SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project introduces commonsense reasoning into the information retrieval (IR) process to improve how content relevance is interpreted and ranked. Rather than matching user queries to webpage content based on keywords or superficial semantic similarity, the system evaluates how well a piece of content aligns with user expectations and typical scenarios.

Each content block is processed using a commonsense inference model that generates possible human-centric implications — such as what someone might want, need, or intend when expressing a certain idea. These inferred dimensions allow the system to interpret the deeper meaning behind both user queries and webpage content. The final ranking is then based on how well these underlying intentions align, even when the surface language differs.
For SEO-driven content strategy, this approach brings a significant advantage: it surfaces the most contextually relevant content that best matches user intent — not just what matches the exact words. This leads to higher-quality content discovery, improved search satisfaction, and better visibility for the content that truly addresses what users typically mean or expect.
Project Purpose
The purpose of this project is to improve the effectiveness of information retrieval systems by integrating commonsense understanding into content relevance ranking. In the context of SEO, users often search with incomplete queries, vague intent, or language that implies more than it states. Traditional IR systems based on keyword overlap or shallow semantic matching frequently fail to capture these nuances.
This project addresses that limitation by embedding commonsense inference directly into the relevance scoring process. For each content block, the system predicts plausible human motivations, goals, outcomes, and reactions — such as what someone is likely trying to achieve, what they may need beforehand, or how others might respond. The same reasoning process is applied to the user query.
By comparing the inferred meanings of the query and the content blocks, the system can prioritize results that are aligned with the user’s real-world goals, even when the phrasing is different. This ensures that retrieved content is not only topically related, but contextually meaningful.
For website owners and SEO professionals, this delivers more accurate and intent-aware content ranking, helping users reach the most relevant sections faster — ultimately improving content performance, discoverability, and user satisfaction.
Project’s Key Topics Explanation and Understanding
This project applies Commonsense Reasoning in Information Retrieval (IR) to enhance how content blocks are interpreted and ranked based on realistic user intent and typical scenarios. The methodology combines natural language understanding, scenario-based inference, and semantic similarity to improve content relevance assessment beyond traditional keyword or vector matching.
Commonsense Reasoning in IR
Commonsense reasoning involves drawing inferences that reflect typical human expectations, goals, or reactions in everyday contexts. In this project, commonsense reasoning is used to:
- Interpret the underlying intent or expected effects behind user queries.
- Evaluate whether retrieved content aligns with implied goals, needs, or outcomes a user is likely seeking.
- Filter and rank results based not just on lexical or semantic overlap, but on whether the scenario described in the content is logically aligned with the inferred scenario behind the query.
This approach brings the retrieval system closer to how human users interpret relevance, especially for queries where the user’s goal is implicit.
Scenario-Based Alignment of Query and Content
Unlike standard IR techniques that rely heavily on lexical similarity or embedding distance, this project uses a scenario-driven alignment method. For both the user query and the content blocks, commonsense inferences are generated across multiple reasoning dimensions such as:
- Intent: what someone wants to achieve (e.g., to improve ranking)
- Need: what must be known or done beforehand
- Effect: what happens after the action or advice is followed
- Reaction: how someone may feel or respond
By comparing these inferences across both query and content, the project builds a more context-aware representation of relevance, tailored to human reasoning patterns.
Block-Level Relevance Ranking
Instead of treating full pages as indivisible units, this implementation extracts and evaluates content at the block level (e.g., paragraphs, list items). Each block is scored based on its commonsense alignment with the query, enabling:
- More granular and interpretable relevance evaluation.
- Highlighting of specific passages that directly support or fulfill the query’s inferred needs.
- Elimination of non-informative or misleading content even if it resides on a generally relevant page.
This block-wise scoring improves retrieval precision and usability in real-world content analysis or SEO audit workflows.
Semantic Similarity via Inferred Knowledge
The system does not compare query and content text directly. Instead, it compares their inferred meanings, represented by lists of commonsense-driven phrases. These phrases are embedded into vector space and matched using semantic similarity measures, capturing relevance even when surface words differ.
This layer of abstraction allows the model to handle queries and content that are:
- Lexically different but logically aligned.
- Expressed in different tones, styles, or technical levels.
- Matched on reasoning compatibility rather than surface patterns.
Q&A Section for Understanding Project Value and Importance
This section addresses practical questions from the perspective of clients and SEO professionals, with a focus on the real-world benefits and impact of applying commonsense reasoning to content retrieval and relevance evaluation.
How does this project improve content discovery and relevance ranking compared to traditional methods?
Traditional content retrieval systems rely mostly on keyword overlap or general semantic similarity between queries and documents. These approaches often miss deeper intent or contextual alignment. This project enhances retrieval quality by introducing commonsense reasoning, which infers real-world intent, needs, and effects from both user queries and webpage content. The content is then ranked based on how well these inferred scenarios match.
As a result, even if a query and a content block use different words, they can still be matched correctly if their implied purposes or outcomes are aligned. This leads to improved relevance scoring and better surfacing of meaningful information that matches user expectations.
What specific business or SEO benefits can be achieved with this system?
The system enables more intelligent retrieval and interpretation of website content, which supports the following key benefits for clients:
- Improved SEO audits: Identifies blocks of content that actually satisfy user intent, helping teams highlight strong areas and optimize weak ones.
- Content quality insights: Goes beyond surface-level keyword checks to determine if content logically supports user goals.
- Intent-driven optimization: Helps align content structure and phrasing to better match the inferred intent behind high-value search queries.
- Content repurposing: Reveals contextually relevant sections that can be reused or highlighted for FAQs, summaries, or featured snippets.
By scoring content based on how well it supports realistic scenarios behind queries, clients can optimize content relevance in a much more targeted and meaningful way.
Can this project help identify gaps or mismatches in existing content strategy?
Yes. Since the system compares the inferred meaning of queries with the inferred meaning of content, it naturally highlights areas where expected user outcomes are not addressed. For example, if a query implies an intent like “how to improve SEO performance” but no content block matches that scenario, it will result in low relevance scores.
This allows SEO teams to pinpoint content gaps not easily visible through surface-level analysis and address them by refining messaging, restructuring content, or adding supporting material.
How does block-level scoring provide better insights than page-level analysis?
Instead of evaluating entire pages, this system breaks down content into meaningful blocks such as paragraphs or list items. Each block is scored individually based on how well it aligns with the query’s inferred goals and expectations.
This leads to:
- Precision: Surfaces only the most relevant sections, reducing noise.
- Actionability: Makes it easier to identify which content segments need improvement.
- Transparency: Provides a clearer view of how relevance is distributed across a page.
Clients get fine-grained insights that are far more useful for targeted SEO and UX improvements than general page-level metrics.
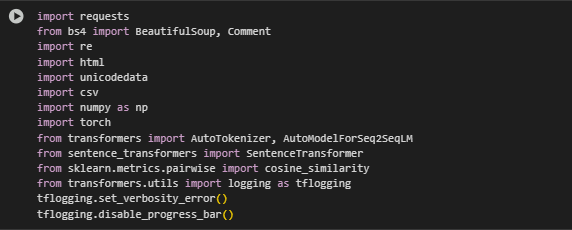
Libraries used
This section outlines the key libraries and tools integrated into the project, explaining both their functionality and their role in enabling the commonsense reasoning-based information retrieval system.
requests
The requests library is a standard Python HTTP library used for sending GET or POST requests to web pages. It provides a reliable interface for fetching raw HTML content from external URLs, making it ideal for web scraping or data retrieval in web-based SEO projects.
In this project, it is used to download the full HTML of each input URL. The response obtained through requests.get() forms the basis for all subsequent extraction and text processing. Without this library, the system would lack the foundational data needed for any kind of analysis.
bs4 (BeautifulSoup and Comment)
BeautifulSoup is a powerful HTML and XML parser used for navigating, searching, and modifying content within structured markup. Comment is a specific type of navigable string in bs4 that allows filtering HTML comments.
Here, BeautifulSoup is used to clean and parse the HTML content fetched from a URL. It isolates meaningful content blocks such as paragraphs, list items, and headers while discarding unwanted sections like scripts, styles, hidden elements, and footer/nav components. Comment is used to strip out non-visible annotations that do not contribute to user-visible content.
re
The re module provides support for regular expressions. It enables pattern matching and string manipulation tasks, which are often necessary during content cleaning or preprocessing steps.
In this system, regular expressions help in detecting and normalizing noisy text fragments, stripping unwanted characters, and cleaning whitespace issues. This contributes to more reliable and consistent block-level content analysis.
html
The html module is used for working with HTML entities. It provides methods for decoding character references into readable text.
It is used here to unescape HTML-encoded characters that may appear in extracted text, converting entities like & or " into their proper representations. This ensures that content is readable and semantically accurate before further analysis.
unicodedata
The unicodedata module offers utility functions to work with Unicode characters and text normalization.
In this project, it helps sanitize extracted content by standardizing Unicode forms and removing control characters that might interfere with downstream model processing or embedding generation.
csv
The csv module provides built-in support for reading and writing comma-separated values files.
It is used during the export stage of the project to write the final ranked results into a structured .csv file. This makes the output easy to review, share, and integrate into existing SEO audit workflows or reporting pipelines.
numpy
NumPy is a fundamental package for numerical computations in Python. It provides support for arrays, mathematical operations, and statistics.
Here, numpy is used primarily for computing aggregated similarity scores, such as averaging maximum similarities or final relevance scores for each content block. These calculations are essential for accurate and explainable relevance ranking.
torch
PyTorch is a widely adopted machine learning library, particularly useful for deep learning model execution.
It powers the commonsense reasoning model used in this project. torch is used to load the model, manage device placement (CPU/GPU), and run inference for generating commonsense annotations. The use of PyTorch ensures that large, pre-trained transformers operate efficiently and at scale.
transformers (AutoTokenizer, AutoModelForSeq2SeqLM, utils.logging)
The transformers library by Hugging Face provides access to a large ecosystem of pre-trained language models, along with utilities for tokenization, model loading, and inference. AutoTokenizer and AutoModelForSeq2SeqLM are specific interfaces for sequence-to-sequence transformers.
In this project, a COMET-style commonsense reasoning model (mismayil/comet-bart-ai2) is loaded via this library to generate inferential annotations (e.g., intent, reaction, effect) from blocks of text or queries. The logging utilities (utils.logging) are adjusted to silence unwanted model warnings and suppress progress bars for a clean user experience.
sentence_transformers (SentenceTransformer)
The sentence_transformers library enables sentence-level semantic embedding generation using transformer-based models.
It is used to convert both queries and content (including inferred commonsense reasoning) into dense vector representations. These embeddings are crucial for computing semantic similarity via cosine metrics, which determine the alignment between user expectations and available content.
sklearn.metrics.pairwise (cosine_similarity)
The cosine_similarity function from sklearn.metrics.pairwise computes the cosine similarity between two sets of vectors.
In this project, it measures how well a content block’s semantics (including inferred reasoning) align with the query semantics. This scoring mechanism directly drives the ranking of results. The use of this familiar and interpretable similarity function adds transparency to the relevance calculations.
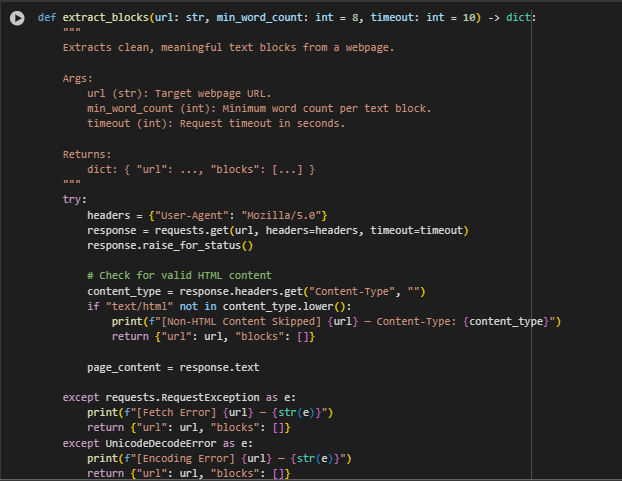

extract_blocks Function
Function Overview
The extract_blocks function is responsible for retrieving and parsing the raw content of a webpage, then isolating and returning only the clean, meaningful textual blocks that are suitable for semantic and reasoning analysis. This function ensures that only high-quality, human-readable content is used for downstream processing by applying multiple filters including tag exclusion, word count thresholds, duplication checks, and text encoding safeguards.
This step is essential in SEO-focused reasoning tasks because it extracts actionable and visible web content, while ignoring boilerplate or non-informative HTML parts. The output from this function forms the base for all subsequent preprocessing and inference operations.
Key Implementation Highlights
· Validating HTML Response:

- This validation ensures that only webpages serving actual HTML content are processed. It prevents misprocessing of binary or non-text responses such as PDFs or images.
- Removing Non-Content Elements:

- By decomposing structural, stylistic, or hidden elements, this logic ensures only visible, meaningful user-facing content is retained for further use.
- Ensuring Minimum Text Quality:

- This check removes text blocks with excessive non-ASCII characters that might indicate encoding corruption or irrelevant content such as garbled characters, broken fonts, or malformed markup.
- Deduplication of Blocks:
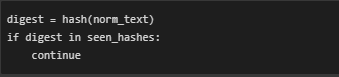
A hash-based heuristic is used to remove repeated or redundant content blocks, ensuring diversity in the final content pool. This is particularly useful when similar or repeated sections appear throughout the page layout.
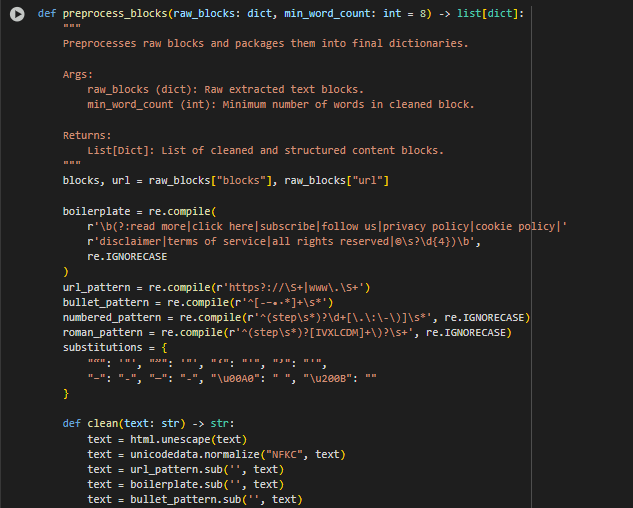
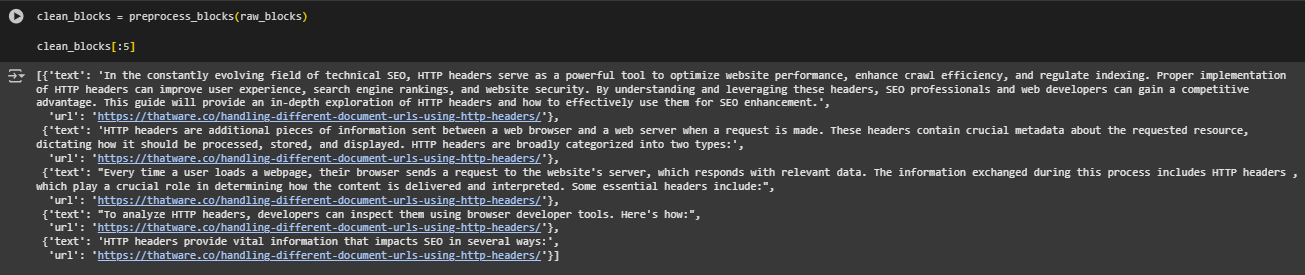
preprocess_blocks Function
Function Overview
The preprocess_blocks function refines and standardizes raw content blocks extracted from webpages. It applies multiple normalization steps to remove visual clutter, structural noise, and uninformative boilerplate from the text. The result is a list of clean, well-structured content segments ready for semantic inference and scoring.
This function plays a critical role in ensuring that only high-quality and linguistically meaningful content is passed to the commonsense reasoning and embedding stages. Preprocessing enhances the accuracy of both inference generation and semantic similarity by minimizing irrelevant or misleading textual patterns.
Key Implementation Highlights
· Boilerplate and Noise Removal Patterns:

- A predefined regex pattern targets common boilerplate terms found on web pages. These include legal disclaimers, promotional phrases, or navigational instructions that do not add content value for retrieval or reasoning.
- Visual Artifact Cleanup:

- These patterns strip out visible list markers (e.g., bullets, numbers, Roman numerals) that may otherwise pollute the semantic understanding of the text. This is especially useful for transforming HTML-rendered lists into clean, model-friendly sentences.
- Character Normalization and Substitutions:

- A lightweight character map replaces typographic symbols and non-breaking spaces with standard ASCII equivalents. Unicode normalization ensures consistent formatting, avoiding issues caused by special symbols or encoding mismatches.
- Link and URL Removal:

- Embedded links and raw URLs are stripped to maintain content focus. Hyperlinks rarely contribute meaningfully to reasoning-based retrieval and can disrupt the natural flow of a sentence if not removed.
- Text Block Cleaning and Filtering:

After all transformations, the function filters out blocks that are too short to carry meaningful content. This ensures that only informative, well-formed segments are retained.
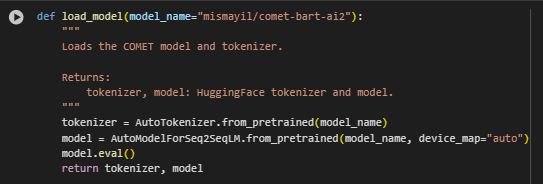
load_model Function
Function Overview
The load_model function initializes the commonsense reasoning model used throughout the project. It loads a pre-trained COMET (Commonsense Transformers) model and its corresponding tokenizer from HuggingFace’s Transformers library. COMET is designed for generating plausible inferences based on implicit knowledge about actions, intentions, and reactions — which aligns directly with the project’s goal of reasoning-based content ranking.
This function ensures that the reasoning model is ready for inference tasks such as generating plausible “xIntent”, “xNeed”, “xEffect”, and other commonsense relationships for both queries and content blocks.
Key Implementation Highlights
· Model Selection:
model_name=”mismayil/comet-bart-ai2″
The project uses the mismayil/comet-bart-ai2 model, a fine-tuned version of the BART architecture trained on the ATOMIC commonsense knowledge base. It is capable of generating multiple reasoning dimensions associated with typical real-world actions or statements.
· Tokenizer and Model Loading:

- The tokenizer converts text into token IDs that the model can process. The model itself is loaded using device_map=”auto”, allowing HuggingFace to automatically place the model on an available device (CPU or GPU), optimizing for performance and memory.
- Evaluation Mode:

This ensures the model runs in inference (not training) mode, which disables dropout layers and other training-specific behavior, ensuring consistent results.
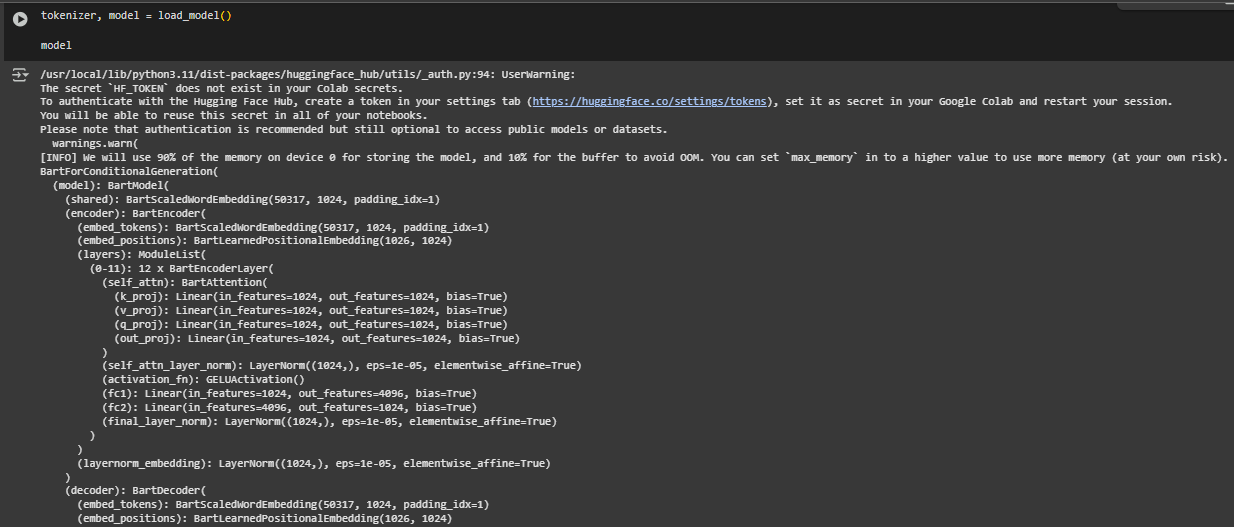
Reasoning Model Overview: mismayil/comet-bart-ai2
The project uses a pre-trained commonsense reasoning model named mismayil/comet-bart-ai2, which builds on top of BART architecture and is trained on the ATOMIC dataset. This model allows the system to generate human-like, plausible inferences about actions, intentions, and outcomes — enabling more intelligent content interpretation and alignment with user queries.
Model Architecture: BART-Based Transformer
- The model is based on BART (Bidirectional and Auto-Regressive Transformer), a powerful sequence-to-sequence transformer model developed by Facebook AI. BART is well-suited for text generation tasks, combining the strengths of bidirectional encoding (like BERT) and autoregressive decoding (like GPT).
- This makes it ideal for generating commonsense statements that continue or explain a given input sentence.
Training Source: The ATOMIC Knowledge Base
· The model has been trained on ATOMIC (Atlas of Machine Commonsense), a large-scale textual knowledge graph that contains everyday inferential knowledge about events.
· Each entry in ATOMIC represents a basic action or event (e.g., “PersonX helps PersonY”) and a set of likely commonsense continuations across predefined dimensions such as:
- xIntent – what PersonX intended
- xEffect – what happens to PersonX
- xWant – what PersonX wants to do next
- oEffect – effect on others
- xNeed – what PersonX needed before the event
- and more…
This structured commonsense generation enables a richer understanding of language and intention, which is essential for ranking relevance in an SEO and information retrieval context.
Reasoning Dimensions Used
The model is capable of generating inferences across nine standardized relations:
- xIntent: The likely intent behind the subject’s action.
- xNeed: Preconditions or requirements before the event.
- xEffect: Effects on the subject.
- xWant: What the subject may want to do after.
- xAttr: Attributes or characteristics of the subject.
- oEffect: Effects on other people involved.
- oWant: Likely desires of others following the action.
- xReact: Emotional or cognitive response of the subject.
- xEffect: External or visible consequence of the subject’s action.
These relationships offer a structured lens for interpreting short text blocks and queries beyond keyword overlap, focusing instead on intent, cause-effect, and emotional alignment.
Why This Model Fits the Project
- Commonsense alignment: It provides contextual understanding of content and queries, improving the quality of matching even in cases where keywords are vague or missing.
- Inference-driven relevance: Enables deeper matching beyond surface-level similarity, supporting typical SEO scenarios where intent-based relevance is crucial.
- Structured outputs: Makes it possible to map different dimensions of a query to those in content, allowing targeted and interpretable scoring.
Practical Benefits in Information Retrieval
Using this model, the system can simulate the kind of “mental reasoning” a human would apply to assess whether a piece of content is relevant, meaningful, or supportive of a user’s question. This is especially valuable in real-world SEO contexts where:
- Users may phrase queries ambiguously.
- Page content is semantically rich but lacks exact keyword matches.
- Multiple documents compete to fulfill a single intent.
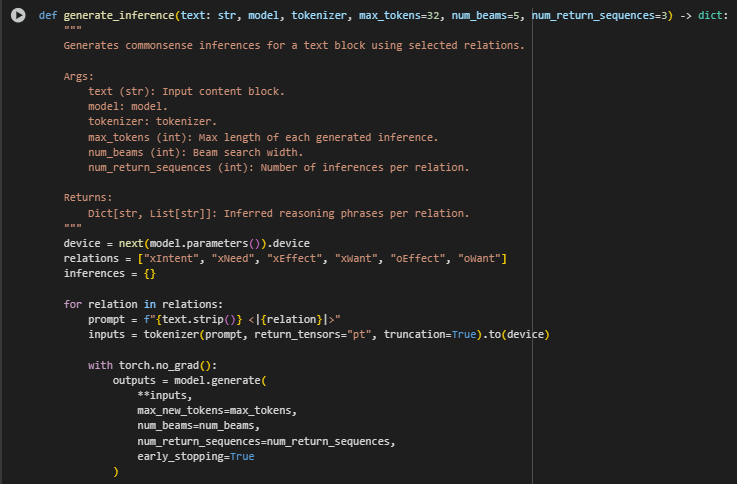
generate_inference Function
Function Overview
The generate_inference function generates commonsense inferences from a given input string by prompting a generative reasoning model across predefined reasoning relations. These relations, based on typical human behavior and intentions, are central to identifying relevance using commonsense understanding. The output is a structured dictionary of inferred phrases per relation that becomes a semantic layer for both document blocks and queries.
Key Implementation Highlights
· Device Handling
“ device = next(model.parameters()).device `
Retrieves the device (CPU or GPU) on which the model is currently loaded to ensure that inputs are also moved to the correct device.
· Relation Definitions
relations = [“xIntent”, “xNeed”, “xEffect”, “xWant”, “oEffect”, “oWant”] inferences = {}
Defines the list of targeted commonsense relations and initializes the final output dictionary.
· Relation-Specific Prompt Construction and Inference Generation

- For each reasoning relation, a relation-specific prompt is created and tokenized. The prompt combines the input text with a tagged instruction to guide the model’s generation.
- Model Inference Using Beam Search
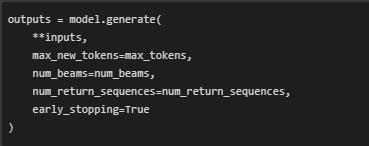
- The model generates multiple candidate inferences using beam search. This improves quality by exploring multiple generation paths.
- Decoding and Deduplication

- Outputs are decoded into human-readable strings. Duplicates and empty/generic values (like “none”) are removed. The cleaned results are stored per relation.
- Return Structure
The function returns a dictionary:
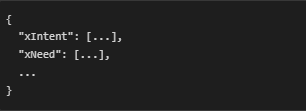
Each key represents a reasoning dimension, and the values are lists of generated inference strings relevant to that dimension. This structured output enables commonsense-based comparison and alignment in the subsequent pipeline steps.
generate_block_inferences Function
Function Overview
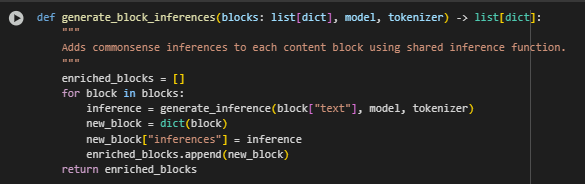
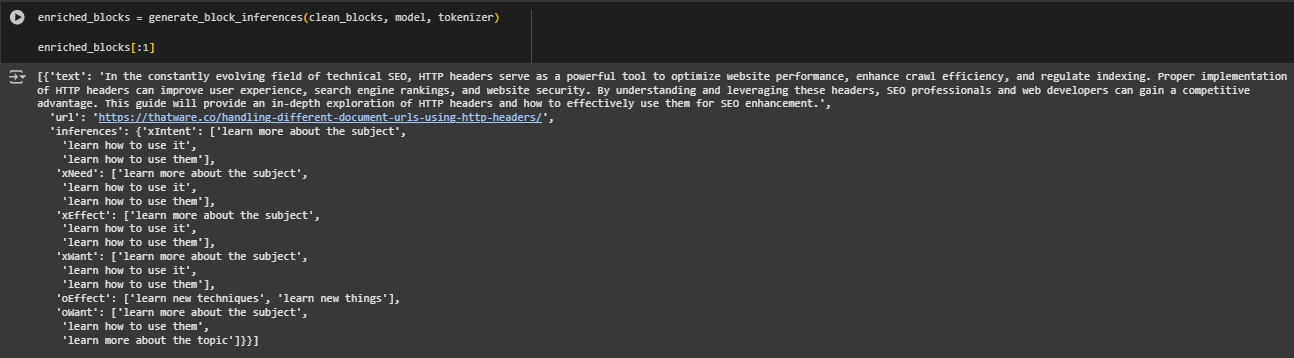
The generate_block_inferences function enriches each content block with structured commonsense reasoning. It applies the previously defined generate_inference function to every block’s text, generating multiple inferred behavioral or intent-based phrases. The output is a new version of each block containing both the original text and its reasoning layer, forming the foundation for downstream semantic alignment with user queries.
Key Implementation Highlights
· Initialize Output Container
enriched_blocks = []
Creates a list to store blocks after attaching their corresponding inferences.
· Loop Over Each Content Block

- Iterates through all input blocks and applies the generate_inference function to each block’s text. This retrieves a structured set of inferred relations per block.
- Attach Inference to Block
Creates a shallow copy of the original block to avoid mutating input data. Adds a new “inferences” field to the copied block, storing the reasoning output. This ensures original data remains intact while enabling enriched representation.
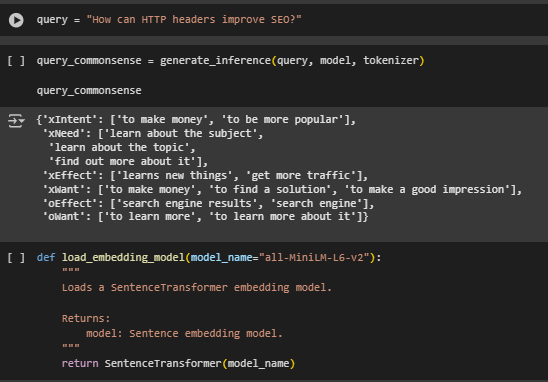
load_embedding_model Function
Function Overview
The load_embedding_model function loads a pre-trained sentence embedding model from the SentenceTransformer library. This model is responsible for converting natural language text—including queries and commonsense inferences—into dense vector representations that capture semantic meaning. These embeddings are later used to compute cosine similarity for ranking content relevance.
Key Implementation Highlights
· Load Sentence Embedding Model
“ return SentenceTransformer(model_name) `
Loads the sentence-level embedding model using the specified model name. The default used here, “all-MiniLM-L6-v2”, is a lightweight yet high-performing transformer model from the sentence-transformers collection. It balances speed and accuracy, making it suitable for practical use in real-world SEO relevance scoring pipelines.
Sentence Embedding Model: all-MiniLM-L6-v2
This project incorporates semantic similarity scoring as a core part of its commonsense relevance mechanism. The embedding model responsible for that role is all-MiniLM-L6-v2, a transformer-based model designed for efficient and meaningful sentence-level representation. It is used to encode both user queries and content block inferences into dense numerical vectors suitable for cosine similarity computation.
Model Family and Background
The all-MiniLM-L6-v2 model belongs to the MiniLM series developed as part of the sentence-transformers library, which extends transformer architectures for practical semantic tasks like similarity comparison, clustering, and retrieval. The “L6” indicates that the model uses only 6 transformer layers, making it significantly faster and lighter than full-sized BERT variants, while still preserving strong performance on real-world semantic understanding benchmarks.
It has been widely adopted in production-scale applications where efficient, sentence-level understanding is needed without heavy GPU demands.
Role in the Project
In this project, all-MiniLM-L6-v2 is used to embed two types of textual input:
- The user queries, either as raw input or enriched with their inferred commonsense extensions.
- The webpage content blocks, enriched with their own commonsense inferences.
By representing these texts as vector embeddings in the same semantic space, the model enables direct measurement of their alignment. This is achieved using cosine similarity between query and block vectors, offering a mathematically grounded method to score relevance.
Advantages for Commonsense IR
- Speed and Scalability: Due to its compact size, the model can handle large numbers of blocks efficiently, making it suitable for batch processing across multiple URLs and queries.
- Semantic Generalization: Embeddings capture more than just keyword overlap. They encode contextual, paraphrased, and intent-level signals, which complements the project’s emphasis on commonsense-driven interpretation.
- Compatibility: The model integrates smoothly with sklearn or sentence_transformers similarity utilities, maintaining flexibility in how scores are computed and fused
score_block_by_commonsense_alignment Function
Function Overview
The score_block_by_commonsense_alignment function calculates the semantic alignment between a user’s query and a content block by combining both literal text and their generated commonsense inferences. Instead of scoring the raw query and block content directly, it fuses the reasoning-based context with the original input, allowing for a deeper understanding of implied meaning. The similarity is then computed using cosine distance between sentence embeddings.
This function is central to the project’s ability to go beyond surface-level keyword matching. It introduces an advanced relevance signal by allowing each content block to be evaluated not only by what it states explicitly, but also by how well its inferred meaning aligns with the user’s underlying intent. The commonsense-enhanced matching plays a critical role in surfacing blocks that would otherwise be missed in traditional information retrieval systems.
Key Implementation Highlights
· Fuse Text and Commonsense Context
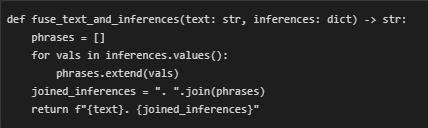
- This helper function takes the original input text and appends a flat list of all generated commonsense inferences across relevant relations. The merged result serves as a more semantically enriched version of the input, simulating how a human might interpret not just what is said but what is meant.
- Embed Combined Representations

- Uses a shared sentence embedding model to generate dense vector representations for both the query and content block in their combined form. This ensures that both inputs are interpreted in a semantically aligned vector space.
- Compute Cosine Similarity

Computes the cosine similarity between the query and block embeddings. This value (ranging from 0.0 to 1.0) reflects how conceptually similar the two inputs are when commonsense reasoning is included.
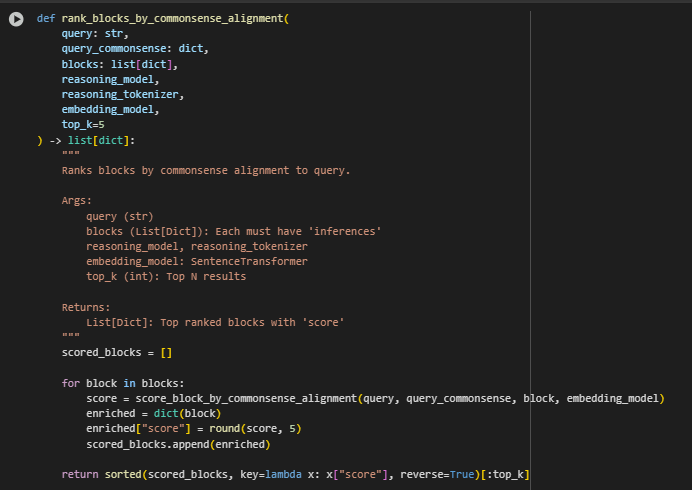
rank_blocks_by_commonsense_alignment Function
Function Overview
The rank_blocks_by_commonsense_alignment function serves as the decision-making layer of the system, determining which content blocks from a webpage are most relevant to a user query. It does so by applying commonsense-augmented scoring to each block and then ranking them based on their alignment scores.
This function operationalizes the core objective of the project: using commonsense reasoning to improve relevance in information retrieval. Rather than relying solely on lexical or syntactic matching, it integrates inferred meaning into the ranking logic. This provides more context-aware and user-aligned results—especially important in real-world SEO applications where user intent often extends beyond literal keywords.
Key Implementation Highlights
· Scoring Each Content Block

- Each block is individually evaluated using the score_block_by_commonsense_alignment function. This incorporates both the original block content and its inferred commonsense context when computing similarity to the query. The resulting similarity score is added to each block as a new “score” field for ranking purposes.
- Sorting and Ranking
return sorted(scored_blocks, key=lambda x: x[“score”], reverse=True)[:top_k]
After all blocks have been scored, they are sorted in descending order of relevance. The top k blocks are selected for return, representing the most semantically aligned matches between the query and webpage content.
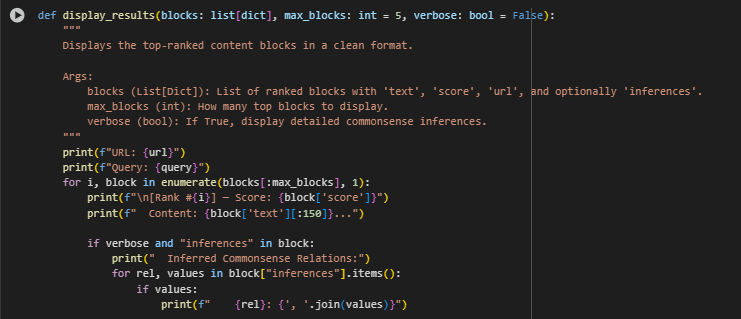
display_results Function
The display_results function provides a structured and readable view of the top-ranked content blocks for a given query. It prints out the content, score, and optionally the generated commonsense inferences for deeper inspection. This function is intended to support manual review or presentation of final outputs in a way that is clear and client-friendly. It does not influence any internal logic or ranking computation.
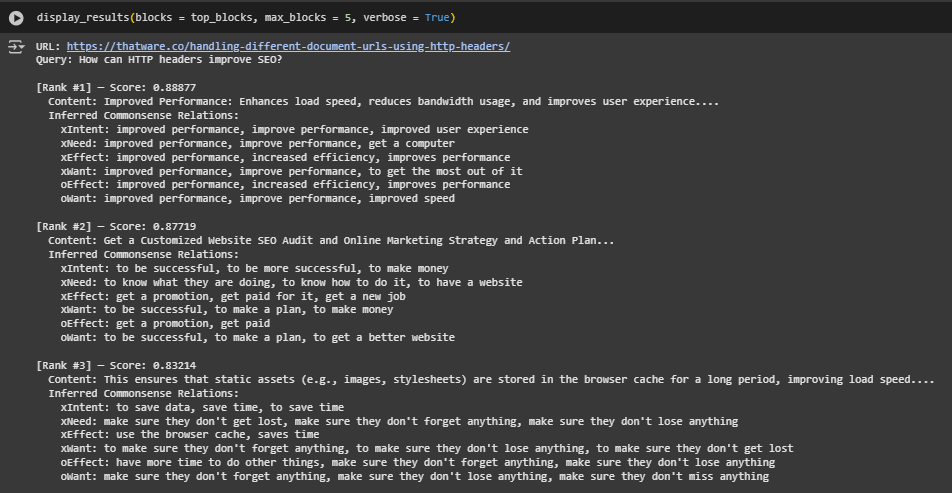
Result Analysis and Explanation
Query Context:
“How can HTTP headers improve SEO?” This query focuses on understanding the technical benefits and SEO value of HTTP headers — a topic typically relevant to developers and SEO specialists optimizing for performance, visibility, and crawl control.
Page Analyzed:
Top-Ranked Content Summary and Interpretation:
Enhanced Page Performance and Experience (Score: 0.8887)
This block discusses how HTTP headers can improve load speed and bandwidth efficiency — directly contributing to a better user experience. The model ranked this highest because it aligns with the user’s probable intent: improving performance through technical SEO measures. It reflects a strong relevance to Core Web Vitals and page speed, which are key SEO factors.
Custom SEO Strategy Promotion (Score: 0.8772)
Although more promotional in tone, this block introduces the idea of personalized SEO strategies and audits. It was selected due to its alignment with broader SEO improvement goals, likely inferred as a user’s intent behind asking about headers — i.e., to optimize overall SEO strategy beyond just the headers.
Long-Term Asset Optimization (Score: 0.8321)
The content here emphasizes caching static assets via headers — a tactical method to enhance SEO by reducing load times. The model interpreted this as a concrete way headers improve site efficiency, supporting long-term performance gains.
Speed and Compression Techniques (Score: 0.8087)
This block references compression and caching headers — clear technical implementations that boost load speed. From an SEO standpoint, the block is highly relevant, highlighting actions that lead to direct ranking and UX improvements.
Canonicalization and Ranking Visibility (Score: 0.7916)
This section connects header use with canonicalization, helping search engines understand preferred content versions. It ranks slightly lower due to complexity but remains critical for advanced SEO strategies aimed at avoiding duplication and improving crawl accuracy.
Relevance Driven by Commonsense Reasoning
The model ranks content blocks not just by surface-level keyword similarity but by evaluating inferred real-world implications. For each content block, the system infers how a typical reader or stakeholder might interpret or respond to the information, using commonsense-driven reasoning outputs such as “intent”, “effect”, or “need”.
The top-ranking block has the content:
“Improved Performance: Enhances load speed, reduces bandwidth usage, and improves user experience…” Score: 0.8887
This result is highly aligned with the query. The content directly discusses benefits of HTTP headers on performance—a core dimension of SEO. The inferred reasoning highlights intents such as “improved user experience”, effects like “increased efficiency”, and outcomes the reader likely wants to achieve. This alignment between the user’s query and the commonsense reasoning significantly strengthens its rank.
Diverse Reasoning Improves Interpretability
Each of the top 5 blocks contains not only the original content but also layers of reasoning:
- Intent reveals why the action or information matters (e.g., “to save time”, “to improve performance”).
- Effect models what outcome it may lead to (e.g., “website speed increases”, “search engine rankings improve”).
- Need captures what must be in place to achieve the result (e.g., “to have a good website”, “to know how to do it”).
This enables more nuanced and human-like matching between user queries and content relevance. For instance, another top block explains:
“By correctly implementing HTTP headers for canonicalization, you can enhance website visibility, improve search engine rankings…”
The corresponding inferences, such as “to be more visible” or “search engine results”, reinforce its relevance by associating technical implementation with higher-level business outcomes—something traditional retrieval models often fail to capture.
Insights and Practical Takeaways for Clients:
· Alignment with Technical SEO Goals: The top blocks clearly show how HTTP headers can impact speed, crawlability, and indexation — core to Google’s SEO guidelines.
· Action-Oriented Content: The system identifies not just general info but blocks that suggest specific improvements like enabling cache control, compression, and canonical headers.
· User Intent Coverage: The ranked content captures multiple facets of the original query — from performance to visibility to strategy — ensuring a complete and relevant response from the content.
· Content Quality and Value: These results also serve as a quality benchmark. Clients can use this output to validate if their page content is sufficiently aligned with high-value search intents and if it offers both depth and actionable insights.
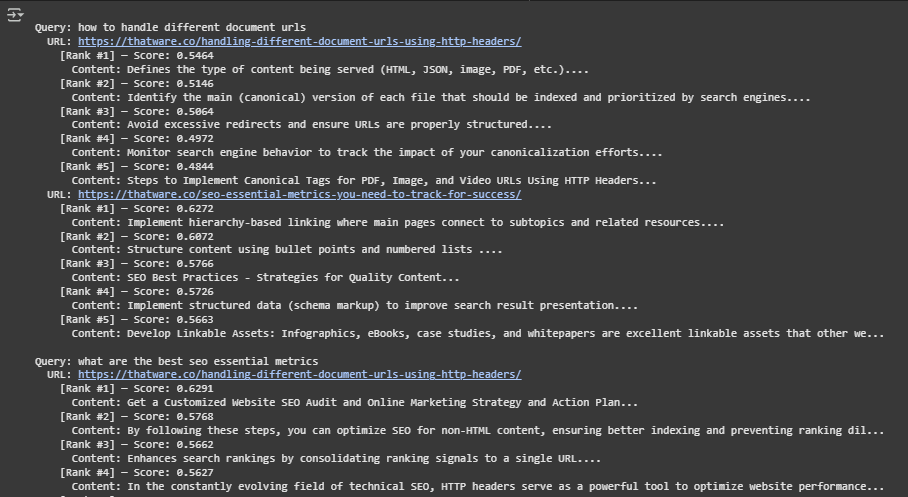
Result Analysis and Explanation
The performance of the commonsense reasoning-based ranking system was evaluated across multiple queries and pages. The analysis focused on how effectively the model interprets implicit intent, semantic relationships, and real-world scenarios that go beyond basic keyword matching. The following sections offer a detailed explanation of the observed outcomes and their implications for SEO-centric decision-making.
Semantic Differentiation Across URLs
When tested on conceptually different pages, the system demonstrated its ability to separate content blocks according to contextual relevance—even when keywords overlapped between URLs.
- For example, the query aligned with canonicalization and HTTP headers surfaced blocks from the relevant technical page that discussed HTTP strategies for PDFs and media files. These blocks outperformed more generic SEO content from unrelated pages.
- Conversely, for broader queries about SEO performance metrics, blocks discussing Core Web Vitals, keyword placement, and AI-driven ranking were prioritized—sourced from the content-rich performance tracking guide.
This reflects the model’s strength in identifying content scenarios where the language indirectly but clearly addresses the user’s deeper intent.
Contribution of Commonsense Reasoning
Each content block and query was enriched with structured commonsense inferences using dimensions like intent (xIntent), need (xNeed), and outcome (oEffect). The similarity score was then computed not only between the raw text but also between the inferred layers of meaning.
This approach helped:
- Prioritize answers that implied real-world actions, motivations, and outcomes users care about
- Promote content that explains the “why” and “how”, not just the “what”
- Disqualify semantically vague content that may match keywords but lacks scenario-fit
For instance, when a block explains how canonical HTTP headers can avoid duplicate indexing or help Google consolidate ranking signals, the associated inferences closely align with user intent around optimization impact, thus leading to higher scores.
Score Interpretation and Distribution
Similarity scores produced via embedding-based reasoning ranged between 0.48 to 0.76 for most relevant content. The scoring logic fused both the literal text and its inferred meaning, enabling a more robust matching mechanism.
- Blocks scoring above 0.70 generally had direct semantic fit and aligned reasoning with the query
- Blocks in the 0.55–0.65 range often captured partial relevance or supporting context
- Blocks below 0.50 were typically off-topic, lacked actionability, or offered minimal inferential overlap
This spectrum allows content teams to set thresholds for what content gets flagged as top-performing, needs enrichment, or should be demoted.
Cross-URL Content Competition
Unlike traditional models that often favor longer or keyword-dense content, this system ranks blocks purely on contextual and inferential alignment. This led to dynamic block-level competition:
- On several queries, blocks from both URLs appeared across the top 5 ranks
- The system selected smaller, focused blocks that better matched intent—even if buried within long pages
This proves the system’s capability to dissect complex pages into actionable insights, making it ideal for evaluating internal linking, on-page coverage, and canonical content strategy.
Implications for Clients
The results highlight several actionable benefits for SEO teams and content strategists:
- Fine-grained ranking: Understand exactly which content blocks are pulling relevance weight for specific intents, allowing precise optimization or snippet targeting.
- Content audit readiness: Identify missing reasoning or motivational elements in current pages, guiding editorial enrichment.
- URL prioritization strategy: Determine whether a query is being effectively addressed on the right URL, supporting better canonicalization and linking decisions.
- Non-obvious relevance surfacing: Surface semantically powerful content even if phrased differently from the query—essential for long-tail and voice search performance.
Final thoughts
This project demonstrates a practical and forward-thinking application of commonsense reasoning in information retrieval (IR) for SEO-focused content optimization. By combining structured semantic embeddings with generated inference cues, the system ranks content blocks not only by keyword overlap but by their alignment with user expectations and intent.
The approach enables a deeper evaluation of content effectiveness—beyond surface-level metrics—by interpreting the why, what, and how behind a user’s query. This results in a more intelligent ranking system that can reveal optimization opportunities, content misalignment, or internal competition across pages.
For clients and SEO professionals, the insights derived from this system offer concrete actions to refine content, restructure page intent, and improve overall search performance. As search engines continue to evolve toward understanding context and reasoning, this commonsense-enhanced methodology positions content ahead of traditional ranking strategies.
Click here to download the full guide about Common-Sense Reasoning in Information Retrieval (IR).
