–0.75 → Moderate depth; some topics may require further elaboration.
- Depth < 0.50 → Low depth; content is shallow or fragmented.
Pages in this dataset generally show depth scores above 0.8, suggesting robust coverage of individual topics and consistent intra-cluster similarity. High depth is beneficial for demonstrating authority on specific SEO concepts.
Breadth Score
Definition: Breadth measures the diversity of concept clusters within a page. A higher breadth score indicates coverage of a wider range of topics.
Interpretation:
· Thresholds for evaluation:
- Breadth > 0.70 → Broad topic coverage; content covers many distinct areas.
- Breadth 0.40–0.70 → Balanced coverage; mix of topic depth and diversity.
- Breadth < 0.40 → Narrow focus; may miss relevant topics or context.
Observed breadth scores vary across pages, indicating some pages focus on fewer, deeper concepts, while others attempt broader coverage. Proper balance between depth and breadth supports both specialized expertise and overall topical comprehensiveness.
Granularity Index
Definition: Granularity Index is a combined measure of depth and breadth, providing an overall representation of knowledge structure.
Interpretation:
· Thresholds for evaluation:
- Granularity > 0.70 → Highly granular; content is both deep and broad.
- Granularity 0.55–0.70 → Moderately granular; generally informative but may lack full coverage.
- Granularity < 0.55 → Low granularity; content may need improvement in either depth or breadth.
Granularity scores in this dataset reflect strong, moderately balanced knowledge structures, with the majority of pages maintaining a solid blend of detailed subsections and coverage diversity.
Concept Clusters
Definition: Represents the number of distinct thematic clusters identified in the page. Higher numbers indicate a richer variety of topics.
Practical Implication:
- Large numbers of concept clusters (>50) suggest high semantic diversity, requiring careful structuring to maintain clarity.
- Small numbers (<20) may indicate concentrated focus on a few core topics.
The analyzed pages demonstrate varying cluster counts, which aligns with their respective breadth and granularity profiles.
Query Alignment Metrics
Page-Level Query Alignment
Definition: Measures how well a page aligns with multiple target queries by computing average cosine similarity between query embeddings and content subsections.
Interpretation:
· Thresholds for evaluation:
- Alignment > 0.50 → Strong relevance; content is highly aligned to query topics.
- Alignment 0.30–0.50 → Moderate relevance; some subsections are well-aligned while others may need improvement.
- Alignment < 0.30 → Low relevance; content may not effectively address target queries.
The dataset shows varying query alignment scores, with some pages demonstrating moderate alignment while others remain low. High alignment ensures that content effectively addresses intended search queries, supporting both SEO visibility and user satisfaction.
Subsection-Level Query Relevance
Definition: Each subsection is evaluated against individual queries to identify the most relevant content segments.
Interpretation:
- Mean query similarity per subsection indicates practical relevance to multiple queries.
- Subsections with higher mean similarity scores can be prioritized for optimization, internal linking, or featured snippets.
Practical Insight: Pages may contain highly relevant subsections for certain queries but underperform for others. Recognizing these patterns allows strategic content refinement and query-specific improvements.
Visualization of Multi-URL, Multi-Query Results
Visualizations play a critical role in summarizing the multi-page, multi-query analysis. The framework provides several key visual perspectives:
Page-Level Knowledge Overview
Visualization: Bar chart comparing Depth, Breadth, and Granularity Index for each page.
Insights:
- Allows quick identification of pages that are conceptually strong or need improvement.
- High bars across all metrics indicate comprehensive and balanced content.
- Useful for prioritizing content review or updating strategy.
Depth–Breadth Correlation
Visualization: Scatter plot of Depth vs Breadth, with marker size representing Granularity Index.
Insights:
- Reveals trade-offs between topic detail and coverage diversity.
- Pages in the upper-right quadrant are both deep and broad.
- Marker size helps identify pages with high overall granularity.
Query Alignment Across Pages
Visualization: Bar plot of average subsection-level similarity per query across pages.
Insights:
- Shows which pages are better aligned to specific queries.
- Queries with consistently low scores across pages may require content expansion or restructuring.
- Supports prioritization of query-specific optimization efforts.
Query Similarity Distribution
Visualization: Boxplots showing distribution of query–subsection similarity scores for all pages and queries.
Insights:
- Highlights variance in content alignment; detects over-optimized or under-aligned content.
- Subsections with extreme low or high scores can be identified for improvement or enhancement.
- Provides an overall diagnostic view for content alignment quality.
Practical Summary of Multi-Page Analysis
- Balanced Depth and Breadth: High depth ensures detailed topic coverage, while breadth indicates coverage diversity. A mix is optimal for search engine ranking and topic authority.
- Granularity Index: Serves as a concise measure of overall content quality, highlighting pages with strong conceptual structure.
- Query Alignment: Identifies gaps in content coverage relative to target queries. Subsection-level metrics allow precise adjustments.
- Visual Diagnostics: Plots provide actionable insights for page comparison, identifying underperforming pages or subsections.
This multi-page, multi-query evaluation provides a comprehensive, actionable view of content quality, supporting targeted SEO improvements and strategic content planning.
Q&A Section: Understanding Results and Action Suggestions
What does a high depth score indicate, and how can it benefit my SEO strategy?
A high depth score reflects strong semantic consistency and detailed coverage within content clusters. In practical terms, it means that each topic on a page is thoroughly explored, with well-developed subsections that reinforce the core subject matter.
Action Suggestions:
- Identify pages with high depth and leverage them as authoritative resources for internal linking.
- Use high-depth sections as reference material for new content creation or expansions.
- Maintain or enhance the depth by updating with fresh insights, examples, and statistics to strengthen topical authority.
Benefits:
- Improved search engine trust and ranking for targeted topics.
- Increased user engagement due to comprehensive content coverage.
How should I interpret the breadth score and adjust my content strategy?
Breadth measures the diversity of topics or concept clusters covered on a page. A high breadth score indicates that a page addresses multiple relevant topics, while a low breadth score suggests narrow focus.
Action Suggestions:
- For pages with low breadth, consider adding sections that cover related topics or user-relevant concepts.
- For pages with very high breadth but moderate depth, review subsections to ensure sufficient detail for each topic.
Benefits:
- Balanced breadth ensures pages are useful to a wider audience and improve topical relevance.
- Supports capturing multiple search intents for related queries (without explicitly targeting intent in the model).
What insights does the granularity index provide, and how can it be leveraged?
The granularity index combines depth and breadth, providing a holistic view of content richness. Higher scores indicate that pages are both detailed and diverse in content coverage.
Action Suggestions:
- Prioritize high-granularity pages for promotional efforts, link-building, or as cornerstone content.
- Analyze low-granularity pages to identify gaps in detail or missing topics and plan content updates.
Benefits:
- Facilitates quick identification of content strengths and weaknesses.
- Guides strategic content optimization to improve SEO performance holistically.
How do page-level and subsection-level query alignment scores inform SEO decisions?
Page-level alignment shows the overall relevance of a page to target queries, while subsection-level scores highlight specific areas where content matches or misses query intent. Higher scores indicate stronger semantic alignment.
Action Suggestions:
- Focus on improving subsections with low query alignment by enriching them with query-relevant information.
- Use high-alignment subsections to support internal linking and anchor texts for related pages.
- Adjust content prioritization based on pages’ overall alignment with key queries.
Benefits:
- Ensures that content effectively addresses target topics and improves discoverability in search results.
- Allows granular adjustments without rewriting entire pages.
How can I use concept cluster information to improve content structure?
Concept clusters group semantically related subsections, revealing the thematic organization of a page. High numbers of clusters indicate diverse content, whereas lower numbers show concentrated focus.
Action Suggestions:
- Review cluster distribution to ensure logical grouping of related content.
- Merge or split subsections to balance clusters for clarity and readability.
- Identify underrepresented clusters and expand them to cover missing topics.
Benefits:
- Improves user experience by presenting logically organized content.
- Supports SEO by ensuring both topic coverage and structure are optimized for search engines.
How can the visualizations provided help in strategic SEO planning?
Visualizations such as bar charts, scatter plots, and distribution plots allow for quick assessment of multiple pages and queries. They highlight which pages are strong or weak in depth, breadth, granularity, and query alignment.
Action Suggestions:
- Use page-level overview charts to compare multiple URLs and prioritize high-potential pages.
- Analyze depth–breadth correlations to find pages that are either too shallow or too narrow.
- Examine query alignment distributions to detect underperforming queries or over-optimized subsections.
Benefits:
- Facilitates data-driven content strategy decisions.
- Provides clear guidance on which pages require updates or expansion.
- Enhances ability to monitor performance across multiple pages simultaneously.
What practical steps can be taken if a page has high depth but low breadth?
High depth but low breadth indicates detailed coverage of a narrow set of topics.
Action Suggestions:
- Expand the page to include related concepts or supporting topics.
- Link to other pages covering complementary subjects to broaden the semantic footprint.
- Ensure new content maintains quality and coherence to preserve depth.
Benefits:
- Creates content that is both authoritative and topically comprehensive.
- Increases chances of ranking for multiple related keywords.
How can low query alignment scores be addressed effectively?
Low alignment scores indicate content subsections may not be closely related to target queries.
Action Suggestions:
- Identify subsections with lowest alignment and enrich content with query-relevant information.
- Consider restructuring content to group related concepts together for better semantic alignment.
- Use embeddings or semantic tools to guide content updates rather than keyword stuffing.
Benefits:
- Enhances page relevance for important queries.
- Improves visibility in search results without sacrificing content quality.
Final Thoughts
The Knowledge Granularity Evaluator project successfully assessed web content across multiple dimensions, providing a clear understanding of conceptual depth, breadth, and semantic coverage. By leveraging structured content extraction, preprocessing, and state-of-the-art embeddings, the project delivered actionable insights into how thoroughly and comprehensively pages address relevant topics.
Pages with higher depth scores demonstrate detailed exploration of individual concepts, while breadth scores reveal the diversity and variety of topics covered. The combined granularity index offers a holistic measure of content richness, balancing both depth and breadth to highlight pages that are information-dense and well-organized.
The query alignment metrics effectively quantify semantic relevance between content and target queries, allowing identification of subsections that are highly aligned or require enhancement. Concept clusters further reveal the structural organization of content, supporting optimization of logical flow and thematic grouping.
Through multi-page, multi-query evaluation and the accompanying visualizations, the project provides a practical framework for understanding content strengths, prioritizing optimizations, and strategically enhancing web pages to maximize topical coverage and relevance. This structured approach ensures that content is both detailed and diversified, aligning with the goals of improving search visibility, user comprehension, and overall informational value.
