SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This project introduces an intelligent, scalable framework for content relevance evaluation using zero-shot and few-shot learning within the context of information retrieval (IR). Built specifically for SEO applications, the system analyzes individual content blocks from webpages and determines how well each aligns with a given set of target search queries — all without requiring labeled training data or task-specific retraining.

At its core, the system leverages two complementary mechanisms:
- Zero-shot retrieval ranks content blocks based on their direct semantic alignment with a query, utilizing a pretrained cross-encoder model.
- Few-shot classification further refines these rankings by semantically validating whether each content block is contextually relevant or not, using minimal hand-crafted examples for each query.
The integration of these components results in a robust pipeline capable of processing any number of URLs and queries. Each URL-query pair is examined through a two-stage process: first by determining relative ranking through zero-shot inference, then by applying lightweight few-shot validation to ensure semantic fit. The final output includes a combined decision layer that generates actionable labels for each content block — such as “Keep”, “Remove”, or “Update” — guiding SEO strategists in optimizing their site’s structure and content.
Designed for real-world, production-oriented usage, this system minimizes manual input requirements while offering clear interpretability and high practical utility. It ensures SEO teams can quickly and confidently align on-page content with strategic keyword intent, enhancing both site quality and organic search performance.
Project Purpose
The primary purpose of this project is to enable intelligent, automated evaluation of web content relevance in relation to SEO-driven search intent — without relying on large volumes of labeled data or manually tuned scoring systems.
In practice, this project addresses a core challenge faced by SEO strategists and digital marketing teams: ensuring that every block of content on a page contributes meaningfully to a target keyword or intent. As modern SEO shifts increasingly toward semantic alignment and search intent coverage, traditional keyword-based heuristics or rule-based methods often fail to scale or capture deeper relevance. This gap is especially pronounced when working with long-form content, multi-section landing pages, or technical documentation where relevance is unevenly distributed.
To solve this, the system integrates two powerful capabilities:
- Zero-shot content ranking, which enables the system to evaluate and prioritize content blocks for entirely new or niche search queries without requiring retraining or labeled data.
- Few-shot classification, which adds a lightweight validation layer capable of generalizing from just a handful of annotated examples to flag misleading, off-topic, or weakly related content.
The system is built for practical, real-world deployment. It eliminates the need for clients or SEO teams to build large-scale labeled datasets, train custom models, or create query-specific rules. Instead, it delivers out-of-the-box interpretability, high recall for relevance, and precise guidance on content optimization actions.
The overarching goal is to help strategists and clients ensure that every page they manage — whether it’s an enterprise blog, product page, or technical resource — is semantically aligned with business-critical search queries and ready for indexing under modern search engine ranking models.
Project’s Key Topics Explanation and Understanding
The core of this project is rooted in two interrelated yet distinct machine learning approaches in Information Retrieval (IR): Zero-Shot Learning and Few-Shot Learning. Both approaches are used in this project not only as model capabilities but as practical strategies to handle real-world SEO tasks where labeled data is either unavailable or insufficient.
The relevance of these two techniques is directly aligned with the project’s goal — enabling models to interpret novel search queries and evaluate web content without relying on large annotated datasets. Below is a detailed explanation of each concept as applied within this project.
Zero-Shot Learning in Information Retrieval
Definition and Context Zero-shot learning refers to the ability of a model to perform a task — such as retrieving or ranking relevant content — without having seen any examples of that specific task or domain during training. In the context of IR, this means evaluating the semantic relationship between a new query and a passage of text without task-specific fine-tuning.
Application in This Project In this project, zero-shot IR is applied using a pretrained cross-encoder model. The model accepts a query and a content block as input and outputs a direct relevance score. These scores are not constrained to a fixed set of labels or templates, allowing the system to handle a wide range of search intents — including niche, brand-specific, or long-tail SEO queries — with no additional supervision.
Operational Behavior
- The model performs semantic matching between the query and each content block independently.
- No keyword overlap is required; instead, the model relies on deep contextual embeddings to infer conceptual relevance.
- Scores are normalized using sigmoid activation to ensure interpretability and comparability across different query-page pairs.
Client Benefit
This enables automated content relevance analysis even when the query is highly specific or has never been evaluated before — a scenario common in evolving SEO campaigns. Clients are not required to create labeled examples or configure rules, making the system immediately deployable for diverse content types and intents.
Few-Shot Learning in Information Retrieval
Definition and Context Few-shot learning allows a model to generalize from a small number of task-specific examples. Unlike zero-shot models that rely purely on pretrained representations, few-shot systems accept minimal human-provided guidance (often a handful of labeled examples) to adapt their reasoning to a particular classification task.
Application in This Project Few-shot learning is used as a second-stage classifier. After the zero-shot model ranks content blocks based on relevance to a query, a few-shot model further determines whether each block is “relevant” or “not relevant” using short in-context examples provided at runtime.
Prompt-Based Semantic Classification
- The model used supports natural language instructions and in-context examples.
- Each prompt includes the query, followed by a few positive (relevant) and negative (irrelevant) content examples.
- The model is then asked to label new, unseen blocks based on those examples.
Client Benefit This method offers flexibility and semantic control. Clients or strategists can supply minimal guidance — often just 2–3 examples — to adapt the system to specific nuances of a campaign. The few-shot classifier enhances interpretability by validating whether high-scoring blocks from the first stage are semantically meaningful in context, rather than just statistically similar.
keyboard_arrow_down
Q&A Section to Understand Project Value and Importance
How does this project help evaluate content relevance without requiring keyword-level optimization or manual review?
This system eliminates the traditional reliance on exact keyword matches or manual evaluation by applying semantic relevance modeling. The zero-shot retrieval model understands the meaning of the search query and compares it directly with the meaning of each content block — even if the wording is completely different. As a result, it can accurately detect whether a piece of content addresses the intent behind a search query without needing manually created rules or labeled examples. This allows content auditing at scale, ensuring even long-form or complex pages can be assessed for alignment with modern search behavior.
Why is zero-shot retrieval especially valuable for SEO teams working with many URLs or diverse search intents?
Zero-shot learning is inherently scalable and adaptable. Since it does not require labeled training data, it can immediately evaluate content across any number of URLs, for any number of queries — including new, seasonal, or long-tail keywords. SEO teams often face the challenge of aligning hundreds or thousands of landing pages with shifting keyword strategies. A zero-shot approach enables broad coverage without the need to train task-specific models, allowing for fast and cost-effective deployment across large digital properties.
What is the benefit of adding a few-shot learning stage after zero-shot ranking? Isn’t zero-shot enough on its own?
While zero-shot scoring effectively ranks content based on semantic similarity, it does so in a relative sense. High scores may still include tangentially related content, especially in complex pages. Few-shot learning introduces semantic classification: it evaluates whether a content block is genuinely relevant or only superficially aligned with the query.
By supplying just a few labeled examples per query — often created in minutes — SEO strategists can inject domain knowledge and contextual expectations into the system. This enhances trust in the output, adds a validation layer before acting on content recommendations, and ensures more precise decisions, such as what to remove, update, or preserve.
Can this system handle new or unfamiliar queries that have never been optimized for before?
Yes. One of the key advantages of zero-shot learning is its ability to handle novel queries. The model is pretrained on a broad corpus of language and web data, enabling it to generalize to unseen queries without retraining. This is critical for capturing emerging search trends, new product terminology, or evolving user questions — all of which are common in dynamic SEO campaigns.
This also means the system can support campaign planning or audits even before traffic data is available, helping clients proactively optimize content around anticipated search behaviors.
How much manual input is required from the client or SEO strategist to use this system?
Minimal input is required. The core ranking system operates fully automatically — clients only need to provide the URLs and associated queries. For the optional few-shot classification layer, a strategist may supply a few example sentences marked as “relevant” or “not relevant” per query. These examples do not require technical formatting and can be written in plain language.
This level of input strikes a balance between automation and control, allowing the system to reflect campaign-specific nuance without requiring ongoing supervision or data annotation.
How does this system contribute to stronger SEO performance and strategic decision-making?
This system empowers SEO teams to make content decisions based on semantic relevance rather than surface-level signals such as keyword frequency or manual heuristics. By interpreting the underlying intent of search queries and directly comparing it to the meaning conveyed in each block of content, the system enables more precise alignment between user needs and on-page information.
Such alignment is central to modern search engine ranking algorithms, which reward topical depth, user intent coverage, and contextual clarity. Additionally, the system’s ability to generalize across any number of queries — including niche or newly emerging ones — ensures that strategists can continuously optimize content in response to shifting search patterns without waiting for manual audits or campaign lags.
The incorporation of both zero-shot and few-shot techniques also allows for progressive refinement: broad automatic detection followed by lightweight contextual validation. This enables confident decisions at scale, leading to improved content quality, stronger organic performance, and more efficient SEO workflows.
Libraries Used
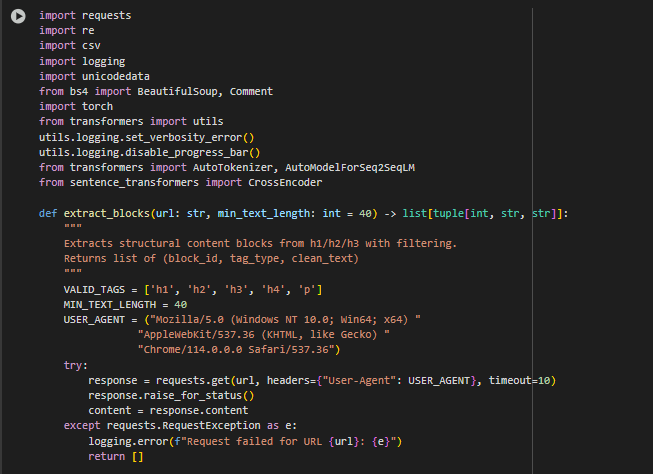
The project leverages a combination of general-purpose utilities, web scraping modules, deep learning frameworks, and transformer-based model toolkits. These libraries are chosen based on maturity, reliability, and compatibility with scalable NLP workflows.
requests
Used for sending HTTP requests to fetch raw HTML content from URLs. It provides robust connection management, error handling, and timeout control, which are critical for real-time page processing.
re
The standard Python regular expression module, used throughout the content preprocessing phase for tasks like:
- Removing extraneous symbols and markup.
- Cleaning whitespace and unwanted fragments (e.g., tracking URLs, boilerplate patterns).
csv
Used in the final stage of the pipeline to export result data in CSV format for client consumption. Ensures structured output that can be opened in Excel or integrated into other reporting pipelines.
logging
Used to monitor and report system-level warnings or errors, especially when URLs fail to load or content blocks cannot be extracted. Enables robust handling of edge cases during batch processing.
unicodedata
Provides Unicode normalization to ensure that text is clean and consistent across different platforms. This is particularly important when handling non-breaking spaces, accented characters, or text copied from diverse page encodings.
bs4 (BeautifulSoup) and Comment
Core tools for parsing and processing HTML documents.
- BeautifulSoup is used to navigate the HTML tree, remove noise elements (e.g., scripts, nav bars), and extract structured content blocks (e.g., <h1>, <p>).
- Comment helps identify and remove HTML comments which often contain irrelevant metadata or code.
torch
The foundational deep learning framework used by all neural components in the pipeline.
- Detects GPU availability.
- Handles model deployment across devices.
- Ensures compatibility with Hugging Face and Sentence-Transformers models.
transformers.utils
This module is used to suppress unnecessary progress bars and verbose model logs, ensuring cleaner console output during inference.
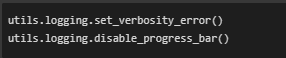
These commands are particularly useful when running batch inference in client-facing notebooks where clean outputs improve usability and professionalism.
transformers.AutoTokenizer, AutoModelForSeq2SeqLM
These classes are used for the few-shot model.
- AutoTokenizer handles tokenization of text inputs for transformer-based sequence-to-sequence models.
- AutoModelForSeq2SeqLM loads the specific few-shot capable model used for semantic classification (e.g., google/flan-t5-large), enabling flexible prompt-based inference with in-context learning.
sentence_transformers.CrossEncoder
This class loads the pretrained cross-encoder model used in the zero-shot phase.
- Takes a pair of inputs (query and content block) and outputs a single score representing their semantic relevance.
- In this project, the cross-encoder operates without task-specific fine-tuning, relying on pretrained language understanding (e.g., from ms-marco or nli models).
Each of these libraries supports a specific layer in the zero-shot and few-shot pipeline — from extracting structured page content to ranking and classifying semantic relevance at the block level.
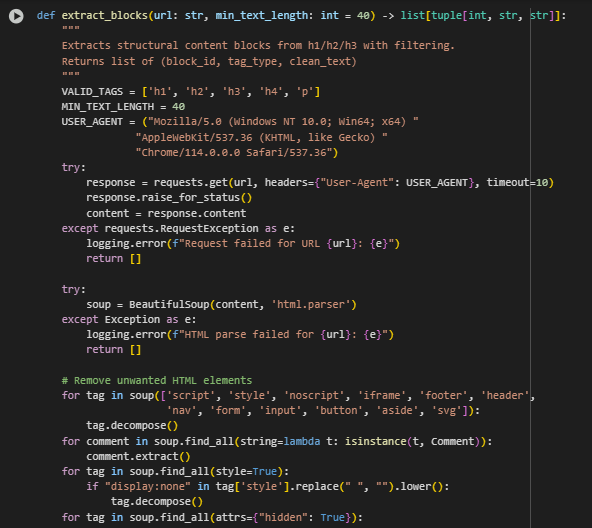
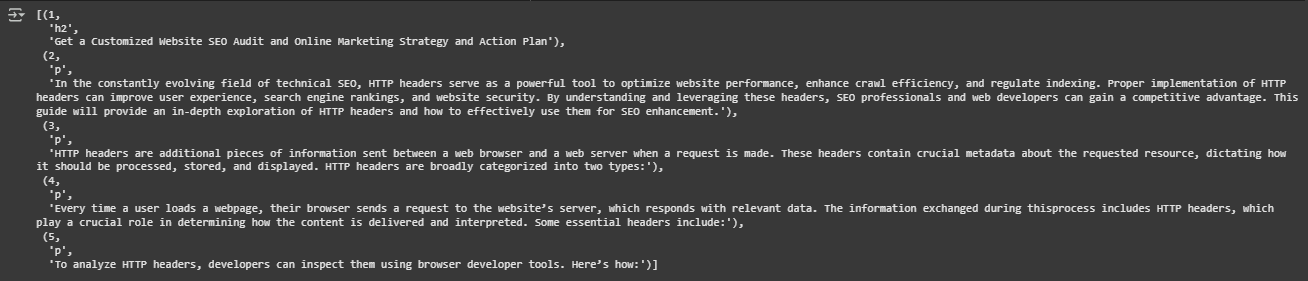
Function: extract_blocks
Function Overview
The extract_blocks function is responsible for extracting meaningful structural content from a webpage, focusing on textual elements that are typically relevant to SEO analysis such as headings (<h1> to <h4>) and paragraphs (<p>). The output is a clean and structured list of blocks, each represented by a unique identifier, its HTML tag, and the associated text content.
This function serves as the foundation for all downstream information retrieval tasks, enabling relevance ranking and semantic analysis to operate on discrete, high-quality content units rather than noisy or fragmented HTML.
Key Objectives:
- Retrieve webpage content using a robust HTTP request method.
- Parse the HTML to extract structural elements.
- Filter out boilerplate, hidden, or low-value blocks.
- Return clean, ready-to-process textual units for semantic scoring.
Highlighted Code Logic and Explanation
response = requests.get(url, headers={“User-Agent”: USER_AGENT}, timeout=10)
- A custom user-agent string is used to avoid blocking from servers and mimic real browser behavior. Timeout ensures the system does not hang indefinitely on slow or unresponsive URLs.
soup = BeautifulSoup(content, ‘html.parser’)
- Parses the HTML content with BeautifulSoup to enable structured navigation of the document tree and tag-based extraction.
for tag in soup([‘script’, ‘style’, ‘noscript’, ‘iframe’, …]): tag.decompose()
- This block removes non-informative elements such as scripts, styles, and structural navigation components that contribute no useful semantic information. This reduces noise in the final block set.

- Tags with inline CSS that hides them from users are discarded. This prevents the inclusion of hidden SEO manipulative content or tracking scripts.
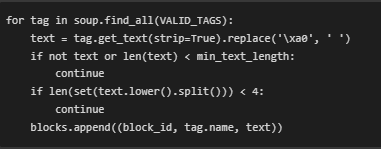
- Iterates over valid tags (h1–h4, p) and extracts clean text content. Filters are applied based on minimum text length and word diversity to eliminate trivial or templated blocks. Each retained block is assigned a unique block_id to enable later reference and scoring.
This function ensures that only high-value, structurally important content blocks are retained for ranking and classification. The quality and consistency of this output significantly impact the accuracy and reliability of both zero-shot and few-shot relevance analysis.
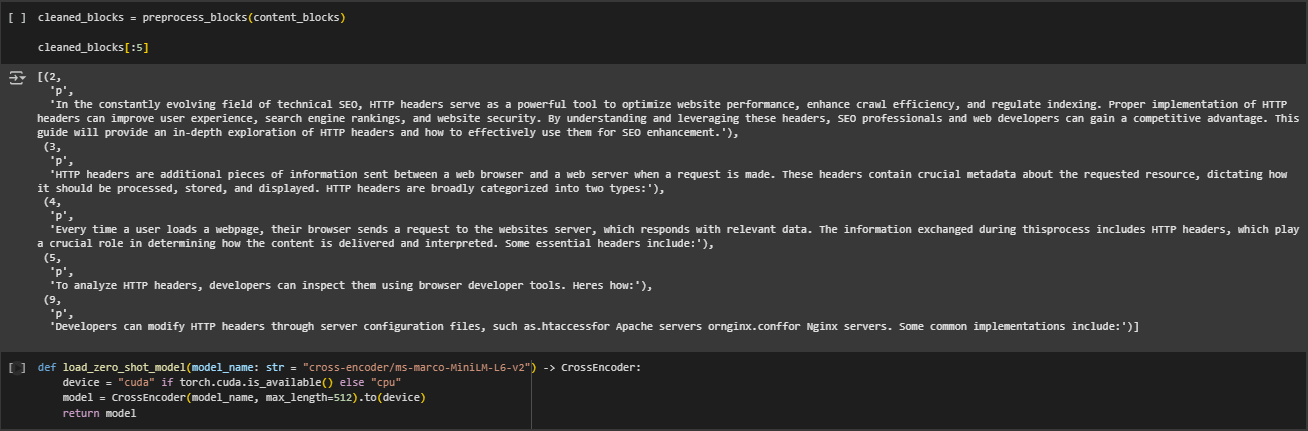
Function: load_zero_shot_model
Function Overview
The load_zero_shot_model function initializes a pretrained cross-encoder model tailored for relevance scoring between a user query and content blocks. This model enables zero-shot inference, where relevance is computed without requiring labeled training data or domain-specific fine-tuning. The selected model—cross-encoder/ms-marco-MiniLM-L6-v2—has been trained on large-scale search relevance data and is capable of assessing query-passage similarity with high accuracy.
The model is loaded with sigmoid activation to bound output scores within the range [0, 1], making it more interpretable and stable across queries and pages.
Key Objectives:
- Load a transformer-based cross-encoder model for passage relevance.
- Apply sigmoid activation for normalized, bounded scoring.
- Automatically manage GPU/CPU device allocation for efficient inference.
Highlighted Code Logic and Explanation
device = “cuda” if torch.cuda.is_available() else “cpu”
- Dynamically determines whether GPU acceleration is available. The model is loaded on GPU when possible to significantly improve inference performance, especially useful in ranking multiple blocks across URLs.
model = CrossEncoder(model_name, max_length=512, activation_fn=torch.nn.Sigmoid()).to(device)
- Loads the cross-encoder model specified by the model_name.
- max_length=512 ensures support for long input sequences (query + block).
- activation_fn=torch.nn.Sigmoid() applies a sigmoid function on the model’s output, converting it into a probability-like score between 0 and 1. This is especially important in client-facing applications where raw scores (e.g., -10 to +10) could be misleading or inconsistent.
return model
- Returns a fully initialized and device-optimized cross-encoder ready for real-time zero-shot ranking tasks.
This model serves as the core of the zero-shot inference layer in the retrieval pipeline, allowing semantic matching between user queries and content without labeled examples. Its integration with sigmoid scoring enhances trust and transparency in the ranking outcomes presented to clients.
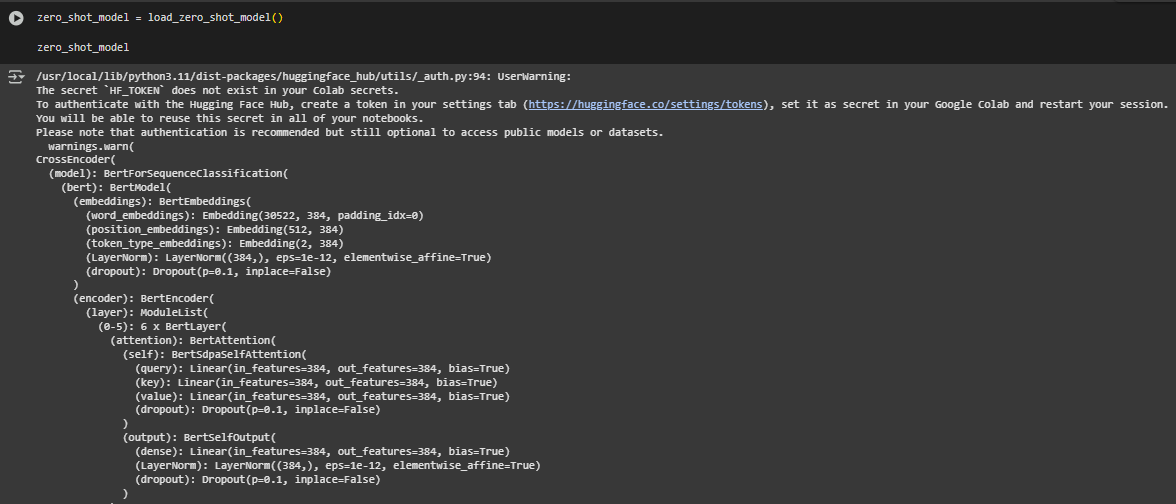
Model Explanation: cross-encoder/ms-marco-MiniLM-L6-v2
What This Model Does
This model is a pretrained cross-encoder designed specifically for relevance ranking between a query and a text passage. Unlike traditional retrieval systems that rely on keyword overlap or embedding similarity, this model reads the query and the content together as a pair and assigns a relevance score based on their semantic relationship. The output is a numerical score indicating how well a block of content answers or aligns with a given search intent.
In the context of this project, the model evaluates each extracted content block from a webpage in direct relation to a user-defined query. This enables precise, intent-driven ranking of content, even when no prior training data is available for the specific query.
Why This Model Was Selected for This Project
This model was selected for its high effectiveness in zero-shot ranking tasks, especially in real-world web content environments. Trained on the MS MARCO dataset—comprising real user queries and human-labeled passages—it is optimized for open-domain relevance scoring.
Several reasons support its inclusion in this project:
- Zero-Shot Capability: It requires no additional fine-tuning or labeled data, making it ideal for SEO use cases where queries vary widely across domains.
- Direct Query-Block Scoring: Unlike bi-encoders or sparse retrievers, this model processes the query and the content together, leading to more accurate scoring for short and structured content blocks typical of web pages.
- Sigmoid Activation for Interpretability: The project uses a sigmoid activation function to constrain scores to the [0,1] range, allowing for easier thresholding and clearer communication of relevance strength to clients.
Other retrieval models were considered, including dense retrieval + reranking pipelines, but they required more infrastructure, added latency, and were less interpretable for SEO strategists.
How It Works Internally
The model uses a cross-encoder architecture built on MiniLM, a distilled transformer designed for efficiency and speed. For each query–block pair:
- The two texts are concatenated and passed through the transformer model.
- The final token representation is used to compute a scalar score indicating the semantic relevance of the block to the query.
This architecture allows the model to evaluate nuanced relationships between phrases and terms in context. For example, the model can understand that “boost rankings with structured data” and “SEO improvement through schema markup” are semantically related, even though they share few direct keywords.
Benefits in Real SEO Environments
This model is particularly well-suited for modern SEO strategies for the following reasons:
- No Training Overhead: Immediate deployment across any domain or niche without labeled training data.
- Granular Block-Level Insight: Instead of scoring entire pages, the model identifies which sections of the page are actually relevant to a specific search intent.
- Scalable Across Diverse Queries: Whether the query is technical, commercial, or informational, the model generalizes well due to its MS MARCO training base.
- Modular and Replaceable: The setup allows easy substitution with higher-performing or domain-specific models if needed, without reworking the pipeline.
These benefits ensure that SEO strategists can obtain detailed, query-specific feedback on content quality and optimization opportunities at scale, making the model a critical component in the project’s architecture.
Function: rank_blocks_with_zero_shot
Function Overview
The rank_blocks_with_zero_shot function is responsible for performing zero-shot semantic ranking between a user-defined search query and preprocessed content blocks extracted from a web page. This function enables content blocks to be scored by relevance without requiring any training data, using a pretrained cross-encoder model.
The output is a structured and ranked list of content blocks, each annotated with a confidence-based score indicating how well it matches the intent of the query. These ranked results serve as a foundation for downstream processes like few-shot classification, display formatting, or export for client review.
Highlighted Code Logic and Explanation
input_pairs = [(query, block[2]) for block in blocks]
- Creates input pairs consisting of the query and each block’s text. The cross-encoder model evaluates each pair together to compute semantic alignment. This is the core mechanism that enables contextual understanding without explicit training.
scores = model.predict(input_pairs)
- Feeds the query–block pairs into the model to compute scores. With sigmoid activation applied in the model loader, these scores are bounded within [0, 1], making the output interpretable and stable across different queries and domains.
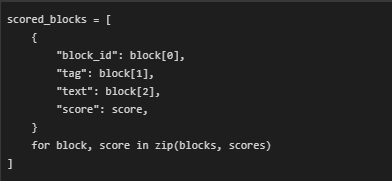
- Builds a structured dictionary for each block containing all relevant metadata (ID, tag type, text) and the computed relevance score. This ensures the output is reusable across visualization and evaluation layers.
The design of this function ensures it is directly usable in production workflows, particularly where clients require automated yet intelligible insights into how content aligns with their strategic search objectives.
Function: select_top_bottom_blocks
Function Overview
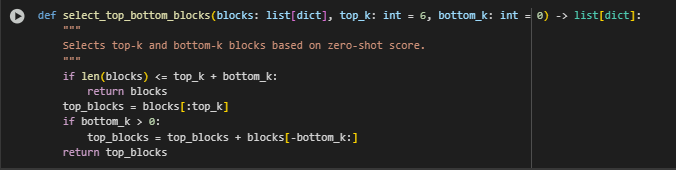
The select_top_bottom_blocks function serves as a strategic utility to extract the most and least relevant content blocks based on their zero-shot semantic scores. It is primarily used as a preparatory step for the few-shot classification stage, where blocks selected from both extremes of the relevance spectrum are evaluated for binary classification (relevant vs not relevant).
This selective filtering ensures that few-shot evaluation is both meaningful and resource-efficient, avoiding the need to classify all blocks while maintaining diversity across the relevance range.
Highlighted Code Logic and Explanation
if len(blocks) <= top_k + bottom_k: return blocks
- This condition acts as a safeguard: if the total number of blocks is less than or equal to the sum of requested top and bottom selections, it returns all blocks. This avoids index errors and ensures that edge cases (e.g., minimal content pages) are handled gracefully.
top_blocks = blocks[:top_k]
- Selects the first top_k entries from the already sorted block list (assumed descending by score). These are presumed to be the most semantically relevant blocks for the given query.
if bottom_k > 0: top_blocks = top_blocks + blocks[-bottom_k:]
- If bottom_k is greater than zero, this line appends the least relevant blocks (those with the lowest scores) to the top selections. This mixed set allows the few-shot model to assess not only the strongest matches but also borderline or weakly matched content that may need review or removal.
Its role is critical in maintaining both efficiency and credibility in a client-oriented SEO pipeline where interpretability and result quality are essential.
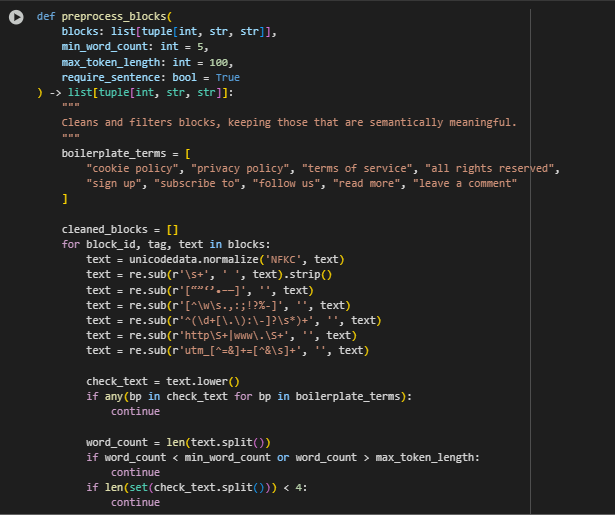
Function: load_few_shot_model
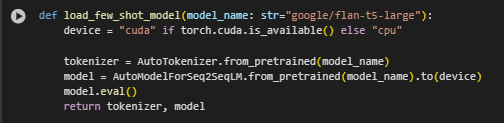
Function Overview
The load_few_shot_model function is responsible for initializing and preparing the few-shot inference model used to classify content blocks as either relevant or not relevant in response to a search query. This model enables the few-shot learning stage of the pipeline, where minimal labeled examples guide the system in handling new, unseen data.
By loading the model with proper device allocation and evaluation mode settings, the function ensures that few-shot classification is both accurate and performance-optimized in a real-world, production-ready environment.
Highlighted Code Logic and Explanation
device = “cuda” if torch.cuda.is_available() else “cpu”
- Checks for GPU availability and dynamically selects the appropriate device. This allows seamless deployment in both development and production environments, improving inference performance where GPU acceleration is available.
tokenizer = AutoTokenizer.from_pretrained(model_name)
- Loads the tokenizer corresponding to the chosen few-shot model (google/flan-t5-large by default). The tokenizer is essential for converting raw text prompts into tokenized format understood by the model.
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(device)
- Loads the few-shot model itself and moves it to the selected device. The chosen model, flan-t5-large, is specifically tuned for following natural language instructions, making it ideal for classification tasks framed through examples.
model.eval()
- Sets the model to evaluation mode, disabling training-related components such as dropout. This improves consistency and reliability of predictions during inference.
Through this function, the pipeline benefits from instruction-following intelligence, making the system capable of dynamic classification using only minimal client-provided examples.
Few-Shot Classification Model: google/flan-t5-large
Model Purpose
The few-shot component of this project uses the google/flan-t5-large model to determine whether a content block is relevant or not relevant to a query. This supports deeper semantic judgment beyond raw similarity, allowing more precise actions like content pruning or strategic updates.
Unlike the zero-shot stage, which ranks content based on general relevance scores, the few-shot stage performs binary classification by evaluating contextual fit based on explicit labeled examples.
About the Model
flan-t5-large is a large instruction-tuned encoder-decoder model from the FLAN (Fine-tuned Language Net) series. It is designed to follow structured prompts and examples, making it ideal for few-shot inference tasks that simulate classification with natural language guidance.
The model supports:
- Classification via input/output prompting.
- Natural language instruction parsing.
- Robust generalization with very few examples.
The model was trained on a wide variety of tasks framed as natural language instructions, making it highly adaptable to customized client contexts and SEO content scenarios.
Model Architecture
- Base Architecture: T5 (Text-to-Text Transfer Transformer)
- Size: ~780 million parameters
- Type: Encoder-decoder transformer
- Tuning: Instruction-tuned using prompt-based multi-task datasets
This structure allows it to take flexible input prompts and generate short, meaningful outputs (e.g., “relevant” or “not relevant”) based on learned patterns.
How It Works in This Project
In this implementation:
- The model receives a prompt constructed from a query, a content block, and few-shot labeled examples (relevant and not relevant).
- The model then generates a label as output — typically “relevant” or “not relevant.”
- This output is used to determine content treatment actions such as keeping, removing, or reviewing the block.
This mechanism simulates how a human strategist would assess content given a goal (query intent) and a few illustrations of what qualifies as useful vs irrelevant.
Why Chosen for This Project
- Prompt-based Reasoning: Works with textual examples, avoiding traditional labeled datasets.
- Client-Friendly Input Format: Requires minimal setup — just 2–3 examples per query.
- No Fine-Tuning Needed: Pretrained for instruction-following tasks, eliminating the need for training overhead.
- Highly Interpretable Output: Direct generation of human-readable labels simplifies downstream decision making.
This model fits seamlessly into a real-world SEO pipeline where manual labeling is expensive and clients expect intelligent, self-adapting tools that can operate with minimal supervision.
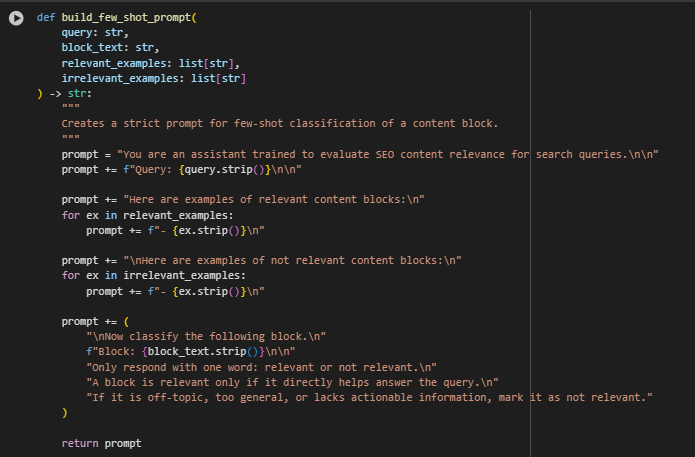
Function: build_few_shot_prompt
Function Overview
The build_few_shot_prompt function constructs a structured prompt specifically tailored for few-shot inference using instruction-tuned language models like FLAN-T5. The objective of this prompt is to classify a given content block as either relevant or not relevant in the context of a specific search query. By injecting curated examples into the prompt — including both relevant and irrelevant samples — the model is primed to learn decision boundaries without explicit training.
This function directly supports the few-shot learning use case in the project by providing a clear and constrained template that minimizes model confusion and optimizes instruction adherence. The structured and minimal language ensures compatibility with zero-shot + few-shot chaining where interpretability and control are critical.
Highlighted Code Logic and Explanation
- Prompt Initialization
prompt = “You are an assistant trained to evaluate SEO content relevance for search queries.\n\n”
- Establishes model behavior and domain. This sets an explicit instruction to align the model’s task understanding with SEO relevance evaluation, rather than leaving the interpretation open-ended.
- Query Context Definition
prompt += f”Query: {query.strip()}\n\n”
- Clearly injects the user’s search query to anchor the model’s classification logic.
- Injection of Positive Examples

- Demonstrates what a relevant content block looks like. These guide the model with style, tone, and topical patterns that signal relevance.
- Injection of Negative Examples

- Negative samples create contrast in instruction. These are critical to help the model distinguish between merely “on-topic” and genuinely useful content.
- Block Classification Section
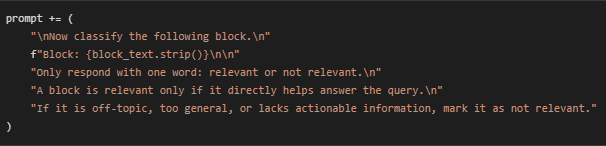
- This final section presents the block under evaluation and constrains the model to produce a one-word classification. The post-instruction acts as a strict filter, ensuring the model only selects between the two expected outcomes, reducing noise or hallucinated text in generation.
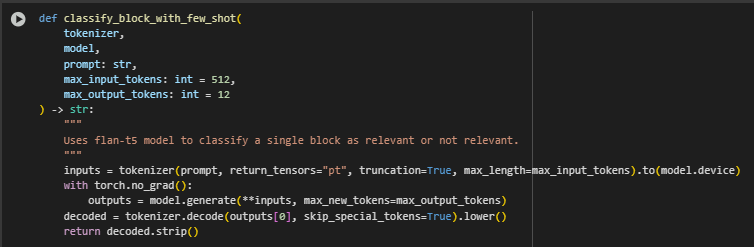
Function: classify_block_with_few_shot
Function Overview
The classify_block_with_few_shot function performs the actual classification of a single content block using a preloaded few-shot capable language model, such as google/flan-t5-large. This function receives a structured prompt (prepared using build_few_shot_prompt) and returns a simple prediction: whether the block is relevant or not relevant to the provided query.
It forms a critical link in the few-shot inference pipeline, enabling classification based on a few labeled examples. This approach avoids full-scale supervised training, reducing the operational cost for client-side SEO automation while still leveraging model generalization from prior instruction tuning.
Highlighted Code Logic and Explanation
- Prompt Tokenization and Preparation
inputs = tokenizer(prompt, return_tensors=”pt”, truncation=True, max_length=max_input_tokens).to(model.device)
- The full prompt is tokenized and converted to PyTorch tensor format. It is truncated to ensure the model input size constraint (default 512 tokens) is respected. The tokenized input is then moved to the same device (CPU/GPU) as the model to avoid device mismatch errors — a critical step when using hardware acceleration.
- Inference Without Gradient Tracking
with torch.no_grad(): outputs = model.generate(**inputs, max_new_tokens=max_output_tokens)
- The model’s generation head is used to perform inference. torch.no_grad() disables gradient computation, reducing memory usage and ensuring the function operates in pure inference mode. The max_new_tokens constraint (default 12) ensures the output is short and controlled, aligning with the strict instruction for one-word classification.
- Output Decoding and Cleanup
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True).lower() return decoded.strip()
- The raw output token IDs are decoded back to text. Special tokens are removed, and the result is lowercased and stripped of whitespace to enforce consistency and ease downstream processing. This ensures the output aligns exactly with expected labels (“relevant” or “not relevant”), which supports automated decision logic later in the pipeline.
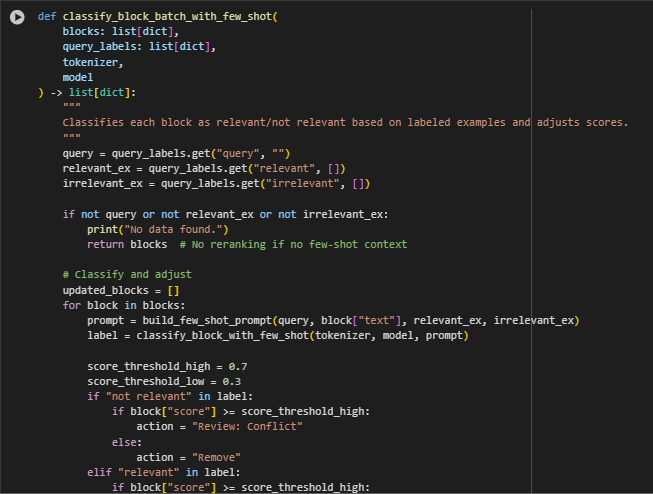
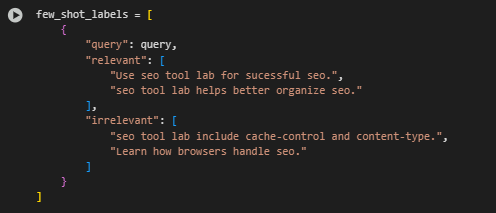
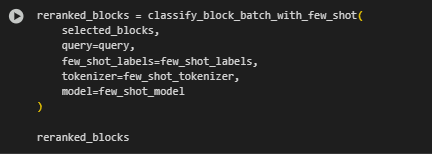
Function: classify_block_batch_with_few_shot
Function Overview
The classify_block_batch_with_few_shot function performs batch-wise few-shot classification of a list of content blocks for a specific query using an instruction-tuned model. It not only assigns a relevance label (“relevant” or “not relevant”) to each block but also derives a practical action recommendation by intelligently combining the zero-shot score with the few-shot classification outcome.
This step bridges zero-shot ranking and final decision making, making the results actionable and interpretable for SEO strategists and clients.
Highlighted Code Logic and Explanation
· Extract Query-Specific Few-Shot Labels
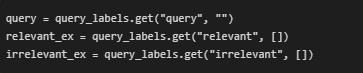
- Retrieves the target query and the relevant/irrelevant example lists from the few-shot input dictionary. These are used to build prompts dynamically for each block.
- Fail-Safe: Missing Context Handling
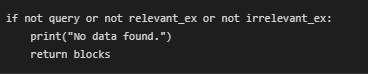
- If no few-shot examples are provided, the function returns the original blocks untouched. This avoids failure in real-world usage where the client might skip example inputs.
- Prompt Creation, Inference, and Action Logic

- Each block is evaluated with a dynamically built prompt. The prediction is used along with the block’s original zero-shot score to determine next actions.
- Action Assignment Strategy
if “not relevant” in label:…
- The block’s zero-shot score is used as a confidence signal to qualify the few-shot label:
- If the label is not relevant but the score is high, a conflict is flagged for manual review.
- If the label is relevant but the score is weak, the content is marked for update or retained with a low-confidence note.
- Only strong agreement between few-shot relevance and high zero-shot score results in an automatic Keep decision.
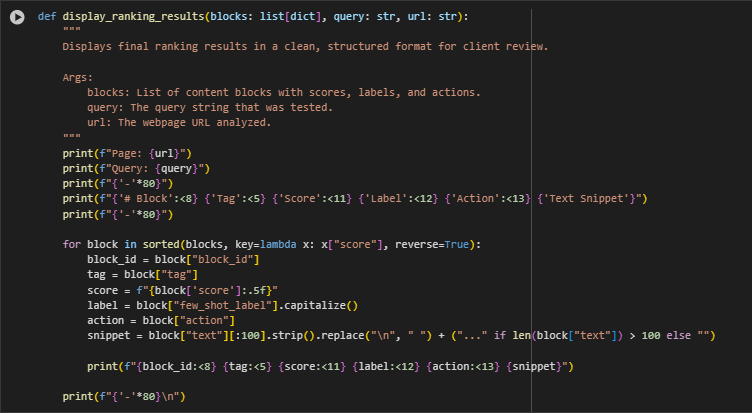
Function: display_ranking_results
Function Overview
The display_ranking_results function provides a simple yet structured console output to help SEO strategists and clients review the final ranking results clearly. It formats and presents content blocks along with their corresponding scores, classification labels, and recommended actions. This is especially useful during real-time analysis in the notebook without needing to export the data.
Result Analysis and Explanation
The project combines zero-shot semantic relevance scoring with few-shot content classification to determine the final SEO relevance of each content block. This hybrid approach ensures both algorithmic precision and contextual understanding in evaluating which parts of a webpage are useful for a given query.
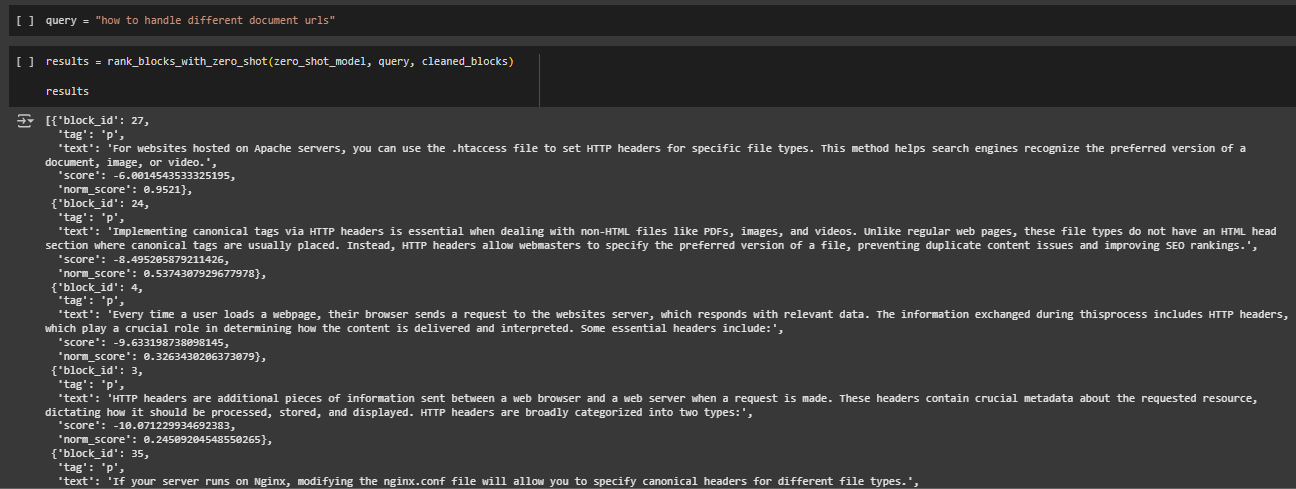
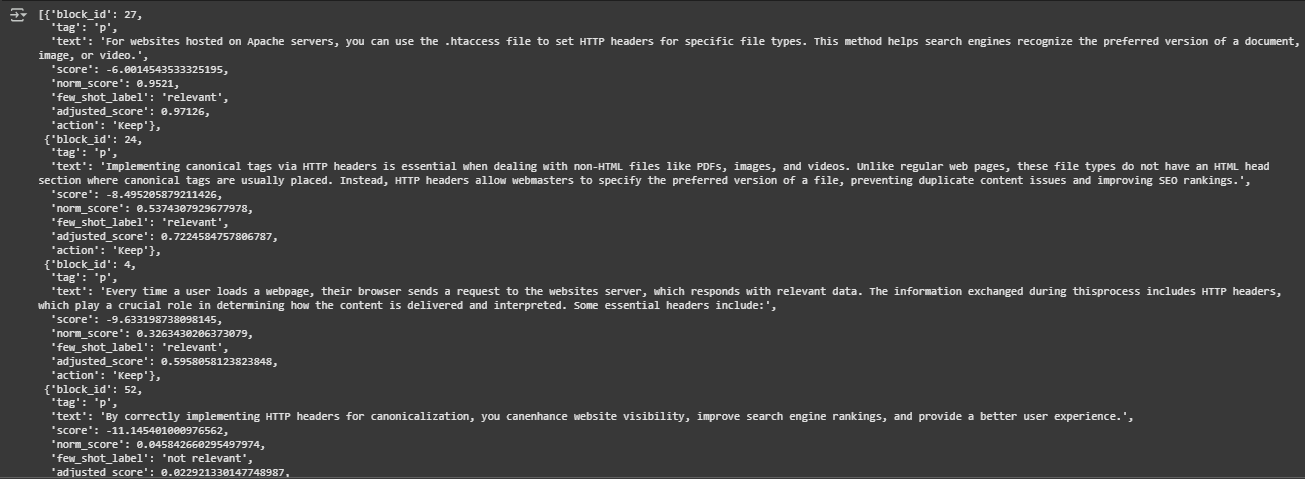
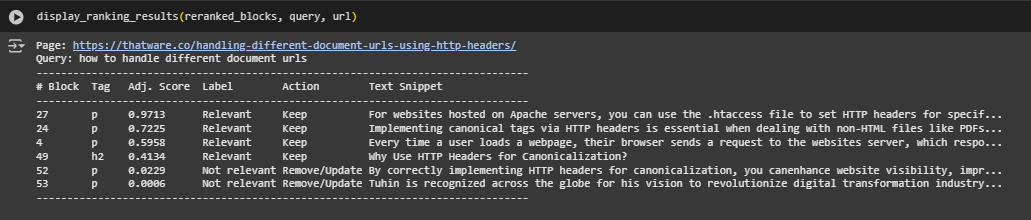
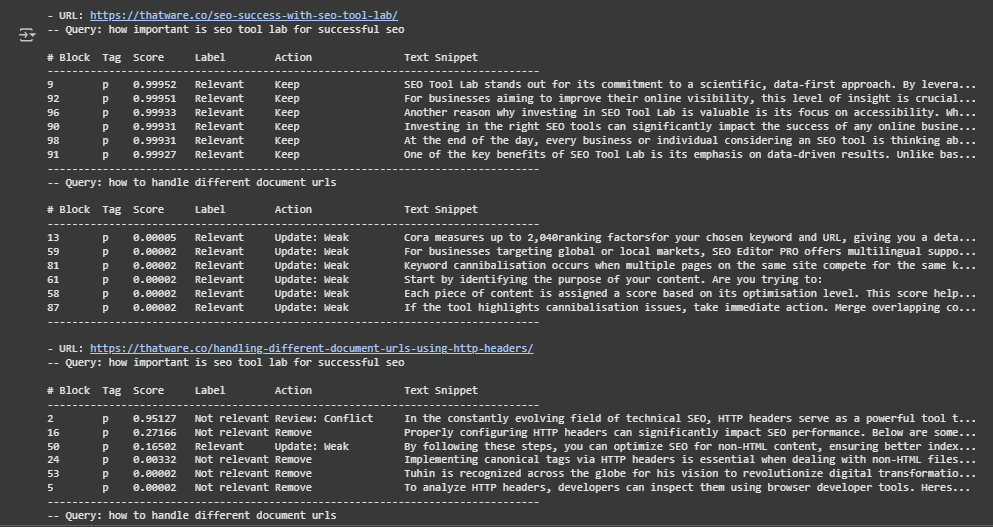
Test Page and Query Context
- Page: https://thatware.co/handling-different-document-urls-using-http-headers/
- Query: how to handle different document urls
This query targets a technical SEO concern regarding how to correctly implement and manage different document URLs (such as PDFs or videos) through HTTP headers. The model’s task is to identify blocks of the page that address this topic directly and filter out content that does not support the user’s intent.
Understanding the Scoring and Labeling
The system processes each content block in three stages:
- Zero-Shot Scoring: A pre-trained cross-encoder assigns a numerical score between 0 and 1 to each block, representing its semantic relevance to the query.
- Few-Shot Classification: Each block is further classified as Relevant or Not relevant based on a prompt-engineered few-shot instruction using previously labeled examples.
- Action Assignment: A final action label (Keep, Remove/Update) is assigned by combining the score and classification outcome.
Score Interpretation
- Scores close to 1 (e.g., 0.9713, 0.7225) indicate a high degree of semantic alignment with the query. These blocks are considered highly relevant by the model.
- Scores in the mid-range (e.g., 0.4134, 0.5958) reflect moderate alignment, where the content partially addresses the query or offers supporting context.
- Very low scores (e.g., 0.0229, 0.0006) typically signal a semantic mismatch, off-topic information, or general content that does not help answer the query directly.
Few-Shot Classification Outcome
The few-shot classifier uses labeled examples of relevant and irrelevant content to guide its judgment on the test blocks:
- Relevant: Indicates that the block provides direct, helpful, or actionable information in response to the query.
- Not Relevant: Signals that the content is either tangential, too general, or entirely unrelated to the query intent.
Action Field Interpretation
Each block is assigned a final recommendation for SEO strategists:
- Keep: The block is both semantically relevant and contextually appropriate. It should remain as-is.
- Remove/Update: The block is not relevant to the query’s intent and should either be removed or rewritten to provide value for SEO targeting.
Key Takeaway
This result demonstrates the strength of combining zero-shot relevance scoring with few-shot classification:
- Zero-shot provides a scalable mechanism to filter content across any unseen query.
- Few-shot adds contextual rigor and reduces false positives.
- Action labels offer clear and practical editorial guidance for SEO optimization.
This dual-layer relevance assessment makes the system robust for real-world SEO decision-making across a wide range of technical and strategic queries.
Result Analysis and Explanation
This section provides a comprehensive interpretation of the final output generated from the combined zero-shot and few-shot stages. The analysis focuses on how semantic relevance scores, classification labels, and final action guidance together serve as a robust decision-support system for real-world content optimization.
Understanding the Relevance Score
The semantic score returned from the zero-shot model reflects how well each content block aligns with a given query. These scores, constrained between 0 and 1 using a sigmoid activation, offer an interpretable signal of alignment intensity. In practical SEO evaluation, the following score bands are used to determine content quality:
- 0.70 to 1.00 — Strong semantic relevance; high alignment with query intent.
- 0.30 to 0.70 — Partial alignment; useful for context or support, but not independently valuable.
- 0.00 to 0.30 — Low relevance; typically vague, general, or off-topic.
Few-Shot Label: Semantic Confirmation
The few-shot label serves as a binary semantic check:
- Relevant: Confirms the block meaningfully addresses the query.
- Not relevant: Flags blocks that may be off-topic, generic, or superficial.
This step ensures that even high-scoring blocks are validated against domain-specific intent and tone, reducing manual review overhead.
The few-shot step serves as a validation layer to catch over- or under-estimated scores from the zero-shot phase. For example, blocks with high scores but poor topical match can be flagged as not relevant, and blocks with modest scores but direct utility may be retained as relevant.
Illustrative Result Analysis
1. Strong Intent Match
- Blocks with scores near 0.999 and labeled Relevant are automatically flagged as Keep.
- These represent strategic, valuable content segments that directly reinforce SEO goals.
2. Mixed Semantic Relevance
- Blocks with medium scores (e.g., 0.41–0.59) but still labeled Relevant are assigned Update: Weak.
- These blocks contribute to context but require enrichment—such as deeper explanations, examples, or formatting improvements.
3. Intent Mismatch
- High-score blocks labeled Not relevant are marked Review: Conflict — a trust signal that indicates potential edge cases or nuance requiring editorial insight.
4. Irrelevant or Promotional Content
- Low-score blocks flagged Not relevant are labeled Remove and can be pruned or rewritten.
Operational Benefit of This Result Analysis
This combined framework turns a long, unstructured content page into a ranked, annotated, and actionable map of relevance. It eliminates guesswork and prioritizes editorial effort by:
- Highlighting what content to preserve and promote.
- Identifying weaker but promising sections that can be enhanced.
- Flagging irrelevant content that adds no semantic value.
- Surfacing uncertain cases for review, reducing editorial risk.
This approach mirrors and enhances the decision-making process used in high-quality SEO audits, but at scale and with consistent interpretability.
Final Thoughts
This project demonstrates a practical and scalable approach to content-level optimization using a combination of zero-shot and few-shot learning techniques. Instead of relying solely on generic keyword tools or manual audits, the system provides a structured, model-driven evaluation of how well specific content blocks align with real user intents.
By integrating semantic scoring through zero-shot models and relevance validation via few-shot prompting, the methodology offers a high-resolution lens into content performance. It identifies not only what content is relevant but also how confidently it meets the user query and what actionable changes are necessary. This includes preserving high-performing content, refining weak sections, and removing irrelevant text — all of which contribute to improved search visibility, better alignment with user expectations, and more efficient editorial decision-making.
The project is designed with real-world constraints and practical needs in mind, supporting multi-page, multi-query evaluation in a transparent and interpretable format. It transforms abstract semantic understanding into concrete, page-level optimization strategies that align with long-term SEO goals.
This hybrid framework of semantic evaluation and instruction-based classification represents a powerful, future-ready step in intelligent information retrieval and strategic content refinement.
Click here to download the full guide about Zero-Shot & Few-Shot Learning in IR.
