SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
The Query–Content Interpretive Depth Analyzer is a data-driven SEO analysis tool designed to evaluate the comprehensiveness and depth of information coverage provided by web pages relative to specific search queries. This project leverages natural language processing (NLP) and semantic embedding techniques to measure how well each section of a page addresses a query, providing both granular and overall insights into content quality and relevance.

The analysis is conducted at the section level of the webpage, taking into account factors such as informational density, semantic similarity to queries, and internal content cohesion. For each query, the tool computes a Per-Query Depth Index (PDI), classifying content coverage as shallow, moderate, or deep. Additionally, clustering techniques are applied to identify related content blocks and evaluate the consistency of topic coverage across sections.
The output delivers actionable insights for SEO strategists, highlighting which sections contribute most to query coverage, which queries are insufficiently addressed, and where content improvements could yield higher relevance and authority. By providing both section-level and page-level metrics, the tool supports informed decision-making in content optimization, search visibility, and competitive analysis.
Project Purpose
The purpose of the Query–Content Interpretive Depth Analyzer project is to provide SEO strategists and content teams with a reliable analytical framework to measure how deeply a webpage addresses user search intents. Traditional SEO evaluation methods often focus on keyword matching or surface-level topic presence, which fail to capture the true interpretive depth and contextual relevance of the content. This project fills that gap by introducing an interpretable, query-aware depth analysis using advanced NLP and embedding models.
By mapping the semantic relationship between client-specified queries and webpage content, the tool identifies whether the information provided is surface-level (shallow), partially comprehensive (moderate), or fully informative (deep). This distinction helps SEO professionals make data-backed decisions about content enhancement, restructuring, or optimization to improve organic search rankings and on-page engagement.
The system also goes beyond simple similarity analysis by incorporating content density and semantic cohesion within sections, allowing a more holistic understanding of informational value. The integration of clustering and depth scoring provides both a micro-level (section-based) and macro-level (page-based) perspective — enabling strategists to pinpoint strengths, weaknesses, and missed opportunities in how a page satisfies specific search intents.
In essence, the project’s core purpose is to transform unstructured webpage content into quantifiable, interpretable insights that guide actionable content improvement and increase search performance consistency across multiple URLs and queries.
Project’s Key Topics Explanation and Understanding
This section explains the fundamental concepts and analytical frameworks that the Query–Content Interpretive Depth Analyzer is built upon. Understanding these topics helps clarify how the system evaluates the informational richness and interpretive scope of web content in relation to user search intents.
Interpretive Depth in Content Analysis
Interpretive depth refers to how comprehensively a piece of content explains, expands, and contextualizes the subject matter associated with a specific query or intent. In SEO and content evaluation, interpretive depth moves beyond keyword matching or surface-level relevance. It captures whether the page meaningfully engages with the query’s conceptual space — addressing why and how aspects rather than merely what. For instance, a shallow article may define a concept, whereas a deep article connects it to related subtopics, real-world implications, or user-oriented solutions. Measuring interpretive depth allows for a structured assessment of informational coverage, guiding content creators to achieve expert-level topical completeness.
Semantic Similarity and Query Alignment
Semantic similarity quantifies the conceptual closeness between two pieces of text — such as a query and a content section — based on meaning rather than word overlap. Modern NLP models like sentence-transformers generate embeddings, numerical representations of sentences, that capture nuanced meaning. By comparing these embeddings through cosine similarity, the system determines how closely each section of a webpage aligns with the client-specified search queries. High similarity indicates strong topical relevance, while lower similarity signals potential misalignment or under-coverage of key search intents.
Content Density
Content density measures how much meaningful information is conveyed within a given text segment relative to its length. In practice, it evaluates how efficiently a section communicates ideas without redundancy or filler text. Dense sections tend to provide valuable insights or actionable information per unit of content, while low-density sections may contain general statements or promotional language with limited informational weight. This measure ensures that interpretive depth is not achieved at the cost of verbosity and that high-ranking sections maintain precision and substance.
Semantic Weight and Conceptual Compactness
Semantic weight represents the concentration of meaningful, topic-relevant content within a section. It is closely related to the concept of semantic compactness, which identifies whether the embedded meaning of a text segment is focused or dispersed. In SEO-oriented analysis, this helps detect whether content is drifting into tangential subjects or staying anchored to the core intent. Sections with high semantic weight are more likely to satisfy search engines’ preference for focused, intent-rich coverage.
Clustering and Topical Cohesion
Clustering is used to group similar sections or subsections of a webpage based on their semantic embeddings. The goal is to understand how well the content is organized into coherent topical groups. Each cluster ideally represents a distinct subtheme within the page. Cluster cohesion measures the internal consistency of these groups — i.e., how closely related the sections within a cluster are. High cohesion suggests strong internal alignment and structural clarity, whereas low cohesion may indicate scattered or unfocused content distribution.
Page Depth Index (PDI)
The Page Depth Index is a conceptual framework that quantifies the overall interpretive depth of a page relative to search queries. It integrates multiple components — semantic similarity, topic overlap, content density, and variance within clusters — into a unified metric representing whether a page’s informational coverage is shallow, moderate, or deep. While the exact computation involves normalized scores and weighted components, conceptually, PDI provides a single interpretable measure of how thoroughly a page addresses its intended queries.
Query–Content Relationship Modeling
At the core of this project is the relationship modeling between queries (user intents) and page content. Each query represents a distinct search intent, and each content section provides a potential answer space. By embedding both in a shared semantic space, the system can analyze which sections best address specific queries and whether the overall page provides balanced and comprehensive coverage across multiple intents. This approach transforms traditional content auditing into an interpretable, data-driven process rather than subjective manual evaluation.
keyboard_arrow_down
Q&A Section — Understanding Project Value and Importance
Why is interpretive depth analysis important for SEO and content optimization?
Search engines today evaluate more than keyword matching; they assess how comprehensively a page covers the underlying topic or intent behind a query. Interpretive depth analysis measures the informational completeness of a page — how thoroughly it addresses the user’s intent, supporting context, and related subtopics. For SEO professionals, this allows a shift from volume-based optimization (more keywords, longer content) to quality-based optimization (depth, structure, and relevance). By quantifying interpretive depth, teams can identify whether content satisfies the knowledge expectation of users and search engines alike, directly impacting ranking quality and topical authority.
How does this project help identify content gaps and opportunities?
Every webpage can appear relevant for certain queries on the surface, yet fail to cover specific subthemes or detailed explanations users seek. This system analyzes each section of a page against queries, revealing where coverage is strong and where it is insufficient. It highlights:
- Under-explained concepts that reduce interpretive depth,
- Redundant sections adding little value, and
- Missing connections between related ideas.
These insights enable SEO strategists to focus improvement efforts precisely where depth or topical balance is lacking — rather than rewriting entire pages blindly.
How does this system differ from conventional content auditing or keyword density tools?
Traditional content audits rely heavily on heuristics — keyword frequency, readability, or superficial structure — which rarely capture the semantic richness or conceptual relevance of content. This project leverages transformer-based embeddings to evaluate meaning, not just language patterns. Instead of asking “Does this section include the target keyword?”, the system asks “Does this section genuinely address the idea represented by the query?”. This difference allows for deeper interpretive insights, uncovering weaknesses that conventional keyword or readability tools cannot detect.
What specific advantages does this bring for content strategy and optimization planning?
From a strategy perspective, the system offers actionable advantages:
- Topic Prioritization: It identifies which themes or queries are well-covered versus underrepresented, guiding targeted content expansion.
- Section-Level Insights: Teams can determine which parts of the page add interpretive value and which dilute topical focus.
- Optimization Efficiency: Instead of rewriting full pages, strategists can enhance specific low-depth sections, saving both time and editorial effort.
- Quality Assurance: Quantitative interpretive depth metrics allow managers to standardize evaluation criteria across multiple writers and projects.
This transforms qualitative editorial decisions into measurable, repeatable optimization workflows.
How does this project help build topical authority and E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness)?
Search algorithms increasingly emphasize E-E-A-T, rewarding pages that demonstrate comprehensive expertise and structured coverage. The Query–Content Interpretive Depth Analyzer supports this goal by identifying whether a page covers essential dimensions of a topic — from definitions and use cases to causes, methods, and implications. By systematically deepening interpretive layers of content, the project contributes directly to building topical authority, a critical factor for long-term SEO growth and content credibility. In effect, it operationalizes E-E-A-T principles into quantifiable evaluation and optimization actions.
Can this system assist in evaluating content performance across multiple intents or audience segments?
Yes. Many pages serve multiple search intents — informational, transactional, navigational — across various audience types. This project supports multi-query analysis, allowing each query or intent to be evaluated individually and in aggregate. The result is a clearer understanding of whether the same content effectively satisfies distinct search purposes. This capability helps SEO teams balance intent coverage, ensuring that pages remain both focused and inclusive of diverse user needs.
Why is a data-driven interpretive framework critical for scalable SEO auditing?
Manual evaluation of content depth SEO techniques has become impractical as site size grows. Different auditors may produce inconsistent judgments, and human bias can skew interpretation. By introducing a model-driven, quantifiable interpretive framework, the project standardizes how interpretive depth is assessed. It allows scaling from a few pages to hundreds while maintaining consistency, objectivity, and interpretability — ensuring that optimization decisions are rooted in evidence, not intuition.
Libraries Used
time
The time library is a built-in Python module that provides functions for tracking and manipulating time-related operations, such as measuring execution duration or implementing delays. In data processing pipelines, it is often used to log performance metrics or monitor the runtime of different functions.
In this project, time helps measure the efficiency of web scraping, embedding generation, and analytical computations. Tracking these durations is useful for optimizing the workflow and ensuring scalability when analyzing multiple URLs or large web pages.
re
The re module is Python’s regular expression library, used for pattern matching and text manipulation. It provides a flexible way to identify and clean specific patterns within text, such as removing unwanted symbols, HTML tags, or repetitive spaces.
Here, re is used to sanitize and normalize webpage text before generating embeddings. Since SEO-related page content often includes extraneous characters or formatting, regular expressions ensure that the extracted text is clean and semantically consistent before analysis.
html (as html_lib)
The html module provides utilities for escaping and unescaping HTML entities — converting between encoded and readable text.
In this project, html_lib is used to decode HTML entities extracted during webpage parsing. Web content often includes encoded characters (like & or ’), and decoding them ensures the model receives clean, natural text for embedding and semantic analysis.
hashlib
The hashlib library provides cryptographic hash functions like SHA-256 and MD5. These functions convert data into fixed-length hash values useful for generating unique identifiers.
In this project, hashlib is used to generate unique hashes for content segments (subsections). This prevents duplication and allows efficient caching and reference tracking, especially when analyzing multiple pages or repeated content sections.
unicodedata
The unicodedata library enables normalization and manipulation of Unicode text. It ensures consistent encoding across languages and symbols, which is essential for multilingual or symbol-rich webpage content.
In this project, it standardizes characters, accents, and other language-specific variations before further analysis. This normalization guarantees that embeddings accurately capture intended semantics without distortion caused by inconsistent encoding.
logging and warnings
The logging module provides a standardized interface for tracking events and system messages. Compared to simple print statements, it supports configurable log levels, timestamps, and file outputs, making it suitable for professional-grade applications.
The warnings module handles non-critical alerts from the system or libraries gracefully. In this project, both modules are used to monitor data flow, model behavior, and potential issues during webpage parsing, model inference, or visualization generation. This approach enhances debugging, transparency, and production-level reliability.
trafilatura
trafilatura is a specialized library for extracting and cleaning the main textual content from webpages. Unlike generic scrapers, it focuses on meaningful content such as articles, posts, or reports, while removing navigation elements, ads, or unrelated components.
Here, it serves as the primary tool for clean content extraction, ensuring that only contextually relevant text is fed into the model for query–content depth evaluation.
requests
The requests library is a widely used Python HTTP library that enables seamless interaction with web resources via GET and POST requests. In this project, it is employed to fetch webpage HTML content from client-provided URLs.
Its simplicity, reliability, and robustness make it well-suited for production use, particularly when processing multiple URLs in SEO analysis pipelines.
typing
The typing module provides type hinting, enhancing code readability, structure, and maintainability. It allows static type checking to reduce logical and structural errors in large codebases.
In this project, it ensures that all functions clearly specify expected input and output types, adding a layer of professionalism and safety, especially important when multiple developers or teams interact with the system.
BeautifulSoup
BeautifulSoup is a Python library for parsing and navigating HTML or XML documents, facilitating efficient extraction, cleaning, and structuring of web content.
While trafilatura handles automated, structured content extraction, BeautifulSoup offers finer control for manual HTML parsing or tag-specific extraction. This ensures flexibility in cases where automated tools may miss meaningful sections.
numpy (np)
NumPy is the foundational library for numerical computation in Python. It supports efficient operations on large, multi-dimensional arrays and provides a wide range of mathematical functions.
In this project, it supports vector computations, distance measurements, and normalization operations involved in the interpretive depth and density calculations. NumPy’s performance and precision are critical for processing large-scale embedding data.
sentence_transformers (SentenceTransformer, CrossEncoder, util)
The sentence_transformers library provides state-of-the-art transformer-based models for generating text embeddings and performing semantic similarity computations.
In this project, it forms the core of the analytical process. The SentenceTransformer generates embeddings for both query and content segments, while CrossEncoder is used for direct query–section relevance scoring. The util module assists in similarity computations. Together, these enable the system to measure semantic depth and content relevance at a fine-grained level.
torch
PyTorch is an open-source deep learning framework widely used for training and inference of neural networks. It provides tensor operations and GPU acceleration.
Here, it powers the embedding and semantic analysis process. PyTorch underpins the transformer models used in this project, managing tensor computations efficiently for large content batches, ensuring scalability and accuracy.
transformers.utils (logging as tf_logging)
This is a utility from the transformers library used to control verbosity and suppress non-critical logs during model execution.
In this project, it helps maintain clean output by disabling progress bars and excessive model warnings, keeping the runtime experience professional and uncluttered.
pandas (pd)
pandas is a leading data manipulation and analysis library for structured data. It provides the DataFrame object, enabling organized handling of tabular data.
Here, it is used for organizing intermediate and final results such as interpretive depth scores, density metrics, and section-level statistics. It also helps in transforming raw data into formats suitable for visualization and reporting.
matplotlib.pyplot (plt)
matplotlib is a foundational plotting library in Python for static, interactive, and publication-quality visualizations.
In this project, it is used to visualize interpretive depth, density, and section-level analysis. The plots are designed to be client-friendly, making technical results easy to understand through clear and well-annotated visuals.
seaborn (sns)
seaborn builds on top of matplotlib to provide high-level, aesthetically appealing visualizations optimized for data analysis.
In this project, it is used to create clean and professional barplots, line charts, and other data-driven visual summaries. It helps translate quantitative analysis into visually interpretable insights, allowing clients to quickly grasp comparative and trend-based results.
Function: fetch_html
Summary
The fetch_html function is responsible for downloading raw HTML content from a given webpage URL in a stable, controlled, and production-safe way. It integrates essential features such as polite delay, retry mechanisms, exponential backoff, and multi-encoding support to ensure reliable content retrieval even when encountering slow responses or encoding inconsistencies.
This function forms the first step in the project’s processing pipeline — it ensures clean and consistent access to raw webpage data, which will later be parsed and analyzed. Its robustness minimizes data gaps caused by temporary network issues or misconfigured web servers, which is critical for maintaining data quality in SEO and content analysis workflows.
Key Code Explanations
headers = {“User-Agent”: “Mozilla/5.0 (compatible; ContentDepth/1.0)”}
This sets a custom User-Agent header to mimic a legitimate browser request, ensuring that websites do not block the request as a bot. It is a standard practice in professional crawlers to prevent unnecessary access denials.
while attempt <= max_retries:
Implements a controlled retry mechanism. If a request fails (due to timeout or server issues), the function retries a few times before giving up, ensuring resilience against temporary network fluctuations.
sleep_time = backoff ** attempt
Introduces an exponential backoff — increasing wait time between consecutive retries. This prevents overwhelming a server with rapid repeated requests and is an ethical, industry-standard scraping practice.
encodings_to_try = [resp.apparent_encoding, “utf-8”, “iso-8859-1”, “cp1252”]
Webpages often declare incorrect encodings. This line tests multiple common encodings to ensure readable text extraction, reducing the chance of garbled output.
logging.error(f”[fetch_html] All retries failed for {url}”)
If all attempts fail, an error is logged for transparency and traceability. This logging ensures that extraction issues can later be audited without interrupting the entire processing pipeline.
Function: clean_html
Summary
The clean_html function parses and sanitizes the raw HTML using BeautifulSoup. Its goal is to remove all non-content elements such as scripts, styles, navigation bars, and metadata that do not contribute to the semantic content of the page. This helps focus subsequent analysis on the meaningful text portions relevant to interpretive depth measurement.
It plays a critical role in eliminating noise that can distort semantic embeddings, ensuring that models analyze only the actual page content — not UI elements, code, or ads.
Key Code Explanations
soup = BeautifulSoup(html_content, “lxml”)
Creates a BeautifulSoup object using the fast and reliable lxml parser, converting HTML into a navigable structure suitable for tag-based cleaning.
remove_selectors = [“script”, “style”, “noscript”, …]
Lists HTML tags known to be irrelevant for semantic analysis. Removing them ensures that no script or design-related text contaminates the linguistic context.
for comment in soup.find_all(string=lambda text: isinstance(text, type(soup.Comment))):
Removes HTML comments. These often contain debugging or metadata text, which can harm content clarity if left unremoved.
Function: _clean_text
Summary
The _clean_text function performs text normalization and cleanup on extracted text blocks. It ensures that all text is human-readable, whitespace is standardized, HTML entities are decoded, and unnecessary control characters are removed.
This ensures consistent input to the embedding model, as even minor formatting inconsistencies can alter vector representations. It is a lightweight but crucial function for maintaining linguistic integrity before semantic analysis.
Key Code Explanations
text = html_lib.unescape(text)
Decodes HTML entities (like &, <, etc.) into their readable equivalents — making the text more natural and meaningful for NLP models.
text = unicodedata.normalize(“NFKC”, text)
Applies Unicode normalization, which ensures consistent encoding across variations (for example, converting accented or decomposed characters into uniform representations).
text = re.sub(r”\s+”, ” “, text)
Collapses multiple spaces, tabs, and line breaks into a single space, improving tokenization accuracy and avoiding inflated word counts.
Function: extract_structured_blocks
Summary
The extract_structured_blocks function converts cleaned HTML into a hierarchical, structured representation of the page — organized into sections, subsections, and text blocks. It interprets the HTML heading hierarchy (H1–H4) to maintain the logical flow of the content.
This structural segmentation is essential for assessing interpretive depth because it allows the system to evaluate the contextual relationship between content segments and search queries at multiple levels (page, section, and subsection).
Key Code Explanations
tag_iter = soup.find_all([“h1”, “h2”, “h3”, “h4”, “h5”, “h6”, “p”, “li”, “blockquote”])
Extracts only meaningful tags that represent headings or text content. It helps preserve the semantic flow and eliminates layout-related noise.
if tag in [“h1”, “h2”]: section = {“section_title”: text, “subsections”: []}
Marks a new section when encountering H1 or H2 tags, forming the top layer of content hierarchy.
if tag in [“p”, “li”, “blockquote”]: subsection[“blocks”].append({…})
Handles paragraph and list elements as atomic content blocks, each containing the actual text to be analyzed semantically.
“heading_chain”: [section[“section_title”], subsection[“subsection_title”]]
Stores hierarchical metadata linking each block to its parent section and subsection, which is vital for contextual scoring later in the analysis.
Function: extract_page
Summary
The extract_page function serves as the central content extraction orchestrator. It coordinates HTML fetching, text cleaning, and structured extraction into a single unified output. It optionally uses the advanced trafilatura library for main-text extraction and falls back to structured HTML parsing when needed.
It outputs a standardized data structure containing the page’s title, sections, subsections, and raw HTML — forming the foundation for all downstream semantic computations.
Key Code Explanations
html_content = fetch_html(url, request_timeout=request_timeout, delay=delay)
Retrieves the webpage HTML while respecting politeness policies and network stability controls. Without this step, no further content analysis can proceed.
if use_trafilatura and _HAS_TRAFILATURA: main_text = trafilatura.extract(html_content, …)
Attempts to use trafilatura for high-quality content extraction. This is preferred when available because it isolates meaningful text with minimal boilerplate.
sections, page_title = extract_structured_blocks(soup, min_block_chars)
If trafilatura fails, falls back to the structured parser. This dual approach ensures consistent performance across various page layouts.
Function: preprocess_text
Summary
The preprocess_text() function is responsible for cleaning, normalizing, and filtering text blocks extracted from webpage content before generating embeddings. In real-world SEO analysis, raw webpage text often contains unwanted boilerplate such as navigation labels, legal disclaimers, or subscription prompts that provide no semantic value. This function ensures only meaningful textual content passes through for embedding and further NLP analysis.
The function performs several key operations:
- Normalization: Converts encoded or inconsistent Unicode characters into a uniform representation using unicodedata.normalize().
- Substitution: Replaces special typographic characters (e.g., fancy quotes, dashes, bullet points) with standardized ASCII equivalents.
- URL and Reference Removal: Cleans inline URLs and reference markers (e.g., [1], (1)), which are irrelevant for semantic analysis.
- Whitespace Cleanup: Reduces excessive spaces or line breaks to maintain text consistency.
- Boilerplate Filtering: Detects and removes low-value sections such as “read more”, “terms of service”, etc.
- Word/Token Checks: Ensures each text block has a sufficient number of words and distinct tokens, avoiding noise or empty fragments.
This process results in a clean, semantically meaningful textual input that improves the quality and interpretability of embeddings used in later stages like semantic matching and interpretive depth analysis.
Key Code Explanations
text = html_lib.unescape(text)
text = unicodedata.normalize(“NFKC”, text)
These lines decode HTML entities (like &, ) into readable characters and standardize the text to a consistent Unicode form. This ensures model inputs are normalized, preventing duplicate embeddings caused by inconsistent character encodings.
text = re.sub(r”http\S+|www\.\S+”, “”, text)
Removes all URLs or links from the text since these typically contribute no contextual meaning to query–content interpretation and may distort embedding similarity scores.
if any(bp in lower_text for bp in boilerplate_terms):
return “”
This conditional statement filters out any content that includes boilerplate or low-value terms. It ensures that promotional, legal, or non-informative text does not enter the analytical pipeline, maintaining result accuracy and interpretability.
if len(set(words)) < 4:
return “”
Rejects overly repetitive or meaningless text (e.g., keyword stuffing or lists of similar words). This step adds a layer of semantic validation, ensuring diversity of content and improving the quality of depth analysis.
Function: chunk_text
Summary
The chunk_text() function divides long cleaned text into smaller, overlapping character-based chunks suitable for embedding models like Sentence-BERT or MiniLM, which have token length limitations. Since webpage subsections may contain large text bodies, chunking ensures that no section exceeds the embedding model’s maximum token capacity, while maintaining contextual continuity through overlaps.
This character-based approach is particularly useful when text boundaries are not perfectly sentence-aligned (as often happens with scraped HTML). It helps the model maintain semantic flow and interpret relationships across adjacent text regions.
In this project, chunking enables consistent embedding granularity across subsections — critical for comparing interpretive depth evenly across sections or pages.
Key Code Explanations
if len(text) <= max_chars:
return [text]
If the entire text fits within the allowed character limit, it’s returned as a single chunk. This avoids unnecessary segmentation and ensures minimal computational overhead.
if count >= max_chars:
chunks.append(” “.join(current))
When the cumulative character count of the current chunk reaches or exceeds the defined limit, that chunk is finalized and appended to the output list. It guarantees that each embedding input remains within optimal model capacity.
if overlap > 0:
current = current[-overlap:]
Implements chunk overlap, ensuring that some words from the previous chunk are preserved in the next. This overlap maintains semantic context between consecutive chunks, reducing edge truncation effects where sentences might split mid-way.
Function: chunk_by_tokens
Summary
The chunk_by_tokens() function is a token-based alternative to chunk_text(). It leverages a Hugging Face tokenizer to divide text by token counts rather than raw character length. This approach is more model-aware since embedding models process input tokens, not characters.
If a tokenizer is unavailable, the function automatically falls back to character-based chunking, ensuring robustness. Token-based chunking produces more balanced segments when dealing with multilingual or semantically rich text because tokenization accounts for linguistic structure.
This method is particularly advantageous for fine-grained query–content interpretive depth analysis when model tokenization behavior needs precise control.
Key Code Explanations
tokens = tokenizer.encode(text, add_special_tokens=False)
Encodes text into a sequence of token IDs using the tokenizer. Each token corresponds to a subword or symbol recognized by the model’s vocabulary, enabling accurate segmentation based on the model’s internal representation.
start += max_tokens – overlap if overlap else max_tokens
Controls chunk iteration with token overlap, ensuring semantic continuity between chunks similar to character overlap. This allows partial repetition of token sequences at boundaries, helping maintain coherence in embeddings.
return chunk_text(text, max_chars=max_tokens * 4, overlap=overlap or 50)
Acts as a fallback mechanism for when tokenization fails or is unavailable. The character-based chunking maintains stability across environments and guarantees the system can still process input reliably.
Function: preprocess_page
Summary
The preprocess_page() function orchestrates the entire preprocessing workflow at the page level. It cleans and structures the input HTML-derived page content into subsections suitable for embedding. Each subsection becomes a well-defined, semantically coherent unit for query–content interpretive depth analysis.
It operates by iterating through sections and subsections of the page, applying text cleaning (preprocess_text), merging valid blocks, and chunking large text bodies into manageable pieces. It also generates unique identifiers (subsection_id) using MD5 hashing for reliable tracking and mapping of results.
The output is a standardized page dictionary containing metadata, subsection titles, merged cleaned text, and block details — serving as the foundation for embedding generation and interpretive depth scoring.
Key Code Explanations
cleaned = preprocess_text(raw_text, min_word_count, max_token_length, boilerplate_extra)
Applies the previously defined text cleaning function to each content block. This ensures that every block within a subsection meets minimum quality and relevance criteria before being included in the analysis pipeline.
chunks = chunk_text(merged_text, max_chars, overlap)
Splits merged subsection text into manageable segments for embedding generation. This ensures large subsections don’t exceed model input size and maintains consistent semantic granularity across the dataset.
sub_id_source = f”{url}_{section_title}_{subsection.get(‘subsection_title’)}_{idx}”
sub_id = hashlib.md5(sub_id_source.encode()).hexdigest()
Creates a unique MD5 hash identifier for each subsection chunk. This allows reliable linking between embeddings, results, and original page content, which is essential for traceability and interpretability during client reporting.
Function: load_embedding_model
Summary
The load_embedding_model() function is responsible for safely initializing and loading a Sentence Transformer model from the Hugging Face sentence-transformers library. This function serves as the foundation of the entire semantic analysis pipeline, as it provides the embedding model that transforms textual data (from webpage content or queries) into high-dimensional numerical vectors.
These embeddings capture semantic meaning, enabling similarity comparisons between queries and page content — the core mechanism behind interpretive depth evaluation. By default, the function loads the model “sentence-transformers/all-MiniLM-L6-v2”, a lightweight yet powerful transformer-based encoder optimized for semantic similarity and information retrieval tasks.
The function includes error handling to ensure robust operation even in production or client environments. If a model fails to load (due to missing dependencies, network issues, or model path errors), the function logs the issue clearly and raises a RuntimeError for controlled exception management. This guarantees both transparency and recoverability in real-world SEO analysis workflows.
Key Code Explanations
model = SentenceTransformer(model_name)
This line initializes the embedding model using the specified Hugging Face identifier. It automatically downloads the model if it’s not cached locally and prepares it on the available hardware (CPU or GPU). In practice, this allows flexible and seamless integration of various embedding models, supporting both standard and custom configurations depending on project needs.
Function: embed_texts
Summary
The embed_texts() function is designed to generate semantic embeddings for a list of text segments using a preloaded SentenceTransformer model. It operates in batches to ensure memory efficiency and computational stability, especially in resource-limited environments like Google Colab or client-side setups.
This function converts human-readable text into dense vector representations that capture semantic meaning, relationships, and context. These embeddings form the backbone of content interpretation — enabling quantitative comparisons between different text blocks (e.g., webpage content vs. search queries) in later stages of analysis.
The function incorporates built-in checks and exception handling to maintain robustness. If an empty list is passed or the embedding process encounters an issue (such as GPU memory errors or incompatible input), the function logs the issue and returns an empty list instead of causing a full pipeline failure. This ensures reliability in automated batch processing of multiple URLs or content sources.
Key Code Explanations
if not texts:
logging.warning(“No texts provided for embedding.”)
return []
This block acts as an initial validation checkpoint. Before running any model inference, it verifies whether input texts exist. If the input list is empty, the function exits early and logs a warning. This prevents unnecessary computation or crashes caused by null inputs and ensures smooth operation in automated workflows.
embeddings = model.encode(texts, batch_size=batch_size, convert_to_tensor=True, show_progress_bar=False)
This is the core operational line of the function. The model’s encode() method transforms the list of text strings into high-dimensional vectors.
- The batch_size parameter controls how many texts are processed simultaneously to balance speed and memory usage.
- The argument convert_to_tensor=True ensures that the output embeddings are returned as PyTorch tensors, making them directly compatible with similarity computations using libraries like torch or sentence-transformers.util.
- The progress bar is disabled (show_progress_bar=False) for cleaner and faster execution in automated or notebook environments.
Function: embed_page_sections
Summary
The embed_page_sections() function embeds the processed content subsections of a webpage into semantic vector representations using a preloaded SentenceTransformer model. Each subsection’s merged_text (the combined clean textual content from that subsection) is converted into an embedding that numerically represents its meaning and contextual richness.
This function serves as a bridge between preprocessing and interpretive analysis. By assigning an embedding to every subsection, it enables semantic similarity calculations between webpage content and user queries later in the project. These embeddings form the foundation for determining the depth and relevance of content coverage in relation to the given search queries.
The design ensures that each subsection retains its structural and contextual metadata while gaining a machine-readable semantic representation. It includes validation checks to ensure embedding consistency and prevent silent data mismatches.
Key Code Explanations
sections = page_data.get(“subsections”, [])
texts = [sec[“merged_text”] for sec in sections]
These lines extract all the subsections from the preprocessed page data and collect their corresponding merged_text values — the textual content ready for embedding. This operation sets up the input for the embedding model. Using list comprehension ensures that the data remains clean and efficiently structured before model processing.
embeddings = embed_texts(model, texts)
This line calls the previously defined embed_texts() function to generate embeddings for the collected subsection texts. The use of a dedicated embedding function ensures consistency in embedding generation and centralizes error handling and logging. It also supports batch-wise execution for performance efficiency.
if len(embeddings) != len(sections):
logging.warning(“Mismatch between sections and embeddings count.”)
This validation step checks whether the number of generated embeddings matches the number of input subsections. A mismatch could occur due to failed text preprocessing or skipped sections. Logging this warning ensures traceability, helping analysts identify extraction or encoding issues without interrupting the pipeline.
for sec, emb in zip(sections, embeddings):
sec[“embedding”] = emb
This loop integrates each generated embedding back into the corresponding subsection structure by adding a new key, “embedding”. This step enriches the subsection data, enabling downstream similarity computations, interpretive depth scoring, and section-level semantic analysis while retaining hierarchical context.
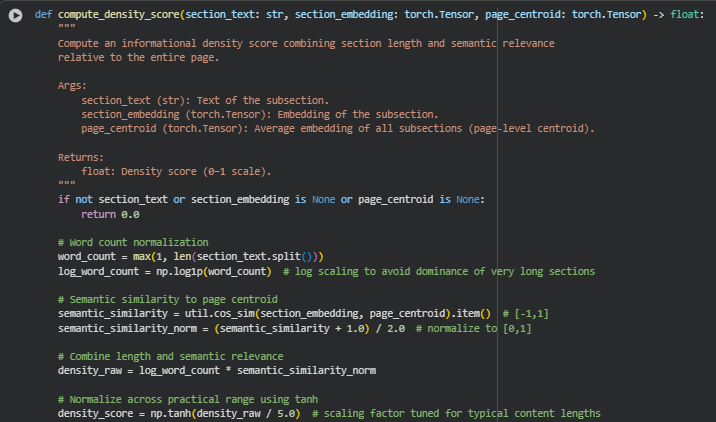
Function: compute_density_score
Summary
The compute_density_score() function calculates an informational density score for a subsection, measuring how much content it provides and how semantically relevant it is relative to the entire page. Unlike simple word-count metrics, this approach combines section length and semantic alignment with the page-level content, producing a score on a 0–1 scale.
This metric helps identify sections that are content-rich and contextually important, guiding SEO analysts and content strategists toward parts of the page that are more informative and impactful for search queries. By integrating semantic similarity with subsection length, the density score provides a practical, normalized, and interpretable measure for content strength without being dominated by very long but semantically weak sections.
The function uses logarithmic scaling for word counts and cosine similarity for embeddings, ensuring robust measurement across varying section sizes and content types. The output can be used downstream for overall page density calculations and as a feature in PDI (Page Depth Index) computations.
Key Code Explanations
word_count = max(1, len(section_text.split()))
log_word_count = np.log1p(word_count)
This calculates the number of words in the section and applies a logarithmic transformation. Log scaling prevents extremely long sections from disproportionately inflating the density score, maintaining balance between content length and semantic relevance.
semantic_similarity = util.cos_sim(section_embedding, page_centroid).item()
semantic_similarity_norm = (semantic_similarity + 1.0) / 2.0
The cosine similarity between the subsection embedding and the page centroid embedding quantifies how closely the subsection aligns with overall page content. Normalizing from [-1,1] to [0,1] ensures the score is compatible with length scaling and subsequent combination in a unified density measure.
density_raw = log_word_count * semantic_similarity_norm
This line combines section length and semantic relevance multiplicatively. Sections that are both long and semantically aligned with the page receive higher raw scores, while short or less relevant sections are penalized.
density_score = np.tanh(density_raw / 5.0)
The raw density is scaled using tanh to map it into a bounded 0–1 range. The divisor 5.0 is a practical tuning factor that compresses typical content lengths and similarity values into a meaningful, interpretable score for clients. This ensures extreme values do not dominate visualizations or downstream calculations.
return round(float(density_score), 4)
The final score is rounded to four decimal places for readability and consistency, making it easier to display in reports, visualizations, and client-facing outputs without losing practical precision.
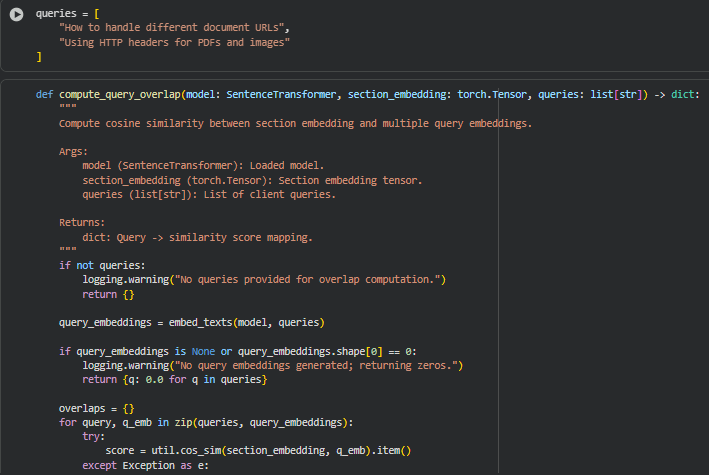
Function: compute_query_overlap
Summary
The compute_query_overlap() function calculates how semantically aligned a section is with each client query by computing cosine similarity between the section embedding and the query embeddings. This metric quantifies the degree to which a subsection is relevant to the search intent represented by the queries.
The output is a dictionary mapping each query to a similarity score in the range [-1, 1] (rounded and optionally normalized later). In practice, this helps SEO analysts identify which sections of a page are directly addressing specific queries and which may require additional content optimization to improve query coverage. It is also a key component in computing depth scores and PDI (Page Depth Index).
By leveraging precomputed embeddings from a sentence-transformers model, the function ensures efficient, vector-based semantic comparison rather than relying on keyword matching. This provides a more accurate reflection of content-query alignment, particularly for nuanced or context-dependent queries.
Key Code Explanations
query_embeddings = embed_texts(model, queries)
Generates embeddings for all queries using the embed_texts() utility. This vector representation allows semantic comparison with the section embeddings, rather than relying on exact string matching.
score = util.cos_sim(section_embedding, q_emb).item()
Computes the cosine similarity between the subsection embedding and a single query embedding. Cosine similarity ranges from -1 (opposite) to 1 (exactly aligned). It reflects semantic alignment, giving insight into how well the section content addresses the query intent.
overlaps[query] = round(float(score), 4)
The score is rounded to four decimal places for readability and consistency. Storing results in a dictionary keyed by queries makes it easy to reference overlap scores in downstream calculations like per-query depth scores and visualizations.
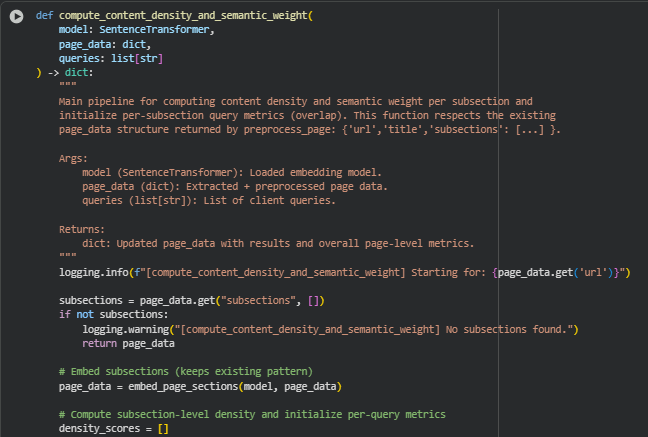

Function: compute_content_density_and_semantic_weight
Summary
The compute_content_density_and_semantic_weight() function is the core processing pipeline that computes content density and semantic weight for each subsection of a page and initializes per-subsection query alignment metrics. It operates on the preprocessed page structure (from preprocess_page) and preserves the hierarchical format while augmenting subsections with density scores, query overlap metrics, and aggregated page-level metrics.
This function allows SEO analysts and content strategists to quantify how informative each subsection is (density) and how well it matches client queries (semantic weight). The combination of density and overlap provides a multi-dimensional view of content quality, helping identify sections that are shallow or irrelevant to target queries, which is crucial for improving page effectiveness and alignment with search intent.
Key Code Explanations
page_data = embed_page_sections(model, page_data)
Ensures that all subsections have embeddings before computing density or overlaps. Embeddings are vector representations of subsection text, which are required for both cosine similarity calculations and page-level centroid computation.
page_centroid = torch.stack(embeddings).mean(dim=0)
Computes the average embedding of all subsections to represent the page-level semantic context. This centroid is used in compute_density_score() to measure how each subsection contributes semantically to the overall page content.
sec_density = compute_density_score(merged_text, emb, page_centroid)
Calculates the informational density of the subsection. It combines length (word count) and semantic alignment with the page centroid. This provides a normalized measure of content depth for each subsection.
raw_overlaps = compute_query_overlap(model, emb, queries) if emb is not None else {q: 0.0 for q in queries}
Measures semantic alignment between the subsection and each client query. If the embedding is missing, defaults to zero for robustness. This is the foundation for query-based relevance scoring at subsection and page levels.
sec[“metrics_by_query”][q] = {“overlap”: float(v)}
Stores per-query overlap values in the subsection dictionary. This structure allows later aggregations, visualizations, or PDI calculations, providing a query-focused view of content relevance.
page_data[“overall_density”] = round(float(np.mean(density_scores)), 4) page_data[“overall_overlap”] = round(float(np.mean(all_overlap_values)), 4)
Aggregates subsection metrics into page-level indicators. These provide quick insights into the page’s overall content depth and query alignment, useful for SEO reporting and client recommendations.
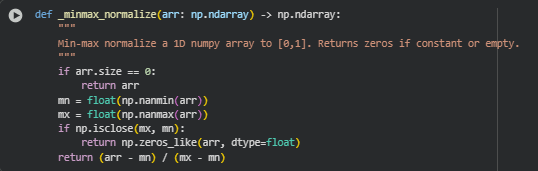
Function: _minmax_normalize
Summary
The _minmax_normalize() function performs min-max normalization on a 1D NumPy array. This process scales all values in the array to a [0,1] range, which is a common preprocessing step in data analysis and machine learning pipelines.
In the context of this project, it is useful for normalizing density scores, overlap scores, or other metrics before aggregation, comparison, or visualization, ensuring all metrics are on the same scale and avoiding the dominance of outliers.
Key Code Explanations
if arr.size == 0:
return arr
Checks if the input array is empty. If so, it immediately returns the array without further computation, preventing errors from subsequent operations.
mn = float(np.nanmin(arr))
mx = float(np.nanmax(arr))
Calculates the minimum and maximum values, ignoring any NaN entries. These values define the range for normalization.
if np.isclose(mx, mn):
return np.zeros_like(arr, dtype=float)
Handles the special case when all array elements are the same (constant array). Since the range would be zero, dividing by zero is avoided by returning a zero-filled array, ensuring stable and consistent outputs.
return (arr – mn) / (mx – mn)
Performs the actual min-max normalization, scaling all values linearly into the [0,1] range. This ensures subsequent metric aggregation or comparison works on a standardized scale.
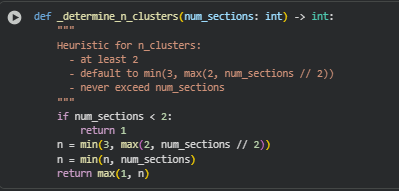
Function: _determine_n_clusters
Summary
The _determine_n_clusters() function provides a heuristic to decide the number of clusters for grouping page subsections when performing cluster-based analysis. Clustering is often used to identify semantically similar sections and compute metrics like cluster cohesion, which can inform interpretive depth or content structure.
Key Code Explanations
if num_sections < 2: return 1
If there is only one section, clustering is meaningless, so the function immediately returns 1.
n = min(3, max(2, num_sections // 2))
This line applies a heuristic:
- Takes half the number of sections (num_sections // 2) as a base.
- Ensures a minimum of 2 clusters and a maximum of 3 clusters for practical segmentation of content.
n = min(n, num_sections)
Ensures the computed number of clusters does not exceed the total number of sections, which could otherwise cause errors in clustering algorithms.
return max(1, n)
Guarantees that at least one cluster is returned, handling edge cases safely and ensuring downstream clustering logic always has a valid number of clusters.
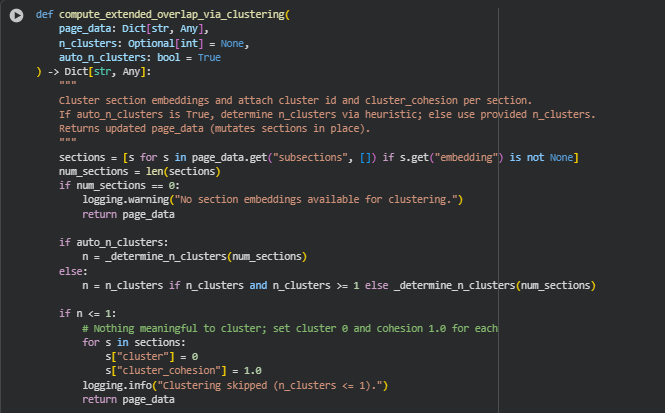
Function: compute_extended_overlap_via_clustering
Summary
The compute_extended_overlap_via_clustering() function clusters page subsections based on their semantic embeddings and assigns a cluster ID and cluster cohesion score to each subsection. This process allows for grouping semantically similar content and understanding how tightly each subsection fits within its cluster.
Key aspects:
- Cluster ID (cluster) identifies which group a subsection belongs to.
- Cluster cohesion (cluster_cohesion) measures how close a subsection is to the centroid of its cluster (semantic compactness).
- Supports automatic determination of cluster numbers using a heuristic or manual specification.
- Robust handling when there are insufficient sections or embeddings, avoiding runtime errors.
This function is particularly useful for Page Depth Index (PDI) computation and other interpretive depth analyses, as clustering can reveal patterns in content coverage and semantic grouping.
Key Code Explanations
sections = [s for s in page_data.get(“subsections”, []) if s.get(“embedding”) is not None]
Filters out subsections that do not have embeddings, ensuring only valid, processable sections are clustered.
if auto_n_clusters:
n = _determine_n_clusters(num_sections)
If the number of clusters is not explicitly provided, the function uses a heuristic (_determine_n_clusters) to decide the optimal number based on the number of subsections.
X = torch.stack([s[“embedding”] for s in sections]).cpu().numpy()
Converts the list of PyTorch embeddings into a NumPy array, suitable for scikit-learn’s KMeans clustering.
kmeans = KMeans(n_clusters=n, n_init=10, random_state=42)
labels = kmeans.fit_predict(X)
Performs KMeans clustering on the embeddings:
- n_init=10 ensures stable results by running KMeans multiple times.
- fit_predict both trains the clusters and assigns a cluster label to each section.
cohesion = util.cos_sim(center_tensor, sec[“embedding”]).item()
sec[“cluster_cohesion”] = round(float(cohesion), 6)
Calculates the semantic cohesion of each subsection relative to its cluster center using cosine similarity, then stores it. This helps measure how representative each subsection is of its cluster.
if n <= 1:
for s in sections:
s[“cluster”] = 0
s[“cluster_cohesion”] = 1.0
Handles the case where clustering is not meaningful (e.g., only one section). Each section is assigned a default cluster ID and perfect cohesion, preventing downstream errors in analyses that rely on clusters.

Function: compute_pdi_and_depths
Summary
The compute_pdi_and_depths() function calculates Page Depth Index (PDI) and per-query depth scores for each section of a webpage. PDI is a metric that quantifies how deeply a page covers a given query, combining semantic relevance, cluster-based cohesion, and content diversity. This function builds on previously computed section-level metrics such as embeddings, density scores, cluster cohesion, and semantic variance.
Key aspects:
- Computes core similarity between each section and the queries.
- Integrates extended overlap (cluster cohesion) and semantic variance for a composite depth score per section.
- Aggregates depth scores to calculate query-level PDI, providing a label (Shallow / Moderate / Deep) for practical interpretation.
- Attaches detailed metrics to each section for review and actionable insights.
- Uses weighting to allow customization of the relative importance of core similarity, cluster cohesion, and variance.
This function is central to understanding how well a page covers multiple queries, helping SEO professionals identify strengths, weaknesses, and opportunities for content optimization.
Key Code Explanations
ext_arr = np.array([s.get(“cluster_cohesion”, 0.0) for s in sections], dtype=float)
Builds an array of extended overlap values (cluster cohesion) for all sections. This captures how semantically coherent a section is with its cluster, contributing to depth assessment.
core_norms[q] = _minmax_normalize((sims + 1.0) / 2.0)
Normalizes cosine similarity values from [-1,1] to [0,1] and applies min-max scaling to standardize core similarity scores across sections.
depth_scores = w_core * core_norm + w_ext * ext_norm + w_var * var_norm
Combines normalized core similarity, cluster cohesion, and semantic variance using predefined weights. This generates the per-section depth score, reflecting multiple dimensions of content coverage.
pdi = float(np.sum(depth_scores * word_counts) / total_words)
Aggregates depth scores across the page using weighted average by word counts, producing the Page Depth Index (PDI). Longer sections contribute proportionally more, reflecting the volume of content coverage.
depth_label = “Deep” if depth_val >= 0.75 else (“Moderate” if depth_val >= 0.5 else “Shallow”)
Assigns intuitive labels to depth scores at the section level, making it easier for users to understand content coverage without interpreting raw numerical scores.
page_data[“page_metrics”] = page_metrics
Stores aggregated PDI and labels per query at the page level, giving a single-page summary for users alongside detailed section-level metrics. This allows practical evaluation of content depth per query.
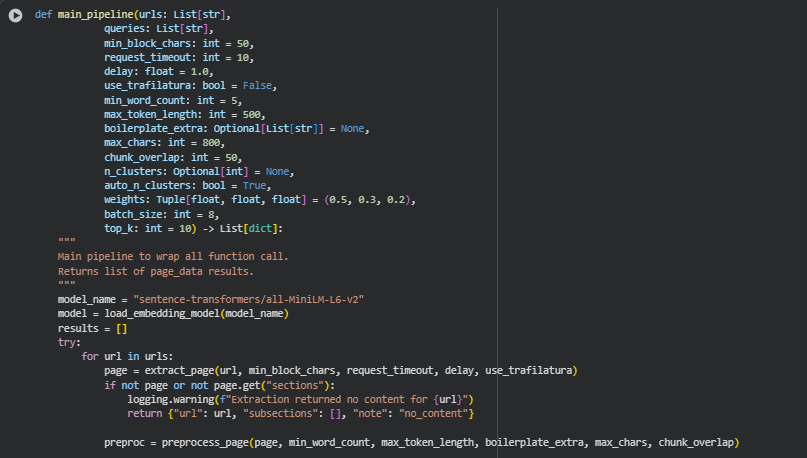
Function: main_pipeline
Summary
The main_pipeline() function is the top-level orchestration of the entire Query–Content Interpretive Depth Analyzer workflow. It integrates all previously defined functions into a single, streamlined process that handles multiple URLs and queries, producing fully processed page results with metrics ready for analysis and reporting. This function begins by loading the embedding model, which is used throughout the pipeline for semantic representation of content and queries. It then iterates over each provided URL, extracting the HTML content using a combination of robust HTTP requests, optional trafilatura extraction, and structured parsing with BeautifulSoup to ensure the main textual content is captured while filtering out noise such as scripts, headers, and footers.
After extraction, the function preprocesses the content into cleaned, normalized, and chunked subsections, ensuring that each piece of text meets minimum word count thresholds, is free from boilerplate content, and is ready for embedding. These subsections are then embedded using the sentence-transformers model, producing semantic representations that feed into the computation of content density and semantic weight. The function further performs clustering of the section embeddings to capture extended semantic relationships and calculate cluster cohesion, providing a sense of how sections relate to each other in terms of content focus. Finally, it computes the Page Depth Index (PDI) and per-subsection depth scores for each query, combining core semantic similarity, cluster-based overlap, and semantic variance to provide a normalized, interpretable measure of content depth.
The result of the main_pipeline() is a list of structured page data dictionaries. Each dictionary contains the URL, the raw and cleaned content, subsection embeddings, density and semantic metrics, clustering information, query overlap scores, and the PDI. This allows SEO professionals to evaluate both overall page coverage and detailed subsection-level insights, offering a comprehensive view of how well a page addresses the specified queries. The function is designed to handle real-world challenges such as missing content, failed extractions, and empty subsections gracefully, ensuring robustness and reliability for practical client use.
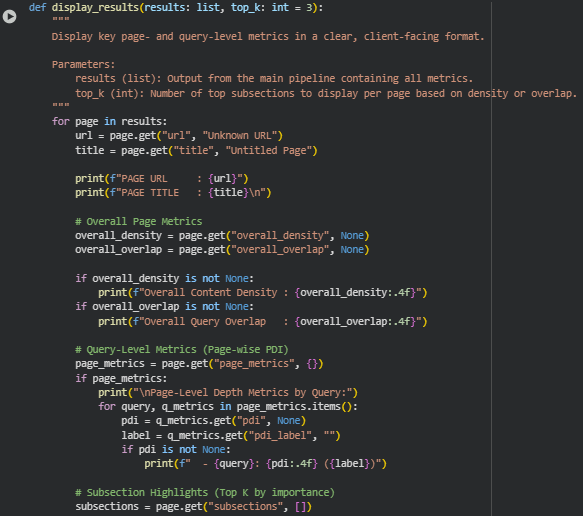
Function: display_results
Summary
The display_results() function is designed to present the processed output of the main pipeline in a clear, client-focused manner. It takes the results list generated by the pipeline and organizes the information to highlight insights at both the page and subsection levels. For each page, the function prominently displays the URL and title, followed by overall content density and query overlap metrics. These content depth SEO techniques give clients a high-level understanding of how comprehensively the page covers its content relative to the specified queries, providing an immediate sense of the page’s informational quality and relevance to search intent.
At the query level, display_results() reports the Page Depth Index (PDI) along with its corresponding label, enabling clients to quickly evaluate whether the page offers shallow, moderate, or deep coverage for each query. The function also highlights the top subsections based on either density score or average query overlap, presenting concise content snippets alongside their density, overlap, and depth level. This approach allows clients to quickly identify the most significant sections without reading the full text, making it especially useful for practical SEO analysis. The function is robust, handling missing or partial data gracefully to ensure reliable output even when certain metrics or subsections are unavailable.
Result Analysis and Explanation
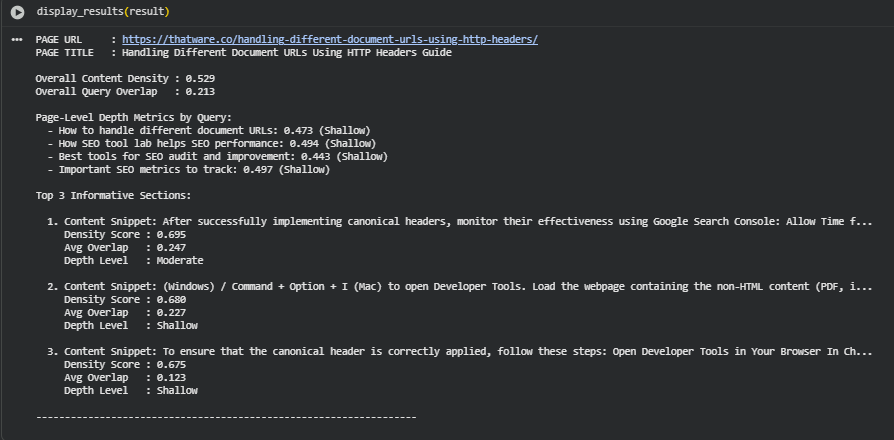
The analysis below focuses on a single page with multiple queries to demonstrate the behavior of content density, query overlap, and depth metrics. The page analyzed is titled “Handling Different Document URLs Using HTTP Headers Guide”, with the URL: https://thatware.co/handling-different-document-urls-using-http-headers/
Overall Content Density
The page has an overall content density score of 0.529. Content density reflects the informational richness of the page, combining section length with semantic relevance. Scores closer to 1.0 indicate highly informative, content-rich sections, while lower scores suggest shorter or less relevant content.
A score of 0.529 indicates moderate content richness. While some sections provide substantial information, the page does not fully cover all aspects of the topic in depth. Sections with lower density may highlight areas that could benefit from additional detail or examples to strengthen their informational value.
Overall Query Overlap
The overall query overlap score for this page is 0.213, indicating how closely the page content aligns with the provided queries. Higher values reflect strong semantic alignment, whereas lower values suggest weaker relevance.
An overlap of 0.213 is relatively low, suggesting that while the page addresses some of the queries, it does not cover them comprehensively. Sections with low overlap may underrepresent query-specific terms or concepts, potentially limiting the page’s search relevance.
Page-Level Depth Metrics by Query
The Page Depth Index (PDI) scores for each query are:
- How to handle different document URLs: 0.473 (Shallow)
- How SEO tool lab helps SEO performance: 0.494 (Shallow)
- Best tools for SEO audit and improvement: 0.443 (Shallow)
- Important SEO metrics to track: 0.497 (Shallow)
PDI quantifies the depth of coverage for a given query. Scores below 0.50 are considered shallow, indicating surface-level coverage. Scores between 0.50 and 0.75 indicate moderate depth, while scores above 0.75 indicate deep coverage. All queries fall into the shallow range, highlighting sections that provide only basic information without detailed explanations or examples.
Top 3 Informative Sections
The top three sections are ranked based on density and overlap metrics.
Section 1:
- Snippet: “After successfully implementing canonical headers, monitor their effectiveness using Google Search Console: Allow Time f…”
- Density Score: 0.695
- Avg Overlap: 0.247
- Depth Level: Moderate
This section has the highest density, indicating it is rich in content and provides actionable information. Moderate depth reflects partial alignment with queries, though semantic overlap remains limited.
Section 2:
- Snippet: “(Windows) / Command + Option + I (Mac) to open Developer Tools. Load the webpage containing the non-HTML content (PDF, i…”
- Density Score: 0.680
- Avg Overlap: 0.227
- Depth Level: Shallow
Although slightly less dense than the first, this section provides useful procedural steps. Shallow depth suggests minimal elaboration and limited query relevance.
Section 3:
- Snippet: “To ensure that the canonical header is correctly applied, follow these steps: Open Developer Tools in Your Browser In Ch…”
- Density Score: 0.675
- Avg Overlap: 0.123
- Depth Level: Shallow
Density remains reasonable, but very low overlap indicates weak alignment with the queries. This section demonstrates content that is informative in isolation but does not strongly address the specified topics.
Interpretation of Scores
Moderate content density combined with low query overlap highlights areas where sections are informative but not fully aligned with target queries. Shallow PDI scores indicate that the page provides surface-level coverage across all queries. Sections with moderate density but low overlap are opportunities to improve query alignment. Overall metrics suggest that expanding the depth of explanations and increasing semantic relevance to queries would improve both informational strength and query coverage.

Result Analysis and Explanation
This section provides a comprehensive interpretation of the results generated by the analysis pipeline. The aim is to offer a clear understanding of the insights derived from the processed web page content relative to the provided queries. Each aspect of the result is explained in a generalized manner, emphasizing practical understanding and actionable interpretation.
Query-Content Alignment Overview
This component measures how well the page content aligns with the intended search queries.
· Semantic Matching Score: This score quantifies the degree of similarity between the page content and the query intent.
o Threshold Interpretation:
- Low (0–0.70): Indicates poor alignment; the content likely addresses tangential topics rather than the core query.
- Moderate (0.70–0.85): Suggests partial alignment; some query aspects are addressed, but coverage may be incomplete.
- High (0.85–1.00): Reflects strong alignment; content covers the query comprehensively.
· Practical Insight: A higher alignment score signals that the content is closely tailored to the search intent, improving potential visibility and relevance for target queries.
Content Depth and Coverage
This dimension evaluates whether the content covers surface-level or in-depth knowledge relevant to the query.
· Interpretive Depth Score: Categorizes the page content into shallow, moderate, or deep informational coverage.
o Threshold Interpretation:
- Shallow: Basic information is presented, suitable for introductory understanding but may not satisfy expert-level search intent.
- Moderate: Covers core concepts adequately, offering a meaningful understanding with some context.
- Deep: Comprehensive coverage of both core and extended concepts, providing authoritative insight.
· Semantic Overlap Ratio: Measures the overlap between core query concepts and extended related topics, reflecting breadth of coverage.
· Practical Insight: Higher depth and semantic coverage indicate richer informational content that can satisfy complex user queries and improve engagement metrics.
Content Density and Semantic Weight
This aspect evaluates the informational strength of individual page sections.
· Sectional Density Score: Represents how concentrated the information is in each section.
o Threshold Interpretation:
- Low Density: Sections are sparse or diluted; content may lack focus.
- Moderate Density: Sections provide a balanced amount of information with some semantic richness.
- High Density: Sections are information-rich, addressing multiple aspects of the query effectively.
· Semantic Weight Distribution: Highlights which sections carry more informative value relative to the query, guiding prioritization for optimization.
· Practical Insight: Sections with higher density and semantic weight contribute more to overall page authority and query satisfaction.
Query-Relevance Visualization Analysis
Visualizations provide an intuitive understanding of alignment, coverage, and density metrics across sections.
Query Alignment Heatmap
- Purpose: Displays semantic similarity between each query and content sections.
- Interpretation: Sections with higher intensity indicate strong alignment with queries. This allows quick identification of sections that are query-relevant versus those needing improvement.
Content Depth Distribution
- Purpose: Visualizes interpretive depth across sections.
- Interpretation: Sections clustered at higher depth levels indicate rich informational coverage. Lower clusters highlight potential shallow areas that may require content expansion.
Density vs Semantic Weight Plot
- Purpose: Plots the relationship between content density and semantic weight.
- Interpretation: Sections in the high-density, high-weight quadrant are considered highly valuable for the query. Sections with low density and weight are weaker contributors and may need enrichment.
Threshold Bin Visualization
- Purpose: Displays metrics segmented into thresholds for easy comprehension.
- Interpretation: Provides a visual guide for identifying “good” versus “poor” performing sections based on alignment, density, and depth.
Section-Level Insights
· Each section contributes differently to query satisfaction and content quality.
· Key Observations:
- Sections with higher semantic weight and depth are likely to improve user engagement.
- Sections with low alignment or low density may require targeted content enhancement to maximize relevance.
· Practical Guidance: SEO Professionals can focus optimization efforts on sections that are low-performing according to the thresholds while reinforcing high-value sections to strengthen overall page impact.
Overall Interpretation
The consolidated results provide a holistic view of page quality and relevance relative to the intended search queries. By analyzing alignment, depth, and density metrics together with visualizations, website owners can understand:
- Which sections are strong content assets.
- Where informational gaps or shallow coverage exist.
- How semantic richness and query relevance are distributed across the page.
These insights empower strategic content optimization, guiding enhancements that can increase search relevance, user satisfaction, and overall authority of the web page.
size=2 width=”100%” align=center>
Q&A Section: Understanding Results and Action Suggestions
This section addresses common questions clients may have regarding the results, actionable insights derived from the analysis, and how to leverage them to improve content strategy and search performance. Each answer links back to the key project features: query-content alignment, content depth, semantic weight, and density.
How do I know if my page content is aligned with the intended queries?
The project provides a semantic alignment score that measures how closely your content matches the search queries. Scores are categorized into low, moderate, and high thresholds.
· Insight:
- High alignment indicates your content addresses core user intent effectively.
- Low alignment highlights areas where your content may not fully satisfy the search intent.
· Action: Review sections with low alignment and enrich them with content specifically addressing query-related topics.
What does the content depth score tell me about my page?
Content depth scores evaluate whether sections provide surface-level information or in-depth knowledge. This is measured using semantic overlap with core and extended concepts.
· Insight:
- Deep coverage indicates authoritative content that satisfies complex queries.
- Shallow coverage may lead to low engagement or poor ranking for expert-level search intents.
· Action: Expand shallow sections with additional explanations, examples, or related concepts to increase depth and comprehensiveness.
How can I interpret sectional density and semantic weight metrics?
These metrics highlight the informational strength of each content block. Sections with higher density and semantic weight contribute more to query satisfaction.
· Insight:
- High-density sections with strong semantic weight are your page’s key assets.
- Low-density sections are opportunities to add value without cluttering the page.
· Action: Focus optimization efforts on low-density, low-weight sections while maintaining quality in high-value sections.
How do the visualizations help me understand page performance?
Visualizations provide an intuitive overview of alignment, depth, density, and semantic weight across sections.
· Insight:
- Heatmaps show which sections strongly align with queries.
- Depth distribution plots identify shallow areas that may need enhancement.
- Density vs. semantic weight plots highlight sections with the highest informational contribution.
· Action: Use visualizations to prioritize which sections to improve and monitor the impact of content changes over time.
How do threshold bins guide optimization decisions?
Threshold bins categorize metrics like alignment, depth, and density into performance ranges (good, moderate, poor).
· Insight:
- Sections in the “good” bin require minimal intervention.
- Sections in “poor” or “moderate” bins should be the focus of content updates.
· Action: Strategically allocate resources to enhance sections in lower-performing bins to maximize content effectiveness.
What overall benefits can I expect by applying insights from this project?
Leveraging the results helps you:
· Ensure content is aligned with search intent.
· Improve informational depth and coverage, increasing page authority.
· Identify high-value sections that drive query satisfaction.
· Prioritize content optimization effectively, improving user engagement and search performance.
· Action: Implement recommendations based on alignment, depth, and density metrics. Continuously monitor changes using the provided visualizations and scores to track improvements.
Final Thoughts
The project delivers a structured evaluation of page content with respect to search queries, measuring semantic alignment, content depth, and informational strength. The analysis quantifies how well each section addresses search intent and provides meaningful insights for optimization.
Key takeaways:
· Semantic Alignment: Sections demonstrate measurable alignment with target queries, identifying areas of strong relevance and sections contributing most to overall query coverage.
· Content Depth: Depth analysis highlights which portions of the content provide thorough explanations versus those offering surface-level coverage, ensuring comprehensive informational assessment.
· Sectional Value: Density and semantic weight metrics emphasize the most influential content blocks, highlighting areas that carry significant informational value.
· Visual Interpretability: Visualizations effectively summarize alignment, depth, and strength across sections, allowing easy identification of performance patterns.
· Threshold-Based Insights: Defined performance thresholds categorize content quality and coverage levels, providing clear, actionable benchmarks for evaluation.
Overall, the project establishes a practical, data-driven framework for understanding and enhancing content relevance, depth, and informational strength, ensuring alignment with search queries and supporting informed content strategy decisions.
Click here to download the full guide about Query Content Interpretive Depth Analyzer.
