
Sematic SEO are the search engine optimization strategies that enable the search query to produce meaningful results to the customer through knowing the purpose behind that question. Semantic search results provide the consumer with contextualized information by not limiting it to the search query’s specific keywords, but rather establishing a link to it.
If you want to acquire the best visibility and search rankings for your websites then you should optimize your landing pages and website based on artificial intelligence modules which are related with semantic search, information retrieval, NLP, and etc.
Now, as a matter of fact, AI is not easy for a common man to execute and it requires cutting-edge codes and high-end technology. Well, we at ThatWare are on a mission to make AI simple with step-by-step processes which can be utilized by any common for a proper optimization of pages based on semantic search. Without further delay, let us proceed:
1.COSINE SIMILARITY
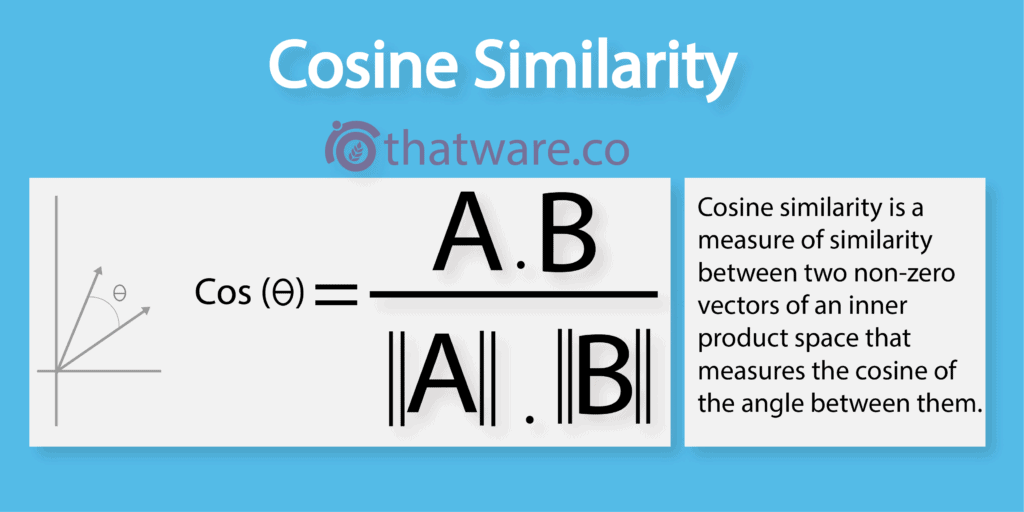
Cosine similarity uses a non-zero vector to calculate the angle between two vectors and if the angle between them are close then they are similar and if the angle between two vectors is 90 degrees then they are dissimilar.
Google uses cosine similarity for calculating the similarity between the content of a page and the search term. Suppose, you want to optimize a page based on a particular search term then at first you need to check the cos values of the websites which are ranking higher. Then use those values as a relative score to optimize your own landing page. Just remember more the degrees are closer to each other; more is a similarity. Good similarity will ensure better search rankings.
2.LATENT DIRICHLET ALLOCATION (LDA)
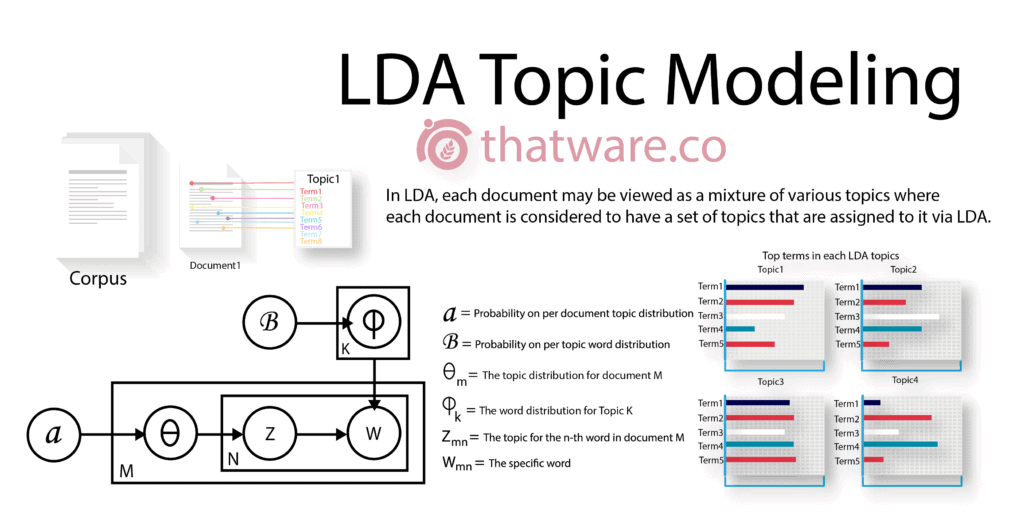
Latent Dirichlet Allocation (LDA), is a topic modeling algorithm in which the algorithm is used for calculating the document to topic distribution and then after topic to word distribution. The topics are latent and each word belongs to a particular topic by its belonging probability.
In layman terms, LDA calculates how relevant a document is when compared against a set of a query or another document set. It is also widely used by search engines especially Google.
Suppose one of your competitors are ranking extremely well for a high competitive keyword. Then you can optimize your landing based against the competitor’s landing page using LDA value. Better the value, better will be the ranking probability.
3.PROBABILISTIC LSA
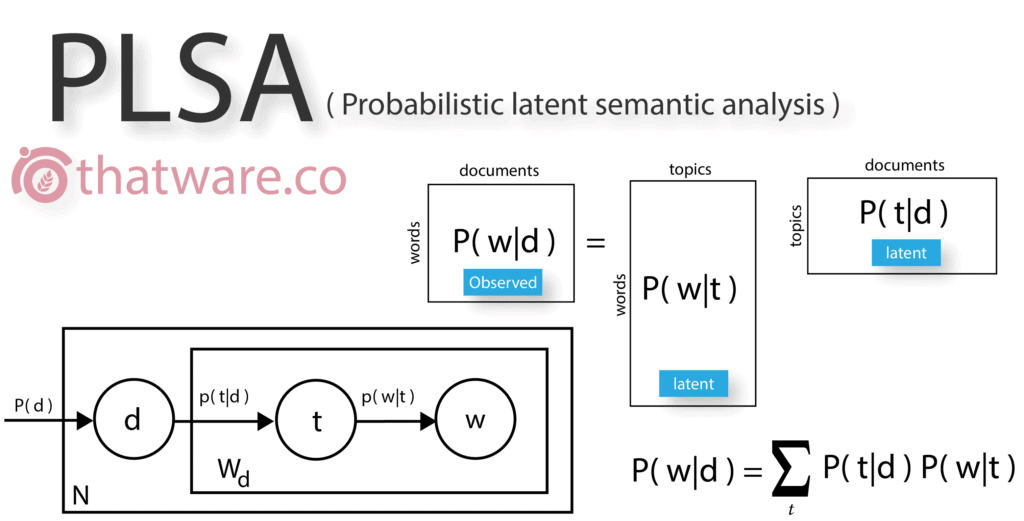
The probabilistic latent semantic analysis is also known as probabilistic latent semantic indexing, commonly known as PLSA. PLSA find its application in modern information retrieval and text mining. Basically, PLSA creates a latent vector space model which has a balanced probability of every word (in a document) within a latent topic.
4.JACCARD INDEX

Unlike cosine similarity, Jaccard index works without binary values and thus the output tends to be more efficient. Jaccard index algorithm is generally used to compare two sets of the document for similarity.
This algorithm basically uses an intersection of two particular sets of document (min. value) and then the Union of two particular sets ( intersection/Union). In search engine optimization world, a professional seo company uses Jaccard index to separate the use of tags.
Just as everyone knows that extra tags causes extra pages and results in crawl budget wastage. Using the Jaccard index will help in segregating all the similar tags on the same side and thus one tag from one branch can be used which contains the same similarity ratio. Thus, it will reduce the usage of tags.
5.KAPPA COEFFICIENT

Kappa coefficient came into existence from Kohen’s kappa which uses two iterators to calculate the percentage of agreement and the percentage of disagreement.
In the digital marketing world, for calculating critical agreements steps Kappa is very important, in fact, a study showed that 81.56% of the recommendations are a direct result of the strong agreement itself.
6.TOPIC MODELING

This algorithm is basically used to discover topic clusters which occur within a collection of the corpus of a document set. This is a customized modeling set where the principal algorithm which is used are namely LDA and PLSA.
In the seo world, topic modeling is widely used for specifying the intent behind the content. This is very important, especially for the rankbrain algorithm.
7.VECTOR SPACE MODELING

A vector space model is such a model where document D is represented as an m-dimensional vector, where each dimension corresponds to a unique term. Here m is treated as the total number of terms used in the corpus or also known as the collection of documents.
This is very important for search engines as it allows search engines to rank pages based on query versus landing page relevance calculation.
8.LINK INTERSECT USING R
Link intersect is a piece of program which will help in finding out the common backlinks between two or more set of websites. The process uses a technology which is known as vector intersection.
9.ROCCHIO ALGORITHM

As per the basic theoretical approach, each and every page has a TF-IDF value according to a particular set of the search query. The PageRank value will change depending on the search query or the search term.
10.BAG OF WORDS (BOW)

Each document or a corpus has its own sets of word cluster. If a corpus or a document set is passed through a document-term matrix then the output of the same will be converted into a data frame. This frame will then be segregated based on the word cloud and highest term frequency order. Thus, a bag of a word will be created.
In search engine optimization world, a BOW is very important as it will help in picking up important tag clusters which can later be utilized for numerous seo purposes.
11.BEST MATCHES CORRELATION (BM25)

Basically, this algorithm stands for best matches pair, if you compare and correlate between ‘n’ pairs or components then it will be represented as BMn.
The main principal formula is based on the probabilistic retrieval (part of modern information retrieval) which is a ranking function used by search engine crawlers to rank matching documents according to their relevance for a given search query.
12.HIERARCHICAL CLUSTERING

This is a special type of clustering which is performed by a cluster process algorithm within the same document set. The output is generally is in the form of a dendrogram. The principal mechanism uses a distance algorithm.
This technique is an advanced technique and can be utilized for multiple operations for a complete SERP experience. For example, HC can be used to classify pages based on selective sets of keywords and tags and which can be later utilized for optimizing your main landing page.
13.DOCUMENT HEAT MAP
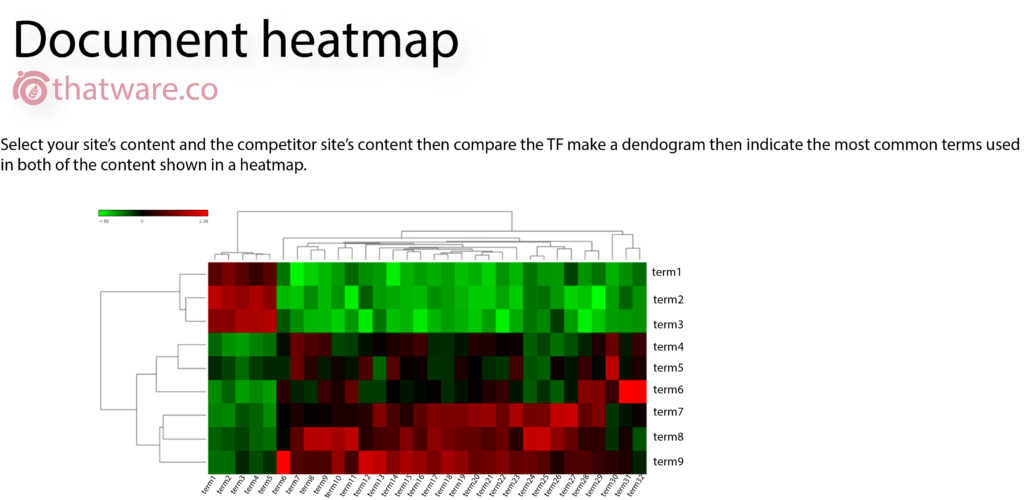
It is basically a creation of a heatmap module which will indicate two websites TF while comparing to each other. The main benefit of this process is that – one can compare the heatmap of the landing pages of competitors and then optimize the changes based on the output.
14.SENTIMENT ANALYSIS
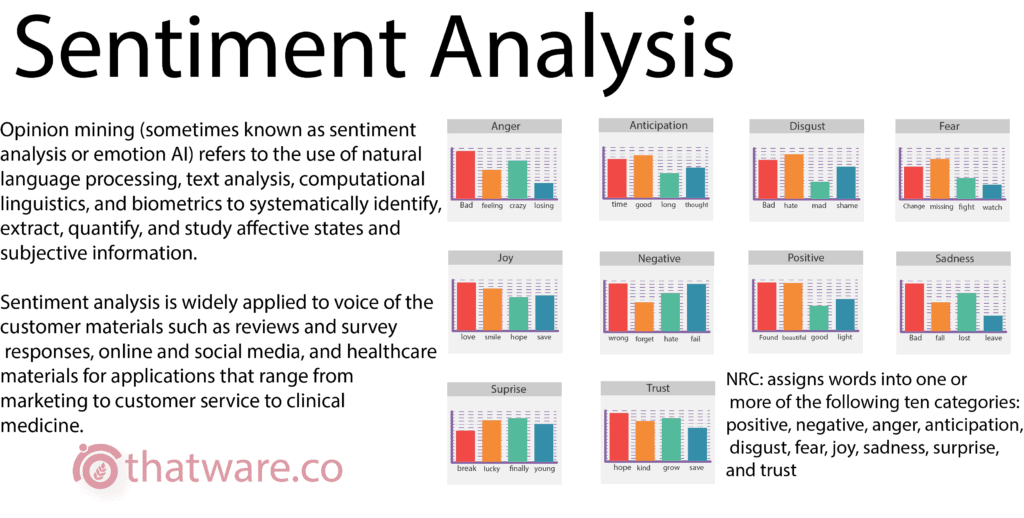
Sentiment analysis is an AI algorithm which is used to get an idea about the percentage of positiveness and negativeness of a particular data or a document set. The process uses AFFIN, NRC, bing dataset.
Furthermore, it can also be used to subdivide the positiveness and negativeness based on anger, joy, trust, disappoint, and etc. In the seo world, sentiment analysis is very important in many ways. One of the ways is to check on the user comments and behavioral pattern as for whether it is leading to a negative sense or positive sense.
15.DOCUMENT VS. DOCUMENT SIMILARITY

Doc to Doc similarity uses cosine similarity to find out the similarity percentage between the two document set. If the angle between them is less then they are pretty much similar to each other. In most cases, we prefer the values to be within 0. 3 – 0.5
In a ranking point of view, more your landing page is technically similar to the ranked #1 page; more will be the ranking benefit.
16.ANCHOR TEXT SIMILARITY
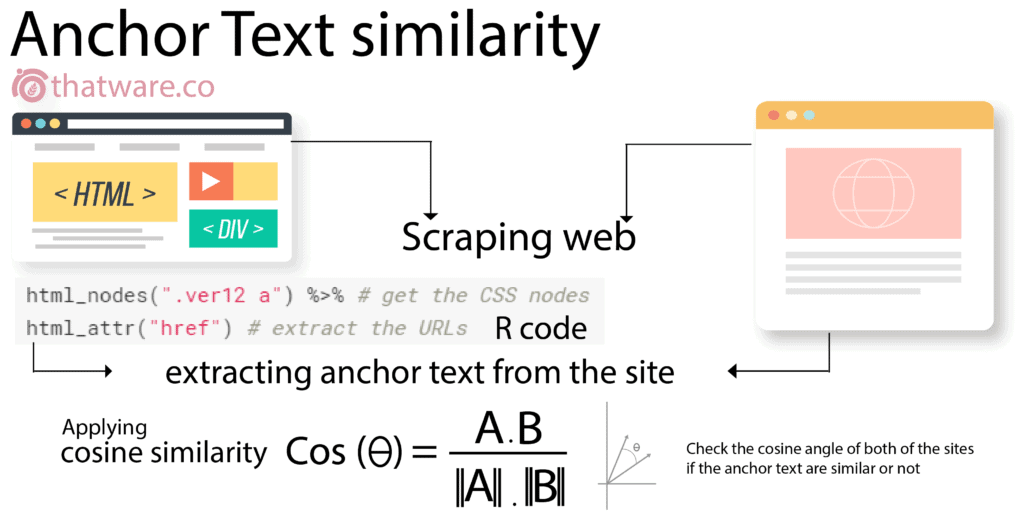
This is a concept where we use AI codes to scrape out the main site and its competitor site’s anchor text and perform intersection to find out similar anchor text of both of the sites.
This technique is very much helpful especially when you are keen on using the anchor texts based on your top ranking competitor’s.
17.CO-OCCURRENCE

This is used to find out the co-occurrence of a term within both of the document, this can be used for image recognition. In addition to this, it can be used for optimizing page content based on co-occurring terms.
18.K-MEAN CLUSTERING
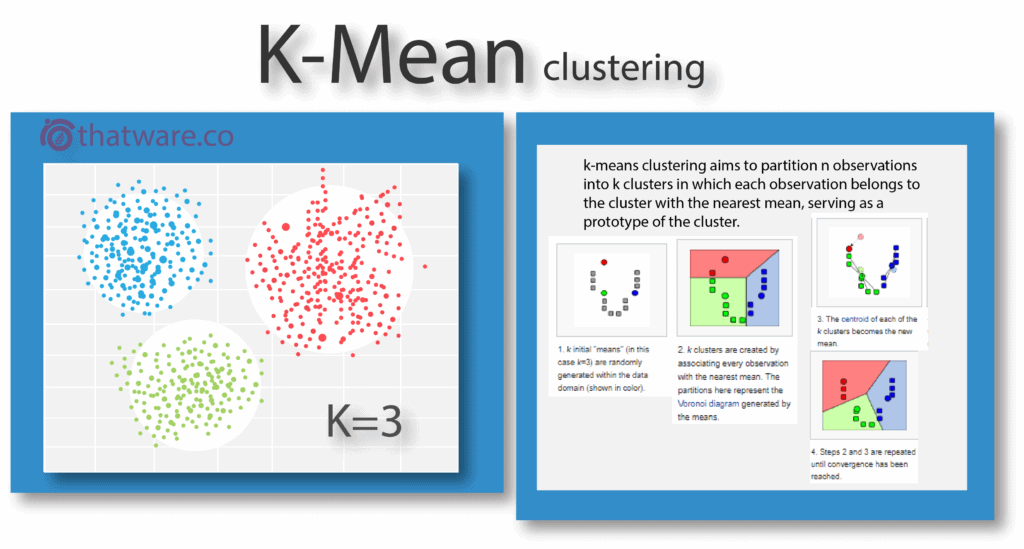
K-mean algorithm creates a cluster based on distance algorithm like Euclidean distance where each centroid defines one of the clusters. K is a number of a group which will indicate the number of clusters. This process is helpful for optimizing pages based on semantic search.
19.FLAT CLUSTERING

Clustering algorithms(like flat-mean ) group a set of documents into subsets or clusters. Documents within a cluster should be as similar as possible, and documents in one cluster should be as dissimilar as possible from documents in other clusters.
20.NAIVE BAYES
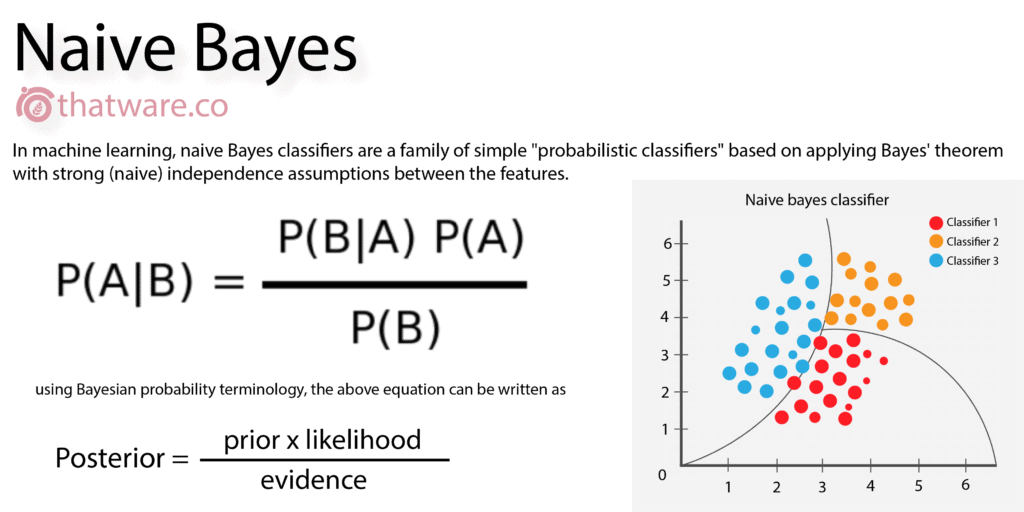
Naive Bayes originated from Bayes theorem and this basically used for prediction based on previous data. Many prediction analysis can be done using naive Bayes theorem. In search engine ranking, predictions can be used to check for future outcomes based on current KPI records.
21.PREDICTIVE ANALYSIS USING MARKOV CHAIN
This is basically a multi-state transition algorithm which is solely used for prediction analysis with higher accuracy and low noise ratio. In the digital marketing world, this can be specifically used for the prediction of stock and share market values.
22.SEMANTIC PROXIMITY
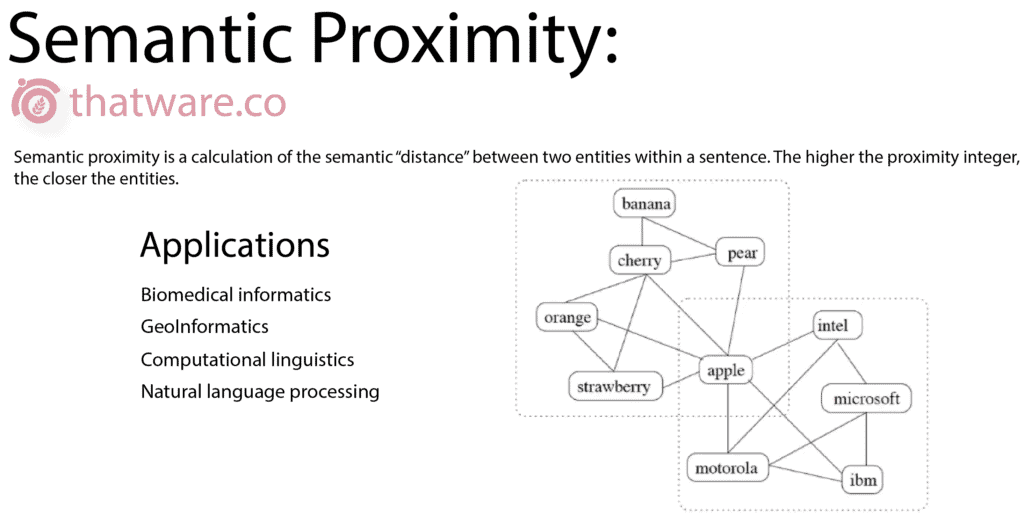
Semantic proximity measures the distance between similar words or searches terms within a specific document set. It works on a different algorithm which is known as Euclidean cosine.
In seo, semantic proximity is very important. As per generic rule – each of the semantic keywords within a document set should be equally spaced and balanced.
23.ADABOOST ALGORITHM

This takes all the weak cluster then it combines it into a strong cluster. Also, this can use to boost your algorithm by reducing the time complexity. When you have a huge e-commerce website with over a million pages then the time complexity for the optimization can be reduced with the help of the Adaboost algorithm.
24.PREDICTION OF TRENDS
For a particular search query, there is a particular search result and also there are some particular topics which are in trends. We at ThatWare, have built a custom machine learning module which can help in identifying the trend based on the set of entered queries.
25.FUZZY C
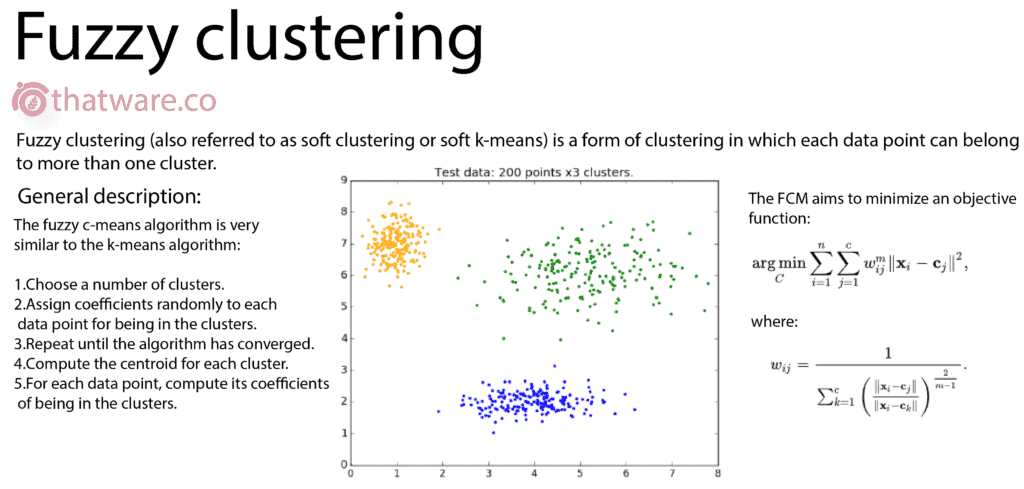
This is a form of clustering in which each data point can belong to more than one cluster. This algorithm is extensively used in special cases of business intelligence.
26.LEARNING VECTOR QUANTIZATION (LVQ)

This is a supervised version of vector quantization. This learning technique uses the class information to reposition the Voronoi vectors slightly. It has extensive uses for some of the advanced seo operations (this is beyond the scope of discussion as of now – since it involves advanced codes).
27.TF-IDF
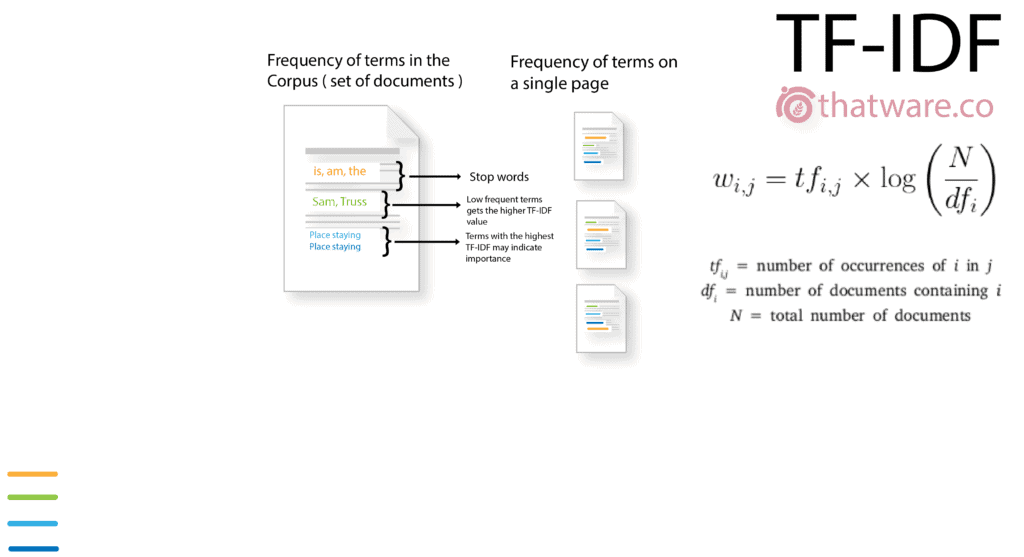
This basically indicates the relevance of a search query within a specific set of documents or corpus. TF is term frequency and IDF is inverse document frequency. There has been a direct strong correlation that if-idf improves a lot of search rankings.
28.PRECISION

In the field of information retrieval, precision is the fraction of retrieved documents that are relevant to the query which also called positive predictive value. This will give a relative value as for how the document is compared to the given query.
29.RECALL

In information retrieval, recall is the fraction of the relevant documents that are successfully retrieved which is also known as sensitivity. Better the sensitivity, better is the ranking.
30.F-MEASURE

A measure that combines precision and recall, This measure is approximately the average of the two when they are close.
31.CHAMPION LIST (IR)

A vector space model to avoid computing relevancy rankings for all documents each time a document collection is queried. The champion list contains a set of n documents with the highest weights for the given term. It is frequently used for ranking pages based on semantic engineering.
32.MANUAL CORA

Website correlation, or website matching, is a process used to identify websites that have similar content or similar tags or similar structure.
The main idea of semantic engineering is to incorporate language tags and meta-data that are interrelated to the main topic into the text so that the search engine can react to the specified query semantically for a particular question even if does not correlate to same keyword. This methodology utilizes artificial intelligence (AI) technologies to create a vocabulary cloud around a specific topic depending on the meaning and intent behind a search query to improve the central theme and user experience.
What is Semantic Engineering? Is Semantic SEO is the New SEO?
Semantic engineering is the process of search engine optimized content creation around a particular topic rather than the same keywords.
Compared with traditional media, the digital world is changing quite quickly and emerging technologies and strategies are being introduced to establish the most attractive experience for users. In 2011, Google and other large search engines begin utilizing semantic SEO Natural Language Processing Techniques (NLP) and Artificial Intelligence (AI) tools and techniques to classify users’ search purpose.
The goal of the consumer is enhanced by their previous searches to offer the semantic quest for the UI a meaning. AI tools and techniques are innovated and implemented contributing to the introduction of Semantic SEO in the software industry. The semantic SEO resources often detect some stuffing of black hat keywords whose immoral approaches drive traffic to the website.
Another major trend is the use of keywords from LSI (Latent Semantic Indexing), which is a collection of keywords that are correlated semantically with each other and can help to improve content by semantic SEO. There are many LSI keyword finders and LSI keyword generators that recommend you apply keywords to the content to help it organically creep up to the top SERP ranks on the website.
How Does Semantic Search Impact SEO?
1. Users switching to Voice Search
Semantic search has grown primarily because of expanded voice search. According to research from Stone Temple Consulting, mobile voice commands are now widespread and use voice commands on smartphones other than “regularly” or “quite frequently” among 33 percent of high income households.
Optimizing voice search is very different from traditional SEO, as you need to get to the point for purpose based searches quickly to make the posts much more conversational.
Create content that addresses a typical question clearly and concisely at the top of the page before delving into more specific details. To help search engines appreciate the material and meaning, make sure to use structured data.
2. Emphasis moves from Keywords to Topics
The content created shall not be just revolving around keywords anymore. Therefore, you should talk of broad topics in your field that you will be able to cover in detail. The aim here is to create a content that are extensive, original and of high quality.
Instead of producing hundreds of small, scattered pages each with their own topic, consider creating “ultimate guides” and more detailed content that will be useful to your customers.
3. Searcher intent becomes a Priority
One of the best approaches to targeting keywords is not actually targeting keywords so much as it is targeting purpose. Through analyzing the questions leading people to your page, you will be able to develop a bunch of subjects that are perfect for developing content around.
In order to do this, make a list of keywords and then group them by user purpose. When you grasp the purpose of the searcher, start creating content that discusses their intent explicitly, rather than creating content around specific keywords or broad topics.
4. Focus shifts to User Experience
User satisfaction in an era of semantic engineering should be guiding all of our SEO activities. Google cares for user satisfaction and their software is constantly fine-turned to better understand and satisfy the searchers. SEO practitioners, too, will rely on UX.
For this, boost page speed as much as possible, maintain consistency of your mobile site (especially now that Google gives priority to indexing mobile sites), and keep an eye on metrics such as bounce rate and session duration.
5. Technical SEO matters just as much as Content
The algorithm is not yet smart enough to infer sense or interpretation on its own, even with Google’s change from “string to things.” Your website also needs to be designed to help Google understand your content.
- Keywords – Yes, keywords are still relevant. For common questions and related long-tail keywords that you can integrate into your writing, use a content analysis method. Include keywords, as long as it fits automatically, into your title tags, URLs, text, header tags and meta tags.
- Link Building – Authoritative backlinks remain one of the most important cues for the rating. Prioritize material that draws ties, obviously. Also, don’t forget to use proper internal connection systems to build profound ties to other valuable content you have developed.
- Site Speed – Minify resources, compact files, user browser caching and obey the checklist of Google to maximize the pace of your website.
Horrific and surprising to see how old school SEO tactics such as backlinks, keywords and guest blogging still applicable in 2020 and costing thousands of dollars a month from using those methods of course. These are not working for Semantic Search and Conversational AI any more.
Growth Hacking at Semantic SEO using AI is a new trend. Stop wasting your money, keywords and backlinks on a guest post. Write relevant and useful contents which react to the search purpose of the consumer. Google search now responds to machines and utilizes conversational AI. Currently you just require only two resources namely Google Analytics and CrawlQ Business Analytics.

