SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project leverages Meta’s DRAMA (Dynamic Representations Across Multiple Abstractions) model to provide semantic insight into webpage content for SEO purposes. Unlike traditional keyword-based or vector similarity methods, DRAMA captures multi-layered semantic representations, enabling a detailed understanding of how well a page covers topics and maintains content focus.

The implementation focuses on analyzing individual webpages using client-provided URLs and queries, extracting structured content blocks, preprocessing them for semantic embedding, and computing section-level and page-level insights. Core metrics include semantic depth, topical focus, and query relevance, all derived from DRAMA embeddings to reflect conceptual content coverage and alignment with query topics.
This approach allows for interpretable, actionable insights into content structure, highlighting areas of strong semantic coverage as well as sections that may require enhancement. The output is designed for SEO professionals to assess content effectiveness at both granular and overall page levels, facilitating informed optimization decisions.
Project Purpose
The primary purpose of this project is to provide actionable semantic insights into webpage content that enable SEO professionals to understand content coverage and focus at both subsection and page levels. Traditional SEO analysis often relies on keyword matching or surface-level similarity metrics, which may overlook deeper conceptual alignment between content and target queries.
By applying Meta’s DRAMA model, the project addresses this gap, allowing for:
· Evaluation of Content Depth: Understanding whether each section of a webpage provides superficial, moderate, or in-depth coverage of the topic.
· Assessment of Topical Focus: Identifying content areas that may drift from the main subject, ensuring that pages maintain cohesive and relevant topic coverage.
· Query Relevance Mapping: Measuring the semantic alignment of content with specific target queries, highlighting areas of high or low relevance.
· Interpretability for Optimization: Producing easy-to-understand, actionable insights that guide content improvement, ensuring both clarity and precision.
Overall, the project enables strategic content assessment, helping SEO teams make data-driven decisions to enhance page quality, strengthen topical coverage, and improve search visibility. The results are structured to be readily interpretable and directly applicable in content optimization workflows.
Project’s Key Topics Explanation and Understanding
DRAMA Model Overview
The DRAMA (Dynamic Representations Across Multiple Abstractions) model is a transformer-based architecture developed by Meta AI to capture hierarchical and multi-level semantic representations of text. Unlike traditional embedding models that generate a single vector per sentence or paragraph, DRAMA constructs representations across multiple layers of abstraction, allowing deeper understanding of both surface-level semantics and conceptual relationships.
Evolution and Motivation
Modern NLP models initially focused on surface-level similarity or token-level embeddings, which could capture syntactic similarity but often failed to identify conceptual depth. DRAMA was introduced to overcome these limitations by:
- Modeling semantic depth across different levels of granularity (words, phrases, sentences, and paragraphs).
- Preserving contextual hierarchies, enabling better interpretability of relationships between ideas within text.
- Allowing downstream applications to measure not just relevance, but informational completeness and topical precision.
Hierarchical Representations
DRAMA uses a layered architecture in which:
- Lower layers capture local, surface-level semantics, such as keyword usage and phrase structure.
- Intermediate layers capture sentence- and paragraph-level coherence, understanding the logical flow of concepts.
- Higher layers capture abstract, conceptual meaning, enabling comparisons of how thoroughly a topic is covered across a document.
This hierarchy allows DRAMA to provide richer embeddings that can be leveraged to measure semantic depth, topic focus, and alignment with queries, making it highly suitable for content analysis in SEO.
Interpretability and Practical Relevance
One of the unique strengths of DRAMA is its interpretive capability. Unlike black-box embeddings, DRAMA’s multi-abstraction embeddings allow:
- Identification of underdeveloped content areas.
- Detection of off-topic content drift.
- Mapping of semantic alignment across document sections, providing actionable insights for content optimization.
For SEO applications, this interpretability is critical because it provides quantifiable evidence of content depth and relevance that can guide improvements without relying solely on surface-level keyword metrics.
Key Content Metrics and Their Significance
To translate DRAMA embeddings into actionable SEO insights, the project computes the following metrics:
Semantic Depth
Semantic depth refers to the completeness and richness of content coverage in relation to a specific query or topic. High semantic depth indicates that a webpage:
· Explains core concepts thoroughly.
· Provides nuanced information beyond basic definitions.
· Offers logical connections between ideas and subtopics.
· Semantic Depth Score Measurement
Measures how thoroughly each subsection addresses the query topic. Higher values indicate in-depth coverage, guiding content expansion where necessary.
Topical Precision
Topical precision measures how focused the content is on the intended topic, minimizing drift into unrelated areas. Maintaining high topical precision ensures that search engines and readers perceive the content as authoritative and relevant, which directly impacts SEO performance.
· Topical Precision Metric Measurement
Captures how concentrated the content remains on the main topic. Lower precision highlights areas where content may be diverging from the core subject.
Query-Content Relevance
Query-content relevance quantifies the semantic alignment between user queries and content sections. This ensures that each subsection contributes meaningfully to satisfying the informational goal of the query, allowing targeted content optimization.
· Query–Content Relevance Mapping Measurement
Quantifies the alignment between specific queries and subsections, providing fine-grained insight into which parts of a page effectively satisfy user information needs.
These metrics are derived from DRAMA’s hierarchical embeddings, leveraging both surface-level and conceptual representations to provide a multi-dimensional view of content quality and focus.
Content Coverage and Content Focus
· Topic Coverage (How Webpages Cover Topics) This means granularity: does the page include all relevant concepts? Are there content gaps? Do sections dive into subtopics or explain context, definitions, examples, and related concepts? Indicators: number of high relevance subsections, semantic depth of subsections.
· Content Focus (Maintain Content Focus) This means coherence: does the content stay aligned with the main subject? Is there drift (off-topic material)? Are there sections that diverge from what user expects given the query? Indicators: topical precision metric, query relevance, comparing content with page topic centroid vs query alignment.
These correspond directly to the computed metrics, and inform where content is strong vs where it needs refinement.
keyboard_arrow_down
Q&A: Understanding Project Value and Features
What are the key benefits of this project for SEO?
This project provides a deep semantic evaluation of content, allowing SEO professionals to assess how comprehensively and accurately pages cover target topics. By highlighting both topic coverage gaps and off-topic content, it supports strategic content optimization, improves search visibility, and ensures pages meet user informational needs more effectively. This approach goes beyond keyword matching to provide multi-dimensional insights into content quality and focus.
What is the primary value of using the DRAMA model in this project?
DRAMA captures multi-layered semantic relationships within content, including both surface-level phrasing and deeper conceptual meaning. This enables the project to evaluate topic depth, focus, and relevance more accurately than traditional embeddings or keyword-based analysis. It provides actionable insights for prioritizing content improvements, guiding SEO teams to enhance the informational strength and authority of webpages.
How does the project help in assessing content quality?
The project converts DRAMA embeddings into interpretable metrics, giving a clear picture of content depth, topical precision, and query alignment. This allows SEO professionals to quickly identify underdeveloped sections, redundancies, or content drift, ensuring pages are comprehensive, focused, and authoritative. These insights support evidence-based decisions for content refinement.
Which types of content or webpages benefit most from this approach?
Long-form content, pillar pages, and complex topic pages benefit significantly. These pages often contain multiple sections or content blocks, where evaluating both depth and focus is essential. The project helps pinpoint areas for expansion or refinement, ensuring each section contributes meaningfully to the overall page quality and SEO performance.
How does the project support content planning and optimization?
By providing a structured, metric-driven view of semantic coverage, the project highlights areas that require content expansion, reorganization, or topic refocusing. SEO teams can use these insights to strategically plan content updates, prioritize high-impact improvements, and enhance alignment with target topics and user intent.
Why is this project important for modern SEO strategies?
Search engines increasingly evaluate semantic relevance and content comprehensiveness rather than just keyword frequency. This project equips SEO teams with advanced, model-backed insights that reveal true topic understanding, supporting strategic optimization and improved ranking potential while enhancing user engagement.
How user-friendly are the insights for SEO professionals?
Insights are presented using concise metrics and visualizations, allowing professionals to quickly interpret performance at the page and section level. This design ensures that actionable recommendations are easy to identify, enabling SEO teams to apply improvements efficiently without requiring advanced technical expertise.
Libraries Used
time
The time library in Python provides functions for time-related operations, such as pausing execution, measuring elapsed time, or working with timestamps. It is a standard library widely used for implementing delays, timeouts, and performance measurement.
In this project, time is used to implement polite delays when fetching web pages, helping avoid server overloading and managing retries efficiently. It also supports timing operations, allowing monitoring of performance when processing multiple pages or embeddings.
re
The re library is Python’s standard regular expression module for pattern matching, searching, and string manipulation. It allows complex text processing tasks such as cleaning, filtering, and extracting patterns from content.
Within this project, re is applied for text preprocessing, including removing URLs, inline references, excessive whitespace, and special characters from web page content. This ensures the extracted content is clean and suitable for embedding and metric computations.
html (imported as html_lib)
The html library provides utilities for escaping and unescaping HTML entities, enabling proper handling of web-based text data. It ensures that content with HTML-encoded symbols is accurately converted to readable text.
In this project, html_lib is used to decode HTML entities in page content, allowing DRAMA embeddings to process clean, human-readable text. It helps maintain the semantic integrity of the content during preprocessing.
hashlib
The hashlib library is a standard Python module for generating cryptographic hashes such as MD5, SHA1, and SHA256. Hashing is often used for creating unique identifiers for objects or content.
Here, hashlib is used to generate unique IDs for sections and content blocks, ensuring that every piece of content can be referenced reliably across the pipeline, especially when aggregating metrics or mapping results back to the original content.
unicodedata
The unicodedata library allows Unicode character normalization and manipulation, enabling standardized text processing across multiple character sets.
In this project, unicodedata ensures that content extracted from web pages is normalized to a consistent format, eliminating hidden or unusual Unicode characters that may interfere with text processing, tokenization, or embedding computation.
logging
The logging library provides a flexible system for tracking application events, warnings, and errors. It is used for debugging, monitoring, and maintaining robust production pipelines.
This project employs logging to capture runtime events during page extraction, preprocessing, and embedding generation, providing insight into failures, retries, and potential content issues, which is essential for professional and reliable client-oriented implementations.
warnings
The warnings library in Python allows developers to manage and filter warning messages during code execution.
In this project, warnings is used to suppress non-critical warnings from libraries like BeautifulSoup, transformers, or PyTorch, keeping the output clean and professional for easier interpretation during development and reporting.
requests
requests is a widely-used Python library for making HTTP requests in a simple and human-friendly manner. It supports GET/POST methods, headers, timeouts, retries, and more.
In this project, requests handles fetching web page content from client-provided URLs. It enables robust web scraping by integrating timeouts, retries, and headers, ensuring reliable and polite extraction of HTML content for downstream analysis.
typing
The typing module provides type hints for Python functions and variables, supporting code readability, maintainability, and static type checking.
This project uses typing annotations extensively to define input and output types for functions, making the code more understandable, safer, and professional. It ensures developers and clients can clearly see the expected data structures and types in the processing pipeline.
BeautifulSoup (from bs4)
BeautifulSoup is a popular library for parsing and navigating HTML or XML content, providing easy methods to extract text, tags, and hierarchical structures.
In this project, BeautifulSoup is employed to clean HTML pages and extract structured sections, sections, and blocks. It allows the pipeline to retain meaningful content while removing irrelevant tags, supporting accurate semantic analysis and embedding generation.
numpy
NumPy is a fundamental library for numerical computing in Python, supporting multidimensional arrays, vectorized operations, and mathematical functions.
Here, NumPy is used to handle embedding arrays, compute distances, and perform vector-based metric calculations. It provides efficient processing for semantic depth, topical precision, and query relevance calculations, enabling scalable analysis of large web pages.
sentence_transformers (SentenceTransformer, util)
The sentence_transformers library enables transformer-based embeddings for sentences, paragraphs, or documents, supporting semantic similarity and clustering.
In this project, DRAMA embeddings are handled using SentenceTransformer, and cosine similarity functions from util are used to compute semantic depth, topical precision, and query-content alignment. This allows the project to provide actionable, model-driven SEO insights.
torch
PyTorch (torch) is a widely used library for tensor computation and deep learning, supporting GPU acceleration and neural network operations.
In this project, torch powers the SentenceTransformer backend, ensuring efficient computation of DRAMA embeddings for large sections or pages. It enables fast and scalable semantic evaluation of content.
transformers.utils.logging
The transformers logging module allows fine control over verbosity for HuggingFace models, enabling suppression of unnecessary warnings or progress bars.
In this project, it is used to disable verbose logging from the transformers library, maintaining clean and professional output while computing embeddings with DRAMA models.
pandas
Pandas is a Python library for data manipulation and analysis, providing DataFrames for structured tabular data operations.
Here, Pandas is used to organize metric results, prepare data for visualizations, and support summary reporting. It simplifies grouping, filtering, and aggregating results for both section-level and page-level insights.
matplotlib.pyplot
Matplotlib is a standard library for 2D plotting in Python, supporting bar charts, scatter plots, line charts, and customization of figures.
In this project, it is used to plot SEO metrics, semantic depth, topical precision, and query relevance, providing visual insights into page content performance in a way that is understandable for SEO strategists.
seaborn
Seaborn is a statistical data visualization library built on Matplotlib, offering enhanced aesthetics, color palettes, and aggregation functions.
Here, Seaborn is employed to create colorful, user-friendly visualizations that illustrate page-level and section-level performance, improving the readability and interpretability of SEO insights.
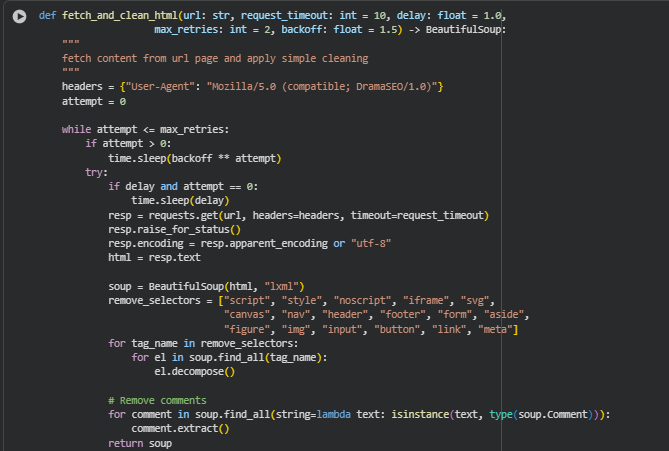
Function fetch_and_clean_html
Overview
The fetch_and_clean_html function retrieves the HTML content from a given URL and applies initial cleaning to remove unnecessary elements. It handles network retries, implements delays to avoid overloading servers, and converts HTML content into a structured BeautifulSoup object. This function forms the foundation of the pipeline, ensuring that subsequent analysis works on clean, readable, and relevant content.
Key Code Explanations
· headers = {“User-Agent”: “Mozilla/5.0 (compatible; DramaSEO/1.0)”}
Sets a custom user-agent to mimic a real browser request. This improves request reliability and prevents being blocked by servers.
· resp = requests.get(url, headers=headers, timeout=request_timeout)
Sends an HTTP GET request to the URL with a timeout. This ensures that slow or unresponsive servers do not halt the pipeline.
· soup = BeautifulSoup(html, “lxml”)
Parses the HTML using BeautifulSoup with the lxml parser for efficient and robust parsing. Converts raw HTML into a navigable tree structure.
· for tag_name in remove_selectors: … el.decompose()
Iterates over tags like <script>, <style>, <iframe>, and removes them. This cleans irrelevant content, focusing on text that contributes to SEO insights.
· for comment in soup.find_all(string=lambda text: isinstance(text, type(soup.Comment))): comment.extract()
Removes HTML comments to avoid noise in text embeddings, ensuring that the DRAMA model receives meaningful content only.
Retry logic The while attempt <= max_retries loop implements exponential backoff in case of request failures. It ensures robust handling of network errors, increasing reliability in production environments.
Function extract_sections
Overview
The extract_sections function processes a BeautifulSoup object to identify and structure content into sections, subsections, and blocks. It organizes content hierarchically based on HTML headings (h1–h4) and paragraphs (p, li, blockquote). This structure provides a foundation for semantic analysis, enabling computation of metrics at both subsection and page level.
Key Code Explanations
· page_title = h1_tags[0].get_text(strip=True) …
Extracts the page title using the first <h1> tag or <title> fallback. The title is used for reference in reports and visualizations.
· tags_iter = soup.find_all([“h1″,”h2″,”h3″,”h4″,”p”,”li”,”blockquote”])
Creates an iterator over relevant tags to traverse the page content sequentially, ensuring that the hierarchical structure is preserved.
· if tag in [“h1″,”h2”]: section = {“section_title”: text, “subsections”: []}
Detects main section headings and initializes a new section dictionary, creating a top-level content structure.
· if tag in [“h3″,”h4”]: subsection = {“subsection_title”: text, “blocks”: []}
Detects subsection headings and creates a subsection dictionary, nested under the parent section.
· subsection[“blocks”].append({ “block_id”: block_idx, “text”: text, “tag_type”: tag, “heading_chain”: [section[“section_title”], subsection[“subsection_title”]] })
Stores individual content blocks, capturing text, HTML tag type, and heading hierarchy. This allows granular metric calculation per content block.
Function extract_page
Overview
The extract_page function provides a single entry point to extract structured content from a URL. It combines fetch_and_clean_html and extract_sections to return a well-structured dictionary containing URL, page title, and hierarchical content. This dictionary serves as the base input for preprocessing, embeddings, and metric calculations.
Key Code Explanations
· soup = fetch_and_clean_html(url, request_timeout, delay, max_retries, backoff)
Calls the HTML fetch function to obtain cleaned HTML content. Any request failures are handled internally, ensuring that downstream processing receives a valid object or None.
· sections, page_title = extract_sections(soup, min_block_chars)
Processes the BeautifulSoup object to generate structured sections, subsections, and blocks, while filtering out very small content blocks based on min_block_chars.
· return {“url”: url, “title”: page_title, “sections”: sections}
Returns a comprehensive dictionary capturing all relevant page content in a hierarchical structure, ready for embedding computation and SEO metric evaluation.


Function preprocess_block
Overview
The preprocess_block function performs text cleaning and filtering at the block level. It standardizes HTML entities, removes boilerplate text, normalizes unicode characters, and filters out blocks that are too short to be meaningful. This ensures that only high-quality, relevant text is passed to embeddings for semantic analysis.
Key Code Explanations
· text = html_lib.unescape(text)
Converts HTML entities (like &, <) into readable characters, ensuring that text is correctly interpreted.
· text = unicodedata.normalize(“NFKC”, text)
Normalizes unicode characters to canonical form, which avoids inconsistencies in embeddings caused by visually similar characters.
· substitutions = {…} for k,v in substitutions.items(): text = text.replace(k,v)
Replaces non-standard or special characters with standard equivalents (e.g., quotes, dashes). This improves text consistency for embedding computation.
· text = re.sub(r”http\S+|www\.\S+”, “”, text)
Removes URLs from text to focus embeddings on meaningful content, rather than irrelevant links.
· if any(bp in lower_text for bp in boilerplate_terms): return “”
Filters out common website boilerplate, like “Read more” or “Privacy Policy”, which do not contribute to SEO insights.
· if len(lower_text.split()) < min_words: return “”
Ensures that only blocks with sufficient content are kept, improving embedding quality and semantic reliability.
Function merge_blocks_to_subsections
Overview
This function merges multiple blocks into embedding-ready subsections, each with a unique ID, merged text, and reference to constituent blocks. It splits large subsections based on word count (max_words) to maintain manageable input sizes for embeddings while preserving the sectional hierarchy.
Key Code Explanations
· cleaned = preprocess_block(block[“text”], min_words, boilerplate_terms)
Cleans each block individually to remove noise and standardize text, ensuring only meaningful content is included in subsections.
· merged_pieces.extend(block_words); word_acc += len(block_words)
Accumulates words from blocks until reaching max_words, controlling the size of each merged subsection.
· sub_id = hashlib.md5(sub_id_source.encode()).hexdigest()
Generates a unique identifier for each subsection based on section title, subsection title, and chunk index. This ensures traceability and uniqueness across large pages.
Subsection splitting logic When word_acc >= max_words, the function creates a new subsection and resets accumulators. This prevents embeddings from exceeding practical input length limits, while preserving content continuity.
Function preprocess_page
Overview
The preprocess_page function processes a fully extracted page dictionary by cleaning its text blocks and merging them into embedding-ready subsections. The returned dictionary contains the URL, page title, and structured subsections, forming the standardized input for DRAMA embeddings and metric computation.
Key Code Explanations
· sections = extracted_page.get(“sections”, [])
Extracts the hierarchical section data from the raw page extraction, ensuring robust handling if the key is missing.
· subsections = merge_blocks_to_subsections(sections, min_words, max_words, boilerplate_terms)
Converts raw blocks into embedding-ready subsections, integrating cleaning, boilerplate removal, and subsection splitting.
· return {“url”: extracted_page.get(“url”), “title”: extracted_page.get(“title”), “subsections”: subsections}
Provides a clean, hierarchical page representation that is consistent across all URLs, enabling downstream semantic depth, topical precision, and query relevance calculations.
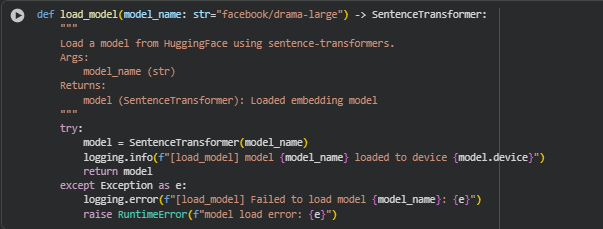
Function load_model
Overview
The load_model function is responsible for loading a SentenceTransformer model from HuggingFace for generating embeddings. This model is the backbone for computing semantic depth, topical precision, and query-content relevance, providing high-quality contextual representations of page content. The function accepts a single model_name parameter, allowing flexibility to switch models if needed, while ensuring consistent device placement for efficient computation.
Key Code Explanations
· model = SentenceTransformer(model_name)
Initializes a SentenceTransformer model from HuggingFace. This converts text into dense embeddings that encode semantic meaning, enabling the downstream metrics to quantify content quality and relevance.
Model Overview — DRAMA-large
Summary
DRAMA-large is a state-of-the-art dense retrieval model developed by Meta (Facebook) designed to generate high-quality semantic embeddings for textual content. It is optimized to understand the meaning, intent, and context of text at a granular level, enabling precise measurement of content relevance, coverage, and depth. Its combination of representational power and efficiency makes it particularly effective for analyzing web pages in SEO workflows, providing actionable insights for content optimization and query alignment.
The model excels at bridging the gap between user intent and content, ensuring that pages are assessed not just for keywords but for true semantic relevance. This capability is essential for modern SEO strategies that prioritize comprehensive, contextually rich content.
Architecture and Model Design
DRAMA-large is built upon a compact, high-performing transformer architecture that captures nuanced relationships between text segments with 0.3B parameters. Unlike traditional models that rely on surface-level lexical matching, DRAMA-large produces dense vector representations with the default embedding size of 1024 that encode both semantic meaning and contextual relevance.
- Embedding Vectors: Each sentence or content block is transformed into a multi-dimensional vector, where semantically similar content is mapped closer together in the embedding space.
- Layered Understanding: The model leverages multiple transformer layers to capture subtle syntactic and semantic nuances, enabling differentiation between shallow coverage and in-depth explanation.
- Efficiency-Oriented Design: By pruning non-essential model components while retaining core semantic capabilities, DRAMA-large balances computational efficiency with high retrieval accuracy.
This architecture ensures that even complex queries or long-form content are represented accurately for downstream analysis, making it practical for large-scale SEO assessments.
Training Approach
DRAMA-large is trained using a diverse set of data curated to represent a wide range of topics, writing styles, and content structures. Key aspects include:
- Contextual Relevance Training: The model is fine-tuned to prioritize semantically meaningful matches between queries and content sections, rather than mere keyword overlap.
- Contrastive Learning: It learns to distinguish between relevant and non-relevant content, refining its ability to capture subtle differences in meaning.
- Robust Generalization: Exposure to varied data ensures the model performs consistently across multiple domains, including technical, commercial, and informational content.
This training strategy allows DRAMA-large to produce reliable embeddings even for pages with specialized vocabulary or uncommon phrasing, ensuring accurate content scoring in diverse SEO scenarios.
Multilingual and Cross-Domain Capabilities
DRAMA-large is capable of handling multilingual content effectively, which is increasingly important for global SEO strategies. Its embeddings maintain semantic consistency across languages, enabling meaningful cross-lingual analysis of web pages.
In addition, the model generalizes well across content domains:
- Technical documentation, product descriptions, blog posts, and news articles are all represented in a way that highlights topic relevance and content depth.
- The model can identify nuanced semantic relationships between queries and content, even when phrasing differs significantly, supporting more comprehensive SEO evaluation.
Efficiency and Practical Application
DRAMA-large is designed for real-world, scalable use. Its efficient architecture allows rapid embedding generation for multiple URLs or large web pages without requiring extensive computing resources.
Practical applications in SEO include:
- Semantic Relevance Scoring: Accurately measures how closely content sections align with target queries.
- Content Depth Assessment: Highlights which parts of a page provide comprehensive coverage versus superficial mentions.
- Query Alignment: Identifies gaps in coverage relative to desired search intents.
These capabilities ensure that SEO professionals can focus on actionable insights rather than raw data processing, streamlining content optimization workflows.
Evaluation and Performance
DRAMA-large delivers high-quality embeddings that reliably capture semantic meaning and content importance. Performance highlights include:
- Precision in Retrieval Tasks: Relevant content is ranked accurately, supporting precise content evaluation.
- Nuanced Differentiation: Distinguishes between high-value and low-value content sections, which is critical for optimizing both user experience and search performance.
- Scalability: Embeddings can be generated quickly for large datasets, enabling analysis of multiple pages and queries efficiently.
Overall, the model provides robust, reliable, and interpretable insights into content quality and semantic coverage.
Relevance to This Project
For this project, DRAMA-large is the backbone of semantic analysis, enabling:
- In-depth Content Evaluation: Quantifies how thoroughly page sections address specific queries or topics.
- Precise Query-Content Matching: Measures semantic alignment between search intent and page content.
- Actionable Insights for Optimization: Identifies content gaps, strengths, and opportunities for enhancing informational value.
By leveraging DRAMA-large, the project transforms raw web page text into structured, interpretable metrics, enabling SEO professionals to make informed, results-driven content optimization decisions.
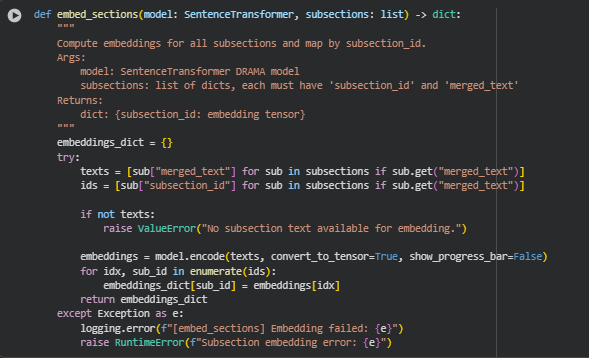
Function embed_sections
Overview
The embed_sections function generates dense semantic embeddings for each subsection using the loaded DRAMA SentenceTransformer model. Embeddings transform textual content into numerical vectors that capture contextual meaning, allowing downstream metrics like semantic depth, topical precision, and query-content relevance to be computed efficiently. Each embedding is mapped to its corresponding subsection_id for traceability and easy reference in subsequent analyses.
Key Code Explanations
· texts = [sub[“merged_text”] for sub in subsections if sub.get(“merged_text”)]
Extracts the textual content from each subsection. Only non-empty merged_text entries are included, ensuring the embedding process is applied to valid text data.
· ids = [sub[“subsection_id”] for sub in subsections if sub.get(“merged_text”)]
Collects the corresponding subsection_id values to maintain mapping between embeddings and their subsections. This is critical for linking metric calculations back to the original content structure.
· embeddings = model.encode(texts, convert_to_tensor=True, show_progress_bar=False)
Uses the DRAMA model to compute embeddings. convert_to_tensor=True ensures outputs are PyTorch tensors, which allow fast similarity computations and integration with GPU acceleration if available.
· Mapping embeddings to subsection IDs
· for idx, sub_id in enumerate(ids):
embeddings_dict[sub_id] = embeddings[idx]
Each embedding is stored in a dictionary keyed by subsection_id, providing direct access for later calculations like cosine similarity and metric derivation.
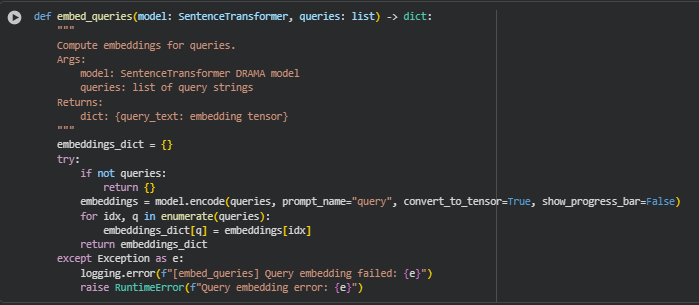
unction embed_queries
Overview
The embed_queries function generates semantic embeddings for each query using the loaded DRAMA SentenceTransformer model. These embeddings allow direct comparison between user queries and content subsections, enabling the computation of query-content relevance metrics. Each query is mapped to its original text for traceability and easy reference in downstream analyses.
Key Code Explanations
· if not queries: return {}
Ensures that the function handles empty input gracefully, returning an empty dictionary without errors if no queries are provided.
· embeddings = model.encode(queries, prompt_name=”query”, convert_to_tensor=True, show_progress_bar=False)
Uses the DRAMA model to compute embeddings for all queries.
- prompt_name=”query” allows the model to treat queries differently if supported, optimizing semantic representation.
- convert_to_tensor=True returns PyTorch tensors, enabling efficient similarity calculations with subsection embeddings.
· Mapping embeddings to query text
· for idx, q in enumerate(queries):
embeddings_dict[q] = embeddings[idx]
Stores each embedding in a dictionary keyed by the original query string, ensuring that subsequent computations can directly link similarity scores back to the corresponding query.
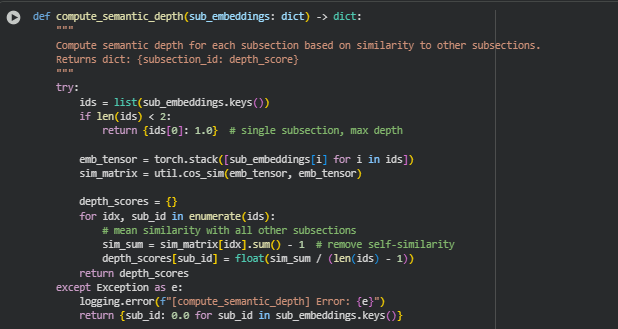
Function compute_semantic_depth
Overview
The compute_semantic_depth function calculates the semantic richness of each subsection by comparing its embedding with all other subsection embeddings on the same page. A higher semantic depth indicates that a subsection contains content that is more conceptually connected to other sections, reflecting thorough coverage and interlinked ideas. This metric helps identify subsections that are central to content comprehension and those that may need additional context or expansion.
Key Code Explanations
· ids = list(sub_embeddings.keys())
Extracts all subsection IDs to maintain a reference for mapping the computed scores.
· if len(ids) < 2: return {ids[0]: 1.0}
Handles the edge case of a single subsection, assigning it a maximum semantic depth of 1.0 since it cannot be compared to others.
· Compute similarity matrix
· emb_tensor = torch.stack([sub_embeddings[i] for i in ids])
sim_matrix = util.cos_sim(emb_tensor, emb_tensor)
- torch.stack creates a 2D tensor containing all subsection embeddings.
- util.cos_sim computes pairwise cosine similarity, producing a matrix where each entry represents the similarity between two subsections.
· Calculate depth scores
· for idx, sub_id in enumerate(ids):
sim_sum = sim_matrix[idx].sum() – 1 # remove self-similarity
depth_scores[sub_id] = float(sim_sum / (len(ids) – 1))
- For each subsection, the function averages its similarity to all other subsections, ignoring self-similarity.
- This average represents the semantic depth, with higher values indicating better conceptual coverage and cohesion.
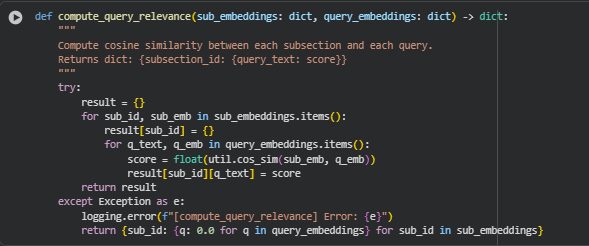
Function compute_query_relevance
Overview
The compute_query_relevance function measures the semantic alignment between each page subsection and the user-provided queries. By computing cosine similarity between subsection embeddings and query embeddings, it quantifies how well the content satisfies specific informational needs. This allows for fine-grained analysis of which subsections effectively address user queries, guiding targeted content optimization and SEO improvement strategies.
Key Code Explanations
· Iterate over subsections and queries
· for sub_id, sub_emb in sub_embeddings.items():
result[sub_id] = {}
for q_text, q_emb in query_embeddings.items():
score = float(util.cos_sim(sub_emb, q_emb))
result[sub_id][q_text] = score
- For each subsection (sub_id), a nested dictionary is initialized to store query-specific relevance scores.
- util.cos_sim(sub_emb, q_emb) computes cosine similarity between the subsection embedding and each query embedding, producing a relevance score between -1 and 1.
- Scores are stored in the structure {subsection_id: {query_text: score}} for easy downstream analysis.
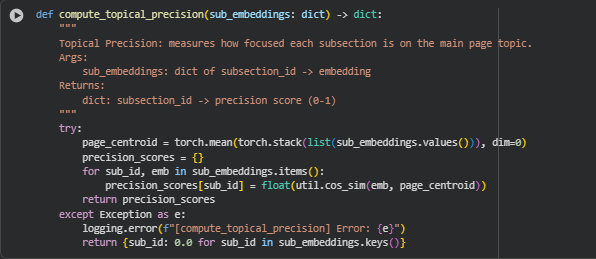
Function compute_topical_precision
Overview
The compute_topical_precision function measures how focused each subsection is on the main topic of the page. By comparing each subsection embedding to the centroid embedding of the page, it quantifies the concentration of content around the central theme. High topical precision indicates strong alignment with the main topic, while lower values suggest content drift or off-topic subsections. This metric is crucial for maintaining SEO relevance and content quality.
Key Code Explanations
· Compute page centroid
page_centroid = torch.mean(torch.stack(list(sub_embeddings.values())), dim=0)
- Stacks all subsection embeddings into a single tensor and computes the mean vector, representing the central theme of the page.
- This centroid acts as a reference embedding for measuring how focused each subsection is relative to the overall page topic.
· Calculate cosine similarity for each subsection
· for sub_id, emb in sub_embeddings.items():
precision_scores[sub_id] = float(util.cos_sim(emb, page_centroid))
- Computes the cosine similarity between each subsection embedding and the page centroid.
- Results in a precision score between -1 and 1, reflecting alignment with the main page topic.
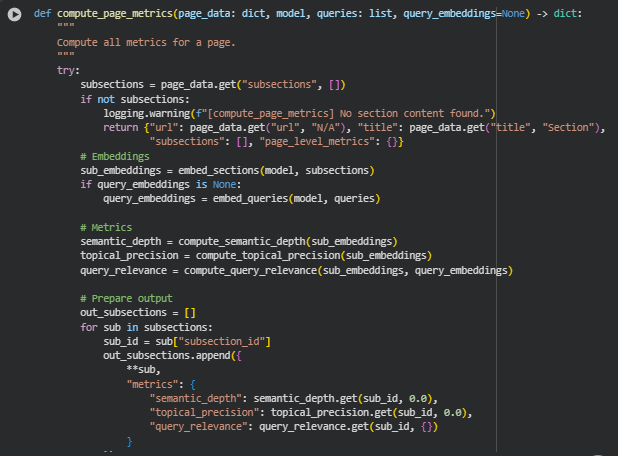
Function: compute_page_metrics
Overview
The compute_page_metrics function serves as a wrapper to compute key SEO semantic metrics for a webpage. It integrates all individual metric computations—semantic depth, topical precision, and query relevance—for each subsection and also aggregates page-level metrics for an overall view.
Key Code Explanations
· Embeddings Computation
· sub_embeddings = embed_sections(model, subsections)
if query_embeddings is None:
query_embeddings = embed_queries(model, queries)
These lines generate embeddings for subsections using the DRAMA model and compute embeddings for queries if not provided. Subsection embeddings allow measuring semantic similarity and topical focus, while query embeddings enable alignment assessment.
· Metric Calculations
· semantic_depth = compute_semantic_depth(sub_embeddings)
topical_precision = compute_topical_precision(sub_embeddings)
query_relevance = compute_query_relevance(sub_embeddings, query_embeddings)
These calls invoke the core metric functions:
- Semantic Depth evaluates how comprehensively each subsection covers the content.
- Topical Precision measures focus and prevents content drift.
- Query Relevance quantifies alignment between each subsection and client queries.
· Section Metrics Aggregation*
· out_subsections.append({
**sub,
“metrics”: {
“semantic_depth”: semantic_depth.get(sub_id, 0.0),
“topical_precision”: topical_precision.get(sub_id, 0.0),
“query_relevance”: query_relevance.get(sub_id, {})
}
})
Each subsection dictionary is updated to include the computed metrics. This enables fine-grained, subsection-level insight for content evaluation and optimization.
· Page-Level Metrics Calculation
· page_level_metrics = {
“mean_semantic_depth”: float(torch.tensor(list(semantic_depth.values())).mean()) if semantic_depth else 0.0,
“mean_topical_precision”: float(torch.tensor(list(topical_precision.values())).mean()) if topical_precision else 0.0,
“mean_query_relevance”: mean_query_relevance
}
Aggregates subsection metrics to provide overall page-level insight. Means of semantic depth and topical precision give a holistic view of content coverage and focus, while mean query relevance summarizes how well the page aligns with the provided queries.
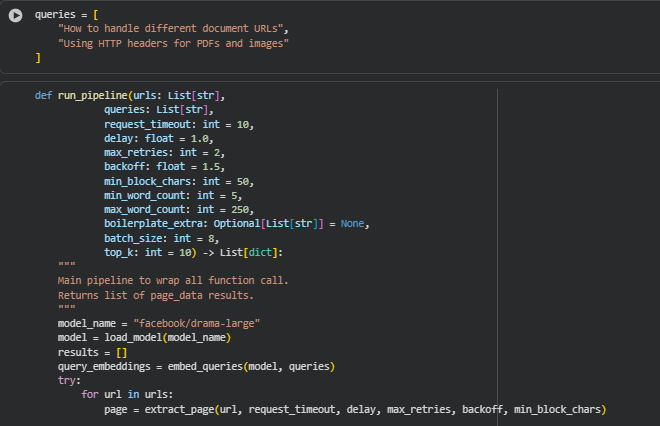
Function: run_pipeline
Overview
The run_pipeline function serves as the central execution layer that integrates every stage of the project’s workflow into a single cohesive process. It automates the complete sequence of operations—from webpage extraction to metric computation—allowing multiple URLs to be analyzed efficiently in a single run.
The function begins by loading the DRAMA model and encoding all query texts once to ensure computational efficiency. For each input URL, it executes the following steps sequentially:
- Content Extraction: Uses extract_page() to retrieve and structure the webpage content into sections and subsections.
- Text Preprocessing: Applies preprocess_page() to clean and merge text blocks, preparing them for embedding.
- Embedding and Metric Computation: Utilizes compute_page_metrics() to generate embeddings and compute all three metrics—semantic depth, topical precision, and query-content relevance.
- Aggregation: Compiles all page-level results, storing them in a structured list of dictionaries for further analysis or visualization.
By combining all lower-level operations into one streamlined pipeline, this function provides a ready-to-use framework for large-scale SEO analysis. It ensures consistent processing across multiple URLs, minimizes redundant computations, and maintains a standardized structure for the output data—making it the main operational function of the DRAMA-powered SEO analysis system.
Function: display_results
Overview
The display_results function is responsible for presenting the final analysis outputs in a structured and user-understandable format. It summarizes the SEO insights derived from the DRAMA-powered analysis, highlighting the most meaningful sections of each webpage based on the computed semantic metrics.
For each analyzed URL, the function prints page-level metrics such as mean semantic depth, mean topical precision, and average query relevance, providing a clear overview of overall content quality and focus. It then displays the top content sections—ranked by semantic depth—to emphasize which parts of the page contribute most effectively to topic coverage and search alignment.
By converting complex model outputs into a clean, textual summary, this function bridges the gap between technical results and practical understanding. It ensures that insights can be easily interpreted and acted upon by SEO professionals without requiring any additional technical interpretation or visualization.
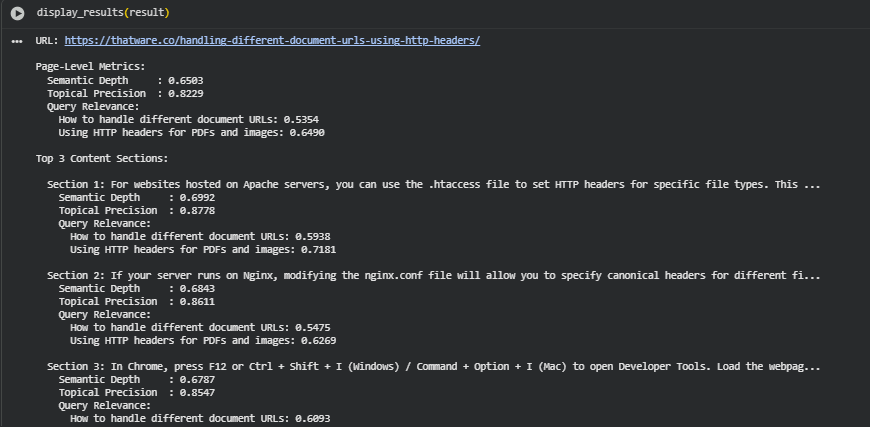
Result Analysis and Explanation
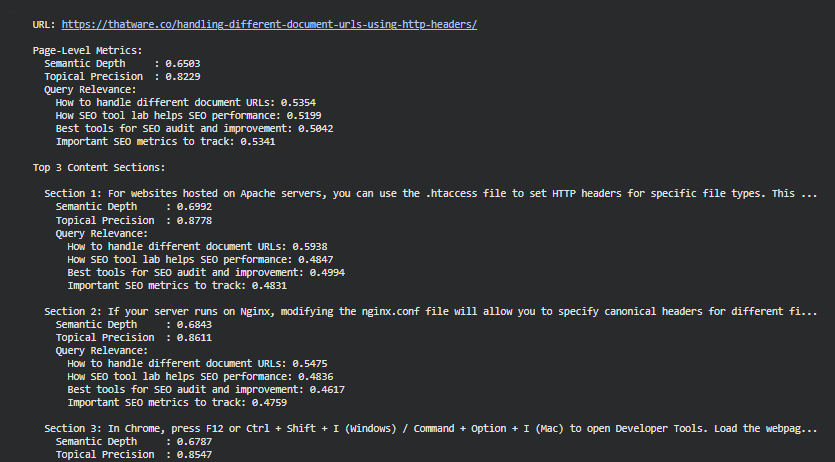
URL: https://thatware.co/handling-different-document-urls-using-http-headers/
Queries analyzed:
- How to handle different document URLs
- Using HTTP headers for PDFs and images
Summary
The page shows moderate–good overall semantic quality. Page-level semantic depth (0.6503) indicates reasonable conceptual coverage, and topical precision (0.8229) shows the content is well-focused on the page’s main topic. Query relevance varies by query: the page aligns more strongly with the HTTP headers for PDFs and images query (0.6490) than with the broader handling different document URLs query (0.5354). Top three sections are the strongest parts of the page and are the best candidates both to preserve and to expand for improved query coverage.
Scoring thresholds (how to read the numbers)
Use these practical thresholds to interpret scores consistently:
- High: ≥ 0.75 — strong / good / likely to satisfy that metric
- Moderate: 0.50 – 0.74 — acceptable, likely needs some improvement to be outstanding
- Low: < 0.50 — weak, needs attention
All metrics here are cosine-similarity based and roughly mapped to the ranges above for interpretation and prioritization.
Page-level interpretation
Semantic Depth — 0.6503 (Moderate)
- Interpretation: The page covers the topic with a reasonable degree of conceptual richness but is not fully exhaustive. It likely includes several important concepts and practical instructions but may miss deeper examples or edge cases.
- Implication: The page can perform adequately for informative queries, but there is upside in adding depth (examples, troubleshooting, detailed steps) to become a stronger resource.
Topical Precision — 0.8229 (High)
- Interpretation: The content stays closely on-topic; it does not wander into unrelated subjects. The page’s sections are coherent and aligned with the central theme (HTTP header handling for documents).
- Implication: High precision means adding depth (rather than changing topic) is the recommended path — expand within the same focused domain.
Query Relevance (page-level mean)
- How to handle different document URLs: 0.5354 (Moderate) — the page touches this general query but could better address higher-level URL handling scenarios or broader strategies.
- Using HTTP headers for PDFs and images: 0.6490 (Moderate–High) — the page already offers useful, more specific coverage for this query; further targeted expansion would make it strong.
section-level analysis (Top 3 sections)
Each section is listed with its scores and a concise interpretation and recommendation.
Section 1 (Previewed):
· Semantic Depth: 0.6992 (Moderate)
· Topical Precision: 0.8778 (High)
· Query relevance:
- How to handle different document URLs: 0.5938 (Moderate)
- Using HTTP headers for PDFs and images: 0.7181 (High)
Interpretation: Section 1 is one of the page’s strongest blocks in focus and relevance for the HTTP headers use case. It is well-aligned and contains conceptually useful material but still has room to increase depth.
Recommended updates for Section 1:
- Add code snippets or concrete .htaccess examples (copy-pastable blocks) labeled with clear headings.
- Include a short “When to use .htaccess” decision checklist to expand conceptual coverage.
- Add internal anchor links and a short FAQ (one or two Q&As) addressing common edge cases (e.g., caching headers for pdfs).
Section 2 (Previewed):
· Semantic Depth: 0.6843 (Moderate)
· Topical Precision: 0.8611 (High)
· Query relevance:
- How to handle different document URLs: 0.5475 (Moderate)
- Using HTTP headers for PDFs and images: 0.6269 (Moderate–High)
Interpretation: Section 2 is focused and directly relevant (Nginx configuration). It provides practical steps but could benefit from deeper examples and troubleshooting scenarios.
Recommended updates for Section 2:
- Add complete nginx.conf snippet(s) for common use cases (PDFs, images, canonical headers).
- Provide a short “common pitfalls” list (e.g., order of directives, MIME types).
- Link to Section 1 where applicable for cross-reference (improves semantic cohesion).
Section 3 (Previewed):
· Semantic Depth: 0.6787 (Moderate)
· Topical Precision: 0.8547 (High)
· Query relevance:
- How to handle different document URLs: 0.6093 (Moderate–High)
- Using HTTP headers for PDFs and images: 0.6790 (Moderate–High)
Interpretation: This section—developer tools / testing workflow—supports the how-to aspect and contributes to practical breadth. It helps users validate configurations but is still moderate in depth.
Recommended updates for Section 3:
- Add step-by-step validation procedures with sample responses (HTTP response headers screenshots or text).
- Describe how to test PDF/image header changes in CI or staging environments.
- Consider adding short troubleshooting commands (curl examples) to increase depth and query coverage.
Query-specific analysis and suggestions
Query: How to handle different document URLs — score(s)
- Page-level: 0.5354 (Moderate)
- Section scores: 0.5938 / 0.5475 / 0.6093 (Moderate–Moderate-High)
Interpretation & actions:
- The page addresses URL-handling to some extent, but the coverage is somewhat tactical (server config) rather than strategic (URL design, canonicalization, redirects, sitemap handling). To strengthen relevance for this broader query, add a short section or a framed sidebar covering URL strategy for documents: canonical choices, redirect strategy, sitemap entries for non-HTML objects, and best practices for serving documents with distinct URLs.
Query: Using HTTP headers for PDFs and images — score(s)
- Page-level: 0.6490 (Moderate–High)
- Section scores: 0.7181 / 0.6269 / 0.6790 (Moderate–High)
Interpretation & actions:
- The page already performs well for this specific, technical query. To convert the page to a clear leader for this query, add detailed examples: exact MIME types, caching header examples (Cache-Control, Expires), content-disposition uses for inline vs attachment, and sample response headers. A downloadable checklist or short template for server admins would likely raise relevance above the high threshold.
Result Analysis and Explanation
This report section interprets the analytical results from both a technical and practical SEO standpoint. It explains what each score represents, why the value matters, and what actions should be taken based on the observed ranges. The goal is to translate analytical findings into concrete optimization steps that improve content quality, topical alignment, and ranking potential.
Overview of Analytical Dimensions
Each web page is decomposed into sections and scored along three major analytical dimensions:
- Semantic Depth — evaluates how meaningfully and contextually the topic is explored.
- Topical Precision — measures how focused and coherent the writing remains around the core subject.
- Query Relevance — assesses how closely the content aligns with the provided search intents.
Together, these form a 3D interpretability model that describes both content strength and search intent alignment at section and page levels.
Semantic Depth — Interpreting Content Richness
Definition: Semantic Depth measures conceptual elaboration — how effectively a section conveys complete and contextually rich meaning. High values indicate comprehensive explanations, nuanced coverage, and the presence of well-connected supporting concepts.
Threshold Interpretation:
· > 0.75 (High Depth): Content is informative, detailed, and contextually robust. It often answers related subtopics naturally, showing depth of understanding. Action: Keep structure consistent; consider repurposing for pillar or hub content.
· 0.60 – 0.75 (Moderate Depth): Provides basic explanations but lacks detailed context or examples. Action: Add secondary details, supporting examples, and contextual references to enrich meaning.
· < 0.60 (Low Depth): Indicates surface-level explanations, thin paragraphs, or missing conceptual layers. Action: Expand content with more “why” and “how” coverage — address implicit user questions, not just direct ones.
SEO Implication: High semantic depth strengthens authority and topical comprehensiveness. It signals to search engines that the page is an in-depth resource, improving potential for featured snippets or higher topical relevance weighting.
Topical Precision — Measuring Focus and Alignment
Definition: Topical Precision quantifies how consistently a section stays within its thematic boundaries. It detects drift — where the text mixes unrelated subtopics or overextends contextually.
Threshold Interpretation:
· > 0.80 (High Precision): Writing stays sharply on-topic, with coherent progression and minimal tangents. Action: Maintain existing structure; use these sections as content models for others.
· 0.65 – 0.80 (Balanced Precision): Generally focused but may contain partial drift or redundant phrasing. Action: Revisit sentence transitions and eliminate loosely related tangents or filler text.
· < 0.65 (Low Precision): Indicates conceptual fragmentation or thematic drift. Action: Refine headings and reorganize paragraphs to restore topical hierarchy. Keep only information directly reinforcing the section intent.
SEO Implication: High topical precision improves content interpretability for ranking models. It ensures that search algorithms can clearly identify the topic and intent of each section, increasing the likelihood of being ranked for the right queries.
Query Relevance — Aligning with Search Intent
Definition: Query Relevance measures semantic closeness between the content and each target search query. It captures whether the section effectively addresses what users are actually searching for.
Threshold Interpretation:
· > 0.55 (High Relevance): The section directly answers user intent and uses strong contextual alignment with the query’s semantics. Action: Reinforce this structure — these are your “conversion” or “ranking” zones.
· 0.35 – 0.55 (Moderate Relevance): The section partially aligns with the query but may lack explicit contextual or keyword signals. Action: Rephrase headings, strengthen topical entities, or add connecting sentences referencing user goals.
· < 0.35 (Low Relevance): Indicates misalignment with the query or content written from a different intent perspective. Action: Rework copy to reflect user problems, intent types, or solution-oriented framing. Realign subheadings with the target queries.
SEO Implication: Relevance is the most direct ranking influence. High scores correlate with improved match confidence in semantic retrieval systems, particularly in transformer-based ranking models. Optimizing these sections yields immediate gains in query visibility.
Page-Level Insights — Balancing Quality Across Sections
The page-level metrics represent aggregated averages from all section scores. They describe the page’s overall SEO posture:
· High Semantic Depth + High Precision: Content is both comprehensive and coherent — typically the best-performing combination for evergreen SEO value.
· High Depth + Low Precision: Indicates overly detailed or digressive content. Streamlining can improve focus without losing richness.
· High Precision + Low Depth: Focused but shallow content; ideal candidates for topic expansion or related-term enrichment.
· Balanced Scores (~0.65–0.75): Shows consistent, good-quality writing — but strategic fine-tuning can elevate the page from competitive parity to leadership.
Action Strategy: Identify which sections deviate most from the mean and prioritize optimization there. Improving low-scoring sections has disproportionate impact on the overall page authority signal.
Visualization-Based Interpretations
Five visualizations were designed to make the analytical outputs intuitive and actionable. Each chart presents a unique perspective for diagnosing performance patterns and guiding optimization.
Section-Wise Semantic Depth Distribution
Purpose: Displays the variation of semantic depth across different sections.
Interpretation: A balanced distribution indicates consistent content depth across sections. Large fluctuations suggest uneven elaboration — where certain parts might require enrichment or simplification. This plot helps pinpoint shallow content zones that weaken page authority.
Action: Target sections at the bottom end of the curve for expansion or elaboration.
Section-Wise Topical Precision Distribution
Purpose: Illustrates how tightly each subsection adheres to its main topic.
Interpretation: A narrow high-scoring range indicates a focused content structure with minimal off-topic drift. Broader ranges or low outliers show where sections might include loosely related information or mixed messaging that can confuse both readers and search engines.
Action: Consolidate low-scoring sections, rewrite with tighter semantic boundaries.
Query Relevance Across Topics
Purpose: Visualizes how well different subsections align with each user-defined query.
Interpretation: This visualization highlights the connection between section content and target search intents. Sections that score well for multiple queries reflect semantic flexibility, while narrow coverage may suggest that optimization efforts are concentrated around only a subset of search intents.
Action: Focus on sections that underperform for high-priority queries — revise headings or integrate target phrases organically.
Interrelation Plot Between Metrics
Purpose: Demonstrates the relationship among Semantic Depth, Topical Precision, and Query Relevance using a correlation or scatter matrix.
Interpretation: Helps identify whether higher semantic detail contributes positively to relevance or precision. For instance, if deeper content consistently aligns with stronger relevance, the strategy should emphasize elaborative writing styles. Conversely, if high depth lowers topical precision, it indicates over-elaboration or drift.
Action: If increasing semantic depth lowers precision, revise phrasing for conciseness. If higher precision raises relevance, prioritize tighter topic structuring.
Comparative Page-Level Performance Plot
Purpose: Shows a summarized comparison across analyzed URLs using mean metric values.
Interpretation: This comparison identifies which pages exhibit the most balanced optimization. High-performing pages serve as a model for structural and topical improvements across weaker URLs. The visualization also helps track content consistency across a site or domain.
Action: Use high-performing pages as templates for weaker ones, especially if they share similar intent or topic scope.
Holistic Interpretation Framework
The value of the analysis lies in understanding metric interdependence rather than viewing scores in isolation. For example:
- Depth improvements often enhance precision if done contextually.
- Excessive elaboration may dilute topical focus.
- Relevance boosts when both depth and precision are well-balanced.
A strong optimization cycle follows this pattern: Identify gaps -> Enhance meaning -> Refine focus -> Align with intent.
Recommended Optimization Actions
· Shallow Content Low Semantic Depth but high Precision. Expand with examples, add practical details.
· Off-topic Drift High Depth but low Precision. Simplify and reorganize headings.
· Weak Intent Match Low Query Relevance. Rewrite for intent clarity, update phrasing.
· Consistent but Moderate Scores Balanced around 0.65. Add subtopics or entity connections.
· Overly Uniform Scores All high (>0.8). Maintain but audit for redundancy.
Strategic Value of This Analysis
This analytical layer bridges interpretability and optimization. By quantifying semantic, topical, and relevance characteristics:
· It pinpoints why a page ranks or underperforms.
· It prioritizes which sections to fix rather than rewriting the entire page.
· It connects NLP metrics to SEO strategy, creating a measurable and explainable content optimization process.
The metrics together form a transparent framework for assessing content quality, topical authority, and intent satisfaction, all of which are essential for sustained search performance.
size=2 width=”100%” align=center>
Q&A Section for Result Interpretation and Action Suggestions
What does a high Semantic Depth score indicate, and how should it influence content strategy?
A high Semantic Depth score indicates that a page or section effectively captures the conceptual and contextual layers of its topic. It reflects not just keyword presence, but how meaningfully the topic is explored — including causes, effects, examples, and surrounding ideas.
From a content strategy perspective, such sections represent topic authority anchors. They demonstrate the writer’s understanding of user intent and provide comprehensive information that answers implicit and explicit user questions. These sections can be leveraged as pillar content, knowledge hubs, or reference anchors to improve internal linking structure.
When optimizing across multiple URLs, identifying high-depth pages allows focusing on content clustering — linking supporting articles or supplementary subtopics to strengthen topical coverage and reinforce search engine understanding of domain expertise.
What are the implications of low Semantic Depth, and how can it be improved without overloading the text?
Low Semantic Depth typically arises from surface-level writing, lacking conceptual expansion, examples, or explanations that build user understanding. Such content may cover the “what” but not the “why” or “how.”
Improvement requires contextual enrichment rather than adding unnecessary length. The goal is to add depth through intentful elaboration. This includes:
- Expanding with clarifying examples or real-world use cases.
- Integrating related terminologies and entities that reinforce topic understanding.
- Answering adjacent user queries that naturally arise from the main topic.
- Using explanatory connectors — “because,” “this means,” or “as a result” — to strengthen coherence between ideas.
Deepening content improves E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) signals, a core factor in search ranking models, without requiring word count inflation.
How does Topical Precision affect ranking performance and user satisfaction?
Topical Precision reflects how tightly a section stays aligned with its core subject. High precision ensures that content is focused, coherent, and semantically relevant — reducing off-topic noise that can confuse ranking models and readers.
From a ranking standpoint, transformer-based retrieval models like those used in modern search algorithms rely on semantic focus to determine intent clarity. Pages with high topical precision produce consistent context embeddings, making it easier for the search engine to classify them under the right query space.
From a user experience perspective, precise writing reduces cognitive load — users find exactly what they searched for without scanning irrelevant content. This directly affects dwell time, engagement rate, and conversion likelihood.
Improving precision involves content pruning: removing redundant phrases, reorganizing sentences for logical flow, and ensuring each paragraph contributes directly to the main theme. Precision-driven sections tend to perform best in featured snippets and People Also Ask boxes due to their concise and answer-oriented structure.
Why is Query Relevance a critical factor in interpreting content quality, and how is it optimized?
Query Relevance quantifies how effectively the content satisfies a given search intent. It is not simply keyword overlap but a semantic measure that assesses whether the language and context of a section truly address what the searcher expects to find.
Its importance lies in being the most direct determinant of search alignment. Even if content is deep and focused, it will underperform if the intent mismatch persists — for example, when a section written for informational intent targets a commercial query.
To improve Query Relevance:
- Reassess the intent type (informational, transactional, navigational, or comparative).
- Adjust tone and structure to reflect intent — e.g., how-to phrasing for informational, benefit-driven phrasing for commercial.
- Introduce semantic anchors (key phrases, entities, and query synonyms) that match how users articulate search problems.
- Align subheadings and paragraph introductions with the phrasing patterns of the query cluster.
Optimizing for relevance makes content discoverable under multiple query formulations and enhances its positioning across intent-segmented SERP spaces.
What does the relationship between Semantic Depth and Topical Precision reveal about content balance?
The interplay between these two metrics provides valuable insights into structural efficiency. High Semantic Depth but low Topical Precision typically indicates content that is rich in detail but suffers from drift — covering too many loosely connected aspects. Conversely, high Precision but low Depth suggests content that is well-focused but lacks elaboration, leading to under-explained ideas.
A balanced combination — moderate-to-high scores in both metrics — yields content that is both informative and digestible.
When plotted as a scatter distribution, this relationship visually identifies optimization zones:
- Upper-right quadrant (high depth, high precision): Ideal content; use as reference models.
- Lower-right quadrant (high depth, low precision): Overextended sections; condense and refocus.
- Upper-left quadrant (low depth, high precision): Shallow but focused; expand meaningfully.
- Lower-left quadrant (low both): Weak sections requiring full rework.
Maintaining balance across both dimensions ensures content remains comprehensive without redundancy — an optimal configuration for modern ranking systems.
How should multiple URLs with varied scores be interpreted collectively?
When analyzing multiple URLs, the goal is to benchmark relative strengths and weaknesses rather than treating each page in isolation. Pages with high overall semantic and precision scores represent topic leaders within the site structure. These pages can be positioned as content anchors in internal linking hierarchies, boosting authority signals across weaker URLs.
Conversely, pages with moderate or low scores can serve as supporting nodes, addressing subtopics or related long-tail queries. The aggregated visualization across URLs helps identify which parts of the site demonstrate thematic consistency and which require optimization for semantic alignment.
Collectively, this approach transforms raw scores into a hierarchical SEO roadmap — pinpointing where to reinforce content, which URLs to internally link, and which ones to restructure for broader topical coverage.
How can insights from section-level relevance be used for granular optimization?
Section-level query relevance identifies exactly which content blocks align or misalign with specific queries. This granularity is crucial because entire pages rarely target a single intent — sections often differ in query alignment.
The visualization highlights sections that perform well for particular queries. These can be repurposed as stand-alone snippets or used in content segmentation, enabling tailored optimization for multiple intents on the same page.
Sections with low query relevance should be rewritten by:
- Adjusting their introductory sentences to reflect the exact user problem.
- Using context-specific examples or definitions relevant to the search term.
- Integrating high-relevance entities and maintaining coherence with surrounding text.
This process turns content refinement from a page-wide task into a targeted, precision-based optimization workflow, improving efficiency and measurable ranking impact.
What is the practical SEO value of combining all three metrics — Depth, Precision, and Relevance?
Together, these three metrics create a 360° interpretability framework that directly connects NLP-driven analysis with measurable SEO outcomes.
- Semantic Depth enhances topical authority.
- Topical Precision ensures intent clarity and ranking focus.
- Query Relevance guarantees discoverability and alignment with user search language.
When jointly analyzed, they pinpoint both strength areas (content leadership) and weak zones (optimization priorities). This synergy transforms abstract content evaluation into actionable insights.
In practice, optimizing for all three dimensions improves:
- Ranking accuracy: Pages appear under the most relevant search intents.
- Crawl efficiency: Clearer topical boundaries aid search engine understanding.
- Content trustworthiness: Well-balanced, contextually sound writing signals expertise.
This integrated interpretation turns content evaluation into a continuous feedback system that keeps content aligned with both search algorithms and human understanding.
What tangible SEO benefits does this entire project deliver?
The project introduces a data-driven, interpretable layer of content quality assessment — one that goes beyond keyword frequency or readability. By quantifying Semantic Depth, Topical Precision, and Query Relevance, it provides measurable insight into why pages perform the way they do.
Key SEO benefits include:
- Transparent ranking interpretability: Understanding not just what ranks, but why it ranks.
- Efficient optimization targeting: Identifying underperforming sections rather than rewriting entire pages.
- Topical authority reinforcement: Strengthening semantic networks across related URLs.
- Search intent satisfaction: Aligning every section with what users truly seek.
- Improved long-term stability: Building algorithm-resilient content optimized for meaning, not just terms.
Overall, this project converts language model interpretability into strategic SEO intelligence — bridging the gap between linguistic analysis and real-world optimization outcomes.
Final Thoughts
The project successfully demonstrates how advanced transformer-based modeling, powered by the Drama model, can be applied to measure and interpret the semantic quality of online content in a quantifiable, SEO-relevant manner. Through the combined evaluation of Semantic Depth, Topical Precision, and Query Relevance, it establishes a robust interpretability framework that explains why a page performs well and how each content block contributes to its overall search value.
By operationalizing deep NLP representations, the implementation delivers actionable insights across both page-level and section-level dimensions. The resulting analysis transforms abstract semantic relationships into tangible SEO intelligence—revealing which sections build topical authority, which maintain precision and focus, and which align most effectively with specific search intents.The project achieves its core goal of bringing explainability and transparency into content performance evaluation. It bridges model-driven interpretation with practical optimization strategy, allowing real-world application in query alignment, content structuring, and authority building. Overall, it represents a significant step toward interpretable, intent-aware SEO optimization, enabling a deeper understanding of the semantic factors that govern ranking success.
Click here to download the full guide about Drama-Powered Semantic Insight for SEO.
