SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
A wise man once said, “Knowledge of Languages is the Doorway to Wisdom”.
It’s actually a 13th-century quote. However, that does not mean that it is any less true as of now. In fact, it is perhaps one of the most important subjects of study in the 21st century since the applications of this concept have grown tremendously. Today we know it as Natural Language Processing, and we know for sure Google takes it very seriously.

In this article, I will be explaining the basic concepts of NLP namely, POS Tagging and Dependency Parsing.
Parts of Speech Tagging
Since our school days when we learned English for the first time, we have come across different forms of words, namely nouns, adjectives, prepositions, verbs, determiners and other kinds of subjects and modifiers.
Such identifiers were created in order to understand the relation of each word in a sentence with another. The concept is so basic, that defining the purpose of each word in a sentence became the foundation for Natural Language Processing.
That is where Part of Speech Tagging comes from. POS Tags are labels assigned to different words in a sentence to understand the context of the “parts of speech”.
What is Natural Language Processing (NLP)?
Natural Language Processing (NLP) is a branch of artificial intelligence (AI) that focuses on enabling machines to understand, interpret, and generate human language. It involves the intersection of computer science, linguistics, and machine learning, working to bridge the gap between human communication and computer comprehension. NLP allows computers to process and analyze large amounts of natural language data, facilitating human-like interaction with machines through text or voice.
At its core, NLP is concerned with understanding the meaning of words, phrases, and sentences in context, as well as understanding the nuances and complexities of human language. Human language is full of ambiguities, nuances, and subtle meanings, which makes it incredibly challenging for machines to interpret. However, the advancements in NLP over the years have helped computers make significant strides in understanding the intricacies of language.
Importance of NLP in Understanding Human Language
NLP plays a crucial role in helping machines understand human language. For humans, communication comes naturally. We convey ideas, emotions, and thoughts through words and phrases that often carry layered meanings. However, for computers, interpreting this unstructured data can be a challenging task due to the inherent complexities in language—such as sarcasm, regional dialects, and ambiguous word meanings. NLP solves this problem by providing tools and models that help machines decode and interpret human language with remarkable accuracy.
The importance of NLP is evident in everyday technologies that we use, such as virtual assistants (like Siri and Alexa), translation services, chatbots, content recommendation systems, and even the way we interact with search engines. With the help of NLP, these systems can process user input, understand context, and generate human-like responses, creating seamless and effective communication between humans and machines.
Role of NLP in Google Search
How Google Uses NLP to Process and Understand Search Queries
Google Search has evolved significantly over the years. Initially, it relied on simple keyword matching to return relevant results. However, with the continuous advancements in NLP, Google has been able to transition from purely keyword-based algorithms to models that understand the full context of a search query. This has led to a more refined and user-centric search experience, where the goal is not only to match keywords but to understand the intent behind the query.
NLP plays a vital role in how Google processes search queries. When a user enters a query, Google’s search engine uses NLP to analyze the words and structure of the sentence to determine the user’s intent. The traditional approach of simply matching keywords has been replaced with a more advanced understanding of the context, allowing Google to return results that are more relevant and useful to the user.
For example, consider the query “best pizza in New York.” NLP allows Google to understand that the user is looking for recommendations for pizza restaurants in New York, rather than just any information related to pizza or New York. Additionally, Google can process more complex queries, such as “What’s the best pizza place in New York for a vegan diet?” Here, NLP helps Google identify that the user is not only asking for pizza places but also has dietary restrictions.
NLP also helps Google process synonyms and variations of words to ensure that users find the information they are looking for, even if they don’t use the exact words in their query.
2. The Evolution of Google Search
From Keyword Matching to Contextual Understanding
In the early days of Google, search algorithms focused primarily on keyword matching. If a user searched for a term, Google’s search engine would return results that contained those exact keywords. This approach worked for relatively simple queries but often struggled to deliver accurate results for more complex or ambiguous search terms. As language is highly nuanced, keyword-based searches were limited in their ability to understand context and the underlying intent behind a query.
The evolution of Google Search took a major step forward with the introduction of more advanced algorithms that incorporated NLP. These algorithms allowed Google to go beyond keyword matching and understand the meaning behind words, the relationships between them, and the context of the entire query.
Early Search Algorithms (Keyword Matching)
In the early days, Google’s algorithms were largely based on matching keywords in web pages to the search query. While this worked reasonably well for simpler queries, it became increasingly clear that this approach could not adequately address the full complexity of human language. For example, a search for “jaguar” could refer to a car, an animal, or even a football team, depending on the context. Keyword matching alone couldn’t resolve this ambiguity.
Introduction of RankBrain and BERT for Better Context Understanding
RankBrain, introduced by Google in 2015, marked a significant shift towards incorporating machine learning into search algorithms. RankBrain was designed to understand the meaning behind search queries, especially those that were ambiguous or contained rare words. It used machine learning to interpret the query’s intent, improving search result relevance by analyzing how users interacted with the results.
BERT (Bidirectional Encoder Representations from Transformers), introduced in 2019, took contextual understanding even further. Unlike previous models, BERT could understand the meaning of words in context—considering not only the words surrounding them but also their relationships within the entire sentence. This made Google Search even more accurate at understanding natural language queries, especially when they contained complex phrasing or long-tail queries.
The Shift to AI and Machine Learning
The rise of AI and machine learning has played a pivotal role in improving search results. These technologies enable Google’s algorithms to continuously learn from vast amounts of data, adapt to new language patterns, and refine search results over time.
Machine learning, especially deep learning, has empowered Google to create more advanced models capable of processing and understanding the intricacies of language. Google’s transition to using AI has transformed the way search results are generated, making them more personalized, relevant, and context-aware.
3. Core Components of NLP
NLP involves several core components that allow machines to process and understand human language effectively. These components include:
Tokenization
Tokenization is the process of breaking down text into individual units, such as words or phrases. This is one of the first steps in NLP and helps convert raw text into a structured format that machines can analyze. For example, in the sentence “I love pizza,” tokenization would break it into three tokens: “I,” “love,” and “pizza.”
Part-of-Speech Tagging
Part-of-speech (POS) tagging refers to the process of identifying the function of each word in a sentence. Each word is assigned a specific grammatical role, such as a noun, verb, adjective, etc. This helps machines understand the structure of a sentence and its meaning. For example, in the sentence “She runs fast,” “She” would be tagged as a pronoun, “runs” as a verb, and “fast” as an adverb.
Named Entity Recognition (NER)
Named Entity Recognition (NER) is a technique used to identify and classify named entities in text, such as names of people, places, organizations, dates, and other specific items. For example, in the sentence “Barack Obama visited London in 2018,” NER would identify “Barack Obama” as a person, “London” as a location, and “2018” as a date.
Sentiment Analysis
Sentiment analysis is used to determine the emotional tone or sentiment behind a piece of text. This can be positive, negative, or neutral, and it helps machines understand the underlying emotions or opinions expressed in text. For example, analyzing a product review might reveal whether the sentiment is positive or negative, which can influence search results or recommendations.
4. How Google Uses NLP
Understanding User Intent
User intent refers to the goal or purpose behind a search query. Google uses NLP to interpret user intent and deliver results that match it. For example, when a user searches for “best pizza in New York,” Google understands that the user is likely looking for a list of pizza restaurants or reviews in New York, rather than just general information about pizza.
Google analyzes the words and structure of the query, using NLP techniques to determine the most relevant results based on the user’s intent, even if the query is ambiguous or incomplete.
Contextual Search
Contextual search is the ability to understand the meaning of a search query in relation to previous interactions or broader context. BERT, for example, allows Google to interpret search queries based on the entire sentence, rather than just individual words. This enables Google to better understand complex or nuanced queries, such as “How much protein is in a vegan burger?”
Handling Ambiguity in Search Queries
Google also uses NLP to handle ambiguity in search queries. For example, if a user searches for “apple,” the search engine must disambiguate whether the user is referring to the fruit or the technology company. NLP techniques allow Google to make these distinctions based on context, providing more accurate search results.
5. The Role of Machine Learning in NLP
Training Models to Improve Search Results
Machine learning models are trained on large datasets of language data to improve their ability to understand text. Google trains its NLP models using vast amounts of text data, including web pages, books, and other sources, to teach the models how to process and interpret human language. The more data these models are trained on, the better they become at understanding and predicting language.
Deep Learning and Neural Networks
Deep learning and neural networks are key technologies that enable Google to improve its NLP capabilities. These technologies allow Google’s algorithms to process language in a way that mimics human cognition, recognizing patterns and relationships within text that traditional methods might miss.
6. Challenges in NLP
Language Nuances
One of the biggest challenges in NLP is dealing with the nuances of language. Humans often use slang, idioms, and figurative language, making it difficult for machines to fully understand the intended meaning. Additionally, regional dialects and variations in language use further complicate the task. Google must constantly adapt its NLP models to handle these challenges.
Multilingual Search
With users around the world, Google must also be able to process queries in multiple languages. NLP models must be trained to understand not just English but a wide variety of languages, each with its own grammar, vocabulary, and syntax.
7. The Future of NLP in Google Search
Advancements in AI and NLP
As AI and NLP technologies continue to evolve, Google is likely to further improve its search capabilities. Innovations in deep learning, neural networks, and reinforcement learning will enable even more accurate and nuanced understanding of language, leading to a more refined search experience.
User Experience and Personalization
The future of NLP in Google Search will also be heavily influenced by user experience and personalization. As NLP models become better at understanding individual preferences and context, Google will be able to deliver even more personalized search results, anticipating user needs and providing highly relevant information.
There are mainly two types of Tags:
- Universal POS Tags
These tags include NOUN(Common Noun), ADJ(Adjective), ADV(Adverb).
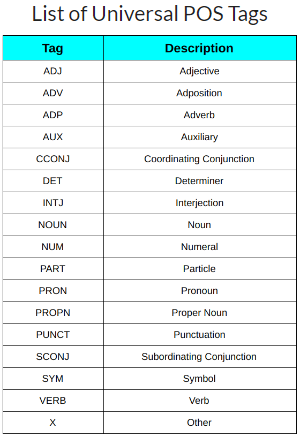
You can learn more about them in this document.
- Detailed POS Tags
These include secondary tags NNS for common plural nouns and NN for the singular common noun compared to NOUN for common nouns in English.
Now that we know about POS Tags, we can run a program that returns such relations between each word in a sentence.
Let us take an example: “The quick brown fox jumping over the lazy dog”
Run the Following Code in Python:
Terminal Commands:
(base) C:\Users\USER>pip install spacy
(base) C:\Users\USER>conda install -c conda-forge spacy-model-en_core_web_sm
(base) C:\Users\USER>python -m spacy download en_core_web_sm
(base) C:\Users\USER>pip install networkx
Python Code:
>>> import spacy
>>> nlp=spacy.load(‘en_core_web_sm’)
>>> import en_core_web_sm
>>> nlp = en_core_web_sm.load()
>>> from spacy import displacy
>>> displacy.render(nlp(text),jupyter=True)
<IPython.core.display.HTML object>
>>> sentence = “The quick brown fox jumping over the lazy dog”
>>> doc = nlp(sentence)
>>> print(f”{‘Node (from)–>’:<15} {‘Relation’:^10} {‘–>Node (to)’:>15}\n”)
>>> for token in doc:
… print(“{:<15} {:^10} {:>15}”.format(str(token.head.text), str(token.dep_),
str(token.text)))
…
Output
Node (from)–> Relation –>Node (to)
fox det The
fox amod quick
fox amod brown
fox ROOT fox
fox acl jumping
jumping prep over
dog det the
dog amod lazy
over pobj dog
Dependency Parsing
It involves making sense of the grammatical structure of the sentence based on the
dependencies between the words of a sentence.
For example in the above sentence “The quick brown fox jumping over the lazy dog”,
“brown” acts as an adjective that modifies the noun “fox”. Hence there is a dependency on the word “fox” to the word “brown”. This dependency is defined by the “amod” tag known as the adjective modifier.
A thing to note is that dependency always occurs between two words in a sentence. Let’s now write a program that can return such dependencies between different words in the following sentence.
“It took me more than two hours to translate a few pages of English.”
Terminal Commands:
(base) C:\Users\USER>pip install spacy
(base) C:\Users\USER>conda install -c conda-forge spacy-model-en_core_web_sm
(base) C:\Users\USER>python -m spacy download en_core_web_sm
(base) C:\Users\USER>pip install networkx
Python Code:
>>> import spacy
>>> nlp=spacy.load(‘en_core_web_sm’)
>>> import en_core_web_sm
>>> nlp = en_core_web_sm.load()
>>> text=’It took me more than two hours to translate a few pages of English.’
>>> for token in nlp(text):
print(token.text,’=>’,token.dep_,’=>’,token.head.text)
…
//First column is the text
//Second column is the Tag
//Third column is the head term
Output
It => nsubj => took
took => ROOT => took
me => dobj => took
more => amod => two
than => quantmod => two
two => nummod => hours
hours => dobj => took
to => aux => translate
translate => xcomp => took
a => quantmod => few
few => amod => pages
pages => dobj => translate
of => prep => pages
English => pobj => of
. => punct => took
Finding Shortest Dependency Path With Spacy
Semantic dependency parsing has been often used as a way to obtain information between words(entities) that are related but are far in sentence distance.
The Shortest Dependency Path or SDP contains all the information that is just enough to define the relationship between two words in a sentence.
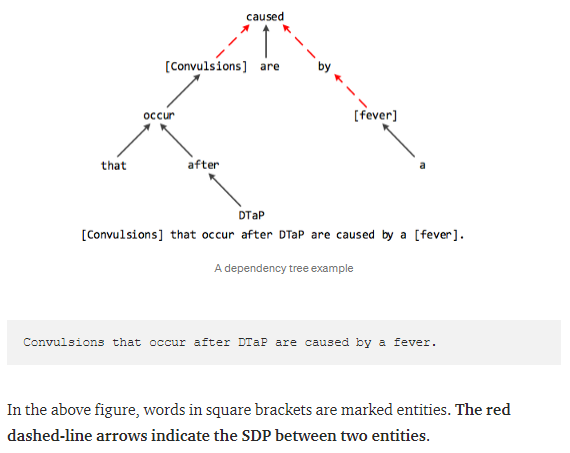
Now let’s find the SDP with the help of a Python Program.
Terminal Commands:
(base) C:\Users\USER>pip install spacy
(base) C:\Users\USER>conda install -c conda-forge spacy-model-en_core_web_sm
(base) C:\Users\USER>python -m spacy download en_core_web_sm
(base) C:\Users\USER>pip install networkx
Python Code:
>>> import spacy
>>> import networkx as nx
>>> nlp = spacy.load(“en_core_web_sm”)
>>> doc = nlp(u’Convulsions that occur after DTaP are caused by a fever.’)
>>> print(‘sentence:’.format(doc))
sentence:
>>> edges = []
>>> for token in doc:
… for child in token.children:
… edges.append((‘{0}’.format(token.lower_),
… ‘{0}’.format(child.lower_)))
…
>>> graph = nx.Graph(edges)
>>> entity1 = ‘Convulsions’.lower()
>>> entity2 = ‘fever’
>>> print(nx.shortest_path_length(graph, source=entity1, target=entity2))
3
>>> print(nx.shortest_path(graph, source=entity1, target=entity2))
[‘convulsions’, ’caused’, ‘by’, ‘fever’]
As you can see, the shortest path length function returns 3 as the shortest number of jumps of hops made to establish the relationship.
The shortest path function returns the exact words which are part of the SDP.
Conclusion
These are some elements that help gives an elementary idea of how an AI makes relationships between different words and hence is an introduction to the vast subject of NLP. Obviously, Google AI is much more complex than two or three Python scripts, however, our purpose was to share a brief idea of how a machine can create a semantic relationship between words in a text.
